From 3edd3984f48e76a22a95add26f9f29f8b232926b Mon Sep 17 00:00:00 2001
From: CyC2018 <1029579233@qq.com>
Date: Thu, 30 Aug 2018 20:25:57 +0800
Subject: [PATCH] auto commit
---
notes/Docker.md | 32 +++------
notes/Git.md | 32 ++++-----
notes/HTTP.md | 46 ++++++------
"notes/Java \345\271\266\345\217\221.md" | 33 +++++----
...a \350\231\232\346\213\237\346\234\272.md" | 30 +-------
notes/Linux.md | 10 ++-
.../\345\210\206\345\270\203\345\274\217.md" | 26 ++++---
...04\345\273\272\345\267\245\345\205\267.md" | 29 +++-----
...10\346\201\257\351\230\237\345\210\227.md" | 2 +-
"notes/\347\256\227\346\263\225.md" | 70 +++++++++----------
"notes/\347\274\223\345\255\230.md" | 26 +++----
...27\346\234\272\347\275\221\347\273\234.md" | 6 +-
...76\350\256\241\346\250\241\345\274\217.md" | 13 ++--
"notes/\351\207\215\346\236\204.md" | 6 +-
"notes/\351\233\206\347\276\244.md" | 6 +-
...71\350\261\241\346\200\235\346\203\263.md" | 5 +-
16 files changed, 169 insertions(+), 203 deletions(-)
diff --git a/notes/Docker.md b/notes/Docker.md
index 80108896..1b61a7fe 100644
--- a/notes/Docker.md
+++ b/notes/Docker.md
@@ -4,6 +4,7 @@
* [三、优势](#三优势)
* [四、使用场景](#四使用场景)
* [五、镜像与容器](#五镜像与容器)
+* [参考资料](#参考资料)
@@ -15,11 +16,6 @@
Docker 主要解决环境配置问题,它是一种虚拟化技术,对进程进行隔离,被隔离的进程独立于宿主操作系统和其它隔离的进程。使用 Docker 可以不修改应用程序代码,不需要开发人员学习特定环境下的技术,就能够将现有的应用程序部署在其他机器中。
-参考资料:
-
-- [DOCKER 101: INTRODUCTION TO DOCKER WEBINAR RECAP](https://blog.docker.com/2017/08/docker-101-introduction-docker-webinar-recap/)
-- [Docker 入门教程](http://www.ruanyifeng.com/blog/2018/02/docker-tutorial.html)
-
# 二、与虚拟机的比较
虚拟机也是一种虚拟化技术,它与 Docker 最大的区别在于它是通过模拟硬件,并在硬件上安装操作系统来实现。
@@ -40,30 +36,22 @@ Docker 主要解决环境配置问题,它是一种虚拟化技术,对进程
而 Docker 只是一个进程,只需要将应用以及相关的组件打包,在运行时占用很少的资源,一台机器可以开启成千上万个 Docker。
-参考资料:
-
-- [Docker container vs Virtual machine](http://www.bogotobogo.com/DevOps/Docker/Docker_Container_vs_Virtual_Machine.php)
-
# 三、优势
除了启动速度快以及占用资源少之外,Docker 具有以下优势:
## 更容易迁移
-Docker 可以提供一致性的运行环境,可以在不同的机器上进行迁移,而不用担心环境变化导致无法运行。
+提供一致性的运行环境,可以在不同的机器上进行迁移,而不用担心环境变化导致无法运行。
## 更容易维护
-Docker 使用分层技术和镜像,使得应用可以更容易复用重复部分。复用程度越高,维护工作也越容易。
+使用分层技术和镜像,使得应用可以更容易复用重复部分。复用程度越高,维护工作也越容易。
## 更容易扩展
可以使用基础镜像进一步扩展得到新的镜像,并且官方和开源社区提供了大量的镜像,通过扩展这些镜像可以非常容易得到我们想要的镜像。
-参考资料:
-
-- [为什么要使用 Docker?](https://yeasy.gitbooks.io/docker_practice/introduction/why.html)
-
# 四、使用场景
## 持续集成
@@ -80,11 +68,6 @@ Docker 具有轻量级以及隔离性的特点,在将代码集成到一个 Doc
Docker 轻量级的特点使得它很适合用于部署、维护、组合微服务。
-参考资料:
-
-- [What is Docker](https://www.docker.com/what-docker)
-- [持续集成是什么?](http://www.ruanyifeng.com/blog/2015/09/continuous-integration.html)
-
# 五、镜像与容器
镜像是一种静态的结构,可以看成面向对象里面的类,而容器是镜像的一个实例。
@@ -95,9 +78,14 @@ Docker 轻量级的特点使得它很适合用于部署、维护、组合微服

-参考资料:
+# 参考资料
+- [DOCKER 101: INTRODUCTION TO DOCKER WEBINAR RECAP](https://blog.docker.com/2017/08/docker-101-introduction-docker-webinar-recap/)
+- [Docker 入门教程](http://www.ruanyifeng.com/blog/2018/02/docker-tutorial.html)
+- [Docker container vs Virtual machine](http://www.bogotobogo.com/DevOps/Docker/Docker_Container_vs_Virtual_Machine.php)
- [How to Create Docker Container using Dockerfile](https://linoxide.com/linux-how-to/dockerfile-create-docker-container/)
- [理解 Docker(2):Docker 镜像](http://www.cnblogs.com/sammyliu/p/5877964.html)
-
+- [为什么要使用 Docker?](https://yeasy.gitbooks.io/docker_practice/introduction/why.html)
+- [What is Docker](https://www.docker.com/what-docker)
+- [持续集成是什么?](http://www.ruanyifeng.com/blog/2015/09/continuous-integration.html)
diff --git a/notes/Git.md b/notes/Git.md
index 4bb0a543..71ff502c 100644
--- a/notes/Git.md
+++ b/notes/Git.md
@@ -1,8 +1,7 @@
-* [学习资料](#学习资料)
* [集中式与分布式](#集中式与分布式)
-* [Git 的中心服务器](#git-的中心服务器)
-* [Git 工作流](#git-工作流)
+* [中心服务器](#中心服务器)
+* [工作流](#工作流)
* [分支实现](#分支实现)
* [冲突](#冲突)
* [Fast forward](#fast-forward)
@@ -11,16 +10,10 @@
* [SSH 传输设置](#ssh-传输设置)
* [.gitignore 文件](#gitignore-文件)
* [Git 命令一览](#git-命令一览)
+* [参考资料](#参考资料)
-# 学习资料
-
-- [Git - 简明指南](http://rogerdudler.github.io/git-guide/index.zh.html)
-- [图解 Git](http://marklodato.github.io/visual-git-guide/index-zh-cn.html)
-- [廖雪峰 : Git 教程](https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000)
-- [Learn Git Branching](https://learngitbranching.js.org/)
-
# 集中式与分布式
Git 属于分布式版本控制系统,而 SVN 属于集中式。
@@ -33,11 +26,13 @@ Git 属于分布式版本控制系统,而 SVN 属于集中式。
分布式版本控制新建分支、合并分支操作速度非常快,而集中式版本控制新建一个分支相当于复制一份完整代码。
-# Git 的中心服务器
+# 中心服务器
-Git 的中心服务器用来交换每个用户的修改。没有中心服务器也能工作,但是中心服务器能够 24 小时保持开机状态,这样就能更方便的交换修改。Github 就是一种 Git 中心服务器。
+中心服务器用来交换每个用户的修改,没有中心服务器也能工作,但是中心服务器能够 24 小时保持开机状态,这样就能更方便的交换修改。
-# Git 工作流
+Github 就是一个中心服务器。
+
+# 工作流

@@ -54,14 +49,14 @@ Git 版本库有一个称为 stage 的暂存区,还有自动创建的 master

-可以跳过暂存区域直接从分支中取出修改或者直接提交修改到分支中
+可以跳过暂存区域直接从分支中取出修改,或者直接提交修改到分支中。
- git commit -a 直接把所有文件的修改添加到暂缓区然后执行提交
- git checkout HEAD -- files 取出最后一次修改,可以用来进行回滚操作
# 分支实现
-Git 把每次提交都连成一条时间线。分支使用指针来实现,例如 master 分支指针指向时间线的最后一个节点,也就是最后一次提交。HEAD 指针指向的是当前分支。
+使用指针将每个提交连接成一条时间线,HEAD 指针指向当前分支指针。

@@ -69,7 +64,7 @@ Git 把每次提交都连成一条时间线。分支使用指针来实现,例

-每次提交只会让当前分支向前移动,而其它分支不会移动。
+每次提交只会让当前分支指针向前移动,而其它分支指针不会移动。

@@ -155,4 +150,9 @@ $ ssh-keygen -t rsa -C "youremail@example.com"
比较详细的地址:http://www.cheat-sheets.org/saved-copy/git-cheat-sheet.pdf
