English | [简体中文](README_ch.md)








## Introduction
PaddleOCR aims to create multilingual, awesome, leading, and practical OCR tools that help users train better models and apply them into practice.
## 📣 Recent updates
- **🔥2022.8.24 Release PaddleOCR [release/2.6](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.6)**
- Release [PP-Structurev2](./ppstructure/),with functions and performance fully upgraded, adapted to Chinese scenes, and new support for [Layout Recovery](./ppstructure/recovery) and **one line command to convert PDF to Word**;
- [Layout Analysis](./ppstructure/layout) optimization: model storage reduced by 95%, while speed increased by 11 times, and the average CPU time-cost is only 41ms;
- [Table Recognition](./ppstructure/table) optimization: 3 optimization strategies are designed, and the model accuracy is improved by 6% under comparable time consumption;
- [Key Information Extraction](./ppstructure/kie) optimization:a visual-independent model structure is designed, the accuracy of semantic entity recognition is increased by 2.8%, and the accuracy of relation extraction is increased by 9.1%.
- **🔥2022.7 Release [OCR scene application collection](./applications/README_en.md)**
- Release **9 vertical models** such as digital tube, LCD screen, license plate, handwriting recognition model, high-precision SVTR model, etc, covering the main OCR vertical applications in general, manufacturing, finance, and transportation industries.
- **🔥2022.5.9 Release PaddleOCR [release/2.5](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.5)**
- Release [PP-OCRv3](./doc/doc_en/ppocr_introduction_en.md#pp-ocrv3): With comparable speed, the effect of Chinese scene is further improved by 5% compared with PP-OCRv2, the effect of English scene is improved by 11%, and the average recognition accuracy of 80 language multilingual models is improved by more than 5%.
- Release [PPOCRLabelv2](./PPOCRLabel): Add the annotation function for table recognition task, key information extraction task and irregular text image.
- Release interactive e-book [*"Dive into OCR"*](./doc/doc_en/ocr_book_en.md), covers the cutting-edge theory and code practice of OCR full stack technology.
- [more](./doc/doc_en/update_en.md)
## 🌟 Features
PaddleOCR support a variety of cutting-edge algorithms related to OCR, and developed industrial featured models/solution [PP-OCR](./doc/doc_en/ppocr_introduction_en.md) and [PP-Structure](./ppstructure/README.md) on this basis, and get through the whole process of data production, model training, compression, inference and deployment.
## ⚡ Quick Experience
```bash
pip3 install paddlepaddle # for gpu user please install paddlepaddle-gpu
pip3 install paddleocr
paddleocr --image_dir ./doc/imgs_en/254.jpg --lang=en # change for i18n abbr
```
> If you don't have Python environment, please follow [Environment Preparation](./doc/doc_en/environment_en.md). We recommend you starting with [Tutorials](#Tutorials).
## 📚 E-book: *Dive Into OCR*
- [Dive Into OCR ](./doc/doc_en/ocr_book_en.md)
## 👫 Community
For international developers, we regard [PaddleOCR Discussions](https://github.com/PaddlePaddle/PaddleOCR/discussions) as our international community platform. All ideas and questions can be discussed here in English.
## 🛠️ PP-OCR Series Model List
| Model introduction | Model name | Recommended scene | Detection model | Direction classifier | Recognition model |
| ------------------------------------------------------------ | ---------------------------- | ----------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| i18n models | I18n model | Mobile & Server | | | |
| English ultra-lightweight PP-OCRv3 model(13.4M) | en_PP-OCRv3_xx | Mobile & Server | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar) | [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
| Chinese and English ultra-lightweight PP-OCRv3 model(16.2M) | ch_PP-OCRv3_xx | Mobile & Server | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar) | [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar) |
- For more model downloads (including multiple languages), please refer to [PP-OCR series model downloads](./doc/doc_en/models_list_en.md).
- For a new language request, please refer to [Guideline for new language_requests](#language_requests).
- For structural document analysis models, please refer to [PP-Structure models](./ppstructure/docs/models_list_en.md).
