diff --git a/PPOCRLabel/PPOCRLabel.py b/PPOCRLabel/PPOCRLabel.py
index 7d1df9d2034b4ec927a2ac3a879861df62f78a28..b9f35aa352d5be3a77de693a6f3c1acf7469ac41 100644
--- a/PPOCRLabel/PPOCRLabel.py
+++ b/PPOCRLabel/PPOCRLabel.py
@@ -152,16 +152,6 @@ class MainWindow(QMainWindow):
self.fileListWidget.setIconSize(QSize(25, 25))
filelistLayout.addWidget(self.fileListWidget)
- self.AutoRecognition = QToolButton()
- self.AutoRecognition.setToolButtonStyle(Qt.ToolButtonTextBesideIcon)
- self.AutoRecognition.setIcon(newIcon('Auto'))
- autoRecLayout = QHBoxLayout()
- autoRecLayout.setContentsMargins(0, 0, 0, 0)
- autoRecLayout.addWidget(self.AutoRecognition)
- autoRecContainer = QWidget()
- autoRecContainer.setLayout(autoRecLayout)
- filelistLayout.addWidget(autoRecContainer)
-
fileListContainer = QWidget()
fileListContainer.setLayout(filelistLayout)
self.fileListName = getStr('fileList')
@@ -172,17 +162,30 @@ class MainWindow(QMainWindow):
# ================== Key List ==================
if self.kie_mode:
- # self.keyList = QListWidget()
self.keyList = UniqueLabelQListWidget()
- # self.keyList.itemSelectionChanged.connect(self.keyListSelectionChanged)
- # self.keyList.itemDoubleClicked.connect(self.editBox)
- # self.keyList.itemChanged.connect(self.keyListItemChanged)
+
+ # set key list height
+ key_list_height = int(QApplication.desktop().height() // 4)
+ if key_list_height < 50:
+ key_list_height = 50
+ self.keyList.setMaximumHeight(key_list_height)
+
self.keyListDockName = getStr('keyListTitle')
self.keyListDock = QDockWidget(self.keyListDockName, self)
self.keyListDock.setWidget(self.keyList)
self.keyListDock.setFeatures(QDockWidget.NoDockWidgetFeatures)
filelistLayout.addWidget(self.keyListDock)
+ self.AutoRecognition = QToolButton()
+ self.AutoRecognition.setToolButtonStyle(Qt.ToolButtonTextBesideIcon)
+ self.AutoRecognition.setIcon(newIcon('Auto'))
+ autoRecLayout = QHBoxLayout()
+ autoRecLayout.setContentsMargins(0, 0, 0, 0)
+ autoRecLayout.addWidget(self.AutoRecognition)
+ autoRecContainer = QWidget()
+ autoRecContainer.setLayout(autoRecLayout)
+ filelistLayout.addWidget(autoRecContainer)
+
# ================== Right Area ==================
listLayout = QVBoxLayout()
listLayout.setContentsMargins(0, 0, 0, 0)
@@ -431,8 +434,7 @@ class MainWindow(QMainWindow):
# ================== New Actions ==================
edit = action(getStr('editLabel'), self.editLabel,
- 'Ctrl+E', 'edit', getStr('editLabelDetail'),
- enabled=False)
+ 'Ctrl+E', 'edit', getStr('editLabelDetail'), enabled=False)
AutoRec = action(getStr('autoRecognition'), self.autoRecognition,
'', 'Auto', getStr('autoRecognition'), enabled=False)
@@ -465,11 +467,10 @@ class MainWindow(QMainWindow):
'Ctrl+Z', "undo", getStr("undo"), enabled=False)
change_cls = action(getStr("keyChange"), self.change_box_key,
- 'Ctrl+B', "edit", getStr("keyChange"), enabled=False)
+ 'Ctrl+X', "edit", getStr("keyChange"), enabled=False)
lock = action(getStr("lockBox"), self.lockSelectedShape,
- None, "lock", getStr("lockBoxDetail"),
- enabled=False)
+ None, "lock", getStr("lockBoxDetail"), enabled=False)
self.editButton.setDefaultAction(edit)
self.newButton.setDefaultAction(create)
@@ -534,9 +535,10 @@ class MainWindow(QMainWindow):
fileMenuActions=(opendir, open_dataset_dir, saveLabel, resetAll, quit),
beginner=(), advanced=(),
editMenu=(createpoly, edit, copy, delete, singleRere, None, undo, undoLastPoint,
- None, rotateLeft, rotateRight, None, color1, self.drawSquaresOption, lock),
+ None, rotateLeft, rotateRight, None, color1, self.drawSquaresOption, lock,
+ None, change_cls),
beginnerContext=(
- create, edit, copy, delete, singleRere, rotateLeft, rotateRight, lock, change_cls),
+ create, edit, copy, delete, singleRere, rotateLeft, rotateRight, lock, change_cls),
advancedContext=(createMode, editMode, edit, copy,
delete, shapeLineColor, shapeFillColor),
onLoadActive=(create, createMode, editMode),
@@ -1105,7 +1107,9 @@ class MainWindow(QMainWindow):
shapes = [format_shape(shape) for shape in self.canvas.shapes if shape.line_color != DEFAULT_LOCK_COLOR]
# Can add differrent annotation formats here
for box in self.result_dic:
- trans_dic = {"label": box[1][0], "points": box[0], "difficult": False, "key_cls": "None"}
+ trans_dic = {"label": box[1][0], "points": box[0], "difficult": False}
+ if self.kie_mode:
+ trans_dic.update({"key_cls": "None"})
if trans_dic["label"] == "" and mode == 'Auto':
continue
shapes.append(trans_dic)
@@ -1113,8 +1117,10 @@ class MainWindow(QMainWindow):
try:
trans_dic = []
for box in shapes:
- trans_dic.append({"transcription": box['label'], "points": box['points'],
- "difficult": box['difficult'], "key_cls": box['key_cls']})
+ trans_dict = {"transcription": box['label'], "points": box['points'], "difficult": box['difficult']}
+ if self.kie_mode:
+ trans_dict.update({"key_cls": box['key_cls']})
+ trans_dic.append(trans_dict)
self.PPlabel[annotationFilePath] = trans_dic
if mode == 'Auto':
self.Cachelabel[annotationFilePath] = trans_dic
@@ -1424,15 +1430,17 @@ class MainWindow(QMainWindow):
# box['ratio'] of the shapes saved in lockedShapes contains the ratio of the
# four corner coordinates of the shapes to the height and width of the image
for box in self.canvas.lockedShapes:
+ key_cls = None if not self.kie_mode else box['key_cls']
if self.canvas.isInTheSameImage:
shapes.append((box['transcription'], [[s[0] * width, s[1] * height] for s in box['ratio']],
- DEFAULT_LOCK_COLOR, box['key_cls'], box['difficult']))
+ DEFAULT_LOCK_COLOR, key_cls, box['difficult']))
else:
shapes.append(('锁定框:待检测', [[s[0] * width, s[1] * height] for s in box['ratio']],
- DEFAULT_LOCK_COLOR, box['key_cls'], box['difficult']))
+ DEFAULT_LOCK_COLOR, key_cls, box['difficult']))
if imgidx in self.PPlabel.keys():
for box in self.PPlabel[imgidx]:
- shapes.append((box['transcription'], box['points'], None, box['key_cls'], box['difficult']))
+ key_cls = None if not self.kie_mode else box['key_cls']
+ shapes.append((box['transcription'], box['points'], None, key_cls, box['difficult']))
self.loadLabels(shapes)
self.canvas.verified = False
@@ -1460,6 +1468,7 @@ class MainWindow(QMainWindow):
def adjustScale(self, initial=False):
value = self.scalers[self.FIT_WINDOW if initial else self.zoomMode]()
self.zoomWidget.setValue(int(100 * value))
+ self.imageSlider.setValue(self.zoomWidget.value()) # set zoom slider value
def scaleFitWindow(self):
"""Figure out the size of the pixmap in order to fit the main widget."""
@@ -1600,7 +1609,6 @@ class MainWindow(QMainWindow):
else:
self.keyDialog.labelList.addItems(self.existed_key_cls_set)
-
def importDirImages(self, dirpath, isDelete=False):
if not self.mayContinue() or not dirpath:
return
@@ -2238,13 +2246,22 @@ class MainWindow(QMainWindow):
print('The program will automatically save once after confirming 5 images (default)')
def change_box_key(self):
+ if not self.kie_mode:
+ return
key_text, _ = self.keyDialog.popUp(self.key_previous_text)
if key_text is None:
return
self.key_previous_text = key_text
for shape in self.canvas.selectedShapes:
shape.key_cls = key_text
+ if not self.keyList.findItemsByLabel(key_text):
+ item = self.keyList.createItemFromLabel(key_text)
+ self.keyList.addItem(item)
+ rgb = self._get_rgb_by_label(key_text, self.kie_mode)
+ self.keyList.setItemLabel(item, key_text, rgb)
+
self._update_shape_color(shape)
+ self.keyDialog.addLabelHistory(key_text)
def undoShapeEdit(self):
self.canvas.restoreShape()
@@ -2288,9 +2305,10 @@ class MainWindow(QMainWindow):
shapes = [format_shape(shape) for shape in self.canvas.selectedShapes]
trans_dic = []
for box in shapes:
- trans_dic.append({"transcription": box['label'], "ratio": box['ratio'],
- "difficult": box['difficult'],
- "key_cls": "None" if "key_cls" not in box else box["key_cls"]})
+ trans_dict = {"transcription": box['label'], "ratio": box['ratio'], "difficult": box['difficult']}
+ if self.kie_mode:
+ trans_dict.update({"key_cls": box["key_cls"]})
+ trans_dic.append(trans_dict)
self.canvas.lockedShapes = trans_dic
self.actions.save.setEnabled(True)
diff --git a/PPOCRLabel/README.md b/PPOCRLabel/README.md
index 9d5eea048350156957b0079e27a0239ae5e482e3..21db1867aa6b6504595096de56b17f01dbf3e4f6 100644
--- a/PPOCRLabel/README.md
+++ b/PPOCRLabel/README.md
@@ -9,7 +9,7 @@ PPOCRLabel is a semi-automatic graphic annotation tool suitable for OCR field, w
### Recent Update
- 2022.02:(by [PeterH0323](https://github.com/peterh0323) )
- - Added KIE mode, for [detection + identification + keyword extraction] labeling.
+ - Add KIE Mode by using `--kie`, for [detection + identification + keyword extraction] labeling.
- 2022.01:(by [PeterH0323](https://github.com/peterh0323) )
- Improve user experience: prompt for the number of files and labels, optimize interaction, and fix bugs such as only use CPU when inference
- 2021.11.17:
@@ -54,7 +54,10 @@ PPOCRLabel can be started in two ways: whl package and Python script. The whl pa
```bash
pip install PPOCRLabel # install
-PPOCRLabel # run
+
+# Select label mode and run
+PPOCRLabel # [Normal mode] for [detection + recognition] labeling
+PPOCRLabel --kie True # [KIE mode] for [detection + recognition + keyword extraction] labeling
```
> If you getting this error `OSError: [WinError 126] The specified module could not be found` when you install shapely on windows. Please try to download Shapely whl file using http://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely.
@@ -67,13 +70,18 @@ PPOCRLabel # run
```bash
pip3 install PPOCRLabel
pip3 install trash-cli
-PPOCRLabel
+
+# Select label mode and run
+PPOCRLabel # [Normal mode] for [detection + recognition] labeling
+PPOCRLabel --kie True # [KIE mode] for [detection + recognition + keyword extraction] labeling
```
#### MacOS
```bash
pip3 install PPOCRLabel
pip3 install opencv-contrib-python-headless==4.2.0.32
+
+# Select label mode and run
PPOCRLabel # [Normal mode] for [detection + recognition] labeling
PPOCRLabel --kie True # [KIE mode] for [detection + recognition + keyword extraction] labeling
```
@@ -90,6 +98,8 @@ pip3 install dist/PPOCRLabel-1.0.2-py2.py3-none-any.whl
```bash
cd ./PPOCRLabel # Switch to the PPOCRLabel directory
+
+# Select label mode and run
python PPOCRLabel.py # [Normal mode] for [detection + recognition] labeling
python PPOCRLabel.py --kie True # [KIE mode] for [detection + recognition + keyword extraction] labeling
```
@@ -156,6 +166,7 @@ python PPOCRLabel.py --kie True # [KIE mode] for [detection + recognition + keyw
| X | Rotate the box anti-clockwise |
| C | Rotate the box clockwise |
| Ctrl + E | Edit label of the selected box |
+| Ctrl + X | Change key class of the box when enable `--kie` |
| Ctrl + R | Re-recognize the selected box |
| Ctrl + C | Copy and paste the selected box |
| Ctrl + Left Mouse Button | Multi select the label box |
diff --git a/PPOCRLabel/README_ch.md b/PPOCRLabel/README_ch.md
index a25871d9310d9c04a2f2fcbb68013938e26aa956..9728686e0232f4cdc387d579b8344b09366beafd 100644
--- a/PPOCRLabel/README_ch.md
+++ b/PPOCRLabel/README_ch.md
@@ -9,7 +9,7 @@ PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置P
#### 近期更新
- 2022.02:(by [PeterH0323](https://github.com/peterh0323) )
- - 新增:KIE 功能,用于打【检测+识别+关键字提取】的标签
+ - 新增:使用 `--kie` 进入 KIE 功能,用于打【检测+识别+关键字提取】的标签
- 2022.01:(by [PeterH0323](https://github.com/peterh0323) )
- 提升用户体验:新增文件与标记数目提示、优化交互、修复gpu使用等问题
- 2021.11.17:
@@ -57,7 +57,10 @@ PPOCRLabel可通过whl包与Python脚本两种方式启动,whl包形式启动
```bash
pip install PPOCRLabel # 安装
-PPOCRLabel --lang ch # 运行
+
+# 选择标签模式来启动
+PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
+PPOCRLabel --lang ch --kie True # 启动 【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签
```
> 注意:通过whl包安装PPOCRLabel会自动下载 `paddleocr` whl包,其中shapely依赖可能会出现 `[winRrror 126] 找不到指定模块的问题。` 的错误,建议从[这里](https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely)下载并安装
##### Ubuntu Linux
@@ -65,13 +68,18 @@ PPOCRLabel --lang ch # 运行
```bash
pip3 install PPOCRLabel
pip3 install trash-cli
-PPOCRLabel --lang ch
+
+# 选择标签模式来启动
+PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
+PPOCRLabel --lang ch --kie True # 启动 【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签
```
##### MacOS
```bash
pip3 install PPOCRLabel
pip3 install opencv-contrib-python-headless==4.2.0.32 # 如果下载过慢请添加"-i https://mirror.baidu.com/pypi/simple"
+
+# 选择标签模式来启动
PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
PPOCRLabel --lang ch --kie True # 启动 【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签
```
@@ -92,6 +100,8 @@ pip3 install dist/PPOCRLabel-1.0.2-py2.py3-none-any.whl -i https://mirror.baidu.
