[English](README.md) | 简体中文
# 版面恢复
- [1. 简介](#1)
- [2. 安装](#2)
- [2.1 安装PaddlePaddle](#2.1)
- [2.2 安装PaddleOCR](#2.2)
- [3. 使用](#3)
- [3.1 下载模型](#3.1)
- [3.2 版面恢复](#3.2)
- [4. 更多](#4)
## 1. 简介
版面恢复就是在OCR识别后,内容仍然像原文档图片那样排列着,段落不变、顺序不变的输出到word文档中等。
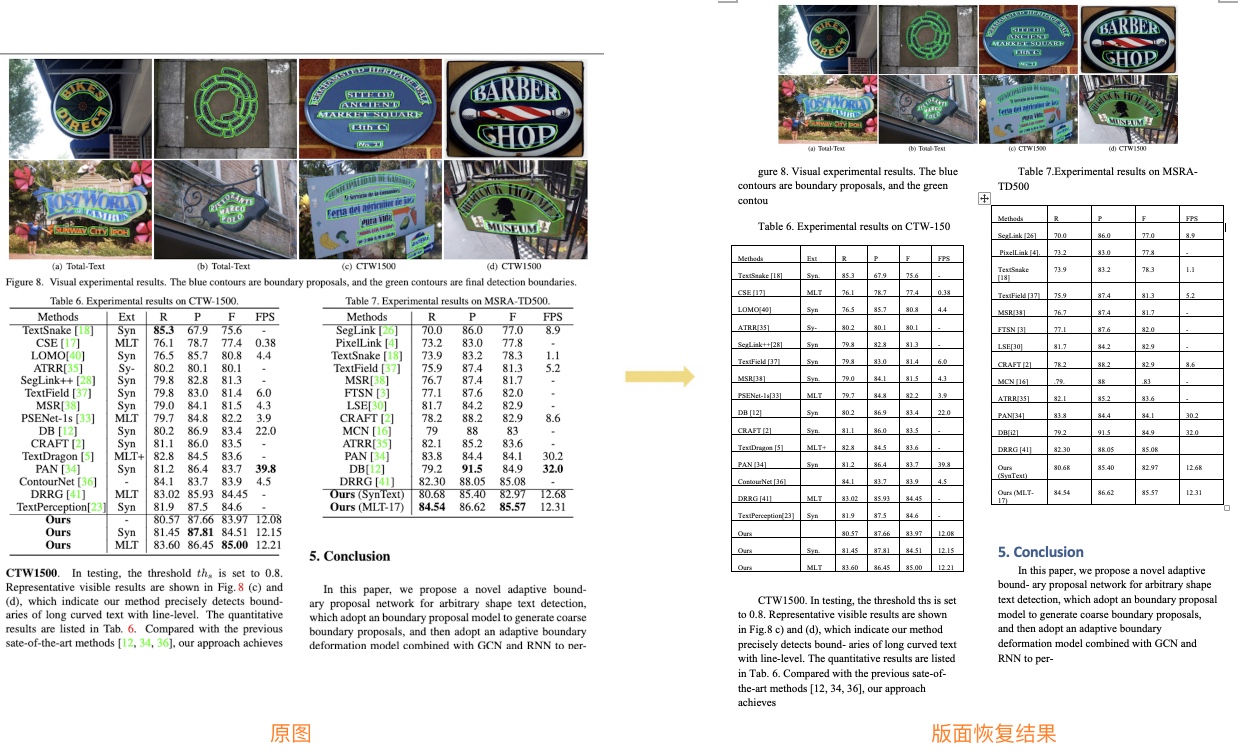
版面恢复结合了[版面分析](../layout/README_ch.md)、[表格识别](../table/README_ch.md)技术,从而更好地恢复图片、表格、标题等内容,支持中、英文pdf文档、文档图片格式的输入文件,下图分别展示了英文文档和中文文档版面恢复的效果:
## 2. 安装
### 2.1 安装PaddlePaddle
```bash
python3 -m pip install --upgrade pip
# 您的机器安装的是CUDA9或CUDA10,请运行以下命令安装
python3 -m pip install "paddlepaddle-gpu" -i https://mirror.baidu.com/pypi/simple
# 您的机器是CPU,请运行以下命令安装
python3 -m pip install "paddlepaddle" -i https://mirror.baidu.com/pypi/simple
```
更多需求,请参照[安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
### 2.2 安装PaddleOCR
- **(1)下载版面恢复源码**
```bash
【推荐】git clone https://github.com/PaddlePaddle/PaddleOCR
# 如果因为网络问题无法pull成功,也可选择使用码云上的托管:
git clone https://gitee.com/paddlepaddle/PaddleOCR
# 注:码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先使用推荐方式。
```
- **(2)安装recovery的`requirements`**
版面恢复导出为docx、pdf文件,所以需要安装python-docx、docx2pdf API,同时处理pdf格式的输入文件,需要安装PyMuPDF API([要求Python >= 3.7](https://pypi.org/project/PyMuPDF/))。
```bash
python3 -m pip install -r ppstructure/recovery/requirements.txt
```
## 3. 使用
我们通过版面分析对图片/pdf形式的文档进行区域划分,定位其中的关键区域,如文字、表格、图片等,记录每个区域的位置、类别、区域像素值信息。对不同的区域分别处理,其中:
- 文字区域直接进行OCR检测和识别,在之前信息基础上增加OCR检测框坐标和文本内容信息
- 表格区域进行表格识别,记录表格html和文字信息
- 图片直接保存
我们通过版面信息、OCR检测和识别结构、表格信息、保存的图片,对测试图片进行恢复即可。
提供如下代码实现版面恢复,也提供了whl包的形式方便快速使用,详见 [quickstart](../docs/quickstart.md)。
### 3.1 下载模型
如果输入为英文文档类型,下载OCR检测和识别、版面分析、表格识别的英文模型
```bash
cd PaddleOCR/ppstructure
# 下载模型
mkdir inference && cd inference
# 下载英文超轻量PP-OCRv3检测模型并解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar && tar xf en_PP-OCRv3_det_infer.tar
# 下载英文超轻量PP-OCRv3识别模型并解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar && tar xf en_PP-OCRv3_rec_infer.tar
# 下载英文表格识别模型并解压
wget https://paddleocr.bj.bcebos.com/ppstructure/models/slanet/en_ppstructure_mobile_v2.0_SLANet_infer.tar
tar xf en_ppstructure_mobile_v2.0_SLANet_infer.tar
# 下载英文版面分析模型
wget https://paddleocr.bj.bcebos.com/ppstructure/models/layout/picodet_lcnet_x1_0_fgd_layout_infer.tar
