> points = box;
+
+ int x_collect[4] = {box[0][0], box[1][0], box[2][0], box[3][0]};
+ int y_collect[4] = {box[0][1], box[1][1], box[2][1], box[3][1]};
+ int left = int(*std::min_element(x_collect, x_collect + 4));
+ int right = int(*std::max_element(x_collect, x_collect + 4));
+ int top = int(*std::min_element(y_collect, y_collect + 4));
+ int bottom = int(*std::max_element(y_collect, y_collect + 4));
+
+ cv::Mat img_crop;
+ image(cv::Rect(left, top, right - left, bottom - top)).copyTo(img_crop);
+
+ for (int i = 0; i < points.size(); i++) {
+ points[i][0] -= left;
+ points[i][1] -= top;
+ }
+
+ int img_crop_width = int(sqrt(pow(points[0][0] - points[1][0], 2) +
+ pow(points[0][1] - points[1][1], 2)));
+ int img_crop_height = int(sqrt(pow(points[0][0] - points[3][0], 2) +
+ pow(points[0][1] - points[3][1], 2)));
+
+ cv::Point2f pts_std[4];
+ pts_std[0] = cv::Point2f(0., 0.);
+ pts_std[1] = cv::Point2f(img_crop_width, 0.);
+ pts_std[2] = cv::Point2f(img_crop_width, img_crop_height);
+ pts_std[3] = cv::Point2f(0.f, img_crop_height);
+
+ cv::Point2f pointsf[4];
+ pointsf[0] = cv::Point2f(points[0][0], points[0][1]);
+ pointsf[1] = cv::Point2f(points[1][0], points[1][1]);
+ pointsf[2] = cv::Point2f(points[2][0], points[2][1]);
+ pointsf[3] = cv::Point2f(points[3][0], points[3][1]);
+
+ cv::Mat M = cv::getPerspectiveTransform(pointsf, pts_std);
+
+ cv::Mat dst_img;
+ cv::warpPerspective(img_crop, dst_img, M,
+ cv::Size(img_crop_width, img_crop_height),
+ cv::BORDER_REPLICATE);
+
+ if (float(dst_img.rows) >= float(dst_img.cols) * 1.5) {
+ cv::Mat srcCopy = cv::Mat(dst_img.rows, dst_img.cols, dst_img.depth());
+ cv::transpose(dst_img, srcCopy);
+ cv::flip(srcCopy, srcCopy, 0);
+ return srcCopy;
+ } else {
+ return dst_img;
+ }
+}
+
+DEFINE_OP(GeneralDetectionOp);
+
+} // namespace serving
+} // namespace paddle_serving
+} // namespace baidu
diff --git a/deploy/pdserving/imgs/pipeline_result.png b/deploy/pdserving/imgs/pipeline_result.png
new file mode 100644
index 0000000000000000000000000000000000000000..ba7f24a2cce6e1fa9889b175fe83a5944e8b7c67
Binary files /dev/null and b/deploy/pdserving/imgs/pipeline_result.png differ
diff --git a/deploy/pdserving/ocr_cpp_client.py b/deploy/pdserving/ocr_cpp_client.py
index 2baa7565ac78b9551c788c7b36457bce38828eb5..cb42943923879d1138e065881a15da893a505083 100755
--- a/deploy/pdserving/ocr_cpp_client.py
+++ b/deploy/pdserving/ocr_cpp_client.py
@@ -45,10 +45,8 @@ for img_file in os.listdir(test_img_dir):
image_data = file.read()
image = cv2_to_base64(image_data)
res_list = []
- #print(image)
fetch_map = client.predict(
feed={"x": image}, fetch=["save_infer_model/scale_0.tmp_1"], batch=True)
- print("fetrch map:", fetch_map)
one_batch_res = ocr_reader.postprocess(fetch_map, with_score=True)
for res in one_batch_res:
res_list.append(res[0])
diff --git a/deploy/pdserving/pipeline_http_client.py b/deploy/pdserving/pipeline_http_client.py
index 61d13178220118eaf53c51723a9ef65201373ffb..7bc4d882e5039640e138f3e634b2c33fc6a8e48c 100644
--- a/deploy/pdserving/pipeline_http_client.py
+++ b/deploy/pdserving/pipeline_http_client.py
@@ -34,12 +34,28 @@ test_img_dir = args.image_dir
for idx, img_file in enumerate(os.listdir(test_img_dir)):
with open(os.path.join(test_img_dir, img_file), 'rb') as file:
image_data1 = file.read()
+ # print file name
+ print('{}{}{}'.format('*' * 10, img_file, '*' * 10))
image = cv2_to_base64(image_data1)
- for i in range(1):
- data = {"key": ["image"], "value": [image]}
- r = requests.post(url=url, data=json.dumps(data))
- print(r.json())
-
+ data = {"key": ["image"], "value": [image]}
+ r = requests.post(url=url, data=json.dumps(data))
+ result = r.json()
+ print("erro_no:{}, err_msg:{}".format(result["err_no"], result["err_msg"]))
+ # check success
+ if result["err_no"] == 0:
+ ocr_result = result["value"][0]
+ try:
+ for item in eval(ocr_result):
+ # return transcription and points
+ print("{}, {}".format(item[0], item[1]))
+ except Exception as e:
+ print("No results")
+ continue
+
+ else:
+ print(
+ "For details about error message, see PipelineServingLogs/pipeline.log"
+ )
print("==> total number of test imgs: ", len(os.listdir(test_img_dir)))
diff --git a/deploy/pdserving/web_service.py b/deploy/pdserving/web_service.py
index b97c6e1f564a61bb9792542b9e9f1e88d782e80d..07fd6102beaef4001f87574a2f0631e2b1012613 100644
--- a/deploy/pdserving/web_service.py
+++ b/deploy/pdserving/web_service.py
@@ -15,6 +15,7 @@ from paddle_serving_server.web_service import WebService, Op
import logging
import numpy as np
+import copy
import cv2
import base64
# from paddle_serving_app.reader import OCRReader
@@ -36,7 +37,7 @@ class DetOp(Op):
self.filter_func = FilterBoxes(10, 10)
self.post_func = DBPostProcess({
"thresh": 0.3,
- "box_thresh": 0.5,
+ "box_thresh": 0.6,
"max_candidates": 1000,
"unclip_ratio": 1.5,
"min_size": 3
@@ -79,8 +80,10 @@ class RecOp(Op):
raw_im = input_dict["image"]
data = np.frombuffer(raw_im, np.uint8)
im = cv2.imdecode(data, cv2.IMREAD_COLOR)
- dt_boxes = input_dict["dt_boxes"]
- dt_boxes = self.sorted_boxes(dt_boxes)
+ self.dt_list = input_dict["dt_boxes"]
+ self.dt_list = self.sorted_boxes(self.dt_list)
+ # deepcopy to save origin dt_boxes
+ dt_boxes = copy.deepcopy(self.dt_list)
feed_list = []
img_list = []
max_wh_ratio = 0
@@ -126,25 +129,29 @@ class RecOp(Op):
imgs[id] = norm_img
feed = {"x": imgs.copy()}
feed_list.append(feed)
-
return feed_list, False, None, ""
def postprocess(self, input_dicts, fetch_data, data_id, log_id):
- res_list = []
+ rec_list = []
+ dt_num = len(self.dt_list)
if isinstance(fetch_data, dict):
if len(fetch_data) > 0:
rec_batch_res = self.ocr_reader.postprocess(
fetch_data, with_score=True)
for res in rec_batch_res:
- res_list.append(res[0])
+ rec_list.append(res)
elif isinstance(fetch_data, list):
for one_batch in fetch_data:
one_batch_res = self.ocr_reader.postprocess(
one_batch, with_score=True)
for res in one_batch_res:
- res_list.append(res[0])
-
- res = {"res": str(res_list)}
+ rec_list.append(res)
+ result_list = []
+ for i in range(dt_num):
+ text = rec_list[i]
+ dt_box = self.dt_list[i]
+ result_list.append([text, dt_box.tolist()])
+ res = {"result": str(result_list)}
return res, None, ""
diff --git a/deploy/slim/quantization/README.md b/deploy/slim/quantization/README.md
index 8d3f779e0028a62d8396601166283f0ee54d43a7..d7c67a3bad4851aab5a27abb695da14314a7282e 100644
--- a/deploy/slim/quantization/README.md
+++ b/deploy/slim/quantization/README.md
@@ -42,7 +42,7 @@ python deploy/slim/quantization/quant.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3
# 比如下载提供的训练模型
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar
tar -xf ch_ppocr_mobile_v2.0_det_train.tar
-python deploy/slim/quantization/quant.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.pretrained_model=./ch_ppocr_mobile_v2.0_det_train/best_accuracy Global.save_model_dir=./output/quant_inference_model
+python deploy/slim/quantization/quant.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.pretrained_model=./ch_ppocr_mobile_v2.0_det_train/best_accuracy Global.save_model_dir=./output/quant_model
```
如果要训练识别模型的量化,修改配置文件和加载的模型参数即可。
diff --git a/deploy/slim/quantization/export_model.py b/deploy/slim/quantization/export_model.py
index 822fd5da4c30a934d0e590ab1067f9f9188213c2..90f79dab34a5f20d4556ae4b10ad1d4e1f8b7f0d 100755
--- a/deploy/slim/quantization/export_model.py
+++ b/deploy/slim/quantization/export_model.py
@@ -35,17 +35,7 @@ from ppocr.metrics import build_metric
import tools.program as program
from paddleslim.dygraph.quant import QAT
from ppocr.data import build_dataloader
-
-
-def export_single_model(quanter, model, infer_shape, save_path, logger):
- quanter.save_quantized_model(
- model,
- save_path,
- input_spec=[
- paddle.static.InputSpec(
- shape=[None] + infer_shape, dtype='float32')
- ])
- logger.info('inference QAT model is saved to {}'.format(save_path))
+from tools.export_model import export_single_model
def main():
@@ -84,17 +74,54 @@ def main():
config['Global'])
# build model
- # for rec algorithm
if hasattr(post_process_class, 'character'):
char_num = len(getattr(post_process_class, 'character'))
if config['Architecture']["algorithm"] in ["Distillation",
]: # distillation model
for key in config['Architecture']["Models"]:
- config['Architecture']["Models"][key]["Head"][
- 'out_channels'] = char_num
+ if config['Architecture']['Models'][key]['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ # update SARLoss params
+ assert list(config['Loss']['loss_config_list'][-1].keys())[
+ 0] == 'DistillationSARLoss'
+ config['Loss']['loss_config_list'][-1][
+ 'DistillationSARLoss']['ignore_index'] = char_num + 1
+ out_channels_list = {}
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config['Architecture']["Models"][key]["Head"][
+ 'out_channels'] = char_num
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ # update SARLoss params
+ assert list(config['Loss']['loss_config_list'][1].keys())[
+ 0] == 'SARLoss'
+ if config['Loss']['loss_config_list'][1]['SARLoss'] is None:
+ config['Loss']['loss_config_list'][1]['SARLoss'] = {
+ 'ignore_index': char_num + 1
+ }
+ else:
+ config['Loss']['loss_config_list'][1]['SARLoss'][
+ 'ignore_index'] = char_num + 1
+ out_channels_list = {}
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config['Architecture']["Head"]['out_channels'] = char_num
+ if config['PostProcess']['name'] == 'SARLabelDecode': # for SAR model
+ config['Loss']['ignore_index'] = char_num - 1
+
model = build_model(config['Architecture'])
# get QAT model
@@ -120,21 +147,22 @@ def main():
for k, v in metric.items():
logger.info('{}:{}'.format(k, v))
- infer_shape = [3, 32, 100] if model_type == "rec" else [3, 640, 640]
-
save_path = config["Global"]["save_inference_dir"]
arch_config = config["Architecture"]
+
+ arch_config = config["Architecture"]
+
if arch_config["algorithm"] in ["Distillation", ]: # distillation model
+ archs = list(arch_config["Models"].values())
for idx, name in enumerate(model.model_name_list):
model.model_list[idx].eval()
sub_model_save_path = os.path.join(save_path, name, "inference")
- export_single_model(quanter, model.model_list[idx], infer_shape,
- sub_model_save_path, logger)
+ export_single_model(model.model_list[idx], archs[idx],
+ sub_model_save_path, logger, quanter)
else:
save_path = os.path.join(save_path, "inference")
- model.eval()
- export_single_model(quanter, model, infer_shape, save_path, logger)
+ export_single_model(model, arch_config, save_path, logger, quanter)
if __name__ == "__main__":
diff --git a/deploy/slim/quantization/quant.py b/deploy/slim/quantization/quant.py
index 1dffaab0eef35ec41c27c9c6e00f25dda048d490..f7acb185add5d40b749e7442111891869dfaeb22 100755
--- a/deploy/slim/quantization/quant.py
+++ b/deploy/slim/quantization/quant.py
@@ -112,10 +112,48 @@ def main(config, device, logger, vdl_writer):
if config['Architecture']["algorithm"] in ["Distillation",
]: # distillation model
for key in config['Architecture']["Models"]:
- config['Architecture']["Models"][key]["Head"][
- 'out_channels'] = char_num
+ if config['Architecture']['Models'][key]['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ # update SARLoss params
+ assert list(config['Loss']['loss_config_list'][-1].keys())[
+ 0] == 'DistillationSARLoss'
+ config['Loss']['loss_config_list'][-1][
+ 'DistillationSARLoss']['ignore_index'] = char_num + 1
+ out_channels_list = {}
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config['Architecture']["Models"][key]["Head"][
+ 'out_channels'] = char_num
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ # update SARLoss params
+ assert list(config['Loss']['loss_config_list'][1].keys())[
+ 0] == 'SARLoss'
+ if config['Loss']['loss_config_list'][1]['SARLoss'] is None:
+ config['Loss']['loss_config_list'][1]['SARLoss'] = {
+ 'ignore_index': char_num + 1
+ }
+ else:
+ config['Loss']['loss_config_list'][1]['SARLoss'][
+ 'ignore_index'] = char_num + 1
+ out_channels_list = {}
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config['Architecture']["Head"]['out_channels'] = char_num
+
+ if config['PostProcess']['name'] == 'SARLabelDecode': # for SAR model
+ config['Loss']['ignore_index'] = char_num - 1
model = build_model(config['Architecture'])
pre_best_model_dict = dict()
@@ -137,7 +175,7 @@ def main(config, device, logger, vdl_writer):
config['Optimizer'],
epochs=config['Global']['epoch_num'],
step_each_epoch=len(train_dataloader),
- parameters=model.parameters())
+ model=model)
# resume PACT training process
if config["Global"]["checkpoints"] is not None:
diff --git a/doc/PPOCR.pdf b/doc/PPOCR.pdf
deleted file mode 100644
index 219621ddb58a96b4b85ef4d74f05dd517c2eb630..0000000000000000000000000000000000000000
Binary files a/doc/PPOCR.pdf and /dev/null differ
diff --git a/doc/datasets/CDLA_demo/val_0633.jpg b/doc/datasets/CDLA_demo/val_0633.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..834848547afbc6b0ab479030fab71924e11fd5b1
Binary files /dev/null and b/doc/datasets/CDLA_demo/val_0633.jpg differ
diff --git a/doc/datasets/CDLA_demo/val_0941.jpg b/doc/datasets/CDLA_demo/val_0941.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..f7d548e120b644185c8685766523f83cb295b433
Binary files /dev/null and b/doc/datasets/CDLA_demo/val_0941.jpg differ
diff --git a/doc/datasets/publaynet_demo/gt_PMC3724501_00006.jpg b/doc/datasets/publaynet_demo/gt_PMC3724501_00006.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..3b7ee8921ed9ce8e8a9a4b4ed6bb1534edba46aa
Binary files /dev/null and b/doc/datasets/publaynet_demo/gt_PMC3724501_00006.jpg differ
diff --git a/doc/datasets/publaynet_demo/gt_PMC5086060_00002.jpg b/doc/datasets/publaynet_demo/gt_PMC5086060_00002.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..cad8f3035b5e5fc348cd63e30bd064122ecc162d
Binary files /dev/null and b/doc/datasets/publaynet_demo/gt_PMC5086060_00002.jpg differ
diff --git a/doc/datasets/table_PubTabNet_demo/PMC524509_007_00.png b/doc/datasets/table_PubTabNet_demo/PMC524509_007_00.png
new file mode 100755
index 0000000000000000000000000000000000000000..5b9d631cba434e4bd6ac6fe2108b7f6c081c4811
Binary files /dev/null and b/doc/datasets/table_PubTabNet_demo/PMC524509_007_00.png differ
diff --git a/doc/datasets/table_PubTabNet_demo/PMC535543_007_01.png b/doc/datasets/table_PubTabNet_demo/PMC535543_007_01.png
new file mode 100755
index 0000000000000000000000000000000000000000..e808de72d62325ae4cbd009397b7beaeed0d88fc
Binary files /dev/null and b/doc/datasets/table_PubTabNet_demo/PMC535543_007_01.png differ
diff --git a/doc/datasets/table_tal_demo/1.jpg b/doc/datasets/table_tal_demo/1.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e7ddd6d1db59ca27a0461ab93b3672aeec4a8941
Binary files /dev/null and b/doc/datasets/table_tal_demo/1.jpg differ
diff --git a/doc/datasets/table_tal_demo/2.jpg b/doc/datasets/table_tal_demo/2.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e7ddd6d1db59ca27a0461ab93b3672aeec4a8941
Binary files /dev/null and b/doc/datasets/table_tal_demo/2.jpg differ
diff --git a/doc/datasets/tablebank_demo/004.png b/doc/datasets/tablebank_demo/004.png
new file mode 100644
index 0000000000000000000000000000000000000000..c1a2d36dfe9dc8f530445a7807ea195b76dfda2a
Binary files /dev/null and b/doc/datasets/tablebank_demo/004.png differ
diff --git a/doc/datasets/tablebank_demo/005.png b/doc/datasets/tablebank_demo/005.png
new file mode 100644
index 0000000000000000000000000000000000000000..0d4d6ab46a8f2829d3dc83b9a1bb33e918ef6a64
Binary files /dev/null and b/doc/datasets/tablebank_demo/005.png differ
diff --git a/doc/deployment.png b/doc/deployment.png
new file mode 100644
index 0000000000000000000000000000000000000000..afd3cf5110e4fa12e2c48cb0991fa8a58cb80b2e
Binary files /dev/null and b/doc/deployment.png differ
diff --git a/doc/deployment_en.png b/doc/deployment_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..b9d23e48923171d51a81b986308f7ba91dadf428
Binary files /dev/null and b/doc/deployment_en.png differ
diff --git a/doc/doc_ch/algorithm.md b/doc/doc_ch/algorithm.md
new file mode 100644
index 0000000000000000000000000000000000000000..3056f35d5260812686447367f7cbddc1e1cad531
--- /dev/null
+++ b/doc/doc_ch/algorithm.md
@@ -0,0 +1,13 @@
+# 前沿算法与模型
+
+PaddleOCR将**持续新增**支持OCR领域前沿算法与模型,已支持的模型与使用教程可点击下方列表查看:
+
+- [文本检测算法](./algorithm_overview.md#11-%E6%96%87%E6%9C%AC%E6%A3%80%E6%B5%8B%E7%AE%97%E6%B3%95)
+- [文本识别算法](./algorithm_overview.md#12-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E7%AE%97%E6%B3%95)
+- [端到端算法](./algorithm_overview.md#2-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E7%AE%97%E6%B3%95)
+
+**欢迎广大开发者合作共建,贡献更多算法,合入有奖🎁!具体可查看[社区常规赛](https://github.com/PaddlePaddle/PaddleOCR/issues/4982)。**
+
+新增算法可参考如下教程:
+
+- [使用PaddleOCR架构添加新算法](./add_new_algorithm.md)
\ No newline at end of file
diff --git a/doc/doc_ch/algorithm_det_db.md b/doc/doc_ch/algorithm_det_db.md
new file mode 100644
index 0000000000000000000000000000000000000000..90837c2ac1ebbc04ee47cbb74ed6466352710e88
--- /dev/null
+++ b/doc/doc_ch/algorithm_det_db.md
@@ -0,0 +1,99 @@
+# DB
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Real-time Scene Text Detection with Differentiable Binarization](https://arxiv.org/abs/1911.08947)
+> Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang
+> AAAI, 2020
+
+在ICDAR2015文本检测公开数据集上,算法复现效果如下:
+
+|模型|骨干网络|配置文件|precision|recall|Hmean|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|DB|ResNet50_vd|[configs/det/det_r50_vd_db.yml](../../configs/det/det_r50_vd_db.yml)|86.41%|78.72%|82.38%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_db_v2.0_train.tar)|
+|DB|MobileNetV3|[configs/det/det_mv3_db.yml](../../configs/det/det_mv3_db.yml)|77.29%|73.08%|75.12%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_mv3_db_v2.0_train.tar)|
+
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本检测训练教程](./detection.md)。PaddleOCR对代码进行了模块化,训练不同的检测模型只需要**更换配置文件**即可。
+
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将DB文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在ICDAR2015英文数据集训练的模型为例( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_db_v2.0_train.tar) ),可以使用如下命令进行转换:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_db.yml -o Global.pretrained_model=./det_r50_vd_db_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_db
+```
+
+DB文本检测模型推理,可以执行如下命令:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_db/"
+```
+
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+**注意**:由于ICDAR2015数据集只有1000张训练图像,且主要针对英文场景,所以上述模型对中文文本图像检测效果会比较差。
+
+
+### 4.2 C++推理
+
+准备好推理模型后,参考[cpp infer](../../deploy/cpp_infer/)教程进行操作即可。
+
+
+### 4.3 Serving服务化部署
+
+准备好推理模型后,参考[pdserving](../../deploy/pdserving/)教程进行Serving服务化部署,包括Python Serving和C++ Serving两种模式。
+
+
+### 4.4 更多推理部署
+
+DB模型还支持以下推理部署方式:
+
+- Paddle2ONNX推理:准备好推理模型后,参考[paddle2onnx](../../deploy/paddle2onnx/)教程操作。
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@inproceedings{liao2020real,
+ title={Real-time scene text detection with differentiable binarization},
+ author={Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang},
+ booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
+ volume={34},
+ number={07},
+ pages={11474--11481},
+ year={2020}
+}
+```
\ No newline at end of file
diff --git a/doc/doc_ch/algorithm_det_fcenet.md b/doc/doc_ch/algorithm_det_fcenet.md
new file mode 100644
index 0000000000000000000000000000000000000000..bd2e734204d32bbf575ddea9f889953a72582c59
--- /dev/null
+++ b/doc/doc_ch/algorithm_det_fcenet.md
@@ -0,0 +1,104 @@
+# FCENet
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Fourier Contour Embedding for Arbitrary-Shaped Text Detection](https://arxiv.org/abs/2104.10442)
+> Yiqin Zhu and Jianyong Chen and Lingyu Liang and Zhanghui Kuang and Lianwen Jin and Wayne Zhang
+> CVPR, 2021
+
+在CTW1500文本检测公开数据集上,算法复现效果如下:
+
+| 模型 |骨干网络|配置文件|precision|recall|Hmean|下载链接|
+|-----| --- | --- | --- | --- | --- | --- |
+| FCE | ResNet50_dcn | [configs/det/det_r50_vd_dcn_fce_ctw.yml](../../configs/det/det_r50_vd_dcn_fce_ctw.yml)| 88.39%|82.18%|85.27%|[训练模型](https://paddleocr.bj.bcebos.com/contribution/det_r50_dcn_fce_ctw_v2.0_train.tar)|
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+上述FCE模型使用CTW1500文本检测公开数据集训练得到,数据集下载可参考 [ocr_datasets](./dataset/ocr_datasets.md)。
+
+数据下载完成后,请参考[文本检测训练教程](./detection.md)进行训练。PaddleOCR对代码进行了模块化,训练不同的检测模型只需要**更换配置文件**即可。
+
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将FCE文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd_dcn骨干网络,在CTW1500英文数据集训练的模型为例( [模型下载地址](https://paddleocr.bj.bcebos.com/contribution/det_r50_dcn_fce_ctw_v2.0_train.tar) ),可以使用如下命令进行转换:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_dcn_fce_ctw.yml -o Global.pretrained_model=./det_r50_dcn_fce_ctw_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_fce
+```
+
+FCE文本检测模型推理,执行非弯曲文本检测,可以执行如下命令:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_fce/" --det_algorithm="FCE" --det_fce_box_type=quad
+```
+
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+如果想执行弯曲文本检测,可以执行如下命令:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_fce/" --det_algorithm="FCE" --det_fce_box_type=poly
+```
+
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+**注意**:由于CTW1500数据集只有1000张训练图像,且主要针对英文场景,所以上述模型对中文文本图像检测效果会比较差。
+
+
+### 4.2 C++推理
+
+由于后处理暂未使用CPP编写,FCE文本检测模型暂不支持CPP推理。
+
+
+### 4.3 Serving服务化部署
+
+暂未支持
+
+
+### 4.4 更多推理部署
+
+暂未支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@InProceedings{zhu2021fourier,
+ title={Fourier Contour Embedding for Arbitrary-Shaped Text Detection},
+ author={Yiqin Zhu and Jianyong Chen and Lingyu Liang and Zhanghui Kuang and Lianwen Jin and Wayne Zhang},
+ year={2021},
+ booktitle = {CVPR}
+}
+```
diff --git a/doc/doc_ch/algorithm_det_psenet.md b/doc/doc_ch/algorithm_det_psenet.md
new file mode 100644
index 0000000000000000000000000000000000000000..58d8ccf97292f4e988861b618697fb0e7694fbab
--- /dev/null
+++ b/doc/doc_ch/algorithm_det_psenet.md
@@ -0,0 +1,106 @@
+# PSENet
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Shape robust text detection with progressive scale expansion network](https://arxiv.org/abs/1903.12473)
+> Wang, Wenhai and Xie, Enze and Li, Xiang and Hou, Wenbo and Lu, Tong and Yu, Gang and Shao, Shuai
+> CVPR, 2019
+
+在ICDAR2015文本检测公开数据集上,算法复现效果如下:
+
+|模型|骨干网络|配置文件|precision|recall|Hmean|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|PSE| ResNet50_vd | [configs/det/det_r50_vd_pse.yml](../../configs/det/det_r50_vd_pse.yml)| 85.81% |79.53%|82.55%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_r50_vd_pse_v2.0_train.tar)|
+|PSE| MobileNetV3| [configs/det/det_mv3_pse.yml](../../configs/det/det_mv3_pse.yml) | 82.20% |70.48%|75.89%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_mv3_pse_v2.0_train.tar)|
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+上述PSE模型使用ICDAR2015文本检测公开数据集训练得到,数据集下载可参考 [ocr_datasets](./dataset/ocr_datasets.md)。
+
+数据下载完成后,请参考[文本检测训练教程](./detection.md)进行训练。PaddleOCR对代码进行了模块化,训练不同的检测模型只需要**更换配置文件**即可。
+
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将PSE文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在ICDAR2015英文数据集训练的模型为例( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_r50_vd_pse_v2.0_train.tar) ),可以使用如下命令进行转换:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_pse.yml -o Global.pretrained_model=./det_r50_vd_pse_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_pse
+```
+
+PSE文本检测模型推理,执行非弯曲文本检测,可以执行如下命令:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_pse/" --det_algorithm="PSE" --det_pse_box_type=quad
+```
+
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+如果想执行弯曲文本检测,可以执行如下命令:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_pse/" --det_algorithm="PSE" --det_pse_box_type=poly
+```
+
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+**注意**:由于ICDAR2015数据集只有1000张训练图像,且主要针对英文场景,所以上述模型对中文或弯曲文本图像检测效果会比较差。
+
+
+### 4.2 C++推理
+
+由于后处理暂未使用CPP编写,PSE文本检测模型暂不支持CPP推理。
+
+
+### 4.3 Serving服务化部署
+
+暂未支持
+
+
+### 4.4 更多推理部署
+
+暂未支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@inproceedings{wang2019shape,
+ title={Shape robust text detection with progressive scale expansion network},
+ author={Wang, Wenhai and Xie, Enze and Li, Xiang and Hou, Wenbo and Lu, Tong and Yu, Gang and Shao, Shuai},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={9336--9345},
+ year={2019}
+}
+```
diff --git a/doc/doc_ch/pgnet.md b/doc/doc_ch/algorithm_e2e_pgnet.md
similarity index 99%
rename from doc/doc_ch/pgnet.md
rename to doc/doc_ch/algorithm_e2e_pgnet.md
index 0aee58ec1aca24d06305c47569fdf156df6ee874..83c1114e58a69355dadfa91902e576b552e8dcab 100644
--- a/doc/doc_ch/pgnet.md
+++ b/doc/doc_ch/algorithm_e2e_pgnet.md
@@ -43,7 +43,7 @@ PGNet算法细节详见[论文](https://www.aaai.org/AAAI21Papers/AAAI-2885.Wang
## 二、环境配置
-请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《PaddleOCR全景图与项目克隆》](./paddleOCR_overview.md)克隆项目
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目
## 三、快速使用
diff --git a/doc/doc_ch/inference.md b/doc/doc_ch/algorithm_inference.md
similarity index 99%
rename from doc/doc_ch/inference.md
rename to doc/doc_ch/algorithm_inference.md
index ade1a2dbdf728ac785efef3e5a82b4c932674b87..0222dec85a0be0973b2546cbb6e5347852242093 100755
--- a/doc/doc_ch/inference.md
+++ b/doc/doc_ch/algorithm_inference.md
@@ -14,12 +14,14 @@ inference 模型(`paddle.jit.save`保存的模型)
- [识别模型转inference模型](#识别模型转inference模型)
- [方向分类模型转inference模型](#方向分类模型转inference模型)
+
- [二、文本检测模型推理](#文本检测模型推理)
- [1. 超轻量中文检测模型推理](#超轻量中文检测模型推理)
- [2. DB文本检测模型推理](#DB文本检测模型推理)
- [3. EAST文本检测模型推理](#EAST文本检测模型推理)
- [4. SAST文本检测模型推理](#SAST文本检测模型推理)
+
- [三、文本识别模型推理](#文本识别模型推理)
- [1. 超轻量中文识别模型推理](#超轻量中文识别模型推理)
- [2. 基于CTC损失的识别模型推理](#基于CTC损失的识别模型推理)
@@ -27,15 +29,19 @@ inference 模型(`paddle.jit.save`保存的模型)
- [4. 自定义文本识别字典的推理](#自定义文本识别字典的推理)
- [5. 多语言模型的推理](#多语言模型的推理)
+
- [四、方向分类模型推理](#方向识别模型推理)
- [1. 方向分类模型推理](#方向分类模型推理)
+
- [五、文本检测、方向分类和文字识别串联推理](#文本检测、方向分类和文字识别串联推理)
- [1. 超轻量中文OCR模型推理](#超轻量中文OCR模型推理)
- [2. 其他模型推理](#其他模型推理)
+
- [六、参数解释](#参数解释)
+
- [七、FAQ](#FAQ)
diff --git a/doc/doc_ch/algorithm_overview.md b/doc/doc_ch/algorithm_overview.md
index a784067a001ee575adf72c258f8e96de6e615a7a..313ef9b15e7e3a2d8e7aa3ea31add75f18bb27e3 100755
--- a/doc/doc_ch/algorithm_overview.md
+++ b/doc/doc_ch/algorithm_overview.md
@@ -1,29 +1,30 @@
-# 两阶段算法
+# OCR算法
-- [两阶段算法](#两阶段算法)
- - [1. 算法介绍](#1-算法介绍)
+- [1. 两阶段算法](#1-两阶段算法)
- [1.1 文本检测算法](#11-文本检测算法)
- [1.2 文本识别算法](#12-文本识别算法)
- - [2. 模型训练](#2-模型训练)
- - [3. 模型推理](#3-模型推理)
+- [2. 端到端算法](#2-端到端算法)
+
+
+本文给出了PaddleOCR已支持的OCR算法列表,以及每个算法在**英文公开数据集**上的模型和指标,主要用于算法简介和算法性能对比,更多包括中文在内的其他数据集上的模型请参考[PP-OCR v2.0 系列模型下载](./models_list.md)。
-## 1. 算法介绍
-本文给出了PaddleOCR已支持的文本检测算法和文本识别算法列表,以及每个算法在**英文公开数据集**上的模型和指标,主要用于算法简介和算法性能对比,更多包括中文在内的其他数据集上的模型请参考[PP-OCR v2.0 系列模型下载](./models_list.md)。
+## 1. 两阶段算法
### 1.1 文本检测算法
-PaddleOCR开源的文本检测算法列表:
-- [x] DB([paper]( https://arxiv.org/abs/1911.08947)) [2](ppocr推荐)
-- [x] EAST([paper](https://arxiv.org/abs/1704.03155))[1]
-- [x] SAST([paper](https://arxiv.org/abs/1908.05498))[4]
-- [x] PSENet([paper](https://arxiv.org/abs/1903.12473v2))
-- [x] FCENet([paper](https://arxiv.org/abs/2104.10442))
+已支持的文本检测算法列表(戳链接获取使用教程):
+- [x] [DB](./algorithm_det_db.md)
+- [x] [EAST](./algorithm_det_east.md)
+- [x] [SAST](./algorithm_det_sast.md)
+- [x] [PSENet](./algorithm_det_psenet.md)
+- [x] [FCENet](./algorithm_det_fcenet.md)
在ICDAR2015文本检测公开数据集上,算法效果如下:
+
|模型|骨干网络|precision|recall|Hmean|下载链接|
| --- | --- | --- | --- | --- | --- |
|EAST|ResNet50_vd|88.71%|81.36%|84.88%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_east_v2.0_train.tar)|
@@ -50,19 +51,20 @@ PaddleOCR开源的文本检测算法列表:
* [百度云地址](https://pan.baidu.com/s/12cPnZcVuV1zn5DOd4mqjVw) (提取码: 2bpi)
* [Google Drive下载地址](https://drive.google.com/drive/folders/1ll2-XEVyCQLpJjawLDiRlvo_i4BqHCJe?usp=sharing)
+
### 1.2 文本识别算法
-PaddleOCR基于动态图开源的文本识别算法列表:
-- [x] CRNN([paper](https://arxiv.org/abs/1507.05717))[7](ppocr推荐)
-- [x] Rosetta([paper](https://arxiv.org/abs/1910.05085))[10]
-- [x] STAR-Net([paper](http://www.bmva.org/bmvc/2016/papers/paper043/index.html))[11]
-- [x] RARE([paper](https://arxiv.org/abs/1603.03915v1))[12]
-- [x] SRN([paper](https://arxiv.org/abs/2003.12294))[5]
-- [x] NRTR([paper](https://arxiv.org/abs/1806.00926v2))[13]
-- [x] SAR([paper](https://arxiv.org/abs/1811.00751v2))
-- [x] SEED([paper](https://arxiv.org/pdf/2005.10977.pdf))
+已支持的文本识别算法列表(戳链接获取使用教程):
+- [x] [CRNN](./algorithm_rec_crnn.md)
+- [x] [Rosetta](./algorithm_rec_rosetta.md)
+- [x] [STAR-Net](./algorithm_rec_starnet.md)
+- [x] [RARE](./algorithm_rec_rare.md)
+- [x] [SRN](./algorithm_rec_srn.md)
+- [x] [NRTR](./algorithm_rec_nrtr.md)
+- [x] [SAR](./algorithm_rec_sar.md)
+- [x] [SEED](./algorithm_rec_seed.md)
参考[DTRB](https://arxiv.org/abs/1904.01906)[3]文字识别训练和评估流程,使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法效果如下:
@@ -81,14 +83,12 @@ PaddleOCR基于动态图开源的文本识别算法列表:
|SAR|Resnet31| 87.20% | rec_r31_sar | [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar) |
|SEED|Aster_Resnet| 85.35% | rec_resnet_stn_bilstm_att | [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_resnet_stn_bilstm_att.tar) |
-
-## 2. 模型训练
+
-PaddleOCR文本检测算法的训练和使用请参考文档教程中[模型训练/评估中的文本检测部分](./detection.md)。文本识别算法的训练和使用请参考文档教程中[模型训练/评估中的文本识别部分](./recognition.md)。
+## 2. 端到端算法
-
+已支持的端到端OCR算法列表(戳链接获取使用教程):
+- [x] [PGNet](./algorithm_e2e_pgnet.md)
-## 3. 模型推理
-上述模型中除PP-OCR系列模型以外,其余模型仅支持基于Python引擎的推理,具体内容可参考[基于Python预测引擎推理](./inference.md)
diff --git a/doc/doc_ch/algorithm_rec_sar.md b/doc/doc_ch/algorithm_rec_sar.md
new file mode 100644
index 0000000000000000000000000000000000000000..aedc16714518b2de220118f755e00c3ba6bc7a5e
--- /dev/null
+++ b/doc/doc_ch/algorithm_rec_sar.md
@@ -0,0 +1,114 @@
+# SAR
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition](https://arxiv.org/abs/1811.00751)
+> Hui Li, Peng Wang, Chunhua Shen, Guyu Zhang
+> AAAI, 2019
+
+使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法复现效果如下:
+
+|模型|骨干网络|配置文件|Acc|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|SAR|ResNet31|[rec_r31_sar.yml](../../configs/rec/rec_r31_sar.yml)|87.20%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar)|
+
+注:除了使用MJSynth和SynthText两个文字识别数据集外,还加入了[SynthAdd](https://pan.baidu.com/share/init?surl=uV0LtoNmcxbO-0YA7Ch4dg)数据(提取码:627x),和部分真实数据,具体数据细节可以参考论文。
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本识别教程](./recognition.md)。PaddleOCR对代码进行了模块化,训练不同的识别模型只需要**更换配置文件**即可。
+
+训练
+
+具体地,在完成数据准备后,便可以启动训练,训练命令如下:
+
+```
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/rec_r31_sar.yml
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r31_sar.yml
+```
+
+评估
+
+```
+# GPU 评估, Global.pretrained_model 为待测权重
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+预测:
+
+```
+# 预测使用的配置文件必须与训练一致
+python3 tools/infer_rec.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将SAR文本识别训练过程中保存的模型,转换成inference model。( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar) ),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model=./rec_r31_sar_train/best_accuracy Global.save_inference_dir=./inference/rec_sar
+```
+
+SAR文本识别模型推理,可以执行如下命令:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_sar/" --rec_image_shape="3, 48, 48, 160" --rec_char_type="ch" --rec_algorithm="SAR" --rec_char_dict_path="ppocr/utils/dict90.txt" --max_text_length=30 --use_space_char=False
+```
+
+
+### 4.2 C++推理
+
+由于C++预处理后处理还未支持SAR,所以暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂不支持
+
+
+### 4.4 更多推理部署
+
+暂不支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@article{Li2019ShowAA,
+ title={Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition},
+ author={Hui Li and Peng Wang and Chunhua Shen and Guyu Zhang},
+ journal={ArXiv},
+ year={2019},
+ volume={abs/1811.00751}
+}
+```
diff --git a/doc/doc_ch/algorithm_rec_srn.md b/doc/doc_ch/algorithm_rec_srn.md
new file mode 100644
index 0000000000000000000000000000000000000000..b124790761eed875434ecf509f7647fe23d1bc90
--- /dev/null
+++ b/doc/doc_ch/algorithm_rec_srn.md
@@ -0,0 +1,113 @@
+# SRN
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Towards Accurate Scene Text Recognition with Semantic Reasoning Networks](https://arxiv.org/abs/2003.12294#)
+> Deli Yu, Xuan Li, Chengquan Zhang, Junyu Han, Jingtuo Liu, Errui Ding
+> CVPR,2020
+
+使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法复现效果如下:
+
+|模型|骨干网络|配置文件|Acc|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|SRN|Resnet50_vd_fpn|[rec_r50_fpn_srn.yml](../../configs/rec/rec_r50_fpn_srn.yml)|86.31%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar)|
+
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本识别教程](./recognition.md)。PaddleOCR对代码进行了模块化,训练不同的识别模型只需要**更换配置文件**即可。
+
+训练
+
+具体地,在完成数据准备后,便可以启动训练,训练命令如下:
+
+```
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+```
+
+评估
+
+```
+# GPU 评估, Global.pretrained_model 为待测权重
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+预测:
+
+```
+# 预测使用的配置文件必须与训练一致
+python3 tools/infer_rec.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将SRN文本识别训练过程中保存的模型,转换成inference model。( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar) ),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model=./rec_r50_vd_srn_train/best_accuracy Global.save_inference_dir=./inference/rec_srn
+```
+
+SRN文本识别模型推理,可以执行如下命令:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_srn/" --rec_image_shape="1,64,256" --rec_char_type="ch" --rec_algorithm="SRN" --rec_char_dict_path=./ppocr/utils/ic15_dict.txt --use_space_char=False
+```
+
+
+### 4.2 C++推理
+
+由于C++预处理后处理还未支持SRN,所以暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂不支持
+
+
+### 4.4 更多推理部署
+
+暂不支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@article{Yu2020TowardsAS,
+ title={Towards Accurate Scene Text Recognition With Semantic Reasoning Networks},
+ author={Deli Yu and Xuan Li and Chengquan Zhang and Junyu Han and Jingtuo Liu and Errui Ding},
+ journal={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year={2020},
+ pages={12110-12119}
+}
+```
diff --git a/doc/doc_ch/android_demo.md b/doc/doc_ch/android_demo.md
deleted file mode 100644
index 3b12308257c998387d0a95a46bcfdc7d8837caaf..0000000000000000000000000000000000000000
--- a/doc/doc_ch/android_demo.md
+++ /dev/null
@@ -1,57 +0,0 @@
-# Android Demo 快速测试
-
-
-### 1. 安装最新版本的Android Studio
-
-可以从 https://developer.android.com/studio 下载。本Demo使用是4.0版本Android Studio编写。
-
-### 2. 创建新项目
-
-Demo测试的时候使用的是NDK 20b版本,20版本以上均可以支持编译成功。
-
-如果您是初学者,可以用以下方式安装和测试NDK编译环境。
-点击 File -> New ->New Project, 新建 "Native C++" project
-
-
-1. Start a new Android Studio project
- 在项目模版中选择 Native C++ 选择PaddleOCR/deploy/android_demo 路径
- 进入项目后会自动编译,第一次编译会花费较长的时间,建议添加代理加速下载。
-
-**代理添加:**
-
-选择 Android Studio -> Preferences -> Appearance & Behavior -> System Settings -> HTTP Proxy -> Manual proxy configuration
-
-
-
-2. 开始编译
-
-点击编译按钮,连接手机,跟着Android Studio的引导完成操作。
-
-在 Android Studio 里看到下图,表示编译完成:
-
-
-
-**提示:** 此时如果出现下列找不到OpenCV的报错信息,请重新点击编译,编译完成后退出项目,再次进入。
-
-
-
-### 3. 发送到手机端
-
-完成编译,点击运行,在手机端查看效果。
-
-### 4. 如何自定义demo图片
-
-1. 图片存放路径:android_demo/app/src/main/assets/images
-
- 将自定义图片放置在该路径下
-
-2. 配置文件: android_demo/app/src/main/res/values/strings.xml
-
- 修改 IMAGE_PATH_DEFAULT 为自定义图片名即可
-
-
-# 获得更多支持
-前往[端计算模型生成平台EasyEdge](https://ai.baidu.com/easyedge/app/open_source_demo?referrerUrl=paddlelite),获得更多开发支持:
-
-- Demo APP:可使用手机扫码安装,方便手机端快速体验文字识别
-- SDK:模型被封装为适配不同芯片硬件和操作系统SDK,包括完善的接口,方便进行二次开发
diff --git a/doc/doc_ch/application.md b/doc/doc_ch/application.md
new file mode 100644
index 0000000000000000000000000000000000000000..6dd465f9e71951bfbc1f749b0ca93d66cbfeb220
--- /dev/null
+++ b/doc/doc_ch/application.md
@@ -0,0 +1 @@
+# 场景应用
\ No newline at end of file
diff --git a/doc/doc_ch/clone.md b/doc/doc_ch/clone.md
new file mode 100644
index 0000000000000000000000000000000000000000..f2ec15fd26277a337ca2f1de1cf299fdff168b7c
--- /dev/null
+++ b/doc/doc_ch/clone.md
@@ -0,0 +1,23 @@
+# 项目克隆
+
+## 1. 克隆PaddleOCR repo代码
+
+```
+【推荐】git clone https://github.com/PaddlePaddle/PaddleOCR
+```
+
+如果因为网络问题无法pull成功,也可选择使用码云上的托管:
+
+```
+git clone https://gitee.com/paddlepaddle/PaddleOCR
+```
+
+注:码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先使用推荐方式。
+
+## 2. 安装第三方库
+
+```
+cd PaddleOCR
+pip3 install -r requirements.txt
+```
+
diff --git a/doc/doc_ch/config.md b/doc/doc_ch/config.md
index 1668eba19eb0bcec6bfe3abd39bb6ca73b8f6c14..3c62acea7734ab629c71d515127aff4fcfb62d34 100644
--- a/doc/doc_ch/config.md
+++ b/doc/doc_ch/config.md
@@ -45,18 +45,18 @@
### Optimizer ([ppocr/optimizer](../../ppocr/optimizer))
-| 字段 | 用途 | 默认值 | 备注 |
-| :---------------------: | :---------------------: | :--------------: | :--------------------: |
-| name | 优化器类名 | Adam | 目前支持`Momentum`,`Adam`,`RMSProp`, 见[ppocr/optimizer/optimizer.py](../../ppocr/optimizer/optimizer.py) |
-| beta1 | 设置一阶矩估计的指数衰减率 | 0.9 | \ |
-| beta2 | 设置二阶矩估计的指数衰减率 | 0.999 | \ |
-| clip_norm | 所允许的二范数最大值 | | \ |
-| **lr** | 设置学习率decay方式 | - | \ |
-| name | 学习率decay类名 | Cosine | 目前支持`Linear`,`Cosine`,`Step`,`Piecewise`, 见[ppocr/optimizer/learning_rate.py](../../ppocr/optimizer/learning_rate.py) |
-| learning_rate | 基础学习率 | 0.001 | \ |
-| **regularizer** | 设置网络正则化方式 | - | \ |
-| name | 正则化类名 | L2 | 目前支持`L1`,`L2`, 见[ppocr/optimizer/regularizer.py](../../ppocr/optimizer/regularizer.py) |
-| factor | 学习率衰减系数 | 0.00004 | \ |
+| 字段 | 用途 | 默认值 | 备注 |
+| :---------------------: |:-------------:|:-------------:| :--------------------: |
+| name | 优化器类名 | Adam | 目前支持`Momentum`,`Adam`,`RMSProp`, 见[ppocr/optimizer/optimizer.py](../../ppocr/optimizer/optimizer.py) |
+| beta1 | 设置一阶矩估计的指数衰减率 | 0.9 | \ |
+| beta2 | 设置二阶矩估计的指数衰减率 | 0.999 | \ |
+| clip_norm | 所允许的二范数最大值 | | \ |
+| **lr** | 设置学习率decay方式 | - | \ |
+| name | 学习率decay类名 | Cosine | 目前支持`Linear`,`Cosine`,`Step`,`Piecewise`, 见[ppocr/optimizer/learning_rate.py](../../ppocr/optimizer/learning_rate.py) |
+| learning_rate | 基础学习率 | 0.001 | \ |
+| **regularizer** | 设置网络正则化方式 | - | \ |
+| name | 正则化类名 | L2 | 目前支持`L1`,`L2`, 见[ppocr/optimizer/regularizer.py](../../ppocr/optimizer/regularizer.py) |
+| factor | 正则化系数 | 0.00001 | \ |
### Architecture ([ppocr/modeling](../../ppocr/modeling))
diff --git a/doc/doc_ch/datasets.md b/doc/doc_ch/dataset/datasets.md
similarity index 90%
rename from doc/doc_ch/datasets.md
rename to doc/doc_ch/dataset/datasets.md
index d365fd711aff2dffcd30dd06028734cc707d5df0..aad4f50b2d8baa369cf6f2576a24127a23cb5c48 100644
--- a/doc/doc_ch/datasets.md
+++ b/doc/doc_ch/dataset/datasets.md
@@ -6,17 +6,17 @@
- [中文文档文字识别](#中文文档文字识别)
- [ICDAR2019-ArT](#ICDAR2019-ArT)
-除了开源数据,用户还可使用合成工具自行合成,可参考[数据合成工具](./data_synthesis.md);
+除了开源数据,用户还可使用合成工具自行合成,可参考[数据合成工具](../data_synthesis.md);
-如果需要标注自己的数据,可参考[数据标注工具](./data_annotation.md)。
+如果需要标注自己的数据,可参考[数据标注工具](../data_annotation.md)。
#### 1、ICDAR2019-LSVT
- **数据来源**:https://ai.baidu.com/broad/introduction?dataset=lsvt
- **数据简介**: 共45w中文街景图像,包含5w(2w测试+3w训练)全标注数据(文本坐标+文本内容),40w弱标注数据(仅文本内容),如下图所示:
- 
+ 
(a) 全标注数据
- 
+ 
(b) 弱标注数据
- **下载地址**:https://ai.baidu.com/broad/download?dataset=lsvt
- **说明**:其中,test数据集的label目前没有开源,如要评估结果,可以去官网提交:https://rrc.cvc.uab.es/?ch=16
@@ -25,16 +25,16 @@
#### 2、ICDAR2017-RCTW-17
- **数据来源**:https://rctw.vlrlab.net/
- **数据简介**:共包含12,000+图像,大部分图片是通过手机摄像头在野外采集的。有些是截图。这些图片展示了各种各样的场景,包括街景、海报、菜单、室内场景和手机应用程序的截图。
- 
+ 
- **下载地址**:https://rctw.vlrlab.net/dataset/
-#### 3、中文街景文字识别
+#### 3、中文街景文字识别
- **数据来源**:https://aistudio.baidu.com/aistudio/competition/detail/8
- **数据简介**:ICDAR2019-LSVT行识别任务,共包括29万张图片,其中21万张图片作为训练集(带标注),8万张作为测试集(无标注)。数据集采自中国街景,并由街景图片中的文字行区域(例如店铺标牌、地标等等)截取出来而形成。所有图像都经过一些预处理,将文字区域利用仿射变化,等比映射为一张高为48像素的图片,如图所示:
- 
+ 
(a) 标注:魅派集成吊顶
- 
+ 
(b) 标注:母婴用品连锁
- **下载地址**
https://aistudio.baidu.com/aistudio/datasetdetail/8429
@@ -48,15 +48,15 @@ https://aistudio.baidu.com/aistudio/datasetdetail/8429
- 包含汉字、英文字母、数字和标点共5990个字符(字符集合:https://github.com/YCG09/chinese_ocr/blob/master/train/char_std_5990.txt )
- 每个样本固定10个字符,字符随机截取自语料库中的句子
- 图片分辨率统一为280x32
- 
- 
+ 
+ 
- **下载地址**:https://pan.baidu.com/s/1QkI7kjah8SPHwOQ40rS1Pw (密码:lu7m)
#### 5、ICDAR2019-ArT
- **数据来源**:https://ai.baidu.com/broad/introduction?dataset=art
- **数据简介**:共包含10,166张图像,训练集5603图,测试集4563图。由Total-Text、SCUT-CTW1500、Baidu Curved Scene Text (ICDAR2019-LSVT部分弯曲数据) 三部分组成,包含水平、多方向和弯曲等多种形状的文本。
- 
+ 
- **下载地址**:https://ai.baidu.com/broad/download?dataset=art
## 参考文献
diff --git a/doc/doc_ch/dataset/docvqa_datasets.md b/doc/doc_ch/dataset/docvqa_datasets.md
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/doc/doc_ch/handwritten_datasets.md b/doc/doc_ch/dataset/handwritten_datasets.md
similarity index 95%
rename from doc/doc_ch/handwritten_datasets.md
rename to doc/doc_ch/dataset/handwritten_datasets.md
index 46e85e4f9dc22e4732f654f9a1ef2a715a498fcf..6485870cdf3ede140c55e7fccce28741b22ab04d 100644
--- a/doc/doc_ch/handwritten_datasets.md
+++ b/doc/doc_ch/dataset/handwritten_datasets.md
@@ -9,7 +9,7 @@
- **数据简介**:
* 包含在线和离线两类手写数据,`HWDB1.0~1.2`总共有3895135个手写单字样本,分属7356类(7185个汉字和171个英文字母、数字、符号);`HWDB2.0~2.2`总共有5091页图像,分割为52230个文本行和1349414个文字。所有文字和文本样本均存为灰度图像。部分单字样本图片如下所示。
- 
+ 
- **下载地址**:http://www.nlpr.ia.ac.cn/databases/handwriting/Download.html
- **使用建议**:数据为单字,白色背景,可以大量合成文字行进行训练。白色背景可以处理成透明状态,方便添加各种背景。对于需要语义的情况,建议从真实语料出发,抽取单字组成文字行
@@ -22,7 +22,7 @@
- **数据简介**: NIST19数据集适用于手写文档和字符识别的模型训练,从3600位作者的手写样本表格中提取得到,总共包含81万张字符图片。其中9张图片示例如下。
- 
+ 
- **下载地址**: [https://www.nist.gov/srd/nist-special-database-19](https://www.nist.gov/srd/nist-special-database-19)
diff --git a/doc/doc_ch/dataset/layout_datasets.md b/doc/doc_ch/dataset/layout_datasets.md
new file mode 100644
index 0000000000000000000000000000000000000000..e7055b4e607aae358a9ec1e93f3640b2b68ea4a1
--- /dev/null
+++ b/doc/doc_ch/dataset/layout_datasets.md
@@ -0,0 +1,53 @@
+## 版面分析数据集
+
+这里整理了常用版面分析数据集,持续更新中,欢迎各位小伙伴贡献数据集~
+- [publaynet数据集](#publaynet)
+- [CDLA数据集](#CDLA)
+- [TableBank数据集](#TableBank)
+
+版面分析数据集多为目标检测数据集,除了开源数据,用户还可使用合成工具自行合成,如[labelme](https://github.com/wkentaro/labelme)等。
+
+
+
+
+#### 1、publaynet数据集
+- **数据来源**:https://github.com/ibm-aur-nlp/PubLayNet
+- **数据简介**:publaynet数据集的训练集合中包含35万张图像,验证集合中包含1.1万张图像。总共包含5个类别,分别是: `text, title, list, table, figure`。部分图像以及标注框可视化如下所示。
+
+
+

+

+
+

+

+
+

+

+
+  +
+
+
+将下载到的数据集解压到工作目录下,假设解压在 PaddleOCR/train_data/下。然后从上表中下载转换好的标注文件。
+
+PaddleOCR 也提供了数据格式转换脚本,可以将官网 label 转换支持的数据格式。 数据转换工具在 `ppocr/utils/gen_label.py`, 这里以训练集为例:
+
+```
+# 将官网下载的标签文件转换为 train_icdar2015_label.txt
+python gen_label.py --mode="det" --root_path="/path/to/icdar_c4_train_imgs/" \
+ --input_path="/path/to/ch4_training_localization_transcription_gt" \
+ --output_label="/path/to/train_icdar2015_label.txt"
+```
+
+解压数据集和下载标注文件后,PaddleOCR/train_data/ 有两个文件夹和两个文件,按照如下方式组织icdar2015数据集:
+```
+/PaddleOCR/train_data/icdar2015/text_localization/
+ └─ icdar_c4_train_imgs/ icdar 2015 数据集的训练数据
+ └─ ch4_test_images/ icdar 2015 数据集的测试数据
+ └─ train_icdar2015_label.txt icdar 2015 数据集的训练标注
+ └─ test_icdar2015_label.txt icdar 2015 数据集的测试标注
+```
+
+## 2. 文本识别
+
+### 2.1 PaddleOCR 文字识别数据格式
+
+PaddleOCR 中的文字识别算法支持两种数据格式:
+
+ - `lmdb` 用于训练以lmdb格式存储的数据集,使用 [lmdb_dataset.py](../../../ppocr/data/lmdb_dataset.py) 进行读取;
+ - `通用数据` 用于训练以文本文件存储的数据集,使用 [simple_dataset.py](../../../ppocr/data/simple_dataset.py)进行读取。
+
+下面以通用数据集为例, 介绍如何准备数据集:
+
+* 训练集
+
+建议将训练图片放入同一个文件夹,并用一个txt文件(rec_gt_train.txt)记录图片路径和标签,txt文件里的内容如下:
+
+**注意:** txt文件中默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错。
+
+```
+" 图像文件名 图像标注信息 "
+
+train_data/rec/train/word_001.jpg 简单可依赖
+train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
+...
