diff --git a/README.md b/README.md
index 19b848772d8ac5ee91f76c00ff2f6a89f77c226c..9b03b7567291976d155145e401d949c6fcc71fa2 100644
--- a/README.md
+++ b/README.md
@@ -118,7 +118,7 @@ For a new language request, please refer to [Guideline for new language_requests
- [Table Recognition](./ppstructure/table/README.md)
- Academic Circles
- [Two-stage Algorithm](./doc/doc_en/algorithm_overview_en.md)
- - [PGNet Algorithm](./doc/doc_en/algorithm_overview_en.md)
+ - [PGNet Algorithm](./doc/doc_en/pgnet_en.md)
- [Python Inference](./doc/doc_en/inference_en.md)
- [Use PaddleOCR Architecture to Add New Algorithms](./doc/doc_en/add_new_algorithm_en.md)
- Data Annotation and Synthesis
diff --git a/README_ch.md b/README_ch.md
index f58bd3c711cd93b1e1d3b6a02f339d4512a3b872..243d730c868ae1c1205c60e45311c6a02a487f18 100755
--- a/README_ch.md
+++ b/README_ch.md
@@ -108,16 +108,16 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
- [PP-Structure信息提取](./ppstructure/README_ch.md)
- [版面分析](./ppstructure/layout/README_ch.md)
- [表格识别](./ppstructure/table/README_ch.md)
-- 数据标注与合成
- - [半自动标注工具PPOCRLabel](./PPOCRLabel/README_ch.md)
- - [数据合成工具Style-Text](./StyleText/README_ch.md)
- - [其它数据标注工具](./doc/doc_ch/data_annotation.md)
- - [其它数据合成工具](./doc/doc_ch/data_synthesis.md)
- OCR学术圈
- [两阶段算法](./doc/doc_ch/algorithm_overview.md)
- [端到端PGNet算法](./doc/doc_ch/pgnet.md)
- [基于Python脚本预测引擎推理](./doc/doc_ch/inference.md)
- [使用PaddleOCR架构添加新算法](./doc/doc_ch/add_new_algorithm.md)
+- 数据标注与合成
+ - [半自动标注工具PPOCRLabel](./PPOCRLabel/README_ch.md)
+ - [数据合成工具Style-Text](./StyleText/README_ch.md)
+ - [其它数据标注工具](./doc/doc_ch/data_annotation.md)
+ - [其它数据合成工具](./doc/doc_ch/data_synthesis.md)
- 数据集
- [通用中英文OCR数据集](./doc/doc_ch/datasets.md)
- [手写中文OCR数据集](./doc/doc_ch/handwritten_datasets.md)
diff --git a/configs/cls/cls_mv3.yml b/configs/cls/cls_mv3.yml
index 5e643dc3839b2e2edf3c811db813dd6a90797366..2d8b52a44e9cf9a24b32b8258d59aed259ac17d2 100644
--- a/configs/cls/cls_mv3.yml
+++ b/configs/cls/cls_mv3.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/cls/mv3/
save_epoch_step: 3
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 1000 iterations after the 0th iteration
eval_batch_step: [0, 1000]
cal_metric_during_train: True
pretrained_model:
diff --git a/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_cml.yml b/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_cml.yml
index 0f08909add17d8c73ad6e1b00e17d4c351def7e5..a7221d7c4c39f6f37328e290b80577af407b6949 100644
--- a/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_cml.yml
+++ b/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_cml.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 2
save_model_dir: ./output/ch_db_mv3/
save_epoch_step: 1200
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 3000th iteration
eval_batch_step: [3000, 2000]
cal_metric_during_train: False
pretrained_model: ./pretrain_models/ch_PP-OCRv2_det_distill_train/best_accuracy
diff --git a/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_distill.yml b/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_distill.yml
index 1159d71bf94c330e26c3009b38c5c2b4a9c96f52..9566a3f7b2dbda633d7333dc890565006d2c570c 100644
--- a/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_distill.yml
+++ b/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_distill.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 2
save_model_dir: ./output/ch_db_mv3/
save_epoch_step: 1200
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 3000th iteration
eval_batch_step: [3000, 2000]
cal_metric_during_train: False
pretrained_model: ./pretrain_models/MobileNetV3_large_x0_5_pretrained
diff --git a/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_dml.yml b/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_dml.yml
index 7fe2d2e1a065b54d0e2479475f5f67ac5e38a166..3a6f181104ea21df99d6896f7b620dd28a2ceb9d 100644
--- a/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_dml.yml
+++ b/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_dml.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 2
save_model_dir: ./output/ch_db_mv3/
save_epoch_step: 1200
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 3000th iteration
eval_batch_step: [3000, 2000]
cal_metric_during_train: False
pretrained_model: ./pretrain_models/MobileNetV3_large_x0_5_pretrained
diff --git a/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_student.yml b/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_student.yml
index cca2a596ce73d7f66a14e5967e5926c5ee36295c..f07f38168cd2ba3234f6adc3764c055667882590 100644
--- a/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_student.yml
+++ b/configs/det/ch_PP-OCRv2/ch_PP-OCR_det_student.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/ch_db_mv3/
save_epoch_step: 1200
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 400 iterations after the 0th iteration
eval_batch_step: [0, 400]
cal_metric_during_train: False
pretrained_model: ./pretrain_models/student.pdparams
diff --git a/configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml b/configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml
index 87718cad68743880dbfcd6b4c574bb09b9f53204..5951ff65b53621a133483c33d269b1ca3916f9e7 100644
--- a/configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml
+++ b/configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 2
save_model_dir: ./output/ch_db_mv3/
save_epoch_step: 1200
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 3000th iteration
eval_batch_step: [3000, 2000]
cal_metric_during_train: False
pretrained_model: ./pretrain_models/MobileNetV3_large_x0_5_pretrained
diff --git a/configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml b/configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml
index 7b07ef99648956a70b5a71f1e61f09b592226f90..f819a0c24744dabd820027b2175658ee85a07020 100644
--- a/configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml
+++ b/configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 2
save_model_dir: ./output/ch_db_res18/
save_epoch_step: 1200
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 3000th iteration
eval_batch_step: [3000, 2000]
cal_metric_during_train: False
pretrained_model: ./pretrain_models/ResNet18_vd_pretrained
diff --git a/configs/det/det_mv3_db.yml b/configs/det/det_mv3_db.yml
index b69ed58cd6f64b82b419d46f4f91458d7d167d84..addbf9f56fac64f9dcedda3962a5827d075f7041 100644
--- a/configs/det/det_mv3_db.yml
+++ b/configs/det/det_mv3_db.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/db_mv3/
save_epoch_step: 1200
- # evaluation is run every 2000 iterations
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: False
pretrained_model: ./pretrain_models/MobileNetV3_large_x0_5_pretrained
diff --git a/configs/det/det_r50_vd_db.yml b/configs/det/det_r50_vd_db.yml
index 42b3898ef463b8dba6338f37824ade0c93794212..3104aec0acce11dc3a14c0395399c8839fcdd6b4 100644
--- a/configs/det/det_r50_vd_db.yml
+++ b/configs/det/det_r50_vd_db.yml
@@ -5,8 +5,8 @@ Global:
print_batch_step: 10
save_model_dir: ./output/det_r50_vd/
save_epoch_step: 1200
- # evaluation is run every 2000 iterations
- eval_batch_step: [0,2000]
+ # evaluation is run every 2000 iterations after the 0th iteration
+ eval_batch_step: [0, 2000]
cal_metric_during_train: False
pretrained_model: ./pretrain_models/ResNet50_vd_ssld_pretrained
checkpoints:
diff --git a/configs/e2e/e2e_r50_vd_pg.yml b/configs/e2e/e2e_r50_vd_pg.yml
index 4a6e19f4461c7236f3a9a5253437eff97fa72f67..14ad3df63f711ddeab577c9810f067fe98283e47 100644
--- a/configs/e2e/e2e_r50_vd_pg.yml
+++ b/configs/e2e/e2e_r50_vd_pg.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/pgnet_r50_vd_totaltext/
save_epoch_step: 10
- # evaluation is run every 0 iterationss after the 1000th iteration
+ # evaluation is run every 1000 iterationss after the 0th iteration
eval_batch_step: [ 0, 1000 ]
cal_metric_during_train: False
pretrained_model:
@@ -94,7 +94,7 @@ Eval:
label_file_list: [./train_data/total_text/test/test.txt]
transforms:
- DecodeImage: # load image
- img_mode: RGB
+ img_mode: BGR
channel_first: False
- E2ELabelEncodeTest:
- E2EResizeForTest:
@@ -111,4 +111,4 @@ Eval:
shuffle: False
drop_last: False
batch_size_per_card: 1 # must be 1
- num_workers: 2
\ No newline at end of file
+ num_workers: 2
diff --git a/configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml b/configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml
index 38f77f7372c4e422b5601deb5119c24fd1e3f787..21e55b03b8a21c1e7d571220ca0bea7745e36b4d 100644
--- a/configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml
+++ b/configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml
