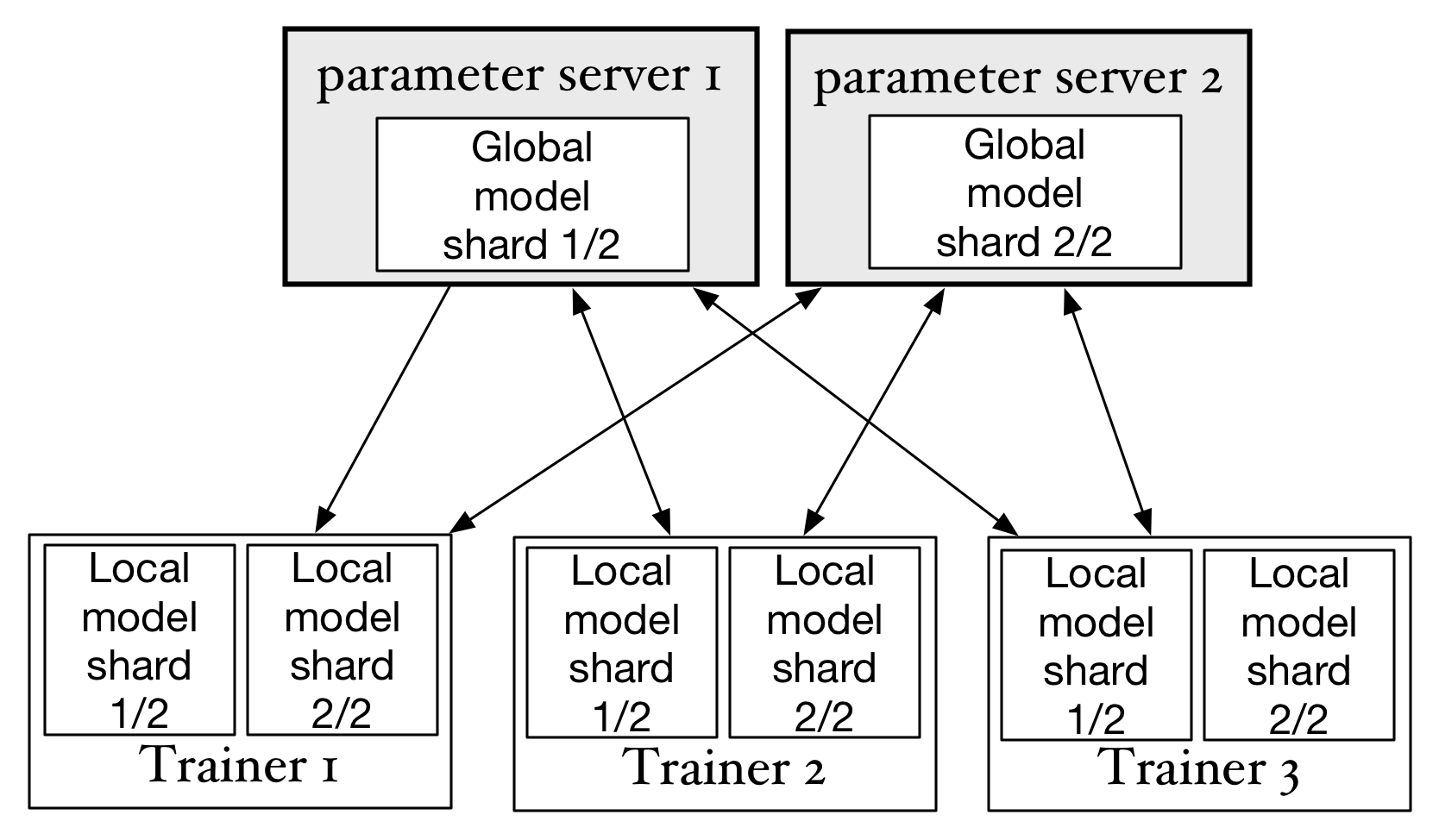
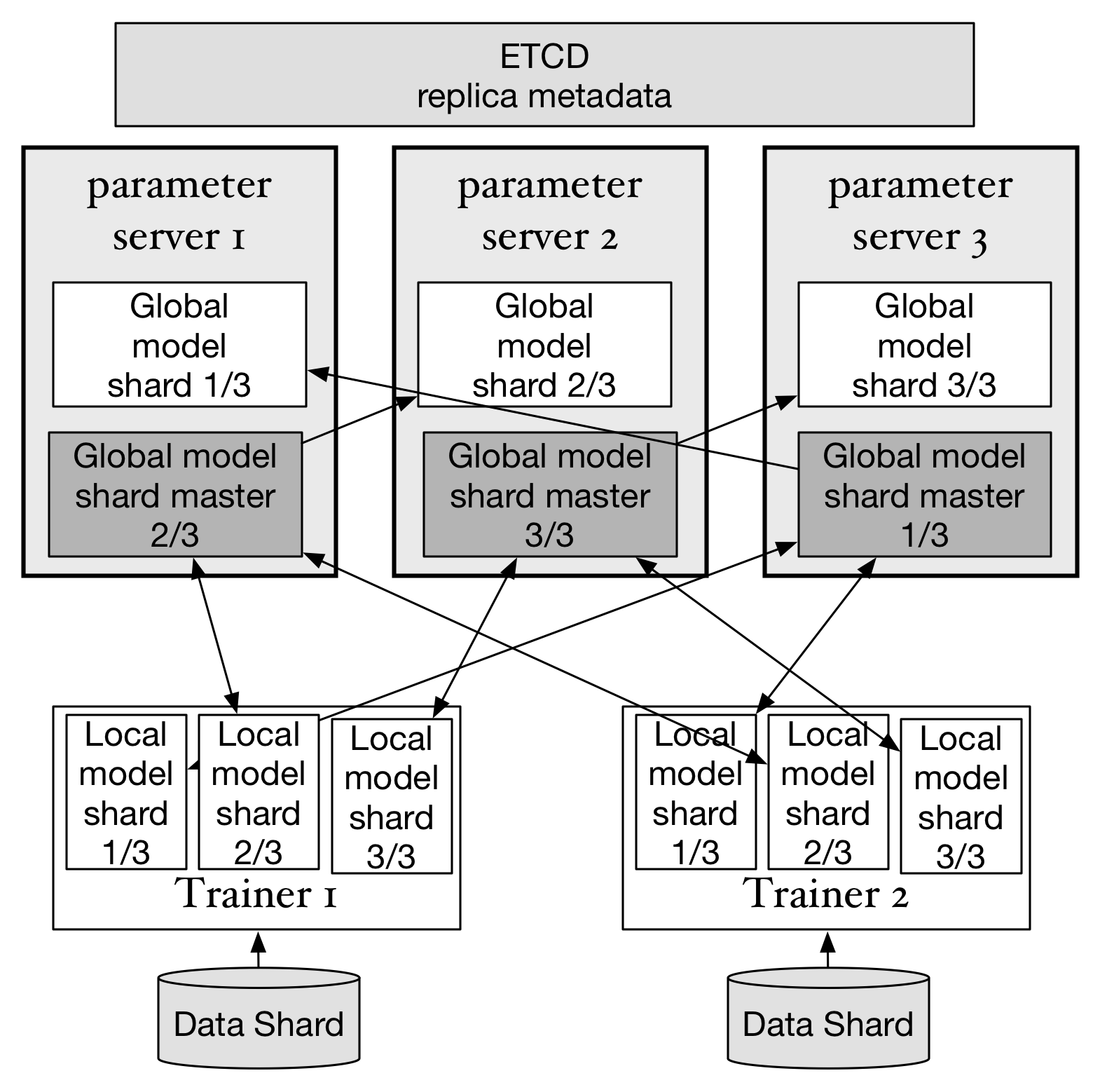
处于"master"状态的副本是当前活动的副本。当一台parameter server故障时,集群中剩下的parameter server
处于"master"状态的副本是当前活动的副本。当一台parameter server故障时,集群中剩下的parameter server
会重新选举出新的"master"副本并继续提供服务。
会重新选举出新的"master"副本并继续提供服务。比如如果parameter server 3故障,仍然可以从parameter server 1和2中找出完整的3个副本。此时虽然性能会临时降低,但可以确保训练任务继续运行,只要有新的parameter server上线,并完成副本的重新分布,就可以恢复原先的集群状态。
*[Large Scale Distributed Deep Networks](http://papers.nips.cc/paper/4687-large-scale-distributed-deep-networks.pdf), Jeffrey Dean, Greg S. Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc V. Le, Mark Z. Mao, Marc’Aurelio Ranzato, Andrew Senior, Paul Tucker, Ke Yang, Andrew Y. Ng
{kind=link}
{kind=link}
{kind=link}
{kind=link}