@@ -196,8 +198,8 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
-
-- RE(关系提取)
+
+- RE(关系提取)
diff --git "a/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md" "b/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md"
index a831813c1504a0d00db23f0218154cbf36741118..2143a6da86abb5eb83788944cd0381b91dad86c1 100644
--- "a/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md"
+++ "b/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md"
@@ -16,7 +16,7 @@
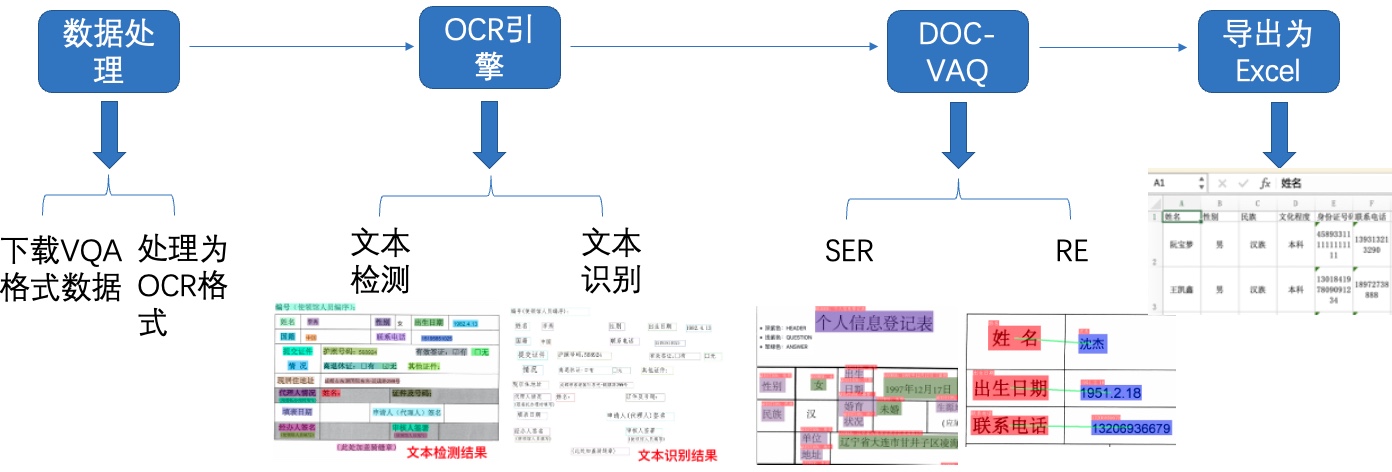 图1 多模态表单识别流程图
-注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: 多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
diff --git a/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml b/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml
new file mode 100644
index 0000000000000000000000000000000000000000..3e77577c17abe2111c501d96ce6b1087ac44f8d6
--- /dev/null
+++ b/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml
@@ -0,0 +1,234 @@
+Global:
+ debug: false
+ use_gpu: true
+ epoch_num: 500
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/ch_PP-OCR_v3_det/
+ save_epoch_step: 100
+ eval_batch_step:
+ - 0
+ - 400
+ cal_metric_during_train: false
+ pretrained_model: null
+ checkpoints: null
+ save_inference_dir: null
+ use_visualdl: false
+ infer_img: doc/imgs_en/img_10.jpg
+ save_res_path: ./checkpoints/det_db/predicts_db.txt
+ distributed: true
+
+Architecture:
+ name: DistillationModel
+ algorithm: Distillation
+ model_type: det
+ Models:
+ Student:
+ model_type: det
+ algorithm: DB
+ Transform: null
+ Backbone:
+ name: MobileNetV3
+ scale: 0.5
+ model_name: large
+ disable_se: true
+ Neck:
+ name: RSEFPN
+ out_channels: 96
+ shortcut: True
+ Head:
+ name: DBHead
+ k: 50
+ Student2:
+ model_type: det
+ algorithm: DB
+ Transform: null
+ Backbone:
+ name: MobileNetV3
+ scale: 0.5
+ model_name: large
+ disable_se: true
+ Neck:
+ name: RSEFPN
+ out_channels: 96
+ shortcut: True
+ Head:
+ name: DBHead
+ k: 50
+ Teacher:
+ freeze_params: true
+ return_all_feats: false
+ model_type: det
+ algorithm: DB
+ Backbone:
+ name: ResNet
+ in_channels: 3
+ layers: 50
+ Neck:
+ name: LKPAN
+ out_channels: 256
+ Head:
+ name: DBHead
+ kernel_list: [7,2,2]
+ k: 50
+
+Loss:
+ name: CombinedLoss
+ loss_config_list:
+ - DistillationDilaDBLoss:
+ weight: 1.0
+ model_name_pairs:
+ - ["Student", "Teacher"]
+ - ["Student2", "Teacher"]
+ key: maps
+ balance_loss: true
+ main_loss_type: DiceLoss
+ alpha: 5
+ beta: 10
+ ohem_ratio: 3
+ - DistillationDMLLoss:
+ model_name_pairs:
+ - ["Student", "Student2"]
+ maps_name: "thrink_maps"
+ weight: 1.0
+ # act: None
+ model_name_pairs: ["Student", "Student2"]
+ key: maps
+ - DistillationDBLoss:
+ weight: 1.0
+ model_name_list: ["Student", "Student2"]
+ # key: maps
+ # name: DBLoss
+ balance_loss: true
+ main_loss_type: DiceLoss
+ alpha: 5
+ beta: 10
+ ohem_ratio: 3
+
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.999
+ lr:
+ name: Cosine
+ learning_rate: 0.001
+ warmup_epoch: 2
+ regularizer:
+ name: L2
+ factor: 5.0e-05
+
+PostProcess:
+ name: DistillationDBPostProcess
+ model_name: ["Student"]
+ key: head_out
+ thresh: 0.3
+ box_thresh: 0.6
+ max_candidates: 1000
+ unclip_ratio: 1.5
+
+Metric:
+ name: DistillationMetric
+ base_metric_name: DetMetric
+ main_indicator: hmean
+ key: "Student"
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/icdar2015/text_localization/
+ label_file_list:
+ - ./train_data/icdar2015/text_localization/train_icdar2015_label.txt
+ ratio_list: [1.0]
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - DetLabelEncode: null
+ - CopyPaste:
+ - IaaAugment:
+ augmenter_args:
+ - type: Fliplr
+ args:
+ p: 0.5
+ - type: Affine
+ args:
+ rotate:
+ - -10
+ - 10
+ - type: Resize
+ args:
+ size:
+ - 0.5
+ - 3
+ - EastRandomCropData:
+ size:
+ - 960
+ - 960
+ max_tries: 50
+ keep_ratio: true
+ - MakeBorderMap:
+ shrink_ratio: 0.4
+ thresh_min: 0.3
+ thresh_max: 0.7
+ - MakeShrinkMap:
+ shrink_ratio: 0.4
+ min_text_size: 8
+ - NormalizeImage:
+ scale: 1./255.
+ mean:
+ - 0.485
+ - 0.456
+ - 0.406
+ std:
+ - 0.229
+ - 0.224
+ - 0.225
+ order: hwc
+ - ToCHWImage: null
+ - KeepKeys:
+ keep_keys:
+ - image
+ - threshold_map
+ - threshold_mask
+ - shrink_map
+ - shrink_mask
+ loader:
+ shuffle: true
+ drop_last: false
+ batch_size_per_card: 8
+ num_workers: 4
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/icdar2015/text_localization/
+ label_file_list:
+ - ./train_data/icdar2015/text_localization/test_icdar2015_label.txt
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - DetLabelEncode: null
+ - DetResizeForTest: null
+ - NormalizeImage:
+ scale: 1./255.
+ mean:
+ - 0.485
+ - 0.456
+ - 0.406
+ std:
+ - 0.229
+ - 0.224
+ - 0.225
+ order: hwc
+ - ToCHWImage: null
+ - KeepKeys:
+ keep_keys:
+ - image
+ - shape
+ - polys
+ - ignore_tags
+ loader:
+ shuffle: false
+ drop_last: false
+ batch_size_per_card: 1
+ num_workers: 2
diff --git a/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml b/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml
new file mode 100644
index 0000000000000000000000000000000000000000..0e8af776479ea26f834ca9ddc169f80b3982e86d
--- /dev/null
+++ b/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml
@@ -0,0 +1,163 @@
+Global:
+ debug: false
+ use_gpu: true
+ epoch_num: 500
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/ch_PP-OCR_V3_det/
+ save_epoch_step: 100
+ eval_batch_step:
+ - 0
+ - 400
+ cal_metric_during_train: false
+ pretrained_model: null
+ checkpoints: null
+ save_inference_dir: null
+ use_visualdl: false
+ infer_img: doc/imgs_en/img_10.jpg
+ save_res_path: ./checkpoints/det_db/predicts_db.txt
+ distributed: true
+
+Architecture:
+ model_type: det
+ algorithm: DB
+ Transform:
+ Backbone:
+ name: MobileNetV3
+ scale: 0.5
+ model_name: large
+ disable_se: True
+ Neck:
+ name: RSEFPN
+ out_channels: 96
+ shortcut: True
+ Head:
+ name: DBHead
+ k: 50
+
+Loss:
+ name: DBLoss
+ balance_loss: true
+ main_loss_type: DiceLoss
+ alpha: 5
+ beta: 10
+ ohem_ratio: 3
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.999
+ lr:
+ name: Cosine
+ learning_rate: 0.001
+ warmup_epoch: 2
+ regularizer:
+ name: L2
+ factor: 5.0e-05
+PostProcess:
+ name: DBPostProcess
+ thresh: 0.3
+ box_thresh: 0.6
+ max_candidates: 1000
+ unclip_ratio: 1.5
+Metric:
+ name: DetMetric
+ main_indicator: hmean
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/icdar2015/text_localization/
+ label_file_list:
+ - ./train_data/icdar2015/text_localization/train_icdar2015_label.txt
+ ratio_list: [1.0]
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - DetLabelEncode: null
+ - IaaAugment:
+ augmenter_args:
+ - type: Fliplr
+ args:
+ p: 0.5
+ - type: Affine
+ args:
+ rotate:
+ - -10
+ - 10
+ - type: Resize
+ args:
+ size:
+ - 0.5
+ - 3
+ - EastRandomCropData:
+ size:
+ - 960
+ - 960
+ max_tries: 50
+ keep_ratio: true
+ - MakeBorderMap:
+ shrink_ratio: 0.4
+ thresh_min: 0.3
+ thresh_max: 0.7
+ - MakeShrinkMap:
+ shrink_ratio: 0.4
+ min_text_size: 8
+ - NormalizeImage:
+ scale: 1./255.
+ mean:
+ - 0.485
+ - 0.456
+ - 0.406
+ std:
+ - 0.229
+ - 0.224
+ - 0.225
+ order: hwc
+ - ToCHWImage: null
+ - KeepKeys:
+ keep_keys:
+ - image
+ - threshold_map
+ - threshold_mask
+ - shrink_map
+ - shrink_mask
+ loader:
+ shuffle: true
+ drop_last: false
+ batch_size_per_card: 8
+ num_workers: 4
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/icdar2015/text_localization/
+ label_file_list:
+ - ./train_data/icdar2015/text_localization/test_icdar2015_label.txt
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - DetLabelEncode: null
+ - DetResizeForTest: null
+ - NormalizeImage:
+ scale: 1./255.
+ mean:
+ - 0.485
+ - 0.456
+ - 0.406
+ std:
+ - 0.229
+ - 0.224
+ - 0.225
+ order: hwc
+ - ToCHWImage: null
+ - KeepKeys:
+ keep_keys:
+ - image
+ - shape
+ - polys
+ - ignore_tags
+ loader:
+ shuffle: false
+ drop_last: false
+ batch_size_per_card: 1
+ num_workers: 2
diff --git a/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml b/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
similarity index 100%
rename from configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml
rename to configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
diff --git a/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml b/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
similarity index 100%
rename from configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
rename to configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
diff --git a/doc/doc_ch/docvqa_datasets.md b/configs/rec/PP-OCRv3/multi_language/.gitkeep
similarity index 100%
rename from doc/doc_ch/docvqa_datasets.md
rename to configs/rec/PP-OCRv3/multi_language/.gitkeep
diff --git a/deploy/slim/quantization/export_model.py b/deploy/slim/quantization/export_model.py
index 90f79dab34a5f20d4556ae4b10ad1d4e1f8b7f0d..fd1c3e5e109667fa74f5ade18b78f634e4d325db 100755
--- a/deploy/slim/quantization/export_model.py
+++ b/deploy/slim/quantization/export_model.py
@@ -17,9 +17,9 @@ import sys
__dir__ = os.path.dirname(os.path.abspath(__file__))
sys.path.append(__dir__)
-sys.path.append(os.path.abspath(os.path.join(__dir__, '..', '..', '..')))
-sys.path.append(
- os.path.abspath(os.path.join(__dir__, '..', '..', '..', 'tools')))
+sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '..', '..', '..')))
+sys.path.insert(
+ 0, os.path.abspath(os.path.join(__dir__, '..', '..', '..', 'tools')))
import argparse
@@ -129,7 +129,6 @@ def main():
quanter.quantize(model)
load_model(config, model)
- model.eval()
# build metric
eval_class = build_metric(config['Metric'])
@@ -142,6 +141,7 @@ def main():
# start eval
metric = program.eval(model, valid_dataloader, post_process_class,
eval_class, model_type, use_srn)
+ model.eval()
logger.info('metric eval ***************')
for k, v in metric.items():
@@ -156,7 +156,6 @@ def main():
if arch_config["algorithm"] in ["Distillation", ]: # distillation model
archs = list(arch_config["Models"].values())
for idx, name in enumerate(model.model_name_list):
- model.model_list[idx].eval()
sub_model_save_path = os.path.join(save_path, name, "inference")
export_single_model(model.model_list[idx], archs[idx],
sub_model_save_path, logger, quanter)
diff --git a/doc/datasets/funsd_demo/gt_train_00040534.jpg b/doc/datasets/funsd_demo/gt_train_00040534.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..9f7cf4d4977689b73e2ca91cbe9c877bb8f0c7ff
Binary files /dev/null and b/doc/datasets/funsd_demo/gt_train_00040534.jpg differ
diff --git a/doc/datasets/funsd_demo/gt_train_00070353.jpg b/doc/datasets/funsd_demo/gt_train_00070353.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..36d3345e5ec4c262764e63a972aaa82e98877681
Binary files /dev/null and b/doc/datasets/funsd_demo/gt_train_00070353.jpg differ
diff --git a/doc/datasets/table_PubTabNet_demo/PMC524509_007_00.png b/doc/datasets/table_PubTabNet_demo/PMC524509_007_00.png
new file mode 100755
index 0000000000000000000000000000000000000000..5b9d631cba434e4bd6ac6fe2108b7f6c081c4811
Binary files /dev/null and b/doc/datasets/table_PubTabNet_demo/PMC524509_007_00.png differ
diff --git a/doc/datasets/table_PubTabNet_demo/PMC535543_007_01.png b/doc/datasets/table_PubTabNet_demo/PMC535543_007_01.png
new file mode 100755
index 0000000000000000000000000000000000000000..e808de72d62325ae4cbd009397b7beaeed0d88fc
Binary files /dev/null and b/doc/datasets/table_PubTabNet_demo/PMC535543_007_01.png differ
diff --git a/doc/datasets/table_tal_demo/1.jpg b/doc/datasets/table_tal_demo/1.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e7ddd6d1db59ca27a0461ab93b3672aeec4a8941
Binary files /dev/null and b/doc/datasets/table_tal_demo/1.jpg differ
diff --git a/doc/datasets/table_tal_demo/2.jpg b/doc/datasets/table_tal_demo/2.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e7ddd6d1db59ca27a0461ab93b3672aeec4a8941
Binary files /dev/null and b/doc/datasets/table_tal_demo/2.jpg differ
diff --git a/doc/datasets/xfund_demo/gt_zh_train_0.jpg b/doc/datasets/xfund_demo/gt_zh_train_0.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6fdaf12fa1d79e6ea9029d665ab7488223459436
Binary files /dev/null and b/doc/datasets/xfund_demo/gt_zh_train_0.jpg differ
diff --git a/doc/datasets/xfund_demo/gt_zh_train_1.jpg b/doc/datasets/xfund_demo/gt_zh_train_1.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6a1e53a3ba09b6f84809cfd10a15c42f42b9a163
Binary files /dev/null and b/doc/datasets/xfund_demo/gt_zh_train_1.jpg differ
diff --git a/doc/doc_ch/algorithm_det_fcenet.md b/doc/doc_ch/algorithm_det_fcenet.md
new file mode 100644
index 0000000000000000000000000000000000000000..bd2e734204d32bbf575ddea9f889953a72582c59
--- /dev/null
+++ b/doc/doc_ch/algorithm_det_fcenet.md
@@ -0,0 +1,104 @@
+# FCENet
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Fourier Contour Embedding for Arbitrary-Shaped Text Detection](https://arxiv.org/abs/2104.10442)
+> Yiqin Zhu and Jianyong Chen and Lingyu Liang and Zhanghui Kuang and Lianwen Jin and Wayne Zhang
+> CVPR, 2021
+
+在CTW1500文本检测公开数据集上,算法复现效果如下:
+
+| 模型 |骨干网络|配置文件|precision|recall|Hmean|下载链接|
+|-----| --- | --- | --- | --- | --- | --- |
+| FCE | ResNet50_dcn | [configs/det/det_r50_vd_dcn_fce_ctw.yml](../../configs/det/det_r50_vd_dcn_fce_ctw.yml)| 88.39%|82.18%|85.27%|[训练模型](https://paddleocr.bj.bcebos.com/contribution/det_r50_dcn_fce_ctw_v2.0_train.tar)|
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+上述FCE模型使用CTW1500文本检测公开数据集训练得到,数据集下载可参考 [ocr_datasets](./dataset/ocr_datasets.md)。
+
+数据下载完成后,请参考[文本检测训练教程](./detection.md)进行训练。PaddleOCR对代码进行了模块化,训练不同的检测模型只需要**更换配置文件**即可。
+
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将FCE文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd_dcn骨干网络,在CTW1500英文数据集训练的模型为例( [模型下载地址](https://paddleocr.bj.bcebos.com/contribution/det_r50_dcn_fce_ctw_v2.0_train.tar) ),可以使用如下命令进行转换:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_dcn_fce_ctw.yml -o Global.pretrained_model=./det_r50_dcn_fce_ctw_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_fce
+```
+
+FCE文本检测模型推理,执行非弯曲文本检测,可以执行如下命令:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_fce/" --det_algorithm="FCE" --det_fce_box_type=quad
+```
+
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+如果想执行弯曲文本检测,可以执行如下命令:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_fce/" --det_algorithm="FCE" --det_fce_box_type=poly
+```
+
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+**注意**:由于CTW1500数据集只有1000张训练图像,且主要针对英文场景,所以上述模型对中文文本图像检测效果会比较差。
+
+
+### 4.2 C++推理
+
+由于后处理暂未使用CPP编写,FCE文本检测模型暂不支持CPP推理。
+
+
+### 4.3 Serving服务化部署
+
+暂未支持
+
+
+### 4.4 更多推理部署
+
+暂未支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@InProceedings{zhu2021fourier,
+ title={Fourier Contour Embedding for Arbitrary-Shaped Text Detection},
+ author={Yiqin Zhu and Jianyong Chen and Lingyu Liang and Zhanghui Kuang and Lianwen Jin and Wayne Zhang},
+ year={2021},
+ booktitle = {CVPR}
+}
+```
diff --git a/doc/doc_ch/algorithm_det_psenet.md b/doc/doc_ch/algorithm_det_psenet.md
new file mode 100644
index 0000000000000000000000000000000000000000..58d8ccf97292f4e988861b618697fb0e7694fbab
--- /dev/null
+++ b/doc/doc_ch/algorithm_det_psenet.md
@@ -0,0 +1,106 @@
+# PSENet
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Shape robust text detection with progressive scale expansion network](https://arxiv.org/abs/1903.12473)
+> Wang, Wenhai and Xie, Enze and Li, Xiang and Hou, Wenbo and Lu, Tong and Yu, Gang and Shao, Shuai
+> CVPR, 2019
+
+在ICDAR2015文本检测公开数据集上,算法复现效果如下:
+
+|模型|骨干网络|配置文件|precision|recall|Hmean|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|PSE| ResNet50_vd | [configs/det/det_r50_vd_pse.yml](../../configs/det/det_r50_vd_pse.yml)| 85.81% |79.53%|82.55%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_r50_vd_pse_v2.0_train.tar)|
+|PSE| MobileNetV3| [configs/det/det_mv3_pse.yml](../../configs/det/det_mv3_pse.yml) | 82.20% |70.48%|75.89%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_mv3_pse_v2.0_train.tar)|
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+上述PSE模型使用ICDAR2015文本检测公开数据集训练得到,数据集下载可参考 [ocr_datasets](./dataset/ocr_datasets.md)。
+
+数据下载完成后,请参考[文本检测训练教程](./detection.md)进行训练。PaddleOCR对代码进行了模块化,训练不同的检测模型只需要**更换配置文件**即可。
+
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将PSE文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在ICDAR2015英文数据集训练的模型为例( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_r50_vd_pse_v2.0_train.tar) ),可以使用如下命令进行转换:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_pse.yml -o Global.pretrained_model=./det_r50_vd_pse_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_pse
+```
+
+PSE文本检测模型推理,执行非弯曲文本检测,可以执行如下命令:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_pse/" --det_algorithm="PSE" --det_pse_box_type=quad
+```
+
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+如果想执行弯曲文本检测,可以执行如下命令:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_pse/" --det_algorithm="PSE" --det_pse_box_type=poly
+```
+
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+**注意**:由于ICDAR2015数据集只有1000张训练图像,且主要针对英文场景,所以上述模型对中文或弯曲文本图像检测效果会比较差。
+
+
+### 4.2 C++推理
+
+由于后处理暂未使用CPP编写,PSE文本检测模型暂不支持CPP推理。
+
+
+### 4.3 Serving服务化部署
+
+暂未支持
+
+
+### 4.4 更多推理部署
+
+暂未支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@inproceedings{wang2019shape,
+ title={Shape robust text detection with progressive scale expansion network},
+ author={Wang, Wenhai and Xie, Enze and Li, Xiang and Hou, Wenbo and Lu, Tong and Yu, Gang and Shao, Shuai},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={9336--9345},
+ year={2019}
+}
+```
diff --git a/doc/doc_ch/algorithm_det_sast.md b/doc/doc_ch/algorithm_det_sast.md
new file mode 100644
index 0000000000000000000000000000000000000000..038d73fc15f3203bbcc17997c1a8e1c208f80ba8
--- /dev/null
+++ b/doc/doc_ch/algorithm_det_sast.md
@@ -0,0 +1,115 @@
+# SAST
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning](https://arxiv.org/abs/1908.05498)
+> Wang, Pengfei and Zhang, Chengquan and Qi, Fei and Huang, Zuming and En, Mengyi and Han, Junyu and Liu, Jingtuo and Ding, Errui and Shi, Guangming
+> ACM MM, 2019
+
+在ICDAR2015文本检测公开数据集上,算法复现效果如下:
+
+|模型|骨干网络|配置文件|precision|recall|Hmean|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|SAST|ResNet50_vd|[configs/det/det_r50_vd_sast_icdar15.yml](../../configs/det/det_r50_vd_sast_icdar15.yml)|91.39%|83.77%|87.42%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_icdar15_v2.0_train.tar)|
+
+
+在Total-text文本检测公开数据集上,算法复现效果如下:
+
