[](https://gitter.im/PaddlePaddle/Deep_Learning?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
The `process`function yield 7 lists which are six features and labels.
The `process`function yield 9 lists which are 8 features and label.
### Neural Network Config
### Neural Network Config
`db_lstm.py` is the neural network config file to load the dictionaries and define the data provider module and network architecture during the training procedure.
`db_lstm.py` is the neural network config file to load the dictionaries and define the data provider module and network architecture during the training procedure.
Seven `data_layer` load instances from data provider. Six features are transformed into embedddings respectively, and mixed by `mixed_layer` . Deep bidirectional LSTM layers extract features for the softmax layer. The objective function is cross entropy of labels.
Nine `data_layer` load instances from data provider. Eight features are transformed into embedddings respectively, and mixed by `mixed_layer` . Deep bidirectional LSTM layers extract features for the softmax layer. The objective function is cross entropy of labels.
### Run Training
### Run Training
The script for training is `train.sh`, user just need to execute:
The script for training is `train.sh`, user just need to execute:
...
@@ -115,27 +120,36 @@ The content in `train.sh`:
...
@@ -115,27 +120,36 @@ The content in `train.sh`:
```
```
paddle train \
paddle train \
--config=./db_lstm.py \
--config=./db_lstm.py \
--use_gpu=0 \
--log_period=5000 \
--trainer_count=1 \
--show_parameter_stats_period=5000 \
--save_dir=./output \
--save_dir=./output \
--trainer_count=4 \
--num_passes=10000 \
--log_period=10 \
--average_test_period=10000000 \
--num_passes=500 \
--init_model_path=./data \
--use_gpu=false \
--load_missing_parameter_strategy=rand \
--show_parameter_stats_period=10 \
--test_all_data_in_one_period=1 \
--test_all_data_in_one_period=1 \
2>&1 | tee 'train.log'
2>&1 | tee 'train.log'
```
```
-\--config=./db_lstm.py : network config file.
-\--config=./db_lstm.py : network config file.
-\--save_di=./output: output path to save models.
-\--use_gpu=false: use CPU to train, set true, if you install GPU version of PaddlePaddle and want to use GPU to train, until now crf_layer do not support GPU
-\--trainer_count=4 : set thread number (or GPU count).
-\--log_period=500: print log every 20 batches.
-\--log_period=10 : print log every 20 batches.
-\--trainer_count=1: set thread number (or GPU count).
-\--num_passes=500: set pass number, one pass in PaddlePaddle means training all samples in dataset one time.
-\--show_parameter_stats_period=5000: show parameter statistic every 100 batches.
-\--use_gpu=false: use CPU to train, set true, if you install GPU version of PaddlePaddle and want to use GPU to train.
-\--save_dir=./output: output path to save models.
-\--show_parameter_stats_period=10: show parameter statistic every 100 batches.
-\--num_passes=10000: set pass number, one pass in PaddlePaddle means training all samples in dataset one time.
-\--test_all_data_in_one_period=1: test all data in every testing.
-\--average_test_period=10000000: do test on average parameter every average_test_period batches
-\--load_missing_parameter_strategy=rand: random initialization unexisted parameters
After training, the models will be saved in directory `output`.
-\--test_all_data_in_one_period=1: test all data in one period
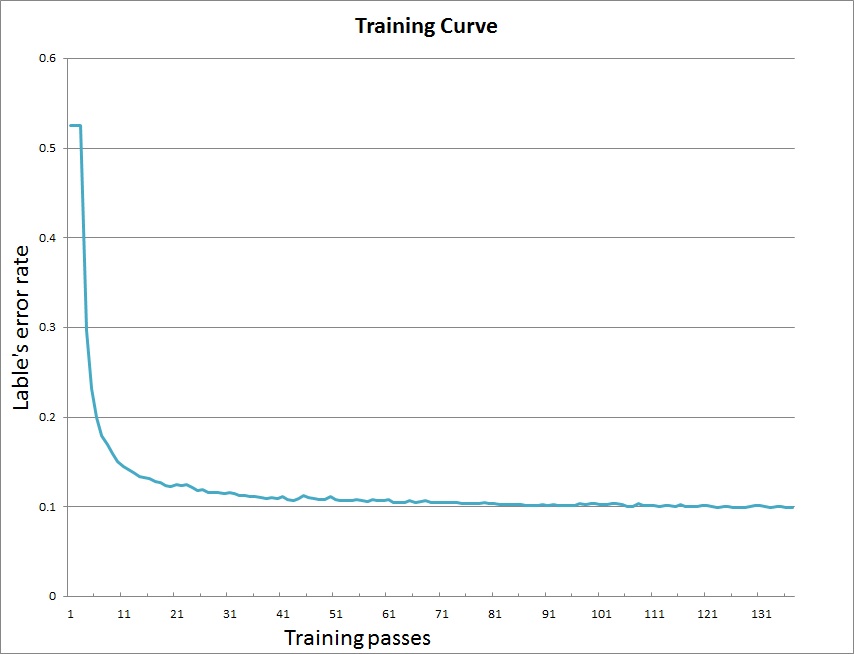
After training, the models will be saved in directory `output`. Our training curve is as following:
<center>

</center>
### Run testing
### Run testing
The script for testing is `test.sh`, user just need to execute:
The script for testing is `test.sh`, user just need to execute:
...
@@ -155,6 +169,7 @@ paddle train \
...
@@ -155,6 +169,7 @@ paddle train \
-\--model_list=$model_list.list: model list file
-\--model_list=$model_list.list: model list file
-\--job=test: indicate the test job
-\--job=test: indicate the test job
-\--config_args=is_test=1: flag to indicate test
-\--config_args=is_test=1: flag to indicate test
-\--test_all_data_in_one_period=1: test all data in 1 period
### Run prediction
### Run prediction
...
@@ -166,11 +181,13 @@ The script for prediction is `predict.sh`, user just need to execute:
...
@@ -166,11 +181,13 @@ The script for prediction is `predict.sh`, user just need to execute:
In `predict.sh`, user should offer the network config file, model path, label file, word dictionary file, feature file
In `predict.sh`, user should offer the network config file, model path, label file, word dictionary file, feature file
```
```
python predict.py
python predict.py
-c $config_file
-c $config_file \
-w $model_path
-w $best_model_path \
-l $label_file
-l $label_file \
-d $dict_file
-p $predicate_dict_file \
-i $input_file
-d $dict_file \
-i $input_file \
-o $output_file
```
```
`predict.py` is the main executable python script, which includes functions: load model, load data, data prediction. The network model will output the probability distribution of labels. In the demo, we take the label with maximum probability as result. User can also implement the beam search or viterbi decoding upon the probability distribution matrix.
`predict.py` is the main executable python script, which includes functions: load model, load data, data prediction. The network model will output the probability distribution of labels. In the demo, we take the label with maximum probability as result. User can also implement the beam search or viterbi decoding upon the probability distribution matrix.
{kind=link}