diff --git a/doc/doc_ch/kie.md b/doc/doc_ch/kie.md
index eed0694a6b6a80327c73e035b3bc0a4794a4430f..da86797a21648d9b987a55493b714f6b21f21c01 100644
--- a/doc/doc_ch/kie.md
+++ b/doc/doc_ch/kie.md
@@ -112,7 +112,7 @@ PaddleOCR也支持了关键信息抽取模型的标注,具体使用方法请
# 2. 开始训练
-PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以 VI_LayoutXLM 多模态预训练模型为例进行讲解。
+PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以 VI-LayoutXLM 多模态预训练模型为例进行讲解。
> 如果希望使用基于SDMGR的关键信息抽取算法,请参考:[SDMGR使用](./algorithm_kie_sdmgr.md)。
@@ -144,7 +144,7 @@ wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layou
开始训练:
- 如果您安装的是cpu版本,请将配置文件中的 `use_gpu` 字段修改为false
-- PaddleOCR在训练时,会默认下载VI_LayoutXLM预训练模型,这里无需预先下载。
+- PaddleOCR在训练时,会默认下载VI-LayoutXLM预训练模型,这里无需预先下载。
```bash
# GPU训练 支持单卡,多卡训练
diff --git a/ppstructure/docs/models_list.md b/ppstructure/docs/models_list.md
index 42d44009dad1ba1b07bb410c199993c6f79f3d5d..89fa98d3b77a1a17f53e0f5efa770396360c87b1 100644
--- a/ppstructure/docs/models_list.md
+++ b/ppstructure/docs/models_list.md
@@ -4,8 +4,7 @@
- [2. OCR和表格识别模型](#2-ocr和表格识别模型)
- [2.1 OCR](#21-ocr)
- [2.2 表格识别模型](#22-表格识别模型)
-- [3. VQA模型](#3-vqa模型)
-- [4. KIE模型](#4-kie模型)
+- [3. KIE模型](#3-kie模型)
@@ -38,19 +37,26 @@
|en_ppocr_mobile_v2.0_table_structure|PubTabNet数据集训练的英文表格场景的表格结构预测|18.6M|[推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/table/en_ppocr_mobile_v2.0_table_structure_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/table/en_ppocr_mobile_v2.0_table_structure_train.tar) |
-## 3. VQA模型
-|模型名称|模型简介|推理模型大小|下载地址|
-| --- | --- | --- | --- |
-|ser_LayoutXLM_xfun_zh|基于LayoutXLM在xfun中文数据集上训练的SER模型|1.4G|[推理模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar) |
-|re_LayoutXLM_xfun_zh|基于LayoutXLM在xfun中文数据集上训练的RE模型|1.4G|[推理模型 coming soon]() / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar) |
