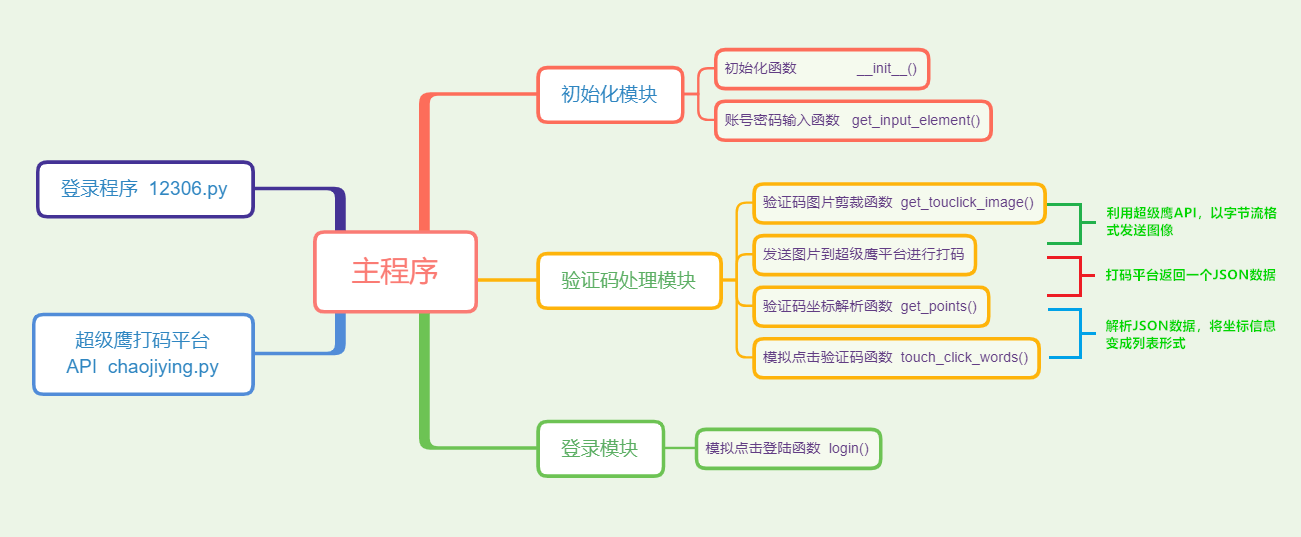
俗话说得好:预先善其事,必先利其器,作为一个程序员,经常会用到 GitHub、Google、Stack Overflow 啥的,由于国内政策原因,想要访问国外网站就得科学上网,最常见的工具就是 ShadowsocksR,又被称为酸酸乳、SSR、小飞机,目前市面上有很多很多的机场,价格也不是很高,完全可以订阅别人的,但是订阅别人的,数据安全没有保障,有可能你的浏览历史啥的别人都能掌握,别人也有随时跑路的可能,总之,只有完全属于自己的东西才是最香的!
购买 VPS
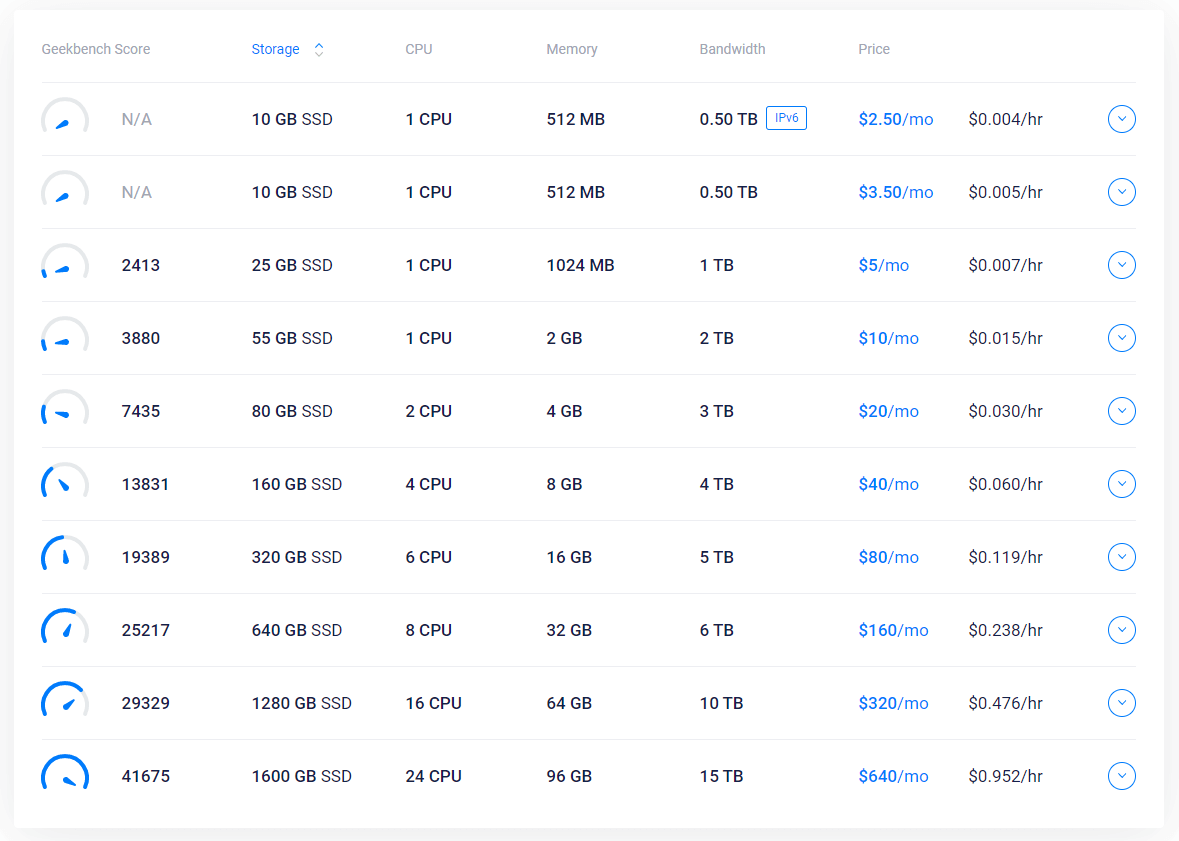
VPS(Virtual Private Server)即虚拟专用服务器技术,在购买 VPS 服务器的时候要选择国外的,推荐 Vultr,国际知名,性价比比较高,最低有$2.5/月、$3.5/月的,个人用的话应该足够了。
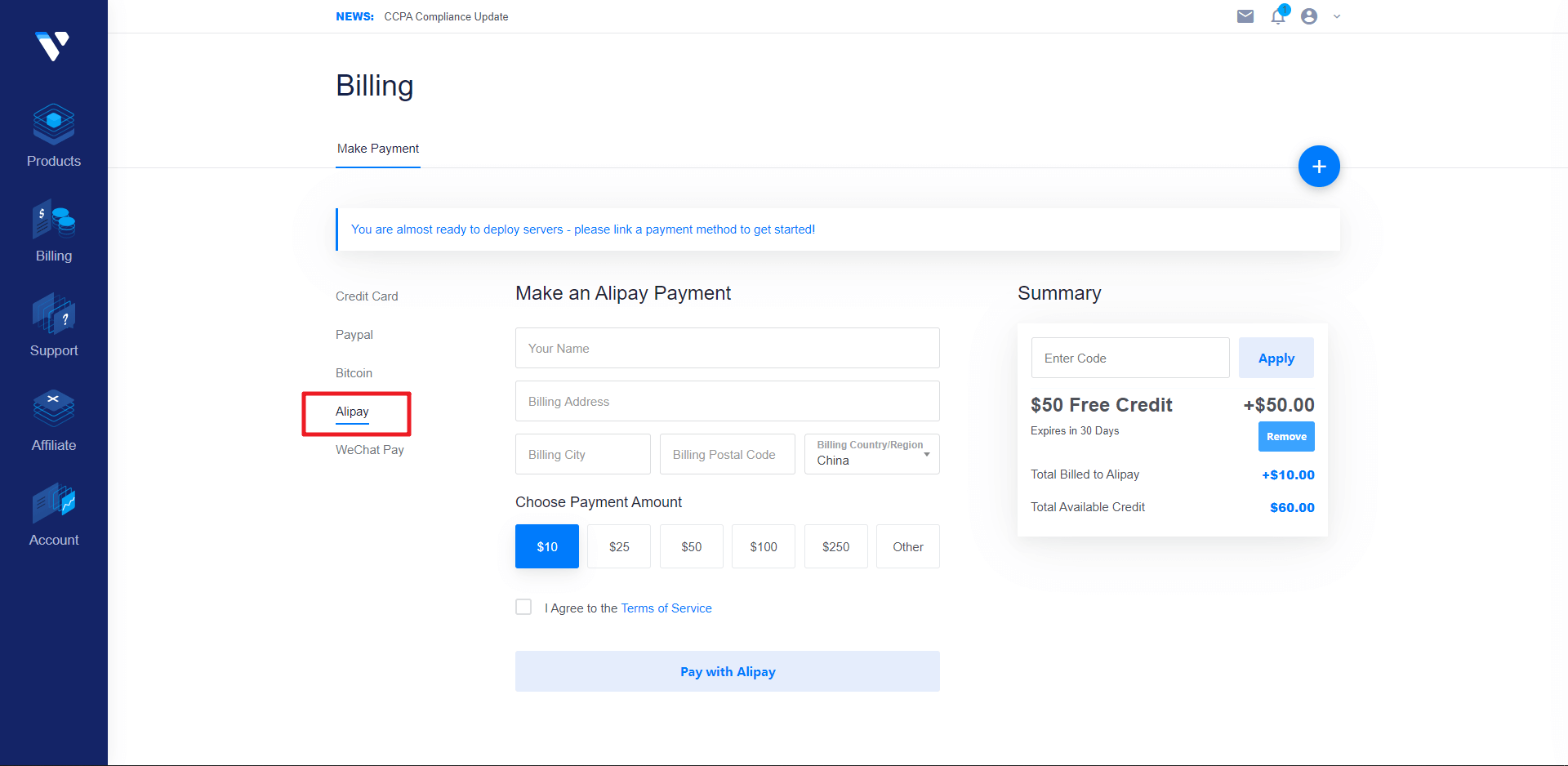
点击链接注册 Vultr 账号:https://www.vultr.com/?ref=8367048,目前新注册用户充值10刀可以赠送50刀,注册完毕之后来到充值页面,最低充值10刀,可以选择支付宝或者微信支付。