@@ -6,6 +6,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_mobile_pp-OCRv2
save_epoch_step: 3
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model:
diff --git a/configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml b/configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml
index d2308fd5747f3fadf3bb1c98c5602c67d5e63eca..852502987b04359f51e64053f4d20672a92c63bd 100644
--- a/configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml
+++ b/configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml
@@ -6,6 +6,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_pp-OCRv2_distillation
save_epoch_step: 3
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model:
diff --git a/configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml b/configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml
index 717c16814bac2f6fca78aa63566df12bd8cbf67b..3f3cd4b325f52de88a70200974904adf600af2f1 100644
--- a/configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml
+++ b/configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_chinese_common_v2.0
save_epoch_step: 3
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: True
pretrained_model:
diff --git a/configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml b/configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml
index 660465f301047110db7001db7a32e687f2917b61..94d19e8af86445139c446f923b896e06addb9b47 100644
--- a/configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml
+++ b/configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_chinese_lite_v2.0
save_epoch_step: 3
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: True
pretrained_model:
diff --git a/configs/rec/multi_language/rec_arabic_lite_train.yml b/configs/rec/multi_language/rec_arabic_lite_train.yml
index 6dcfd1b69988b09c7dfc05cdbacce9756ea1f7cb..22487d1b43c7ce45ba0f1b550bd48560cd8a66ec 100644
--- a/configs/rec/multi_language/rec_arabic_lite_train.yml
+++ b/configs/rec/multi_language/rec_arabic_lite_train.yml
@@ -5,9 +5,8 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_arabic_lite
save_epoch_step: 3
- eval_batch_step:
- - 0
- - 2000
+ # evaluation is run every 2000 iterations after the 0th iteration
+ eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model: null
checkpoints: null
diff --git a/configs/rec/multi_language/rec_cyrillic_lite_train.yml b/configs/rec/multi_language/rec_cyrillic_lite_train.yml
index 52527c1dfb9a306429bbab9241c623581d546e45..3fe189531edacc7e9645ca17f8cabe7e0c9cd89d 100644
--- a/configs/rec/multi_language/rec_cyrillic_lite_train.yml
+++ b/configs/rec/multi_language/rec_cyrillic_lite_train.yml
@@ -5,9 +5,8 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_cyrillic_lite
save_epoch_step: 3
- eval_batch_step:
- - 0
- - 2000
+ # evaluation is run every 2000 iterations after the 0th iteration
+ eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model: null
checkpoints: null
diff --git a/configs/rec/multi_language/rec_devanagari_lite_train.yml b/configs/rec/multi_language/rec_devanagari_lite_train.yml
index e1a7c829c3e6d3c3a57f1d501cdd80a560703ec7..aab87bbcfa3b8db5dc572661a2931f3270f26681 100644
--- a/configs/rec/multi_language/rec_devanagari_lite_train.yml
+++ b/configs/rec/multi_language/rec_devanagari_lite_train.yml
@@ -5,9 +5,8 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_devanagari_lite
save_epoch_step: 3
- eval_batch_step:
- - 0
- - 2000
+ # evaluation is run every 2000 iterations after the 0th iteration
+ eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model: null
checkpoints: null
diff --git a/configs/rec/multi_language/rec_en_number_lite_train.yml b/configs/rec/multi_language/rec_en_number_lite_train.yml
index fff4dfcd905b406964bb07cf14017af22f40e91e..b413d89843544b620e300169febc89fdd10f7933 100644
--- a/configs/rec/multi_language/rec_en_number_lite_train.yml
+++ b/configs/rec/multi_language/rec_en_number_lite_train.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_en_number_lite
save_epoch_step: 3
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
# if pretrained_model is saved in static mode, load_static_weights must set to True
cal_metric_during_train: True
diff --git a/configs/rec/multi_language/rec_french_lite_train.yml b/configs/rec/multi_language/rec_french_lite_train.yml
index 63378d38a0d31fc77c33173e0ed864f28c5c3a8b..ebd3fab910f4193c2ebcea57da1300967a15d134 100644
--- a/configs/rec/multi_language/rec_french_lite_train.yml
+++ b/configs/rec/multi_language/rec_french_lite_train.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_french_lite
save_epoch_step: 3
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
# if pretrained_model is saved in static mode, load_static_weights must set to True
cal_metric_during_train: True
diff --git a/configs/rec/multi_language/rec_german_lite_train.yml b/configs/rec/multi_language/rec_german_lite_train.yml
index 1651510c5e4597e82298135d2f6c64aa747cf961..b02cd640cf9ee5d3b6e8574c3e15ceea58dc7574 100644
--- a/configs/rec/multi_language/rec_german_lite_train.yml
+++ b/configs/rec/multi_language/rec_german_lite_train.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_german_lite
save_epoch_step: 3
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
# if pretrained_model is saved in static mode, load_static_weights must set to True
cal_metric_during_train: True
diff --git a/configs/rec/multi_language/rec_japan_lite_train.yml b/configs/rec/multi_language/rec_japan_lite_train.yml
index bb47584edbc70f68d8d2d89dced3ec9b12f0e1cb..c1414f462716044ebcb1256ea0c8f99343896002 100644
--- a/configs/rec/multi_language/rec_japan_lite_train.yml
+++ b/configs/rec/multi_language/rec_japan_lite_train.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_japan_lite
save_epoch_step: 3
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
# if pretrained_model is saved in static mode, load_static_weights must set to True
cal_metric_during_train: True
diff --git a/configs/rec/multi_language/rec_korean_lite_train.yml b/configs/rec/multi_language/rec_korean_lite_train.yml
index 77f15524f78cd7f1c3dcf4988960e718422f5d89..1ca0d6457050fab1b2d97ca23bb24379af6c5169 100644
--- a/configs/rec/multi_language/rec_korean_lite_train.yml
+++ b/configs/rec/multi_language/rec_korean_lite_train.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_korean_lite
save_epoch_step: 3
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
# if pretrained_model is saved in static mode, load_static_weights must set to True
cal_metric_during_train: True
diff --git a/configs/rec/multi_language/rec_latin_lite_train.yml b/configs/rec/multi_language/rec_latin_lite_train.yml
index e71112b4b4f0afd3ceab9f10078bc5d518ee9e59..2aee8861f53f2e1e5b33e33e7ba8e4a58ed572ae 100644
--- a/configs/rec/multi_language/rec_latin_lite_train.yml
+++ b/configs/rec/multi_language/rec_latin_lite_train.yml
@@ -5,9 +5,8 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_latin_lite
save_epoch_step: 3
- eval_batch_step:
- - 0
- - 2000
+ # evaluation is run every 2000 iterations after the 0th iteration
+ eval_batch_step: [0, 2000]
cal_metric_during_train: true
pretrained_model: null
checkpoints: null
diff --git a/configs/rec/multi_language/rec_multi_language_lite_train.yml b/configs/rec/multi_language/rec_multi_language_lite_train.yml
index c42a3d1a3a5971365967effd4fdb2cc43725ef75..67eaeea34cc2de31c6e254afee3ed4f5bb90105c 100644
--- a/configs/rec/multi_language/rec_multi_language_lite_train.yml
+++ b/configs/rec/multi_language/rec_multi_language_lite_train.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec_multi_language_lite
save_epoch_step: 3
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
# if pretrained_model is saved in static mode, load_static_weights must set to True
cal_metric_during_train: True
diff --git a/configs/rec/rec_icdar15_train.yml b/configs/rec/rec_icdar15_train.yml
index 17a4d76483635d648ebb8cb897f621a186dcd516..ac58262d3b5143ca2aea12bf4fe2e6d7d6795b2d 100644
--- a/configs/rec/rec_icdar15_train.yml
+++ b/configs/rec/rec_icdar15_train.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec/ic15/
save_epoch_step: 3
- # evaluation is run every 2000 iterations
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: True
pretrained_model:
diff --git a/configs/rec/rec_mtb_nrtr.yml b/configs/rec/rec_mtb_nrtr.yml
index 635c392d705acd1fcfbf9f744a8d7167c448d74c..aad3c3f725ee05ddd44da545bf76c2c8263fd61c 100644
--- a/configs/rec/rec_mtb_nrtr.yml
+++ b/configs/rec/rec_mtb_nrtr.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec/nrtr/
save_epoch_step: 1
- # evaluation is run every 2000 iterations