```bash
cd ./PPOCRLabel # 切换到PPOCRLabel目录
+
+# 选择标签模式来启动
python PPOCRLabel.py --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
python PPOCRLabel.py --lang ch --kie True # 启动 【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签
```
@@ -137,25 +147,27 @@ python PPOCRLabel.py --lang ch --kie True # 启动 【KIE 模式】,用于打
### 3.1 快捷键
-| 快捷键 | 说明 |
-|------------------|----------------|
-| Ctrl + shift + R | 对当前图片的所有标记重新识别 |
-| W | 新建矩形框 |
-| Q | 新建四点框 |
-| X | 框逆时针旋转 |
-| C | 框顺时针旋转 |
-| Ctrl + E | 编辑所选框标签 |
-| Ctrl + R | 重新识别所选标记 |
-| Ctrl + C | 复制并粘贴选中的标记框 |
-| Ctrl + 鼠标左键 | 多选标记框 |
-| Backspace | 删除所选框 |
-| Ctrl + V | 确认本张图片标记 |
-| Ctrl + Shift + d | 删除本张图片 |
-| D | 下一张图片 |
-| A | 上一张图片 |
-| Ctrl++ | 缩小 |
-| Ctrl-- | 放大 |
-| ↑→↓← | 移动标记框 |
+| 快捷键 | 说明 |
+|------------------|---------------------------------|
+| Ctrl + shift + R | 对当前图片的所有标记重新识别 |
+| W | 新建矩形框 |
+| Q | 新建四点框 |
+| X | 框逆时针旋转 |
+| C | 框顺时针旋转 |
+| Ctrl + E | 编辑所选框标签 |
+| Ctrl + X | `--kie` 模式下,修改 Box 的关键字种类 |
+| Ctrl + R | 重新识别所选标记 |
+| Ctrl + C | 复制并粘贴选中的标记框 |
+| Ctrl + 鼠标左键 | 多选标记框 |
+| Backspac | 删除所选框 |
+| Ctrl + V | 确认本张图片标记 |
+| Ctrl + Shift + d | 删除本张图片 |
+| D | 下一张图片 |
+| A | 上一张图片 |
+| Ctrl++ | 缩小 |
+| Ctrl-- | 放大 |
+| ↑→↓← | 移动标记框 |
+
### 3.2 内置模型
diff --git a/PPOCRLabel/libs/canvas.py b/PPOCRLabel/libs/canvas.py
index 6c1043da43a5049f1c47f58152431259df9fa36a..e6cddf13ede235fa193daf84d4395d77c371049a 100644
--- a/PPOCRLabel/libs/canvas.py
+++ b/PPOCRLabel/libs/canvas.py
@@ -546,7 +546,7 @@ class Canvas(QWidget):
# Give up if both fail.
for shape in shapes:
point = shape[0]
- offset = QPointF(2.0, 2.0)
+ offset = QPointF(5.0, 5.0)
self.calculateOffsets(shape, point)
self.prevPoint = point
if not self.boundedMoveShape(shape, point - offset):
diff --git a/PPOCRLabel/libs/unique_label_qlist_widget.py b/PPOCRLabel/libs/unique_label_qlist_widget.py
index f1eff7a172d3fecf9c18579ccead5f62ba65ecd5..07ae05fe67d8b1a924d04666220e33f664891e83 100644
--- a/PPOCRLabel/libs/unique_label_qlist_widget.py
+++ b/PPOCRLabel/libs/unique_label_qlist_widget.py
@@ -1,6 +1,6 @@
# -*- encoding: utf-8 -*-
-from PyQt5.QtCore import Qt
+from PyQt5.QtCore import Qt, QSize
from PyQt5 import QtWidgets
@@ -40,6 +40,7 @@ class UniqueLabelQListWidget(EscapableQListWidget):
qlabel.setText('● {} '.format(*color, label))
qlabel.setAlignment(Qt.AlignBottom)
- item.setSizeHint(qlabel.sizeHint())
+ # item.setSizeHint(qlabel.sizeHint())
+ item.setSizeHint(QSize(25, 25))
self.setItemWidget(item, qlabel)
diff --git a/README_ch.md b/README_ch.md
index e6b8b5772e2f2069c24d200fffe121468f6dd4ae..3788f9f0d4003a0a8aa636cd1dd6148936598411 100755
--- a/README_ch.md
+++ b/README_ch.md
@@ -32,7 +32,7 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
- PP-OCR系列高质量预训练模型,准确的识别效果
- 超轻量PP-OCRv2系列:检测(3.1M)+ 方向分类器(1.4M)+ 识别(8.5M)= 13.0M
- 超轻量PP-OCR mobile移动端系列:检测(3.0M)+方向分类器(1.4M)+ 识别(5.0M)= 9.4M
- - 通用PPOCR server系列:检测(47.1M)+方向分类器(1.4M)+ 识别(94.9M)= 143.4M
+ - 通用PP-OCR server系列:检测(47.1M)+方向分类器(1.4M)+ 识别(94.9M)= 143.4M
- 支持中英文数字组合识别、竖排文本识别、长文本识别
- 支持多语言识别:韩语、日语、德语、法语等约80种语言
- PP-Structure文档结构化系统
diff --git a/benchmark/run_benchmark_det.sh b/benchmark/run_benchmark_det.sh
index 818aa7e3e1fb342174a0cf5be4d45af0b0205a39..9f5b46cde1da58ccc3fbb128e52aa1cfe4f3dd53 100644
--- a/benchmark/run_benchmark_det.sh
+++ b/benchmark/run_benchmark_det.sh
@@ -1,5 +1,4 @@
#!/usr/bin/env bash
-set -xe
# 运行示例:CUDA_VISIBLE_DEVICES=0 bash run_benchmark.sh ${run_mode} ${bs_item} ${fp_item} 500 ${model_mode}
# 参数说明
function _set_params(){
@@ -34,11 +33,13 @@ function _train(){
train_cmd="python tools/train.py "${train_cmd}""
;;
mp)
+ rm -rf ./mylog
train_cmd="python -m paddle.distributed.launch --log_dir=./mylog --gpus=$CUDA_VISIBLE_DEVICES tools/train.py ${train_cmd}"
;;
*) echo "choose run_mode(sp or mp)"; exit 1;
esac
# 以下不用修改
+ echo ${train_cmd}
timeout 15m ${train_cmd} > ${log_file} 2>&1
if [ $? -ne 0 ];then
echo -e "${model_name}, FAIL"
diff --git a/configs/det/det_mv3_pse.yml b/configs/det/det_mv3_pse.yml
index 61ac24727acbd4f0b1eea15af08c0f9e71ce95a3..f80180ce7c1604cfda42ede36930e1bd9fdb8e21 100644
--- a/configs/det/det_mv3_pse.yml
+++ b/configs/det/det_mv3_pse.yml
@@ -56,7 +56,7 @@ PostProcess:
thresh: 0
box_thresh: 0.85
min_area: 16
- box_type: box # 'box' or 'poly'
+ box_type: quad # 'quad' or 'poly'
scale: 1
Metric:
diff --git a/configs/det/det_r50_vd_dcn_fce_ctw.yml b/configs/det/det_r50_vd_dcn_fce_ctw.yml
new file mode 100755
index 0000000000000000000000000000000000000000..a9f7c4143d4e9380c819f8cbc39d69f0149111b2
--- /dev/null
+++ b/configs/det/det_r50_vd_dcn_fce_ctw.yml
@@ -0,0 +1,139 @@
+Global:
+ use_gpu: true
+ epoch_num: 1500
+ log_smooth_window: 20
+ print_batch_step: 20
+ save_model_dir: ./output/det_r50_dcn_fce_ctw/
+ save_epoch_step: 100
+ # evaluation is run every 835 iterations
+ eval_batch_step: [0, 835]
+ cal_metric_during_train: False
+ pretrained_model: ./pretrain_models/ResNet50_vd_ssld_pretrained
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: False
+ infer_img: doc/imgs_en/img_10.jpg
+ save_res_path: ./output/det_fce/predicts_fce.txt
+
+
+Architecture:
+ model_type: det
+ algorithm: FCE
+ Transform:
+ Backbone:
+ name: ResNet
+ layers: 50
+ dcn_stage: [False, True, True, True]
+ out_indices: [1,2,3]
+ Neck:
+ name: FCEFPN
+ out_channels: 256
+ has_extra_convs: False
+ extra_stage: 0
+ Head:
+ name: FCEHead
+ fourier_degree: 5
+Loss:
+ name: FCELoss
+ fourier_degree: 5
+ num_sample: 50
+
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.999
+ lr:
+ learning_rate: 0.0001
+ regularizer:
+ name: 'L2'
+ factor: 0
+
+PostProcess:
+ name: FCEPostProcess
+ scales: [8, 16, 32]
+ alpha: 1.0
+ beta: 1.0
+ fourier_degree: 5
+ box_type: 'poly'
+
+Metric:
+ name: DetFCEMetric
+ main_indicator: hmean
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/ctw1500/imgs/
+ label_file_list:
+ - ./train_data/ctw1500/imgs/training.txt
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ ignore_orientation: True
+ - DetLabelEncode: # Class handling label
+ - ColorJitter:
+ brightness: 0.142
+ saturation: 0.5
+ contrast: 0.5
+ - RandomScaling:
+ - RandomCropFlip:
+ crop_ratio: 0.5
+ - RandomCropPolyInstances:
+ crop_ratio: 0.8
+ min_side_ratio: 0.3
+ - RandomRotatePolyInstances:
+ rotate_ratio: 0.5
+ max_angle: 30
+ pad_with_fixed_color: False
+ - SquareResizePad:
+ target_size: 800
+ pad_ratio: 0.6
+ - IaaAugment:
+ augmenter_args:
+ - { 'type': Fliplr, 'args': { 'p': 0.5 } }
+ - FCENetTargets:
+ fourier_degree: 5
+ - NormalizeImage:
+ scale: 1./255.
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: 'hwc'
+ - ToCHWImage:
+ - KeepKeys:
+ keep_keys: ['image', 'p3_maps', 'p4_maps', 'p5_maps'] # dataloader will return list in this order
+ loader:
+ shuffle: True
+ drop_last: False
+ batch_size_per_card: 6
+ num_workers: 8
+
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/ctw1500/imgs/
+ label_file_list:
+ - ./train_data/ctw1500/imgs/test.txt
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ ignore_orientation: True
+ - DetLabelEncode: # Class handling label
+ - DetResizeForTest:
+ limit_type: 'min'
+ limit_side_len: 736
+ - NormalizeImage:
+ scale: 1./255.
+ mean: [0.485, 0.456, 0.406]
+ std: [0.229, 0.224, 0.225]
+ order: 'hwc'
+ - Pad:
+ - ToCHWImage:
+ - KeepKeys:
+ keep_keys: ['image', 'shape', 'polys', 'ignore_tags']
+ loader:
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 1 # must be 1
+ num_workers: 2
\ No newline at end of file
diff --git a/configs/det/det_r50_vd_pse.yml b/configs/det/det_r50_vd_pse.yml
index 4629210747d3b61344cc47b11dcff01e6b738586..8e77506c410af5397a04f73674b414cb28a87c4d 100644
--- a/configs/det/det_r50_vd_pse.yml
+++ b/configs/det/det_r50_vd_pse.yml
@@ -55,7 +55,7 @@ PostProcess:
thresh: 0
box_thresh: 0.85
min_area: 16
- box_type: box # 'box' or 'poly'
+ box_type: quad # 'quad' or 'poly'
scale: 1
Metric:
diff --git a/configs/rec/rec_efficientb3_fpn_pren.yml b/configs/rec/rec_efficientb3_fpn_pren.yml
new file mode 100644
index 0000000000000000000000000000000000000000..0fac6a7a8abcc5c1e4301b1040e6e98df74abed9
--- /dev/null
+++ b/configs/rec/rec_efficientb3_fpn_pren.yml
@@ -0,0 +1,92 @@
+Global:
+ use_gpu: True
+ epoch_num: 8
+ log_smooth_window: 20
+ print_batch_step: 5
+ save_model_dir: ./output/rec/pren_new
+ save_epoch_step: 3
+ # evaluation is run every 2000 iterations after the 4000th iteration
+ eval_batch_step: [4000, 2000]
+ cal_metric_during_train: True
+ pretrained_model:
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: False
+ infer_img: doc/imgs_words/ch/word_1.jpg
+ # for data or label process
+ character_dict_path:
+ max_text_length: &max_text_length 25
+ infer_mode: False
+ use_space_char: False
+ save_res_path: ./output/rec/predicts_pren.txt
+
+Optimizer:
+ name: Adadelta
+ lr:
+ name: Piecewise
+ decay_epochs: [2, 5, 7]
+ values: [0.5, 0.1, 0.01, 0.001]
+
+Architecture:
+ model_type: rec
+ algorithm: PREN
+ in_channels: 3
+ Backbone:
+ name: EfficientNetb3_PREN
+ Neck:
+ name: PRENFPN
+ n_r: 5
+ d_model: 384
+ max_len: *max_text_length
+ dropout: 0.1
+ Head:
+ name: PRENHead
+
+Loss:
+ name: PRENLoss
+
+PostProcess:
+ name: PRENLabelDecode
+
+Metric:
+ name: RecMetric
+ main_indicator: acc
+
+Train:
+ dataset:
+ name: LMDBDataSet
