diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
index a5052e2897ab9f09a6ed7b747f9fa1198af2a8ab..ee13bacffdb65e6300a034531a527fdca4ed29f9 100644
--- "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
+++ "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
@@ -206,7 +206,11 @@ Eval.dataset.transforms.DetResizeForTest: 尺寸
limit_type: 'min'
```
-然后执行评估代码
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+

+
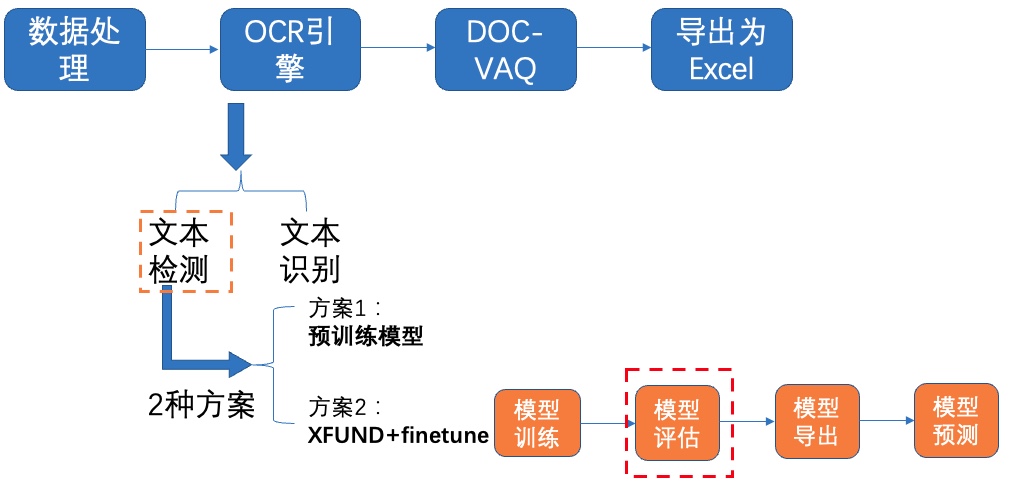 图8 文本检测方案2-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
图8 文本检测方案2-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+
+
-
-