+```
+
+最终训练集应有如下文件结构:
+```
+|-train_data
+ |-rec
+ |- rec_gt_train.txt
+ |- train
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+```
+
+除上述单张图像为一行格式之外,PaddleOCR也支持对离线增广后的数据进行训练,为了防止相同样本在同一个batch中被多次采样,我们可以将相同标签对应的图片路径写在一行中,以列表的形式给出,在训练中,PaddleOCR会随机选择列表中的一张图片进行训练。对应地,标注文件的格式如下。
+
+```
+["11.jpg", "12.jpg"] 简单可依赖
+["21.jpg", "22.jpg", "23.jpg"] 用科技让复杂的世界更简单
+3.jpg ocr
+```
+
+上述示例标注文件中,"11.jpg"和"12.jpg"的标签相同,都是`简单可依赖`,在训练的时候,对于该行标注,会随机选择其中的一张图片进行训练。
+
+
+- 验证集
+
+同训练集类似,验证集也需要提供一个包含所有图片的文件夹(test)和一个rec_gt_test.txt,验证集的结构如下所示:
+
+```
+|-train_data
+ |-rec
+ |- rec_gt_test.txt
+ |- test
+ |- word_001.jpg
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+```
+
+
+### 2.2 公开数据集
+
+| 数据集名称 | 图片下载地址 | PaddleOCR 标注下载地址 |
+|---|---|---------------------------------------------------------------------|
+| en benchmark(MJ, SJ, IIIT, SVT, IC03, IC13, IC15, SVTP, and CUTE.) | [DTRB](https://github.com/clovaai/deep-text-recognition-benchmark#download-lmdb-dataset-for-traininig-and-evaluation-from-here) | LMDB格式,可直接用[lmdb_dataset.py](../../../ppocr/data/lmdb_dataset.py)加载 |
+|ICDAR 2015| http://rrc.cvc.uab.es/?ch=4&com=downloads | [train](https://paddleocr.bj.bcebos.com/dataset/rec_gt_train.txt)/ [test](https://paddleocr.bj.bcebos.com/dataset/rec_gt_test.txt) |
+| 多语言数据集 |[百度网盘](https://pan.baidu.com/s/1bS_u207Rm7YbY33wOECKDA) 提取码:frgi
[google drive](https://drive.google.com/file/d/18cSWX7wXSy4G0tbKJ0d9PuIaiwRLHpjA/view) | 图片下载地址中已包含 |
+
+#### 2.1 ICDAR 2015
+
+ICDAR 2015 数据集可以在上表中链接下载,用于快速验证。也可以从上表中下载 en benchmark 所需的lmdb格式数据集。
+
+下载完图片后从上表中下载转换好的标注文件。
+
+PaddleOCR 也提供了数据格式转换脚本,可以将ICDAR官网 label 转换为PaddleOCR支持的数据格式。 数据转换工具在 `ppocr/utils/gen_label.py`, 这里以训练集为例:
+
+```
+# 将官网下载的标签文件转换为 rec_gt_label.txt
+python gen_label.py --mode="rec" --input_path="{path/of/origin/label}" --output_label="rec_gt_label.txt"
+```
+
+数据样式格式如下,(a)为原始图片,(b)为每张图片对应的 Ground Truth 文本文件:
+
+
+
+## 3. 数据存放路径
+
+PaddleOCR训练数据的默认存储路径是 `PaddleOCR/train_data`,如果您的磁盘上已有数据集,只需创建软链接至数据集目录:
+
+```
+# linux and mac os
+ln -sf /train_data/dataset
+# windows
+mklink /d /train_data/dataset
+```
diff --git a/doc/doc_ch/dataset/table_datasets.md b/doc/doc_ch/dataset/table_datasets.md
new file mode 100644
index 0000000000000000000000000000000000000000..ae902b23ccf985d522386b7454c7f76a74917502
--- /dev/null
+++ b/doc/doc_ch/dataset/table_datasets.md
@@ -0,0 +1,33 @@
+# 表格识别数据集
+
+- [数据集汇总](#数据集汇总)
+- [1. PubTabNet数据集](#1-pubtabnet数据集)
+- [2. 好未来表格识别竞赛数据集](#2-好未来表格识别竞赛数据集)
+
+这里整理了常用表格识别数据集,持续更新中,欢迎各位小伙伴贡献数据集~
+
+## 数据集汇总
+
+| 数据集名称 |图片下载地址| PPOCR标注下载地址 |
+|---|---|---|
+| PubTabNet |https://github.com/ibm-aur-nlp/PubTabNet| jsonl格式,可直接用[pubtab_dataset.py](../../../ppocr/data/pubtab_dataset.py)加载 |
+| 好未来表格识别竞赛数据集 |https://ai.100tal.com/dataset| jsonl格式,可直接用[pubtab_dataset.py](../../../ppocr/data/pubtab_dataset.py)加载 |
+
+## 1. PubTabNet数据集
+- **数据简介**:PubTabNet数据集的训练集合中包含50万张图像,验证集合中包含0.9万张图像。部分图像可视化如下所示。
+
+
+
+

+

+
+

+

+
-  -
-
-
-将下载到的数据集解压到工作目录下,假设解压在 PaddleOCR/train_data/下。另外,PaddleOCR将零散的标注文件整理成单独的标注文件
-,您可以通过wget的方式进行下载。
-```shell
-# 在PaddleOCR路径下
-cd PaddleOCR/
-wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/train_icdar2015_label.txt
-wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/test_icdar2015_label.txt
-```
-
-PaddleOCR 也提供了数据格式转换脚本,可以将官网 label 转换支持的数据格式。 数据转换工具在 `ppocr/utils/gen_label.py`, 这里以训练集为例:
-
-```
-# 将官网下载的标签文件转换为 train_icdar2015_label.txt
-python gen_label.py --mode="det" --root_path="/path/to/icdar_c4_train_imgs/" \
- --input_path="/path/to/ch4_training_localization_transcription_gt" \
- --output_label="/path/to/train_icdar2015_label.txt"
-```
-
-解压数据集和下载标注文件后,PaddleOCR/train_data/ 有两个文件夹和两个文件,按照如下方式组织icdar2015数据集:
-```
-/PaddleOCR/train_data/icdar2015/text_localization/
- └─ icdar_c4_train_imgs/ icdar数据集的训练数据
- └─ ch4_test_images/ icdar数据集的测试数据
- └─ train_icdar2015_label.txt icdar数据集的训练标注
- └─ test_icdar2015_label.txt icdar数据集的测试标注
-```
-
-提供的标注文件格式如下,中间用"\t"分隔:
-```
-" 图像文件名 json.dumps编码的图像标注信息"
-ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
-```
-json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 `points` 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。
-`transcription` 表示当前文本框的文字,**当其内容为“###”时,表示该文本框无效,在训练时会跳过。**
-
-如果您想在其他数据集上训练,可以按照上述形式构建标注文件。
## 1.2 下载预训练模型
@@ -103,9 +62,6 @@ python3 tools/train.py -c configs/det/det_mv3_db.yml \
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
-# 多机多卡训练,通过 --ips 参数设置使用的机器IP地址,通过 --gpus 参数设置使用的GPU ID
-python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
- -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
```
上述指令中,通过-c 选择训练使用configs/det/det_db_mv3.yml配置文件。
@@ -116,15 +72,6 @@ python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1
python3 tools/train.py -c configs/det/det_mv3_db.yml -o Optimizer.base_lr=0.0001
```
-**注意:** 采用多机多卡训练时,需要替换上面命令中的ips值为您机器的地址,机器之间需要能够相互ping通。另外,训练时需要在多个机器上分别启动命令。查看机器ip地址的命令为`ifconfig`。
-
-如果您想进一步加快训练速度,可以使用[自动混合精度训练](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/01_paddle2.0_introduction/basic_concept/amp_cn.html), 以单机单卡为例,命令如下:
-```shell
-python3 tools/train.py -c configs/det/det_mv3_db.yml \
- -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained \
- Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
- ```
-
## 2.2 断点训练
@@ -183,14 +130,52 @@ args1: args1
**注意**:如果要更换网络的其他模块,可以参考[文档](./add_new_algorithm.md)。
+
+## 2.4 混合精度训练
+
+如果您想进一步加快训练速度,可以使用[自动混合精度训练](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/01_paddle2.0_introduction/basic_concept/amp_cn.html), 以单机单卡为例,命令如下:
+
+```shell
+python3 tools/train.py -c configs/det/det_mv3_db.yml \
+ -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained \
+ Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
+ ```
+
+
+## 2.5 分布式训练
+
+多机多卡训练时,通过 `--ips` 参数设置使用的机器IP地址,通过 `--gpus` 参数设置使用的GPU ID:
-
+```bash
+python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
+ -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
+```
+
+**注意:** 采用多机多卡训练时,需要替换上面命令中的ips值为您机器的地址,机器之间需要能够相互ping通。另外,训练时需要在多个机器上分别启动命令。查看机器ip地址的命令为`ifconfig`。
-## 2.4 知识蒸馏训练
+
+
+
+## 2.6 知识蒸馏训练
PaddleOCR支持了基于知识蒸馏的检测模型训练过程,更多内容可以参考[知识蒸馏说明文档](./knowledge_distillation.md)。
+**注意:** 知识蒸馏训练目前只支持PP-OCR使用的`DB`和`CRNN`算法。
+
+
+
+## 2.7 其他训练环境
+
+- Windows GPU/CPU
+在Windows平台上与Linux平台略有不同:
+Windows平台只支持`单卡`的训练与预测,指定GPU进行训练`set CUDA_VISIBLE_DEVICES=0`
+在Windows平台,DataLoader只支持单进程模式,因此需要设置 `num_workers` 为0;
+
+- macOS
+不支持GPU模式,需要在配置文件中设置`use_gpu`为False,其余训练评估预测命令与Linux GPU完全相同。
+- Linux DCU
+DCU设备上运行需要设置环境变量 `export HIP_VISIBLE_DEVICES=0,1,2,3`,其余训练评估预测命令与Linux GPU完全相同。
# 3. 模型评估与预测
@@ -206,22 +191,22 @@ PaddleOCR计算三个OCR检测相关的指标,分别是:Precision、Recall
python3 tools/eval.py -c configs/det/det_mv3_db.yml -o Global.checkpoints="{path/to/weights}/best_accuracy"
```
-* 注:`box_thresh`、`unclip_ratio`是DB后处理所需要的参数,在评估EAST模型时不需要设置
## 3.2 测试检测效果
-测试单张图像的检测效果
+测试单张图像的检测效果:
```shell
python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/img_10.jpg" Global.pretrained_model="./output/det_db/best_accuracy"
```
-测试DB模型时,调整后处理阈值
+测试DB模型时,调整后处理阈值:
```shell
python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/img_10.jpg" Global.pretrained_model="./output/det_db/best_accuracy" PostProcess.box_thresh=0.6 PostProcess.unclip_ratio=2.0
```
+* 注:`box_thresh`、`unclip_ratio`是DB后处理参数,其他检测模型不支持。
-测试文件夹下所有图像的检测效果
+测试文件夹下所有图像的检测效果:
```shell
python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/" Global.pretrained_model="./output/det_db/best_accuracy"
```
diff --git a/doc/doc_ch/ocr_book.md b/doc/doc_ch/ocr_book.md
new file mode 100644
index 0000000000000000000000000000000000000000..fb2369e414ec454f0e3c51f4f2e83c1f5d155c6c
--- /dev/null
+++ b/doc/doc_ch/ocr_book.md
@@ -0,0 +1,16 @@
+# 《动手学OCR》电子书
+
+特点:
+- 覆盖OCR全栈技术
+- 理论实践相结合
+- Notebook交互式学习
+- 配套教学视频
+
+[电子书下载]()
+
+目录:
+![]()
+
+[notebook教程](../../notebook/notebook_ch/)
+
+[教学视频](https://aistudio.baidu.com/aistudio/education/group/info/25207)
\ No newline at end of file
diff --git a/doc/doc_ch/paddleOCR_overview.md b/doc/doc_ch/paddleOCR_overview.md
deleted file mode 100644
index f49c1ae302607ff6629da2462f91a36793b4db3a..0000000000000000000000000000000000000000
--- a/doc/doc_ch/paddleOCR_overview.md
+++ /dev/null
@@ -1,33 +0,0 @@
-# PaddleOCR全景图与项目克隆
-
-## 1. PaddleOCR全景图
-
-PaddleOCR包含丰富的文本检测、文本识别以及端到端算法。结合实际测试与产业经验,PaddleOCR选择DB和CRNN作为基础的检测和识别模型,经过一系列优化策略提出面向产业应用的PP-OCR模型。PP-OCR模型针对通用场景,根据不同语种形成了PP-OCR模型库。基于PP-OCR的能力,PaddleOCR针对文档场景任务发布PP-Structure工具库,包含版面分析和表格识别两大任务。为了打通产业落地的全流程,PaddleOCR提供了规模化的数据生产工具和多种预测部署工具,助力开发者快速落地。
-
-
-

-
+

+
+PP-OCRv2 中文模型
+
+
+

+

+
+

+

+
+
+
+
+PP-OCRv2 英文模型
+
+
+

+
+
+
+
+PP-OCRv2 其他语言模型
+
+
+

+

+
+
+
+
+## 5. 使用教程
+
+
+### 5.1 快速体验
+
+- 在线网站体验:超轻量PP-OCR mobile模型体验地址:https://www.paddlepaddle.org.cn/hub/scene/ocr
+- 移动端demo体验:[安装包DEMO下载地址](https://ai.baidu.com/easyedge/app/openSource?from=paddlelite)(基于EasyEdge和Paddle-Lite, 支持iOS和Android系统)
+- 一行命令快速使用:[快速开始(中英文/多语言)](./doc/doc_ch/quickstart.md)
+
+
+### 5.2 模型训练、压缩、推理部署
+
+更多教程,包括模型训练、模型压缩、推理部署等,请参考[文档教程](../../README_ch.md#文档教程)。
+
+
+## 6. 模型库
+
+PP-OCR中英文模型列表如下:
+
+| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
+| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
+| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
+| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
+
+更多模型下载(包括英文数字模型、多语言模型、Paddle-Lite模型等),可以参考[PP-OCR 系列模型下载](./models_list.md)。
\ No newline at end of file
diff --git a/doc/doc_ch/quickstart.md b/doc/doc_ch/quickstart.md
index 57931aa26143f2f442f3e4d579abc2549c11322b..ce0f6b1570f1570f7d12bf1ad24d7d9f9914f5f0 100644
--- a/doc/doc_ch/quickstart.md
+++ b/doc/doc_ch/quickstart.md
@@ -1,25 +1,23 @@
-- [PaddleOCR快速开始](#paddleocr快速开始)
- - [1. 安装](#1-安装)
- - [1.1 安装PaddlePaddle](#11-安装paddlepaddle)
- - [1.2 安装PaddleOCR whl包](#12-安装paddleocr-whl包)
- - [2. 便捷使用](#2-便捷使用)
- - [2.1 命令行使用](#21-命令行使用)
- - [2.1.1 中英文模型](#211-中英文模型)
- - [2.1.2 多语言模型](#212-多语言模型)
- - [2.1.3 版面分析](#213-版面分析)
- - [2.2 Python脚本使用](#22-python脚本使用)
- - [2.2.1 中英文与多语言使用](#221-中英文与多语言使用)
- - [2.2.2 版面分析](#222-版面分析)
- - [3. 小结](#3-小结)
-
-# PaddleOCR快速开始
+# PaddleOCR 快速开始
+
+**说明:** 本文主要介绍PaddleOCR wheel包对PP-OCR系列模型的快速使用,如要体验文档分析相关功能,请参考[PP-Structure快速使用教程](../../ppstructure/docs/quickstart.md)。
+
+- [1. 安装](#1)
+ - [1.1 安装PaddlePaddle](#11)
+ - [1.2 安装PaddleOCR whl包](#12)
+- [2. 便捷使用](#2)
+ - [2.1 命令行使用](#21)
+ - [2.1.1 中英文模型](#211)
+ - [2.1.2 多语言模型](#212)
+ - [2.2 Python脚本使用](#22)
+ - [2.2.1 中英文与多语言使用](#221)
+- [3.小结](#3)
-
+
## 1. 安装
-
### 1.1 安装PaddlePaddle
> 如果您没有基础的Python运行环境,请参考[运行环境准备](./environment.md)。
@@ -39,22 +37,13 @@
更多的版本需求,请参照[飞桨官网安装文档](https://www.paddlepaddle.org.cn/install/quick)中的说明进行操作。
-
### 1.2 安装PaddleOCR whl包
```bash
pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本
```
-- 对于Windows环境用户:
-
- 直接通过pip安装的shapely库可能出现`[winRrror 126] 找不到指定模块的问题`。建议从[这里](https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely)下载shapely安装包完成安装,
-
-- 使用**版面分析**功能时,运行以下命令**安装 Layout-Parser**
-
- ```bash
- pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
- ```
+- 对于Windows环境用户:直接通过pip安装的shapely库可能出现`[winRrror 126] 找不到指定模块的问题`。建议从[这里](https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely)下载shapely安装包完成安装。
@@ -68,7 +57,8 @@ PaddleOCR提供了一系列测试图片,点击[这里](https://paddleocr.bj.bc
cd /path/to/ppocr_img
```
-如果不使用提供的测试图片,可以将下方`--image_dir`参数替换为相应的测试图片路径
+如果不使用提供的测试图片,可以将下方`--image_dir`参数替换为相应的测试图片路径。
+
#### 2.1.1 中英文模型
@@ -154,60 +144,6 @@ paddleocr --image_dir ./imgs_en/254.jpg --lang=en
| 繁体中文 | chinese_cht | | 意大利文 | it | | 俄罗斯文 | ru |
全部语种及其对应的缩写列表可查看[多语言模型教程](./multi_languages.md)
-
-
-#### 2.1.3 版面分析
-
-版面分析是指对文档图片中的文字、标题、列表、图片和表格5类区域进行划分。对于前三类区域,直接使用OCR模型完成对应区域文字检测与识别,并将结果保存在txt中。对于表格类区域,经过表格结构化处理后,表格图片转换为相同表格样式的Excel文件。图片区域会被单独裁剪成图像。
-
-使用PaddleOCR的版面分析功能,需要指定`--type=structure`
-
-```bash
-paddleocr --image_dir=./table/1.png --type=structure
-```
-
-- **返回结果说明**
-
- PP-Structure的返回结果为一个dict组成的list,示例如下
-
- ```shell
- [{ 'type': 'Text',
- 'bbox': [34, 432, 345, 462],
- 'res': ([[36.0, 437.0, 341.0, 437.0, 341.0, 446.0, 36.0, 447.0], [41.0, 454.0, 125.0, 453.0, 125.0, 459.0, 41.0, 460.0]],
- [('Tigure-6. The performance of CNN and IPT models using difforen', 0.90060663), ('Tent ', 0.465441)])
- }
- ]
- ```
-
- 其中各个字段说明如下
-
- | 字段 | 说明 |
- | ---- | ------------------------------------------------------------ |
- | type | 图片区域的类型 |
- | bbox | 图片区域的在原图的坐标,分别[左上角x,左上角y,右下角x,右下角y] |
- | res | 图片区域的OCR或表格识别结果。
表格: 表格的HTML字符串;
OCR: 一个包含各个单行文字的检测坐标和识别结果的元组 |
-
- 运行完成后,每张图片会在`output`字段指定的目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名为表格在图片里的坐标。
-
- ```
- /output/table/1/
- └─ res.txt
- └─ [454, 360, 824, 658].xlsx 表格识别结果
- └─ [16, 2, 828, 305].jpg 被裁剪出的图片区域
- └─ [17, 361, 404, 711].xlsx 表格识别结果
- ```
-
-- **参数说明**
-
- | 字段 | 说明 | 默认值 |
- | --------------- | ---------------------------------------- | -------------------------------------------- |
- | output | excel和识别结果保存的地址 | ./output/table |
- | table_max_len | 表格结构模型预测时,图像的长边resize尺度 | 488 |
- | table_model_dir | 表格结构模型 inference 模型地址 | None |
- | table_char_dict_path | 表格结构模型所用字典地址 | ../ppocr/utils/dict/table_structure_dict.txt |
-
- 大部分参数和paddleocr whl包保持一致,见 [whl包文档](./whl.md)
-
@@ -256,35 +192,7 @@ im_show.save('result.jpg')

-
-
-#### 2.2.2 版面分析
-
-```python
-import os
-import cv2
-from paddleocr import PPStructure,draw_structure_result,save_structure_res
-table_engine = PPStructure(show_log=True)
-
-save_folder = './output/table'
-img_path = './table/paper-image.jpg'
-img = cv2.imread(img_path)
-result = table_engine(img)
-save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])
-
-for line in result:
- line.pop('img')
- print(line)
-
-from PIL import Image
-
-font_path = './fonts/simfang.ttf' # PaddleOCR下提供字体包
-image = Image.open(img_path).convert('RGB')
-im_show = draw_structure_result(image, result,font_path=font_path)
-im_show = Image.fromarray(im_show)
-im_show.save('result.jpg')
-```
@@ -292,4 +200,4 @@ im_show.save('result.jpg')
通过本节内容,相信您已经熟练掌握PaddleOCR whl包的使用方法并获得了初步效果。
-PaddleOCR是一套丰富领先实用的OCR工具库,打通数据、模型训练、压缩和推理部署全流程,因此在[下一节](./paddleOCR_overview.md)中我们将首先为您介绍PaddleOCR的全景图,然后克隆PaddleOCR项目,正式开启PaddleOCR的应用之旅。
+PaddleOCR是一套丰富领先实用的OCR工具库,打通数据、模型训练、压缩和推理部署全流程,您可以参考[文档教程](../../README_ch.md#文档教程),正式开启PaddleOCR的应用之旅。
diff --git a/doc/doc_ch/recognition.md b/doc/doc_ch/recognition.md
index 6cdd547517ebb8888374b22c1b52314da53eebab..34a462f7ab704ce7c57fc7b8ef7f0fb3f1fb8931 100644
--- a/doc/doc_ch/recognition.md
+++ b/doc/doc_ch/recognition.md
@@ -2,25 +2,32 @@
本文提供了PaddleOCR文本识别任务的全流程指南,包括数据准备、模型训练、调优、评估、预测,各个阶段的详细说明:
-- [文字识别](#文字识别)
- - [1. 数据准备](#1-数据准备)
- - [1.1 自定义数据集](#11-自定义数据集)
- - [1.2 数据下载](#12-数据下载)
- - [1.3 字典](#13-字典)
- - [1.4 添加空格类别](#14-添加空格类别)
- - [2. 启动训练](#2-启动训练)
- - [2.1 数据增强](#21-数据增强)
- - [2.2 通用模型训练](#22-通用模型训练)
- - [2.3 多语言模型训练](#23-多语言模型训练)
- - [2.4 知识蒸馏训练](#24-知识蒸馏训练)
- - [3 评估](#3-评估)
- - [4 预测](#4-预测)
- - [5. 转Inference模型测试](#5-转inference模型测试)
-
-
-
-## 1. 数据准备
-
+- [1. 数据准备](#1-数据准备)
+ * [1.1 自定义数据集](#11-自定义数据集)
+ * [1.2 数据下载](#12-数据下载)
+ * [1.3 字典](#13-字典)
+ * [1.4 添加空格类别](#14-添加空格类别)
+ * [1.5 数据增强](#15-数据增强)
+- [2. 开始训练](#2-开始训练)
+ * [2.1 启动训练](#21-----)
+ * [2.2 断点训练](#22-----)
+ * [2.3 更换Backbone 训练](#23---backbone---)
+ * [2.4 混合精度训练](#24---amp---)
+ * [2.5 分布式训练](#25---fleet---)
+ * [2.6 知识蒸馏训练](#26---distill---)
+ * [2.7 多语言模型训练](#27-多语言模型训练)
+ * [2.8 其他训练环境(Windows/macOS/Linux DCU)](#28---other---)
+- [3. 模型评估与预测](#3--------)
+ * [3.1 指标评估](#31-----)
+ * [3.2 测试识别效果](#32-------)
+- [4. 模型导出与预测](#4--------)
+- [5. FAQ](#5-faq)
+
+
+
+# 1. 数据准备
+
+### 1.1 准备数据集
PaddleOCR 支持两种数据格式:
- `lmdb` 用于训练以lmdb格式存储的数据集(LMDBDataSet);
@@ -35,8 +42,8 @@ ln -sf /train_data/dataset
mklink /d /train_data/dataset
```
-
-### 1.1 自定义数据集
+
+## 1.1 自定义数据集
下面以通用数据集为例, 介绍如何准备数据集:
* 训练集
@@ -91,9 +98,8 @@ train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
| ...
```
-
-
-### 1.2 数据下载
+
+## 1.2 数据下载
- ICDAR2015
@@ -127,8 +133,8 @@ python gen_label.py --mode="rec" --input_path="{path/of/origin/label}" --output_
* [google drive](https://drive.google.com/file/d/18cSWX7wXSy4G0tbKJ0d9PuIaiwRLHpjA/view)
-
-### 1.3 字典
+
+## 1.3 字典
最后需要提供一个字典({word_dict_name}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。
@@ -163,9 +169,6 @@ PaddleOCR内置了一部分字典,可以按需使用。
`ppocr/utils/en_dict.txt` 是一个包含96个字符的英文字典
-
-
-
目前的多语言模型仍处在demo阶段,会持续优化模型并补充语种,**非常欢迎您为我们提供其他语言的字典和字体**,
如您愿意可将字典文件提交至 [dict](../../ppocr/utils/dict),我们会在Repo中感谢您。
@@ -174,16 +177,12 @@ PaddleOCR内置了一部分字典,可以按需使用。
如需自定义dic文件,请在 `configs/rec/rec_icdar15_train.yml` 中添加 `character_dict_path` 字段, 指向您的字典路径。
-### 1.4 添加空格类别
+## 1.4 添加空格类别
如果希望支持识别"空格"类别, 请将yml文件中的 `use_space_char` 字段设置为 `True`。
-
-
-## 2. 启动训练
-
-### 2.1 数据增强
+## 1.5 数据增强
PaddleOCR提供了多种数据增强方式,默认配置文件中已经添加了数据增广。
@@ -193,11 +192,14 @@ PaddleOCR提供了多种数据增强方式,默认配置文件中已经添加
*由于OpenCV的兼容性问题,扰动操作暂时只支持Linux*
-
-### 2.2 通用模型训练
+
+# 2. 开始训练
PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以 CRNN 识别模型为例:
+
+## 2.1 启动训练
+
首先下载pretrain model,您可以下载训练好的模型在 icdar2015 数据上进行finetune
```
@@ -317,8 +319,96 @@ Eval:
```
**注意,预测/评估时的配置文件请务必与训练一致。**
-
-### 2.3 多语言模型训练
+
+
+## 2.2 断点训练
+
+如果训练程序中断,如果希望加载训练中断的模型从而恢复训练,可以通过指定Global.checkpoints指定要加载的模型路径:
+```shell
+python3 tools/train.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints=./your/trained/model
+```
+
+**注意**:`Global.checkpoints`的优先级高于`Global.pretrained_model`的优先级,即同时指定两个参数时,优先加载`Global.checkpoints`指定的模型,如果`Global.checkpoints`指定的模型路径有误,会加载`Global.pretrained_model`指定的模型。
+
+
+## 2.3 更换Backbone 训练
+
+PaddleOCR将网络划分为四部分,分别在[ppocr/modeling](../../ppocr/modeling)下。 进入网络的数据将按照顺序(transforms->backbones->necks->heads)依次通过这四个部分。
+
+```bash
+├── architectures # 网络的组网代码
+├── transforms # 网络的图像变换模块
+├── backbones # 网络的特征提取模块
+├── necks # 网络的特征增强模块
+└── heads # 网络的输出模块
+```
+如果要更换的Backbone 在PaddleOCR中有对应实现,直接修改配置yml文件中`Backbone`部分的参数即可。
+
+如果要使用新的Backbone,更换backbones的例子如下:
+
+1. 在 [ppocr/modeling/backbones](../../ppocr/modeling/backbones) 文件夹下新建文件,如my_backbone.py。
+2. 在 my_backbone.py 文件内添加相关代码,示例代码如下:
+
+```python
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+class MyBackbone(nn.Layer):
+ def __init__(self, *args, **kwargs):
+ super(MyBackbone, self).__init__()
+ # your init code
+ self.conv = nn.xxxx
+
+ def forward(self, inputs):
+ # your network forward
+ y = self.conv(inputs)
+ return y
+```
+
+3. 在 [ppocr/modeling/backbones/\__init\__.py](../../ppocr/modeling/backbones/__init__.py)文件内导入添加的`MyBackbone`模块,然后修改配置文件中Backbone进行配置即可使用,格式如下:
+
+```yaml
+Backbone:
+name: MyBackbone
+args1: args1
+```
+
+**注意**:如果要更换网络的其他模块,可以参考[文档](./add_new_algorithm.md)。
+
+
+## 2.4 混合精度训练
+
+如果您想进一步加快训练速度,可以使用[自动混合精度训练](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/01_paddle2.0_introduction/basic_concept/amp_cn.html), 以单机单卡为例,命令如下:
+
+```shell
+python3 tools/train.py -c configs/rec/rec_icdar15_train.yml \
+ -o Global.pretrained_model=./pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train \
+ Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
+ ```
+
+
+## 2.5 分布式训练
+
+多机多卡训练时,通过 `--ips` 参数设置使用的机器IP地址,通过 `--gpus` 参数设置使用的GPU ID:
+
+```bash
+python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_icdar15_train.yml \
+ -o Global.pretrained_model=./pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train
+```
+
+**注意:** 采用多机多卡训练时,需要替换上面命令中的ips值为您机器的地址,机器之间需要能够相互ping通。另外,训练时需要在多个机器上分别启动命令。查看机器ip地址的命令为`ifconfig`。
+
+
+
+## 2.6 知识蒸馏训练
+
+PaddleOCR支持了基于知识蒸馏的文本识别模型训练过程,更多内容可以参考[知识蒸馏说明文档](./knowledge_distillation.md)。
+
+
+
+## 2.7 多语言模型训练
PaddleOCR目前已支持80种(除中文外)语种识别,`configs/rec/multi_languages` 路径下提供了一个多语言的配置文件模版: [rec_multi_language_lite_train.yml](../../configs/rec/multi_language/rec_multi_language_lite_train.yml)。
@@ -374,24 +464,36 @@ Eval:
...
```
-
+
+## 2.8 其他训练环境
-### 2.4 知识蒸馏训练
+- Windows GPU/CPU
+在Windows平台上与Linux平台略有不同:
+Windows平台只支持`单卡`的训练与预测,指定GPU进行训练`set CUDA_VISIBLE_DEVICES=0`
+在Windows平台,DataLoader只支持单进程模式,因此需要设置 `num_workers` 为0;
+
+- macOS
+不支持GPU模式,需要在配置文件中设置`use_gpu`为False,其余训练评估预测命令与Linux GPU完全相同。
+
+- Linux DCU
+DCU设备上运行需要设置环境变量 `export HIP_VISIBLE_DEVICES=0,1,2,3`,其余训练评估预测命令与Linux GPU完全相同。
-PaddleOCR支持了基于知识蒸馏的文本识别模型训练过程,更多内容可以参考[知识蒸馏说明文档](./knowledge_distillation.md)。
-
-## 3 评估
+
+# 3. 模型评估与预测
-评估数据集可以通过 `configs/rec/rec_icdar15_train.yml` 修改Eval中的 `label_file_path` 设置。
+
+## 3.1 指标评估
+
+训练中模型参数默认保存在`Global.save_model_dir`目录下。在评估指标时,需要设置`Global.checkpoints`指向保存的参数文件。评估数据集可以通过 `configs/rec/rec_icdar15_train.yml` 修改Eval中的 `label_file_path` 设置。
```
# GPU 评估, Global.checkpoints 为待测权重
python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints={path/to/weights}/best_accuracy
```
-
-## 4 预测
+
+## 3.2 测试识别效果
使用 PaddleOCR 训练好的模型,可以通过以下脚本进行快速预测。
@@ -450,9 +552,14 @@ infer_img: doc/imgs_words/ch/word_1.jpg
result: ('韩国小馆', 0.997218)
```
-
-## 5. 转Inference模型测试
+
+# 4. 模型导出与预测
+
+inference 模型(`paddle.jit.save`保存的模型)
+一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。
+训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。
+与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
识别模型转inference模型与检测的方式相同,如下:
@@ -483,3 +590,11 @@ python3 tools/export_model.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_trai
```
python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words_en/word_336.png" --rec_model_dir="./your inference model" --rec_image_shape="3, 32, 100" --rec_char_dict_path="your text dict path"
```
+
+
+
+# 5. FAQ
+
+Q1: 训练模型转inference 模型之后预测效果不一致?
+
+**A**:此类问题出现较多,问题多是trained model预测时候的预处理、后处理参数和inference model预测的时候的预处理、后处理参数不一致导致的。可以对比训练使用的配置文件中的预处理、后处理和预测时是否存在差异。
diff --git a/doc/doc_ch/training.md b/doc/doc_ch/training.md
index 231b83e64b48d6c6fe1192b34b1d2f11a06f4cd8..d46b9af701ee1c605526c18d6994842b3faf8e14 100644
--- a/doc/doc_ch/training.md
+++ b/doc/doc_ch/training.md
@@ -81,13 +81,13 @@ Optimizer:
- 检测:
- 英文数据集,ICDAR2015
- 中文数据集,LSVT街景数据集训练数据3w张图片
-
+
- 识别:
- 英文数据集,MJSynth和SynthText合成数据,数据量上千万。
- 中文数据集,LSVT街景数据集根据真值将图crop出来,并进行位置校准,总共30w张图像。此外基于LSVT的语料,合成数据500w。
- 小语种数据集,使用不同语料和字体,分别生成了100w合成数据集,并使用ICDAR-MLT作为验证集。
-其中,公开数据集都是开源的,用户可自行搜索下载,也可参考[中文数据集](./datasets.md),合成数据暂不开源,用户可使用开源合成工具自行合成,可参考的合成工具包括[text_renderer](https://github.com/Sanster/text_renderer) 、[SynthText](https://github.com/ankush-me/SynthText) 、[TextRecognitionDataGenerator](https://github.com/Belval/TextRecognitionDataGenerator) 等。
+其中,公开数据集都是开源的,用户可自行搜索下载,也可参考[中文数据集](dataset/datasets.md),合成数据暂不开源,用户可使用开源合成工具自行合成,可参考的合成工具包括[text_renderer](https://github.com/Sanster/text_renderer) 、[SynthText](https://github.com/ankush-me/SynthText) 、[TextRecognitionDataGenerator](https://github.com/Belval/TextRecognitionDataGenerator) 等。
### 3.2 垂类场景
@@ -120,17 +120,17 @@ PaddleOCR主要聚焦通用OCR,如果有垂类需求,您可以用PaddleOCR+
**Q**:训练CRNN识别时,如何选择合适的网络输入shape?
A:一般高度采用32,最长宽度的选择,有两种方法:
-
+
(1)统计训练样本图像的宽高比分布。最大宽高比的选取考虑满足80%的训练样本。
-
+
(2)统计训练样本文字数目。最长字符数目的选取考虑满足80%的训练样本。然后中文字符长宽比近似认为是1,英文认为3:1,预估一个最长宽度。
**Q**:识别训练时,训练集精度已经到达90了,但验证集精度一直在70,涨不上去怎么办?
A:训练集精度90,测试集70多的话,应该是过拟合了,有两个可尝试的方法:
-
+
(1)加入更多的增广方式或者调大增广prob的[概率](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/ppocr/data/imaug/rec_img_aug.py#L341),默认为0.4。
-
+
(2)调大系统的[l2 dcay值](https://github.com/PaddlePaddle/PaddleOCR/blob/a501603d54ff5513fc4fc760319472e59da25424/configs/rec/ch_ppocr_v1.1/rec_chinese_lite_train_v1.1.yml#L47)
**Q**: 识别模型训练时,loss能正常下降,但acc一直为0
@@ -141,12 +141,11 @@ PaddleOCR主要聚焦通用OCR,如果有垂类需求,您可以用PaddleOCR+
***
-具体的训练教程可点击下方链接跳转:
+具体的训练教程可点击下方链接跳转:
-- [文本检测模型训练](./detection.md)
+- [文本检测模型训练](./detection.md)
- [文本识别模型训练](./recognition.md)
- [文本方向分类器训练](./angle_class.md)
- [知识蒸馏](./knowledge_distillation.md)
-
diff --git a/doc/doc_ch/update.md b/doc/doc_ch/update.md
index c4c870681c6ccb5ad7702101312e5dbe47e9cb85..9071e673910f8d87762dc8f9dd097d444f36e624 100644
--- a/doc/doc_ch/update.md
+++ b/doc/doc_ch/update.md
@@ -22,7 +22,7 @@
- 2020.7.15 整理OCR相关数据集、常用数据标注以及合成工具
- 2020.7.9 添加支持空格的识别模型,识别效果,预测及训练方式请参考快速开始和文本识别训练相关文档
- 2020.7.9 添加数据增强、学习率衰减策略,具体参考[配置文件](./config.md)
-- 2020.6.8 添加[数据集](./datasets.md),并保持持续更新
+- 2020.6.8 添加[数据集](dataset/datasets.md),并保持持续更新
- 2020.6.5 支持 `attetnion` 模型导出 `inference_model`
- 2020.6.5 支持单独预测识别时,输出结果得分
- 2020.5.30 提供超轻量级中文OCR在线体验
diff --git a/doc/doc_en/FAQ_en.md b/doc/doc_en/FAQ_en.md
index 5cf82a78720d15ce5b0aac37c409921474923813..5b0884276543645cc5569a99a0e24b40c29581a6 100644
--- a/doc/doc_en/FAQ_en.md
+++ b/doc/doc_en/FAQ_en.md
@@ -42,7 +42,7 @@ At present, the open source model, dataset and magnitude are as follows:
English dataset: MJSynth and SynthText synthetic dataset, the amount of data is tens of millions.
Chinese dataset: LSVT street view dataset with cropped text area, a total of 30w images. In addition, the synthesized data based on LSVT corpus is 500w.
- Among them, the public datasets are opensourced, users can search and download by themselves, or refer to [Chinese data set](./datasets_en.md), synthetic data is not opensourced, users can use open-source synthesis tools to synthesize data themselves. Current available synthesis tools include [text_renderer](https://github.com/Sanster/text_renderer), [SynthText](https://github.com/ankush-me/SynthText), [TextRecognitionDataGenerator](https://github.com/Belval/TextRecognitionDataGenerator), etc.
+ Among them, the public datasets are opensourced, users can search and download by themselves, or refer to [Chinese data set](dataset/datasets_en.md), synthetic data is not opensourced, users can use open-source synthesis tools to synthesize data themselves. Current available synthesis tools include [text_renderer](https://github.com/Sanster/text_renderer), [SynthText](https://github.com/ankush-me/SynthText), [TextRecognitionDataGenerator](https://github.com/Belval/TextRecognitionDataGenerator), etc.
10. **Error in using the model with TPS module for prediction**
Error message: Input(X) dims[3] and Input(Grid) dims[2] should be equal, but received X dimension[3]\(108) != Grid dimension[2]\(100)
diff --git a/doc/doc_en/algorithm_det_db_en.md b/doc/doc_en/algorithm_det_db_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..f5f333a039acded88f0f28d302821c5eb10d7402
--- /dev/null
+++ b/doc/doc_en/algorithm_det_db_en.md
@@ -0,0 +1,99 @@
+# DB
+
+- [1. Introduction](#1)
+- [2. Environment](#2)
+- [3. Model Training / Evaluation / Prediction](#3)
+ - [3.1 Training](#3-1)
+ - [3.2 Evaluation](#3-2)
+ - [3.3 Prediction](#3-3)
+- [4. Inference and Deployment](#4)
+ - [4.1 Python Inference](#4-1)
+ - [4.2 C++ Inference](#4-2)
+ - [4.3 Serving](#4-3)
+ - [4.4 More](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. Introduction
+
+Paper:
+> [Real-time Scene Text Detection with Differentiable Binarization](https://arxiv.org/abs/1911.08947)
+> Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang
+> AAAI, 2020
+
+On the ICDAR2015 dataset, the text detection result is as follows:
+
+|Model|Backbone|Configuration|Precision|Recall|Hmean|Download|
+| --- | --- | --- | --- | --- | --- | --- |
+|DB|ResNet50_vd|[configs/det/det_r50_vd_db.yml](../../configs/det/det_r50_vd_db.yml)|86.41%|78.72%|82.38%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_db_v2.0_train.tar)|
+|DB|MobileNetV3|[configs/det/det_mv3_db.yml](../../configs/det/det_mv3_db.yml)|77.29%|73.08%|75.12%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_mv3_db_v2.0_train.tar)|
+
+
+
+## 2. Environment
+Please prepare your environment referring to [prepare the environment](./environment_en.md) and [clone the repo](./clone_en.md).
+
+
+
+## 3. Model Training / Evaluation / Prediction
+
+Please refer to [text detection training tutorial](./detection_en.md). PaddleOCR has modularized the code structure, so that you only need to **replace the configuration file** to train different detection models.
+
+
+## 4. Inference and Deployment
+
+
+### 4.1 Python Inference
+First, convert the model saved in the DB text detection training process into an inference model. Taking the model based on the Resnet50_vd backbone network and trained on the ICDAR2015 English dataset as example ([model download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_db_v2.0_train.tar)), you can use the following command to convert:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_db.yml -o Global.pretrained_model=./det_r50_vd_db_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_db
+```
+
+DB text detection model inference, you can execute the following command:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_db/"
+```
+
+The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
+
+
+
+**Note**: Since the ICDAR2015 dataset has only 1,000 training images, mainly for English scenes, the above model has very poor detection result on Chinese text images.
+
+
+
+### 4.2 C++ Inference
+
+With the inference model prepared, refer to the [cpp infer](../../deploy/cpp_infer/) tutorial for C++ inference.
+
+
+### 4.3 Serving
+
+With the inference model prepared, refer to the [pdserving](../../deploy/pdserving/) tutorial for service deployment by Paddle Serving.
+
+
+### 4.4 More
+
+More deployment schemes supported for DB:
+
+- Paddle2ONNX: with the inference model prepared, please refer to the [paddle2onnx](../../deploy/paddle2onnx/) tutorial.
