First, of course, is to run web ui with --api commandline argument
+
+
example in your “webui-user.bat”: set COMMANDLINE_ARGS=--api
+
+
+
This enables the api which can be reviewed at http://127.0.0.1:7860/docs (or whever the URL is + /docs)
+The basic ones I’m interested in are these two. Let’s just focus only on /sdapi/v1/txt2img
+
+
+
+
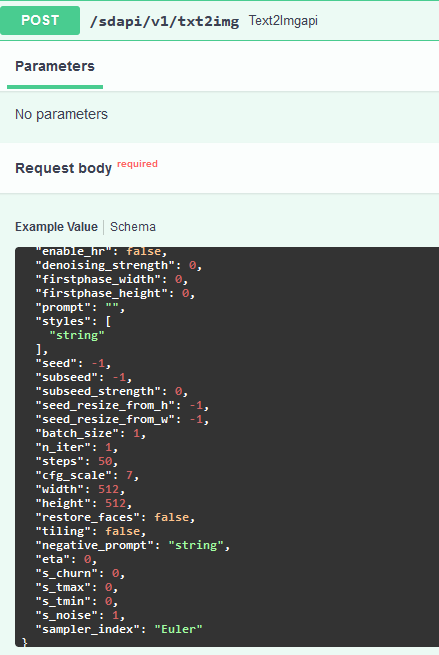
When you expand that tab, it gives an example of a payload to send to the API. I used this often as reference.
+
+
+
+
+
So that’s the backend. The API basically says what’s available, what it’s asking for, and where to send it. Now moving onto the frontend, I’ll start with constructing a payload with the parameters I want. An example can be:
Again, this URL needs to match the web ui’s URL.
+If we execute this code, the web ui will generate an image based on the payload. That’s great, but then what? There is no image anywhere…
+
+
+
After the backend does its thing, the API sends the response back in a variable that was assigned above: response. The response contains three entries; “images”, “parameters”, and “info”, and I have to find some way to get the information from these entries.
+
First, I put this line r = response.json() to make it easier to work with the response.
+
“images” is the generated image, which is what I want mostly. There’s no link or anything; it’s a giant string of random characters, apparently we have to decode it. This is how I do it:
+
+
for i in r['images']:
+ image = Image.open(io.BytesIO(base64.b64decode(i.split(",",1)[0])))
+
+
+
With that, we have an image in the image variable that we can work with, for example saving it with image.save('output.png').
+
“parameters” shows what was sent to the API, which could be useful, but what I want in this case is “info”. I use it to insert metadata into the image, so I can drop it into web ui PNG Info. For that, I can access the /sdapi/v1/png-info API. I’ll need to feed the image I got above into it.
for each image, send it to png info API and get that info back
+
define a plugin to add png info, then add the png info I defined into it
+
at the end here, save the image with the png info
+
+
+
A note on "override_settings".
+The purpose of this endpoint is to override the web ui settings for a single request, such as the CLIP skip. The settings that can be passed into this parameter are visible here at the url’s /docs.
+
+
You can expand the tab and the API will provide a list. There are a few ways you can add this value to your payload, but this is how I do it. I’ll demonstrate with “filter_nsfw”, and “CLIP_stop_at_last_layers”.
after that, initialize a dictionary (I call it “override_settings”, but maybe not the best name)
+
then I can add as many key:value pairs as I want to it
+
make a new payload with just this parameter
+
update the original payload to add this one to it
+
+
So in this case, when I send the payload, I should get a “cirno” at 20 steps, with the CLIP skip at 2, as well as the NSFW filter on.
+
For certain settings or situations, you may want your changes to stay. For that you can post to the /sdapi/v1/options API endpoint
+We can use what we learned so far and set up the code easily for this. Here is an example:
After sending this payload to the API, the model should swap to the one I set and set the CLIP skip to 2. Reiterating, this is different from “override_settings”, because this change will persist, while “override_settings” is for a single request.
+Note that if you’re changing the sd_model_checkpoint, the value should be the name of the checkpoint as it appears in the web ui. This can be referenced with this API endpoint (same way we reference “options” API)
+
+
The “title” (name and hash) is what you want to use.
For a more complete implementation of a frontend, my Discord bot is here if anyone wants to look at it as an example. Most of the action happens in stablecog.py. There are many comments explaining what each code does.
+
+
+
+
+
+
diff --git a/sd2/API.md b/sd2/API.md
new file mode 100644
index 0000000000000000000000000000000000000000..6a86f4492a3a3ebe82f2b68700f2c9eba6d39826
--- /dev/null
+++ b/sd2/API.md
@@ -0,0 +1,155 @@
+## API guide by [@Kilvoctu](https://github.com/Kilvoctu)
+
+- First, of course, is to run web ui with `--api` commandline argument
+ - example in your "webui-user.bat": `set COMMANDLINE_ARGS=--api`
+- This enables the api which can be reviewed at http://127.0.0.1:7860/docs (or whever the URL is + /docs)
+The basic ones I'm interested in are these two. Let's just focus only on ` /sdapi/v1/txt2img`
+
+
+
+- When you expand that tab, it gives an example of a payload to send to the API. I used this often as reference.
+
+
+
+------
+
+- So that's the backend. The API basically says what's available, what it's asking for, and where to send it. Now moving onto the frontend, I'll start with constructing a payload with the parameters I want. An example can be:
+```py
+payload = {
+ "prompt": "maltese puppy",
+ "steps": 5
+}
+```
+I can put in as few or as many parameters as I want in the payload. The API will use the defaults for anything I don't set.
+
+- After that, I can send it to the API
+```py
+response = requests.post(url=f'http://127.0.0.1:7860/sdapi/v1/txt2img', json=payload)
+```
+Again, this URL needs to match the web ui's URL.
+If we execute this code, the web ui will generate an image based on the payload. That's great, but then what? There is no image anywhere...
+
+------
+
+- After the backend does its thing, the API sends the response back in a variable that was assigned above: `response`. The response contains three entries; "images", "parameters", and "info", and I have to find some way to get the information from these entries.
+- First, I put this line `r = response.json()` to make it easier to work with the response.
+- "images" is the generated image, which is what I want mostly. There's no link or anything; it's a giant string of random characters, apparently we have to decode it. This is how I do it:
+```py
+for i in r['images']:
+ image = Image.open(io.BytesIO(base64.b64decode(i.split(",",1)[0])))
+```
+- With that, we have an image in the `image` variable that we can work with, for example saving it with `image.save('output.png')`.
+- "parameters" shows what was sent to the API, which could be useful, but what I want in this case is "info". I use it to insert metadata into the image, so I can drop it into web ui PNG Info. For that, I can access the `/sdapi/v1/png-info` API. I'll need to feed the image I got above into it.