+|模型|骨干网络|配置文件|precision|recall|Hmean|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|SAST|ResNet50_vd|[configs/det/det_r50_vd_sast_totaltext.yml](../../configs/det/det_r50_vd_sast_totaltext.yml)|89.63%|78.44%|83.66%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_totaltext_v2.0_train.tar)|
+
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本检测训练教程](./detection.md)。PaddleOCR对代码进行了模块化,训练不同的检测模型只需要**更换配置文件**即可。
+
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+#### (1). 四边形文本检测模型(ICDAR2015)
+首先将SAST文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在ICDAR2015英文数据集训练的模型为例([模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_icdar15_v2.0_train.tar)),可以使用如下命令进行转换:
+```
+python3 tools/export_model.py -c configs/det/det_r50_vd_sast_icdar15.yml -o Global.pretrained_model=./det_r50_vd_sast_icdar15_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_sast_ic15
+
+```
+**SAST文本检测模型推理,需要设置参数`--det_algorithm="SAST"`**,可以执行如下命令:
+```
+python3 tools/infer/predict_det.py --det_algorithm="SAST" --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_sast_ic15/"
+```
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+#### (2). 弯曲文本检测模型(Total-Text)
+首先将SAST文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在Total-Text英文数据集训练的模型为例([模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_totaltext_v2.0_train.tar)),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/det/det_r50_vd_sast_totaltext.yml -o Global.pretrained_model=./det_r50_vd_sast_totaltext_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_sast_tt
+
+```
+
+SAST文本检测模型推理,需要设置参数`--det_algorithm="SAST"`,同时,还需要增加参数`--det_sast_polygon=True`,可以执行如下命令:
+```
+python3 tools/infer/predict_det.py --det_algorithm="SAST" --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_sast_tt/" --det_sast_polygon=True
+```
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+**注意**:本代码库中,SAST后处理Locality-Aware NMS有python和c++两种版本,c++版速度明显快于python版。由于c++版本nms编译版本问题,只有python3.5环境下会调用c++版nms,其他情况将调用python版nms。
+
+
+### 4.2 C++推理
+
+暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂未支持
+
+
+### 4.4 更多推理部署
+
+暂未支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@inproceedings{wang2019single,
+ title={A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning},
+ author={Wang, Pengfei and Zhang, Chengquan and Qi, Fei and Huang, Zuming and En, Mengyi and Han, Junyu and Liu, Jingtuo and Ding, Errui and Shi, Guangming},
+ booktitle={Proceedings of the 27th ACM International Conference on Multimedia},
+ pages={1277--1285},
+ year={2019}
+}
+```
diff --git a/doc/doc_ch/algorithm_rec_sar.md b/doc/doc_ch/algorithm_rec_sar.md
new file mode 100644
index 0000000000000000000000000000000000000000..b8304313994754480a89d708e39149d67f828c0d
--- /dev/null
+++ b/doc/doc_ch/algorithm_rec_sar.md
@@ -0,0 +1,114 @@
+# SAR
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition](https://arxiv.org/abs/1811.00751)
+> Hui Li, Peng Wang, Chunhua Shen, Guyu Zhang
+> AAAI, 2019
+
+使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法复现效果如下:
+
+|模型|骨干网络|配置文件|Acc|下载链接|
+| --- | --- | --- | --- | --- |
+|SAR|ResNet31|[rec_r31_sar.yml](../../configs/rec/rec_r31_sar.yml)|87.20%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar)|
+
+注:除了使用MJSynth和SynthText两个文字识别数据集外,还加入了[SynthAdd](https://pan.baidu.com/share/init?surl=uV0LtoNmcxbO-0YA7Ch4dg)数据(提取码:627x),和部分真实数据,具体数据细节可以参考论文。
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本识别教程](./recognition.md)。PaddleOCR对代码进行了模块化,训练不同的识别模型只需要**更换配置文件**即可。
+
+训练
+
+具体地,在完成数据准备后,便可以启动训练,训练命令如下:
+
+```
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/rec_r31_sar.yml
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r31_sar.yml
+```
+
+评估
+
+```
+# GPU 评估, Global.pretrained_model 为待测权重
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+预测:
+
+```
+# 预测使用的配置文件必须与训练一致
+python3 tools/infer_rec.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将SAR文本识别训练过程中保存的模型,转换成inference model。( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar) ),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model=./rec_r31_sar_train/best_accuracy Global.save_inference_dir=./inference/rec_sar
+```
+
+SAR文本识别模型推理,可以执行如下命令:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_sar/" --rec_image_shape="3, 48, 48, 160" --rec_char_type="ch" --rec_algorithm="SAR" --rec_char_dict_path="ppocr/utils/dict90.txt" --max_text_length=30 --use_space_char=False
+```
+
+
+### 4.2 C++推理
+
+由于C++预处理后处理还未支持SAR,所以暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂不支持
+
+
+### 4.4 更多推理部署
+
+暂不支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@article{Li2019ShowAA,
+ title={Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition},
+ author={Hui Li and Peng Wang and Chunhua Shen and Guyu Zhang},
+ journal={ArXiv},
+ year={2019},
+ volume={abs/1811.00751}
+}
+```
diff --git a/doc/doc_ch/algorithm_rec_srn.md b/doc/doc_ch/algorithm_rec_srn.md
new file mode 100644
index 0000000000000000000000000000000000000000..ca7961359eb902fafee959b26d02f324aece233a
--- /dev/null
+++ b/doc/doc_ch/algorithm_rec_srn.md
@@ -0,0 +1,113 @@
+# SRN
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Towards Accurate Scene Text Recognition with Semantic Reasoning Networks](https://arxiv.org/abs/2003.12294#)
+> Deli Yu, Xuan Li, Chengquan Zhang, Junyu Han, Jingtuo Liu, Errui Ding
+> CVPR,2020
+
+使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法复现效果如下:
+
+|模型|骨干网络|配置文件|Acc|下载链接|
+| --- | --- | --- | --- | --- |
+|SRN|Resnet50_vd_fpn|[rec_r50_fpn_srn.yml](../../configs/rec/rec_r50_fpn_srn.yml)|86.31%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar)|
+
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本识别教程](./recognition.md)。PaddleOCR对代码进行了模块化,训练不同的识别模型只需要**更换配置文件**即可。
+
+训练
+
+具体地,在完成数据准备后,便可以启动训练,训练命令如下:
+
+```
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+```
+
+评估
+
+```
+# GPU 评估, Global.pretrained_model 为待测权重
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+预测:
+
+```
+# 预测使用的配置文件必须与训练一致
+python3 tools/infer_rec.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将SRN文本识别训练过程中保存的模型,转换成inference model。( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar) ),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model=./rec_r50_vd_srn_train/best_accuracy Global.save_inference_dir=./inference/rec_srn
+```
+
+SRN文本识别模型推理,可以执行如下命令:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_srn/" --rec_image_shape="1,64,256" --rec_char_type="ch" --rec_algorithm="SRN" --rec_char_dict_path=./ppocr/utils/ic15_dict.txt --use_space_char=False
+```
+
+
+### 4.2 C++推理
+
+由于C++预处理后处理还未支持SRN,所以暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂不支持
+
+
+### 4.4 更多推理部署
+
+暂不支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@article{Yu2020TowardsAS,
+ title={Towards Accurate Scene Text Recognition With Semantic Reasoning Networks},
+ author={Deli Yu and Xuan Li and Chengquan Zhang and Junyu Han and Jingtuo Liu and Errui Ding},
+ journal={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year={2020},
+ pages={12110-12119}
+}
+```
diff --git a/doc/doc_ch/datasets.md b/doc/doc_ch/dataset/datasets.md
similarity index 90%
rename from doc/doc_ch/datasets.md
rename to doc/doc_ch/dataset/datasets.md
index d365fd711aff2dffcd30dd06028734cc707d5df0..aad4f50b2d8baa369cf6f2576a24127a23cb5c48 100644
--- a/doc/doc_ch/datasets.md
+++ b/doc/doc_ch/dataset/datasets.md
@@ -6,17 +6,17 @@
- [中文文档文字识别](#中文文档文字识别)
- [ICDAR2019-ArT](#ICDAR2019-ArT)
-除了开源数据,用户还可使用合成工具自行合成,可参考[数据合成工具](./data_synthesis.md);
+除了开源数据,用户还可使用合成工具自行合成,可参考[数据合成工具](../data_synthesis.md);
-如果需要标注自己的数据,可参考[数据标注工具](./data_annotation.md)。
+如果需要标注自己的数据,可参考[数据标注工具](../data_annotation.md)。
#### 1、ICDAR2019-LSVT
- **数据来源**:https://ai.baidu.com/broad/introduction?dataset=lsvt
- **数据简介**: 共45w中文街景图像,包含5w(2w测试+3w训练)全标注数据(文本坐标+文本内容),40w弱标注数据(仅文本内容),如下图所示:
- 
+ 
(a) 全标注数据
- 
+ 
(b) 弱标注数据
- **下载地址**:https://ai.baidu.com/broad/download?dataset=lsvt
- **说明**:其中,test数据集的label目前没有开源,如要评估结果,可以去官网提交:https://rrc.cvc.uab.es/?ch=16
@@ -25,16 +25,16 @@
#### 2、ICDAR2017-RCTW-17
- **数据来源**:https://rctw.vlrlab.net/
- **数据简介**:共包含12,000+图像,大部分图片是通过手机摄像头在野外采集的。有些是截图。这些图片展示了各种各样的场景,包括街景、海报、菜单、室内场景和手机应用程序的截图。
- 
+ 
- **下载地址**:https://rctw.vlrlab.net/dataset/
-#### 3、中文街景文字识别
+#### 3、中文街景文字识别
- **数据来源**:https://aistudio.baidu.com/aistudio/competition/detail/8
- **数据简介**:ICDAR2019-LSVT行识别任务,共包括29万张图片,其中21万张图片作为训练集(带标注),8万张作为测试集(无标注)。数据集采自中国街景,并由街景图片中的文字行区域(例如店铺标牌、地标等等)截取出来而形成。所有图像都经过一些预处理,将文字区域利用仿射变化,等比映射为一张高为48像素的图片,如图所示:
- 
+ 
(a) 标注:魅派集成吊顶
- 
+ 
(b) 标注:母婴用品连锁
- **下载地址**
https://aistudio.baidu.com/aistudio/datasetdetail/8429
@@ -48,15 +48,15 @@ https://aistudio.baidu.com/aistudio/datasetdetail/8429
- 包含汉字、英文字母、数字和标点共5990个字符(字符集合:https://github.com/YCG09/chinese_ocr/blob/master/train/char_std_5990.txt )
- 每个样本固定10个字符,字符随机截取自语料库中的句子
- 图片分辨率统一为280x32
- 
- 
+ 
+ 
- **下载地址**:https://pan.baidu.com/s/1QkI7kjah8SPHwOQ40rS1Pw (密码:lu7m)
#### 5、ICDAR2019-ArT
- **数据来源**:https://ai.baidu.com/broad/introduction?dataset=art
- **数据简介**:共包含10,166张图像,训练集5603图,测试集4563图。由Total-Text、SCUT-CTW1500、Baidu Curved Scene Text (ICDAR2019-LSVT部分弯曲数据) 三部分组成,包含水平、多方向和弯曲等多种形状的文本。
- 
+ 
- **下载地址**:https://ai.baidu.com/broad/download?dataset=art
## 参考文献
diff --git a/doc/doc_ch/dataset/docvqa_datasets.md b/doc/doc_ch/dataset/docvqa_datasets.md
new file mode 100644
index 0000000000000000000000000000000000000000..3ec1865ee42be99ec19343428cd9ad6439686f15
--- /dev/null
+++ b/doc/doc_ch/dataset/docvqa_datasets.md
@@ -0,0 +1,27 @@
+## DocVQA数据集
+这里整理了常见的DocVQA数据集,持续更新中,欢迎各位小伙伴贡献数据集~
+- [FUNSD数据集](#funsd)
+- [XFUND数据集](#xfund)
+
+
+#### 1、FUNSD数据集
+- **数据来源**:https://guillaumejaume.github.io/FUNSD/
+- **数据简介**:FUNSD数据集是一个用于表单理解的数据集,它包含199张真实的、完全标注的扫描版图片,类型包括市场报告、广告以及学术报告等,并分为149张训练集以及50张测试集。FUNSD数据集适用于多种类型的DocVQA任务,如字段级实体分类、字段级实体连接等。部分图像以及标注框可视化如下所示:
+
图1 多模态表单识别流程图
-注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: 多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
diff --git a/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml b/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml
new file mode 100644
index 0000000000000000000000000000000000000000..3e77577c17abe2111c501d96ce6b1087ac44f8d6
--- /dev/null
+++ b/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml
@@ -0,0 +1,234 @@
+Global:
+ debug: false
+ use_gpu: true
+ epoch_num: 500
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/ch_PP-OCR_v3_det/
+ save_epoch_step: 100
+ eval_batch_step:
+ - 0
+ - 400
+ cal_metric_during_train: false
+ pretrained_model: null
+ checkpoints: null
+ save_inference_dir: null
+ use_visualdl: false
+ infer_img: doc/imgs_en/img_10.jpg
+ save_res_path: ./checkpoints/det_db/predicts_db.txt
+ distributed: true
+
+Architecture:
+ name: DistillationModel
+ algorithm: Distillation
+ model_type: det
+ Models:
+ Student:
+ model_type: det
+ algorithm: DB
+ Transform: null
+ Backbone:
+ name: MobileNetV3
+ scale: 0.5
+ model_name: large
+ disable_se: true
+ Neck:
+ name: RSEFPN
+ out_channels: 96
+ shortcut: True
+ Head:
+ name: DBHead
+ k: 50
+ Student2:
+ model_type: det
+ algorithm: DB
+ Transform: null
+ Backbone:
+ name: MobileNetV3
+ scale: 0.5
+ model_name: large
+ disable_se: true
+ Neck:
+ name: RSEFPN
+ out_channels: 96
+ shortcut: True
+ Head:
+ name: DBHead
+ k: 50
+ Teacher:
+ freeze_params: true
+ return_all_feats: false
+ model_type: det
+ algorithm: DB
+ Backbone:
+ name: ResNet
+ in_channels: 3
+ layers: 50
+ Neck:
+ name: LKPAN
+ out_channels: 256
+ Head:
+ name: DBHead
+ kernel_list: [7,2,2]
+ k: 50
+
+Loss:
+ name: CombinedLoss
+ loss_config_list:
+ - DistillationDilaDBLoss:
+ weight: 1.0
+ model_name_pairs:
+ - ["Student", "Teacher"]
+ - ["Student2", "Teacher"]
+ key: maps
+ balance_loss: true
+ main_loss_type: DiceLoss
+ alpha: 5
+ beta: 10
+ ohem_ratio: 3
+ - DistillationDMLLoss:
+ model_name_pairs:
+ - ["Student", "Student2"]
+ maps_name: "thrink_maps"
+ weight: 1.0
+ # act: None
+ model_name_pairs: ["Student", "Student2"]
+ key: maps
+ - DistillationDBLoss:
+ weight: 1.0
+ model_name_list: ["Student", "Student2"]
+ # key: maps
+ # name: DBLoss
+ balance_loss: true
+ main_loss_type: DiceLoss
+ alpha: 5
+ beta: 10
+ ohem_ratio: 3
+
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.999
+ lr:
+ name: Cosine
+ learning_rate: 0.001
+ warmup_epoch: 2
+ regularizer:
+ name: L2
+ factor: 5.0e-05
+
+PostProcess:
+ name: DistillationDBPostProcess
+ model_name: ["Student"]
+ key: head_out
+ thresh: 0.3
+ box_thresh: 0.6
+ max_candidates: 1000
+ unclip_ratio: 1.5
+
+Metric:
+ name: DistillationMetric
+ base_metric_name: DetMetric
+ main_indicator: hmean
+ key: "Student"
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/icdar2015/text_localization/
+ label_file_list:
+ - ./train_data/icdar2015/text_localization/train_icdar2015_label.txt
+ ratio_list: [1.0]
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - DetLabelEncode: null
+ - CopyPaste:
+ - IaaAugment:
+ augmenter_args:
+ - type: Fliplr
+ args:
+ p: 0.5
+ - type: Affine
+ args:
+ rotate:
+ - -10
+ - 10
+ - type: Resize
+ args:
+ size:
+ - 0.5
+ - 3
+ - EastRandomCropData:
+ size:
+ - 960
+ - 960
+ max_tries: 50
+ keep_ratio: true
+ - MakeBorderMap:
+ shrink_ratio: 0.4
+ thresh_min: 0.3
+ thresh_max: 0.7
+ - MakeShrinkMap:
+ shrink_ratio: 0.4
+ min_text_size: 8
+ - NormalizeImage:
+ scale: 1./255.
+ mean:
+ - 0.485
+ - 0.456
+ - 0.406
+ std:
+ - 0.229
+ - 0.224
+ - 0.225
+ order: hwc
+ - ToCHWImage: null
+ - KeepKeys:
+ keep_keys:
+ - image
+ - threshold_map
+ - threshold_mask
+ - shrink_map
+ - shrink_mask
+ loader:
+ shuffle: true
+ drop_last: false
+ batch_size_per_card: 8
+ num_workers: 4
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/icdar2015/text_localization/
+ label_file_list:
+ - ./train_data/icdar2015/text_localization/test_icdar2015_label.txt
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - DetLabelEncode: null
+ - DetResizeForTest: null
+ - NormalizeImage:
+ scale: 1./255.
+ mean:
+ - 0.485
+ - 0.456
+ - 0.406
+ std:
+ - 0.229
+ - 0.224
+ - 0.225
+ order: hwc
+ - ToCHWImage: null
+ - KeepKeys:
+ keep_keys:
+ - image
+ - shape
+ - polys
+ - ignore_tags
+ loader:
+ shuffle: false
+ drop_last: false
+ batch_size_per_card: 1
+ num_workers: 2
diff --git a/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml b/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml
new file mode 100644
index 0000000000000000000000000000000000000000..0e8af776479ea26f834ca9ddc169f80b3982e86d
--- /dev/null
+++ b/configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml
@@ -0,0 +1,163 @@
+Global:
+ debug: false
+ use_gpu: true
+ epoch_num: 500
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/ch_PP-OCR_V3_det/
+ save_epoch_step: 100
+ eval_batch_step:
+ - 0
+ - 400
+ cal_metric_during_train: false
+ pretrained_model: null
+ checkpoints: null
+ save_inference_dir: null
+ use_visualdl: false
+ infer_img: doc/imgs_en/img_10.jpg
+ save_res_path: ./checkpoints/det_db/predicts_db.txt
+ distributed: true
+
+Architecture:
+ model_type: det
+ algorithm: DB
+ Transform:
+ Backbone:
+ name: MobileNetV3
+ scale: 0.5
+ model_name: large
+ disable_se: True
+ Neck:
+ name: RSEFPN
+ out_channels: 96
+ shortcut: True
+ Head:
+ name: DBHead
+ k: 50
+
+Loss:
+ name: DBLoss
+ balance_loss: true
+ main_loss_type: DiceLoss
+ alpha: 5
+ beta: 10
+ ohem_ratio: 3
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.999
+ lr:
+ name: Cosine
+ learning_rate: 0.001
+ warmup_epoch: 2
+ regularizer:
+ name: L2
+ factor: 5.0e-05
+PostProcess:
+ name: DBPostProcess
+ thresh: 0.3
+ box_thresh: 0.6
+ max_candidates: 1000
+ unclip_ratio: 1.5
+Metric:
+ name: DetMetric
+ main_indicator: hmean
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/icdar2015/text_localization/
+ label_file_list:
+ - ./train_data/icdar2015/text_localization/train_icdar2015_label.txt
+ ratio_list: [1.0]
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - DetLabelEncode: null
+ - IaaAugment:
+ augmenter_args:
+ - type: Fliplr
+ args:
+ p: 0.5
+ - type: Affine
+ args:
+ rotate:
+ - -10
+ - 10
+ - type: Resize
+ args:
+ size:
+ - 0.5
+ - 3
+ - EastRandomCropData:
+ size:
+ - 960
+ - 960
+ max_tries: 50
+ keep_ratio: true
+ - MakeBorderMap:
+ shrink_ratio: 0.4
+ thresh_min: 0.3
+ thresh_max: 0.7
+ - MakeShrinkMap:
+ shrink_ratio: 0.4
+ min_text_size: 8
+ - NormalizeImage:
+ scale: 1./255.
+ mean:
+ - 0.485
+ - 0.456
+ - 0.406
+ std:
+ - 0.229
+ - 0.224
+ - 0.225
+ order: hwc
+ - ToCHWImage: null
+ - KeepKeys:
+ keep_keys:
+ - image
+ - threshold_map
+ - threshold_mask
+ - shrink_map
+ - shrink_mask
+ loader:
+ shuffle: true
+ drop_last: false
+ batch_size_per_card: 8
+ num_workers: 4
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/icdar2015/text_localization/
+ label_file_list:
+ - ./train_data/icdar2015/text_localization/test_icdar2015_label.txt
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - DetLabelEncode: null
+ - DetResizeForTest: null
+ - NormalizeImage:
+ scale: 1./255.
+ mean:
+ - 0.485
+ - 0.456
+ - 0.406
+ std:
+ - 0.229
+ - 0.224
+ - 0.225
+ order: hwc
+ - ToCHWImage: null
+ - KeepKeys:
+ keep_keys:
+ - image
+ - shape
+ - polys
+ - ignore_tags
+ loader:
+ shuffle: false
+ drop_last: false
+ batch_size_per_card: 1
+ num_workers: 2
diff --git a/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml b/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
similarity index 100%
rename from configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml
rename to configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
diff --git a/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml b/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
similarity index 100%
rename from configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
rename to configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
diff --git a/doc/doc_ch/docvqa_datasets.md b/configs/rec/PP-OCRv3/multi_language/.gitkeep
similarity index 100%
rename from doc/doc_ch/docvqa_datasets.md
rename to configs/rec/PP-OCRv3/multi_language/.gitkeep
diff --git a/deploy/slim/quantization/export_model.py b/deploy/slim/quantization/export_model.py
index 90f79dab34a5f20d4556ae4b10ad1d4e1f8b7f0d..fd1c3e5e109667fa74f5ade18b78f634e4d325db 100755
--- a/deploy/slim/quantization/export_model.py
+++ b/deploy/slim/quantization/export_model.py
@@ -17,9 +17,9 @@ import sys
__dir__ = os.path.dirname(os.path.abspath(__file__))
sys.path.append(__dir__)
-sys.path.append(os.path.abspath(os.path.join(__dir__, '..', '..', '..')))
