diff --git a/README_ch.md b/README_ch.md
index f837980498c4b2e2c55a44192b7d3a2c7afb0ba9..e801ce561cb41aafb376f81a3016f0a6b838320d 100755
--- a/README_ch.md
+++ b/README_ch.md
@@ -71,6 +71,8 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
## 《动手学OCR》电子书
- [《动手学OCR》电子书📚](./doc/doc_ch/ocr_book.md)
+## 场景应用
+- PaddleOCR场景应用覆盖通用,制造、金融、交通行业的主要OCR垂类应用,在PP-OCR、PP-Structure的通用能力基础之上,以notebook的形式展示利用场景数据微调、模型优化方法、数据增广等内容,为开发者快速落地OCR应用提供示范与启发。详情可查看[README](./applications)。
## 开源社区
diff --git "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md" "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
index a5052e2897ab9f09a6ed7b747f9fa1198af2a8ab..ee13bacffdb65e6300a034531a527fdca4ed29f9 100644
--- "a/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
+++ "b/applications/PCB\345\255\227\347\254\246\350\257\206\345\210\253/PCB\345\255\227\347\254\246\350\257\206\345\210\253.md"
@@ -206,7 +206,11 @@ Eval.dataset.transforms.DetResizeForTest: 尺寸
limit_type: 'min'
```
-然后执行评估代码
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+

+
+
+
 +
+目前光功率计缺少将数据直接输出的功能,需要人工读数。这一项工作单调重复,如果可以使用机器替代人工,将节约大量成本。针对上述问题,希望通过摄像头拍照->智能读数的方式高效地完成此任务。
+
+为实现智能读数,通常会采取文本检测+文本识别的方案:
+
+第一步,使用文本检测模型定位出光功率计中的数字部分;
+
+第二步,使用文本识别模型获得准确的数字和单位信息。
+
+本项目主要介绍如何完成第二步文本识别部分,包括:真实评估集的建立、训练数据的合成、基于 PP-OCRv3 和 SVTR_Tiny 两个模型进行训练,以及评估和推理。
+
+本项目难点如下:
+
+- 光功率计数码管字符数据较少,难以获取。
+- 数码管中小数点占像素较少,容易漏识别。
+
+针对以上问题, 本例选用 PP-OCRv3 和 SVTR_Tiny 两个高精度模型训练,同时提供了真实数据挖掘案例和数据合成案例。基于 PP-OCRv3 模型,在构建的真实评估集上精度从 52% 提升至 72%,SVTR_Tiny 模型精度可达到 78.9%。
+
+aistudio项目链接: [光功率计数码管字符识别](https://aistudio.baidu.com/aistudio/projectdetail/4049044?contributionType=1)
+
+## 2. PaddleOCR 快速使用
+
+PaddleOCR 旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
+
+
+
+
+官方提供了适用于通用场景的高精轻量模型,首先使用官方提供的 PP-OCRv3 模型预测图片,验证下当前模型在光功率计场景上的效果。
+
+- 准备环境
+
+```
+python3 -m pip install -U pip
+python3 -m pip install paddleocr
+```
+
+
+- 测试效果
+
+测试图:
+
+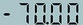
+
+
+```
+paddleocr --lang=ch --det=Fase --image_dir=data
+```
+
+得到如下测试结果:
+
+```
+('.7000', 0.6885431408882141)
+```
+
+发现数字识别较准,然而对负号和小数点识别不准确。 由于PP-OCRv3的训练数据大多为通用场景数据,在特定的场景上效果可能不够好。因此需要基于场景数据进行微调。
+
+下面就主要介绍如何在光功率计(数码管)场景上微调训练。
+
+
+## 3. 开始训练
+
+### 3.1 数据准备
+
+特定的工业场景往往很难获取开源的真实数据集,光功率计也是如此。在实际工业场景中,可以通过摄像头采集的方法收集大量真实数据,本例中重点介绍数据合成方法和真实数据挖掘方法,如何利用有限的数据优化模型精度。
+
+数据集分为两个部分:合成数据,真实数据, 其中合成数据由 text_renderer 工具批量生成得到, 真实数据通过爬虫等方式在百度图片中搜索并使用 PPOCRLabel 标注得到。
+
+
+- 合成数据
+
+本例中数据合成工具使用的是 [text_renderer](https://github.com/Sanster/text_renderer), 该工具可以合成用于文本识别训练的文本行数据:
+
+
+
+
+
+
+```
+export https_proxy=http://172.19.57.45:3128
+git clone https://github.com/oh-my-ocr/text_renderer
+```
+
+```
+import os
+python3 setup.py develop
+python3 -m pip install -r docker/requirements.txt
+python3 main.py \
+ --config example_data/example.py \
+ --dataset img \
+ --num_processes 2 \