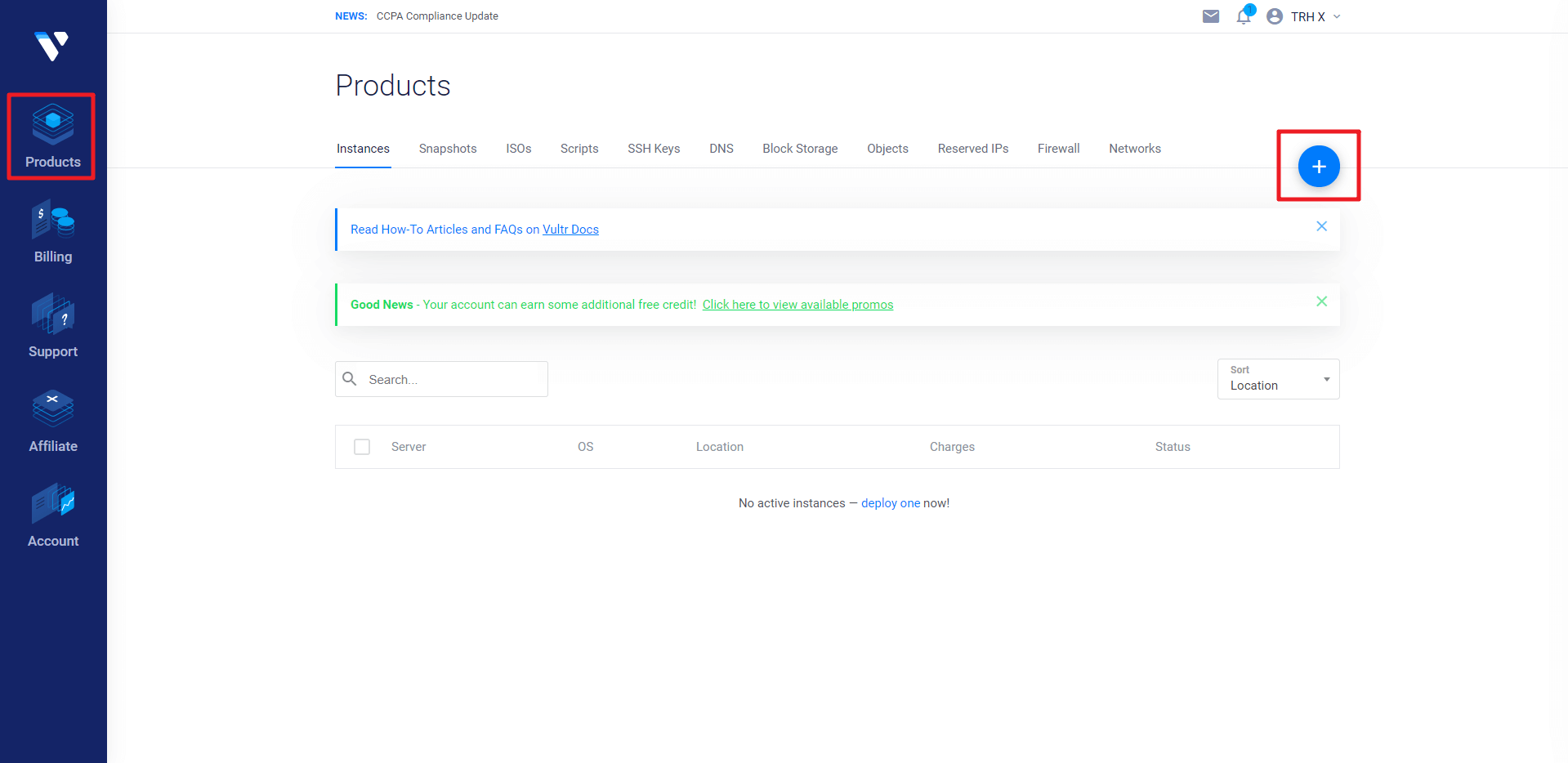
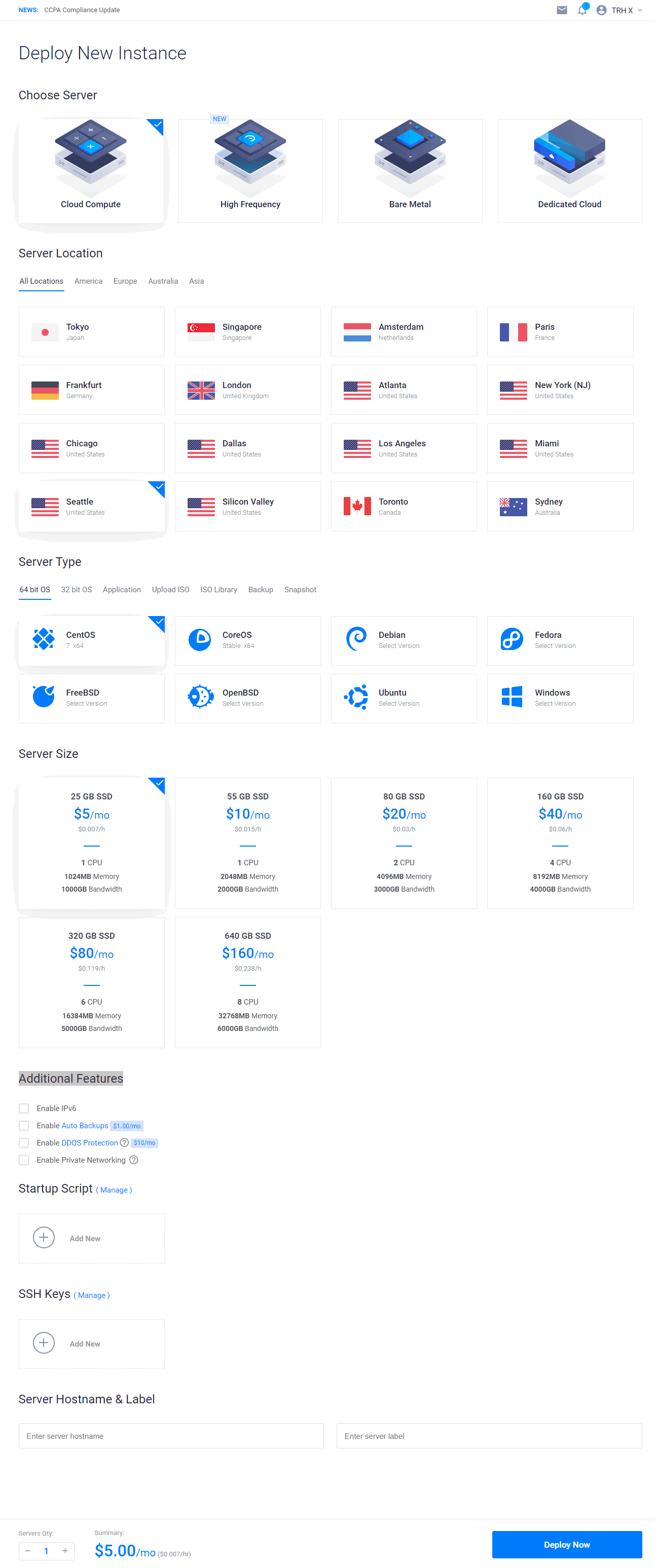
充值完毕之后,点击左侧 Products,选择服务器,一共有16个地区的,选择不同地区的服务器,最后的网速也有差别,那如何选择一个速度最优的呢?很简单,你可以一次性选择多个服务器,都部署上去,搭建完毕之后,测试其速度,选择最快的,最后再把其他的都删了,可能你会想,部署多个,那费用岂不是很贵,这里注意,虽然写的是多少钱一个月,而实际上它是按照小时计费的,从你部署之后开始计费,$5/月 ≈ $0.00694/小时,你部署完毕再删掉,这段时间的费用很低,可以忽略不计,一般来说,日本和新加坡的比较快一点,也有人说日本和新加坡服务器的端口封得比较多,容易搭建失败,具体可以自己测试一下,还有就是,只有部分地区的服务器有$2.5/月、$3.5/月的套餐,其中$2.5/月的只支持 IPv6,可以根据自己情况选择,最后操作系统建议选择 CentOS 7 x64 的,后面还有个 Enable IPv6 的选项,对 IPv6 有需求的话可以勾上,其他选项就可以不用管了。
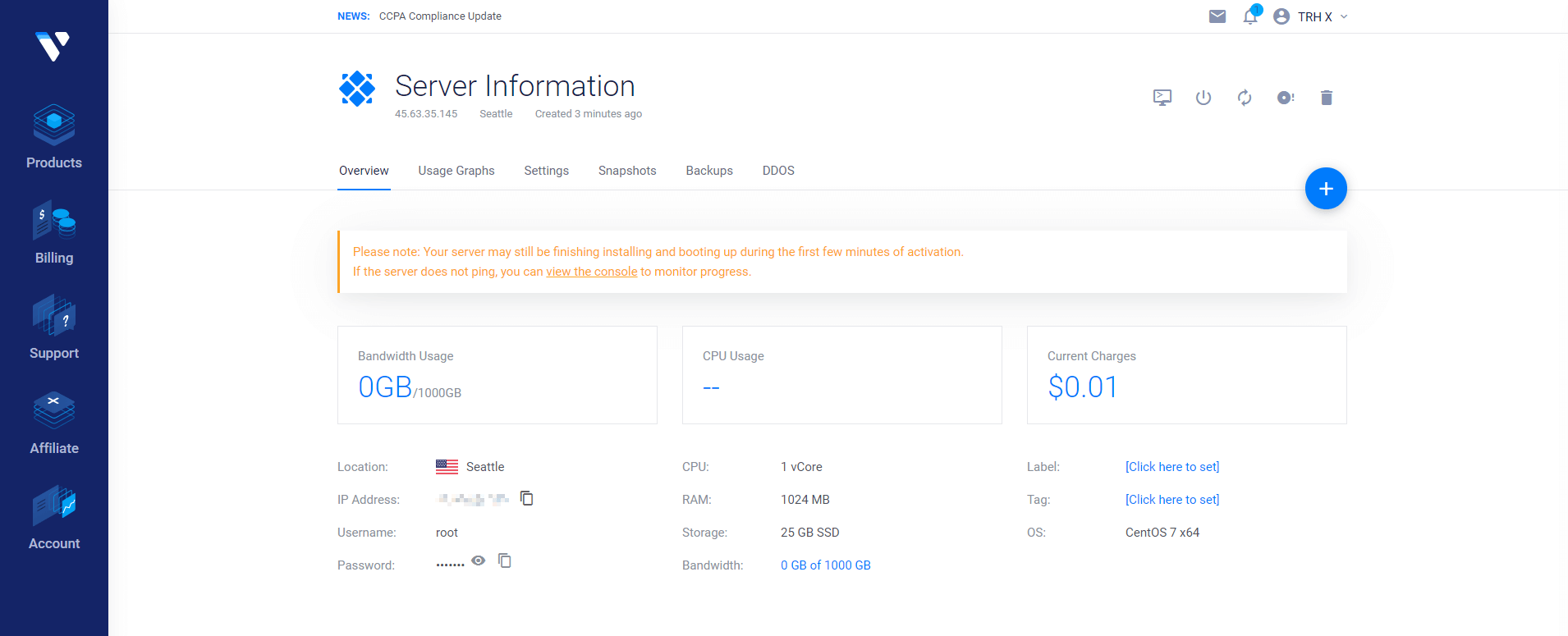