+# 参考资料
+- [Git - 简明指南](http://rogerdudler.github.io/git-guide/index.zh.html)
+- [图解 Git](http://marklodato.github.io/visual-git-guide/index-zh-cn.html)
+- [廖雪峰 : Git 教程](https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000)
+- [Learn Git Branching](https://learngitbranching.js.org/)
diff --git a/notes/HTTP.md b/notes/HTTP.md
index 537b24fe..aae807e6 100644
--- a/notes/HTTP.md
+++ b/notes/HTTP.md
@@ -25,6 +25,7 @@
* [实体首部字段](#实体首部字段)
* [五、具体应用](#五具体应用)
* [Cookie](#cookie)
+ * [6. Secure](#6-secure)
* [缓存](#缓存)
* [连接管理](#连接管理)
* [内容协商](#内容协商)
@@ -310,7 +311,7 @@ HTTP 协议是无状态的,主要是为了让 HTTP 协议尽可能简单,使
Cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器之后向同一服务器再次发起请求时被携带上,用于告知服务端两个请求是否来自同一浏览器。由于之后每次请求都会需要携带 Cookie 数据,因此会带来额外的性能开销(尤其是在移动环境下)。
-Cookie 曾一度用于客户端数据的存储,因为当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie 渐渐被淘汰。新的浏览器 API 已经允许开发者直接将数据存储到本地,如使用 Web storage API (本地存储和会话存储)或 IndexedDB。
+Cookie 曾一度用于客户端数据的存储,因为当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie 渐渐被淘汰。新的浏览器 API 已经允许开发者直接将数据存储到本地,如使用 Web storage API(本地存储和会话存储)或 IndexedDB。
### 1. 用途
@@ -348,7 +349,17 @@ Cookie: yummy_cookie=choco; tasty_cookie=strawberry
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT;
```
-### 4. JavaScript 获取 Cookie
+### 4. 作用域
+
+Domain 标识指定了哪些主机可以接受 Cookie。如果不指定,默认为当前文档的主机(不包含子域名)。如果指定了 Domain,则一般包含子域名。例如,如果设置 Domain=mozilla.org,则 Cookie 也包含在子域名中(如 developer.mozilla.org)。
+
+Path 标识指定了主机下的哪些路径可以接受 Cookie(该 URL 路径必须存在于请求 URL 中)。以字符 %x2F ("/") 作为路径分隔符,子路径也会被匹配。例如,设置 Path=/docs,则以下地址都会匹配:
+
+- /docs
+- /docs/Web/
+- /docs/Web/HTTP
+
+### 5. JavaScript
通过 `Document.cookie` 属性可创建新的 Cookie,也可通过该属性访问非 HttpOnly 标记的 Cookie。
@@ -358,9 +369,7 @@ document.cookie = "tasty_cookie=strawberry";
console.log(document.cookie);
```
-### 5. Secure 和 HttpOnly
-
-标记为 Secure 的 Cookie 只能通过被 HTTPS 协议加密过的请求发送给服务端。但即便设置了 Secure 标记,敏感信息也不应该通过 Cookie 传输,因为 Cookie 有其固有的不安全性,Secure 标记也无法提供确实的安全保障。
+### 6. HttpOnly
标记为 HttpOnly 的 Cookie 不能被 JavaScript 脚本调用。跨站脚本攻击 (XSS) 常常使用 JavaScript 的 `Document.cookie` API 窃取用户的 Cookie 信息,因此使用 HttpOnly 标记可以在一定程度上避免 XSS 攻击。
@@ -368,15 +377,9 @@ console.log(document.cookie);
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT; Secure; HttpOnly
```
-### 6. 作用域
-
-Domain 标识指定了哪些主机可以接受 Cookie。如果不指定,默认为当前文档的主机(不包含子域名)。如果指定了 Domain,则一般包含子域名。例如,如果设置 Domain=mozilla.org,则 Cookie 也包含在子域名中(如 developer.mozilla.org)。
+## 6. Secure
-Path 标识指定了主机下的哪些路径可以接受 Cookie(该 URL 路径必须存在于请求 URL 中)。以字符 %x2F ("/") 作为路径分隔符,子路径也会被匹配。例如,设置 Path=/docs,则以下地址都会匹配:
-
-- /docs
-- /docs/Web/
-- /docs/Web/HTTP
+标记为 Secure 的 Cookie 只能通过被 HTTPS 协议加密过的请求发送给服务端。但即便设置了 Secure 标记,敏感信息也不应该通过 Cookie 传输,因为 Cookie 有其固有的不安全性,Secure 标记也无法提供确实的安全保障。
### 7. Session
@@ -387,8 +390,7 @@ Session 可以存储在服务器上的文件、数据库或者内存中。也可
使用 Session 维护用户登录状态的过程如下:
- 用户进行登录时,用户提交包含用户名和密码的表单,放入 HTTP 请求报文中;
-- 服务器验证该用户名和密码;
-- 如果正确则把用户信息存储到 Redis 中,它在 Redis 中的 Key 称为 Session ID;
+- 服务器验证该用户名和密码,如果正确则把用户信息存储到 Redis 中,它在 Redis 中的 Key 称为 Session ID;
- 服务器返回的响应报文的 Set-Cookie 首部字段包含了这个 Session ID,客户端收到响应报文之后将该 Cookie 值存入浏览器中;
- 客户端之后对同一个服务器进行请求时会包含该 Cookie 值,服务器收到之后提取出 Session ID,从 Redis 中取出用户信息,继续之前的业务操作。
@@ -462,13 +464,13 @@ Cache-Control: max-age=31536000
Expires 首部字段也可以用于告知缓存服务器该资源什么时候会过期。
-- 在 HTTP/1.1 中,会优先处理 max-age 指令;
-- 在 HTTP/1.0 中,max-age 指令会被忽略掉。
-
```html
Expires: Wed, 04 Jul 2012 08:26:05 GMT
```
+- 在 HTTP/1.1 中,会优先处理 max-age 指令;
+- 在 HTTP/1.0 中,max-age 指令会被忽略掉。
+
### 4. 缓存验证
需要先了解 ETag 首部字段的含义,它是资源的唯一标识。URL 不能唯一表示资源,例如 `http://www.google.com/` 有中文和英文两个资源,只有 ETag 才能对这两个资源进行唯一标识。
@@ -727,7 +729,7 @@ HTTPs 的报文摘要功能之所以安全,是因为它结合了加密和认
## HTTP/1.x 缺陷
- HTTP/1.x 实现简单是以牺牲性能为代价的:
+HTTP/1.x 实现简单是以牺牲性能为代价的:
- 客户端需要使用多个连接才能实现并发和缩短延迟;
- 不会压缩请求和响应首部,从而导致不必要的网络流量;
@@ -741,9 +743,9 @@ HTTP/2.0 将报文分成 HEADERS 帧和 DATA 帧,它们都是二进制格式
在通信过程中,只会有一个 TCP 连接存在,它承载了任意数量的双向数据流(Stream)。
-- 一个数据流都有一个唯一标识符和可选的优先级信息,用于承载双向信息。
-- 消息(Message)是与逻辑请求或响应消息对应的完整的一系列帧。
-- 帧(Fram)是最小的通信单位,来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
+- 一个数据流(Stream)都有一个唯一标识符和可选的优先级信息,用于承载双向信息。
+- 消息(Message)是与逻辑请求或响应对应的完整的一系列帧。
+- 帧(Frame)是最小的通信单位,来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。

diff --git "a/notes/Java \345\271\266\345\217\221.md" "b/notes/Java \345\271\266\345\217\221.md"
index 1403f764..03aaa9fd 100644
--- "a/notes/Java \345\271\266\345\217\221.md"
+++ "b/notes/Java \345\271\266\345\217\221.md"
@@ -637,6 +637,7 @@ B
```java
public class WaitNotifyExample {
+
public synchronized void before() {
System.out.println("before");
notifyAll();
@@ -674,12 +675,15 @@ after
## await() signal() signalAll()
-java.util.concurrent 类库中提供了 Condition 类来实现线程之间的协调,可以在 Condition 上调用 await() 方法使线程等待,其它线程调用 signal() 或 signalAll() 方法唤醒等待的线程。相比于 wait() 这种等待方式,await() 可以指定等待的条件,因此更加灵活。
+java.util.concurrent 类库中提供了 Condition 类来实现线程之间的协调,可以在 Condition 上调用 await() 方法使线程等待,其它线程调用 signal() 或 signalAll() 方法唤醒等待的线程。
+
+相比于 wait() 这种等待方式,await() 可以指定等待的条件,因此更加灵活。
使用 Lock 来获取一个 Condition 对象。
```java
public class AwaitSignalExample {
+
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
@@ -809,7 +813,7 @@ before..before..before..before..before..before..before..before..before..before..
