Rust 中的动态内存分配¶
到目前为止,如果将我们的内核也看成一个应用,那么其中所有的变量都是被静态分配在内存中的。为了在接下来一些功能的实现中 进一步释放 Rust 语言的强表达能力来减轻我们的编码负担,本节我们尝试在内核中支持动态内存分配以待后面使用。
静态与动态内存分配¶
若在某一时间点观察一个应用的地址空间,可以看到若干块连续内存,每一块都对应于一个生命周期尚未结束的变量。这个变量可能 是一个局部变量,它来自于当前正在执行的函数或者当前函数调用栈上某个正在等待调用返回的函数的栈帧,也即它是被分配在 栈上;这个变量也可能是一个全局变量,它被分配在数据段中。它们有一个共同点:在编译的时候编译器已经知道它们类型的字节大小, 于是给它们分配一块等大的内存将它们存储其中,这块内存在变量所属函数的栈帧/数据段中的位置也已经被固定了下来。
这些变量是被 静态分配 (Static Allocation) 的,这一过程来源于我们在程序中对变量的声明,在编译期由编译器完成。 如果应用仅使用静态分配,它也许可以应付绝大部分的需求,但是某些情况则不够灵活。比如,需要将一个文件读到内存进行处理, 而且必须将文件一次性完整读进来处理才能正确。此时,可以选择声明一个栈上的局部变量或者数据段中的全局变量作为缓冲区来暂存 文件的内容。但在编程的时候我们并不知道待处理的文件的大小,只能根据经验将缓冲区的大小设置为某一固定常数。在代码真正运行 的时候,如果待处理的文件很小,那么缓冲区多出的部分是被浪费掉的,也拉高了应用的内存占用;如果待处理的文件很大,应用则 无法正常运行。就像缓冲区的大小设置一样,还有很多其他的问题来源于某些数据结构需求的内存大小取决于应用的实际运行情况。
此时,使用 动态分配 (Dynamic Allocation) 则可以解决这个问题。动态分配就是指应用不仅在自己的地址空间放置那些
自编译期开始就大小固定、用于静态内存分配的逻辑段(如全局数据段、栈段),还另外放置一个大小可以随着应用的运行动态增减
的逻辑段,它的名字叫做堆。同时,应用还要能够将这个段真正管理起来,即支持在运行的时候从里面分配一块空间来存放变量,而
在变量的生命周期结束之后,这块空间需要被回收以待后面的使用。如果堆的大小固定,那么这其实就是一个连续内存分配问题,
我们课上所介绍到的那些算法都可以随意使用。取决于应用的实际运行状况,每次分配的空间大小可能会有不同,因此也会产生外碎片。
如果在某次分配的时候发现堆空间不足,我们并不会像上一小节介绍的那样移动变量的存放位置让它们紧凑起来从而释放间隙用来分配
(事实上它很难做到这一点),
一般情况下应用会直接通过系统调用(如类 Unix 内核提供的 sbrk 调用)来向内核请求增加它地址空间内堆的大小,之后
就可以正常分配了。注意这一类系统调用也能缩减堆的大小。
鉴于动态分配是一项非常基础的功能,很多高级语言的标准库中都实现了它。以 C 语言为例,C 标准库中提供了如下两个动态分配 的接口函数:
void* malloc (size_t size);
void free (void* ptr);
其中,malloc 的作用是从堆中分配一块大小为 size 字节的空间,并返回一个指向它的指针。而后续不用的时候,将这个
