[English](../doc_en/PP-OCRv3_introduction_en.md) | 简体中文
# PP-OCR
- [1. 简介](#1)
- [2. 特性](#2)
- [3. benchmark](#3)
## 1. 简介
PP-OCR是PaddleOCR自研的实用的超轻量OCR系统。在实现[前沿算法](algorithm.md)的基础上,考虑精度与速度的平衡,进行**模型瘦身**和**深度优化**,使其尽可能满足产业落地需求。
#### PP-OCR
PP-OCR是一个两阶段的OCR系统,其中文本检测算法选用[DB](algorithm_det_db.md),文本识别算法选用[CRNN](algorithm_rec_crnn.md),并在检测和识别模块之间添加[文本方向分类器](angle_class.md),以应对不同方向的文本识别。
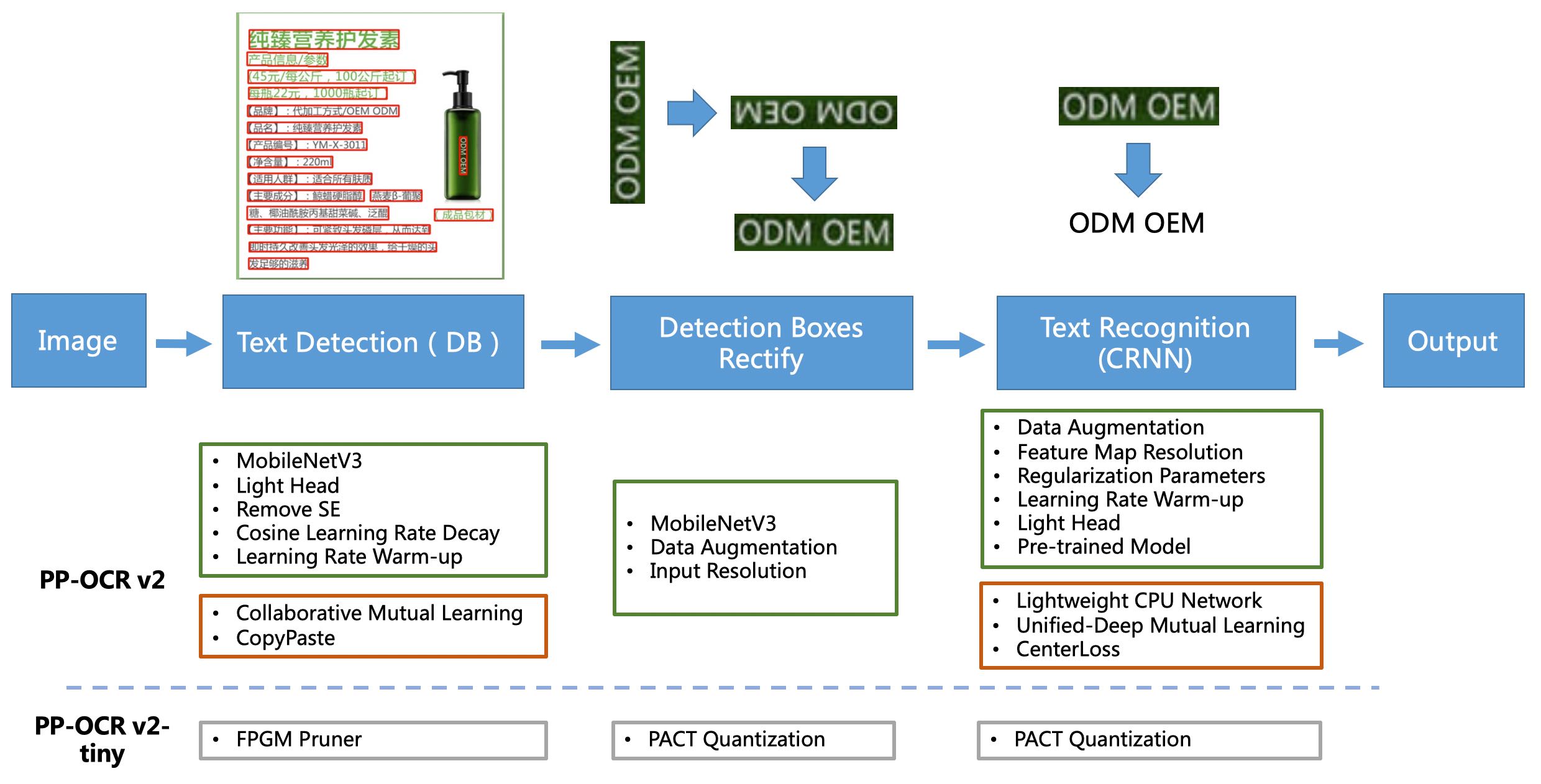
PP-OCRv2系统pipeline如下:
PP-OCR系统在持续迭代优化,目前已发布PP-OCR、PP-OCRv2、PPOCRv3两个版本:
PP-OCRv2从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身(如绿框所示),最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。更多细节请参考PP-OCR技术方案 https://arxiv.org/abs/2009.09941