+ data_dir: ./train_data/data_lmdb_release/training/
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: False
+ - PRENLabelEncode:
+ - RecAug:
+ - PRENResizeImg:
+ image_shape: [64, 256] # h,w
+ - KeepKeys:
+ keep_keys: ['image', 'label']
+ loader:
+ shuffle: True
+ batch_size_per_card: 128
+ drop_last: True
+ num_workers: 8
+
+Eval:
+ dataset:
+ name: LMDBDataSet
+ data_dir: ./train_data/data_lmdb_release/validation/
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: False
+ - PRENLabelEncode:
+ - PRENResizeImg:
+ image_shape: [64, 256] # h,w
+ - KeepKeys:
+ keep_keys: ['image', 'label']
+ loader:
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 64
+ num_workers: 8
diff --git a/deploy/android_demo/README.md b/deploy/android_demo/README.md
index 1642323ebb347dfcaf0f14f0fc00c139065f53cf..ba615fba904eed9686f645b51bf7f9821b555653 100644
--- a/deploy/android_demo/README.md
+++ b/deploy/android_demo/README.md
@@ -1,19 +1,118 @@
-# 如何快速测试
-### 1. 安装最新版本的Android Studio
-可以从 https://developer.android.com/studio 下载。本Demo使用是4.0版本Android Studio编写。
+- [Android Demo](#android-demo)
+ - [1. 简介](#1-简介)
+ - [2. 近期更新](#2-近期更新)
+ - [3. 快速使用](#3-快速使用)
+ - [3.1 环境准备](#31-环境准备)
+ - [3.2 导入项目](#32-导入项目)
+ - [3.3 运行demo](#33-运行demo)
+ - [3.4 运行模式](#34-运行模式)
+ - [3.5 设置](#35-设置)
+ - [4 更多支持](#4-更多支持)
-### 2. 按照NDK 20 以上版本
-Demo测试的时候使用的是NDK 20b版本,20版本以上均可以支持编译成功。
+# Android Demo
-如果您是初学者,可以用以下方式安装和测试NDK编译环境。
-点击 File -> New ->New Project, 新建 "Native C++" project
+## 1. 简介
+此为PaddleOCR的Android Demo,目前支持文本检测,文本方向分类器和文本识别模型的使用。使用 [PaddleLite v2.10](https://github.com/PaddlePaddle/Paddle-Lite/tree/release/v2.10) 进行开发。
+
+## 2. 近期更新
+* 2022.02.27
+ * 预测库更新到PaddleLite v2.10
+ * 支持6种运行模式:
+ * 检测+分类+识别
+ * 检测+识别
+ * 分类+识别
+ * 检测
+ * 识别
+ * 分类
+
+## 3. 快速使用
+
+### 3.1 环境准备
+1. 在本地环境安装好 Android Studio 工具,详细安装方法请见[Android Stuido 官网](https://developer.android.com/studio)。
+2. 准备一部 Android 手机,并开启 USB 调试模式。开启方法: `手机设置 -> 查找开发者选项 -> 打开开发者选项和 USB 调试模式`
+
+**注意**:如果您的 Android Studio 尚未配置 NDK ,请根据 Android Studio 用户指南中的[安装及配置 NDK 和 CMake ](https://developer.android.com/studio/projects/install-ndk)内容,预先配置好 NDK 。您可以选择最新的 NDK 版本,或者使用 Paddle Lite 预测库版本一样的 NDK
+
+### 3.2 导入项目
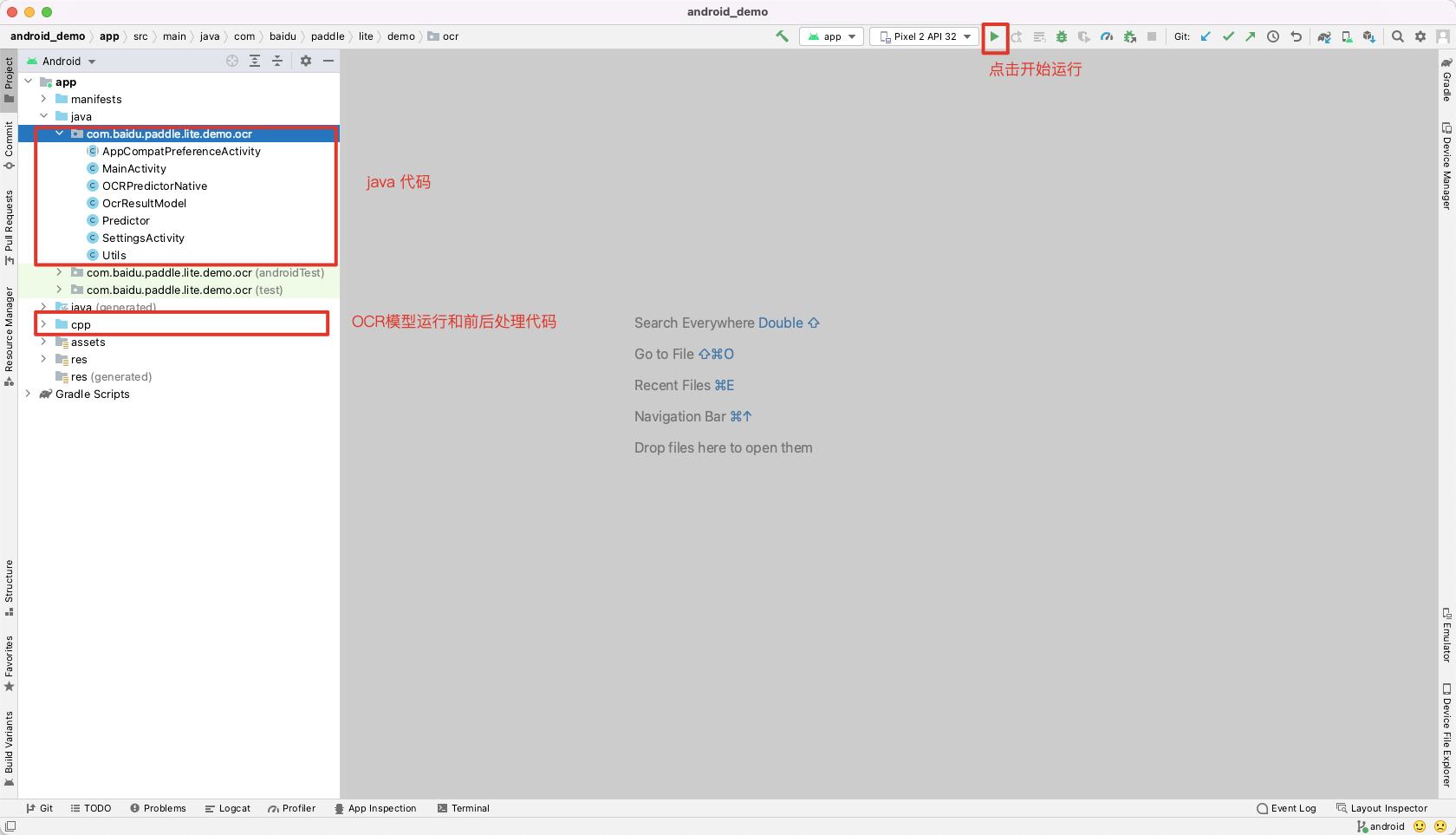
-### 3. 导入项目
点击 File->New->Import Project..., 然后跟着Android Studio的引导导入
+导入完成后呈现如下界面
+
+
+### 3.3 运行demo
+将手机连接上电脑后,点击Android Studio工具栏中的运行按钮即可运行demo。在此过程中,手机会弹出"允许从 USB 安装软件权限"的弹窗,点击允许即可。
+
+软件安转到手机上后会在手机主屏最后一页看到如下app
+
+

+
+

+
 +
+模型运行完成后,模型和运行状态显示区`STATUS`字段显示了当前模型的运行状态,这里显示为`run model successed`表明模型运行成功。
+
+模型的运行结果显示在运行结果显示区,显示格式为
+```text
+序号:Det:(x1,y1)(x2,y2)(x3,y3)(x4,y4) Rec: 识别文本,识别置信度 Cls:分类类别,分类分时
+```
+
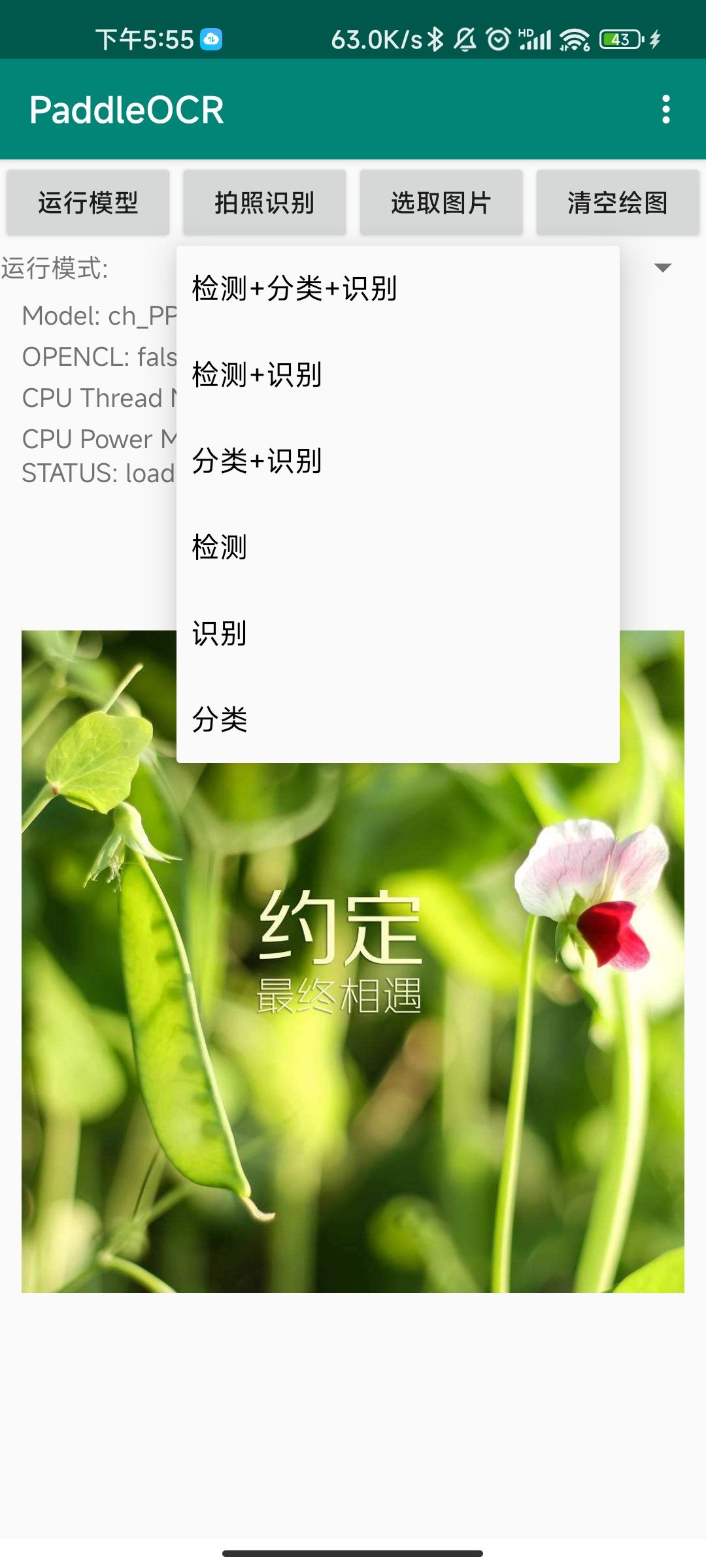
+### 3.4 运行模式
+
+PaddleOCR demo共提供了6种运行模式,如下图
+
+
+模型运行完成后,模型和运行状态显示区`STATUS`字段显示了当前模型的运行状态,这里显示为`run model successed`表明模型运行成功。
+
+模型的运行结果显示在运行结果显示区,显示格式为
+```text
+序号:Det:(x1,y1)(x2,y2)(x3,y3)(x4,y4) Rec: 识别文本,识别置信度 Cls:分类类别,分类分时
+```
+
+### 3.4 运行模式
+
+PaddleOCR demo共提供了6种运行模式,如下图
+
+
+
 |
|  |
+
+
+| 检测 | 识别 | 分类 |
+|----------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------|
+|
|
+
+
+| 检测 | 识别 | 分类 |
+|----------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------|
+|  |
|  |
|  |
+
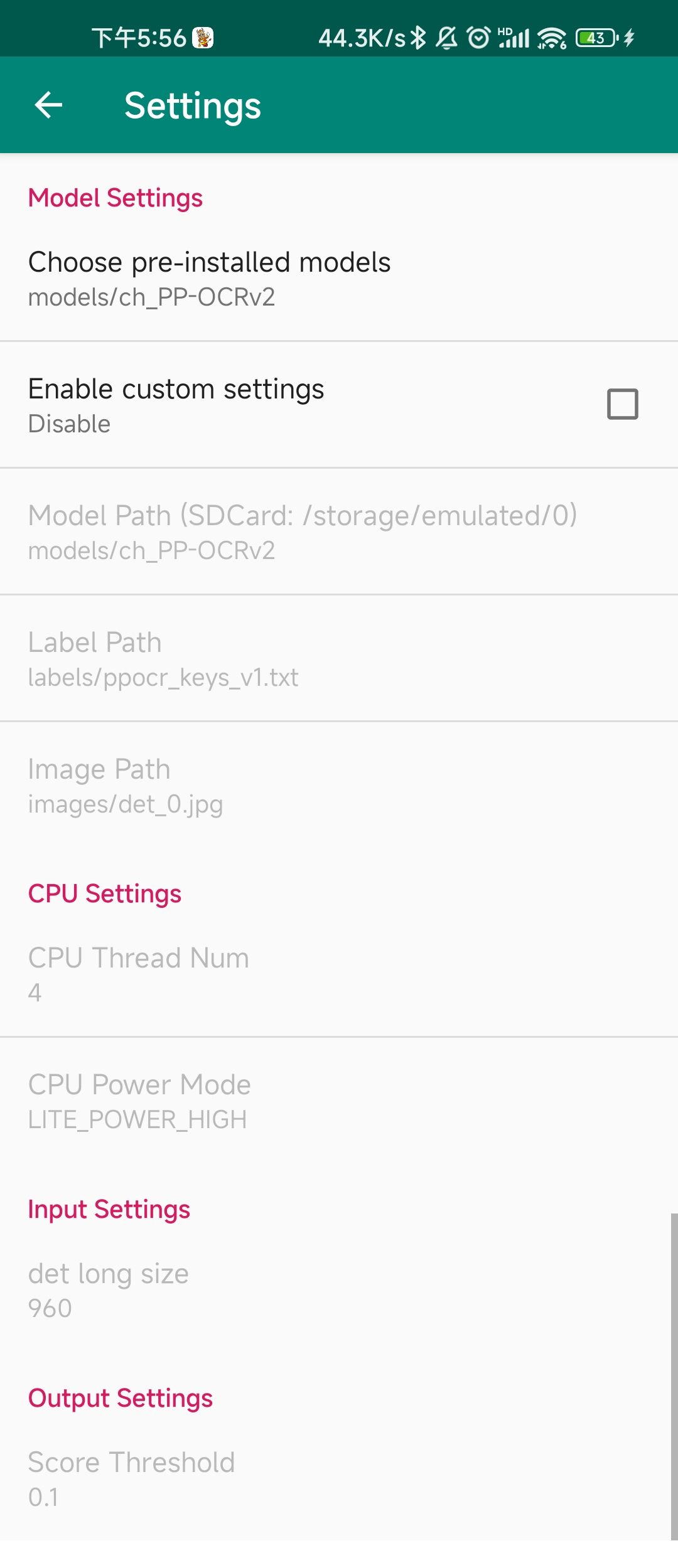
+### 3.5 设置
+
+设置界面如下
+
|
+
+### 3.5 设置
+
+设置界面如下
+
+
+
- 0.jpg
- - 90.jpg
- - 180.jpg
- - 270.jpg
+ - det_0.jpg
+ - det_90.jpg
+ - det_180.jpg
+ - det_270.jpg
+ - rec_0.jpg
+ - rec_0_180.jpg
+ - rec_1.jpg
+ - rec_1_180.jpg
- - images/0.jpg
- - images/90.jpg
- - images/180.jpg
- - images/270.jpg
+ - images/det_0.jpg
+ - images/det_90.jpg
+ - images/det_180.jpg
+ - images/det_270.jpg
+ - images/rec_0.jpg
+ - images/rec_0_180.jpg
+ - images/rec_1.jpg
+ - images/rec_1_180.jpg
- 1 threads
@@ -48,4 +56,12 @@
- BGR
- RGB
+
+ - 检测+分类+识别
+ - 检测+识别
+ - 分类+识别
+ - 检测
+ - 识别
+ - 分类
+
\ No newline at end of file
diff --git a/deploy/android_demo/app/src/main/res/values/strings.xml b/deploy/android_demo/app/src/main/res/values/strings.xml
index 0228af09af6b9bc90af56f78c6d73b82939e5918..6ee1f30f31e75b46b2e60576bf6e00b9ff6cffd9 100644
--- a/deploy/android_demo/app/src/main/res/values/strings.xml
+++ b/deploy/android_demo/app/src/main/res/values/strings.xml
@@ -1,5 +1,5 @@
- OCR Chinese
+ PaddleOCR
CHOOSE_PRE_INSTALLED_MODEL_KEY
ENABLE_CUSTOM_SETTINGS_KEY
MODEL_PATH_KEY
@@ -7,20 +7,14 @@
IMAGE_PATH_KEY
CPU_THREAD_NUM_KEY
CPU_POWER_MODE_KEY
- INPUT_COLOR_FORMAT_KEY
- INPUT_SHAPE_KEY
- INPUT_MEAN_KEY
- INPUT_STD_KEY
+ DET_LONG_SIZE_KEY
SCORE_THRESHOLD_KEY
- models/ocr_v2_for_cpu
+ models/ch_PP-OCRv2
labels/ppocr_keys_v1.txt
- images/0.jpg
+ images/det_0.jpg
4
LITE_POWER_HIGH
- BGR
- 1,3,960
- 0.485, 0.456, 0.406
- 0.229,0.224,0.225
+ 960
0.1
diff --git a/deploy/android_demo/app/src/main/res/xml/settings.xml b/deploy/android_demo/app/src/main/res/xml/settings.xml
index 049727e833ca20d21c6947f13089a798d1f5eb89..8c2ea62a142cd94fb50cb423ea98861d6303ec45 100644
--- a/deploy/android_demo/app/src/main/res/xml/settings.xml
+++ b/deploy/android_demo/app/src/main/res/xml/settings.xml
@@ -47,26 +47,10 @@
android:entryValues="@array/cpu_power_mode_values"/>
-
-
-
+ android:key="@string/DET_LONG_SIZE_KEY"
+ android:defaultValue="@string/DET_LONG_SIZE_DEFAULT"
+ android:title="det long size" />
use_gpu_ = use_gpu;
this->gpu_id_ = gpu_id;
this->gpu_mem_ = gpu_mem;
@@ -59,6 +60,7 @@ public:
this->det_db_box_thresh_ = det_db_box_thresh;
this->det_db_unclip_ratio_ = det_db_unclip_ratio;
this->use_polygon_score_ = use_polygon_score;
+ this->use_dilation_ = use_dilation;
this->visualize_ = visualize;
this->use_tensorrt_ = use_tensorrt;
@@ -71,7 +73,8 @@ public:
void LoadModel(const std::string &model_dir);
// Run predictor
- void Run(cv::Mat &img, std::vector>> &boxes, std::vector *times);
+ void Run(cv::Mat &img, std::vector>> &boxes,
+ std::vector *times);
private:
std::shared_ptr predictor_;
@@ -88,6 +91,7 @@ private:
double det_db_box_thresh_ = 0.5;
double det_db_unclip_ratio_ = 2.0;
bool use_polygon_score_ = false;
+ bool use_dilation_ = false;
bool visualize_ = true;
bool use_tensorrt_ = false;
diff --git a/deploy/cpp_infer/readme.md b/deploy/cpp_infer/readme.md
index d901366235db21727ceac88528d83ae1120fd030..725197ad5cf9c7bf54be445f2bb3698096e7f9fb 100644
--- a/deploy/cpp_infer/readme.md
+++ b/deploy/cpp_infer/readme.md
@@ -4,16 +4,20 @@
C++在性能计算上优于python,因此,在大多数CPU、GPU部署场景,多采用C++的部署方式,本节将介绍如何在Linux\Windows (CPU\GPU)环境下配置C++环境并完成
PaddleOCR模型部署。
-* [1. 准备环境](#1)
- + [1.0 运行准备](#10)
- + [1.1 编译opencv库](#11)
- + [1.2 下载或者编译Paddle预测库](#12)
- - [1.2.1 直接下载安装](#121)
- - [1.2.2 预测库源码编译](#122)
-* [2 开始运行](#2)
- + [2.1 将模型导出为inference model](#21)
- + [2.2 编译PaddleOCR C++预测demo](#22)
- + [2.3运行demo](#23)
+- [服务器端C++预测](#服务器端c预测)
+ - [1. 准备环境](#1-准备环境)
+ - [1.0 运行准备](#10-运行准备)
+ - [1.1 编译opencv库](#11-编译opencv库)
+ - [1.2 下载或者编译Paddle预测库](#12-下载或者编译paddle预测库)
+ - [1.2.1 直接下载安装](#121-直接下载安装)
+ - [1.2.2 预测库源码编译](#122-预测库源码编译)
+ - [2 开始运行](#2-开始运行)
+ - [2.1 将模型导出为inference model](#21-将模型导出为inference-model)
+ - [2.2 编译PaddleOCR C++预测demo](#22-编译paddleocr-c预测demo)
+ - [2.3 运行demo](#23-运行demo)
+ - [1. 只调用检测:](#1-只调用检测)
+ - [2. 只调用识别:](#2-只调用识别)
+ - [3. 调用串联:](#3-调用串联)
@@ -103,7 +107,7 @@ opencv3/
#### 1.2.1 直接下载安装
-* [Paddle预测库官网](https://paddle-inference.readthedocs.io/en/latest/user_guides/download_lib.html) 上提供了不同cuda版本的Linux预测库,可以在官网查看并选择合适的预测库版本(*建议选择paddle版本>=2.0.1版本的预测库* )。
+* [Paddle预测库官网](https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html#linux) 上提供了不同cuda版本的Linux预测库,可以在官网查看并选择合适的预测库版本(*建议选择paddle版本>=2.0.1版本的预测库* )。
* 下载之后使用下面的方法解压。
@@ -249,7 +253,7 @@ CUDNN_LIB_DIR=/your_cudnn_lib_dir
|gpu_id|int|0|GPU id,使用GPU时有效|
|gpu_mem|int|4000|申请的GPU内存|
|cpu_math_library_num_threads|int|10|CPU预测时的线程数,在机器核数充足的情况下,该值越大,预测速度越快|
-|use_mkldnn|bool|true|是否使用mkldnn库|
+|enable_mkldnn|bool|true|是否使用mkldnn库|
- 检测模型相关
diff --git a/deploy/cpp_infer/readme_en.md b/deploy/cpp_infer/readme_en.md
index 8c5a323af40e64f77e76cba23fd5c4408c643de5..f4cfab24350c1a6be3d8ebebf6b47b0baaa4f26e 100644
--- a/deploy/cpp_infer/readme_en.md
+++ b/deploy/cpp_infer/readme_en.md
@@ -78,7 +78,7 @@ opencv3/
#### 1.2.1 Direct download and installation
-[Paddle inference library official website](https://paddle-inference.readthedocs.io/en/latest/user_guides/download_lib.html). You can review and select the appropriate version of the inference library on the official website.
+[Paddle inference library official website](https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html#linux). You can review and select the appropriate version of the inference library on the official website.
* After downloading, use the following command to extract files.
@@ -231,7 +231,7 @@ More parameters are as follows,
|gpu_id|int|0|GPU id when use_gpu is true|
|gpu_mem|int|4000|GPU memory requested|
|cpu_math_library_num_threads|int|10|Number of threads when using CPU inference. When machine cores is enough, the large the value, the faster the inference speed|
-|use_mkldnn|bool|true|Whether to use mkdlnn library|
+|enable_mkldnn|bool|true|Whether to use mkdlnn library|
- Detection related parameters
diff --git a/deploy/cpp_infer/src/main.cpp b/deploy/cpp_infer/src/main.cpp
index b7a199b548beca881e4ab69491adcc9351f52c0f..664b10b2f579fd8681c65dcf1ded5ebe53d0424c 100644