+ --log_period 10
+```
+
+给定字体和语料,就可以合成较为丰富样式的文本行数据。 光功率计识别场景,目标是正确识别数码管文本,因此需要收集部分数码管字体,训练语料,用于合成文本识别数据。
+
+将收集好的语料存放在 example_data 路径下:
+
+```
+ln -s ./fonts/DS* text_renderer/example_data/font/
+ln -s ./corpus/digital.txt text_renderer/example_data/text/
+```
+
+修改 text_renderer/example_data/font_list/font_list.txt ,选择需要的字体开始合成:
+
+```
+python3 main.py \
+ --config example_data/digital_example.py \
+ --dataset img \
+ --num_processes 2 \
+ --log_period 10
+```
+
+合成图片会被存在目录 text_renderer/example_data/digital/chn_data 下
+
+查看合成的数据样例:
+
+
+
+
+- 真实数据挖掘
+
+模型训练需要使用真实数据作为评价指标,否则很容易过拟合到简单的合成数据中。没有开源数据的情况下,可以利用部分无标注数据+标注工具获得真实数据。
+
+
+1. 数据搜集
+
+使用[爬虫工具](https://github.com/Joeclinton1/google-images-download.git)获得无标注数据
+
+2. [PPOCRLabel](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.5/PPOCRLabel) 完成半自动标注
+
+PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注、表格标注、不规则文本标注、关键信息标注模式,导出格式可直接用于PaddleOCR检测和识别模型的训练。
+
+
+
+
+收集完数据后就可以进行分配了,验证集中一般都是真实数据,训练集中包含合成数据+真实数据。本例中标注了155张图片,其中训练集和验证集的数目为100和55。
+
+
+最终 `data` 文件夹应包含以下几部分:
+
+```
+|-data
+ |- synth_train.txt
+ |- real_train.txt
+ |- real_eval.txt
+ |- synthetic_data
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+ |- real_data
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+ ...
+```
+
+### 3.2 模型选择
+
+本案例提供了2种文本识别模型:PP-OCRv3 识别模型 和 SVTR_Tiny:
+
+[PP-OCRv3 识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md):PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。并进行了一系列结构改进加速模型预测。
+
+[SVTR_Tiny](https://arxiv.org/abs/2205.00159):SVTR提出了一种用于场景文本识别的单视觉模型,该模型在patch-wise image tokenization框架内,完全摒弃了序列建模,在精度具有竞争力的前提下,模型参数量更少,速度更快。
+
+以上两个策略在自建中文数据集上的精度和速度对比如下:
+
+| ID | 策略 | 模型大小 | 精度 | 预测耗时(CPU + MKLDNN)|
+|-----|-----|--------|----| --- |
+| 01 | PP-OCRv2 | 8M | 74.8% | 8.54ms |
+| 02 | SVTR_Tiny | 21M | 80.1% | 97ms |
+| 03 | SVTR_LCNet(h32) | 12M | 71.9% | 6.6ms |
+| 04 | SVTR_LCNet(h48) | 12M | 73.98% | 7.6ms |
+| 05 | + GTC | 12M | 75.8% | 7.6ms |
+| 06 | + TextConAug | 12M | 76.3% | 7.6ms |
+| 07 | + TextRotNet | 12M | 76.9% | 7.6ms |
+| 08 | + UDML | 12M | 78.4% | 7.6ms |
+| 09 | + UIM | 12M | 79.4% | 7.6ms |
+
+
+### 3.3 开始训练
+
+首先下载 PaddleOCR 代码库
+
+```
+git clone -b release/2.5 https://github.com/PaddlePaddle/PaddleOCR.git
+```
+
+PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以 PP-OCRv3 中文识别模型为例:
+
+**Step1:下载预训练模型**
+
+首先下载 pretrain model,您可以下载训练好的模型在自定义数据上进行finetune
+
+```
+cd PaddleOCR/
+# 下载PP-OCRv3 中文预训练模型
+wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
+# 解压模型参数
+cd pretrain_models
+tar -xf ch_PP-OCRv3_rec_train.tar && rm -rf ch_PP-OCRv3_rec_train.tar
+```
+
+**Step2:自定义字典文件**
+
+接下来需要提供一个字典({word_dict_name}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。
+
+因此字典需要包含所有希望被正确识别的字符,{word_dict_name}.txt需要写成如下格式,并以 `utf-8` 编码格式保存:
+
+```
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+-
+.
