From 44086577ebd8fd73aa5dc7bc137ce31b9c7399b3 Mon Sep 17 00:00:00 2001
From: an1018 <614803115@qq.com>
Date: Fri, 10 Jun 2022 19:56:45 +0800
Subject: [PATCH] add pcb
---
...27\347\254\246\350\257\206\345\210\253.md" | 648 ++++++++++++++++++
.../gen_data/background/bg.jpg" | Bin 0 -> 2071 bytes
.../gen_data/corpus/text.txt" | 30 +
.../gen_data/det_background/1.png" | Bin 0 -> 145 bytes
.../gen_data/det_background/2.png" | Bin 0 -> 141 bytes
.../gen_data/gen.py" | 261 +++++++
6 files changed, 939 insertions(+)
create mode 100644 "applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
create mode 100644 "applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/background/bg.jpg"
create mode 100644 "applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/corpus/text.txt"
create mode 100644 "applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/1.png"
create mode 100644 "applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/2.png"
create mode 100644 "applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/gen.py"
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
new file mode 100644
index 00000000..a5052e28
--- /dev/null
+++ "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
@@ -0,0 +1,648 @@
+# 基于PP-OCRv3的PCB字符识别
+
+- [1. 项目介绍](#1-项目介绍)
+- [2. 安装说明](#2-安装说明)
+- [3. 数据准备](#3-数据准备)
+- [4. 文本检测](#4-文本检测)
+ - [4.1 预训练模型直接评估](#41-预训练模型直接评估)
+ - [4.2 预训练模型+验证集padding直接评估](#42-预训练模型验证集padding直接评估)
+ - [4.3 预训练模型+fine-tune](#43-预训练模型fine-tune)
+- [5. 文本识别](#5-文本识别)
+ - [5.1 预训练模型直接评估](#51-预训练模型直接评估)
+ - [5.2 三种fine-tune方案](#52-三种fine-tune方案)
+- [6. 模型导出](#6-模型导出)
+- [7. 端对端评测](#7-端对端评测)
+- [8. Jetson部署](#8-Jetson部署)
+- [9. 总结](#9-总结)
+- [更多资源](#更多资源)
+
+# 1. 项目介绍
+
+印刷电路板(PCB)是电子产品中的核心器件,对于板件质量的测试与监控是生产中必不可少的环节。在一些场景中,通过PCB中信号灯颜色和文字组合可以定位PCB局部模块质量问题,PCB文字识别中存在如下难点:
+
+- 裁剪出的PCB图片宽高比例较小
+- 文字区域整体面积也较小
+- 包含垂直、水平多种方向文本
+
+针对本场景,PaddleOCR基于全新的PP-OCRv3通过合成数据、微调以及其他场景适配方法完成小字符文本识别任务,满足企业上线要求。PCB检测、识别效果如 **图1** 所示:
+
+
+图1 PCB检测识别效果
+
+注:欢迎在AIStudio领取免费算力体验线上实训,项目链接: [基于PP-OCRv3实现PCB字符识别](https://aistudio.baidu.com/aistudio/projectdetail/4008973)
+
+# 2. 安装说明
+
+
+下载PaddleOCR源码,安装依赖环境。
+
+
+```python
+# 如仍需安装or安装更新,可以执行以下步骤
+git clone https://github.com/PaddlePaddle/PaddleOCR.git
+# git clone https://gitee.com/PaddlePaddle/PaddleOCR
+```
+
+
+```python
+# 安装依赖包
+pip install -r /home/aistudio/PaddleOCR/requirements.txt
+```
+
+# 3. 数据准备
+
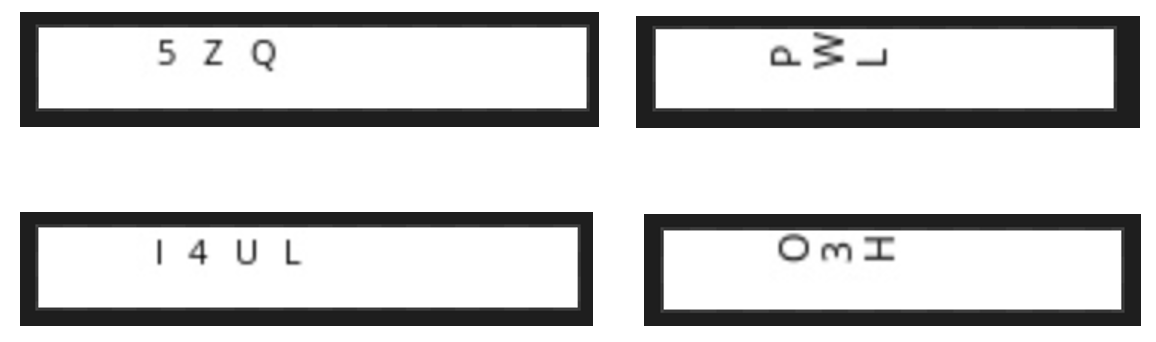
+我们通过图片合成工具生成 **图2** 所示的PCB图片,整图只有高25、宽150左右、文字区域高9、宽45左右,包含垂直和水平2种方向的文本:
+
+
+图2 数据集示例
+
+暂时不开源生成的PCB数据集,但是通过更换背景,通过如下代码生成数据即可:
+
+```
+cd gen_data
+python3 gen.py --num_img=10
+```
+
+生成图片参数解释:
+
+```
+num_img:生成图片数量
+font_min_size、font_max_size:字体最大、最小尺寸
+bg_path:文字区域背景存放路径
+det_bg_path:整图背景存放路径
+fonts_path:字体路径
+corpus_path:语料路径
+output_dir:生成图片存储路径
+```
+
+这里生成 **100张** 相同尺寸和文本的图片,如 **图3** 所示,方便大家跑通实验。通过如下代码解压数据集:
+
+
+图3 案例提供数据集示例
+
+
+```python
+tar xf ./data/data148165/dataset.tar -C ./
+```
+
+在生成数据集的时需要生成检测和识别训练需求的格式:
+
+
+- **文本检测**
+
+标注文件格式如下,中间用'\t'分隔:
+
+```
+" 图像文件名 json.dumps编码的图像标注信息"
+ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
+```
+
+json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 `points` 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。 `transcription` 表示当前文本框的文字,***当其内容为“###”时,表示该文本框无效,在训练时会跳过。***
+
+- **文本识别**
+
+标注文件的格式如下, txt文件中默认请将图片路径和图片标签用'\t'分割,如用其他方式分割将造成训练报错。
+
+```
+" 图像文件名 图像标注信息 "
+
+train_data/rec/train/word_001.jpg 简单可依赖
+train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
+...
