Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
BaiXuePrincess
Paddle
提交
a0fefc27
P
Paddle
项目概览
BaiXuePrincess
/
Paddle
与 Fork 源项目一致
Fork自
PaddlePaddle / Paddle
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
a0fefc27
编写于
7月 04, 2018
作者:
W
Wu Yi
提交者:
GitHub
7月 04, 2018
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Add NCCL2 dist train design doc (#11885)
* add_nccl2_dist_design * update * update by comments
上级
78790ed8
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
35 addition
and
0 deletion
+35
-0
doc/fluid/design/dist_train/dist_train_nccl2.md
doc/fluid/design/dist_train/dist_train_nccl2.md
+35
-0
doc/fluid/design/dist_train/src/ncc2_design.graffle
doc/fluid/design/dist_train/src/ncc2_design.graffle
+0
-0
doc/fluid/design/dist_train/src/ncc2_design.png
doc/fluid/design/dist_train/src/ncc2_design.png
+0
-0
未找到文件。
doc/fluid/design/dist_train/dist_train_nccl2.md
0 → 100644
浏览文件 @
a0fefc27
# Distributed Training with NCCL2
We design a pattern that can enable training with
`ParallelExecutor`
and
using
[
NCCL2
](
https://developer.nvidia.com/nccl
)
as it's collective
communication library.
In
`ParallelExecutor`
we can use
`AllReduce`
or
`Reduce`
and
`Broadcast`
to do multi GPU training. And if we initialize NCCL2 communicators as
ranks in a distributed environment, we can simply run the
`ParallelExecutor`
as a distributed program! The only thing that may be different than in
the single node version is that we need to broadcast the NCCL unique ID
to all the nodes, and initialize communicators using that ID, so NCCL2
will know each other as ranks.
To achieve this feature, we introduce a new operator:
`gen_nccl_id`
op,
so we are
***not**
*
"bind to" running NCCL2 with MPI, we can run it in
what ever platform you like.
It have two running modes:
1.
Generate and broadcast mode, which should be used on trainer 0;
1.
Listen and fetch mode, which should be used on trainers other than 0.
In both two modes, this op can save the NCCL ID into current scope as a
persistable variable, Then we can insert this op at the end of
"startup program" of fluid, so that all workers can get the same ID to
initialize NCCL communicator objects.
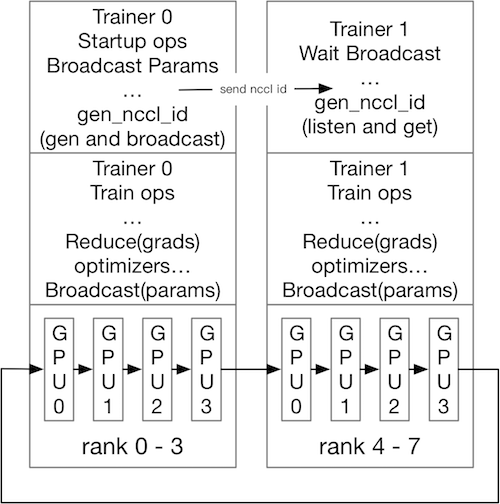
<img
src=
"src/ncc2_design.png"
>
The above figure indicates the general process when training with NCCL2
distributed. Each trainer have the number of communicators equal to the
number of GPUs, but the ranks should match the global ranks number: here
we have total 8 GPUs, so
`nranks==8`
, for each trainer, the ranks should
be from 0 ~ 3 on trainer 0 and 4 ~ 7 on trainer 1.
doc/fluid/design/dist_train/src/ncc2_design.graffle
0 → 100644
浏览文件 @
a0fefc27
文件已添加
doc/fluid/design/dist_train/src/ncc2_design.png
0 → 100644
浏览文件 @
a0fefc27
91.6 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}