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: True
pretrained_model:
@@ -46,7 +46,7 @@ Architecture:
name: Transformer
d_model: 512
num_encoder_layers: 6
- beam_size: 10 # When Beam size is greater than 0, it means to use beam search when evaluation.
+ beam_size: -1 # When Beam size is greater than 0, it means to use beam search when evaluation.
Loss:
@@ -65,7 +65,7 @@ Train:
name: LMDBDataSet
data_dir: ./train_data/data_lmdb_release/training/
transforms:
- - NRTRDecodeImage: # load image
+ - DecodeImage: # load image
img_mode: BGR
channel_first: False
- NRTRLabelEncode: # Class handling label
@@ -85,7 +85,7 @@ Eval:
name: LMDBDataSet
data_dir: ./train_data/data_lmdb_release/evaluation/
transforms:
- - NRTRDecodeImage: # load image
+ - DecodeImage: # load image
img_mode: BGR
channel_first: False
- NRTRLabelEncode: # Class handling label
diff --git a/configs/rec/rec_mv3_none_bilstm_ctc.yml b/configs/rec/rec_mv3_none_bilstm_ctc.yml
index 9e0bd23edba053b44fc7241c0a587ced5cd1ac76..2d6abc668af3236ebb42b8ecd5f7d895da02ef89 100644
--- a/configs/rec/rec_mv3_none_bilstm_ctc.yml
+++ b/configs/rec/rec_mv3_none_bilstm_ctc.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec/mv3_none_bilstm_ctc/
save_epoch_step: 3
- # evaluation is run every 2000 iterations
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: True
pretrained_model:
diff --git a/configs/rec/rec_mv3_none_none_ctc.yml b/configs/rec/rec_mv3_none_none_ctc.yml
index 904afe1134b565d6459cdcda4cbfa43ae4925b92..8557e9ca94739a1bf5b783310bb346477f2729b6 100644
--- a/configs/rec/rec_mv3_none_none_ctc.yml
+++ b/configs/rec/rec_mv3_none_none_ctc.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec/mv3_none_none_ctc/
save_epoch_step: 3
- # evaluation is run every 2000 iterations
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: True
pretrained_model:
diff --git a/configs/rec/rec_mv3_tps_bilstm_att.yml b/configs/rec/rec_mv3_tps_bilstm_att.yml
index feaeb0545c687774938521e4c45c026207172f11..759bcc0699d419b116f963502bc4b34ed6878b4c 100644
--- a/configs/rec/rec_mv3_tps_bilstm_att.yml
+++ b/configs/rec/rec_mv3_tps_bilstm_att.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec/rec_mv3_tps_bilstm_att/
save_epoch_step: 3
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: True
pretrained_model:
diff --git a/configs/rec/rec_mv3_tps_bilstm_ctc.yml b/configs/rec/rec_mv3_tps_bilstm_ctc.yml
index 65ab23c42aff54ee548867e3482d7400603551ad..7b886fcd2ae56af0483a1511d1b787823d958fc4 100644
--- a/configs/rec/rec_mv3_tps_bilstm_ctc.yml
+++ b/configs/rec/rec_mv3_tps_bilstm_ctc.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec/mv3_tps_bilstm_ctc/
save_epoch_step: 3
- # evaluation is run every 2000 iterations
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: True
pretrained_model:
diff --git a/configs/rec/rec_r34_vd_none_bilstm_ctc.yml b/configs/rec/rec_r34_vd_none_bilstm_ctc.yml
index 331bb36ed84b83dc62a0f9b15524457238dedc13..8c91af49687bdbffb6c01c152d53d13930cf5888 100644
--- a/configs/rec/rec_r34_vd_none_bilstm_ctc.yml
+++ b/configs/rec/rec_r34_vd_none_bilstm_ctc.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec/r34_vd_none_bilstm_ctc/
save_epoch_step: 3
- # evaluation is run every 2000 iterations
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: True
pretrained_model:
diff --git a/configs/rec/rec_r34_vd_none_none_ctc.yml b/configs/rec/rec_r34_vd_none_none_ctc.yml
index 695a46958f669e4cb9508646080b45ac0767b8c9..47be09de66a536bb902f604e765f0e5425a83027 100644
--- a/configs/rec/rec_r34_vd_none_none_ctc.yml
+++ b/configs/rec/rec_r34_vd_none_none_ctc.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec/r34_vd_none_none_ctc/
save_epoch_step: 3
- # evaluation is run every 2000 iterations
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: True
pretrained_model:
diff --git a/configs/rec/rec_r34_vd_tps_bilstm_att.yml b/configs/rec/rec_r34_vd_tps_bilstm_att.yml
index fdd3588c844ffd7ed61de73077ae2994f0ad498d..6d7e5ef64d50fdd6bb5a0130ca5ef30391064480 100644
--- a/configs/rec/rec_r34_vd_tps_bilstm_att.yml
+++ b/configs/rec/rec_r34_vd_tps_bilstm_att.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec/b3_rare_r34_none_gru/
save_epoch_step: 3
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: True
pretrained_model:
diff --git a/configs/rec/rec_r34_vd_tps_bilstm_ctc.yml b/configs/rec/rec_r34_vd_tps_bilstm_ctc.yml
index 67108a6eaca2dd6f239261f5184341e5ade00dc0..4f14cc37f1565c1d4e758e3c8cb17516edaab0b5 100644
--- a/configs/rec/rec_r34_vd_tps_bilstm_ctc.yml
+++ b/configs/rec/rec_r34_vd_tps_bilstm_ctc.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 10
save_model_dir: ./output/rec/r34_vd_tps_bilstm_ctc/
save_epoch_step: 3
- # evaluation is run every 2000 iterations
+ # evaluation is run every 2000 iterations after the 0th iteration
eval_batch_step: [0, 2000]
cal_metric_during_train: True
pretrained_model:
diff --git a/configs/rec/rec_r50_fpn_srn.yml b/configs/rec/rec_r50_fpn_srn.yml
index fa7b1ae4e5fed41d3aa3670d6672cca01b63c359..8ad4e7074c9dfcf9215b1918624b44183f9d3903 100644
--- a/configs/rec/rec_r50_fpn_srn.yml
+++ b/configs/rec/rec_r50_fpn_srn.yml
@@ -5,7 +5,7 @@ Global:
print_batch_step: 5
save_model_dir: ./output/rec/srn_new
save_epoch_step: 3
- # evaluation is run every 5000 iterations after the 4000th iteration
+ # evaluation is run every 5000 iterations after the 0th iteration
eval_batch_step: [0, 5000]
cal_metric_during_train: True
pretrained_model:
diff --git a/deploy/cpp_infer/docs/vs2019_build_withgpu_config.png b/deploy/cpp_infer/docs/vs2019_build_withgpu_config.png
new file mode 100644
index 0000000000000000000000000000000000000000..beff2884480790d97ef3577c77c0336fc04557ed
Binary files /dev/null and b/deploy/cpp_infer/docs/vs2019_build_withgpu_config.png differ
diff --git a/deploy/cpp_infer/docs/windows_vs2019_build.md b/deploy/cpp_infer/docs/windows_vs2019_build.md
index e46f542a323dbe539b4a7f596e4587f7729a4420..24a1e55cd7e5728e9cd56da8a35a72892380d28b 100644
--- a/deploy/cpp_infer/docs/windows_vs2019_build.md
+++ b/deploy/cpp_infer/docs/windows_vs2019_build.md
@@ -5,20 +5,20 @@ PaddleOCR在Windows 平台下基于`Visual Studio 2019 Community` 进行了测
## 前置条件
* Visual Studio 2019
-* CUDA 9.0 / CUDA 10.0,cudnn 7+ (仅在使用GPU版本的预测库时需要)
+* CUDA 10.2,cudnn 7+ (仅在使用GPU版本的预测库时需要)
* CMake 3.0+
请确保系统已经安装好上述基本软件,我们使用的是`VS2019`的社区版。
**下面所有示例以工作目录为 `D:\projects`演示**。
-### Step1: 下载PaddlePaddle C++ 预测库 fluid_inference
+### Step1: 下载PaddlePaddle C++ 预测库 paddle_inference
PaddlePaddle C++ 预测库针对不同的`CPU`和`CUDA`版本提供了不同的预编译版本,请根据实际情况下载: [C++预测库下载列表](https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html#windows)
-解压后`D:\projects\fluid_inference`目录包含内容为:
+解压后`D:\projects\paddle_inference`目录包含内容为:
```
-fluid_inference
+paddle_inference
├── paddle # paddle核心库和头文件
|
├── third_party # 第三方依赖库和头文件
@@ -46,13 +46,13 @@ fluid_inference
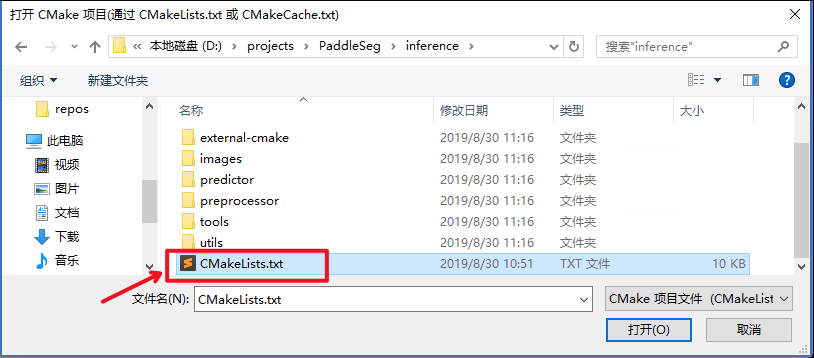
-3. 点击:`项目`->`cpp_inference_demo的CMake设置`
+3. 点击:`项目`->`CMake设置`
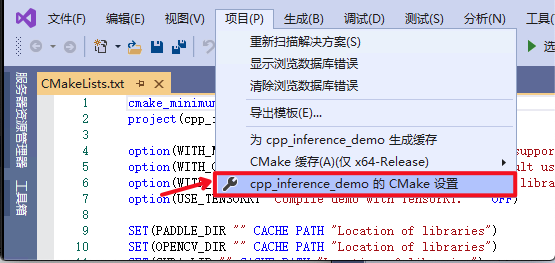
-4. 点击`浏览`,分别设置编译选项指定`CUDA`、`CUDNN_LIB`、`OpenCV`、`Paddle预测库`的路径
+4. 分别设置编译选项指定`CUDA`、`CUDNN_LIB`、`OpenCV`、`Paddle预测库`的路径
-三个编译参数的含义说明如下(带`*`表示仅在使用**GPU版本**预测库时指定, 其中CUDA库版本尽量对齐,**使用9.0、10.0版本,不使用9.2、10.1等版本CUDA库**):
+三个编译参数的含义说明如下(带`*`表示仅在使用**GPU版本**预测库时指定, 其中CUDA库版本尽量对齐):
| 参数名 | 含义 |
| ---- | ---- |
@@ -67,6 +67,11 @@ fluid_inference
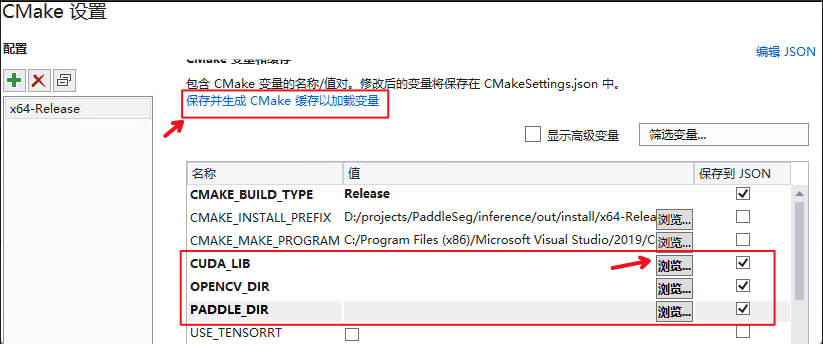
+下面给出with GPU的配置示例:
+
+**注意:**
+ CMAKE_BACKWARDS的版本要根据平台安装cmake的版本进行设置。
+
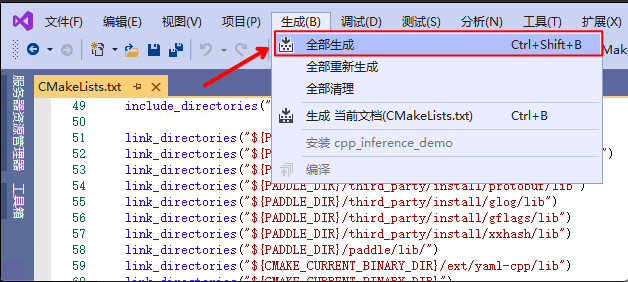
**设置完成后**, 点击上图中`保存并生成CMake缓存以加载变量`。
5. 点击`生成`->`全部生成`
@@ -74,24 +79,34 @@ fluid_inference
-### Step4: 预测及可视化
+### Step4: 预测
-上述`Visual Studio 2019`编译产出的可执行文件在`out\build\x64-Release`目录下,打开`cmd`,并切换到该目录:
+上述`Visual Studio 2019`编译产出的可执行文件在`out\build\x64-Release\Release`目录下,打开`cmd`,并切换到`D:\projects\PaddleOCR\deploy\cpp_infer\`:
```
-cd D:\projects\PaddleOCR\deploy\cpp_infer\out\build\x64-Release
+cd D:\projects\PaddleOCR\deploy\cpp_infer
```
-可执行文件`ocr_system.exe`即为样例的预测程序,其主要使用方法如下
+可执行文件`ppocr.exe`即为样例的预测程序,其主要使用方法如下,更多使用方法可以参考[说明文档](../readme.md)`运行demo`部分。
```shell
-#预测图片 `D:\projects\PaddleOCR\doc\imgs\10.jpg`
-.\ocr_system.exe D:\projects\PaddleOCR\deploy\cpp_infer\tools\config.txt D:\projects\PaddleOCR\doc\imgs\10.jpg
+#识别中文图片 `D:\projects\PaddleOCR\doc\imgs_words\ch\`
+.\out\build\x64-Release\Release\ppocr.exe rec --rec_model_dir=D:\projects\PaddleOCR\ch_ppocr_mobile_v2.0_rec_infer --image_dir=D:\projects\PaddleOCR\doc\imgs_words\ch\
+
+#识别英文图片 'D:\projects\PaddleOCR\doc\imgs_words\en\'
+.\out\build\x64-Release\Release\ppocr.exe rec --rec_model_dir=D:\projects\PaddleOCR\inference\rec_mv3crnn --image_dir=D:\projects\PaddleOCR\doc\imgs_words\en\ --char_list_file=D:\projects\PaddleOCR\ppocr\utils\dict\en_dict.txt
