Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into sampler
Showing
.copyright.hook
0 → 100644
CODE_OF_CONDUCT.md
0 → 100644
CODE_OF_CONDUCT_cn.md
0 → 100644
benchmark/cluster/README.md
0 → 100644
{kind=link}
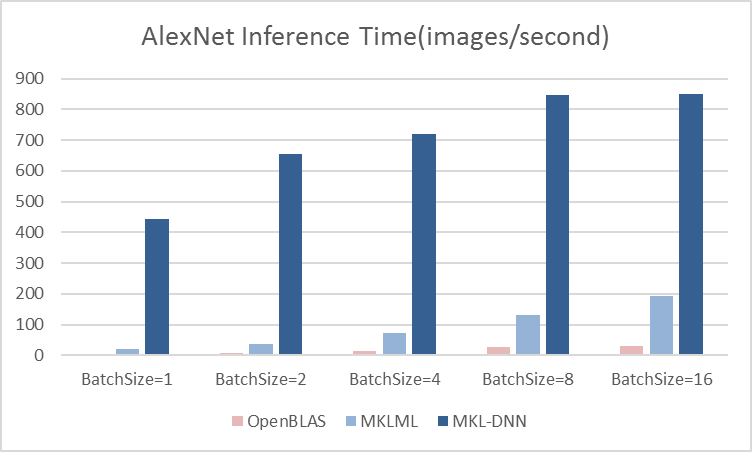
15.1 KB
{kind=link}
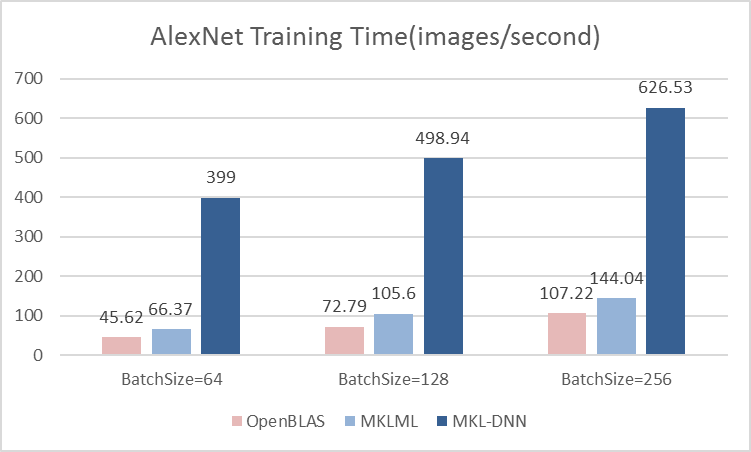
15.6 KB
{kind=link}
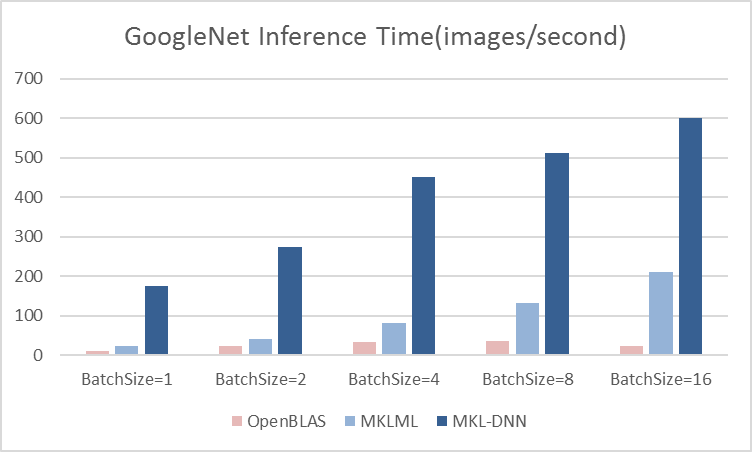
14.1 KB
{kind=link}
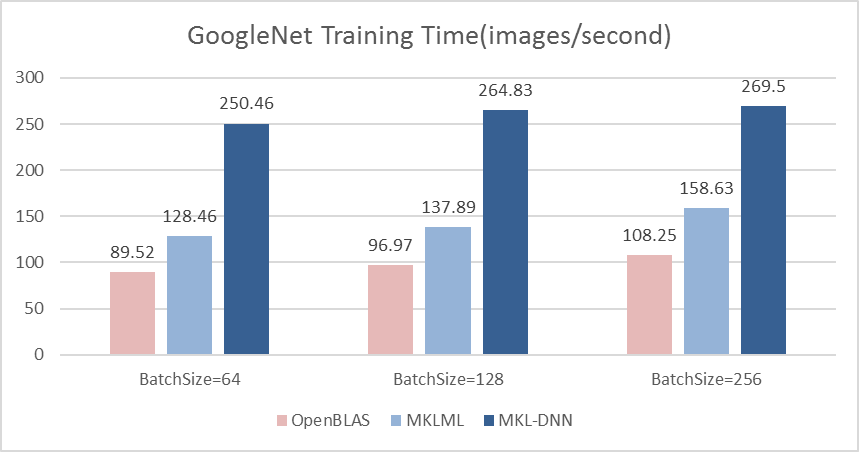
18.8 KB
{kind=link}
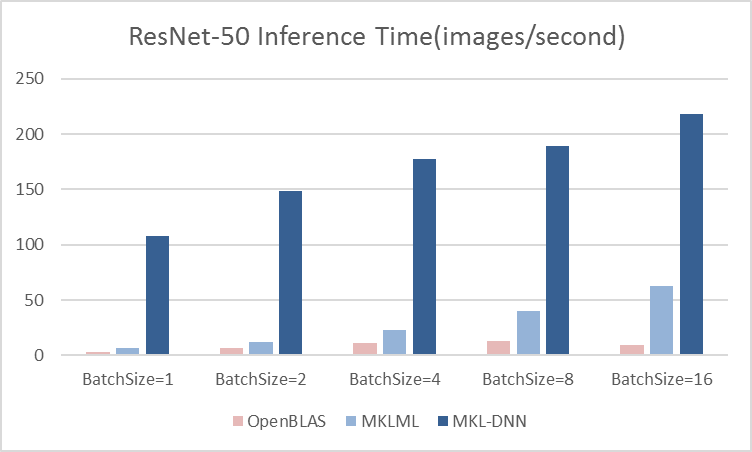
13.7 KB
{kind=link}
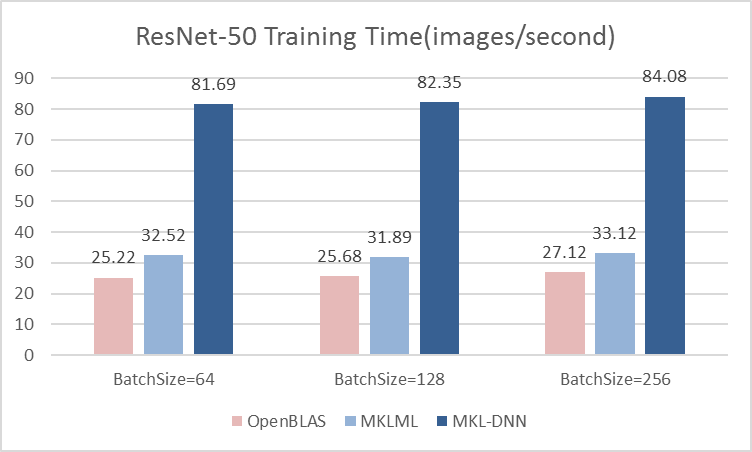
17.6 KB
benchmark/figs/vgg-cpu-infer.png
0 → 100644
{kind=link}
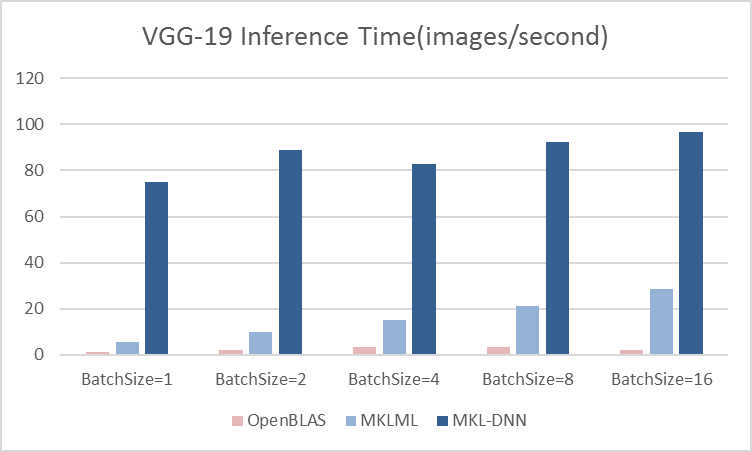
13.7 KB
benchmark/figs/vgg-cpu-train.png
0 → 100644
