Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into feature/fix_buffer_unit_test
Showing
cmake/inference_lib.cmake
0 → 100644
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
doc/design/cpp_data_feeding.md
0 → 100644
{kind=link}
doc/dev/index_cn.rst
0 → 100644
doc/dev/index_en.rst
0 → 100644
doc/getstarted/quickstart_cn.rst
0 → 100644
doc/getstarted/quickstart_en.rst
0 → 100644
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
doc/howto/cluster/index_cn.rst
0 → 100644
doc/howto/cluster/index_en.rst
0 → 100644
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
{kind=link}
doc/howto/cluster/src/trainer.png
0 → 100644
{kind=link}
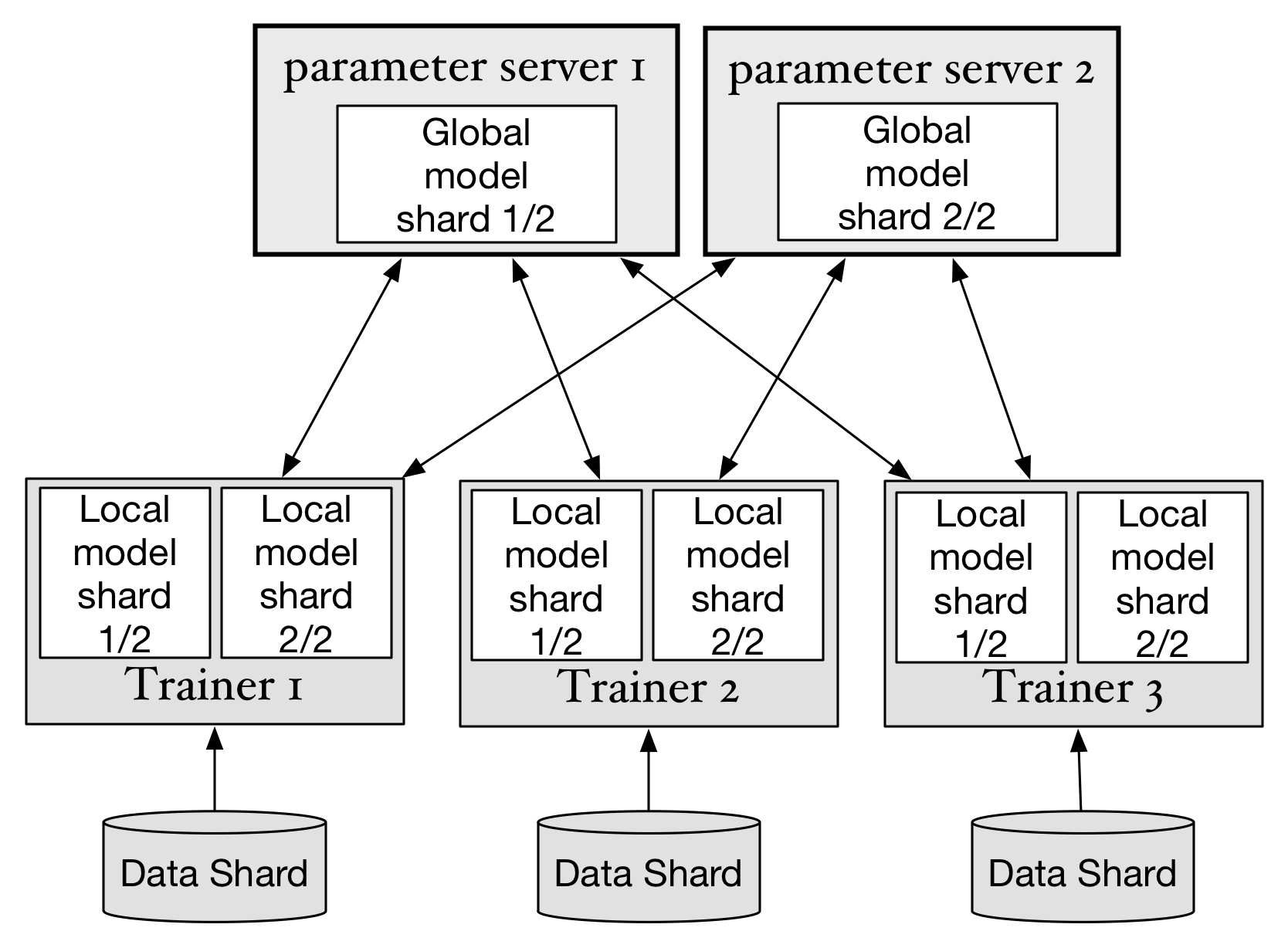
141.7 KB
{kind=link}
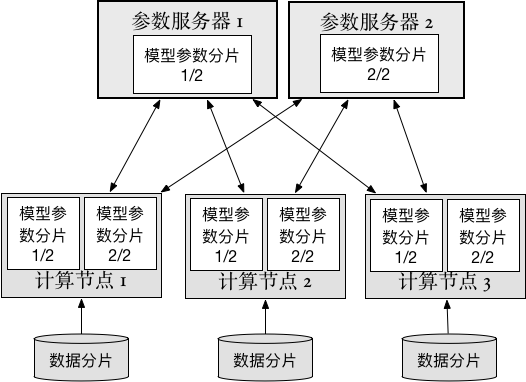
33.1 KB
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
{kind=link}
{kind=link}
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
paddle/framework/reader.cc
0 → 100644
paddle/framework/reader.h
0 → 100644
paddle/operators/read_op.cc
0 → 100644