```
-第一个参数为配置文件路径,第二个参数为需要预测的图片路径。
+
+第一个参数为配置文件路径,第二个参数为需要预测的图片路径,第三个参数为配置文本识别的字典。
-### 注意
+### FQA
* 在Windows下的终端中执行文件exe时,可能会发生乱码的现象,此时需要在终端中输入`CHCP 65001`,将终端的编码方式由GBK编码(默认)改为UTF-8编码,更加具体的解释可以参考这篇博客:[https://blog.csdn.net/qq_35038153/article/details/78430359](https://blog.csdn.net/qq_35038153/article/details/78430359)。
-* 编译时,如果报错`错误:C1083 无法打开包括文件:"dirent.h":No such file or directory`,可以参考该[文档](https://blog.csdn.net/Dora_blank/article/details/117740837#41_C1083_direnthNo_such_file_or_directory_54),新建`dirent.h`文件,并添加到`VC++`的包含目录中。
+* 编译时,如果报错`错误:C1083 无法打开包括文件:"dirent.h":No such file or directory`,可以参考该[文档](https://blog.csdn.net/Dora_blank/article/details/117740837#41_C1083_direnthNo_such_file_or_directory_54),新建`dirent.h`文件,并添加到`utility.cpp`的头文件引用中。同时修改`utility.cpp`70行:`lstat`改成`stat`。
+
+* 编译时,如果报错`Autolog未定义`,新建`autolog.h`文件,内容为:[autolog.h](https://github.com/LDOUBLEV/AutoLog/blob/main/auto_log/autolog.h),并添加到`main.cpp`的头文件引用中,再次编译。
+
+* 运行时,如果弹窗报错找不到`paddle_inference.dll`或者`openblas.dll`,在`D:\projects\paddle_inference`预测库内找到这两个文件,复制到`D:\projects\PaddleOCR\deploy\cpp_infer\out\build\x64-Release\Release`目录下。不用重新编译,再次运行即可。
+
+* 运行时,弹窗报错提示`应用程序无法正常启动(0xc0000142)`,并且`cmd`窗口内提示`You are using Paddle compiled with TensorRT, but TensorRT dynamic library is not found.`,把tensort目录下的lib里面的所有dll文件复制到release目录下,再次运行即可。
diff --git a/doc/doc_ch/detection.md b/doc/doc_ch/detection.md
index 089b3b8f40e6af7bc10b0c0191bf553be8812ddd..5ec880b7996015d4baad4e50442ac67f1d260f69 100644
--- a/doc/doc_ch/detection.md
+++ b/doc/doc_ch/detection.md
@@ -96,11 +96,11 @@ wget -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/dyg
```shell
# 单机单卡训练 mv3_db 模型
python3 tools/train.py -c configs/det/det_mv3_db.yml \
- -o Global.pretrain_weights=./pretrain_models/MobileNetV3_large_x0_5_pretrained
+ -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
# 单机多卡训练,通过 --gpus 参数设置使用的GPU ID
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
- -o Global.pretrain_weights=./pretrain_models/MobileNetV3_large_x0_5_pretrained
+ -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
```
上述指令中,通过-c 选择训练使用configs/det/det_db_mv3.yml配置文件。
@@ -119,7 +119,7 @@ python3 tools/train.py -c configs/det/det_mv3_db.yml -o Optimizer.base_lr=0.0001
python3 tools/train.py -c configs/det/det_mv3_db.yml -o Global.checkpoints=./your/trained/model
```
-**注意**:`Global.checkpoints`的优先级高于`Global.pretrain_weights`的优先级,即同时指定两个参数时,优先加载`Global.checkpoints`指定的模型,如果`Global.checkpoints`指定的模型路径有误,会加载`Global.pretrain_weights`指定的模型。
+**注意**:`Global.checkpoints`的优先级高于`Global.pretrained_model`的优先级,即同时指定两个参数时,优先加载`Global.checkpoints`指定的模型,如果`Global.checkpoints`指定的模型路径有误,会加载`Global.pretrained_model`指定的模型。
## 2.3 更换Backbone 训练
@@ -230,6 +230,7 @@ python3 tools/infer/predict_det.py --det_algorithm="EAST" --det_model_dir="./out
# 5. FAQ
Q1: 训练模型转inference 模型之后预测效果不一致?
+
**A**:此类问题出现较多,问题多是trained model预测时候的预处理、后处理参数和inference model预测的时候的预处理、后处理参数不一致导致的。以det_mv3_db.yml配置文件训练的模型为例,训练模型、inference模型预测结果不一致问题解决方式如下:
- 检查[trained model预处理](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/configs/det/det_mv3_db.yml#L116),和[inference model的预测预处理](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/tools/infer/predict_det.py#L42)函数是否一致。算法在评估的时候,输入图像大小会影响精度,为了和论文保持一致,训练icdar15配置文件中将图像resize到[736, 1280],但是在inference model预测的时候只有一套默认参数,会考虑到预测速度问题,默认限制图像最长边为960做resize的。训练模型预处理和inference模型的预处理函数位于[ppocr/data/imaug/operators.py](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/ppocr/data/imaug/operators.py#L147)
- 检查[trained model后处理](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/configs/det/det_mv3_db.yml#L51),和[inference 后处理参数](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/tools/infer/utility.py#L50)是否一致。
diff --git a/doc/doc_ch/environment.md b/doc/doc_ch/environment.md
index f71f5bd9b6c62328d8caef82d2fbcca15d7b394e..41c37e2919c6f3069abd2d51acc0a0cf2545c917 100644
--- a/doc/doc_ch/environment.md
+++ b/doc/doc_ch/environment.md
@@ -294,11 +294,12 @@ cd /home/Projects
# 首次运行需创建一个docker容器,再次运行时不需要运行当前命令
# 创建一个名字为ppocr的docker容器,并将当前目录映射到容器的/paddle目录下
-如果您希望在CPU环境下使用docker,使用docker而不是nvidia-docker创建docker
-sudo docker run --name ppocr -v $PWD:/paddle --network=host -it paddlepaddle/paddle:latest-dev-cuda10.1-cudnn7-gcc82 /bin/bash
+#如果您希望在CPU环境下使用docker,使用docker而不是nvidia-docker创建docker
+sudo docker run --name ppocr -v $PWD:/paddle --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-cuda10.2-cudnn7 /bin/bash
-如果使用CUDA10,请运行以下命令创建容器,设置docker容器共享内存shm-size为64G,建议设置32G以上
-sudo nvidia-docker run --name ppocr -v $PWD:/paddle --shm-size=64G --network=host -it paddlepaddle/paddle:latest-dev-cuda10.1-cudnn7-gcc82 /bin/bash
+#如果使用CUDA10,请运行以下命令创建容器,设置docker容器共享内存shm-size为64G,建议设置32G以上
+# 如果是CUDA11+CUDNN8,推荐使用镜像registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-cuda11.2-cudnn8
+sudo nvidia-docker run --name ppocr -v $PWD:/paddle --shm-size=64G --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-cuda10.2-cudnn7 /bin/bash
# ctrl+P+Q可退出docker 容器,重新进入docker 容器使用如下命令
sudo docker container exec -it ppocr /bin/bash
diff --git a/doc/doc_ch/pgnet.md b/doc/doc_ch/pgnet.md
index 357d222d2160002436e9e757c50de179bb55f932..9aa7f255e54ce8dec3a20d475cccb71847d95cc7 100644
--- a/doc/doc_ch/pgnet.md
+++ b/doc/doc_ch/pgnet.md
@@ -28,9 +28,9 @@ PGNet算法细节详见[论文](https://www.aaai.org/AAAI21Papers/AAAI-2885.Wang
### 性能指标
-测试集: Total Text
+#### 测试集: Total Text
-测试环境: NVIDIA Tesla V100-SXM2-16GB
+#### 测试环境: NVIDIA Tesla V100-SXM2-16GB
|PGNetA|det_precision|det_recall|det_f_score|e2e_precision|e2e_recall|e2e_f_score|FPS|下载|
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
@@ -92,7 +92,7 @@ python3 tools/infer/predict_e2e.py --e2e_algorithm="PGNet" --image_dir="./doc/im
|- train.txt # total_text数据集的训练标注
```
-total_text.txt标注文件格式如下,文件名和标注信息中间用"\t"分隔:
+train.txt标注文件格式如下,文件名和标注信息中间用"\t"分隔:
```
" 图像文件名 json.dumps编码的图像标注信息"
rgb/img11.jpg [{"transcription": "ASRAMA", "points": [[214.0, 325.0], [235.0, 308.0], [259.0, 296.0], [286.0, 291.0], [313.0, 295.0], [338.0, 305.0], [362.0, 320.0], [349.0, 347.0], [330.0, 337.0], [310.0, 329.0], [290.0, 324.0], [269.0, 328.0], [249.0, 336.0], [231.0, 346.0]]}, {...}]
diff --git a/doc/doc_ch/quickstart.md b/doc/doc_ch/quickstart.md
index 1896d7a137f0768c6b2a8e0c02b18ff61fbfd03c..d9ff5a628fbd8d8effd50fb2b276d89d5e13225a 100644
--- a/doc/doc_ch/quickstart.md
+++ b/doc/doc_ch/quickstart.md
@@ -47,10 +47,10 @@ cd /path/to/ppocr_img
#### 2.1.1 中英文模型
-* 检测+方向分类器+识别全流程:设置方向分类器参数`--use_angle_cls true`后可对竖排文本进行识别。
+* 检测+方向分类器+识别全流程:`--use_angle_cls true`设置使用方向分类器识别180度旋转文字,`--use_gpu false`设置不使用GPU
```bash
- paddleocr --image_dir ./imgs/11.jpg --use_angle_cls true
+ paddleocr --image_dir ./imgs/11.jpg --use_angle_cls true --use_gpu false
```
结果是一个list,每个item包含了文本框,文字和识别置信度
diff --git a/doc/doc_ch/training.md b/doc/doc_ch/training.md
index c0dddd33bd268c8749f2507bacb2603452afd910..8dc94546cbf0bf683adf35393cbf3a3a6c95f06f 100644
--- a/doc/doc_ch/training.md
+++ b/doc/doc_ch/training.md
@@ -4,7 +4,7 @@
同时会简单介绍PaddleOCR模型训练数据的组成部分,以及如何在垂类场景中准备数据finetune模型。
-- [1.配置文件](#配置文件)
+- [1.配置文件说明](#配置文件)
- [2. 基本概念](#基本概念)
* [2.1 学习率](#学习率)
* [2.2 正则化](#正则化)
@@ -30,7 +30,7 @@ PaddleOCR模型使用配置文件管理网络训练、评估的参数。在配
模型训练过程中需要手动调整一些超参数,帮助模型以最小的代价获得最优指标。不同的数据量可能需要不同的超参,当您希望在自己的数据上finetune或对模型效果调优时,有以下几个参数调整策略可供参考:
-### 1.1 学习率
+### 2.1 学习率
学习率是训练神经网络的重要超参数之一,它代表在每一次迭代中梯度向损失函数最优解移动的步长。
在PaddleOCR中提供了多种学习率更新策略,可以通过配置文件修改,例如:
@@ -49,7 +49,7 @@ Piecewise 代表分段常数衰减,在不同的学习阶段指定不同的学
warmup_epoch 代表在前5个epoch中,学习率将逐渐从0增加到base_lr。全部策略可以参考代码[learning_rate.py](../../ppocr/optimizer/learning_rate.py) 。
-### 1.2 正则化
+### 2.2 正则化
正则化可以有效的避免算法过拟合,PaddleOCR中提供了L1、L2正则方法,L1 和 L2 正则化是最常用的正则化方法。L1 正则化向目标函数添加正则化项,以减少参数的绝对值总和;而 L2 正则化中,添加正则化项的目的在于减少参数平方的总和。配置方法如下:
@@ -62,7 +62,7 @@ Optimizer:
```
-### 1.3 评估指标
+### 2.3 评估指标
(1)检测阶段:先按照检测框和标注框的IOU评估,IOU大于某个阈值判断为检测准确。这里检测框和标注框不同于一般的通用目标检测框,是采用多边形进行表示。检测准确率:正确的检测框个数在全部检测框的占比,主要是判断检测指标。检测召回率:正确的检测框个数在全部标注框的占比,主要是判断漏检的指标。
@@ -72,10 +72,10 @@ Optimizer:
-## 2. 数据与垂类场景
+## 3. 数据与垂类场景
-### 2.1 训练数据
+### 3.1 训练数据
目前开源的模型,数据集和量级如下:
- 检测:
@@ -90,13 +90,14 @@ Optimizer:
其中,公开数据集都是开源的,用户可自行搜索下载,也可参考[中文数据集](./datasets.md),合成数据暂不开源,用户可使用开源合成工具自行合成,可参考的合成工具包括[text_renderer](https://github.com/Sanster/text_renderer) 、[SynthText](https://github.com/ankush-me/SynthText) 、[TextRecognitionDataGenerator](https://github.com/Belval/TextRecognitionDataGenerator) 等。
-### 2.2 垂类场景
+### 3.2 垂类场景
PaddleOCR主要聚焦通用OCR,如果有垂类需求,您可以用PaddleOCR+垂类数据自己训练;
如果缺少带标注的数据,或者不想投入研发成本,建议直接调用开放的API,开放的API覆盖了目前比较常见的一些垂类。
-### 2.3 自己构建数据集
+
+### 3.3 自己构建数据集
在构建数据集时有几个经验可供参考:
@@ -114,7 +115,7 @@ PaddleOCR主要聚焦通用OCR,如果有垂类需求,您可以用PaddleOCR+
-## 3. 常见问题
+## 4. 常见问题
**Q**:训练CRNN识别时,如何选择合适的网络输入shape?
diff --git a/doc/doc_en/detection_en.md b/doc/doc_en/detection_en.md
index 14180c6faa01ee2d5ba3e34986dd4a55facc4f25..4f8143d03f09a83d51bdbe3a9674bbfe4e3181ef 100644
--- a/doc/doc_en/detection_en.md
+++ b/doc/doc_en/detection_en.md
@@ -75,14 +75,14 @@ wget -P ./pretrain_models/ https://paddle-imagenet-models-name.bj.bcebos.com/dyg
```
-# 2. TRAINING
+## 2. Training
### 2.1 Start Training
*If CPU version installed, please set the parameter `use_gpu` to `false` in the configuration.*
```shell
python3 tools/train.py -c configs/det/det_mv3_db.yml \
- -o Global.pretrain_weights=./pretrain_models/MobileNetV3_large_x0_5_pretrained
+ -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
```
In the above instruction, use `-c` to select the training to use the `configs/det/det_db_mv3.yml` configuration file.
@@ -92,12 +92,12 @@ You can also use `-o` to change the training parameters without modifying the ym
```shell
# single GPU training
python3 tools/train.py -c configs/det/det_mv3_db.yml -o \
- Global.pretrain_weights=./pretrain_models/MobileNetV3_large_x0_5_pretrained \
+ Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained \
Optimizer.base_lr=0.0001
# multi-GPU training
# Set the GPU ID used by the '--gpus' parameter.
-python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml -o Global.pretrain_weights=./pretrain_models/MobileNetV3_large_x0_5_pretrained
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
```
@@ -109,7 +109,7 @@ For example:
python3 tools/train.py -c configs/det/det_mv3_db.yml -o Global.checkpoints=./your/trained/model
```
-**Note**: The priority of `Global.checkpoints` is higher than that of `Global.pretrain_weights`, that is, when two parameters are specified at the same time, the model specified by `Global.checkpoints` will be loaded first. If the model path specified by `Global.checkpoints` is wrong, the one specified by `Global.pretrain_weights` will be loaded.
+**Note**: The priority of `Global.checkpoints` is higher than that of `Global.pretrained_model`, that is, when two parameters are specified at the same time, the model specified by `Global.checkpoints` will be loaded first. If the model path specified by `Global.checkpoints` is wrong, the one specified by `Global.pretrained_model` will be loaded.
### 2.3 Training with New Backbone
@@ -223,6 +223,7 @@ python3 tools/infer/predict_det.py --det_algorithm="EAST" --det_model_dir="./out
## 5. FAQ
Q1: The prediction results of trained model and inference model are inconsistent?
+
**A**: Most of the problems are caused by the inconsistency of the pre-processing and post-processing parameters during the prediction of the trained model and the pre-processing and post-processing parameters during the prediction of the inference model. Taking the model trained by the det_mv3_db.yml configuration file as an example, the solution to the problem of inconsistent prediction results between the training model and the inference model is as follows:
- Check whether the [trained model preprocessing](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/configs/det/det_mv3_db.yml#L116) is consistent with the prediction [preprocessing function of the inference model](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/tools/infer/predict_det.py#L42). When the algorithm is evaluated, the input image size will affect the accuracy. In order to be consistent with the paper, the image is resized to [736, 1280] in the training icdar15 configuration file, but there is only a set of default parameters when the inference model predicts, which will be considered To predict the speed problem, the longest side of the image is limited to 960 for resize by default. The preprocessing function of the training model preprocessing and the inference model is located in [ppocr/data/imaug/operators.py](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/ppocr/data/imaug/operators.py#L147)
- Check whether the [post-processing of the trained model](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/configs/det/det_mv3_db.yml#L51) is consistent with the [post-processing parameters of the inference](https://github.com/PaddlePaddle/PaddleOCR/blob/c1ed243fb68d5d466258243092e56cbae32e2c14/tools/infer/utility.py#L50).
diff --git a/doc/doc_en/environment_en.md b/doc/doc_en/environment_en.md
index 7c15add42abb571144020417a112d6c21c066a41..8ec080f86a51e5a241689d3bda75d0afb614bd0a 100644
--- a/doc/doc_en/environment_en.md
+++ b/doc/doc_en/environment_en.md
@@ -311,7 +311,11 @@ cd /home/Projects
# Create a docker container named ppocr and map the current directory to the /paddle directory of the container
# If using CPU, use docker instead of nvidia-docker to create docker
-sudo docker run --name ppocr -v $PWD:/paddle --network=host -it paddlepaddle/paddle:latest-dev-cuda10.1-cudnn7-gcc82 /bin/bash
+sudo docker run --name ppocr -v $PWD:/paddle --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-cuda10.2-cudnn7 /bin/bash
+
+# If using GPU, use nvidia-docker to create docker
+# docker image registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-cuda11.2-cudnn8 is recommended for CUDA11.2 + CUDNN8.
+sudo nvidia-docker run --name ppocr -v $PWD:/paddle --shm-size=64G --network=host -it registry.baidubce.com/paddlepaddle/paddle:2.1.3-gpu-cuda10.2-cudnn7 /bin/bash
```
diff --git a/doc/doc_en/pgnet_en.md b/doc/doc_en/pgnet_en.md
index df5610e59f80bbc390c43b15ce1e0dee81ae8689..d2c6b30248ebad920c41ca53ee38cce828dddb8c 100644
--- a/doc/doc_en/pgnet_en.md
+++ b/doc/doc_en/pgnet_en.md
@@ -24,9 +24,9 @@ The results of detection and recognition are as follows:


### Performance
-####Test set: Total Text
+#### Test set: Total Text
-####Test environment: NVIDIA Tesla V100-SXM2-16GB
+#### Test environment: NVIDIA Tesla V100-SXM2-16GB
|PGNetA|det_precision|det_recall|det_f_score|e2e_precision|e2e_recall|e2e_f_score|FPS|download|
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
|Paper|85.30|86.80|86.1|-|-|61.7|38.20 (size=640)|-|
diff --git a/doc/doc_en/quickstart_en.md b/doc/doc_en/quickstart_en.md
index 0055d8f7a89d0d218d001ea94fd4c620de5d037f..9ed83aceb9f562ac3099f22eaf264b966c0d48c7 100644
--- a/doc/doc_en/quickstart_en.md
+++ b/doc/doc_en/quickstart_en.md
@@ -53,10 +53,10 @@ If you do not use the provided test image, you can replace the following `--imag
#### 2.1.1 Chinese and English Model
-* Detection, direction classification and recognition: set the direction classifier parameter`--use_angle_cls true` to recognize vertical text.
+* Detection, direction classification and recognition: set the parameter`--use_gpu false` to disable the gpu device
```bash
- paddleocr --image_dir ./imgs_en/img_12.jpg --use_angle_cls true --lang en
+ paddleocr --image_dir ./imgs_en/img_12.jpg --use_angle_cls true --lang en --use_gpu false
```
Output will be a list, each item contains bounding box, text and recognition confidence
diff --git a/ppocr/data/imaug/label_ops.py b/ppocr/data/imaug/label_ops.py
index f6263950959b0ee6a96647fb248098bb5c567651..8c260a92a2d60b4896a1e115db25493670e85fad 100644
--- a/ppocr/data/imaug/label_ops.py
+++ b/ppocr/data/imaug/label_ops.py
@@ -174,21 +174,26 @@ class NRTRLabelEncode(BaseRecLabelEncode):
super(NRTRLabelEncode,
self).__init__(max_text_length, character_dict_path,
character_type, use_space_char)
+
def __call__(self, data):
text = data['label']
text = self.encode(text)
if text is None:
return None
+ if len(text) >= self.max_text_len - 1:
+ return None
data['length'] = np.array(len(text))
text.insert(0, 2)
text.append(3)
text = text + [0] * (self.max_text_len - len(text))
data['label'] = np.array(text)
return data
+
def add_special_char(self, dict_character):
- dict_character = ['blank','','',''] + dict_character
+ dict_character = ['blank', '', '', ''] + dict_character
return dict_character
+
class CTCLabelEncode(BaseRecLabelEncode):
""" Convert between text-label and text-index """
diff --git a/ppocr/data/imaug/rec_img_aug.py b/ppocr/data/imaug/rec_img_aug.py
index e914d3844606b5b88333a89e5d0e5fda65729458..86d70c5fd0d239dd569fd3915565ccde34e6a33b 100644
--- a/ppocr/data/imaug/rec_img_aug.py
+++ b/ppocr/data/imaug/rec_img_aug.py
@@ -44,12 +44,33 @@ class ClsResizeImg(object):
class NRTRRecResizeImg(object):
- def __init__(self, image_shape, resize_type, **kwargs):
+ def __init__(self, image_shape, resize_type, padding=False, **kwargs):
self.image_shape = image_shape
self.resize_type = resize_type
+ self.padding = padding
def __call__(self, data):
img = data['image']
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
+ image_shape = self.image_shape
+ if self.padding:
+ imgC, imgH, imgW = image_shape
+ # todo: change to 0 and modified image shape
+ h = img.shape[0]
+ w = img.shape[1]
+ ratio = w / float(h)
+ if math.ceil(imgH * ratio) > imgW:
+ resized_w = imgW
+ else:
+ resized_w = int(math.ceil(imgH * ratio))
+ resized_image = cv2.resize(img, (resized_w, imgH))
+ norm_img = np.expand_dims(resized_image, -1)
+ norm_img = norm_img.transpose((2, 0, 1))
+ resized_image = norm_img.astype(np.float32) / 128. - 1.
+ padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
+ padding_im[:, :, 0:resized_w] = resized_image
+ data['image'] = padding_im
+ return data
if self.resize_type == 'PIL':
image_pil = Image.fromarray(np.uint8(img))
img = image_pil.resize(self.image_shape, Image.ANTIALIAS)
diff --git a/ppocr/data/simple_dataset.py b/ppocr/data/simple_dataset.py
index e9c3394cbe930d5169ae005e7582a2902e697b7e..6a33e1342506f26ccaa4a146f3f02fadfbd741a2 100644
--- a/ppocr/data/simple_dataset.py
+++ b/ppocr/data/simple_dataset.py
@@ -15,7 +15,6 @@ import numpy as np
import os
import random
from paddle.io import Dataset
-
from .imaug import transform, create_operators
diff --git a/ppocr/modeling/backbones/rec_nrtr_mtb.py b/ppocr/modeling/backbones/rec_nrtr_mtb.py
index 04b5c9bb5fdff448fbf7ad366bc39bf0e3ebfe6b..22e02a6371c3ff8b28fd88b5cfa1087309d551f8 100644
--- a/ppocr/modeling/backbones/rec_nrtr_mtb.py
+++ b/ppocr/modeling/backbones/rec_nrtr_mtb.py
@@ -13,6 +13,7 @@
# limitations under the License.
from paddle import nn
+import paddle
class MTB(nn.Layer):
@@ -40,7 +41,8 @@ class MTB(nn.Layer):
x = self.block(images)
if self.cnn_num == 2:
# (b, w, h, c)
- x = x.transpose([0, 3, 2, 1])
- x_shape = x.shape
- x = x.reshape([x_shape[0], x_shape[1], x_shape[2] * x_shape[3]])
+ x = paddle.transpose(x, [0, 3, 2, 1])
+ x_shape = paddle.shape(x)
+ x = paddle.reshape(
+ x, [x_shape[0], x_shape[1], x_shape[2] * x_shape[3]])
return x
diff --git a/ppocr/modeling/heads/multiheadAttention.py b/ppocr/modeling/heads/multiheadAttention.py
index 651d4f577d2f5d1c11e36f90d1c7fea5fc3ab86e..900865ba1a8d80a108b3247ce1aff91c242860f2 100755
--- a/ppocr/modeling/heads/multiheadAttention.py
+++ b/ppocr/modeling/heads/multiheadAttention.py
@@ -71,8 +71,6 @@ class MultiheadAttention(nn.Layer):
value,
key_padding_mask=None,
incremental_state=None,
- need_weights=True,
- static_kv=False,
attn_mask=None):
"""
Inputs of forward function
@@ -88,46 +86,42 @@ class MultiheadAttention(nn.Layer):
attn_output: [target length, batch size, embed dim]
attn_output_weights: [batch size, target length, sequence length]
"""
- tgt_len, bsz, embed_dim = query.shape
- assert embed_dim == self.embed_dim
- assert list(query.shape) == [tgt_len, bsz, embed_dim]
- assert key.shape == value.shape
-
+ q_shape = paddle.shape(query)
+ src_shape = paddle.shape(key)
q = self._in_proj_q(query)
k = self._in_proj_k(key)
v = self._in_proj_v(value)
q *= self.scaling
-
- q = q.reshape([tgt_len, bsz * self.num_heads, self.head_dim]).transpose(
- [1, 0, 2])
- k = k.reshape([-1, bsz * self.num_heads, self.head_dim]).transpose(
- [1, 0, 2])
- v = v.reshape([-1, bsz * self.num_heads, self.head_dim]).transpose(
- [1, 0, 2])
-
- src_len = k.shape[1]
-
+ q = paddle.transpose(
+ paddle.reshape(
+ q, [q_shape[0], q_shape[1], self.num_heads, self.head_dim]),
+ [1, 2, 0, 3])
+ k = paddle.transpose(
+ paddle.reshape(
+ k, [src_shape[0], q_shape[1], self.num_heads, self.head_dim]),
+ [1, 2, 0, 3])
+ v = paddle.transpose(
+ paddle.reshape(
+ v, [src_shape[0], q_shape[1], self.num_heads, self.head_dim]),
+ [1, 2, 0, 3])
if key_padding_mask is not None:
- assert key_padding_mask.shape[0] == bsz
- assert key_padding_mask.shape[1] == src_len
-
- attn_output_weights = paddle.bmm(q, k.transpose([0, 2, 1]))
- assert list(attn_output_weights.
- shape) == [bsz * self.num_heads, tgt_len, src_len]
-
+ assert key_padding_mask.shape[0] == q_shape[1]
+ assert key_padding_mask.shape[1] == src_shape[0]
+ attn_output_weights = paddle.matmul(q,
+ paddle.transpose(k, [0, 1, 3, 2]))
if attn_mask is not None:
- attn_mask = attn_mask.unsqueeze(0)
+ attn_mask = paddle.unsqueeze(paddle.unsqueeze(attn_mask, 0), 0)
attn_output_weights += attn_mask
if key_padding_mask is not None:
- attn_output_weights = attn_output_weights.reshape(
- [bsz, self.num_heads, tgt_len, src_len])
- key = key_padding_mask.unsqueeze(1).unsqueeze(2).astype('float32')
- y = paddle.full(shape=key.shape, dtype='float32', fill_value='-inf')
+ attn_output_weights = paddle.reshape(
+ attn_output_weights,
+ [q_shape[1], self.num_heads, q_shape[0], src_shape[0]])
+ key = paddle.unsqueeze(paddle.unsqueeze(key_padding_mask, 1), 2)
+ key = paddle.cast(key, 'float32')
+ y = paddle.full(
+ shape=paddle.shape(key), dtype='float32', fill_value='-inf')
y = paddle.where(key == 0., key, y)
attn_output_weights += y
- attn_output_weights = attn_output_weights.reshape(
- [bsz * self.num_heads, tgt_len, src_len])
-
attn_output_weights = F.softmax(
attn_output_weights.astype('float32'),
axis=-1,
@@ -136,43 +130,34 @@ class MultiheadAttention(nn.Layer):
attn_output_weights = F.dropout(
attn_output_weights, p=self.dropout, training=self.training)
- attn_output = paddle.bmm(attn_output_weights, v)
- assert list(attn_output.
- shape) == [bsz * self.num_heads, tgt_len, self.head_dim]
- attn_output = attn_output.transpose([1, 0, 2]).reshape(
- [tgt_len, bsz, embed_dim])
+ attn_output = paddle.matmul(attn_output_weights, v)
+ attn_output = paddle.reshape(
+ paddle.transpose(attn_output, [2, 0, 1, 3]),
+ [q_shape[0], q_shape[1], self.embed_dim])
attn_output = self.out_proj(attn_output)
- if need_weights:
- # average attention weights over heads
- attn_output_weights = attn_output_weights.reshape(
- [bsz, self.num_heads, tgt_len, src_len])
- attn_output_weights = attn_output_weights.sum(
- axis=1) / self.num_heads
- else:
- attn_output_weights = None
- return attn_output, attn_output_weights
+ return attn_output
def _in_proj_q(self, query):
- query = query.transpose([1, 2, 0])
+ query = paddle.transpose(query, [1, 2, 0])
query = paddle.unsqueeze(query, axis=2)
res = self.conv1(query)
res = paddle.squeeze(res, axis=2)
- res = res.transpose([2, 0, 1])
+ res = paddle.transpose(res, [2, 0, 1])
return res
def _in_proj_k(self, key):
- key = key.transpose([1, 2, 0])
+ key = paddle.transpose(key, [1, 2, 0])
key = paddle.unsqueeze(key, axis=2)
res = self.conv2(key)
res = paddle.squeeze(res, axis=2)
- res = res.transpose([2, 0, 1])
+ res = paddle.transpose(res, [2, 0, 1])
return res
def _in_proj_v(self, value):
- value = value.transpose([1, 2, 0]) #(1, 2, 0)
+ value = paddle.transpose(value, [1, 2, 0]) #(1, 2, 0)
value = paddle.unsqueeze(value, axis=2)
res = self.conv3(value)
res = paddle.squeeze(res, axis=2)
- res = res.transpose([2, 0, 1])
+ res = paddle.transpose(res, [2, 0, 1])
return res
diff --git a/ppocr/modeling/heads/rec_nrtr_head.py b/ppocr/modeling/heads/rec_nrtr_head.py
index 05dba677b4109897b6a20888151e680e652d6741..38ba0c917840ea7d1e2a3c2bf0da32c2c35f2b40 100644
--- a/ppocr/modeling/heads/rec_nrtr_head.py
+++ b/ppocr/modeling/heads/rec_nrtr_head.py
@@ -61,12 +61,12 @@ class Transformer(nn.Layer):
custom_decoder=None,
in_channels=0,
out_channels=0,
- dst_vocab_size=99,
scale_embedding=True):
super(Transformer, self).__init__()
+ self.out_channels = out_channels + 1
self.embedding = Embeddings(
d_model=d_model,
- vocab=dst_vocab_size,
+ vocab=self.out_channels,
padding_idx=0,
scale_embedding=scale_embedding)
self.positional_encoding = PositionalEncoding(
@@ -96,9 +96,10 @@ class Transformer(nn.Layer):
self.beam_size = beam_size
self.d_model = d_model
self.nhead = nhead
- self.tgt_word_prj = nn.Linear(d_model, dst_vocab_size, bias_attr=False)
+ self.tgt_word_prj = nn.Linear(
+ d_model, self.out_channels, bias_attr=False)
w0 = np.random.normal(0.0, d_model**-0.5,
- (d_model, dst_vocab_size)).astype(np.float32)
+ (d_model, self.out_channels)).astype(np.float32)
self.tgt_word_prj.weight.set_value(w0)
self.apply(self._init_weights)