部署成功后,点 Server Details 可以看到服务器的详细信息,其中有 IP、用户名、密码等信息,后面搭建 SSR 的时候会用到,此时你可以 ping 一下你的服务器 IP,如果 ping 不通的话,可以删掉再重新开一个服务器。
搭建 SSR
我们购买的是虚拟的服务器,因此需要工具远程连接到 VPS,如果是 Mac/Linux 系统,可以直接在终端用 SSH 连接 VPS:
1 | ssh root@你VPS的IP -p 22 (22是你VPS的SSH端口) |
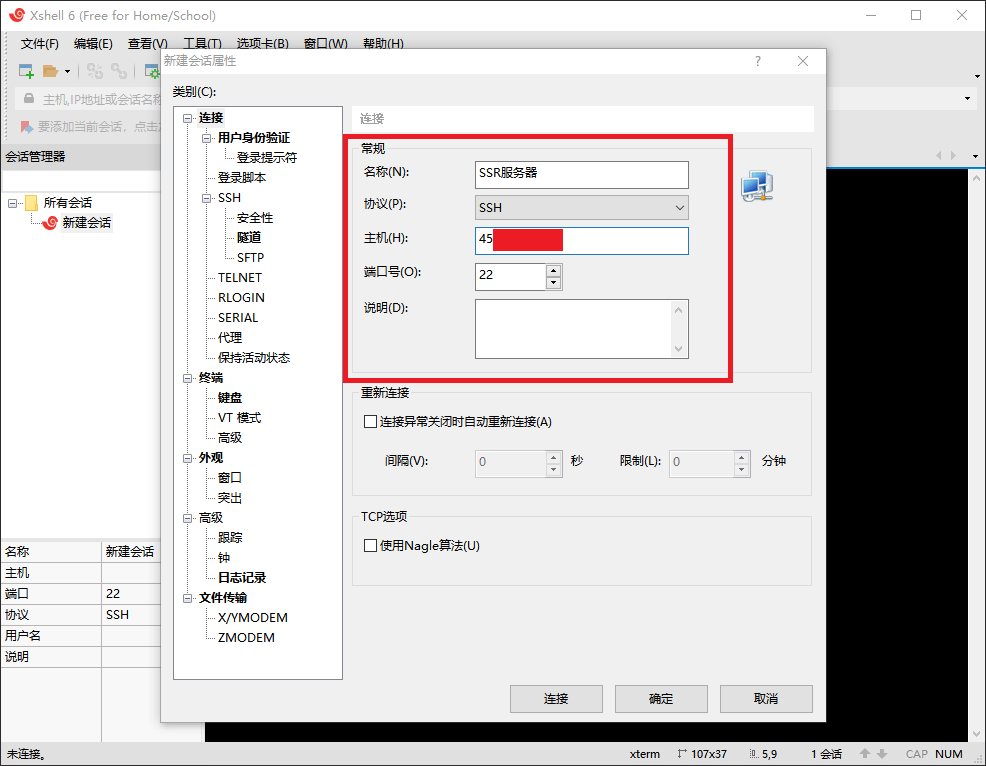
如果是 Windows 系统,可以用第三方工具连接到 VPS,如:Xshell、Putty 等,可以百度下载,以下以 Xshell 为例:
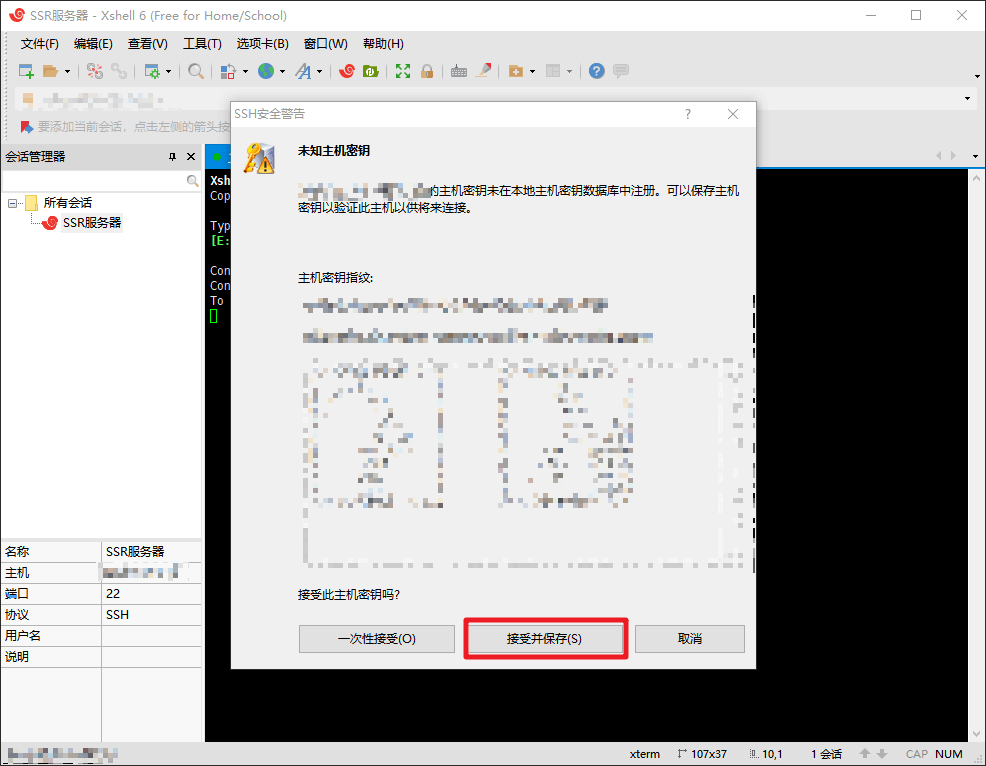
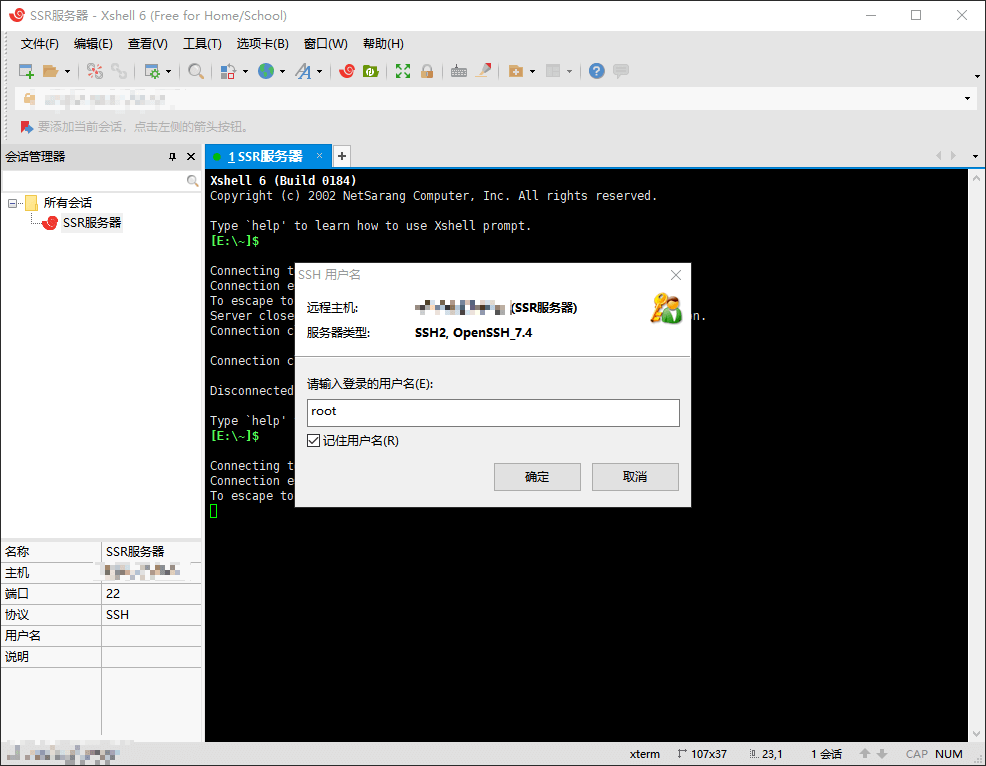
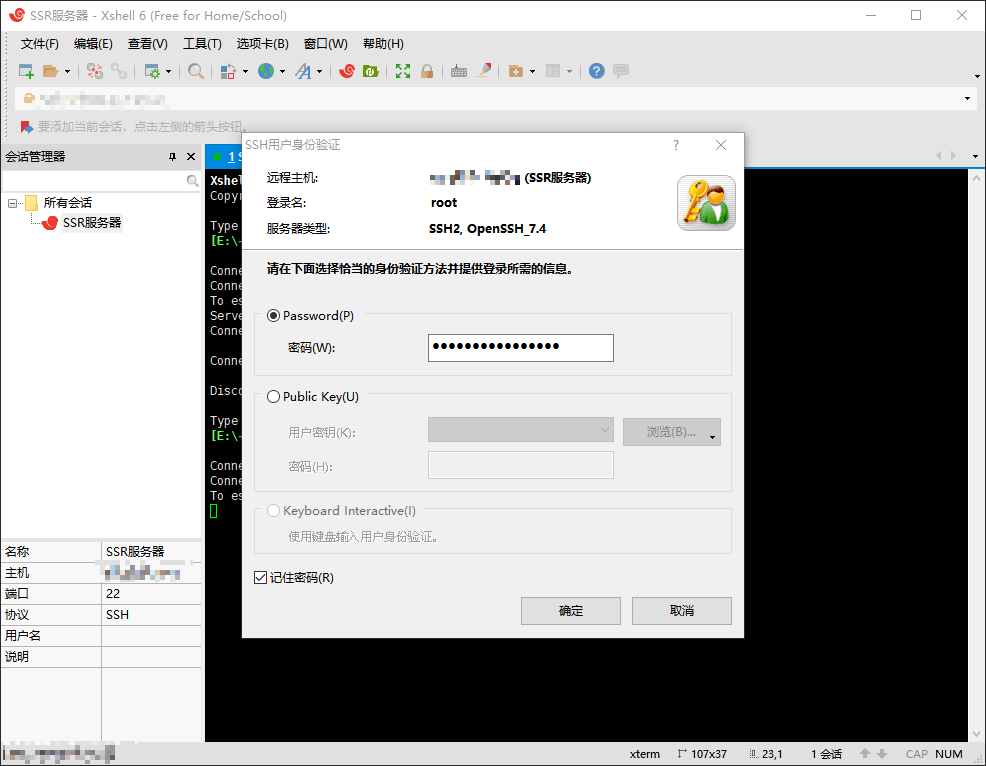
点击文件,新建会话,名称可以随便填,协议为 SSH,主机为你服务器的 IP 地址,点击确定,左侧双击这个会话开始连接,最开始会出现一个 SSH安全警告,点击接受并保存即可,然后会让你输入服务器的用户名和密码,直接在 Vultr 那边复制过来即可,最后看到 [root@vultr ~]# 字样表示连接成功。