## PP-OCRv3策略简介
### PP-OCRv3文本检测模型优化策略
PP-OCRv3在PP-OCRv2的基础上进一步升级。
PP-OCRv3文本检测从网络结构、蒸馏训练策略两个方向做了进一步优化:
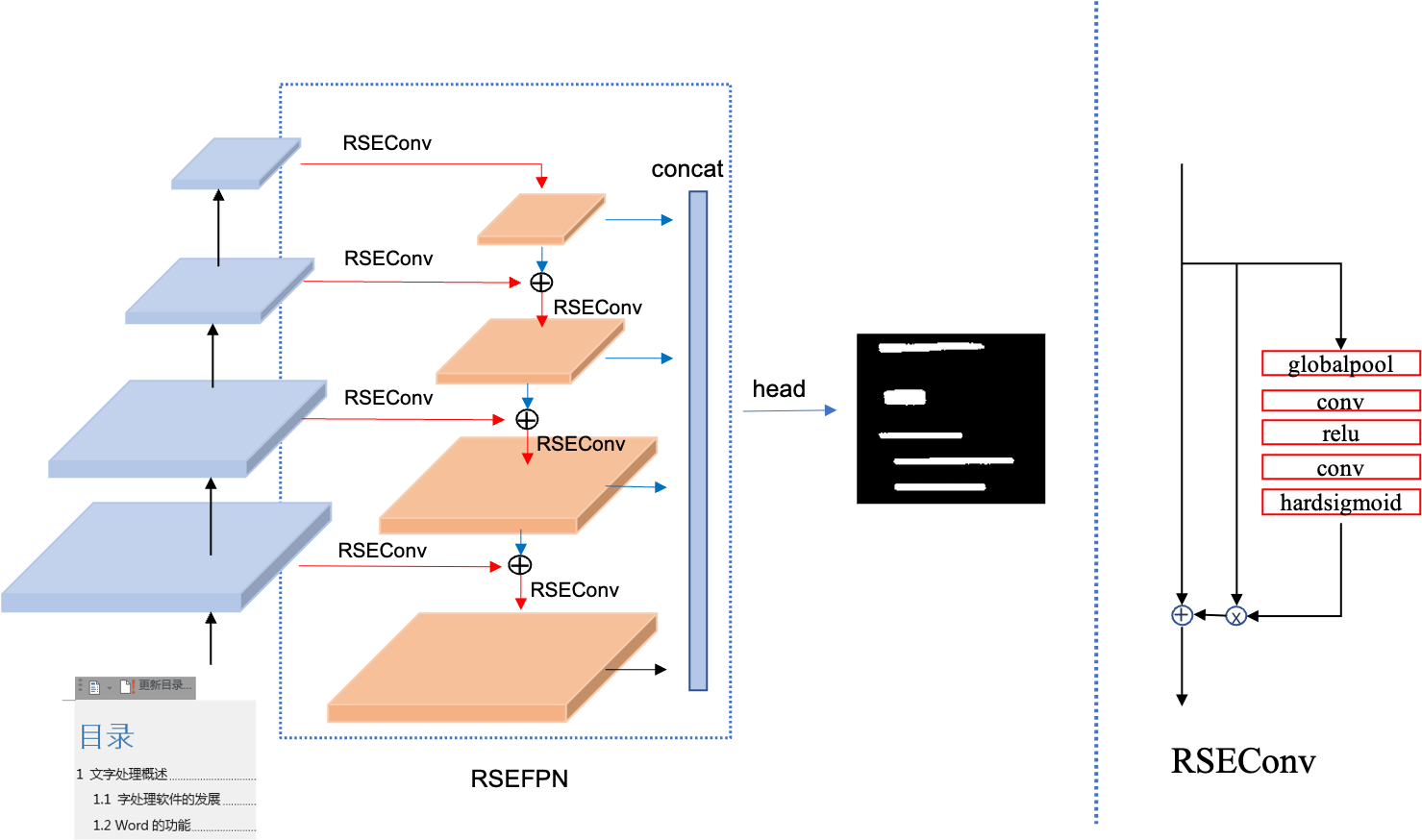
1. 网络结构改进:提出两种改进后的FPN网络结构,RSEFPN,LKPAN,分别从channel attention、更大感受野的角度优化FPN结构。
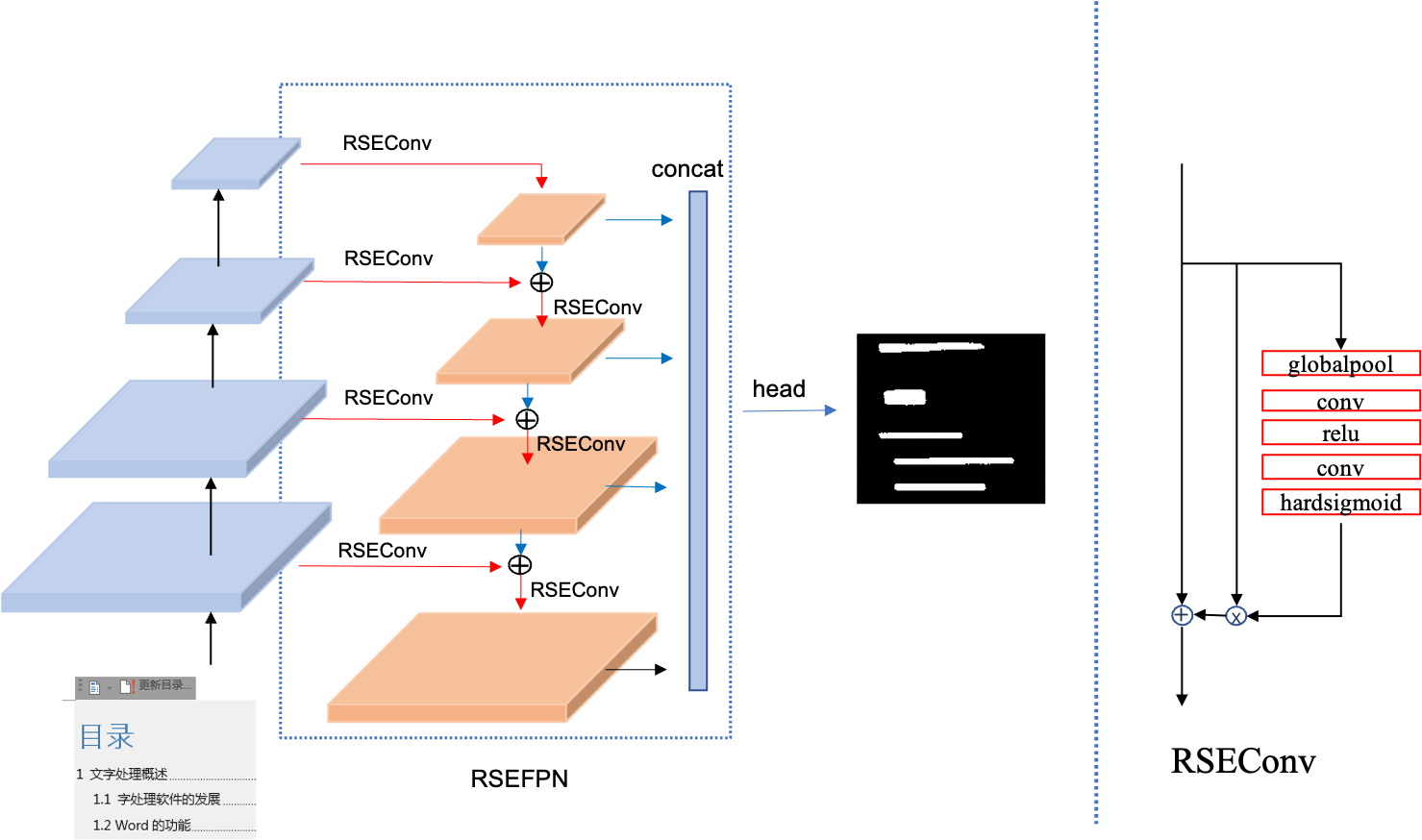
PPOCRv2检测模型的FPN结构由纯卷积和上采样层构成,不包含BN层,激活函数等模块。PPOCRv3对PPOCRv2检测模型中的FPN结构进行改进,借鉴channel attention的思想,将FPN中的卷积层换为带残差结构的RSEBlock,其网络结构如上图所示;SEBlock起到channel attention的作用;另外,考虑到PPOCR文本检测模型FPN网络的通道数较小(channel=96),channel atttion可能抑制掉某些包含重要特征的channel;因此,PPOCRv3引入了残差结构。实验表明引入残差结构相比只引入SEBlock有2.7%的精度提升。RSEFPN将base检测模型的精度hmean从81.3%提升到84.5%。