+```
+
+
+# 4. 文本检测
+
+选用飞桨OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)中的PP-OCRv3模型进行文本检测和识别。针对检测模型和识别模型,进行了共计9个方面的升级:
+
+- PP-OCRv3检测模型对PP-OCRv2中的CML协同互学习文本检测蒸馏策略进行了升级,分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
+
+- PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。PP-OCRv3通过轻量级文本识别网络SVTR_LCNet、Attention损失指导CTC损失训练策略、挖掘文字上下文信息的数据增广策略TextConAug、TextRotNet自监督预训练模型、UDML联合互学习策略、UIM无标注数据挖掘方案,6个方面进行模型加速和效果提升。
+
+更多细节请参考PP-OCRv3[技术报告](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md)。
+
+
+我们使用 **3种方案** 进行检测模型的训练、评估:
+- **PP-OCRv3英文超轻量检测预训练模型直接评估**
+- PP-OCRv3英文超轻量检测预训练模型 + **验证集padding**直接评估
+- PP-OCRv3英文超轻量检测预训练模型 + **fine-tune**
+
+## **4.1 预训练模型直接评估**
+
+我们首先通过PaddleOCR提供的预训练模型在验证集上进行评估,如果评估指标能满足效果,可以直接使用预训练模型,不再需要训练。
+
+使用预训练模型直接评估步骤如下:
+
+**1)下载预训练模型**
+
+
+PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示:
+
+| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
+| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar) |
+| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
+| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
+| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
+| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
+
+更多模型下载(包括多语言),可以参[考PP-OCR系列模型下载](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/models_list.md)
+
+这里我们使用PP-OCRv3英文超轻量检测模型,下载并解压预训练模型:
+
+
+
+
+```python
+# 如果更换其他模型,更新下载链接和解压指令就可以
+cd /home/aistudio/PaddleOCR
+mkdir pretrain_models
+cd pretrain_models
+# 下载英文预训练模型
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar
+tar xf en_PP-OCRv3_det_distill_train.tar && rm -rf en_PP-OCRv3_det_distill_train.tar
+%cd ..
+```
+
+**模型评估**
+
+
+首先修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml`中的以下字段:
+```
+Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset'
+Eval.dataset.label_file_list:指向验证集标注文件,'/home/aistudio/dataset/det_gt_val.txt'
+Eval.dataset.transforms.DetResizeForTest: 尺寸
+ limit_side_len: 48
+ limit_type: 'min'
+```
+
+然后在验证集上进行评估,具体代码如下:
+
+
+
+```python
+cd /home/aistudio/PaddleOCR
+python tools/eval.py \
+ -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml \
+ -o Global.checkpoints="./pretrain_models/en_PP-OCRv3_det_distill_train/best_accuracy"
+```
+
+## **4.2 预训练模型+验证集padding直接评估**
+
+考虑到PCB图片比较小,宽度只有25左右、高度只有140-170左右,我们在原图的基础上进行padding,再进行检测评估,padding前后效果对比如 **图4** 所示:
+
+
+图4 padding前后对比图
+
+将图片都padding到300*300大小,因为坐标信息发生了变化,我们同时要修改标注文件,在`/home/aistudio/dataset`目录里也提供了padding之后的图片,大家也可以尝试训练和评估:
+
+同上,我们需要修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml`中的以下字段:
+```
+Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset'
+Eval.dataset.label_file_list:指向验证集标注文件,/home/aistudio/dataset/det_gt_padding_val.txt
+Eval.dataset.transforms.DetResizeForTest: 尺寸
+ limit_side_len: 1100
+ limit_type: 'min'
+```
+
+然后执行评估代码
+
+
+```python
+cd /home/aistudio/PaddleOCR
+python tools/eval.py \
+ -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml \
+ -o Global.checkpoints="./pretrain_models/en_PP-OCRv3_det_distill_train/best_accuracy"
+```
+
+## **4.3 预训练模型+fine-tune**
+
+
+基于预训练模型,在生成的1500图片上进行fine-tune训练和评估,其中train数据1200张,val数据300张,修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml`中的以下字段:
+```
+Global.epoch_num: 这里设置为1,方便快速跑通,实际中根据数据量调整该值
+Global.save_model_dir:模型保存路径
+Global.pretrained_model:指向预训练模型路径,'./pretrain_models/en_PP-OCRv3_det_distill_train/student.pdparams'
+Optimizer.lr.learning_rate:调整学习率,本实验设置为0.0005
+Train.dataset.data_dir:指向训练集图片存放目录,'/home/aistudio/dataset'
+Train.dataset.label_file_list:指向训练集标注文件,'/home/aistudio/dataset/det_gt_train.txt'