+```py
+png_payload = {
+ "image": "data:image/png;base64," + i
+ }
+ response2 = requests.post(url=f'http://127.0.0.1:7860/sdapi/v1/png-info', json=png_payload)
+```
+After that, I can get the information with `response2.json().get("info")`
+
+------
+
+A sample code that should work can look like this:
+```py
+import json
+import requests
+import io
+import base64
+from PIL import Image, PngImagePlugin
+
+url = "http://127.0.0.1:7860"
+
+payload = {
+ "prompt": "puppy dog",
+ "steps": 5
+}
+
+response = requests.post(url=f'{url}/sdapi/v1/txt2img', json=payload)
+
+r = response.json()
+
+for i in r['images']:
+ image = Image.open(io.BytesIO(base64.b64decode(i.split(",",1)[0])))
+
+ png_payload = {
+ "image": "data:image/png;base64," + i
+ }
+ response2 = requests.post(url=f'{url}/sdapi/v1/png-info', json=png_payload)
+
+ pnginfo = PngImagePlugin.PngInfo()
+ pnginfo.add_text("parameters", response2.json().get("info"))
+ image.save('output.png', pnginfo=pnginfo)
+```
+- Import the things I need
+- define the url and the payload to send
+- send said payload to said url through the API
+- in a loop grab "images" and decode it
+- for each image, send it to png info API and get that info back
+- define a plugin to add png info, then add the png info I defined into it
+- at the end here, save the image with the png info
+
+-----
+
+A note on `"override_settings"`.
+The purpose of this endpoint is to override the web ui settings for a single request, such as the CLIP skip. The settings that can be passed into this parameter are visible here at the url's /docs.
+
+
+
+You can expand the tab and the API will provide a list. There are a few ways you can add this value to your payload, but this is how I do it. I'll demonstrate with "filter_nsfw", and "CLIP_stop_at_last_layers".
+
+```py
+payload = {
+ "prompt": "cirno",
+ "steps": 20
+}
+
+override_settings = {}
+override_settings["filter_nsfw"] = true
+override_settings["CLIP_stop_at_last_layers"] = 2
+
+override_payload = {
+ "override_settings": override_settings
+ }
+payload.update(override_payload)
+```
+- Have the normal payload
+- after that, initialize a dictionary (I call it "override_settings", but maybe not the best name)
+- then I can add as many key:value pairs as I want to it
+- make a new payload with just this parameter
+- update the original payload to add this one to it
+
+So in this case, when I send the payload, I should get a "cirno" at 20 steps, with the CLIP skip at 2, as well as the NSFW filter on.
+
+
+For certain settings or situations, you may want your changes to stay. For that you can post to the `/sdapi/v1/options` API endpoint
+We can use what we learned so far and set up the code easily for this. Here is an example:
+```py
+url = "http://127.0.0.1:7860"
+
+option_payload = {
+ "sd_model_checkpoint": "Anything-V3.0-pruned.ckpt [2700c435]",
+ "CLIP_stop_at_last_layers": 2
+}
+
+response = requests.post(url=f'{url}/sdapi/v1/options', json=option_payload)
+```
+After sending this payload to the API, the model should swap to the one I set and set the CLIP skip to 2. Reiterating, this is different from "override_settings", because this change will persist, while "override_settings" is for a single request.
+Note that if you're changing the `sd_model_checkpoint`, the value should be the name of the checkpoint as it appears in the web ui. This can be referenced with this API endpoint (same way we reference "options" API)
+
+
+
+The "title" (name and hash) is what you want to use.
+
+-----
+
+This is as of commit [47a44c7](https://github.com/AUTOMATIC1111/stable-diffusion-webui/commit/47a44c7e421b98ca07e92dbf88769b04c9e28f86)
+
+For a more complete implementation of a frontend, my Discord bot is [here](https://github.com/Kilvoctu/aiyabot) if anyone wants to look at it as an example. Most of the action happens in stablecog.py. There are many comments explaining what each code does.
+
+------
+
+This guide can be found in [discussions](https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/3734) page.
+
+Also, check out this python API client library for webui: https://github.com/mix1009/sdwebuiapi
+Using custom scripts/extensions example: [here](https://github.com/mix1009/sdwebuiapi/commit/fe269dc2d4f8a98e96c63c8a7d3b5f039625bc18)
\ No newline at end of file
diff --git a/sd2/Change-model-folder-location.html b/sd2/Change-model-folder-location.html
new file mode 100644
index 0000000000000000000000000000000000000000..7fa02eb8aa5146abdf43fd4b26765876a15ff79c
--- /dev/null
+++ b/sd2/Change-model-folder-location.html
@@ -0,0 +1,76 @@
+
+
+
+
+
+Change-model-folder-location.md
+
+
+
+
+
+
+
+
+
+
+
+
+
Sometimes it might be useful to move your models to another location. Reasons for this could be:
+
+
Main disk has low disk space
+
You are using models in multiple tools and don’t want to store them twice
+
+
The default model folder is stable-diffusion-webui/models
+
macOS Finder
+
+
Open in Finder two windows e.g. stable-diffusion-webui/models/Stable-diffusion and the folder where your models are located.
+
Press option ⌥ + command ⌘ while dragging your model from the model folder to the target folder
+
This will make an alias instead of moving the models
+
+
Command line
+
+
Let’s assume your model openjourney-v4.ckpt is stored in ~/ai/models/
+
Now we make a symbolic link (i.e. alias) to this model
+
Open your terminal and navigate to your Stable Diffusion model folder e.g. cd ~/stable-diffusion-webui/models/Stable-diffusion
+
Make a symbolic link to your model with ln -sf ~/ai/models/openjourney-v4.ckpt
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/sd2/Change-model-folder-location.md b/sd2/Change-model-folder-location.md
new file mode 100644
index 0000000000000000000000000000000000000000..edb09a001b1083dc6b2c490d39c51dac8f08bd47
--- /dev/null
+++ b/sd2/Change-model-folder-location.md
@@ -0,0 +1,16 @@
+Sometimes it might be useful to move your models to another location. Reasons for this could be:
+- Main disk has low disk space
+- You are using models in multiple tools and don't want to store them twice
+
+The default model folder is `stable-diffusion-webui/models`
+
+## macOS Finder
+- Open in Finder two windows e.g. `stable-diffusion-webui/models/Stable-diffusion` and the folder where your models are located.