LKPAN是一个具有更大感受野的轻量级PAN结构。其网络结构如图3所示。 LKPAN对输入的特征首先使用`1*1`conv统一特征的通道, 在LKPAN的path augmentation中,使用kernel size为`9*9`的深度可分离卷积。更大的kernelsize意味着更大的感受野,更容易检测大字体的文字以及极端长宽比的文字。使用深度可分离卷积可以显著降低模型的参数量。LKPAN将base检测模型的精度hmean从81.3%提升到84.9%。
2. CML蒸馏训练策略调整:PPOCRv3文本检测模型训练中,仍采用[CML](https://arxiv.org/pdf/2109.03144.pdf)的蒸馏策略。首先,在蒸馏teacher模型选择上,使用ResNet50作为teacher的Backbone,使用LKPAN作为FPN部分,最终使用[DML](https://arxiv.org/abs/1706.00384)蒸馏策略训练得到更高精度的teacher模型。然后,在CML蒸馏训练时,随训练epoch数增加,线性降低teacher模型和student模型之间损失函数的比例,loss比例计算公式如下:
```
α = 1 – (epoch/total_epoch)*0.4
```
最后,在蒸馏时,考虑到模型大小及预测速度,采用RSEFPN作为蒸馏student模型的FPN结构。优化后的CML蒸馏将PPOCRv2的精度hmean从83.3%提升到84.4%,同时模型的召回能力显著提升。
3. 消融实验
|序号|策略|模型大小|hmean|Intel Gold 6148CPU+mkldnn预测耗时|
|-|-|-|-|-|
|0|ppocr_mobile|3M|81.3|117ms|
|1|PPOCRV2|3M|83.3|117ms|
|2|0 + RESFPN|3.6M|84.5|124ms|
|3|0 + LKPAN|4.6M|84.9|156ms|
|4|teacher DML + LKPAN|124M|86.0|-|
|5|0 + 2 + 4 + CML|3.6M|85.4|124ms|
## 2. 特性
- 超轻量PP-OCRv2系列:检测(3.1M)+ 方向分类器(1.4M)+ 识别(8.5M)= 13.0M
- 超轻量PP-OCR mobile移动端系列:检测(3.0M)+方向分类器(1.4M)+ 识别(5.0M)= 9.4M
- 通用PP-OCR server系列:检测(47.1M)+方向分类器(1.4M)+ 识别(94.9M)= 143.4M
- 支持中英文数字组合识别、竖排文本识别、长文本识别
- 支持多语言识别:韩语、日语、德语、法语等约80种语言
## 3. benchmark
关于PP-OCR系列模型之间的性能对比,请查看[benchmark](./benchmark.md)文档。