+
+
+## 5. FAQ
+
+
+## Citation
+
+```bibtex
+@inproceedings{liao2020real,
+ title={Real-time scene text detection with differentiable binarization},
+ author={Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang},
+ booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
+ volume={34},
+ number={07},
+ pages={11474--11481},
+ year={2020}
+}
+```
\ No newline at end of file
diff --git a/doc/doc_en/algorithm_det_fcenet_en.md b/doc/doc_en/algorithm_det_fcenet_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..e15fb9a07ede3296d3de83c134457194d4639a1c
--- /dev/null
+++ b/doc/doc_en/algorithm_det_fcenet_en.md
@@ -0,0 +1,104 @@
+# FCENet
+
+- [1. Introduction](#1)
+- [2. Environment](#2)
+- [3. Model Training / Evaluation / Prediction](#3)
+ - [3.1 Training](#3-1)
+ - [3.2 Evaluation](#3-2)
+ - [3.3 Prediction](#3-3)
+- [4. Inference and Deployment](#4)
+ - [4.1 Python Inference](#4-1)
+ - [4.2 C++ Inference](#4-2)
+ - [4.3 Serving](#4-3)
+ - [4.4 More](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. Introduction
+
+Paper:
+> [Fourier Contour Embedding for Arbitrary-Shaped Text Detection](https://arxiv.org/abs/2104.10442)
+> Yiqin Zhu and Jianyong Chen and Lingyu Liang and Zhanghui Kuang and Lianwen Jin and Wayne Zhang
+> CVPR, 2021
+
+On the CTW1500 dataset, the text detection result is as follows:
+
+|Model|Backbone|Configuration|Precision|Recall|Hmean|Download|
+| --- | --- | --- | --- | --- | --- | --- |
+| FCE | ResNet50_dcn | [configs/det/det_r50_vd_dcn_fce_ctw.yml](../../configs/det/det_r50_vd_dcn_fce_ctw.yml)| 88.39%|82.18%|85.27%|[trained model](https://paddleocr.bj.bcebos.com/contribution/det_r50_dcn_fce_ctw_v2.0_train.tar)|
+
+
+## 2. Environment
+Please prepare your environment referring to [prepare the environment](./environment_en.md) and [clone the repo](./clone_en.md).
+
+
+
+## 3. Model Training / Evaluation / Prediction
+
+The above FCE model is trained using the CTW1500 text detection public dataset. For the download of the dataset, please refer to [ocr_datasets](./dataset/ocr_datasets_en.md).
+
+After the data download is complete, please refer to [Text Detection Training Tutorial](./detection.md) for training. PaddleOCR has modularized the code structure, so that you only need to **replace the configuration file** to train different detection models.
+
+
+## 4. Inference and Deployment
+
+
+### 4.1 Python Inference
+First, convert the model saved in the FCE text detection training process into an inference model. Taking the model based on the Resnet50_vd_dcn backbone network and trained on the CTW1500 English dataset as example ([model download link](https://paddleocr.bj.bcebos.com/contribution/det_r50_dcn_fce_ctw_v2.0_train.tar)), you can use the following command to convert:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_dcn_fce_ctw.yml -o Global.pretrained_model=./det_r50_dcn_fce_ctw_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_fce
+```
+
+FCE text detection model inference, to perform non-curved text detection, you can run the following commands:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_fce/" --det_algorithm="FCE" --det_fce_box_type=quad
+```
+
+The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
+
+
+
+If you want to perform curved text detection, you can execute the following command:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_fce/" --det_algorithm="FCE" --det_fce_box_type=poly
+```
+
+The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
+
+
+
+**Note**: Since the CTW1500 dataset has only 1,000 training images, mainly for English scenes, the above model has very poor detection result on Chinese or curved text images.
+
+
+
+### 4.2 C++ Inference
+
+Since the post-processing is not written in CPP, the FCE text detection model does not support CPP inference.
+
+
+### 4.3 Serving
+
+Not supported
+
+
+### 4.4 More
+
+Not supported
+
+
+## 5. FAQ
+
+
+## Citation
+
+```bibtex
+@InProceedings{zhu2021fourier,
+ title={Fourier Contour Embedding for Arbitrary-Shaped Text Detection},
+ author={Yiqin Zhu and Jianyong Chen and Lingyu Liang and Zhanghui Kuang and Lianwen Jin and Wayne Zhang},
+ year={2021},
+ booktitle = {CVPR}
+}
+```
diff --git a/doc/doc_en/algorithm_det_psenet_en.md b/doc/doc_en/algorithm_det_psenet_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..d4cb3ea7d1e82a3f9c261c6e44cd6df6b0f6bf1e
--- /dev/null
+++ b/doc/doc_en/algorithm_det_psenet_en.md
@@ -0,0 +1,107 @@
+# PSENet
+
+- [1. Introduction](#1)
+- [2. Environment](#2)
+- [3. Model Training / Evaluation / Prediction](#3)
+ - [3.1 Training](#3-1)
+ - [3.2 Evaluation](#3-2)
+ - [3.3 Prediction](#3-3)
+- [4. Inference and Deployment](#4)
+ - [4.1 Python Inference](#4-1)
+ - [4.2 C++ Inference](#4-2)
+ - [4.3 Serving](#4-3)
+ - [4.4 More](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. Introduction
+
+Paper:
+> [Shape robust text detection with progressive scale expansion network](https://arxiv.org/abs/1903.12473)
+> Wang, Wenhai and Xie, Enze and Li, Xiang and Hou, Wenbo and Lu, Tong and Yu, Gang and Shao, Shuai
+> CVPR, 2019
+
+On the ICDAR2015 dataset, the text detection result is as follows:
+
+|Model|Backbone|Configuration|Precision|Recall|Hmean|Download|
+| --- | --- | --- | --- | --- | --- | --- |
+|PSE| ResNet50_vd | [configs/det/det_r50_vd_pse.yml](../../configs/det/det_r50_vd_pse.yml)| 85.81% |79.53%|82.55%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_r50_vd_pse_v2.0_train.tar)|
+|PSE| MobileNetV3| [configs/det/det_mv3_pse.yml](../../configs/det/det_mv3_pse.yml) | 82.20% |70.48%|75.89%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_mv3_pse_v2.0_train.tar)|
+
+
+
+## 2. Environment
+Please prepare your environment referring to [prepare the environment](./environment_en.md) and [clone the repo](./clone_en.md).
+
+
+
+## 3. Model Training / Evaluation / Prediction
+
+The above PSE model is trained using the ICDAR2015 text detection public dataset. For the download of the dataset, please refer to [ocr_datasets](./dataset/ocr_datasets_en.md).
+
+After the data download is complete, please refer to [Text Detection Training Tutorial](./detection.md) for training. PaddleOCR has modularized the code structure, so that you only need to **replace the configuration file** to train different detection models.
+
+
+## 4. Inference and Deployment
+
+
+### 4.1 Python Inference
+First, convert the model saved in the PSE text detection training process into an inference model. Taking the model based on the Resnet50_vd backbone network and trained on the ICDAR2015 English dataset as example ([model download link](https://paddleocr.bj.bcebos.com/dygraph_v2.1/en_det/det_r50_vd_pse_v2.0_train.tar)), you can use the following command to convert:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_pse.yml -o Global.pretrained_model=./det_r50_vd_pse_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_pse
+```
+
+PSE text detection model inference, to perform non-curved text detection, you can run the following commands:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_pse/" --det_algorithm="PSE" --det_pse_box_type=quad
+```
+
+The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
+
+
+
+If you want to perform curved text detection, you can execute the following command:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_pse/" --det_algorithm="PSE" --det_pse_box_type=poly
+```
+
+The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
+
+
+
+**Note**: Since the ICDAR2015 dataset has only 1,000 training images, mainly for English scenes, the above model has very poor detection result on Chinese or curved text images.
+
+
+
+### 4.2 C++ Inference
+
+Since the post-processing is not written in CPP, the PSE text detection model does not support CPP inference.
+
+
+### 4.3 Serving
+
+Not supported
+
+
+### 4.4 More
+
+Not supported
+
+
+## 5. FAQ
+
+
+## Citation
+
+```bibtex
+@inproceedings{wang2019shape,
+ title={Shape robust text detection with progressive scale expansion network},
+ author={Wang, Wenhai and Xie, Enze and Li, Xiang and Hou, Wenbo and Lu, Tong and Yu, Gang and Shao, Shuai},
+ booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
+ pages={9336--9345},
+ year={2019}
+}
+```
diff --git a/doc/doc_en/pgnet_en.md b/doc/doc_en/algorithm_e2e_pgnet_en.md
similarity index 100%
rename from doc/doc_en/pgnet_en.md
rename to doc/doc_en/algorithm_e2e_pgnet_en.md
diff --git a/doc/doc_en/algorithm_en.md b/doc/doc_en/algorithm_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..fa7887eb2681271f2b02296516221b00f9cf4626
--- /dev/null
+++ b/doc/doc_en/algorithm_en.md
@@ -0,0 +1,10 @@
+# Academic Algorithms and Models
+
+PaddleOCR will add cutting-edge OCR algorithms and models continuously. Check out the supported models and tutorials by clicking the following list:
+
+
+- [text detection algorithms](./algorithm_overview_en.md#11)
+- [text recognition algorithms](./algorithm_overview_en.md#12)
+- [end-to-end algorithms](./algorithm_overview_en.md#2)
+
+Developers are welcome to contribute more algorithms! Please refer to [add new algorithm](./add_new_algorithm_en.md) guideline.
\ No newline at end of file
diff --git a/doc/doc_en/algorithm_overview_en.md b/doc/doc_en/algorithm_overview_en.md
index 3e94360653b17443536297f33c05e338656bd89b..0cee8f4a41088a8a4d4a8df86c8ebdbe41a2c814 100755
--- a/doc/doc_en/algorithm_overview_en.md
+++ b/doc/doc_en/algorithm_overview_en.md
@@ -1,30 +1,27 @@
-# Two-stage Algorithm
+# OCR Algorithms
-- [1. Algorithm Introduction](#1-algorithm-introduction)
- * [1.1 Text Detection Algorithm](#11-text-detection-algorithm)
- * [1.2 Text Recognition Algorithm](#12-text-recognition-algorithm)
-- [2. Training](#2-training)
-- [3. Inference](#3-inference)
+- [1. Two-stage Algorithms](#1)
+ * [1.1 Text Detection Algorithms](#11)
+ * [1.2 Text Recognition Algorithms](#12)
+- [2. End-to-end Algorithms](#2)
-
-## 1. Algorithm Introduction
+This tutorial lists the OCR algorithms supported by PaddleOCR, as well as the models and metrics of each algorithm on **English public datasets**. It is mainly used for algorithm introduction and algorithm performance comparison. For more models on other datasets including Chinese, please refer to [PP-OCR v2.0 models list](./models_list_en.md).
-This tutorial lists the text detection algorithms and text recognition algorithms supported by PaddleOCR, as well as the models and metrics of each algorithm on **English public datasets**. It is mainly used for algorithm introduction and algorithm performance comparison. For more models on other datasets including Chinese, please refer to [PP-OCR v2.0 models list](./models_list_en.md).
+
+## 1. Two-stage Algorithms
-- [1. Text Detection Algorithm](#TEXTDETECTIONALGORITHM)
-- [2. Text Recognition Algorithm](#TEXTRECOGNITIONALGORITHM)
+
-
+### 1.1 Text Detection Algorithms
-### 1.1 Text Detection Algorithm
-
-PaddleOCR open source text detection algorithms list:
-- [x] EAST([paper](https://arxiv.org/abs/1704.03155))[2]
-- [x] DB([paper](https://arxiv.org/abs/1911.08947))[1]
-- [x] SAST([paper](https://arxiv.org/abs/1908.05498))[4]
-- [x] PSENet([paper](https://arxiv.org/abs/1903.12473v2))
+Supported text detection algorithms (Click the link to get the tutorial):
+- [x] [DB](./algorithm_det_db_en.md)
+- [x] [EAST](./algorithm_det_east_en.md)
+- [x] [SAST](./algorithm_det_sast_en.md)
+- [x] [PSENet](./algorithm_det_psenet_en.md)
+- [x] [FCENet](./algorithm_det_fcenet_en.md)
On the ICDAR2015 dataset, the text detection result is as follows:
@@ -48,20 +45,19 @@ On Total-Text dataset, the text detection result is as follows:
* [Baidu Drive](https://pan.baidu.com/s/12cPnZcVuV1zn5DOd4mqjVw) (download code: 2bpi).
* [Google Drive](https://drive.google.com/drive/folders/1ll2-XEVyCQLpJjawLDiRlvo_i4BqHCJe?usp=sharing)
-For the training guide and use of PaddleOCR text detection algorithms, please refer to the document [Text detection model training/evaluation/prediction](./detection_en.md)
-
-### 1.2 Text Recognition Algorithm
+
+### 1.2 Text Recognition Algorithms
-PaddleOCR open-source text recognition algorithms list:
-- [x] CRNN([paper](https://arxiv.org/abs/1507.05717))[7]
-- [x] Rosetta([paper](https://arxiv.org/abs/1910.05085))[10]
-- [x] STAR-Net([paper](http://www.bmva.org/bmvc/2016/papers/paper043/index.html))[11]
-- [x] RARE([paper](https://arxiv.org/abs/1603.03915v1))[12]
-- [x] SRN([paper](https://arxiv.org/abs/2003.12294))[5]
-- [x] NRTR([paper](https://arxiv.org/abs/1806.00926v2))[13]
-- [x] SAR([paper](https://arxiv.org/abs/1811.00751v2))
-- [x] SEED([paper](https://arxiv.org/pdf/2005.10977.pdf))
+Supported text recognition algorithms (Click the link to get the tutorial):
+- [x] [CRNN](./algorithm_rec_crnn_en.md)
+- [x] [Rosetta](./algorithm_rec_rosetta_en.md)
+- [x] [STAR-Net](./algorithm_rec_starnet_en.md)
+- [x] [RARE](./algorithm_rec_rare_en.md)
+- [x] [SRN](./algorithm_rec_srn_en.md)
+- [x] [NRTR](./algorithm_rec_nrtr_en.md)
+- [x] [SAR](./algorithm_rec_sar_en.md)
+- [x] [SEED](./algorithm_rec_seed_en.md)
Refer to [DTRB](https://arxiv.org/abs/1904.01906), the training and evaluation result of these above text recognition (using MJSynth and SynthText for training, evaluate on IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE) is as follow:
@@ -80,12 +76,10 @@ Refer to [DTRB](https://arxiv.org/abs/1904.01906), the training and evaluation r
|SAR|Resnet31| 87.20% | rec_r31_sar | [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar) |
|SEED|Aster_Resnet| 85.35% | rec_resnet_stn_bilstm_att | [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_resnet_stn_bilstm_att.tar) |
-Please refer to the document for training guide and use of PaddleOCR
-
-## 2. Training
-For the training guide and use of PaddleOCR text detection algorithms, please refer to the document [Text detection model training/evaluation/prediction](./detection_en.md). For text recognition algorithms, please refer to [Text recognition model training/evaluation/prediction](./recognition_en.md)
+
-## 3. Inference
+## 2. End-to-end Algorithms
-Except for the PP-OCR series models of the above models, the other models only support inference based on the Python engine. For details, please refer to [Inference based on Python prediction engine](./inference_en.md)
+Supported end-to-end algorithms (Click the link to get the tutorial):
+- [x] [PGNet](./algorithm_e2e_pgnet_en.md)
diff --git a/doc/doc_en/algorithm_rec_sar_en.md b/doc/doc_en/algorithm_rec_sar_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..c8656f5071358951d3f408f525b4b48c2e89817e
--- /dev/null
+++ b/doc/doc_en/algorithm_rec_sar_en.md
@@ -0,0 +1,114 @@
+# SAR
+
+- [1. Introduction](#1)
+- [2. Environment](#2)
+- [3. Model Training / Evaluation / Prediction](#3)
+ - [3.1 Training](#3-1)
+ - [3.2 Evaluation](#3-2)
+ - [3.3 Prediction](#3-3)
+- [4. Inference and Deployment](#4)
+ - [4.1 Python Inference](#4-1)
+ - [4.2 C++ Inference](#4-2)
+ - [4.3 Serving](#4-3)
+ - [4.4 More](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. Introduction
+
+Paper:
+> [Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition](https://arxiv.org/abs/1811.00751)
+> Hui Li, Peng Wang, Chunhua Shen, Guyu Zhang
+> AAAI, 2019
+
+Using MJSynth and SynthText two text recognition datasets for training, and evaluating on IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE datasets, the algorithm reproduction effect is as follows:
+
+|Model|Backbone|config|Acc|Download link|
+| --- | --- | --- | --- | --- | --- | --- |
+|SAR|ResNet31|[rec_r31_sar.yml](../../configs/rec/rec_r31_sar.yml)|87.20%|[train model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar)|
+
+Note:In addition to using the two text recognition datasets MJSynth and SynthText, [SynthAdd](https://pan.baidu.com/share/init?surl=uV0LtoNmcxbO-0YA7Ch4dg) data (extraction code: 627x), and some real data are used in training, the specific data details can refer to the paper.
+
+
+## 2. Environment
+Please refer to ["Environment Preparation"](./environment.md) to configure the PaddleOCR environment, and refer to ["Project Clone"](./clone.md) to clone the project code.
+
+
+
+## 3. Model Training / Evaluation / Prediction
+
+Please refer to [Text Recognition Tutorial](./recognition.md). PaddleOCR modularizes the code, and training different recognition models only requires **changing the configuration file**.
+
+Training:
+
+Specifically, after the data preparation is completed, the training can be started. The training command is as follows:
+
+```
+#Single GPU training (long training period, not recommended)
+python3 tools/train.py -c configs/rec/rec_r31_sar.yml
+
+#Multi GPU training, specify the gpu number through the --gpus parameter
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r31_sar.yml
+```
+
+Evaluation:
+
+```
+# GPU evaluation
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+Prediction:
+
+```
+# The configuration file used for prediction must match the training
+python3 tools/infer_rec.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. Inference and Deployment
+
+
+### 4.1 Python Inference
+First, the model saved during the SAR text recognition training process is converted into an inference model. ( [Model download link](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar) ), you can use the following command to convert:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model=./rec_r31_sar_train/best_accuracy Global.save_inference_dir=./inference/rec_sar
+```
+
+For SAR text recognition model inference, the following commands can be executed:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_sar/" --rec_image_shape="3, 48, 48, 160" --rec_char_type="ch" --rec_algorithm="SAR" --rec_char_dict_path="ppocr/utils/dict90.txt" --max_text_length=30 --use_space_char=False
+```
+
+
+### 4.2 C++ Inference
+
+Not supported
+
+
+### 4.3 Serving
+
+Not supported
+
+
+### 4.4 More
+
+Not supported
+
+
+## 5. FAQ
+
+
+## Citation
+
+```bibtex
+@article{Li2019ShowAA,
+ title={Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition},
+ author={Hui Li and Peng Wang and Chunhua Shen and Guyu Zhang},
+ journal={ArXiv},
+ year={2019},
+ volume={abs/1811.00751}
+}
+```
diff --git a/doc/doc_en/algorithm_rec_srn_en.md b/doc/doc_en/algorithm_rec_srn_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..ebc4a74ffd0215bd46467b38ac48db160c8ada74
--- /dev/null
+++ b/doc/doc_en/algorithm_rec_srn_en.md
@@ -0,0 +1,113 @@
+# SRN
+
+- [1. Introduction](#1)
+- [2. Environment](#2)
+- [3. Model Training / Evaluation / Prediction](#3)
+ - [3.1 Training](#3-1)
+ - [3.2 Evaluation](#3-2)
+ - [3.3 Prediction](#3-3)
+- [4. Inference and Deployment](#4)
+ - [4.1 Python Inference](#4-1)
+ - [4.2 C++ Inference](#4-2)
+ - [4.3 Serving](#4-3)
+ - [4.4 More](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. Introduction
+
+Paper:
+> [Towards Accurate Scene Text Recognition with Semantic Reasoning Networks](https://arxiv.org/abs/2003.12294#)
+> Deli Yu, Xuan Li, Chengquan Zhang, Junyu Han, Jingtuo Liu, Errui Ding
+> CVPR,2020
+
+Using MJSynth and SynthText two text recognition datasets for training, and evaluating on IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE datasets, the algorithm reproduction effect is as follows:
+
+|Model|Backbone|config|Acc|Download link|
+| --- | --- | --- | --- | --- | --- | --- |
+|SRN|Resnet50_vd_fpn|[rec_r50_fpn_srn.yml](../../configs/rec/rec_r50_fpn_srn.yml)|86.31%|[train model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar)|
+
+
+
+## 2. Environment
+Please refer to ["Environment Preparation"](./environment.md) to configure the PaddleOCR environment, and refer to ["Project Clone"](./clone.md) to clone the project code.
+
+
+
+## 3. Model Training / Evaluation / Prediction
+
+Please refer to [Text Recognition Tutorial](./recognition.md). PaddleOCR modularizes the code, and training different recognition models only requires **changing the configuration file**.
+
+Training:
+
+Specifically, after the data preparation is completed, the training can be started. The training command is as follows:
+
+```
+#Single GPU training (long training period, not recommended)
+python3 tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+
+#Multi GPU training, specify the gpu number through the --gpus parameter
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+```
+
+Evaluation:
+
+```
+# GPU evaluation
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+Prediction:
+
+```
+# The configuration file used for prediction must match the training
+python3 tools/infer_rec.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. Inference and Deployment
+
+
+### 4.1 Python Inference
+First, the model saved during the SRN text recognition training process is converted into an inference model. ( [Model download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar) ), you can use the following command to convert:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model=./rec_r50_vd_srn_train/best_accuracy Global.save_inference_dir=./inference/rec_srn
+```
+
+For SRN text recognition model inference, the following commands can be executed:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_srn/" --rec_image_shape="1,64,256" --rec_char_type="ch" --rec_algorithm="SRN" --rec_char_dict_path="ppocr/utils/ic15_dict.txt" --use_space_char=False
+```
+
+
+### 4.2 C++ Inference
+
+Not supported
+
+
+### 4.3 Serving
+
+Not supported
+
+
+### 4.4 More
+
+Not supported
+
+
+## 5. FAQ
+
+
+## Citation
+
+```bibtex
+@article{Yu2020TowardsAS,
+ title={Towards Accurate Scene Text Recognition With Semantic Reasoning Networks},
+ author={Deli Yu and Xuan Li and Chengquan Zhang and Junyu Han and Jingtuo Liu and Errui Ding},
+ journal={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year={2020},
+ pages={12110-12119}
+}
+```
diff --git a/doc/doc_en/android_demo_en.md b/doc/doc_en/android_demo_en.md
deleted file mode 100644
index fd962bb2911d952a4ec9919eebf1903daca323c7..0000000000000000000000000000000000000000
--- a/doc/doc_en/android_demo_en.md
+++ /dev/null
@@ -1,60 +0,0 @@
-# Android Demo quick start
-
-### 1. Install the latest version of Android Studio
-
-It can be downloaded from https://developer.android.com/studio . This Demo is written by Android Studio version 4.0.
-
-### 2. Create a new project
-
-The NDK version 20b is used in the demo test, and the compilation can be successfully supported for version 20 and above.
-
-If you are a beginner, you can install and test the NDK compilation environment in the following ways.
-
-File -> New ->New Project to create "Native C++" project
-
-1. Start a new Android Studio project
-
- Select Native C++ in the project template, select Paddle OCR/deploy/android_demo path
- After entering the project, it will be automatically compiled. The first compilation
- will take a long time. It is recommended to add an agent to speed up the download.
-
-**Agent add:**
-
- Android Studio -> Preferences -> Appearance & Behavior -> System Settings -> HTTP Proxy -> Manual proxy configuration
-
-
-
-2. Start compilation
-
-Click the compile button, connect the phone, and follow the instructions of Android Studio to complete the operation.
-
-When you see the following picture in Android Studio, the compilation is complete:
-
-
-
-**Tip:** At this time, if the following error message that OpenCV cannot be found appears, please re-click compile,
-exit the project after compiling, and enter again.
-
-
-
-### 3. Send to mobile
-
-Complete the compilation, click Run, and check the effect on the mobile phone.
-
-### 4. How to customize the demo picture
-
-1. Image storage path: android_demo/app/src/main/assets/images
-
- Place the custom picture under this path
-
-2. Configuration file: android_demo/app/src/main/res/values/strings.xml
-
- Modify IMAGE_PATH_DEFAULT to a custom picture name
-
-# Get more support
-
-Go to [EasyEdge](https://ai.baidu.com/easyedge/app/open_source_demo?referrerUrl=paddlelite) to get more development support:
-
-- Demo APP: You can use your mobile phone to scan the code to install, which is convenient for the mobile terminal to quickly experience text recognition
-
-- SDK: The model is packaged to adapt to different chip hardware and operating system SDKs, including a complete interface to facilitate secondary development
diff --git a/doc/doc_en/clone_en.md b/doc/doc_en/clone_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..9594d9a0b453685fa328d3b1bd221de3e15ad8b7
--- /dev/null
+++ b/doc/doc_en/clone_en.md
@@ -0,0 +1,27 @@
+# Project Clone
+
+## 1. Clone PaddleOCR
+
+```bash
+# Recommend
+git clone https://github.com/PaddlePaddle/PaddleOCR
+
+# If you cannot pull successfully due to network problems, you can switch to the mirror hosted on Gitee:
+
+git clone https://gitee.com/paddlepaddle/PaddleOCR
+
+# Note: The mirror on Gitee may not keep in synchronization with the latest project on GitHub. There might be a delay of 3-5 days. Please try GitHub at first.
+```
+
+## 2. Install third-party libraries
+
+```bash
+cd PaddleOCR
+pip3 install -r requirements.txt
+```
+
+If you getting this error `OSError: [WinError 126] The specified module could not be found` when you install shapely on windows.
+
+Please try to download Shapely whl file from [http://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely](http://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely).
+
+Reference: [Solve shapely installation on windows](https://stackoverflow.com/questions/44398265/install-shapely-oserror-winerror-126-the-specified-module-could-not-be-found)
diff --git a/doc/doc_en/config_en.md b/doc/doc_en/config_en.md
index d7bf5eaddd7b10d178cd472caf8081c4706f15b6..68c2b5f0c14f0c9b09d854f5a8b33ca86cc4bdf7 100644
--- a/doc/doc_en/config_en.md
+++ b/doc/doc_en/config_en.md
@@ -56,7 +56,7 @@ Take rec_chinese_lite_train_v2.0.yml as an example
| learning_rate | Set the base learning rate | 0.001 | \ |
| **regularizer** | Set network regularization method | - | \ |
| name | Regularizer class name | L2 | Currently support`L1`,`L2`, see[ppocr/optimizer/regularizer.py](../../ppocr/optimizer/regularizer.py) |
-| factor | Learning rate decay coefficient | 0.00004 | \ |
+| factor | Regularizer coefficient | 0.00001 | \ |
### Architecture ([ppocr/modeling](../../ppocr/modeling))
diff --git a/doc/doc_en/datasets_en.md b/doc/doc_en/dataset/datasets_en.md
similarity index 92%
rename from doc/doc_en/datasets_en.md
rename to doc/doc_en/dataset/datasets_en.md
index 0e6b6f381e9d008add802c5f8a30d5498a4f94b2..d81c058caa5e82097641405ff1ba048e95a2e3d7 100644
--- a/doc/doc_en/datasets_en.md
+++ b/doc/doc_en/dataset/datasets_en.md
@@ -12,12 +12,12 @@ In addition to opensource data, users can also use synthesis tools to synthesize
#### 1. ICDAR2019-LSVT
- **Data sources**:https://ai.baidu.com/broad/introduction?dataset=lsvt
- **Introduction**: A total of 45w Chinese street view images, including 5w (2w test + 3w training) fully labeled data (text coordinates + text content), 40w weakly labeled data (text content only), as shown in the following figure:
- 
+ 
(a) Fully labeled data
- 
-
+ 
+
(b) Weakly labeled data
- **Download link**:https://ai.baidu.com/broad/download?dataset=lsvt
@@ -25,7 +25,7 @@ In addition to opensource data, users can also use synthesis tools to synthesize
#### 2. ICDAR2017-RCTW-17
- **Data sources**:https://rctw.vlrlab.net/
- **Introduction**:It contains 12000 + images, most of them are collected in the wild through mobile camera. Some are screenshots. These images show a variety of scenes, including street views, posters, menus, indoor scenes and screenshots of mobile applications.
- 
+ 
- **Download link**:https://rctw.vlrlab.net/dataset/
@@ -33,9 +33,9 @@ In addition to opensource data, users can also use synthesis tools to synthesize
- **Data sources**:https://aistudio.baidu.com/aistudio/competition/detail/8
- **Introduction**:A total of 290000 pictures are included, of which 210000 are used as training sets (with labels) and 80000 are used as test sets (without labels). The dataset is collected from the Chinese street view, and is formed by by cutting out the text line area (such as shop signs, landmarks, etc.) in the street view picture. All the images are preprocessed: by using affine transform, the text area is proportionally mapped to a picture with a height of 48 pixels, as shown in the figure:
- 
+ 
(a) Label: 魅派集成吊顶
- 
+ 
(b) Label: 母婴用品连锁
- **Download link**
https://aistudio.baidu.com/aistudio/datasetdetail/8429
@@ -49,13 +49,13 @@ https://aistudio.baidu.com/aistudio/datasetdetail/8429
- 5990 characters including Chinese characters, English letters, numbers and punctuation(Characters set: https://github.com/YCG09/chinese_ocr/blob/master/train/char_std_5990.txt )
- Each sample is fixed with 10 characters, and the characters are randomly intercepted from the sentences in the corpus
- Image resolution is 280x32
- 
- 
+ 
+ 
- **Download link**:https://pan.baidu.com/s/1QkI7kjah8SPHwOQ40rS1Pw (Password: lu7m)
#### 5、ICDAR2019-ArT
- **Data source**:https://ai.baidu.com/broad/introduction?dataset=art
- **Introduction**:It includes 10166 images, 5603 in training sets and 4563 in test sets. It is composed of three parts: total text, scut-ctw1500 and Baidu curved scene text, including text with various shapes such as horizontal, multi-directional and curved.
- 
+ 
- **Download link**:https://ai.baidu.com/broad/download?dataset=art
diff --git a/doc/doc_en/handwritten_datasets_en.md b/doc/doc_en/dataset/handwritten_datasets_en.md
similarity index 96%
rename from doc/doc_en/handwritten_datasets_en.md
rename to doc/doc_en/dataset/handwritten_datasets_en.md
index da6008a2acfa684dd6efe37fda42eb0e2c7eb97a..2059549601eba285eb56f27d6b7e721cd05c97f1 100644
--- a/doc/doc_en/handwritten_datasets_en.md
+++ b/doc/doc_en/dataset/handwritten_datasets_en.md
@@ -9,7 +9,7 @@ Here we have sorted out the commonly used handwritten OCR dataset datasets, whic
- **Data introduction**:
* It includes online and offline handwritten data,`HWDB1.0~1.2` has totally 3895135 handwritten single character samples, which belong to 7356 categories (7185 Chinese characters and 171 English letters, numbers and symbols);`HWDB2.0~2.2` has totally 5091 pages of images, which are divided into 52230 text lines and 1349414 words. All text and text samples are stored as grayscale images. Some sample words are shown below.
- 
+ 
- **Download address**:http://www.nlpr.ia.ac.cn/databases/handwriting/Download.html
- **使用建议**:Data for single character, white background, can form a large number of text lines for training. White background can be processed into transparent state, which is convenient to add various backgrounds. For the case of semantic needs, it is suggested to extract single character from real corpus to form text lines.
@@ -22,7 +22,7 @@ Here we have sorted out the commonly used handwritten OCR dataset datasets, whic
- **Data introduction**: NIST19 dataset is suitable for handwritten document and character recognition model training. It is extracted from the handwritten sample form of 3600 authors and contains 810000 character images in total. Nine of them are shown below.
- 
+ 
- **Download address**: [https://www.nist.gov/srd/nist-special-database-19](https://www.nist.gov/srd/nist-special-database-19)
diff --git a/doc/doc_en/dataset/ocr_datasets_en.md b/doc/doc_en/dataset/ocr_datasets_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..0b9abd529ddb6d0cf0bc294d74e3249215c8fd45
--- /dev/null
+++ b/doc/doc_en/dataset/ocr_datasets_en.md
@@ -0,0 +1,157 @@
+# OCR datasets
+
+- [1. Text detection](#1-text-detection)
+ - [1.1 PaddleOCR text detection format annotation](#11-paddleocr-text-detection-format-annotation)
+ - [1.2 Public dataset](#12-public-dataset)
+ - [1.2.1 ICDAR 2015](#121-icdar-2015)
+- [2. Text recognition](#2-text-recognition)
+ - [2.1 PaddleOCR text recognition format annotation](#21-paddleocr-text-recognition-format-annotation)
+ - [2.2 Public dataset](#22-public-dataset)
+ - [2.1 ICDAR 2015](#21-icdar-2015)
+- [3. Data storage path](#3-data-storage-path)
+
+Here is a list of public datasets commonly used in OCR, which are being continuously updated. Welcome to contribute datasets~
+
+## 1. Text detection
+
+### 1.1 PaddleOCR text detection format annotation
+
+The annotation file formats supported by the PaddleOCR text detection algorithm are as follows, separated by "\t":
+```
+" Image file name Image annotation information encoded by json.dumps"
+ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
+```
+The image annotation after **json.dumps()** encoding is a list containing multiple dictionaries.
+
+The `points` in the dictionary represent the coordinates (x, y) of the four points of the text box, arranged clockwise from the point at the upper left corner.
+
+`transcription` represents the text of the current text box. **When its content is "###" it means that the text box is invalid and will be skipped during training.**
+
+If you want to train PaddleOCR on other datasets, please build the annotation file according to the above format.
+
+### 1.2 Public dataset
+| dataset | Image download link | PaddleOCR format annotation download link |
+|---|---|---|
+| ICDAR 2015 | https://rrc.cvc.uab.es/?ch=4&com=downloads | [train](https://paddleocr.bj.bcebos.com/dataset/train_icdar2015_label.txt) / [test](https://paddleocr.bj.bcebos.com/dataset/test_icdar2015_label.txt) |
+| ctw1500 | https://paddleocr.bj.bcebos.com/dataset/ctw1500.zip | Included in the downloaded image zip |
+| total text | https://paddleocr.bj.bcebos.com/dataset/total_text.tar | Included in the downloaded image zip |
+
+#### 1.2.1 ICDAR 2015
+
+The icdar2015 dataset contains train set which has 1000 images obtained with wearable cameras and test set which has 500 images obtained with wearable cameras. The icdar2015 dataset can be downloaded from the link in the table above. Registration is required for downloading.
+
+
+After registering and logging in, download the part marked in the red box in the figure below. And, the content downloaded by `Training Set Images` should be saved as the folder `icdar_c4_train_imgs`, and the content downloaded by `Test Set Images` is saved as the folder `ch4_test_images`
+
+
+
+
+
+Decompress the downloaded dataset to the working directory, assuming it is decompressed under PaddleOCR/train_data/. Then download the PaddleOCR format annotation file from the table above.
+
+PaddleOCR also provides a data format conversion script, which can convert the official website label to the PaddleOCR format. The data conversion tool is in `ppocr/utils/gen_label.py`, here is the training set as an example:
+```
+# Convert the label file downloaded from the official website to train_icdar2015_label.txt
+python gen_label.py --mode="det" --root_path="/path/to/icdar_c4_train_imgs/" \
+ --input_path="/path/to/ch4_training_localization_transcription_gt" \
+ --output_label="/path/to/train_icdar2015_label.txt"
+```
+
+After decompressing the data set and downloading the annotation file, PaddleOCR/train_data/ has two folders and two files, which are:
+```
+/PaddleOCR/train_data/icdar2015/text_localization/
+ └─ icdar_c4_train_imgs/ Training data of icdar dataset
+ └─ ch4_test_images/ Testing data of icdar dataset
+ └─ train_icdar2015_label.txt Training annotation of icdar dataset
+ └─ test_icdar2015_label.txt Test annotation of icdar dataset
+```
+
+
+## 2. Text recognition
+
+### 2.1 PaddleOCR text recognition format annotation
+
+The text recognition algorithm in PaddleOCR supports two data formats:
+ - `lmdb` is used to train data sets stored in lmdb format, use [lmdb_dataset.py](../../../ppocr/data/lmdb_dataset.py) to load;
+ - `common dataset` is used to train data sets stored in text files, use [simple_dataset.py](../../../ppocr/data/simple_dataset.py) to load.
+
+
+If you want to use your own data for training, please refer to the following to organize your data.
+
+- Training set
+
+It is recommended to put the training images in the same folder, and use a txt file (rec_gt_train.txt) to store the image path and label. The contents of the txt file are as follows:
+
+* Note: by default, the image path and image label are split with \t, if you use other methods to split, it will cause training error
+
+```
+" Image file name Image annotation "
+
+train_data/rec/train/word_001.jpg 简单可依赖
+train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
+...
+```
+
+The final training set should have the following file structure:
+
+```
+|-train_data
+ |-rec
+ |- rec_gt_train.txt
+ |- train
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+```
+
+- Test set
+
+Similar to the training set, the test set also needs to be provided a folder containing all images (test) and a rec_gt_test.txt. The structure of the test set is as follows:
+
+```
+|-train_data
+ |-rec
+ |-ic15_data
+ |- rec_gt_test.txt
+ |- test
+ |- word_001.jpg
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+```
+
+### 2.2 Public dataset
+| dataset | Image download link | PaddleOCR format annotation download link |
+|---|---|---|
+| en benchmark(MJ, SJ, IIIT, SVT, IC03, IC13, IC15, SVTP, and CUTE.) | [DTRB](https://github.com/clovaai/deep-text-recognition-benchmark#download-lmdb-dataset-for-traininig-and-evaluation-from-here) | LMDB format, which can be loaded directly with [lmdb_dataset.py](../../../ppocr/data/lmdb_dataset.py) |
+|ICDAR 2015| http://rrc.cvc.uab.es/?ch=4&com=downloads | [train](https://paddleocr.bj.bcebos.com/dataset/rec_gt_train.txt)/ [test](https://paddleocr.bj.bcebos.com/dataset/rec_gt_test.txt) |
+| Multilingual datasets |[Baidu network disk](https://pan.baidu.com/s/1bS_u207Rm7YbY33wOECKDA) Extraction code: frgi
[google drive](https://drive.google.com/file/d/18cSWX7wXSy4G0tbKJ0d9PuIaiwRLHpjA/view) | Included in the downloaded image zip |
+
+#### 2.1 ICDAR 2015
+
+The ICDAR 2015 dataset can be downloaded from the link in the table above for quick validation. The lmdb format dataset required by en benchmark can also be downloaded from the table above.
+
+Then download the PaddleOCR format annotation file from the table above.
+
+PaddleOCR also provides a data format conversion script, which can convert the ICDAR official website label to the data format supported by PaddleOCR. The data conversion tool is in `ppocr/utils/gen_label.py`, here is the training set as an example:
+
+```
+# Convert the label file downloaded from the official website to rec_gt_label.txt
+python gen_label.py --mode="rec" --input_path="{path/of/origin/label}" --output_label="rec_gt_label.txt"
+```
+
+The data format is as follows, (a) is the original picture, (b) is the Ground Truth text file corresponding to each picture:
+
+
+
+## 3. Data storage path
+
+The default storage path for PaddleOCR training data is `PaddleOCR/train_data`, if you already have a dataset on your disk, just create a soft link to the dataset directory:
+
+```
+# linux and mac os
+ln -sf /train_data/dataset
+# windows
+mklink /d /train_data/dataset
+```
diff --git a/doc/doc_en/dataset/table_datasets_en.md b/doc/doc_en/dataset/table_datasets_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..e30147909812a153f311add50f0bef5d1d1e0e32
--- /dev/null
+++ b/doc/doc_en/dataset/table_datasets_en.md
@@ -0,0 +1,32 @@
+# Table Recognition Datasets
+
+- [Dataset Summary](#dataset-summary)
+- [1. PubTabNet](#1-pubtabnet)
+- [2. TAL Table Recognition Competition Dataset](#2-tal-table-recognition-competition-dataset)
+
+Here are the commonly used table recognition datasets, which are being updated continuously. Welcome to contribute datasets~
+
+## Dataset Summary
+
+| dataset | Image download link | PPOCR format annotation download link |
+|---|---|---|
+| PubTabNet |https://github.com/ibm-aur-nlp/PubTabNet| jsonl format, which can be loaded directly with [pubtab_dataset.py](../../../ppocr/data/pubtab_dataset.py) |
+| TAL Table Recognition Competition Dataset |https://ai.100tal.com/dataset| jsonl format, which can be loaded directly with [pubtab_dataset.py](../../../ppocr/data/pubtab_dataset.py) |
+
+## 1. PubTabNet
+- **Data Introduction**:The training set of the PubTabNet dataset contains 500,000 images and the validation set contains 9000 images. Part of the image visualization is shown below.
+
+
+
+
+
+
+
+
-
-
-
-Decompress the downloaded dataset to the working directory, assuming it is decompressed under PaddleOCR/train_data/. In addition, PaddleOCR organizes many scattered annotation files into two separate annotation files for train and test respectively, which can be downloaded by wget:
-```shell
-# Under the PaddleOCR path
-cd PaddleOCR/
-wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/train_icdar2015_label.txt
-wget -P ./train_data/ https://paddleocr.bj.bcebos.com/dataset/test_icdar2015_label.txt
-```
-
-After decompressing the data set and downloading the annotation file, PaddleOCR/train_data/ has two folders and two files, which are:
-```
-/PaddleOCR/train_data/icdar2015/text_localization/
- └─ icdar_c4_train_imgs/ Training data of icdar dataset
- └─ ch4_test_images/ Testing data of icdar dataset
- └─ train_icdar2015_label.txt Training annotation of icdar dataset
- └─ test_icdar2015_label.txt Test annotation of icdar dataset
-```
-
-The provided annotation file format is as follow, separated by "\t":
-```
-" Image file name Image annotation information encoded by json.dumps"
-ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
-```
-The image annotation after **json.dumps()** encoding is a list containing multiple dictionaries.
-
-The `points` in the dictionary represent the coordinates (x, y) of the four points of the text box, arranged clockwise from the point at the upper left corner.
-
-`transcription` represents the text of the current text box. **When its content is "###" it means that the text box is invalid and will be skipped during training.**
-
-If you want to train PaddleOCR on other datasets, please build the annotation file according to the above format.
-
+To prepare datasets, refer to [ocr_datasets](./dataset/ocr_datasets_en.md) .
### 1.2 Download Pre-trained Model
@@ -175,11 +140,44 @@ After adding the four-part modules of the network, you only need to configure th
**NOTE**: More details about replace Backbone and other mudule can be found in [doc](add_new_algorithm_en.md).
+### 2.4 Mixed Precision Training
-### 2.4 Training with knowledge distillation
+If you want to speed up your training further, you can use [Auto Mixed Precision Training](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/01_paddle2.0_introduction/basic_concept/amp_cn.html), taking a single machine and a single gpu as an example, the commands are as follows:
+
+```shell
+python3 tools/train.py -c configs/det/det_mv3_db.yml \
+ -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained \
+ Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
+ ```
+
+### 2.5 Distributed Training
+
+During multi-machine multi-gpu training, use the `--ips` parameter to set the used machine IP address, and the `--gpus` parameter to set the used GPU ID:
+
+```bash
+python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
+ -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
+```
+
+**Note:** When using multi-machine and multi-gpu training, you need to replace the ips value in the above command with the address of your machine, and the machines need to be able to ping each other. In addition, training needs to be launched separately on multiple machines. The command to view the ip address of the machine is `ifconfig`.
+
+### 2.6 Training with knowledge distillation
Knowledge distillation is supported in PaddleOCR for text detection training process. For more details, please refer to [doc](./knowledge_distillation_en.md).
+### 2.7 Training on other platform(Windows/macOS/Linux DCU)
+
+- Windows GPU/CPU
+The Windows platform is slightly different from the Linux platform:
+Windows platform only supports `single gpu` training and inference, specify GPU for training `set CUDA_VISIBLE_DEVICES=0`
+On the Windows platform, DataLoader only supports single-process mode, so you need to set `num_workers` to 0;
+
+- macOS
+GPU mode is not supported, you need to set `use_gpu` to False in the configuration file, and the rest of the training evaluation prediction commands are exactly the same as Linux GPU.
+
+- Linux DCU
+Running on a DCU device requires setting the environment variable `export HIP_VISIBLE_DEVICES=0,1,2,3`, and the rest of the training and evaluation prediction commands are exactly the same as the Linux GPU.
+
## 3. Evaluation and Test
### 3.1 Evaluation
diff --git a/doc/doc_en/ocr_book_en.md b/doc/doc_en/ocr_book_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..bbf202cbde31c25ef7da771fa03ad0819f2b7c4e
--- /dev/null
+++ b/doc/doc_en/ocr_book_en.md
@@ -0,0 +1 @@
+# E-book: *Dive Into OCR*
\ No newline at end of file
diff --git a/doc/doc_en/paddleOCR_overview_en.md b/doc/doc_en/paddleOCR_overview_en.md
deleted file mode 100644
index fe64b0bd6c60f4e678ee2e44a303c124bab479ec..0000000000000000000000000000000000000000
--- a/doc/doc_en/paddleOCR_overview_en.md
+++ /dev/null
@@ -1,39 +0,0 @@
-# PaddleOCR Overview and Project Clone
-
-## 1. PaddleOCR Overview
-
-PaddleOCR contains rich text detection, text recognition and end-to-end algorithms. With the experience from real world scenarios and the industry, PaddleOCR chooses DB and CRNN as the basic detection and recognition models, and proposes a series of models, named PP-OCR, for industrial applications after a series of optimization strategies. The PP-OCR model is aimed at general scenarios and forms a model library of different languages. Based on the capabilities of PP-OCR, PaddleOCR releases the PP-Structure toolkit for document scene tasks, including two major tasks: layout analysis and table recognition. In order to get through the entire process of industrial landing, PaddleOCR provides large-scale data production tools and a variety of prediction deployment tools to help developers quickly turn ideas into reality.
-
-
-

-
+
+
+PP-OCRv2 English model
+
+
+
+
+
+
+PP-OCRv2 Chinese model
+
+
+
+
+
+
+
+
+
+
+PP-OCRv2 Multilingual model
+
+
+
+
+
+
+
+
+## 5. Tutorial
+
+
+### 5.1 Quick start
+
+- You can also quickly experience the ultra-lightweight OCR : [Online Experience](https://www.paddlepaddle.org.cn/hub/scene/ocr)
+- Mobile DEMO experience (based on EasyEdge and Paddle-Lite, supports iOS and Android systems): [Sign in to the website to obtain the QR code for installing the App](https://ai.baidu.com/easyedge/app/openSource?from=paddlelite)
+- One line of code quick use: [Quick Start](./quickstart_en.md)
+
+
+### 5.2 Model training / compression / deployment
+
+For more tutorials, including model training, model compression, deployment, etc., please refer to [tutorials](../../README.md#Tutorials)。
+
+
+## 6. Model zoo
+
+## PP-OCR Series Model List(Update on September 8th)
+
+| Model introduction | Model name | Recommended scene | Detection model | Direction classifier | Recognition model |
+| ------------------------------------------------------------ | ---------------------------- | ----------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| Chinese and English ultra-lightweight PP-OCRv2 model(11.6M) | ch_PP-OCRv2_xx |Mobile & Server|[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar)| [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar)|
+| Chinese and English ultra-lightweight PP-OCR model (9.4M) | ch_ppocr_mobile_v2.0_xx | Mobile & server |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar)|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_train.tar) |
+| Chinese and English general PP-OCR model (143.4M) | ch_ppocr_server_v2.0_xx | Server |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_train.tar) |
+
+
+For more model downloads (including multiple languages), please refer to [PP-OCR series model downloads](./models_list_en.md).
+
+For a new language request, please refer to [Guideline for new language_requests](../../README.md#language_requests).
diff --git a/doc/doc_en/recognition_en.md b/doc/doc_en/recognition_en.md
index c3700070b9d01c89cf8189a7af5f13d877114fb2..a6b255f9501a0c2d34c31162385bcf03ff578aa3 100644
--- a/doc/doc_en/recognition_en.md
+++ b/doc/doc_en/recognition_en.md
@@ -1,130 +1,37 @@
# Text Recognition
- [1. Data Preparation](#DATA_PREPARATION)
- - [1.1 Costom Dataset](#Costom_Dataset)
- - [1.2 Dataset Download](#Dataset_download)
- - [1.3 Dictionary](#Dictionary)
- - [1.4 Add Space Category](#Add_space_category)
-
+ * [1.1 Costom Dataset](#Costom_Dataset)
+ * [1.2 Dataset Download](#Dataset_download)
+ * [1.3 Dictionary](#Dictionary)
+ * [1.4 Add Space Category](#Add_space_category)
+ * [1.5 Data Augmentation](#Data_Augmentation)
- [2. Training](#TRAINING)
- - [2.1 Data Augmentation](#Data_Augmentation)
- - [2.2 General Training](#Training)
- - [2.3 Multi-language Training](#Multi_language)
- - [2.4 Training with Knowledge Distillation](#kd)
-
-- [3. Evaluation](#EVALUATION)
-
-- [4. Prediction](#PREDICTION)
-- [5. Convert to Inference Model](#Inference)
+ * [2.1 Start Training](#21-start-training)
+ * [2.2 Load Trained Model and Continue Training](#22-load-trained-model-and-continue-training)
+ * [2.3 Training with New Backbone](#23-training-with-new-backbone)
+ * [2.4 Mixed Precision Training](#24-amp-training)
+ * [2.5 Distributed Training](#25-distributed-training)
+ * [2.6 Training with knowledge distillation](#kd)
+ * [2.7 Multi-language Training](#Multi_language)
+ * [2.8 Training on other platform(Windows/macOS/Linux DCU)](#28)
+- [3. Evaluation and Test](#3-evaluation-and-test)
+ * [3.1 Evaluation](#31-evaluation)
+ * [3.2 Test](#32-test)
+- [4. Inference](#4-inference)
+- [5. FAQ](#5-faq)
## 1. Data Preparation
+### 1.1 DataSet Preparation
-PaddleOCR supports two data formats:
-- `LMDB` is used to train data sets stored in lmdb format(LMDBDataSet);
-- `general data` is used to train data sets stored in text files(SimpleDataSet):
-
-Please organize the dataset as follows:
-
-The default storage path for training data is `PaddleOCR/train_data`, if you already have a dataset on your disk, just create a soft link to the dataset directory:
-
-```
-# linux and mac os
-ln -sf /train_data/dataset
-# windows
-mklink /d /train_data/dataset
-```
-
-
-### 1.1 Costom Dataset
-
-If you want to use your own data for training, please refer to the following to organize your data.