## 📖 Tutorials
- [Environment Preparation](./doc/doc_en/environment_en.md)
- [PP-OCR 🔥](./doc/doc_en/ppocr_introduction_en.md)
- [Quick Start](./doc/doc_en/quickstart_en.md)
- [Model Zoo](./doc/doc_en/models_en.md)
- [Model training](./doc/doc_en/training_en.md)
- [Text Detection](./doc/doc_en/detection_en.md)
- [Text Recognition](./doc/doc_en/recognition_en.md)
- [Text Direction Classification](./doc/doc_en/angle_class_en.md)
- Model Compression
- [Model Quantization](./deploy/slim/quantization/README_en.md)
- [Model Pruning](./deploy/slim/prune/README_en.md)
- [Knowledge Distillation](./doc/doc_en/knowledge_distillation_en.md)
- [Inference and Deployment](./deploy/README.md)
- [Python Inference](./doc/doc_en/inference_ppocr_en.md)
- [C++ Inference](./deploy/cpp_infer/readme.md)
- [Serving](./deploy/pdserving/README.md)
- [Mobile](./deploy/lite/readme.md)
- [Paddle2ONNX](./deploy/paddle2onnx/readme.md)
- [PaddleCloud](./deploy/paddlecloud/README.md)
- [Benchmark](./doc/doc_en/benchmark_en.md)
- [PP-Structure 🔥](./ppstructure/README.md)
- [Quick Start](./ppstructure/docs/quickstart_en.md)
- [Model Zoo](./ppstructure/docs/models_list_en.md)
- [Model training](./doc/doc_en/training_en.md)
- [Layout Analysis](./ppstructure/layout/README.md)
- [Table Recognition](./ppstructure/table/README.md)
- [Key Information Extraction](./ppstructure/kie/README.md)
- [Inference and Deployment](./deploy/README.md)
- [Python Inference](./ppstructure/docs/inference_en.md)
- [C++ Inference](./deploy/cpp_infer/readme.md)
- [Serving](./deploy/hubserving/readme_en.md)
- [Academic Algorithms](./doc/doc_en/algorithm_overview_en.md)
- [Text detection](./doc/doc_en/algorithm_overview_en.md)
- [Text recognition](./doc/doc_en/algorithm_overview_en.md)
- [End-to-end OCR](./doc/doc_en/algorithm_overview_en.md)
- [Table Recognition](./doc/doc_en/algorithm_overview_en.md)
- [Key Information Extraction](./doc/doc_en/algorithm_overview_en.md)
- [Add New Algorithms to PaddleOCR](./doc/doc_en/add_new_algorithm_en.md)
- Data Annotation and Synthesis
- [Semi-automatic Annotation Tool: PPOCRLabel](./PPOCRLabel/README.md)
- [Data Synthesis Tool: Style-Text](./StyleText/README.md)
- [Other Data Annotation Tools](./doc/doc_en/data_annotation_en.md)
- [Other Data Synthesis Tools](./doc/doc_en/data_synthesis_en.md)
- Datasets
- [General OCR Datasets(Chinese/English)](doc/doc_en/dataset/datasets_en.md)
- [HandWritten_OCR_Datasets(Chinese)](doc/doc_en/dataset/handwritten_datasets_en.md)
- [Various OCR Datasets(multilingual)](doc/doc_en/dataset/vertical_and_multilingual_datasets_en.md)
- [Layout Analysis](doc/doc_en/dataset/layout_datasets_en.md)
- [Table Recognition](doc/doc_en/dataset/table_datasets_en.md)
- [Key Information Extraction](doc/doc_en/dataset/kie_datasets_en.md)
- [Code Structure](./doc/doc_en/tree_en.md)
- [Visualization](#Visualization)
- [Community](#Community)
- [New language requests](#language_requests)
- [FAQ](./doc/doc_en/FAQ_en.md)
- [References](./doc/doc_en/reference_en.md)
- [License](#LICENSE)
## 🇺🇳 Guideline for New Language Requests
If you want to **request a new language model**, please vote in [Vote for Multilingual Model Upgrades](https://github.com/PaddlePaddle/PaddleOCR/discussions/7253). We will upgrade model according to the result regularly. **Invite your friends to vote together!**
If you need to **train a new language model** based on your scenario, the tutorial in [Multilingual Model Training Project](https://github.com/PaddlePaddle/PaddleOCR/discussions/7252) will help you prepare dataset and show you the whole process step by step.
