3.**插入和删除是否受元素位置的影响:** ① **`ArrayList` 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e)`方法的时候, `ArrayList` 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element)`)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **`LinkedList` 采用链表存储,所以对于`add(E e)`方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置`i`插入和删除元素的话(`(add(int index, E element)`) 时间复杂度近似为`o(n))`因为需要先移动到指定位置再插入。**
{kind=link}
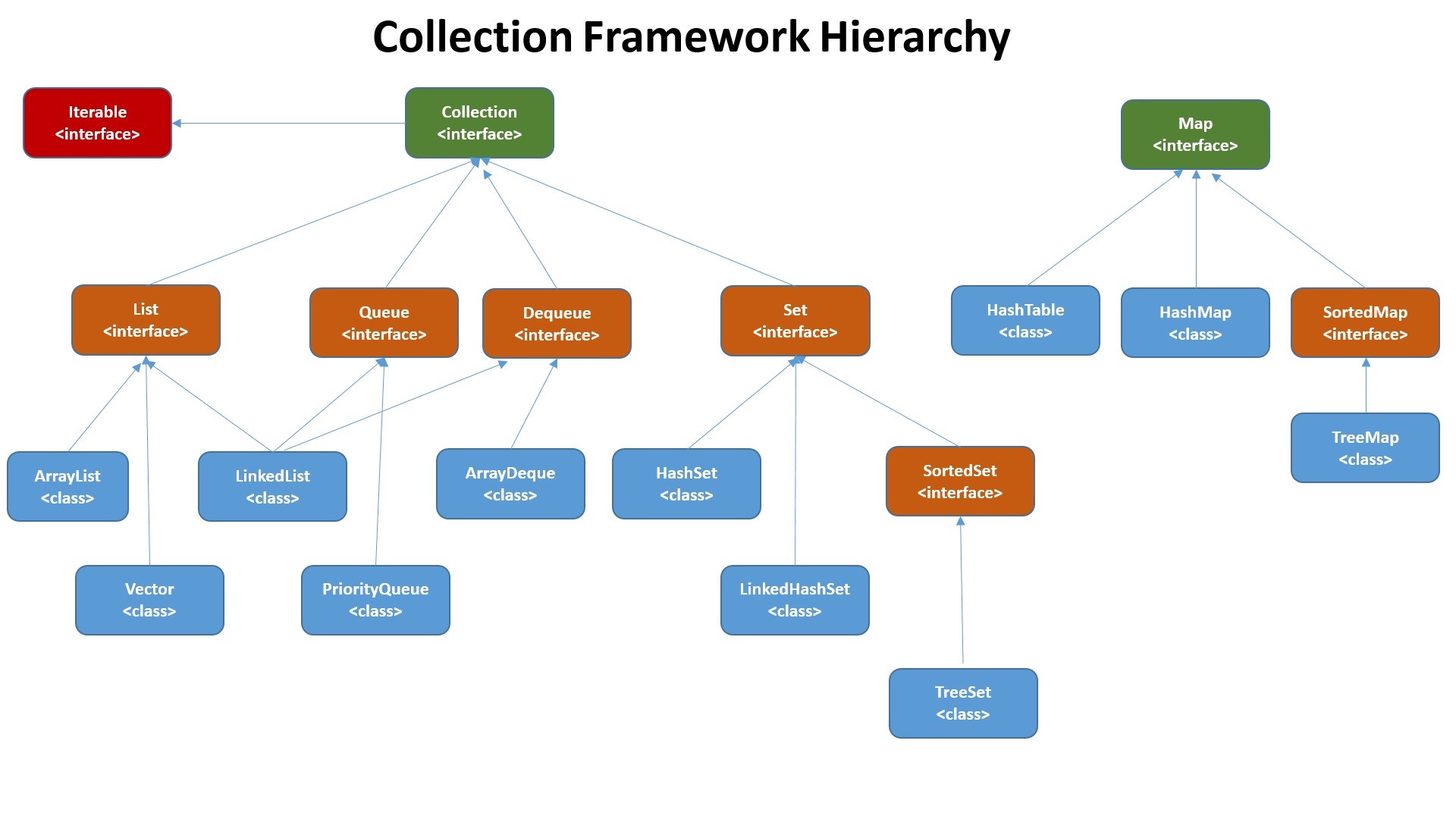
{kind=link}