-
-- Training set
-
-It is recommended to put the training images in the same folder, and use a txt file (rec_gt_train.txt) to store the image path and label. The contents of the txt file are as follows:
-
-* Note: by default, the image path and image label are split with \t, if you use other methods to split, it will cause training error
-
-```
-" Image file name Image annotation "
-
-train_data/rec/train/word_001.jpg 简单可依赖
-train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
-...
-```
-
-The final training set should have the following file structure:
-
-```
-|-train_data
- |-rec
- |- rec_gt_train.txt
- |- train
- |- word_001.png
- |- word_002.jpg
- |- word_003.jpg
- | ...
-```
-
-- Test set
-
-Similar to the training set, the test set also needs to be provided a folder containing all images (test) and a rec_gt_test.txt. The structure of the test set is as follows:
-
-```
-|-train_data
- |-rec
- |-ic15_data
- |- rec_gt_test.txt
- |- test
- |- word_001.jpg
- |- word_002.jpg
- |- word_003.jpg
- | ...
-```
-
-
-### 1.2 Dataset Download
-
-- ICDAR2015
-
-If you do not have a dataset locally, you can download it on the official website [icdar2015](http://rrc.cvc.uab.es/?ch=4&com=downloads).
-Also refer to [DTRB](https://github.com/clovaai/deep-text-recognition-benchmark#download-lmdb-dataset-for-traininig-and-evaluation-from-here) ,download the lmdb format dataset required for benchmark
+To prepare datasets, refer to [ocr_datasets](./dataset/ocr_datasets.md) .
If you want to reproduce the paper SAR, you need to download extra dataset [SynthAdd](https://pan.baidu.com/share/init?surl=uV0LtoNmcxbO-0YA7Ch4dg), extraction code: 627x. Besides, icdar2013, icdar2015, cocotext, IIIT5k datasets are also used to train. For specific details, please refer to the paper SAR.
-PaddleOCR provides label files for training the icdar2015 dataset, which can be downloaded in the following ways:
-
-```
-# Training set label
-wget -P ./train_data/ic15_data https://paddleocr.bj.bcebos.com/dataset/rec_gt_train.txt
-# Test Set Label
-wget -P ./train_data/ic15_data https://paddleocr.bj.bcebos.com/dataset/rec_gt_test.txt
-```
-
-PaddleOCR also provides a data format conversion script, which can convert ICDAR official website label to a data format
-supported by PaddleOCR. The data conversion tool is in `ppocr/utils/gen_label.py`, here is the training set as an example:
-
-```
-# convert the official gt to rec_gt_label.txt
-python gen_label.py --mode="rec" --input_path="{path/of/origin/label}" --output_label="rec_gt_label.txt"
-```
-
-The data format is as follows, (a) is the original picture, (b) is the Ground Truth text file corresponding to each picture:
-
-
-
-
-- Multilingual dataset
-
-The multi-language model training method is the same as the Chinese model. The training data set is 100w synthetic data. A small amount of fonts and test data can be downloaded using the following two methods.
-* [Baidu Netdisk](https://pan.baidu.com/s/1bS_u207Rm7YbY33wOECKDA) ,Extraction code:frgi.
-* [Google drive](https://drive.google.com/file/d/18cSWX7wXSy4G0tbKJ0d9PuIaiwRLHpjA/view)
-
-
-### 1.3 Dictionary
+### 1.2 Dictionary
Finally, a dictionary ({word_dict_name}.txt) needs to be provided so that when the model is trained, all the characters that appear can be mapped to the dictionary index.
@@ -173,11 +80,8 @@ If you need to customize dic file, please add character_dict_path field in confi
If you want to support the recognition of the `space` category, please set the `use_space_char` field in the yml file to `True`.
-
-## 2.Training
-
-### 2.1 Data Augmentation
+### 1.5 Data Augmentation
PaddleOCR provides a variety of data augmentation methods. All the augmentation methods are enabled by default.
@@ -185,11 +89,14 @@ The default perturbation methods are: cvtColor, blur, jitter, Gasuss noise, rand
Each disturbance method is selected with a 40% probability during the training process. For specific code implementation, please refer to: [rec_img_aug.py](../../ppocr/data/imaug/rec_img_aug.py)
-
-### 2.2 General Training
+
+## 2.Training
PaddleOCR provides training scripts, evaluation scripts, and prediction scripts. In this section, the CRNN recognition model will be used as an example:
+
+### 2.1 Start Training
+
First download the pretrain model, you can download the trained model to finetune on the icdar2015 data:
```
@@ -305,8 +212,99 @@ Eval:
```
**Note that the configuration file for prediction/evaluation must be consistent with the training.**
+
+### 2.2 Load Trained Model and Continue Training
+
+If you expect to load trained model and continue the training again, you can specify the parameter `Global.checkpoints` as the model path to be loaded.
+
+For example:
+```shell
+python3 tools/train.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints=./your/trained/model
+```
+
+**Note**: The priority of `Global.checkpoints` is higher than that of `Global.pretrained_model`, that is, when two parameters are specified at the same time, the model specified by `Global.checkpoints` will be loaded first. If the model path specified by `Global.checkpoints` is wrong, the one specified by `Global.pretrained_model` will be loaded.
+
+
+### 2.3 Training with New Backbone
+
+The network part completes the construction of the network, and PaddleOCR divides the network into four parts, which are under [ppocr/modeling](../../ppocr/modeling). The data entering the network will pass through these four parts in sequence(transforms->backbones->
+necks->heads).
+
+```bash
+├── architectures # Code for building network
+├── transforms # Image Transformation Module
+├── backbones # Feature extraction module
+├── necks # Feature enhancement module
+└── heads # Output module
+```
+
+If the Backbone to be replaced has a corresponding implementation in PaddleOCR, you can directly modify the parameters in the `Backbone` part of the configuration yml file.
+
+However, if you want to use a new Backbone, an example of replacing the backbones is as follows:
+
+1. Create a new file under the [ppocr/modeling/backbones](../../ppocr/modeling/backbones) folder, such as my_backbone.py.
+2. Add code in the my_backbone.py file, the sample code is as follows:
+
+```python
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+class MyBackbone(nn.Layer):
+ def __init__(self, *args, **kwargs):
+ super(MyBackbone, self).__init__()
+ # your init code
+ self.conv = nn.xxxx
+
+ def forward(self, inputs):
+ # your network forward
+ y = self.conv(inputs)
+ return y
+```
+
+3. Import the added module in the [ppocr/modeling/backbones/\__init\__.py](../../ppocr/modeling/backbones/__init__.py) file.
+
+After adding the four-part modules of the network, you only need to configure them in the configuration file to use, such as:
+
+```yaml
+ Backbone:
+ name: MyBackbone
+ args1: args1
+```
+
+**NOTE**: More details about replace Backbone and other mudule can be found in [doc](add_new_algorithm_en.md).
+
+
+### 2.4 Mixed Precision Training
+
+If you want to speed up your training further, you can use [Auto Mixed Precision Training](https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/01_paddle2.0_introduction/basic_concept/amp_cn.html), taking a single machine and a single gpu as an example, the commands are as follows:
+
+```shell
+python3 tools/train.py -c configs/rec/rec_icdar15_train.yml \
+ -o Global.pretrained_model=./pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train \
+ Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True
+ ```
+
+
+### 2.5 Distributed Training
+
+During multi-machine multi-gpu training, use the `--ips` parameter to set the used machine IP address, and the `--gpus` parameter to set the used GPU ID:
+
+```bash
+python3 -m paddle.distributed.launch --ips="xx.xx.xx.xx,xx.xx.xx.xx" --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_icdar15_train.yml \
+ -o Global.pretrained_model=./pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train
+```
+
+**Note:** When using multi-machine and multi-gpu training, you need to replace the ips value in the above command with the address of your machine, and the machines need to be able to ping each other. In addition, training needs to be launched separately on multiple machines. The command to view the ip address of the machine is `ifconfig`.
+
+
+### 2.6 Training with Knowledge Distillation
+
+Knowledge distillation is supported in PaddleOCR for text recognition training process. For more details, please refer to [doc](./knowledge_distillation_en.md).
+
-### 2.3 Multi-language Training
+### 2.7 Multi-language Training
Currently, the multi-language algorithms supported by PaddleOCR are:
@@ -362,25 +360,35 @@ Eval:
...
```
-
+
+### 2.8 Training on other platform(Windows/macOS/Linux DCU)
-### 2.4 Training with Knowledge Distillation
+- Windows GPU/CPU
+The Windows platform is slightly different from the Linux platform:
+Windows platform only supports `single gpu` training and inference, specify GPU for training `set CUDA_VISIBLE_DEVICES=0`
+On the Windows platform, DataLoader only supports single-process mode, so you need to set `num_workers` to 0;
-Knowledge distillation is supported in PaddleOCR for text recognition training process. For more details, please refer to [doc](./knowledge_distillation_en.md).
+- macOS
+GPU mode is not supported, you need to set `use_gpu` to False in the configuration file, and the rest of the training evaluation prediction commands are exactly the same as Linux GPU.
+
+- Linux DCU
+Running on a DCU device requires setting the environment variable `export HIP_VISIBLE_DEVICES=0,1,2,3`, and the rest of the training and evaluation prediction commands are exactly the same as the Linux GPU.
-
+
+## 3. Evaluation and Test
-## 3. Evalution
+
+### 3.1 Evaluation
-The evaluation dataset can be set by modifying the `Eval.dataset.label_file_list` field in the `configs/rec/rec_icdar15_train.yml` file.
+The model parameters during training are saved in the `Global.save_model_dir` directory by default. When evaluating indicators, you need to set `Global.checkpoints` to point to the saved parameter file. The evaluation dataset can be set by modifying the `Eval.dataset.label_file_list` field in the `configs/rec/rec_icdar15_train.yml` file.
```
# GPU evaluation, Global.checkpoints is the weight to be tested
python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints={path/to/weights}/best_accuracy
```
-
-## 4. Prediction
+
+### 3.2 Test
Using the model trained by paddleocr, you can quickly get prediction through the following script.
@@ -442,9 +450,14 @@ infer_img: doc/imgs_words/ch/word_1.jpg
result: ('韩国小馆', 0.997218)
```
-
+
+## 4. Inference
-## 5. Convert to Inference Model
+The inference model (the model saved by `paddle.jit.save`) is generally a solidified model saved after the model training is completed, and is mostly used to give prediction in deployment.
+
+The model saved during the training process is the checkpoints model, which saves the parameters of the model and is mostly used to resume training.
+
+Compared with the checkpoints model, the inference model will additionally save the structural information of the model. Therefore, it is easier to deploy because the model structure and model parameters are already solidified in the inference model file, and is suitable for integration with actual systems.
The recognition model is converted to the inference model in the same way as the detection, as follows:
@@ -462,7 +475,7 @@ If you have a model trained on your own dataset with a different dictionary file
After the conversion is successful, there are three files in the model save directory:
```
-inference/det_db/
+inference/rec_crnn/
├── inference.pdiparams # The parameter file of recognition inference model
├── inference.pdiparams.info # The parameter information of recognition inference model, which can be ignored
└── inference.pdmodel # The program file of recognition model
@@ -475,3 +488,10 @@ inference/det_db/
```
python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words_en/word_336.png" --rec_model_dir="./your inference model" --rec_image_shape="3, 32, 100" --rec_char_dict_path="your text dict path"
```
+
+
+## 5. FAQ
+
+Q1: After the training model is transferred to the inference model, the prediction effect is inconsistent?
+
+**A**: There are many such problems, and the problems are mostly caused by inconsistent preprocessing and postprocessing parameters when the trained model predicts and the preprocessing and postprocessing parameters when the inference model predicts. You can compare whether there are differences in preprocessing, postprocessing, and prediction in the configuration files used for training.
diff --git a/doc/doc_en/training_en.md b/doc/doc_en/training_en.md
index 89992ff905426faaf7d22707a76dd9daaa8bcbb7..86c4deb3868081552f5b27d67c627693c3f95a62 100644
--- a/doc/doc_en/training_en.md
+++ b/doc/doc_en/training_en.md
@@ -94,7 +94,7 @@ The current open source models, data sets and magnitudes are as follows:
- Chinese data set, LSVT street view data set crops the image according to the truth value, and performs position calibration, a total of 30w images. In addition, based on the LSVT corpus, 500w of synthesized data.
- Small language data set, using different corpora and fonts, respectively generated 100w synthetic data set, and using ICDAR-MLT as the verification set.
-Among them, the public data sets are all open source, users can search and download by themselves, or refer to [Chinese data set](./datasets_en.md), synthetic data is not open source, users can use open source synthesis tools to synthesize by themselves. Synthesis tools include [text_renderer](https://github.com/Sanster/text_renderer), [SynthText](https://github.com/ankush-me/SynthText), [TextRecognitionDataGenerator](https://github.com/Belval/TextRecognitionDataGenerator) etc.
+Among them, the public data sets are all open source, users can search and download by themselves, or refer to [Chinese data set](dataset/datasets_en.md), synthetic data is not open source, users can use open source synthesis tools to synthesize by themselves. Synthesis tools include [text_renderer](https://github.com/Sanster/text_renderer), [SynthText](https://github.com/ankush-me/SynthText), [TextRecognitionDataGenerator](https://github.com/Belval/TextRecognitionDataGenerator) etc.
diff --git a/doc/doc_en/update_en.md b/doc/doc_en/update_en.md
index 39fd936d1bd4e5f8d8535805f865792820ee1199..8ec74fe8b73d89cc97904e2ce156e14bbd596eb4 100644
--- a/doc/doc_en/update_en.md
+++ b/doc/doc_en/update_en.md
@@ -19,7 +19,7 @@
- 2020.7.15, Add several related datasets, data annotation and synthesis tools.
- 2020.7.9 Add a new model to support recognize the character "space".
- 2020.7.9 Add the data augument and learning rate decay strategies during training.
-- 2020.6.8 Add [datasets](./datasets_en.md) and keep updating
+- 2020.6.8 Add [datasets](dataset/datasets_en.md) and keep updating
- 2020.6.5 Support exporting `attention` model to `inference_model`
- 2020.6.5 Support separate prediction and recognition, output result score
- 2020.5.30 Provide Lightweight Chinese OCR online experience
diff --git a/doc/features.png b/doc/features.png
new file mode 100644
index 0000000000000000000000000000000000000000..7d6342c1eb83e0544df0045a0cfa71bc083022fe
Binary files /dev/null and b/doc/features.png differ
diff --git a/doc/features_en.png b/doc/features_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..9f0a66299bb5e922257e3327b0c6cf2d3ebfe05b
Binary files /dev/null and b/doc/features_en.png differ
diff --git a/doc/imgs_results/det_res_img623_fce.jpg b/doc/imgs_results/det_res_img623_fce.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..938ae4cabf32cf5f89519f81b33259b188ed494a
Binary files /dev/null and b/doc/imgs_results/det_res_img623_fce.jpg differ
diff --git a/doc/imgs_results/det_res_img_10_fce.jpg b/doc/imgs_results/det_res_img_10_fce.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..fb32950ffda29f3263ab8bddc445e7c71f7d2ee0
Binary files /dev/null and b/doc/imgs_results/det_res_img_10_fce.jpg differ
diff --git a/doc/imgs_results/det_res_img_10_pse.jpg b/doc/imgs_results/det_res_img_10_pse.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..cdb7625dd05e6865ff3d6d476a33466f42cb3aee
Binary files /dev/null and b/doc/imgs_results/det_res_img_10_pse.jpg differ
diff --git a/doc/imgs_results/det_res_img_10_pse_poly.jpg b/doc/imgs_results/det_res_img_10_pse_poly.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..9c06a17ccb6a6d99c82a79eca5cf5755af4d0ce5
Binary files /dev/null and b/doc/imgs_results/det_res_img_10_pse_poly.jpg differ
diff --git a/doc/ocr-android-easyedge.png b/doc/ocr-android-easyedge.png
deleted file mode 100644
index 8b2a846fa406fcb9b1d3314d76ce8b4cc2e76f2a..0000000000000000000000000000000000000000
Binary files a/doc/ocr-android-easyedge.png and /dev/null differ
diff --git a/doc/overview.png b/doc/overview.png
deleted file mode 100644
index c5c4e09d6730bb0b1ca2c0b5442079ceb41ecdfa..0000000000000000000000000000000000000000
Binary files a/doc/overview.png and /dev/null differ
diff --git a/paddleocr.py b/paddleocr.py
index d07082f0ddc1133b3e9b3a7a7703d87f7cfeeedb..cb2c34f69f68d289b317d4737bd23385c77c3d95 100644
--- a/paddleocr.py
+++ b/paddleocr.py
@@ -47,7 +47,7 @@ __all__ = [
]
SUPPORT_DET_MODEL = ['DB']
-VERSION = '2.4.0.4'
+VERSION = '2.5'
SUPPORT_REC_MODEL = ['CRNN']
BASE_DIR = os.path.expanduser("~/.paddleocr/")
@@ -442,7 +442,7 @@ class PPStructure(StructureSystem):
logger.debug(params)
super().__init__(params)
- def __call__(self, img):
+ def __call__(self, img, return_ocr_result_in_table=False):
if isinstance(img, str):
# download net image
if img.startswith('http'):
@@ -460,7 +460,7 @@ class PPStructure(StructureSystem):
if isinstance(img, np.ndarray) and len(img.shape) == 2:
img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
- res = super().__call__(img)
+ res = super().__call__(img, return_ocr_result_in_table)
return res
diff --git a/ppocr/data/__init__.py b/ppocr/data/__init__.py
index 60ab7bd0b4ceab846982c8744d5b277ee17185df..78c3279656e184a3a34bff3847d3936b5e8977b6 100644
--- a/ppocr/data/__init__.py
+++ b/ppocr/data/__init__.py
@@ -72,6 +72,7 @@ def build_dataloader(config, mode, device, logger, seed=None):
use_shared_memory = loader_config['use_shared_memory']
else:
use_shared_memory = True
+
if mode == "Train":
# Distribute data to multiple cards
batch_sampler = DistributedBatchSampler(
diff --git a/ppocr/data/collate_fn.py b/ppocr/data/collate_fn.py
index 89c6b4fd5ae151e1d703ea5c59abf0177dfc3a8b..0da6060f042a0e60cdf211d8bc13aede32d5930a 100644
--- a/ppocr/data/collate_fn.py
+++ b/ppocr/data/collate_fn.py
@@ -56,3 +56,17 @@ class ListCollator(object):
for idx in to_tensor_idxs:
data_dict[idx] = paddle.to_tensor(data_dict[idx])
return list(data_dict.values())
+
+
+class SSLRotateCollate(object):
+ """
+ bach: [
+ [(4*3xH*W), (4,)]
+ [(4*3xH*W), (4,)]
+ ...
+ ]
+ """
+
+ def __call__(self, batch):
+ output = [np.concatenate(d, axis=0) for d in zip(*batch)]
+ return output
diff --git a/ppocr/data/imaug/__init__.py b/ppocr/data/imaug/__init__.py
index 164f1d2224d6cdba589d0502fc17438d346788dd..20aaf48e119d68e6c37ce9246a87701fb149d5e7 100644
--- a/ppocr/data/imaug/__init__.py
+++ b/ppocr/data/imaug/__init__.py
@@ -22,8 +22,9 @@ from .make_shrink_map import MakeShrinkMap
from .random_crop_data import EastRandomCropData, RandomCropImgMask
from .make_pse_gt import MakePseGt
-from .rec_img_aug import RecAug, RecResizeImg, ClsResizeImg, \
- SRNRecResizeImg, NRTRRecResizeImg, SARRecResizeImg, PRENResizeImg
+from .rec_img_aug import RecAug, RecConAug, RecResizeImg, ClsResizeImg, \
+ SRNRecResizeImg, NRTRRecResizeImg, SARRecResizeImg, PRENResizeImg, SVTRRecResizeImg
+from .ssl_img_aug import SSLRotateResize
from .randaugment import RandAugment
from .copy_paste import CopyPaste
from .ColorJitter import ColorJitter
diff --git a/ppocr/data/imaug/label_ops.py b/ppocr/data/imaug/label_ops.py
index 6f86be7da002cc6a9fb649f532a73b109286be6b..c9bc2e7722e8027ce870e4969bfcdab720495c28 100644
--- a/ppocr/data/imaug/label_ops.py
+++ b/ppocr/data/imaug/label_ops.py
@@ -22,6 +22,7 @@ import numpy as np
import string
from shapely.geometry import LineString, Point, Polygon
import json
+import copy
from ppocr.utils.logging import get_logger
@@ -112,14 +113,14 @@ class BaseRecLabelEncode(object):
dict_character = list(self.character_str)
self.lower = True
else:
- self.character_str = ""
+ self.character_str = []
with open(character_dict_path, "rb") as fin:
lines = fin.readlines()
for line in lines:
line = line.decode('utf-8').strip("\n").strip("\r\n")
- self.character_str += line
+ self.character_str.append(line)
if use_space_char:
- self.character_str += " "
+ self.character_str.append(" ")
dict_character = list(self.character_str)
dict_character = self.add_special_char(dict_character)
self.dict = {}
@@ -1007,3 +1008,34 @@ class VQATokenLabelEncode(object):
gt_label.extend([self.label2id_map[("i-" + label).upper()]] *
(len(encode_res["input_ids"]) - 1))
return gt_label
+
+
+class MultiLabelEncode(BaseRecLabelEncode):
+ def __init__(self,
+ max_text_length,
+ character_dict_path=None,
+ use_space_char=False,
+ **kwargs):
+ super(MultiLabelEncode, self).__init__(
+ max_text_length, character_dict_path, use_space_char)
+
+ self.ctc_encode = CTCLabelEncode(max_text_length, character_dict_path,
+ use_space_char, **kwargs)
+ self.sar_encode = SARLabelEncode(max_text_length, character_dict_path,
+ use_space_char, **kwargs)
+
+ def __call__(self, data):
+
+ data_ctc = copy.deepcopy(data)
+ data_sar = copy.deepcopy(data)
+ data_out = dict()
+ data_out['img_path'] = data.get('img_path', None)
+ data_out['image'] = data['image']
+ ctc = self.ctc_encode.__call__(data_ctc)
+ sar = self.sar_encode.__call__(data_sar)
+ if ctc is None or sar is None:
+ return None
+ data_out['label_ctc'] = ctc['label']
+ data_out['label_sar'] = sar['label']
+ data_out['length'] = ctc['length']
+ return data_out
diff --git a/ppocr/data/imaug/rec_img_aug.py b/ppocr/data/imaug/rec_img_aug.py
index 6f59fef63d85090b0e433d79b0c3e3f381ac1b38..2f70b51a3b88422274353046209c6d0d4dc79489 100644
--- a/ppocr/data/imaug/rec_img_aug.py
+++ b/ppocr/data/imaug/rec_img_aug.py
@@ -16,6 +16,7 @@ import math
import cv2
import numpy as np
import random
+import copy
from PIL import Image
from .text_image_aug import tia_perspective, tia_stretch, tia_distort
@@ -32,13 +33,56 @@ class RecAug(object):
return data
+class RecConAug(object):
+ def __init__(self,
+ prob=0.5,
+ image_shape=(32, 320, 3),
+ max_text_length=25,
+ ext_data_num=1,
+ **kwargs):
+ self.ext_data_num = ext_data_num
+ self.prob = prob
+ self.max_text_length = max_text_length
+ self.image_shape = image_shape
+ self.max_wh_ratio = self.image_shape[1] / self.image_shape[0]
+
+ def merge_ext_data(self, data, ext_data):
+ ori_w = round(data['image'].shape[1] / data['image'].shape[0] *
+ self.image_shape[0])
+ ext_w = round(ext_data['image'].shape[1] / ext_data['image'].shape[0] *
+ self.image_shape[0])
+ data['image'] = cv2.resize(data['image'], (ori_w, self.image_shape[0]))
+ ext_data['image'] = cv2.resize(ext_data['image'],
+ (ext_w, self.image_shape[0]))
+ data['image'] = np.concatenate(
+ [data['image'], ext_data['image']], axis=1)
+ data["label"] += ext_data["label"]
+ return data
+
+ def __call__(self, data):
+ rnd_num = random.random()
+ if rnd_num > self.prob:
+ return data
+ for idx, ext_data in enumerate(data["ext_data"]):
+ if len(data["label"]) + len(ext_data[
+ "label"]) > self.max_text_length:
+ break
+ concat_ratio = data['image'].shape[1] / data['image'].shape[
+ 0] + ext_data['image'].shape[1] / ext_data['image'].shape[0]
+ if concat_ratio > self.max_wh_ratio:
+ break
+ data = self.merge_ext_data(data, ext_data)
+ data.pop("ext_data")
+ return data
+
+
class ClsResizeImg(object):
def __init__(self, image_shape, **kwargs):
self.image_shape = image_shape
def __call__(self, data):
img = data['image']
- norm_img = resize_norm_img(img, self.image_shape)
+ norm_img, _ = resize_norm_img(img, self.image_shape)
data['image'] = norm_img
return data
@@ -98,10 +142,13 @@ class RecResizeImg(object):
def __call__(self, data):
img = data['image']
if self.infer_mode and self.character_dict_path is not None:
- norm_img = resize_norm_img_chinese(img, self.image_shape)
+ norm_img, valid_ratio = resize_norm_img_chinese(img,
+ self.image_shape)
else:
- norm_img = resize_norm_img(img, self.image_shape, self.padding)
+ norm_img, valid_ratio = resize_norm_img(img, self.image_shape,
+ self.padding)
data['image'] = norm_img
+ data['valid_ratio'] = valid_ratio
return data
@@ -160,6 +207,25 @@ class PRENResizeImg(object):
return data
+class SVTRRecResizeImg(object):
+ def __init__(self,
+ image_shape,
+ infer_mode=False,
+ character_dict_path='./ppocr/utils/ppocr_keys_v1.txt',
+ padding=True,
+ **kwargs):
+ self.image_shape = image_shape
+ self.infer_mode = infer_mode
+ self.character_dict_path = character_dict_path
+ self.padding = padding
+
+ def __call__(self, data):
+ img = data['image']
+ norm_img = resize_norm_img_svtr(img, self.image_shape, self.padding)
+ data['image'] = norm_img
+ return data
+
+
def resize_norm_img_sar(img, image_shape, width_downsample_ratio=0.25):
imgC, imgH, imgW_min, imgW_max = image_shape
h = img.shape[0]
@@ -220,7 +286,8 @@ def resize_norm_img(img, image_shape, padding=True):
resized_image /= 0.5
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
- return padding_im
+ valid_ratio = min(1.0, float(resized_w / imgW))
+ return padding_im, valid_ratio
def resize_norm_img_chinese(img, image_shape):
@@ -230,7 +297,7 @@ def resize_norm_img_chinese(img, image_shape):
h, w = img.shape[0], img.shape[1]
ratio = w * 1.0 / h
max_wh_ratio = max(max_wh_ratio, ratio)
- imgW = int(32 * max_wh_ratio)
+ imgW = int(imgH * max_wh_ratio)
if math.ceil(imgH * ratio) > imgW:
resized_w = imgW
else:
@@ -246,7 +313,8 @@ def resize_norm_img_chinese(img, image_shape):
resized_image /= 0.5
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
- return padding_im
+ valid_ratio = min(1.0, float(resized_w / imgW))
+ return padding_im, valid_ratio
def resize_norm_img_srn(img, image_shape):
@@ -276,6 +344,58 @@ def resize_norm_img_srn(img, image_shape):
return np.reshape(img_black, (c, row, col)).astype(np.float32)
+def resize_norm_img_svtr(img, image_shape, padding=False):
+ imgC, imgH, imgW = image_shape
+ h = img.shape[0]
+ w = img.shape[1]
+ if not padding:
+ if h > 2.0 * w:
+ image = Image.fromarray(img)
+ image1 = image.rotate(90, expand=True)
+ image2 = image.rotate(-90, expand=True)
+ img1 = np.array(image1)
+ img2 = np.array(image2)
+ else:
+ img1 = copy.deepcopy(img)
+ img2 = copy.deepcopy(img)
+
+ resized_image = cv2.resize(
+ img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_image1 = cv2.resize(
+ img1, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_image2 = cv2.resize(
+ img2, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_w = imgW
+ else:
+ ratio = w / float(h)
+ if math.ceil(imgH * ratio) > imgW:
+ resized_w = imgW
+ else:
+ resized_w = int(math.ceil(imgH * ratio))
+ resized_image = cv2.resize(img, (resized_w, imgH))
+ resized_image = resized_image.astype('float32')
+ resized_image1 = resized_image1.astype('float32')
+ resized_image2 = resized_image2.astype('float32')
+ if image_shape[0] == 1:
+ resized_image = resized_image / 255
+ resized_image = resized_image[np.newaxis, :]
+ else:
+ resized_image = resized_image.transpose((2, 0, 1)) / 255
+ resized_image1 = resized_image1.transpose((2, 0, 1)) / 255
+ resized_image2 = resized_image2.transpose((2, 0, 1)) / 255
+ resized_image -= 0.5
+ resized_image /= 0.5
+ resized_image1 -= 0.5
+ resized_image1 /= 0.5
+ resized_image2 -= 0.5
+ resized_image2 /= 0.5
+ padding_im = np.zeros((3, imgC, imgH, imgW), dtype=np.float32)
+ padding_im[0, :, :, 0:resized_w] = resized_image
+ padding_im[1, :, :, 0:resized_w] = resized_image1
+ padding_im[2, :, :, 0:resized_w] = resized_image2
+ return padding_im
+
+
def srn_other_inputs(image_shape, num_heads, max_text_length):
imgC, imgH, imgW = image_shape
diff --git a/ppocr/data/imaug/ssl_img_aug.py b/ppocr/data/imaug/ssl_img_aug.py
new file mode 100644
index 0000000000000000000000000000000000000000..f9ed6ac3e230ae85754bf40189c392c7e6e29b63
--- /dev/null
+++ b/ppocr/data/imaug/ssl_img_aug.py
@@ -0,0 +1,60 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import math
+import cv2
+import numpy as np
+import random
+from PIL import Image
+
+from .rec_img_aug import resize_norm_img
+
+
+class SSLRotateResize(object):
+ def __init__(self,
+ image_shape,
+ padding=False,
+ select_all=True,
+ mode="train",
+ **kwargs):
+ self.image_shape = image_shape
+ self.padding = padding
+ self.select_all = select_all
+ self.mode = mode
+
+ def __call__(self, data):
+ img = data["image"]
+
+ data["image_r90"] = cv2.rotate(img, cv2.ROTATE_90_CLOCKWISE)
+ data["image_r180"] = cv2.rotate(data["image_r90"],
+ cv2.ROTATE_90_CLOCKWISE)
+ data["image_r270"] = cv2.rotate(data["image_r180"],
+ cv2.ROTATE_90_CLOCKWISE)
+
+ images = []
+ for key in ["image", "image_r90", "image_r180", "image_r270"]:
+ images.append(
+ resize_norm_img(
+ data.pop(key),
+ image_shape=self.image_shape,
+ padding=self.padding)[0])
+ data["image"] = np.stack(images, axis=0)
+ data["label"] = np.array(list(range(4)))
+ if not self.select_all:
+ data["image"] = data["image"][0::2] # just choose 0 and 180
+ data["label"] = data["label"][0:2] # label needs to be continuous
+ if self.mode == "test":
+ data["image"] = data["image"][0]
+ data["label"] = data["label"][0]
+ return data
diff --git a/ppocr/data/simple_dataset.py b/ppocr/data/simple_dataset.py
index 13f9411e29430843bb808aede15e8305dbc2d028..b5da9b8898423facf888839f941dff01caa03643 100644
--- a/ppocr/data/simple_dataset.py
+++ b/ppocr/data/simple_dataset.py
@@ -49,7 +49,8 @@ class SimpleDataSet(Dataset):
if self.mode == "train" and self.do_shuffle:
self.shuffle_data_random()
self.ops = create_operators(dataset_config['transforms'], global_config)
-
+ self.ext_op_transform_idx = dataset_config.get("ext_op_transform_idx",
+ 2)
self.need_reset = True in [x < 1 for x in ratio_list]
def get_image_info_list(self, file_list, ratio_list):
@@ -87,7 +88,7 @@ class SimpleDataSet(Dataset):
if hasattr(op, 'ext_data_num'):
ext_data_num = getattr(op, 'ext_data_num')
break
- load_data_ops = self.ops[:2]
+ load_data_ops = self.ops[:self.ext_op_transform_idx]
ext_data = []
while len(ext_data) < ext_data_num:
@@ -108,8 +109,11 @@ class SimpleDataSet(Dataset):
data['image'] = img
data = transform(data, load_data_ops)
- if data is None or data['polys'].shape[1] != 4:
+ if data is None:
continue
+ if 'polys' in data.keys():
+ if data['polys'].shape[1] != 4:
+ continue
ext_data.append(data)
return ext_data
diff --git a/ppocr/losses/__init__.py b/ppocr/losses/__init__.py
index 6505fca77ec6ff6b18dc840c6b2e443eecf2af2a..de8419b7c1cf6a30ab7195a1cbcbb10a5e52642d 100755
--- a/ppocr/losses/__init__.py
+++ b/ppocr/losses/__init__.py
@@ -34,6 +34,7 @@ from .rec_nrtr_loss import NRTRLoss
from .rec_sar_loss import SARLoss
from .rec_aster_loss import AsterLoss
from .rec_pren_loss import PRENLoss
+from .rec_multi_loss import MultiLoss
# cls loss
from .cls_loss import ClsLoss
@@ -60,7 +61,7 @@ def build_loss(config):
'DBLoss', 'PSELoss', 'EASTLoss', 'SASTLoss', 'FCELoss', 'CTCLoss',
'ClsLoss', 'AttentionLoss', 'SRNLoss', 'PGLoss', 'CombinedLoss',
'NRTRLoss', 'TableAttentionLoss', 'SARLoss', 'AsterLoss', 'SDMGRLoss',
- 'VQASerTokenLayoutLMLoss', 'LossFromOutput', 'PRENLoss'
+ 'VQASerTokenLayoutLMLoss', 'LossFromOutput', 'PRENLoss', 'MultiLoss'
]
config = copy.deepcopy(config)
module_name = config.pop('name')
diff --git a/ppocr/losses/basic_loss.py b/ppocr/losses/basic_loss.py
index b19ce57dcaf463d8be30fd1111b521d632308786..2df96ea2642d10a50eb892d738f89318dc5e0f4c 100644
--- a/ppocr/losses/basic_loss.py
+++ b/ppocr/losses/basic_loss.py
@@ -106,8 +106,8 @@ class DMLLoss(nn.Layer):
def forward(self, out1, out2):
if self.act is not None:
- out1 = self.act(out1)
- out2 = self.act(out2)
+ out1 = self.act(out1) + 1e-10
+ out2 = self.act(out2) + 1e-10
if self.use_log:
# for recognition distillation, log is needed for feature map
log_out1 = paddle.log(out1)
diff --git a/ppocr/losses/combined_loss.py b/ppocr/losses/combined_loss.py
index 72f706e37d6eb0c640cc30de80afe00bce82fd13..f4cdee8f90465e863b89d1e32b4a0285adb29eff 100644
--- a/ppocr/losses/combined_loss.py
+++ b/ppocr/losses/combined_loss.py
@@ -18,8 +18,10 @@ import paddle.nn as nn
from .rec_ctc_loss import CTCLoss
from .center_loss import CenterLoss
from .ace_loss import ACELoss
+from .rec_sar_loss import SARLoss
from .distillation_loss import DistillationCTCLoss
+from .distillation_loss import DistillationSARLoss
from .distillation_loss import DistillationDMLLoss
from .distillation_loss import DistillationDistanceLoss, DistillationDBLoss, DistillationDilaDBLoss
diff --git a/ppocr/losses/distillation_loss.py b/ppocr/losses/distillation_loss.py
index 06aa7fa8458a5deece75f1393fe7300e8227d3ca..565b066d1334e6caa1b6b4094706265f363b66ef 100644
--- a/ppocr/losses/distillation_loss.py
+++ b/ppocr/losses/distillation_loss.py
@@ -18,6 +18,7 @@ import numpy as np
import cv2
from .rec_ctc_loss import CTCLoss
+from .rec_sar_loss import SARLoss
from .basic_loss import DMLLoss
from .basic_loss import DistanceLoss
from .det_db_loss import DBLoss
@@ -46,11 +47,15 @@ class DistillationDMLLoss(DMLLoss):
act=None,
use_log=False,
key=None,
+ multi_head=False,
+ dis_head='ctc',
maps_name=None,
name="dml"):
super().__init__(act=act, use_log=use_log)
assert isinstance(model_name_pairs, list)
self.key = key
+ self.multi_head = multi_head
+ self.dis_head = dis_head
self.model_name_pairs = self._check_model_name_pairs(model_name_pairs)
self.name = name
self.maps_name = self._check_maps_name(maps_name)
@@ -97,7 +102,11 @@ class DistillationDMLLoss(DMLLoss):
out2 = out2[self.key]
if self.maps_name is None:
- loss = super().forward(out1, out2)
+ if self.multi_head:
+ loss = super().forward(out1[self.dis_head],
+ out2[self.dis_head])
+ else:
+ loss = super().forward(out1, out2)
if isinstance(loss, dict):
for key in loss:
loss_dict["{}_{}_{}_{}".format(key, pair[0], pair[1],
@@ -123,11 +132,16 @@ class DistillationDMLLoss(DMLLoss):
class DistillationCTCLoss(CTCLoss):
- def __init__(self, model_name_list=[], key=None, name="loss_ctc"):
+ def __init__(self,
+ model_name_list=[],
+ key=None,
+ multi_head=False,
+ name="loss_ctc"):
super().__init__()
self.model_name_list = model_name_list
self.key = key
self.name = name
+ self.multi_head = multi_head
def forward(self, predicts, batch):
loss_dict = dict()
@@ -135,7 +149,45 @@ class DistillationCTCLoss(CTCLoss):
out = predicts[model_name]
if self.key is not None:
out = out[self.key]
- loss = super().forward(out, batch)
+ if self.multi_head:
+ assert 'ctc' in out, 'multi head has multi out'
+ loss = super().forward(out['ctc'], batch[:2] + batch[3:])
+ else:
+ loss = super().forward(out, batch)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}".format(self.name, model_name,
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, model_name)] = loss
+ return loss_dict
+
+
+class DistillationSARLoss(SARLoss):
+ def __init__(self,
+ model_name_list=[],
+ key=None,
+ multi_head=False,
+ name="loss_sar",
+ **kwargs):
+ ignore_index = kwargs.get('ignore_index', 92)
+ super().__init__(ignore_index=ignore_index)
+ self.model_name_list = model_name_list
+ self.key = key
+ self.name = name
+ self.multi_head = multi_head
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+ for idx, model_name in enumerate(self.model_name_list):
+ out = predicts[model_name]
+ if self.key is not None:
+ out = out[self.key]
+ if self.multi_head:
+ assert 'sar' in out, 'multi head has multi out'
+ loss = super().forward(out['sar'], batch[:1] + batch[2:])
+ else:
+ loss = super().forward(out, batch)
if isinstance(loss, dict):
for key in loss:
loss_dict["{}_{}_{}".format(self.name, model_name,
diff --git a/ppocr/losses/rec_multi_loss.py b/ppocr/losses/rec_multi_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..09f007afe6303e83b9a6948df553ec0fca8b6b2d
--- /dev/null
+++ b/ppocr/losses/rec_multi_loss.py
@@ -0,0 +1,58 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import paddle
+from paddle import nn
+
+from .rec_ctc_loss import CTCLoss
+from .rec_sar_loss import SARLoss
+
+
+class MultiLoss(nn.Layer):
+ def __init__(self, **kwargs):
+ super().__init__()
+ self.loss_funcs = {}
+ self.loss_list = kwargs.pop('loss_config_list')
+ self.weight_1 = kwargs.get('weight_1', 1.0)
+ self.weight_2 = kwargs.get('weight_2', 1.0)
+ self.gtc_loss = kwargs.get('gtc_loss', 'sar')
+ for loss_info in self.loss_list:
+ for name, param in loss_info.items():
+ if param is not None:
+ kwargs.update(param)
+ loss = eval(name)(**kwargs)
+ self.loss_funcs[name] = loss
+
+ def forward(self, predicts, batch):
+ self.total_loss = {}
+ total_loss = 0.0
+ # batch [image, label_ctc, label_sar, length, valid_ratio]
+ for name, loss_func in self.loss_funcs.items():
+ if name == 'CTCLoss':
+ loss = loss_func(predicts['ctc'],
+ batch[:2] + batch[3:])['loss'] * self.weight_1
+ elif name == 'SARLoss':
+ loss = loss_func(predicts['sar'],
+ batch[:1] + batch[2:])['loss'] * self.weight_2
+ else:
+ raise NotImplementedError(
+ '{} is not supported in MultiLoss yet'.format(name))
+ self.total_loss[name] = loss
+ total_loss += loss
+ self.total_loss['loss'] = total_loss
+ return self.total_loss
diff --git a/ppocr/losses/rec_sar_loss.py b/ppocr/losses/rec_sar_loss.py
index c8bd8bb0ca395fa4658e57b8dcac52a3e94aadce..a4f83f03c08e4c4e6bab308aebc2daa8aa612400 100644
--- a/ppocr/losses/rec_sar_loss.py
+++ b/ppocr/losses/rec_sar_loss.py
@@ -9,8 +9,9 @@ from paddle import nn
class SARLoss(nn.Layer):
def __init__(self, **kwargs):
super(SARLoss, self).__init__()
+ ignore_index = kwargs.get('ignore_index', 92) # 6626
self.loss_func = paddle.nn.loss.CrossEntropyLoss(
- reduction="mean", ignore_index=92)
+ reduction="mean", ignore_index=ignore_index)
def forward(self, predicts, batch):
predict = predicts[:, :
diff --git a/ppocr/metrics/rec_metric.py b/ppocr/metrics/rec_metric.py
index b047bbcb972cadf227daaeb8797c46095ac0af43..515b9372e38a7213cde29fdc9834ed6df45a0a80 100644
--- a/ppocr/metrics/rec_metric.py
+++ b/ppocr/metrics/rec_metric.py
@@ -17,9 +17,14 @@ import string
class RecMetric(object):
- def __init__(self, main_indicator='acc', is_filter=False, **kwargs):
+ def __init__(self,
+ main_indicator='acc',
+ is_filter=False,
+ ignore_space=True,
+ **kwargs):
self.main_indicator = main_indicator
self.is_filter = is_filter
+ self.ignore_space = ignore_space
self.eps = 1e-5
self.reset()
@@ -34,8 +39,9 @@ class RecMetric(object):
all_num = 0
norm_edit_dis = 0.0
for (pred, pred_conf), (target, _) in zip(preds, labels):
- pred = pred.replace(" ", "")
- target = target.replace(" ", "")
+ if self.ignore_space:
+ pred = pred.replace(" ", "")
+ target = target.replace(" ", "")
if self.is_filter:
pred = self._normalize_text(pred)
target = self._normalize_text(target)
diff --git a/ppocr/modeling/architectures/base_model.py b/ppocr/modeling/architectures/base_model.py
index e622db25677069f9a4470db4966b7523def35472..f5b29f94057d5b1f1fbec27686d5f1d679b15479 100644
--- a/ppocr/modeling/architectures/base_model.py
+++ b/ppocr/modeling/architectures/base_model.py
@@ -83,7 +83,11 @@ class BaseModel(nn.Layer):
y["neck_out"] = x
if self.use_head:
x = self.head(x, targets=data)
- if isinstance(x, dict):
+ # for multi head, save ctc neck out for udml
+ if isinstance(x, dict) and 'ctc_neck' in x.keys():
+ y["neck_out"] = x["ctc_neck"]
+ y["head_out"] = x
+ elif isinstance(x, dict):
y.update(x)
else:
y["head_out"] = x
diff --git a/ppocr/modeling/architectures/distillation_model.py b/ppocr/modeling/architectures/distillation_model.py
index 5e867940e796841111fc668a0b3eb12547807d76..cce8fd311d4e847afda0fbb035743f0a10564c7d 100644
--- a/ppocr/modeling/architectures/distillation_model.py
+++ b/ppocr/modeling/architectures/distillation_model.py
@@ -53,8 +53,8 @@ class DistillationModel(nn.Layer):
self.model_list.append(self.add_sublayer(key, model))
self.model_name_list.append(key)
- def forward(self, x):
+ def forward(self, x, data=None):
result_dict = dict()
for idx, model_name in enumerate(self.model_name_list):
- result_dict[model_name] = self.model_list[idx](x)
+ result_dict[model_name] = self.model_list[idx](x, data)
return result_dict
diff --git a/ppocr/modeling/backbones/__init__.py b/ppocr/modeling/backbones/__init__.py
index c89c7c25aeb7c905428a4813d74f0514ed59e8e1..072d6e0f84d4126d256c26aa5baf17c9dc4e63df 100755
--- a/ppocr/modeling/backbones/__init__.py
+++ b/ppocr/modeling/backbones/__init__.py
@@ -31,9 +31,11 @@ def build_backbone(config, model_type):
from .rec_resnet_aster import ResNet_ASTER
from .rec_micronet import MicroNet
from .rec_efficientb3_pren import EfficientNetb3_PREN
+ from .rec_svtrnet import SVTRNet
support_dict = [
'MobileNetV1Enhance', 'MobileNetV3', 'ResNet', 'ResNetFPN', 'MTB',
- "ResNet31", "ResNet_ASTER", 'MicroNet', 'EfficientNetb3_PREN'
+ "ResNet31", "ResNet_ASTER", 'MicroNet', 'EfficientNetb3_PREN',
+ 'SVTRNet'
]
elif model_type == "e2e":
from .e2e_resnet_vd_pg import ResNet
diff --git a/ppocr/modeling/backbones/rec_mv1_enhance.py b/ppocr/modeling/backbones/rec_mv1_enhance.py
index d8a7f4b5646eb70b5202aa3b3ac6494318b424ad..bb6af5e82cf13ac42d9a970787596a65986ade54 100644
--- a/ppocr/modeling/backbones/rec_mv1_enhance.py
+++ b/ppocr/modeling/backbones/rec_mv1_enhance.py
@@ -103,7 +103,12 @@ class DepthwiseSeparable(nn.Layer):
class MobileNetV1Enhance(nn.Layer):
- def __init__(self, in_channels=3, scale=0.5, **kwargs):
+ def __init__(self,
+ in_channels=3,
+ scale=0.5,
+ last_conv_stride=1,
+ last_pool_type='max',
+ **kwargs):
super().__init__()
self.scale = scale
self.block_list = []
@@ -200,7 +205,7 @@ class MobileNetV1Enhance(nn.Layer):
num_filters1=1024,
num_filters2=1024,
num_groups=1024,
- stride=1,
+ stride=last_conv_stride,
dw_size=5,
padding=2,
use_se=True,
@@ -208,8 +213,10 @@ class MobileNetV1Enhance(nn.Layer):
self.block_list.append(conv6)
self.block_list = nn.Sequential(*self.block_list)
-
- self.pool = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
+ if last_pool_type == 'avg':
+ self.pool = nn.AvgPool2D(kernel_size=2, stride=2, padding=0)
+ else:
+ self.pool = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
self.out_channels = int(1024 * scale)
def forward(self, inputs):
diff --git a/ppocr/modeling/backbones/rec_svtrnet.py b/ppocr/modeling/backbones/rec_svtrnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ded74378c60e6f08a4adf68671afaa1168737b6
--- /dev/null
+++ b/ppocr/modeling/backbones/rec_svtrnet.py
@@ -0,0 +1,597 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from collections import Callable
+from paddle import ParamAttr
+from paddle.nn.initializer import KaimingNormal
+import numpy as np
+import paddle
+import paddle.nn as nn
+from paddle.nn.initializer import TruncatedNormal, Constant, Normal
+
+trunc_normal_ = TruncatedNormal(std=.02)
+normal_ = Normal
+zeros_ = Constant(value=0.)
+ones_ = Constant(value=1.)
