
Merge pull request #3467 from WenmuZhou/table2
replace image in layoutparse doc
Showing
{kind=link}
55.4 KB
doc/table/layout.jpg
0 → 100644
{kind=link}

671.5 KB
{kind=link}
{kind=link}

| W: | H:
| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
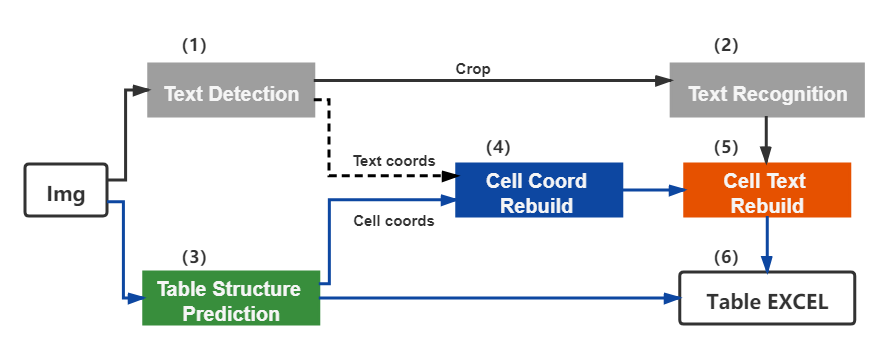
| W: | H:
| W: | H:
ppstructure/layout/README_en.md
0 → 100644