[English](../doc_en/PP-OCRv3_introduction_en.md) | 简体中文
# PP-OCR
- [1. 简介](#1)
- [2. 特性](#2)
- [3. benchmark](#3)
## 1. 简介
PP-OCR是PaddleOCR自研的实用的超轻量OCR系统。在实现[前沿算法](algorithm.md)的基础上,考虑精度与速度的平衡,进行**模型瘦身**和**深度优化**,使其尽可能满足产业落地需求。
#### PP-OCR
PP-OCR是一个两阶段的OCR系统,其中文本检测算法选用[DB](algorithm_det_db.md),文本识别算法选用[CRNN](algorithm_rec_crnn.md),并在检测和识别模块之间添加[文本方向分类器](angle_class.md),以应对不同方向的文本识别。
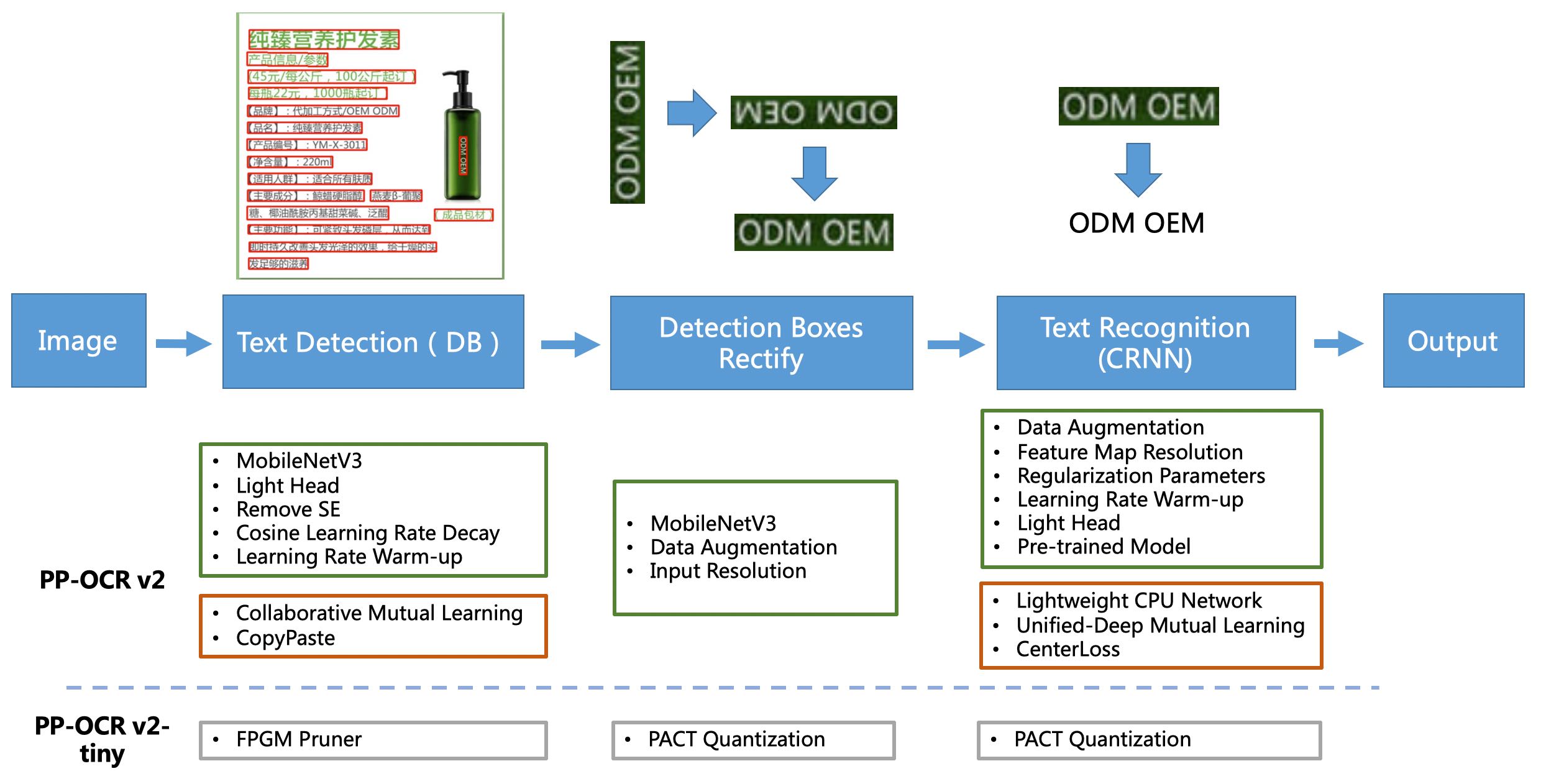
PP-OCRv2系统pipeline如下:
PP-OCR系统在持续迭代优化,目前已发布PP-OCR、PP-OCRv2、PP-OCRv3三个版本:
PP-OCR从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身(如绿框所示),最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。更多细节请参考PP-OCR技术方案 https://arxiv.org/abs/2009.09941