+
+
+def drop_path(x, drop_prob=0., training=False):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+ the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
+ See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
+ """
+ if drop_prob == 0. or not training:
+ return x
+ keep_prob = paddle.to_tensor(1 - drop_prob)
+ shape = (paddle.shape(x)[0], ) + (1, ) * (x.ndim - 1)
+ random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
+ random_tensor = paddle.floor(random_tensor) # binarize
+ output = x.divide(keep_prob) * random_tensor
+ return output
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=0,
+ bias_attr=False,
+ groups=1,
+ act=nn.GELU):
+ super().__init__()
+ self.conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ weight_attr=paddle.ParamAttr(
+ initializer=nn.initializer.KaimingUniform()),
+ bias_attr=bias_attr)
+ self.norm = nn.BatchNorm2D(out_channels)
+ self.act = act()
+
+ def forward(self, inputs):
+ out = self.conv(inputs)
+ out = self.norm(out)
+ out = self.act(out)
+ return out
+
+
+class DropPath(nn.Layer):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+ """
+
+ def __init__(self, drop_prob=None):
+ super(DropPath, self).__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, x):
+ return drop_path(x, self.drop_prob, self.training)
+
+
+class Identity(nn.Layer):
+ def __init__(self):
+ super(Identity, self).__init__()
+
+ def forward(self, input):
+ return input
+
+
+class Mlp(nn.Layer):
+ def __init__(self,
+ in_features,
+ hidden_features=None,
+ out_features=None,
+ act_layer=nn.GELU,
+ drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+class ConvMixer(nn.Layer):
+ def __init__(
+ self,
+ dim,
+ num_heads=8,
+ HW=[8, 25],
+ local_k=[3, 3], ):
+ super().__init__()
+ self.HW = HW
+ self.dim = dim
+ self.local_mixer = nn.Conv2D(
+ dim,
+ dim,
+ local_k,
+ 1, [local_k[0] // 2, local_k[1] // 2],
+ groups=num_heads,
+ weight_attr=ParamAttr(initializer=KaimingNormal()))
+
+ def forward(self, x):
+ h = self.HW[0]
+ w = self.HW[1]
+ x = x.transpose([0, 2, 1]).reshape([0, self.dim, h, w])
+ x = self.local_mixer(x)
+ x = x.flatten(2).transpose([0, 2, 1])
+ return x
+
+
+class Attention(nn.Layer):
+ def __init__(self,
+ dim,
+ num_heads=8,
+ mixer='Global',
+ HW=[8, 25],
+ local_k=[7, 11],
+ qkv_bias=False,
+ qk_scale=None,
+ attn_drop=0.,
+ proj_drop=0.):
+ super().__init__()
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim**-0.5
+
+ self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+ self.proj_drop = nn.Dropout(proj_drop)
+ self.HW = HW
+ if HW is not None:
+ H = HW[0]
+ W = HW[1]
+ self.N = H * W
+ self.C = dim
+ if mixer == 'Local' and HW is not None:
+
+ hk = local_k[0]
+ wk = local_k[1]
+ mask = np.ones([H * W, H * W])
+ for h in range(H):
+ for w in range(W):
+ for kh in range(-(hk // 2), (hk // 2) + 1):
+ for kw in range(-(wk // 2), (wk // 2) + 1):
+ if H > (h + kh) >= 0 and W > (w + kw) >= 0:
+ mask[h * W + w][(h + kh) * W + (w + kw)] = 0
+ mask_paddle = paddle.to_tensor(mask, dtype='float32')
+ mask_inf = paddle.full([H * W, H * W], '-inf', dtype='float32')
+ mask = paddle.where(mask_paddle < 1, mask_paddle, mask_inf)
+ self.mask = mask.unsqueeze([0, 1])
+ self.mixer = mixer
+
+ def forward(self, x):
+ if self.HW is not None:
+ N = self.N
+ C = self.C
+ else:
+ _, N, C = x.shape
+ qkv = self.qkv(x).reshape((0, N, 3, self.num_heads, C //
+ self.num_heads)).transpose((2, 0, 3, 1, 4))
+ q, k, v = qkv[0] * self.scale, qkv[1], qkv[2]
+
+ attn = (q.matmul(k.transpose((0, 1, 3, 2))))
+ if self.mixer == 'Local':
+ attn += self.mask
+ attn = nn.functional.softmax(attn, axis=-1)
+ attn = self.attn_drop(attn)
+
+ x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((0, N, C))
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+
+class Block(nn.Layer):
+ def __init__(self,
+ dim,
+ num_heads,
+ mixer='Global',
+ local_mixer=[7, 11],
+ HW=[8, 25],
+ mlp_ratio=4.,
+ qkv_bias=False,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ act_layer=nn.GELU,
+ norm_layer='nn.LayerNorm',
+ epsilon=1e-6,
+ prenorm=True):
+ super().__init__()
+ if isinstance(norm_layer, str):
+ self.norm1 = eval(norm_layer)(dim, epsilon=epsilon)
+ elif isinstance(norm_layer, Callable):
+ self.norm1 = norm_layer(dim)
+ else:
+ raise TypeError(
+ "The norm_layer must be str or paddle.nn.layer.Layer class")
+ if mixer == 'Global' or mixer == 'Local':
+ self.mixer = Attention(
+ dim,
+ num_heads=num_heads,
+ mixer=mixer,
+ HW=HW,
+ local_k=local_mixer,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop=attn_drop,
+ proj_drop=drop)
+ elif mixer == 'Conv':
+ self.mixer = ConvMixer(
+ dim, num_heads=num_heads, HW=HW, local_k=local_mixer)
+ else:
+ raise TypeError("The mixer must be one of [Global, Local, Conv]")
+
+ # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
+ self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
+ if isinstance(norm_layer, str):
+ self.norm2 = eval(norm_layer)(dim, epsilon=epsilon)
+ elif isinstance(norm_layer, Callable):
+ self.norm2 = norm_layer(dim)
+ else:
+ raise TypeError(
+ "The norm_layer must be str or paddle.nn.layer.Layer class")
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp_ratio = mlp_ratio
+ self.mlp = Mlp(in_features=dim,
+ hidden_features=mlp_hidden_dim,
+ act_layer=act_layer,
+ drop=drop)
+ self.prenorm = prenorm
+
+ def forward(self, x):
+ if self.prenorm:
+ x = self.norm1(x + self.drop_path(self.mixer(x)))
+ x = self.norm2(x + self.drop_path(self.mlp(x)))
+ else:
+ x = x + self.drop_path(self.mixer(self.norm1(x)))
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+ return x
+
+
+class PatchEmbed(nn.Layer):
+ """ Image to Patch Embedding
+ """
+
+ def __init__(self,
+ img_size=[32, 100],
+ in_channels=3,
+ embed_dim=768,
+ sub_num=2):
+ super().__init__()
+ num_patches = (img_size[1] // (2 ** sub_num)) * \
+ (img_size[0] // (2 ** sub_num))
+ self.img_size = img_size
+ self.num_patches = num_patches
+ self.embed_dim = embed_dim
+ self.norm = None
+ if sub_num == 2:
+ self.proj = nn.Sequential(
+ ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=embed_dim // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None),
+ ConvBNLayer(
+ in_channels=embed_dim // 2,
+ out_channels=embed_dim,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None))
+ if sub_num == 3:
+ self.proj = nn.Sequential(
+ ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=embed_dim // 4,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None),
+ ConvBNLayer(
+ in_channels=embed_dim // 4,
+ out_channels=embed_dim // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None),
+ ConvBNLayer(
+ embed_dim // 2,
+ embed_dim,
+ in_channels=embed_dim // 2,
+ out_channels=embed_dim,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None))
+
+ def forward(self, x):
+ B, C, H, W = x.shape
+ assert H == self.img_size[0] and W == self.img_size[1], \
+ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
+ x = self.proj(x).flatten(2).transpose((0, 2, 1))
+ return x
+
+
+class SubSample(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ types='Pool',
+ stride=[2, 1],
+ sub_norm='nn.LayerNorm',
+ act=None):
+ super().__init__()
+ self.types = types
+ if types == 'Pool':
+ self.avgpool = nn.AvgPool2D(
+ kernel_size=[3, 5], stride=stride, padding=[1, 2])
+ self.maxpool = nn.MaxPool2D(
+ kernel_size=[3, 5], stride=stride, padding=[1, 2])
+ self.proj = nn.Linear(in_channels, out_channels)
+ else:
+ self.conv = nn.Conv2D(
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ weight_attr=ParamAttr(initializer=KaimingNormal()))
+ self.norm = eval(sub_norm)(out_channels)
+ if act is not None:
+ self.act = act()
+ else:
+ self.act = None
+
+ def forward(self, x):
+
+ if self.types == 'Pool':
+ x1 = self.avgpool(x)
+ x2 = self.maxpool(x)
+ x = (x1 + x2) * 0.5
+ out = self.proj(x.flatten(2).transpose((0, 2, 1)))
+ else:
+ x = self.conv(x)
+ out = x.flatten(2).transpose((0, 2, 1))
+ out = self.norm(out)
+ if self.act is not None:
+ out = self.act(out)
+
+ return out
+
+
+class SVTRNet(nn.Layer):
+ def __init__(
+ self,
+ img_size=[32, 100],
+ in_channels=3,
+ embed_dim=[64, 128, 256],
+ depth=[3, 6, 3],
+ num_heads=[2, 4, 8],
+ mixer=['Local'] * 6 + ['Global'] *
+ 6, # Local atten, Global atten, Conv
+ local_mixer=[[7, 11], [7, 11], [7, 11]],
+ patch_merging='Conv', # Conv, Pool, None
+ mlp_ratio=4,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ last_drop=0.1,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ norm_layer='nn.LayerNorm',
+ sub_norm='nn.LayerNorm',
+ epsilon=1e-6,
+ out_channels=192,
+ out_char_num=25,
+ block_unit='Block',
+ act='nn.GELU',
+ last_stage=True,
+ sub_num=2,
+ prenorm=True,
+ use_lenhead=False,
+ **kwargs):
+ super().__init__()
+ self.img_size = img_size
+ self.embed_dim = embed_dim
+ self.out_channels = out_channels
+ self.prenorm = prenorm
+ patch_merging = None if patch_merging != 'Conv' and patch_merging != 'Pool' else patch_merging
+ self.patch_embed = PatchEmbed(
+ img_size=img_size,
+ in_channels=in_channels,
+ embed_dim=embed_dim[0],
+ sub_num=sub_num)
+ num_patches = self.patch_embed.num_patches
+ self.HW = [img_size[0] // (2**sub_num), img_size[1] // (2**sub_num)]
+ self.pos_embed = self.create_parameter(
+ shape=[1, num_patches, embed_dim[0]], default_initializer=zeros_)
+ self.add_parameter("pos_embed", self.pos_embed)
+ self.pos_drop = nn.Dropout(p=drop_rate)
+ Block_unit = eval(block_unit)
+
+ dpr = np.linspace(0, drop_path_rate, sum(depth))
+ self.blocks1 = nn.LayerList([
+ Block_unit(
+ dim=embed_dim[0],
+ num_heads=num_heads[0],
+ mixer=mixer[0:depth[0]][i],
+ HW=self.HW,
+ local_mixer=local_mixer[0],
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ act_layer=eval(act),
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[0:depth[0]][i],
+ norm_layer=norm_layer,
+ epsilon=epsilon,
+ prenorm=prenorm) for i in range(depth[0])
+ ])
+ if patch_merging is not None:
+ self.sub_sample1 = SubSample(
+ embed_dim[0],
+ embed_dim[1],
+ sub_norm=sub_norm,
+ stride=[2, 1],
+ types=patch_merging)
+ HW = [self.HW[0] // 2, self.HW[1]]
+ else:
+ HW = self.HW
+ self.patch_merging = patch_merging
+ self.blocks2 = nn.LayerList([
+ Block_unit(
+ dim=embed_dim[1],
+ num_heads=num_heads[1],
+ mixer=mixer[depth[0]:depth[0] + depth[1]][i],
+ HW=HW,
+ local_mixer=local_mixer[1],
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ act_layer=eval(act),
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[depth[0]:depth[0] + depth[1]][i],
+ norm_layer=norm_layer,
+ epsilon=epsilon,
+ prenorm=prenorm) for i in range(depth[1])
+ ])
+ if patch_merging is not None:
+ self.sub_sample2 = SubSample(
+ embed_dim[1],
+ embed_dim[2],
+ sub_norm=sub_norm,
+ stride=[2, 1],
+ types=patch_merging)
+ HW = [self.HW[0] // 4, self.HW[1]]
+ else:
+ HW = self.HW
+ self.blocks3 = nn.LayerList([
+ Block_unit(
+ dim=embed_dim[2],
+ num_heads=num_heads[2],
+ mixer=mixer[depth[0] + depth[1]:][i],
+ HW=HW,
+ local_mixer=local_mixer[2],
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ act_layer=eval(act),
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[depth[0] + depth[1]:][i],
+ norm_layer=norm_layer,
+ epsilon=epsilon,
+ prenorm=prenorm) for i in range(depth[2])
+ ])
+ self.last_stage = last_stage
+ if last_stage:
+ self.avg_pool = nn.AdaptiveAvgPool2D([1, out_char_num])
+ self.last_conv = nn.Conv2D(
+ in_channels=embed_dim[2],
+ out_channels=self.out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias_attr=False)
+ self.hardswish = nn.Hardswish()
+ self.dropout = nn.Dropout(p=last_drop, mode="downscale_in_infer")
+ if not prenorm:
+ self.norm = eval(norm_layer)(embed_dim[-1], epsilon=epsilon)
+ self.use_lenhead = use_lenhead
+ if use_lenhead:
+ self.len_conv = nn.Linear(embed_dim[2], self.out_channels)
+ self.hardswish_len = nn.Hardswish()
+ self.dropout_len = nn.Dropout(
+ p=last_drop, mode="downscale_in_infer")
+
+ trunc_normal_(self.pos_embed)
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ zeros_(m.bias)
+ elif isinstance(m, nn.LayerNorm):
+ zeros_(m.bias)
+ ones_(m.weight)
+
+ def forward_features(self, x):
+ x = self.patch_embed(x)
+ x = x + self.pos_embed
+ x = self.pos_drop(x)
+ for blk in self.blocks1:
+ x = blk(x)
+ if self.patch_merging is not None:
+ x = self.sub_sample1(
+ x.transpose([0, 2, 1]).reshape(
+ [0, self.embed_dim[0], self.HW[0], self.HW[1]]))
+ for blk in self.blocks2:
+ x = blk(x)
+ if self.patch_merging is not None:
+ x = self.sub_sample2(
+ x.transpose([0, 2, 1]).reshape(
+ [0, self.embed_dim[1], self.HW[0] // 2, self.HW[1]]))
+ for blk in self.blocks3:
+ x = blk(x)
+ if not self.prenorm:
+ x = self.norm(x)
+ return x
+
+ def forward(self, x):
+ x = self.forward_features(x)
+ if self.use_lenhead:
+ len_x = self.len_conv(x.mean(1))
+ len_x = self.dropout_len(self.hardswish_len(len_x))
+ if self.last_stage:
+ if self.patch_merging is not None:
+ h = self.HW[0] // 4
+ else:
+ h = self.HW[0]
+ x = self.avg_pool(
+ x.transpose([0, 2, 1]).reshape(
+ [0, self.embed_dim[2], h, self.HW[1]]))
+ x = self.last_conv(x)
+ x = self.hardswish(x)
+ x = self.dropout(x)
+ if self.use_lenhead:
+ return x, len_x
+ return x
diff --git a/ppocr/modeling/heads/__init__.py b/ppocr/modeling/heads/__init__.py
index b13fe2ecfdf877771237ad7a1fb0ef829de94a15..1670ea38e66baa683e6faab0ec4b12bc517f3c41 100755
--- a/ppocr/modeling/heads/__init__.py
+++ b/ppocr/modeling/heads/__init__.py
@@ -32,6 +32,7 @@ def build_head(config):
from .rec_sar_head import SARHead
from .rec_aster_head import AsterHead
from .rec_pren_head import PRENHead
+ from .rec_multi_head import MultiHead
# cls head
from .cls_head import ClsHead
@@ -44,7 +45,8 @@ def build_head(config):
support_dict = [
'DBHead', 'PSEHead', 'FCEHead', 'EASTHead', 'SASTHead', 'CTCHead',
'ClsHead', 'AttentionHead', 'SRNHead', 'PGHead', 'Transformer',
- 'TableAttentionHead', 'SARHead', 'AsterHead', 'SDMGRHead', 'PRENHead'
+ 'TableAttentionHead', 'SARHead', 'AsterHead', 'SDMGRHead', 'PRENHead',
+ 'MultiHead'
]
#table head
diff --git a/ppocr/modeling/heads/det_db_head.py b/ppocr/modeling/heads/det_db_head.py
index f76cb34d37af7d81b5e628d06c1a4cfe126f8bb4..a686ae5ab0662ad31ddfd339bd1999c45c370cf0 100644
--- a/ppocr/modeling/heads/det_db_head.py
+++ b/ppocr/modeling/heads/det_db_head.py
@@ -31,13 +31,14 @@ def get_bias_attr(k):
class Head(nn.Layer):
- def __init__(self, in_channels, name_list):
+ def __init__(self, in_channels, name_list, kernel_list=[3, 2, 2], **kwargs):
super(Head, self).__init__()
+
self.conv1 = nn.Conv2D(
in_channels=in_channels,
out_channels=in_channels // 4,
- kernel_size=3,
- padding=1,
+ kernel_size=kernel_list[0],
+ padding=int(kernel_list[0] // 2),
weight_attr=ParamAttr(),
bias_attr=False)
self.conv_bn1 = nn.BatchNorm(
@@ -50,7 +51,7 @@ class Head(nn.Layer):
self.conv2 = nn.Conv2DTranspose(
in_channels=in_channels // 4,
out_channels=in_channels // 4,
- kernel_size=2,
+ kernel_size=kernel_list[1],
stride=2,
weight_attr=ParamAttr(
initializer=paddle.nn.initializer.KaimingUniform()),
@@ -65,7 +66,7 @@ class Head(nn.Layer):
self.conv3 = nn.Conv2DTranspose(
in_channels=in_channels // 4,
out_channels=1,
- kernel_size=2,
+ kernel_size=kernel_list[2],
stride=2,
weight_attr=ParamAttr(
initializer=paddle.nn.initializer.KaimingUniform()),
@@ -100,8 +101,8 @@ class DBHead(nn.Layer):
'conv2d_57', 'batch_norm_49', 'conv2d_transpose_2', 'batch_norm_50',
'conv2d_transpose_3', 'thresh'
]
- self.binarize = Head(in_channels, binarize_name_list)
- self.thresh = Head(in_channels, thresh_name_list)
+ self.binarize = Head(in_channels, binarize_name_list, **kwargs)
+ self.thresh = Head(in_channels, thresh_name_list, **kwargs)
def step_function(self, x, y):
return paddle.reciprocal(1 + paddle.exp(-self.k * (x - y)))
diff --git a/ppocr/modeling/heads/rec_multi_head.py b/ppocr/modeling/heads/rec_multi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f10e7bdf90025d3304128e720ce561c8bb269c1
--- /dev/null
+++ b/ppocr/modeling/heads/rec_multi_head.py
@@ -0,0 +1,73 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import math
+import paddle
+from paddle import ParamAttr
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+from ppocr.modeling.necks.rnn import Im2Seq, EncoderWithRNN, EncoderWithFC, SequenceEncoder, EncoderWithSVTR
+from .rec_ctc_head import CTCHead
+from .rec_sar_head import SARHead
+
+
+class MultiHead(nn.Layer):
+ def __init__(self, in_channels, out_channels_list, **kwargs):
+ super().__init__()
+ self.head_list = kwargs.pop('head_list')
+ self.gtc_head = 'sar'
+ assert len(self.head_list) >= 2
+ for idx, head_name in enumerate(self.head_list):
+ name = list(head_name)[0]
+ if name == 'SARHead':
+ # sar head
+ sar_args = self.head_list[idx][name]
+ self.sar_head = eval(name)(in_channels=in_channels, \
+ out_channels=out_channels_list['SARLabelDecode'], **sar_args)
+ elif name == 'CTCHead':
+ # ctc neck
+ self.encoder_reshape = Im2Seq(in_channels)
+ neck_args = self.head_list[idx][name]['Neck']
+ encoder_type = neck_args.pop('name')
+ self.encoder = encoder_type
+ self.ctc_encoder = SequenceEncoder(in_channels=in_channels, \
+ encoder_type=encoder_type, **neck_args)
+ # ctc head
+ head_args = self.head_list[idx][name]['Head']
+ self.ctc_head = eval(name)(in_channels=self.ctc_encoder.out_channels, \
+ out_channels=out_channels_list['CTCLabelDecode'], **head_args)
+ else:
+ raise NotImplementedError(
+ '{} is not supported in MultiHead yet'.format(name))
+
+ def forward(self, x, targets=None):
+ ctc_encoder = self.ctc_encoder(x)
+ ctc_out = self.ctc_head(ctc_encoder, targets)
+ head_out = dict()
+ head_out['ctc'] = ctc_out
+ head_out['ctc_neck'] = ctc_encoder
+ # eval mode
+ if not self.training:
+ return ctc_out
+ if self.gtc_head == 'sar':
+ sar_out = self.sar_head(x, targets[1:])
+ head_out['sar'] = sar_out
+ return head_out
+ else:
+ return head_out
diff --git a/ppocr/modeling/heads/rec_sar_head.py b/ppocr/modeling/heads/rec_sar_head.py
index 3b7674268772d8a332b963fd6b82dfb71ee40212..27693ebc16a2b494d25455892ac4513b4d16803b 100644
--- a/ppocr/modeling/heads/rec_sar_head.py
+++ b/ppocr/modeling/heads/rec_sar_head.py
@@ -349,7 +349,10 @@ class ParallelSARDecoder(BaseDecoder):
class SARHead(nn.Layer):
def __init__(self,
+ in_channels,
out_channels,
+ enc_dim=512,
+ max_text_length=30,
enc_bi_rnn=False,
enc_drop_rnn=0.1,
enc_gru=False,
@@ -358,14 +361,17 @@ class SARHead(nn.Layer):
dec_gru=False,
d_k=512,
pred_dropout=0.1,
- max_text_length=30,
pred_concat=True,
**kwargs):
super(SARHead, self).__init__()
# encoder module
self.encoder = SAREncoder(
- enc_bi_rnn=enc_bi_rnn, enc_drop_rnn=enc_drop_rnn, enc_gru=enc_gru)
+ enc_bi_rnn=enc_bi_rnn,
+ enc_drop_rnn=enc_drop_rnn,
+ enc_gru=enc_gru,
+ d_model=in_channels,
+ d_enc=enc_dim)
# decoder module
self.decoder = ParallelSARDecoder(
@@ -374,6 +380,8 @@ class SARHead(nn.Layer):
dec_bi_rnn=dec_bi_rnn,
dec_drop_rnn=dec_drop_rnn,
dec_gru=dec_gru,
+ d_model=in_channels,
+ d_enc=enc_dim,
d_k=d_k,
pred_dropout=pred_dropout,
max_text_length=max_text_length,
@@ -390,7 +398,7 @@ class SARHead(nn.Layer):
label = paddle.to_tensor(label, dtype='int64')
final_out = self.decoder(
feat, holistic_feat, label, img_metas=targets)
- if not self.training:
+ else:
final_out = self.decoder(
feat,
holistic_feat,
diff --git a/ppocr/modeling/necks/__init__.py b/ppocr/modeling/necks/__init__.py
index 54837dc65be4b6243136559cf281dc62c441512b..e10b082d11be69b1865f0093b6fec442b255f03a 100644
--- a/ppocr/modeling/necks/__init__.py
+++ b/ppocr/modeling/necks/__init__.py
@@ -16,7 +16,7 @@ __all__ = ['build_neck']
def build_neck(config):
- from .db_fpn import DBFPN
+ from .db_fpn import DBFPN, RSEFPN, LKPAN
from .east_fpn import EASTFPN
from .sast_fpn import SASTFPN
from .rnn import SequenceEncoder
@@ -26,8 +26,8 @@ def build_neck(config):
from .fce_fpn import FCEFPN
from .pren_fpn import PRENFPN
support_dict = [
- 'FPN', 'FCEFPN', 'DBFPN', 'EASTFPN', 'SASTFPN', 'SequenceEncoder',
- 'PGFPN', 'TableFPN', 'PRENFPN'
+ 'FPN', 'FCEFPN', 'LKPAN', 'DBFPN', 'RSEFPN', 'EASTFPN', 'SASTFPN',
+ 'SequenceEncoder', 'PGFPN', 'TableFPN', 'PRENFPN'
]
module_name = config.pop('name')
diff --git a/ppocr/modeling/necks/db_fpn.py b/ppocr/modeling/necks/db_fpn.py
index 1cf30cedd5b23e8a7ba243726a6d7eea7924750c..93ed2dbfd1fac9bf2d163c54d23a20e16b537981 100644
--- a/ppocr/modeling/necks/db_fpn.py
+++ b/ppocr/modeling/necks/db_fpn.py
@@ -20,6 +20,88 @@ import paddle
from paddle import nn
import paddle.nn.functional as F
from paddle import ParamAttr
+import os
+import sys
+
+__dir__ = os.path.dirname(os.path.abspath(__file__))
+sys.path.append(__dir__)
+sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '../../..')))
+
+from ppocr.modeling.backbones.det_mobilenet_v3 import SEModule
+
+
+class DSConv(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ padding,
+ stride=1,
+ groups=None,
+ if_act=True,
+ act="relu",
+ **kwargs):
+ super(DSConv, self).__init__()
+ if groups == None:
+ groups = in_channels
+ self.if_act = if_act
+ self.act = act
+ self.conv1 = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ bias_attr=False)
+
+ self.bn1 = nn.BatchNorm(num_channels=in_channels, act=None)
+
+ self.conv2 = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=int(in_channels * 4),
+ kernel_size=1,
+ stride=1,
+ bias_attr=False)
+
+ self.bn2 = nn.BatchNorm(num_channels=int(in_channels * 4), act=None)
+
+ self.conv3 = nn.Conv2D(
+ in_channels=int(in_channels * 4),
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ bias_attr=False)
+ self._c = [in_channels, out_channels]
+ if in_channels != out_channels:
+ self.conv_end = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=1,
+ bias_attr=False)
+
+ def forward(self, inputs):
+
+ x = self.conv1(inputs)
+ x = self.bn1(x)
+
+ x = self.conv2(x)
+ x = self.bn2(x)
+ if self.if_act:
+ if self.act == "relu":
+ x = F.relu(x)
+ elif self.act == "hardswish":
+ x = F.hardswish(x)
+ else:
+ print("The activation function({}) is selected incorrectly.".
+ format(self.act))
+ exit()
+
+ x = self.conv3(x)
+ if self._c[0] != self._c[1]:
+ x = x + self.conv_end(inputs)
+ return x
class DBFPN(nn.Layer):
@@ -106,3 +188,171 @@ class DBFPN(nn.Layer):
fuse = paddle.concat([p5, p4, p3, p2], axis=1)
return fuse
+
+
+class RSELayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, shortcut=True):
+ super(RSELayer, self).__init__()
+ weight_attr = paddle.nn.initializer.KaimingUniform()
+ self.out_channels = out_channels
+ self.in_conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=self.out_channels,
+ kernel_size=kernel_size,
+ padding=int(kernel_size // 2),
+ weight_attr=ParamAttr(initializer=weight_attr),
+ bias_attr=False)
+ self.se_block = SEModule(self.out_channels)
+ self.shortcut = shortcut
+
+ def forward(self, ins):
+ x = self.in_conv(ins)
+ if self.shortcut:
+ out = x + self.se_block(x)
+ else:
+ out = self.se_block(x)
+ return out
+
+
+class RSEFPN(nn.Layer):
+ def __init__(self, in_channels, out_channels, shortcut=True, **kwargs):
+ super(RSEFPN, self).__init__()
+ self.out_channels = out_channels
+ self.ins_conv = nn.LayerList()
+ self.inp_conv = nn.LayerList()
+
+ for i in range(len(in_channels)):
+ self.ins_conv.append(
+ RSELayer(
+ in_channels[i],
+ out_channels,
+ kernel_size=1,
+ shortcut=shortcut))
+ self.inp_conv.append(
+ RSELayer(
+ out_channels,
+ out_channels // 4,
+ kernel_size=3,
+ shortcut=shortcut))
+
+ def forward(self, x):
+ c2, c3, c4, c5 = x
+
+ in5 = self.ins_conv[3](c5)
+ in4 = self.ins_conv[2](c4)
+ in3 = self.ins_conv[1](c3)
+ in2 = self.ins_conv[0](c2)
+
+ out4 = in4 + F.upsample(
+ in5, scale_factor=2, mode="nearest", align_mode=1) # 1/16
+ out3 = in3 + F.upsample(
+ out4, scale_factor=2, mode="nearest", align_mode=1) # 1/8
+ out2 = in2 + F.upsample(
+ out3, scale_factor=2, mode="nearest", align_mode=1) # 1/4
+
+ p5 = self.inp_conv[3](in5)
+ p4 = self.inp_conv[2](out4)
+ p3 = self.inp_conv[1](out3)
+ p2 = self.inp_conv[0](out2)
+
+ p5 = F.upsample(p5, scale_factor=8, mode="nearest", align_mode=1)
+ p4 = F.upsample(p4, scale_factor=4, mode="nearest", align_mode=1)
+ p3 = F.upsample(p3, scale_factor=2, mode="nearest", align_mode=1)
+
+ fuse = paddle.concat([p5, p4, p3, p2], axis=1)
+ return fuse
+
+
+class LKPAN(nn.Layer):
+ def __init__(self, in_channels, out_channels, mode='large', **kwargs):
+ super(LKPAN, self).__init__()
+ self.out_channels = out_channels
+ weight_attr = paddle.nn.initializer.KaimingUniform()
+
+ self.ins_conv = nn.LayerList()
+ self.inp_conv = nn.LayerList()
+ # pan head
+ self.pan_head_conv = nn.LayerList()
+ self.pan_lat_conv = nn.LayerList()
+
+ if mode.lower() == 'lite':
+ p_layer = DSConv
+ elif mode.lower() == 'large':
+ p_layer = nn.Conv2D
+ else:
+ raise ValueError(
+ "mode can only be one of ['lite', 'large'], but received {}".
+ format(mode))
+
+ for i in range(len(in_channels)):
+ self.ins_conv.append(
+ nn.Conv2D(
+ in_channels=in_channels[i],
+ out_channels=self.out_channels,
+ kernel_size=1,
+ weight_attr=ParamAttr(initializer=weight_attr),
+ bias_attr=False))
+
+ self.inp_conv.append(
+ p_layer(
+ in_channels=self.out_channels,
+ out_channels=self.out_channels // 4,
+ kernel_size=9,
+ padding=4,
+ weight_attr=ParamAttr(initializer=weight_attr),
+ bias_attr=False))
+
+ if i > 0:
+ self.pan_head_conv.append(
+ nn.Conv2D(
+ in_channels=self.out_channels // 4,
+ out_channels=self.out_channels // 4,
+ kernel_size=3,
+ padding=1,
+ stride=2,
+ weight_attr=ParamAttr(initializer=weight_attr),
+ bias_attr=False))
+ self.pan_lat_conv.append(
+ p_layer(
+ in_channels=self.out_channels // 4,
+ out_channels=self.out_channels // 4,
+ kernel_size=9,
+ padding=4,
+ weight_attr=ParamAttr(initializer=weight_attr),
+ bias_attr=False))
+
+ def forward(self, x):
+ c2, c3, c4, c5 = x
+
+ in5 = self.ins_conv[3](c5)
+ in4 = self.ins_conv[2](c4)
+ in3 = self.ins_conv[1](c3)
+ in2 = self.ins_conv[0](c2)
+
+ out4 = in4 + F.upsample(
+ in5, scale_factor=2, mode="nearest", align_mode=1) # 1/16
+ out3 = in3 + F.upsample(
+ out4, scale_factor=2, mode="nearest", align_mode=1) # 1/8
+ out2 = in2 + F.upsample(
+ out3, scale_factor=2, mode="nearest", align_mode=1) # 1/4
+
+ f5 = self.inp_conv[3](in5)
+ f4 = self.inp_conv[2](out4)
+ f3 = self.inp_conv[1](out3)
+ f2 = self.inp_conv[0](out2)
+
+ pan3 = f3 + self.pan_head_conv[0](f2)
+ pan4 = f4 + self.pan_head_conv[1](pan3)
+ pan5 = f5 + self.pan_head_conv[2](pan4)
+
+ p2 = self.pan_lat_conv[0](f2)
+ p3 = self.pan_lat_conv[1](pan3)
+ p4 = self.pan_lat_conv[2](pan4)
+ p5 = self.pan_lat_conv[3](pan5)
+
+ p5 = F.upsample(p5, scale_factor=8, mode="nearest", align_mode=1)
+ p4 = F.upsample(p4, scale_factor=4, mode="nearest", align_mode=1)
+ p3 = F.upsample(p3, scale_factor=2, mode="nearest", align_mode=1)
+
+ fuse = paddle.concat([p5, p4, p3, p2], axis=1)
+ return fuse
diff --git a/ppocr/modeling/necks/rnn.py b/ppocr/modeling/necks/rnn.py
index 86e649028f8fbb76cb5a1fd85381bd361277c6ee..c8a774b8c543b9ccc14223c52f1b79ce690592f6 100644
--- a/ppocr/modeling/necks/rnn.py
+++ b/ppocr/modeling/necks/rnn.py
@@ -16,9 +16,11 @@ from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
+import paddle
from paddle import nn
from ppocr.modeling.heads.rec_ctc_head import get_para_bias_attr
+from ppocr.modeling.backbones.rec_svtrnet import Block, ConvBNLayer, trunc_normal_, zeros_, ones_
class Im2Seq(nn.Layer):
@@ -64,29 +66,126 @@ class EncoderWithFC(nn.Layer):
return x
+class EncoderWithSVTR(nn.Layer):
+ def __init__(
+ self,
+ in_channels,
+ dims=64, # XS
+ depth=2,
+ hidden_dims=120,
+ use_guide=False,
+ num_heads=8,
+ qkv_bias=True,
+ mlp_ratio=2.0,
+ drop_rate=0.1,
+ attn_drop_rate=0.1,
+ drop_path=0.,
+ qk_scale=None):
+ super(EncoderWithSVTR, self).__init__()
+ self.depth = depth
+ self.use_guide = use_guide
+ self.conv1 = ConvBNLayer(
+ in_channels, in_channels // 8, padding=1, act=nn.Swish)
+ self.conv2 = ConvBNLayer(
+ in_channels // 8, hidden_dims, kernel_size=1, act=nn.Swish)
+
+ self.svtr_block = nn.LayerList([
+ Block(
+ dim=hidden_dims,
+ num_heads=num_heads,
+ mixer='Global',
+ HW=None,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ act_layer=nn.Swish,
+ attn_drop=attn_drop_rate,
+ drop_path=drop_path,
+ norm_layer='nn.LayerNorm',
+ epsilon=1e-05,
+ prenorm=False) for i in range(depth)
+ ])
+ self.norm = nn.LayerNorm(hidden_dims, epsilon=1e-6)
+ self.conv3 = ConvBNLayer(
+ hidden_dims, in_channels, kernel_size=1, act=nn.Swish)
+ # last conv-nxn, the input is concat of input tensor and conv3 output tensor
+ self.conv4 = ConvBNLayer(
+ 2 * in_channels, in_channels // 8, padding=1, act=nn.Swish)
+
+ self.conv1x1 = ConvBNLayer(
+ in_channels // 8, dims, kernel_size=1, act=nn.Swish)
+ self.out_channels = dims
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ zeros_(m.bias)
+ elif isinstance(m, nn.LayerNorm):
+ zeros_(m.bias)
+ ones_(m.weight)
+
+ def forward(self, x):
+ # for use guide
+ if self.use_guide:
+ z = x.clone()
+ z.stop_gradient = True
+ else:
+ z = x
+ # for short cut
+ h = z
+ # reduce dim
+ z = self.conv1(z)
+ z = self.conv2(z)
+ # SVTR global block
+ B, C, H, W = z.shape
+ z = z.flatten(2).transpose([0, 2, 1])
+ for blk in self.svtr_block:
+ z = blk(z)
+ z = self.norm(z)
+ # last stage
+ z = z.reshape([0, H, W, C]).transpose([0, 3, 1, 2])
+ z = self.conv3(z)
+ z = paddle.concat((h, z), axis=1)
+ z = self.conv1x1(self.conv4(z))
+ return z
+
+
class SequenceEncoder(nn.Layer):
def __init__(self, in_channels, encoder_type, hidden_size=48, **kwargs):
super(SequenceEncoder, self).__init__()
self.encoder_reshape = Im2Seq(in_channels)
self.out_channels = self.encoder_reshape.out_channels
+ self.encoder_type = encoder_type
if encoder_type == 'reshape':
self.only_reshape = True
else:
support_encoder_dict = {
'reshape': Im2Seq,
'fc': EncoderWithFC,
- 'rnn': EncoderWithRNN
+ 'rnn': EncoderWithRNN,
+ 'svtr': EncoderWithSVTR
}
assert encoder_type in support_encoder_dict, '{} must in {}'.format(
encoder_type, support_encoder_dict.keys())
-
- self.encoder = support_encoder_dict[encoder_type](
- self.encoder_reshape.out_channels, hidden_size)
+ if encoder_type == "svtr":
+ self.encoder = support_encoder_dict[encoder_type](
+ self.encoder_reshape.out_channels, **kwargs)
+ else:
+ self.encoder = support_encoder_dict[encoder_type](
+ self.encoder_reshape.out_channels, hidden_size)
self.out_channels = self.encoder.out_channels
self.only_reshape = False
def forward(self, x):
- x = self.encoder_reshape(x)
- if not self.only_reshape:
+ if self.encoder_type != 'svtr':
+ x = self.encoder_reshape(x)
+ if not self.only_reshape:
+ x = self.encoder(x)
+ return x
+ else:
x = self.encoder(x)
- return x
+ x = self.encoder_reshape(x)
+ return x
diff --git a/ppocr/modeling/transforms/stn.py b/ppocr/modeling/transforms/stn.py
index 6f2bdda050f217d8253740001901fbff4065782a..1b15d5b8a7b7a1b1ab686d20acea750437463939 100644
--- a/ppocr/modeling/transforms/stn.py
+++ b/ppocr/modeling/transforms/stn.py
@@ -128,6 +128,8 @@ class STN_ON(nn.Layer):
self.out_channels = in_channels
def forward(self, image):
+ if len(image.shape)==5:
+ image = image.reshape([0, image.shape[-3], image.shape[-2], image.shape[-1]])
stn_input = paddle.nn.functional.interpolate(
image, self.tps_inputsize, mode="bilinear", align_corners=True)
stn_img_feat, ctrl_points = self.stn_head(stn_input)
diff --git a/ppocr/modeling/transforms/tps_spatial_transformer.py b/ppocr/modeling/transforms/tps_spatial_transformer.py
index 043bb56b8a526c12b2e0799bf41e128c6499c1fc..cb1cb10aaa98dffa2f720dc81afdf82d25e071ca 100644
--- a/ppocr/modeling/transforms/tps_spatial_transformer.py
+++ b/ppocr/modeling/transforms/tps_spatial_transformer.py
@@ -138,9 +138,9 @@ class TPSSpatialTransformer(nn.Layer):
assert source_control_points.shape[2] == 2
batch_size = paddle.shape(source_control_points)[0]
- self.padding_matrix = paddle.expand(
+ padding_matrix = paddle.expand(
self.padding_matrix, shape=[batch_size, 3, 2])
- Y = paddle.concat([source_control_points, self.padding_matrix], 1)
+ Y = paddle.concat([source_control_points, padding_matrix], 1)
mapping_matrix = paddle.matmul(self.inverse_kernel, Y)
source_coordinate = paddle.matmul(self.target_coordinate_repr,
mapping_matrix)
diff --git a/ppocr/optimizer/__init__.py b/ppocr/optimizer/__init__.py
index 4110fb47678583cff826a9bc855b3fb378a533f9..a6bd2ebb4a81427245dc10e446cd2da101d53bd4 100644
--- a/ppocr/optimizer/__init__.py
+++ b/ppocr/optimizer/__init__.py
@@ -30,7 +30,7 @@ def build_lr_scheduler(lr_config, epochs, step_each_epoch):
return lr
-def build_optimizer(config, epochs, step_each_epoch, parameters):
+def build_optimizer(config, epochs, step_each_epoch, model):
from . import regularizer, optimizer
config = copy.deepcopy(config)
# step1 build lr
@@ -43,6 +43,8 @@ def build_optimizer(config, epochs, step_each_epoch, parameters):
if not hasattr(regularizer, reg_name):
reg_name += 'Decay'
reg = getattr(regularizer, reg_name)(**reg_config)()
+ elif 'weight_decay' in config:
+ reg = config.pop('weight_decay')
else:
reg = None
@@ -57,4 +59,4 @@ def build_optimizer(config, epochs, step_each_epoch, parameters):
weight_decay=reg,
grad_clip=grad_clip,
**config)
- return optim(parameters), lr
+ return optim(model), lr
diff --git a/ppocr/optimizer/optimizer.py b/ppocr/optimizer/optimizer.py
index b98081227e180edbf023a8b5b7a0b82bb7c631e5..c450a3a3684eb44cdc758a2b27783b5a81945c38 100644
--- a/ppocr/optimizer/optimizer.py
+++ b/ppocr/optimizer/optimizer.py
@@ -42,13 +42,13 @@ class Momentum(object):
self.weight_decay = weight_decay
self.grad_clip = grad_clip
- def __call__(self, parameters):
+ def __call__(self, model):
opt = optim.Momentum(
learning_rate=self.learning_rate,
momentum=self.momentum,
weight_decay=self.weight_decay,
grad_clip=self.grad_clip,
- parameters=parameters)
+ parameters=model.parameters())
return opt
@@ -75,7 +75,7 @@ class Adam(object):
self.name = name
self.lazy_mode = lazy_mode
- def __call__(self, parameters):
+ def __call__(self, model):
opt = optim.Adam(
learning_rate=self.learning_rate,
beta1=self.beta1,
@@ -85,7 +85,7 @@ class Adam(object):
grad_clip=self.grad_clip,
name=self.name,
lazy_mode=self.lazy_mode,
- parameters=parameters)
+ parameters=model.parameters())
return opt
@@ -117,7 +117,7 @@ class RMSProp(object):
self.weight_decay = weight_decay
self.grad_clip = grad_clip
- def __call__(self, parameters):
+ def __call__(self, model):
opt = optim.RMSProp(
learning_rate=self.learning_rate,
momentum=self.momentum,
@@ -125,7 +125,7 @@ class RMSProp(object):
epsilon=self.epsilon,
weight_decay=self.weight_decay,
grad_clip=self.grad_clip,
- parameters=parameters)
+ parameters=model.parameters())
return opt
@@ -148,7 +148,7 @@ class Adadelta(object):
self.grad_clip = grad_clip
self.name = name
- def __call__(self, parameters):
+ def __call__(self, model):
opt = optim.Adadelta(
learning_rate=self.learning_rate,
epsilon=self.epsilon,
@@ -156,7 +156,7 @@ class Adadelta(object):
weight_decay=self.weight_decay,
grad_clip=self.grad_clip,
name=self.name,
- parameters=parameters)
+ parameters=model.parameters())
return opt
@@ -165,31 +165,55 @@ class AdamW(object):
learning_rate=0.001,
beta1=0.9,
beta2=0.999,
- epsilon=1e-08,
+ epsilon=1e-8,
weight_decay=0.01,
+ multi_precision=False,
grad_clip=None,
+ no_weight_decay_name=None,
+ one_dim_param_no_weight_decay=False,
name=None,
lazy_mode=False,
- **kwargs):
+ **args):
+ super().__init__()
self.learning_rate = learning_rate
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
- self.learning_rate = learning_rate
+ self.grad_clip = grad_clip
self.weight_decay = 0.01 if weight_decay is None else weight_decay
self.grad_clip = grad_clip
self.name = name
self.lazy_mode = lazy_mode
-
- def __call__(self, parameters):
+ self.multi_precision = multi_precision
+ self.no_weight_decay_name_list = no_weight_decay_name.split(
+ ) if no_weight_decay_name else []
+ self.one_dim_param_no_weight_decay = one_dim_param_no_weight_decay
+
+ def __call__(self, model):
+ parameters = model.parameters()
+
+ self.no_weight_decay_param_name_list = [
+ p.name for n, p in model.named_parameters() if any(nd in n for nd in self.no_weight_decay_name_list)
+ ]
+
+ if self.one_dim_param_no_weight_decay:
+ self.no_weight_decay_param_name_list += [
+ p.name for n, p in model.named_parameters() if len(p.shape) == 1
+ ]
+
opt = optim.AdamW(
learning_rate=self.learning_rate,
beta1=self.beta1,
beta2=self.beta2,
epsilon=self.epsilon,
+ parameters=parameters,
weight_decay=self.weight_decay,
+ multi_precision=self.multi_precision,
grad_clip=self.grad_clip,
name=self.name,
lazy_mode=self.lazy_mode,
- parameters=parameters)
+ apply_decay_param_fun=self._apply_decay_param_fun)
return opt
+
+ def _apply_decay_param_fun(self, name):
+ return name not in self.no_weight_decay_param_name_list
\ No newline at end of file
diff --git a/ppocr/postprocess/__init__.py b/ppocr/postprocess/__init__.py
index 14be63ddf93bd3bdab5df9bfa9e949ee4326a5ef..390f6f4560f9814a3af757a4fd16c55fe93d01f9 100644
--- a/ppocr/postprocess/__init__.py
+++ b/ppocr/postprocess/__init__.py
@@ -27,7 +27,7 @@ from .sast_postprocess import SASTPostProcess
from .fce_postprocess import FCEPostProcess
from .rec_postprocess import CTCLabelDecode, AttnLabelDecode, SRNLabelDecode, \
DistillationCTCLabelDecode, TableLabelDecode, NRTRLabelDecode, SARLabelDecode, \
- SEEDLabelDecode, PRENLabelDecode
+ SEEDLabelDecode, PRENLabelDecode, SVTRLabelDecode
from .cls_postprocess import ClsPostProcess
from .pg_postprocess import PGPostProcess
from .vqa_token_ser_layoutlm_postprocess import VQASerTokenLayoutLMPostProcess
@@ -41,7 +41,8 @@ def build_post_process(config, global_config=None):
'PGPostProcess', 'DistillationCTCLabelDecode', 'TableLabelDecode',
'DistillationDBPostProcess', 'NRTRLabelDecode', 'SARLabelDecode',
'SEEDLabelDecode', 'VQASerTokenLayoutLMPostProcess',
- 'VQAReTokenLayoutLMPostProcess', 'PRENLabelDecode'
+ 'VQAReTokenLayoutLMPostProcess', 'PRENLabelDecode',
+ 'DistillationSARLabelDecode', 'SVTRLabelDecode'
]
if config['name'] == 'PSEPostProcess':
diff --git a/ppocr/postprocess/cls_postprocess.py b/ppocr/postprocess/cls_postprocess.py
index 77e7f46d6f774ffb81f8e9cbd6b100c780665dca..9a27ba0831358564d99a6ec698a5019eae1c25f7 100644
--- a/ppocr/postprocess/cls_postprocess.py
+++ b/ppocr/postprocess/cls_postprocess.py
@@ -17,17 +17,26 @@ import paddle
class ClsPostProcess(object):
""" Convert between text-label and text-index """
- def __init__(self, label_list, **kwargs):
+ def __init__(self, label_list=None, key=None, **kwargs):
super(ClsPostProcess, self).__init__()
self.label_list = label_list
+ self.key = key
def __call__(self, preds, label=None, *args, **kwargs):
+ if self.key is not None:
+ preds = preds[self.key]
+
+ label_list = self.label_list
+ if label_list is None:
+ label_list = {idx: idx for idx in range(preds.shape[-1])}
+
if isinstance(preds, paddle.Tensor):
preds = preds.numpy()
+
pred_idxs = preds.argmax(axis=1)
- decode_out = [(self.label_list[idx], preds[i, idx])
+ decode_out = [(label_list[idx], preds[i, idx])
for i, idx in enumerate(pred_idxs)]
if label is None:
return decode_out
- label = [(self.label_list[idx], 1.0) for idx in label]
+ label = [(label_list[idx], 1.0) for idx in label]
return decode_out, label
diff --git a/ppocr/postprocess/rec_postprocess.py b/ppocr/postprocess/rec_postprocess.py
index 3bc7bcdf9b388bb8da6c656682e2e06a18a0f4fb..50f11f899fb4dd49da75199095772a92cc4a8d7b 100644
--- a/ppocr/postprocess/rec_postprocess.py
+++ b/ppocr/postprocess/rec_postprocess.py
@@ -73,7 +73,7 @@ class BaseRecLabelDecode(object):
conf_list = [0]
text = ''.join(char_list)
- result_list.append((text, np.mean(conf_list)))
+ result_list.append((text, np.mean(conf_list).tolist()))
return result_list
def get_ignored_tokens(self):
@@ -117,6 +117,7 @@ class DistillationCTCLabelDecode(CTCLabelDecode):
use_space_char=False,
model_name=["student"],
key=None,
+ multi_head=False,
**kwargs):
super(DistillationCTCLabelDecode, self).__init__(character_dict_path,
use_space_char)
@@ -125,6 +126,7 @@ class DistillationCTCLabelDecode(CTCLabelDecode):
self.model_name = model_name
self.key = key
+ self.multi_head = multi_head
def __call__(self, preds, label=None, *args, **kwargs):
output = dict()
@@ -132,6 +134,8 @@ class DistillationCTCLabelDecode(CTCLabelDecode):
pred = preds[name]
if self.key is not None:
pred = pred[self.key]
+ if self.multi_head and isinstance(pred, dict):
+ pred = pred['ctc']
output[name] = super().__call__(pred, label=label, *args, **kwargs)
return output
@@ -196,7 +200,7 @@ class NRTRLabelDecode(BaseRecLabelDecode):
else:
conf_list.append(1)
text = ''.join(char_list)
- result_list.append((text.lower(), np.mean(conf_list)))
+ result_list.append((text.lower(), np.mean(conf_list).tolist()))
return result_list
@@ -241,7 +245,7 @@ class AttnLabelDecode(BaseRecLabelDecode):
else:
conf_list.append(1)
text = ''.join(char_list)
- result_list.append((text, np.mean(conf_list)))
+ result_list.append((text, np.mean(conf_list).tolist()))
return result_list
def __call__(self, preds, label=None, *args, **kwargs):
@@ -333,7 +337,7 @@ class SEEDLabelDecode(BaseRecLabelDecode):
else:
conf_list.append(1)
text = ''.join(char_list)
- result_list.append((text, np.mean(conf_list)))
+ result_list.append((text, np.mean(conf_list).tolist()))
return result_list
def __call__(self, preds, label=None, *args, **kwargs):
@@ -417,7 +421,7 @@ class SRNLabelDecode(BaseRecLabelDecode):
conf_list.append(1)
text = ''.join(char_list)
- result_list.append((text, np.mean(conf_list)))
+ result_list.append((text, np.mean(conf_list).tolist()))
return result_list
def add_special_char(self, dict_character):
@@ -636,7 +640,7 @@ class SARLabelDecode(BaseRecLabelDecode):
comp = re.compile('[^A-Z^a-z^0-9^\u4e00-\u9fa5]')
text = text.lower()
text = comp.sub('', text)
- result_list.append((text, np.mean(conf_list)))
+ result_list.append((text, np.mean(conf_list).tolist()))
return result_list
def __call__(self, preds, label=None, *args, **kwargs):
@@ -656,6 +660,40 @@ class SARLabelDecode(BaseRecLabelDecode):
return [self.padding_idx]
+class DistillationSARLabelDecode(SARLabelDecode):
+ """
+ Convert
+ Convert between text-label and text-index
+ """
+
+ def __init__(self,
+ character_dict_path=None,
+ use_space_char=False,
+ model_name=["student"],
+ key=None,
+ multi_head=False,
+ **kwargs):
+ super(DistillationSARLabelDecode, self).__init__(character_dict_path,
+ use_space_char)
+ if not isinstance(model_name, list):
+ model_name = [model_name]
+ self.model_name = model_name
+
+ self.key = key
+ self.multi_head = multi_head
+
+ def __call__(self, preds, label=None, *args, **kwargs):
+ output = dict()
+ for name in self.model_name:
+ pred = preds[name]
+ if self.key is not None:
+ pred = pred[self.key]
+ if self.multi_head and isinstance(pred, dict):
+ pred = pred['sar']
+ output[name] = super().__call__(pred, label=label, *args, **kwargs)
+ return output
+
+
class PRENLabelDecode(BaseRecLabelDecode):
""" Convert between text-label and text-index """
@@ -699,7 +737,7 @@ class PRENLabelDecode(BaseRecLabelDecode):
text = ''.join(char_list)
if len(text) > 0:
- result_list.append((text, np.mean(conf_list)))
+ result_list.append((text, np.mean(conf_list).tolist()))
else:
# here confidence of empty recog result is 1
result_list.append(('', 1))
@@ -714,3 +752,40 @@ class PRENLabelDecode(BaseRecLabelDecode):
return text
label = self.decode(label)
return text, label
+
+
+class SVTRLabelDecode(BaseRecLabelDecode):
+ """ Convert between text-label and text-index """
+
+ def __init__(self, character_dict_path=None, use_space_char=False,
+ **kwargs):
+ super(SVTRLabelDecode, self).__init__(character_dict_path,
+ use_space_char)
+
+ def __call__(self, preds, label=None, *args, **kwargs):
+ if isinstance(preds, tuple):
+ preds = preds[-1]
+ if isinstance(preds, paddle.Tensor):
+ preds = preds.numpy()
+ preds_idx = preds.argmax(axis=-1)
+ preds_prob = preds.max(axis=-1)
+
+ text = self.decode(preds_idx, preds_prob, is_remove_duplicate=True)
+ return_text = []
+ for i in range(0, len(text), 3):
+ text0 = text[i]
+ text1 = text[i + 1]
+ text2 = text[i + 2]
+
+ text_pred = [text0[0], text1[0], text2[0]]
+ text_prob = [text0[1], text1[1], text2[1]]
+ id_max = text_prob.index(max(text_prob))
+ return_text.append((text_pred[id_max], text_prob[id_max]))
+ if label is None:
+ return return_text
+ label = self.decode(label)
+ return return_text, label
+
+ def add_special_char(self, dict_character):
+ dict_character = ['blank'] + dict_character
+ return dict_character
\ No newline at end of file
diff --git a/ppocr/utils/dict/ka_dict.txt b/ppocr/utils/dict/ka_dict.txt
index 33d605c4de106c3c4b2504f5b3c42cdadd076dd8..d506b691bd1a6c55299ad89a72cf3a69a2c879a9 100644
--- a/ppocr/utils/dict/ka_dict.txt
+++ b/ppocr/utils/dict/ka_dict.txt
@@ -21,7 +21,7 @@ l
8
.