## Semaphore
-Semaphore 就是操作系统中的信号量,可以控制对互斥资源的访问线程数。
+Semaphore 类似于操作系统中的信号量,可以控制对互斥资源的访问线程数。

@@ -1098,11 +1102,11 @@ Java 内存模型定义了 8 个操作来完成主内存和工作内存的交互
Java 内存模型保证了 read、load、use、assign、store、write、lock 和 unlock 操作具有原子性,例如对一个 int 类型的变量执行 assign 赋值操作,这个操作就是原子性的。但是 Java 内存模型允许虚拟机将没有被 volatile 修饰的 64 位数据(long,double)的读写操作划分为两次 32 位的操作来进行,即 load、store、read 和 write 操作可以不具备原子性。
-有一个错误认识就是,int 等原子性的变量在多线程环境中不会出现线程安全问题。前面的线程不安全示例代码中,cnt 变量属于 int 类型变量,1000 个线程对它进行自增操作之后,得到的值为 997 而不是 1000。
+有一个错误认识就是,int 等原子性的类型在多线程环境中不会出现线程安全问题。前面的线程不安全示例代码中,cnt 属于 int 类型变量,1000 个线程对它进行自增操作之后,得到的值为 997 而不是 1000。
为了方便讨论,将内存间的交互操作简化为 3 个:load、assign、store。
-下图演示了两个线程同时对 cnt 变量进行操作,load、assign、store 这一系列操作整体上看不具备原子性,那么在 T1 修改 cnt 并且还没有将修改后的值写入主内存,T2 依然可以读入该变量的值。可以看出,这两个线程虽然执行了两次自增运算,但是主内存中 cnt 的值最后为 1 而不是 2。因此对 int 类型读写操作满足原子性只是说明 load、assign、store 这些单个操作具备原子性。
+下图演示了两个线程同时对 cnt 进行操作,load、assign、store 这一系列操作整体上看不具备原子性,那么在 T1 修改 cnt 并且还没有将修改后的值写入主内存,T2 依然可以读入旧值。可以看出,这两个线程虽然执行了两次自增运算,但是主内存中 cnt 的值最后为 1 而不是 2。因此对 int 类型读写操作满足原子性只是说明 load、assign、store 这些单个操作具备原子性。

@@ -1200,9 +1204,7 @@ public static void main(String[] args) throws InterruptedException {
### 3. 有序性
-有序性是指:在本线程内观察,所有操作都是有序的。在一个线程观察另一个线程,所有操作都是无序的,无序是因为发生了指令重排序。
-
-在 Java 内存模型中,允许编译器和处理器对指令进行重排序,重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
+有序性是指:在本线程内观察,所有操作都是有序的。在一个线程观察另一个线程,所有操作都是无序的,无序是因为发生了指令重排序。在 Java 内存模型中,允许编译器和处理器对指令进行重排序,重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
volatile 关键字通过添加内存屏障的方式来禁止指令重排,即重排序时不能把后面的指令放到内存屏障之前。
@@ -1413,7 +1415,7 @@ synchronized 和 ReentrantLock。
**(二)AtomicInteger**
-J.U.C 包里面的整数原子类 AtomicInteger,其中的 compareAndSet() 和 getAndIncrement() 等方法都使用了 Unsafe 类的 CAS 操作。
+J.U.C 包里面的整数原子类 AtomicInteger 的方法调用了 Unsafe 类的 CAS 操作。
以下代码使用了 AtomicInteger 执行了自增的操作。
@@ -1425,7 +1427,7 @@ public void add() {
}
```
-以下代码是 incrementAndGet() 的源码,它调用了 unsafe 的 getAndAddInt() 。
+以下代码是 incrementAndGet() 的源码,它调用了 Unsafe 的 getAndAddInt() 。
```java
public final int incrementAndGet() {
@@ -1463,9 +1465,6 @@ J.U.C 包提供了一个带有标记的原子引用类 AtomicStampedReference
多个线程访问同一个方法的局部变量时,不会出现线程安全问题,因为局部变量存储在虚拟机栈中,属于线程私有的。
```java
-import java.util.concurrent.ExecutorService;
-import java.util.concurrent.Executors;
-
public class StackClosedExample {
public void add100() {
int cnt = 0;
@@ -1555,7 +1554,7 @@ public class ThreadLocalExample1 {

-每个 Thread 都有一个 ThreadLocal.ThreadLocalMap 对象,Thread 类中就定义了 ThreadLocal.ThreadLocalMap 成员。
+每个 Thread 都有一个 ThreadLocal.ThreadLocalMap 对象。
```java
/* ThreadLocal values pertaining to this thread. This map is maintained
@@ -1686,15 +1685,15 @@ JDK 1.6 引入了偏向锁和轻量级锁,从而让锁拥有了四个状态:
- 缩小同步范围,从而减少锁争用。例如对于 synchronized,应该尽量使用同步块而不是同步方法。
-- 多用同步工具少用 wait() 和 notify()。首先,CountDownLatch, CyclicBarrier, Semaphore 和 Exchanger 这些同步类简化了编码操作,而用 wait() 和 notify() 很难实现复杂控制流;其次,这些同步类是由最好的企业编写和维护,在后续的 JDK 中还会不断优化和完善,使用这些更高等级的同步工具你的程序可以不费吹灰之力获得优化。
+- 多用同步工具少用 wait() 和 notify()。首先,CountDownLatch, CyclicBarrier, Semaphore 和 Exchanger 这些同步类简化了编码操作,而用 wait() 和 notify() 很难实现复杂控制流;其次,这些同步类是由最好的企业编写和维护,在后续的 JDK 中还会不断优化和完善。
+
+- 使用 BlockingQueue 实现生产者消费者问题。
- 多用并发集合少用同步集合,例如应该使用 ConcurrentHashMap 而不是 Hashtable。
- 使用本地变量和不可变类来保证线程安全。
-- 使用线程池而不是直接创建 Thread 对象,这是因为创建线程代价很高,线程池可以有效地利用有限的线程来启动任务。
-
-- 使用 BlockingQueue 实现生产者消费者问题。
+- 使用线程池而不是直接创建线程,这是因为创建线程代价很高,线程池可以有效地利用有限的线程来启动任务。
# 参考资料
diff --git "a/notes/Java \350\231\232\346\213\237\346\234\272.md" "b/notes/Java \350\231\232\346\213\237\346\234\272.md"
index 40972bfd..1dc4d1d6 100644
--- "a/notes/Java \350\231\232\346\213\237\346\234\272.md"
+++ "b/notes/Java \350\231\232\346\213\237\346\234\272.md"
@@ -7,8 +7,6 @@
* [方法区](#方法区)
* [运行时常量池](#运行时常量池)
* [直接内存](#直接内存)
- * [类的创建过程](#类的创建过程)
- * [对象的结构](#对象的结构)
* [二、垃圾收集](#二垃圾收集)
* [判断一个对象是否可被回收](#判断一个对象是否可被回收)
* [引用类型](#引用类型)
@@ -104,28 +102,6 @@ Class 文件中的常量池(编译器生成的各种字面量和符号引用
这样能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆中来回复制数据。
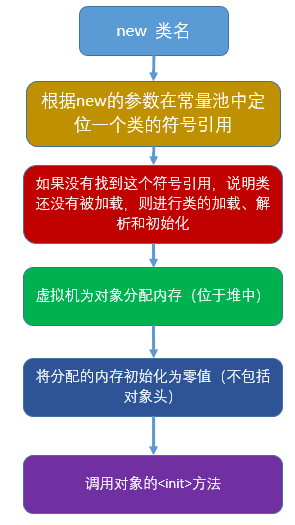
-## 对象的创建过程
-
-[图解JAVA对象的创建过程](https://www.cnblogs.com/chenyangyao/p/5296807.html)
-
-
-
-## 对象的结构
-
-对象包含 3 个部分:
-1. Header(对象头):如下图所示;
-2. InstanceData(实例数据):将等宽的类型放在一起;
-3. Padding(对齐填充):Hotspot 虚拟机的内存管理系统要求对象的起始地址要是 8 个字节的整数倍,而对象头就是 8 个字节的整数倍。padding 是用来填充实例数据不足 8 个字节整数倍的部分,可以理解为占位符。
-
-
-
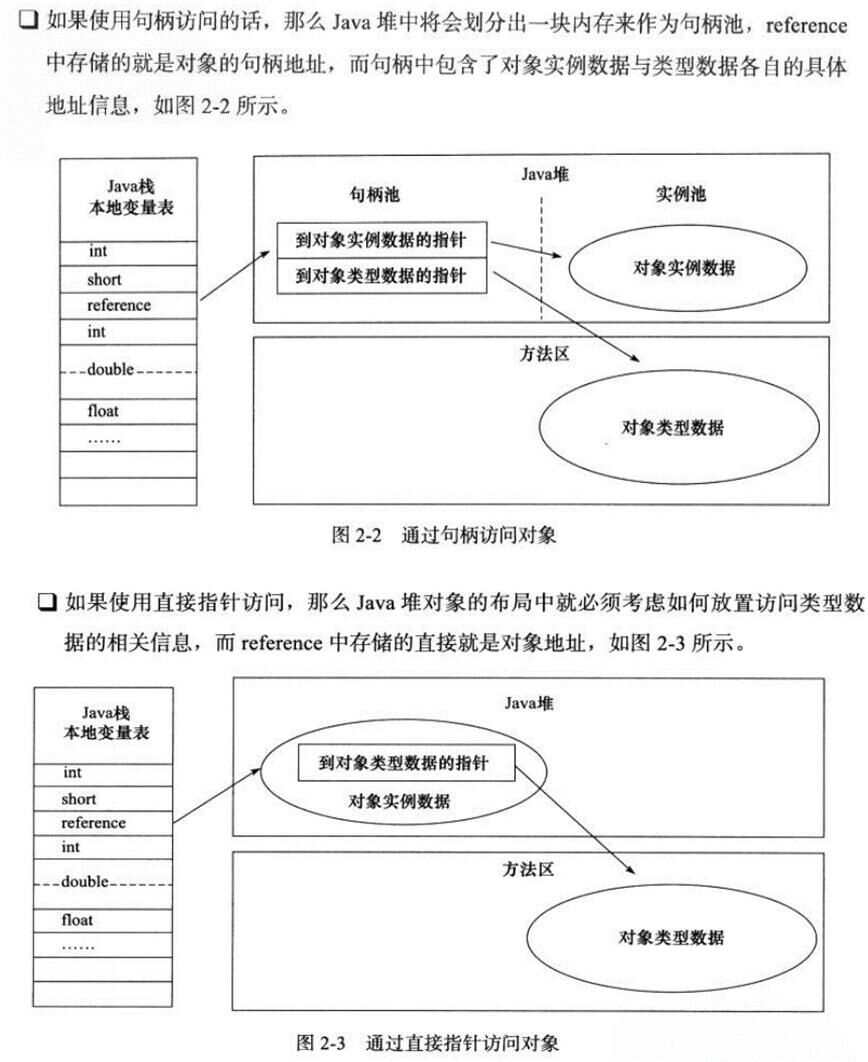
-## 对象的地址访问
-