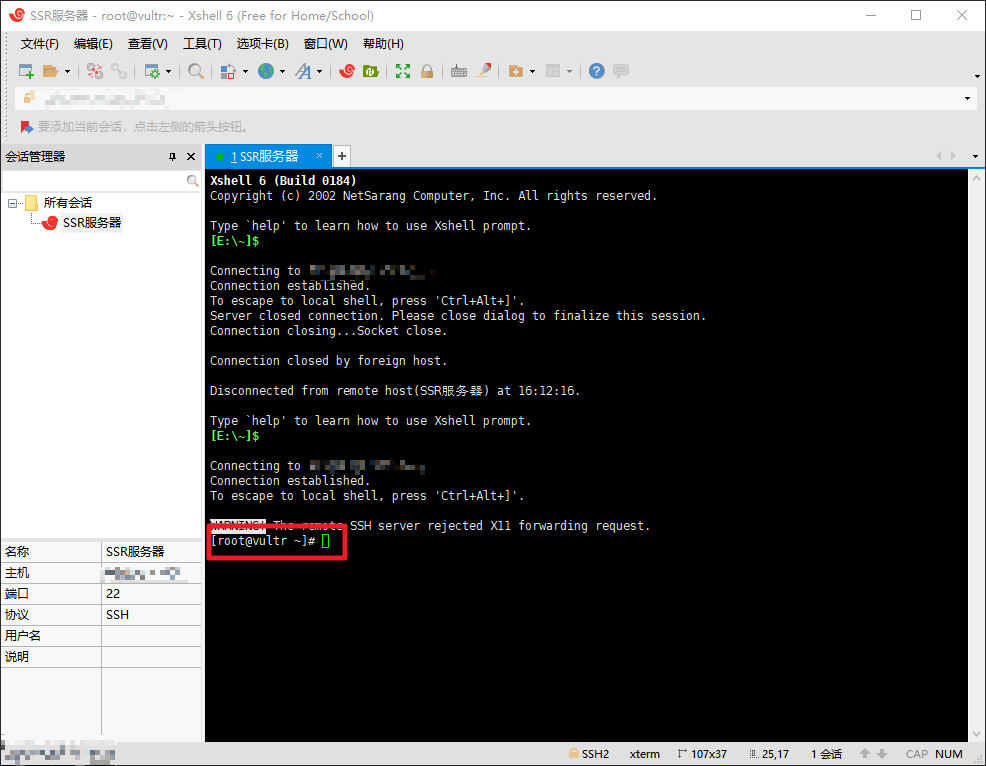
连接成功后执行以下命令开始安装 SSR:
1 | wget --no-check-certificate https://freed.ga/github/shadowsocksR.sh; bash shadowsocksR.sh |
如果提示 wget :command not found,可先执行 yum -y install wget,再执行上述命令即可。
执行完毕后会让你设置 SSR 连接密码和端口,然后按任意键开始搭建。
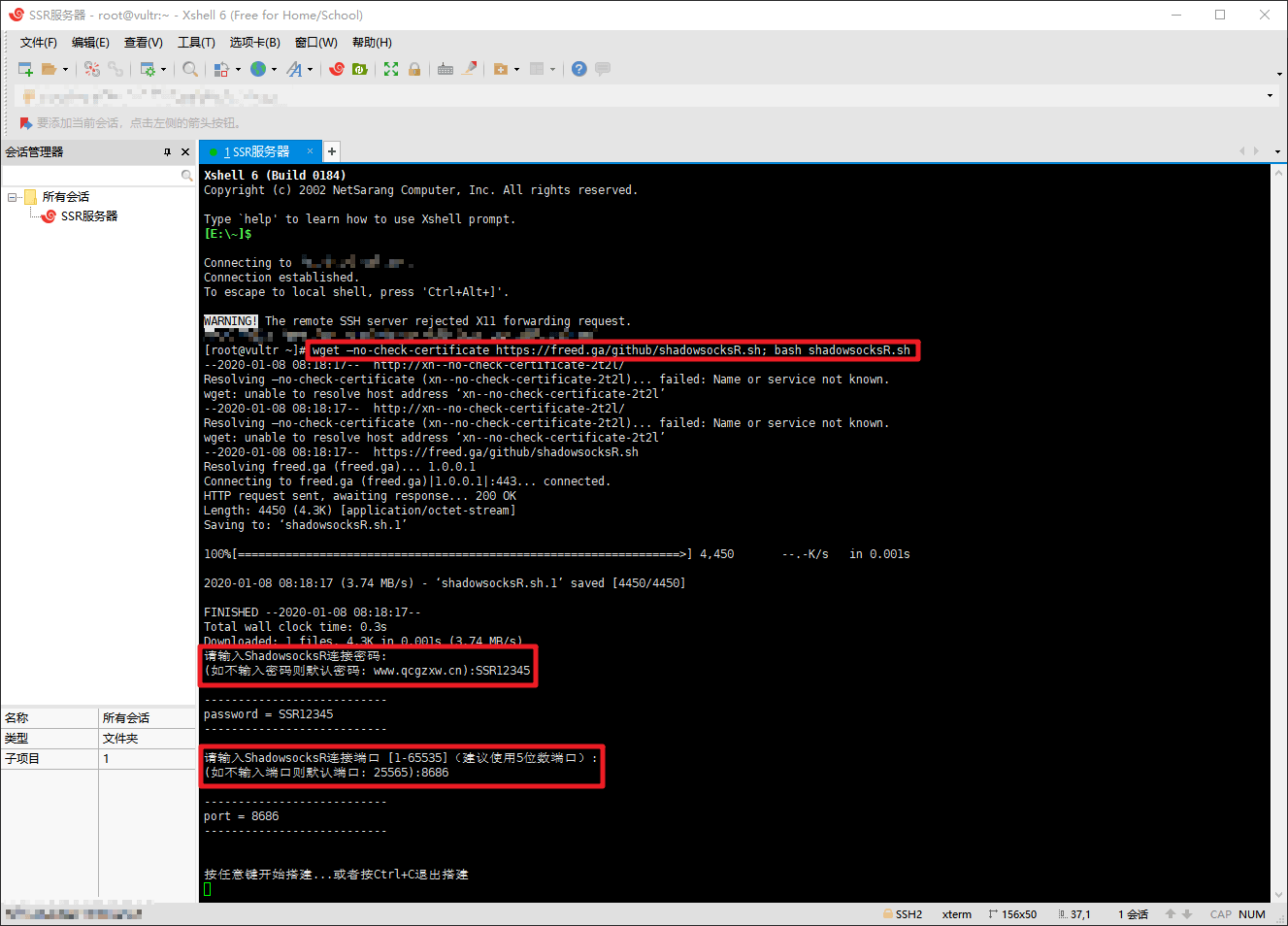
搭建成功后会显示你服务器 IP,端口,连接密码,协议等信息,这些信息要记住,后面使用 ShadowsocksR 的时候要用到。
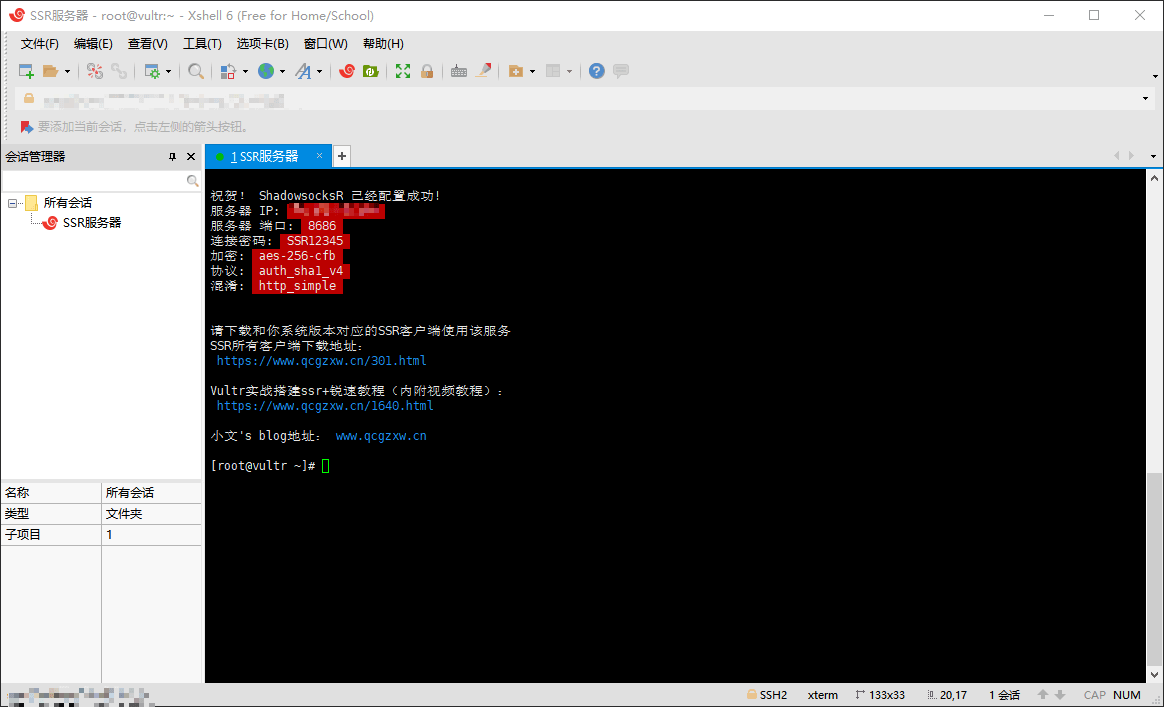
安装锐速
由于我们购买的服务器位于国外,如果遇到上网高峰期,速度就会变慢,而锐速就是一款专业的连接加速器,可以充分利用服务器带宽,提升带宽吞吐量,其他还有类似的程序如 Google BBR 等,可以自行比较其加速效果,以下以操作系统为 CentOS 6&7 锐速的安装为例。
如果你服务器操作系统选择的是 CentOS 6 x64,则直接执行以下命令,一直回车即可:
