Merge branch 'dygraph' of https://github.com/PaddlePaddle/PaddleOCR into dygraph
Showing
因为 它太大了无法显示 source diff 。你可以改为 查看blob。
configs/e2e/e2e_r50_vd_pg.yml
0 → 100644
deploy/android_demo/.gitignore
0 → 100644
deploy/android_demo/README.md
0 → 100644

62.2 KB

63.1 KB

170.7 KB

61.1 KB


4.8 KB


2.7 KB

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

6.7 KB
{kind=link}

6.2 KB
{kind=link}

10.2 KB
{kind=link}

8.9 KB
{kind=link}

14.8 KB
deploy/android_demo/build.gradle
0 → 100644
文件已添加
deploy/android_demo/gradlew
0 → 100644
deploy/android_demo/gradlew.bat
0 → 100644
{kind=link}

26.2 KB
deploy/cpp_infer/src/preprocess_op.cpp
100644 → 100755
deploy/lite/Makefile
0 → 100644
deploy/lite/cls_process.cc
0 → 100644
deploy/lite/cls_process.h
0 → 100644
deploy/lite/config.txt
0 → 100644
deploy/lite/crnn_process.cc
0 → 100644
deploy/lite/crnn_process.h
0 → 100644
deploy/lite/db_post_process.cc
0 → 100644
deploy/lite/db_post_process.h
0 → 100644
deploy/lite/imgs/lite_demo.png
0 → 100644
{kind=link}
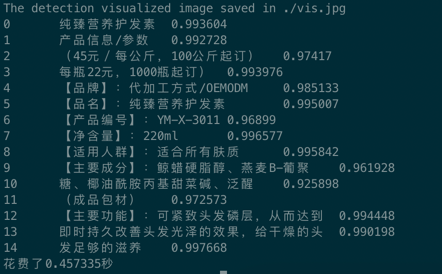
94.1 KB
deploy/lite/ocr_db_crnn.cc
0 → 100644
deploy/lite/prepare.sh
0 → 100644
deploy/lite/readme.md
0 → 100644
deploy/lite/readme_en.md
0 → 100644
doc/doc_ch/multi_languages.md
0 → 100644
doc/doc_ch/pgnet.md
0 → 100644
doc/doc_en/multi_languages_en.md
0 → 100644
doc/doc_en/pgnet_en.md
0 → 100644
doc/imgs_en/254.jpg
0 → 100644
{kind=link}

63.6 KB
{kind=link}

662.8 KB
{kind=link}

466.8 KB
{kind=link}

133.6 KB
{kind=link}

337.2 KB
{kind=link}

21.0 KB
{kind=link}

533.8 KB
{kind=link}

558.2 KB
{kind=link}

231.7 KB
{kind=link}

249.3 KB
{kind=link}

106.6 KB
{kind=link}

231.3 KB
{kind=link}

561.2 KB
{kind=link}

460.7 KB
{kind=link}

920.6 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
doc/pgnet_framework.png
0 → 100644
{kind=link}
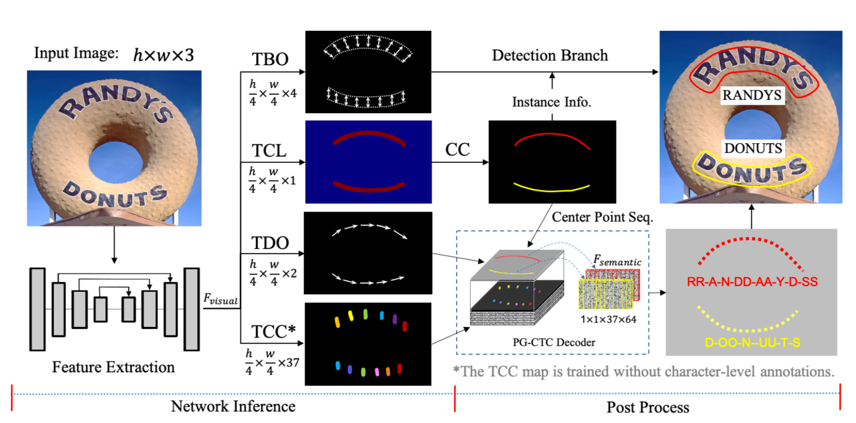
241.7 KB
ppocr/data/imaug/pg_process.py
0 → 100644
ppocr/data/pgnet_dataset.py
0 → 100644
ppocr/losses/e2e_pg_loss.py
0 → 100644
ppocr/metrics/e2e_metric.py
0 → 100644
ppocr/modeling/necks/pg_fpn.py
0 → 100644
ppocr/utils/dict/arabic_dict.txt
0 → 100644
ppocr/utils/dict/latin_dict.txt
0 → 100644
ppocr/utils/e2e_metric/Deteval.py
0 → 100755
ppocr/utils/e2e_utils/visual.py
0 → 100644
ppocr/utils/en_dict.txt
0 → 100644
| ... | @@ -3,8 +3,8 @@ scikit-image==0.17.2 | ... | @@ -3,8 +3,8 @@ scikit-image==0.17.2 |
| imgaug==0.4.0 | imgaug==0.4.0 | ||
| pyclipper | pyclipper | ||
| lmdb | lmdb | ||
| opencv-python==4.2.0.32 | |||
| tqdm | tqdm | ||
| numpy | numpy | ||
| visualdl | visualdl | ||
| python-Levenshtein | python-Levenshtein | ||
| \ No newline at end of file | opencv-contrib-python==4.2.0.32 | ||
| \ No newline at end of file |
tools/infer/predict_e2e.py
0 → 100755
tools/infer_e2e.py
0 → 100755