diff --git a/PPOCRLabel/README.md b/PPOCRLabel/README.md
index 46c2ed85124fd8d992ac17f10ff257bda0b39cd8..368a835c203f62d529bb874b3cbbf7593b96a8ba 100644
--- a/PPOCRLabel/README.md
+++ b/PPOCRLabel/README.md
@@ -2,7 +2,7 @@ English | [简体中文](README_ch.md)
# PPOCRLabel
-PPOCRLabel is a semi-automatic graphic annotation tool suitable for OCR field, with built-in PPOCR model to automatically detect and re-recognize data. It is written in python3 and pyqt5, supporting rectangular box annotation and four-point annotation modes. Annotations can be directly used for the training of PPOCR detection and recognition models.
+PPOCRLabel is a semi-automatic graphic annotation tool suitable for OCR field, with built-in PPOCR model to automatically detect and re-recognize data. It is written in python3 and pyqt5, supporting rectangular box, table and multi-point annotation modes. Annotations can be directly used for the training of PPOCR detection and recognition models.
 diff --git a/README.md b/README.md
index 34421fff56ac33de940a0d2489adf21ebafded28..33898c7f84b9c46fa9b361e835c2f6a472169bfc 100644
--- a/README.md
+++ b/README.md
@@ -18,21 +18,25 @@ English | [简体中文](README_ch.md)
PaddleOCR aims to create multilingual, awesome, leading, and practical OCR tools that help users train better models and apply them into practice.
diff --git a/README.md b/README.md
index 34421fff56ac33de940a0d2489adf21ebafded28..33898c7f84b9c46fa9b361e835c2f6a472169bfc 100644
--- a/README.md
+++ b/README.md
@@ -18,21 +18,25 @@ English | [简体中文](README_ch.md)
PaddleOCR aims to create multilingual, awesome, leading, and practical OCR tools that help users train better models and apply them into practice.
-

+

-

+

-PP-OCRv2 Chinese model
+PP-OCRv3 Chinese model
-PP-OCRv2 English model
+PP-OCRv3 English model
-PP-OCRv2 Multilingual model
+PP-OCRv3 Multilingual model
diff --git a/README_ch.md b/README_ch.md
index eb5cf8bce4ddb1e4be9d8f7e44c4e9a82d7e286f..9de3110531ae10004e3b29497a9baeb5fb6fc449 100755
--- a/README_ch.md
+++ b/README_ch.md
@@ -22,7 +22,7 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
-
+
-PP-OCRv2 中文模型
+PP-OCRv3 中文模型
-