-1. 直接指针:对象的引用直接指向堆中的内存地址 (Hotspot 采用的方式);
-2. 使用句柄:Java 堆中划分出一块内存作为句柄池,对象的引用指向句柄池。
-
-
-
# 二、垃圾收集
垃圾收集主要是针对堆和方法区进行。
@@ -162,8 +138,8 @@ public class ReferenceCountingGC {
Java 虚拟机使用该算法来判断对象是否可被回收,在 Java 中 GC Roots 一般包含以下内容:
-- 虚拟机栈 (局部变量表) 中引用的对象
-- 本地方法栈中引用的对象
+- 虚拟机栈中局部变量表中引用的对象
+- 本地方法栈中 JNI 中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中的常量引用的对象
@@ -292,7 +268,7 @@ HotSpot 虚拟机的 Eden 和 Survivor 的大小比例默认为 8:1,保证了
以上是 HotSpot 虚拟机中的 7 个垃圾收集器,连线表示垃圾收集器可以配合使用。
- 单线程与多线程:单线程指的是垃圾收集器只使用一个线程进行收集,而多线程使用多个线程;
-- 串行与并行:串行指的是垃圾收集器与用户程序交替执行,这意味着在执行垃圾收集的时候需要停顿用户程序;并行指的是垃圾收集器和用户程序同时执行。除了 CMS 和 G1 之外,其它垃圾收集器都是以串行的方式执行。
+- 串行与并行:串行指的是垃圾收集器与用户程序交替执行,这意味着在执行垃圾收集的时候需要停顿用户程序;并形指的是垃圾收集器和用户程序同时执行。除了 CMS 和 G1 之外,其它垃圾收集器都是以串行的方式执行。
### 1. Serial 收集器
diff --git a/notes/Linux.md b/notes/Linux.md
index 73a2e9ec..4ba647a7 100644
--- a/notes/Linux.md
+++ b/notes/Linux.md
@@ -644,7 +644,7 @@ locate 使用 /var/lib/mlocate/ 这个数据库来进行搜索,它存储在内
example: find . -name "shadow*"
```
-(一)与时间有关的选项
+**① 与时间有关的选项**
```html
-mtime n :列出在 n 天前的那一天修改过内容的文件
@@ -657,7 +657,7 @@ example: find . -name "shadow*"

-(二)与文件拥有者和所属群组有关的选项
+**② 与文件拥有者和所属群组有关的选项**
```html
-uid n
@@ -668,7 +668,7 @@ example: find . -name "shadow*"
-nogroup:搜索所属群组不存在于 /etc/group 的文件
```
-(三)与文件权限和名称有关的选项
+**③ 与文件权限和名称有关的选项**
```html
-name filename
@@ -1038,9 +1038,7 @@ $ grep -n 'go\{2,5\}g' regular_express.txt
## printf
-用于格式化输出。
-
-它不属于管道命令,在给 printf 传数据时需要使用 $( ) 形式。
+用于格式化输出。它不属于管道命令,在给 printf 传数据时需要使用 $( ) 形式。
```html
$ printf '%10s %5i %5i %5i %8.2f \n' $(cat printf.txt)
diff --git "a/notes/\345\210\206\345\270\203\345\274\217.md" "b/notes/\345\210\206\345\270\203\345\274\217.md"
index e98f2860..113837ce 100644
--- "a/notes/\345\210\206\345\270\203\345\274\217.md"
+++ "b/notes/\345\210\206\345\270\203\345\274\217.md"
@@ -29,18 +29,18 @@
# 一、分布式锁
-在单机场景下,可以使用 Java 提供的内置锁来实现进程同步。但是在分布式场景下,需要同步的进程可能位于不同的节点上,那么就需要使用分布式锁。
+在单机场景下,可以使用语言的内置锁来实现进程同步。但是在分布式场景下,需要同步的进程可能位于不同的节点上,那么就需要使用分布式锁。
阻塞锁通常使用互斥量来实现:
-- 互斥量为 1 表示有其它进程在使用锁,此时处于锁定状态;
-- 互斥量为 0 表示未锁定状态。
+- 互斥量为 0 表示有其它进程在使用锁,此时处于锁定状态;
+- 互斥量为 1 表示未锁定状态。
-1 和 0 可以用一个整型值表示,也可以用某个数据是否存在表示,存在表示互斥量为 1。
+1 和 0 可以用一个整型值表示,也可以用某个数据是否存在表示。
## 数据库的唯一索引
-当想要获得锁时,就向表中插入一条记录,释放锁时就删除这条记录。唯一索引可以保证该记录只被插入一次,那么就可以用这个记录是否存在来判断是否存于锁定状态。
+获得锁时向表中插入一条记录,释放锁时删除这条记录。唯一索引可以保证该记录只被插入一次,那么就可以用这个记录是否存在来判断是否存于锁定状态。
存在以下几个问题:
@@ -91,11 +91,11 @@ Zookeeper 提供了一种树形结构级的命名空间,/app1/p_1 节点的父
### 5. 会话超时
-如果一个已经获得锁的会话超时了,因为创建的是临时节点,所以该会话对应的临时节点会被删除,其它会话就可以获得锁了。可以看到,Zookeeper 分布式锁不会出现数据库的唯一索引实现分布式锁的释放锁失败问题。
+如果一个已经获得锁的会话超时了,因为创建的是临时节点,所以该会话对应的临时节点会被删除,其它会话就可以获得锁了。可以看到,Zookeeper 分布式锁不会出现数据库的唯一索引实现的分布式锁释放锁失败问题。
### 6. 羊群效应
-一个节点未获得锁,需要监听自己的前一个子节点,这是因为如果监听所有的子节点,那么任意一个子节点状态改变,其它所有子节点都会收到通知(羊群效应),而我们只希望它的后一个子节点收到通知。
+一个节点未获得锁,只需要监听自己的前一个子节点,这是因为如果监听所有的子节点,那么任意一个子节点状态改变,其它所有子节点都会收到通知(羊群效应),而我们只希望它的后一个子节点收到通知。
# 二、分布式事务
@@ -159,9 +159,7 @@ Zookeeper 提供了一种树形结构级的命名空间,/app1/p_1 节点的父
## 一致性
-一致性指的是多个数据副本是否能保持一致的特性。
-
-在一致性的条件下,系统在执行数据更新操作之后能够从一致性状态转移到另一个一致性状态。
+一致性指的是多个数据副本是否能保持一致的特性,在一致性的条件下,系统在执行数据更新操作之后能够从一致性状态转移到另一个一致性状态。
对系统的一个数据更新成功之后,如果所有用户都能够读取到最新的值,该系统就被认为具有强一致性。
@@ -169,7 +167,7 @@ Zookeeper 提供了一种树形结构级的命名空间,/app1/p_1 节点的父
可用性指分布式系统在面对各种异常时可以提供正常服务的能力,可以用系统可用时间占总时间的比值来衡量,4 个 9 的可用性表示系统 99.99% 的时间是可用的。
-在可用性条件下,要求系统提供的服务一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。
+在可用性条件下,要求系统提供的服务一直处于可用的状态,对于用户的每一个操,请求总是能够在有限的时间内返回结果。
## 分区容忍性
@@ -179,9 +177,9 @@ Zookeeper 提供了一种树形结构级的命名空间,/app1/p_1 节点的父
## 权衡
-在分布式系统中,分区容忍性必不可少,因为需要总是假设网络是不可靠的。因此,CAP 理论实际在是要在可用性和一致性之间做权衡。
+在分布式系统中,分区容忍性必不可少,因为需要总是假设网络是不可靠的。因此,CAP 理论实际上是要在可用性和一致性之间做权衡。
-可用性和一致性往往是冲突的,很难都使它们同时满足。在多个节点之间进行数据同步时,
+可用性和一致性往往是冲突的,很难使它们同时满足。在多个节点之间进行数据同步时,
- 为了保证一致性(CP),就需要让所有节点下线成为不可用的状态,等待同步完成;
- 为了保证可用性(AP),在同步过程中允许读取所有节点的数据,但是数据可能不一致。
@@ -204,7 +202,7 @@ BASE 理论是对 CAP 中一致性和可用性权衡的结果,它的核心思
## 软状态
-指允许系统中的数据存在中间状态,并认为该中间状态不会影响系统整体可用性,即允许系统不同节点的数据副本之间进行同步的过程存在延时。
+指允许系统中的数据存在中间状态,并认为该中间状态不会影响系统整体可用性,即允许系统不同节点的数据副本之间进行同步的过程存在时延。
## 最终一致性
diff --git "a/notes/\346\236\204\345\273\272\345\267\245\345\205\267.md" "b/notes/\346\236\204\345\273\272\345\267\245\345\205\267.md"
index ce157934..34fef54b 100644
--- "a/notes/\346\236\204\345\273\272\345\267\245\345\205\267.md"
+++ "b/notes/\346\236\204\345\273\272\345\267\245\345\205\267.md"
@@ -1,11 +1,12 @@
-* [一、什么是构建工具](#一什么是构建工具)
