更新了最后10天的文档
Showing
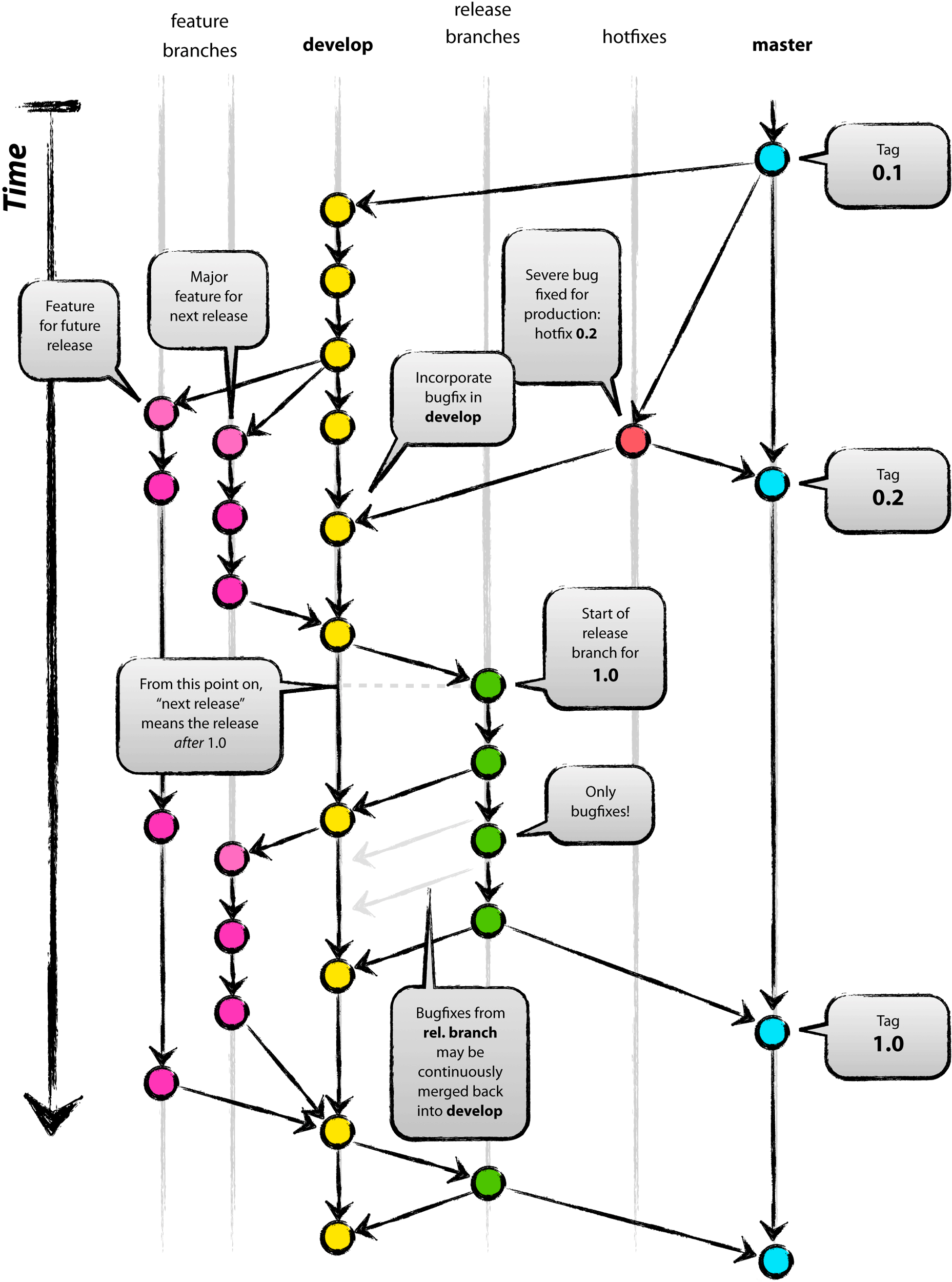
Day91-100/res/git-flow.png
0 → 100644
{kind=link}
367.6 KB
Day91-100/res/git_logo.png
已删除
100644 → 0
{kind=link}
188.9 KB