## PP-OCRv3策略简介
### PP-OCRv3文本检测模型优化策略
PP-OCRv3采用PP-OCRv2的[CML](https://arxiv.org/pdf/2109.03144.pdf)蒸馏策略,在蒸馏的student模型、teacher模型精度提升,CML蒸馏策略上分别做了优化。
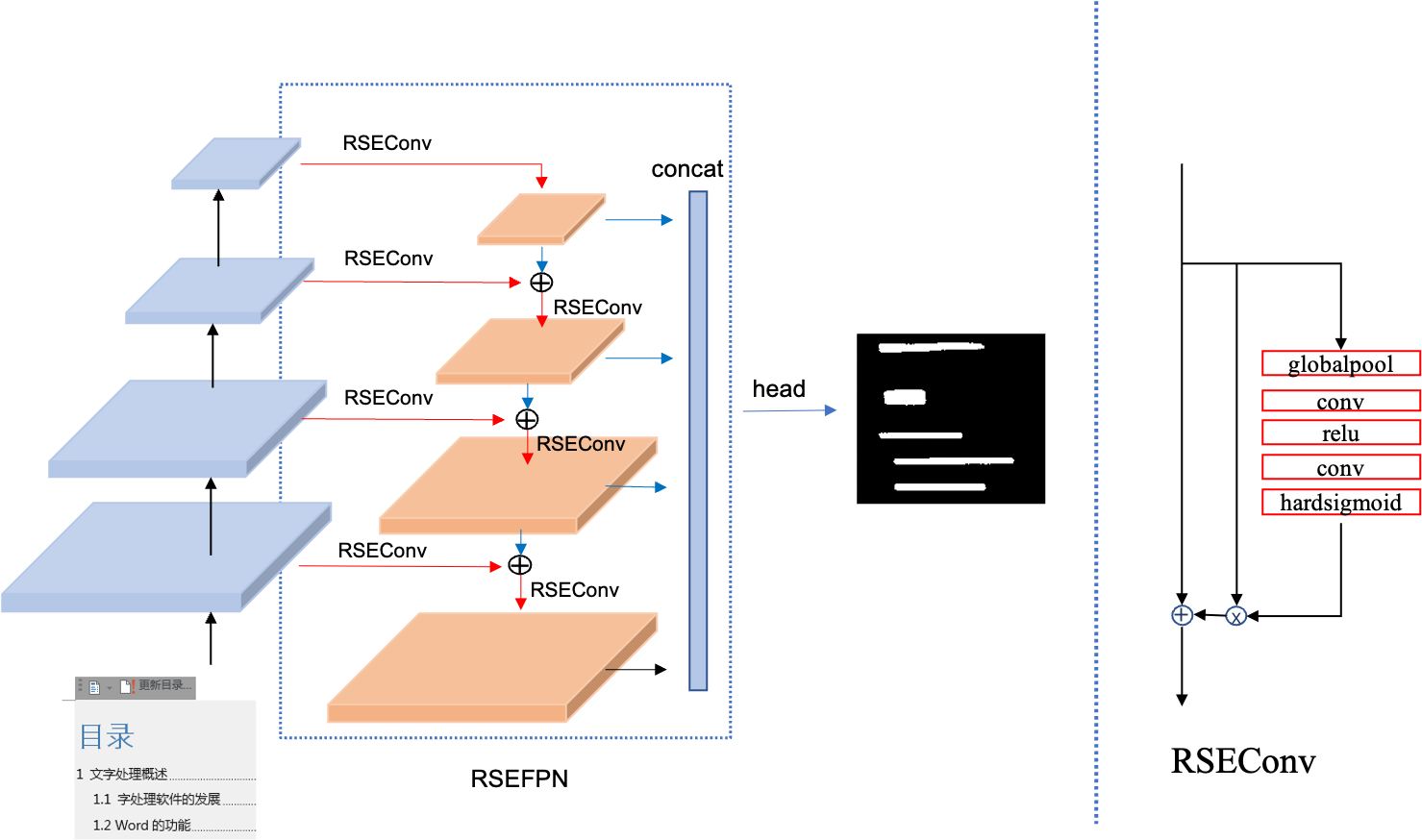
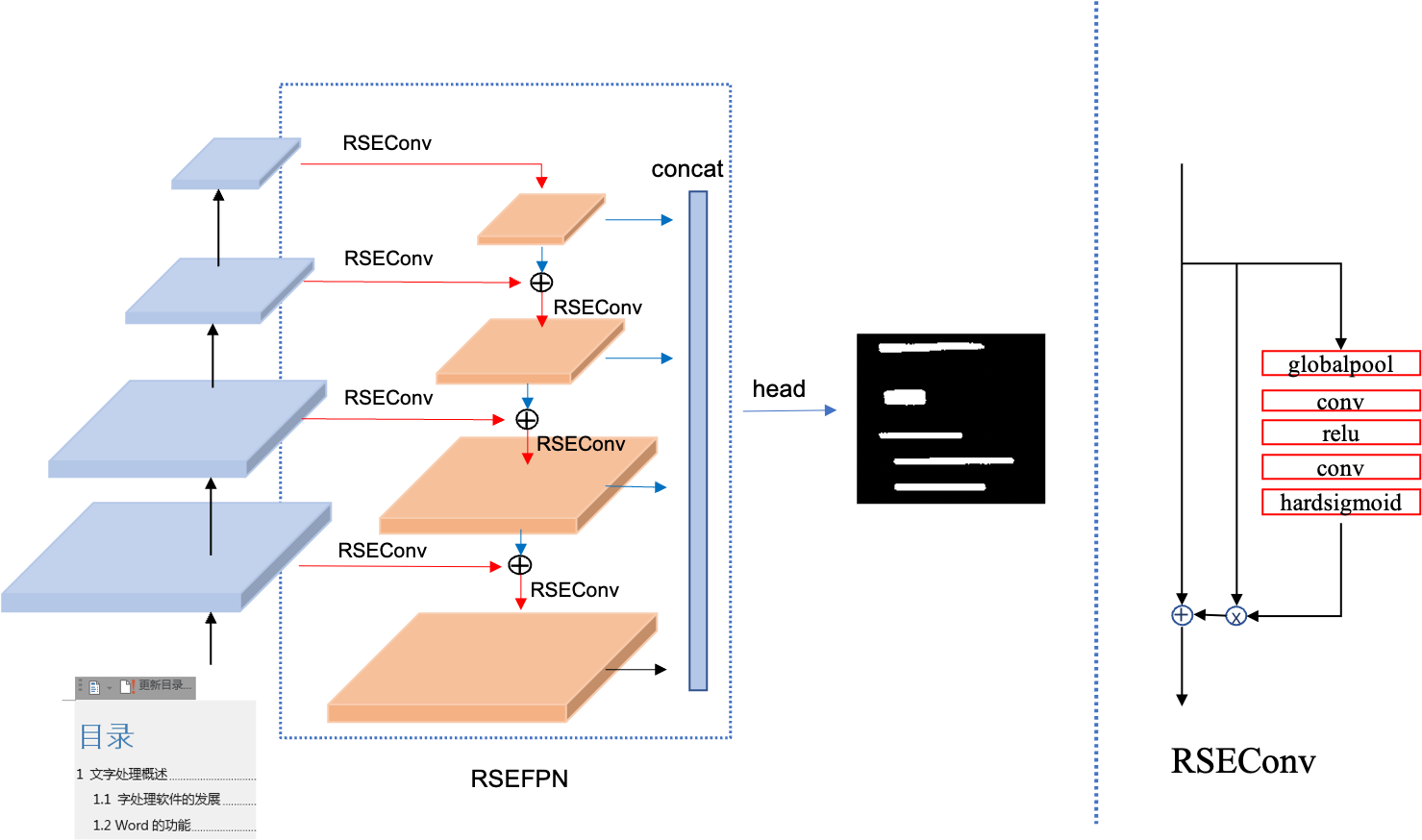
- 在蒸馏student模型精度提升方面,提出了PP-OCRv2的FPN结构改进版RSEFPN(Residual Squeeze-and-Excitation FPN),用于提升student模型精度和召回。
RSEFPN的网络结构如下图所示,RSEFPN在PP-OCRv2的FPN基础上,将FPN中的卷积层更换为了通道注意力结构的RSEConv层。
RSEFPN将PP-OCR检测模型的精度hmean从81.3%提升到84.5%。模型大小从3M变为3.6M。
- 在蒸馏的teacher模型精度提升方面,提出了LKPAN结构替换PP-OCRv2的FPN结构,并且使用ResNet50作为Backbone,更大的模型带来更多的精度提升。另外,对teacher模型使用[DML](https://arxiv.org/abs/1706.00384)蒸馏策略进一步提升teacher模型的精度。最终teacher的模型指标hmean从83.2%提升到了86.0%。