+* [一、构建工具的作用](#一构建工具的作用)
* [二、Java 主流构建工具](#二java-主流构建工具)
* [三、Maven](#三maven)
+* [参考资料](#参考资料)
-# 一、什么是构建工具
+# 一、构建工具的作用
构建工具是用于构建项目的自动化工具,主要包含以下工作:
@@ -29,10 +30,6 @@
不再需要通过 FTP 将 Jar 包上传到服务器上。
-参考资料:
-
-- [What is a build tool?](https://stackoverflow.com/questions/7249871/what-is-a-build-tool)
-
# 二、Java 主流构建工具
主要包括 Ant、Maven 和 Gradle。
@@ -72,12 +69,6 @@ dependencies {
}
```
-参考资料:
-
-- [Java Build Tools Comparisons: Ant vs Maven vs Gradle](https://programmingmitra.blogspot.com/2016/05/java-build-tools-comparisons-ant-vs.html)
-- [maven 2 gradle](http://sagioto.github.io/maven2gradle/)
-- [新一代构建工具 gradle](https://www.imooc.com/learn/833)
-
# 三、Maven
## 概述
@@ -114,7 +105,7 @@ POM 代表项目对象模型,它是一个 XML 文件,保存在项目根目
## 依赖原则
-### 依赖路径最短优先原则
+### 1. 依赖路径最短优先原则
```html
A -> B -> C -> X(1.0)
@@ -122,7 +113,7 @@ A -> D -> X(2.0)
```
由于 X(2.0) 路径最短,所以使用 X(2.0)。
-### 声明顺序优先原则
+### 2. 声明顺序优先原则
```html
A -> B -> X(1.0)
@@ -131,7 +122,7 @@ A -> C -> X(2.0)
在 POM 中最先声明的优先,上面的两个依赖如果先声明 B,那么最后使用 X(1.0)。
-### 覆写优先原则
+### 3. 覆写优先原则
子 POM 内声明的依赖优先于父 POM 中声明的依赖。
@@ -139,9 +130,11 @@ A -> C -> X(2.0)
找到 Maven 加载的 Jar 包版本,使用 `mvn dependency:tree` 查看依赖树,根据依赖原则来调整依赖在 POM 文件的声明顺序。
-参考资料:
+# 参考资料
- [POM Reference](http://maven.apache.org/pom.html#Dependency_Version_Requirement_Specification)
-
-
+- [What is a build tool?](https://stackoverflow.com/questions/7249871/what-is-a-build-tool)
+- [Java Build Tools Comparisons: Ant vs Maven vs Gradle](https://programmingmitra.blogspot.com/2016/05/java-build-tools-comparisons-ant-vs.html)
+- [maven 2 gradle](http://sagioto.github.io/maven2gradle/)
+- [新一代构建工具 gradle](https://www.imooc.com/learn/833)
diff --git "a/notes/\346\266\210\346\201\257\351\230\237\345\210\227.md" "b/notes/\346\266\210\346\201\257\351\230\237\345\210\227.md"
index 209d962a..bc80894d 100644
--- "a/notes/\346\266\210\346\201\257\351\230\237\345\210\227.md"
+++ "b/notes/\346\266\210\346\201\257\351\230\237\345\210\227.md"
@@ -40,7 +40,7 @@
发送者将消息发送给消息队列之后,不需要同步等待消息接收者处理完毕,而是立即返回进行其它操作。消息接收者从消息队列中订阅消息之后异步处理。
-例如在注册流程中通常需要发送验证邮件来确保注册用户的身份合法,可以使用消息队列使发送验证邮件的操作异步处理,用户在填写完注册信息之后就可以完成注册,而将发送验证邮件这一消息发送到消息队列中。
+例如在注册流程中通常需要发送验证邮件来确保注册用户身份的合法性,可以使用消息队列使发送验证邮件的操作异步处理,用户在填写完注册信息之后就可以完成注册,而将发送验证邮件这一消息发送到消息队列中。
只有在业务流程允许异步处理的情况下才能这么做,例如上面的注册流程中,如果要求用户对验证邮件进行点击之后才能完成注册的话,就不能再使用消息队列。
diff --git "a/notes/\347\256\227\346\263\225.md" "b/notes/\347\256\227\346\263\225.md"
index 53edc1c1..cb83830b 100644
--- "a/notes/\347\256\227\346\263\225.md"
+++ "b/notes/\347\256\227\346\263\225.md"
@@ -379,7 +379,7 @@ public class Insertion> extends Sort {
对于大规模的数组,插入排序很慢,因为它只能交换相邻的元素,每次只能将逆序数量减少 1。
-希尔排序的出现就是为了改进插入排序的这种局限性,它通过交换不相邻的元素,每次可以将逆序数量减少大于 1。
+希尔排序的出现就是为了解决插入排序的这种局限性,它通过交换不相邻的元素,每次可以将逆序数量减少大于 1。
希尔排序使用插入排序对间隔 h 的序列进行排序。通过不断减小 h,最后令 h=1,就可以使得整个数组是有序的。
@@ -571,15 +571,15 @@ private int partition(T[] nums, int l, int h) {
### 4. 算法改进
-(一)切换到插入排序
+#### 4.1 切换到插入排序
因为快速排序在小数组中也会递归调用自己,对于小数组,插入排序比快速排序的性能更好,因此在小数组中可以切换到插入排序。
-(二)三数取中
+#### 4.2 三数取中
最好的情况下是每次都能取数组的中位数作为切分元素,但是计算中位数的代价很高。人们发现取 3 个元素并将大小居中的元素作为切分元素的效果最好。
-(三)三向切分
+#### 4.3 三向切分
对于有大量重复元素的数组,可以将数组切分为三部分,分别对应小于、等于和大于切分元素。
@@ -645,7 +645,7 @@ public T select(T[] nums, int k) {
堆的某个节点的值总是大于等于子节点的值,并且堆是一颗完全二叉树。
-堆可以用数组来表示,因为堆是完全二叉树,而完全二叉树很容易就存储在数组中。位置 k 的节点的父节点位置为 k/2,而它的两个子节点的位置分别为 2k 和 2k+1。这里不使用数组索引为 0 的位置,是为了更清晰地描述节点的位置关系。
+堆可以用数组来表示,这是因为堆是完全二叉树,而完全二叉树很容易就存储在数组中。位置 k 的节点的父节点位置为 k/2,而它的两个子节点的位置分别为 2k 和 2k+1。这里不使用数组索引为 0 的位置,是为了更清晰地描述节点的位置关系。

@@ -739,15 +739,15 @@ public T delMax() {
### 5. 堆排序
-由于堆可以很容易得到最大的元素并删除它,不断地进行这种操作可以得到一个递减序列。如果把最大元素和当前堆中数组的最后一个元素交换位置,并且不删除它,那么就可以得到一个从尾到头的递减序列,从正向来看就是一个递增序列。因此很容易使用堆来进行排序。并且堆排序是原地排序,不占用额外空间。
+把最大元素和当前堆中数组的最后一个元素交换位置,并且不删除它,那么就可以得到一个从尾到头的递减序列,从正向来看就是一个递增序列,这就是堆排序。
-(一)构建堆
+#### 5.1 构建堆
-无序数组建立堆最直接的方法是从左到右遍历数组,然后进行上浮操作。一个更高效的方法是从右至左进行下沉操作,如果一个节点的两个节点都已经是堆有序,那么进行下沉操作可以使得这个节点为根节点的堆有序。叶子节点不需要进行下沉操作,可以忽略叶子节点的元素,因此只需要遍历一半的元素即可。
+无序数组建立堆最直接的方法是从左到右遍历数组进行上浮操作。一个更高效的方法是从右至左进行下沉操作,如果一个节点的两个节点都已经是堆有序,那么进行下沉操作可以使得这个节点为根节点的堆有序。叶子节点不需要进行下沉操作,可以忽略叶子节点的元素,因此只需要遍历一半的元素即可。

-(二)交换堆顶元素与最后一个元素
+#### 5.2 交换堆顶元素与最后一个元素
交换之后需要进行下沉操作维持堆的有序状态。
@@ -804,7 +804,7 @@ public class HeapSort> extends Sort {
### 1. 排序算法的比较
-| 算法 | 稳定 | 时间复杂度 | 空间复杂度 | 备注 |
+| 算法 | 稳定性 | 时间复杂度 | 空间复杂度 | 备注 |
| :---: | :---: |:---: | :---: | :---: |
