Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
BaiXuePrincess
Paddle
提交
cb7891a4
P
Paddle
项目概览
BaiXuePrincess
/
Paddle
与 Fork 源项目一致
Fork自
PaddlePaddle / Paddle
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
cb7891a4
编写于
3月 14, 2018
作者:
Y
Yancey1989
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Add large model design doc
上级
5a159f34
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
40 addition
and
0 deletion
+40
-0
doc/fluid/design/dist_train/large_model.md
doc/fluid/design/dist_train/large_model.md
+40
-0
doc/fluid/design/dist_train/src/prefetch_parameters.graffle
doc/fluid/design/dist_train/src/prefetch_parameters.graffle
+0
-0
doc/fluid/design/dist_train/src/prefetch_parameters.png
doc/fluid/design/dist_train/src/prefetch_parameters.png
+0
-0
doc/fluid/design/dist_train/src/split_parameter.graffle
doc/fluid/design/dist_train/src/split_parameter.graffle
+0
-0
doc/fluid/design/dist_train/src/split_parameter.png
doc/fluid/design/dist_train/src/split_parameter.png
+0
-0
未找到文件。
doc/fluid/design/dist_train/large_model.md
0 → 100644
浏览文件 @
cb7891a4
# Design Doc: Large Model
## Abstract
We propose an approach to support the large parameter.
For embedding layer, the parameter may very large and could
not be stored in one trainer's memory. In this approach, a Trainer would
prefetch a sliced parameter from different Parameter Server instances
according to the input
`Ids`
, and then run forward, backward and send
the gradient to Parameter Server to execute the optimize program.
## Design
Fluid large model distributed training use
[
Distributed Transpiler
](
./parameter_server.md#distributed-transpiler
)
to split
a large parameter into multiple parameters which stored on Parameter Server, and
the Trainer would prefetch them by
`RPC`
interface.
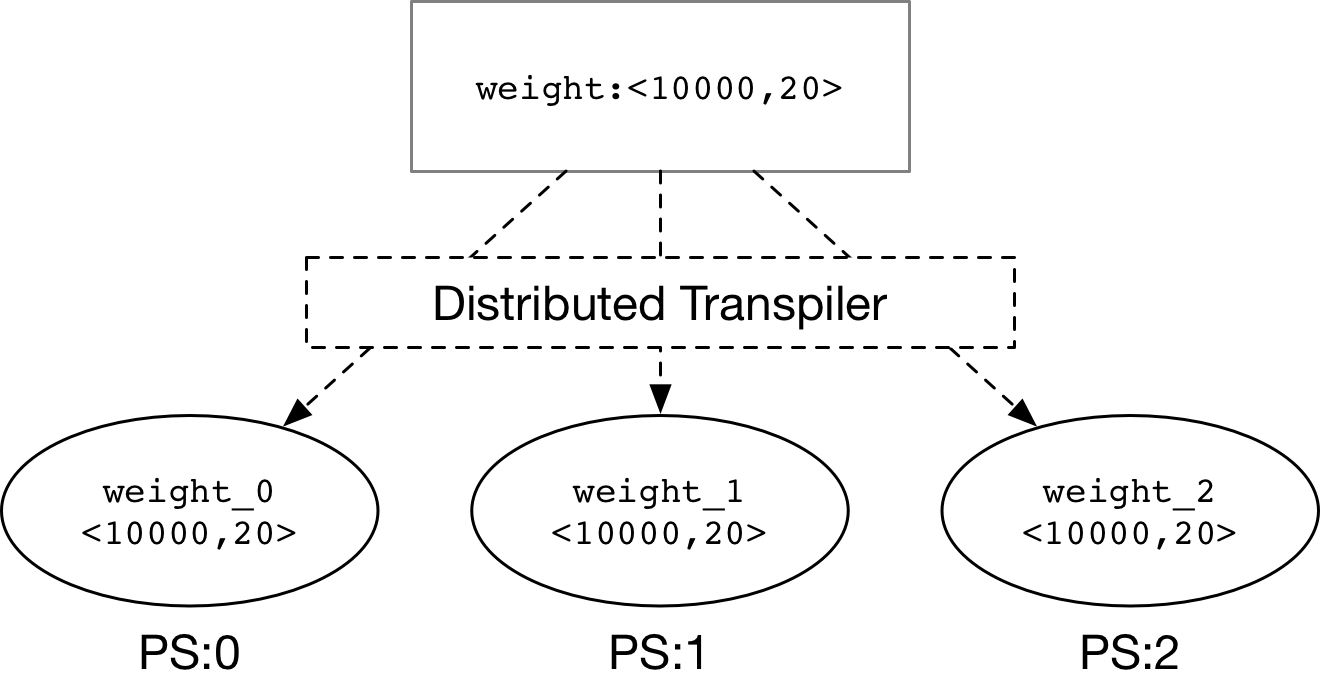
### Split Large Parameter
<img
src=
"src/split_parameter.png"
width=
"400"
/>
**Distributed Transpiler**
would split the large parameter
(weight) into some sliced parameters (weight_0, weight_1, weight_2) as the
figure above.