{kind=link}
178.2 KB
{kind=link}
192.0 KB
Day91-100/res/gitlab-about.png
0 → 100644
{kind=link}
1.5 MB
Day91-100/res/unlock-jenkins.png
0 → 100644
{kind=link}
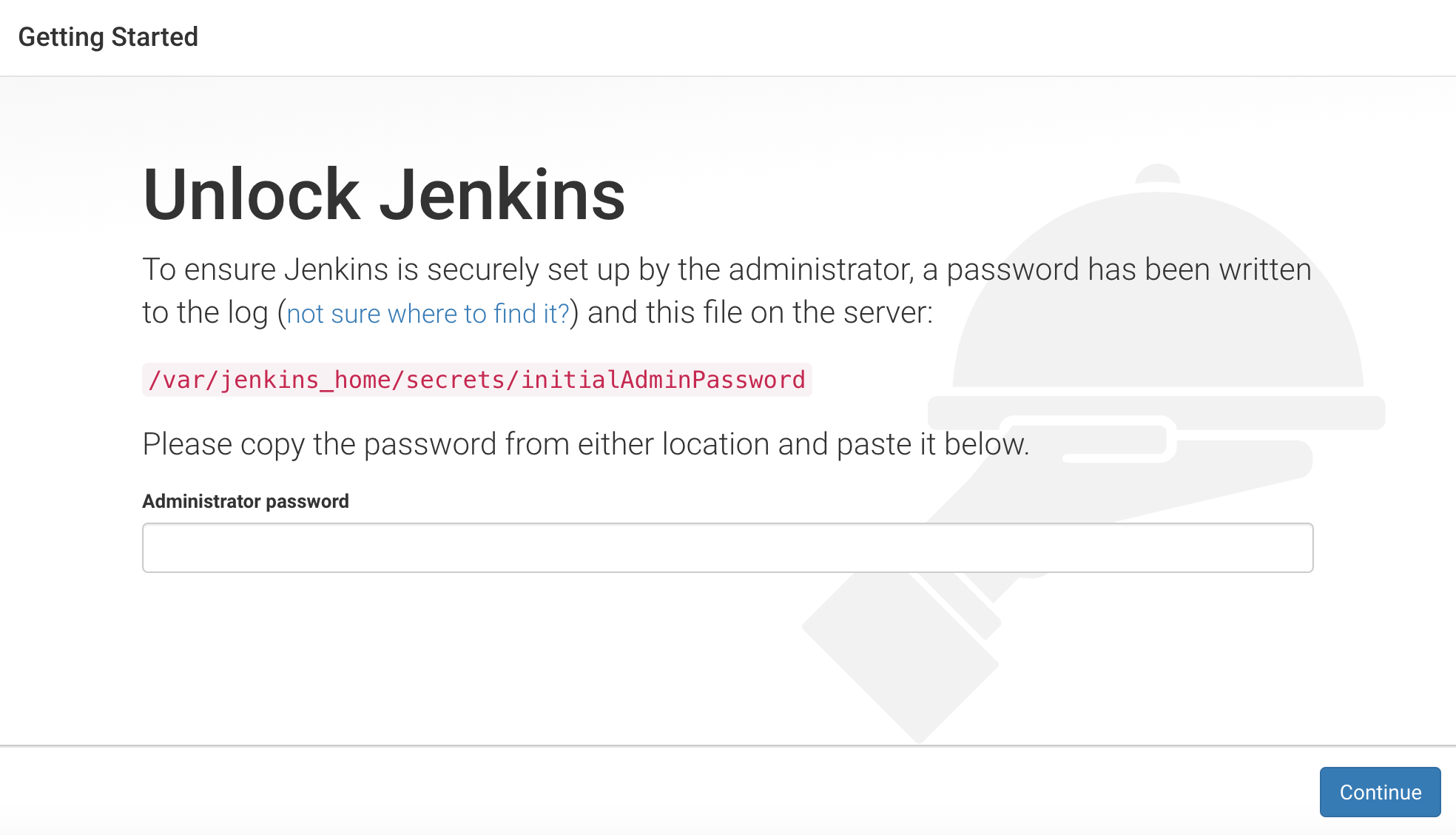
203.7 KB
Day91-100/res/zentao-index.png
0 → 100644
{kind=link}
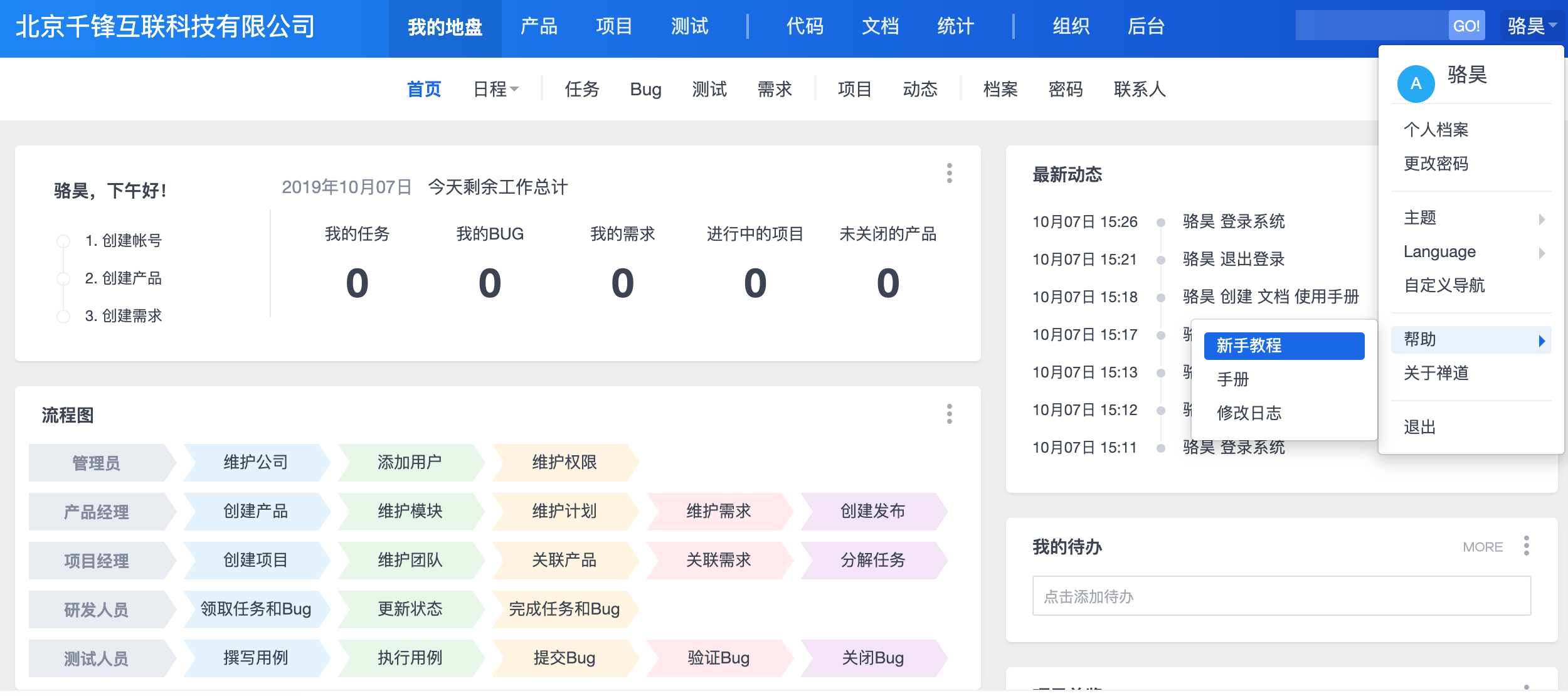
520.7 KB
Day91-100/res/zentao-login.png
0 → 100644