+Train.dataset.transforms.EastRandomCropData.size:训练尺寸改为[480,64]
+Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset/'
+Eval.dataset.label_file_list:指向验证集标注文件,'/home/aistudio/dataset/det_gt_val.txt'
+Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
+ limit_side_len: 64
+ limit_type:'min'
+```
+执行下面命令启动训练:
+
+
+```python
+cd /home/aistudio/PaddleOCR/
+python tools/train.py \
+ -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml
+```
+
+**模型评估**
+
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`:
+
+
+```python
+cd /home/aistudio/PaddleOCR/
+python3 tools/eval.py \
+ -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml \
+ -o Global.checkpoints="./output/ch_PP-OCR_V3_det/latest"
+```
+
+使用训练好的模型进行评估,指标如下所示:
+
+
+| 序号 | 方案 | hmean | 效果提升 | 实验分析 |
+| -------- | -------- | -------- | -------- | -------- |
+| 1 | PP-OCRv3英文超轻量检测预训练模型 | 64.64% | - | 提供的预训练模型具有泛化能力 |
+| 2 | PP-OCRv3英文超轻量检测预训练模型 + 验证集padding | 72.13% |+7.5% | padding可以提升尺寸较小图片的检测效果|
+| 3 | PP-OCRv3英文超轻量检测预训练模型 + fine-tune | 100% | +27.9% | fine-tune会提升垂类场景效果 |
+
+
+```
+注:上述实验结果均是在1500张图片(1200张训练集,300张测试集)上训练、评估的得到,AIstudio只提供了100张数据,所以指标有所差异属于正常,只要策略有效、规律相同即可。
+```
+
+# 5. 文本识别
+
+我们分别使用如下4种方案进行训练、评估:
+
+- **方案1**:**PP-OCRv3中英文超轻量识别预训练模型直接评估**
+- **方案2**:PP-OCRv3中英文超轻量检测预训练模型 + **fine-tune**
+- **方案3**:PP-OCRv3中英文超轻量检测预训练模型 + fine-tune + **公开通用识别数据集**
+- **方案4**:PP-OCRv3中英文超轻量检测预训练模型 + fine-tune + **增加PCB图像数量**
+
+
+## **5.1 预训练模型直接评估**
+
+同检测模型,我们首先使用PaddleOCR提供的识别预训练模型在PCB验证集上进行评估。
+
+使用预训练模型直接评估步骤如下:
+
+**1)下载预训练模型**
+
+
+我们使用PP-OCRv3中英文超轻量文本识别模型,下载并解压预训练模型:
+
+
+```python
+# 如果更换其他模型,更新下载链接和解压指令就可以
+cd /home/aistudio/PaddleOCR/pretrain_models/
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
+tar xf ch_PP-OCRv3_rec_train.tar && rm -rf ch_PP-OCRv3_rec_train.tar
+cd ..
+```
+
+**模型评估**
+
+
+首先修改配置文件`configs/det/ch_PP-OCRv3/ch_PP-OCRv2_rec_distillation.yml`中的以下字段:
+
+```
+Metric.ignore_space: True:忽略空格
+Eval.dataset.data_dir:指向验证集图片存放目录,'/home/aistudio/dataset'
+Eval.dataset.label_file_list:指向验证集标注文件,'/home/aistudio/dataset/rec_gt_val.txt'
+```
+
+我们使用下载的预训练模型进行评估:
+
+
+```python
+cd /home/aistudio/PaddleOCR
+python3 tools/eval.py \
+ -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml \
+ -o Global.checkpoints=pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
+
+```
+
+## **5.2 三种fine-tune方案**
+
+方案2、3、4训练和评估方式是相同的,因此在我们了解每个技术方案之后,再具体看修改哪些参数是相同,哪些是不同的。
+
+**方案介绍:**
+
+1) **方案2**:预训练模型 + **fine-tune**
+
+- 在预训练模型的基础上进行fine-tune,使用1500张PCB进行训练和评估,其中训练集1200张,验证集300张。
+
+
+2) **方案3**:预训练模型 + fine-tune + **公开通用识别数据集**
+
+- 当识别数据比较少的情况,可以考虑添加公开通用识别数据集。在方案2的基础上,添加公开通用识别数据集,如lsvt、rctw等。
+
+3)**方案4**:预训练模型 + fine-tune + **增加PCB图像数量**
+
+- 如果能够获取足够多真实场景,我们可以通过增加数据量提升模型效果。在方案2的基础上,增加PCB的数量到2W张左右。
+
+
+**参数修改:**
+
+接着我们看需要修改的参数,以上方案均需要修改配置文件`configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml`的参数,**修改一次即可**:
+
+```
+Global.pretrained_model:指向预训练模型路径,'pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy'
+Optimizer.lr.values:学习率,本实验设置为0.0005
+Train.loader.batch_size_per_card: batch size,默认128,因为数据量小于128,因此我们设置为8,数据量大可以按默认的训练
+Eval.loader.batch_size_per_card: batch size,默认128,设置为4
+Metric.ignore_space: 忽略空格,本实验设置为True
+```
+
+**更换不同的方案**每次需要修改的参数:
+```
+Global.epoch_num: 这里设置为1,方便快速跑通,实际中根据数据量调整该值
+Global.save_model_dir:指向模型保存路径
+Train.dataset.data_dir:指向训练集图片存放目录
+Train.dataset.label_file_list:指向训练集标注文件
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+
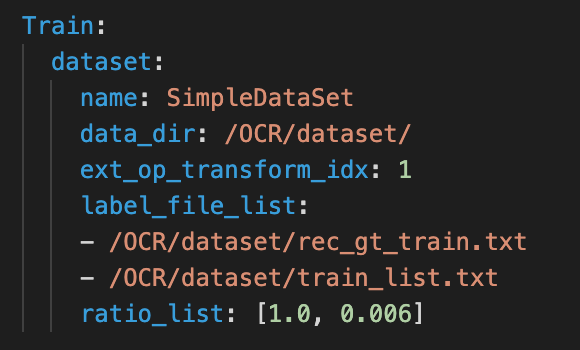
+同时**方案3**修改以下参数
+```
+Eval.dataset.label_file_list:添加公开通用识别数据标注文件
+Eval.dataset.ratio_list:数据和公开通用识别数据每次采样比例,按实际修改即可
+```