j
-p
+p
ಗ
ು
ಣ
diff --git a/ppocr/utils/dict/ta_dict.txt b/ppocr/utils/dict/ta_dict.txt
index d1bae501ad2556bb59b16a6c4b27a27091a6cbcf..19d81892c205627f296adbf8b20ea41aba2de5d0 100644
--- a/ppocr/utils/dict/ta_dict.txt
+++ b/ppocr/utils/dict/ta_dict.txt
@@ -22,7 +22,7 @@ l
8
.
j
-p
+p
ப
ூ
த
diff --git a/ppstructure/README_ch.md b/ppstructure/README_ch.md
index dc7ac1e9b22fc839e4f581b54962406c7d0f931c..ddacbb077937f325db0430846b8f05bfda9619cd 100644
--- a/ppstructure/README_ch.md
+++ b/ppstructure/README_ch.md
@@ -1,30 +1,34 @@
[English](README.md) | 简体中文
-- [1. 简介](#1-简介)
-- [2. 近期更新](#2-近期更新)
-- [3. 特性](#3-特性)
-- [4. 效果展示](#4-效果展示)
- - [4.1 版面分析和表格识别](#41-版面分析和表格识别)
- - [4.2 DOC-VQA](#42-doc-vqa)
-- [5. 快速体验](#5-快速体验)
-- [6. PP-Structure 介绍](#6-pp-structure-介绍)
- - [6.1 版面分析+表格识别](#61-版面分析表格识别)
- - [6.1.1 版面分析](#611-版面分析)
- - [6.1.2 表格识别](#612-表格识别)
- - [6.2 DOC-VQA](#62-doc-vqa)
-- [7. 模型库](#7-模型库)
- - [7.1 版面分析模型](#71-版面分析模型)
- - [7.2 OCR和表格识别模型](#72-ocr和表格识别模型)
- - [7.2 DOC-VQA 模型](#72-doc-vqa-模型)
-
-
+# PP-Structure 文档分析
+
+- [1. 简介](#1)
+- [2. 近期更新](#2)
+- [3. 特性](#3)
+- [4. 效果展示](#4)
+ - [4.1 版面分析和表格识别](#41)
+ - [4.2 DocVQA](#42)
+- [5. 快速体验](#5)
+- [6. PP-Structure 介绍](#6)
+ - [6.1 版面分析+表格识别](#61)
+ - [6.1.1 版面分析](#611)
+ - [6.1.2 表格识别](#612)
+ - [6.2 DocVQA](#62)
+- [7. 模型库](#7)
+ - [7.1 版面分析模型](#71)
+ - [7.2 OCR和表格识别模型](#72)
+ - [7.3 DocVQA 模型](#73)
+
+
## 1. 简介
PP-Structure是一个可用于复杂文档结构分析和处理的OCR工具包,旨在帮助开发者更好的完成文档理解相关任务。
+
## 2. 近期更新
-* 2022.02.12 DOC-VQA增加LayoutLMv2模型。
+* 2022.02.12 DocVQA增加LayoutLMv2模型。
* 2021.12.07 新增[DOC-VQA任务SER和RE](vqa/README.md)。
+
## 3. 特性
PP-Structure的主要特性如下:
@@ -33,21 +37,24 @@ PP-Structure的主要特性如下:
- 支持表格区域进行结构化分析,最终结果输出Excel文件
- 支持python whl包和命令行两种方式,简单易用
- 支持版面分析和表格结构化两类任务自定义训练
-- 支持文档视觉问答(Document Visual Question Answering,DOC-VQA)任务-语义实体识别(Semantic Entity Recognition,SER)和关系抽取(Relation Extraction,RE)
+- 支持文档视觉问答(Document Visual Question Answering,DocVQA)任务-语义实体识别(Semantic Entity Recognition,SER)和关系抽取(Relation Extraction,RE)
+
## 4. 效果展示
+
### 4.1 版面分析和表格识别
- +
+ 图中展示了版面分析+表格识别的整体流程,图片先有版面分析划分为图像、文本、标题和表格四种区域,然后对图像、文本和标题三种区域进行OCR的检测识别,对表格进行表格识别,其中图像还会被存储下来以便使用。
+
### 4.2 DOC-VQA
* SER
- | 
+ | 
---|---
图中不同颜色的框表示不同的类别,对于XFUN数据集,有`QUESTION`, `ANSWER`, `HEADER` 3种类别
@@ -60,46 +67,55 @@ PP-Structure的主要特性如下:
* RE
- | 
+ | 
---|---
图中红色框表示问题,蓝色框表示答案,问题和答案之间使用绿色线连接。在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
+
## 5. 快速体验
-请参考[快速安装](./docs/quickstart.md)教程。
+请参考[快速使用](./docs/quickstart.md)教程。
+
## 6. PP-Structure 介绍
+
### 6.1 版面分析+表格识别
-
+
在PP-Structure中,图片会先经由Layout-Parser进行版面分析,在版面分析中,会对图片里的区域进行分类,包括**文字、标题、图片、列表和表格**5类。对于前4类区域,直接使用PP-OCR完成对应区域文字检测与识别。对于表格类区域,经过表格结构化处理后,表格图片转换为相同表格样式的Excel文件。
+
#### 6.1.1 版面分析
版面分析对文档数据进行区域分类,其中包括版面分析工具的Python脚本使用、提取指定类别检测框、性能指标以及自定义训练版面分析模型,详细内容可以参考[文档](layout/README_ch.md)。
+
#### 6.1.2 表格识别
表格识别将表格图片转换为excel文档,其中包含对于表格文本的检测和识别以及对于表格结构和单元格坐标的预测,详细说明参考[文档](table/README_ch.md)。
-### 6.2 DOC-VQA
+
+### 6.2 DocVQA
-DOC-VQA指文档视觉问答,其中包括语义实体识别 (Semantic Entity Recognition, SER) 和关系抽取 (Relation Extraction, RE) 任务。基于 SER 任务,可以完成对图像中的文本识别与分类;基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair),详细说明参考[文档](vqa/README.md)。
+DocVQA指文档视觉问答,其中包括语义实体识别 (Semantic Entity Recognition, SER) 和关系抽取 (Relation Extraction, RE) 任务。基于 SER 任务,可以完成对图像中的文本识别与分类;基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair),详细说明参考[文档](vqa/README.md)。
+
## 7. 模型库
PP-Structure系列模型列表(更新中)
+
### 7.1 版面分析模型
|模型名称|模型简介|下载地址| label_map|
| --- | --- | --- | --- |
| ppyolov2_r50vd_dcn_365e_publaynet | PubLayNet 数据集训练的版面分析模型,可以划分**文字、标题、表格、图片以及列表**5类区域 | [PubLayNet](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_publaynet.tar) | {0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"}|
+
### 7.2 OCR和表格识别模型
|模型名称|模型简介|模型大小|下载地址|
@@ -108,7 +124,8 @@ PP-Structure系列模型列表(更新中)
|ch_PP-OCRv2_rec_slim|【最新】slim量化版超轻量模型,支持中英文、数字识别| 9M |[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_train.tar) |
|en_ppocr_mobile_v2.0_table_structure|PubLayNet数据集训练的英文表格场景的表格结构预测|18.6M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar) |
-### 7.2 DOC-VQA 模型
+
+### 7.3 DocVQA 模型
|模型名称|模型简介|模型大小|下载地址|
| --- | --- | --- | --- |
diff --git a/ppstructure/docs/inference.md b/ppstructure/docs/inference.md
new file mode 100644
index 0000000000000000000000000000000000000000..7604246da5a79b0ee2939c9fb4c91602531ec7de
--- /dev/null
+++ b/ppstructure/docs/inference.md
@@ -0,0 +1,80 @@
+# 基于Python预测引擎推理
+
+- [1. Structure](#1)
+ - [1.1 版面分析+表格识别](#1.1)
+ - [1.2 版面分析](#1.2)
+ - [1.3 表格识别](#1.3)
+- [2. DocVQA](#2)
+
+
+## 1. Structure
+进入`ppstructure`目录
+
+```bash
+cd ppstructure
+````
+下载模型
+```bash
+mkdir inference && cd inference
+# 下载PP-OCRv2文本检测模型并解压
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar && tar xf ch_PP-OCRv2_det_slim_quant_infer.tar
+# 下载PP-OCRv2文本识别模型并解压
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar && tar xf ch_PP-OCRv2_rec_slim_quant_infer.tar
+# 下载超轻量级英文表格预测模型并解压
+wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar && tar xf en_ppocr_mobile_v2.0_table_structure_infer.tar
+cd ..
+```
+
+### 1.1 版面分析+表格识别
+```bash
+python3 predict_system.py --det_model_dir=inference/ch_PP-OCRv2_det_slim_quant_infer \
+ --rec_model_dir=inference/ch_PP-OCRv2_rec_slim_quant_infer \
+ --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer \
+ --image_dir=./docs/table/1.png \
+ --rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt \
+ --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
+ --output=../output \
+ --vis_font_path=../doc/fonts/simfang.ttf
+```
+运行完成后,每张图片会在`output`字段指定的目录下的`structure`目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名为表格在图片里的坐标。详细的结果会存储在`res.txt`文件中。
+
+
+### 1.2 版面分析
+```bash
+python3 predict_system.py --image_dir=./docs/table/1.png --table=false --ocr=false --output=../output/
+```
+运行完成后,每张图片会在`output`字段指定的目录下的`structure`目录下有一个同名目录,图片区域会被裁剪之后保存下来,图片名为表格在图片里的坐标。版面分析结果会存储在`res.txt`文件中。
+
+
+### 1.3 表格识别
+```bash
+python3 predict_system.py --det_model_dir=inference/ch_PP-OCRv2_det_slim_quant_infer \
+ --rec_model_dir=inference/ch_PP-OCRv2_rec_slim_quant_infer \
+ --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer \
+ --image_dir=./docs/table/table.jpg \
+ --rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt \
+ --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
+ --output=../output \
+ --vis_font_path=../doc/fonts/simfang.ttf \
+ --layout=false
+```
+运行完成后,每张图片会在`output`字段指定的目录下的`structure`目录下有一个同名目录,表格会存储为一个excel,excel文件名为`[0,0,img_h,img_w]`。
+
+
+## 2. DocVQA
+
+```bash
+cd ppstructure
+
+# 下载模型
+mkdir inference && cd inference
+# 下载SER xfun 模型并解压
+wget https://paddleocr.bj.bcebos.com/pplayout/PP-Layout_v1.0_ser_pretrained.tar && tar xf PP-Layout_v1.0_ser_pretrained.tar
+cd ..
+
+python3 predict_system.py --model_name_or_path=vqa/PP-Layout_v1.0_ser_pretrained/ \
+ --mode=vqa \
+ --image_dir=vqa/images/input/zh_val_0.jpg \
+ --vis_font_path=../doc/fonts/simfang.ttf
+```
+运行完成后,每张图片会在`output`字段指定的目录下的`vqa`目录下存放可视化之后的图片,图片名和输入图片名一致。
diff --git a/ppstructure/docs/inference_en.md b/ppstructure/docs/inference_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..2a0fb30543eaa06c4ede5f82a443135c959db37d
--- /dev/null
+++ b/ppstructure/docs/inference_en.md
@@ -0,0 +1,81 @@
+# Python Inference
+
+- [1. Structure](#1)
+ - [1.1 layout analysis + table recognition](#1.1)
+ - [1.2 layout analysis](#1.2)
+ - [1.3 table recognition](#1.3)
+- [2. DocVQA](#2)
+
+
+## 1. Structure
+Go to the `ppstructure` directory
+
+```bash
+cd ppstructure
+````
+
+download model
+
+```bash
+mkdir inference && cd inference
+# Download the PP-OCRv2 text detection model and unzip it
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar && tar xf ch_PP-OCRv2_det_slim_quant_infer.tar
+# Download the PP-OCRv2 text recognition model and unzip it
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar && tar xf ch_PP-OCRv2_rec_slim_quant_infer.tar
+# Download the ultra-lightweight English table structure model and unzip it
+wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar && tar xf en_ppocr_mobile_v2.0_table_structure_infer.tar
+cd ..
+```
+
+### 1.1 layout analysis + table recognition
+```bash
+python3 predict_system.py --det_model_dir=inference/ch_PP-OCRv2_det_slim_quant_infer \
+ --rec_model_dir=inference/ch_PP-OCRv2_rec_slim_quant_infer \
+ --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer \
+ --image_dir=./docs/table/1.png \
+ --rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt \
+ --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
+ --output=../output \
+ --vis_font_path=../doc/fonts/simfang.ttf
+```
+After the operation is completed, each image will have a directory with the same name in the `structure` directory under the directory specified by the `output` field. Each table in the image will be stored as an excel, and the picture area will be cropped and saved. The filename of excel and picture is their coordinates in the image. Detailed results are stored in the `res.txt` file.
+
+
+### 1.2 layout analysis
+```bash
+python3 predict_system.py --image_dir=./docs/table/1.png --table=false --ocr=false --output=../output/
+```
+After the operation is completed, each image will have a directory with the same name in the `structure` directory under the directory specified by the `output` field. Each picture in image will be cropped and saved. The filename of picture area is their coordinates in the image. Layout analysis results will be stored in the `res.txt` file
+
+
+### 1.3 table recognition
+```bash
+python3 predict_system.py --det_model_dir=inference/ch_PP-OCRv2_det_slim_quant_infer \
+ --rec_model_dir=inference/ch_PP-OCRv2_rec_slim_quant_infer \
+ --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer \
+ --image_dir=./docs/table/table.jpg \
+ --rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt \
+ --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
+ --output=../output \
+ --vis_font_path=../doc/fonts/simfang.ttf \
+ --layout=false
+```
+After the operation is completed, each image will have a directory with the same name in the `structure` directory under the directory specified by the `output` field. Each table in the image will be stored as an excel. The filename of excel is their coordinates in the image.
+
+
+## 2. DocVQA
+
+```bash
+cd ppstructure
+
+# download model
+mkdir inference && cd inference
+wget https://paddleocr.bj.bcebos.com/pplayout/PP-Layout_v1.0_ser_pretrained.tar && tar xf PP-Layout_v1.0_ser_pretrained.tar
+cd ..
+
+python3 predict_system.py --model_name_or_path=vqa/PP-Layout_v1.0_ser_pretrained/ \
+ --mode=vqa \
+ --image_dir=vqa/images/input/zh_val_0.jpg \
+ --vis_font_path=../doc/fonts/simfang.ttf
+```
+After the operation is completed, each image will store the visualized image in the `vqa` directory under the directory specified by the `output` field, and the image name is the same as the input image name.
diff --git a/ppstructure/docs/models_list.md b/ppstructure/docs/models_list.md
index 5de7394d7e4e250f74471bbbb2fa89f779b70516..c7dab999ff6e370c56c5495e22e91f117b3d1275 100644
--- a/ppstructure/docs/models_list.md
+++ b/ppstructure/docs/models_list.md
@@ -1,15 +1,15 @@
-- [PP-Structure 系列模型列表](#pp-structure-系列模型列表)
- - [1. LayoutParser 模型](#1-layoutparser-模型)
- - [2. OCR和表格识别模型](#2-ocr和表格识别模型)
- - [2.1 OCR](#21-ocr)
- - [2.2 表格识别模型](#22-表格识别模型)
- - [3. VQA模型](#3-vqa模型)
- - [4. KIE模型](#4-kie模型)
-
# PP-Structure 系列模型列表
+- [1. 版面分析模型](#1)
+- [2. OCR和表格识别模型](#2)
+ - [2.1 OCR](#21)
+ - [2.2 表格识别模型](#22)
+- [3. VQA模型](#3)
+- [4. KIE模型](#4)
+
-## 1. LayoutParser 模型
+
+## 1. 版面分析模型
|模型名称|模型简介|下载地址|label_map|
| --- | --- | --- | --- |
@@ -17,8 +17,10 @@
| ppyolov2_r50vd_dcn_365e_tableBank_word | TableBank Word 数据集训练的版面分析模型,只能检测表格 | [推理模型](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_tableBank_word.tar) | {0:"Table"}|
| ppyolov2_r50vd_dcn_365e_tableBank_latex | TableBank Latex 数据集训练的版面分析模型,只能检测表格 | [推理模型](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_tableBank_latex.tar) | {0:"Table"}|
+
## 2. OCR和表格识别模型
+
### 2.1 OCR
|模型名称|模型简介|推理模型大小|下载地址|
@@ -28,12 +30,14 @@
如需要使用其他OCR模型,可以在 [PP-OCR model_list](../../doc/doc_ch/models_list.md) 下载模型或者使用自己训练好的模型配置到 `det_model_dir`, `rec_model_dir`两个字段即可。
+
### 2.2 表格识别模型
|模型名称|模型简介|推理模型大小|下载地址|
| --- | --- | --- | --- |
|en_ppocr_mobile_v2.0_table_structure|PubLayNet数据集训练的英文表格场景的表格结构预测|18.6M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar) |
+
## 3. VQA模型
|模型名称|模型简介|推理模型大小|下载地址|
@@ -44,6 +48,7 @@
|re_LayoutLMv2_xfun_zh|基于LayoutLMv2在xfun中文数据集上训练的RE模型|765M|[推理模型 coming soon]() / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutLMv2_xfun_zh.tar) |
|ser_LayoutLM_xfun_zh|基于LayoutLM在xfun中文数据集上训练的SER模型|430M|[推理模型 coming soon]() / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLM_xfun_zh.tar) |
+
## 4. KIE模型
|模型名称|模型简介|模型大小|下载地址|
diff --git a/ppstructure/docs/models_list_en.md b/ppstructure/docs/models_list_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..b92c10c241df72c85649b64f915b4266cd3fe410
--- /dev/null
+++ b/ppstructure/docs/models_list_en.md
@@ -0,0 +1,56 @@
+# PP-Structure Model list
+
+- [1. Layout Analysis](#1)
+- [2. OCR and Table Recognition](#2)
+ - [2.1 OCR](#21)
+ - [2.2 Table Recognition](#22)
+- [3. VQA](#3)
+- [4. KIE](#4)
+
+
+
+## 1. Layout Analysis
+
+|model name| description |download|label_map|
+| --- |---------------------------------------------------------------------------------------------------------------------------------------------------------| --- | --- |
+| ppyolov2_r50vd_dcn_365e_publaynet | The layout analysis model trained on the PubLayNet dataset, the model can recognition 5 types of areas such as **text, title, table, picture and list** | [inference model](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_publaynet.tar) / [trained model](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_publaynet_pretrained.pdparams) |{0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"}|
+| ppyolov2_r50vd_dcn_365e_tableBank_word | The layout analysis model trained on the TableBank Word dataset, the model can only detect tables | [inference model](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_tableBank_word.tar) | {0:"Table"}|
+| ppyolov2_r50vd_dcn_365e_tableBank_latex | The layout analysis model trained on the TableBank Latex dataset, the model can only detect tables | [inference model](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_tableBank_latex.tar) | {0:"Table"}|
+
+
+## 2. OCR and Table Recognition
+
+
+### 2.1 OCR
+
+|model name| description | inference model size |download|
+| --- |---|---| --- |
+|en_ppocr_mobile_v2.0_table_det| Text detection model of English table scenes trained on PubTabNet dataset | 4.7M |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_det_train.tar) |
+|en_ppocr_mobile_v2.0_table_rec| Text recognition model of English table scenes trained on PubTabNet dataset | 6.9M |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_rec_train.tar) |
+
+If you need to use other OCR models, you can download the model in [PP-OCR model_list](../../doc/doc_ch/models_list.md) or use the model you trained yourself to configure to `det_model_dir`, `rec_model_dir` field.
+
+
+### 2.2 Table Recognition
+
+|model| description |inference model size|download|
+| --- |-----------------------------------------------------------------------------| --- | --- |
+|en_ppocr_mobile_v2.0_table_structure| Table structure model for English table scenes trained on PubTabNet dataset |18.6M|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar) |
+
+
+## 3. VQA
+
+|model| description |inference model size|download|
+| --- |----------------------------------------------------------------| --- | --- |
+|ser_LayoutXLM_xfun_zh| SER model trained on xfun Chinese dataset based on LayoutXLM |1.4G|[inference model coming soon]() / [trained model](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar) |
+|re_LayoutXLM_xfun_zh| Re model trained on xfun Chinese dataset based on LayoutXLM |1.4G|[inference model coming soon]() / [trained model](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar) |
+|ser_LayoutLMv2_xfun_zh| SER model trained on xfun Chinese dataset based on LayoutXLMv2 |778M|[inference model coming soon]() / [trained model](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLMv2_xfun_zh.tar) |
+|re_LayoutLMv2_xfun_zh| Re model trained on xfun Chinese dataset based on LayoutXLMv2 |765M|[inference model coming soon]() / [trained model](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutLMv2_xfun_zh.tar) |
+|ser_LayoutLM_xfun_zh| SER model trained on xfun Chinese dataset based on LayoutLM |430M|[inference model coming soon]() / [trained model](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLM_xfun_zh.tar) |
+
+
+## 4. KIE
+
+|model|description|model size|download|
+| --- | --- | --- | --- |
+|SDMGR|Key Information Extraction Model|78M|[inference model coming soon]() / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/kie/kie_vgg16.tar)|
diff --git a/ppstructure/docs/quickstart.md b/ppstructure/docs/quickstart.md
index 52e0c77dd1d9716827e06819cc957e36f02ee1f8..6610035d1442f988ac69763724ce78f6db35ae20 100644
--- a/ppstructure/docs/quickstart.md
+++ b/ppstructure/docs/quickstart.md
@@ -1,43 +1,71 @@
# PP-Structure 快速开始
-- [PP-Structure 快速开始](#pp-structure-快速开始)
- - [1. 安装依赖包](#1-安装依赖包)
- - [2. 便捷使用](#2-便捷使用)
- - [2.1 命令行使用](#21-命令行使用)
- - [2.2 Python脚本使用](#22-python脚本使用)
- - [2.3 返回结果说明](#23-返回结果说明)
- - [2.4 参数说明](#24-参数说明)
- - [3. Python脚本使用](#3-python脚本使用)
-
+- [1. 安装依赖包](#1)
+- [2. 便捷使用](#2)
+ - [2.1 命令行使用](#21)
+ - [2.1.1 版面分析+表格识别](#211)
+ - [2.1.2 版面分析](#212)
+ - [2.1.3 表格识别](#213)
+ - [2.1.4 DocVQA](#214)
+ - [2.2 代码使用](#22)
+ - [2.2.1 版面分析+表格识别](#221)
+ - [2.2.2 版面分析](#222)
+ - [2.2.3 表格识别](#223)
+ - [2.2.4 DocVQA](#224)
+ - [2.3 返回结果说明](#23)
+ - [2.3.1 版面分析+表格识别](#231)
+ - [2.3.2 DocVQA](#232)
+ - [2.4 参数说明](#24)
+
+
+
## 1. 安装依赖包
```bash
-pip install "paddleocr>=2.3.0.2" # 推荐使用2.3.0.2+版本
+# 安装 paddleocr,推荐使用2.5+版本
+pip3 install "paddleocr>=2.5"
+# 安装 版面分析依赖包layoutparser(如不需要版面分析功能,可跳过)
pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
-
-# 安装 PaddleNLP
-git clone https://github.com/PaddlePaddle/PaddleNLP -b develop
-cd PaddleNLP
-pip3 install -e .
+# 安装 DocVQA依赖包paddlenlp(如不需要DocVQA功能,可跳过)
+pip install paddlenlp
```
+
## 2. 便捷使用
-### 2.1 命令行使用
+
+### 2.1 命令行使用
-* 版面分析+表格识别
+
+#### 2.1.1 版面分析+表格识别
```bash
-paddleocr --image_dir=../doc/table/1.png --type=structure
+paddleocr --image_dir=PaddleOCR/ppstructure/docs/table/1.png --type=structure
```
-* VQA
+
+#### 2.1.2 版面分析
+```bash
+paddleocr --image_dir=PaddleOCR/ppstructure/docs/table/1.png --type=structure --table=false --ocr=false
+```
+
+
+#### 2.1.3 表格识别
+```bash
+paddleocr --image_dir=PaddleOCR/ppstructure/docs/table/table.jpg --type=structure --layout=false
+```
+
+
+#### 2.1.4 DocVQA
请参考:[文档视觉问答](../vqa/README.md)。
-### 2.2 Python脚本使用
+
+### 2.2 代码使用
+
+
+#### 2.2.1 版面分析+表格识别
-* 版面分析+表格识别
```python
import os
import cv2
@@ -45,8 +73,8 @@ from paddleocr import PPStructure,draw_structure_result,save_structure_res
table_engine = PPStructure(show_log=True)
-save_folder = './output/table'
-img_path = '../doc/table/1.png'
+save_folder = './output'
+img_path = 'PaddleOCR/ppstructure/docs/table/1.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])
@@ -57,21 +85,66 @@ for line in result:
from PIL import Image
-font_path = '../doc/fonts/simfang.ttf' # PaddleOCR下提供字体包
+font_path = 'PaddleOCR/doc/fonts/simfang.ttf' # PaddleOCR下提供字体包
image = Image.open(img_path).convert('RGB')
im_show = draw_structure_result(image, result,font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
```
-* VQA
+
+#### 2.2.2 版面分析
+
+```python
+import os
+import cv2
+from paddleocr import PPStructure,save_structure_res
+
+table_engine = PPStructure(table=False, ocr=False, show_log=True)
+
+save_folder = './output'
+img_path = 'PaddleOCR/ppstructure/docs/table/1.png'
+img = cv2.imread(img_path)
+result = table_engine(img)
+save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0])
+
+for line in result:
+ line.pop('img')
+ print(line)
+```
+
+
+#### 2.2.3 表格识别
+
+```python
+import os
+import cv2
+from paddleocr import PPStructure,save_structure_res
+
+table_engine = PPStructure(layout=False, show_log=True)
+
+save_folder = './output'
+img_path = 'PaddleOCR/ppstructure/docs/table/table.jpg'
+img = cv2.imread(img_path)
+result = table_engine(img)
+save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0])
+
+for line in result:
+ line.pop('img')
+ print(line)
+```
+
+
+#### 2.2.4 DocVQA
请参考:[文档视觉问答](../vqa/README.md)。
+
### 2.3 返回结果说明
PP-Structure的返回结果为一个dict组成的list,示例如下
-* 版面分析+表格识别
+
+#### 2.3.1 版面分析+表格识别
```shell
[
{ 'type': 'Text',
@@ -83,77 +156,43 @@ PP-Structure的返回结果为一个dict组成的list,示例如下
```
dict 里各个字段说明如下
-| 字段 | 说明 |
-| --------------- | -------------|
-|type|图片区域的类型|
-|bbox|图片区域的在原图的坐标,分别[左上角x,左上角y,右下角x,右下角y]|
-|res|图片区域的OCR或表格识别结果。
图中展示了版面分析+表格识别的整体流程,图片先有版面分析划分为图像、文本、标题和表格四种区域,然后对图像、文本和标题三种区域进行OCR的检测识别,对表格进行表格识别,其中图像还会被存储下来以便使用。
+
### 4.2 DOC-VQA
* SER
- | 
+ | 
---|---
图中不同颜色的框表示不同的类别,对于XFUN数据集,有`QUESTION`, `ANSWER`, `HEADER` 3种类别
@@ -60,46 +67,55 @@ PP-Structure的主要特性如下:
* RE
- | 
+ | 
---|---
图中红色框表示问题,蓝色框表示答案,问题和答案之间使用绿色线连接。在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
+
## 5. 快速体验
-请参考[快速安装](./docs/quickstart.md)教程。
+请参考[快速使用](./docs/quickstart.md)教程。
+
## 6. PP-Structure 介绍
+
### 6.1 版面分析+表格识别
-
+
在PP-Structure中,图片会先经由Layout-Parser进行版面分析,在版面分析中,会对图片里的区域进行分类,包括**文字、标题、图片、列表和表格**5类。对于前4类区域,直接使用PP-OCR完成对应区域文字检测与识别。对于表格类区域,经过表格结构化处理后,表格图片转换为相同表格样式的Excel文件。
+
#### 6.1.1 版面分析
版面分析对文档数据进行区域分类,其中包括版面分析工具的Python脚本使用、提取指定类别检测框、性能指标以及自定义训练版面分析模型,详细内容可以参考[文档](layout/README_ch.md)。
+
#### 6.1.2 表格识别
表格识别将表格图片转换为excel文档,其中包含对于表格文本的检测和识别以及对于表格结构和单元格坐标的预测,详细说明参考[文档](table/README_ch.md)。
-### 6.2 DOC-VQA
+
+### 6.2 DocVQA
-DOC-VQA指文档视觉问答,其中包括语义实体识别 (Semantic Entity Recognition, SER) 和关系抽取 (Relation Extraction, RE) 任务。基于 SER 任务,可以完成对图像中的文本识别与分类;基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair),详细说明参考[文档](vqa/README.md)。
+DocVQA指文档视觉问答,其中包括语义实体识别 (Semantic Entity Recognition, SER) 和关系抽取 (Relation Extraction, RE) 任务。基于 SER 任务,可以完成对图像中的文本识别与分类;基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair),详细说明参考[文档](vqa/README.md)。
+
## 7. 模型库
PP-Structure系列模型列表(更新中)
+
### 7.1 版面分析模型
|模型名称|模型简介|下载地址| label_map|
| --- | --- | --- | --- |
| ppyolov2_r50vd_dcn_365e_publaynet | PubLayNet 数据集训练的版面分析模型,可以划分**文字、标题、表格、图片以及列表**5类区域 | [PubLayNet](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_publaynet.tar) | {0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"}|
+
### 7.2 OCR和表格识别模型
|模型名称|模型简介|模型大小|下载地址|
@@ -108,7 +124,8 @@ PP-Structure系列模型列表(更新中)
|ch_PP-OCRv2_rec_slim|【最新】slim量化版超轻量模型,支持中英文、数字识别| 9M |[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_train.tar) |
|en_ppocr_mobile_v2.0_table_structure|PubLayNet数据集训练的英文表格场景的表格结构预测|18.6M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar) |
-### 7.2 DOC-VQA 模型
+
+### 7.3 DocVQA 模型
|模型名称|模型简介|模型大小|下载地址|
| --- | --- | --- | --- |
diff --git a/ppstructure/docs/inference.md b/ppstructure/docs/inference.md
new file mode 100644
index 0000000000000000000000000000000000000000..7604246da5a79b0ee2939c9fb4c91602531ec7de
--- /dev/null
+++ b/ppstructure/docs/inference.md
@@ -0,0 +1,80 @@
+# 基于Python预测引擎推理
+
+- [1. Structure](#1)
+ - [1.1 版面分析+表格识别](#1.1)
+ - [1.2 版面分析](#1.2)
+ - [1.3 表格识别](#1.3)
+- [2. DocVQA](#2)
+
+
+## 1. Structure
+进入`ppstructure`目录
+
+```bash
+cd ppstructure
+````
+下载模型
+```bash
+mkdir inference && cd inference
+# 下载PP-OCRv2文本检测模型并解压
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar && tar xf ch_PP-OCRv2_det_slim_quant_infer.tar
+# 下载PP-OCRv2文本识别模型并解压
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar && tar xf ch_PP-OCRv2_rec_slim_quant_infer.tar
+# 下载超轻量级英文表格预测模型并解压
+wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar && tar xf en_ppocr_mobile_v2.0_table_structure_infer.tar
+cd ..
+```
+
+### 1.1 版面分析+表格识别
+```bash
+python3 predict_system.py --det_model_dir=inference/ch_PP-OCRv2_det_slim_quant_infer \
+ --rec_model_dir=inference/ch_PP-OCRv2_rec_slim_quant_infer \
+ --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer \
+ --image_dir=./docs/table/1.png \
+ --rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt \
+ --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
+ --output=../output \
+ --vis_font_path=../doc/fonts/simfang.ttf
+```
+运行完成后,每张图片会在`output`字段指定的目录下的`structure`目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名为表格在图片里的坐标。详细的结果会存储在`res.txt`文件中。
+
+
+### 1.2 版面分析
+```bash
+python3 predict_system.py --image_dir=./docs/table/1.png --table=false --ocr=false --output=../output/
+```
+运行完成后,每张图片会在`output`字段指定的目录下的`structure`目录下有一个同名目录,图片区域会被裁剪之后保存下来,图片名为表格在图片里的坐标。版面分析结果会存储在`res.txt`文件中。
+
+
+### 1.3 表格识别
+```bash
+python3 predict_system.py --det_model_dir=inference/ch_PP-OCRv2_det_slim_quant_infer \
+ --rec_model_dir=inference/ch_PP-OCRv2_rec_slim_quant_infer \
+ --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer \
+ --image_dir=./docs/table/table.jpg \
+ --rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt \
+ --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
+ --output=../output \
+ --vis_font_path=../doc/fonts/simfang.ttf \
+ --layout=false
+```
+运行完成后,每张图片会在`output`字段指定的目录下的`structure`目录下有一个同名目录,表格会存储为一个excel,excel文件名为`[0,0,img_h,img_w]`。
+
+
+## 2. DocVQA
+
+```bash
+cd ppstructure
+
+# 下载模型
+mkdir inference && cd inference
+# 下载SER xfun 模型并解压
+wget https://paddleocr.bj.bcebos.com/pplayout/PP-Layout_v1.0_ser_pretrained.tar && tar xf PP-Layout_v1.0_ser_pretrained.tar
+cd ..
+
+python3 predict_system.py --model_name_or_path=vqa/PP-Layout_v1.0_ser_pretrained/ \
+ --mode=vqa \
+ --image_dir=vqa/images/input/zh_val_0.jpg \
+ --vis_font_path=../doc/fonts/simfang.ttf
+```
+运行完成后,每张图片会在`output`字段指定的目录下的`vqa`目录下存放可视化之后的图片,图片名和输入图片名一致。
diff --git a/ppstructure/docs/inference_en.md b/ppstructure/docs/inference_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..2a0fb30543eaa06c4ede5f82a443135c959db37d
--- /dev/null
+++ b/ppstructure/docs/inference_en.md
@@ -0,0 +1,81 @@
+# Python Inference
+
+- [1. Structure](#1)
+ - [1.1 layout analysis + table recognition](#1.1)
+ - [1.2 layout analysis](#1.2)
+ - [1.3 table recognition](#1.3)
+- [2. DocVQA](#2)
+
+
+## 1. Structure
+Go to the `ppstructure` directory
+
+```bash
+cd ppstructure
+````
+
+download model
+
+```bash
+mkdir inference && cd inference
+# Download the PP-OCRv2 text detection model and unzip it
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar && tar xf ch_PP-OCRv2_det_slim_quant_infer.tar
+# Download the PP-OCRv2 text recognition model and unzip it
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar && tar xf ch_PP-OCRv2_rec_slim_quant_infer.tar
+# Download the ultra-lightweight English table structure model and unzip it
+wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar && tar xf en_ppocr_mobile_v2.0_table_structure_infer.tar
+cd ..
+```
+
+### 1.1 layout analysis + table recognition
+```bash
+python3 predict_system.py --det_model_dir=inference/ch_PP-OCRv2_det_slim_quant_infer \
+ --rec_model_dir=inference/ch_PP-OCRv2_rec_slim_quant_infer \
+ --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer \
+ --image_dir=./docs/table/1.png \
+ --rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt \
+ --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
+ --output=../output \
+ --vis_font_path=../doc/fonts/simfang.ttf
+```
+After the operation is completed, each image will have a directory with the same name in the `structure` directory under the directory specified by the `output` field. Each table in the image will be stored as an excel, and the picture area will be cropped and saved. The filename of excel and picture is their coordinates in the image. Detailed results are stored in the `res.txt` file.
+
+
+### 1.2 layout analysis
+```bash
+python3 predict_system.py --image_dir=./docs/table/1.png --table=false --ocr=false --output=../output/
+```
+After the operation is completed, each image will have a directory with the same name in the `structure` directory under the directory specified by the `output` field. Each picture in image will be cropped and saved. The filename of picture area is their coordinates in the image. Layout analysis results will be stored in the `res.txt` file
+
+
+### 1.3 table recognition
+```bash
+python3 predict_system.py --det_model_dir=inference/ch_PP-OCRv2_det_slim_quant_infer \
+ --rec_model_dir=inference/ch_PP-OCRv2_rec_slim_quant_infer \
+ --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer \
+ --image_dir=./docs/table/table.jpg \
+ --rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt \
+ --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
+ --output=../output \
+ --vis_font_path=../doc/fonts/simfang.ttf \
+ --layout=false
+```
+After the operation is completed, each image will have a directory with the same name in the `structure` directory under the directory specified by the `output` field. Each table in the image will be stored as an excel. The filename of excel is their coordinates in the image.
+
+
+## 2. DocVQA
+
+```bash
+cd ppstructure
+
+# download model
+mkdir inference && cd inference
+wget https://paddleocr.bj.bcebos.com/pplayout/PP-Layout_v1.0_ser_pretrained.tar && tar xf PP-Layout_v1.0_ser_pretrained.tar
+cd ..
+
+python3 predict_system.py --model_name_or_path=vqa/PP-Layout_v1.0_ser_pretrained/ \
+ --mode=vqa \
+ --image_dir=vqa/images/input/zh_val_0.jpg \
+ --vis_font_path=../doc/fonts/simfang.ttf
+```
+After the operation is completed, each image will store the visualized image in the `vqa` directory under the directory specified by the `output` field, and the image name is the same as the input image name.
diff --git a/ppstructure/docs/models_list.md b/ppstructure/docs/models_list.md
index 5de7394d7e4e250f74471bbbb2fa89f779b70516..c7dab999ff6e370c56c5495e22e91f117b3d1275 100644
--- a/ppstructure/docs/models_list.md
+++ b/ppstructure/docs/models_list.md
@@ -1,15 +1,15 @@
-- [PP-Structure 系列模型列表](#pp-structure-系列模型列表)
- - [1. LayoutParser 模型](#1-layoutparser-模型)
- - [2. OCR和表格识别模型](#2-ocr和表格识别模型)
- - [2.1 OCR](#21-ocr)
- - [2.2 表格识别模型](#22-表格识别模型)
- - [3. VQA模型](#3-vqa模型)
- - [4. KIE模型](#4-kie模型)
-
# PP-Structure 系列模型列表
+- [1. 版面分析模型](#1)
+- [2. OCR和表格识别模型](#2)
+ - [2.1 OCR](#21)
+ - [2.2 表格识别模型](#22)
+- [3. VQA模型](#3)
+- [4. KIE模型](#4)
+
-## 1. LayoutParser 模型
+
+## 1. 版面分析模型
|模型名称|模型简介|下载地址|label_map|
| --- | --- | --- | --- |
@@ -17,8 +17,10 @@
| ppyolov2_r50vd_dcn_365e_tableBank_word | TableBank Word 数据集训练的版面分析模型,只能检测表格 | [推理模型](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_tableBank_word.tar) | {0:"Table"}|
| ppyolov2_r50vd_dcn_365e_tableBank_latex | TableBank Latex 数据集训练的版面分析模型,只能检测表格 | [推理模型](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_tableBank_latex.tar) | {0:"Table"}|
+
## 2. OCR和表格识别模型
+
### 2.1 OCR
|模型名称|模型简介|推理模型大小|下载地址|
@@ -28,12 +30,14 @@
如需要使用其他OCR模型,可以在 [PP-OCR model_list](../../doc/doc_ch/models_list.md) 下载模型或者使用自己训练好的模型配置到 `det_model_dir`, `rec_model_dir`两个字段即可。
+
### 2.2 表格识别模型
|模型名称|模型简介|推理模型大小|下载地址|
| --- | --- | --- | --- |
|en_ppocr_mobile_v2.0_table_structure|PubLayNet数据集训练的英文表格场景的表格结构预测|18.6M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar) |
+
## 3. VQA模型
|模型名称|模型简介|推理模型大小|下载地址|
@@ -44,6 +48,7 @@
|re_LayoutLMv2_xfun_zh|基于LayoutLMv2在xfun中文数据集上训练的RE模型|765M|[推理模型 coming soon]() / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutLMv2_xfun_zh.tar) |
|ser_LayoutLM_xfun_zh|基于LayoutLM在xfun中文数据集上训练的SER模型|430M|[推理模型 coming soon]() / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLM_xfun_zh.tar) |
+
## 4. KIE模型
|模型名称|模型简介|模型大小|下载地址|
diff --git a/ppstructure/docs/models_list_en.md b/ppstructure/docs/models_list_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..b92c10c241df72c85649b64f915b4266cd3fe410
--- /dev/null
+++ b/ppstructure/docs/models_list_en.md
@@ -0,0 +1,56 @@
+# PP-Structure Model list
+
+- [1. Layout Analysis](#1)
+- [2. OCR and Table Recognition](#2)
+ - [2.1 OCR](#21)
+ - [2.2 Table Recognition](#22)
+- [3. VQA](#3)
+- [4. KIE](#4)
+
+
+
+## 1. Layout Analysis
+
+|model name| description |download|label_map|
+| --- |---------------------------------------------------------------------------------------------------------------------------------------------------------| --- | --- |
+| ppyolov2_r50vd_dcn_365e_publaynet | The layout analysis model trained on the PubLayNet dataset, the model can recognition 5 types of areas such as **text, title, table, picture and list** | [inference model](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_publaynet.tar) / [trained model](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_publaynet_pretrained.pdparams) |{0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"}|
+| ppyolov2_r50vd_dcn_365e_tableBank_word | The layout analysis model trained on the TableBank Word dataset, the model can only detect tables | [inference model](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_tableBank_word.tar) | {0:"Table"}|
+| ppyolov2_r50vd_dcn_365e_tableBank_latex | The layout analysis model trained on the TableBank Latex dataset, the model can only detect tables | [inference model](https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_tableBank_latex.tar) | {0:"Table"}|
+
+
+## 2. OCR and Table Recognition
+
+
+### 2.1 OCR
+
+|model name| description | inference model size |download|
+| --- |---|---| --- |
+|en_ppocr_mobile_v2.0_table_det| Text detection model of English table scenes trained on PubTabNet dataset | 4.7M |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_det_train.tar) |
+|en_ppocr_mobile_v2.0_table_rec| Text recognition model of English table scenes trained on PubTabNet dataset | 6.9M |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_rec_train.tar) |
+
+If you need to use other OCR models, you can download the model in [PP-OCR model_list](../../doc/doc_ch/models_list.md) or use the model you trained yourself to configure to `det_model_dir`, `rec_model_dir` field.
+
+
+### 2.2 Table Recognition
+
+|model| description |inference model size|download|
+| --- |-----------------------------------------------------------------------------| --- | --- |
+|en_ppocr_mobile_v2.0_table_structure| Table structure model for English table scenes trained on PubTabNet dataset |18.6M|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar) |
+
+
+## 3. VQA
+
+|model| description |inference model size|download|
+| --- |----------------------------------------------------------------| --- | --- |
+|ser_LayoutXLM_xfun_zh| SER model trained on xfun Chinese dataset based on LayoutXLM |1.4G|[inference model coming soon]() / [trained model](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar) |
+|re_LayoutXLM_xfun_zh| Re model trained on xfun Chinese dataset based on LayoutXLM |1.4G|[inference model coming soon]() / [trained model](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar) |
+|ser_LayoutLMv2_xfun_zh| SER model trained on xfun Chinese dataset based on LayoutXLMv2 |778M|[inference model coming soon]() / [trained model](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLMv2_xfun_zh.tar) |
+|re_LayoutLMv2_xfun_zh| Re model trained on xfun Chinese dataset based on LayoutXLMv2 |765M|[inference model coming soon]() / [trained model](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutLMv2_xfun_zh.tar) |
+|ser_LayoutLM_xfun_zh| SER model trained on xfun Chinese dataset based on LayoutLM |430M|[inference model coming soon]() / [trained model](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLM_xfun_zh.tar) |
+
+
+## 4. KIE
+
+|model|description|model size|download|
+| --- | --- | --- | --- |
+|SDMGR|Key Information Extraction Model|78M|[inference model coming soon]() / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.1/kie/kie_vgg16.tar)|
diff --git a/ppstructure/docs/quickstart.md b/ppstructure/docs/quickstart.md
index 52e0c77dd1d9716827e06819cc957e36f02ee1f8..6610035d1442f988ac69763724ce78f6db35ae20 100644
--- a/ppstructure/docs/quickstart.md
+++ b/ppstructure/docs/quickstart.md
@@ -1,43 +1,71 @@
# PP-Structure 快速开始
-- [PP-Structure 快速开始](#pp-structure-快速开始)
- - [1. 安装依赖包](#1-安装依赖包)
- - [2. 便捷使用](#2-便捷使用)
- - [2.1 命令行使用](#21-命令行使用)
- - [2.2 Python脚本使用](#22-python脚本使用)
- - [2.3 返回结果说明](#23-返回结果说明)
- - [2.4 参数说明](#24-参数说明)
- - [3. Python脚本使用](#3-python脚本使用)
-
+- [1. 安装依赖包](#1)
+- [2. 便捷使用](#2)
+ - [2.1 命令行使用](#21)
+ - [2.1.1 版面分析+表格识别](#211)
+ - [2.1.2 版面分析](#212)
+ - [2.1.3 表格识别](#213)
+ - [2.1.4 DocVQA](#214)
+ - [2.2 代码使用](#22)
+ - [2.2.1 版面分析+表格识别](#221)
+ - [2.2.2 版面分析](#222)
+ - [2.2.3 表格识别](#223)
+ - [2.2.4 DocVQA](#224)
+ - [2.3 返回结果说明](#23)
+ - [2.3.1 版面分析+表格识别](#231)
+ - [2.3.2 DocVQA](#232)
+ - [2.4 参数说明](#24)
+
+
+
## 1. 安装依赖包
```bash
-pip install "paddleocr>=2.3.0.2" # 推荐使用2.3.0.2+版本
+# 安装 paddleocr,推荐使用2.5+版本
+pip3 install "paddleocr>=2.5"
+# 安装 版面分析依赖包layoutparser(如不需要版面分析功能,可跳过)
pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
-
-# 安装 PaddleNLP
-git clone https://github.com/PaddlePaddle/PaddleNLP -b develop
-cd PaddleNLP
-pip3 install -e .