+- Press option ⌥ + command ⌘ while dragging your model from the model folder to the target folder
+- This will make an alias instead of moving the models
+
+## Command line
+- Let's assume your model `openjourney-v4.ckpt` is stored in `~/ai/models/`
+- Now we make a symbolic link (i.e. alias) to this model
+- Open your terminal and navigate to your Stable Diffusion model folder e.g. `cd ~/stable-diffusion-webui/models/Stable-diffusion`
+- Make a symbolic link to your model with `ln -sf ~/ai/models/openjourney-v4.ckpt`
\ No newline at end of file
diff --git a/sd2/Command-Line-Arguments-and-Settings.html b/sd2/Command-Line-Arguments-and-Settings.html
new file mode 100644
index 0000000000000000000000000000000000000000..acca1677aec84d3456a6ef78f4d945a504955328
--- /dev/null
+++ b/sd2/Command-Line-Arguments-and-Settings.html
@@ -0,0 +1,784 @@
+
+
+
+
+
+All command line arguments
+
+
+
+
+
+
+
+
+
+
+
+
+
Environment variables
+
+
+
+
Name
+
Description
+
+
+
+
+
PYTHON
+
Sets a custom path for Python executable.
+
+
+
VENV_DIR
+
Specifies the path for the virtual environment. Default is venv. Special value - runs the script without creating virtual environment.
+
+
+
COMMANDLINE_ARGS
+
Additional commandline arguments for the main program.
+
+
+
IGNORE_CMD_ARGS_ERRORS
+
Set to anything to make the program not exit with an error if an unexpected commandline argument is encountered.
+
+
+
REQS_FILE
+
Name of requirements.txt file with dependencies that will be installed when launch.py is run. Defaults to requirements_versions.txt.
+
+
+
TORCH_COMMAND
+
Command for installing PyTorch.
+
+
+
INDEX_URL
+
--index-url parameter for pip.
+
+
+
TRANSFORMERS_CACHE
+
Path to where transformers library will download and keep its files related to the CLIP model.
+
+
+
CUDA_VISIBLE_DEVICES
+
Select GPU to use for your instance on a system with multiple GPUs. For example, if you want to use secondary GPU, put “1”. (add a new line to webui-user.bat not in COMMANDLINE_ARGS): set CUDA_VISIBLE_DEVICES=0 Alternatively, just use --device-id flag in COMMANDLINE_ARGS.
+
+
+
+
webui-user
+
The recommended way to specify environment variables is by editing webui-user.bat (Windows) and webui-user.sh (Linux):
+
+
set VARNAME=VALUE for Windows
+
export VARNAME="VALUE" for Linux
+
+
For example, in Windows:
+
set COMMANDLINE_ARGS=--allow-code --xformers --skip-torch-cuda-test --no-half-vae --api --ckpt-dir A:\\stable-diffusion-checkpoints
+
+
Running online
+
Use the --share option to run online. You will get a xxx.app.gradio link. This is the intended way to use the program in colabs. You may set up authentication for said gradio shared instance with the flag --gradio-auth username:password, optionally providing multiple sets of usernames and passwords separated by commas.
+
Running within Local Area Network
+
Use --listen to make the server listen to network connections. This will allow computers on the local network to access the UI, and if you configure port forwarding, also computers on the internet. Example address: http://192.168.1.3:7860
+Where your “192.168.1.3” is the local IP address.
+
Use --port xxxx to make the server listen on a specific port, xxxx being the wanted port. Remember that all ports below 1024 need root/admin rights, for this reason it is advised to use a port above 1024. Defaults to port 7860 if available.
+
Running on CPU
+
Running with only your CPU is possible, but not recommended.
+It is very slow and there is no fp16 implementation.
+
To run, you must have all these flags enabled: --use-cpu all --precision full --no-half --skip-torch-cuda-test
+
Though this is a questionable way to run webui, due to the very slow generation speeds; using the various AI upscalers and captioning tools may be useful to some people.
+Extras:
+
For the technically inclined, here are some steps a user provided to boost CPU performance:
Path to checkpoint of Stable Diffusion model; if specified, this checkpoint will be added to the list of checkpoints and loaded.
+
+
+
–ckpt-dir
+
CKPT_DIR
+
None
+
Path to directory with Stable Diffusion checkpoints.
+
+
+
–no-download-sd-model
+
None
+
False
+
Don’t download SD1.5 model even if no model is found.
+
+
+
–vae-dir
+
VAE_PATH
+
None
+
Path to Variational Autoencoders model
+
+
+
–vae-path
+
VAE_PATH
+
None
+
Checkpoint to use as VAE; setting this argument
+
+
+
–gfpgan-dir
+
GFPGAN_DIR
+
GFPGAN/
+
GFPGAN directory.
+
+
+
–gfpgan-model
+
GFPGAN_MODEL
+
GFPGAN model file name.
+
+
+
+
–codeformer-models-path
+
CODEFORMER_MODELS_PATH
+
models/Codeformer/
+
Path to directory with codeformer model file(s).
+
+
+
–gfpgan-models-path
+
GFPGAN_MODELS_PATH
+
models/GFPGAN
+
Path to directory with GFPGAN model file(s).
+
+
+
–esrgan-models-path
+
ESRGAN_MODELS_PATH
+
models/ESRGAN
+
Path to directory with ESRGAN model file(s).
+
+
+
–bsrgan-models-path
+
BSRGAN_MODELS_PATH
+
models/BSRGAN
+
Path to directory with BSRGAN model file(s).
+
+
+
–realesrgan-models-path
+
REALESRGAN_MODELS_PATH
+
models/RealESRGAN
+
Path to directory with RealESRGAN model file(s).
+
+
+
–scunet-models-path
+
SCUNET_MODELS_PATH
+
models/ScuNET
+
Path to directory with ScuNET model file(s).
+
+
+
–swinir-models-path
+
SWINIR_MODELS_PATH
+
models/SwinIR
+
Path to directory with SwinIR and SwinIR v2 model file(s).
+
+
+
–ldsr-models-path
+
LDSR_MODELS_PATH
+
models/LDSR
+
Path to directory with LDSR model file(s).
+
+
+
–lora-dir
+
LORA_DIR
+
models/Lora
+
Path to directory with Lora networks.
+
+
+
–clip-models-path
+
CLIP_MODELS_PATH
+
None
+
Path to directory with CLIP model file(s).
+
+
+
–embeddings-dir
+
EMBEDDINGS_DIR
+
embeddings/
+
Embeddings directory for textual inversion (default: embeddings).
+
+
+
–textual-inversion-templates-dir
+
TEXTUAL_INVERSION_TEMPLATES_DIR
+
textual_inversion_templates
+
Directory with textual inversion templates.
+
+
+
–hypernetwork-dir
+
HYPERNETWORK_DIR
+
models/hypernetworks/
+
hypernetwork directory.
+
+
+
–localizations-dir
+
LOCALIZATIONS_DIR
+
localizations/
+
Localizations directory.
+
+
+
–styles-file
+
STYLES_FILE
+
styles.csv
+
Filename to use for styles.