-|ser_LayoutLMv2_xfun_zh|基于LayoutLMv2在xfun中文数据集上训练的SER模型|778M|[推理模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLMv2_xfun_zh_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLMv2_xfun_zh.tar) |
-|re_LayoutLMv2_xfun_zh|基于LayoutLMv2在xfun中文数据集上训练的RE模型|765M|[推理模型 coming soon]() / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutLMv2_xfun_zh.tar) |
-|ser_LayoutLM_xfun_zh|基于LayoutLM在xfun中文数据集上训练的SER模型|430M|[推理模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLM_xfun_zh_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLM_xfun_zh.tar) |
+## 3. KIE模型
-
-## 4. KIE模型
+在XFUND_zh数据集上,不同模型的精度与V100 GPU上速度信息如下所示。
-|模型名称|模型简介|模型大小|下载地址|
-| --- | --- | --- | --- |
-|SDMGR|关键信息提取模型|78M|[推理模型 coming soon]() / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/kie/kie_vgg16.tar)|
+|模型名称|模型简介 | 推理模型大小| 精度(hmean) | 预测耗时(ms) | 下载地址|
+| --- | --- | --- |--- |--- | --- |
+|ser_VI-LayoutXLM_xfund_zh|基于VI-LayoutXLM在xfund中文数据集上训练的SER模型|1.1G| 93.19% | 15.49 | [推理模型](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_pretrained.tar) |
+|re_VI-LayoutXLM_xfund_zh|基于VI-LayoutXLM在xfund中文数据集上训练的RE模型|1.1G| 83.92% | 15.49 |[推理模型 coming soon]() / [训练模型](https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_pretrained.tar) |
+|ser_LayoutXLM_xfund_zh|基于LayoutXLM在xfund中文数据集上训练的SER模型|1.4G| 90.38% | 19.49 |[推理模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar) |
+|re_LayoutXLM_xfund_zh|基于LayoutXLM在xfund中文数据集上训练的RE模型|1.4G| 74.83% | 19.49 |[推理模型 coming soon]() / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar) |
+|ser_LayoutLMv2_xfund_zh|基于LayoutLMv2在xfund中文数据集上训练的SER模型|778M| 85.44% | 31.46 |[推理模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLMv2_xfun_zh_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLMv2_xfun_zh.tar) |
+|re_LayoutLMv2_xfund_zh|基于LayoutLMv2在xfun中文数据集上训练的RE模型|765M| 67.77% | 31.46 |[推理模型 coming soon]() / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/re_LayoutLMv2_xfun_zh.tar) |