1 | wget --no-check-certificate -O appex.sh https://raw.githubusercontent.com/hombo125/doubi/master/appex.sh && bash appex.sh install '2.6.32-642.el6.x86_64' |
如果你服务器操作系统选择的是 CentOS 7 x64,则需要先执行以下命令更换内核:
1 | wget --no-check-certificate -O rskernel.sh https://raw.githubusercontent.com/hombo125/doubi/master/rskernel.sh && bash rskernel.sh |
如下图所示表示内核更换完毕,此时已经断开与服务器的连接,我们需要重新连接到服务器,再执行后面的操作:
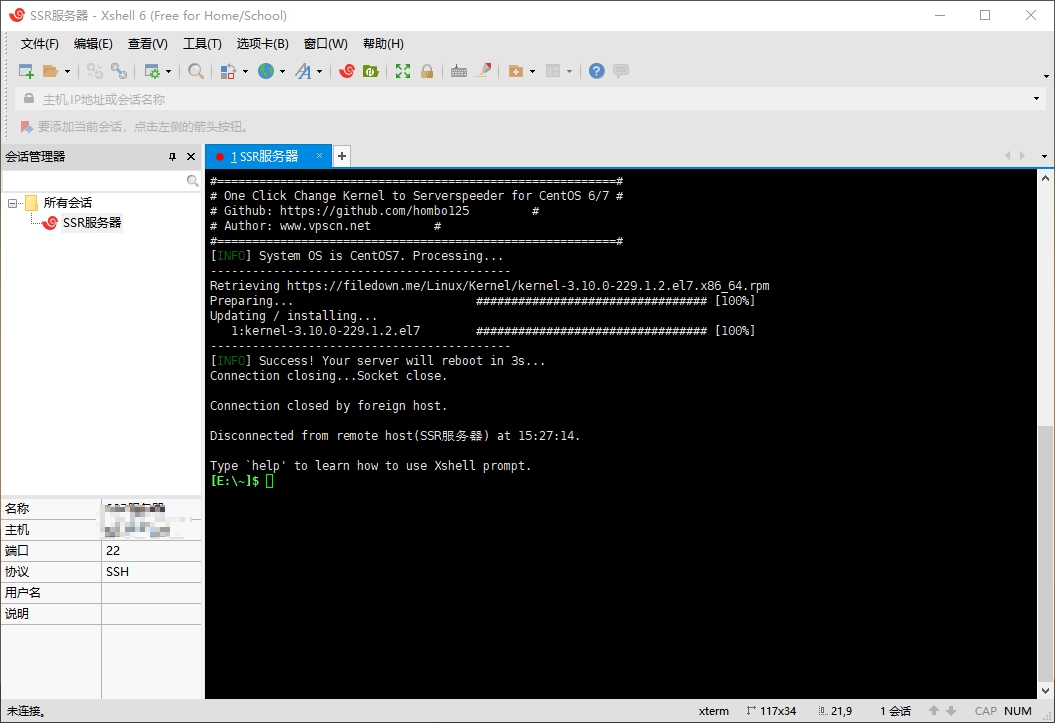
重新连接到服务器后,再执行以下命令:
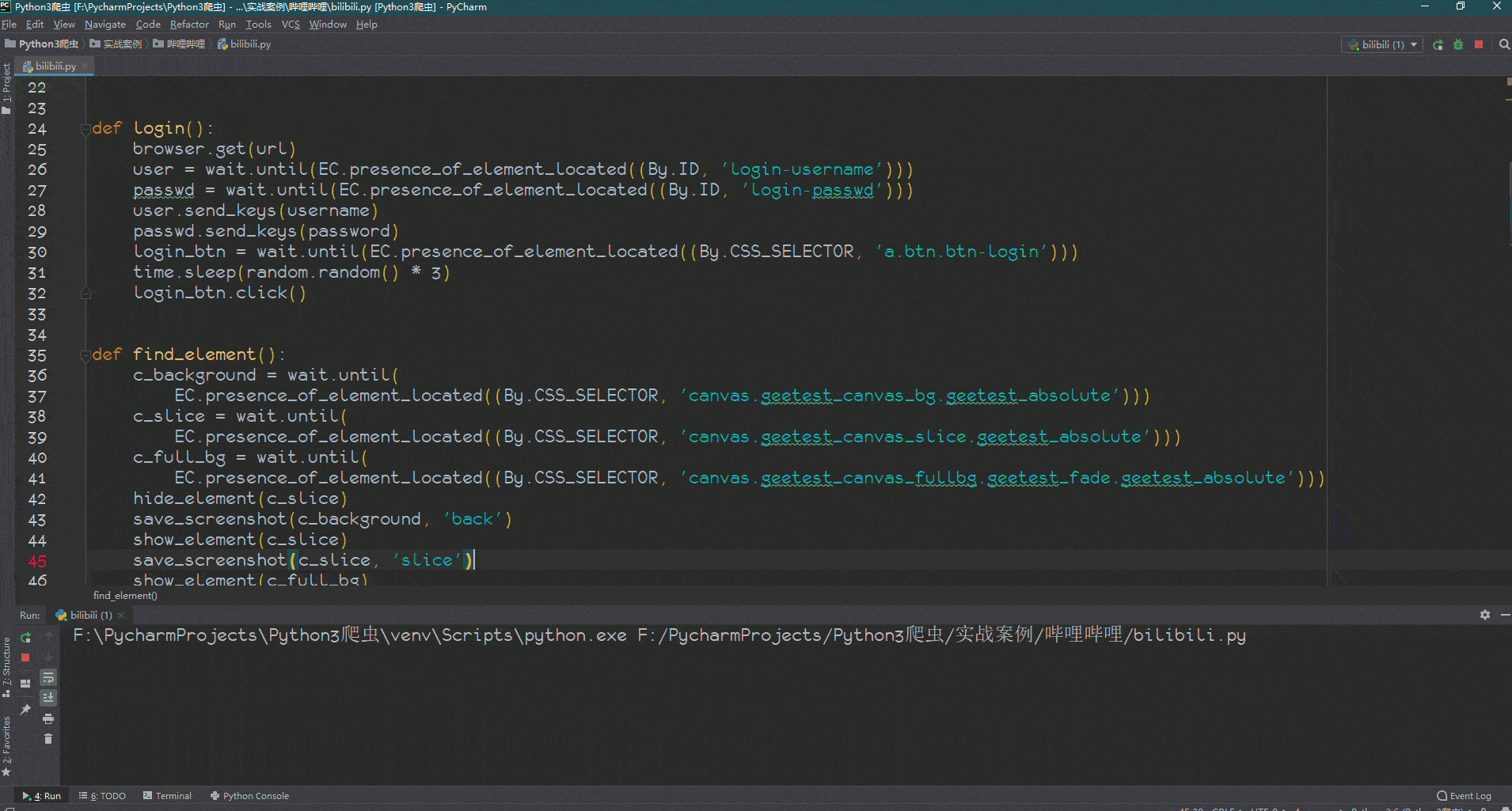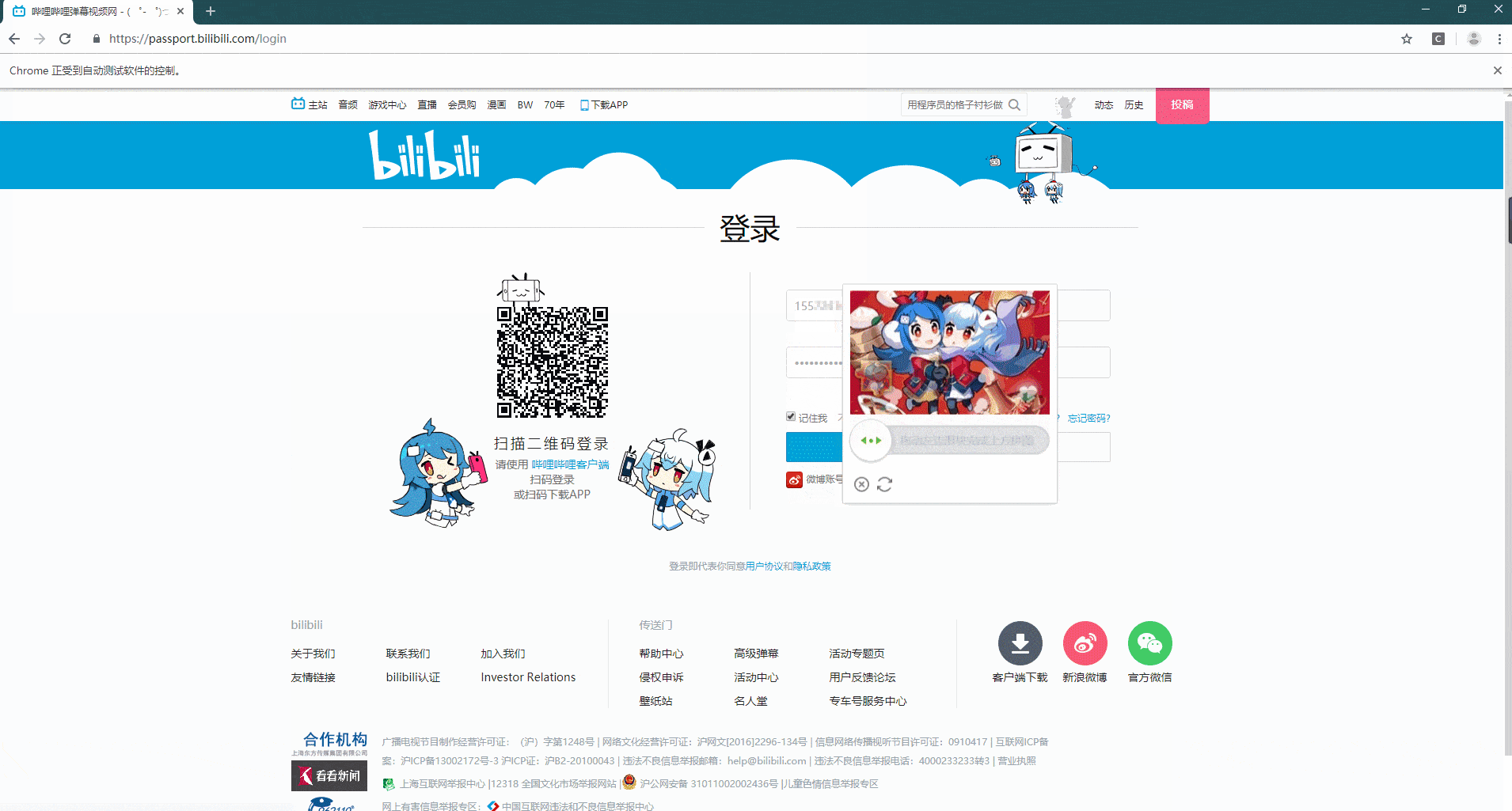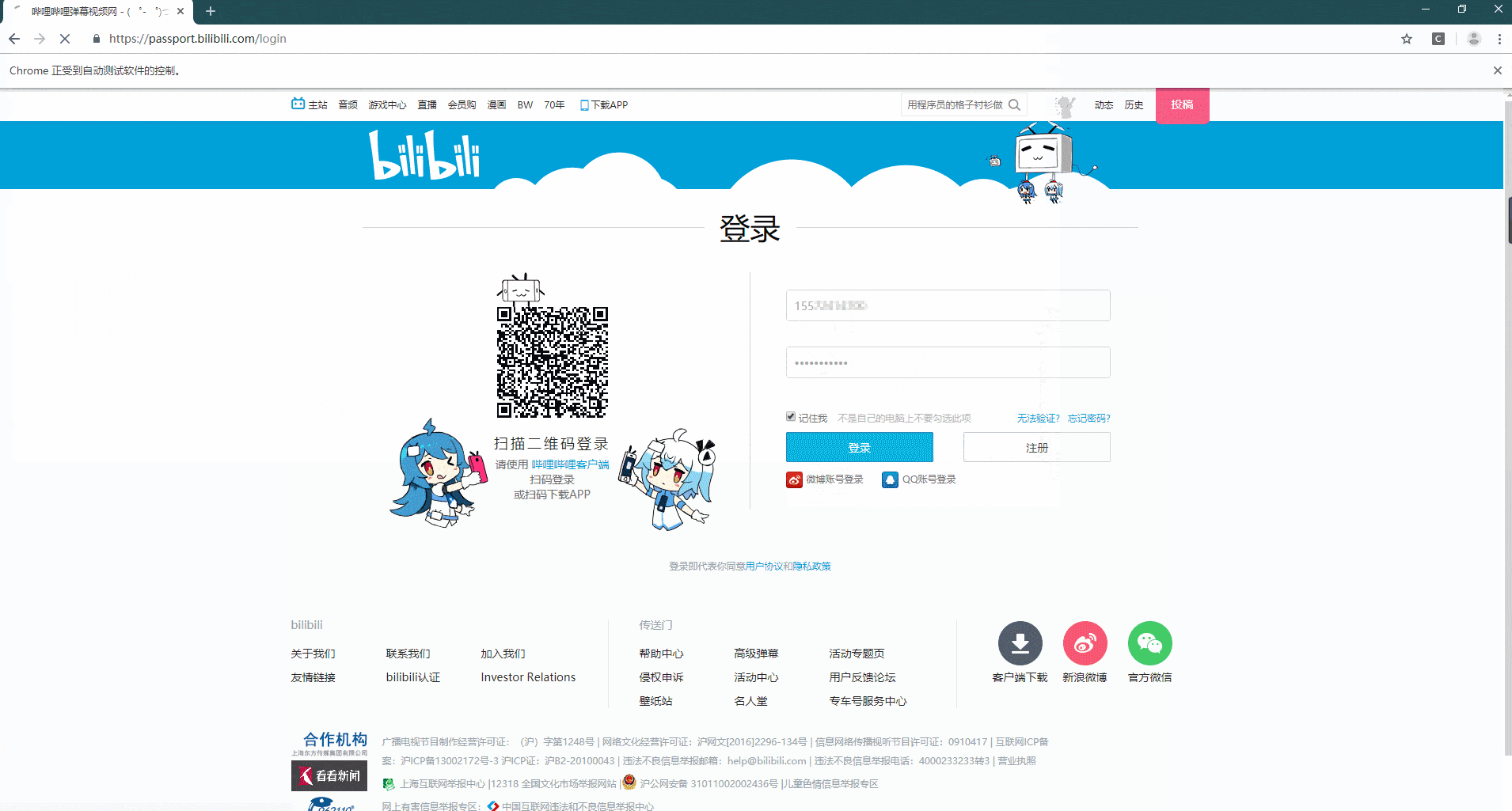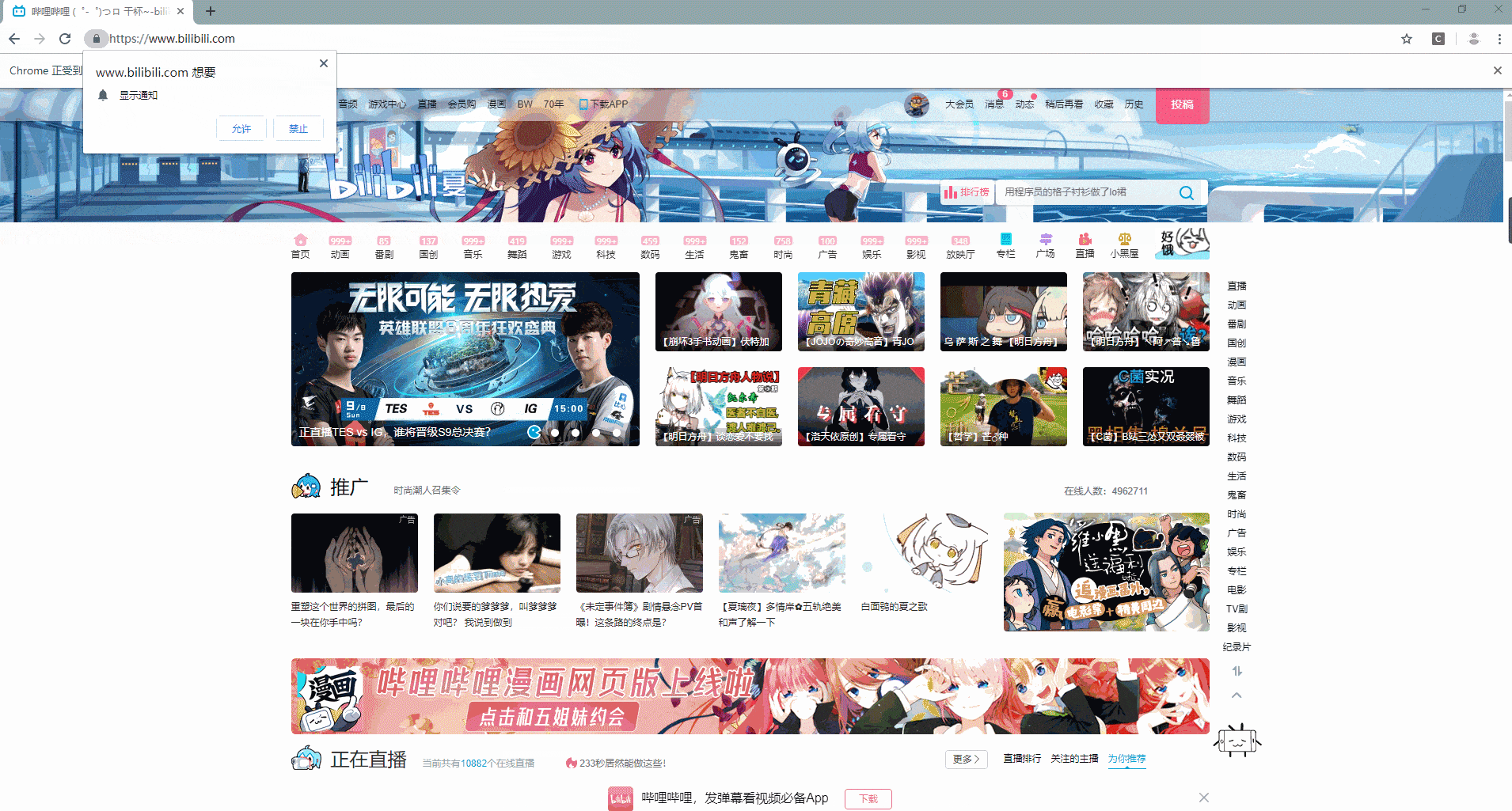