*注:[PP-OCRv2的FPN结构](https://github.com/PaddlePaddle/PaddleOCR/blob/77acb3bfe51c8a46c684527f73cd218cefedb4a3/ppocr/modeling/necks/db_fpn.py#L107)对DB算法FPN结构做了轻量级设计*
LKPAN的网络结构如下图所示:
LKPAN(Large Kernel PAN)是一个具有更大感受野的轻量级[PAN](https://arxiv.org/pdf/1803.01534.pdf)结构。在LKPAN的path augmentation中,使用kernel size为`9*9`的卷积;更大的kernel size意味着更大的感受野,更容易检测大字体的文字以及极端长宽比的文字。LKPAN将base检测模型的精度hmean从81.3%提升到84.9%。
*注:LKPAN相比RSEFPN有更多的精度提升,但是考虑到模型大小和预测速度等因素,在student模型中使用RSEFPN。*
采用上述策略,PP-OCRv3相比PP-OCRv2,hmean指标从83.3%提升到85.4%;预测速度从平均117ms/image变为124ms/image。
3. PP-OCRv3检测模型消融实验
|序号|策略|模型大小|hmean|Intel Gold 6148CPU+mkldnn预测耗时|
|-|-|-|-|-|
|0|PP-OCR|3M|81.3%|117ms|
|1|PP-OCRV2|3M|83.3%|117ms|
|2|0 + RESFPN|3.6M|84.5%|124ms|
|3|0 + LKPAN|4.6M|84.9%|156ms|
|4|teacher |124M|83.2%|-|
|5|teacher + DML + LKPAN|124M|86.0%|-|
|6|0 + 2 + 5 + CML|3.6M|85.4%|124ms|
## 2. 特性
- 超轻量PP-OCRv2系列:检测(3.1M)+ 方向分类器(1.4M)+ 识别(8.5M)= 13.0M
- 超轻量PP-OCR mobile移动端系列:检测(3.0M)+方向分类器(1.4M)+ 识别(5.0M)= 9.4M
- 通用PP-OCR server系列:检测(47.1M)+方向分类器(1.4M)+ 识别(94.9M)= 143.4M
- 支持中英文数字组合识别、竖排文本识别、长文本识别
- 支持多语言识别:韩语、日语、德语、法语等约80种语言
## 3. benchmark
关于PP-OCR系列模型之间的性能对比,请查看[benchmark](./benchmark.md)文档。