指针传给 free 即可在堆中回收这块空间。我们通过返回的指针变量来间接访问堆上的空间,而无法直接进行
访问。事实上,我们在程序中能够 直接 看到的变量都是被静态分配在栈或者全局数据段上的,它们大小在编译期已知,比如这里
一个指针类型的大小就等于平台的位宽。这样的它们却可以作为背后一块大小在编译期无法确定的空间的代表,这是一件非常有趣的
事情。
除了可以灵活利用内存之外,动态分配还允许我们以尽可能小的代价灵活调整变量的生命周期。一个局部变量被静态分配在它所在函数
的栈帧中,一旦函数返回,这个局部变量的生命周期也就结束了;而静态分配在数据段中的全局变量则是在应用的整个运行期间均存在。
动态分配允许我们构造另一种并不一直存在也不绑定于函数调用的变量生命周期:以 C 语言为例,可以说自 malloc 拿到指向
一个变量的指针到 free 将它回收之前的这段时间,这个变量在堆上存在。由于需要跨越函数调用,我们需要作为堆上数据代表
的变量在函数间以参数或返回值的形式进行传递,而这些变量一般都很小(如一个指针),其拷贝开销可以忽略。
而动态内存分配的缺点在于:它背后运行着连续内存分配算法,它相比静态分配会带来一些额外的开销。如果动态分配非常频繁, 它甚至可能会成为应用的性能瓶颈。
Rust 中的堆数据结构¶
Rust 的标准库中提供了很多开箱即用的堆数据结构,利用它们能够大大提升我们的开发效率。
首先是一类 智能指针 (Smart Pointer) 。智能指针和 Rust 中的其他两类指针也即裸指针 *const T/*mut T
以及引用 &T/&mut T 一样,都指向地址空间中的另一个区域并包含它的位置信息。但不同在于,它们携带的信息数量不等,
需要经过编译器不同等级的安全检查,可靠性和灵活程度也不同。
裸指针
*const T/*mut T基本等价于 C/C++ 里面的普通指针T*,它自身的内容仅仅是一个地址。它最为灵活, 但是也最不安全。编译器只能对它进行最基本的可变性检查, 第一章 曾经提到,对于裸指针 解引用访问它指向的那块数据是 unsafe 行为,需要被包裹在 unsafe 块中。引用
&T/&mut T自身的内容也仅仅是一个地址,但是 Rust 编译器会在编译的时候进行比较严格的 借用检查 (Borrow Check) ,要求引用的生命周期必须在被借用的变量的生命周期之内,同时可变借用和不可变借用不能共存,一个 变量可以同时存在多个不可变借用,而可变借用同时最多只能存在一个。这能在编译期就解决掉很多内存不安全问题。智能指针不仅包含它指向的区域的地址,还含有一些额外的信息,因此这个类型的字节大小大于平台的位宽,属于一种胖指针。 从用途上看,它不仅可以作为一个媒介来访问它指向的数据,还能在这个过程中起到一些管理和控制的功能。
在 Rust 中,与动态内存分配相关的智能指针有如下这些:
