Commits (5)
Showing
{kind=link}

510.2 KB
{kind=link}

510.2 KB
{kind=link}
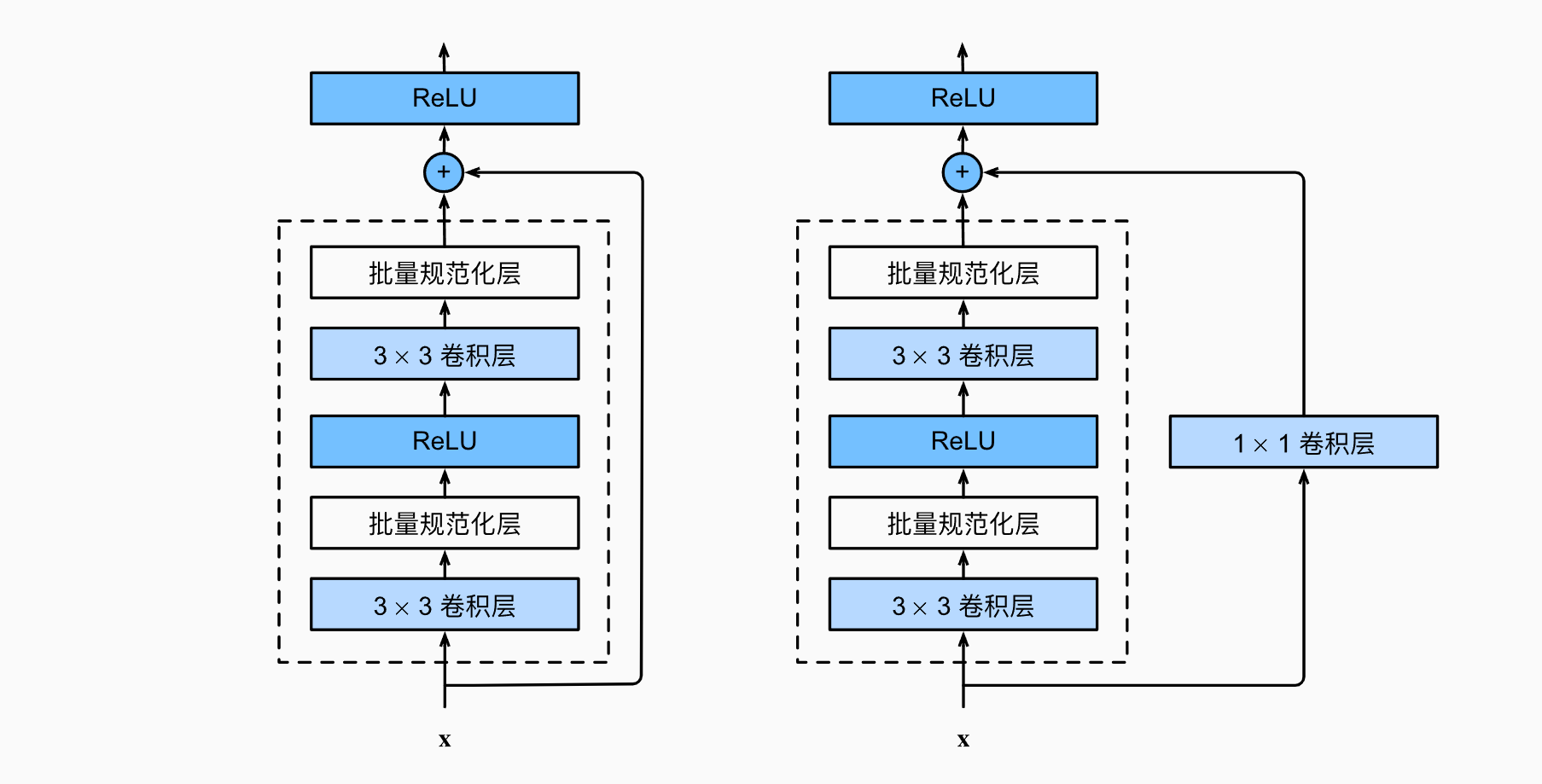
56.0 KB
{kind=link}

471 字节
{kind=link}

14.4 KB
{kind=link}
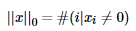
1.6 KB
{kind=link}
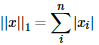
1.3 KB
{kind=link}
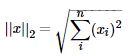
2.6 KB
{kind=link}
56.4 KB
{kind=link}
16.0 KB
{kind=link}
24.6 KB
{kind=link}
2.4 KB
{kind=link}
1021 字节
{kind=link}