+# 安装 DocVQA依赖包paddlenlp(如不需要DocVQA功能,可跳过)
+pip install paddlenlp
```
+
## 2. 便捷使用
-### 2.1 命令行使用
+
+### 2.1 命令行使用
-* 版面分析+表格识别
+
+#### 2.1.1 版面分析+表格识别
```bash
-paddleocr --image_dir=../doc/table/1.png --type=structure
+paddleocr --image_dir=PaddleOCR/ppstructure/docs/table/1.png --type=structure
```
-* VQA
+
+#### 2.1.2 版面分析
+```bash
+paddleocr --image_dir=PaddleOCR/ppstructure/docs/table/1.png --type=structure --table=false --ocr=false
+```
+
+
+#### 2.1.3 表格识别
+```bash
+paddleocr --image_dir=PaddleOCR/ppstructure/docs/table/table.jpg --type=structure --layout=false
+```
+
+
+#### 2.1.4 DocVQA
请参考:[文档视觉问答](../vqa/README.md)。
-### 2.2 Python脚本使用
+
+### 2.2 代码使用
+
+
+#### 2.2.1 版面分析+表格识别
-* 版面分析+表格识别
```python
import os
import cv2
@@ -45,8 +73,8 @@ from paddleocr import PPStructure,draw_structure_result,save_structure_res
table_engine = PPStructure(show_log=True)
-save_folder = './output/table'
-img_path = '../doc/table/1.png'
+save_folder = './output'
+img_path = 'PaddleOCR/ppstructure/docs/table/1.png'
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])
@@ -57,21 +85,66 @@ for line in result:
from PIL import Image
-font_path = '../doc/fonts/simfang.ttf' # PaddleOCR下提供字体包
+font_path = 'PaddleOCR/doc/fonts/simfang.ttf' # PaddleOCR下提供字体包
image = Image.open(img_path).convert('RGB')
im_show = draw_structure_result(image, result,font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
```
-* VQA
+
+#### 2.2.2 版面分析
+
+```python
+import os
+import cv2
+from paddleocr import PPStructure,save_structure_res
+
+table_engine = PPStructure(table=False, ocr=False, show_log=True)
+
+save_folder = './output'
+img_path = 'PaddleOCR/ppstructure/docs/table/1.png'
+img = cv2.imread(img_path)
+result = table_engine(img)
+save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0])
+
+for line in result:
+ line.pop('img')
+ print(line)
+```
+
+
+#### 2.2.3 表格识别
+
+```python
+import os
+import cv2
+from paddleocr import PPStructure,save_structure_res
+
+table_engine = PPStructure(layout=False, show_log=True)
+
+save_folder = './output'
+img_path = 'PaddleOCR/ppstructure/docs/table/table.jpg'
+img = cv2.imread(img_path)
+result = table_engine(img)
+save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0])
+
+for line in result:
+ line.pop('img')
+ print(line)
+```
+
+
+#### 2.2.4 DocVQA
请参考:[文档视觉问答](../vqa/README.md)。
+
### 2.3 返回结果说明
PP-Structure的返回结果为一个dict组成的list,示例如下
-* 版面分析+表格识别
+
+#### 2.3.1 版面分析+表格识别
```shell
[
{ 'type': 'Text',
@@ -83,77 +156,43 @@ PP-Structure的返回结果为一个dict组成的list,示例如下
```
dict 里各个字段说明如下
-| 字段 | 说明 |
-| --------------- | -------------|
-|type|图片区域的类型|
-|bbox|图片区域的在原图的坐标,分别[左上角x,左上角y,右下角x,右下角y]|
-|res|图片区域的OCR或表格识别结果。
表格: 表格的HTML字符串;
OCR: 一个包含各个单行文字的检测坐标和识别结果的元组|
+| 字段 | 说明 |
+| --------------- |-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+|type| 图片区域的类型 |
+|bbox| 图片区域的在原图的坐标,分别[左上角x,左上角y,右下角x,右下角y] |
+|res| 图片区域的OCR或表格识别结果。
表格: 一个dict,字段说明如下
`html`: 表格的HTML字符串
在代码使用模式下,前向传入return_ocr_result_in_table=True可以拿到表格中每个文本的检测识别结果,对应为如下字段:
`boxes`: 文本检测坐标
`rec_res`: 文本识别结果。
OCR: 一个包含各个单行文字的检测坐标和识别结果的元组 |
-* VQA
+运行完成后,每张图片会在`output`字段指定的目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名为表格在图片里的坐标。
+
+ ```
+ /output/table/1/
+ └─ res.txt
+ └─ [454, 360, 824, 658].xlsx 表格识别结果
+ └─ [16, 2, 828, 305].jpg 被裁剪出的图片区域
+ └─ [17, 361, 404, 711].xlsx 表格识别结果
+ ```
+
+
+#### 2.3.2 DocVQA
请参考:[文档视觉问答](../vqa/README.md)。
+
### 2.4 参数说明
-| 字段 | 说明 | 默认值 |
-| --------------- | ---------------------------------------- | ------------------------------------------- |
-| output | excel和识别结果保存的地址 | ./output/table |
-| table_max_len | 表格结构模型预测时,图像的长边resize尺度 | 488 |
-| table_model_dir | 表格结构模型 inference 模型地址 | None |
-| table_char_dict_path | 表格结构模型所用字典地址 | ../ppocr/utils/dict/table_structure_dict.txt |
-| layout_path_model | 版面分析模型模型地址,可以为在线地址或者本地地址,当为本地地址时,需要指定 layout_label_map, 命令行模式下可通过--layout_label_map='{0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"}' 指定 | lp://PubLayNet/ppyolov2_r50vd_dcn_365e_publaynet/config |
-| layout_label_map | 版面分析模型模型label映射字典 | None |
-| model_name_or_path | VQA SER模型地址 | None |
-| max_seq_length | VQA SER模型最大支持token长度 | 512 |
-| label_map_path | VQA SER 标签文件地址 | ./vqa/labels/labels_ser.txt |
-| mode | pipeline预测模式,structure: 版面分析+表格识别; VQA: SER文档信息抽取 | structure |
+| 字段 | 说明 | 默认值 |
+|----------------------|----------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------|
+| output | excel和识别结果保存的地址 | ./output/table |
+| table_max_len | 表格结构模型预测时,图像的长边resize尺度 | 488 |
+| table_model_dir | 表格结构模型 inference 模型地址 | None |
+| table_char_dict_path | 表格结构模型所用字典地址 | ../ppocr/utils/dict/table_structure_dict.txt |
+| layout_path_model | 版面分析模型模型地址,可以为在线地址或者本地地址,当为本地地址时,需要指定 layout_label_map, 命令行模式下可通过--layout_label_map='{0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"}' 指定 | lp://PubLayNet/ppyolov2_r50vd_dcn_365e_publaynet/config |
+| layout_label_map | 版面分析模型模型label映射字典 | None |
+| model_name_or_path | VQA SER模型地址 | None |
+| max_seq_length | VQA SER模型最大支持token长度 | 512 |
+| label_map_path | VQA SER 标签文件地址 | ./vqa/labels/labels_ser.txt |
+| layout | 前向中是否执行版面分析 | True |
+| table | 前向中是否执行表格识别 | True |
+| ocr | 对于版面分析中的非表格区域,是否执行ocr。当layout为False时会被自动设置为False | True |
大部分参数和PaddleOCR whl包保持一致,见 [whl包文档](../../doc/doc_ch/whl.md)
-
-运行完成后,每张图片会在`output`字段指定的目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名名为表格在图片里的坐标。
-
-## 3. Python脚本使用
-
-* 版面分析+表格识别
-
-```bash
-cd ppstructure
-
-# 下载模型
-mkdir inference && cd inference
-# 下载PP-OCRv2文本检测模型并解压
-wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar && tar xf ch_PP-OCRv2_det_slim_quant_infer.tar
-# 下载PP-OCRv2文本识别模型并解压
-wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar && tar xf ch_PP-OCRv2_rec_slim_quant_infer.tar
-# 下载超轻量级英文表格预测模型并解压
-wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar && tar xf en_ppocr_mobile_v2.0_table_structure_infer.tar
-cd ..
-
-python3 predict_system.py --det_model_dir=inference/ch_PP-OCRv2_det_slim_quant_infer \
- --rec_model_dir=inference/ch_PP-OCRv2_rec_slim_quant_infer \
- --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer \
- --image_dir=../doc/table/1.png \
- --rec_char_dict_path=../ppocr/utils/ppocr_keys_v1.txt \
- --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \
- --output=../output/table \
- --vis_font_path=../doc/fonts/simfang.ttf
-```
-运行完成后,每张图片会在`output`字段指定的目录下的`talbe`目录下有一个同名目录,图片里的每个表格会存储为一个excel,图片区域会被裁剪之后保存下来,excel文件和图片名名为表格在图片里的坐标。
-
-* VQA
-
-```bash
-cd ppstructure
-
-# 下载模型
-mkdir inference && cd inference
-# 下载SER xfun 模型并解压
-wget https://paddleocr.bj.bcebos.com/pplayout/PP-Layout_v1.0_ser_pretrained.tar && tar xf PP-Layout_v1.0_ser_pretrained.tar
-cd ..
-
-python3 predict_system.py --model_name_or_path=vqa/PP-Layout_v1.0_ser_pretrained/ \
- --mode=vqa \
- --image_dir=vqa/images/input/zh_val_0.jpg \
- --vis_font_path=../doc/fonts/simfang.ttf
-```
-运行完成后,每张图片会在`output`字段指定的目录下的`vqa`目录下存放可视化之后的图片,图片名和输入图片名一致。
diff --git a/ppstructure/docs/quickstart_en.md b/ppstructure/docs/quickstart_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..853436ff07e665fb140a749e8ccbde4392ea5c13
--- /dev/null
+++ b/ppstructure/docs/quickstart_en.md
@@ -0,0 +1,198 @@
+# PP-Structure Quick Start
+
+- [1. Install package](#1)
+- [2. Use](#2)
+ - [2.1 Use by command line](#21)
+ - [2.1.1 layout analysis + table recognition](#211)
+ - [2.1.2 layout analysis](#212)
+ - [2.1.3 table recognition](#213)
+ - [2.1.4 DocVQA](#214)
+ - [2.2 Use by code](#22)
+ - [2.2.1 layout analysis + table recognition](#221)
+ - [2.2.2 layout analysis](#222)
+ - [2.2.3 table recognition](#223)
+ - [2.2.4 DocVQA](#224)
+ - [2.3 Result description](#23)
+ - [2.3.1 layout analysis + table recognition](#231)
+ - [2.3.2 DocVQA](#232)
+ - [2.4 Parameter Description](#24)
+
+
+
+## 1. Install package
+
+```bash
+# Install paddleocr, version 2.5+ is recommended
+pip3 install "paddleocr>=2.5"
+# Install layoutparser (if you do not use the layout analysis, you can skip it)
+pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
+# Install the DocVQA dependency package paddlenlp (if you do not use the DocVQA, you can skip it)
+pip install paddlenlp
+
+```
+
+
+## 2. Use
+
+
+### 2.1 Use by command line
+
+
+#### 2.1.1 layout analysis + table recognition
+```bash
+paddleocr --image_dir=PaddleOCR/ppstructure/docs/table/1.png --type=structure
+```
+
+
+#### 2.1.2 layout analysis
+```bash
+paddleocr --image_dir=PaddleOCR/ppstructure/docs/table/1.png --type=structure --table=false --ocr=false
+```
+
+
+#### 2.1.3 table recognition
+```bash
+paddleocr --image_dir=PaddleOCR/ppstructure/docs/table/table.jpg --type=structure --layout=false
+```
+
+
+#### 2.1.4 DocVQA
+
+Please refer to: [Documentation Visual Q&A](../vqa/README.md) .
+
+
+### 2.2 Use by code
+
+
+#### 2.2.1 layout analysis + table recognition
+
+```python
+import os
+import cv2
+from paddleocr import PPStructure,draw_structure_result,save_structure_res
+
+table_engine = PPStructure(show_log=True)
+
+save_folder = './output'
+img_path = 'PaddleOCR/ppstructure/docs/table/1.png'
+img = cv2.imread(img_path)
+result = table_engine(img)
+save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])
+
+for line in result:
+ line.pop('img')
+ print(line)
+
+from PIL import Image
+
+font_path = 'PaddleOCR/doc/fonts/simfang.ttf' # PaddleOCR下提供字体包
+image = Image.open(img_path).convert('RGB')
+im_show = draw_structure_result(image, result,font_path=font_path)
+im_show = Image.fromarray(im_show)
+im_show.save('result.jpg')
+```
+
+
+#### 2.2.2 layout analysis
+
+```python
+import os
+import cv2
+from paddleocr import PPStructure,save_structure_res
+
+table_engine = PPStructure(table=False, ocr=False, show_log=True)
+
+save_folder = './output'
+img_path = 'PaddleOCR/ppstructure/docs/table/1.png'
+img = cv2.imread(img_path)
+result = table_engine(img)
+save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0])
+
+for line in result:
+ line.pop('img')
+ print(line)
+```
+
+
+#### 2.2.3 table recognition
+
+```python
+import os
+import cv2
+from paddleocr import PPStructure,save_structure_res
+
+table_engine = PPStructure(layout=False, show_log=True)
+
+save_folder = './output'
+img_path = 'PaddleOCR/ppstructure/docs/table/table.jpg'
+img = cv2.imread(img_path)
+result = table_engine(img)
+save_structure_res(result, save_folder, os.path.basename(img_path).split('.')[0])
+
+for line in result:
+ line.pop('img')
+ print(line)
+```
+
+
+#### 2.2.4 DocVQA
+
+Please refer to: [Documentation Visual Q&A](../vqa/README.md) .
+
+
+### 2.3 Result description
+
+The return of PP-Structure is a list of dicts, the example is as follows:
+
+
+#### 2.3.1 layout analysis + table recognition
+```shell
+[
+ { 'type': 'Text',
+ 'bbox': [34, 432, 345, 462],
+ 'res': ([[36.0, 437.0, 341.0, 437.0, 341.0, 446.0, 36.0, 447.0], [41.0, 454.0, 125.0, 453.0, 125.0, 459.0, 41.0, 460.0]],
+ [('Tigure-6. The performance of CNN and IPT models using difforen', 0.90060663), ('Tent ', 0.465441)])
+ }
+]
+```
+Each field in dict is described as follows:
+
+| field | description |
+| --------------- |--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+|type| Type of image area. |
+|bbox| The coordinates of the image area in the original image, respectively [upper left corner x, upper left corner y, lower right corner x, lower right corner y]. |
+|res| OCR or table recognition result of the image area.
table: a dict with field descriptions as follows:
`html`: html str of table.
In the code usage mode, set return_ocr_result_in_table=True whrn call can get the detection and recognition results of each text in the table area, corresponding to the following fields:
`boxes`: text detection boxes.
`rec_res`: text recognition results.
OCR: A tuple containing the detection boxes and recognition results of each single text. |
+
+After the recognition is completed, each image will have a directory with the same name under the directory specified by the `output` field. Each table in the image will be stored as an excel, and the picture area will be cropped and saved. The filename of excel and picture is their coordinates in the image.
+ ```
+ /output/table/1/
+ └─ res.txt
+ └─ [454, 360, 824, 658].xlsx table recognition result
+ └─ [16, 2, 828, 305].jpg picture in Image
+ └─ [17, 361, 404, 711].xlsx table recognition result
+ ```
+
+
+#### 2.3.2 DocVQA
+
+Please refer to: [Documentation Visual Q&A](../vqa/README.md) .
+
+
+### 2.4 Parameter Description
+
+| field | description | default |
+|----------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------|
+| output | The save path of result | ./output/table |
+| table_max_len | When the table structure model predicts, the long side of the image | 488 |
+| table_model_dir | the path of table structure model | None |
+| table_char_dict_path | the dict path of table structure model | ../ppocr/utils/dict/table_structure_dict.txt |
+| layout_path_model | The model path of the layout analysis model, which can be an online address or a local path. When it is a local path, layout_label_map needs to be set. In command line mode, use --layout_label_map='{0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"}' | lp://PubLayNet/ppyolov2_r50vd_dcn_365e_publaynet/config |
+| layout_label_map | Layout analysis model model label mapping dictionary path | None |
+| model_name_or_path | the model path of VQA SER model | None |
+| max_seq_length | the max token length of VQA SER model | 512 |
+| label_map_path | the label path of VQA SER model | ./vqa/labels/labels_ser.txt |
+| layout | Whether to perform layout analysis in forward | True |
+| table | Whether to perform table recognition in forward | True |
+| ocr | Whether to perform ocr for non-table areas in layout analysis. When layout is False, it will be automatically set to False | True |
+
+Most of the parameters are consistent with the PaddleOCR whl package, see [whl package documentation](../../doc/doc_en/whl.md)
diff --git a/doc/table/1.png b/ppstructure/docs/table/1.png
similarity index 100%
rename from doc/table/1.png
rename to ppstructure/docs/table/1.png
diff --git a/doc/table/layout.jpg b/ppstructure/docs/table/layout.jpg
similarity index 100%
rename from doc/table/layout.jpg
rename to ppstructure/docs/table/layout.jpg
diff --git a/doc/table/paper-image.jpg b/ppstructure/docs/table/paper-image.jpg
similarity index 100%
rename from doc/table/paper-image.jpg
rename to ppstructure/docs/table/paper-image.jpg
diff --git a/doc/table/pipeline.jpg b/ppstructure/docs/table/pipeline.jpg
similarity index 100%
rename from doc/table/pipeline.jpg
rename to ppstructure/docs/table/pipeline.jpg
diff --git a/doc/table/pipeline_en.jpg b/ppstructure/docs/table/pipeline_en.jpg
similarity index 100%
rename from doc/table/pipeline_en.jpg
rename to ppstructure/docs/table/pipeline_en.jpg
diff --git a/doc/table/ppstructure.GIF b/ppstructure/docs/table/ppstructure.GIF
similarity index 100%
rename from doc/table/ppstructure.GIF
rename to ppstructure/docs/table/ppstructure.GIF
diff --git a/doc/table/result_all.jpg b/ppstructure/docs/table/result_all.jpg
similarity index 100%
rename from doc/table/result_all.jpg
rename to ppstructure/docs/table/result_all.jpg
diff --git a/doc/table/result_text.jpg b/ppstructure/docs/table/result_text.jpg
similarity index 100%
rename from doc/table/result_text.jpg
rename to ppstructure/docs/table/result_text.jpg
diff --git a/doc/table/table.jpg b/ppstructure/docs/table/table.jpg
similarity index 100%
rename from doc/table/table.jpg
rename to ppstructure/docs/table/table.jpg
diff --git a/doc/table/tableocr_pipeline.jpg b/ppstructure/docs/table/tableocr_pipeline.jpg
similarity index 100%
rename from doc/table/tableocr_pipeline.jpg
rename to ppstructure/docs/table/tableocr_pipeline.jpg
diff --git a/doc/table/tableocr_pipeline_en.jpg b/ppstructure/docs/table/tableocr_pipeline_en.jpg
similarity index 100%
rename from doc/table/tableocr_pipeline_en.jpg
rename to ppstructure/docs/table/tableocr_pipeline_en.jpg
diff --git a/doc/vqa/input/zh_val_0.jpg b/ppstructure/docs/vqa/input/zh_val_0.jpg
similarity index 100%
rename from doc/vqa/input/zh_val_0.jpg
rename to ppstructure/docs/vqa/input/zh_val_0.jpg
diff --git a/doc/vqa/input/zh_val_21.jpg b/ppstructure/docs/vqa/input/zh_val_21.jpg
similarity index 100%
rename from doc/vqa/input/zh_val_21.jpg
rename to ppstructure/docs/vqa/input/zh_val_21.jpg
diff --git a/doc/vqa/input/zh_val_40.jpg b/ppstructure/docs/vqa/input/zh_val_40.jpg
similarity index 100%
rename from doc/vqa/input/zh_val_40.jpg
rename to ppstructure/docs/vqa/input/zh_val_40.jpg
diff --git a/doc/vqa/input/zh_val_42.jpg b/ppstructure/docs/vqa/input/zh_val_42.jpg
similarity index 100%
rename from doc/vqa/input/zh_val_42.jpg
rename to ppstructure/docs/vqa/input/zh_val_42.jpg
diff --git a/doc/vqa/result_re/zh_val_21_re.jpg b/ppstructure/docs/vqa/result_re/zh_val_21_re.jpg
similarity index 100%
rename from doc/vqa/result_re/zh_val_21_re.jpg
rename to ppstructure/docs/vqa/result_re/zh_val_21_re.jpg
diff --git a/doc/vqa/result_re/zh_val_40_re.jpg b/ppstructure/docs/vqa/result_re/zh_val_40_re.jpg
similarity index 100%
rename from doc/vqa/result_re/zh_val_40_re.jpg
rename to ppstructure/docs/vqa/result_re/zh_val_40_re.jpg
diff --git a/doc/vqa/result_ser/zh_val_0_ser.jpg b/ppstructure/docs/vqa/result_ser/zh_val_0_ser.jpg
similarity index 100%
rename from doc/vqa/result_ser/zh_val_0_ser.jpg
rename to ppstructure/docs/vqa/result_ser/zh_val_0_ser.jpg
diff --git a/doc/vqa/result_ser/zh_val_42_ser.jpg b/ppstructure/docs/vqa/result_ser/zh_val_42_ser.jpg
similarity index 100%
rename from doc/vqa/result_ser/zh_val_42_ser.jpg
rename to ppstructure/docs/vqa/result_ser/zh_val_42_ser.jpg
diff --git a/ppstructure/layout/README_ch.md b/ppstructure/layout/README_ch.md
index 825ff62b116171fda277528017292434bd75b941..69419ad1eee3523d498b0d845a72133b619b3787 100644
--- a/ppstructure/layout/README_ch.md
+++ b/ppstructure/layout/README_ch.md
@@ -1,18 +1,21 @@
[English](README.md) | 简体中文
-- [版面分析使用说明](#版面分析使用说明)
- - [1. 安装whl包](#1--安装whl包)
- - [2. 使用](#2-使用)
- - [3. 后处理](#3-后处理)
- - [4. 指标](#4-指标)
- - [5. 训练版面分析模型](#5-训练版面分析模型)
# 版面分析使用说明
+- [1. 安装whl包](#1)
+- [2. 使用](#2)
+- [3. 后处理](#3)
+- [4. 指标](#4)
+- [5. 训练版面分析模型](#5)
+
+
+
## 1. 安装whl包
```bash
pip install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
```
+
## 2. 使用
使用layoutparser识别给定文档的布局:
@@ -20,7 +23,7 @@ pip install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-a
```python
import cv2
import layoutparser as lp
-image = cv2.imread("doc/table/layout.jpg")
+image = cv2.imread("ppstructure/docs/table/layout.jpg")
image = image[..., ::-1]
# 加载模型
@@ -40,7 +43,7 @@ show_img.show()
下图展示了结果,不同颜色的检测框表示不同的类别,并通过`show_element_type`在框的左上角显示具体类别:
-

+

-

+

', '', '', '', '',
- '', '', '', '', '',
- '', '', '', ''
- ]
- res = []
- for box, rec_res in zip(filter_boxes, filter_rec_res):
- rec_str, rec_conf = rec_res
- for token in style_token:
- if token in rec_str:
- rec_str = rec_str.replace(token, '')
- box += [x1, y1]
- res.append({
- 'text': rec_str,
- 'confidence': float(rec_conf),
- 'text_region': box.tolist()
- })
+ if self.text_system is not None:
+ filter_boxes, filter_rec_res = self.text_system(roi_img)
+ # remove style char
+ style_token = [
+ '', '', '', '', '',
+ '', '', '', '',
+ '', '', '', '',
+ ''
+ ]
+ res = []
+ for box, rec_res in zip(filter_boxes, filter_rec_res):
+ rec_str, rec_conf = rec_res
+ for token in style_token:
+ if token in rec_str:
+ rec_str = rec_str.replace(token, '')
+ box += [x1, y1]
+ res.append({
+ 'text': rec_str,
+ 'confidence': float(rec_conf),
+ 'text_region': box.tolist()
+ })
res_list.append({
'type': region.type,
'bbox': [x1, y1, x2, y2],
'img': roi_img,
'res': res
})
+ return res_list
elif self.mode == 'vqa':
raise NotImplementedError
- return res_list
+ return None
def save_structure_res(res, save_folder, img_name):
excel_save_folder = os.path.join(save_folder, img_name)
os.makedirs(excel_save_folder, exist_ok=True)
+ res_cp = deepcopy(res)
# save res
with open(
os.path.join(excel_save_folder, 'res.txt'), 'w',
encoding='utf8') as f:
- for region in res:
- if region['type'] == 'Table':
+ for region in res_cp:
+ roi_img = region.pop('img')
+ f.write('{}\n'.format(json.dumps(region)))
+
+ if region['type'] == 'Table' and len(region[
+ 'res']) > 0 and 'html' in region['res']:
excel_path = os.path.join(excel_save_folder,
'{}.xlsx'.format(region['bbox']))
- to_excel(region['res'], excel_path)
+ to_excel(region['res']['html'], excel_path)
elif region['type'] == 'Figure':
- roi_img = region['img']
img_path = os.path.join(excel_save_folder,
'{}.jpg'.format(region['bbox']))
cv2.imwrite(img_path, roi_img)
- else:
- for text_result in region['res']:
- f.write('{}\n'.format(json.dumps(text_result)))
def main(args):
diff --git a/ppstructure/table/README.md b/ppstructure/table/README.md
index 65d2cd22b6f18d06fe538ffe1fd243c0c0bfaa3c..d21ef4aa3813b4ff49dc0580be35c5e2e0483c8f 100644
--- a/ppstructure/table/README.md
+++ b/ppstructure/table/README.md
@@ -51,7 +51,7 @@ wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_tab
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar && tar xf en_ppocr_mobile_v2.0_table_structure_infer.tar
cd ..
# run
-python3 table/predict_table.py --det_model_dir=inference/en_ppocr_mobile_v2.0_table_det_infer --rec_model_dir=inference/en_ppocr_mobile_v2.0_table_rec_infer --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer --image_dir=../doc/table/table.jpg --rec_char_dict_path=../ppocr/utils/dict/table_dict.txt --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt --det_limit_side_len=736 --det_limit_type=min --output ../output/table
+python3 table/predict_table.py --det_model_dir=inference/en_ppocr_mobile_v2.0_table_det_infer --rec_model_dir=inference/en_ppocr_mobile_v2.0_table_rec_infer --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer --image_dir=./docs/table/table.jpg --rec_char_dict_path=../ppocr/utils/dict/table_dict.txt --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt --det_limit_side_len=736 --det_limit_type=min --output ./output/table
```
Note: The above model is trained on the PubLayNet dataset and only supports English scanning scenarios. If you need to identify other scenarios, you need to train the model yourself and replace the three fields `det_model_dir`, `rec_model_dir`, `table_model_dir`.
diff --git a/ppstructure/table/README_ch.md b/ppstructure/table/README_ch.md
index 4a617eeb46455b0bd13c8a848419671354eec8fd..a0a64d6b7ebcb272e4b607975170a679abd036ab 100644
--- a/ppstructure/table/README_ch.md
+++ b/ppstructure/table/README_ch.md
@@ -1,14 +1,17 @@
-- [表格识别](#表格识别)
- - [1. 表格识别 pipeline](#1-表格识别-pipeline)
- - [2. 性能](#2-性能)
- - [3. 使用](#3-使用)
- - [3.1 快速开始](#31-快速开始)
- - [3.2 训练](#32-训练)
- - [3.3 评估](#33-评估)
- - [3.4 预测](#34-预测)
+[English](README.md) | 简体中文
# 表格识别
+- [1. 表格识别 pipeline](#1)
+- [2. 性能](#2)
+- [3. 使用](#3)
+ - [3.1 快速开始](#31)
+ - [3.2 训练](#32)
+ - [3.3 评估](#33)
+ - [3.4 预测](#34)
+
+
+
## 1. 表格识别 pipeline
表格识别主要包含三个模型
@@ -18,7 +21,7 @@
具体流程图如下
-
+
流程说明:
@@ -28,7 +31,9 @@
4. 单元格的识别结果和表格结构一起构造表格的html字符串。
+
## 2. 性能
+
我们在 PubTabNet[1] 评估数据集上对算法进行了评估,性能如下
@@ -37,8 +42,10 @@
| EDD[2] | 88.3 |
| Ours | 93.32 |
+
## 3. 使用
+
### 3.1 快速开始
```python
@@ -54,12 +61,13 @@ wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_tab
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar && tar xf en_ppocr_mobile_v2.0_table_structure_infer.tar
cd ..
# 执行预测
-python3 table/predict_table.py --det_model_dir=inference/en_ppocr_mobile_v2.0_table_det_infer --rec_model_dir=inference/en_ppocr_mobile_v2.0_table_rec_infer --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer --image_dir=../doc/table/table.jpg --rec_char_dict_path=../ppocr/utils/dict/table_dict.txt --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt --det_limit_side_len=736 --det_limit_type=min --output ../output/table
+python3 table/predict_table.py --det_model_dir=inference/en_ppocr_mobile_v2.0_table_det_infer --rec_model_dir=inference/en_ppocr_mobile_v2.0_table_rec_infer --table_model_dir=inference/en_ppocr_mobile_v2.0_table_structure_infer --image_dir=./docs/table/table.jpg --rec_char_dict_path=../ppocr/utils/dict/table_dict.txt --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt --det_limit_side_len=736 --det_limit_type=min --output ./output/table
```
运行完成后,每张图片的excel表格会保存到output字段指定的目录下
note: 上述模型是在 PubLayNet 数据集上训练的表格识别模型,仅支持英文扫描场景,如需识别其他场景需要自己训练模型后替换 `det_model_dir`,`rec_model_dir`,`table_model_dir`三个字段即可。
+
### 3.2 训练
在这一章节中,我们仅介绍表格结构模型的训练,[文字检测](../../doc/doc_ch/detection.md)和[文字识别](../../doc/doc_ch/recognition.md)的模型训练请参考对应的文档。
@@ -89,6 +97,7 @@ python3 tools/train.py -c configs/table/table_mv3.yml -o Global.checkpoints=./yo
**注意**:`Global.checkpoints`的优先级高于`Global.pretrain_weights`的优先级,即同时指定两个参数时,优先加载`Global.checkpoints`指定的模型,如果`Global.checkpoints`指定的模型路径有误,会加载`Global.pretrain_weights`指定的模型。
+
### 3.3 评估
表格使用 [TEDS(Tree-Edit-Distance-based Similarity)](https://github.com/ibm-aur-nlp/PubTabNet/tree/master/src) 作为模型的评估指标。在进行模型评估之前,需要将pipeline中的三个模型分别导出为inference模型(我们已经提供好),还需要准备评估的gt, gt示例如下:
@@ -113,6 +122,8 @@ python3 table/eval_table.py --det_model_dir=path/to/det_model_dir --rec_model_di
```bash
teds: 93.32
```
+
+
### 3.4 预测
```python
@@ -120,6 +131,6 @@ cd PaddleOCR/ppstructure
python3 table/predict_table.py --det_model_dir=path/to/det_model_dir --rec_model_dir=path/to/rec_model_dir --table_model_dir=path/to/table_model_dir --image_dir=../doc/table/1.png --rec_char_dict_path=../ppocr/utils/dict/table_dict.txt --table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt --det_limit_side_len=736 --det_limit_type=min --output ../output/table
```
-Reference
+# Reference
1. https://github.com/ibm-aur-nlp/PubTabNet
2. https://arxiv.org/pdf/1911.10683
diff --git a/ppstructure/table/predict_table.py b/ppstructure/table/predict_table.py
index 352ae84de1f435f91258cf0ced4dce9345de1220..402d6c24189d044e2ee6d359edef8624d4aae145 100644
--- a/ppstructure/table/predict_table.py
+++ b/ppstructure/table/predict_table.py
@@ -54,16 +54,20 @@ def expand(pix, det_box, shape):
class TableSystem(object):
def __init__(self, args, text_detector=None, text_recognizer=None):
- self.text_detector = predict_det.TextDetector(args) if text_detector is None else text_detector
- self.text_recognizer = predict_rec.TextRecognizer(args) if text_recognizer is None else text_recognizer
+ self.text_detector = predict_det.TextDetector(
+ args) if text_detector is None else text_detector
+ self.text_recognizer = predict_rec.TextRecognizer(
+ args) if text_recognizer is None else text_recognizer
self.table_structurer = predict_strture.TableStructurer(args)
- def __call__(self, img):
+ def __call__(self, img, return_ocr_result_in_table=False):
+ result = dict()
ori_im = img.copy()
structure_res, elapse = self.table_structurer(copy.deepcopy(img))
dt_boxes, elapse = self.text_detector(copy.deepcopy(img))
dt_boxes = sorted_boxes(dt_boxes)
-
+ if return_ocr_result_in_table:
+ result['boxes'] = [x.tolist() for x in dt_boxes]
r_boxes = []
for box in dt_boxes:
x_min = box[:, 0].min() - 1
@@ -88,14 +92,17 @@ class TableSystem(object):
rec_res, elapse = self.text_recognizer(img_crop_list)
logger.debug("rec_res num : {}, elapse : {}".format(
len(rec_res), elapse))
-
+ if return_ocr_result_in_table:
+ result['rec_res'] = rec_res
pred_html, pred = self.rebuild_table(structure_res, dt_boxes, rec_res)
- return pred_html
+ result['html'] = pred_html
+ return result
def rebuild_table(self, structure_res, dt_boxes, rec_res):
pred_structures, pred_bboxes = structure_res
matched_index = self.match_result(dt_boxes, pred_bboxes)
- pred_html, pred = self.get_pred_html(pred_structures, matched_index, rec_res)
+ pred_html, pred = self.get_pred_html(pred_structures, matched_index,
+ rec_res)
return pred_html, pred
def match_result(self, dt_boxes, pred_bboxes):
@@ -104,11 +111,13 @@ class TableSystem(object):
# gt_box = [np.min(gt_box[:, 0]), np.min(gt_box[:, 1]), np.max(gt_box[:, 0]), np.max(gt_box[:, 1])]
distances = []
for j, pred_box in enumerate(pred_bboxes):
- distances.append(
- (distance(gt_box, pred_box), 1. - compute_iou(gt_box, pred_box))) # 获取两两cell之间的L1距离和 1- IOU
+ distances.append((distance(gt_box, pred_box),
+ 1. - compute_iou(gt_box, pred_box)
+ )) # 获取两两cell之间的L1距离和 1- IOU
sorted_distances = distances.copy()
# 根据距离和IOU挑选最"近"的cell
- sorted_distances = sorted(sorted_distances, key=lambda item: (item[1], item[0]))
+ sorted_distances = sorted(
+ sorted_distances, key=lambda item: (item[1], item[0]))
if distances.index(sorted_distances[0]) not in matched.keys():
matched[distances.index(sorted_distances[0])] = [i]
else:
@@ -122,7 +131,8 @@ class TableSystem(object):
if '' in tag:
if td_index in matched_index.keys():
b_with = False
- if '' in ocr_contents[matched_index[td_index][0]] and len(matched_index[td_index]) > 1:
+ if '' in ocr_contents[matched_index[td_index][
+ 0]] and len(matched_index[td_index]) > 1:
b_with = True
end_html.extend('')
for i, td_index_index in enumerate(matched_index[td_index]):
@@ -138,7 +148,8 @@ class TableSystem(object):
content = content[:-4]
if len(content) == 0:
continue
- if i != len(matched_index[td_index]) - 1 and ' ' != content[-1]:
+ if i != len(matched_index[
+ td_index]) - 1 and ' ' != content[-1]:
content += ' '
end_html.extend(content)
if b_with:
@@ -187,18 +198,19 @@ def main(args):
for i, image_file in enumerate(image_file_list):
logger.info("[{}/{}] {}".format(i, img_num, image_file))
img, flag = check_and_read_gif(image_file)
- excel_path = os.path.join(args.output, os.path.basename(image_file).split('.')[0] + '.xlsx')
+ excel_path = os.path.join(
+ args.output, os.path.basename(image_file).split('.')[0] + '.xlsx')
if not flag:
img = cv2.imread(image_file)
if img is None:
logger.error("error in loading image:{}".format(image_file))
continue
starttime = time.time()
- pred_html = text_sys(img)
-
+ pred_res = text_sys(img)
+ pred_html = pred_res['html']
+ logger.info(pred_html)
to_excel(pred_html, excel_path)
logger.info('excel saved to {}'.format(excel_path))
- logger.info(pred_html)
elapse = time.time() - starttime
logger.info("Predict time : {:.3f}s".format(elapse))
diff --git a/ppstructure/utility.py b/ppstructure/utility.py
index 081a5f6ae3cd4a01bc2d1ba4812f39086e16cfe9..938c12f951730ed1b81186608dd10efb383e8cfc 100644
--- a/ppstructure/utility.py
+++ b/ppstructure/utility.py
@@ -15,7 +15,7 @@
import ast
from PIL import Image
import numpy as np
-from tools.infer.utility import draw_ocr_box_txt, init_args as infer_args
+from tools.infer.utility import draw_ocr_box_txt, str2bool, init_args as infer_args
def init_args():
@@ -30,6 +30,7 @@ def init_args():
"--table_char_dict_path",
type=str,
default="../ppocr/utils/dict/table_structure_dict.txt")
+ # params for layout
parser.add_argument(
"--layout_path_model",
type=str,
@@ -39,11 +40,27 @@ def init_args():
type=ast.literal_eval,
default=None,
help='label map according to ppstructure/layout/README_ch.md')
+ # params for inference
parser.add_argument(
"--mode",
type=str,
default='structure',
help='structure and vqa is supported')
+ parser.add_argument(
+ "--layout",
+ type=str2bool,
+ default=True,
+ help='Whether to enable layout analysis')
+ parser.add_argument(
+ "--table",
+ type=str2bool,
+ default=True,
+ help='In the forward, whether the table area uses table recognition')
+ parser.add_argument(
+ "--ocr",
+ type=str2bool,
+ default=True,
+ help='In the forward, whether the non-table area is recognition by ocr')
return parser
diff --git a/ppstructure/vqa/README.md b/ppstructure/vqa/README.md
index a2117c9e0601360750e354d4faecd43b2a2a0a68..e3a10671ddb6494eb15073e7ac007aa1e8e6a32a 100644
--- a/ppstructure/vqa/README.md
+++ b/ppstructure/vqa/README.md
@@ -51,9 +51,10 @@ We evaluate the algorithm on the Chinese dataset of [XFUND](https://github.com/d
**Note:** The test images are from the XFUND dataset.
+
### 3.1 SER
- | 
+ | 
---|---
Boxes with different colors in the figure represent different categories. For the XFUND dataset, there are 3 categories: `QUESTION`, `ANSWER`, `HEADER`
@@ -64,9 +65,10 @@ Boxes with different colors in the figure represent different categories. For th
The corresponding categories and OCR recognition results are also marked on the upper left of the OCR detection frame.
+
### 3.2 RE
- | 
+ | 
---|---
@@ -150,6 +152,7 @@ wget https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar && tar -x
cd ../
````
+
### 5.2 SER
Before starting training, you need to modify the following four fields
@@ -203,6 +206,7 @@ export CUDA_VISIBLE_DEVICES=0
python3 tools/eval_with_label_end2end.py --gt_json_path XFUND/zh_val/xfun_normalize_val.json --pred_json_path output_res/infer_results.txt
````
+
### 5.3 RE
* start training
diff --git a/requirements.txt b/requirements.txt
index b60d48371337e38bde6e51171aa6ecfb9573fb4d..b15176db3eb42c381c1612f404fd15c6b020b3dc 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -12,3 +12,4 @@ cython
lxml
premailer
openpyxl
+attrdict
diff --git a/test_tipc/configs/ch_PP-OCRv2_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv2_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..033d40a80a3569f8bfd408cdb6df37e7ba5ecd0c
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv2_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_PPOCRv2_det
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=500
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml -o
+quant_export:null
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv2_det_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
diff --git a/test_tipc/configs/ch_PP-OCRv2_det_PACT/train_infer_python.txt b/test_tipc/configs/ch_PP-OCRv2_det_PACT/train_infer_python.txt
index e6ed9df937e9b8def00513e3b4ac6c6310b6692c..038fa850614d45dbefe076b866571cead57b8450 100644
--- a/test_tipc/configs/ch_PP-OCRv2_det_PACT/train_infer_python.txt
+++ b/test_tipc/configs/ch_PP-OCRv2_det_PACT/train_infer_python.txt
@@ -6,7 +6,7 @@ Global.use_gpu:True|True
Global.auto_cast:fp32
Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=500
Global.save_model_dir:./output/
-Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Train.loader.batch_size_per_card:lite_train_lite_infer=1|whole_train_whole_infer=4
Global.pretrained_model:null
train_model_name:latest
train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
diff --git a/test_tipc/configs/ch_PP-OCRv2_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv2_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..d922a4a5dad67da81e3c9cf7bed48a0431a88b84
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv2_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_PPOCRv2_det_PACT
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=500
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml -o
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv2_det_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
diff --git a/test_tipc/configs/ch_PP-OCRv2_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv2_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..7c438cb8a3b6907c9ca352e90605d8b4f6fb17fd
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv2_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:PPOCRv2_ocr_rec
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv2_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:False|True
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,320]}]
diff --git a/test_tipc/configs/ch_PP-OCRv2_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv2_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e22d8a564b008206611469048b424b528dd379bd
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv2_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_PPOCRv2_rec_PACT
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml -o
+fpgm_export: null
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv2_rec_slim_quant_infer
+infer_export:null
+infer_quant:True
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:False|True
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,320]}]
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/det_mv3_db.yml b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/det_mv3_db.yml
deleted file mode 100644
index 5eada6d53dd3364238bdfc6a3c40515ca0726688..0000000000000000000000000000000000000000
--- a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/det_mv3_db.yml
+++ /dev/null
@@ -1,126 +0,0 @@
-Global:
- use_gpu: false
- epoch_num: 5
- log_smooth_window: 20
- print_batch_step: 1
- save_model_dir: ./output/db_mv3/
- save_epoch_step: 1200
- # evaluation is run every 2000 iterations
- eval_batch_step: [0, 400]
- cal_metric_during_train: False
- pretrained_model: ./pretrain_models/MobileNetV3_large_x0_5_pretrained
- checkpoints:
- save_inference_dir:
- use_visualdl: False
- infer_img: doc/imgs_en/img_10.jpg
- save_res_path: ./output/det_db/predicts_db.txt
-
-Architecture:
- model_type: det
- algorithm: DB
- Transform:
- Backbone:
- name: MobileNetV3
- scale: 0.5
- model_name: large
- disable_se: False
- Neck:
- name: DBFPN
- out_channels: 256
- Head:
- name: DBHead
- k: 50
-
-Loss:
- name: DBLoss
- balance_loss: true
- main_loss_type: DiceLoss
- alpha: 5
- beta: 10
- ohem_ratio: 3
-
-Optimizer:
- name: Adam #Momentum
- #momentum: 0.9
- beta1: 0.9
- beta2: 0.999
- lr:
- learning_rate: 0.001
- regularizer:
- name: 'L2'
- factor: 0
-
-PostProcess:
- name: DBPostProcess
- thresh: 0.3
- box_thresh: 0.6
- max_candidates: 1000
- unclip_ratio: 1.5
-
-Metric:
- name: DetMetric
- main_indicator: hmean
-
-Train:
- dataset:
- name: SimpleDataSet
- data_dir: ./train_data/icdar2015/text_localization/
- label_file_list:
- - ./train_data/icdar2015/text_localization/train_icdar2015_label.txt
- ratio_list: [1.0]
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - DetLabelEncode: # Class handling label
- - Resize:
- size: [640, 640]
- - MakeBorderMap:
- shrink_ratio: 0.4
- thresh_min: 0.3
- thresh_max: 0.7
- - MakeShrinkMap:
- shrink_ratio: 0.4
- min_text_size: 8
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - ToCHWImage:
- - KeepKeys:
- keep_keys: ['image', 'threshold_map', 'threshold_mask', 'shrink_map', 'shrink_mask'] # the order of the dataloader list
- loader:
- shuffle: False
- drop_last: False
- batch_size_per_card: 1
- num_workers: 0
- use_shared_memory: False
-
-Eval:
- dataset:
- name: SimpleDataSet
- data_dir: ./train_data/icdar2015/text_localization/
- label_file_list:
- - ./train_data/icdar2015/text_localization/test_icdar2015_label.txt
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - DetLabelEncode: # Class handling label
- - DetResizeForTest:
- image_shape: [736, 1280]
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - ToCHWImage:
- - KeepKeys:
- keep_keys: ['image', 'shape', 'polys', 'ignore_tags']
- loader:
- shuffle: False
- drop_last: False
- batch_size_per_card: 1 # must be 1
- num_workers: 0
- use_shared_memory: False
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
index ff1c7432df75f78fd6c45d995f50a9642d44637c..593e7ec7ed42af9b65c520852ff6372f89890170 100644
--- a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -1,10 +1,10 @@
===========================train_params===========================
-model_name:ocr_det
+model_name:ch_ppocr_mobile_v2.0_det
python:python3.7
gpu_list:0|0,1
Global.use_gpu:True|True
Global.auto_cast:amp
-Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=300
+Global.epoch_num:lite_train_lite_infer=100|whole_train_whole_infer=300
Global.save_model_dir:./output/
Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
Global.pretrained_model:null
@@ -12,10 +12,10 @@ train_model_name:latest
train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
null:null
##
-trainer:norm_train|pact_train|fpgm_train
-norm_train:tools/train.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
-pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
-fpgm_train:deploy/slim/prune/sensitivity_anal.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/det_mv3_db_v2.0_train/best_accuracy
+trainer:norm_train
+norm_train:tools/train.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
+pact_train:null
+fpgm_train:null
distill_train:null
null:null
null:null
@@ -26,10 +26,10 @@ null:null
##
===========================infer_params===========================
Global.save_inference_dir:./output/
-Global.pretrained_model:
-norm_export:tools/export_model.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
-quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
-fpgm_export:deploy/slim/prune/export_prune_model.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
+quant_export:null
+fpgm_export:null
distill_export:null
export1:null
export2:null
@@ -49,3 +49,5 @@ inference:tools/infer/predict_det.py
null:null
--benchmark:True
null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
\ No newline at end of file
diff --git a/test_tipc/configs/ch_ppocr_mobile_V2.0_det_FPGM/train_infer_python.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_infer_python.txt
similarity index 97%
rename from test_tipc/configs/ch_ppocr_mobile_V2.0_det_FPGM/train_infer_python.txt
rename to test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_infer_python.txt
index 331d6bdb7103294eb1b33b9978e5f99c2212195b..47ccf2e69e75bc8c215be8d1837e5248d1b4b513 100644
--- a/test_tipc/configs/ch_ppocr_mobile_V2.0_det_FPGM/train_infer_python.txt
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_infer_python.txt
@@ -1,5 +1,5 @@
===========================train_params===========================
-model_name:ocr_det
+model_name:ch_ppocr_mobile_v2.0_det_FPGM
python:python3.7
gpu_list:0|0,1
Global.use_gpu:True|True
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..5a95f026850b750bfadb85e0955f7426e5e73cb6
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_det_FPGM
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=5|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:fpgm_train
+norm_train:null
+pact_train:null
+fpgm_train:deploy/slim/prune/sensitivity_anal.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.pretrained_model=./pretrain_models/det_mv3_db_v2.0_train/best_accuracy
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:null
+fpgm_export:deploy/slim/prune/export_prune_model.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
+distill_export:null
+export1:null
+export2:null
+inference_dir:null
+train_model:null
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
\ No newline at end of file
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1f9bec12ada6894fcffbe697ae4da2f0df95cc62
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_det_PACT
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=20|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:null
+train_model:./inference/ch_ppocr_mobile_v2.0_det_prune_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..30fb939bff646adf301191f88a9a499acf9c61de
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_rec
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=2|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=128|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/rec_icdar15_train.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:tools/eval.py -c configs/rec/rec_icdar15_train.yml -o
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/rec_icdar15_train.yml -o
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+##
+train_model:./inference/ch_ppocr_mobile_v2.0_rec_train/best_accuracy
+infer_export:tools/export_model.py -c configs/rec/rec_icdar15_train.yml -o
+infer_quant:False
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:True|False
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+--save_log_path:./test/output/
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,100]}]
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..fda9cf4ddec6d3ab64045a4a7fdbb62183212021
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_rec_FPGM
+python:python3.7
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=128|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/ic15_data/test/word_1.png
+null:null
+##
+trainer:fpgm_train
+norm_train:null
+pact_train:null
+fpgm_train:deploy/slim/prune/sensitivity_anal.py -c test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model=./pretrain_models/ch_ppocr_mobile_v2.0_rec_train/best_accuracy
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:null
+fpgm_export:deploy/slim/prune/export_prune_model.py -c test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/rec_chinese_lite_train_v2.0.yml -o
+distill_export:null
+export1:null
+export2:null
+inference_dir:null
+train_model:null
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,320]}]
\ No newline at end of file
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..abed3cfba9b3f8c0ed626dbfcbda8621d8787001
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_rec_PACT
+python:python3.7
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=128|whole_train_whole_infer=128
+Global.checkpoints:null
+train_model_name:latest
+train_infer_img_dir:./train_data/ic15_data/test/word_1.png
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/rec_chinese_lite_train_v2.0.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/rec_chinese_lite_train_v2.0.yml -o
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:null
+infer_model:./inference/ch_ppocr_mobile_v2.0_rec_slim_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_char_dict_path=./ppocr/utils/ppocr_keys_v1.txt --rec_image_shape="3,32,100"
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:False|True
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+--save_log_path:./test/output/
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,320]}]
diff --git a/test_tipc/configs/ch_ppocr_server_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_server_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3e3764e8c6f62c72ffb8ceb268c8ceee660d02de
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_server_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_server_v2.0_det
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=2|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_lite_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c test_tipc/configs/ch_ppocr_server_v2.0_det/det_r50_vd_db.yml -o
+quant_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:tools/eval.py -c test_tipc/configs/ch_ppocr_server_v2.0_det/det_r50_vd_db.yml -o
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c test_tipc/configs/ch_ppocr_server_v2.0_det/det_r50_vd_db.yml -o
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+##
+train_model:./inference/ch_ppocr_server_v2.0_det_train/best_accuracy
+infer_export:tools/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml -o
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+--save_log_path:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
\ No newline at end of file
diff --git a/test_tipc/configs/ch_ppocr_server_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_server_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..78c15047fb522127075591cc9687392af77a300a
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_server_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_server_v2.0_rec
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=5|whole_train_whole_infer=100
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=128|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c test_tipc/configs/ch_ppocr_server_v2.0_rec/rec_icdar15_train.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:tools/eval.py -c test_tipc/configs/ch_ppocr_server_v2.0_rec/rec_icdar15_train.yml -o
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c test_tipc/configs/ch_ppocr_server_v2.0_rec/rec_icdar15_train.yml -o
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+##
+train_model:./inference/ch_ppocr_server_v2.0_rec_train/best_accuracy
+infer_export:tools/export_model.py -c test_tipc/configs/ch_ppocr_server_v2.0_rec/rec_icdar15_train.yml -o
+infer_quant:False
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:True|False
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+--save_log_path:./test/output/
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,100]}]
diff --git a/test_tipc/configs/rec_mv3_tps_bilstm_att_v2.0/train_infer_python.txt b/test_tipc/configs/rec_mv3_tps_bilstm_att_v2.0/train_infer_python.txt
index 32df669f9779f730d78d128d8aceac022ce78616..c22767c60fa8294aa244536b4c04135f7f7ade02 100644
--- a/test_tipc/configs/rec_mv3_tps_bilstm_att_v2.0/train_infer_python.txt
+++ b/test_tipc/configs/rec_mv3_tps_bilstm_att_v2.0/train_infer_python.txt
@@ -37,7 +37,7 @@ export2:null
train_model:./inference/rec_mv3_tps_bilstm_att_v2.0_train/best_accuracy
infer_export:tools/export_model.py -c test_tipc/configs/rec_mv3_tps_bilstm_att_v2.0/rec_mv3_tps_bilstm_att.yml -o
infer_quant:False
-inference:tools/infer/predict_rec.py --rec_char_dict_path=./ppocr/utils/ic15_dict.txt --rec_image_shape="3,32,100" --rec_algorithm="RARE"
+inference:tools/infer/predict_rec.py --rec_char_dict_path=./ppocr/utils/ic15_dict.txt --rec_image_shape="3,32,100" --rec_algorithm="RARE" --min_subgraph_size=5
--use_gpu:True|False
--enable_mkldnn:True|False
--cpu_threads:1|6
diff --git a/tools/eval.py b/tools/eval.py
index f6fcf14c873984e15606b9fae1799bae6b021f05..7fd4fa7ada7b1550bcca8766f5acb9b4d4ed2049 100755
--- a/tools/eval.py
+++ b/tools/eval.py
@@ -47,14 +47,40 @@ def main():
if config['Architecture']["algorithm"] in ["Distillation",
]: # distillation model
for key in config['Architecture']["Models"]:
- config['Architecture']["Models"][key]["Head"][
- 'out_channels'] = char_num
+ if config['Architecture']['Models'][key]['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ out_channels_list = {}
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config['Architecture']["Models"][key]["Head"][
+ 'out_channels'] = char_num
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ out_channels_list = {}
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config['Architecture']["Head"]['out_channels'] = char_num
model = build_model(config['Architecture'])
- extra_input = config['Architecture'][
- 'algorithm'] in ["SRN", "NRTR", "SAR", "SEED"]
+ extra_input_models = ["SRN", "NRTR", "SAR", "SEED", "SVTR"]
+ extra_input = False
+ if config['Architecture']['algorithm'] == 'Distillation':
+ for key in config['Architecture']["Models"]:
+ extra_input = extra_input or config['Architecture']['Models'][key][
+ 'algorithm'] in extra_input_models
+ else:
+ extra_input = config['Architecture']['algorithm'] in extra_input_models
if "model_type" in config['Architecture'].keys():
model_type = config['Architecture']['model_type']
else:
diff --git a/tools/export_model.py b/tools/export_model.py
index bd647fc72cf111b910d215fecbbef354bd5e6c08..1f9f29e396fe4960914ae802769b65d20c103bd3 100755
--- a/tools/export_model.py
+++ b/tools/export_model.py
@@ -31,7 +31,7 @@ from ppocr.utils.logging import get_logger
from tools.program import load_config, merge_config, ArgsParser
-def export_single_model(model, arch_config, save_path, logger):
+def export_single_model(model, arch_config, save_path, logger, quanter=None):
if arch_config["algorithm"] == "SRN":
max_text_length = arch_config["Head"]["max_text_length"]
other_shape = [
@@ -55,6 +55,18 @@ def export_single_model(model, arch_config, save_path, logger):
shape=[None, 3, 48, 160], dtype="float32"),
]
model = to_static(model, input_spec=other_shape)
+ elif arch_config["algorithm"] == "SVTR":
+ if arch_config["Head"]["name"] == 'MultiHead':
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None, 3, 48, -1], dtype="float32"),
+ ]
+ else:
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None, 3, 64, 256], dtype="float32"),
+ ]
+ model = to_static(model, input_spec=other_shape)
elif arch_config["algorithm"] == "PREN":
other_shape = [
paddle.static.InputSpec(
@@ -83,7 +95,10 @@ def export_single_model(model, arch_config, save_path, logger):
shape=[None] + infer_shape, dtype="float32")
])
- paddle.jit.save(model, save_path)
+ if quanter is None:
+ paddle.jit.save(model, save_path)
+ else:
+ quanter.save_quantized_model(model, save_path)
logger.info("inference model is saved to {}".format(save_path))
return
@@ -105,13 +120,35 @@ def main():
if config["Architecture"]["algorithm"] in ["Distillation",
]: # distillation model
for key in config["Architecture"]["Models"]:
- config["Architecture"]["Models"][key]["Head"][
- "out_channels"] = char_num
+ if config["Architecture"]["Models"][key]["Head"][
+ "name"] == 'MultiHead': # multi head
+ out_channels_list = {}
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config["Architecture"]["Models"][key]["Head"][
+ "out_channels"] = char_num
# just one final tensor needs to to exported for inference
config["Architecture"]["Models"][key][
"return_all_feats"] = False
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # multi head
+ out_channels_list = {}
+ char_num = len(getattr(post_process_class, 'character'))
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config["Architecture"]["Head"]["out_channels"] = char_num
+
model = build_model(config["Architecture"])
load_model(config, model)
model.eval()
diff --git a/tools/infer/predict_det.py b/tools/infer/predict_det.py
index 695587a9aa39f27fb5e37ba8d5447fb9f085e1e1..5f2675d667c2aab8186886a60d8d447f43419954 100755
--- a/tools/infer/predict_det.py
+++ b/tools/infer/predict_det.py
@@ -158,7 +158,7 @@ class TextDetector(object):
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
-
+
def clip_det_res(self, points, img_height, img_width):
for pno in range(points.shape[0]):
points[pno, 0] = int(min(max(points[pno, 0], 0), img_width - 1))
@@ -284,7 +284,7 @@ if __name__ == "__main__":
total_time += elapse
count += 1
save_pred = os.path.basename(image_file) + "\t" + str(
- json.dumps(np.array(dt_boxes).astype(np.int32).tolist())) + "\n"
+ json.dumps([x.tolist() for x in dt_boxes])) + "\n"
save_results.append(save_pred)
logger.info(save_pred)
logger.info("The predict time of {}: {}".format(image_file, elapse))
diff --git a/tools/infer/predict_rec.py b/tools/infer/predict_rec.py
index c5aacb060060068ec4b0b9432b2fb045aaff0370..2abc0220937175f95ee4c1e4b0b949d24d5fa3e8 100755
--- a/tools/infer/predict_rec.py
+++ b/tools/infer/predict_rec.py
@@ -107,7 +107,7 @@ class TextRecognizer(object):
return norm_img.astype(np.float32) / 128. - 1.