@@ -156,46 +157,41 @@ class Transformer(nn.Layer):
return self.forward_test(src)
def forward_test(self, src):
- bs = src.shape[0]
+ bs = paddle.shape(src)[0]
if self.encoder is not None:
- src = self.positional_encoding(src.transpose([1, 0, 2]))
+ src = self.positional_encoding(paddle.transpose(src, [1, 0, 2]))
memory = self.encoder(src)
else:
- memory = src.squeeze(2).transpose([2, 0, 1])
+ memory = paddle.transpose(paddle.squeeze(src, 2), [2, 0, 1])
dec_seq = paddle.full((bs, 1), 2, dtype=paddle.int64)
+ dec_prob = paddle.full((bs, 1), 1., dtype=paddle.float32)
for len_dec_seq in range(1, 25):
- src_enc = memory.clone()
- tgt_key_padding_mask = self.generate_padding_mask(dec_seq)
- dec_seq_embed = self.embedding(dec_seq).transpose([1, 0, 2])
+ dec_seq_embed = paddle.transpose(self.embedding(dec_seq), [1, 0, 2])
dec_seq_embed = self.positional_encoding(dec_seq_embed)
- tgt_mask = self.generate_square_subsequent_mask(dec_seq_embed.shape[
- 0])
+ tgt_mask = self.generate_square_subsequent_mask(
+ paddle.shape(dec_seq_embed)[0])
output = self.decoder(
dec_seq_embed,
- src_enc,
+ memory,
tgt_mask=tgt_mask,
memory_mask=None,
- tgt_key_padding_mask=tgt_key_padding_mask,
+ tgt_key_padding_mask=None,
memory_key_padding_mask=None)
- dec_output = output.transpose([1, 0, 2])
-
- dec_output = dec_output[:,
- -1, :] # Pick the last step: (bh * bm) * d_h
- word_prob = F.log_softmax(self.tgt_word_prj(dec_output), axis=1)
- word_prob = word_prob.reshape([1, bs, -1])
- preds_idx = word_prob.argmax(axis=2)
-
+ dec_output = paddle.transpose(output, [1, 0, 2])
+ dec_output = dec_output[:, -1, :]
+ word_prob = F.softmax(self.tgt_word_prj(dec_output), axis=1)
+ preds_idx = paddle.argmax(word_prob, axis=1)
if paddle.equal_all(
- preds_idx[-1],
+ preds_idx,
paddle.full(
- preds_idx[-1].shape, 3, dtype='int64')):
+ paddle.shape(preds_idx), 3, dtype='int64')):
break
-
- preds_prob = word_prob.max(axis=2)
+ preds_prob = paddle.max(word_prob, axis=1)
dec_seq = paddle.concat(
- [dec_seq, preds_idx.reshape([-1, 1])], axis=1)
-
- return dec_seq
+ [dec_seq, paddle.reshape(preds_idx, [-1, 1])], axis=1)
+ dec_prob = paddle.concat(
+ [dec_prob, paddle.reshape(preds_prob, [-1, 1])], axis=1)
+ return [dec_seq, dec_prob]
def forward_beam(self, images):
''' Translation work in one batch '''
@@ -211,14 +207,15 @@ class Transformer(nn.Layer):
n_prev_active_inst, n_bm):
''' Collect tensor parts associated to active instances. '''
- _, *d_hs = beamed_tensor.shape
+ beamed_tensor_shape = paddle.shape(beamed_tensor)
n_curr_active_inst = len(curr_active_inst_idx)
- new_shape = (n_curr_active_inst * n_bm, *d_hs)
+ new_shape = (n_curr_active_inst * n_bm, beamed_tensor_shape[1],
+ beamed_tensor_shape[2])
beamed_tensor = beamed_tensor.reshape([n_prev_active_inst, -1])
beamed_tensor = beamed_tensor.index_select(
- paddle.to_tensor(curr_active_inst_idx), axis=0)
- beamed_tensor = beamed_tensor.reshape([*new_shape])
+ curr_active_inst_idx, axis=0)
+ beamed_tensor = beamed_tensor.reshape(new_shape)
return beamed_tensor
@@ -249,44 +246,26 @@ class Transformer(nn.Layer):
b.get_current_state() for b in inst_dec_beams if not b.done
]
dec_partial_seq = paddle.stack(dec_partial_seq)
-
dec_partial_seq = dec_partial_seq.reshape([-1, len_dec_seq])
return dec_partial_seq
- def prepare_beam_memory_key_padding_mask(
- inst_dec_beams, memory_key_padding_mask, n_bm):
- keep = []
- for idx in (memory_key_padding_mask):
- if not inst_dec_beams[idx].done:
- keep.append(idx)
- memory_key_padding_mask = memory_key_padding_mask[
- paddle.to_tensor(keep)]
- len_s = memory_key_padding_mask.shape[-1]
- n_inst = memory_key_padding_mask.shape[0]
- memory_key_padding_mask = paddle.concat(
- [memory_key_padding_mask for i in range(n_bm)], axis=1)
- memory_key_padding_mask = memory_key_padding_mask.reshape(
- [n_inst * n_bm, len_s]) #repeat(1, n_bm)
- return memory_key_padding_mask
-
def predict_word(dec_seq, enc_output, n_active_inst, n_bm,
memory_key_padding_mask):
- tgt_key_padding_mask = self.generate_padding_mask(dec_seq)
- dec_seq = self.embedding(dec_seq).transpose([1, 0, 2])
+ dec_seq = paddle.transpose(self.embedding(dec_seq), [1, 0, 2])
dec_seq = self.positional_encoding(dec_seq)
- tgt_mask = self.generate_square_subsequent_mask(dec_seq.shape[
- 0])
+ tgt_mask = self.generate_square_subsequent_mask(
+ paddle.shape(dec_seq)[0])
dec_output = self.decoder(
dec_seq,
enc_output,
tgt_mask=tgt_mask,
- tgt_key_padding_mask=tgt_key_padding_mask,
- memory_key_padding_mask=memory_key_padding_mask,
- ).transpose([1, 0, 2])
+ tgt_key_padding_mask=None,
+ memory_key_padding_mask=memory_key_padding_mask, )
+ dec_output = paddle.transpose(dec_output, [1, 0, 2])
dec_output = dec_output[:,
-1, :] # Pick the last step: (bh * bm) * d_h
- word_prob = F.log_softmax(self.tgt_word_prj(dec_output), axis=1)
- word_prob = word_prob.reshape([n_active_inst, n_bm, -1])
+ word_prob = F.softmax(self.tgt_word_prj(dec_output), axis=1)
+ word_prob = paddle.reshape(word_prob, [n_active_inst, n_bm, -1])
return word_prob
def collect_active_inst_idx_list(inst_beams, word_prob,
@@ -302,9 +281,8 @@ class Transformer(nn.Layer):
n_active_inst = len(inst_idx_to_position_map)
dec_seq = prepare_beam_dec_seq(inst_dec_beams, len_dec_seq)
- memory_key_padding_mask = None
word_prob = predict_word(dec_seq, enc_output, n_active_inst, n_bm,
- memory_key_padding_mask)
+ None)
# Update the beam with predicted word prob information and collect incomplete instances
active_inst_idx_list = collect_active_inst_idx_list(
inst_dec_beams, word_prob, inst_idx_to_position_map)
@@ -324,27 +302,21 @@ class Transformer(nn.Layer):
with paddle.no_grad():
#-- Encode
-
if self.encoder is not None:
src = self.positional_encoding(images.transpose([1, 0, 2]))
- src_enc = self.encoder(src).transpose([1, 0, 2])
+ src_enc = self.encoder(src)
else:
src_enc = images.squeeze(2).transpose([0, 2, 1])
- #-- Repeat data for beam search
n_bm = self.beam_size
- n_inst, len_s, d_h = src_enc.shape
- src_enc = paddle.concat([src_enc for i in range(n_bm)], axis=1)
- src_enc = src_enc.reshape([n_inst * n_bm, len_s, d_h]).transpose(
- [1, 0, 2])
- #-- Prepare beams
- inst_dec_beams = [Beam(n_bm) for _ in range(n_inst)]
-
- #-- Bookkeeping for active or not
- active_inst_idx_list = list(range(n_inst))
+ src_shape = paddle.shape(src_enc)
+ inst_dec_beams = [Beam(n_bm) for _ in range(1)]
+ active_inst_idx_list = list(range(1))
+ # Repeat data for beam search
+ src_enc = paddle.tile(src_enc, [1, n_bm, 1])
inst_idx_to_position_map = get_inst_idx_to_tensor_position_map(
active_inst_idx_list)
- #-- Decode
+ # Decode
for len_dec_seq in range(1, 25):
src_enc_copy = src_enc.clone()
active_inst_idx_list = beam_decode_step(
@@ -358,10 +330,19 @@ class Transformer(nn.Layer):
batch_hyp, batch_scores = collect_hypothesis_and_scores(inst_dec_beams,
1)
result_hyp = []
- for bs_hyp in batch_hyp:
- bs_hyp_pad = bs_hyp[0] + [3] * (25 - len(bs_hyp[0]))
+ hyp_scores = []
+ for bs_hyp, score in zip(batch_hyp, batch_scores):
+ l = len(bs_hyp[0])
+ bs_hyp_pad = bs_hyp[0] + [3] * (25 - l)
result_hyp.append(bs_hyp_pad)
- return paddle.to_tensor(np.array(result_hyp), dtype=paddle.int64)
+ score = float(score) / l
+ hyp_score = [score for _ in range(25)]
+ hyp_scores.append(hyp_score)
+ return [
+ paddle.to_tensor(
+ np.array(result_hyp), dtype=paddle.int64),
+ paddle.to_tensor(hyp_scores)
+ ]
def generate_square_subsequent_mask(self, sz):
"""Generate a square mask for the sequence. The masked positions are filled with float('-inf').
