English | [简体中文](README_ch.md)
- [Getting Started](#getting-started)
- [1. Install whl package](#1--install-whl-package)
- [2. Quick Start](#2-quick-start)
- [3. PostProcess](#3-postprocess)
- [4. Results](#4-results)
- [5. Training](#5-training)
# Getting Started
## 1. Install whl package
```bash
wget https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
pip install -U layoutparser-0.0.0-py3-none-any.whl
```
## 2. Quick Start
Use LayoutParser to identify the layout of a document:
```python
import cv2
import layoutparser as lp
image = cv2.imread("doc/table/layout.jpg")
image = image[..., ::-1]
# load model
model = lp.PaddleDetectionLayoutModel(config_path="lp://PubLayNet/ppyolov2_r50vd_dcn_365e_publaynet/config",
threshold=0.5,
label_map={0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"},
enforce_cpu=False,
enable_mkldnn=True)
# detect
layout = model.detect(image)
# show result
show_img = lp.draw_box(image, layout, box_width=3, show_element_type=True)
show_img.show()
```
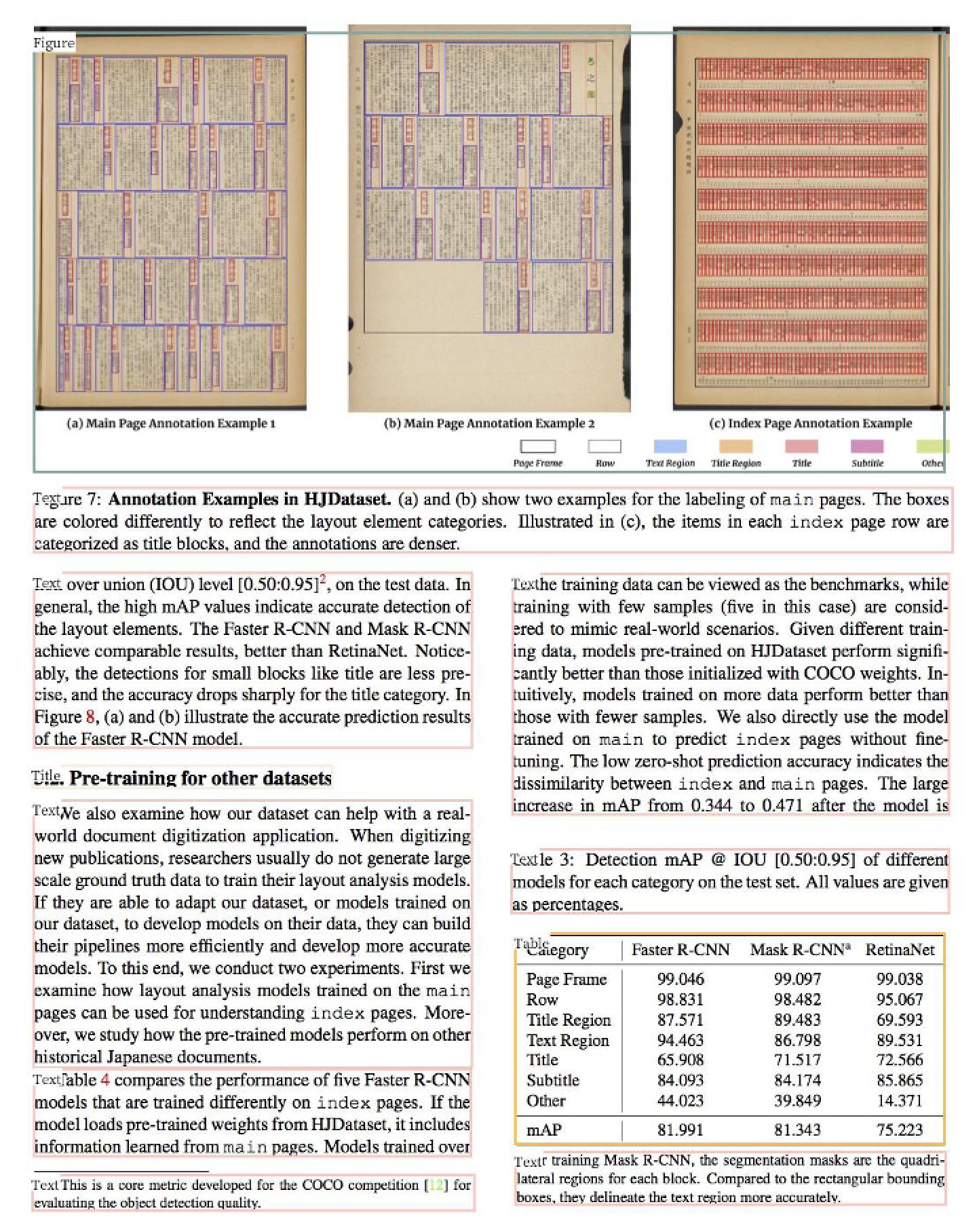
The following figure shows the result, with different colored detection boxes representing different categories and displaying specific categories in the upper left corner of the box with `show_element_type`
`PaddleDetectionLayoutModel`parameters are described as follows:
| parameter | description | default | remark |
| :------------: | :------------------------------------------------------: | :---------: | :----------------------------------------------------------: |
| config_path | model config path | None | Specify config_ path will automatically download the model (only for the first time,the model will exist and will not be downloaded again) |
| model_path | model path | None | local model path, config_ path and model_ path must be set to one, cannot be none at the same time |
| threshold | threshold of prediction score | 0.5 | \ |
| input_shape | picture size of reshape | [3,640,640] | \ |
| batch_size | testing batch size | 1 | \ |
| label_map | category mapping table | None | Setting config_ path, it can be none, and the label is automatically obtained according to the dataset name_ map |
| enforce_cpu | whether to use CPU | False | False to use GPU, and True to force the use of CPU |
| enforce_mkldnn | whether mkldnn acceleration is enabled in CPU prediction | True | \ |
| thread_num | the number of CPU threads | 10 | \ |
The following model configurations and label maps are currently supported, which you can use by modifying '--config_path' and '--label_map' to detect different types of content:
| dataset | config_path | label_map |