--- a/deploy/cpp_infer/src/main.cpp
+++ b/deploy/cpp_infer/src/main.cpp
@@ -28,14 +28,14 @@
#include
#include
-#include
#include
+#include
#include
#include
#include
-#include
#include "auto_log/autolog.h"
+#include
DEFINE_bool(use_gpu, false, "Infering with GPU or CPU.");
DEFINE_int32(gpu_id, 0, "Device id of GPU to execute.");
@@ -51,9 +51,10 @@ DEFINE_string(image_dir, "", "Dir of input image.");
DEFINE_string(det_model_dir, "", "Path of det inference model.");
DEFINE_int32(max_side_len, 960, "max_side_len of input image.");
DEFINE_double(det_db_thresh, 0.3, "Threshold of det_db_thresh.");
-DEFINE_double(det_db_box_thresh, 0.5, "Threshold of det_db_box_thresh.");
-DEFINE_double(det_db_unclip_ratio, 1.6, "Threshold of det_db_unclip_ratio.");
+DEFINE_double(det_db_box_thresh, 0.6, "Threshold of det_db_box_thresh.");
+DEFINE_double(det_db_unclip_ratio, 1.5, "Threshold of det_db_unclip_ratio.");
DEFINE_bool(use_polygon_score, false, "Whether use polygon score.");
+DEFINE_bool(use_dilation, false, "Whether use the dilation on output map.");
DEFINE_bool(visualize, true, "Whether show the detection results.");
// classification related
DEFINE_bool(use_angle_cls, false, "Whether use use_angle_cls.");
@@ -62,281 +63,260 @@ DEFINE_double(cls_thresh, 0.9, "Threshold of cls_thresh.");
// recognition related
DEFINE_string(rec_model_dir, "", "Path of rec inference model.");
DEFINE_int32(rec_batch_num, 6, "rec_batch_num.");
-DEFINE_string(char_list_file, "../../ppocr/utils/ppocr_keys_v1.txt", "Path of dictionary.");
-
+DEFINE_string(char_list_file, "../../ppocr/utils/ppocr_keys_v1.txt",
+ "Path of dictionary.");
using namespace std;
using namespace cv;
using namespace PaddleOCR;
-
-static bool PathExists(const std::string& path){
+static bool PathExists(const std::string &path) {
#ifdef _WIN32
struct _stat buffer;
return (_stat(path.c_str(), &buffer) == 0);
#else
struct stat buffer;
return (stat(path.c_str(), &buffer) == 0);
-#endif // !_WIN32
+#endif // !_WIN32
}
-
int main_det(std::vector cv_all_img_names) {
- std::vector time_info = {0, 0, 0};
- DBDetector det(FLAGS_det_model_dir, FLAGS_use_gpu, FLAGS_gpu_id,
- FLAGS_gpu_mem, FLAGS_cpu_threads,
- FLAGS_enable_mkldnn, FLAGS_max_side_len, FLAGS_det_db_thresh,
- FLAGS_det_db_box_thresh, FLAGS_det_db_unclip_ratio,
- FLAGS_use_polygon_score, FLAGS_visualize,
- FLAGS_use_tensorrt, FLAGS_precision);
-
- for (int i = 0; i < cv_all_img_names.size(); ++i) {
-// LOG(INFO) << "The predict img: " << cv_all_img_names[i];
-
- cv::Mat srcimg = cv::imread(cv_all_img_names[i], cv::IMREAD_COLOR);
- if (!srcimg.data) {
- std::cerr << "[ERROR] image read failed! image path: " << cv_all_img_names[i] << endl;
- exit(1);
- }
- std::vector>> boxes;
- std::vector det_times;
-
- det.Run(srcimg, boxes, &det_times);
-
- time_info[0] += det_times[0];
- time_info[1] += det_times[1];
- time_info[2] += det_times[2];
-
- if (FLAGS_benchmark) {
- cout << cv_all_img_names[i] << '\t';
- for (int n = 0; n < boxes.size(); n++) {
- for (int m = 0; m < boxes[n].size(); m++) {
- cout << boxes[n][m][0] << ' ' << boxes[n][m][1] << ' ';
- }
- }
- cout << endl;
- }
+ std::vector time_info = {0, 0, 0};
+ DBDetector det(FLAGS_det_model_dir, FLAGS_use_gpu, FLAGS_gpu_id,
+ FLAGS_gpu_mem, FLAGS_cpu_threads, FLAGS_enable_mkldnn,
+ FLAGS_max_side_len, FLAGS_det_db_thresh,
+ FLAGS_det_db_box_thresh, FLAGS_det_db_unclip_ratio,
+ FLAGS_use_polygon_score, FLAGS_use_dilation, FLAGS_visualize,
+ FLAGS_use_tensorrt, FLAGS_precision);
+
+ for (int i = 0; i < cv_all_img_names.size(); ++i) {
+ // LOG(INFO) << "The predict img: " << cv_all_img_names[i];
+
+ cv::Mat srcimg = cv::imread(cv_all_img_names[i], cv::IMREAD_COLOR);
+ if (!srcimg.data) {
+ std::cerr << "[ERROR] image read failed! image path: "
+ << cv_all_img_names[i] << endl;
+ exit(1);
}
-
+ std::vector>> boxes;
+ std::vector det_times;
+
+ det.Run(srcimg, boxes, &det_times);
+
+ time_info[0] += det_times[0];
+ time_info[1] += det_times[1];
+ time_info[2] += det_times[2];
+
if (FLAGS_benchmark) {
- AutoLogger autolog("ocr_det",
- FLAGS_use_gpu,
- FLAGS_use_tensorrt,
- FLAGS_enable_mkldnn,
- FLAGS_cpu_threads,
- 1,
- "dynamic",
- FLAGS_precision,
- time_info,
- cv_all_img_names.size());
- autolog.report();
+ cout << cv_all_img_names[i] << '\t';
+ for (int n = 0; n < boxes.size(); n++) {
+ for (int m = 0; m < boxes[n].size(); m++) {
+ cout << boxes[n][m][0] << ' ' << boxes[n][m][1] << ' ';
+ }
+ }
+ cout << endl;
}
- return 0;
-}
+ }
+ if (FLAGS_benchmark) {
+ AutoLogger autolog("ocr_det", FLAGS_use_gpu, FLAGS_use_tensorrt,
+ FLAGS_enable_mkldnn, FLAGS_cpu_threads, 1, "dynamic",
+ FLAGS_precision, time_info, cv_all_img_names.size());
+ autolog.report();
+ }
+ return 0;
+}
int main_rec(std::vector cv_all_img_names) {
- std::vector time_info = {0, 0, 0};
-
- std::string char_list_file = FLAGS_char_list_file;
- if (FLAGS_benchmark)
- char_list_file = FLAGS_char_list_file.substr(6);
- cout << "label file: " << char_list_file << endl;
-
- CRNNRecognizer rec(FLAGS_rec_model_dir, FLAGS_use_gpu, FLAGS_gpu_id,
- FLAGS_gpu_mem, FLAGS_cpu_threads,
- FLAGS_enable_mkldnn, char_list_file,
- FLAGS_use_tensorrt, FLAGS_precision, FLAGS_rec_batch_num);
+ std::vector time_info = {0, 0, 0};
- std::vector img_list;
- for (int i = 0; i < cv_all_img_names.size(); ++i) {
- LOG(INFO) << "The predict img: " << cv_all_img_names[i];
+ std::string char_list_file = FLAGS_char_list_file;
+ if (FLAGS_benchmark)
+ char_list_file = FLAGS_char_list_file.substr(6);
+ cout << "label file: " << char_list_file << endl;
- cv::Mat srcimg = cv::imread(cv_all_img_names[i], cv::IMREAD_COLOR);
- if (!srcimg.data) {
- std::cerr << "[ERROR] image read failed! image path: " << cv_all_img_names[i] << endl;
- exit(1);
- }
- img_list.push_back(srcimg);
- }
- std::vector rec_times;
- rec.Run(img_list, &rec_times);
- time_info[0] += rec_times[0];
- time_info[1] += rec_times[1];
- time_info[2] += rec_times[2];
-
- if (FLAGS_benchmark) {
- AutoLogger autolog("ocr_rec",
- FLAGS_use_gpu,
- FLAGS_use_tensorrt,
- FLAGS_enable_mkldnn,
- FLAGS_cpu_threads,
- FLAGS_rec_batch_num,
- "dynamic",
- FLAGS_precision,
- time_info,
- cv_all_img_names.size());
- autolog.report();
+ CRNNRecognizer rec(FLAGS_rec_model_dir, FLAGS_use_gpu, FLAGS_gpu_id,
+ FLAGS_gpu_mem, FLAGS_cpu_threads, FLAGS_enable_mkldnn,
+ char_list_file, FLAGS_use_tensorrt, FLAGS_precision,
+ FLAGS_rec_batch_num);
+
+ std::vector img_list;
+ for (int i = 0; i < cv_all_img_names.size(); ++i) {
+ LOG(INFO) << "The predict img: " << cv_all_img_names[i];
+
+ cv::Mat srcimg = cv::imread(cv_all_img_names[i], cv::IMREAD_COLOR);
+ if (!srcimg.data) {
+ std::cerr << "[ERROR] image read failed! image path: "
+ << cv_all_img_names[i] << endl;
+ exit(1);
}
- return 0;
-}
+ img_list.push_back(srcimg);
+ }
+ std::vector rec_times;
+ rec.Run(img_list, &rec_times);
+ time_info[0] += rec_times[0];
+ time_info[1] += rec_times[1];
+ time_info[2] += rec_times[2];
+ if (FLAGS_benchmark) {
+ AutoLogger autolog("ocr_rec", FLAGS_use_gpu, FLAGS_use_tensorrt,
+ FLAGS_enable_mkldnn, FLAGS_cpu_threads,
+ FLAGS_rec_batch_num, "dynamic", FLAGS_precision,
+ time_info, cv_all_img_names.size());
+ autolog.report();
+ }
+ return 0;
+}
int main_system(std::vector cv_all_img_names) {
- std::vector time_info_det = {0, 0, 0};
- std::vector time_info_rec = {0, 0, 0};
-
- DBDetector det(FLAGS_det_model_dir, FLAGS_use_gpu, FLAGS_gpu_id,
- FLAGS_gpu_mem, FLAGS_cpu_threads,
- FLAGS_enable_mkldnn, FLAGS_max_side_len, FLAGS_det_db_thresh,
- FLAGS_det_db_box_thresh, FLAGS_det_db_unclip_ratio,
- FLAGS_use_polygon_score, FLAGS_visualize,
- FLAGS_use_tensorrt, FLAGS_precision);
-
- Classifier *cls = nullptr;
- if (FLAGS_use_angle_cls) {
- cls = new Classifier(FLAGS_cls_model_dir, FLAGS_use_gpu, FLAGS_gpu_id,
- FLAGS_gpu_mem, FLAGS_cpu_threads,
- FLAGS_enable_mkldnn, FLAGS_cls_thresh,
- FLAGS_use_tensorrt, FLAGS_precision);
- }
+ std::vector time_info_det = {0, 0, 0};
+ std::vector time_info_rec = {0, 0, 0};
- std::string char_list_file = FLAGS_char_list_file;
- if (FLAGS_benchmark)
- char_list_file = FLAGS_char_list_file.substr(6);
- cout << "label file: " << char_list_file << endl;
-
- CRNNRecognizer rec(FLAGS_rec_model_dir, FLAGS_use_gpu, FLAGS_gpu_id,
- FLAGS_gpu_mem, FLAGS_cpu_threads,
- FLAGS_enable_mkldnn, char_list_file,
- FLAGS_use_tensorrt, FLAGS_precision, FLAGS_rec_batch_num);
-
- for (int i = 0; i < cv_all_img_names.size(); ++i) {
- LOG(INFO) << "The predict img: " << cv_all_img_names[i];
-
- cv::Mat srcimg = cv::imread(cv_all_img_names[i], cv::IMREAD_COLOR);
- if (!srcimg.data) {
- std::cerr << "[ERROR] image read failed! image path: " << cv_all_img_names[i] << endl;
- exit(1);
- }
- std::vector>> boxes;
- std::vector det_times;
- std::vector rec_times;
-
- det.Run(srcimg, boxes, &det_times);
- time_info_det[0] += det_times[0];
- time_info_det[1] += det_times[1];
- time_info_det[2] += det_times[2];
-
- std::vector img_list;
- for (int j = 0; j < boxes.size(); j++) {
- cv::Mat crop_img;
- crop_img = Utility::GetRotateCropImage(srcimg, boxes[j]);
- if (cls != nullptr) {
- crop_img = cls->Run(crop_img);
- }
- img_list.push_back(crop_img);
- }
+ DBDetector det(FLAGS_det_model_dir, FLAGS_use_gpu, FLAGS_gpu_id,
