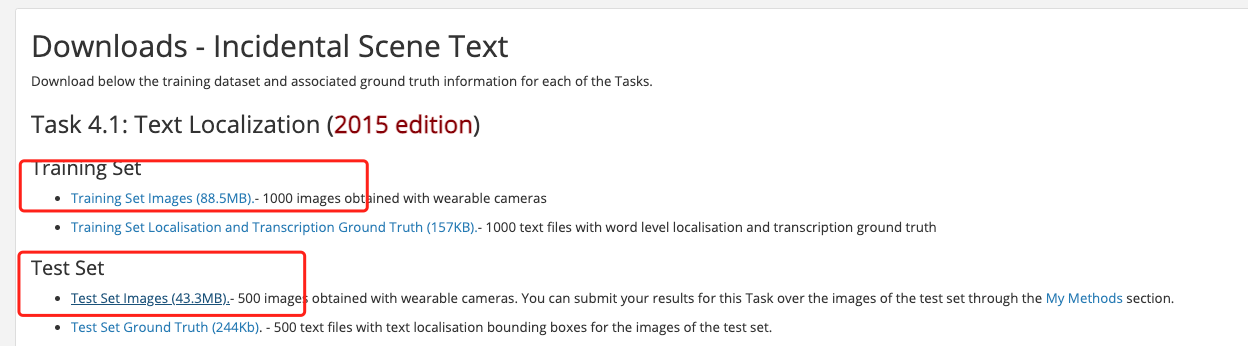
将下载到的数据集解压到工作目录下,假设解压在 PaddleOCR/train_data/下。另外,PaddleOCR将零散的标注文件整理成单独的标注文件 ,您可以通过wget的方式进行下载。 ```shell # 在PaddleOCR路径下 cd PaddleOCR/ wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/train_icdar2015_label.txt wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/test_icdar2015_label.txt ``` PaddleOCR 也提供了数据格式转换脚本,可以将官网 label 转换支持的数据格式。 数据转换工具在 `ppocr/utils/gen_label.py`, 这里以训练集为例: ``` # 将官网下载的标签文件转换为 train_icdar2015_label.txt python gen_label.py --mode="det" --root_path="/path/to/icdar_c4_train_imgs/" \ --input_path="/path/to/ch4_training_localization_transcription_gt" \ --output_label="/path/to/train_icdar2015_label.txt" ``` 解压数据集和下载标注文件后,PaddleOCR/train_data/ 有两个文件夹和两个文件,按照如下方式组织icdar2015数据集: ``` /PaddleOCR/train_data/icdar2015/text_localization/ └─ icdar_c4_train_imgs/ icdar数据集的训练数据 └─ ch4_test_images/ icdar数据集的测试数据 └─ train_icdar2015_label.txt icdar数据集的训练标注 └─ test_icdar2015_label.txt icdar数据集的测试标注 ``` 提供的标注文件格式如下,中间用"\t"分隔: ``` " 图像文件名 json.dumps编码的图像标注信息" ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}] ``` json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 `points` 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。 `transcription` 表示当前文本框的文字,**当其内容为“###”时,表示该文本框无效,在训练时会跳过。** 如果您想在其他数据集上训练,可以按照上述形式构建标注文件。 ## 1.2 下载预训练模型 首先下载模型backbone的pretrain model,PaddleOCR的检测模型目前支持两种backbone,分别是MobileNetV3、ResNet_vd系列, 您可以根据需求使用[PaddleClas](https://github.com/PaddlePaddle/PaddleClas/tree/release/2.0/ppcls/modeling/architectures)中的模型更换backbone, 对应的backbone预训练模型可以从[PaddleClas repo 主页中找到下载链接](https://github.com/PaddlePaddle/PaddleClas/blob/release%2F2.0/README_cn.md#resnet%E5%8F%8A%E5%85%B6vd%E7%B3%BB%E5%88%97)。 ```shell cd PaddleOCR/ # 根据backbone的不同选择下载对应的预训练模型 # 下载MobileNetV3的预训练模型 wget -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/MobileNetV3_large_x0_5_pretrained.pdparams # 或,下载ResNet18_vd的预训练模型 wget -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/ResNet18_vd_pretrained.pdparams # 或,下载ResNet50_vd的预训练模型 wget -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/ResNet50_vd_ssld_pretrained.pdparams ``` ## 1.3 启动训练 *如果您安装的是cpu版本,请将配置文件中的 `use_gpu` 字段修改为false* ```shell # 单机单卡训练 mv3_db 模型 python3 tools/train.py -c configs/det/det_mv3_db.yml \ -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained # 单机多卡训练,通过 --gpus 参数设置使用的GPU ID python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \ -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained # 多机多卡训练,通过 --ips 参数设置使用的机器IP地址,通过 --gpus 参数设置使用的GPU ID python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \ -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained ``` 上述指令中,通过-c 选择训练使用configs/det/det_db_mv3.yml配置文件。 有关配置文件的详细解释,请参考[链接](./config.md)。 您也可以通过-o参数在不需要修改yml文件的情况下,改变训练的参数,比如,调整训练的学习率为0.0001 ```shell python3 tools/train.py -c configs/det/det_mv3_db.yml -o Optimizer.base_lr=0.0001 ``` **注意:** 采用多机多卡训练时,需要替换上面命令中的ips值为您机器的地址,机器之间需要能够相互ping通。另外,训练时需要在多个机器上分别启动命令。查看机器ip地址的命令为`ifconfig`。 如果您想进一步加快训练速度,可以使用[自动混合精度训练](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/01_paddle2.0_introduction/basic_concept/amp_cn.html), 以单机单卡为例,命令如下: ```shell python3 tools/train.py -c configs/det/det_mv3_db.yml \ -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained \ Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True ``` ## 1.4 断点训练 如果训练程序中断,如果希望加载训练中断的模型从而恢复训练,可以通过指定Global.checkpoints指定要加载的模型路径: ```shell python3 tools/train.py -c configs/det/det_mv3_db.yml -o Global.checkpoints=./your/trained/model ``` **注意**:`Global.checkpoints`的优先级高于`Global.pretrained_model`的优先级,即同时指定两个参数时,优先加载`Global.checkpoints`指定的模型,如果`Global.checkpoints`指定的模型路径有误,会加载`Global.pretrained_model`指定的模型。 ## 1.5 更换Backbone 训练 PaddleOCR将网络划分为四部分,分别在[ppocr/modeling](../../ppocr/modeling)下。 进入网络的数据将按照顺序(transforms->backbones-> necks->heads)依次通过这四个部分。 ```bash ├── architectures # 网络的组网代码 ├── transforms # 网络的图像变换模块 ├── backbones # 网络的特征提取模块 ├── necks # 网络的特征增强模块 └── heads # 网络的输出模块 ``` 如果要更换的Backbone 在PaddleOCR中有对应实现,直接修改配置yml文件中`Backbone`部分的参数即可。 如果要使用新的Backbone,更换backbones的例子如下: 1. 在 [ppocr/modeling/backbones](../../ppocr/modeling/backbones) 文件夹下新建文件,如my_backbone.py。 2. 在 my_backbone.py 文件内添加相关代码,示例代码如下: ```python import paddle import paddle.nn as nn import paddle.nn.functional as F class MyBackbone(nn.Layer): def __init__(self, *args, **kwargs): super(MyBackbone, self).__init__() # your init code self.conv = nn.xxxx def forward(self, inputs): # your network forward y = self.conv(inputs) return y ``` 3. 在 [ppocr/modeling/backbones/\__init\__.py](../../ppocr/modeling/backbones/__init__.py)文件内导入添加的`MyBackbone`模块,然后修改配置文件中Backbone进行配置即可使用,格式如下: ```yaml Backbone: name: MyBackbone args1: args1 ``` **注意**:如果要更换网络的其他模块,可以参考[文档](./add_new_algorithm.md)。 ## 1.6 指标评估 PaddleOCR计算三个OCR检测相关的指标,分别是:Precision、Recall、Hmean(F-Score)。 训练中模型参数默认保存在`Global.save_model_dir`目录下。在评估指标时,需要设置`Global.checkpoints`指向保存的参数文件。 ```shell python3 tools/eval.py -c configs/det/det_mv3_db.yml -o Global.checkpoints="{path/to/weights}/best_accuracy" ``` * 注:`box_thresh`、`unclip_ratio`是DB后处理所需要的参数,在评估EAST模型时不需要设置 ## 1.7 测试检测效果 测试单张图像的检测效果 ```shell python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/img_10.jpg" Global.pretrained_model="./output/det_db/best_accuracy" ``` 测试DB模型时,调整后处理阈值 ```shell python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/img_10.jpg" Global.pretrained_model="./output/det_db/best_accuracy" PostProcess.box_thresh=0.6 PostProcess.unclip_ratio=2.0 ``` 测试文件夹下所有图像的检测效果 ```shell python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/" Global.pretrained_model="./output/det_db/best_accuracy" ``` ## 1.8 转inference模型测试 inference 模型(`paddle.jit.save`保存的模型) 一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。 训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。 与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。 检测模型转inference 模型方式: ```shell # 加载配置文件`det_mv3_db.yml`,从`output/det_db`目录下加载`best_accuracy`模型,inference模型保存在`./output/det_db_inference`目录下 python3 tools/export_model.py -c configs/det/det_mv3_db.yml -o Global.pretrained_model="./output/det_db/best_accuracy" Global.save_inference_dir="./output/det_db_inference/" ``` DB检测模型inference 模型预测: ```shell python3 tools/infer/predict_det.py --det_algorithm="DB" --det_model_dir="./output/det_db_inference/" --image_dir="./doc/imgs/" --use_gpu=True ``` 如果是其他检测,比如EAST模型,det_algorithm参数需要修改为EAST,默认为DB算法: ```shell python3 tools/infer/predict_det.py --det_algorithm="EAST" --det_model_dir="./output/det_db_inference/" --image_dir="./doc/imgs/" --use_gpu=True ``` # 2. FAQ Q1: 训练模型转inference 模型之后预测效果不一致? **A**:此类问题出现较多,问题多是trained model预测时候的预处理、后处理参数和inference model预测的时候的预处理、后处理参数不一致导致的。以det_mv3_db.yml配置文件训练的模型为例,训练模型、inference模型预测结果不一致问题解决方式如下: - 检查[trained model预处理](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/configs/det/det_mv3_db.yml#L116),和[inference model的预测预处理](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/tools/infer/predict_det.py#L42)函数是否一致。算法在评估的时候,输入图像大小会影响精度,为了和论文保持一致,训练icdar15配置文件中将图像resize到[736, 1280],但是在inference model预测的时候只有一套默认参数,会考虑到预测速度问题,默认限制图像最长边为960做resize的。训练模型预处理和inference模型的预处理函数位于[ppocr/data/imaug/operators.py](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/ppocr/data/imaug/operators.py#L147) - 检查[trained model后处理](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/configs/det/det_mv3_db.yml#L51),和[inference 后处理参数](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/tools/infer/utility.py#L50)是否一致。