assert imgC == img.shape[2]
- imgW = int((32 * max_wh_ratio))
+ imgW = int((imgH * max_wh_ratio))
if self.use_onnx:
w = self.input_tensor.shape[3:][0]
if w is not None and w > 0:
@@ -131,6 +131,17 @@ class TextRecognizer(object):
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
+
+ def resize_norm_img_svtr(self, img, image_shape):
+
+ imgC, imgH, imgW = image_shape
+ resized_image = cv2.resize(
+ img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_image = resized_image.astype('float32')
+ resized_image = resized_image.transpose((2, 0, 1)) / 255
+ resized_image -= 0.5
+ resized_image /= 0.5
+ return resized_image
def resize_norm_img_srn(self, img, image_shape):
imgC, imgH, imgW = image_shape
@@ -255,18 +266,16 @@ class TextRecognizer(object):
for beg_img_no in range(0, img_num, batch_num):
end_img_no = min(img_num, beg_img_no + batch_num)
norm_img_batch = []
- max_wh_ratio = 0
+ imgC, imgH, imgW = self.rec_image_shape
+ max_wh_ratio = imgW / imgH
+ # max_wh_ratio = 0
for ino in range(beg_img_no, end_img_no):
h, w = img_list[indices[ino]].shape[0:2]
wh_ratio = w * 1.0 / h
max_wh_ratio = max(max_wh_ratio, wh_ratio)
for ino in range(beg_img_no, end_img_no):
- if self.rec_algorithm != "SRN" and self.rec_algorithm != "SAR":
- norm_img = self.resize_norm_img(img_list[indices[ino]],
- max_wh_ratio)
- norm_img = norm_img[np.newaxis, :]
- norm_img_batch.append(norm_img)
- elif self.rec_algorithm == "SAR":
+
+ if self.rec_algorithm == "SAR":
norm_img, _, _, valid_ratio = self.resize_norm_img_sar(
img_list[indices[ino]], self.rec_image_shape)
norm_img = norm_img[np.newaxis, :]
@@ -274,7 +283,7 @@ class TextRecognizer(object):
valid_ratios = []
valid_ratios.append(valid_ratio)
norm_img_batch.append(norm_img)
- else:
+ elif self.rec_algorithm == "SRN":
norm_img = self.process_image_srn(
img_list[indices[ino]], self.rec_image_shape, 8, 25)
encoder_word_pos_list = []
@@ -286,6 +295,16 @@ class TextRecognizer(object):
gsrm_slf_attn_bias1_list.append(norm_img[3])
gsrm_slf_attn_bias2_list.append(norm_img[4])
norm_img_batch.append(norm_img[0])
+ elif self.rec_algorithm == "SVTR":
+ norm_img = self.resize_norm_img_svtr(
+ img_list[indices[ino]], self.rec_image_shape)
+ norm_img = norm_img[np.newaxis, :]
+ norm_img_batch.append(norm_img)
+ else:
+ norm_img = self.resize_norm_img(img_list[indices[ino]],
+ max_wh_ratio)
+ norm_img = norm_img[np.newaxis, :]
+ norm_img_batch.append(norm_img)
norm_img_batch = np.concatenate(norm_img_batch)
norm_img_batch = norm_img_batch.copy()
if self.benchmark:
diff --git a/tools/infer/utility.py b/tools/infer/utility.py
index b16aecd496ec291fcbe9c66dccf3ec04bb662034..c92e8e152a9ee4d86d269aec7ff5645f23cad443 100644
--- a/tools/infer/utility.py
+++ b/tools/infer/utility.py
@@ -271,9 +271,10 @@ def create_predictor(args, mode, logger):
elif mode == "rec":
if args.rec_algorithm != "CRNN":
use_dynamic_shape = False
- min_input_shape = {"x": [1, 3, 32, 10]}
- max_input_shape = {"x": [args.rec_batch_num, 3, 32, 1536]}
- opt_input_shape = {"x": [args.rec_batch_num, 3, 32, 320]}
+ imgH = int(args.rec_image_shape.split(',')[-2])
+ min_input_shape = {"x": [1, 3, imgH, 10]}
+ max_input_shape = {"x": [args.rec_batch_num, 3, imgH, 1536]}
+ opt_input_shape = {"x": [args.rec_batch_num, 3, imgH, 320]}
elif mode == "cls":
min_input_shape = {"x": [1, 3, 48, 10]}
max_input_shape = {"x": [args.rec_batch_num, 3, 48, 1024]}
@@ -300,8 +301,8 @@ def create_predictor(args, mode, logger):
# enable memory optim
config.enable_memory_optim()
config.disable_glog_info()
-
config.delete_pass("conv_transpose_eltwiseadd_bn_fuse_pass")
+ config.delete_pass("matmul_transpose_reshape_fuse_pass")
if mode == 'table':
config.delete_pass("fc_fuse_pass") # not supported for table
config.switch_use_feed_fetch_ops(False)
diff --git a/tools/infer_cls.py b/tools/infer_cls.py
index 4be30bbb3c2f8bbf6a59179220faa942e6cc27b8..7fd6b536fbe50fb1240d84ca3a5e87236940c0f5 100755
--- a/tools/infer_cls.py
+++ b/tools/infer_cls.py
@@ -57,6 +57,8 @@ def main():
continue
elif op_name == 'KeepKeys':
op[op_name]['keep_keys'] = ['image']
+ elif op_name == "SSLRotateResize":
+ op[op_name]["mode"] = "test"
transforms.append(op)
global_config['infer_mode'] = True
ops = create_operators(transforms, global_config)
diff --git a/tools/infer_rec.py b/tools/infer_rec.py
index 02b3afd8a1b32c3c9c1e4a9a121f08b58c10151d..63d410b627f3868191c9299f9bc99e7fcab69d35 100755
--- a/tools/infer_rec.py
+++ b/tools/infer_rec.py
@@ -51,8 +51,28 @@ def main():
if config['Architecture']["algorithm"] in ["Distillation",
]: # distillation model
for key in config['Architecture']["Models"]:
- config['Architecture']["Models"][key]["Head"][
- 'out_channels'] = char_num
+ if config['Architecture']['Models'][key]['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ out_channels_list = {}
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config['Architecture']["Models"][key]["Head"][
+ 'out_channels'] = char_num
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # for multi head loss
+ out_channels_list = {}
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config['Architecture']["Head"]['out_channels'] = char_num
diff --git a/tools/program.py b/tools/program.py
index 8ec152bb92f0855d44b2597ce2420b16a4fa007e..90fd309ae9e1ae23723d8e67c62a905e79a073d3 100755
--- a/tools/program.py
+++ b/tools/program.py
@@ -201,12 +201,19 @@ def train(config,
model.train()
use_srn = config['Architecture']['algorithm'] == "SRN"
- extra_input = config['Architecture'][
- 'algorithm'] in ["SRN", "NRTR", "SAR", "SEED"]
+ extra_input_models = ["SRN", "NRTR", "SAR", "SEED", "SVTR"]
+ extra_input = False
+ if config['Architecture']['algorithm'] == 'Distillation':
+ for key in config['Architecture']["Models"]:
+ extra_input = extra_input or config['Architecture']['Models'][key][
+ 'algorithm'] in extra_input_models
+ else:
+ extra_input = config['Architecture']['algorithm'] in extra_input_models
try:
model_type = config['Architecture']['model_type']
except:
model_type = None
+
algorithm = config['Architecture']['algorithm']
start_epoch = best_model_dict[
@@ -269,7 +276,12 @@ def train(config,
if model_type in ['table', 'kie']:
eval_class(preds, batch)
else:
- post_result = post_process_class(preds, batch[1])
+ if config['Loss']['name'] in ['MultiLoss', 'MultiLoss_v2'
+ ]: # for multi head loss
+ post_result = post_process_class(
+ preds['ctc'], batch[1]) # for CTC head out
+ else:
+ post_result = post_process_class(preds, batch[1])
eval_class(post_result, batch)
metric = eval_class.get_metric()
train_stats.update(metric)
@@ -541,7 +553,7 @@ def preprocess(is_train=False):
assert alg in [
'EAST', 'DB', 'SAST', 'Rosetta', 'CRNN', 'STARNet', 'RARE', 'SRN',
'CLS', 'PGNet', 'Distillation', 'NRTR', 'TableAttn', 'SAR', 'PSE',
- 'SEED', 'SDMGR', 'LayoutXLM', 'LayoutLM', 'PREN', 'FCE'
+ 'SEED', 'SDMGR', 'LayoutXLM', 'LayoutLM', 'PREN', 'FCE', 'SVTR'
]
device = 'cpu'
diff --git a/tools/train.py b/tools/train.py
index f6cd0e7d12cdc572dd8d2c402e03e160001a9f4a..42aba548d6bf5fc35f033ef2baca0fb54d79e75a 100755
--- a/tools/train.py
+++ b/tools/train.py
@@ -74,11 +74,49 @@ def main(config, device, logger, vdl_writer):
if config['Architecture']["algorithm"] in ["Distillation",
]: # distillation model
for key in config['Architecture']["Models"]:
- config['Architecture']["Models"][key]["Head"][
- 'out_channels'] = char_num
+ if config['Architecture']['Models'][key]['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ # update SARLoss params
+ assert list(config['Loss']['loss_config_list'][-1].keys())[
+ 0] == 'DistillationSARLoss'
+ config['Loss']['loss_config_list'][-1][
+ 'DistillationSARLoss']['ignore_index'] = char_num + 1
+ out_channels_list = {}
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config['Architecture']["Models"][key]["Head"][
+ 'out_channels'] = char_num
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ # update SARLoss params
+ assert list(config['Loss']['loss_config_list'][1].keys())[
+ 0] == 'SARLoss'
+ if config['Loss']['loss_config_list'][1]['SARLoss'] is None:
+ config['Loss']['loss_config_list'][1]['SARLoss'] = {
+ 'ignore_index': char_num + 1
+ }
+ else:
+ config['Loss']['loss_config_list'][1]['SARLoss'][
+ 'ignore_index'] = char_num + 1
+ out_channels_list = {}
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config['Architecture']["Head"]['out_channels'] = char_num
+ if config['PostProcess']['name'] == 'SARLabelDecode': # for SAR model
+ config['Loss']['ignore_index'] = char_num - 1
+
model = build_model(config['Architecture'])
if config['Global']['distributed']:
model = paddle.DataParallel(model)
@@ -91,7 +129,7 @@ def main(config, device, logger, vdl_writer):
config['Optimizer'],
epochs=config['Global']['epoch_num'],
step_each_epoch=len(train_dataloader),
- parameters=model.parameters())
+ model=model)
# build metric
eval_class = build_metric(config['Metric'])


 -
-  -
-  -
- -
- +
+ -
- +
+ +
+



 +
+ +
+ +
+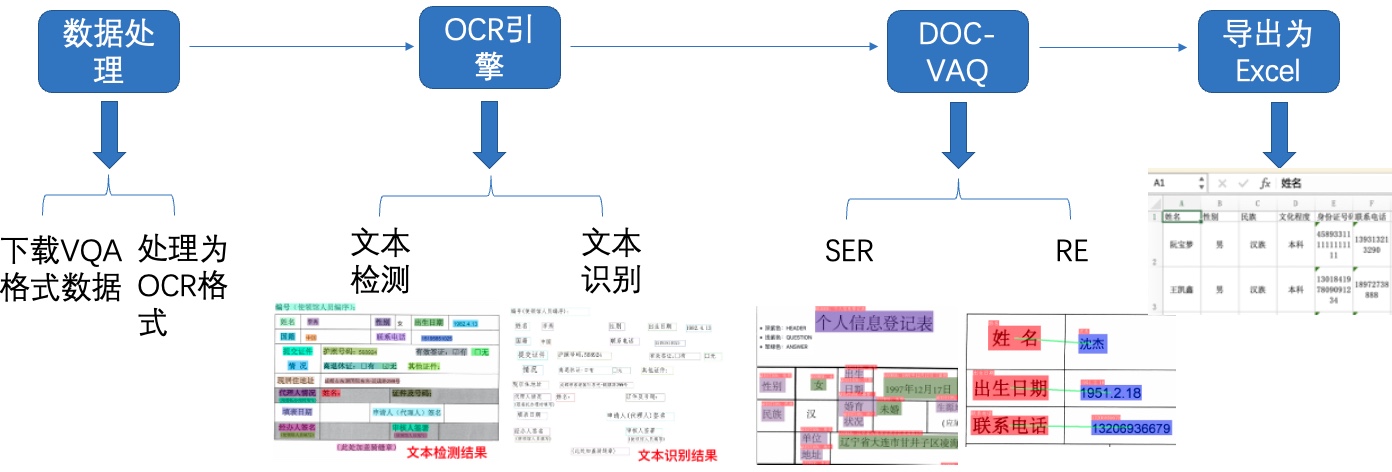

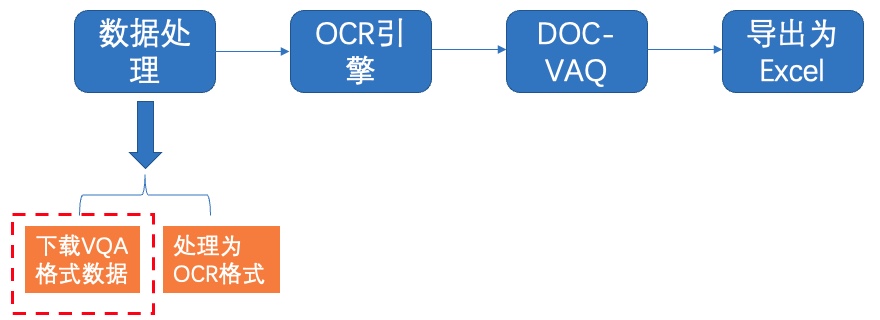
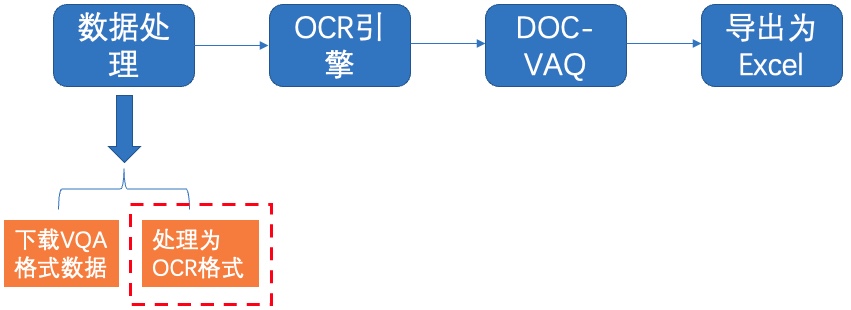
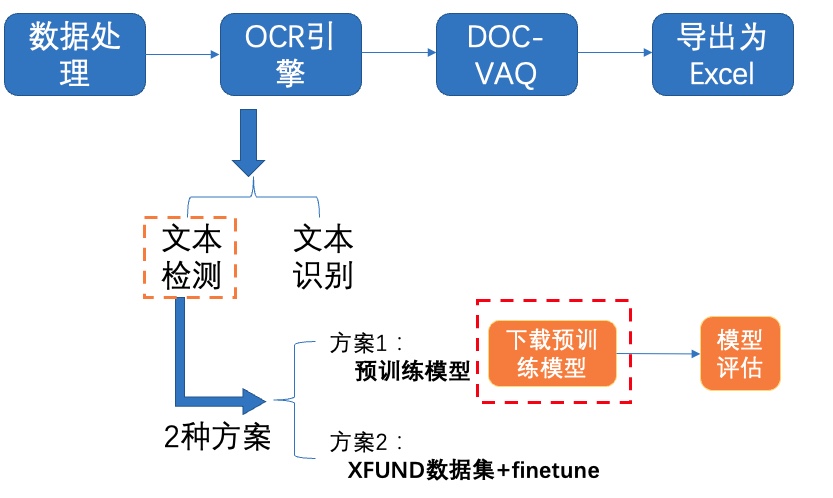
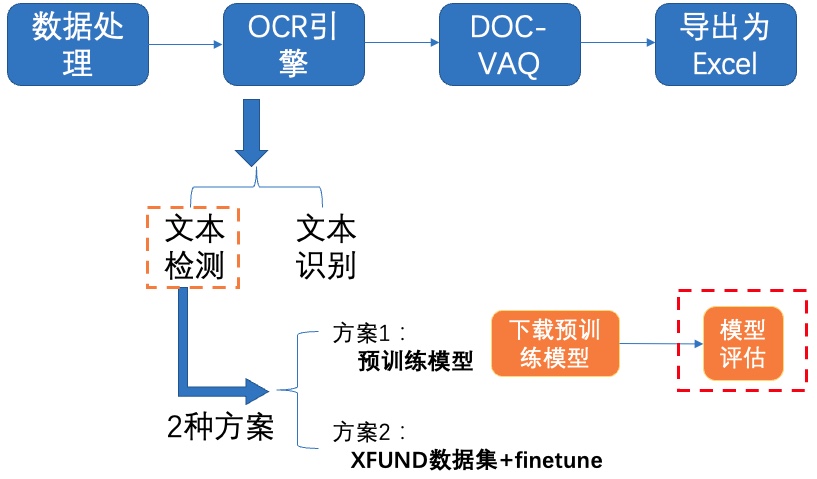
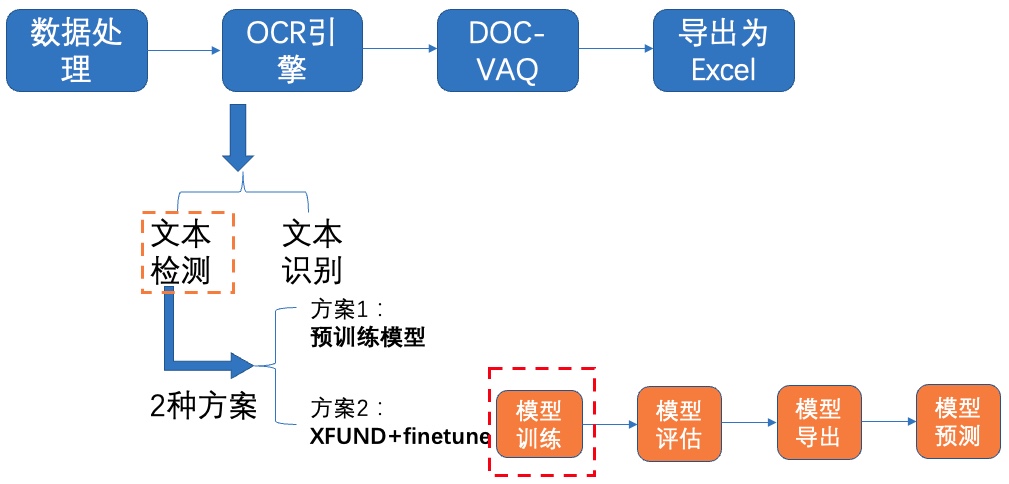
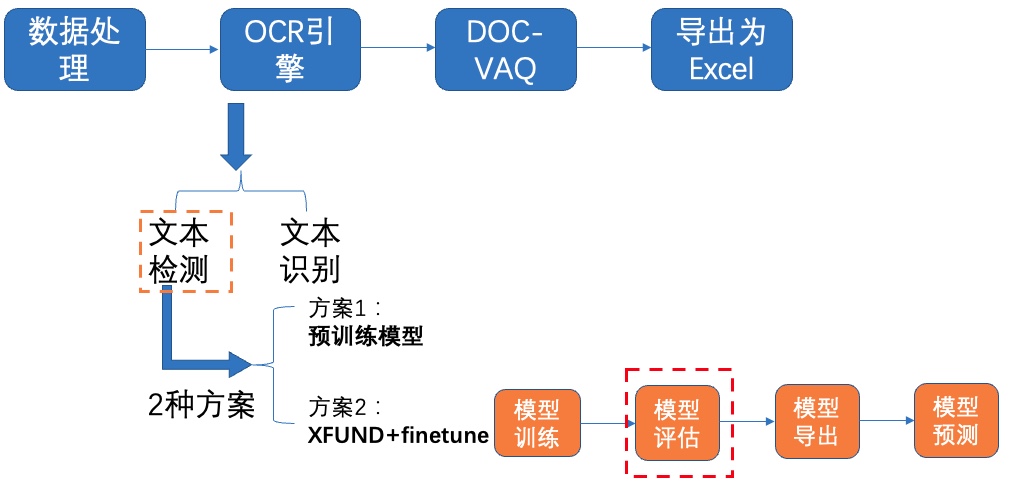
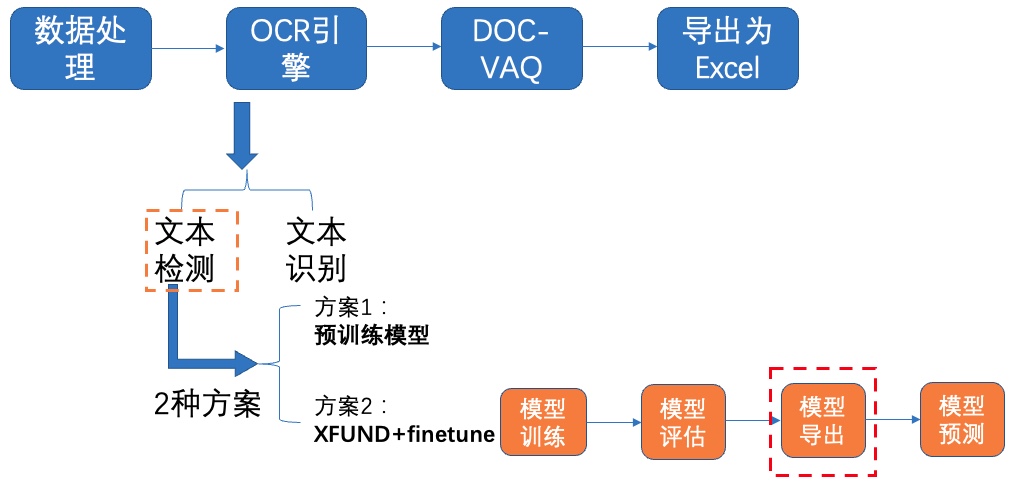
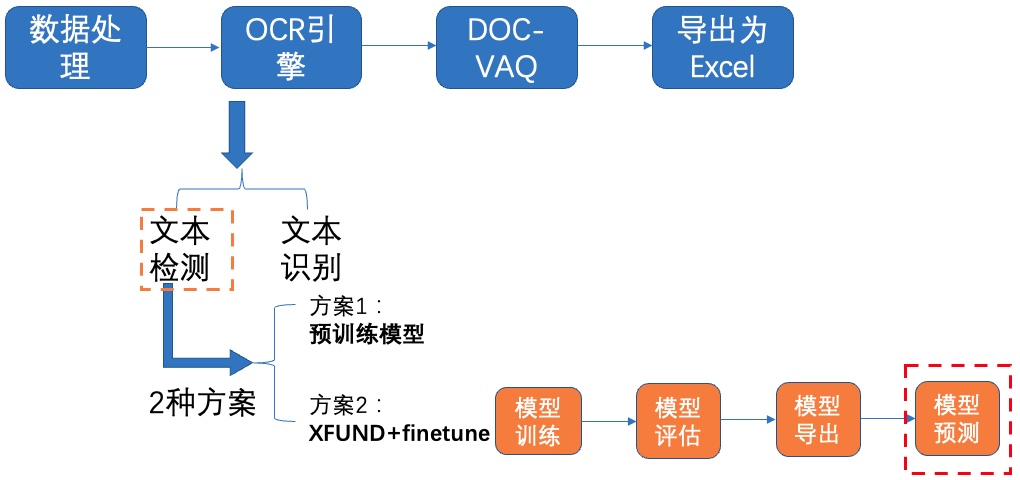
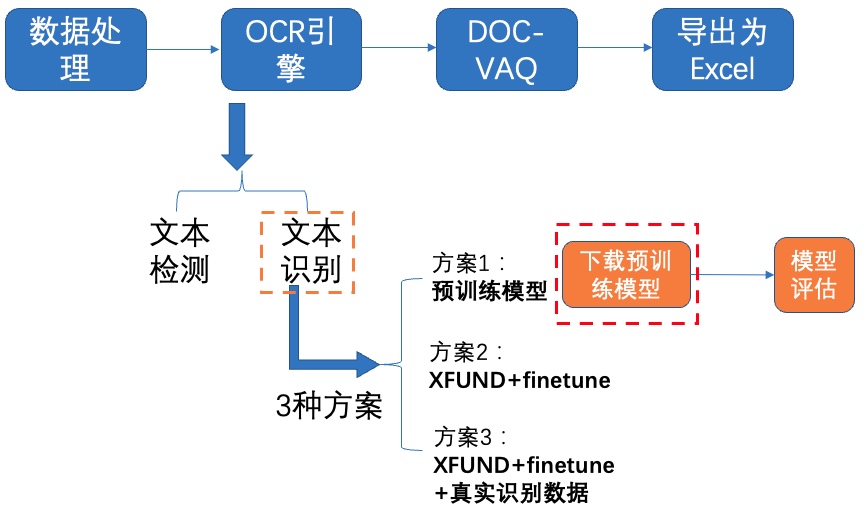
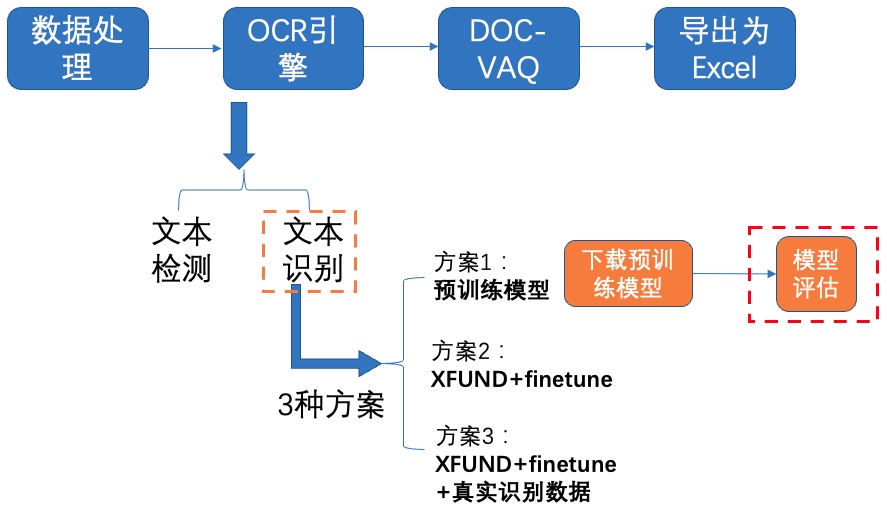
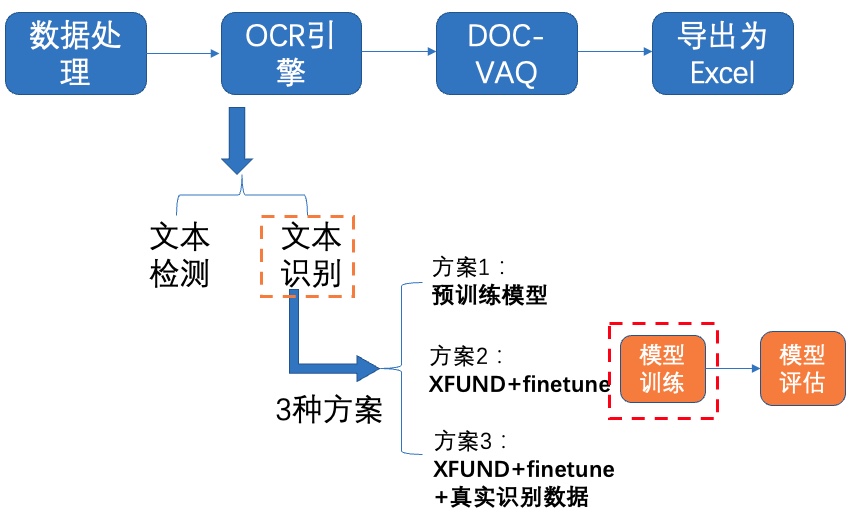
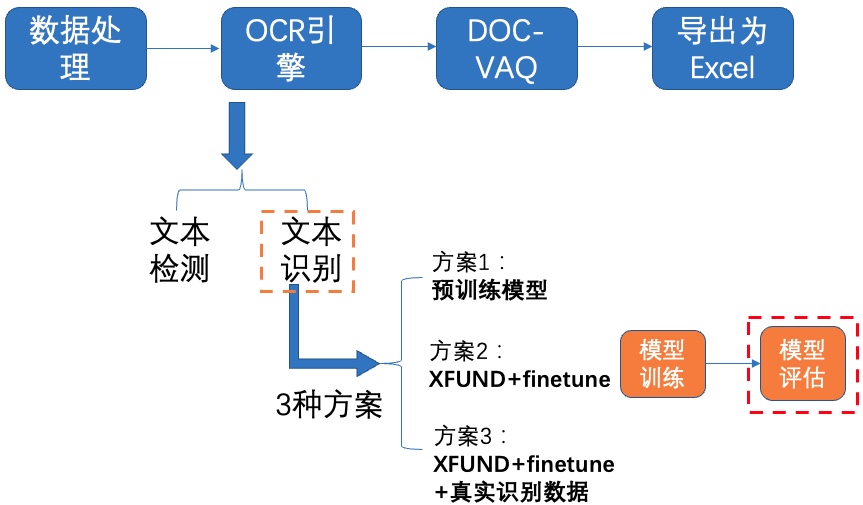
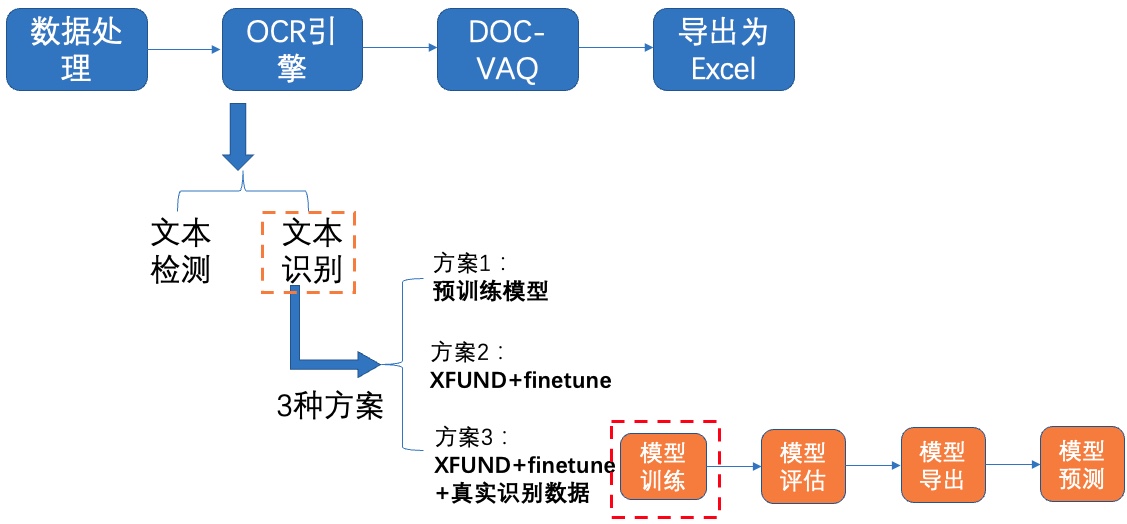
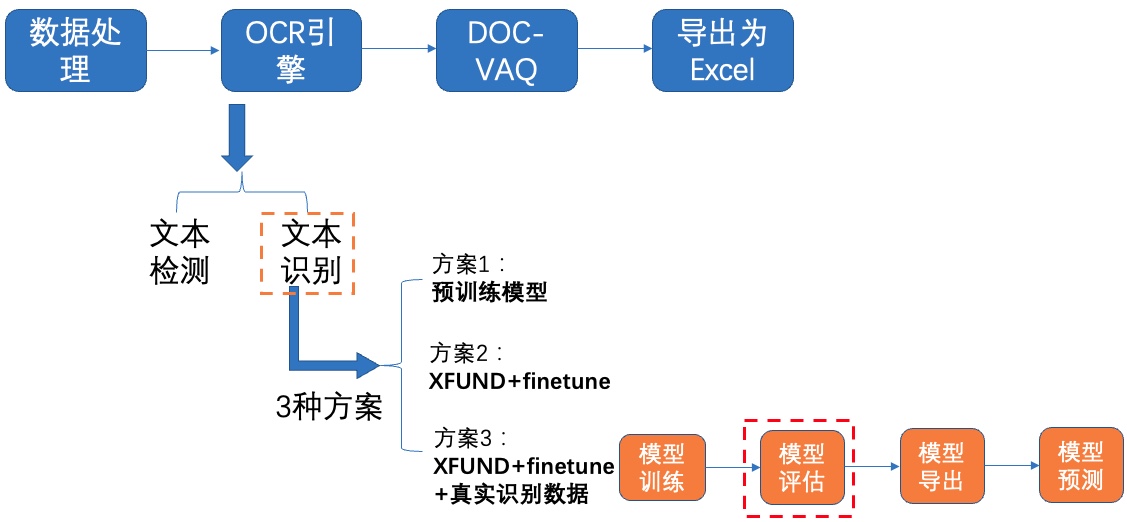
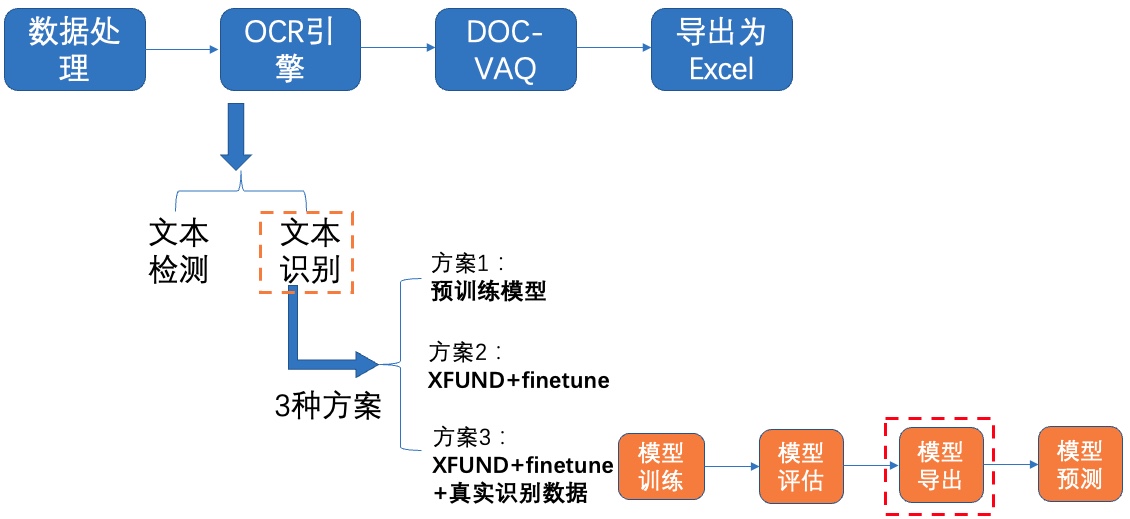
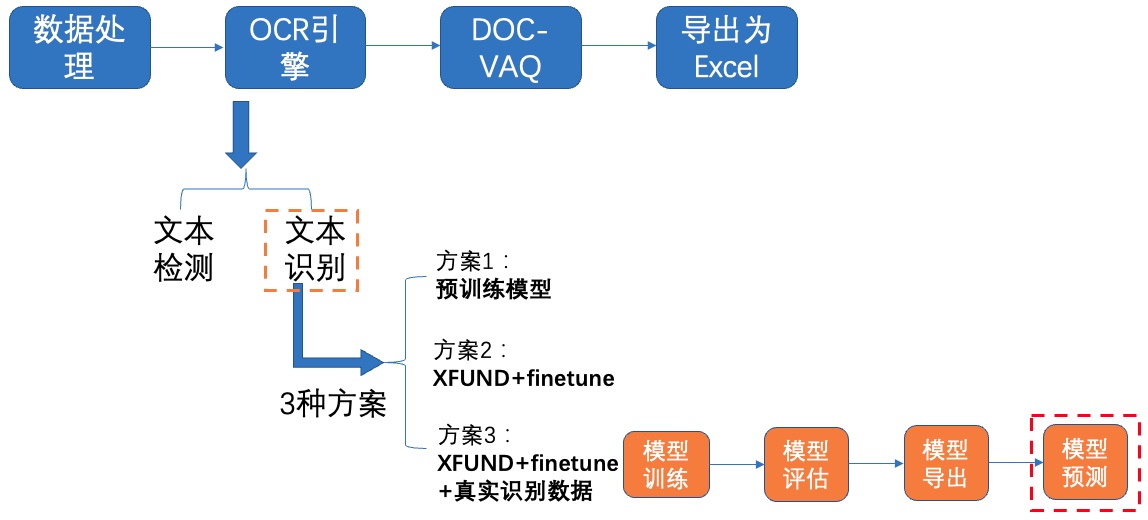

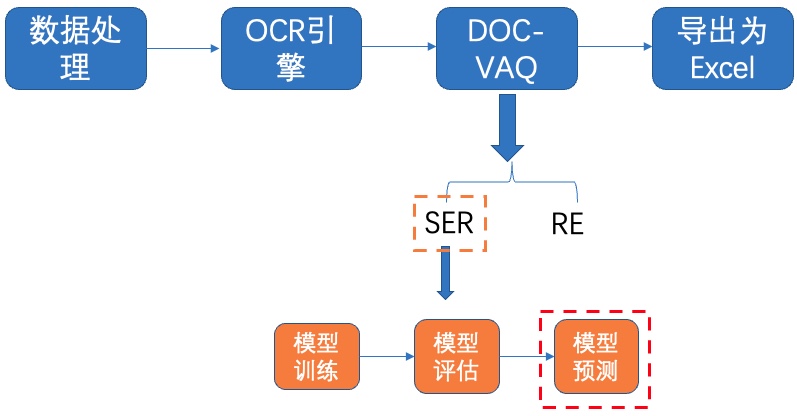

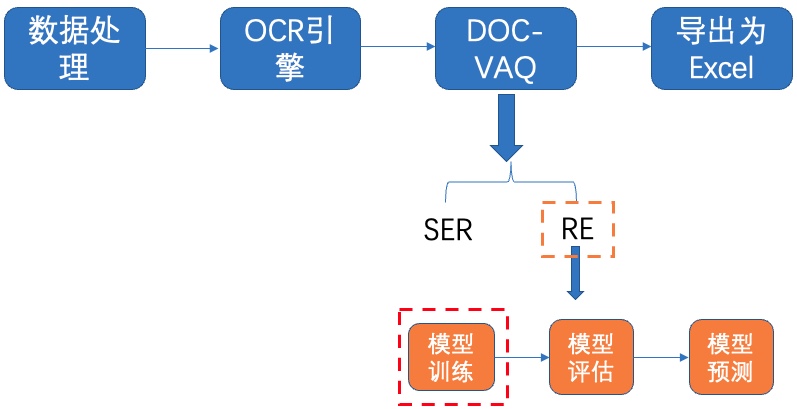
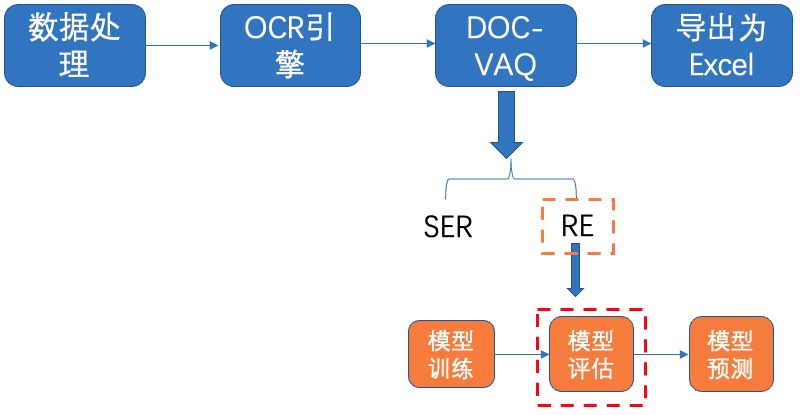
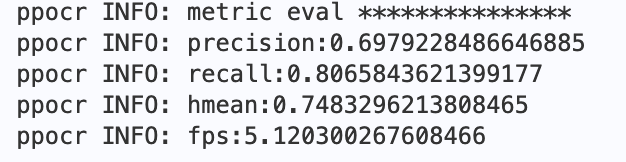
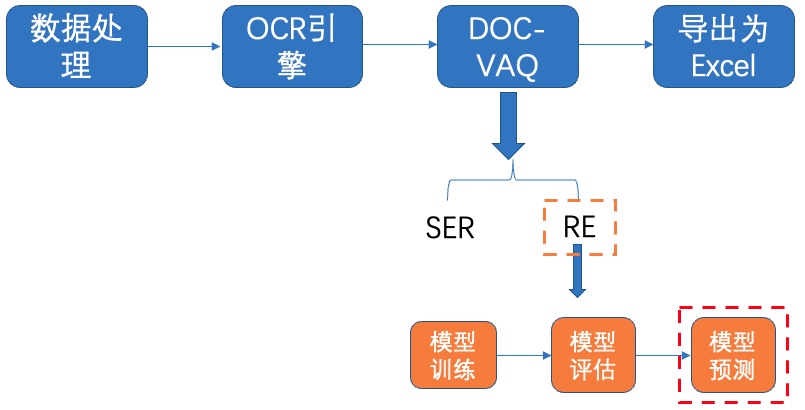

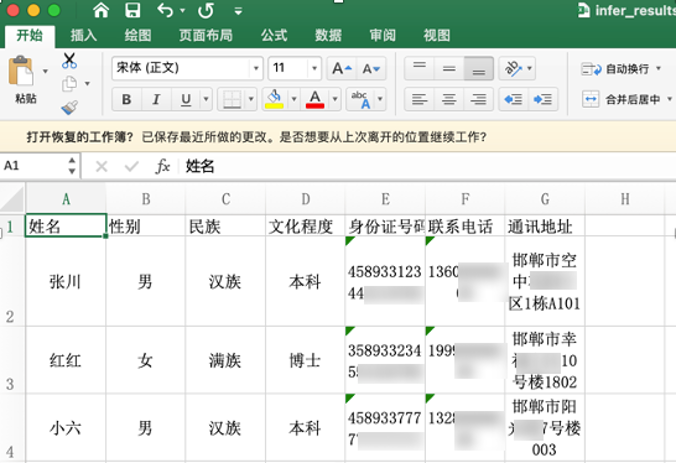
 +
+ +
+
 +
+ +
+ +
+