{kind=link}
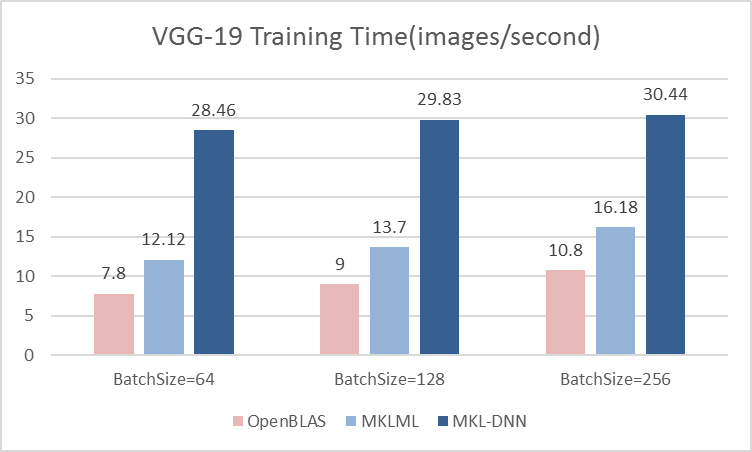
16.7 KB
benchmark/paddle/image/plotlog.py
0 → 100644
doc/api/v2/fluid/io.rst
0 → 100644
doc/design/backward.md
0 → 100644
doc/design/ci_build_whl.png
0 → 100644
{kind=link}
280.4 KB
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
189.2 KB
文件已移动
{kind=link}
文件已移动
文件已添加
{kind=link}
102.5 KB
文件已添加
{kind=link}
350.4 KB
{kind=link}
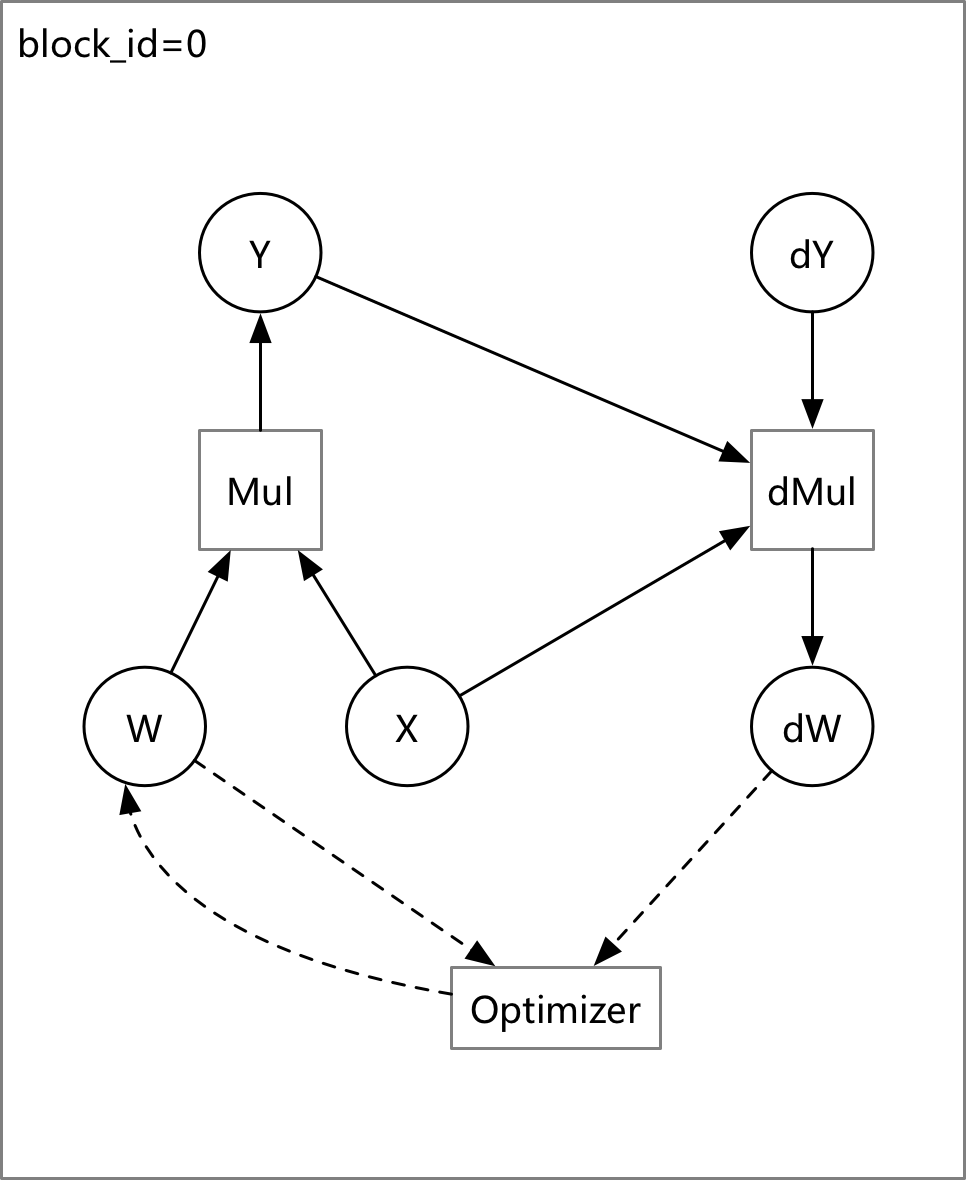
76.3 KB
文件已移动
{kind=link}
文件已移动
文件已添加
{kind=link}
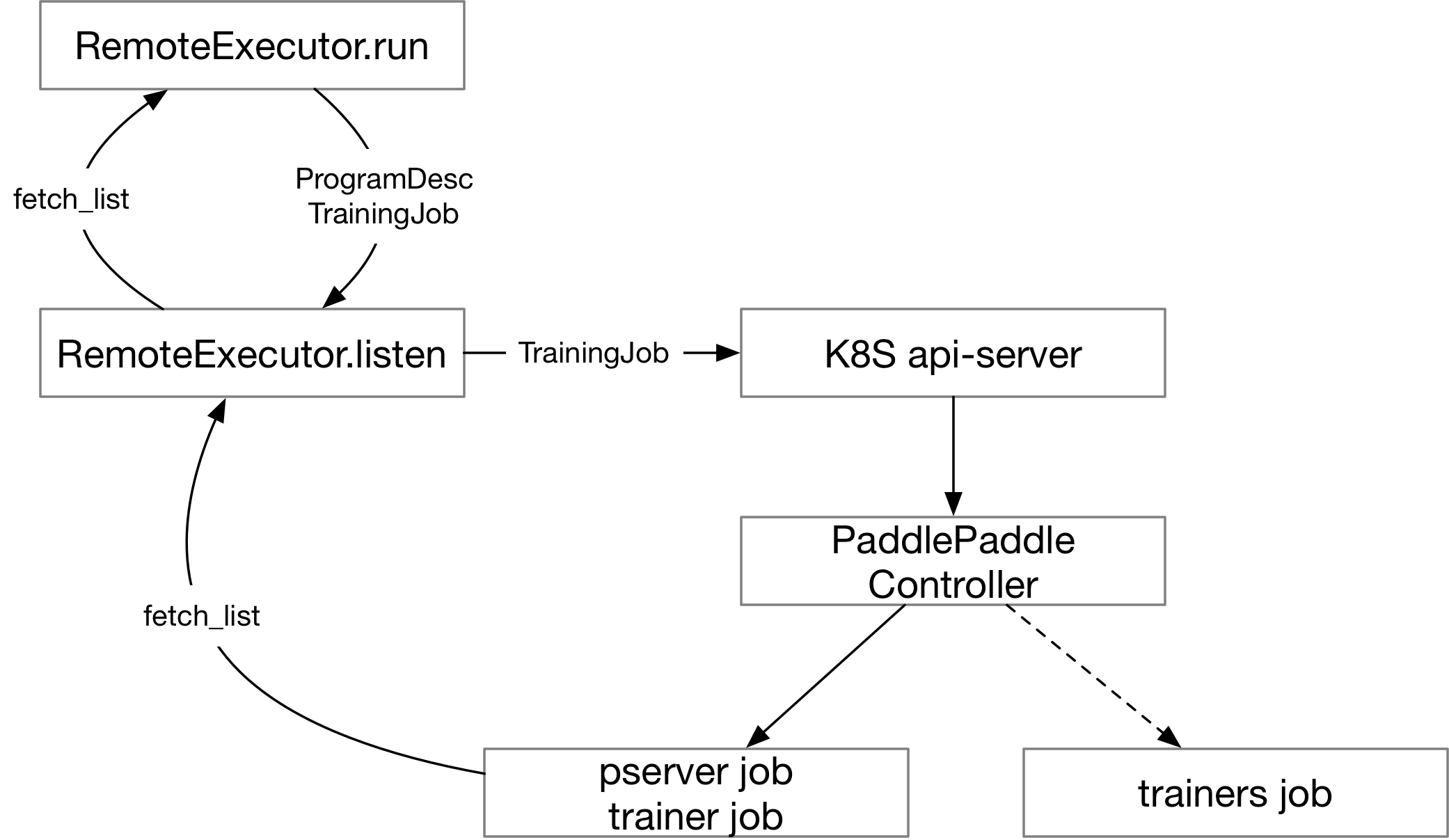
134.5 KB
doc/design/error_clip.md
0 → 100644
doc/design/fluid-compiler.graffle
0 → 100644
文件已添加
doc/design/fluid-compiler.png
0 → 100644
{kind=link}
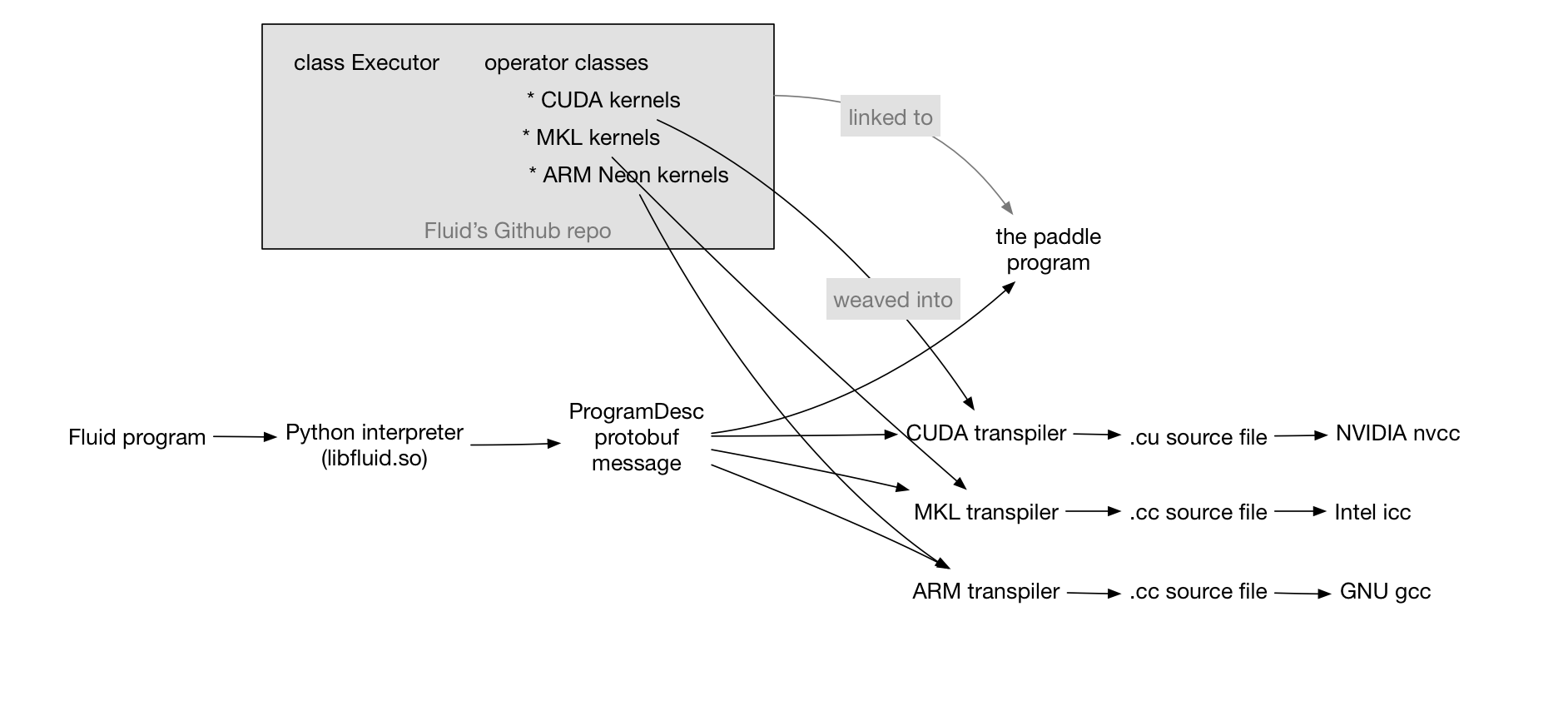
121.2 KB