-

-
-PP-OCRv2 英文模型
+PP-OCRv3 英文模型
-PP-OCRv2 其他语言模型
+PP-OCRv3 多语言模型
diff --git "a/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md" "b/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md"
index e64a22e169482ae51cadf8b25d75c5d98651e80b..d47bbe77045d502d82a5a8d8b8eca685963e6380 100644
--- "a/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md"
+++ "b/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md"
@@ -16,14 +16,14 @@
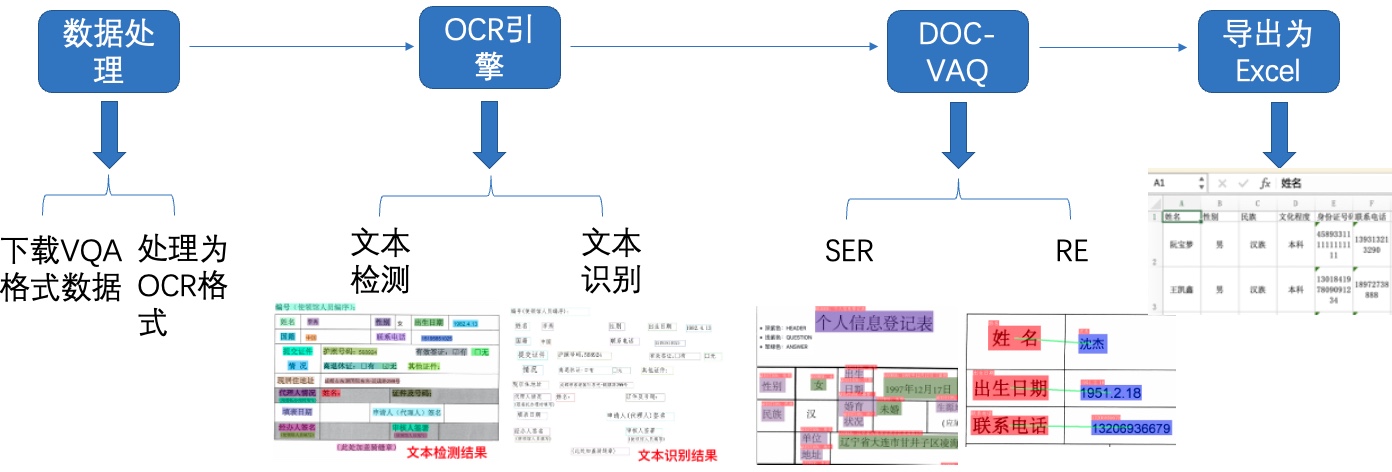 图1 多模态表单识别流程图
-注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375)(配备Tesla V100、A100等高级算力资源)
# 2 安装说明
-下载PaddleOCR源码,本项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
+下载PaddleOCR源码,上述AIStudio项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
```python
@@ -33,7 +33,7 @@
```python
# 如仍需安装or安装更新,可以执行以下步骤
-! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
+# ! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
# ! git clone https://gitee.com/PaddlePaddle/PaddleOCR
```
@@ -290,7 +290,7 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
图1 多模态表单识别流程图
-注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375)(配备Tesla V100、A100等高级算力资源)
# 2 安装说明
-下载PaddleOCR源码,本项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
+下载PaddleOCR源码,上述AIStudio项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
```python
@@ -33,7 +33,7 @@
```python
# 如仍需安装or安装更新,可以执行以下步骤
-! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
+# ! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
# ! git clone https://gitee.com/PaddlePaddle/PaddleOCR
```
@@ -290,7 +290,7 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
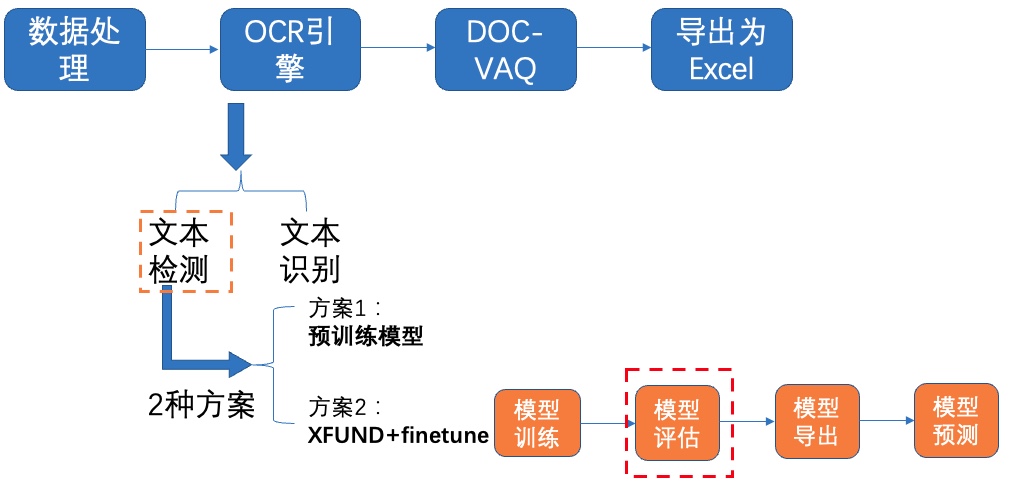 图8 文本检测方案2-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`,[模型下载地址](https://paddleocr.bj.bcebos.com/fanliku/sheet_recognition/ch_db_mv3-student1600-finetune.zip)
```python
@@ -538,7 +538,7 @@ Train.dataset.ratio_list:动态采样
图16 文本识别方案3-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-readldata/best_accuracy`
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-readldata/best_accuracy`,[模型下载地址](https://paddleocr.bj.bcebos.com/fanliku/sheet_recognition/rec_mobile_pp-OCRv2-student-realdata.zip)
```python
diff --git a/deploy/pdserving/ocr_cpp_client.py b/deploy/pdserving/ocr_cpp_client.py
index cb42943923879d1138e065881a15da893a505083..7f9333dd858aad5440ff256d501cf1e5d2f5fb1f 100755
--- a/deploy/pdserving/ocr_cpp_client.py
+++ b/deploy/pdserving/ocr_cpp_client.py
@@ -30,7 +30,7 @@ client.load_client_config(sys.argv[1:])
client.connect(["127.0.0.1:9293"])
import paddle
-test_img_dir = "test_img/"
+test_img_dir = "../../doc/imgs/"
ocr_reader = OCRReader(char_dict_path="../../ppocr/utils/ppocr_keys_v1.txt")
@@ -45,8 +45,7 @@ for img_file in os.listdir(test_img_dir):
image_data = file.read()
image = cv2_to_base64(image_data)
res_list = []
- fetch_map = client.predict(
- feed={"x": image}, fetch=["save_infer_model/scale_0.tmp_1"], batch=True)
+ fetch_map = client.predict(feed={"x": image}, fetch=[], batch=True)
one_batch_res = ocr_reader.postprocess(fetch_map, with_score=True)
for res in one_batch_res:
res_list.append(res[0])
diff --git a/doc/doc_ch/algorithm_overview.md b/doc/doc_ch/algorithm_overview.md
index 313ef9b15e7e3a2d8e7aa3ea31add75f18bb27e3..6227a21498eda7d8527e21e7f2567995251d9e47 100755
--- a/doc/doc_ch/algorithm_overview.md
+++ b/doc/doc_ch/algorithm_overview.md
@@ -44,7 +44,7 @@
在CTW1500文本检测公开数据集上,算法效果如下:
|模型|骨干网络|precision|recall|Hmean|下载链接|
-| --- | --- | --- | --- | --- | --- |
+| --- | --- | --- | --- | --- | --- |
|FCE|ResNet50_dcn|88.39%|82.18%|85.27%|[训练模型](https://paddleocr.bj.bcebos.com/contribution/det_r50_dcn_fce_ctw_v2.0_train.tar)|
**说明:** SAST模型训练额外加入了icdar2013、icdar2017、COCO-Text、ArT等公开数据集进行调优。PaddleOCR用到的经过整理格式的英文公开数据集下载:
@@ -65,6 +65,7 @@
- [x] [NRTR](./algorithm_rec_nrtr.md)
- [x] [SAR](./algorithm_rec_sar.md)
- [x] [SEED](./algorithm_rec_seed.md)
+- [x] [SVTR](./algorithm_rec_svtr.md)
参考[DTRB](https://arxiv.org/abs/1904.01906)[3]文字识别训练和评估流程,使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法效果如下:
@@ -82,6 +83,7 @@
|NRTR|NRTR_MTB| 84.21% | rec_mtb_nrtr | [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_mtb_nrtr_train.tar) |
|SAR|Resnet31| 87.20% | rec_r31_sar | [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar) |
|SEED|Aster_Resnet| 85.35% | rec_resnet_stn_bilstm_att | [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_resnet_stn_bilstm_att.tar) |
+|SVTR|SVTR-Tiny| 89.25% | rec_svtr_tiny_none_ctc_en | [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/rec_svtr_tiny_none_ctc_en_train.tar) |