+
+
+
–ui-config-file
+
UI_CONFIG_FILE
+
ui-config.json
+
Filename to use for UI configuration.
+
+
+
–no-progressbar-hiding
+
None
+
False
+
Do not hide progress bar in gradio UI (we hide it because it slows down ML if you have hardware acceleration in browser).
+
+
+
–max-batch-count
+
MAX_BATCH_COUNT
+
16
+
Maximum batch count value for the UI.
+
+
+
–ui-settings-file
+
UI_SETTINGS_FILE
+
config.json
+
Filename to use for UI settings.
+
+
+
–allow-code
+
None
+
False
+
Allow custom script execution from web UI.
+
+
+
–share
+
None
+
False
+
Use share=True for gradio and make the UI accessible through their site.
+
+
+
–listen
+
None
+
False
+
Launch gradio with 0.0.0.0 as server name, allowing to respond to network requests.
+
+
+
–port
+
PORT
+
7860
+
Launch gradio with given server port, you need root/admin rights for ports < 1024; defaults to 7860 if available.
+
+
+
–hide-ui-dir-config
+
None
+
False
+
Hide directory configuration from web UI.
+
+
+
–freeze-settings
+
None
+
False
+
disable editing settings
+
+
+
–enable-insecure-extension-access
+
None
+
False
+
Enable extensions tab regardless of other options.
+
+
+
–gradio-debug
+
None
+
False
+
Launch gradio with --debug option.
+
+
+
–gradio-auth
+
GRADIO_AUTH
+
None
+
Set gradio authentication like username:password; or comma-delimit multiple like u1:p1,u2:p2,u3:p3.
+
+
+
–gradio-auth-path
+
GRADIO_AUTH_PATH
+
None
+
Set gradio authentication file path ex. /path/to/auth/file same auth format as --gradio-auth.
+
+
+
–disable-console-progressbars
+
None
+
False
+
Do not output progress bars to console.
+
+
+
–enable-console-prompts
+
None
+
False
+
Print prompts to console when generating with txt2img and img2img.
+
+
+
–api
+
None
+
False
+
Launch web UI with API.
+
+
+
–api-auth
+
API_AUTH
+
None
+
Set authentication for API like username:password; or comma-delimit multiple like u1:p1,u2:p2,u3:p3.
+
+
+
–api-log
+
None
+
False
+
Enable logging of all API requests.
+
+
+
–nowebui
+
None
+
False
+
Only launch the API, without the UI.
+
+
+
–ui-debug-mode
+
None
+
False
+
Don’t load model to quickly launch UI.
+
+
+
–device-id
+
DEVICE_ID
+
None
+
Select the default CUDA device to use (export CUDA_VISIBLE_DEVICES=0,1 etc might be needed before).
+
+
+
–administrator
+
None
+
False
+
Administrator privileges.
+
+
+
–cors-allow-origins
+
CORS_ALLOW_ORIGINS
+
None
+
Allowed CORS origin(s) in the form of a comma-separated list (no spaces).
+
+
+
–cors-allow-origins-regex
+
CORS_ALLOW_ORIGINS_REGEX
+
None
+
Allowed CORS origin(s) in the form of a single regular expression.
+
+
+
–tls-keyfile
+
TLS_KEYFILE
+
None
+
Partially enables TLS, requires --tls-certfile to fully function.
+
+
+
–tls-certfile
+
TLS_CERTFILE
+
None
+
Partially enables TLS, requires --tls-keyfile to fully function.
+
+
+
–disable-tls-verify
+
None
+
False
+
When passed, enables the use of self-signed certificates.
+
+
+
–server-name
+
SERVER_NAME
+
None
+
Sets hostname of server.
+
+
+
–no-gradio-queue
+
None
+
False
+
Disables gradio queue; causes the webpage to use http requests instead of websockets; was the default in earlier versions.
+
+
+
–no-hashing
+
None
+
False
+
Disable SHA-256 hashing of checkpoints to help loading performance.
+
+
+
–skip-version-check
+
None
+
False
+
Do not check versions of torch and xformers.
+
+
+
–skip-python-version-check
+
None
+
False
+
Do not check versions of Python.
+
+
+
–skip-torch-cuda-test
+
None
+
False
+
Do not check if CUDA is able to work properly.
+
+
+
–skip-install
+
None
+
False
+
Skip installation of packages.
+
+
+
PERFORMANCE
+
+
+
+
+
+
–xformers
+
None
+
False
+
Enable xformers for cross attention layers.
+
+
+
–force-enable-xformers
+
None
+
False
+
Enable xformers for cross attention layers regardless of whether the checking code thinks you can run it; do not make bug reports if this fails to work.
+
+
+
–xformers-flash-attention
+
None
+
False
+
Enable xformers with Flash Attention to improve reproducibility (supported for SD2.x or variant only).
Upcast sampling. No effect with --no-half. Usually produces similar results to --no-half with better performance while using less memory.
+
+
+
–medvram
+
None
+
False
+
Enable Stable Diffusion model optimizations for sacrificing a some performance for low VRAM usage.
+
+
+
–lowvram
+
None
+
False
+
Enable Stable Diffusion model optimizations for sacrificing a lot of speed for very low VRAM usage.
+
+
+
–lowram
+
None
+
False
+
Load Stable Diffusion checkpoint weights to VRAM instead of RAM.
+
+
+
–always-batch-cond-uncond
+
None
+
False
+
Disables cond/uncond batching that is enabled to save memory with --medvram or --lowvram.
+
+
+
FEATURES
+
+
+
+
+
+
–autolaunch
+
None
+
False
+
Open the web UI URL in the system’s default browser upon launch.
+
+
+
–theme
+
None
+
Unset
+
Open the web UI with the specified theme (light or dark). If not specified, uses the default browser theme.
+
+
+
–use-textbox-seed
+
None
+
False
+
Use textbox for seeds in UI (no up/down, but possible to input long seeds).
+
+
+
–disable-safe-unpickle
+
None
+
False
+
Disable checking PyTorch models for malicious code.
+
+
+
–ngrok
+
NGROK
+
None
+
ngrok authtoken, alternative to gradio --share.
+
+
+
–ngrok-region
+
NGROK_REGION
+
us
+
The region in which ngrok should start.
+
+
+
–update-check
+
None
+
None
+
On startup, notifies whether or not your web UI version (commit) is up-to-date with the current master branch.
+
+
+
–update-all-extensions
+
None
+
None
+
On startup, it pulls the latest updates for all extensions you have installed.
+
+
+
–reinstall-xformers
+
None
+
False
+
Force-reinstall xformers. Useful for upgrading - but remove it after upgrading or you’ll reinstall xformers perpetually.