Box<T>在创建时会在堆上分配一个类型为T的变量,它自身也只保存在堆上的那个变量的位置。而和裸指针或引用 不同的是,当Box<T>被回收的时候,它指向的——也就是在堆上被动态分配的那个变量也会被回收。Rc<T>是一个单线程上使用的引用计数类型,Arc<T>与其功能相同,只是它可以在多线程上使用。它提供了 多所有权,也即地址空间中同时可以存在指向同一个堆上变量的Rc<T>,它们都可以拿到指向变量的不可变引用来 访问这同一个变量。而它同时也是一个引用计数,事实上在堆上的另一个位置维护了堆上这个变量目前被引用了多少次, 也就是存在多少个Rc<T>。这个计数会随着Rc<T>的创建或复制而增加,并当Rc<T>生命周期结束 被回收时减少。当这个计数变为零之后,这个计数变量本身以及被引用的变量都会从堆上被回收。Mutex<T>是一个互斥锁,在多线程中使用,它可以保护里层被动态分配到堆上的变量同一时间只有一个线程能对它 进行操作,从而避免数据竞争,这是并发安全的问题,会在后面详细说明。同时,它能够提供 内部可变性 。Mutex<T>时常和Arc<T>配套使用,因为它是用来 保护多个线程可能同时访问的数据,其前提就是多个线程都拿到指向同一块堆上数据的Mutex<T>。于是,要么就是 这个Mutex<T>作为全局变量被分配到数据段上,要么就是我们需要将Mutex<T>包裹上一层多所有权变成Arc<Mutex<T>>,让它可以在线程间进行传递。请记住Arc<Mutex<T>>这个经典组合,我们后面会经常用到。之前我们通过
RefCell<T>来获得内部可变性。可以将Mutex<T>看成RefCell<T>的多线程版本, 因为RefCell<T>是只能在单线程上使用的。而且RefCell<T>并不会在堆上分配内存,它仅用到静态内存 分配。
这和 C++ 很像, Box<T> 可以对标 C++ 的 std::unique_ptr ;而 Arc<T> 则类似于 C++ 的
std::shared_ptr 。
随后,是一些 集合 (Collection) 或称 容器 (Container) 类型,它们负责管理一组数目可变的元素,这些元素 的类型相同或是有着一些同样的特征。在 C++/Python/Java 等高级语言中我们已经对它们的使用方法非常熟悉了,对于 Rust 而言,我们则可以直接使用以下容器:
向量
Vec<T>类似于 C++ 中的std::vector;键值对容器
BTreeMap<K, V>类似于 C++ 中的std::map;有序集合
BTreeSet<T>类似于 C++ 中的std::set;链表
LinkedList<T>类似于 C++ 中的std::list;双端队列
VecDeque<T>类似于 C++ 中的std::deque。变长字符串
String类似于 C++ 中的std::string。
下面是一张 Rust 智能指针/容器及其他类型的内存布局的经典图示,来自 这里 。
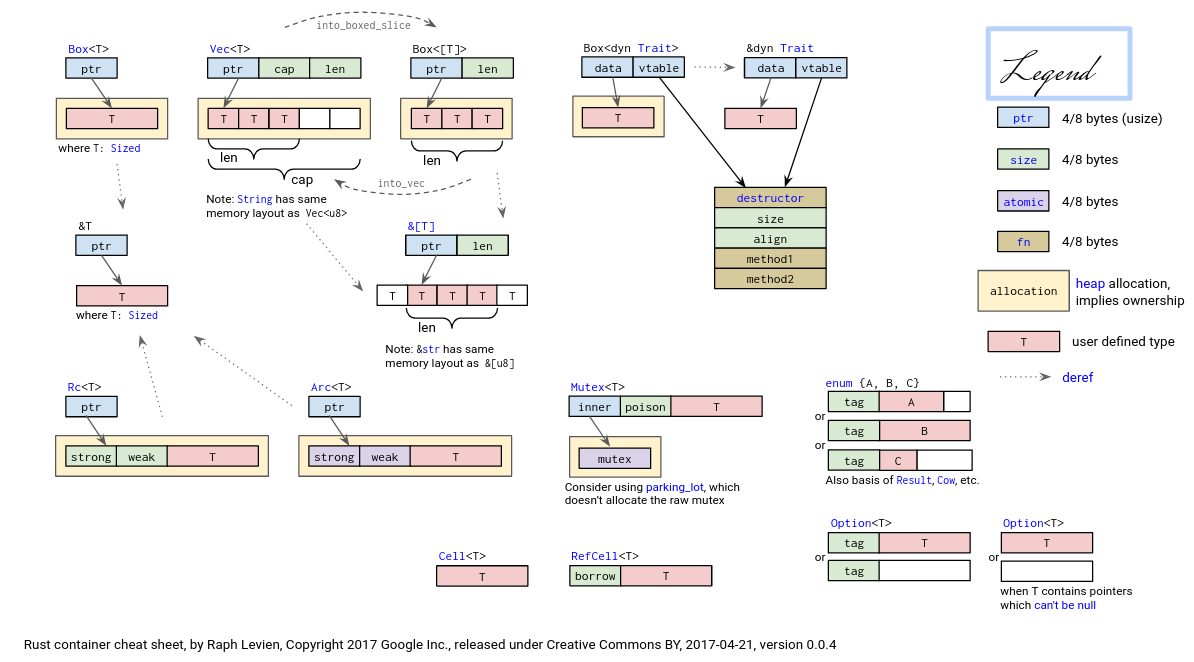
可以发现,在动态内存分配方面 Rust 和 C++ 很像,事实上 Rust 有意从 C++ 借鉴了这部分优秀特性。让我们先来看其他一些语言 使用动态内存的方式:
C 语言仅支持