@@ -90,5 +92,3 @@
已支持的端到端OCR算法列表(戳链接获取使用教程):
- [x] [PGNet](./algorithm_e2e_pgnet.md)
-
-
diff --git a/doc/doc_ch/application.md b/doc/doc_ch/application.md
deleted file mode 100644
index 6dd465f9e71951bfbc1f749b0ca93d66cbfeb220..0000000000000000000000000000000000000000
--- a/doc/doc_ch/application.md
+++ /dev/null
@@ -1 +0,0 @@
-# 场景应用
\ No newline at end of file
diff --git a/doc/doc_ch/models_list.md b/doc/doc_ch/models_list.md
index 2012381af5a1cfe53771903e0ab99bab0b7cbc08..318d5874f5e01390976723ccdb98012b95a6eb7f 100644
--- a/doc/doc_ch/models_list.md
+++ b/doc/doc_ch/models_list.md
@@ -97,7 +97,7 @@ PaddleOCR提供的可下载模型包括`推理模型`、`训练模型`、`预训
|模型名称|模型简介|配置文件|推理模型大小|下载地址|
| --- | --- | --- | --- | --- |
|en_PP-OCRv3_rec_slim |【最新】slim量化版超轻量模型,支持英文、数字识别 | [en_PP-OCRv3_rec.yml](../../configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml)| 3.2M |[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_slim_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_slim_train.tar) / [nb模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_slim_infer.nb) |
-|en_PP-OCRv3_rec |【最新】原始超轻量模型,支持英文、数字识别|[en_PP-OCRv3_rec.yml](../../configs/rec/en_PP-OCRv3/en_PP-OCRv3_rec.yml)| 9.6M | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
+|en_PP-OCRv3_rec |【最新】原始超轻量模型,支持英文、数字识别|[en_PP-OCRv3_rec.yml](../../configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml)| 9.6M | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
|en_number_mobile_slim_v2.0_rec|slim裁剪量化版超轻量模型,支持英文、数字识别|[rec_en_number_lite_train.yml](../../configs/rec/multi_language/rec_en_number_lite_train.yml)| 2.7M | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/en_number_mobile_v2.0_rec_slim_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/en_number_mobile_v2.0_rec_slim_train.tar) |
|en_number_mobile_v2.0_rec|原始超轻量模型,支持英文、数字识别|[rec_en_number_lite_train.yml](../../configs/rec/multi_language/rec_en_number_lite_train.yml)|2.6M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/en_number_mobile_v2.0_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/en_number_mobile_v2.0_rec_train.tar) |
@@ -118,7 +118,7 @@ PaddleOCR提供的可下载模型包括`推理模型`、`训练模型`、`预训
| cyrillic_PP-OCRv3_rec | ppocr/utils/dict/cyrillic_dict.txt | 斯拉夫字母 | [cyrillic_PP-OCRv3_rec.yml](../../configs/rec/PP-OCRv3/multi_language/cyrillic_PP-OCRv3_rec.yml) |9.6M|[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/cyrillic_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/cyrillic_PP-OCRv3_rec_train.tar) |
| devanagari_PP-OCRv3_rec | ppocr/utils/dict/devanagari_dict.txt |梵文字母 | [devanagari_PP-OCRv3_rec.yml](../../configs/rec/PP-OCRv3/multi_language/devanagari_PP-OCRv3_rec.yml) |9.9M|[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/devanagari_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/devanagari_PP-OCRv3_rec_train.tar) |
-更多支持语种请参考: [多语言模型](./multi_languages.md)
+查看完整语种列表与使用教程请参考: [多语言模型](./multi_languages.md)
diff --git a/doc/doc_ch/multi_languages.md b/doc/doc_ch/multi_languages.md
index 6838b350403a7044e629e5fcc5893bced98af9d3..499fdd9881563b3a784b5f4ba4feace54f1a3a6a 100644
--- a/doc/doc_ch/multi_languages.md
+++ b/doc/doc_ch/multi_languages.md
@@ -2,6 +2,7 @@
**近期更新**
+- 2022.5.8 更新`PP-OCRv3`版 多语言检测和识别模型,平均识别准确率提升5%以上。
- 2021.4.9 支持**80种**语言的检测和识别
- 2021.4.9 支持**轻量高精度**英文模型检测识别
@@ -254,7 +255,7 @@ python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs
|英文|english|en| |乌克兰文|Ukranian|uk|
|法文|french|fr| |白俄罗斯文|Belarusian|be|
|德文|german|german| |泰卢固文|Telugu |te|
-|日文|japan|japan| | 阿巴扎文 | Abaza | abq |
+|日文|japan|japan| | 阿巴扎文 |Abaza | abq |
|韩文|korean|korean| |泰米尔文|Tamil |ta|
|中文繁体|chinese traditional |chinese_cht| |南非荷兰文 |Afrikaans |af|
|意大利文| Italian |it| |阿塞拜疆文 |Azerbaijani |az|
diff --git a/doc/doc_ch/ocr_book.md b/doc/doc_ch/ocr_book.md
index fb2369e414ec454f0e3c51f4f2e83c1f5d155c6c..03a6011b6b921eff82ab41863058341fc599e41b 100644
--- a/doc/doc_ch/ocr_book.md
+++ b/doc/doc_ch/ocr_book.md
@@ -1,16 +1,25 @@
# 《动手学OCR》电子书
-特点:
-- 覆盖OCR全栈技术
-- 理论实践相结合
-- Notebook交互式学习
-- 配套教学视频
+《动手学OCR》是PaddleOCR团队携手复旦大学青年研究员陈智能、中国移动研究院视觉领域资深专家黄文辉等产学研同仁,以及OCR开发者共同打造的结合OCR前沿理论与代码实践的教材。主要特色如下:
-[电子书下载]()
+- 覆盖从文本检测识别到文档分析的OCR全栈技术
+- 紧密结合理论实践,跨越代码实现鸿沟,并配套教学视频
+- Notebook交互式学习,灵活修改代码,即刻获得结果
-目录:
-![]()
-[notebook教程](../../notebook/notebook_ch/)
+## 本书结构
-[教学视频](https://aistudio.baidu.com/aistudio/education/group/info/25207)
\ No newline at end of file
+
+
+- 第一部分是本书的推荐序、序言与预备知识,包含本书的定位与使用书籍内容的过程中需要用到的知识索引、资源链接等
+- 第二部分是本书的4-8章,介绍与OCR核心的检测、识别能力相关的概念、应用与产业实践。在“OCR技术导论”中总括性的解释OCR的应用场景和挑战、技术基本概念以及在产业应用中的痛点问题。然后在