tar xf picodet_lcnet_x1_0_fgd_layout_infer.tar
cd ..
```
如果输入为中文文档类型,在下述链接中下载中文模型即可:
[PP-OCRv3中英文超轻量文本检测和识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/README_ch.md#pp-ocr%E7%B3%BB%E5%88%97%E6%A8%A1%E5%9E%8B%E5%88%97%E8%A1%A8%E6%9B%B4%E6%96%B0%E4%B8%AD)、[表格识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/ppstructure/docs/models_list.md#22-表格识别模型)、[版面分析模型](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/ppstructure/docs/models_list.md#1-版面分析模型)
### 3.2 版面恢复
使用下载的模型恢复给定文档的版面,以英文模型为例,执行如下命令:
```bash
python3 predict_system.py \
--image_dir=./docs/table/1.png \
--det_model_dir=inference/en_PP-OCRv3_det_infer \
--rec_model_dir=inference/en_PP-OCRv3_rec_infer \
--rec_char_dict_path=../ppocr/utils/en_dict.txt \
--table_model_dir=inference/en_ppstructure_mobile_v2.0_SLANet_infer \
--table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
--layout_model_dir=inference/picodet_lcnet_x1_0_fgd_layout_infer \
--layout_dict_path=../ppocr/utils/dict/layout_dict/layout_publaynet_dict.txt \
--vis_font_path=../doc/fonts/simfang.ttf \
--recovery=True \
--save_pdf=False \
--output=../output/
```
运行完成后,恢复版面的docx文档会保存到`output`字段指定的目录下
字段含义:
- image_dir:测试文件,可以是图片、图片目录、pdf文件、pdf文件目录
- det_model_dir:OCR检测模型路径
- rec_model_dir:OCR识别模型路径
- rec_char_dict_path:OCR识别字典,如果更换为中文模型,需要更改为"../ppocr/utils/ppocr_keys_v1.txt",如果您在自己的数据集上训练的模型,则更改为训练的字典的文件
- table_model_dir:表格识别模型路径
- table_char_dict_path:表格识别字典,如果更换为中文模型,不需要更换字典
- layout_model_dir:版面分析模型路径
- layout_dict_path:版面分析字典,如果更换为中文模型,需要更改为"../ppocr/utils/dict/layout_dict/layout_cdla_dict.txt"
- recovery:是否进行版面恢复,默认False
- save_pdf:进行版面恢复导出docx文档的同时,是否保存为pdf文件,默认为False
- output:版面恢复结果保存路径
## 4. 更多
关于OCR检测模型的训练评估与推理,请参考:[文本检测教程](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_ch/detection.md)
关于OCR识别模型的训练评估与推理,请参考:[文本识别教程](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_ch/recognition.md)
关于版面分析模型的训练评估与推理,请参考:[版面分析教程](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/ppstructure/layout/README_ch.md)
关于表格识别模型的训练评估与推理,请参考:[表格识别教程](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/ppstructure/table/README_ch.md)