auto commit
Showing
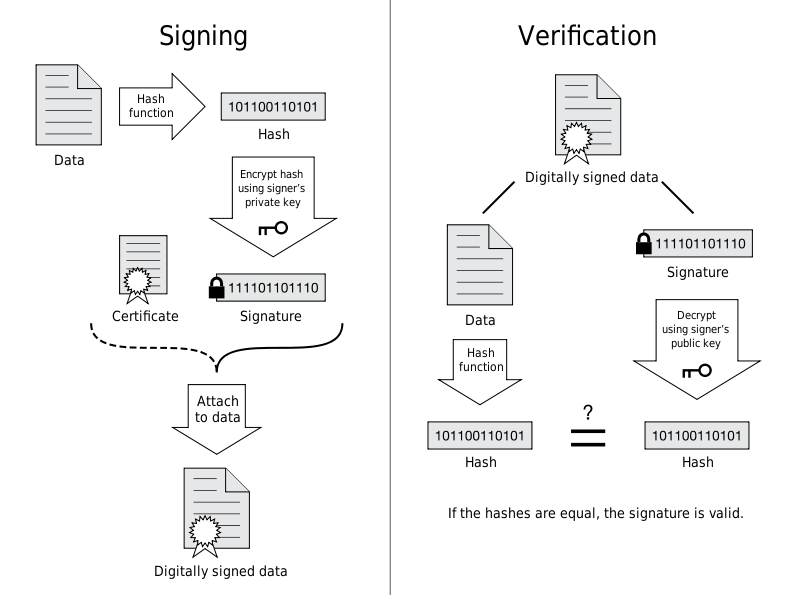
pics/2017-06-11-ca.png
0 → 100644
{kind=link}
55.0 KB
{kind=link}
29.0 KB
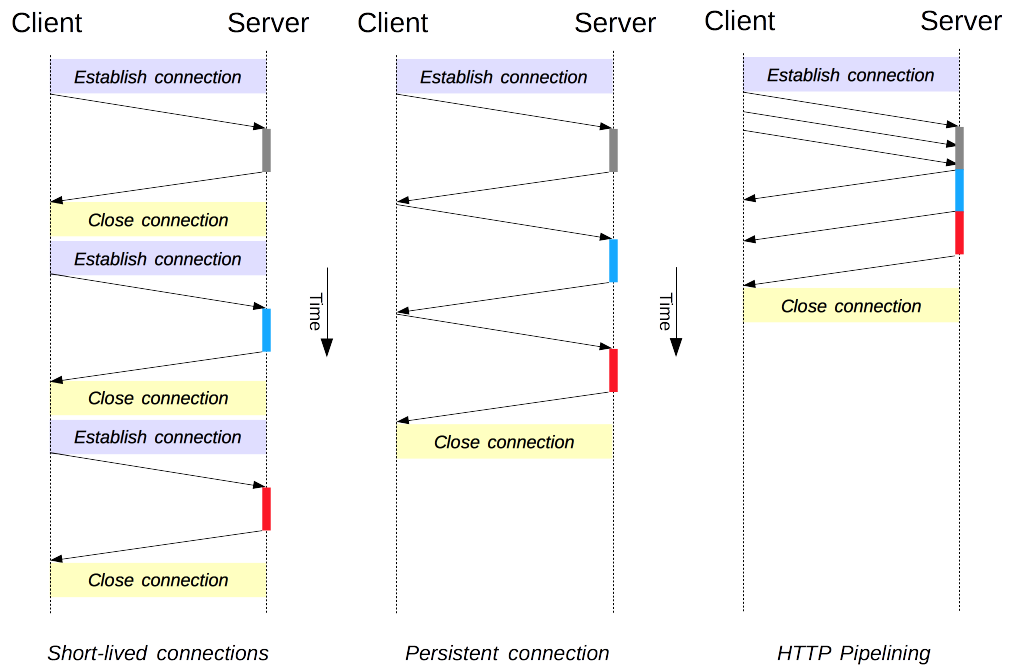
pics/HTTP1_x_Connections.png
0 → 100644
{kind=link}
127.0 KB
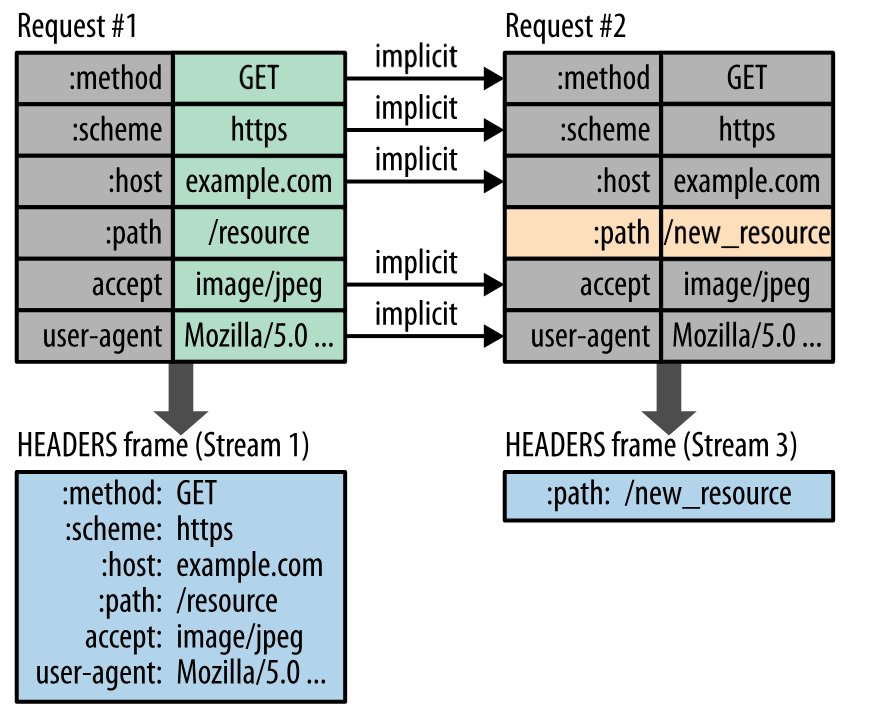
pics/_u4E0B_u8F7D.png
0 → 100644
{kind=link}
142.0 KB
{kind=link}
68.0 KB
{kind=link}
47.0 KB
从无法访问的项目Fork
55.0 KB
29.0 KB
127.0 KB
142.0 KB
68.0 KB
47.0 KB