+“文本检测”与“文本识别”两章中介绍OCR的两个基本任务,并在每章中配套一个算法展开代码详解与实战练习。第6、7章是关于PP-OCR系列模型的详细介绍,PP-OCR是一套面向产业应用的OCR系统,在
+基础检测和识别模型的基础之上经过一系列优化策略达到通用领域的产业级SOTA模型,同时打通多种预测部署方案,赋能企业快速落地OCR应用。
+- 第三部分是本书的9-12章,介绍两阶段OCR引擎之外的应用,包括数据合成、预处理算法、端到端模型,重点展开了OCR在文档场景下的版面分析、表格识别、视觉文档问答的能力,同样通过算法与代码结
+合的方式使得读者能够深入理解并应用。
+
+
+## 资料地址
+- 中文版电子书下载请扫描首页二维码入群后领取
+- [notebook教程](../../notebook/notebook_ch/)
+- [教学视频](https://aistudio.baidu.com/aistudio/education/group/info/25207)
diff --git a/doc/doc_ch/ppocr_introduction.md b/doc/doc_ch/ppocr_introduction.md
index 14f95f1cd65da249d58da39c5228cb6d4bcb045e..59de124e2ab855d0b4abb90d0a356aefd6db586d 100644
--- a/doc/doc_ch/ppocr_introduction.md
+++ b/doc/doc_ch/ppocr_introduction.md
@@ -71,38 +71,28 @@ PP-OCRv3系统pipeline如下:
## 4. 效果展示 [more](./visualization.md)
图8 文本检测方案2-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`,[模型下载地址](https://paddleocr.bj.bcebos.com/fanliku/sheet_recognition/ch_db_mv3-student1600-finetune.zip)
```python
@@ -538,7 +538,7 @@ Train.dataset.ratio_list:动态采样
图16 文本识别方案3-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-readldata/best_accuracy`
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-readldata/best_accuracy`,[模型下载地址](https://paddleocr.bj.bcebos.com/fanliku/sheet_recognition/rec_mobile_pp-OCRv2-student-realdata.zip)
```python
diff --git a/deploy/pdserving/ocr_cpp_client.py b/deploy/pdserving/ocr_cpp_client.py
index cb42943923879d1138e065881a15da893a505083..7f9333dd858aad5440ff256d501cf1e5d2f5fb1f 100755
--- a/deploy/pdserving/ocr_cpp_client.py
+++ b/deploy/pdserving/ocr_cpp_client.py
@@ -30,7 +30,7 @@ client.load_client_config(sys.argv[1:])
client.connect(["127.0.0.1:9293"])
import paddle
-test_img_dir = "test_img/"
+test_img_dir = "../../doc/imgs/"
ocr_reader = OCRReader(char_dict_path="../../ppocr/utils/ppocr_keys_v1.txt")
@@ -45,8 +45,7 @@ for img_file in os.listdir(test_img_dir):
image_data = file.read()
image = cv2_to_base64(image_data)
res_list = []
- fetch_map = client.predict(
- feed={"x": image}, fetch=["save_infer_model/scale_0.tmp_1"], batch=True)
+ fetch_map = client.predict(feed={"x": image}, fetch=[], batch=True)
one_batch_res = ocr_reader.postprocess(fetch_map, with_score=True)
for res in one_batch_res:
res_list.append(res[0])
diff --git a/doc/doc_ch/algorithm_overview.md b/doc/doc_ch/algorithm_overview.md
index 313ef9b15e7e3a2d8e7aa3ea31add75f18bb27e3..6227a21498eda7d8527e21e7f2567995251d9e47 100755
--- a/doc/doc_ch/algorithm_overview.md
+++ b/doc/doc_ch/algorithm_overview.md
@@ -44,7 +44,7 @@
在CTW1500文本检测公开数据集上,算法效果如下:
|模型|骨干网络|precision|recall|Hmean|下载链接|
-| --- | --- | --- | --- | --- | --- |
+| --- | --- | --- | --- | --- | --- |
|FCE|ResNet50_dcn|88.39%|82.18%|85.27%|[训练模型](https://paddleocr.bj.bcebos.com/contribution/det_r50_dcn_fce_ctw_v2.0_train.tar)|
**说明:** SAST模型训练额外加入了icdar2013、icdar2017、COCO-Text、ArT等公开数据集进行调优。PaddleOCR用到的经过整理格式的英文公开数据集下载:
@@ -65,6 +65,7 @@
- [x] [NRTR](./algorithm_rec_nrtr.md)
- [x] [SAR](./algorithm_rec_sar.md)
- [x] [SEED](./algorithm_rec_seed.md)
+- [x] [SVTR](./algorithm_rec_svtr.md)
参考[DTRB](https://arxiv.org/abs/1904.01906)[3]文字识别训练和评估流程,使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法效果如下:
@@ -82,6 +83,7 @@
|NRTR|NRTR_MTB| 84.21% | rec_mtb_nrtr | [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_mtb_nrtr_train.tar) |
|SAR|Resnet31| 87.20% | rec_r31_sar | [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar) |
|SEED|Aster_Resnet| 85.35% | rec_resnet_stn_bilstm_att | [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_resnet_stn_bilstm_att.tar) |
+|SVTR|SVTR-Tiny| 89.25% | rec_svtr_tiny_none_ctc_en | [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/rec_svtr_tiny_none_ctc_en_train.tar) |
@@ -90,5 +92,3 @@
已支持的端到端OCR算法列表(戳链接获取使用教程):
- [x] [PGNet](./algorithm_e2e_pgnet.md)
-
-
diff --git a/doc/doc_ch/application.md b/doc/doc_ch/application.md
deleted file mode 100644
index 6dd465f9e71951bfbc1f749b0ca93d66cbfeb220..0000000000000000000000000000000000000000
--- a/doc/doc_ch/application.md
+++ /dev/null
@@ -1 +0,0 @@
-# 场景应用
\ No newline at end of file
diff --git a/doc/doc_ch/models_list.md b/doc/doc_ch/models_list.md
index 2012381af5a1cfe53771903e0ab99bab0b7cbc08..318d5874f5e01390976723ccdb98012b95a6eb7f 100644
--- a/doc/doc_ch/models_list.md
+++ b/doc/doc_ch/models_list.md
@@ -97,7 +97,7 @@ PaddleOCR提供的可下载模型包括`推理模型`、`训练模型`、`预训
|模型名称|模型简介|配置文件|推理模型大小|下载地址|
| --- | --- | --- | --- | --- |