+ FLAGS_gpu_mem, FLAGS_cpu_threads, FLAGS_enable_mkldnn,
+ FLAGS_max_side_len, FLAGS_det_db_thresh,
+ FLAGS_det_db_box_thresh, FLAGS_det_db_unclip_ratio,
+ FLAGS_use_polygon_score, FLAGS_use_dilation, FLAGS_visualize,
+ FLAGS_use_tensorrt, FLAGS_precision);
+
+ Classifier *cls = nullptr;
+ if (FLAGS_use_angle_cls) {
+ cls = new Classifier(FLAGS_cls_model_dir, FLAGS_use_gpu, FLAGS_gpu_id,
+ FLAGS_gpu_mem, FLAGS_cpu_threads, FLAGS_enable_mkldnn,
+ FLAGS_cls_thresh, FLAGS_use_tensorrt, FLAGS_precision);
+ }
+
+ std::string char_list_file = FLAGS_char_list_file;
+ if (FLAGS_benchmark)
+ char_list_file = FLAGS_char_list_file.substr(6);
+ cout << "label file: " << char_list_file << endl;
+
+ CRNNRecognizer rec(FLAGS_rec_model_dir, FLAGS_use_gpu, FLAGS_gpu_id,
+ FLAGS_gpu_mem, FLAGS_cpu_threads, FLAGS_enable_mkldnn,
+ char_list_file, FLAGS_use_tensorrt, FLAGS_precision,
+ FLAGS_rec_batch_num);
+
+ for (int i = 0; i < cv_all_img_names.size(); ++i) {
+ LOG(INFO) << "The predict img: " << cv_all_img_names[i];
- rec.Run(img_list, &rec_times);
- time_info_rec[0] += rec_times[0];
- time_info_rec[1] += rec_times[1];
- time_info_rec[2] += rec_times[2];
+ cv::Mat srcimg = cv::imread(cv_all_img_names[i], cv::IMREAD_COLOR);
+ if (!srcimg.data) {
+ std::cerr << "[ERROR] image read failed! image path: "
+ << cv_all_img_names[i] << endl;
+ exit(1);
}
-
- if (FLAGS_benchmark) {
- AutoLogger autolog_det("ocr_det",
- FLAGS_use_gpu,
- FLAGS_use_tensorrt,
- FLAGS_enable_mkldnn,
- FLAGS_cpu_threads,
- 1,
- "dynamic",
- FLAGS_precision,
- time_info_det,
- cv_all_img_names.size());
- AutoLogger autolog_rec("ocr_rec",
- FLAGS_use_gpu,
- FLAGS_use_tensorrt,
- FLAGS_enable_mkldnn,
- FLAGS_cpu_threads,
- FLAGS_rec_batch_num,
- "dynamic",
- FLAGS_precision,
- time_info_rec,
- cv_all_img_names.size());
- autolog_det.report();
- std::cout << endl;
- autolog_rec.report();
- }
- return 0;
-}
+ std::vector>> boxes;
+ std::vector det_times;
+ std::vector rec_times;
+ det.Run(srcimg, boxes, &det_times);
+ time_info_det[0] += det_times[0];
+ time_info_det[1] += det_times[1];
+ time_info_det[2] += det_times[2];
-void check_params(char* mode) {
- if (strcmp(mode, "det")==0) {
- if (FLAGS_det_model_dir.empty() || FLAGS_image_dir.empty()) {
- std::cout << "Usage[det]: ./ppocr --det_model_dir=/PATH/TO/DET_INFERENCE_MODEL/ "
- << "--image_dir=/PATH/TO/INPUT/IMAGE/" << std::endl;
- exit(1);
- }
+ std::vector img_list;
+ for (int j = 0; j < boxes.size(); j++) {
+ cv::Mat crop_img;
+ crop_img = Utility::GetRotateCropImage(srcimg, boxes[j]);
+ if (cls != nullptr) {
+ crop_img = cls->Run(crop_img);
+ }
+ img_list.push_back(crop_img);
}
- if (strcmp(mode, "rec")==0) {
- if (FLAGS_rec_model_dir.empty() || FLAGS_image_dir.empty()) {
- std::cout << "Usage[rec]: ./ppocr --rec_model_dir=/PATH/TO/REC_INFERENCE_MODEL/ "
- << "--image_dir=/PATH/TO/INPUT/IMAGE/" << std::endl;
- exit(1);
- }
+
+ rec.Run(img_list, &rec_times);
+ time_info_rec[0] += rec_times[0];
+ time_info_rec[1] += rec_times[1];
+ time_info_rec[2] += rec_times[2];
+ }
+
+ if (FLAGS_benchmark) {
+ AutoLogger autolog_det("ocr_det", FLAGS_use_gpu, FLAGS_use_tensorrt,
+ FLAGS_enable_mkldnn, FLAGS_cpu_threads, 1, "dynamic",
+ FLAGS_precision, time_info_det,
+ cv_all_img_names.size());
+ AutoLogger autolog_rec("ocr_rec", FLAGS_use_gpu, FLAGS_use_tensorrt,
+ FLAGS_enable_mkldnn, FLAGS_cpu_threads,
+ FLAGS_rec_batch_num, "dynamic", FLAGS_precision,
+ time_info_rec, cv_all_img_names.size());
+ autolog_det.report();
+ std::cout << endl;
+ autolog_rec.report();
+ }
+ return 0;
+}
+
+void check_params(char *mode) {
+ if (strcmp(mode, "det") == 0) {
+ if (FLAGS_det_model_dir.empty() || FLAGS_image_dir.empty()) {
+ std::cout << "Usage[det]: ./ppocr "
+ "--det_model_dir=/PATH/TO/DET_INFERENCE_MODEL/ "
+ << "--image_dir=/PATH/TO/INPUT/IMAGE/" << std::endl;
+ exit(1);
}
- if (strcmp(mode, "system")==0) {
- if ((FLAGS_det_model_dir.empty() || FLAGS_rec_model_dir.empty() || FLAGS_image_dir.empty()) ||
- (FLAGS_use_angle_cls && FLAGS_cls_model_dir.empty())) {
- std::cout << "Usage[system without angle cls]: ./ppocr --det_model_dir=/PATH/TO/DET_INFERENCE_MODEL/ "
- << "--rec_model_dir=/PATH/TO/REC_INFERENCE_MODEL/ "
- << "--image_dir=/PATH/TO/INPUT/IMAGE/" << std::endl;
- std::cout << "Usage[system with angle cls]: ./ppocr --det_model_dir=/PATH/TO/DET_INFERENCE_MODEL/ "
- << "--use_angle_cls=true "
- << "--cls_model_dir=/PATH/TO/CLS_INFERENCE_MODEL/ "
- << "--rec_model_dir=/PATH/TO/REC_INFERENCE_MODEL/ "
- << "--image_dir=/PATH/TO/INPUT/IMAGE/" << std::endl;
- exit(1);
- }
+ }
+ if (strcmp(mode, "rec") == 0) {
+ if (FLAGS_rec_model_dir.empty() || FLAGS_image_dir.empty()) {
+ std::cout << "Usage[rec]: ./ppocr "
+ "--rec_model_dir=/PATH/TO/REC_INFERENCE_MODEL/ "
+ << "--image_dir=/PATH/TO/INPUT/IMAGE/" << std::endl;
+ exit(1);
}
- if (FLAGS_precision != "fp32" && FLAGS_precision != "fp16" && FLAGS_precision != "int8") {
- cout << "precison should be 'fp32'(default), 'fp16' or 'int8'. " << endl;
- exit(1);
+ }
+ if (strcmp(mode, "system") == 0) {
+ if ((FLAGS_det_model_dir.empty() || FLAGS_rec_model_dir.empty() ||
+ FLAGS_image_dir.empty()) ||
+ (FLAGS_use_angle_cls && FLAGS_cls_model_dir.empty())) {
+ std::cout << "Usage[system without angle cls]: ./ppocr "
+ "--det_model_dir=/PATH/TO/DET_INFERENCE_MODEL/ "
+ << "--rec_model_dir=/PATH/TO/REC_INFERENCE_MODEL/ "
+ << "--image_dir=/PATH/TO/INPUT/IMAGE/" << std::endl;
+ std::cout << "Usage[system with angle cls]: ./ppocr "
+ "--det_model_dir=/PATH/TO/DET_INFERENCE_MODEL/ "
+ << "--use_angle_cls=true "
+ << "--cls_model_dir=/PATH/TO/CLS_INFERENCE_MODEL/ "
+ << "--rec_model_dir=/PATH/TO/REC_INFERENCE_MODEL/ "
+ << "--image_dir=/PATH/TO/INPUT/IMAGE/" << std::endl;
+ exit(1);
}
+ }
+ if (FLAGS_precision != "fp32" && FLAGS_precision != "fp16" &&
+ FLAGS_precision != "int8") {
+ cout << "precison should be 'fp32'(default), 'fp16' or 'int8'. " << endl;
+ exit(1);
+ }
}
-
int main(int argc, char **argv) {
- if (argc<=1 || (strcmp(argv[1], "det")!=0 && strcmp(argv[1], "rec")!=0 && strcmp(argv[1], "system")!=0)) {
- std::cout << "Please choose one mode of [det, rec, system] !" << std::endl;
- return -1;
- }
- std::cout << "mode: " << argv[1] << endl;
-
- // Parsing command-line
- google::ParseCommandLineFlags(&argc, &argv, true);
- check_params(argv[1]);
-
- if (!PathExists(FLAGS_image_dir)) {
- std::cerr << "[ERROR] image path not exist! image_dir: " << FLAGS_image_dir << endl;
- exit(1);
- }
-
- std::vector cv_all_img_names;
- cv::glob(FLAGS_image_dir, cv_all_img_names);
- std::cout << "total images num: " << cv_all_img_names.size() << endl;
-
- if (strcmp(argv[1], "det")==0) {
- return main_det(cv_all_img_names);
- }
- if (strcmp(argv[1], "rec")==0) {
- return main_rec(cv_all_img_names);
- }
- if (strcmp(argv[1], "system")==0) {
- return main_system(cv_all_img_names);
- }
+ if (argc <= 1 ||
+ (strcmp(argv[1], "det") != 0 && strcmp(argv[1], "rec") != 0 &&
+ strcmp(argv[1], "system") != 0)) {
+ std::cout << "Please choose one mode of [det, rec, system] !" << std::endl;
+ return -1;
+ }
+ std::cout << "mode: " << argv[1] << endl;
+
+ // Parsing command-line
+ google::ParseCommandLineFlags(&argc, &argv, true);
+ check_params(argv[1]);
+
+ if (!PathExists(FLAGS_image_dir)) {
+ std::cerr << "[ERROR] image path not exist! image_dir: " << FLAGS_image_dir
+ << endl;
+ exit(1);
+ }
+
+ std::vector cv_all_img_names;
+ cv::glob(FLAGS_image_dir, cv_all_img_names);
+ std::cout << "total images num: " << cv_all_img_names.size() << endl;
+ if (strcmp(argv[1], "det") == 0) {
+ return main_det(cv_all_img_names);
+ }
+ if (strcmp(argv[1], "rec") == 0) {
+ return main_rec(cv_all_img_names);
+ }
+ if (strcmp(argv[1], "system") == 0) {
+ return main_system(cv_all_img_names);
+ }
}
diff --git a/deploy/cpp_infer/src/ocr_det.cpp b/deploy/cpp_infer/src/ocr_det.cpp
index a69f5ca1bd3ee7665f8b2f5610c67dd6feb7eb54..ad78999449d94dcaf2e336087de5c6837f3b233c 100644
--- a/deploy/cpp_infer/src/ocr_det.cpp
+++ b/deploy/cpp_infer/src/ocr_det.cpp
@@ -14,7 +14,6 @@
#include
-
namespace PaddleOCR {
void DBDetector::LoadModel(const std::string &model_dir) {
@@ -30,13 +29,10 @@ void DBDetector::LoadModel(const std::string &model_dir) {
if (this->precision_ == "fp16") {
precision = paddle_infer::Config::Precision::kHalf;
}
- if (this->precision_ == "int8") {
+ if (this->precision_ == "int8") {
precision = paddle_infer::Config::Precision::kInt8;
- }
- config.EnableTensorRtEngine(
- 1 << 20, 10, 3,
- precision,
- false, false);
+ }
+ config.EnableTensorRtEngine(1 << 20, 10, 3, precision, false, false);
std::map> min_input_shape = {
{"x", {1, 3, 50, 50}},
{"conv2d_92.tmp_0", {1, 96, 20, 20}},
@@ -105,7 +101,7 @@ void DBDetector::Run(cv::Mat &img,
cv::Mat srcimg;
cv::Mat resize_img;
img.copyTo(srcimg);
-
+
auto preprocess_start = std::chrono::steady_clock::now();
this->resize_op_.Run(img, resize_img, this->max_side_len_, ratio_h, ratio_w,
this->use_tensorrt_);
@@ -116,16 +112,16 @@ void DBDetector::Run(cv::Mat &img,
std::vector input(1 * 3 * resize_img.rows * resize_img.cols, 0.0f);
this->permute_op_.Run(&resize_img, input.data());
auto preprocess_end = std::chrono::steady_clock::now();
-
+
// Inference.