1 | yum install net-tools -y && wget --no-check-certificate -O appex.sh https://raw.githubusercontent.com/0oVicero0/serverSpeeder_Install/master/appex.sh && bash appex.sh install |
然后一直回车即可,系统会自动安装锐速。
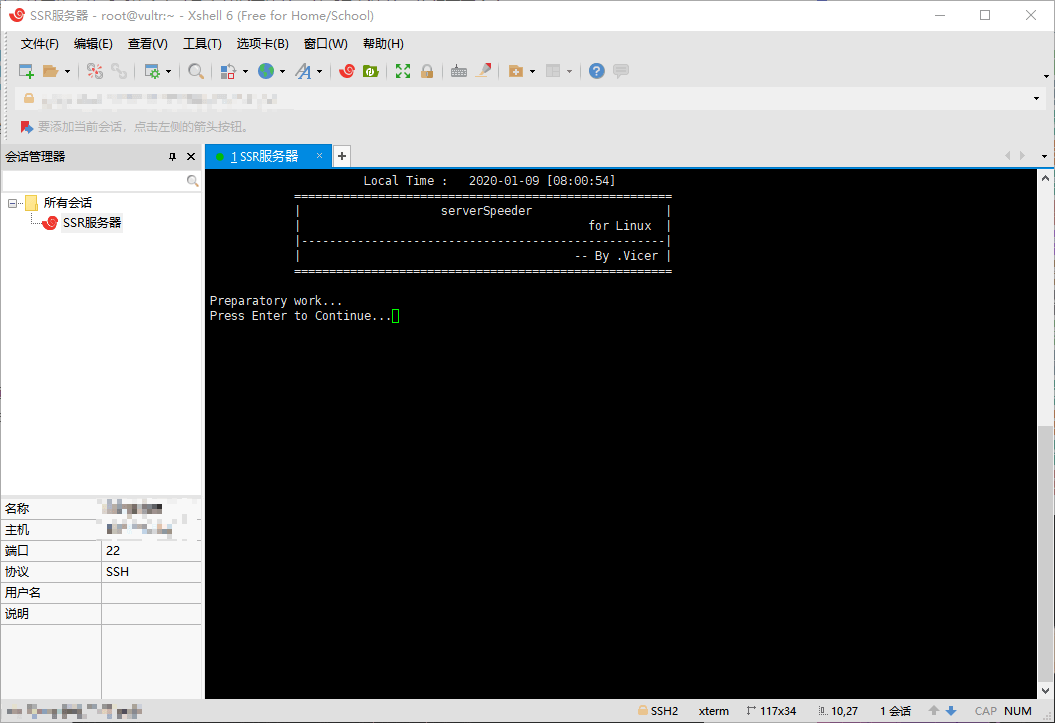
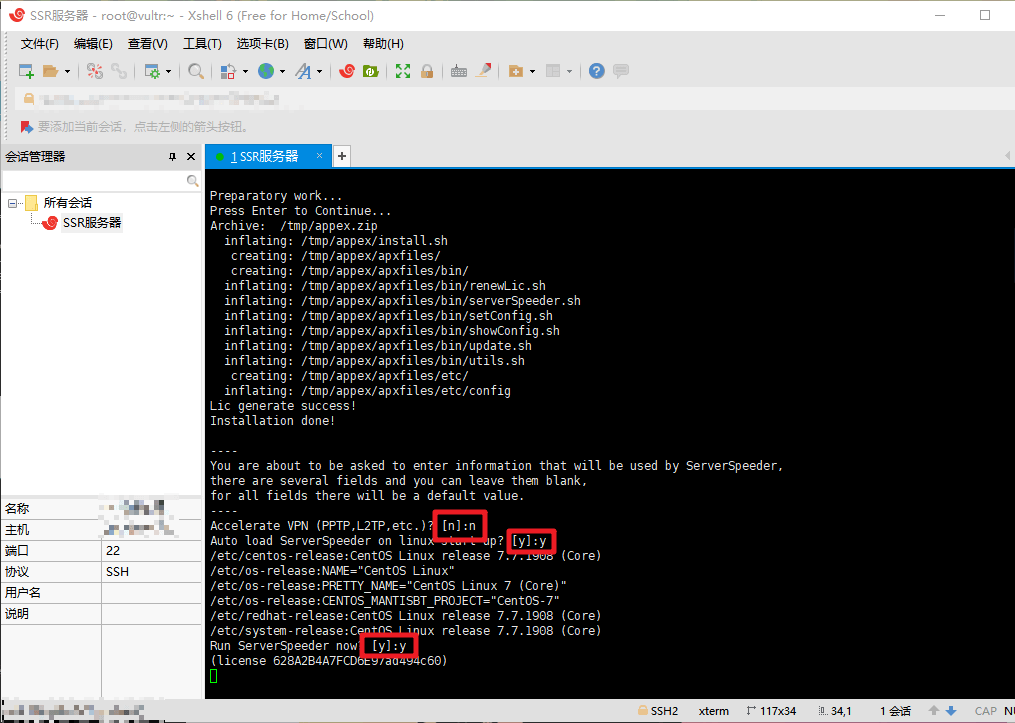
出现以下信息表示安装成功:
使用 SSR
常见的工具有 ShadowsocksR、SSTap(原本是个游戏加速器,现在已经停止维护,但 GitHub 上仍然可以找到)等。
Shadowsocks 官网:https://shadowsocks.org/
ShadowsocksR 下载地址:https://github.com/Anankke/SSRR-Windows
SSTap GitHub 地址:https://github.com/FQrabbit/SSTap-Rule