|en_PP-OCRv3_rec_slim |【最新】slim量化版超轻量模型,支持英文、数字识别 | [en_PP-OCRv3_rec.yml](../../configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml)| 3.2M |[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_slim_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_slim_train.tar) / [nb模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_slim_infer.nb) |
-|en_PP-OCRv3_rec |【最新】原始超轻量模型,支持英文、数字识别|[en_PP-OCRv3_rec.yml](../../configs/rec/en_PP-OCRv3/en_PP-OCRv3_rec.yml)| 9.6M | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
+|en_PP-OCRv3_rec |【最新】原始超轻量模型,支持英文、数字识别|[en_PP-OCRv3_rec.yml](../../configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml)| 9.6M | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
|en_number_mobile_slim_v2.0_rec|slim裁剪量化版超轻量模型,支持英文、数字识别|[rec_en_number_lite_train.yml](../../configs/rec/multi_language/rec_en_number_lite_train.yml)| 2.7M | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/en_number_mobile_v2.0_rec_slim_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/en_number_mobile_v2.0_rec_slim_train.tar) |
|en_number_mobile_v2.0_rec|原始超轻量模型,支持英文、数字识别|[rec_en_number_lite_train.yml](../../configs/rec/multi_language/rec_en_number_lite_train.yml)|2.6M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/en_number_mobile_v2.0_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/multilingual/en_number_mobile_v2.0_rec_train.tar) |
@@ -118,7 +118,7 @@ PaddleOCR提供的可下载模型包括`推理模型`、`训练模型`、`预训
| cyrillic_PP-OCRv3_rec | ppocr/utils/dict/cyrillic_dict.txt | 斯拉夫字母 | [cyrillic_PP-OCRv3_rec.yml](../../configs/rec/PP-OCRv3/multi_language/cyrillic_PP-OCRv3_rec.yml) |9.6M|[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/cyrillic_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/cyrillic_PP-OCRv3_rec_train.tar) |
| devanagari_PP-OCRv3_rec | ppocr/utils/dict/devanagari_dict.txt |梵文字母 | [devanagari_PP-OCRv3_rec.yml](../../configs/rec/PP-OCRv3/multi_language/devanagari_PP-OCRv3_rec.yml) |9.9M|[推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/devanagari_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/multilingual/devanagari_PP-OCRv3_rec_train.tar) |
-更多支持语种请参考: [多语言模型](./multi_languages.md)
+查看完整语种列表与使用教程请参考: [多语言模型](./multi_languages.md)
diff --git a/doc/doc_ch/multi_languages.md b/doc/doc_ch/multi_languages.md
index 6838b350403a7044e629e5fcc5893bced98af9d3..499fdd9881563b3a784b5f4ba4feace54f1a3a6a 100644
--- a/doc/doc_ch/multi_languages.md
+++ b/doc/doc_ch/multi_languages.md
@@ -2,6 +2,7 @@
**近期更新**
+- 2022.5.8 更新`PP-OCRv3`版 多语言检测和识别模型,平均识别准确率提升5%以上。
- 2021.4.9 支持**80种**语言的检测和识别
- 2021.4.9 支持**轻量高精度**英文模型检测识别
@@ -254,7 +255,7 @@ python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs
|英文|english|en| |乌克兰文|Ukranian|uk|
|法文|french|fr| |白俄罗斯文|Belarusian|be|
|德文|german|german| |泰卢固文|Telugu |te|
-|日文|japan|japan| | 阿巴扎文 | Abaza | abq |
+|日文|japan|japan| | 阿巴扎文 |Abaza | abq |
|韩文|korean|korean| |泰米尔文|Tamil |ta|
|中文繁体|chinese traditional |chinese_cht| |南非荷兰文 |Afrikaans |af|
|意大利文| Italian |it| |阿塞拜疆文 |Azerbaijani |az|
diff --git a/doc/doc_ch/ocr_book.md b/doc/doc_ch/ocr_book.md
index fb2369e414ec454f0e3c51f4f2e83c1f5d155c6c..03a6011b6b921eff82ab41863058341fc599e41b 100644
--- a/doc/doc_ch/ocr_book.md
+++ b/doc/doc_ch/ocr_book.md
@@ -1,16 +1,25 @@
# 《动手学OCR》电子书
-特点:
-- 覆盖OCR全栈技术
-- 理论实践相结合
-- Notebook交互式学习
-- 配套教学视频
+《动手学OCR》是PaddleOCR团队携手复旦大学青年研究员陈智能、中国移动研究院视觉领域资深专家黄文辉等产学研同仁,以及OCR开发者共同打造的结合OCR前沿理论与代码实践的教材。主要特色如下:
-[电子书下载]()
+- 覆盖从文本检测识别到文档分析的OCR全栈技术
+- 紧密结合理论实践,跨越代码实现鸿沟,并配套教学视频
+- Notebook交互式学习,灵活修改代码,即刻获得结果
-目录:
-![]()
-[notebook教程](../../notebook/notebook_ch/)
+## 本书结构
-[教学视频](https://aistudio.baidu.com/aistudio/education/group/info/25207)
\ No newline at end of file
+
+
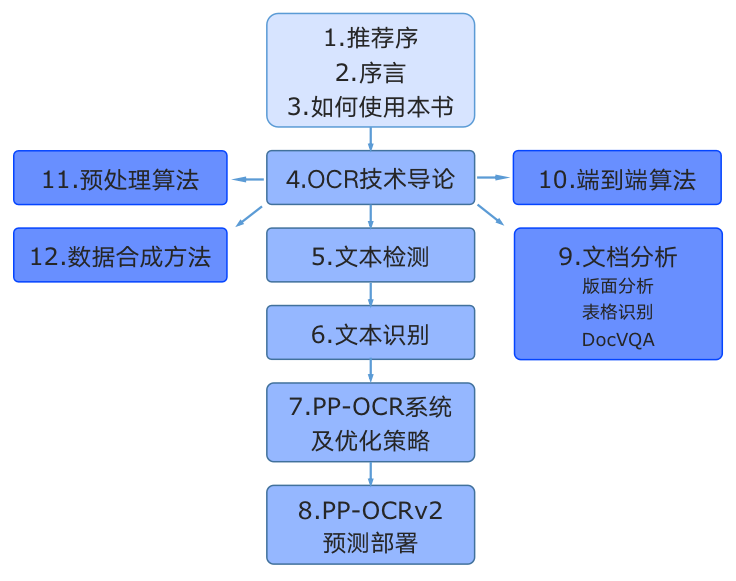
+- 第一部分是本书的推荐序、序言与预备知识,包含本书的定位与使用书籍内容的过程中需要用到的知识索引、资源链接等
+- 第二部分是本书的4-8章,介绍与OCR核心的检测、识别能力相关的概念、应用与产业实践。在“OCR技术导论”中总括性的解释OCR的应用场景和挑战、技术基本概念以及在产业应用中的痛点问题。然后在
+“文本检测”与“文本识别”两章中介绍OCR的两个基本任务,并在每章中配套一个算法展开代码详解与实战练习。第6、7章是关于PP-OCR系列模型的详细介绍,PP-OCR是一套面向产业应用的OCR系统,在
+基础检测和识别模型的基础之上经过一系列优化策略达到通用领域的产业级SOTA模型,同时打通多种预测部署方案,赋能企业快速落地OCR应用。
+- 第三部分是本书的9-12章,介绍两阶段OCR引擎之外的应用,包括数据合成、预处理算法、端到端模型,重点展开了OCR在文档场景下的版面分析、表格识别、视觉文档问答的能力,同样通过算法与代码结
+合的方式使得读者能够深入理解并应用。
+
+
+## 资料地址
+- 中文版电子书下载请扫描首页二维码入群后领取
+- [notebook教程](../../notebook/notebook_ch/)
+- [教学视频](https://aistudio.baidu.com/aistudio/education/group/info/25207)
diff --git a/doc/doc_ch/ppocr_introduction.md b/doc/doc_ch/ppocr_introduction.md
index 14f95f1cd65da249d58da39c5228cb6d4bcb045e..59de124e2ab855d0b4abb90d0a356aefd6db586d 100644
--- a/doc/doc_ch/ppocr_introduction.md
+++ b/doc/doc_ch/ppocr_introduction.md
@@ -71,38 +71,28 @@ PP-OCRv3系统pipeline如下:
## 4. 效果展示 [more](./visualization.md)
-PP-OCRv2 中文模型
-
-
-