auto input_names = this->predictor_->GetInputNames();
auto input_t = this->predictor_->GetInputHandle(input_names[0]);
input_t->Reshape({1, 3, resize_img.rows, resize_img.cols});
auto inference_start = std::chrono::steady_clock::now();
input_t->CopyFromCpu(input.data());
-
+
this->predictor_->Run();
-
+
std::vector out_data;
auto output_names = this->predictor_->GetOutputNames();
auto output_t = this->predictor_->GetOutputHandle(output_names[0]);
@@ -136,7 +132,7 @@ void DBDetector::Run(cv::Mat &img,
out_data.resize(out_num);
output_t->CopyToCpu(out_data.data());
auto inference_end = std::chrono::steady_clock::now();
-
+
auto postprocess_start = std::chrono::steady_clock::now();
int n2 = output_shape[2];
int n3 = output_shape[3];
@@ -157,24 +153,29 @@ void DBDetector::Run(cv::Mat &img,
const double maxvalue = 255;
cv::Mat bit_map;
cv::threshold(cbuf_map, bit_map, threshold, maxvalue, cv::THRESH_BINARY);
- cv::Mat dilation_map;
- cv::Mat dila_ele = cv::getStructuringElement(cv::MORPH_RECT, cv::Size(2, 2));
- cv::dilate(bit_map, dilation_map, dila_ele);
+ if (this->use_dilation_) {
+ cv::Mat dila_ele =
+ cv::getStructuringElement(cv::MORPH_RECT, cv::Size(2, 2));
+ cv::dilate(bit_map, bit_map, dila_ele);
+ }
+
boxes = post_processor_.BoxesFromBitmap(
- pred_map, dilation_map, this->det_db_box_thresh_,
- this->det_db_unclip_ratio_, this->use_polygon_score_);
+ pred_map, bit_map, this->det_db_box_thresh_, this->det_db_unclip_ratio_,
+ this->use_polygon_score_);
boxes = post_processor_.FilterTagDetRes(boxes, ratio_h, ratio_w, srcimg);
auto postprocess_end = std::chrono::steady_clock::now();
std::cout << "Detected boxes num: " << boxes.size() << endl;
- std::chrono::duration preprocess_diff = preprocess_end - preprocess_start;
+ std::chrono::duration preprocess_diff =
+ preprocess_end - preprocess_start;
times->push_back(double(preprocess_diff.count() * 1000));
std::chrono::duration inference_diff = inference_end - inference_start;
times->push_back(double(inference_diff.count() * 1000));
- std::chrono::duration postprocess_diff = postprocess_end - postprocess_start;
+ std::chrono::duration postprocess_diff =
+ postprocess_end - postprocess_start;
times->push_back(double(postprocess_diff.count() * 1000));
-
+
//// visualization
if (this->visualize_) {
Utility::VisualizeBboxes(srcimg, boxes);
diff --git a/deploy/cpp_infer/src/ocr_rec.cpp b/deploy/cpp_infer/src/ocr_rec.cpp
index f1a97a99a3d3487988c35766592668ba3f43c784..25224f88acecd33f5efaa34a9dfc71639663d53f 100644
--- a/deploy/cpp_infer/src/ocr_rec.cpp
+++ b/deploy/cpp_infer/src/ocr_rec.cpp
@@ -15,108 +15,115 @@
#include
namespace PaddleOCR {
-
-void CRNNRecognizer::Run(std::vector img_list, std::vector *times) {
- std::chrono::duration preprocess_diff = std::chrono::steady_clock::now() - std::chrono::steady_clock::now();
- std::chrono::duration inference_diff = std::chrono::steady_clock::now() - std::chrono::steady_clock::now();
- std::chrono::duration postprocess_diff = std::chrono::steady_clock::now() - std::chrono::steady_clock::now();
-
- int img_num = img_list.size();
- std::vector width_list;
- for (int i = 0; i < img_num; i++) {
- width_list.push_back(float(img_list[i].cols) / img_list[i].rows);
+
+void CRNNRecognizer::Run(std::vector img_list,
+ std::vector *times) {
+ std::chrono::duration preprocess_diff =
+ std::chrono::steady_clock::now() - std::chrono::steady_clock::now();
+ std::chrono::duration inference_diff =
+ std::chrono::steady_clock::now() - std::chrono::steady_clock::now();
+ std::chrono::duration postprocess_diff =
+ std::chrono::steady_clock::now() - std::chrono::steady_clock::now();
+
+ int img_num = img_list.size();
+ std::vector width_list;
+ for (int i = 0; i < img_num; i++) {
+ width_list.push_back(float(img_list[i].cols) / img_list[i].rows);
+ }
+ std::vector indices = Utility::argsort(width_list);
+
+ for (int beg_img_no = 0; beg_img_no < img_num;
+ beg_img_no += this->rec_batch_num_) {
+ auto preprocess_start = std::chrono::steady_clock::now();
+ int end_img_no = min(img_num, beg_img_no + this->rec_batch_num_);
+ float max_wh_ratio = 0;
+ for (int ino = beg_img_no; ino < end_img_no; ino++) {
+ int h = img_list[indices[ino]].rows;
+ int w = img_list[indices[ino]].cols;
+ float wh_ratio = w * 1.0 / h;
+ max_wh_ratio = max(max_wh_ratio, wh_ratio);
}
- std::vector indices = Utility::argsort(width_list);
-
- for (int beg_img_no = 0; beg_img_no < img_num; beg_img_no += this->rec_batch_num_) {
- auto preprocess_start = std::chrono::steady_clock::now();
- int end_img_no = min(img_num, beg_img_no + this->rec_batch_num_);
- float max_wh_ratio = 0;
- for (int ino = beg_img_no; ino < end_img_no; ino ++) {
- int h = img_list[indices[ino]].rows;
- int w = img_list[indices[ino]].cols;
- float wh_ratio = w * 1.0 / h;
- max_wh_ratio = max(max_wh_ratio, wh_ratio);
- }
- std::vector norm_img_batch;
- for (int ino = beg_img_no; ino < end_img_no; ino ++) {
- cv::Mat srcimg;
- img_list[indices[ino]].copyTo(srcimg);
- cv::Mat resize_img;
- this->resize_op_.Run(srcimg, resize_img, max_wh_ratio, this->use_tensorrt_);
- this->normalize_op_.Run(&resize_img, this->mean_, this->scale_, this->is_scale_);
- norm_img_batch.push_back(resize_img);
- }
-
- int batch_width = int(ceilf(32 * max_wh_ratio)) - 1;
- std::vector input(this->rec_batch_num_ * 3 * 32 * batch_width, 0.0f);
- this->permute_op_.Run(norm_img_batch, input.data());
- auto preprocess_end = std::chrono::steady_clock::now();
- preprocess_diff += preprocess_end - preprocess_start;
-
- // Inference.
- auto input_names = this->predictor_->GetInputNames();
- auto input_t = this->predictor_->GetInputHandle(input_names[0]);
- input_t->Reshape({this->rec_batch_num_, 3, 32, batch_width});
- auto inference_start = std::chrono::steady_clock::now();
- input_t->CopyFromCpu(input.data());
- this->predictor_->Run();
-
- std::vector predict_batch;
- auto output_names = this->predictor_->GetOutputNames();
- auto output_t = this->predictor_->GetOutputHandle(output_names[0]);
- auto predict_shape = output_t->shape();
-
- int out_num = std::accumulate(predict_shape.begin(), predict_shape.end(), 1,
- std::multiplies());
- predict_batch.resize(out_num);
-
- output_t->CopyToCpu(predict_batch.data());
- auto inference_end = std::chrono::steady_clock::now();
- inference_diff += inference_end - inference_start;
-
- // ctc decode
- auto postprocess_start = std::chrono::steady_clock::now();
- for (int m = 0; m < predict_shape[0]; m++) {
- std::vector str_res;
- int argmax_idx;
- int last_index = 0;
- float score = 0.f;
- int count = 0;
- float max_value = 0.0f;
-
- for (int n = 0; n < predict_shape[1]; n++) {
- argmax_idx =
- int(Utility::argmax(&predict_batch[(m * predict_shape[1] + n) * predict_shape[2]],
- &predict_batch[(m * predict_shape[1] + n + 1) * predict_shape[2]]));
- max_value =
- float(*std::max_element(&predict_batch[(m * predict_shape[1] + n) * predict_shape[2]],
- &predict_batch[(m * predict_shape[1] + n + 1) * predict_shape[2]]));
-
- if (argmax_idx > 0 && (!(n > 0 && argmax_idx == last_index))) {
- score += max_value;
- count += 1;
- str_res.push_back(label_list_[argmax_idx]);
- }
- last_index = argmax_idx;
- }
- score /= count;
- if (isnan(score))
- continue;
- for (int i = 0; i < str_res.size(); i++) {
- std::cout << str_res[i];
- }
- std::cout << "\tscore: " << score << std::endl;
+ int batch_width = 0;
+ std::vector norm_img_batch;
+ for (int ino = beg_img_no; ino < end_img_no; ino++) {
+ cv::Mat srcimg;
+ img_list[indices[ino]].copyTo(srcimg);
+ cv::Mat resize_img;
+ this->resize_op_.Run(srcimg, resize_img, max_wh_ratio,
+ this->use_tensorrt_);
+ this->normalize_op_.Run(&resize_img, this->mean_, this->scale_,
+ this->is_scale_);
+ norm_img_batch.push_back(resize_img);
+ batch_width = max(resize_img.cols, batch_width);
+ }
+
+ std::vector input(this->rec_batch_num_ * 3 * 32 * batch_width, 0.0f);
+ this->permute_op_.Run(norm_img_batch, input.data());
+ auto preprocess_end = std::chrono::steady_clock::now();
+ preprocess_diff += preprocess_end - preprocess_start;
+
+ // Inference.