-sys.path.append(
- os.path.abspath(os.path.join(__dir__, '..', '..', '..', 'tools')))
+sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '..', '..', '..')))
+sys.path.insert(
+ 0, os.path.abspath(os.path.join(__dir__, '..', '..', '..', 'tools')))
import argparse
@@ -129,7 +129,6 @@ def main():
quanter.quantize(model)
load_model(config, model)
- model.eval()
# build metric
eval_class = build_metric(config['Metric'])
@@ -142,6 +141,7 @@ def main():
# start eval
metric = program.eval(model, valid_dataloader, post_process_class,
eval_class, model_type, use_srn)
+ model.eval()
logger.info('metric eval ***************')
for k, v in metric.items():
@@ -156,7 +156,6 @@ def main():
if arch_config["algorithm"] in ["Distillation", ]: # distillation model
archs = list(arch_config["Models"].values())
for idx, name in enumerate(model.model_name_list):
- model.model_list[idx].eval()
sub_model_save_path = os.path.join(save_path, name, "inference")
export_single_model(model.model_list[idx], archs[idx],
sub_model_save_path, logger, quanter)
diff --git a/doc/datasets/funsd_demo/gt_train_00040534.jpg b/doc/datasets/funsd_demo/gt_train_00040534.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..9f7cf4d4977689b73e2ca91cbe9c877bb8f0c7ff
Binary files /dev/null and b/doc/datasets/funsd_demo/gt_train_00040534.jpg differ
diff --git a/doc/datasets/funsd_demo/gt_train_00070353.jpg b/doc/datasets/funsd_demo/gt_train_00070353.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..36d3345e5ec4c262764e63a972aaa82e98877681
Binary files /dev/null and b/doc/datasets/funsd_demo/gt_train_00070353.jpg differ
diff --git a/doc/datasets/table_PubTabNet_demo/PMC524509_007_00.png b/doc/datasets/table_PubTabNet_demo/PMC524509_007_00.png
new file mode 100755
index 0000000000000000000000000000000000000000..5b9d631cba434e4bd6ac6fe2108b7f6c081c4811
Binary files /dev/null and b/doc/datasets/table_PubTabNet_demo/PMC524509_007_00.png differ
diff --git a/doc/datasets/table_PubTabNet_demo/PMC535543_007_01.png b/doc/datasets/table_PubTabNet_demo/PMC535543_007_01.png
new file mode 100755
index 0000000000000000000000000000000000000000..e808de72d62325ae4cbd009397b7beaeed0d88fc
Binary files /dev/null and b/doc/datasets/table_PubTabNet_demo/PMC535543_007_01.png differ
diff --git a/doc/datasets/table_tal_demo/1.jpg b/doc/datasets/table_tal_demo/1.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e7ddd6d1db59ca27a0461ab93b3672aeec4a8941
Binary files /dev/null and b/doc/datasets/table_tal_demo/1.jpg differ
diff --git a/doc/datasets/table_tal_demo/2.jpg b/doc/datasets/table_tal_demo/2.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e7ddd6d1db59ca27a0461ab93b3672aeec4a8941
Binary files /dev/null and b/doc/datasets/table_tal_demo/2.jpg differ
diff --git a/doc/datasets/xfund_demo/gt_zh_train_0.jpg b/doc/datasets/xfund_demo/gt_zh_train_0.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6fdaf12fa1d79e6ea9029d665ab7488223459436
Binary files /dev/null and b/doc/datasets/xfund_demo/gt_zh_train_0.jpg differ
diff --git a/doc/datasets/xfund_demo/gt_zh_train_1.jpg b/doc/datasets/xfund_demo/gt_zh_train_1.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6a1e53a3ba09b6f84809cfd10a15c42f42b9a163
Binary files /dev/null and b/doc/datasets/xfund_demo/gt_zh_train_1.jpg differ
diff --git a/doc/doc_ch/algorithm_det_fcenet.md b/doc/doc_ch/algorithm_det_fcenet.md
new file mode 100644
index 0000000000000000000000000000000000000000..bd2e734204d32bbf575ddea9f889953a72582c59
--- /dev/null
+++ b/doc/doc_ch/algorithm_det_fcenet.md
@@ -0,0 +1,104 @@
+# FCENet
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Fourier Contour Embedding for Arbitrary-Shaped Text Detection](https://arxiv.org/abs/2104.10442)
+> Yiqin Zhu and Jianyong Chen and Lingyu Liang and Zhanghui Kuang and Lianwen Jin and Wayne Zhang
+> CVPR, 2021
+
+在CTW1500文本检测公开数据集上,算法复现效果如下:
+
+| 模型 |骨干网络|配置文件|precision|recall|Hmean|下载链接|
+|-----| --- | --- | --- | --- | --- | --- |
+| FCE | ResNet50_dcn | [configs/det/det_r50_vd_dcn_fce_ctw.yml](../../configs/det/det_r50_vd_dcn_fce_ctw.yml)| 88.39%|82.18%|85.27%|[训练模型](https://paddleocr.bj.bcebos.com/contribution/det_r50_dcn_fce_ctw_v2.0_train.tar)|
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+上述FCE模型使用CTW1500文本检测公开数据集训练得到,数据集下载可参考 [ocr_datasets](./dataset/ocr_datasets.md)。
+
+数据下载完成后,请参考[文本检测训练教程](./detection.md)进行训练。PaddleOCR对代码进行了模块化,训练不同的检测模型只需要**更换配置文件**即可。
+
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将FCE文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd_dcn骨干网络,在CTW1500英文数据集训练的模型为例( [模型下载地址](https://paddleocr.bj.bcebos.com/contribution/det_r50_dcn_fce_ctw_v2.0_train.tar) ),可以使用如下命令进行转换:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_dcn_fce_ctw.yml -o Global.pretrained_model=./det_r50_dcn_fce_ctw_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_fce
+```
+
+FCE文本检测模型推理,执行非弯曲文本检测,可以执行如下命令:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_fce/" --det_algorithm="FCE" --det_fce_box_type=quad
+```
+
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+如果想执行弯曲文本检测,可以执行如下命令:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_fce/" --det_algorithm="FCE" --det_fce_box_type=poly
+```
+
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+**注意**:由于CTW1500数据集只有1000张训练图像,且主要针对英文场景,所以上述模型对中文文本图像检测效果会比较差。
+
+
+### 4.2 C++推理
+
+由于后处理暂未使用CPP编写,FCE文本检测模型暂不支持CPP推理。
+
+
+### 4.3 Serving服务化部署
+
+暂未支持
+
+
+### 4.4 更多推理部署
+
+暂未支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@InProceedings{zhu2021fourier,
+ title={Fourier Contour Embedding for Arbitrary-Shaped Text Detection},
+ author={Yiqin Zhu and Jianyong Chen and Lingyu Liang and Zhanghui Kuang and Lianwen Jin and Wayne Zhang},
+ year={2021},
+ booktitle = {CVPR}
+}
+```
diff --git a/doc/doc_ch/algorithm_det_psenet.md b/doc/doc_ch/algorithm_det_psenet.md
new file mode 100644
index 0000000000000000000000000000000000000000..58d8ccf97292f4e988861b618697fb0e7694fbab
--- /dev/null
+++ b/doc/doc_ch/algorithm_det_psenet.md
@@ -0,0 +1,106 @@
+# PSENet
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Shape robust text detection with progressive scale expansion network](https://arxiv.org/abs/1903.12473)
+> Wang, Wenhai and Xie, Enze and Li, Xiang and Hou, Wenbo and Lu, Tong and Yu, Gang and Shao, Shuai
+> CVPR, 2019
+
+在ICDAR2015文本检测公开数据集上,算法复现效果如下:
+
+|模型|骨干网络|配置文件|precision|recall|Hmean|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|PSE| ResNet50_vd | [configs/det/det_r50_vd_pse.yml](../../configs/det/det_r50_vd_pse.yml)| 85.81% |79.53%|82.55%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_r50_vd_pse_v2.0_train.tar)|
+|PSE| MobileNetV3| [configs/det/det_mv3_pse.yml](../../configs/det/det_mv3_pse.yml) | 82.20% |70.48%|75.89%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_mv3_pse_v2.0_train.tar)|
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+上述PSE模型使用ICDAR2015文本检测公开数据集训练得到,数据集下载可参考 [ocr_datasets](./dataset/ocr_datasets.md)。
+
+数据下载完成后,请参考[文本检测训练教程](./detection.md)进行训练。PaddleOCR对代码进行了模块化,训练不同的检测模型只需要**更换配置文件**即可。
+
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将PSE文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在ICDAR2015英文数据集训练的模型为例( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_r50_vd_pse_v2.0_train.tar) ),可以使用如下命令进行转换:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_pse.yml -o Global.pretrained_model=./det_r50_vd_pse_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_pse
+```
+
+PSE文本检测模型推理,执行非弯曲文本检测,可以执行如下命令:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_pse/" --det_algorithm="PSE" --det_pse_box_type=quad
+```
+
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+如果想执行弯曲文本检测,可以执行如下命令:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_pse/" --det_algorithm="PSE" --det_pse_box_type=poly
+```
+
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+**注意**:由于ICDAR2015数据集只有1000张训练图像,且主要针对英文场景,所以上述模型对中文或弯曲文本图像检测效果会比较差。
+
+
+### 4.2 C++推理
+
+由于后处理暂未使用CPP编写,PSE文本检测模型暂不支持CPP推理。
+
+
+### 4.3 Serving服务化部署
+
+暂未支持
+
+
+### 4.4 更多推理部署
+
+暂未支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@inproceedings{wang2019shape,
+ title={Shape robust text detection with progressive scale expansion network},
+ author={Wang, Wenhai and Xie, Enze and Li, Xiang and Hou, Wenbo and Lu, Tong and Yu, Gang and Shao, Shuai},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={9336--9345},
+ year={2019}
+}
+```
diff --git a/doc/doc_ch/algorithm_det_sast.md b/doc/doc_ch/algorithm_det_sast.md
new file mode 100644
index 0000000000000000000000000000000000000000..038d73fc15f3203bbcc17997c1a8e1c208f80ba8
--- /dev/null
+++ b/doc/doc_ch/algorithm_det_sast.md
@@ -0,0 +1,115 @@
+# SAST
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning](https://arxiv.org/abs/1908.05498)
+> Wang, Pengfei and Zhang, Chengquan and Qi, Fei and Huang, Zuming and En, Mengyi and Han, Junyu and Liu, Jingtuo and Ding, Errui and Shi, Guangming
+> ACM MM, 2019
+
+在ICDAR2015文本检测公开数据集上,算法复现效果如下:
+
+|模型|骨干网络|配置文件|precision|recall|Hmean|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|SAST|ResNet50_vd|[configs/det/det_r50_vd_sast_icdar15.yml](../../configs/det/det_r50_vd_sast_icdar15.yml)|91.39%|83.77%|87.42%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_icdar15_v2.0_train.tar)|
+
+
+在Total-text文本检测公开数据集上,算法复现效果如下:
+
+|模型|骨干网络|配置文件|precision|recall|Hmean|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|SAST|ResNet50_vd|[configs/det/det_r50_vd_sast_totaltext.yml](../../configs/det/det_r50_vd_sast_totaltext.yml)|89.63%|78.44%|83.66%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_totaltext_v2.0_train.tar)|
+
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本检测训练教程](./detection.md)。PaddleOCR对代码进行了模块化,训练不同的检测模型只需要**更换配置文件**即可。
+
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+#### (1). 四边形文本检测模型(ICDAR2015)
+首先将SAST文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在ICDAR2015英文数据集训练的模型为例([模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_icdar15_v2.0_train.tar)),可以使用如下命令进行转换:
+```
+python3 tools/export_model.py -c configs/det/det_r50_vd_sast_icdar15.yml -o Global.pretrained_model=./det_r50_vd_sast_icdar15_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_sast_ic15
+
+```
+**SAST文本检测模型推理,需要设置参数`--det_algorithm="SAST"`**,可以执行如下命令:
+```
+python3 tools/infer/predict_det.py --det_algorithm="SAST" --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_sast_ic15/"
+```
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+#### (2). 弯曲文本检测模型(Total-Text)
+首先将SAST文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在Total-Text英文数据集训练的模型为例([模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_totaltext_v2.0_train.tar)),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/det/det_r50_vd_sast_totaltext.yml -o Global.pretrained_model=./det_r50_vd_sast_totaltext_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_sast_tt
+
+```
+
+SAST文本检测模型推理,需要设置参数`--det_algorithm="SAST"`,同时,还需要增加参数`--det_sast_polygon=True`,可以执行如下命令:
+```
+python3 tools/infer/predict_det.py --det_algorithm="SAST" --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_sast_tt/" --det_sast_polygon=True
+```
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+**注意**:本代码库中,SAST后处理Locality-Aware NMS有python和c++两种版本,c++版速度明显快于python版。由于c++版本nms编译版本问题,只有python3.5环境下会调用c++版nms,其他情况将调用python版nms。
+
+
+### 4.2 C++推理
+
+暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂未支持
+
+
+### 4.4 更多推理部署
+
+暂未支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@inproceedings{wang2019single,
+ title={A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning},
+ author={Wang, Pengfei and Zhang, Chengquan and Qi, Fei and Huang, Zuming and En, Mengyi and Han, Junyu and Liu, Jingtuo and Ding, Errui and Shi, Guangming},
+ booktitle={Proceedings of the 27th ACM International Conference on Multimedia},
+ pages={1277--1285},
+ year={2019}
+}
+```
diff --git a/doc/doc_ch/algorithm_rec_sar.md b/doc/doc_ch/algorithm_rec_sar.md
new file mode 100644
index 0000000000000000000000000000000000000000..b8304313994754480a89d708e39149d67f828c0d
--- /dev/null
+++ b/doc/doc_ch/algorithm_rec_sar.md
@@ -0,0 +1,114 @@
+# SAR
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition](https://arxiv.org/abs/1811.00751)
+> Hui Li, Peng Wang, Chunhua Shen, Guyu Zhang
+> AAAI, 2019
+
+使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法复现效果如下:
+
+|模型|骨干网络|配置文件|Acc|下载链接|
+| --- | --- | --- | --- | --- |
+|SAR|ResNet31|[rec_r31_sar.yml](../../configs/rec/rec_r31_sar.yml)|87.20%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar)|
+
+注:除了使用MJSynth和SynthText两个文字识别数据集外,还加入了[SynthAdd](https://pan.baidu.com/share/init?surl=uV0LtoNmcxbO-0YA7Ch4dg)数据(提取码:627x),和部分真实数据,具体数据细节可以参考论文。
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本识别教程](./recognition.md)。PaddleOCR对代码进行了模块化,训练不同的识别模型只需要**更换配置文件**即可。
+
+训练
+
+具体地,在完成数据准备后,便可以启动训练,训练命令如下:
+
+```
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/rec_r31_sar.yml
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r31_sar.yml
+```
+
+评估
+
+```
+# GPU 评估, Global.pretrained_model 为待测权重
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+预测:
+
+```
+# 预测使用的配置文件必须与训练一致
+python3 tools/infer_rec.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将SAR文本识别训练过程中保存的模型,转换成inference model。( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar) ),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model=./rec_r31_sar_train/best_accuracy Global.save_inference_dir=./inference/rec_sar
+```
+
+SAR文本识别模型推理,可以执行如下命令:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_sar/" --rec_image_shape="3, 48, 48, 160" --rec_char_type="ch" --rec_algorithm="SAR" --rec_char_dict_path="ppocr/utils/dict90.txt" --max_text_length=30 --use_space_char=False
+```
+
+
+### 4.2 C++推理
+
+由于C++预处理后处理还未支持SAR,所以暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂不支持
+
+
+### 4.4 更多推理部署
+
+暂不支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@article{Li2019ShowAA,
+ title={Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition},
+ author={Hui Li and Peng Wang and Chunhua Shen and Guyu Zhang},
+ journal={ArXiv},
+ year={2019},
+ volume={abs/1811.00751}
+}
+```
diff --git a/doc/doc_ch/algorithm_rec_srn.md b/doc/doc_ch/algorithm_rec_srn.md
new file mode 100644
index 0000000000000000000000000000000000000000..ca7961359eb902fafee959b26d02f324aece233a
--- /dev/null
+++ b/doc/doc_ch/algorithm_rec_srn.md
@@ -0,0 +1,113 @@
+# SRN
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Towards Accurate Scene Text Recognition with Semantic Reasoning Networks](https://arxiv.org/abs/2003.12294#)
+> Deli Yu, Xuan Li, Chengquan Zhang, Junyu Han, Jingtuo Liu, Errui Ding
+> CVPR,2020
+
+使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法复现效果如下:
+
+|模型|骨干网络|配置文件|Acc|下载链接|
+| --- | --- | --- | --- | --- |
+|SRN|Resnet50_vd_fpn|[rec_r50_fpn_srn.yml](../../configs/rec/rec_r50_fpn_srn.yml)|86.31%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar)|
+
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本识别教程](./recognition.md)。PaddleOCR对代码进行了模块化,训练不同的识别模型只需要**更换配置文件**即可。
+
+训练
+
+具体地,在完成数据准备后,便可以启动训练,训练命令如下:
+
+```
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+```
+
+评估
+
+```
+# GPU 评估, Global.pretrained_model 为待测权重
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+预测:
+
+```
+# 预测使用的配置文件必须与训练一致
+python3 tools/infer_rec.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将SRN文本识别训练过程中保存的模型,转换成inference model。( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar) ),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model=./rec_r50_vd_srn_train/best_accuracy Global.save_inference_dir=./inference/rec_srn
+```
+
+SRN文本识别模型推理,可以执行如下命令:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_srn/" --rec_image_shape="1,64,256" --rec_char_type="ch" --rec_algorithm="SRN" --rec_char_dict_path=./ppocr/utils/ic15_dict.txt --use_space_char=False
+```
+
+
+### 4.2 C++推理
+
+由于C++预处理后处理还未支持SRN,所以暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂不支持
+
+
+### 4.4 更多推理部署
+
+暂不支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@article{Yu2020TowardsAS,
+ title={Towards Accurate Scene Text Recognition With Semantic Reasoning Networks},
+ author={Deli Yu and Xuan Li and Chengquan Zhang and Junyu Han and Jingtuo Liu and Errui Ding},
+ journal={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year={2020},
+ pages={12110-12119}
+}
+```
diff --git a/doc/doc_ch/datasets.md b/doc/doc_ch/dataset/datasets.md
similarity index 90%
rename from doc/doc_ch/datasets.md
rename to doc/doc_ch/dataset/datasets.md
index d365fd711aff2dffcd30dd06028734cc707d5df0..aad4f50b2d8baa369cf6f2576a24127a23cb5c48 100644
--- a/doc/doc_ch/datasets.md
+++ b/doc/doc_ch/dataset/datasets.md
@@ -6,17 +6,17 @@
- [中文文档文字识别](#中文文档文字识别)
- [ICDAR2019-ArT](#ICDAR2019-ArT)
-除了开源数据,用户还可使用合成工具自行合成,可参考[数据合成工具](./data_synthesis.md);
+除了开源数据,用户还可使用合成工具自行合成,可参考[数据合成工具](../data_synthesis.md);
-如果需要标注自己的数据,可参考[数据标注工具](./data_annotation.md)。
+如果需要标注自己的数据,可参考[数据标注工具](../data_annotation.md)。
#### 1、ICDAR2019-LSVT
- **数据来源**:https://ai.baidu.com/broad/introduction?dataset=lsvt
- **数据简介**: 共45w中文街景图像,包含5w(2w测试+3w训练)全标注数据(文本坐标+文本内容),40w弱标注数据(仅文本内容),如下图所示:
- 
+ 
(a) 全标注数据
- 
+ 
(b) 弱标注数据
- **下载地址**:https://ai.baidu.com/broad/download?dataset=lsvt
- **说明**:其中,test数据集的label目前没有开源,如要评估结果,可以去官网提交:https://rrc.cvc.uab.es/?ch=16
@@ -25,16 +25,16 @@
#### 2、ICDAR2017-RCTW-17
- **数据来源**:https://rctw.vlrlab.net/
- **数据简介**:共包含12,000+图像,大部分图片是通过手机摄像头在野外采集的。有些是截图。这些图片展示了各种各样的场景,包括街景、海报、菜单、室内场景和手机应用程序的截图。
- 
+ 
- **下载地址**:https://rctw.vlrlab.net/dataset/
-#### 3、中文街景文字识别
+#### 3、中文街景文字识别
- **数据来源**:https://aistudio.baidu.com/aistudio/competition/detail/8
- **数据简介**:ICDAR2019-LSVT行识别任务,共包括29万张图片,其中21万张图片作为训练集(带标注),8万张作为测试集(无标注)。数据集采自中国街景,并由街景图片中的文字行区域(例如店铺标牌、地标等等)截取出来而形成。所有图像都经过一些预处理,将文字区域利用仿射变化,等比映射为一张高为48像素的图片,如图所示:
- 
+ 
(a) 标注:魅派集成吊顶
- 
+ 
(b) 标注:母婴用品连锁
- **下载地址**
https://aistudio.baidu.com/aistudio/datasetdetail/8429
@@ -48,15 +48,15 @@ https://aistudio.baidu.com/aistudio/datasetdetail/8429
- 包含汉字、英文字母、数字和标点共5990个字符(字符集合:https://github.com/YCG09/chinese_ocr/blob/master/train/char_std_5990.txt )
- 每个样本固定10个字符,字符随机截取自语料库中的句子
- 图片分辨率统一为280x32
- 
- 
+ 
+ 
- **下载地址**:https://pan.baidu.com/s/1QkI7kjah8SPHwOQ40rS1Pw (密码:lu7m)
#### 5、ICDAR2019-ArT
- **数据来源**:https://ai.baidu.com/broad/introduction?dataset=art
- **数据简介**:共包含10,166张图像,训练集5603图,测试集4563图。由Total-Text、SCUT-CTW1500、Baidu Curved Scene Text (ICDAR2019-LSVT部分弯曲数据) 三部分组成,包含水平、多方向和弯曲等多种形状的文本。
- 
+ 
- **下载地址**:https://ai.baidu.com/broad/download?dataset=art
## 参考文献
diff --git a/doc/doc_ch/dataset/docvqa_datasets.md b/doc/doc_ch/dataset/docvqa_datasets.md
new file mode 100644
index 0000000000000000000000000000000000000000..3ec1865ee42be99ec19343428cd9ad6439686f15
--- /dev/null
+++ b/doc/doc_ch/dataset/docvqa_datasets.md
@@ -0,0 +1,27 @@
+## DocVQA数据集
+这里整理了常见的DocVQA数据集,持续更新中,欢迎各位小伙伴贡献数据集~
+- [FUNSD数据集](#funsd)
+- [XFUND数据集](#xfund)
+
+
+#### 1、FUNSD数据集
+- **数据来源**:https://guillaumejaume.github.io/FUNSD/
+- **数据简介**:FUNSD数据集是一个用于表单理解的数据集,它包含199张真实的、完全标注的扫描版图片,类型包括市场报告、广告以及学术报告等,并分为149张训练集以及50张测试集。FUNSD数据集适用于多种类型的DocVQA任务,如字段级实体分类、字段级实体连接等。部分图像以及标注框可视化如下所示:
+
+

+

+
+

+

+
+  +
+
+
+将下载到的数据集解压到工作目录下,假设解压在 PaddleOCR/train_data/下。然后从上表中下载转换好的标注文件。
+
+PaddleOCR 也提供了数据格式转换脚本,可以将官网 label 转换支持的数据格式。 数据转换工具在 `ppocr/utils/gen_label.py`, 这里以训练集为例:
+
+```
+# 将官网下载的标签文件转换为 train_icdar2015_label.txt
+python gen_label.py --mode="det" --root_path="/path/to/icdar_c4_train_imgs/" \
+ --input_path="/path/to/ch4_training_localization_transcription_gt" \
+ --output_label="/path/to/train_icdar2015_label.txt"
+```
+
+解压数据集和下载标注文件后,PaddleOCR/train_data/ 有两个文件夹和两个文件,按照如下方式组织icdar2015数据集:
+```
+/PaddleOCR/train_data/icdar2015/text_localization/
+ └─ icdar_c4_train_imgs/ icdar 2015 数据集的训练数据
+ └─ ch4_test_images/ icdar 2015 数据集的测试数据
+ └─ train_icdar2015_label.txt icdar 2015 数据集的训练标注
+ └─ test_icdar2015_label.txt icdar 2015 数据集的测试标注
+```
+
+## 2. 文本识别
+
+### 2.1 PaddleOCR 文字识别数据格式
+
+PaddleOCR 中的文字识别算法支持两种数据格式:
+
+ - `lmdb` 用于训练以lmdb格式存储的数据集,使用 [lmdb_dataset.py](../../../ppocr/data/lmdb_dataset.py) 进行读取;
+ - `通用数据` 用于训练以文本文件存储的数据集,使用 [simple_dataset.py](../../../ppocr/data/simple_dataset.py)进行读取。
+
+下面以通用数据集为例, 介绍如何准备数据集:
+
+* 训练集
+
+建议将训练图片放入同一个文件夹,并用一个txt文件(rec_gt_train.txt)记录图片路径和标签,txt文件里的内容如下:
+
+**注意:** txt文件中默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错。
+
+```
+" 图像文件名 图像标注信息 "
+
+train_data/rec/train/word_001.jpg 简单可依赖
+train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
+...