{kind=link}
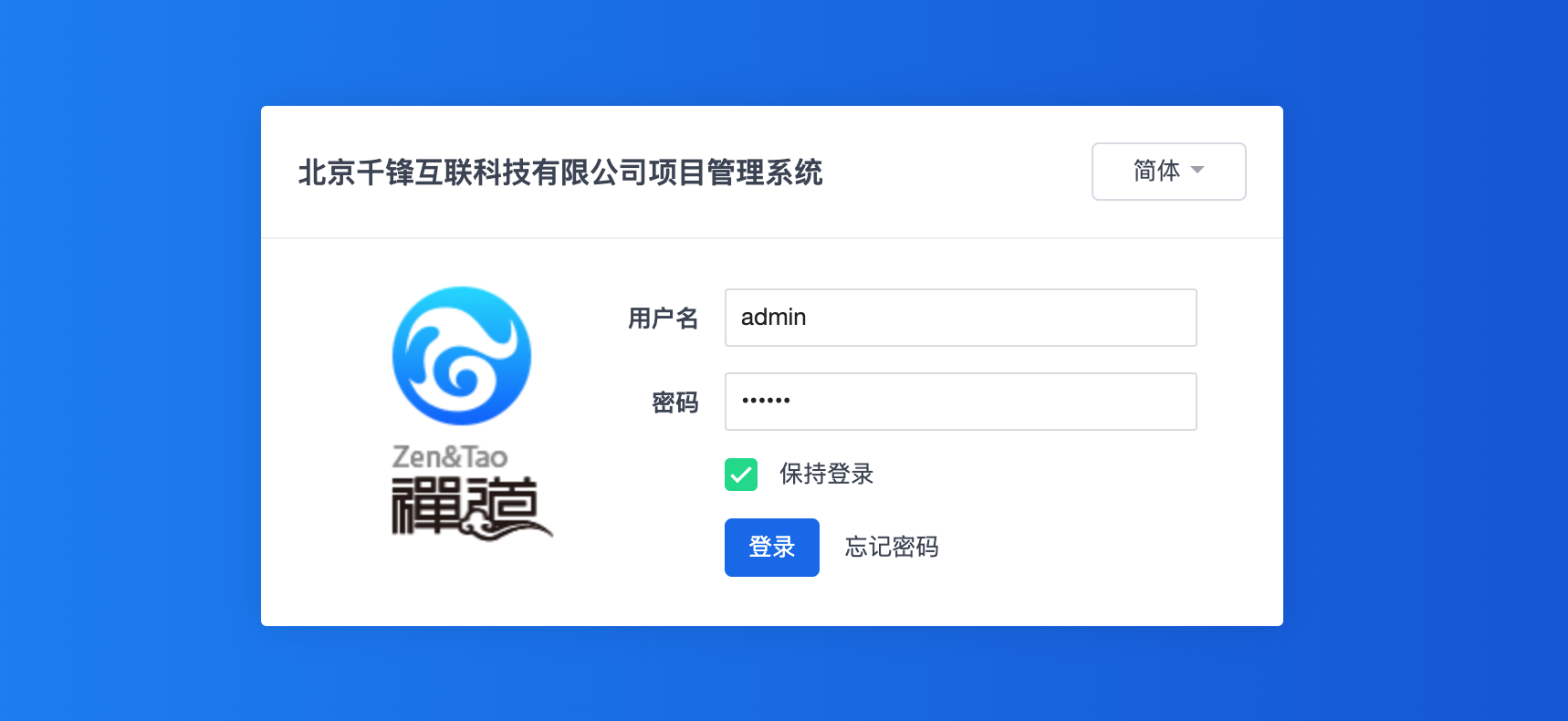
578.6 KB
res/python-qq-group.png
0 → 100644
{kind=link}

849.9 KB
res/python_qq_group.JPG
已删除
100644 → 0
{kind=link}

564.2 KB