+ auto input_names = this->predictor_->GetInputNames();
+ auto input_t = this->predictor_->GetInputHandle(input_names[0]);
+ input_t->Reshape({this->rec_batch_num_, 3, 32, batch_width});
+ auto inference_start = std::chrono::steady_clock::now();
+ input_t->CopyFromCpu(input.data());
+ this->predictor_->Run();
+
+ std::vector predict_batch;
+ auto output_names = this->predictor_->GetOutputNames();
+ auto output_t = this->predictor_->GetOutputHandle(output_names[0]);
+ auto predict_shape = output_t->shape();
+
+ int out_num = std::accumulate(predict_shape.begin(), predict_shape.end(), 1,
+ std::multiplies());
+ predict_batch.resize(out_num);
+
+ output_t->CopyToCpu(predict_batch.data());
+ auto inference_end = std::chrono::steady_clock::now();
+ inference_diff += inference_end - inference_start;
+
+ // ctc decode
+ auto postprocess_start = std::chrono::steady_clock::now();
+ for (int m = 0; m < predict_shape[0]; m++) {
+ std::vector str_res;
+ int argmax_idx;
+ int last_index = 0;
+ float score = 0.f;
+ int count = 0;
+ float max_value = 0.0f;
+
+ for (int n = 0; n < predict_shape[1]; n++) {
+ argmax_idx = int(Utility::argmax(
+ &predict_batch[(m * predict_shape[1] + n) * predict_shape[2]],
+ &predict_batch[(m * predict_shape[1] + n + 1) * predict_shape[2]]));
+ max_value = float(*std::max_element(
+ &predict_batch[(m * predict_shape[1] + n) * predict_shape[2]],
+ &predict_batch[(m * predict_shape[1] + n + 1) * predict_shape[2]]));
+
+ if (argmax_idx > 0 && (!(n > 0 && argmax_idx == last_index))) {
+ score += max_value;
+ count += 1;
+ str_res.push_back(label_list_[argmax_idx]);
}
- auto postprocess_end = std::chrono::steady_clock::now();
- postprocess_diff += postprocess_end - postprocess_start;
+ last_index = argmax_idx;
+ }
+ score /= count;
+ if (isnan(score))
+ continue;
+ for (int i = 0; i < str_res.size(); i++) {
+ std::cout << str_res[i];
+ }
+ std::cout << "\tscore: " << score << std::endl;
}
- times->push_back(double(preprocess_diff.count() * 1000));
- times->push_back(double(inference_diff.count() * 1000));
- times->push_back(double(postprocess_diff.count() * 1000));
+ auto postprocess_end = std::chrono::steady_clock::now();
+ postprocess_diff += postprocess_end - postprocess_start;
+ }
+ times->push_back(double(preprocess_diff.count() * 1000));
+ times->push_back(double(inference_diff.count() * 1000));
+ times->push_back(double(postprocess_diff.count() * 1000));
}
-
void CRNNRecognizer::LoadModel(const std::string &model_dir) {
// AnalysisConfig config;
paddle_infer::Config config;
@@ -130,23 +137,17 @@ void CRNNRecognizer::LoadModel(const std::string &model_dir) {
if (this->precision_ == "fp16") {
precision = paddle_infer::Config::Precision::kHalf;
}
- if (this->precision_ == "int8") {
+ if (this->precision_ == "int8") {
precision = paddle_infer::Config::Precision::kInt8;
- }
- config.EnableTensorRtEngine(
- 1 << 20, 10, 3,
- precision,
- false, false);
+ }
+ config.EnableTensorRtEngine(1 << 20, 10, 3, precision, false, false);
std::map> min_input_shape = {
- {"x", {1, 3, 32, 10}},
- {"lstm_0.tmp_0", {10, 1, 96}}};
+ {"x", {1, 3, 32, 10}}, {"lstm_0.tmp_0", {10, 1, 96}}};
std::map> max_input_shape = {
- {"x", {1, 3, 32, 2000}},
- {"lstm_0.tmp_0", {1000, 1, 96}}};
+ {"x", {1, 3, 32, 2000}}, {"lstm_0.tmp_0", {1000, 1, 96}}};
std::map> opt_input_shape = {
- {"x", {1, 3, 32, 320}},
- {"lstm_0.tmp_0", {25, 1, 96}}};
+ {"x", {1, 3, 32, 320}}, {"lstm_0.tmp_0", {25, 1, 96}}};
config.SetTRTDynamicShapeInfo(min_input_shape, max_input_shape,
opt_input_shape);
@@ -168,7 +169,7 @@ void CRNNRecognizer::LoadModel(const std::string &model_dir) {
config.SwitchIrOptim(true);
config.EnableMemoryOptim();
-// config.DisableGlogInfo();
+ // config.DisableGlogInfo();
this->predictor_ = CreatePredictor(config);
}
diff --git a/deploy/lite/readme.md b/deploy/lite/readme.md
index 365cb02d529bdabcb2346ed576ba3bd3b076e2db..0acc66f9513e54394cae6f4dc7c6a21b194d79e0 100644
--- a/deploy/lite/readme.md
+++ b/deploy/lite/readme.md
@@ -1,3 +1,14 @@
+- [端侧部署](#端侧部署)
+ - [1. 准备环境](#1-准备环境)
+ - [运行准备](#运行准备)
+ - [1.1 准备交叉编译环境](#11-准备交叉编译环境)
+ - [1.2 准备预测库](#12-准备预测库)
+ - [2 开始运行](#2-开始运行)
+ - [2.1 模型优化](#21-模型优化)
+ - [2.2 与手机联调](#22-与手机联调)
+ - [注意:](#注意)
+ - [FAQ](#faq)
+
# 端侧部署
本教程将介绍基于[Paddle Lite](https://github.com/PaddlePaddle/Paddle-Lite) 在移动端部署PaddleOCR超轻量中文检测、识别模型的详细步骤。
@@ -26,17 +37,17 @@ Paddle Lite是飞桨轻量化推理引擎,为手机、IOT端提供高效推理
| 平台 | 预测库下载链接 |
|---|---|
- |Android|[arm7](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.9/inference_lite_lib.android.armv7.gcc.c++_shared.with_extra.with_cv.tar.gz) / [arm8](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.9/inference_lite_lib.android.armv8.gcc.c++_shared.with_extra.with_cv.tar.gz)|
- |IOS|[arm7](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.9/inference_lite_lib.ios.armv7.with_cv.with_extra.with_log.tiny_publish.tar.gz) / [arm8](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.9/inference_lite_lib.ios.armv8.with_cv.with_extra.with_log.tiny_publish.tar.gz)|
+ |Android|[arm7](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.10/inference_lite_lib.android.armv7.gcc.c++_shared.with_extra.with_cv.tar.gz) / [arm8](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.10/inference_lite_lib.android.armv8.gcc.c++_shared.with_extra.with_cv.tar.gz)|
+ |IOS|[arm7](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.10/inference_lite_lib.ios.armv7.with_cv.with_extra.with_log.tiny_publish.tar.gz) / [arm8](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.10/inference_lite_lib.ios.armv8.with_cv.with_extra.with_log.tiny_publish.tar.gz)|
- 注:1. 上述预测库为PaddleLite 2.9分支编译得到,有关PaddleLite 2.9 详细信息可参考 [链接](https://github.com/PaddlePaddle/Paddle-Lite/releases/tag/v2.9) 。
+ 注:1. 上述预测库为PaddleLite 2.10分支编译得到,有关PaddleLite 2.10 详细信息可参考 [链接](https://github.com/PaddlePaddle/Paddle-Lite/releases/tag/v2.10) 。
- 2. [推荐]编译Paddle-Lite得到预测库,Paddle-Lite的编译方式如下:
```
git clone https://github.com/PaddlePaddle/Paddle-Lite.git
cd Paddle-Lite
-# 切换到Paddle-Lite release/v2.9 稳定分支
-git checkout release/v2.9
+# 切换到Paddle-Lite release/v2.10 稳定分支
+git checkout release/v2.10
./lite/tools/build_android.sh --arch=armv8 --with_cv=ON --with_extra=ON
```
@@ -85,8 +96,8 @@ Paddle-Lite 提供了多种策略来自动优化原始的模型,其中包括
|模型版本|模型简介|模型大小|检测模型|文本方向分类模型|识别模型|Paddle-Lite版本|
|---|---|---|---|---|---|---|
-|V2.0|超轻量中文OCR 移动端模型|7.8M|[下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_det_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_cls_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_rec_opt.nb)|v2.9|
-|V2.0(slim)|超轻量中文OCR 移动端模型|3.3M|[下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_det_slim_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_cls_slim_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_rec_slim_opt.nb)|v2.9|
+|PP-OCRv2|蒸馏版超轻量中文OCR移动端模型|11M|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_det_infer_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_ppocr_mobile_v2.0_cls_infer_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_rec_infer_opt.nb)|v2.10|
+|PP-OCRv2(slim)|蒸馏版超轻量中文OCR移动端模型|4.6M|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_det_slim_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_ppocr_mobile_v2.0_cls_slim_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_rec_slim_opt.nb)|v2.10|
如果直接使用上述表格中的模型进行部署,可略过下述步骤,直接阅读 [2.2节](#2.2与手机联调)。
@@ -97,7 +108,7 @@ Paddle-Lite 提供了多种策略来自动优化原始的模型,其中包括
# 如果准备环境时已经clone了Paddle-Lite,则不用重新clone Paddle-Lite
git clone https://github.com/PaddlePaddle/Paddle-Lite.git
cd Paddle-Lite
-git checkout release/v2.9
+git checkout release/v2.10
# 启动编译
./lite/tools/build.sh build_optimize_tool
```
@@ -123,15 +134,15 @@ cd build.opt/lite/api/
下面以PaddleOCR的超轻量中文模型为例,介绍使用编译好的opt文件完成inference模型到Paddle-Lite优化模型的转换。
```
-# 【推荐】 下载PaddleOCR V2.0版本的中英文 inference模型
-wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/slim/ch_ppocr_mobile_v2.0_det_slim_infer.tar && tar xf ch_ppocr_mobile_v2.0_det_slim_infer.tar
-wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/slim/ch_ppocr_mobile_v2.0_rec_slim_infer.tar && tar xf ch_ppocr_mobile_v2.0_rec_slim_infer.tar
+# 【推荐】 下载 PP-OCRv2版本的中英文 inference模型
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar && tar xf ch_PP-OCRv2_det_slim_quant_infer.tar
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar && tar xf ch_PP-OCRv2_rec_slim_quant_infer.tar
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/slim/ch_ppocr_mobile_v2.0_cls_slim_infer.tar && tar xf ch_ppocr_mobile_v2.0_cls_slim_infer.tar
-# 转换V2.0检测模型
-./opt --model_file=./ch_ppocr_mobile_v2.0_det_slim_infer/inference.pdmodel --param_file=./ch_ppocr_mobile_v2.0_det_slim_infer/inference.pdiparams --optimize_out=./ch_ppocr_mobile_v2.0_det_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
-# 转换V2.0识别模型
-./opt --model_file=./ch_ppocr_mobile_v2.0_rec_slim_infer/inference.pdmodel --param_file=./ch_ppocr_mobile_v2.0_rec_slim_infer/inference.pdiparams --optimize_out=./ch_ppocr_mobile_v2.0_rec_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
-# 转换V2.0方向分类器模型
+# 转换检测模型
+./opt --model_file=./ch_PP-OCRv2_det_slim_quant_infer/inference.pdmodel --param_file=./ch_PP-OCRv2_det_slim_quant_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv2_det_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
+# 转换识别模型
+./opt --model_file=./ch_PP-OCRv2_rec_slim_quant_infer/inference.pdmodel --param_file=./ch_PP-OCRv2_rec_slim_quant_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv2_rec_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
+# 转换方向分类器模型
./opt --model_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdmodel --param_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdiparams --optimize_out=./ch_ppocr_mobile_v2.0_cls_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
```
@@ -186,15 +197,15 @@ wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/slim/ch_ppocr_mobile_v2.0_cls
```
准备测试图像,以`PaddleOCR/doc/imgs/11.jpg`为例,将测试的图像复制到`demo/cxx/ocr/debug/`文件夹下。
- 准备lite opt工具优化后的模型文件,比如使用`ch_ppocr_mobile_v2.0_det_slim_opt.nb,ch_ppocr_mobile_v2.0_rec_slim_opt.nb, ch_ppocr_mobile_v2.0_cls_slim_opt.nb`,模型文件放置在`demo/cxx/ocr/debug/`文件夹下。
+ 准备lite opt工具优化后的模型文件,比如使用`ch_PP-OCRv2_det_slim_opt.ch_PP-OCRv2_rec_slim_rec.nb, ch_ppocr_mobile_v2.0_cls_slim_opt.nb`,模型文件放置在`demo/cxx/ocr/debug/`文件夹下。
执行完成后,ocr文件夹下将有如下文件格式:
```
demo/cxx/ocr/
|-- debug/
-| |--ch_ppocr_mobile_v2.0_det_slim_opt.nb 优化后的检测模型文件
-| |--ch_ppocr_mobile_v2.0_rec_slim_opt.nb 优化后的识别模型文件
+| |--ch_PP-OCRv2_det_slim_opt.nb 优化后的检测模型文件
+| |--ch_PP-OCRv2_rec_slim_opt.nb 优化后的识别模型文件
| |--ch_ppocr_mobile_v2.0_cls_slim_opt.nb 优化后的文字方向分类器模型文件
| |--11.jpg 待测试图像
| |--ppocr_keys_v1.txt 中文字典文件
@@ -250,7 +261,7 @@ use_direction_classify 0 # 是否使用方向分类器,0表示不使用,1
export LD_LIBRARY_PATH=${PWD}:$LD_LIBRARY_PATH
# 开始使用,ocr_db_crnn可执行文件的使用方式为:
# ./ocr_db_crnn 检测模型文件 方向分类器模型文件 识别模型文件 测试图像路径 字典文件路径
- ./ocr_db_crnn ch_ppocr_mobile_v2.0_det_slim_opt.nb ch_ppocr_mobile_v2.0_rec_slim_opt.nb ch_ppocr_mobile_v2.0_cls_slim_opt.nb ./11.jpg ppocr_keys_v1.txt
+ ./ocr_db_crnn ch_PP-OCRv2_det_slim_opt.nb ch_PP-OCRv2_rec_slim_opt.nb ch_ppocr_mobile_v2.0_cls_slim_opt.nb ./11.jpg ppocr_keys_v1.txt
```
如果对代码做了修改,则需要重新编译并push到手机上。
diff --git a/deploy/lite/readme_en.md b/deploy/lite/readme_en.md
index d200a615ceef391c17542d10d6812367bb9a822a..4225f8256af85373f5ed8d0213aa902531139c5a 100644
--- a/deploy/lite/readme_en.md
+++ b/deploy/lite/readme_en.md
@@ -1,3 +1,14 @@
+- [Tutorial of PaddleOCR Mobile deployment](#tutorial-of-paddleocr-mobile-deployment)
+ - [1. Preparation](#1-preparation)
+ - [Preparation environment](#preparation-environment)
+ - [1.1 Prepare the cross-compilation environment](#11-prepare-the-cross-compilation-environment)
+ - [1.2 Prepare Paddle-Lite library](#12-prepare-paddle-lite-library)
+ - [2 Run](#2-run)
+ - [2.1 Inference Model Optimization](#21-inference-model-optimization)
+ - [2.2 Run optimized model on Phone](#22-run-optimized-model-on-phone)
+ - [注意:](#注意)
+ - [FAQ](#faq)
+
# Tutorial of PaddleOCR Mobile deployment
This tutorial will introduce how to use [Paddle Lite](https://github.com/PaddlePaddle/Paddle-Lite) to deploy PaddleOCR ultra-lightweight Chinese and English detection models on mobile phones.