+```
+
+最终训练集应有如下文件结构:
+```
+|-train_data
+ |-rec
+ |- rec_gt_train.txt
+ |- train
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+```
+
+除上述单张图像为一行格式之外,PaddleOCR也支持对离线增广后的数据进行训练,为了防止相同样本在同一个batch中被多次采样,我们可以将相同标签对应的图片路径写在一行中,以列表的形式给出,在训练中,PaddleOCR会随机选择列表中的一张图片进行训练。对应地,标注文件的格式如下。
+
+```
+["11.jpg", "12.jpg"] 简单可依赖
+["21.jpg", "22.jpg", "23.jpg"] 用科技让复杂的世界更简单
+3.jpg ocr
+```
+
+上述示例标注文件中,"11.jpg"和"12.jpg"的标签相同,都是`简单可依赖`,在训练的时候,对于该行标注,会随机选择其中的一张图片进行训练。
+
+
+- 验证集
+
+同训练集类似,验证集也需要提供一个包含所有图片的文件夹(test)和一个rec_gt_test.txt,验证集的结构如下所示:
+
+```
+|-train_data
+ |-rec
+ |- rec_gt_test.txt
+ |- test
+ |- word_001.jpg
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+```
+
+
+### 2.2 公开数据集
+
+| 数据集名称 | 图片下载地址 | PaddleOCR 标注下载地址 |
+|---|---|---------------------------------------------------------------------|
+| en benchmark(MJ, SJ, IIIT, SVT, IC03, IC13, IC15, SVTP, and CUTE.) | [DTRB](https://github.com/clovaai/deep-text-recognition-benchmark#download-lmdb-dataset-for-traininig-and-evaluation-from-here) | LMDB格式,可直接用[lmdb_dataset.py](../../../ppocr/data/lmdb_dataset.py)加载 |
+|ICDAR 2015| http://rrc.cvc.uab.es/?ch=4&com=downloads | [train](https://paddleocr.bj.bcebos.com/dataset/rec_gt_train.txt)/ [test](https://paddleocr.bj.bcebos.com/dataset/rec_gt_test.txt) |
+| 多语言数据集 |[百度网盘](https://pan.baidu.com/s/1bS_u207Rm7YbY33wOECKDA) 提取码:frgi
[google drive](https://drive.google.com/file/d/18cSWX7wXSy4G0tbKJ0d9PuIaiwRLHpjA/view) | 图片下载地址中已包含 |
+
+#### 2.1 ICDAR 2015
+
+ICDAR 2015 数据集可以在上表中链接下载,用于快速验证。也可以从上表中下载 en benchmark 所需的lmdb格式数据集。
+
+下载完图片后从上表中下载转换好的标注文件。
+
+PaddleOCR 也提供了数据格式转换脚本,可以将ICDAR官网 label 转换为PaddleOCR支持的数据格式。 数据转换工具在 `ppocr/utils/gen_label.py`, 这里以训练集为例:
+
+```
+# 将官网下载的标签文件转换为 rec_gt_label.txt
+python gen_label.py --mode="rec" --input_path="{path/of/origin/label}" --output_label="rec_gt_label.txt"
+```
+
+数据样式格式如下,(a)为原始图片,(b)为每张图片对应的 Ground Truth 文本文件:
+
+
+
+## 3. 数据存放路径
+
+PaddleOCR训练数据的默认存储路径是 `PaddleOCR/train_data`,如果您的磁盘上已有数据集,只需创建软链接至数据集目录:
+
+```
+# linux and mac os
+ln -sf /train_data/dataset
+# windows
+mklink /d /train_data/dataset
+```
diff --git a/doc/doc_ch/dataset/table_datasets.md b/doc/doc_ch/dataset/table_datasets.md
new file mode 100644
index 0000000000000000000000000000000000000000..ae902b23ccf985d522386b7454c7f76a74917502
--- /dev/null
+++ b/doc/doc_ch/dataset/table_datasets.md
@@ -0,0 +1,33 @@
+# 表格识别数据集
+
+- [数据集汇总](#数据集汇总)
+- [1. PubTabNet数据集](#1-pubtabnet数据集)
+- [2. 好未来表格识别竞赛数据集](#2-好未来表格识别竞赛数据集)
+
+这里整理了常用表格识别数据集,持续更新中,欢迎各位小伙伴贡献数据集~
+
+## 数据集汇总
+
+| 数据集名称 |图片下载地址| PPOCR标注下载地址 |
+|---|---|---|
+| PubTabNet |https://github.com/ibm-aur-nlp/PubTabNet| jsonl格式,可直接用[pubtab_dataset.py](../../../ppocr/data/pubtab_dataset.py)加载 |
+| 好未来表格识别竞赛数据集 |https://ai.100tal.com/dataset| jsonl格式,可直接用[pubtab_dataset.py](../../../ppocr/data/pubtab_dataset.py)加载 |
+
+## 1. PubTabNet数据集
+- **数据简介**:PubTabNet数据集的训练集合中包含50万张图像,验证集合中包含0.9万张图像。部分图像可视化如下所示。
+
+
+
+

+

+
+

+

+
-  -
-
+## 1.1 准备数据集
-将下载到的数据集解压到工作目录下,假设解压在 PaddleOCR/train_data/下。另外,PaddleOCR将零散的标注文件整理成单独的标注文件
-,您可以通过wget的方式进行下载。
-```shell
-# 在PaddleOCR路径下
-cd PaddleOCR/
-wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/train_icdar2015_label.txt
-wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/test_icdar2015_label.txt
-```
+准备数据集可参考 [ocr_datasets](./dataset/ocr_datasets.md) 。
-PaddleOCR 也提供了数据格式转换脚本,可以将官网 label 转换支持的数据格式。 数据转换工具在 `ppocr/utils/gen_label.py`, 这里以训练集为例:
-
-```
-# 将官网下载的标签文件转换为 train_icdar2015_label.txt
-python gen_label.py --mode="det" --root_path="/path/to/icdar_c4_train_imgs/" \
- --input_path="/path/to/ch4_training_localization_transcription_gt" \
- --output_label="/path/to/train_icdar2015_label.txt"
-```
-
-解压数据集和下载标注文件后,PaddleOCR/train_data/ 有两个文件夹和两个文件,按照如下方式组织icdar2015数据集:
-```
-/PaddleOCR/train_data/icdar2015/text_localization/
- └─ icdar_c4_train_imgs/ icdar数据集的训练数据
- └─ ch4_test_images/ icdar数据集的测试数据
- └─ train_icdar2015_label.txt icdar数据集的训练标注
- └─ test_icdar2015_label.txt icdar数据集的测试标注
-```
-
-提供的标注文件格式如下,中间用"\t"分隔:
-```
-" 图像文件名 json.dumps编码的图像标注信息"
-ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
-```
-json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 `points` 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。
-`transcription` 表示当前文本框的文字,**当其内容为“###”时,表示该文本框无效,在训练时会跳过。**
-
-如果您想在其他数据集上训练,可以按照上述形式构建标注文件。
## 1.2 下载预训练模型
@@ -178,7 +134,7 @@ args1: args1
## 2.4 混合精度训练
如果您想进一步加快训练速度,可以使用[自动混合精度训练](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/01_paddle2.0_introduction/basic_concept/amp_cn.html), 以单机单卡为例,命令如下:
-
+
```shell
python3 tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained \
@@ -197,7 +153,7 @@ python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1
**注意:** 采用多机多卡训练时,需要替换上面命令中的ips值为您机器的地址,机器之间需要能够相互ping通。另外,训练时需要在多个机器上分别启动命令。查看机器ip地址的命令为`ifconfig`。
-
+
## 2.6 知识蒸馏训练
@@ -211,12 +167,16 @@ PaddleOCR支持了基于知识蒸馏的检测模型训练过程,更多内容
## 2.7 其他训练环境
- Windows GPU/CPU
-
+在Windows平台上与Linux平台略有不同:
+Windows平台只支持`单卡`的训练与预测,指定GPU进行训练`set CUDA_VISIBLE_DEVICES=0`
+在Windows平台,DataLoader只支持单进程模式,因此需要设置 `num_workers` 为0;
+
- macOS
-
+不支持GPU模式,需要在配置文件中设置`use_gpu`为False,其余训练评估预测命令与Linux GPU完全相同。
+
- Linux DCU
-
-
+DCU设备上运行需要设置环境变量 `export HIP_VISIBLE_DEVICES=0,1,2,3`,其余训练评估预测命令与Linux GPU完全相同。
+
# 3. 模型评估与预测
diff --git a/doc/doc_ch/models_list.md b/doc/doc_ch/models_list.md
index dbe244fe305af6cf5fd8ecdfb3263be7c3f7a02d..1a30aadb366be1329281309417994386d4dd64a2 100644
--- a/doc/doc_ch/models_list.md
+++ b/doc/doc_ch/models_list.md
@@ -1,13 +1,16 @@
-# PP-OCR系列模型列表(V2.1,2021年9月6日更新)
+# PP-OCR系列模型列表(V3,2022年4月28日更新)
> **说明**
-> 1. 2.1版模型相比2.0版模型,2.1的模型在模型精度上做了提升
-> 2. 2.0版模型和[1.1版模型](https://github.com/PaddlePaddle/PaddleOCR/blob/develop/doc/doc_ch/models_list.md) 的主要区别在于动态图训练vs.静态图训练,模型性能上无明显差距。
+> 1. V3版模型相比V2版模型,在模型精度上有进一步提升
+> 2. 2.0+版模型和[1.1版模型](https://github.com/PaddlePaddle/PaddleOCR/blob/develop/doc/doc_ch/models_list.md) 的主要区别在于动态图训练vs.静态图训练,模型性能上无明显差距。
> 3. 本文档提供的是PPOCR自研模型列表,更多基于公开数据集的算法介绍与预训练模型可以参考:[算法概览文档](./algorithm_overview.md)。
-- [PP-OCR系列模型列表(V2.1,2021年9月6日更新)](#pp-ocr系列模型列表v212021年9月6日更新)
+- PP-OCR系列模型列表(V3,2022年4月28日更新)
- [1. 文本检测模型](#1-文本检测模型)
+ - [1.1 中文检测模型](#1.1)
+ - [2.2 英文检测模型](#1.2)
+ - [1.3 多语言检测模型](#1.3)
- [2. 文本识别模型](#2-文本识别模型)
- [2.1 中文识别模型](#21-中文识别模型)
- [2.2 英文识别模型](#22-英文识别模型)
@@ -32,14 +35,42 @@ PaddleOCR提供的可下载模型包括`推理模型`、`训练模型`、`预训
## 1. 文本检测模型
+
+
+### 1.1 中文检测模型
+
|模型名称|模型简介|配置文件|推理模型大小|下载地址|
| --- | --- | --- | --- | --- |
-|ch_PP-OCRv2_det_slim|【最新】slim量化+蒸馏版超轻量模型,支持中英文、多语种文本检测|[ch_PP-OCRv2_det_cml.yml](../../configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml)| 3M |[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar)|
-|ch_PP-OCRv2_det|【最新】原始超轻量模型,支持中英文、多语种文本检测|[ch_PP-OCRv2_det_cml.yml](../../configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml)|3M|[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar)|
+|ch_PP-OCRv3_det_slim|【最新】slim量化+蒸馏版超轻量模型,支持中英文、多语种文本检测|[ch_PP-OCRv3_det_cml.yml](../../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml)| 1.1M |[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_slim_infer.tar) / [训练模型(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_slim_distill_train.tar) / [lite模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_slim_infer.nb)|
+|ch_PP-OCRv3_det| 【最新】原始超轻量模型,支持中英文、多语种文本检测 |[ch_PP-OCRv3_det_cml.yml](../../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml)| 3.8M |[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar)|
+|ch_PP-OCRv2_det_slim| slim量化+蒸馏版超轻量模型,支持中英文、多语种文本检测|[ch_PP-OCRv2_det_cml.yml](../../configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml)| 3M |[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar)|
+|ch_PP-OCRv2_det| 原始超轻量模型,支持中英文、多语种文本检测|[ch_PP-OCRv2_det_cml.yml](../../configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml)|3M|[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar)|
|ch_ppocr_mobile_slim_v2.0_det|slim裁剪版超轻量模型,支持中英文、多语种文本检测|[ch_det_mv3_db_v2.0.yml](../../configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml)| 2.6M |[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/slim/ch_ppocr_mobile_v2.0_det_prune_infer.tar)|
|ch_ppocr_mobile_v2.0_det|原始超轻量模型,支持中英文、多语种文本检测|[ch_det_mv3_db_v2.0.yml](../../configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml)|3M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar)|
|ch_ppocr_server_v2.0_det|通用模型,支持中英文、多语种文本检测,比超轻量模型更大,但效果更好|[ch_det_res18_db_v2.0.yml](../../configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml)|47M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar)|
+
+
+### 1.2 英文检测模型
+
+|模型名称|模型简介|配置文件|推理模型大小|下载地址|
+| --- | --- | --- | --- | --- |
+|en_PP-OCRv3_det_slim |【最新】slim量化版超轻量模型,支持英文、数字检测 | [ch_PP-OCRv3_det_cml.yml](../../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml) | 1.1M |[推理模型(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_slim_infer.tar) / [训练模型(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_slim_distill_train.tar) / [lite模型(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_slim_infer.nb) |
+|ch_PP-OCRv3_det |【最新】原始超轻量模型,支持英文、数字检测|[ch_PP-OCRv3_det_cml.yml](../../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml)| 3.8M | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar) |
+
+* 注:英文检测模型与中文检测模型结构完全相同,只有训练数据不同,在此仅提供相同的配置文件。
+
+
+
+### 1.3 多语言检测模型
+
+|模型名称|模型简介|配置文件|推理模型大小|下载地址|
+| --- | --- | --- | --- | --- |
+| ml_PP-OCRv3_det_slim |【最新】slim量化版超轻量模型,支持多语言检测 | [ch_PP-OCRv3_det_cml.yml](../../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml) | 1.1M |[推理模型(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_slim_infer.tar) / [训练模型(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_slim_distill_train.tar) / [lite model(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_slim_infer.nb) |
+| ml_PP-OCRv3_det |【最新】原始超轻量模型,支持多语言检测 | [ch_PP-OCRv3_det_cml.yml](../../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml)| 3.8M | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_distill_train.tar) |
+
+* 注:多语言检测模型与中文检测模型结构完全相同,只有训练数据不同,在此仅提供相同的配置文件。
+
## 2. 文本识别模型
@@ -50,8 +81,10 @@ PaddleOCR提供的可下载模型包括`推理模型`、`训练模型`、`预训
|模型名称|模型简介|配置文件|推理模型大小|下载地址|
| --- | --- | --- | --- | --- |
-|ch_PP-OCRv2_rec_slim|【最新】slim量化版超轻量模型,支持中英文、数字识别|[ch_PP-OCRv2_rec.yml](../../configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml)| 9M |[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_train.tar) |
-|ch_PP-OCRv2_rec|【最新】原始超轻量模型,支持中英文、数字识别|[ch_PP-OCRv2_rec_distillation.yml](../../configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml)|8.5M|[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
+|ch_PP-OCRv3_rec_slim |【最新】slim量化版超轻量模型,支持中英文、数字识别|[ch_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml)| 4.9M |[推理模型(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_slim_infer.tar) / [训练模型(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/ch/ch_PP-OCRv3_rec_slim_train.tar) / [lite模型(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_slim_infer.nb) |
+|ch_PP-OCRv3_rec|【最新】原始超轻量模型,支持中英文、数字识别|[ch_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml)| 12.4M |[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar) |
+|ch_PP-OCRv2_rec_slim| slim量化版超轻量模型,支持中英文、数字识别|[ch_PP-OCRv2_rec.yml](../../configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml)| 9M |[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_train.tar) |
+|ch_PP-OCRv2_rec| 原始超轻量模型,支持中英文、数字识别|[ch_PP-OCRv2_rec_distillation.yml](../../configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml)|8.5M|[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
|ch_ppocr_mobile_slim_v2.0_rec|slim裁剪量化版超轻量模型,支持中英文、数字识别|[rec_chinese_lite_train_v2.0.yml](../../configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml)| 6M |[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_slim_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_slim_train.tar) |
|ch_ppocr_mobile_v2.0_rec|原始超轻量模型,支持中英文、数字识别|[rec_chinese_lite_train_v2.0.yml](../../configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml)|5.2M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_train.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
|ch_ppocr_server_v2.0_rec|通用模型,支持中英文、数字识别|[rec_chinese_common_train_v2.0.yml](../../configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml)|94.8M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_train.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
@@ -63,9 +96,12 @@ PaddleOCR提供的可下载模型包括`推理模型`、`训练模型`、`预训
|模型名称|模型简介|配置文件|推理模型大小|下载地址|
| --- | --- | --- | --- | --- |
+|en_PP-OCRv3_rec_slim |【最新】slim量化版超轻量模型,支持英文、数字识别 | [en_PP-OCRv3_rec.yml](../../configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml)| - |[推理模型(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_slim_infer.tar) / [训练模型(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_slim_train.tar) / [lite模型(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_slim_infer.nb) |
+|ch_PP-OCRv3_rec |【最新】原始超轻量模型,支持英文、数字识别|[en_PP-OCRv3_rec.yml](../../configs/rec/en_PP-OCRv3/en_PP-OCRv3_rec.yml)| 9.6M | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
|en_number_mobile_slim_v2.0_rec|slim裁剪量化版超轻量模型,支持英文、数字识别|[rec_en_number_lite_train.yml](../../configs/rec/multi_language/rec_en_number_lite_train.yml)| 2.7M | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/en_number_mobile_v2.0_rec_slim_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/en_number_mobile_v2.0_rec_slim_train.tar) |
|en_number_mobile_v2.0_rec|原始超轻量模型,支持英文、数字识别|[rec_en_number_lite_train.yml](../../configs/rec/multi_language/rec_en_number_lite_train.yml)|2.6M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/en_number_mobile_v2.0_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/en_number_mobile_v2.0_rec_train.tar) |
+
### 2.3 多语言识别模型(更多语言持续更新中...)
diff --git a/doc/doc_ch/ppocr_introduction.md b/doc/doc_ch/ppocr_introduction.md
index 926d79e88e48581f850896f7122a16b293630c2a..e962c00b21265abb4e1266f8b8268cd585be8d8c 100644
--- a/doc/doc_ch/ppocr_introduction.md
+++ b/doc/doc_ch/ppocr_introduction.md
@@ -136,7 +136,9 @@ PP-OCR中英文模型列表如下:
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
-| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
+| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar) |
+| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
+| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
diff --git a/doc/doc_ch/recognition.md b/doc/doc_ch/recognition.md
index 55562f20ee8d44871dd1102f117621988ecc4659..9cce4aac0b3f14b3fb1055ba099fb1df289d6dc6 100644
--- a/doc/doc_ch/recognition.md
+++ b/doc/doc_ch/recognition.md
@@ -2,25 +2,32 @@
本文提供了PaddleOCR文本识别任务的全流程指南,包括数据准备、模型训练、调优、评估、预测,各个阶段的详细说明:
-- [文字识别](#文字识别)
- - [1. 数据准备](#1-数据准备)
- - [1.1 自定义数据集](#11-自定义数据集)
- - [1.2 数据下载](#12-数据下载)
- - [1.3 字典](#13-字典)
- - [1.4 添加空格类别](#14-添加空格类别)
- - [2. 启动训练](#2-启动训练)
- - [2.1 数据增强](#21-数据增强)
- - [2.2 通用模型训练](#22-通用模型训练)
- - [2.3 多语言模型训练](#23-多语言模型训练)
- - [2.4 知识蒸馏训练](#24-知识蒸馏训练)
- - [3 评估](#3-评估)
- - [4 预测](#4-预测)
- - [5. 转Inference模型测试](#5-转inference模型测试)
-
-
-
-## 1. 数据准备
-
+- [1. 数据准备](#1-数据准备)
+ * [1.1 自定义数据集](#11-自定义数据集)
+ * [1.2 数据下载](#12-数据下载)
+ * [1.3 字典](#13-字典)
+ * [1.4 添加空格类别](#14-添加空格类别)
+ * [1.5 数据增强](#15-数据增强)
+- [2. 开始训练](#2-开始训练)
+ * [2.1 启动训练](#21-----)
+ * [2.2 断点训练](#22-----)
+ * [2.3 更换Backbone 训练](#23---backbone---)
+ * [2.4 混合精度训练](#24---amp---)
+ * [2.5 分布式训练](#25---fleet---)
+ * [2.6 知识蒸馏训练](#26---distill---)
+ * [2.7 多语言模型训练](#27-多语言模型训练)
+ * [2.8 其他训练环境(Windows/macOS/Linux DCU)](#28---other---)
+- [3. 模型评估与预测](#3--------)
+ * [3.1 指标评估](#31-----)
+ * [3.2 测试识别效果](#32-------)
+- [4. 模型导出与预测](#4--------)
+- [5. FAQ](#5-faq)
+
+
+
+# 1. 数据准备
+
+### 1.1 准备数据集
PaddleOCR 支持两种数据格式:
- `lmdb` 用于训练以lmdb格式存储的数据集(LMDBDataSet);
@@ -35,8 +42,8 @@ ln -sf /train_data/dataset
mklink /d /train_data/dataset
```
-
-### 1.1 自定义数据集
+
+## 1.1 自定义数据集
下面以通用数据集为例, 介绍如何准备数据集:
* 训练集
@@ -91,9 +98,8 @@ train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
| ...