| 选择排序 | × | N2 | 1 | |
| 冒泡排序 | √ | N2 | 1 | |
@@ -815,7 +815,7 @@ public class HeapSort> extends Sort {
| 归并排序 | √ | NlogN | N | |
| 堆排序 | × | NlogN | 1 | | |
-快速排序是最快的通用排序算法,它的内循环的指令很少,而且它还能利用缓存,因为它总是顺序地访问数据。它的运行时间近似为 \~cNlogN,这里的 c 比其他线性对数级别的排序算法都要小。使用三向切分快速排序,实际应用中可能出现的某些分布的输入能够达到线性级别,而其它排序算法仍然需要线性对数时间。
+快速排序是最快的通用排序算法,它的内循环的指令很少,而且它还能利用缓存,因为它总是顺序地访问数据。它的运行时间近似为 \~cNlogN,这里的 c 比其它线性对数级别的排序算法都要小。使用三向切分快速排序,实际应用中可能出现的某些分布的输入能够达到线性级别,而其它排序算法仍然需要线性对数时间。
### 2. Java 的排序算法实现
@@ -882,7 +882,6 @@ public class QuickFindUF extends UF {
@Override
public void union(int p, int q) {
-
int pID = find(p);
int qID = find(q);
@@ -917,7 +916,6 @@ public class QuickUnionUF extends UF {
@Override
public int find(int p) {
-
while (p != id[p]) {
p = id[p];
}
@@ -927,7 +925,6 @@ public class QuickUnionUF extends UF {
@Override
public void union(int p, int q) {
-
int pRoot = find(p);
int qRoot = find(q);
@@ -938,7 +935,7 @@ public class QuickUnionUF extends UF {
}
```
-这种方法可以快速进行 union 操作,但是 find 操作和树高成正比,最坏的情况下树的高度为触点的数目。
+这种方法可以快速进行 union 操作,但是 find 操作和树高成正比,最坏的情况下树的高度为节点的数目。

@@ -1588,7 +1585,7 @@ public class BST, Value> implements OrderedST 
@@ -1806,9 +1803,9 @@ private List keys(Node x, Key l, Key h) {
}
```
-### 10. 性能分析
+### 10. 分析
-复杂度:二叉查找树所有操作在最坏的情况下所需要的时间都和树的高度成正比。
+二叉查找树所有操作在最坏的情况下所需要的时间都和树的高度成正比。
## 2-3 查找树
@@ -1838,7 +1835,7 @@ private List keys(Node x, Key l, Key h) {
## 红黑树
-2-3 查找树需要用到 2- 节点和 3- 节点,红黑树使用红链接来实现 3- 节点。指向一个节点的链接颜色如果为红色,那么这个节点和上层节点表示的是一个 3- 节点,而黑色则是普通链接。
+红黑树是 2-3 查找树,但它不需要分别定义 2- 节点和 3- 节点,而是在普通的二叉查找树之上,为节点添加颜色。指向一个节点的链接颜色如果为红色,那么这个节点和上层节点表示的是一个 3- 节点,而黑色则是普通链接。

@@ -1853,6 +1850,7 @@ private List keys(Node x, Key l, Key h) {
```java
public class RedBlackBST, Value> extends BST {
+
private static final boolean RED = true;
private static final boolean BLACK = false;
@@ -2008,16 +2006,17 @@ int hash = (((day * R + month) % M) * R + year) % M;
R 通常取 31。
-Java 中的 hashCode() 实现了 hash 函数,但是默认使用对象的内存地址值。在使用 hashCode() 函数时,应当结合除留余数法来使用。因为内存地址是 32 位整数,我们只需要 31 位的非负整数,因此应当屏蔽符号位之后再使用除留余数法。
+Java 中的 hashCode() 实现了哈希函数,但是默认使用对象的内存地址值。在使用 hashCode() 时,应当结合除留余数法来使用。因为内存地址是 32 位整数,我们只需要 31 位的非负整数,因此应当屏蔽符号位之后再使用除留余数法。
```java
int hash = (x.hashCode() & 0x7fffffff) % M;
```
-使用 Java 自带的 HashMap 等自带的哈希表实现时,只需要去实现 Key 类型的 hashCode() 函数即可。Java 规定 hashCode() 能够将键均匀分布于所有的 32 位整数,Java 中的 String、Integer 等对象的 hashCode() 都能实现这一点。以下展示了自定义类型如何实现 hashCode():
+使用 Java 的 HashMap 等自带的哈希表实现时,只需要去实现 Key 类型的 hashCode() 函数即可。Java 规定 hashCode() 能够将键均匀分布于所有的 32 位整数,Java 中的 String、Integer 等对象的 hashCode() 都能实现这一点。以下展示了自定义类型如何实现 hashCode():
```java
public class Transaction {
+
private final String who;
private final Date when;
private final double amount;
@@ -2039,17 +2038,17 @@ public class Transaction {
}
```
-### 2. 基于拉链法的散列表
+### 2. 拉链法
拉链法使用链表来存储 hash 值相同的键,从而解决冲突。
查找需要分两步,首先查找 Key 所在的链表,然后在链表中顺序查找。
-对于 N 个键,M 条链表 (N>M),如果 hash 函数能够满足均匀性的条件,每条链表的大小趋向于 N/M,因此未命中的查找和插入操作所需要的比较次数为 \~N/M。
+对于 N 个键,M 条链表 (N>M),如果哈希函数能够满足均匀性的条件,每条链表的大小趋向于 N/M,因此未命中的查找和插入操作所需要的比较次数为 \~N/M。

-### 3. 基于线性探测法的散列表
+### 3. 线性探测法
线性探测法使用空位来解决冲突,当冲突发生时,向前探测一个空位来存储冲突的键。
@@ -2059,6 +2058,7 @@ public class Transaction {
```java
public class LinearProbingHashST implements UnorderedST {
+
private int N = 0;
private int M = 16;
private Key[] keys;
@@ -2084,7 +2084,7 @@ public class LinearProbingHashST implements UnorderedST
}
```
-**(一)查找**
+#### 3.1 查找
```java
public Value get(Key key) {
@@ -2096,7 +2096,7 @@ public Value get(Key key) {
}
```
-**(二)插入**
+#### 3.2 插入
```java
public void put(Key key, Value value) {
@@ -2118,7 +2118,7 @@ private void putInternal(Key key, Value value) {
}
```
-**(三)删除**
+#### 3.3 删除
删除操作应当将右侧所有相邻的键值对重新插入散列表中。
@@ -2151,7 +2151,7 @@ public void delete(Key key) {
}
```
-**(四)调整数组大小**
+#### 3.5 调整数组大小
线性探测法的成本取决于连续条目的长度,连续条目也叫聚簇。当聚簇很长时,在查找和插入时也需要进行很多次探测。例如下图中 2\~5 位置就是一个聚簇。
@@ -2235,15 +2235,15 @@ public class SparseVector {
这是一个经典的递归问题,分为三步求解:
-- 将 n-1 个圆盘从 from -> buffer
+① 将 n-1 个圆盘从 from -> buffer

-- 将 1 个圆盘从 from -> to
+② 将 1 个圆盘从 from -> to

-- 将 n-1 个圆盘从 buffer -> to
+③ 将 n-1 个圆盘从 buffer -> to

@@ -2281,9 +2281,9 @@ from H1 to H3
## 哈夫曼编码
-哈夫曼编码根据数据出现的频率对数据进行编码,从而压缩原始数据。
+根据数据出现的频率对数据进行编码,从而压缩原始数据。
-例如对于文本文件,其中各种字符出现的次数如下:
+例如对于一个文本文件,其中各种字符出现的次数如下:
- a : 10
- b : 20
@@ -2294,7 +2294,7 @@ from H1 to H3