22.6 KB
{kind=link}

23.4 KB
dl/Regularization.assets/640.png
0 → 100644
{kind=link}
2.2 KB
{kind=link}
49.7 KB
{kind=link}
7.4 KB
{kind=link}
22.7 KB
{kind=link}
14.3 KB
{kind=link}
5.5 KB
{kind=link}
109.8 KB
{kind=link}
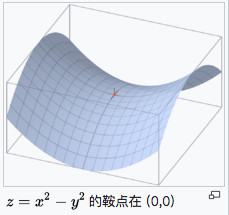
12.4 KB
{kind=link}

71.7 KB
{kind=link}

73.0 KB
{kind=link}

45.4 KB
{kind=link}
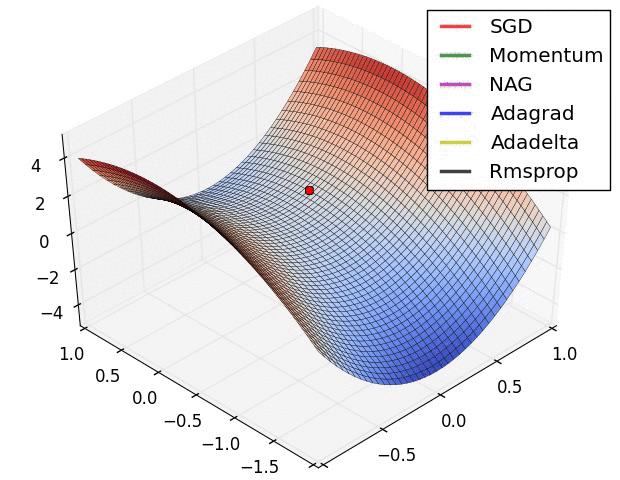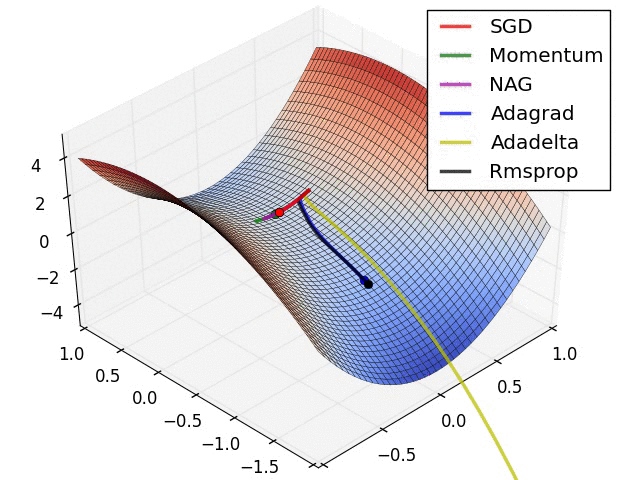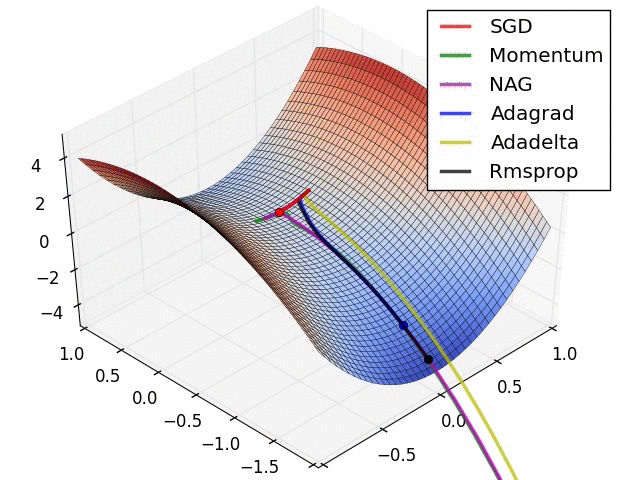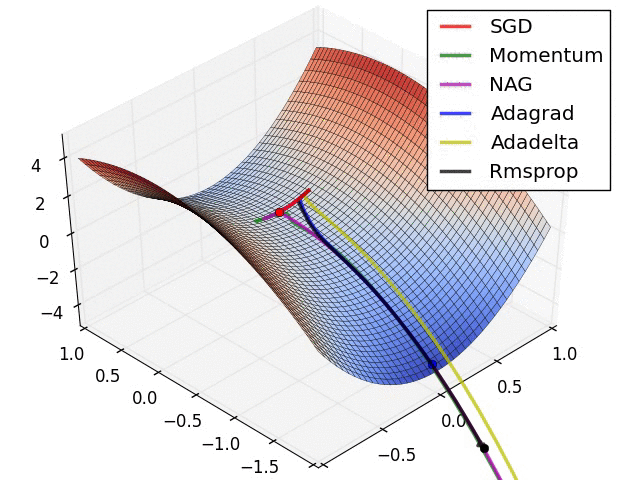
714.0 KB
{kind=link}
893.1 KB
dl/regularization.md
0 → 100644