+如 **图5** 所示:
+
+图5 添加公开通用识别数据配置文件示例
+
+
+我们提取Student模型的参数,在PCB数据集上进行fine-tune,可以参考如下代码:
+
+
+```python
+import paddle
+# 加载预训练模型
+all_params = paddle.load("./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy.pdparams")
+# 查看权重参数的keys
+print(all_params.keys())
+# 学生模型的权重提取
+s_params = {key[len("student_model."):]: all_params[key] for key in all_params if "student_model." in key}
+# 查看学生模型权重参数的keys
+print(s_params.keys())
+# 保存
+paddle.save(s_params, "./pretrain_models/ch_PP-OCRv3_rec_train/student.pdparams")
+```
+
+修改参数后,**每个方案**都执行如下命令启动训练:
+
+
+
+```python
+cd /home/aistudio/PaddleOCR/
+python3 tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
+```
+
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`:
+
+
+```python
+cd /home/aistudio/PaddleOCR/
+python3 tools/eval.py \
+ -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml \
+ -o Global.checkpoints=./output/rec_ppocr_v3/latest
+```
+
+所有方案评估指标如下:
+
+| 序号 | 方案 | acc | 效果提升 | 实验分析 |
+| -------- | -------- | -------- | -------- | -------- |
+| 1 | PP-OCRv3中英文超轻量识别预训练模型直接评估 | 46.67% | - | 提供的预训练模型具有泛化能力 |
+| 2 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune | 42.02% |-4.6% | 在数据量不足的情况,反而比预训练模型效果低(也可以通过调整超参数再试试)|
+| 3 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 公开通用识别数据集 | 77% | +30% | 在数据量不足的情况下,可以考虑补充公开数据训练 |
+| 4 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 99.99% | +23% | 如果能获取更多数据量的情况,可以通过增加数据量提升效果 |
+
+```
+注:上述实验结果均是在1500张图片(1200张训练集,300张测试集)、2W张图片、添加公开通用识别数据集上训练、评估的得到,AIstudio只提供了100张数据,所以指标有所差异属于正常,只要策略有效、规律相同即可。
+```
+
+# 6. 模型导出
+
+inference 模型(paddle.jit.save保存的模型) 一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。 训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。 与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
+
+
+```python
+# 导出检测模型
+python3 tools/export_model.py \
+ -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml \
+ -o Global.pretrained_model="./output/ch_PP-OCR_V3_det/latest" \
+ Global.save_inference_dir="./inference_model/ch_PP-OCR_V3_det/"
+```
+
+因为上述模型只训练了1个epoch,因此我们使用训练最优的模型进行预测,存储在`/home/aistudio/best_models/`目录下,解压即可
+
+
+```python
+cd /home/aistudio/best_models/
+wget https://paddleocr.bj.bcebos.com/fanliku/PCB/det_ppocr_v3_en_infer_PCB.tar
+tar xf /home/aistudio/best_models/det_ppocr_v3_en_infer_PCB.tar -C /home/aistudio/PaddleOCR/pretrain_models/
+```
+
+
+```python
+# 检测模型inference模型预测
+cd /home/aistudio/PaddleOCR/
+python3 tools/infer/predict_det.py \
+ --image_dir="/home/aistudio/dataset/imgs/0000.jpg" \
+ --det_algorithm="DB" \
+ --det_model_dir="./pretrain_models/det_ppocr_v3_en_infer_PCB/" \
+ --det_limit_side_len=48 \
+ --det_limit_type='min' \
+ --det_db_unclip_ratio=2.5 \
+ --use_gpu=True
+```
+
+结果存储在`inference_results`目录下,检测如下图所示:
+
+图6 检测结果
+
+
+同理,导出识别模型并进行推理。
+
+```python
+# 导出识别模型
+python3 tools/export_model.py \
+ -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml \
+ -o Global.pretrained_model="./output/rec_ppocr_v3/latest" \
+ Global.save_inference_dir="./inference_model/rec_ppocr_v3/"
+
+```
+
+同检测模型,识别模型也只训练了1个epoch,因此我们使用训练最优的模型进行预测,存储在`/home/aistudio/best_models/`目录下,解压即可
+
+
+```python
+cd /home/aistudio/best_models/
+wget https://paddleocr.bj.bcebos.com/fanliku/PCB/rec_ppocr_v3_ch_infer_PCB.tar
+tar xf /home/aistudio/best_models/rec_ppocr_v3_ch_infer_PCB.tar -C /home/aistudio/PaddleOCR/pretrain_models/
+```
+
+
+```python
+# 识别模型inference模型预测
+cd /home/aistudio/PaddleOCR/
+python3 tools/infer/predict_rec.py \
+ --image_dir="../test_imgs/0000_rec.jpg" \
+ --rec_model_dir="./pretrain_models/rec_ppocr_v3_ch_infer_PCB" \