首先生成一颗哈夫曼树,每次生成过程中选取频率最少的两个节点,生成一个新节点作为它们的父节点,并且新节点的频率为两个节点的和。选取频率最少的原因是,生成过程使得先选取的节点在树的最底层,那么需要的编码长度更长,频率更少可以使得总编码长度更少。
-生成编码时,从根节点出发,向左遍历则添加二进制位 0,向右则添加二进制位 1,直到遍历到根节点,根节点代表的字符的编码就是这个路径编码。
+生成编码时,从根节点出发,向左遍历则添加二进制位 0,向右则添加二进制位 1,直到遍历到叶子节点,叶子节点代表的字符的编码就是这个路径编码。

diff --git "a/notes/\347\274\223\345\255\230.md" "b/notes/\347\274\223\345\255\230.md"
index ed834253..26d96be1 100644
--- "a/notes/\347\274\223\345\255\230.md"
+++ "b/notes/\347\274\223\345\255\230.md"
@@ -26,16 +26,16 @@
## 淘汰策略
-- FIFO(First In First Out):先进先出策略,在实时性的场景下,需要经常访问最新的数据,那么就可以使用 FIFO,使最先进入的数据(最晚的数据)被淘汰。
+- FIFO(First In First Out):先进先出策略,在实时性的场景下,需要经常访问最新的数据,那么就可以使用 FIFO,使得最先进入的数据(最晚的数据)被淘汰。
-- LRU(Least Recently Used):最近最久未使用策略,优先淘汰最久未使用的数据,也就是上次被访问时间距离现在最远的数据。该策略可以保证内存中的数据都是热点数据,也就是经常被访问的数据,从而保证缓存命中率。
+- LRU(Least Recently Used):最近最久未使用策略,优先淘汰最久未使用的数据,也就是上次被访问时间距离现在最久的数据。该策略可以保证内存中的数据都是热点数据,也就是经常被访问的数据,从而保证缓存命中率。
# 二、LRU
-以下是一个基于 双向链表 + HashMap 的 LRU 算法实现,对算法的解释如下:
+以下是基于 双向链表 + HashMap 的 LRU 算法实现,对算法的解释如下:
-- 最基本的思路是当访问某个节点时,将其从原来的位置删除,并重新插入到链表头部,这样就能保证链表尾部存储的就是最近最久未使用的节点,当节点数量大于缓存最大空间时就删除链表尾部的节点。
-- 为了使删除操作时间复杂度为 O(1),那么就不能采用遍历的方式找到某个节点。HashMap 存储着 Key 到节点的映射,通过 Key 就能以 O(1) 的时间得到节点,然后再以 O(1) 的时间将其从双向队列中删除。
+- 访问某个节点时,将其从原来的位置删除,并重新插入到链表头部。这样就能保证链表尾部存储的就是最近最久未使用的节点,当节点数量大于缓存最大空间时就淘汰链表尾部的节点。
+- 为了使删除操作时间复杂度为 O(1),就不能采用遍历的方式找到某个节点。HashMap 存储着 Key 到节点的映射,通过 Key 就能以 O(1) 的时间得到节点,然后再以 O(1) 的时间将其从双向队列中删除。
```java
public class LRU implements Iterable {
@@ -152,7 +152,7 @@ public class LRU implements Iterable {
## 反向代理
-反向代理位于服务器之前,请求与响应都需要经过反向代理。通过将数据缓存在反向代理,在用户请求时就可以直接使用缓存进行响应。
+反向代理位于服务器之前,请求与响应都需要经过反向代理。通过将数据缓存在反向代理,在用户请求反向代理时就可以直接使用缓存进行响应。
## 本地缓存
@@ -166,7 +166,7 @@ public class LRU implements Iterable {
## 数据库缓存
-MySQL 等数据库管理系统具有自己的查询缓存机制来提高 SQL 查询效率。
+MySQL 等数据库管理系统具有自己的查询缓存机制来提高查询效率。
# 四、CDN
@@ -193,9 +193,9 @@ CDN 主要有以下优点:
## 缓存雪崩
-指的是由于数据没有被加载到缓存中,或者缓存数据在同一时间大面积失效(过期),又或者缓存服务器宕机,导致大量的请求都去到达数据库。
+指的是由于数据没有被加载到缓存中,或者缓存数据在同一时间大面积失效(过期),又或者缓存服务器宕机,导致大量的请求都到达数据库。
-在存在缓存的系统中,系统非常依赖于缓存,缓存分担了很大一部分的数据请求。当发生缓存雪崩时,数据库无法处理这么大的请求,导致数据库崩溃。
+在有缓存的系统中,系统非常依赖于缓存,缓存分担了很大一部分的数据请求。当发生缓存雪崩时,数据库无法处理这么大的请求,导致数据库崩溃。
解决方案:
@@ -233,7 +233,7 @@ CDN 主要有以下优点:
# 七、一致性哈希
-Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了克服传统哈希分布在服务器节点数量变化时大量数据失效的问题。
+Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了克服传统哈希分布在服务器节点数量变化时大量数据迁移的问题。
## 基本原理
@@ -241,7 +241,7 @@ Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了

-一致性哈希在增加或者删除节点时只会影响到哈希环中相邻的节点,例如下图中新增节点 X,只需要将它前一个节点 C 上的数据重新进行分布即可,对于节点 A、B、D 都没有影响。
+一致性哈希在增加或者删除节点时只会影响到哈希环中相邻的节点,例如下图中新增节点 X,只需要将它后一个节点 C 上的数据重新进行分布即可,对于节点 A、B、D 都没有影响。

@@ -249,7 +249,9 @@ Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了
上面描述的一致性哈希存在数据分布不均匀的问题,节点存储的数据量有可能会存在很大的不同。
-数据不均匀主要是因为节点在哈希环上分布的不均匀,这种情况在节点数量很少的情况下尤其明显。解决方式是通过增加虚拟节点,然后将虚拟节点映射到真实节点上。虚拟节点的数量比真实节点来得大,那么虚拟节点在哈希环上分布的均匀性就会比原来的真实节点好,从而使得数据分布也更加均匀。
+数据不均匀主要是因为节点在哈希环上分布的不均匀,这种情况在节点数量很少的情况下尤其明显。
+
+解决方式是通过增加虚拟节点,然后将虚拟节点映射到真实节点上。虚拟节点的数量比真实节点来得多,那么虚拟节点在哈希环上分布的均匀性就会比原来的真实节点好,从而使得数据分布也更加均匀。
# 参考资料
diff --git "a/notes/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md" "b/notes/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
index 99a6fb43..e5b8dfcf 100644
--- "a/notes/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
+++ "b/notes/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234.md"
@@ -59,7 +59,7 @@
网络把主机连接起来,而互联网是把多种不同的网络连接起来,因此互联网是网络的网络。
- 
+
## ISP
@@ -304,7 +304,7 @@ PPP 的帧格式:
MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标识网络适配器(网卡)。
-一台主机拥有多少个适配器就有多少个 MAC 地址。例如笔记本电脑普遍存在无线网络适配器和有线网络适配器,因此就有两个 MAC 地址。
+一台主机拥有多少个网络适配器就有多少个 MAC 地址。例如笔记本电脑普遍存在无线网络适配器和有线网络适配器,因此就有两个 MAC 地址。
## 局域网
@@ -320,7 +320,7 @@ MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标
以太网是一种星型拓扑结构局域网。
-早期使用集线器进行连接,集线器是一种物理层设备,作用于比特而不是帧,当一个比特到达接口时,集线器重新生成这个比特,并将其能量强度放大,从而扩大网络的传输距离,之后再将这个比特发送到其它所有接口。如果集线器同时收到同时从两个不同接口的帧,那么就发生了碰撞。
+早期使用集线器进行连接,集线器是一种物理层设备, 作用于比特而不是帧,当一个比特到达接口时,集线器重新生成这个比特,并将其能量强度放大,从而扩大网络的传输距离,之后再将这个比特发送到其它所有接口。如果集线器同时收到同时从两个不同接口的帧,那么就发生了碰撞。
目前以太网使用交换机替代了集线器,交换机是一种链路层设备,它不会发生碰撞,能根据 MAC 地址进行存储转发。
diff --git "a/notes/\350\256\276\350\256\241\346\250\241\345\274\217.md" "b/notes/\350\256\276\350\256\241\346\250\241\345\274\217.md"
index 531595e3..d7ef735a 100644
--- "a/notes/\350\256\276\350\256\241\346\250\241\345\274\217.md"