-

-
PP-OCRv3 中文模型
-
-
-PP-OCRv2 英文模型
-
+PP-OCRv3 英文模型
-
-
-PP-OCRv2 其他语言模型
-
+PP-OCRv3 多语言模型
-
diff --git a/doc/doc_ch/visualization.md b/doc/doc_ch/visualization.md
index 99d071ec22daccaa295b5087760c5fc0d45f9802..254634753282f53f367e44f4859e5b748f32bffd 100644
--- a/doc/doc_ch/visualization.md
+++ b/doc/doc_ch/visualization.md
@@ -1,23 +1,46 @@
# 效果展示
+
+
+## 超轻量PP-OCRv3效果展示
+
+### PP-OCRv3中文模型
+
+
+### PP-OCRv3英文数字模型
+
+
+
+### PP-OCRv3多语言模型
+
+
+

+

+


 -
+
+
## 通用PP-OCR server 效果展示
diff --git a/doc/doc_en/PP-OCRv3_introduction_en.md b/doc/doc_en/PP-OCRv3_introduction_en.md
index 74b6086837148260742417b9471ac2dc4efeab9e..9ab25653e219c18e1acaaf7c99b050f790bcb1b9 100644
--- a/doc/doc_en/PP-OCRv3_introduction_en.md
+++ b/doc/doc_en/PP-OCRv3_introduction_en.md
@@ -99,7 +99,7 @@ Considering that the features of some channels will be suppressed if the convolu
## 3. Optimization for Text Recognition Model
-The recognition module of PP-OCRv3 is optimized based on the text recognition algorithm [SVTR](https://arxiv.org/abs/2205.00159). RNN is abandoned in SVTR, and the context information of the text line image is more effectively mined by introducing the Transformers structure, thereby improving the text recognition ability.
+The recognition module of PP-OCRv3 is optimized based on the text recognition algorithm [SVTR](https://arxiv.org/abs/2205.00159). RNN is abandoned in SVTR, and the context information of the text line image is more effectively mined by introducing the Transformers structure, thereby improving the text recognition ability.
The recognition accuracy of SVTR_inty outperforms PP-OCRv2 recognition model by 5.3%, while the prediction speed nearly 11 times slower. It takes nearly 100ms to predict a text line on CPU. Therefore, as shown in the figure below, PP-OCRv3 adopts the following six optimization strategies to accelerate the recognition model.
@@ -151,7 +151,7 @@ Due to the limited model structure supported by the MKLDNN acceleration library,
3. The experiment found that the prediction speed of the Global Mixing Block is related to the shape of the input features. Therefore, after moving the position of the Global Mixing Block to the back of pooling layer, the accuracy dropped to 71.9%, and the speed surpassed the PP-OCRv2-baseline based on the CNN structure by 22%. The network structure is as follows:
-
+
+
## 通用PP-OCR server 效果展示
diff --git a/doc/doc_en/PP-OCRv3_introduction_en.md b/doc/doc_en/PP-OCRv3_introduction_en.md
index 74b6086837148260742417b9471ac2dc4efeab9e..9ab25653e219c18e1acaaf7c99b050f790bcb1b9 100644
--- a/doc/doc_en/PP-OCRv3_introduction_en.md
+++ b/doc/doc_en/PP-OCRv3_introduction_en.md
@@ -99,7 +99,7 @@ Considering that the features of some channels will be suppressed if the convolu
## 3. Optimization for Text Recognition Model
-The recognition module of PP-OCRv3 is optimized based on the text recognition algorithm [SVTR](https://arxiv.org/abs/2205.00159). RNN is abandoned in SVTR, and the context information of the text line image is more effectively mined by introducing the Transformers structure, thereby improving the text recognition ability.
+The recognition module of PP-OCRv3 is optimized based on the text recognition algorithm [SVTR](https://arxiv.org/abs/2205.00159). RNN is abandoned in SVTR, and the context information of the text line image is more effectively mined by introducing the Transformers structure, thereby improving the text recognition ability.
The recognition accuracy of SVTR_inty outperforms PP-OCRv2 recognition model by 5.3%, while the prediction speed nearly 11 times slower. It takes nearly 100ms to predict a text line on CPU. Therefore, as shown in the figure below, PP-OCRv3 adopts the following six optimization strategies to accelerate the recognition model.
@@ -151,7 +151,7 @@ Due to the limited model structure supported by the MKLDNN acceleration library,
3. The experiment found that the prediction speed of the Global Mixing Block is related to the shape of the input features. Therefore, after moving the position of the Global Mixing Block to the back of pooling layer, the accuracy dropped to 71.9%, and the speed surpassed the PP-OCRv2-baseline based on the CNN structure by 22%. The network structure is as follows:
-