doc/design/fluid.md
0 → 100644
{kind=link}
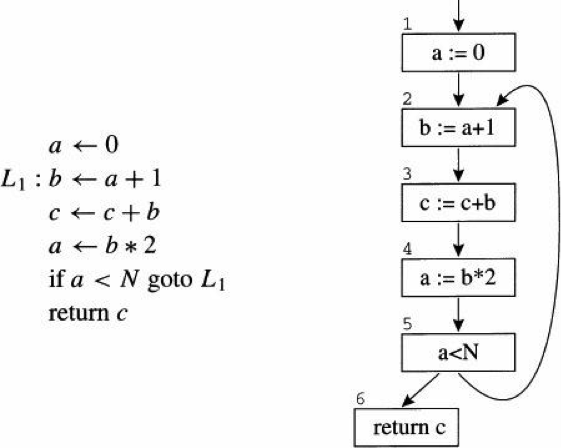
83.3 KB
{kind=link}
22.5 KB
{kind=link}
39.7 KB
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已添加
{kind=link}
108.4 KB
此差异已折叠。
{kind=link}
此差异已折叠。
doc/design/images/profiler.png
0 → 100644
{kind=link}
此差异已折叠。
doc/design/kernel_hint_design.md
0 → 100644
此差异已折叠。
doc/design/memory_optimization.md
0 → 100644
此差异已折叠。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
doc/design/mkl/mkl_packed.md
0 → 100644
此差异已折叠。
doc/design/mkl/mkldnn_fluid.md
0 → 100644
此差异已折叠。
此差异已折叠。
doc/design/paddle_nccl.md
0 → 100644
此差异已折叠。
doc/design/profiler.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
doc/design/support_new_device.md
