The above pictures are the visualizations of the general ppocr_server model. For more effect pictures, please see [More visualizations](./doc/doc_en/visualization_en.md).
Finally you can see the following files in the folder of `paddle_inference/`.
#### 1.2.2 Compile from the source code
* If you want to get the latest Paddle inference library features, you can download the latest code from Paddle github repository and compile the inference library from the source code.
* You can refer to [Paddle inference library] (https://www.paddlepaddle.org.cn/documentation/docs/en/develop/guides/05_inference_deployment/inference/build_and_install_lib_en.html) to get the Paddle source code from github, and then compile To generate the latest inference library. The method of using git to access the code is as follows.
* If you want to get the latest Paddle inference library features, you can download the latest code from Paddle github repository and compile the inference library from the source code. It is recommended to download the inference library with paddle version greater than or equal to 2.0.1.
* You can refer to [Paddle inference library] (https://www.paddlepaddle.org.cn/documentation/docs/en/advanced_guide/inference_deployment/inference/build_and_install_lib_en.html) to get the Paddle source code from github, and then compile To generate the latest inference library. The method of using git to access the code is as follows.
```shell
...
...
@@ -238,7 +238,7 @@ visualize 1 # Whether to visualize the results,when it is set as 1, The predic
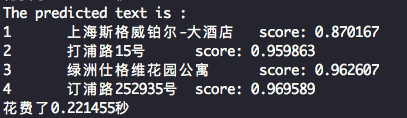
The detection results will be shown on the screen, which is as follows.
@@ -111,7 +111,7 @@ python3 generate_multi_language_configs.py -l it \
| cyrillic_mobile_v2.0_rec | Lightweight model for cyrillic recognition | [rec_cyrillic_lite_train.yml](../../configs/rec/multi_language/rec_cyrillic_lite_train.yml) |2.6M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/cyrillic_ppocr_mobile_v2.0_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/cyrillic_ppocr_mobile_v2.0_rec_train.tar) |
| devanagari_mobile_v2.0_rec | Lightweight model for devanagari recognition | [rec_devanagari_lite_train.yml](../../configs/rec/multi_language/rec_devanagari_lite_train.yml) |2.6M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/devanagari_ppocr_mobile_v2.0_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/devanagari_ppocr_mobile_v2.0_rec_train.tar) |
For more supported languages, please refer to : [Multi-language model](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_en/multi_languages_en.md#4-support-languages-and-abbreviations)
For more supported languages, please refer to : [Multi-language model](./multi_languages_en.md)
{kind=link}
{kind=link}

{kind=link}