```
-
-
-### 1.2 数据下载
+
+## 1.2 数据下载
- ICDAR2015
@@ -125,8 +131,8 @@ python gen_label.py --mode="rec" --input_path="{path/of/origin/label}" --output_
* [google drive](https://drive.google.com/file/d/18cSWX7wXSy4G0tbKJ0d9PuIaiwRLHpjA/view)
-
-### 1.3 字典
+
+## 1.3 字典
最后需要提供一个字典({word_dict_name}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。
@@ -162,7 +168,6 @@ PaddleOCR内置了一部分字典,可以按需使用。
`ppocr/utils/en_dict.txt` 是一个包含96个字符的英文字典
-
目前的多语言模型仍处在demo阶段,会持续优化模型并补充语种,**非常欢迎您为我们提供其他语言的字典和字体**,
如您愿意可将字典文件提交至 [dict](../../ppocr/utils/dict),我们会在Repo中感谢您。
@@ -171,16 +176,12 @@ PaddleOCR内置了一部分字典,可以按需使用。
如需自定义dic文件,请在 `configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml` 中添加 `character_dict_path` 字段, 指向您的字典路径。
-### 1.4 添加空格类别
+## 1.4 添加空格类别
如果希望支持识别"空格"类别, 请将yml文件中的 `use_space_char` 字段设置为 `True`。
-
-
-## 2. 启动训练
-
-### 2.1 数据增强
+## 1.5 数据增强
PaddleOCR提供了多种数据增强方式,默认配置文件中已经添加了数据增广。
@@ -190,11 +191,14 @@ PaddleOCR提供了多种数据增强方式,默认配置文件中已经添加
*由于OpenCV的兼容性问题,扰动操作暂时只支持Linux*
-
-### 2.2 通用模型训练
+
+# 2. 开始训练
PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以 PP-OCRv3 英文识别模型为例:
+
+## 2.1 启动训练
+
首先下载pretrain model,您可以下载训练好的模型在 icdar2015 数据上进行finetune
```
@@ -293,8 +297,96 @@ Eval:
```
**注意,预测/评估时的配置文件请务必与训练一致。**
-
-### 2.3 多语言模型训练
+
+
+## 2.2 断点训练
+
+如果训练程序中断,如果希望加载训练中断的模型从而恢复训练,可以通过指定Global.checkpoints指定要加载的模型路径:
+```shell
+python3 tools/train.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints=./your/trained/model
+```
+
+**注意**:`Global.checkpoints`的优先级高于`Global.pretrained_model`的优先级,即同时指定两个参数时,优先加载`Global.checkpoints`指定的模型,如果`Global.checkpoints`指定的模型路径有误,会加载`Global.pretrained_model`指定的模型。
+
+
+## 2.3 更换Backbone 训练
+
+PaddleOCR将网络划分为四部分,分别在[ppocr/modeling](../../ppocr/modeling)下。 进入网络的数据将按照顺序(transforms->backbones->necks->heads)依次通过这四个部分。
+
+```bash
+├── architectures # 网络的组网代码
+├── transforms # 网络的图像变换模块
+├── backbones # 网络的特征提取模块
+├── necks # 网络的特征增强模块
+└── heads # 网络的输出模块
+```
+如果要更换的Backbone 在PaddleOCR中有对应实现,直接修改配置yml文件中`Backbone`部分的参数即可。
+
+如果要使用新的Backbone,更换backbones的例子如下:
+
+1. 在 [ppocr/modeling/backbones](../../ppocr/modeling/backbones) 文件夹下新建文件,如my_backbone.py。
+2. 在 my_backbone.py 文件内添加相关代码,示例代码如下:
+
+```python
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+class MyBackbone(nn.Layer):
+ def __init__(self, *args, **kwargs):
+ super(MyBackbone, self).__init__()
+ # your init code
+ self.conv = nn.xxxx
+
+ def forward(self, inputs):
+ # your network forward
+ y = self.conv(inputs)
+ return y
+```
+
+3. 在 [ppocr/modeling/backbones/\__init\__.py](../../ppocr/modeling/backbones/__init__.py)文件内导入添加的`MyBackbone`模块,然后修改配置文件中Backbone进行配置即可使用,格式如下:
+
+```yaml
+Backbone:
+name: MyBackbone
+args1: args1
+```
+
+**注意**:如果要更换网络的其他模块,可以参考[文档](./add_new_algorithm.md)。
+
+
+## 2.4 混合精度训练
+
+如果您想进一步加快训练速度,可以使用[自动混合精度训练](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/01_paddle2.0_introduction/basic_concept/amp_cn.html), 以单机单卡为例,命令如下:
+
+```shell
+python3 tools/train.py -c configs/rec/rec_icdar15_train.yml \
+ -o Global.pretrained_model=./pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train \
+ Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
+ ```
+
+
+## 2.5 分布式训练
+
+多机多卡训练时,通过 `--ips` 参数设置使用的机器IP地址,通过 `--gpus` 参数设置使用的GPU ID:
+
+```bash
+python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_icdar15_train.yml \
+ -o Global.pretrained_model=./pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train
+```
+
+**注意:** 采用多机多卡训练时,需要替换上面命令中的ips值为您机器的地址,机器之间需要能够相互ping通。另外,训练时需要在多个机器上分别启动命令。查看机器ip地址的命令为`ifconfig`。
+
+
+
+## 2.6 知识蒸馏训练
+
+PaddleOCR支持了基于知识蒸馏的文本识别模型训练过程,更多内容可以参考[知识蒸馏说明文档](./knowledge_distillation.md)。
+
+
+
+## 2.7 多语言模型训练
PaddleOCR目前已支持80种(除中文外)语种识别,`configs/rec/multi_languages` 路径下提供了一个多语言的配置文件模版: [rec_multi_language_lite_train.yml](../../configs/rec/multi_language/rec_multi_language_lite_train.yml)。
@@ -350,24 +442,37 @@ Eval:
...
```
-
+
+## 2.8 其他训练环境
-### 2.4 知识蒸馏训练
+- Windows GPU/CPU
+在Windows平台上与Linux平台略有不同:
+Windows平台只支持`单卡`的训练与预测,指定GPU进行训练`set CUDA_VISIBLE_DEVICES=0`
+在Windows平台,DataLoader只支持单进程模式,因此需要设置 `num_workers` 为0;
-PaddleOCR支持了基于知识蒸馏的文本识别模型训练过程,更多内容可以参考[知识蒸馏说明文档](./knowledge_distillation.md)。
+- macOS
+不支持GPU模式,需要在配置文件中设置`use_gpu`为False,其余训练评估预测命令与Linux GPU完全相同。
+
+- Linux DCU
+DCU设备上运行需要设置环境变量 `export HIP_VISIBLE_DEVICES=0,1,2,3`,其余训练评估预测命令与Linux GPU完全相同。
+
+
+
+# 3. 模型评估与预测
-
-## 3 评估
+
+## 3.1 指标评估
+
+训练中模型参数默认保存在`Global.save_model_dir`目录下。在评估指标时,需要设置`Global.checkpoints`指向保存的参数文件。评估数据集可以通过 `configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml` 修改Eval中的 `label_file_path` 设置。
-评估数据集可以通过 `configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml` 修改Eval中的 `label_file_path` 设置。
```
# GPU 评估, Global.checkpoints 为待测权重
python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.checkpoints={path/to/weights}/best_accuracy
```
-
-## 4 预测
+
+## 3.2 测试识别效果
使用 PaddleOCR 训练好的模型,可以通过以下脚本进行快速预测。
@@ -426,9 +531,14 @@ infer_img: doc/imgs_words/ch/word_1.jpg
result: ('韩国小馆', 0.997218)
```
-
-## 5. 转Inference模型测试
+
+# 4. 模型导出与预测
+
+inference 模型(`paddle.jit.save`保存的模型)
+一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。
+训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。
+与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
识别模型转inference模型与检测的方式相同,如下:
@@ -459,3 +569,11 @@ inference/en_PP-OCRv3_rec/
```
python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words_en/word_336.png" --rec_model_dir="./your inference model" --rec_image_shape="3, 48, 320" --rec_char_dict_path="your text dict path"
```
+
+
+
+# 5. FAQ
+
+Q1: 训练模型转inference 模型之后预测效果不一致?
+
+**A**:此类问题出现较多,问题多是trained model预测时候的预处理、后处理参数和inference model预测的时候的预处理、后处理参数不一致导致的。可以对比训练使用的配置文件中的预处理、后处理和预测时是否存在差异。
diff --git a/doc/doc_ch/table_datasets.md b/doc/doc_ch/table_datasets.md
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/doc/doc_ch/training.md b/doc/doc_ch/training.md
index 231b83e64b48d6c6fe1192b34b1d2f11a06f4cd8..d46b9af701ee1c605526c18d6994842b3faf8e14 100644
--- a/doc/doc_ch/training.md
+++ b/doc/doc_ch/training.md
@@ -81,13 +81,13 @@ Optimizer:
- 检测:
- 英文数据集,ICDAR2015
- 中文数据集,LSVT街景数据集训练数据3w张图片
-
+
- 识别:
- 英文数据集,MJSynth和SynthText合成数据,数据量上千万。
- 中文数据集,LSVT街景数据集根据真值将图crop出来,并进行位置校准,总共30w张图像。此外基于LSVT的语料,合成数据500w。
- 小语种数据集,使用不同语料和字体,分别生成了100w合成数据集,并使用ICDAR-MLT作为验证集。
-其中,公开数据集都是开源的,用户可自行搜索下载,也可参考[中文数据集](./datasets.md),合成数据暂不开源,用户可使用开源合成工具自行合成,可参考的合成工具包括[text_renderer](https://github.com/Sanster/text_renderer) 、[SynthText](https://github.com/ankush-me/SynthText) 、[TextRecognitionDataGenerator](https://github.com/Belval/TextRecognitionDataGenerator) 等。
+其中,公开数据集都是开源的,用户可自行搜索下载,也可参考[中文数据集](dataset/datasets.md),合成数据暂不开源,用户可使用开源合成工具自行合成,可参考的合成工具包括[text_renderer](https://github.com/Sanster/text_renderer) 、[SynthText](https://github.com/ankush-me/SynthText) 、[TextRecognitionDataGenerator](https://github.com/Belval/TextRecognitionDataGenerator) 等。
### 3.2 垂类场景
@@ -120,17 +120,17 @@ PaddleOCR主要聚焦通用OCR,如果有垂类需求,您可以用PaddleOCR+
**Q**:训练CRNN识别时,如何选择合适的网络输入shape?
A:一般高度采用32,最长宽度的选择,有两种方法:
-
+
(1)统计训练样本图像的宽高比分布。最大宽高比的选取考虑满足80%的训练样本。
-
+
(2)统计训练样本文字数目。最长字符数目的选取考虑满足80%的训练样本。然后中文字符长宽比近似认为是1,英文认为3:1,预估一个最长宽度。
**Q**:识别训练时,训练集精度已经到达90了,但验证集精度一直在70,涨不上去怎么办?
A:训练集精度90,测试集70多的话,应该是过拟合了,有两个可尝试的方法:
-
+
(1)加入更多的增广方式或者调大增广prob的[概率](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/ppocr/data/imaug/rec_img_aug.py#L341),默认为0.4。
-
+
(2)调大系统的[l2 dcay值](https://github.com/PaddlePaddle/PaddleOCR/blob/a501603d54ff5513fc4fc760319472e59da25424/configs/rec/ch_ppocr_v1.1/rec_chinese_lite_train_v1.1.yml#L47)
**Q**: 识别模型训练时,loss能正常下降,但acc一直为0
@@ -141,12 +141,11 @@ PaddleOCR主要聚焦通用OCR,如果有垂类需求,您可以用PaddleOCR+
***
-具体的训练教程可点击下方链接跳转:
+具体的训练教程可点击下方链接跳转:
-- [文本检测模型训练](./detection.md)
+- [文本检测模型训练](./detection.md)
- [文本识别模型训练](./recognition.md)
- [文本方向分类器训练](./angle_class.md)
- [知识蒸馏](./knowledge_distillation.md)
-
diff --git a/doc/doc_ch/update.md b/doc/doc_ch/update.md
index c4c870681c6ccb5ad7702101312e5dbe47e9cb85..9071e673910f8d87762dc8f9dd097d444f36e624 100644
--- a/doc/doc_ch/update.md
+++ b/doc/doc_ch/update.md
@@ -22,7 +22,7 @@
- 2020.7.15 整理OCR相关数据集、常用数据标注以及合成工具
- 2020.7.9 添加支持空格的识别模型,识别效果,预测及训练方式请参考快速开始和文本识别训练相关文档
- 2020.7.9 添加数据增强、学习率衰减策略,具体参考[配置文件](./config.md)
-- 2020.6.8 添加[数据集](./datasets.md),并保持持续更新
+- 2020.6.8 添加[数据集](dataset/datasets.md),并保持持续更新
- 2020.6.5 支持 `attetnion` 模型导出 `inference_model`
- 2020.6.5 支持单独预测识别时,输出结果得分
- 2020.5.30 提供超轻量级中文OCR在线体验
diff --git a/doc/doc_en/FAQ_en.md b/doc/doc_en/FAQ_en.md
index 5cf82a78720d15ce5b0aac37c409921474923813..5b0884276543645cc5569a99a0e24b40c29581a6 100644
--- a/doc/doc_en/FAQ_en.md
+++ b/doc/doc_en/FAQ_en.md
@@ -42,7 +42,7 @@ At present, the open source model, dataset and magnitude are as follows:
English dataset: MJSynth and SynthText synthetic dataset, the amount of data is tens of millions.
Chinese dataset: LSVT street view dataset with cropped text area, a total of 30w images. In addition, the synthesized data based on LSVT corpus is 500w.
- Among them, the public datasets are opensourced, users can search and download by themselves, or refer to [Chinese data set](./datasets_en.md), synthetic data is not opensourced, users can use open-source synthesis tools to synthesize data themselves. Current available synthesis tools include [text_renderer](https://github.com/Sanster/text_renderer), [SynthText](https://github.com/ankush-me/SynthText), [TextRecognitionDataGenerator](https://github.com/Belval/TextRecognitionDataGenerator), etc.
+ Among them, the public datasets are opensourced, users can search and download by themselves, or refer to [Chinese data set](dataset/datasets_en.md), synthetic data is not opensourced, users can use open-source synthesis tools to synthesize data themselves. Current available synthesis tools include [text_renderer](https://github.com/Sanster/text_renderer), [SynthText](https://github.com/ankush-me/SynthText), [TextRecognitionDataGenerator](https://github.com/Belval/TextRecognitionDataGenerator), etc.
10. **Error in using the model with TPS module for prediction**
Error message: Input(X) dims[3] and Input(Grid) dims[2] should be equal, but received X dimension[3]\(108) != Grid dimension[2]\(100)
diff --git a/doc/doc_en/algorithm_det_fcenet_en.md b/doc/doc_en/algorithm_det_fcenet_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..e15fb9a07ede3296d3de83c134457194d4639a1c
--- /dev/null
+++ b/doc/doc_en/algorithm_det_fcenet_en.md
@@ -0,0 +1,104 @@
+# FCENet
+
+- [1. Introduction](#1)
+- [2. Environment](#2)
+- [3. Model Training / Evaluation / Prediction](#3)
+ - [3.1 Training](#3-1)
+ - [3.2 Evaluation](#3-2)
+ - [3.3 Prediction](#3-3)
+- [4. Inference and Deployment](#4)
+ - [4.1 Python Inference](#4-1)
+ - [4.2 C++ Inference](#4-2)
+ - [4.3 Serving](#4-3)
+ - [4.4 More](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. Introduction
+
+Paper:
+> [Fourier Contour Embedding for Arbitrary-Shaped Text Detection](https://arxiv.org/abs/2104.10442)
+> Yiqin Zhu and Jianyong Chen and Lingyu Liang and Zhanghui Kuang and Lianwen Jin and Wayne Zhang
+> CVPR, 2021
+
+On the CTW1500 dataset, the text detection result is as follows:
+
+|Model|Backbone|Configuration|Precision|Recall|Hmean|Download|
+| --- | --- | --- | --- | --- | --- | --- |
+| FCE | ResNet50_dcn | [configs/det/det_r50_vd_dcn_fce_ctw.yml](../../configs/det/det_r50_vd_dcn_fce_ctw.yml)| 88.39%|82.18%|85.27%|[trained model](https://paddleocr.bj.bcebos.com/contribution/det_r50_dcn_fce_ctw_v2.0_train.tar)|
+
+
+## 2. Environment
+Please prepare your environment referring to [prepare the environment](./environment_en.md) and [clone the repo](./clone_en.md).
+
+
+
+## 3. Model Training / Evaluation / Prediction
+
+The above FCE model is trained using the CTW1500 text detection public dataset. For the download of the dataset, please refer to [ocr_datasets](./dataset/ocr_datasets_en.md).
+
+After the data download is complete, please refer to [Text Detection Training Tutorial](./detection.md) for training. PaddleOCR has modularized the code structure, so that you only need to **replace the configuration file** to train different detection models.
+
+
+## 4. Inference and Deployment
+
+
+### 4.1 Python Inference
+First, convert the model saved in the FCE text detection training process into an inference model. Taking the model based on the Resnet50_vd_dcn backbone network and trained on the CTW1500 English dataset as example ([model download link](https://paddleocr.bj.bcebos.com/contribution/det_r50_dcn_fce_ctw_v2.0_train.tar)), you can use the following command to convert:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_dcn_fce_ctw.yml -o Global.pretrained_model=./det_r50_dcn_fce_ctw_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_fce
+```
+
+FCE text detection model inference, to perform non-curved text detection, you can run the following commands:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_fce/" --det_algorithm="FCE" --det_fce_box_type=quad
+```
+
+The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
+
+
+
+If you want to perform curved text detection, you can execute the following command:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_fce/" --det_algorithm="FCE" --det_fce_box_type=poly
+```
+
+The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
+
+
+
+**Note**: Since the CTW1500 dataset has only 1,000 training images, mainly for English scenes, the above model has very poor detection result on Chinese or curved text images.
+
+
+
+### 4.2 C++ Inference
+
+Since the post-processing is not written in CPP, the FCE text detection model does not support CPP inference.
+
+
+### 4.3 Serving
+
+Not supported
+
+
+### 4.4 More
+
+Not supported
+
+
+## 5. FAQ
+
+
+## Citation
+
+```bibtex
+@InProceedings{zhu2021fourier,
+ title={Fourier Contour Embedding for Arbitrary-Shaped Text Detection},
+ author={Yiqin Zhu and Jianyong Chen and Lingyu Liang and Zhanghui Kuang and Lianwen Jin and Wayne Zhang},
+ year={2021},
+ booktitle = {CVPR}
+}
+```
diff --git a/doc/doc_en/algorithm_det_psenet_en.md b/doc/doc_en/algorithm_det_psenet_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..d4cb3ea7d1e82a3f9c261c6e44cd6df6b0f6bf1e
--- /dev/null
+++ b/doc/doc_en/algorithm_det_psenet_en.md
@@ -0,0 +1,107 @@
+# PSENet
+
+- [1. Introduction](#1)
+- [2. Environment](#2)
+- [3. Model Training / Evaluation / Prediction](#3)
+ - [3.1 Training](#3-1)
+ - [3.2 Evaluation](#3-2)
+ - [3.3 Prediction](#3-3)
+- [4. Inference and Deployment](#4)
+ - [4.1 Python Inference](#4-1)
+ - [4.2 C++ Inference](#4-2)
+ - [4.3 Serving](#4-3)
+ - [4.4 More](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. Introduction
+
+Paper:
+> [Shape robust text detection with progressive scale expansion network](https://arxiv.org/abs/1903.12473)
+> Wang, Wenhai and Xie, Enze and Li, Xiang and Hou, Wenbo and Lu, Tong and Yu, Gang and Shao, Shuai
+> CVPR, 2019
+
+On the ICDAR2015 dataset, the text detection result is as follows:
+
+|Model|Backbone|Configuration|Precision|Recall|Hmean|Download|
+| --- | --- | --- | --- | --- | --- | --- |
+|PSE| ResNet50_vd | [configs/det/det_r50_vd_pse.yml](../../configs/det/det_r50_vd_pse.yml)| 85.81% |79.53%|82.55%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_r50_vd_pse_v2.0_train.tar)|
+|PSE| MobileNetV3| [configs/det/det_mv3_pse.yml](../../configs/det/det_mv3_pse.yml) | 82.20% |70.48%|75.89%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_mv3_pse_v2.0_train.tar)|
+
+
+
+## 2. Environment
+Please prepare your environment referring to [prepare the environment](./environment_en.md) and [clone the repo](./clone_en.md).
+
+
+
+## 3. Model Training / Evaluation / Prediction
+
+The above PSE model is trained using the ICDAR2015 text detection public dataset. For the download of the dataset, please refer to [ocr_datasets](./dataset/ocr_datasets_en.md).
+
+After the data download is complete, please refer to [Text Detection Training Tutorial](./detection.md) for training. PaddleOCR has modularized the code structure, so that you only need to **replace the configuration file** to train different detection models.
+
+
+## 4. Inference and Deployment
+
+
+### 4.1 Python Inference
+First, convert the model saved in the PSE text detection training process into an inference model. Taking the model based on the Resnet50_vd backbone network and trained on the ICDAR2015 English dataset as example ([model download link](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_r50_vd_pse_v2.0_train.tar)), you can use the following command to convert:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_pse.yml -o Global.pretrained_model=./det_r50_vd_pse_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_pse
+```
+
+PSE text detection model inference, to perform non-curved text detection, you can run the following commands:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_pse/" --det_algorithm="PSE" --det_pse_box_type=quad
+```
+
+The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
+
+
+
+If you want to perform curved text detection, you can execute the following command:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_pse/" --det_algorithm="PSE" --det_pse_box_type=poly
+```
+
+The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
+
+
+
+**Note**: Since the ICDAR2015 dataset has only 1,000 training images, mainly for English scenes, the above model has very poor detection result on Chinese or curved text images.