@@ -376,7 +357,7 @@ class Transformer(nn.Layer):
return mask
def generate_padding_mask(self, x):
- padding_mask = x.equal(paddle.to_tensor(0, dtype=x.dtype))
+ padding_mask = paddle.equal(x, paddle.to_tensor(0, dtype=x.dtype))
return padding_mask
def _reset_parameters(self):
@@ -514,17 +495,17 @@ class TransformerEncoderLayer(nn.Layer):
src,
src,
attn_mask=src_mask,
- key_padding_mask=src_key_padding_mask)[0]
+ key_padding_mask=src_key_padding_mask)
src = src + self.dropout1(src2)
src = self.norm1(src)
- src = src.transpose([1, 2, 0])
+ src = paddle.transpose(src, [1, 2, 0])
src = paddle.unsqueeze(src, 2)
src2 = self.conv2(F.relu(self.conv1(src)))
src2 = paddle.squeeze(src2, 2)
- src2 = src2.transpose([2, 0, 1])
+ src2 = paddle.transpose(src2, [2, 0, 1])
src = paddle.squeeze(src, 2)
- src = src.transpose([2, 0, 1])
+ src = paddle.transpose(src, [2, 0, 1])
src = src + self.dropout2(src2)
src = self.norm2(src)
@@ -598,7 +579,7 @@ class TransformerDecoderLayer(nn.Layer):
tgt,
tgt,
attn_mask=tgt_mask,
- key_padding_mask=tgt_key_padding_mask)[0]
+ key_padding_mask=tgt_key_padding_mask)
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(
@@ -606,18 +587,18 @@ class TransformerDecoderLayer(nn.Layer):
memory,
memory,
attn_mask=memory_mask,
- key_padding_mask=memory_key_padding_mask)[0]
+ key_padding_mask=memory_key_padding_mask)
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
# default
- tgt = tgt.transpose([1, 2, 0])
+ tgt = paddle.transpose(tgt, [1, 2, 0])
tgt = paddle.unsqueeze(tgt, 2)
tgt2 = self.conv2(F.relu(self.conv1(tgt)))
tgt2 = paddle.squeeze(tgt2, 2)
- tgt2 = tgt2.transpose([2, 0, 1])
+ tgt2 = paddle.transpose(tgt2, [2, 0, 1])
tgt = paddle.squeeze(tgt, 2)
- tgt = tgt.transpose([2, 0, 1])
+ tgt = paddle.transpose(tgt, [2, 0, 1])
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
@@ -656,8 +637,8 @@ class PositionalEncoding(nn.Layer):
(-math.log(10000.0) / dim))
pe[:, 0::2] = paddle.sin(position * div_term)
pe[:, 1::2] = paddle.cos(position * div_term)
- pe = pe.unsqueeze(0)
- pe = pe.transpose([1, 0, 2])
+ pe = paddle.unsqueeze(pe, 0)
+ pe = paddle.transpose(pe, [1, 0, 2])
self.register_buffer('pe', pe)
def forward(self, x):
@@ -670,7 +651,7 @@ class PositionalEncoding(nn.Layer):
Examples:
>>> output = pos_encoder(x)
"""
- x = x + self.pe[:x.shape[0], :]
+ x = x + self.pe[:paddle.shape(x)[0], :]
return self.dropout(x)
@@ -702,7 +683,7 @@ class PositionalEncoding_2d(nn.Layer):
(-math.log(10000.0) / dim))
pe[:, 0::2] = paddle.sin(position * div_term)
pe[:, 1::2] = paddle.cos(position * div_term)
- pe = pe.unsqueeze(0).transpose([1, 0, 2])
+ pe = paddle.transpose(paddle.unsqueeze(pe, 0), [1, 0, 2])
self.register_buffer('pe', pe)
self.avg_pool_1 = nn.AdaptiveAvgPool2D((1, 1))
@@ -722,22 +703,23 @@ class PositionalEncoding_2d(nn.Layer):
Examples:
>>> output = pos_encoder(x)
"""
- w_pe = self.pe[:x.shape[-1], :]
+ w_pe = self.pe[:paddle.shape(x)[-1], :]
w1 = self.linear1(self.avg_pool_1(x).squeeze()).unsqueeze(0)
w_pe = w_pe * w1
- w_pe = w_pe.transpose([1, 2, 0])
- w_pe = w_pe.unsqueeze(2)
+ w_pe = paddle.transpose(w_pe, [1, 2, 0])
+ w_pe = paddle.unsqueeze(w_pe, 2)
- h_pe = self.pe[:x.shape[-2], :]
+ h_pe = self.pe[:paddle.shape(x).shape[-2], :]
w2 = self.linear2(self.avg_pool_2(x).squeeze()).unsqueeze(0)
h_pe = h_pe * w2
- h_pe = h_pe.transpose([1, 2, 0])
- h_pe = h_pe.unsqueeze(3)
+ h_pe = paddle.transpose(h_pe, [1, 2, 0])
+ h_pe = paddle.unsqueeze(h_pe, 3)
x = x + w_pe + h_pe
- x = x.reshape(
- [x.shape[0], x.shape[1], x.shape[2] * x.shape[3]]).transpose(
- [2, 0, 1])
+ x = paddle.transpose(
+ paddle.reshape(x,
+ [x.shape[0], x.shape[1], x.shape[2] * x.shape[3]]),
+ [2, 0, 1])
return self.dropout(x)
@@ -817,7 +799,7 @@ class Beam():
def sort_scores(self):
"Sort the scores."
return self.scores, paddle.to_tensor(
- [i for i in range(self.scores.shape[0])], dtype='int32')
+ [i for i in range(int(self.scores.shape[0]))], dtype='int32')
def get_the_best_score_and_idx(self):
"Get the score of the best in the beam."
diff --git a/ppocr/modeling/necks/rnn.py b/ppocr/modeling/necks/rnn.py
index de87b3d9895168657f8c9722177c026b992c2966..86e649028f8fbb76cb5a1fd85381bd361277c6ee 100644
--- a/ppocr/modeling/necks/rnn.py
+++ b/ppocr/modeling/necks/rnn.py
@@ -51,7 +51,7 @@ class EncoderWithFC(nn.Layer):
super(EncoderWithFC, self).__init__()
self.out_channels = hidden_size
weight_attr, bias_attr = get_para_bias_attr(
- l2_decay=0.00001, k=in_channels, name='reduce_encoder_fea')
+ l2_decay=0.00001, k=in_channels)
self.fc = nn.Linear(
in_channels,
hidden_size,
diff --git a/ppocr/postprocess/rec_postprocess.py b/ppocr/postprocess/rec_postprocess.py
index 9f23b5495f63a41283656ceaf9df76f96b8d1592..07efd972008bd37e7fd46549b58c1ce58a48cbc7 100644
--- a/ppocr/postprocess/rec_postprocess.py
+++ b/ppocr/postprocess/rec_postprocess.py
@@ -176,7 +176,19 @@ class NRTRLabelDecode(BaseRecLabelDecode):
else:
preds_idx = preds
- text = self.decode(preds_idx)
+ if len(preds) == 2:
+ preds_id = preds[0]
+ preds_prob = preds[1]
+ if isinstance(preds_id, paddle.Tensor):
+ preds_id = preds_id.numpy()
+ if isinstance(preds_prob, paddle.Tensor):
+ preds_prob = preds_prob.numpy()
+ if preds_id[0][0] == 2:
+ preds_idx = preds_id[:, 1:]
+ preds_prob = preds_prob[:, 1:]
+ else:
+ preds_idx = preds_id
+ text = self.decode(preds_idx, preds_prob, is_remove_duplicate=False)
if label is None:
return text
label = self.decode(label[:,1:])
diff --git a/tools/export_model.py b/tools/export_model.py
index cae87aca129134d64711e364bf10428d69500a06..8ace6980ba5497b8abdbfc0ed8ad2ec11150b3db 100755
--- a/tools/export_model.py
+++ b/tools/export_model.py
@@ -26,7 +26,7 @@ from paddle.jit import to_static
from ppocr.modeling.architectures import build_model
from ppocr.postprocess import build_post_process
-from ppocr.utils.save_load import init_model
+from ppocr.utils.save_load import load_dygraph_params
from ppocr.utils.logging import get_logger
from tools.program import load_config, merge_config, ArgsParser
@@ -60,6 +60,8 @@ def export_single_model(model, arch_config, save_path, logger):
"When there is tps in the network, variable length input is not supported, and the input size needs to be the same as during training"
)
infer_shape[-1] = 100
+ if arch_config["algorithm"] == "NRTR":
+ infer_shape = [1, 32, 100]
elif arch_config["model_type"] == "table":
infer_shape = [3, 488, 488]
model = to_static(
@@ -99,7 +101,7 @@ def main():
else: # base rec model
config["Architecture"]["Head"]["out_channels"] = char_num
model = build_model(config["Architecture"])
- init_model(config, model)
+ _ = load_dygraph_params(config, model, logger, None)
model.eval()
save_path = config["Global"]["save_inference_dir"]
diff --git a/tools/infer/predict_rec.py b/tools/infer/predict_rec.py
index 7401a16ee662ceed1f8010adc3db0769e3efadb6..332cffd5395f8f511089b0bfde762820af7bbe8c 100755
--- a/tools/infer/predict_rec.py
+++ b/tools/infer/predict_rec.py
@@ -13,7 +13,7 @@
# limitations under the License.
import os
import sys
-
+from PIL import Image
__dir__ = os.path.dirname(os.path.abspath(__file__))
sys.path.append(__dir__)
sys.path.append(os.path.abspath(os.path.join(__dir__, '../..')))
@@ -61,6 +61,13 @@ class TextRecognizer(object):
"character_dict_path": args.rec_char_dict_path,
"use_space_char": args.use_space_char
}
+ elif self.rec_algorithm == 'NRTR':
+ postprocess_params = {
+ 'name': 'NRTRLabelDecode',
+ "character_type": args.rec_char_type,
+ "character_dict_path": args.rec_char_dict_path,
+ "use_space_char": args.use_space_char
+ }
self.postprocess_op = build_post_process(postprocess_params)
self.predictor, self.input_tensor, self.output_tensors, self.config = \
utility.create_predictor(args, 'rec', logger)
@@ -87,6 +94,16 @@ class TextRecognizer(object):
def resize_norm_img(self, img, max_wh_ratio):
imgC, imgH, imgW = self.rec_image_shape
+ if self.rec_algorithm == 'NRTR':
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
+ # return padding_im
+ image_pil = Image.fromarray(np.uint8(img))
+ img = image_pil.resize([100, 32], Image.ANTIALIAS)
+ img = np.array(img)
+ norm_img = np.expand_dims(img, -1)
+ norm_img = norm_img.transpose((2, 0, 1))
+ return norm_img.astype(np.float32) / 128. - 1.
+
assert imgC == img.shape[2]
max_wh_ratio = max(max_wh_ratio, imgW / imgH)
imgW = int((32 * max_wh_ratio))
@@ -252,14 +269,16 @@ class TextRecognizer(object):
else:
self.input_tensor.copy_from_cpu(norm_img_batch)
self.predictor.run()
-
outputs = []
for output_tensor in self.output_tensors:
output = output_tensor.copy_to_cpu()
outputs.append(output)
if self.benchmark:
self.autolog.times.stamp()
- preds = outputs[0]
+ if len(outputs) != 1:
+ preds = outputs
+ else:
+ preds = outputs[0]
rec_result = self.postprocess_op(preds)
for rno in range(len(rec_result)):
rec_res[indices[beg_img_no + rno]] = rec_result[rno]
diff --git a/tools/infer/utility.py b/tools/infer/utility.py
index 466f824c29d5493f56e56bc3243fc907aec24d60..103dd9bd8dcf0c8c3fcca1acfc5d01a3134e28a3 100755
--- a/tools/infer/utility.py
+++ b/tools/infer/utility.py
@@ -264,7 +264,7 @@ def create_predictor(args, mode, logger):
# enable memory optim
config.enable_memory_optim()
- #config.disable_glog_info()
+ config.disable_glog_info()
config.delete_pass("conv_transpose_eltwiseadd_bn_fuse_pass")
if mode == 'table':