+
+
+
–reinstall-torch
+
None
+
False
+
Force-reinstall torch. Useful for upgrading - but remove it after upgrading or you’ll reinstall torch perpetually.
+
+
+
–tests
+
TESTS
+
False
+
Run test to validate web UI functionality, see wiki topic for more details.
+
+
+
–no-tests
+
None
+
False
+
Do not run tests even if --tests option is specified.
+
+
+
DEFUNCT OPTIONS
+
+
+
+
+
+
–show-negative-prompt
+
None
+
False
+
No longer has an effect.
+
+
+
–deepdanbooru
+
None
+
False
+
No longer has an effect.
+
+
+
–unload-gfpgan
+
None
+
False
+
No longer has an effect.
+
+
+
–gradio-img2img-tool
+
GRADIO_IMG2IMG_TOOL
+
None
+
No longer has an effect.
+
+
+
–gradio-inpaint-tool
+
GRADIO_INPAINT_TOOL
+
None
+
No longer has an effect.
+
+
+
–gradio-queue
+
None
+
False
+
No longer has an effect.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/sd2/Command-Line-Arguments-and-Settings.md b/sd2/Command-Line-Arguments-and-Settings.md
new file mode 100644
index 0000000000000000000000000000000000000000..ca4a6672722d541a31b4af617704d308ce3d3e1a
--- /dev/null
+++ b/sd2/Command-Line-Arguments-and-Settings.md
@@ -0,0 +1,162 @@
+## Environment variables
+
+| Name | Description |
+|------------------------|-------------------------------------------------------------------------------------------------------------------------------------------|
+| PYTHON | Sets a custom path for Python executable. |
+| VENV_DIR | Specifies the path for the virtual environment. Default is `venv`. Special value `-` runs the script without creating virtual environment. |
+| COMMANDLINE_ARGS | Additional commandline arguments for the main program. |
+| IGNORE_CMD_ARGS_ERRORS | Set to anything to make the program not exit with an error if an unexpected commandline argument is encountered. |
+| REQS_FILE | Name of `requirements.txt` file with dependencies that will be installed when `launch.py` is run. Defaults to `requirements_versions.txt`. |
+| TORCH_COMMAND | Command for installing PyTorch. |
+| INDEX_URL | `--index-url` parameter for pip. |
+| TRANSFORMERS_CACHE | Path to where transformers library will download and keep its files related to the CLIP model. |
+| CUDA_VISIBLE_DEVICES | Select GPU to use for your instance on a system with multiple GPUs. For example, if you want to use secondary GPU, put "1". (add a new line to webui-user.bat not in COMMANDLINE_ARGS): `set CUDA_VISIBLE_DEVICES=0` Alternatively, just use `--device-id` flag in `COMMANDLINE_ARGS`. |
+
+### webui-user
+The recommended way to specify environment variables is by editing `webui-user.bat` (Windows) and `webui-user.sh` (Linux):
+- `set VARNAME=VALUE` for Windows
+- `export VARNAME="VALUE"` for Linux
+
+For example, in Windows:
+```
+set COMMANDLINE_ARGS=--allow-code --xformers --skip-torch-cuda-test --no-half-vae --api --ckpt-dir A:\\stable-diffusion-checkpoints
+```
+
+### Running online
+Use the `--share` option to run online. You will get a xxx.app.gradio link. This is the intended way to use the program in colabs. You may set up authentication for said gradio shared instance with the flag `--gradio-auth username:password`, optionally providing multiple sets of usernames and passwords separated by commas.
+
+### Running within Local Area Network
+Use `--listen` to make the server listen to network connections. This will allow computers on the local network to access the UI, and if you configure port forwarding, also computers on the internet. Example address: `http://192.168.1.3:7860`
+Where your "192.168.1.3" is the local IP address.
+
+Use `--port xxxx` to make the server listen on a specific port, xxxx being the wanted port. Remember that all ports below 1024 need root/admin rights, for this reason it is advised to use a port above 1024. Defaults to port 7860 if available.
+
+### Running on CPU
+Running with only your CPU is possible, but not recommended.
+It is very slow and there is no fp16 implementation.
+
+To run, you must have all these flags enabled: `--use-cpu all --precision full --no-half --skip-torch-cuda-test`
+
+Though this is a questionable way to run webui, due to the very slow generation speeds; using the various AI upscalers and captioning tools may be useful to some people.
+
+Extras:
+
+For the technically inclined, here are some steps a user provided to boost CPU performance:
+
+https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/10514
+
+https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/10516
+
+
+
+# All command line arguments
+
+| Argument Command | Value | Default | Description |
+| ---------------- | ----- | ------- | ----------- |
+| **CONFIGURATION** |
+-h, --help | None | False | Show this help message and exit. |
+--exit | | | Terminate after installation |
+--data-dir | DATA_DIR | ./ | base path where all user data is stored |
+--config | CONFIG | configs/stable-diffusion/v1-inference.yaml | Path to config which constructs model. |
+--ckpt | CKPT | model.ckpt | Path to checkpoint of Stable Diffusion model; if specified, this checkpoint will be added to the list of checkpoints and loaded. |
+--ckpt-dir | CKPT_DIR | None | Path to directory with Stable Diffusion checkpoints. |
+--no-download-sd-model | None | False | Don't download SD1.5 model even if no model is found. |
+--vae-dir | VAE_PATH | None | Path to Variational Autoencoders model | disables all settings related to VAE.
+--vae-path | VAE_PATH | None | Checkpoint to use as VAE; setting this argument
+--gfpgan-dir| GFPGAN_DIR | GFPGAN/ | GFPGAN directory. |
+--gfpgan-model| GFPGAN_MODEL | GFPGAN model file name. |
+--codeformer-models-path | CODEFORMER_MODELS_PATH | models/Codeformer/ | Path to directory with codeformer model file(s). |
+--gfpgan-models-path | GFPGAN_MODELS_PATH | models/GFPGAN | Path to directory with GFPGAN model file(s). |
+--esrgan-models-path | ESRGAN_MODELS_PATH | models/ESRGAN | Path to directory with ESRGAN model file(s). |
+--bsrgan-models-path | BSRGAN_MODELS_PATH | models/BSRGAN | Path to directory with BSRGAN model file(s). |
+--realesrgan-models-path | REALESRGAN_MODELS_PATH | models/RealESRGAN | Path to directory with RealESRGAN model file(s). |
+--scunet-models-path | SCUNET_MODELS_PATH | models/ScuNET | Path to directory with ScuNET model file(s). |
+--swinir-models-path | SWINIR_MODELS_PATH | models/SwinIR | Path to directory with SwinIR and SwinIR v2 model file(s). |
+--ldsr-models-path | LDSR_MODELS_PATH | models/LDSR | Path to directory with LDSR model file(s). |
+--lora-dir | LORA_DIR | models/Lora | Path to directory with Lora networks.