+ --rec_image_shape="3, 48, 320" \
+ --use_space_char=False \
+ --use_gpu=True
+```
+
+```python
+# 检测+识别模型inference模型预测
+cd /home/aistudio/PaddleOCR/
+python3 tools/infer/predict_system.py \
+ --image_dir="../test_imgs/0000.jpg" \
+ --det_model_dir="./pretrain_models/det_ppocr_v3_en_infer_PCB" \
+ --det_limit_side_len=48 \
+ --det_limit_type='min' \
+ --det_db_unclip_ratio=2.5 \
+ --rec_model_dir="./pretrain_models/rec_ppocr_v3_ch_infer_PCB" \
+ --rec_image_shape="3, 48, 320" \
+ --draw_img_save_dir=./det_rec_infer/ \
+ --use_space_char=False \
+ --use_angle_cls=False \
+ --use_gpu=True
+
+```
+
+端到端预测结果存储在`det_res_infer`文件夹内,结果如下图所示:
+
+图7 检测+识别结果
+
+# 7. 端对端评测
+
+接下来介绍文本检测+文本识别的端对端指标评估方式。主要分为三步:
+
+1)首先运行`tools/infer/predict_system.py`,将`image_dir`改为需要评估的数据文件家,得到保存的结果:
+
+
+```python
+# 检测+识别模型inference模型预测
+python3 tools/infer/predict_system.py \
+ --image_dir="../dataset/imgs/" \
+ --det_model_dir="./pretrain_models/det_ppocr_v3_en_infer_PCB" \
+ --det_limit_side_len=48 \
+ --det_limit_type='min' \
+ --det_db_unclip_ratio=2.5 \
+ --rec_model_dir="./pretrain_models/rec_ppocr_v3_ch_infer_PCB" \
+ --rec_image_shape="3, 48, 320" \
+ --draw_img_save_dir=./det_rec_infer/ \
+ --use_space_char=False \
+ --use_angle_cls=False \
+ --use_gpu=True
+```
+
+得到保存结果,文本检测识别可视化图保存在`det_rec_infer/`目录下,预测结果保存在`det_rec_infer/system_results.txt`中,格式如下:`0018.jpg [{"transcription": "E295", "points": [[88, 33], [137, 33], [137, 40], [88, 40]]}]`
+
+2)然后将步骤一保存的数据转换为端对端评测需要的数据格式: 修改 `tools/end2end/convert_ppocr_label.py`中的代码,convert_label函数中设置输入标签路径,Mode,保存标签路径等,对预测数据的GTlabel和预测结果的label格式进行转换。
+```
+ppocr_label_gt = "/home/aistudio/dataset/det_gt_val.txt"
+convert_label(ppocr_label_gt, "gt", "./save_gt_label/")
+
+ppocr_label_gt = "/home/aistudio/PaddleOCR/PCB_result/det_rec_infer/system_results.txt"
+convert_label(ppocr_label_gt, "pred", "./save_PPOCRV2_infer/")
+```
+
+运行`convert_ppocr_label.py`:
+
+
+```python
+ python3 tools/end2end/convert_ppocr_label.py
+```
+
+得到如下结果:
+```
+├── ./save_gt_label/
+├── ./save_PPOCRV2_infer/
+```
+
+3) 最后,执行端对端评测,运行`tools/end2end/eval_end2end.py`计算端对端指标,运行方式如下:
+
+
+```python
+pip install editdistance
+python3 tools/end2end/eval_end2end.py ./save_gt_label/ ./save_PPOCRV2_infer/
+```
+
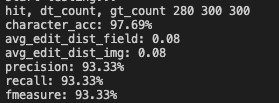
+使用`预训练模型+fine-tune'检测模型`、`预训练模型 + 2W张PCB图片funetune`识别模型,在300张PCB图片上评估得到如下结果,fmeasure为主要关注的指标:
+
+图8 端到端评估指标
+
+```
+注: 使用上述命令不能跑出该结果,因为数据集不相同,可以更换为自己训练好的模型,按上述流程运行
+```
+
+# 8. Jetson部署
+
+我们只需要以下步骤就可以完成Jetson nano部署模型,简单易操作:
+
+**1、在Jetson nano开发版上环境准备:**
+
+* 安装PaddlePaddle
+
+* 下载PaddleOCR并安装依赖
+
+**2、执行预测**
+
+* 将推理模型下载到jetson
+
+* 执行检测、识别、串联预测即可
+
+详细[参考流程](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/deploy/Jetson/readme_ch.md)。
+
+# 9. 总结
+
+检测实验分别使用PP-OCRv3预训练模型在PCB数据集上进行了直接评估、验证集padding、 fine-tune 3种方案,识别实验分别使用PP-OCRv3预训练模型在PCB数据集上进行了直接评估、 fine-tune、添加公开通用识别数据集、增加PCB图片数量4种方案,指标对比如下:
+
+* 检测
+
+
+| 序号 | 方案 | hmean | 效果提升 | 实验分析 |
+| ---- | -------------------------------------------------------- | ------ | -------- | ------------------------------------- |
+| 1 | PP-OCRv3英文超轻量检测预训练模型直接评估 | 64.64% | - | 提供的预训练模型具有泛化能力 |
+| 2 | PP-OCRv3英文超轻量检测预训练模型 + 验证集padding直接评估 | 72.13% | +7.5% | padding可以提升尺寸较小图片的检测效果 |
+| 3 | PP-OCRv3英文超轻量检测预训练模型 + fine-tune | 100% | +27.9% | fine-tune会提升垂类场景效果 |
+
+* 识别
+
+| 序号 | 方案 | acc | 效果提升 | 实验分析 |
+| ---- | ------------------------------------------------------------ | ------ | -------- | ------------------------------------------------------------ |
+| 1 | PP-OCRv3中英文超轻量识别预训练模型直接评估 | 46.67% | - | 提供的预训练模型具有泛化能力 |
