Merge branch 'dygraph' of https://github.com/PaddlePaddle/PaddleOCR into feature_amp_train
Showing
文件已移动
文件已移动
文件已移动
PTDN/docs/compare_cpp_right.png
0 → 100644
{kind=link}

49.4 KB
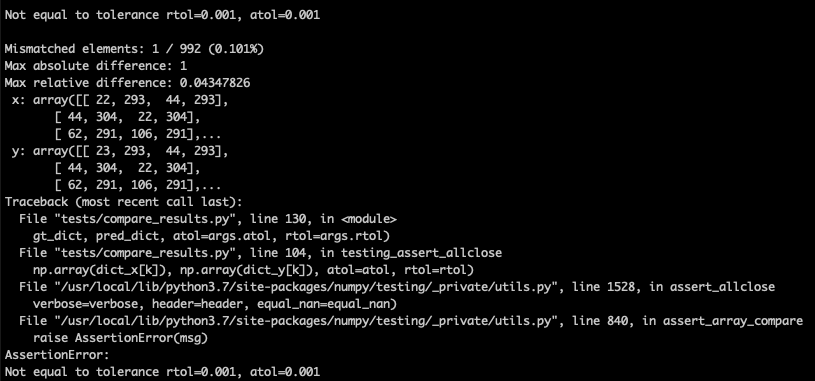
PTDN/docs/compare_cpp_wrong.png
0 → 100644
{kind=link}
63.3 KB
{kind=link}
{kind=link}
{kind=link}
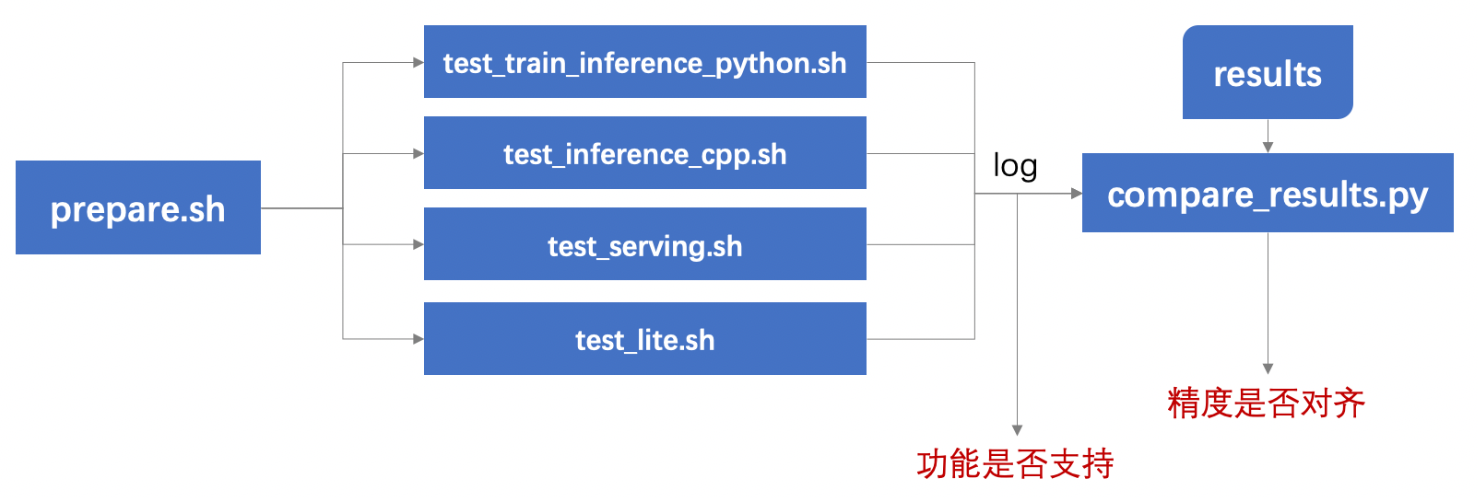
PTDN/docs/test.png
0 → 100644
{kind=link}
223.8 KB
文件已移动
文件已移动
文件已移动
文件已移动
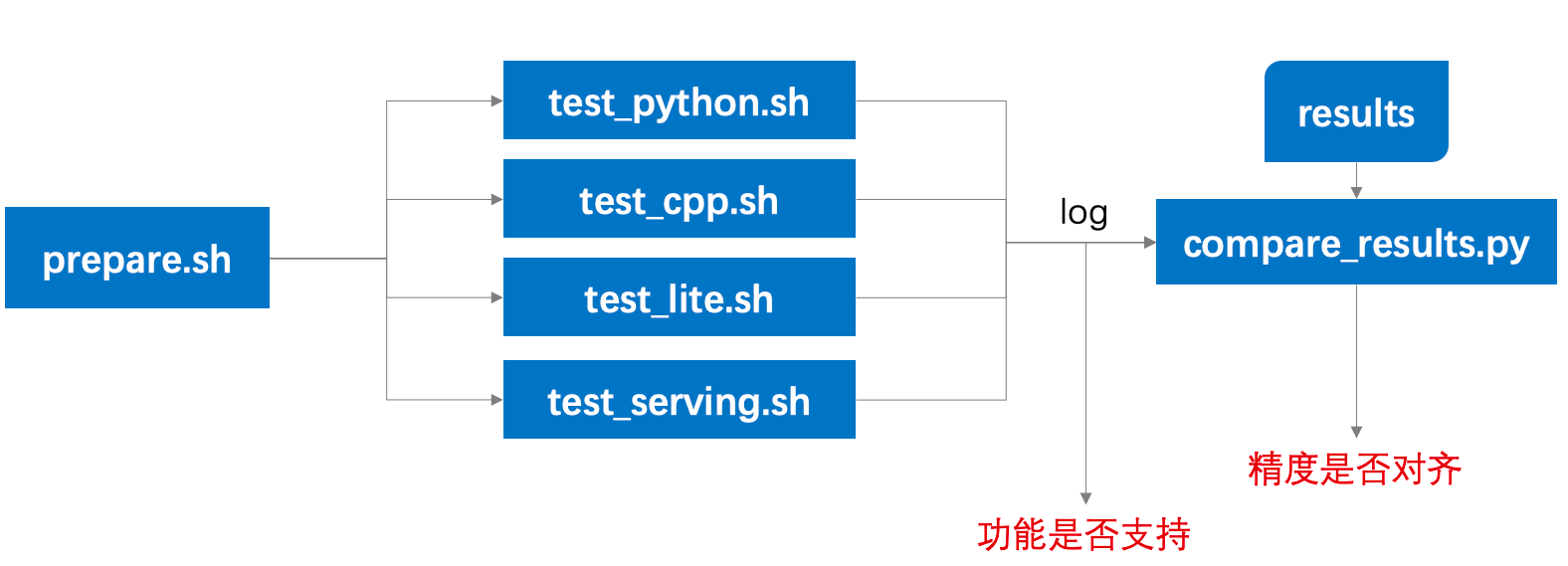
tests/docs/test.png
已删除
100644 → 0
{kind=link}
71.8 KB