+--clip-models-path | CLIP_MODELS_PATH | None | Path to directory with CLIP model file(s). |
+--embeddings-dir | EMBEDDINGS_DIR | embeddings/ | Embeddings directory for textual inversion (default: embeddings). |
+--textual-inversion-templates-dir | TEXTUAL_INVERSION_TEMPLATES_DIR | textual_inversion_templates | Directory with textual inversion templates.
+--hypernetwork-dir | HYPERNETWORK_DIR | models/hypernetworks/ | hypernetwork directory. |
+--localizations-dir | LOCALIZATIONS_DIR | localizations/ | Localizations directory.
+--styles-file | STYLES_FILE | styles.csv | Filename to use for styles. |
+--ui-config-file | UI_CONFIG_FILE | ui-config.json | Filename to use for UI configuration. |
+--no-progressbar-hiding | None | False | Do not hide progress bar in gradio UI (we hide it because it slows down ML if you have hardware acceleration in browser). |
+--max-batch-count| MAX_BATCH_COUNT | 16 | Maximum batch count value for the UI. |
+--ui-settings-file | UI_SETTINGS_FILE | config.json | Filename to use for UI settings. |
+--allow-code | None | False | Allow custom script execution from web UI. |
+--share | None | False | Use `share=True` for gradio and make the UI accessible through their site.
+--listen | None | False | Launch gradio with 0.0.0.0 as server name, allowing to respond to network requests. |
+--port | PORT | 7860 | Launch gradio with given server port, you need root/admin rights for ports < 1024; defaults to 7860 if available. |
+--hide-ui-dir-config | None | False | Hide directory configuration from web UI. |
+--freeze-settings | None | False | disable editing settings |
+--enable-insecure-extension-access | None | False | Enable extensions tab regardless of other options. |
+--gradio-debug | None | False | Launch gradio with `--debug` option. |
+--gradio-auth | GRADIO_AUTH | None | Set gradio authentication like `username:password`; or comma-delimit multiple like `u1:p1,u2:p2,u3:p3`. |
+--gradio-auth-path | GRADIO_AUTH_PATH | None | Set gradio authentication file path ex. `/path/to/auth/file` same auth format as `--gradio-auth`. |
+--disable-console-progressbars | None | False | Do not output progress bars to console. |
+--enable-console-prompts | None | False | Print prompts to console when generating with txt2img and img2img. |
+--api | None | False | Launch web UI with API. |
+--api-auth | API_AUTH | None | Set authentication for API like `username:password`; or comma-delimit multiple like `u1:p1,u2:p2,u3:p3`. |
+--api-log | None | False | Enable logging of all API requests. |
+--nowebui | None | False | Only launch the API, without the UI. |
+--ui-debug-mode | None | False | Don't load model to quickly launch UI. |
+--device-id | DEVICE_ID | None | Select the default CUDA device to use (export `CUDA_VISIBLE_DEVICES=0,1` etc might be needed before). |
+--administrator | None | False | Administrator privileges. |
+--cors-allow-origins | CORS_ALLOW_ORIGINS | None | Allowed CORS origin(s) in the form of a comma-separated list (no spaces). |
+--cors-allow-origins-regex | CORS_ALLOW_ORIGINS_REGEX | None | Allowed CORS origin(s) in the form of a single regular expression. |
+--tls-keyfile | TLS_KEYFILE | None | Partially enables TLS, requires `--tls-certfile` to fully function. |
+--tls-certfile | TLS_CERTFILE | None | Partially enables TLS, requires `--tls-keyfile` to fully function. |
+--disable-tls-verify | None | False | When passed, enables the use of self-signed certificates.
+--server-name | SERVER_NAME | None | Sets hostname of server. |
+--no-gradio-queue | None| False | Disables gradio queue; causes the webpage to use http requests instead of websockets; was the default in earlier versions.
+--no-hashing | None | False | Disable SHA-256 hashing of checkpoints to help loading performance. |
+--skip-version-check | None | False | Do not check versions of torch and xformers. |
+--skip-python-version-check | None | False | Do not check versions of Python. |
+--skip-torch-cuda-test | None | False | Do not check if CUDA is able to work properly. |
+--skip-install | None | False | Skip installation of packages. |
+| **PERFORMANCE** |
+--xformers | None | False | Enable xformers for cross attention layers. |
+--force-enable-xformers | None | False | Enable xformers for cross attention layers regardless of whether the checking code thinks you can run it; ***do not make bug reports if this fails to work***. |
+--xformers-flash-attention | None | False | Enable xformers with Flash Attention to improve reproducibility (supported for SD2.x or variant only).
+--opt-sdp-attention | None | False | Enable scaled dot product cross-attention layer optimization; requires PyTorch 2.*
+--opt-sdp-no-mem-attention | False | None | Enable scaled dot product cross-attention layer optimization without memory efficient attention, makes image generation deterministic; requires PyTorch 2.*
+--opt-split-attention | None | False | Force-enables Doggettx's cross-attention layer optimization. By default, it's on for CUDA-enabled systems. |
+--opt-split-attention-invokeai | None | False | Force-enables InvokeAI's cross-attention layer optimization. By default, it's on when CUDA is unavailable. |
+--opt-split-attention-v1 | None | False | Enable older version of split attention optimization that does not consume all VRAM available. |
+--opt-sub-quad-attention | None | False | Enable memory efficient sub-quadratic cross-attention layer optimization.
+--sub-quad-q-chunk-size | SUB_QUAD_Q_CHUNK_SIZE | 1024 | Query chunk size for the sub-quadratic cross-attention layer optimization to use.
+--sub-quad-kv-chunk-size | SUB_QUAD_KV_CHUNK_SIZE | None | KV chunk size for the sub-quadratic cross-attention layer optimization to use.
+--sub-quad-chunk-threshold | SUB_QUAD_CHUNK_THRESHOLD | None | The percentage of VRAM threshold for the sub-quadratic cross-attention layer optimization to use chunking.
+--opt-channelslast | None | False | Enable alternative layout for 4d tensors, may result in faster inference **only** on Nvidia cards with Tensor cores (16xx and higher). |
+--disable-opt-split-attention | None | False | Force-disables cross-attention layer optimization. |
+--disable-nan-check | None | False | Do not check if produced images/latent spaces have nans; useful for running without a checkpoint in CI.
+--use-cpu | {all, sd, interrogate, gfpgan, bsrgan, esrgan, scunet, codeformer} | None | Use CPU as torch device for specified modules. |
+--no-half | None | False | Do not switch the model to 16-bit floats. |
+--precision | {full,autocast} | autocast | Evaluate at this precision. |
+--no-half-vae | None | False | Do not switch the VAE model to 16-bit floats. |
+--upcast-sampling | None | False | Upcast sampling. No effect with `--no-half`. Usually produces similar results to `--no-half` with better performance while using less memory.
