“9b63d2aaf236bb3963435a44adb0eea64bb14f9e”上不存在“develop/api_doc/overview.html”
Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into seq_expand_op
Showing
{kind=link}
31.5 KB
{kind=link}
45.0 KB
{kind=link}
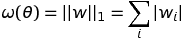
1.1 KB
{kind=link}

989 字节
{kind=link}
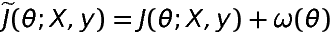
1.6 KB
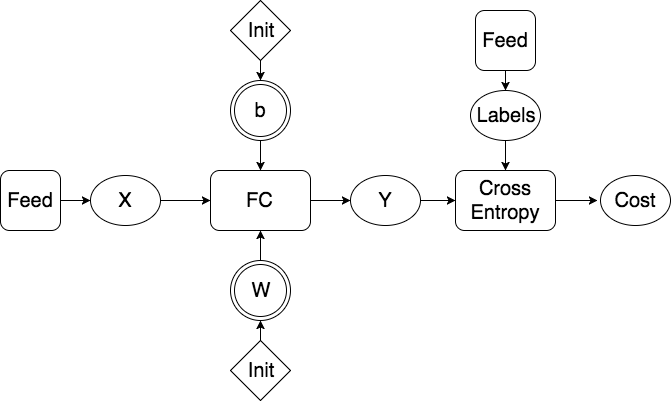
doc/design/prune.md
0 → 100644
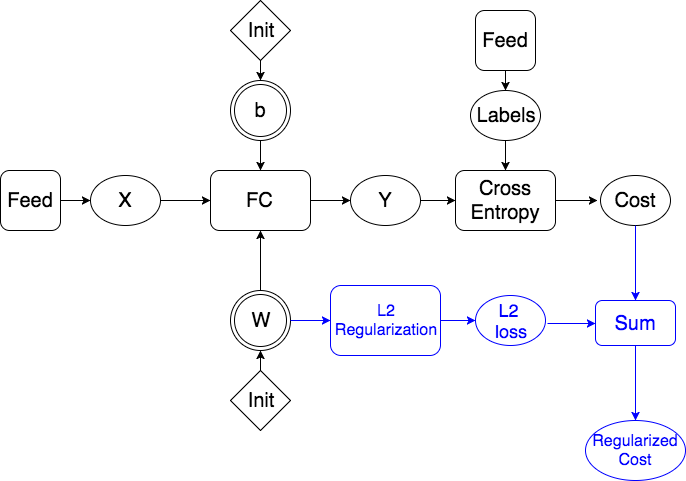
doc/design/regularization.md
0 → 100644
paddle/framework/prune.cc
0 → 100644
paddle/framework/prune.h
0 → 100644
paddle/framework/prune_test.cc
0 → 100644
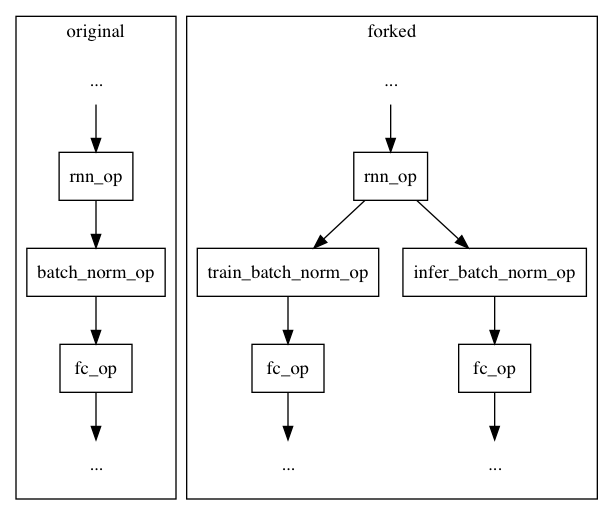
paddle/operators/batch_norm_op.md
0 → 100644
{kind=link}
23.3 KB
{kind=link}

161.3 KB
paddle/operators/proximal_gd_op.h
0 → 100644