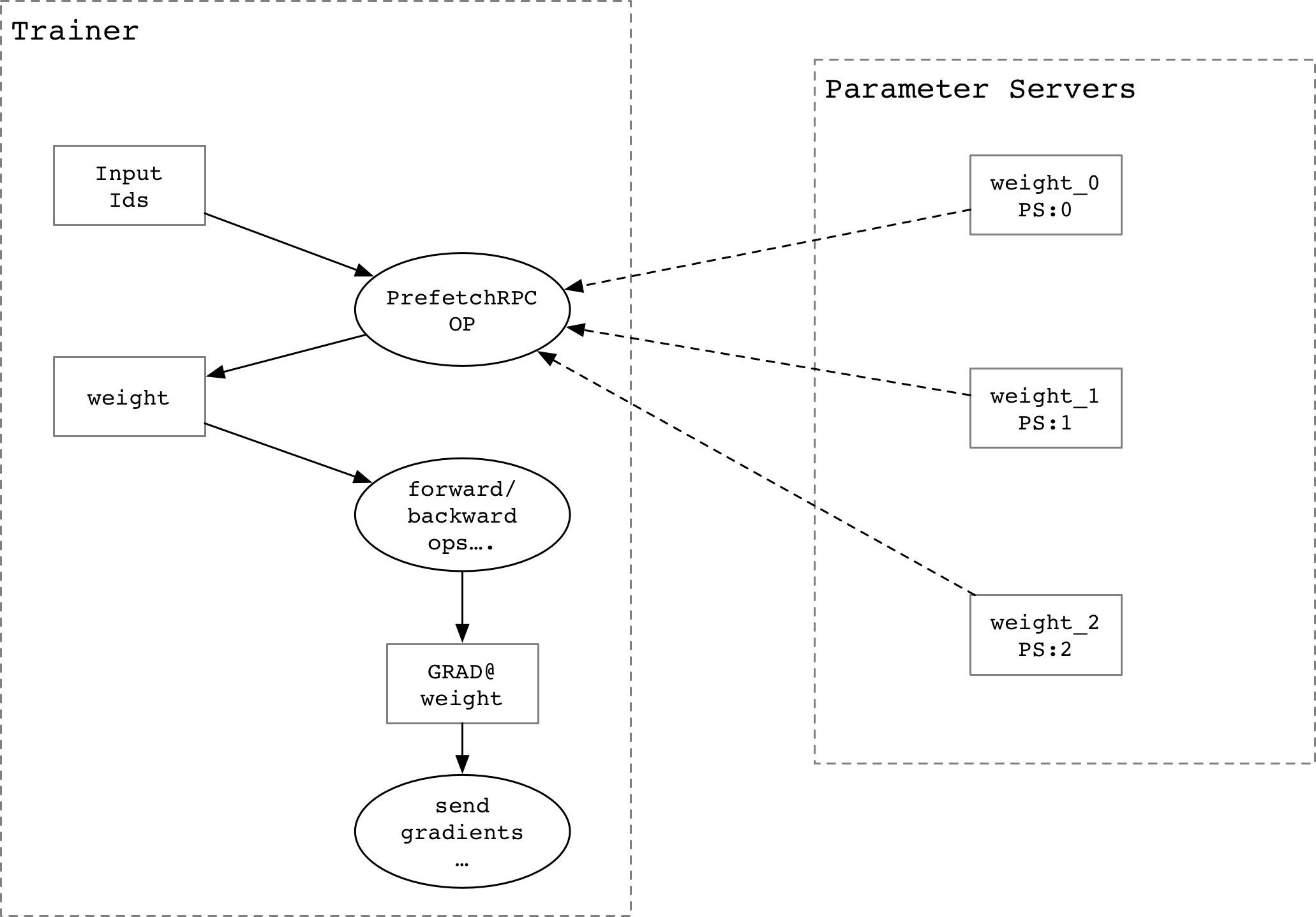
### Prefetch Parameters from Parameter Servers
<img
src=
"src/prefetch_parameters.png"
width=
"400"
/>
-
`PrefetchRpc`
operator would send the rows index the multiple Parameter Servers,
and then receive the SelctedRows.
-
The different with normal Fluid distributed training, we only prefetch the rows
## TODO
-
Async Update
To avoid slow-node, Async update is important for distributed training,
we need an design doc and implement it in future.
doc/fluid/design/dist_train/src/prefetch_parameters.graffle
0 → 100644
浏览文件 @
cb7891a4
文件已添加
doc/fluid/design/dist_train/src/prefetch_parameters.png
0 → 100644
浏览文件 @
cb7891a4
176.0 KB
doc/fluid/design/dist_train/src/split_parameter.graffle
0 → 100644
浏览文件 @
cb7891a4
文件已添加
doc/fluid/design/dist_train/src/split_parameter.png
0 → 100644
浏览文件 @
cb7891a4
67.5 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}