+--medvram | None | False | Enable Stable Diffusion model optimizations for sacrificing a some performance for low VRAM usage. |
+--lowvram | None | False | Enable Stable Diffusion model optimizations for sacrificing a lot of speed for very low VRAM usage. |
+--lowram | None | False | Load Stable Diffusion checkpoint weights to VRAM instead of RAM.
+--always-batch-cond-uncond | None | False | Disables cond/uncond batching that is enabled to save memory with `--medvram` or `--lowvram`.
+| **FEATURES** |
+--autolaunch | None | False | Open the web UI URL in the system's default browser upon launch. |
+--theme | None | Unset | Open the web UI with the specified theme (`light` or `dark`). If not specified, uses the default browser theme. |
+--use-textbox-seed | None | False | Use textbox for seeds in UI (no up/down, but possible to input long seeds). |
+--disable-safe-unpickle | None | False | Disable checking PyTorch models for malicious code. |
+--ngrok | NGROK | None | ngrok authtoken, alternative to gradio `--share`.
+--ngrok-region | NGROK_REGION | us | The region in which ngrok should start.
+--update-check | None | None | On startup, notifies whether or not your web UI version (commit) is up-to-date with the current master branch.
+--update-all-extensions | None | None | On startup, it pulls the latest updates for all extensions you have installed.
+--reinstall-xformers | None | False | Force-reinstall xformers. Useful for upgrading - but remove it after upgrading or you'll reinstall xformers perpetually. |
+--reinstall-torch | None | False | Force-reinstall torch. Useful for upgrading - but remove it after upgrading or you'll reinstall torch perpetually. |
+--tests | TESTS | False | Run test to validate web UI functionality, see wiki topic for more details.
+--no-tests | None | False | Do not run tests even if `--tests` option is specified.
+| **DEFUNCT OPTIONS** |
+--show-negative-prompt | None | False | No longer has an effect. |
+--deepdanbooru | None | False | No longer has an effect. |
+--unload-gfpgan | None | False | No longer has an effect.
+--gradio-img2img-tool | GRADIO_IMG2IMG_TOOL | None | No longer has an effect. |
+--gradio-inpaint-tool | GRADIO_INPAINT_TOOL | None | No longer has an effect. |
+--gradio-queue | None | False | No longer has an effect. |
diff --git a/sd2/Contributing.html b/sd2/Contributing.html
new file mode 100644
index 0000000000000000000000000000000000000000..b5ce1d02e4f6f19aa554ee63a208c9cbd58c5994
--- /dev/null
+++ b/sd2/Contributing.html
@@ -0,0 +1,97 @@
+
+
+
+
+
+Pull requests
+
+
+
+
+
+
+
+
+
+
+
+
+
Pull requests
+
To contribute, clone the repository, make your changes, commit and push to your clone, and submit a pull request.
+
+
Note
+If you’re not a contributor to this repository, you need to fork and clone the repository before pushing your changes. For more information, check out Contributing to Projects in the GitHub documentation.
+
+
+
If you are adding a lot of code, consider making it an extension instead.
+
Do not add multiple unrelated things in same PR.
+
PRs should target the dev branch.
+
Make sure that your changes do not break anything by running tests.
+
Do not submit PRs where you just take existing lines and reformat them without changing what they do.
+
If you are submitting a bug fix, there must be a way for me to reproduce the bug.
+
Do not use your clone’s master or main branch to make a PR - create a branch and PR that.
+
+There is a discord channel for development of the webui (click to expand). Join if you want to talk about a PR in real time. Don't join if you're not involved in development.
+This is a discord for development only, NOT for tech support.
+
If you are making changes to used libraries or the installation script, you must verify them to work on default Windows installation from scratch. If you cannot test if it works (due to your OS or anything else), do not make those changes (with possible exception of changes that explicitly are guarded from being executed on Windows by ifs or something else).
+
Code style
+
We use linters to enforce style for python and javascript. If you make a PR that fails the check, I will ask you to fix the code until the linter does not complain anymore.
+
Here’s how to use linters locally:
+
python
+
Install: pip install ruff
+
Run: ruff . (or python -mruff .)
+
javascript
+
Install: install npm on your system.
+
Run: npx eslint .
+
Quirks
+
+
webui.user.bat is never to be edited
+
requirements_versions.txt is for python 3.10.6
+
requirements.txt is for people running on colabs and whatnot using python 3.7
+
+
Gradio
+
Gradio at some point wanted to add this section to shill their project in the contributing section, which I didn’t have at the time, so here it is now.
+
+
+
+
+
+
diff --git a/sd2/Contributing.md b/sd2/Contributing.md
new file mode 100644
index 0000000000000000000000000000000000000000..6a9c763f1687470859a1795d74074046da214def
--- /dev/null
+++ b/sd2/Contributing.md
@@ -0,0 +1,48 @@
+# Pull requests
+To contribute, clone the repository, make your changes, commit and push to your clone, and submit a pull request.
+
+> **Note**
+If you're not a contributor to this repository, you need to fork and clone the repository before pushing your changes. For more information, check out [Contributing to Projects](https://docs.github.com/en/repositories/creating-and-managing-repositories/cloning-a-repository) in the GitHub documentation.
+
+* If you are adding a lot of code, **consider making it an [extension](Extensions) instead**.
+* Do not add multiple unrelated things in same PR.
+* PRs should target the `dev` branch.
+* Make sure that your changes do not break anything by running [tests](Tests).
+* Do not submit PRs where you just take existing lines and reformat them without changing what they do.
+* If you are submitting a bug fix, there must be a way for me to reproduce the bug.
+* Do not use your clone's `master` or `main` branch to make a PR - create a branch and PR that.
+
+There is a discord channel for development of the webui (click to expand). Join if you want to talk about a PR in real time. Don't join if you're not involved in development.
+This is a discord for development only, NOT for tech support.
+
+
+[Dev discord](https://discord.gg/WG2nzq3YEH)
+
+
+If you are making changes to used libraries or the installation script, you must verify them to work on default Windows installation from scratch. If you cannot test if it works (due to your OS or anything else), do not make those changes (with possible exception of changes that explicitly are guarded from being executed on Windows by `if`s or something else).
+
+# Code style
+We use linters to enforce style for python and javascript. If you make a PR that fails the check, I will ask you to fix the code until the linter does not complain anymore.
+
+Here's how to use linters locally:
+#### python
+Install: `pip install ruff`
+
+Run: `ruff .` (or `python -mruff .`)
+
+#### javascript
+Install: install npm on your system.