malloc/free这一对操作,它们必须恰好成对使用,否则就会出现错误。比如分配了之后没有回收,则会导致 内存溢出;回收之后再次 free 相同的指针,则会造成 Double-Free 问题;又如回收之后再尝试通过指针访问它指向的区域,这 属于 Use-After-Free 问题。总之,这样的内存安全问题层出不穷,毕竟人总是会犯错的。Python/Java 通过 引用计数 (Reference Counting) 对所有的对象进行运行时的动态管理,一套 垃圾回收 (GC, Garbage Collection) 机制会被自动定期触发,每次都会检查所有的对象,如果其引用计数为零则可以将该对象占用的内存 从堆上回收以待后续其他的对象使用。这样做完全杜绝了内存安全问题,但是性能开销则很大,而且 GC 触发的时机和每次 GC 的 耗时都是无法预测的,还使得性能不够稳定。
C++ 的 资源获取即初始化 (RAII, Resource Acquisition Is Initialization) 风格则致力于解决上述问题。
RAII 的含义是说,将一个使用前必须获取的资源的生命周期绑定到一个变量上。以 Box<T> 为例,在它被
创建的时候,会在堆上分配一块空间保存它指向的数据;而在 Box<T> 生命周期结束被回收的时候,堆上的那块空间也会
立即被一并回收。这也就是说,我们无需手动回收资源,它会和绑定到的变量同步由编译器自动回收,我们既不用担心忘记回收更不
可能回收多次;同时,由于我们很清楚一个变量的生命周期,则该资源何时被回收也是完全可预测的,我们也明确知道这次回收
操作的开销。在 Rust 中,不限于堆内存,将某种资源的生命周期与一个变量绑定的这种 RAII 的思想无处不见,甚至这种资源
可能只是另外一种类型的变量。
在内核中支持动态内存分配¶
上边介绍的那些与堆相关的智能指针或容器都可以在 Rust 自带的 alloc crate 中找到。当我们使用 Rust 标准库
std 的时候可以不用关心这个 crate ,因为标准库内已经已经实现了一套堆管理算法,并将 alloc 的内容包含在
std 名字空间之下让开发者可以直接使用。然而我们的内核是在禁用了标准库(即 no_std )的裸机平台,核心库
core 也并没有动态内存分配的功能,这个时候就要考虑利用 alloc 了。
alloc 需要我们提供给它一个全局的动态内存分配器,它会利用该分配器来管理堆空间,从而它提供的数据结构可以正常
工作。我们的动态内存分配器需要实现它提供的 GlobalAlloc Trait,这个 Trait 有两个必须实现的抽象接口:
// alloc::alloc::GlobalAlloc
pub unsafe fn alloc(&self, layout: Layout) -> *mut u8;
pub unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout);
可以看到,它们类似 C 语言中的 malloc/free ,分别代表堆空间的分配和回收,也同样使用一个裸指针(也就是地址)
作为分配的返回值和回收的参数。两个接口中都有一个 alloc::alloc::Layout 类型的参数,
它指出了分配的需求,分为两部分,分别是所需空间的大小 size ,以及返回地址的对齐要求 align 。这个对齐要求
必须是一个 2 的幂次,单位为字节数,限制返回的地址必须是 align 的倍数。
注解
为何 C 语言 malloc 的时候不需要提供对齐需求?