@@ -28,17 +39,17 @@ There are two ways to obtain the Paddle-Lite library:
| Platform | Paddle-Lite library download link |
|---|---|
- |Android|[arm7](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.9/inference_lite_lib.android.armv7.gcc.c++_shared.with_extra.with_cv.tar.gz) / [arm8](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.9/inference_lite_lib.android.armv8.gcc.c++_shared.with_extra.with_cv.tar.gz)|
- |IOS|[arm7](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.9/inference_lite_lib.ios.armv7.with_cv.with_extra.with_log.tiny_publish.tar.gz) / [arm8](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.9/inference_lite_lib.ios.armv8.with_cv.with_extra.with_log.tiny_publish.tar.gz)|
+ |Android|[arm7](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.10/inference_lite_lib.android.armv7.gcc.c++_shared.with_extra.with_cv.tar.gz) / [arm8](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.10/inference_lite_lib.android.armv8.gcc.c++_shared.with_extra.with_cv.tar.gz)|
+ |IOS|[arm7](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.10/inference_lite_lib.ios.armv7.with_cv.with_extra.with_log.tiny_publish.tar.gz) / [arm8](https://github.com/PaddlePaddle/Paddle-Lite/releases/download/v2.10/inference_lite_lib.ios.armv8.with_cv.with_extra.with_log.tiny_publish.tar.gz)|
- Note: 1. The above Paddle-Lite library is compiled from the Paddle-Lite 2.9 branch. For more information about Paddle-Lite 2.9, please refer to [link](https://github.com/PaddlePaddle/Paddle-Lite/releases/tag/v2.9).
+ Note: 1. The above Paddle-Lite library is compiled from the Paddle-Lite 2.10 branch. For more information about Paddle-Lite 2.10, please refer to [link](https://github.com/PaddlePaddle/Paddle-Lite/releases/tag/v2.10).
- 2. [Recommended] Compile Paddle-Lite to get the prediction library. The compilation method of Paddle-Lite is as follows:
```
git clone https://github.com/PaddlePaddle/Paddle-Lite.git
cd Paddle-Lite
-# Switch to Paddle-Lite release/v2.8 stable branch
-git checkout release/v2.8
+# Switch to Paddle-Lite release/v2.10 stable branch
+git checkout release/v2.10
./lite/tools/build_android.sh --arch=armv8 --with_cv=ON --with_extra=ON
```
@@ -87,10 +98,10 @@ The following table also provides a series of models that can be deployed on mob
|Version|Introduction|Model size|Detection model|Text Direction model|Recognition model|Paddle-Lite branch|
|---|---|---|---|---|---|---|
-|V2.0|extra-lightweight chinese OCR optimized model|7.8M|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_det_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_cls_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_rec_opt.nb)|v2.9|
-|V2.0(slim)|extra-lightweight chinese OCR optimized model|3.3M|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_det_slim_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_cls_slim_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/lite/ch_ppocr_mobile_v2.0_rec_slim_opt.nb)|v2.9|
+|PP-OCRv2|extra-lightweight chinese OCR optimized model|11M|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_det_infer_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_ppocr_mobile_v2.0_cls_infer_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_rec_infer_opt.nb)|v2.10|
+|PP-OCRv2(slim)|extra-lightweight chinese OCR optimized model|4.6M|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_det_slim_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_ppocr_mobile_v2.0_cls_slim_opt.nb)|[download link](https://paddleocr.bj.bcebos.com/PP-OCRv2/lite/ch_PP-OCRv2_rec_slim_opt.nb)|v2.10|
-If you directly use the model in the above table for deployment, you can skip the following steps and directly read [Section 2.2](#2.2 Run optimized model on Phone).
+If you directly use the model in the above table for deployment, you can skip the following steps and directly read [Section 2.2](#2.2-Run-optimized-model-on-Phone).
If the model to be deployed is not in the above table, you need to follow the steps below to obtain the optimized model.
@@ -98,7 +109,7 @@ The `opt` tool can be obtained by compiling Paddle Lite.
```
git clone https://github.com/PaddlePaddle/Paddle-Lite.git
cd Paddle-Lite
-git checkout release/v2.9
+git checkout release/v2.10
./lite/tools/build.sh build_optimize_tool
```
@@ -124,22 +135,22 @@ cd build.opt/lite/api/
The following takes the ultra-lightweight Chinese model of PaddleOCR as an example to introduce the use of the compiled opt file to complete the conversion of the inference model to the Paddle-Lite optimized model
```
-# [Recommendation] Download the Chinese and English inference model of PaddleOCR V2.0
-wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/slim/ch_ppocr_mobile_v2.0_det_slim_infer.tar && tar xf ch_ppocr_mobile_v2.0_det_slim_infer.tar
-wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/slim/ch_ppocr_mobile_v2.0_rec_slim_infer.tar && tar xf ch_ppocr_mobile_v2.0_rec_slim_infer.tar
+# 【[Recommendation] Download the Chinese and English inference model of PP-OCRv2
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_slim_quant_infer.tar && tar xf ch_PP-OCRv2_det_slim_quant_infer.tar
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_slim_quant_infer.tar && tar xf ch_PP-OCRv2_rec_slim_quant_infer.tar
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/slim/ch_ppocr_mobile_v2.0_cls_slim_infer.tar && tar xf ch_ppocr_mobile_v2.0_cls_slim_infer.tar
-# Convert V2.0 detection model
-./opt --model_file=./ch_ppocr_mobile_v2.0_det_slim_infer/inference.pdmodel --param_file=./ch_ppocr_mobile_v2.0_det_slim_infer/inference.pdiparams --optimize_out=./ch_ppocr_mobile_v2.0_det_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
-# Convert V2.0 recognition model
-./opt --model_file=./ch_ppocr_mobile_v2.0_rec_slim_infer/inference.pdmodel --param_file=./ch_ppocr_mobile_v2.0_rec_slim_infer/inference.pdiparams --optimize_out=./ch_ppocr_mobile_v2.0_rec_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
-# Convert V2.0 angle classifier model
+# Convert detection model
+./opt --model_file=./ch_PP-OCRv2_det_slim_quant_infer/inference.pdmodel --param_file=./ch_PP-OCRv2_det_slim_quant_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv2_det_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
+# Convert recognition model
+./opt --model_file=./ch_PP-OCRv2_rec_slim_quant_infer/inference.pdmodel --param_file=./ch_PP-OCRv2_rec_slim_quant_infer/inference.pdiparams --optimize_out=./ch_PP-OCRv2_rec_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
+# Convert angle classifier model
./opt --model_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdmodel --param_file=./ch_ppocr_mobile_v2.0_cls_slim_infer/inference.pdiparams --optimize_out=./ch_ppocr_mobile_v2.0_cls_slim_opt --valid_targets=arm --optimize_out_type=naive_buffer
```
After the conversion is successful, there will be more files ending with `.nb` in the inference model directory, which is the successfully converted model file.
-
+
### 2.2 Run optimized model on Phone
Some preparatory work is required first.
@@ -194,8 +205,8 @@ The structure of the OCR demo is as follows after the above command is executed:
```
demo/cxx/ocr/
|-- debug/
-| |--ch_ppocr_mobile_v2.0_det_slim_opt.nb Detection model
-| |--ch_ppocr_mobile_v2.0_rec_slim_opt.nb Recognition model
+| |--ch_PP-OCRv2_det_slim_opt.nb Detection model
+| |--ch_PP-OCRv2_rec_slim_opt.nb Recognition model
| |--ch_ppocr_mobile_v2.0_cls_slim_opt.nb Text direction classification model
| |--11.jpg Image for OCR
| |--ppocr_keys_v1.txt Dictionary file
@@ -249,7 +260,7 @@ After the above steps are completed, you can use adb to push the file to the pho
export LD_LIBRARY_PATH=${PWD}:$LD_LIBRARY_PATH
# The use of ocr_db_crnn is:
# ./ocr_db_crnn Detection model file Orientation classifier model file Recognition model file Test image path Dictionary file path
- ./ocr_db_crnn ch_ppocr_mobile_v2.0_det_opt.nb ch_ppocr_mobile_v2.0_rec_opt.nb ch_ppocr_mobile_v2.0_cls_opt.nb ./11.jpg ppocr_keys_v1.txt
+ ./ocr_db_crnn ch_PP-OCRv2_det_slim_opt.nb ch_PP-OCRv2_rec_slim_opt.nb ch_ppocr_mobile_v2.0_cls_opt.nb ./11.jpg ppocr_keys_v1.txt
```
If you modify the code, you need to recompile and push to the phone.
diff --git a/deploy/paddle2onnx/images/lite_demo_onnx.png b/deploy/paddle2onnx/images/lite_demo_onnx.png
new file mode 100644
index 0000000000000000000000000000000000000000..b096f6eef5cc40dde2d4524e54a54c592d44b083
Binary files /dev/null and b/deploy/paddle2onnx/images/lite_demo_onnx.png differ
diff --git a/deploy/paddle2onnx/images/lite_demo_paddle.png b/deploy/paddle2onnx/images/lite_demo_paddle.png
new file mode 100644
index 0000000000000000000000000000000000000000..b096f6eef5cc40dde2d4524e54a54c592d44b083
Binary files /dev/null and b/deploy/paddle2onnx/images/lite_demo_paddle.png differ
diff --git a/deploy/paddle2onnx/readme.md b/deploy/paddle2onnx/readme.md
index 2148b3262d43f374a4310a5bfaaac854e92f9a32..e08f2adee5d315cecba703ecdf515c09cd1569d2 100644
--- a/deploy/paddle2onnx/readme.md
+++ b/deploy/paddle2onnx/readme.md
@@ -1,10 +1,19 @@
# paddle2onnx 模型转化与预测
-本章节介绍 PaddleOCR 模型如何转化为 ONNX 模型,并基于 ONNX 引擎预测。
+本章节介绍 PaddleOCR 模型如何转化为 ONNX 模型,并基于 ONNXRuntime 引擎预测。
## 1. 环境准备
-需要准备 Paddle2ONNX 模型转化环境,和 ONNX 模型预测环境
+需要准备 PaddleOCR、Paddle2ONNX 模型转化环境,和 ONNXRuntime 预测环境
+
+### PaddleOCR
+
+克隆PaddleOCR的仓库,使用release/2.4分支,并进行安装,由于PaddleOCR仓库比较大,git clone速度比较慢,所以本教程已下载
+
+```
+git clone -b release/2.4 https://github.com/PaddlePaddle/PaddleOCR.git
+cd PaddleOCR && python3.7 setup.py install
+```
### Paddle2ONNX
@@ -16,7 +25,7 @@ Paddle2ONNX 支持将 PaddlePaddle 模型格式转化到 ONNX 模型格式,算
python3.7 -m pip install paddle2onnx
```
-- 安装 ONNX
+- 安装 ONNXRuntime
```
# 建议安装 1.9.0 版本,可根据环境更换版本号
python3.7 -m pip install onnxruntime==1.9.0
@@ -30,11 +39,17 @@ python3.7 -m pip install onnxruntime==1.9.0
有两种方式获取Paddle静态图模型:在 [model_list](../../doc/doc_ch/models_list.md) 中下载PaddleOCR提供的预测模型;
参考[模型导出说明](../../doc/doc_ch/inference.md#训练模型转inference模型)把训练好的权重转为 inference_model。
-以 ppocr 检测模型为例:
+以 ppocr 中文检测、识别、分类模型为例:
```
-wget -nc -P ./inference https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar
-cd ./inference && tar xf ch_ppocr_mobile_v2.0_det_infer.tar && cd ..
+wget -nc -P ./inference https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar
+cd ./inference && tar xf ch_PP-OCRv2_det_infer.tar && cd ..
+
+wget -nc -P ./inference https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar
+cd ./inference && tar xf ch_PP-OCRv2_rec_infer.tar && cd ..
+
+wget -nc -P ./inference https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
+cd ./inference && tar xf ch_ppocr_mobile_v2.0_cls_infer.tar && cd ..
```
- 模型转换
@@ -42,35 +57,160 @@ cd ./inference && tar xf ch_ppocr_mobile_v2.0_det_infer.tar && cd ..
使用 Paddle2ONNX 将Paddle静态图模型转换为ONNX模型格式:
```
-paddle2onnx --model_dir=./inference/ch_ppocr_mobile_v2.0_det_infer/ \
---model_filename=inference.pdmodel \
---params_filename=inference.pdiparams \
---save_file=./inference/det_mobile_onnx/model.onnx \
---opset_version=10 \
---input_shape_dict="{'x': [-1, 3, -1, -1]}" \
---enable_onnx_checker=True
+paddle2onnx --model_dir ./inference/ch_PP-OCRv2_det_infer \
+--model_filename inference.pdmodel \
+--params_filename inference.pdiparams \
+--save_file ./inference/det_onnx/model.onnx \
+--opset_version 10 \
+--input_shape_dict="{'x':[-1,3,-1,-1]}" \
+--enable_onnx_checker True
+
+paddle2onnx --model_dir ./inference/ch_PP-OCRv2_rec_infer \
+--model_filename inference.pdmodel \
+--params_filename inference.pdiparams \
+--save_file ./inference/rec_onnx/model.onnx \
+--opset_version 10 \
+--input_shape_dict="{'x':[-1,3,-1,-1]}" \
+--enable_onnx_checker True
+
+paddle2onnx --model_dir ./inference/ch_ppocr_mobile_v2.0_cls_infer \
+--model_filename ch_ppocr_mobile_v2.0_cls_infer/inference.pdmodel \
+--params_filename ch_ppocr_mobile_v2.0_cls_infer/inference.pdiparams \
+--save_file ./inferencecls_onnx/model.onnx \
+--opset_version 10 \
+--input_shape_dict="{'x':[-1,3,-1,-1]}" \
+--enable_onnx_checker True
```
-执行完毕后,ONNX 模型会被保存在 `./inference/det_mobile_onnx/` 路径下
+执行完毕后,ONNX 模型会被分别保存在 `./inference/det_onnx/`,`./inference/rec_onnx/`,`./inference/cls_onnx/`路径下
* 注意:对于OCR模型,转化过程中必须采用动态shape的形式,即加入选项--input_shape_dict="{'x': [-1, 3, -1, -1]}",否则预测结果可能与直接使用Paddle预测有细微不同。
另外,以下几个模型暂不支持转换为 ONNX 模型:
NRTR、SAR、RARE、SRN
-## 3. onnx 预测
+## 3. 推理预测
+
+以中文OCR模型为例,使用 ONNXRuntime 预测可执行如下命令:
+
+```
+python3.7 tools/infer/predict_system.py --use_gpu=False --use_onnx=True \
+--det_model_dir=./inference/det_onnx/model.onnx \
+--rec_model_dir=./inference/rec_onnx/model.onnx \
+--cls_model_dir=./inference/cls_onnx/model.onnx \
+--image_dir=./deploy/lite/imgs/lite_demo.png
+```
+
+以中文OCR模型为例,使用 Paddle Inference 预测可执行如下命令:
+
+```
+python3.7 tools/infer/predict_system.py --use_gpu=False \
+--cls_model_dir=./inference/ch_ppocr_mobile_v2.0_cls_infer \
+--rec_model_dir=./inference/ch_PP-OCRv2_rec_infer \
+--det_model_dir=./inference/ch_PP-OCRv2_det_infer \
+--image_dir=./deploy/lite/imgs/lite_demo.png
+```
+
+
+执行命令后在终端会打印出预测的识别信息,并在 `./inference_results/` 下保存可视化结果。
+
+ONNXRuntime 执行效果:
+
+
+

+
+

+