0 → 100644
此差异已折叠。
doc/design/switch_kernel.md
0 → 100644
此差异已折叠。
此差异已折叠。
doc/howto/dev/new_op_kernel_en.md
0 → 100644
此差异已折叠。
doc/howto/read_source.md
0 → 100644
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/howto/usage/capi/index_cn.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
文件已移动
文件已移动
文件已移动
此差异已折叠。
文件已移动
文件已移动
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/capi/error.cpp
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/framework/backward.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/framework/data_layout.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/framework/data_transform.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/framework/init.cc
0 → 100644
此差异已折叠。
paddle/framework/init.h
0 → 100644
此差异已折叠。
paddle/framework/init_test.cc
0 → 100644
此差异已折叠。
paddle/framework/library_type.h
0 → 100644
此差异已折叠。
paddle/framework/op_kernel_type.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/framework/tensor_util.cc
0 → 100644
此差异已折叠。
paddle/framework/tensor_util.cu
0 → 120000
此差异已折叠。
paddle/framework/threadpool.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/inference/CMakeLists.txt
0 → 100644
此差异已折叠。
paddle/inference/example.cc
0 → 100644
此差异已折叠。
paddle/inference/inference.cc
0 → 100644
此差异已折叠。
paddle/inference/inference.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/ctc_align_op.cc
0 → 100644
此差异已折叠。
paddle/operators/ctc_align_op.cu
0 → 100644
此差异已折叠。