| ------------------------------------------------------------ | ------------------------------------------------------------ | --------------------------------------------------------- |
| [TableBank](https://doc-analysis.github.io/tablebank-page/index.html) word | lp://TableBank/ppyolov2_r50vd_dcn_365e_tableBank_word/config | {0:"Table"} |
| TableBank latex | lp://TableBank/ppyolov2_r50vd_dcn_365e_tableBank_latex/config | {0:"Table"} |
| [PubLayNet](https://github.com/ibm-aur-nlp/PubLayNet) | lp://PubLayNet/ppyolov2_r50vd_dcn_365e_publaynet/config | {0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"} |
* TableBank word and TableBank latex are trained on datasets of word documents and latex documents respectively;
* Download TableBank dataset contains both word and latex。
## 3. PostProcess
Layout parser contains multiple categories, if you only want to get the detection box for a specific category (such as the "Text" category), you can use the following code:
```python
# follow the above code
# filter areas for a specific text type
text_blocks = lp.Layout([b for b in layout if b.type=='Text'])
figure_blocks = lp.Layout([b for b in layout if b.type=='Figure'])
# text areas may be detected within the image area, delete these areas
text_blocks = lp.Layout([b for b in text_blocks \
if not any(b.is_in(b_fig) for b_fig in figure_blocks)])
# sort text areas and assign ID
h, w = image.shape[:2]
left_interval = lp.Interval(0, w/2*1.05, axis='x').put_on_canvas(image)
left_blocks = text_blocks.filter_by(left_interval, center=True)
left_blocks.sort(key = lambda b:b.coordinates[1])
right_blocks = [b for b in text_blocks if b not in left_blocks]
right_blocks.sort(key = lambda b:b.coordinates[1])
# the two lists are merged and the indexes are added in order
text_blocks = lp.Layout([b.set(id = idx) for idx, b in enumerate(left_blocks + right_blocks)])
# display result
show_img = lp.draw_box(image, text_blocks,
box_width=3,
show_element_id=True)
show_img.show()
```
Displays results with only the "Text" category:
## 4. Results
| Dataset | mAP | CPU time cost | GPU time cost |
| --------- | ---- | ------------- | ------------- |
| PubLayNet | 93.6 | 1713.7ms | 66.6ms |
| TableBank | 96.2 | 1968.4ms | 65.1ms |
**Envrionment:**
**CPU:** Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz,24core
**GPU:** a single NVIDIA Tesla P40
## 5. Training
The above model is based on [PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection). If you want to train your own layout parser model,please refer to:[train_layoutparser_model](train_layoutparser_model.md)