The original [Multilingual OCR Development Plan](https://github.com/PaddlePaddle/PaddleOCR/issues/1048) still shows you a lot of useful corpus and dictionaries
## 👀 Visualization [more](./doc/doc_en/visualization_en.md)
PP-OCRv3 Multilingual model
PP-OCRv3 English model
PP-OCRv3 Chinese model
PP-Structurev2
1. layout analysis + table recognition
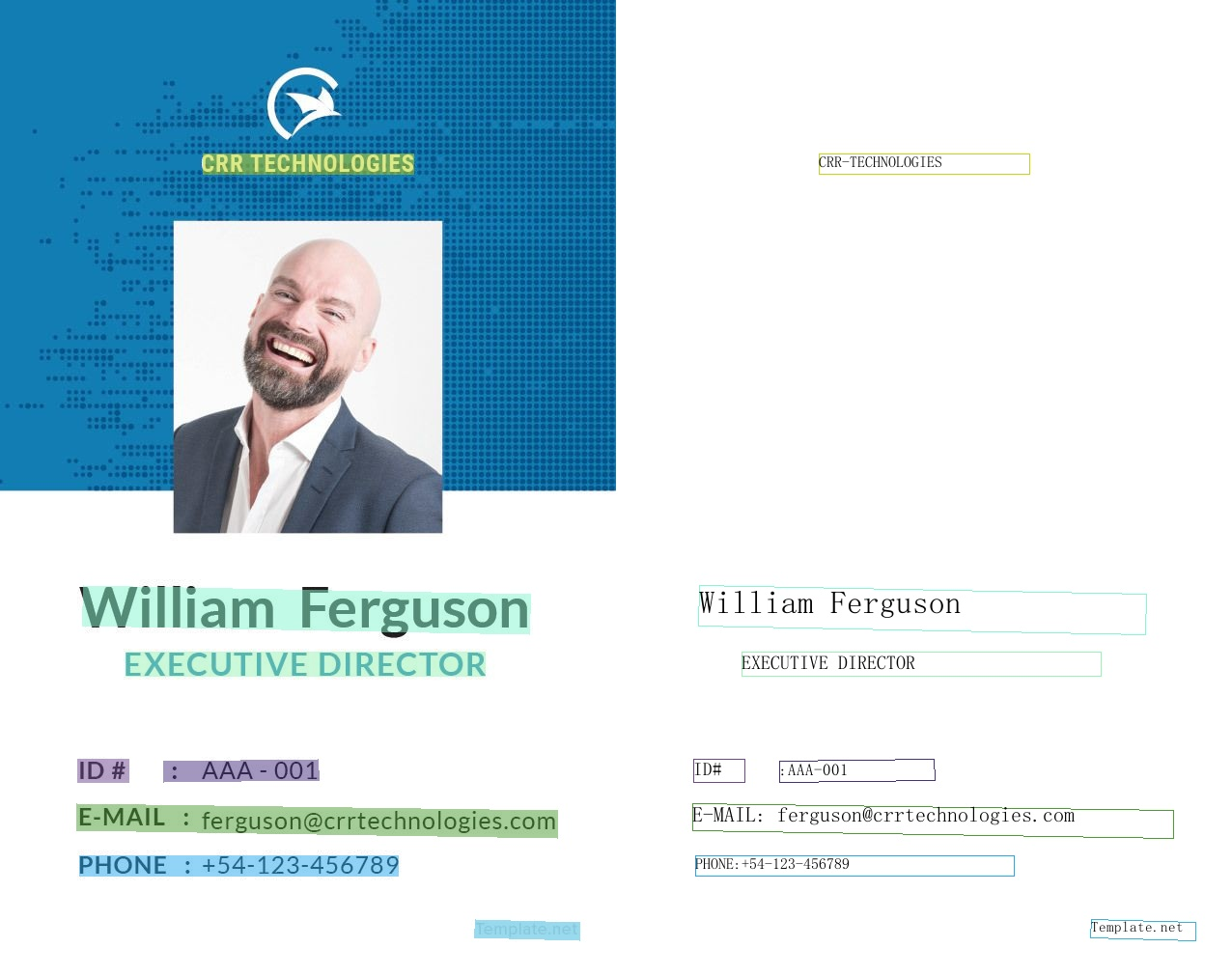
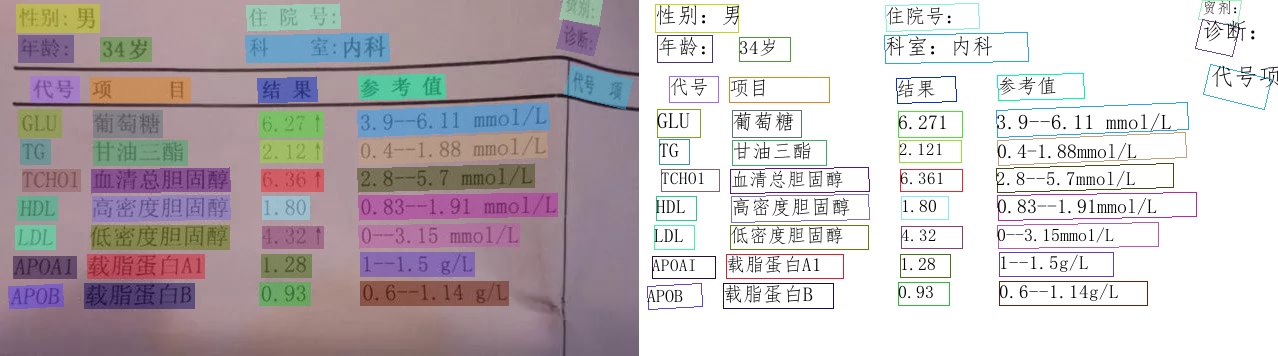
2. SER (Semantic entity recognition)
3. RE (Relation Extraction)
## 📄 License
This project is released under Apache 2.0 license