+|ser_LayoutLM_xfund_zh|基于LayoutLM在xfund中文数据集上训练的SER模型|430M| 77.31% | - |[推理模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLM_xfun_zh_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutLM_xfun_zh.tar) |
+
+* 注:上述预测耗时信息仅包含了inference模型的推理耗时,没有统计预处理与后处理耗时,测试环境为`V100 GPU + CUDA 10.2 + CUDNN 8.1.1 + TRT 7.2.3.4`。
+
+在wildreceipt数据集上,SDMGR模型精度与下载地址如下所示。
+
+
+|模型名称|模型简介|模型大小|精度|下载地址|
+| --- | --- | --- |--- | --- |
+|SDMGR|关键信息提取模型|78M| 86.70% | [推理模型 coming soon]() / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/kie/kie_vgg16.tar)|
diff --git a/ppstructure/vqa/how_to_do_kie.md b/ppstructure/vqa/how_to_do_kie.md
new file mode 100644
index 0000000000000000000000000000000000000000..e7ac562b1e567ac2da30becb966193ba8e16979b
--- /dev/null
+++ b/ppstructure/vqa/how_to_do_kie.md
@@ -0,0 +1,168 @@
+
+# 怎样完成基于图像数据的信息抽取任务
+
+- [1. 简介](#1-简介)
+ - [1.1 背景](#11-背景)
+ - [1.2 主流方法](#12-主流方法)
+- [2. 关键信息抽取任务流程](#2-关键信息抽取任务流程)
+ - [2.1 训练OCR模型](#21-训练OCR模型)
+ - [2.2 训练KIE模型](#22-训练KIE模型)
+- [3. 参考文献](#3-参考文献)
+
+
+## 1. 简介
+
+### 1.1 背景
+
+关键信息抽取 (Key Information Extraction, KIE)指的是是从文本或者图像中,抽取出关键的信息。针对文档图像的关键信息抽取任务作为OCR的下游任务,存在非常多的实际应用场景,如表单识别、车票信息抽取、身份证信息抽取等。然而,使用人力从这些文档图像中提取或者收集关键信息耗时费力,怎样自动化融合图像中的视觉、布局、文字等特征并完成关键信息抽取是一个价值与挑战并存的问题。
+
+对于特定场景的文档图像,其中的关键信息位置、版式等较为固定,因此在研究早期有很多基于模板匹配的方法进行关键信息的抽取,考虑到其流程较为简单,该方法仍然被广泛应用在目前的很多场景中。但是这种基于模板匹配的方法在应用到不同的场景中时,需要耗费大量精力去调整与适配模板,迁移成本较高。
+
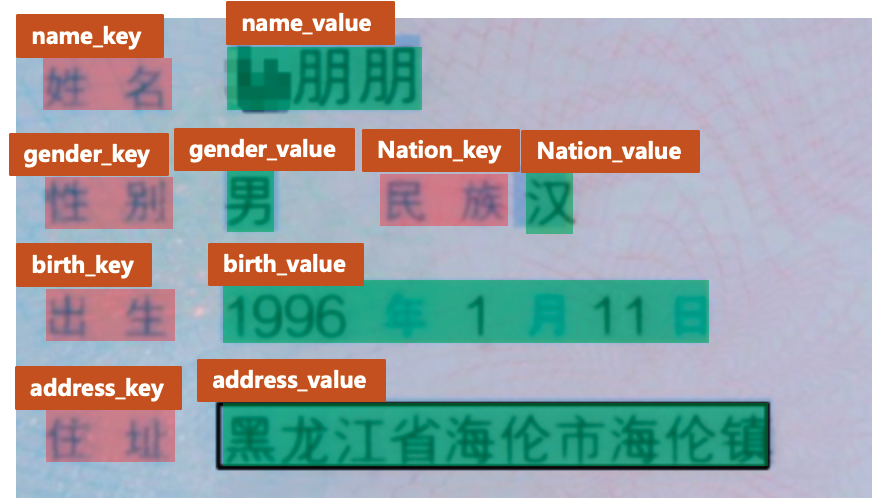
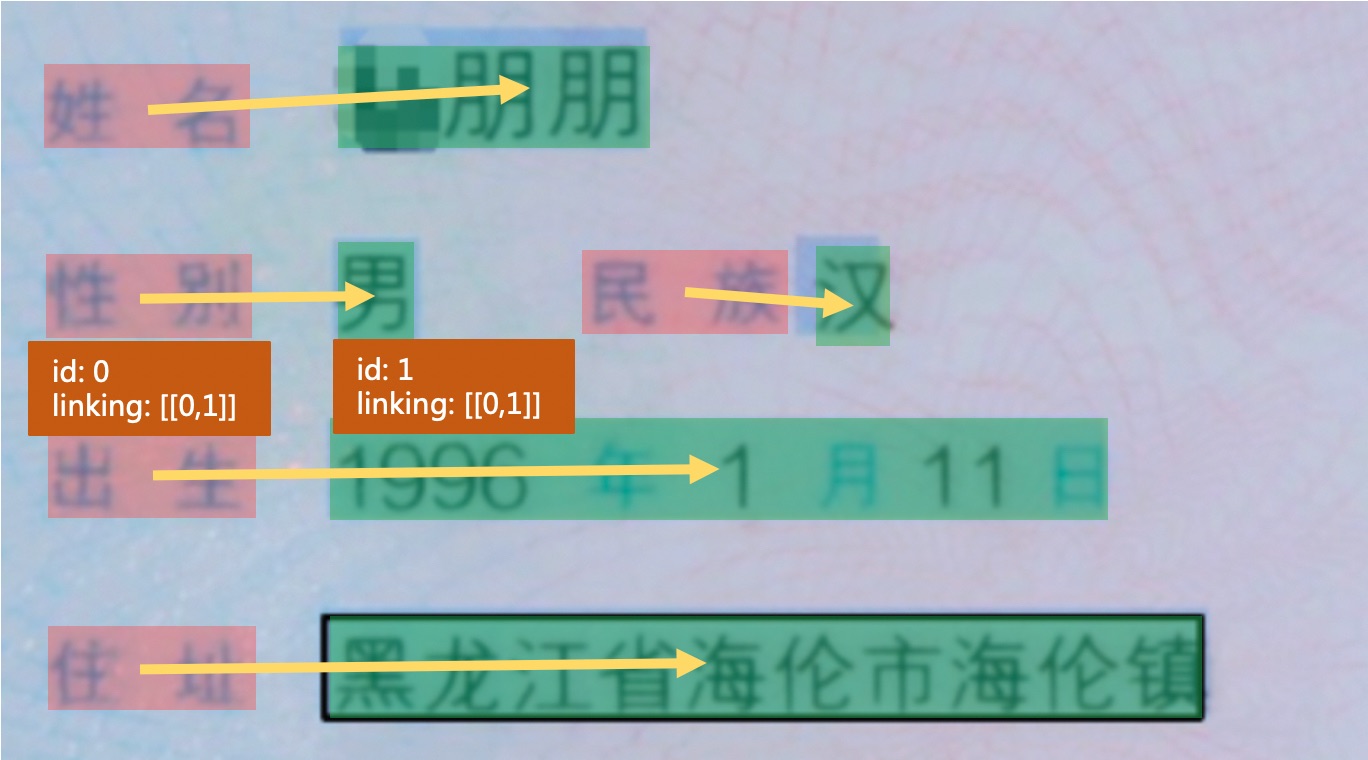
+文档图像中的KIE一般包含2个子任务,示意图如下图所示。
+
+* (1)SER: 语义实体识别 (Semantic Entity Recognition),对每一个检测到的文本进行分类,如将其分为姓名,身份证。如下图中的黑色框和红色框。
+* (2)RE: 关系抽取 (Relation Extraction),对每一个检测到的文本进行分类,如将其分为问题 (key) 和答案 (value) 。然后对每一个问题找到对应的答案,相当于完成key-value的匹配过程。如下图中的红色框和黑色框分别代表问题和答案,黄色线代表问题和答案之间的对应关系。
+
+
+
+

+
+
+
+

+
+
+