+
+
+
+### 4.2 C++ Inference
+
+Since the post-processing is not written in CPP, the PSE text detection model does not support CPP inference.
+
+
+### 4.3 Serving
+
+Not supported
+
+
+### 4.4 More
+
+Not supported
+
+
+## 5. FAQ
+
+
+## Citation
+
+```bibtex
+@inproceedings{wang2019shape,
+ title={Shape robust text detection with progressive scale expansion network},
+ author={Wang, Wenhai and Xie, Enze and Li, Xiang and Hou, Wenbo and Lu, Tong and Yu, Gang and Shao, Shuai},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={9336--9345},
+ year={2019}
+}
+```
diff --git a/doc/doc_en/algorithm_det_sast_en.md b/doc/doc_en/algorithm_det_sast_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..e3437d22be9d75835aaa43e72363b498225db9e1
--- /dev/null
+++ b/doc/doc_en/algorithm_det_sast_en.md
@@ -0,0 +1,118 @@
+# SAST
+
+- [1. Introduction](#1)
+- [2. Environment](#2)
+- [3. Model Training / Evaluation / Prediction](#3)
+ - [3.1 Training](#3-1)
+ - [3.2 Evaluation](#3-2)
+ - [3.3 Prediction](#3-3)
+- [4. Inference and Deployment](#4)
+ - [4.1 Python Inference](#4-1)
+ - [4.2 C++ Inference](#4-2)
+ - [4.3 Serving](#4-3)
+ - [4.4 More](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. Introduction
+
+Paper:
+> [A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning](https://arxiv.org/abs/1908.05498)
+> Wang, Pengfei and Zhang, Chengquan and Qi, Fei and Huang, Zuming and En, Mengyi and Han, Junyu and Liu, Jingtuo and Ding, Errui and Shi, Guangming
+> ACM MM, 2019
+
+On the ICDAR2015 dataset, the text detection result is as follows:
+
+|Model|Backbone|Configuration|Precision|Recall|Hmean|Download|
+| --- | --- | --- | --- | --- | --- | --- |
+|SAST|ResNet50_vd|[configs/det/det_r50_vd_sast_icdar15.yml](../../configs/det/det_r50_vd_sast_icdar15.yml)|91.39%|83.77%|87.42%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_icdar15_v2.0_train.tar)|
+
+
+On the Total-text dataset, the text detection result is as follows:
+
+|Model|Backbone|Configuration|Precision|Recall|Hmean|Download|
+| --- | --- | --- | --- | --- | --- | --- |
+|SAST|ResNet50_vd|[configs/det/det_r50_vd_sast_totaltext.yml](../../configs/det/det_r50_vd_sast_totaltext.yml)|89.63%|78.44%|83.66%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_totaltext_v2.0_train.tar)|
+
+
+
+## 2. Environment
+Please prepare your environment referring to [prepare the environment](./environment_en.md) and [clone the repo](./clone_en.md).
+
+
+
+## 3. Model Training / Evaluation / Prediction
+
+Please refer to [text detection training tutorial](./detection_en.md). PaddleOCR has modularized the code structure, so that you only need to **replace the configuration file** to train different detection models.
+
+
+## 4. Inference and Deployment
+
+
+### 4.1 Python Inference
+#### (1). Quadrangle text detection model (ICDAR2015)
+First, convert the model saved in the SAST text detection training process into an inference model. Taking the model based on the Resnet50_vd backbone network and trained on the ICDAR2015 English dataset as an example ([model download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_icdar15_v2.0_train.tar)), you can use the following command to convert:
+
+```
+python3 tools/export_model.py -c configs/det/det_r50_vd_sast_icdar15.yml -o Global.pretrained_model=./det_r50_vd_sast_icdar15_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_sast_ic15
+```
+
+**For SAST quadrangle text detection model inference, you need to set the parameter `--det_algorithm="SAST"`**, run the following command:
+
+```
+python3 tools/infer/predict_det.py --det_algorithm="SAST" --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_sast_ic15/"
+```
+
+The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
+
+
+
+#### (2). Curved text detection model (Total-Text)
+First, convert the model saved in the SAST text detection training process into an inference model. Taking the model based on the Resnet50_vd backbone network and trained on the Total-Text English dataset as an example ([model download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_totaltext_v2.0_train.tar)), you can use the following command to convert:
+
+```
+python3 tools/export_model.py -c configs/det/det_r50_vd_sast_totaltext.yml -o Global.pretrained_model=./det_r50_vd_sast_totaltext_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_sast_tt
+```
+
+For SAST curved text detection model inference, you need to set the parameter `--det_algorithm="SAST"` and `--det_sast_polygon=True`, run the following command:
+
+```
+python3 tools/infer/predict_det.py --det_algorithm="SAST" --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_sast_tt/" --det_sast_polygon=True
+```
+
+The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
+
+
+
+**Note**: SAST post-processing locality aware NMS has two versions: Python and C++. The speed of C++ version is obviously faster than that of Python version. Due to the compilation version problem of NMS of C++ version, C++ version NMS will be called only in Python 3.5 environment, and python version NMS will be called in other cases.
+
+
+### 4.2 C++ Inference
+
+Not supported
+
+
+### 4.3 Serving
+
+Not supported
+
+
+### 4.4 More
+
+Not supported
+
+
+## 5. FAQ
+
+
+## Citation
+
+```bibtex
+@inproceedings{wang2019single,
+ title={A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning},
+ author={Wang, Pengfei and Zhang, Chengquan and Qi, Fei and Huang, Zuming and En, Mengyi and Han, Junyu and Liu, Jingtuo and Ding, Errui and Shi, Guangming},
+ booktitle={Proceedings of the 27th ACM International Conference on Multimedia},
+ pages={1277--1285},
+ year={2019}
+}
+```
diff --git a/doc/doc_en/algorithm_rec_sar_en.md b/doc/doc_en/algorithm_rec_sar_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..8c1e6dbbfa5cc05da4d7423a535c6db74cf8f4c3
--- /dev/null
+++ b/doc/doc_en/algorithm_rec_sar_en.md
@@ -0,0 +1,114 @@
+# SAR
+
+- [1. Introduction](#1)
+- [2. Environment](#2)
+- [3. Model Training / Evaluation / Prediction](#3)
+ - [3.1 Training](#3-1)
+ - [3.2 Evaluation](#3-2)
+ - [3.3 Prediction](#3-3)
+- [4. Inference and Deployment](#4)
+ - [4.1 Python Inference](#4-1)
+ - [4.2 C++ Inference](#4-2)
+ - [4.3 Serving](#4-3)
+ - [4.4 More](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. Introduction
+
+Paper:
+> [Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition](https://arxiv.org/abs/1811.00751)
+> Hui Li, Peng Wang, Chunhua Shen, Guyu Zhang
+> AAAI, 2019
+
+Using MJSynth and SynthText two text recognition datasets for training, and evaluating on IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE datasets, the algorithm reproduction effect is as follows:
+
+|Model|Backbone|config|Acc|Download link|
+| --- | --- | --- | --- | --- |
+|SAR|ResNet31|[rec_r31_sar.yml](../../configs/rec/rec_r31_sar.yml)|87.20%|[train model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar)|
+
+Note:In addition to using the two text recognition datasets MJSynth and SynthText, [SynthAdd](https://pan.baidu.com/share/init?surl=uV0LtoNmcxbO-0YA7Ch4dg) data (extraction code: 627x), and some real data are used in training, the specific data details can refer to the paper.
+
+
+## 2. Environment
+Please refer to ["Environment Preparation"](./environment.md) to configure the PaddleOCR environment, and refer to ["Project Clone"](./clone.md) to clone the project code.
+
+
+
+## 3. Model Training / Evaluation / Prediction
+
+Please refer to [Text Recognition Tutorial](./recognition.md). PaddleOCR modularizes the code, and training different recognition models only requires **changing the configuration file**.
+
+Training:
+
+Specifically, after the data preparation is completed, the training can be started. The training command is as follows:
+
+```
+#Single GPU training (long training period, not recommended)
+python3 tools/train.py -c configs/rec/rec_r31_sar.yml
+
+#Multi GPU training, specify the gpu number through the --gpus parameter
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r31_sar.yml
+```
+
+Evaluation:
+
+```
+# GPU evaluation
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+Prediction:
+
+```
+# The configuration file used for prediction must match the training
+python3 tools/infer_rec.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. Inference and Deployment
+
+
+### 4.1 Python Inference
+First, the model saved during the SAR text recognition training process is converted into an inference model. ( [Model download link](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar) ), you can use the following command to convert:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model=./rec_r31_sar_train/best_accuracy Global.save_inference_dir=./inference/rec_sar
+```
+
+For SAR text recognition model inference, the following commands can be executed:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_sar/" --rec_image_shape="3, 48, 48, 160" --rec_char_type="ch" --rec_algorithm="SAR" --rec_char_dict_path="ppocr/utils/dict90.txt" --max_text_length=30 --use_space_char=False
+```
+
+
+### 4.2 C++ Inference
+
+Not supported
+
+
+### 4.3 Serving
+
+Not supported
+
+
+### 4.4 More
+
+Not supported
+
+
+## 5. FAQ
+
+
+## Citation
+
+```bibtex
+@article{Li2019ShowAA,
+ title={Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition},
+ author={Hui Li and Peng Wang and Chunhua Shen and Guyu Zhang},
+ journal={ArXiv},
+ year={2019},
+ volume={abs/1811.00751}
+}
+```
diff --git a/doc/doc_en/algorithm_rec_srn_en.md b/doc/doc_en/algorithm_rec_srn_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..c022a81f9e5797c531c79de7e793d44d9a22552c
--- /dev/null
+++ b/doc/doc_en/algorithm_rec_srn_en.md
@@ -0,0 +1,113 @@
+# SRN
+
+- [1. Introduction](#1)
+- [2. Environment](#2)
+- [3. Model Training / Evaluation / Prediction](#3)
+ - [3.1 Training](#3-1)
+ - [3.2 Evaluation](#3-2)
+ - [3.3 Prediction](#3-3)
+- [4. Inference and Deployment](#4)
+ - [4.1 Python Inference](#4-1)
+ - [4.2 C++ Inference](#4-2)
+ - [4.3 Serving](#4-3)
+ - [4.4 More](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. Introduction
+
+Paper:
+> [Towards Accurate Scene Text Recognition with Semantic Reasoning Networks](https://arxiv.org/abs/2003.12294#)
+> Deli Yu, Xuan Li, Chengquan Zhang, Junyu Han, Jingtuo Liu, Errui Ding
+> CVPR,2020
+
+Using MJSynth and SynthText two text recognition datasets for training, and evaluating on IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE datasets, the algorithm reproduction effect is as follows:
+
+|Model|Backbone|config|Acc|Download link|
+| --- | --- | --- | --- | --- |
+|SRN|Resnet50_vd_fpn|[rec_r50_fpn_srn.yml](../../configs/rec/rec_r50_fpn_srn.yml)|86.31%|[train model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar)|
+
+
+
+## 2. Environment
+Please refer to ["Environment Preparation"](./environment.md) to configure the PaddleOCR environment, and refer to ["Project Clone"](./clone.md) to clone the project code.
+
+
+
+## 3. Model Training / Evaluation / Prediction
+
+Please refer to [Text Recognition Tutorial](./recognition.md). PaddleOCR modularizes the code, and training different recognition models only requires **changing the configuration file**.
+
+Training:
+
+Specifically, after the data preparation is completed, the training can be started. The training command is as follows:
+
+```
+#Single GPU training (long training period, not recommended)
+python3 tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+
+#Multi GPU training, specify the gpu number through the --gpus parameter
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+```
+
+Evaluation:
+
+```
+# GPU evaluation
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+Prediction:
+
+```
+# The configuration file used for prediction must match the training
+python3 tools/infer_rec.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. Inference and Deployment
+
+
+### 4.1 Python Inference
+First, the model saved during the SRN text recognition training process is converted into an inference model. ( [Model download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar) ), you can use the following command to convert:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model=./rec_r50_vd_srn_train/best_accuracy Global.save_inference_dir=./inference/rec_srn
+```
+
+For SRN text recognition model inference, the following commands can be executed:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_srn/" --rec_image_shape="1,64,256" --rec_char_type="ch" --rec_algorithm="SRN" --rec_char_dict_path="ppocr/utils/ic15_dict.txt" --use_space_char=False
+```
+
+
+### 4.2 C++ Inference
+
+Not supported
+
+
+### 4.3 Serving
+
+Not supported
+
+
+### 4.4 More
+
+Not supported
+
+
+## 5. FAQ
+
+
+## Citation
+
+```bibtex
+@article{Yu2020TowardsAS,
+ title={Towards Accurate Scene Text Recognition With Semantic Reasoning Networks},
+ author={Deli Yu and Xuan Li and Chengquan Zhang and Junyu Han and Jingtuo Liu and Errui Ding},
+ journal={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year={2020},
+ pages={12110-12119}
+}
+```
diff --git a/doc/doc_en/datasets_en.md b/doc/doc_en/dataset/datasets_en.md
similarity index 92%
rename from doc/doc_en/datasets_en.md
rename to doc/doc_en/dataset/datasets_en.md
index 0e6b6f381e9d008add802c5f8a30d5498a4f94b2..d81c058caa5e82097641405ff1ba048e95a2e3d7 100644
--- a/doc/doc_en/datasets_en.md
+++ b/doc/doc_en/dataset/datasets_en.md
@@ -12,12 +12,12 @@ In addition to opensource data, users can also use synthesis tools to synthesize
#### 1. ICDAR2019-LSVT
- **Data sources**:https://ai.baidu.com/broad/introduction?dataset=lsvt
- **Introduction**: A total of 45w Chinese street view images, including 5w (2w test + 3w training) fully labeled data (text coordinates + text content), 40w weakly labeled data (text content only), as shown in the following figure:
- 
+ 
(a) Fully labeled data
- 
-
+ 
+
(b) Weakly labeled data
- **Download link**:https://ai.baidu.com/broad/download?dataset=lsvt
@@ -25,7 +25,7 @@ In addition to opensource data, users can also use synthesis tools to synthesize
#### 2. ICDAR2017-RCTW-17
- **Data sources**:https://rctw.vlrlab.net/
- **Introduction**:It contains 12000 + images, most of them are collected in the wild through mobile camera. Some are screenshots. These images show a variety of scenes, including street views, posters, menus, indoor scenes and screenshots of mobile applications.
- 
+ 
- **Download link**:https://rctw.vlrlab.net/dataset/
@@ -33,9 +33,9 @@ In addition to opensource data, users can also use synthesis tools to synthesize
- **Data sources**:https://aistudio.baidu.com/aistudio/competition/detail/8
- **Introduction**:A total of 290000 pictures are included, of which 210000 are used as training sets (with labels) and 80000 are used as test sets (without labels). The dataset is collected from the Chinese street view, and is formed by by cutting out the text line area (such as shop signs, landmarks, etc.) in the street view picture. All the images are preprocessed: by using affine transform, the text area is proportionally mapped to a picture with a height of 48 pixels, as shown in the figure:
- 
+ 
(a) Label: 魅派集成吊顶
- 
+ 
(b) Label: 母婴用品连锁
- **Download link**
https://aistudio.baidu.com/aistudio/datasetdetail/8429
@@ -49,13 +49,13 @@ https://aistudio.baidu.com/aistudio/datasetdetail/8429
- 5990 characters including Chinese characters, English letters, numbers and punctuation(Characters set: https://github.com/YCG09/chinese_ocr/blob/master/train/char_std_5990.txt )
- Each sample is fixed with 10 characters, and the characters are randomly intercepted from the sentences in the corpus
- Image resolution is 280x32
- 
- 
+ 
+ 
- **Download link**:https://pan.baidu.com/s/1QkI7kjah8SPHwOQ40rS1Pw (Password: lu7m)
#### 5、ICDAR2019-ArT
- **Data source**:https://ai.baidu.com/broad/introduction?dataset=art
- **Introduction**:It includes 10166 images, 5603 in training sets and 4563 in test sets. It is composed of three parts: total text, scut-ctw1500 and Baidu curved scene text, including text with various shapes such as horizontal, multi-directional and curved.
- 
+ 
- **Download link**:https://ai.baidu.com/broad/download?dataset=art
diff --git a/doc/doc_en/dataset/docvqa_datasets_en.md b/doc/doc_en/dataset/docvqa_datasets_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..820462c324318a391abe409412e8996f11b36279
--- /dev/null
+++ b/doc/doc_en/dataset/docvqa_datasets_en.md
@@ -0,0 +1,27 @@
+## DocVQA dataset
+Here are the common DocVQA datasets, which are being updated continuously. Welcome to contribute datasets~
+- [FUNSD dataset](#funsd)
+- [XFUND dataset](#xfund)
+
+
+#### 1. FUNSD dataset
+- **Data source**: https://guillaumejaume.github.io/FUNSD/
+- **Data Introduction**: The FUNSD dataset is a dataset for form comprehension. It contains 199 real, fully annotated scanned images, including market reports, advertisements, and academic reports, etc., and is divided into 149 50 training sets and 50 test sets. The FUNSD dataset is suitable for many types of DocVQA tasks, such as field-level entity classification, field-level entity connection, etc. Part of the image and the annotation box visualization are shown below:
+
+
+
+
+
+
+
+
+
+
+Decompress the downloaded dataset to the working directory, assuming it is decompressed under PaddleOCR/train_data/. Then download the PaddleOCR format annotation file from the table above.
+
+PaddleOCR also provides a data format conversion script, which can convert the official website label to the PaddleOCR format. The data conversion tool is in `ppocr/utils/gen_label.py`, here is the training set as an example:
+```
+# Convert the label file downloaded from the official website to train_icdar2015_label.txt
+python gen_label.py --mode="det" --root_path="/path/to/icdar_c4_train_imgs/" \
+ --input_path="/path/to/ch4_training_localization_transcription_gt" \
+ --output_label="/path/to/train_icdar2015_label.txt"
+```
+
+After decompressing the data set and downloading the annotation file, PaddleOCR/train_data/ has two folders and two files, which are:
+```
+/PaddleOCR/train_data/icdar2015/text_localization/
+ └─ icdar_c4_train_imgs/ Training data of icdar dataset
+ └─ ch4_test_images/ Testing data of icdar dataset
+ └─ train_icdar2015_label.txt Training annotation of icdar dataset
+ └─ test_icdar2015_label.txt Test annotation of icdar dataset
+```
+
+
+## 2. Text recognition
+
+### 2.1 PaddleOCR text recognition format annotation
+
+The text recognition algorithm in PaddleOCR supports two data formats:
+ - `lmdb` is used to train data sets stored in lmdb format, use [lmdb_dataset.py](../../../ppocr/data/lmdb_dataset.py) to load;
+ - `common dataset` is used to train data sets stored in text files, use [simple_dataset.py](../../../ppocr/data/simple_dataset.py) to load.
+
+
+If you want to use your own data for training, please refer to the following to organize your data.
+
+- Training set
+
+It is recommended to put the training images in the same folder, and use a txt file (rec_gt_train.txt) to store the image path and label. The contents of the txt file are as follows:
+
+* Note: by default, the image path and image label are split with \t, if you use other methods to split, it will cause training error
+
+```
+" Image file name Image annotation "
+
+train_data/rec/train/word_001.jpg 简单可依赖
+train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
+...
+```
+
+The final training set should have the following file structure:
+
+```
+|-train_data
+ |-rec
+ |- rec_gt_train.txt
+ |- train
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+```
+
+- Test set
+
+Similar to the training set, the test set also needs to be provided a folder containing all images (test) and a rec_gt_test.txt. The structure of the test set is as follows:
+
+```
+|-train_data
+ |-rec
+ |-ic15_data
+ |- rec_gt_test.txt
+ |- test
+ |- word_001.jpg
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+```
+
+### 2.2 Public dataset
+| dataset | Image download link | PaddleOCR format annotation download link |
+|---|---|---|
+| en benchmark(MJ, SJ, IIIT, SVT, IC03, IC13, IC15, SVTP, and CUTE.) | [DTRB](https://github.com/clovaai/deep-text-recognition-benchmark#download-lmdb-dataset-for-traininig-and-evaluation-from-here) | LMDB format, which can be loaded directly with [lmdb_dataset.py](../../../ppocr/data/lmdb_dataset.py) |
+|ICDAR 2015| http://rrc.cvc.uab.es/?ch=4&com=downloads | [train](https://paddleocr.bj.bcebos.com/dataset/rec_gt_train.txt)/ [test](https://paddleocr.bj.bcebos.com/dataset/rec_gt_test.txt) |
+| Multilingual datasets |[Baidu network disk](https://pan.baidu.com/s/1bS_u207Rm7YbY33wOECKDA) Extraction code: frgi
[google drive](https://drive.google.com/file/d/18cSWX7wXSy4G0tbKJ0d9PuIaiwRLHpjA/view) | Included in the downloaded image zip |
+
+#### 2.1 ICDAR 2015
+
+The ICDAR 2015 dataset can be downloaded from the link in the table above for quick validation. The lmdb format dataset required by en benchmark can also be downloaded from the table above.
+
+Then download the PaddleOCR format annotation file from the table above.
+
+PaddleOCR also provides a data format conversion script, which can convert the ICDAR official website label to the data format supported by PaddleOCR. The data conversion tool is in `ppocr/utils/gen_label.py`, here is the training set as an example:
+
+```
+# Convert the label file downloaded from the official website to rec_gt_label.txt
+python gen_label.py --mode="rec" --input_path="{path/of/origin/label}" --output_label="rec_gt_label.txt"
+```
+
+The data format is as follows, (a) is the original picture, (b) is the Ground Truth text file corresponding to each picture:
+
+
+
+## 3. Data storage path
+
+The default storage path for PaddleOCR training data is `PaddleOCR/train_data`, if you already have a dataset on your disk, just create a soft link to the dataset directory:
+
+```
+# linux and mac os
+ln -sf /train_data/dataset
+# windows
+mklink /d /train_data/dataset
+```
diff --git a/doc/doc_en/dataset/table_datasets_en.md b/doc/doc_en/dataset/table_datasets_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..e30147909812a153f311add50f0bef5d1d1e0e32
--- /dev/null
+++ b/doc/doc_en/dataset/table_datasets_en.md
@@ -0,0 +1,32 @@
+# Table Recognition Datasets
+
+- [Dataset Summary](#dataset-summary)
+- [1. PubTabNet](#1-pubtabnet)
+- [2. TAL Table Recognition Competition Dataset](#2-tal-table-recognition-competition-dataset)
+
+Here are the commonly used table recognition datasets, which are being updated continuously. Welcome to contribute datasets~
+
+## Dataset Summary
+
+| dataset | Image download link | PPOCR format annotation download link |
+|---|---|---|
+| PubTabNet |https://github.com/ibm-aur-nlp/PubTabNet| jsonl format, which can be loaded directly with [pubtab_dataset.py](../../../ppocr/data/pubtab_dataset.py) |
+| TAL Table Recognition Competition Dataset |https://ai.100tal.com/dataset| jsonl format, which can be loaded directly with [pubtab_dataset.py](../../../ppocr/data/pubtab_dataset.py) |
+
+## 1. PubTabNet
+- **Data Introduction**:The training set of the PubTabNet dataset contains 500,000 images and the validation set contains 9000 images. Part of the image visualization is shown below.