在 C 语言中,所有对齐要求的最大值是一个平台有关的很小的常数,消耗少量内存即可使得每一次分配都符合这个最大 的对齐要求。因此也就不需要区分不同分配的对齐要求了。而在 Rust 中,某些分配的对齐要求可能很大,就只能采用更 加复杂的方法。
之后,只需将我们的动态内存分配器类型实例化为一个全局变量,并使用 #[global_allocator] 语义项标记即可。由于该
分配器的实现比较复杂,我们这里直接使用一个已有的伙伴分配器实现。首先添加 crate 依赖:
# os/Cargo.toml
buddy_system_allocator = "0.6"
接着,需要引入 alloc 的依赖,由于它算是 Rust 内置的 crate ,我们并不是在 Cargo.toml 中进行引入,而是在
main.rs 中声明即可:
// os/src/main.rs
extern crate alloc;
然后,根据 alloc 留好的接口提供全局动态内存分配器:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | // os/src/mm/heap_allocator.rs
use buddy_system_allocator::LockedHeap;
use crate::config::KERNEL_HEAP_SIZE;
#[global_allocator]
static HEAP_ALLOCATOR: LockedHeap = LockedHeap::empty();
static mut HEAP_SPACE: [u8; KERNEL_HEAP_SIZE] = [0; KERNEL_HEAP_SIZE];
pub fn init_heap() {
unsafe {
HEAP_ALLOCATOR
.lock()
.init(HEAP_SPACE.as_ptr() as usize, KERNEL_HEAP_SIZE);
}
}
|
第 7 行,我们直接将
buddy_system_allocator中提供的LockedHeap实例化成一个全局变量,并使用alloc要求的#[global_allocator]语义项进行标记。注意LockedHeap已经实现了GlobalAlloc要求的抽象接口了。第 11 行,在使用任何
alloc中提供的堆数据结构之前,我们需要先调用init_heap函数来给我们的全局分配器 一块内存用于分配。在第 9 行可以看到,这块内存是一个static mut且被零初始化的字节数组,位于内核的.bss段中。LockedHeap也是一个被互斥锁保护的类型,在对它任何进行任何操作之前都要先获取锁以避免其他 线程同时对它进行操作导致数据竞争。然后,调用init方法告知它能够用来分配的空间的起始地址和大小即可。
我们还需要处理动态内存分配失败的情形,在这种情况下我们直接 panic :
// os/src/main.rs
#![feature(alloc_error_handler)]
// os/src/mm/heap_allocator.rs
#[alloc_error_handler]
pub fn handle_alloc_error(layout: core::alloc::Layout) -> ! {
panic!("Heap allocation error, layout = {:?}", layout);
}
最后,让我们尝试一下动态内存分配吧!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | // os/src/mm/heap_allocator.rs
#[allow(unused)]
pub fn heap_test() {
use alloc::boxed::Box;
use alloc::vec::Vec;
extern "C" {
fn sbss();
fn ebss();
}
let bss_range = sbss as usize..ebss as usize;
let a = Box::new(5);
assert_eq!(*a, 5);
assert!(bss_range.contains(&(a.as_ref() as *const _ as usize)));
drop(a);
let mut v: Vec<usize> = Vec::new();
for i in 0..500 {
v.push(i);
}
for i in 0..500 {
assert_eq!(v[i], i);
}
assert!(bss_range.contains(&(v.as_ptr() as usize)));
drop(v);
println!("heap_test passed!");
}
|
其中分别使用智能指针 Box<T> 和向量 Vec<T> 在堆上分配数据并管理它们,通过 as_ref 和 as_ptr
方法可以分别看到它们指向的数据的位置,能够确认它们的确在 .bss 段的堆上。
注解
本节部分内容参考自 BlogOS 的相关章节 。