+++ "b/notes/\350\256\276\350\256\241\346\250\241\345\274\217.md"
@@ -726,7 +726,12 @@ request2 is handle by ConcreteHandler2
### 意图
-将命令封装成对象中,以便使用命令来参数化其它对象,或者将命令对象放入队列中进行排队,或者将命令对象的操作记录到日志中,以及支持可撤销的操作。
+将命令封装成对象中,具有以下作用:
+
+- 使用命令来参数化其它对象
+- 将命令放入队列中进行排队
+- 将命令的操作记录到日志中
+- 支持可撤销的操作
### 类图
@@ -853,8 +858,8 @@ public class Client {
### 类图
-- TerminalExpression:终结符表达式,每个终结符都需要一个 TerminalExpression
-- Context:上下文,包含解释器之外的一些全局信息
+- TerminalExpression:终结符表达式,每个终结符都需要一个 TerminalExpression。
+- Context:上下文,包含解释器之外的一些全局信息。

@@ -1851,7 +1856,7 @@ No gumball dispensed
### 类图
- Strategy 接口定义了一个算法族,它们都具有 behavior() 方法。
-- Context 是使用到该算法族的类,其中的 doSomething() 方法会调用 behavior(),setStrategy(in Strategy) 方法可以动态地改变 strategy 对象,也就是说能动态地改变 Context 所使用的算法。
+- Context 是使用到该算法族的类,其中的 doSomething() 方法会调用 behavior(),setStrategy(Strategy) 方法可以动态地改变 strategy 对象,也就是说能动态地改变 Context 所使用的算法。

diff --git "a/notes/\351\207\215\346\236\204.md" "b/notes/\351\207\215\346\236\204.md"
index b5a834e0..e90fa84e 100644
--- "a/notes/\351\207\215\346\236\204.md"
+++ "b/notes/\351\207\215\346\236\204.md"
@@ -161,6 +161,7 @@ class Customer {
```java
class Rental {
+
private int daysRented;
private Movie movie;
@@ -199,6 +200,7 @@ class Movie {
```java
public class App {
+
public static void main(String[] args) {
Customer customer = new Customer();
Rental rental1 = new Rental(1, new Movie(Movie.Type1));
@@ -236,6 +238,7 @@ public class App {
```java
class Customer {
+
private List rentals = new ArrayList<>();
void addRental(Rental rental) {
@@ -254,6 +257,7 @@ class Customer {
```java
class Rental {
+
private int daysRented;
private Movie movie;
@@ -294,8 +298,6 @@ class Price2 implements Price {
```
```java
-package imp2;
-
class Price3 implements Price {
@Override
public double getCharge() {
diff --git "a/notes/\351\233\206\347\276\244.md" "b/notes/\351\233\206\347\276\244.md"
index 15657e43..338ddcb4 100644
--- "a/notes/\351\233\206\347\276\244.md"
+++ "b/notes/\351\233\206\347\276\244.md"
@@ -119,7 +119,7 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
首先了解一下正向代理与反向代理的区别:
- 正向代理:发生在客户端,是由用户主动发起的。比如翻墙,客户端通过主动访问代理服务器,让代理服务器获得需要的外网数据,然后转发回客户端;
-- 反向代理:发生在服务器端,用户不知道代理的存在。
+- 反向代理:发生在服务器端,用户不知道反向代理的存在。
反向代理服务器位于源服务器前面,用户的请求需要先经过反向代理服务器才能到达源服务器。反向代理可以用来进行缓存、日志记录等,同时也可以用来做为负载均衡服务器。
@@ -153,7 +153,7 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
通过配置源服务器的虚拟 IP 地址和负载均衡服务器的 IP 地址一致,从而不需要修改 IP 地址就可以进行转发。也正因为 IP 地址一样,所以源服务器的响应不需要转发回负载均衡服务器,可以直接转发给客户端,避免了负载均衡服务器的成为瓶颈。
-这是一种三角传输模式,被称为直接路由,对于提供下载和视频服务的网站来说,直接路由避免了大量的网络传输数据经过负载均衡服务器。
+这是一种三角传输模式,被称为直接路由。对于提供下载和视频服务的网站来说,直接路由避免了大量的网络传输数据经过负载均衡服务器。
这是目前大型网站使用最广负载均衡转发方式,在 Linux 平台可以使用的负载均衡服务器为 LVS(Linux Virtual Server)。
@@ -185,7 +185,6 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
- 占用过多内存;
- 同步过程占用网络带宽以及服务器处理器时间。
-
## Session Server
@@ -206,3 +205,4 @@ HTTP 重定向负载均衡服务器使用某种负载均衡算法计算得到服
- [Session Management using Spring Session with JDBC DataStore](https://sivalabs.in/2018/02/session-management-using-spring-session-jdbc-datastore/)
+
diff --git "a/notes/\351\235\242\345\220\221\345\257\271\350\261\241\346\200\235\346\203\263.md" "b/notes/\351\235\242\345\220\221\345\257\271\350\261\241\346\200\235\346\203\263.md"
index 203c7ebf..87b3b033 100644
--- "a/notes/\351\235\242\345\220\221\345\257\271\350\261\241\346\200\235\346\203\263.md"
+++ "b/notes/\351\235\242\345\220\221\345\257\271\350\261\241\346\200\235\346\203\263.md"
@@ -89,24 +89,28 @@ Animal animal = new Cat();
```java
public class Instrument {
+
public void play() {
System.out.println("Instument is playing...");
}
}
public class Wind extends Instrument {
+
public void play() {
System.out.println("Wind is playing...");
}
}
public class Percussion extends Instrument {
+
public void play() {
System.out.println("Percussion is playing...");
}
}
public class Music {
+
public static void main(String[] args) {
List instruments = new ArrayList<>();
instruments.add(new Wind());
@@ -353,4 +357,3 @@ Vihicle .. N
- [看懂 UML 类图和时序图](http://design-patterns.readthedocs.io/zh_CN/latest/read_uml.html#generalization)
- [UML 系列——时序图(顺序图)sequence diagram](http://www.cnblogs.com/wolf-sun/p/UML-Sequence-diagram.html)
- [面向对象编程三大特性 ------ 封装、继承、多态](http://blog.csdn.net/jianyuerensheng/article/details/51602015)
-
--
GitLab