+| 2 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune | 42.02% | -4.6% | 在数据量不足的情况,反而比预训练模型效果低(也可以通过调整超参数再试试) |
+| 3 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 公开通用识别数据集 | 77% | +30% | 在数据量不足的情况下,可以考虑补充公开数据训练 |
+| 4 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 99.99% | +23% | 如果能获取更多数据量的情况,可以通过增加数据量提升效果 |
+
+* 端到端
+
+| det | rec | fmeasure |
+| --------------------------------------------- | ------------------------------------------------------------ | -------- |
+| PP-OCRv3英文超轻量检测预训练模型 + fine-tune | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 93.3% |
+
+*结论*
+
+PP-OCRv3的检测模型在未经过fine-tune的情况下,在PCB数据集上也有64.64%的精度,说明具有泛化能力。验证集padding之后,精度提升7.5%,在图片尺寸较小的情况,我们可以通过padding的方式提升检测效果。经过 fine-tune 后能够极大的提升检测效果,精度达到100%。
+
+PP-OCRv3的识别模型方案1和方案2对比可以发现,当数据量不足的情况,预训练模型精度可能比fine-tune效果还要高,所以我们可以先尝试预训练模型直接评估。如果在数据量不足的情况下想进一步提升模型效果,可以通过添加公开通用识别数据集,识别效果提升30%,非常有效。最后如果我们能够采集足够多的真实场景数据集,可以通过增加数据量提升模型效果,精度达到99.99%。
+
+# 更多资源
+
+- 更多深度学习知识、产业案例、面试宝典等,请参考:[awesome-DeepLearning](https://github.com/paddlepaddle/awesome-DeepLearning)
+
+- 更多PaddleOCR使用教程,请参考:[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph)
+
+
+- 飞桨框架相关资料,请参考:[飞桨深度学习平台](https://www.paddlepaddle.org.cn/?fr=paddleEdu_aistudio)
+
+# 参考
+
+* 数据生成代码库:https://github.com/zcswdt/Color_OCR_image_generator
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/background/bg.jpg" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/background/bg.jpg"
new file mode 100644
index 0000000000000000000000000000000000000000..3cb6eab819c3b7d4f68590d2cdc9d36351590197
GIT binary patch
literal 2071
zcmex=^(PF6}rMnOeST|r4lSw=>~TvNxu(8R<c1}I=;VrF4wW9Q)H;sz?%
zD!{d!pzFb!U9xX3zTPI5o8roG<0MW4oqZMDikqloVbuf*=gfJ(V&YTRE(2~
znmD<{#3dx9RMpfqG__1j&CD$#!}nhriyF8_@n{%~rh(BkFq#GiWg4*me-i-S
C@2wdC
literal 0
HcmV?d00001
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/corpus/text.txt" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/corpus/text.txt"
new file mode 100644
index 00000000..8b8cb793
--- /dev/null
+++ "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/corpus/text.txt"
@@ -0,0 +1,30 @@
+5ZQ
+I4UL
+PWL
+SNOG
+ZL02
+1C30
+O3H
+YHRS
+N03S
+1U5Y
+JTK
+EN4F
+YKJ
+DWNH
+R42W
+X0V
+4OF5
+08AM
+Y93S
+GWE2
+0KR
+9U2A
+DBQ
+Y6J
+ROZ
+K06
+KIEY
+NZQJ
+UN1B
+6X4
\ No newline at end of file
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/1.png" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/1.png"
new file mode 100644
index 0000000000000000000000000000000000000000..8a49eaa6862113044e05d17e32941a0a20911426
GIT binary patch
literal 145
zcmeAS@N?(olHy`uVBq!ia0vp^8-Q4fg9%8^2y$!$QW2gmjv*Cu-d=}dC;|Wg
literal 0
HcmV?d00001
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/2.png" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/det_background/2.png"
new file mode 100644
index 0000000000000000000000000000000000000000..c3fcc0c92826b97b5f6abd970f1a0580eede0f5d
GIT binary patch
literal 141
zcmeAS@N?(olHy`uVBq!ia0vp^-9RkC!2~2-J7>BAsSr;W$B>FSZ!bFXGAIZfFgURP
zxigdhw+vC8oAYM6-uNkdpxL>U@2X|U^MJX;GGgEBG3zSK5X}Ud&*16m=d#Wzp$P!_
Caxi58
literal 0
HcmV?d00001
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/gen.py" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/gen.py"
new file mode 100644
index 00000000..4c768067
--- /dev/null
+++ "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/gen_data/gen.py"
@@ -0,0 +1,261 @@
+# copyright (c) 2020 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This code is refer from:
+https://github.com/zcswdt/Color_OCR_image_generator
+"""
+import os
+import random
+from PIL import Image, ImageDraw, ImageFont