paddle/operators/ctc_align_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/fill_op.cc
0 → 100644
此差异已折叠。
paddle/operators/get_places_op.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/norm_op.cc
0 → 100644
此差异已折叠。
paddle/operators/norm_op.cu
0 → 100644
此差异已折叠。
paddle/operators/norm_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
文件已移动
此差异已折叠。
paddle/operators/print_op.cc
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/operators/row_conv_op.cc
0 → 100644
此差异已折叠。
paddle/operators/row_conv_op.cu
0 → 100644
此差异已折叠。
paddle/operators/row_conv_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/spp_op.cc
0 → 100644
此差异已折叠。
paddle/operators/spp_op.cu.cc
0 → 100644
此差异已折叠。
paddle/operators/spp_op.h
0 → 100644
此差异已折叠。
paddle/operators/tensor.save
已删除
100644 → 0
此差异已折叠。
paddle/operators/warpctc_op.cc
0 → 100644
此差异已折叠。
paddle/operators/warpctc_op.cu.cc
0 → 100644
此差异已折叠。
paddle/operators/warpctc_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/platform/dynload/warpctc.h
0 → 100644
此差异已折叠。
paddle/platform/for_range.h
0 → 100644
此差异已折叠。
paddle/platform/mkldnn_helper.h
0 → 100644
此差异已折叠。
paddle/platform/profiler.cc
0 → 100644
此差异已折叠。
paddle/platform/profiler.h
0 → 100644
此差异已折叠。
paddle/platform/profiler_test.cc
0 → 100644
此差异已折叠。
paddle/pybind/const_value.cc
0 → 100644
此差异已折叠。
paddle/pybind/const_value.h
0 → 100644
此差异已折叠。
paddle/scripts/check_env.sh
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。