+

-

+

-PP-OCRv2 English model
-
+PP-OCRv3 Chinese model
-
-PP-OCRv2 Chinese model
-
-
-
-
-
PP-OCRv3 English model
-
-PP-OCRv2 Multilingual model
-
+PP-OCRv3 Multilingual model
-
diff --git a/doc/doc_en/visualization_en.md b/doc/doc_en/visualization_en.md
index 71cfb043462f34f2b3bef594364d33f15e98d81e..8ea64925eabb55a68e00a1ee13b465cb260db29b 100644
--- a/doc/doc_en/visualization_en.md
+++ b/doc/doc_en/visualization_en.md
@@ -1,5 +1,30 @@
# Visualization
+
+## PP-OCRv3
+
+### PP-OCRv3 Chinese model
+
+
+### PP-OCRv3 English model
+
+
+
+### PP-OCRv3 Multilingual model
+
+
+
+
+


 -
-
-
-  -
-  -
-  -
-  -
-  -
-  diff --git a/doc/features.png b/doc/features.png
index ea7214565869f95d5ecf35bc85be1a8c48318265..273e4beb74771b723ab732f703863fa2a3a4c21c 100644
Binary files a/doc/features.png and b/doc/features.png differ
diff --git a/doc/features_en.png b/doc/features_en.png
index 4e7baec4d563d50b1ace9e997e72b05ae1e803f0..310a1b7e50920304521a5fa68c5c2e2a881d3917 100644
Binary files a/doc/features_en.png and b/doc/features_en.png differ
diff --git a/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic001.jpg b/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic001.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..c35936cc1a9509d4c2aec66bbd9c22345f10694d
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic001.jpg differ
diff --git a/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic002.jpg b/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic002.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e5ad6a4b2a3ab735ec15fad6bae428f4008226e0
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic002.jpg differ
diff --git a/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic003.jpg b/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic003.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..dc024296bdae41a32cf1aa0c5f396caa57383496
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic003.jpg differ
diff --git a/doc/imgs_results/PP-OCRv3/en/en_1.png b/doc/imgs_results/PP-OCRv3/en/en_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..36245613e304fce0e376fe78e795f9a76d3b6015
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/en/en_1.png differ
diff --git a/doc/imgs_results/PP-OCRv3/en/en_2.png b/doc/imgs_results/PP-OCRv3/en/en_2.png
new file mode 100644
index 0000000000000000000000000000000000000000..d2df8556ad30a9f429d943cb940842a95056d604
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/en/en_2.png differ
diff --git a/doc/imgs_results/PP-OCRv3/en/en_3.png b/doc/imgs_results/PP-OCRv3/en/en_3.png
new file mode 100644
index 0000000000000000000000000000000000000000..baf146c0102505a308656d92fdd89d5b1333ccb1
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/en/en_3.png differ
diff --git a/doc/imgs_results/PP-OCRv3/en/en_4.png b/doc/imgs_results/PP-OCRv3/en/en_4.png
new file mode 100644
index 0000000000000000000000000000000000000000..f0f19db95b7917dc884bdb7d2c2f98b9e74c22e1
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/en/en_4.png differ
diff --git a/doc/imgs_results/PP-OCRv3/multi_lang/japan_2.jpg b/doc/imgs_results/PP-OCRv3/multi_lang/japan_2.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..076ced92ad62b7e30b62a389a1849e1709dba87e
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/multi_lang/japan_2.jpg differ
diff --git a/doc/imgs_results/PP-OCRv3/multi_lang/korean_1.jpg b/doc/imgs_results/PP-OCRv3/multi_lang/korean_1.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..f93de40e18fb3bff9d2379c5c61464a85ac3f344
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/multi_lang/korean_1.jpg differ
diff --git a/doc/imgs_results/ch_ppocr_mobile_v2.0/00018069.jpg b/doc/imgs_results/ch_ppocr_mobile_v2.0/00018069.jpg
deleted file mode 100644
index b3d645779428bcce8c120976ef66bef10deee0c5..0000000000000000000000000000000000000000
Binary files a/doc/imgs_results/ch_ppocr_mobile_v2.0/00018069.jpg and /dev/null differ
diff --git a/doc/imgs_results/ch_ppocr_mobile_v2.0/00056221.jpg b/doc/imgs_results/ch_ppocr_mobile_v2.0/00056221.jpg
deleted file mode 100644
index 7dba7708be61d912d574b610fc0b04cfa4e5feea..0000000000000000000000000000000000000000
Binary files a/doc/imgs_results/ch_ppocr_mobile_v2.0/00056221.jpg and /dev/null differ
diff --git a/doc/imgs_results/ch_ppocr_mobile_v2.0/00057937.jpg b/doc/imgs_results/ch_ppocr_mobile_v2.0/00057937.jpg
deleted file mode 100644
index 2168ecd1f0acb75d7ecc9c15202f342d18111495..0000000000000000000000000000000000000000
Binary files a/doc/imgs_results/ch_ppocr_mobile_v2.0/00057937.jpg and /dev/null differ
diff --git a/doc/imgs_results/ch_ppocr_mobile_v2.0/00077949.jpg b/doc/imgs_results/ch_ppocr_mobile_v2.0/00077949.jpg
deleted file mode 100644
index f1acbf0f94a1febbbf0d780ed019723b3dd78fa9..0000000000000000000000000000000000000000
Binary files a/doc/imgs_results/ch_ppocr_mobile_v2.0/00077949.jpg and /dev/null differ
diff --git a/doc/imgs_results/ch_ppocr_mobile_v2.0/00207393.jpg b/doc/imgs_results/ch_ppocr_mobile_v2.0/00207393.jpg
deleted file mode 100644
index 59d9a5632d3054dbf8cc6bdb021ebef224c890a8..0000000000000000000000000000000000000000
Binary files a/doc/imgs_results/ch_ppocr_mobile_v2.0/00207393.jpg and /dev/null differ
diff --git a/doc/ppocr_v3/GTC_en.png b/doc/ppocr_v3/GTC_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..a1a7fc52505f3f7f84f484fb1ee07d462e9e0648
Binary files /dev/null and b/doc/ppocr_v3/GTC_en.png differ
diff --git a/doc/ppocr_v3/LCNet_SVTR_en.png b/doc/ppocr_v3/LCNet_SVTR_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..7890448470957cc7866a0b4e2cd09c36a788e213
Binary files /dev/null and b/doc/ppocr_v3/LCNet_SVTR_en.png differ
diff --git a/paddleocr.py b/paddleocr.py
index f7871db6470c75db82e8251dff5361c099c4adda..a1265f79def7018a5586be954127e5b7fdba011e 100644
--- a/paddleocr.py
+++ b/paddleocr.py
@@ -47,8 +47,8 @@ __all__ = [
]
SUPPORT_DET_MODEL = ['DB']
-VERSION = '2.5.0.1'
-SUPPORT_REC_MODEL = ['CRNN']
+VERSION = '2.5.0.3'
+SUPPORT_REC_MODEL = ['CRNN', 'SVTR_LCNet']
BASE_DIR = os.path.expanduser("~/.paddleocr/")
DEFAULT_OCR_MODEL_VERSION = 'PP-OCRv3'
diff --git a/ppstructure/README.md b/ppstructure/README.md
index 0febf233d883e59e4377777e5b96e354853e2f33..72670e33575ebe444c78b15fbab4e330389a7498 100644
--- a/ppstructure/README.md
+++ b/ppstructure/README.md
@@ -40,7 +40,7 @@ The main features of PP-Structure are as follows:
### 4.1 Layout analysis and table recognition
-
diff --git a/doc/features.png b/doc/features.png
index ea7214565869f95d5ecf35bc85be1a8c48318265..273e4beb74771b723ab732f703863fa2a3a4c21c 100644
Binary files a/doc/features.png and b/doc/features.png differ
diff --git a/doc/features_en.png b/doc/features_en.png
index 4e7baec4d563d50b1ace9e997e72b05ae1e803f0..310a1b7e50920304521a5fa68c5c2e2a881d3917 100644
Binary files a/doc/features_en.png and b/doc/features_en.png differ
diff --git a/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic001.jpg b/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic001.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..c35936cc1a9509d4c2aec66bbd9c22345f10694d
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic001.jpg differ
diff --git a/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic002.jpg b/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic002.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e5ad6a4b2a3ab735ec15fad6bae428f4008226e0
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic002.jpg differ
diff --git a/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic003.jpg b/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic003.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..dc024296bdae41a32cf1aa0c5f396caa57383496
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/ch/PP-OCRv3-pic003.jpg differ
diff --git a/doc/imgs_results/PP-OCRv3/en/en_1.png b/doc/imgs_results/PP-OCRv3/en/en_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..36245613e304fce0e376fe78e795f9a76d3b6015
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/en/en_1.png differ
diff --git a/doc/imgs_results/PP-OCRv3/en/en_2.png b/doc/imgs_results/PP-OCRv3/en/en_2.png
new file mode 100644
index 0000000000000000000000000000000000000000..d2df8556ad30a9f429d943cb940842a95056d604
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/en/en_2.png differ
diff --git a/doc/imgs_results/PP-OCRv3/en/en_3.png b/doc/imgs_results/PP-OCRv3/en/en_3.png
new file mode 100644
index 0000000000000000000000000000000000000000..baf146c0102505a308656d92fdd89d5b1333ccb1
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/en/en_3.png differ
diff --git a/doc/imgs_results/PP-OCRv3/en/en_4.png b/doc/imgs_results/PP-OCRv3/en/en_4.png
new file mode 100644
index 0000000000000000000000000000000000000000..f0f19db95b7917dc884bdb7d2c2f98b9e74c22e1
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/en/en_4.png differ
diff --git a/doc/imgs_results/PP-OCRv3/multi_lang/japan_2.jpg b/doc/imgs_results/PP-OCRv3/multi_lang/japan_2.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..076ced92ad62b7e30b62a389a1849e1709dba87e
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/multi_lang/japan_2.jpg differ
diff --git a/doc/imgs_results/PP-OCRv3/multi_lang/korean_1.jpg b/doc/imgs_results/PP-OCRv3/multi_lang/korean_1.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..f93de40e18fb3bff9d2379c5c61464a85ac3f344
Binary files /dev/null and b/doc/imgs_results/PP-OCRv3/multi_lang/korean_1.jpg differ
diff --git a/doc/imgs_results/ch_ppocr_mobile_v2.0/00018069.jpg b/doc/imgs_results/ch_ppocr_mobile_v2.0/00018069.jpg
deleted file mode 100644
index b3d645779428bcce8c120976ef66bef10deee0c5..0000000000000000000000000000000000000000