+import json
+import argparse
+
+
+def get_char_lines(txt_root_path):
+ """
+ desc:get corpus line
+ """
+ txt_files = os.listdir(txt_root_path)
+ char_lines = []
+ for txt in txt_files:
+ f = open(os.path.join(txt_root_path, txt), mode='r', encoding='utf-8')
+ lines = f.readlines()
+ f.close()
+ for line in lines:
+ char_lines.append(line.strip())
+ return char_lines
+
+
+def get_horizontal_text_picture(image_file, chars, fonts_list, cf):
+ """
+ desc:gen horizontal text picture
+ """
+ img = Image.open(image_file)
+ if img.mode != 'RGB':
+ img = img.convert('RGB')
+ img_w, img_h = img.size
+
+ # random choice font
+ font_path = random.choice(fonts_list)
+ # random choice font size
+ font_size = random.randint(cf.font_min_size, cf.font_max_size)
+ font = ImageFont.truetype(font_path, font_size)
+
+ ch_w = []
+ ch_h = []
+ for ch in chars:
+ wt, ht = font.getsize(ch)
+ ch_w.append(wt)
+ ch_h.append(ht)
+ f_w = sum(ch_w)
+ f_h = max(ch_h)
+
+ # add space
+ char_space_width = max(ch_w)
+ f_w += (char_space_width * (len(chars) - 1))
+
+ x1 = random.randint(0, img_w - f_w)
+ y1 = random.randint(0, img_h - f_h)
+ x2 = x1 + f_w
+ y2 = y1 + f_h
+
+ crop_y1 = y1
+ crop_x1 = x1
+ crop_y2 = y2
+ crop_x2 = x2
+
+ best_color = (0, 0, 0)
+ draw = ImageDraw.Draw(img)
+ for i, ch in enumerate(chars):
+ draw.text((x1, y1), ch, best_color, font=font)
+ x1 += (ch_w[i] + char_space_width)
+ crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
+ return crop_img, chars
+
+
+def get_vertical_text_picture(image_file, chars, fonts_list, cf):
+ """
+ desc:gen vertical text picture
+ """
+ img = Image.open(image_file)
+ if img.mode != 'RGB':
+ img = img.convert('RGB')
+ img_w, img_h = img.size
+ # random choice font
+ font_path = random.choice(fonts_list)
+ # random choice font size
+ font_size = random.randint(cf.font_min_size, cf.font_max_size)
+ font = ImageFont.truetype(font_path, font_size)
+
+ ch_w = []
+ ch_h = []
+ for ch in chars:
+ wt, ht = font.getsize(ch)
+ ch_w.append(wt)
+ ch_h.append(ht)
+ f_w = max(ch_w)
+ f_h = sum(ch_h)
+
+ x1 = random.randint(0, img_w - f_w)
+ y1 = random.randint(0, img_h - f_h)
+ x2 = x1 + f_w
+ y2 = y1 + f_h
+
+ crop_y1 = y1
+ crop_x1 = x1
+ crop_y2 = y2
+ crop_x2 = x2
+
+ best_color = (0, 0, 0)
+ draw = ImageDraw.Draw(img)
+ i = 0
+ for ch in chars:
+ draw.text((x1, y1), ch, best_color, font=font)
+ y1 = y1 + ch_h[i]
+ i = i + 1
+ crop_img = img.crop((crop_x1, crop_y1, crop_x2, crop_y2))
+ crop_img = crop_img.transpose(Image.ROTATE_90)
+ return crop_img, chars
+
+
+def get_fonts(fonts_path):
+ """
+ desc: get all fonts
+ """
+ font_files = os.listdir(fonts_path)
+ fonts_list=[]
+ for font_file in font_files:
+ font_path=os.path.join(fonts_path, font_file)
+ fonts_list.append(font_path)
+ return fonts_list
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--num_img', type=int, default=30, help="Number of images to generate")
+ parser.add_argument('--font_min_size', type=int, default=11)
+ parser.add_argument('--font_max_size', type=int, default=12,
+ help="Help adjust the size of the generated text and the size of the picture")
+ parser.add_argument('--bg_path', type=str, default='./background',
+ help='The generated text pictures will be pasted onto the pictures of this folder')
+ parser.add_argument('--det_bg_path', type=str, default='./det_background',
+ help='The generated text pictures will use the pictures of this folder as the background')
+ parser.add_argument('--fonts_path', type=str, default='../../StyleText/fonts',
+ help='The font used to generate the picture')