+
+
+
+
+
+
+
+
-
-
-
-Decompress the downloaded dataset to the working directory, assuming it is decompressed under PaddleOCR/train_data/. In addition, PaddleOCR organizes many scattered annotation files into two separate annotation files for train and test respectively, which can be downloaded by wget:
-```shell
-# Under the PaddleOCR path
-cd PaddleOCR/
-wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/train_icdar2015_label.txt
-wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/test_icdar2015_label.txt
-```
-
-After decompressing the data set and downloading the annotation file, PaddleOCR/train_data/ has two folders and two files, which are:
-```
-/PaddleOCR/train_data/icdar2015/text_localization/
- └─ icdar_c4_train_imgs/ Training data of icdar dataset
- └─ ch4_test_images/ Testing data of icdar dataset
- └─ train_icdar2015_label.txt Training annotation of icdar dataset
- └─ test_icdar2015_label.txt Test annotation of icdar dataset
-```
-
-The provided annotation file format is as follow, separated by "\t":
-```
-" Image file name Image annotation information encoded by json.dumps"
-ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
-```
-The image annotation after **json.dumps()** encoding is a list containing multiple dictionaries.
-
-The `points` in the dictionary represent the coordinates (x, y) of the four points of the text box, arranged clockwise from the point at the upper left corner.
-
-`transcription` represents the text of the current text box. **When its content is "###" it means that the text box is invalid and will be skipped during training.**
-
-If you want to train PaddleOCR on other datasets, please build the annotation file according to the above format.
-
+To prepare datasets, refer to [ocr_datasets](./dataset/ocr_datasets_en.md) .
### 1.2 Download Pre-trained Model
@@ -175,11 +140,44 @@ After adding the four-part modules of the network, you only need to configure th
**NOTE**: More details about replace Backbone and other mudule can be found in [doc](add_new_algorithm_en.md).
+### 2.4 Mixed Precision Training
-### 2.4 Training with knowledge distillation
+If you want to speed up your training further, you can use [Auto Mixed Precision Training](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/01_paddle2.0_introduction/basic_concept/amp_cn.html), taking a single machine and a single gpu as an example, the commands are as follows:
+
+```shell
+python3 tools/train.py -c configs/det/det_mv3_db.yml \
+ -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained \
+ Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
+ ```
+
+### 2.5 Distributed Training
+
+During multi-machine multi-gpu training, use the `--ips` parameter to set the used machine IP address, and the `--gpus` parameter to set the used GPU ID:
+
+```bash
+python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
+ -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
+```
+
+**Note:** When using multi-machine and multi-gpu training, you need to replace the ips value in the above command with the address of your machine, and the machines need to be able to ping each other. In addition, training needs to be launched separately on multiple machines. The command to view the ip address of the machine is `ifconfig`.
+
+### 2.6 Training with knowledge distillation
Knowledge distillation is supported in PaddleOCR for text detection training process. For more details, please refer to [doc](./knowledge_distillation_en.md).
+### 2.7 Training on other platform(Windows/macOS/Linux DCU)
+
+- Windows GPU/CPU
+The Windows platform is slightly different from the Linux platform:
+Windows platform only supports `single gpu` training and inference, specify GPU for training `set CUDA_VISIBLE_DEVICES=0`
+On the Windows platform, DataLoader only supports single-process mode, so you need to set `num_workers` to 0;
+
+- macOS
+GPU mode is not supported, you need to set `use_gpu` to False in the configuration file, and the rest of the training evaluation prediction commands are exactly the same as Linux GPU.
+
+- Linux DCU
+Running on a DCU device requires setting the environment variable `export HIP_VISIBLE_DEVICES=0,1,2,3`, and the rest of the training and evaluation prediction commands are exactly the same as the Linux GPU.
+
## 3. Evaluation and Test
### 3.1 Evaluation
diff --git a/doc/doc_en/models_list_en.md b/doc/doc_en/models_list_en.md
index e77a5ea96336e91cdd0490b687ca3652ba374df5..29520c593c8097c77123a87c7e24b50b1185c09d 100644
--- a/doc/doc_en/models_list_en.md
+++ b/doc/doc_en/models_list_en.md
@@ -1,11 +1,14 @@
-# OCR Model List(V2.1, updated on 2021.9.6)
+# OCR Model List(V2.1, updated on 2022.4.28)
> **Note**
-> 1. Compared with the model v2.0, the 2.1 version of the detection model has a improvement in accuracy, and the 2.1 version of the recognition model has optimizations in accuracy and speed with CPU.
-> 2. Compared with [models 1.1](https://github.com/PaddlePaddle/PaddleOCR/blob/develop/doc/doc_en/models_list_en.md), which are trained with static graph programming paradigm, models 2.0 are the dynamic graph trained version and achieve close performance.
+> 1. Compared with the model v2, the 3rd version of the detection model has a improvement in accuracy, and the 2.1 version of the recognition model has optimizations in accuracy and speed with CPU.
+> 2. Compared with [models 1.1](https://github.com/PaddlePaddle/PaddleOCR/blob/develop/doc/doc_en/models_list_en.md), which are trained with static graph programming paradigm, models 2.0 or higher are the dynamic graph trained version and achieve close performance.
> 3. All models in this tutorial are all ppocr-series models, for more introduction of algorithms and models based on public dataset, you can refer to [algorithm overview tutorial](./algorithm_overview_en.md).
-- [OCR Model List(V2.1, updated on 2021.9.6)](#ocr-model-listv21-updated-on-202196)
+- [OCR Model List(V3, updated on 2022.4.28)]()
- [1. Text Detection Model](#1-text-detection-model)
+ - [1.1 Chinese Detection Model](#1.1)
+ - [2.2 English Detection Model](#1.2)
+ - [1.3 Multilingual Detection Model](#1.3)
- [2. Text Recognition Model](#2-text-recognition-model)
- [2.1 Chinese Recognition Model](#21-chinese-recognition-model)
- [2.2 English Recognition Model](#22-english-recognition-model)
@@ -28,14 +31,42 @@ Relationship of the above models is as follows.
## 1. Text Detection Model
+
+
+### 1. Chinese Detection Model
+
|model name|description|config|model size|download|
| --- | --- | --- | --- | --- |
-|ch_PP-OCRv2_det_slim|[New] slim quantization with distillation lightweight model, supporting Chinese, English, multilingual text detection|[ch_PP-OCRv2_det_cml.yml](../../configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml)| 3M |[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar)|
-|ch_PP-OCRv2_det|[New] Original lightweight model, supporting Chinese, English, multilingual text detection|[ch_PP-OCRv2_det_cml.yml](../../configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml)|3M|[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar)|
+|ch_PP-OCRv3_det_slim| [New] slim quantization with distillation lightweight model, supporting Chinese, English, multilingual text detection |[ch_PP-OCRv3_det_cml.yml](../../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml)| 1.1M |[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_slim_infer.tar) / [trained model (coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/ch/ch_PP-OCRv3_det_slim_distill_train.tar) / [lite model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_slim_infer.nb)|
+|ch_PP-OCRv3_det| [New] Original lightweight model, supporting Chinese, English, multilingual text detection |[ch_PP-OCRv3_det_cml.yml](../../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml)| 3.8M |[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar)|
+|ch_PP-OCRv2_det_slim| [New] slim quantization with distillation lightweight model, supporting Chinese, English, multilingual text detection|[ch_PP-OCRv2_det_cml.yml](../../configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml)| 3M |[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar)|
+|ch_PP-OCRv2_det| [New] Original lightweight model, supporting Chinese, English, multilingual text detection|[ch_PP-OCRv2_det_cml.yml](../../configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml)|3M|[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar)|
|ch_ppocr_mobile_slim_v2.0_det|Slim pruned lightweight model, supporting Chinese, English, multilingual text detection|[ch_det_mv3_db_v2.0.yml](../../configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml)|2.6M |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/slim/ch_ppocr_mobile_v2.0_det_prune_infer.tar)|
|ch_ppocr_mobile_v2.0_det|Original lightweight model, supporting Chinese, English, multilingual text detection|[ch_det_mv3_db_v2.0.yml](../../configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml)|3M|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar)|
|ch_ppocr_server_v2.0_det|General model, which is larger than the lightweight model, but achieved better performance|[ch_det_res18_db_v2.0.yml](../../configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml)|47M|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar)|
+
+
+### 1.2 English Detection Model
+
+|model name|description|config|model size|download|
+| --- | --- | --- | --- | --- |
+|en_PP-OCRv3_det_slim | [New] Slim qunatization with distillation lightweight detection model, supporting English | [ch_PP-OCRv3_det_cml.yml](../../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml) | 1.1M |[inference model(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_slim_infer.tar) / [trained model (coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_slim_distill_train.tar) / [lite model(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_slim_infer.nb) |
+|ch_PP-OCRv3_det | [New] Original lightweight detection model, supporting English |[ch_PP-OCRv3_det_cml.yml](../../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml)| 3.8M | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar) |
+
+* Note: English configuration file is same as Chinese except training data, here we only provide one configuration file.
+
+
+
+### 1.3 Multilingual Detection Model
+
+|model name|description|config|model size|download|
+| --- | --- | --- | --- | --- |
+| ml_PP-OCRv3_det_slim | [New] Slim qunatization with distillation lightweight detection model, supporting English | [ch_PP-OCRv3_det_cml.yml](../../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml) | 1.1M | [inference model(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_slim_infer.tar) / [trained model (coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_slim_distill_train.tar) / [lite model(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_slim_infer.nb) |
+| ml_PP-OCRv3_det |[New] Original lightweight detection model, supporting English | [ch_PP-OCRv3_det_cml.yml](../../configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml)| 3.8M | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/Multilingual_PP-OCRv3_det_distill_train.tar) |
+
+* Note: English configuration file is same as Chinese except training data, here we only provide one configuration file.
+
## 2. Text Recognition Model
@@ -44,8 +75,10 @@ Relationship of the above models is as follows.
|model name|description|config|model size|download|
| --- | --- | --- | --- | --- |
-|ch_PP-OCRv2_rec_slim|[New] Slim qunatization with distillation lightweight model, supporting Chinese, English, multilingual text recognition|[ch_PP-OCRv2_rec.yml](../../configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml)| 9M |[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_train.tar) |
-|ch_PP-OCRv2_rec|[New] Original lightweight model, supporting Chinese, English, multilingual text recognition|[ch_PP-OCRv2_rec_distillation.yml](../../configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml)|8.5M|[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
+|ch_PP-OCRv3_rec_slim | [New] Slim qunatization with distillation lightweight model, supporting Chinese, English text recognition |[ch_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml)| 4.9M |[inference model(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_slim_infer.tar) / [trained model (coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/ch/ch_PP-OCRv3_rec_slim_train.tar) / [lite model(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_slim_infer.nb) |
+|ch_PP-OCRv3_rec| [New] Original lightweight model, supporting Chinese, English, multilingual text recognition |[ch_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml)| 12.4M |[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar) |
+|ch_PP-OCRv2_rec_slim| Slim qunatization with distillation lightweight model, supporting Chinese, English text recognition|[ch_PP-OCRv2_rec.yml](../../configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml)| 9M |[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_train.tar) |
+|ch_PP-OCRv2_rec| Original lightweight model, supporting Chinese, English, multilingual text recognition |[ch_PP-OCRv2_rec_distillation.yml](../../configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml)|8.5M|[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
|ch_ppocr_mobile_slim_v2.0_rec|Slim pruned and quantized lightweight model, supporting Chinese, English and number recognition|[rec_chinese_lite_train_v2.0.yml](../../configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml)| 6M | [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_slim_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_slim_train.tar) |
|ch_ppocr_mobile_v2.0_rec|Original lightweight model, supporting Chinese, English and number recognition|[rec_chinese_lite_train_v2.0.yml](../../configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml)|5.2M|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_train.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
|ch_ppocr_server_v2.0_rec|General model, supporting Chinese, English and number recognition|[rec_chinese_common_train_v2.0.yml](../../configs/rec/ch_ppocr_v2.0/rec_chinese_common_train_v2.0.yml)|94.8M|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_train.tar) / [pre-trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
@@ -58,6 +91,8 @@ Relationship of the above models is as follows.
|model name|description|config|model size|download|
| --- | --- | --- | --- | --- |
+|en_PP-OCRv3_rec_slim | [New] Slim qunatization with distillation lightweight model, supporting english, English text recognition |[en_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/en_PP-OCRv3_rec_distillation.yml)| 4.9M |[inference model(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_slim_infer.tar) / [trained model (coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_slim_train.tar) / [lite model(coming soon)](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_slim_infer.nb) |
+|en_PP-OCRv3_rec| [New] Original lightweight model, supporting english, English, multilingual text recognition |[en_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/en_PP-OCRv3_rec_distillation.yml)| 12.4M |[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
|en_number_mobile_slim_v2.0_rec|Slim pruned and quantized lightweight model, supporting English and number recognition|[rec_en_number_lite_train.yml](../../configs/rec/multi_language/rec_en_number_lite_train.yml)| 2.7M | [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/en_number_mobile_v2.0_rec_slim_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/en_number_mobile_v2.0_rec_slim_train.tar) |
|en_number_mobile_v2.0_rec|Original lightweight model, supporting English and number recognition|[rec_en_number_lite_train.yml](../../configs/rec/multi_language/rec_en_number_lite_train.yml)|2.6M|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/en_number_mobile_v2.0_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/en_number_mobile_v2.0_rec_train.tar) |
diff --git a/doc/doc_en/ppocr_introduction_en.md b/doc/doc_en/ppocr_introduction_en.md
index 1a8a77006a753f52cc9b36cea5c85bd5ae7f1606..6483d3bf7ae0989f7d9f31d2742cf732924eb086 100644
--- a/doc/doc_en/ppocr_introduction_en.md
+++ b/doc/doc_en/ppocr_introduction_en.md
@@ -51,7 +51,7 @@ For the performance comparison between PP-OCR series models, please check the [b
PP-OCRv2 English model
-
+
@@ -69,20 +69,20 @@ For the performance comparison between PP-OCR series models, please check the [b

 -
+
-
+
PP-OCRv2 Multilingual model
-
+
-
+
-
+
## 5. Tutorial
@@ -101,10 +101,12 @@ For more tutorials, including model training, model compression, deployment, etc
## 6. Model zoo
-## PP-OCR Series Model List(Update on September 8th)
+## PP-OCR Series Model List(Update on 2022.04.28)
| Model introduction | Model name | Recommended scene | Detection model | Direction classifier | Recognition model |
| ------------------------------------------------------------ | ---------------------------- | ----------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| Chinese and English ultra-lightweight PP-OCRv3 model(16.2M) | ch_PP-OCRv3_xx | Mobile & Server | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar) | [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar) |
+| English ultra-lightweight PP-OCRv3 model(13.4M) | en_PP-OCRv3_xx | Mobile & Server | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar) | [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/ch_ppocr_mobile_v2.0_cls_train.tar) | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
| Chinese and English ultra-lightweight PP-OCRv2 model(11.6M) | ch_PP-OCRv2_xx |Mobile & Server|[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar)| [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar)|
| Chinese and English ultra-lightweight PP-OCR model (9.4M) | ch_ppocr_mobile_v2.0_xx | Mobile & server |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar)|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_train.tar) |
| Chinese and English general PP-OCR model (143.4M) | ch_ppocr_server_v2.0_xx | Server |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_train.tar) |
diff --git a/doc/doc_en/recognition_en.md b/doc/doc_en/recognition_en.md
index 8042ef8c10a3797868fba0994ebb9072e73ec8bb..57eb89f935c9c23772b2c278edd414ebdb69d64d 100644
--- a/doc/doc_en/recognition_en.md
+++ b/doc/doc_en/recognition_en.md
@@ -1,96 +1,32 @@
# Text Recognition
- [1. Data Preparation](#DATA_PREPARATION)
- - [1.1 Costom Dataset](#Costom_Dataset)
- - [1.2 Dataset Download](#Dataset_download)
- - [1.3 Dictionary](#Dictionary)
- - [1.4 Add Space Category](#Add_space_category)
-
+ * [1.1 Costom Dataset](#Costom_Dataset)
+ * [1.2 Dataset Download](#Dataset_download)
+ * [1.3 Dictionary](#Dictionary)
+ * [1.4 Add Space Category](#Add_space_category)
+ * [1.5 Data Augmentation](#Data_Augmentation)
- [2. Training](#TRAINING)
- - [2.1 Data Augmentation](#Data_Augmentation)
- - [2.2 General Training](#Training)
- - [2.3 Multi-language Training](#Multi_language)
- - [2.4 Training with Knowledge Distillation](#kd)
-
-- [3. Evaluation](#EVALUATION)
-
-- [4. Prediction](#PREDICTION)
-- [5. Convert to Inference Model](#Inference)
+ * [2.1 Start Training](#21-start-training)
+ * [2.2 Load Trained Model and Continue Training](#22-load-trained-model-and-continue-training)
+ * [2.3 Training with New Backbone](#23-training-with-new-backbone)
+ * [2.4 Mixed Precision Training](#24-amp-training)
+ * [2.5 Distributed Training](#25-distributed-training)
+ * [2.6 Training with knowledge distillation](#kd)
+ * [2.7 Multi-language Training](#Multi_language)
+ * [2.8 Training on other platform(Windows/macOS/Linux DCU)](#28)
+- [3. Evaluation and Test](#3-evaluation-and-test)
+ * [3.1 Evaluation](#31-evaluation)
+ * [3.2 Test](#32-test)
+- [4. Inference](#4-inference)
+- [5. FAQ](#5-faq)
## 1. Data Preparation
+### 1.1 DataSet Preparation
-PaddleOCR supports two data formats:
-- `LMDB` is used to train data sets stored in lmdb format(LMDBDataSet);
-- `general data` is used to train data sets stored in text files(SimpleDataSet):
-
-Please organize the dataset as follows:
-
-The default storage path for training data is `PaddleOCR/train_data`, if you already have a dataset on your disk, just create a soft link to the dataset directory:
-
-```
-# linux and mac os
-ln -sf /train_data/dataset
-# windows
-mklink /d /train_data/dataset
-```
-
-
-### 1.1 Costom Dataset
-
-If you want to use your own data for training, please refer to the following to organize your data.
-
-- Training set
-
-It is recommended to put the training images in the same folder, and use a txt file (rec_gt_train.txt) to store the image path and label. The contents of the txt file are as follows:
-
-* Note: by default, the image path and image label are split with \t, if you use other methods to split, it will cause training error
-
-```
-" Image file name Image annotation "
-
-train_data/rec/train/word_001.jpg 简单可依赖
-train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
-...
-```
-
-The final training set should have the following file structure:
-
-```
-|-train_data
- |-rec
- |- rec_gt_train.txt
- |- train
- |- word_001.png
- |- word_002.jpg
- |- word_003.jpg
- | ...
-```
-
-- Test set
-
-Similar to the training set, the test set also needs to be provided a folder containing all images (test) and a rec_gt_test.txt. The structure of the test set is as follows:
-
-```
-|-train_data
- |-rec
- |-ic15_data
- |- rec_gt_test.txt
- |- test
- |- word_001.jpg
- |- word_002.jpg
- |- word_003.jpg
- | ...
-```
-
-
-### 1.2 Dataset Download
-
-- ICDAR2015
-
-If you do not have a dataset locally, you can download it on the official website [icdar2015](http://rrc.cvc.uab.es/?ch=4&com=downloads).
-Also refer to [DTRB](https://github.com/clovaai/deep-text-recognition-benchmark#download-lmdb-dataset-for-traininig-and-evaluation-from-here) ,download the lmdb format dataset required for benchmark
+To prepare datasets, refer to [ocr_datasets](./dataset/ocr_datasets.md) .
PaddleOCR provides label files for training the icdar2015 dataset, which can be downloaded in the following ways:
@@ -122,7 +58,7 @@ The multi-language model training method is the same as the Chinese model. The t
-### 1.3 Dictionary
+### 1.2 Dictionary
Finally, a dictionary ({word_dict_name}.txt) needs to be provided so that when the model is trained, all the characters that appear can be mapped to the dictionary index.
@@ -171,11 +107,8 @@ If you need to customize dic file, please add character_dict_path field in confi
If you want to support the recognition of the `space` category, please set the `use_space_char` field in the yml file to `True`.
-
-## 2.Training
-
-### 2.1 Data Augmentation
+### 1.5 Data Augmentation
PaddleOCR provides a variety of data augmentation methods. All the augmentation methods are enabled by default.
@@ -183,11 +116,14 @@ The default perturbation methods are: cvtColor, blur, jitter, Gasuss noise, rand
Each disturbance method is selected with a 40% probability during the training process. For specific code implementation, please refer to: [rec_img_aug.py](../../ppocr/data/imaug/rec_img_aug.py)
-
-### 2.2 General Training
+
+## 2.Training
PaddleOCR provides training scripts, evaluation scripts, and prediction scripts. In this section, the CRNN recognition model will be used as an example:
+
+### 2.1 Start Training
+
First download the pretrain model, you can download the trained model to finetune on the icdar2015 data:
```
@@ -286,8 +222,99 @@ Eval:
```
**Note that the configuration file for prediction/evaluation must be consistent with the training.**
+
+### 2.2 Load Trained Model and Continue Training
+
+If you expect to load trained model and continue the training again, you can specify the parameter `Global.checkpoints` as the model path to be loaded.
+
+For example:
+```shell
+python3 tools/train.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints=./your/trained/model
+```
+
+**Note**: The priority of `Global.checkpoints` is higher than that of `Global.pretrained_model`, that is, when two parameters are specified at the same time, the model specified by `Global.checkpoints` will be loaded first. If the model path specified by `Global.checkpoints` is wrong, the one specified by `Global.pretrained_model` will be loaded.
+
+
+### 2.3 Training with New Backbone
+
+The network part completes the construction of the network, and PaddleOCR divides the network into four parts, which are under [ppocr/modeling](../../ppocr/modeling). The data entering the network will pass through these four parts in sequence(transforms->backbones->
+necks->heads).
+
+```bash
+├── architectures # Code for building network
+├── transforms # Image Transformation Module
+├── backbones # Feature extraction module
+├── necks # Feature enhancement module
+└── heads # Output module
+```
+
+If the Backbone to be replaced has a corresponding implementation in PaddleOCR, you can directly modify the parameters in the `Backbone` part of the configuration yml file.
+
+However, if you want to use a new Backbone, an example of replacing the backbones is as follows:
+
+1. Create a new file under the [ppocr/modeling/backbones](../../ppocr/modeling/backbones) folder, such as my_backbone.py.