Binary files a/doc/imgs_results/ch_ppocr_mobile_v2.0/00018069.jpg and /dev/null differ
diff --git a/doc/imgs_results/ch_ppocr_mobile_v2.0/00056221.jpg b/doc/imgs_results/ch_ppocr_mobile_v2.0/00056221.jpg
deleted file mode 100644
index 7dba7708be61d912d574b610fc0b04cfa4e5feea..0000000000000000000000000000000000000000
Binary files a/doc/imgs_results/ch_ppocr_mobile_v2.0/00056221.jpg and /dev/null differ
diff --git a/doc/imgs_results/ch_ppocr_mobile_v2.0/00057937.jpg b/doc/imgs_results/ch_ppocr_mobile_v2.0/00057937.jpg
deleted file mode 100644
index 2168ecd1f0acb75d7ecc9c15202f342d18111495..0000000000000000000000000000000000000000
Binary files a/doc/imgs_results/ch_ppocr_mobile_v2.0/00057937.jpg and /dev/null differ
diff --git a/doc/imgs_results/ch_ppocr_mobile_v2.0/00077949.jpg b/doc/imgs_results/ch_ppocr_mobile_v2.0/00077949.jpg
deleted file mode 100644
index f1acbf0f94a1febbbf0d780ed019723b3dd78fa9..0000000000000000000000000000000000000000
Binary files a/doc/imgs_results/ch_ppocr_mobile_v2.0/00077949.jpg and /dev/null differ
diff --git a/doc/imgs_results/ch_ppocr_mobile_v2.0/00207393.jpg b/doc/imgs_results/ch_ppocr_mobile_v2.0/00207393.jpg
deleted file mode 100644
index 59d9a5632d3054dbf8cc6bdb021ebef224c890a8..0000000000000000000000000000000000000000
Binary files a/doc/imgs_results/ch_ppocr_mobile_v2.0/00207393.jpg and /dev/null differ
diff --git a/doc/ppocr_v3/GTC_en.png b/doc/ppocr_v3/GTC_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..a1a7fc52505f3f7f84f484fb1ee07d462e9e0648
Binary files /dev/null and b/doc/ppocr_v3/GTC_en.png differ
diff --git a/doc/ppocr_v3/LCNet_SVTR_en.png b/doc/ppocr_v3/LCNet_SVTR_en.png
new file mode 100644
index 0000000000000000000000000000000000000000..7890448470957cc7866a0b4e2cd09c36a788e213
Binary files /dev/null and b/doc/ppocr_v3/LCNet_SVTR_en.png differ
diff --git a/paddleocr.py b/paddleocr.py
index f7871db6470c75db82e8251dff5361c099c4adda..a1265f79def7018a5586be954127e5b7fdba011e 100644
--- a/paddleocr.py
+++ b/paddleocr.py
@@ -47,8 +47,8 @@ __all__ = [
]
SUPPORT_DET_MODEL = ['DB']
-VERSION = '2.5.0.1'
-SUPPORT_REC_MODEL = ['CRNN']
+VERSION = '2.5.0.3'
+SUPPORT_REC_MODEL = ['CRNN', 'SVTR_LCNet']
BASE_DIR = os.path.expanduser("~/.paddleocr/")
DEFAULT_OCR_MODEL_VERSION = 'PP-OCRv3'
diff --git a/ppstructure/README.md b/ppstructure/README.md
index 0febf233d883e59e4377777e5b96e354853e2f33..72670e33575ebe444c78b15fbab4e330389a7498 100644
--- a/ppstructure/README.md
+++ b/ppstructure/README.md
@@ -40,7 +40,7 @@ The main features of PP-Structure are as follows:
### 4.1 Layout analysis and table recognition
- +
+ The figure shows the pipeline of layout analysis + table recognition. The image is first divided into four areas of image, text, title and table by layout analysis, and then OCR detection and recognition is performed on the three areas of image, text and title, and the table is performed table recognition, where the image will also be stored for use.
@@ -48,7 +48,7 @@ The figure shows the pipeline of layout analysis + table recognition. The image
* SER
*
- | 
+ | 
---|---
Different colored boxes in the figure represent different categories. For xfun dataset, there are three categories: query, answer and header:
@@ -62,7 +62,7 @@ The corresponding category and OCR recognition results are also marked at the to
* RE
- | 
+ | 
---|---
@@ -76,7 +76,7 @@ Start from [Quick Installation](./docs/quickstart.md)
### 6.1 Layout analysis and table recognition
-
+
In PP-Structure, the image will be divided into 5 types of areas **text, title, image list and table**. For the first 4 types of areas, directly use PP-OCR system to complete the text detection and recognition. For the table area, after the table structuring process, the table in image is converted into an Excel file with the same table style.
diff --git a/ppstructure/docs/table/recovery.jpg b/ppstructure/docs/table/recovery.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..bee2e2fb3499ec4b348e2b2f1475a87c9c562190
Binary files /dev/null and b/ppstructure/docs/table/recovery.jpg differ
diff --git a/ppstructure/predict_system.py b/ppstructure/predict_system.py
index 7f18fcdf8e6b57be6e129f3271f5bb583f4da616..b0ede5f3a1b88df6efed53d7ca33a696bc7a7fff 100644
--- a/ppstructure/predict_system.py
+++ b/ppstructure/predict_system.py
@@ -23,6 +23,7 @@ sys.path.append(os.path.abspath(os.path.join(__dir__, '..')))
os.environ["FLAGS_allocator_strategy"] = 'auto_growth'
import cv2
import json
+import numpy as np
import time
import logging
from copy import deepcopy
@@ -33,6 +34,7 @@ from ppocr.utils.logging import get_logger
from tools.infer.predict_system import TextSystem
from ppstructure.table.predict_table import TableSystem, to_excel
from ppstructure.utility import parse_args, draw_structure_result
+from ppstructure.recovery.docx import convert_info_docx
logger = get_logger()
@@ -104,7 +106,12 @@ class StructureSystem(object):
return_ocr_result_in_table)
else:
if self.text_system is not None:
- filter_boxes, filter_rec_res = self.text_system(roi_img)
+ if args.recovery:
+ wht_im = np.ones(ori_im.shape, dtype=ori_im.dtype)
+ wht_im[y1:y2, x1:x2, :] = roi_img
+ filter_boxes, filter_rec_res = self.text_system(wht_im)
+ else:
+ filter_boxes, filter_rec_res = self.text_system(roi_img)
# remove style char
style_token = [
'
The figure shows the pipeline of layout analysis + table recognition. The image is first divided into four areas of image, text, title and table by layout analysis, and then OCR detection and recognition is performed on the three areas of image, text and title, and the table is performed table recognition, where the image will also be stored for use.
@@ -48,7 +48,7 @@ The figure shows the pipeline of layout analysis + table recognition. The image
* SER
*
- | 
+ | 
---|---
Different colored boxes in the figure represent different categories. For xfun dataset, there are three categories: query, answer and header:
@@ -62,7 +62,7 @@ The corresponding category and OCR recognition results are also marked at the to
* RE
- | 
+ | 
---|---
@@ -76,7 +76,7 @@ Start from [Quick Installation](./docs/quickstart.md)
### 6.1 Layout analysis and table recognition
-
+
In PP-Structure, the image will be divided into 5 types of areas **text, title, image list and table**. For the first 4 types of areas, directly use PP-OCR system to complete the text detection and recognition. For the table area, after the table structuring process, the table in image is converted into an Excel file with the same table style.
diff --git a/ppstructure/docs/table/recovery.jpg b/ppstructure/docs/table/recovery.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..bee2e2fb3499ec4b348e2b2f1475a87c9c562190
Binary files /dev/null and b/ppstructure/docs/table/recovery.jpg differ
diff --git a/ppstructure/predict_system.py b/ppstructure/predict_system.py
index 7f18fcdf8e6b57be6e129f3271f5bb583f4da616..b0ede5f3a1b88df6efed53d7ca33a696bc7a7fff 100644
--- a/ppstructure/predict_system.py
+++ b/ppstructure/predict_system.py
@@ -23,6 +23,7 @@ sys.path.append(os.path.abspath(os.path.join(__dir__, '..')))
os.environ["FLAGS_allocator_strategy"] = 'auto_growth'
import cv2
import json
+import numpy as np
import time
import logging
from copy import deepcopy
@@ -33,6 +34,7 @@ from ppocr.utils.logging import get_logger
from tools.infer.predict_system import TextSystem
from ppstructure.table.predict_table import TableSystem, to_excel
from ppstructure.utility import parse_args, draw_structure_result
+from ppstructure.recovery.docx import convert_info_docx
logger = get_logger()
@@ -104,7 +106,12 @@ class StructureSystem(object):
return_ocr_result_in_table)
else:
if self.text_system is not None:
- filter_boxes, filter_rec_res = self.text_system(roi_img)
+ if args.recovery:
+ wht_im = np.ones(ori_im.shape, dtype=ori_im.dtype)
+ wht_im[y1:y2, x1:x2, :] = roi_img
+ filter_boxes, filter_rec_res = self.text_system(wht_im)
+ else:
+ filter_boxes, filter_rec_res = self.text_system(roi_img)
# remove style char
style_token = [
'', '', '', '', '',
@@ -118,7 +125,8 @@ class StructureSystem(object):
for token in style_token:
if token in rec_str:
rec_str = rec_str.replace(token, '')
- box += [x1, y1]
+ if not args.recovery:
+ box += [x1, y1]
res.append({
'text': rec_str,
'confidence': float(rec_conf),
@@ -192,6 +200,8 @@ def main(args):
# img_save_path = os.path.join(save_folder, img_name + '.jpg')
cv2.imwrite(img_save_path, draw_img)
logger.info('result save to {}'.format(img_save_path))
+ if args.recovery:
+ convert_info_docx(img, res, save_folder, img_name)
elapse = time.time() - starttime
logger.info("Predict time : {:.3f}s".format(elapse))
diff --git a/ppstructure/recovery/README.md b/ppstructure/recovery/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..883dbef3e829dfa213644b610af1ca279dac8641
--- /dev/null
+++ b/ppstructure/recovery/README.md
@@ -0,0 +1,86 @@
+English | [简体中文](README_ch.md)
+
+- [Getting Started](#getting-started)
+ - [1. Introduction](#1)
+ - [2. Install](#2)
+ - [2.1 Installation dependencies](#2.1)
+ - [2.2 Install PaddleOCR](#2.2)
+ - [3. Quick Start](#3)
+
+
+
+## 1. Introduction
+
+Layout recovery means that after OCR recognition, the content is still arranged like the original document pictures, and the paragraphs are output to word document in the same order.
+
+Layout recovery combines [layout analysis](../layout/README.md)、[table recognition](../table/README.md) to better recover images, tables, titles, etc.
+The following figure shows the result:
+
+
+

+
+
+
 -
-  -
-  +
+  +
+  +
+ 
 +
+  +
+ 
 -
-  +
+  +
+ 
 +
+  +
+  +
+ 
 +
+  +
+ 
 -
-  +
+  +
+