+ parser.add_argument('--corpus_path', type=str, default='./corpus',
+ help='The corpus used to generate the text picture')
+ parser.add_argument('--output_dir', type=str, default='./output/', help='Images save dir')
+
+
+ cf = parser.parse_args()
+ # save path
+ if not os.path.exists(cf.output_dir):
+ os.mkdir(cf.output_dir)
+
+ # get corpus
+ txt_root_path = cf.corpus_path
+ char_lines = get_char_lines(txt_root_path=txt_root_path)
+
+ # get all fonts
+ fonts_path = cf.fonts_path
+ fonts_list = get_fonts(fonts_path)
+
+ # rec bg
+ img_root_path = cf.bg_path
+ imnames=os.listdir(img_root_path)
+
+ # det bg
+ det_bg_path = cf.det_bg_path
+ bg_pics = os.listdir(det_bg_path)
+
+ # OCR det files
+ det_val_file = open(cf.output_dir + 'det_gt_val.txt', 'w', encoding='utf-8')
+ det_train_file = open(cf.output_dir + 'det_gt_train.txt', 'w', encoding='utf-8')
+ # det imgs
+ det_save_dir = 'imgs/'
+ if not os.path.exists(cf.output_dir + det_save_dir):
+ os.mkdir(cf.output_dir + det_save_dir)
+ det_val_save_dir = 'imgs_val/'
+ if not os.path.exists(cf.output_dir + det_val_save_dir):
+ os.mkdir(cf.output_dir + det_val_save_dir)
+
+ # OCR rec files
+ rec_val_file = open(cf.output_dir + 'rec_gt_val.txt', 'w', encoding='utf-8')
+ rec_train_file = open(cf.output_dir + 'rec_gt_train.txt', 'w', encoding='utf-8')
+ # rec imgs
+ rec_save_dir = 'rec_imgs/'
+ if not os.path.exists(cf.output_dir + rec_save_dir):
+ os.mkdir(cf.output_dir + rec_save_dir)
+ rec_val_save_dir = 'rec_imgs_val/'
+ if not os.path.exists(cf.output_dir + rec_val_save_dir):
+ os.mkdir(cf.output_dir + rec_val_save_dir)
+
+
+ val_ratio = cf.num_img * 0.2 # val dataset ratio
+
+ print('start generating...')
+ for i in range(0, cf.num_img):
+ imname = random.choice(imnames)
+ img_path = os.path.join(img_root_path, imname)
+
+ rnd = random.random()
+ # gen horizontal text picture
+ if rnd < 0.5:
+ gen_img, chars = get_horizontal_text_picture(img_path, char_lines[i], fonts_list, cf)
+ ori_w, ori_h = gen_img.size
+ gen_img = gen_img.crop((0, 3, ori_w, ori_h))
+ # gen vertical text picture
+ else:
+ gen_img, chars = get_vertical_text_picture(img_path, char_lines[i], fonts_list, cf)
+ ori_w, ori_h = gen_img.size
+ gen_img = gen_img.crop((3, 0, ori_w, ori_h))
+
+ ori_w, ori_h = gen_img.size
+
+ # rec imgs
+ save_img_name = str(i).zfill(4) + '.jpg'
+ if i < val_ratio:
+ save_dir = os.path.join(rec_val_save_dir, save_img_name)
+ line = save_dir + '\t' + char_lines[i] + '\n'
+ rec_val_file.write(line)
+ else:
+ save_dir = os.path.join(rec_save_dir, save_img_name)
+ line = save_dir + '\t' + char_lines[i] + '\n'
+ rec_train_file.write(line)
+ gen_img.save(cf.output_dir + save_dir, quality = 95, subsampling=0)
+
+ # det img
+ # random choice bg
+ bg_pic = random.sample(bg_pics, 1)[0]
+ det_img = Image.open(os.path.join(det_bg_path, bg_pic))
+ # the PCB position is fixed, modify it according to your own scenario
+ if bg_pic == '1.png':
+ x1 = 38
+ y1 = 3
+ else:
+ x1 = 34
+ y1 = 1
+
+ det_img.paste(gen_img, (x1, y1))
+ # text pos
+ chars_pos = [[x1, y1], [x1 + ori_w, y1], [x1 + ori_w, y1 + ori_h], [x1, y1 + ori_h]]
+ label = [{"transcription":char_lines[i], "points":chars_pos}]
+ if i < val_ratio:
+ save_dir = os.path.join(det_val_save_dir, save_img_name)
+ det_val_file.write(save_dir + '\t' + json.dumps(
+ label, ensure_ascii=False) + '\n')
+ else:
+ save_dir = os.path.join(det_save_dir, save_img_name)
+ det_train_file.write(save_dir + '\t' + json.dumps(
+ label, ensure_ascii=False) + '\n')
+ det_img.save(cf.output_dir + save_dir, quality = 95, subsampling=0)
--
GitLab