+2. Add code in the my_backbone.py file, the sample code is as follows:
+
+```python
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+class MyBackbone(nn.Layer):
+ def __init__(self, *args, **kwargs):
+ super(MyBackbone, self).__init__()
+ # your init code
+ self.conv = nn.xxxx
+
+ def forward(self, inputs):
+ # your network forward
+ y = self.conv(inputs)
+ return y
+```
+
+3. Import the added module in the [ppocr/modeling/backbones/\__init\__.py](../../ppocr/modeling/backbones/__init__.py) file.
+
+After adding the four-part modules of the network, you only need to configure them in the configuration file to use, such as:
+
+```yaml
+ Backbone:
+ name: MyBackbone
+ args1: args1
+```
+
+**NOTE**: More details about replace Backbone and other mudule can be found in [doc](add_new_algorithm_en.md).
+
+
+### 2.4 Mixed Precision Training
+
+If you want to speed up your training further, you can use [Auto Mixed Precision Training](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/01_paddle2.0_introduction/basic_concept/amp_cn.html), taking a single machine and a single gpu as an example, the commands are as follows:
+
+```shell
+python3 tools/train.py -c configs/rec/rec_icdar15_train.yml \
+ -o Global.pretrained_model=./pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train \
+ Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
+ ```
+
+
+### 2.5 Distributed Training
+
+During multi-machine multi-gpu training, use the `--ips` parameter to set the used machine IP address, and the `--gpus` parameter to set the used GPU ID:
+
+```bash
+python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_icdar15_train.yml \
+ -o Global.pretrained_model=./pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train
+```
+
+**Note:** When using multi-machine and multi-gpu training, you need to replace the ips value in the above command with the address of your machine, and the machines need to be able to ping each other. In addition, training needs to be launched separately on multiple machines. The command to view the ip address of the machine is `ifconfig`.
+
+
+### 2.6 Training with Knowledge Distillation
+
+Knowledge distillation is supported in PaddleOCR for text recognition training process. For more details, please refer to [doc](./knowledge_distillation_en.md).
+
-### 2.3 Multi-language Training
+### 2.7 Multi-language Training
Currently, the multi-language algorithms supported by PaddleOCR are:
@@ -343,25 +370,36 @@ Eval:
...
```
-
+
+### 2.8 Training on other platform(Windows/macOS/Linux DCU)
-### 2.4 Training with Knowledge Distillation
+- Windows GPU/CPU
+The Windows platform is slightly different from the Linux platform:
+Windows platform only supports `single gpu` training and inference, specify GPU for training `set CUDA_VISIBLE_DEVICES=0`
+On the Windows platform, DataLoader only supports single-process mode, so you need to set `num_workers` to 0;
-Knowledge distillation is supported in PaddleOCR for text recognition training process. For more details, please refer to [doc](./knowledge_distillation_en.md).
+- macOS
+GPU mode is not supported, you need to set `use_gpu` to False in the configuration file, and the rest of the training evaluation prediction commands are exactly the same as Linux GPU.
+
+- Linux DCU
+Running on a DCU device requires setting the environment variable `export HIP_VISIBLE_DEVICES=0,1,2,3`, and the rest of the training and evaluation prediction commands are exactly the same as the Linux GPU.
-
+
+## 3. Evaluation and Test
-## 3. Evalution
+
+### 3.1 Evaluation
+
+The model parameters during training are saved in the `Global.save_model_dir` directory by default. When evaluating indicators, you need to set `Global.checkpoints` to point to the saved parameter file. The evaluation dataset can be set by modifying the `Eval.dataset.label_file_list` field in the `configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml` file.
-The evaluation dataset can be set by modifying the `Eval.dataset.label_file_list` field in the `configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml` file.
```
# GPU evaluation, Global.checkpoints is the weight to be tested
python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.checkpoints={path/to/weights}/best_accuracy
```
-
-## 4. Prediction
+
+### 3.2 Test
Using the model trained by paddleocr, you can quickly get prediction through the following script.
@@ -423,9 +461,14 @@ infer_img: doc/imgs_words/ch/word_1.jpg
result: ('韩国小馆', 0.997218)
```
-
+
+## 4. Inference
+
+The inference model (the model saved by `paddle.jit.save`) is generally a solidified model saved after the model training is completed, and is mostly used to give prediction in deployment.
-## 5. Convert to Inference Model
+The model saved during the training process is the checkpoints model, which saves the parameters of the model and is mostly used to resume training.
+
+Compared with the checkpoints model, the inference model will additionally save the structural information of the model. Therefore, it is easier to deploy because the model structure and model parameters are already solidified in the inference model file, and is suitable for integration with actual systems.
The recognition model is converted to the inference model in the same way as the detection, as follows:
@@ -443,6 +486,7 @@ If you have a model trained on your own dataset with a different dictionary file
After the conversion is successful, there are three files in the model save directory:
```
+
inference/en_PP-OCRv3_rec/
├── inference.pdiparams # The parameter file of recognition inference model
├── inference.pdiparams.info # The parameter information of recognition inference model, which can be ignored
@@ -456,3 +500,10 @@ inference/en_PP-OCRv3_rec/
```
python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words_en/word_336.png" --rec_model_dir="./your inference model" --rec_image_shape="3, 32, 100" --rec_char_dict_path="your text dict path"
```
+
+
+## 5. FAQ
+
+Q1: After the training model is transferred to the inference model, the prediction effect is inconsistent?
+
+**A**: There are many such problems, and the problems are mostly caused by inconsistent preprocessing and postprocessing parameters when the trained model predicts and the preprocessing and postprocessing parameters when the inference model predicts. You can compare whether there are differences in preprocessing, postprocessing, and prediction in the configuration files used for training.
diff --git a/doc/doc_en/training_en.md b/doc/doc_en/training_en.md
index 89992ff905426faaf7d22707a76dd9daaa8bcbb7..86c4deb3868081552f5b27d67c627693c3f95a62 100644
--- a/doc/doc_en/training_en.md
+++ b/doc/doc_en/training_en.md
@@ -94,7 +94,7 @@ The current open source models, data sets and magnitudes are as follows:
- Chinese data set, LSVT street view data set crops the image according to the truth value, and performs position calibration, a total of 30w images. In addition, based on the LSVT corpus, 500w of synthesized data.
- Small language data set, using different corpora and fonts, respectively generated 100w synthetic data set, and using ICDAR-MLT as the verification set.
-Among them, the public data sets are all open source, users can search and download by themselves, or refer to [Chinese data set](./datasets_en.md), synthetic data is not open source, users can use open source synthesis tools to synthesize by themselves. Synthesis tools include [text_renderer](https://github.com/Sanster/text_renderer), [SynthText](https://github.com/ankush-me/SynthText), [TextRecognitionDataGenerator](https://github.com/Belval/TextRecognitionDataGenerator) etc.
+Among them, the public data sets are all open source, users can search and download by themselves, or refer to [Chinese data set](dataset/datasets_en.md), synthetic data is not open source, users can use open source synthesis tools to synthesize by themselves. Synthesis tools include [text_renderer](https://github.com/Sanster/text_renderer), [SynthText](https://github.com/ankush-me/SynthText), [TextRecognitionDataGenerator](https://github.com/Belval/TextRecognitionDataGenerator) etc.
diff --git a/doc/doc_en/update_en.md b/doc/doc_en/update_en.md
index 39fd936d1bd4e5f8d8535805f865792820ee1199..8ec74fe8b73d89cc97904e2ce156e14bbd596eb4 100644
--- a/doc/doc_en/update_en.md
+++ b/doc/doc_en/update_en.md
@@ -19,7 +19,7 @@
- 2020.7.15, Add several related datasets, data annotation and synthesis tools.
- 2020.7.9 Add a new model to support recognize the character "space".
- 2020.7.9 Add the data augument and learning rate decay strategies during training.
-- 2020.6.8 Add [datasets](./datasets_en.md) and keep updating
+- 2020.6.8 Add [datasets](dataset/datasets_en.md) and keep updating
- 2020.6.5 Support exporting `attention` model to `inference_model`
- 2020.6.5 Support separate prediction and recognition, output result score
- 2020.5.30 Provide Lightweight Chinese OCR online experience
diff --git a/doc/imgs_results/det_res_img623_fce.jpg b/doc/imgs_results/det_res_img623_fce.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..938ae4cabf32cf5f89519f81b33259b188ed494a
Binary files /dev/null and b/doc/imgs_results/det_res_img623_fce.jpg differ
diff --git a/doc/imgs_results/det_res_img_10_fce.jpg b/doc/imgs_results/det_res_img_10_fce.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..fb32950ffda29f3263ab8bddc445e7c71f7d2ee0
Binary files /dev/null and b/doc/imgs_results/det_res_img_10_fce.jpg differ
diff --git a/doc/imgs_results/det_res_img_10_pse.jpg b/doc/imgs_results/det_res_img_10_pse.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..cdb7625dd05e6865ff3d6d476a33466f42cb3aee
Binary files /dev/null and b/doc/imgs_results/det_res_img_10_pse.jpg differ
diff --git a/doc/imgs_results/det_res_img_10_pse_poly.jpg b/doc/imgs_results/det_res_img_10_pse_poly.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..9c06a17ccb6a6d99c82a79eca5cf5755af4d0ce5
Binary files /dev/null and b/doc/imgs_results/det_res_img_10_pse_poly.jpg differ
diff --git a/ppocr/modeling/architectures/base_model.py b/ppocr/modeling/architectures/base_model.py
index f5b29f94057d5b1f1fbec27686d5f1d679b15479..c6b50d4886daa9bfd2f863c1d8fd6dbc3d1e42c0 100644
--- a/ppocr/modeling/architectures/base_model.py
+++ b/ppocr/modeling/architectures/base_model.py
@@ -92,6 +92,9 @@ class BaseModel(nn.Layer):
else:
y["head_out"] = x
if self.return_all_feats:
- return y
+ if self.training:
+ return y
+ else:
+ return {"head_out": y["head_out"]}
else:
return x
diff --git a/ppocr/modeling/heads/det_db_head.py b/ppocr/modeling/heads/det_db_head.py
index f76cb34d37af7d81b5e628d06c1a4cfe126f8bb4..a686ae5ab0662ad31ddfd339bd1999c45c370cf0 100644
--- a/ppocr/modeling/heads/det_db_head.py
+++ b/ppocr/modeling/heads/det_db_head.py
@@ -31,13 +31,14 @@ def get_bias_attr(k):
class Head(nn.Layer):
- def __init__(self, in_channels, name_list):
+ def __init__(self, in_channels, name_list, kernel_list=[3, 2, 2], **kwargs):
super(Head, self).__init__()
+
self.conv1 = nn.Conv2D(
in_channels=in_channels,
out_channels=in_channels // 4,
- kernel_size=3,
- padding=1,
+ kernel_size=kernel_list[0],
+ padding=int(kernel_list[0] // 2),
weight_attr=ParamAttr(),
bias_attr=False)
self.conv_bn1 = nn.BatchNorm(
@@ -50,7 +51,7 @@ class Head(nn.Layer):
self.conv2 = nn.Conv2DTranspose(
in_channels=in_channels // 4,
out_channels=in_channels // 4,
- kernel_size=2,
+ kernel_size=kernel_list[1],
stride=2,
weight_attr=ParamAttr(
initializer=paddle.nn.initializer.KaimingUniform()),
@@ -65,7 +66,7 @@ class Head(nn.Layer):
self.conv3 = nn.Conv2DTranspose(
in_channels=in_channels // 4,
out_channels=1,
- kernel_size=2,
+ kernel_size=kernel_list[2],
stride=2,
weight_attr=ParamAttr(
initializer=paddle.nn.initializer.KaimingUniform()),
@@ -100,8 +101,8 @@ class DBHead(nn.Layer):
'conv2d_57', 'batch_norm_49', 'conv2d_transpose_2', 'batch_norm_50',
'conv2d_transpose_3', 'thresh'
]
- self.binarize = Head(in_channels, binarize_name_list)
- self.thresh = Head(in_channels, thresh_name_list)
+ self.binarize = Head(in_channels, binarize_name_list, **kwargs)
+ self.thresh = Head(in_channels, thresh_name_list, **kwargs)
def step_function(self, x, y):
return paddle.reciprocal(1 + paddle.exp(-self.k * (x - y)))
diff --git a/ppocr/modeling/necks/__init__.py b/ppocr/modeling/necks/__init__.py
index 54837dc65be4b6243136559cf281dc62c441512b..e10b082d11be69b1865f0093b6fec442b255f03a 100644
--- a/ppocr/modeling/necks/__init__.py
+++ b/ppocr/modeling/necks/__init__.py
@@ -16,7 +16,7 @@ __all__ = ['build_neck']
def build_neck(config):
- from .db_fpn import DBFPN
+ from .db_fpn import DBFPN, RSEFPN, LKPAN
from .east_fpn import EASTFPN
from .sast_fpn import SASTFPN
from .rnn import SequenceEncoder
@@ -26,8 +26,8 @@ def build_neck(config):
from .fce_fpn import FCEFPN
from .pren_fpn import PRENFPN
support_dict = [
- 'FPN', 'FCEFPN', 'DBFPN', 'EASTFPN', 'SASTFPN', 'SequenceEncoder',
- 'PGFPN', 'TableFPN', 'PRENFPN'
+ 'FPN', 'FCEFPN', 'LKPAN', 'DBFPN', 'RSEFPN', 'EASTFPN', 'SASTFPN',
+ 'SequenceEncoder', 'PGFPN', 'TableFPN', 'PRENFPN'
]
module_name = config.pop('name')
diff --git a/ppocr/modeling/necks/db_fpn.py b/ppocr/modeling/necks/db_fpn.py
index 1cf30cedd5b23e8a7ba243726a6d7eea7924750c..93ed2dbfd1fac9bf2d163c54d23a20e16b537981 100644
--- a/ppocr/modeling/necks/db_fpn.py
+++ b/ppocr/modeling/necks/db_fpn.py
@@ -20,6 +20,88 @@ import paddle
from paddle import nn
import paddle.nn.functional as F
from paddle import ParamAttr
+import os
+import sys
+
+__dir__ = os.path.dirname(os.path.abspath(__file__))
+sys.path.append(__dir__)
+sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '../../..')))
+
+from ppocr.modeling.backbones.det_mobilenet_v3 import SEModule
+
+
+class DSConv(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ padding,
+ stride=1,
+ groups=None,
+ if_act=True,
+ act="relu",
+ **kwargs):
+ super(DSConv, self).__init__()
+ if groups == None:
+ groups = in_channels
+ self.if_act = if_act
+ self.act = act
+ self.conv1 = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ bias_attr=False)
+
+ self.bn1 = nn.BatchNorm(num_channels=in_channels, act=None)
+
+ self.conv2 = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=int(in_channels * 4),
+ kernel_size=1,
+ stride=1,
+ bias_attr=False)
+
+ self.bn2 = nn.BatchNorm(num_channels=int(in_channels * 4), act=None)
+
+ self.conv3 = nn.Conv2D(
+ in_channels=int(in_channels * 4),
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ bias_attr=False)
+ self._c = [in_channels, out_channels]
+ if in_channels != out_channels:
+ self.conv_end = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ bias_attr=False)
+
+ def forward(self, inputs):
+
+ x = self.conv1(inputs)
+ x = self.bn1(x)
+
+ x = self.conv2(x)
+ x = self.bn2(x)
+ if self.if_act:
+ if self.act == "relu":
+ x = F.relu(x)
+ elif self.act == "hardswish":
+ x = F.hardswish(x)
+ else:
+ print("The activation function({}) is selected incorrectly.".
+ format(self.act))
+ exit()
+
+ x = self.conv3(x)
+ if self._c[0] != self._c[1]:
+ x = x + self.conv_end(inputs)
+ return x
class DBFPN(nn.Layer):
@@ -106,3 +188,171 @@ class DBFPN(nn.Layer):
fuse = paddle.concat([p5, p4, p3, p2], axis=1)
return fuse
+
+
+class RSELayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, shortcut=True):
+ super(RSELayer, self).__init__()
+ weight_attr = paddle.nn.initializer.KaimingUniform()
+ self.out_channels = out_channels
+ self.in_conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=self.out_channels,
+ kernel_size=kernel_size,
+ padding=int(kernel_size // 2),
+ weight_attr=ParamAttr(initializer=weight_attr),
+ bias_attr=False)
+ self.se_block = SEModule(self.out_channels)
+ self.shortcut = shortcut
+
+ def forward(self, ins):
+ x = self.in_conv(ins)
+ if self.shortcut:
+ out = x + self.se_block(x)
+ else:
+ out = self.se_block(x)
+ return out
+
+
+class RSEFPN(nn.Layer):
+ def __init__(self, in_channels, out_channels, shortcut=True, **kwargs):
+ super(RSEFPN, self).__init__()
+ self.out_channels = out_channels
+ self.ins_conv = nn.LayerList()
+ self.inp_conv = nn.LayerList()
+
+ for i in range(len(in_channels)):
+ self.ins_conv.append(
+ RSELayer(
+ in_channels[i],
+ out_channels,
+ kernel_size=1,
+ shortcut=shortcut))
+ self.inp_conv.append(
+ RSELayer(
+ out_channels,
+ out_channels // 4,
+ kernel_size=3,
+ shortcut=shortcut))
+
+ def forward(self, x):
+ c2, c3, c4, c5 = x
+
+ in5 = self.ins_conv[3](c5)
+ in4 = self.ins_conv[2](c4)
+ in3 = self.ins_conv[1](c3)
+ in2 = self.ins_conv[0](c2)
+
+ out4 = in4 + F.upsample(
+ in5, scale_factor=2, mode="nearest", align_mode=1) # 1/16
+ out3 = in3 + F.upsample(
+ out4, scale_factor=2, mode="nearest", align_mode=1) # 1/8
+ out2 = in2 + F.upsample(
+ out3, scale_factor=2, mode="nearest", align_mode=1) # 1/4
+
+ p5 = self.inp_conv[3](in5)
+ p4 = self.inp_conv[2](out4)
+ p3 = self.inp_conv[1](out3)
+ p2 = self.inp_conv[0](out2)
+
+ p5 = F.upsample(p5, scale_factor=8, mode="nearest", align_mode=1)
+ p4 = F.upsample(p4, scale_factor=4, mode="nearest", align_mode=1)
+ p3 = F.upsample(p3, scale_factor=2, mode="nearest", align_mode=1)
+
+ fuse = paddle.concat([p5, p4, p3, p2], axis=1)
+ return fuse
+
+
+class LKPAN(nn.Layer):
+ def __init__(self, in_channels, out_channels, mode='large', **kwargs):
+ super(LKPAN, self).__init__()
+ self.out_channels = out_channels
+ weight_attr = paddle.nn.initializer.KaimingUniform()
+
+ self.ins_conv = nn.LayerList()
+ self.inp_conv = nn.LayerList()
+ # pan head
+ self.pan_head_conv = nn.LayerList()
+ self.pan_lat_conv = nn.LayerList()
+
+ if mode.lower() == 'lite':
+ p_layer = DSConv
+ elif mode.lower() == 'large':
+ p_layer = nn.Conv2D
+ else:
+ raise ValueError(
+ "mode can only be one of ['lite', 'large'], but received {}".
+ format(mode))
+
+ for i in range(len(in_channels)):
+ self.ins_conv.append(
+ nn.Conv2D(
+ in_channels=in_channels[i],
+ out_channels=self.out_channels,
+ kernel_size=1,
+ weight_attr=ParamAttr(initializer=weight_attr),
+ bias_attr=False))
+
+ self.inp_conv.append(
+ p_layer(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels // 4,
+ kernel_size=9,
+ padding=4,
+ weight_attr=ParamAttr(initializer=weight_attr),
+ bias_attr=False))
+
+ if i > 0:
+ self.pan_head_conv.append(
+ nn.Conv2D(
+ in_channels=self.out_channels // 4,
+ out_channels=self.out_channels // 4,
+ kernel_size=3,
+ padding=1,
+ stride=2,
+ weight_attr=ParamAttr(initializer=weight_attr),
+ bias_attr=False))
+ self.pan_lat_conv.append(
+ p_layer(
+ in_channels=self.out_channels // 4,
+ out_channels=self.out_channels // 4,
+ kernel_size=9,
+ padding=4,
+ weight_attr=ParamAttr(initializer=weight_attr),
+ bias_attr=False))
+
+ def forward(self, x):
+ c2, c3, c4, c5 = x
+
+ in5 = self.ins_conv[3](c5)
+ in4 = self.ins_conv[2](c4)
+ in3 = self.ins_conv[1](c3)
+ in2 = self.ins_conv[0](c2)
+
+ out4 = in4 + F.upsample(
+ in5, scale_factor=2, mode="nearest", align_mode=1) # 1/16
+ out3 = in3 + F.upsample(
+ out4, scale_factor=2, mode="nearest", align_mode=1) # 1/8
+ out2 = in2 + F.upsample(
+ out3, scale_factor=2, mode="nearest", align_mode=1) # 1/4
+
+ f5 = self.inp_conv[3](in5)
+ f4 = self.inp_conv[2](out4)
+ f3 = self.inp_conv[1](out3)
+ f2 = self.inp_conv[0](out2)
+
+ pan3 = f3 + self.pan_head_conv[0](f2)
+ pan4 = f4 + self.pan_head_conv[1](pan3)
+ pan5 = f5 + self.pan_head_conv[2](pan4)
+
+ p2 = self.pan_lat_conv[0](f2)
+ p3 = self.pan_lat_conv[1](pan3)
+ p4 = self.pan_lat_conv[2](pan4)
+ p5 = self.pan_lat_conv[3](pan5)
+
+ p5 = F.upsample(p5, scale_factor=8, mode="nearest", align_mode=1)
+ p4 = F.upsample(p4, scale_factor=4, mode="nearest", align_mode=1)
+ p3 = F.upsample(p3, scale_factor=2, mode="nearest", align_mode=1)
+
+ fuse = paddle.concat([p5, p4, p3, p2], axis=1)
+ return fuse
diff --git a/tools/infer/predict_det.py b/tools/infer/predict_det.py
index 695587a9aa39f27fb5e37ba8d5447fb9f085e1e1..5f2675d667c2aab8186886a60d8d447f43419954 100755
--- a/tools/infer/predict_det.py
+++ b/tools/infer/predict_det.py
@@ -158,7 +158,7 @@ class TextDetector(object):
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
-
+
def clip_det_res(self, points, img_height, img_width):
for pno in range(points.shape[0]):
points[pno, 0] = int(min(max(points[pno, 0], 0), img_width - 1))
@@ -284,7 +284,7 @@ if __name__ == "__main__":
total_time += elapse
count += 1
save_pred = os.path.basename(image_file) + "\t" + str(
- json.dumps(np.array(dt_boxes).astype(np.int32).tolist())) + "\n"
+ json.dumps([x.tolist() for x in dt_boxes])) + "\n"
save_results.append(save_pred)
logger.info(save_pred)
logger.info("The predict time of {}: {}".format(image_file, elapse))

 -
+
-
+