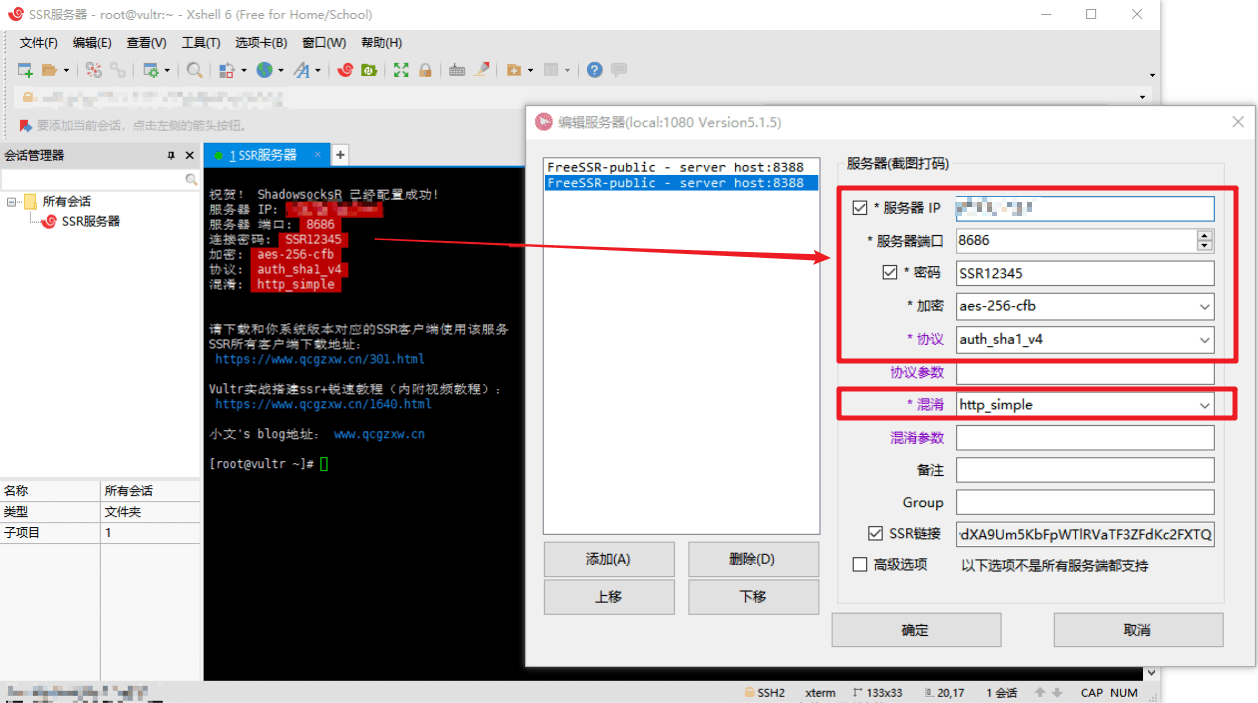
不管什么工具,用法都是一样的,添加一个新的代理服务器,服务器 IP、端口、密码、加密方式等等这些信息保持一致就行了。然后就可以愉快地科学上网了!
多端口配置
经过以上步骤我们就可以科学上网了,但是目前为止只有一个端口,只能一个人用,那么如何实现多个端口多人使用呢?事实上端口、密码等信息是储存在一个叫做 shadowsocks.json 文件里的,如果要添加端口或者更改密码,只需要修改此文件即可。
连接到自己的 VPS,输入以下命令,使用 vim 编辑文件:vi /etc/shadowsocks.json
原文件内容大概如下:
1 | { |
增加端口,我们将其修改为如下内容:
1 | { |
也就是删除原来的 server_port 和 password 这两项,然后增加 port_password 这一项,前面是端口号,后面是密码,注意不要把格式改错了!!!修改完毕并保存!!!
接下来配置一下防火墙,同样的,输入以下命令,用 vim 编辑文件:vi /etc/firewalld/zones/public.xml
初始的防火墙只开放了最初配置 SSR 默认的那个端口,现在需要我们手动加上那几个新加的端口,注意:一个端口需要复制两行,一行是 tcp,一行是 udp。
原文件内容大概如下:
1 | <?xml version="1.0" encoding="utf-8"?> |
修改后的内容如下:
1 | <?xml version="1.0" encoding="utf-8"?> |
修改完毕并保存,最后重启一下 shadowsocks,然后重新载入防火墙即可,两条命令如下:
1 | /etc/init.d/shadowsocks restart |
1 | firewall-cmd –reload |
完成之后,我们新加的这几个端口就可以使用了
另外还可以将配置转换成我们常见的链接形式,如:ss://xxxxx 或 ssr://xxxxx,其实这种链接就是把 IP,端口,密码等信息按照一定的格式拼接起来,然后经过 Base64 编码后实现的,有兴趣或者有需求的可以自行百度。
扩展命令
SSR 常用命令:
启动:/etc/init.d/shadowsocks start
停止:/etc/init.d/shadowsocks stop
重启:/etc/init.d/shadowsocks restart
状态:/etc/init.d/shadowsocks status
卸载:./shadowsocks-all.sh uninstall
更改配置参数:vim /etc/shadowsocks-r/config.json