+
+Run: `npx eslint .`
+
+# Quirks
+* `webui.user.bat` is never to be edited
+* `requirements_versions.txt` is for python 3.10.6
+* `requirements.txt` is for people running on colabs and whatnot using python 3.7
+
+# Gradio
+Gradio at some point wanted to add this section to shill their project in the contributing section, which I didn't have at the time, so here it is now.
+
+For [Gradio](https://github.com/gradio-app/gradio) check out the [docs](https://gradio.app/docs/) to contribute:
+Have an issue or feature request with Gradio? open a issue/feature request on github for support: https://github.com/gradio-app/gradio/issues
+
diff --git a/sd2/Custom-Images-Filename-Name-and-Subdirectory.html b/sd2/Custom-Images-Filename-Name-and-Subdirectory.html
new file mode 100644
index 0000000000000000000000000000000000000000..9aff360d33e5ffad162a52829669510522c275aa
--- /dev/null
+++ b/sd2/Custom-Images-Filename-Name-and-Subdirectory.html
@@ -0,0 +1,270 @@
+
+
+
+
+
+Patterns
+
+
+
+
+
+
+
+
+
+
+
+
+
+
the following information is about the image filename and subdirectory name, not the Paths for saving \ Output directories
+
+
By default, the Web UI saves images in the output directories and output archive with a filename structure of
Web-Ui provides several patterns that can be used as placeholders for inserting information into the filename or subdirectory,
+user can chain these patterns together, forming a filename that suits their use case.
if specified prompt is found in prompts then prompt will be added to filename, else default will be added to filename (default can be blank)
+
[hasprompt] -> girl [hasprompt<girl|no girl><boy|no boy>] -> girlno boy
+
+
+
+
If <Format> is blank or invalid, it will use the default time format “%Y%m%d%H%M%S”
+tip: you can use extra characters inside <Format> for punctuation, such as _ -
+
If <TimeZone> is blank or invalid, it will use the default system time zone
+
If batch size is 1 the [batch_number], [seed_last] along with the previous segment of text will not be added to filename
+
If batch size x batch count is 1 the [generation_number] along with the previous segment of text will not be added to filename
+
[batch_number] and [generation_number] along with the previous segment of text will not be added to filename of zip achive.
+
The Prompts and Style used for the above [prompt] examples
+Prompt:
+
1girl, white space, ((very important)), [not important], (some value:1.5), (whatever), the end
+
this is due to your computer having a maximum file length
+
Add / Remove number to filename when saving
+
you can remove the prefix number
+by unchecking the checkbox under
+
Settings > Saving images/grids > Add number to filename when saving
+
with prefix number
+
00123-`987654321-((masterpiece)).png
+
+
without prefix number
+
987654321-((masterpiece)).png
+
+
Caution
+
The purpose of the prefix number is to ensure that the saved image file name is Unique.
+If you decide to not use the prefix number, make sure that your pattern will generate a unique file name, otherwise files may be overwritten.
+
Generally, datetime down to seconds should be able to guarantee that file name is unique.
+
[datetime<%Y%m%d_%H%M%S>]-[seed]
+
+
20221025_014350-281391998.png
+
+
But some Custom Scripts might generate multiples images using the same seed in a single batch,
+
in this case it is safer to also use %f for Microsecond as a decimal number, zero-padded to 6 digits.
+
[datetime<%Y%m%d_%H%M%S_%f>]-[seed]
+
+
20221025_014350_733877-281391998.png
+
+
Filename Pattern Examples
+
If you’re running Web-Ui on multiple machines, say on Google Colab and your own Computer, you might want to use a filename with a time as the Prefix.
+this is so that when you download the files, you can put them in the same folder.
+
Also since you don’t know what time zone Google Colab is using, you would want to specify the time zone.
It might also be useful to set Subdirectory the date, so that one folder doesn’t have too many images
+
[datetime<%Y-%m-%d><Asia/Tokyo>]
+
+
2022-10-25
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/sd2/Custom-Images-Filename-Name-and-Subdirectory.md b/sd2/Custom-Images-Filename-Name-and-Subdirectory.md
new file mode 100644
index 0000000000000000000000000000000000000000..291cda3e28d5c82307d32f71acda317c986aff37
--- /dev/null
+++ b/sd2/Custom-Images-Filename-Name-and-Subdirectory.md
@@ -0,0 +1,150 @@
+> the following information is about the image filename and subdirectory name, not the `Paths for saving \ Output directories`
+### By default, the Web UI saves images in the output directories and output archive with a filename structure of
+
+Images: `[number]-[seed]-[prompt_spaces]`
+```
+01234-987654321-((masterpiece)), ((best quality)), ((illustration)), extremely detailed,style girl.png
+```
+
+Zip archive: `[datetime]_[[model_name]]_[seed]-[seed_last]`
+```
+20230530133149_[v1-5-pruned-emaonly]_987654321-987654329.zip
+```
+
+A different image filename and optional subdirectory and zip filename can be used if a user wishes.
+
+Image filename pattern can be configured under.
+
+`settings tab` > `Saving images/grids` > `Images filename pattern`
+
+Subdirectory can be configured under settings.
+
+`settings tab` > `Saving to a directory` > `Directory name pattern`
+
+Zip archive can be configured under settings.
+
+`settings tab` > `Saving images/grids` > `Archive filename pattern`
+
+# Patterns
+Web-Ui provides several patterns that can be used as placeholders for inserting information into the filename or subdirectory,
+user can chain these patterns together, forming a filename that suits their use case.
+
+| Pattern | Description | Example |
+|--------------------------------|------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------|
+| `[seed]` | Seed | 1234567890 |
+| `[seed_first]` | First Seed of batch or Seed of single image | [1234567890,1234567891,1234567892,1234567893] -> 1234567890 [1234567891] -> 1234567891
+| `[seed_last]` | Last Seed of batch | [1234567890,1234567891,1234567892,1234567893] -> 1234567893
+| `[steps]` | Steps | 20 |
+| `[cfg]` | CFG scale | 7 |
+| `[sampler]` | Sampling method | Euler a |
+| `[model_name]` | Name of the model | sd-v1-4
+| `[model_hash]` | The first 8 characters of the prompt's SHA-256 hash | 7460a6fa |
+| `[width]` | Image width | 512 |
+| `[height]` | Image height | 512 |
+| `[styles]` | Name of the chosen Styles | my style name |
+| `[date]` | Date of the computer in ISO format | 2022-10-24 |
+| `[datetime]` | Datetime in "%Y%m%d%H%M%S" | 20221025013106 |
+| `[datetime]` | Datetime in specified \ | \[datetime<%Y%m%d_%H%M%S_%f>] 20221025_014350_733877 |
+| `[datetime]` | Datetime at specific \