+```
+
+word_dict.txt 每行有一个单字,将字符与数字索引映射在一起,“3.14” 将被映射成 [3, 11, 1, 4]
+
+* 内置字典
+
+PaddleOCR内置了一部分字典,可以按需使用。
+
+`ppocr/utils/ppocr_keys_v1.txt` 是一个包含6623个字符的中文字典
+
+`ppocr/utils/ic15_dict.txt` 是一个包含36个字符的英文字典
+
+* 自定义字典
+
+内置字典面向通用场景,具体的工业场景中,可能需要识别特殊字符,或者只需识别某几个字符,此时自定义字典会更提升模型精度。例如在光功率计场景中,需要识别数字和单位。
+
+遍历真实数据标签中的字符,制作字典`digital_dict.txt`如下所示:
+
+```
+-
+.
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+B
+E
+F
+H
+L
+N
+T
+W
+d
+k
+m
+n
+o
+z
+```
+
+
+
+
+**Step3:修改配置文件**
+
+为了更好的使用预训练模型,训练推荐使用[ch_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml)配置文件,并参考下列说明修改配置文件:
+
+以 `ch_PP-OCRv3_rec_distillation.yml` 为例:
+```
+Global:
+ ...
+ # 添加自定义字典,如修改字典请将路径指向新字典
+ character_dict_path: ppocr/utils/dict/digital_dict.txt
+ ...
+ # 识别空格
+ use_space_char: True
+
+
+Optimizer:
+ ...
+ # 添加学习率衰减策略
+ lr:
+ name: Cosine
+ learning_rate: 0.001
+ ...
+
+...
+
+Train:
+ dataset:
+ # 数据集格式,支持LMDBDataSet以及SimpleDataSet
+ name: SimpleDataSet
+ # 数据集路径
+ data_dir: ./data/
+ # 训练集标签文件
+ label_file_list:
+ - ./train_data/digital_img/digital_train.txt #11w
+ - ./train_data/digital_img/real_train.txt #100
+ - ./train_data/digital_img/dbm_img/dbm.txt #3w
+ ratio_list:
+ - 0.3
+ - 1.0
+ - 1.0
+ transforms:
+ ...
+ - RecResizeImg:
+ # 修改 image_shape 以适应长文本
+ image_shape: [3, 48, 320]
+ ...
+ loader:
+ ...
+ # 单卡训练的batch_size
+ batch_size_per_card: 256
+ ...
+
+Eval:
+ dataset:
+ # 数据集格式,支持LMDBDataSet以及SimpleDataSet
+ name: SimpleDataSet
+ # 数据集路径
+ data_dir: ./data
+ # 验证集标签文件
+ label_file_list:
+ - ./train_data/digital_img/real_val.txt
+ transforms:
+ ...
+ - RecResizeImg:
+ # 修改 image_shape 以适应长文本
+ image_shape: [3, 48, 320]
+ ...
+ loader:
+ # 单卡验证的batch_size
+ batch_size_per_card: 256
+ ...
+```
+**注意,训练/预测/评估时的配置文件请务必与训练一致。**
+
+**Step4:启动训练**
+
+*如果您安装的是cpu版本,请将配置文件中的 `use_gpu` 字段修改为false*
+
+```
+# GPU训练 支持单卡,多卡训练
+# 训练数码管数据 训练日志会自动保存为 "{save_model_dir}" 下的train.log
+
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
+```
+
+
+PaddleOCR支持训练和评估交替进行, 可以在 `configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml` 中修改 `eval_batch_step` 设置评估频率,默认每500个iter评估一次。评估过程中默认将最佳acc模型,保存为 `output/ch_PP-OCRv3_rec_distill/best_accuracy` 。
+
+如果验证集很大,测试将会比较耗时,建议减少评估次数,或训练完再进行评估。
+
+### SVTR_Tiny 训练
+
+SVTR_Tiny 训练步骤与上面一致,SVTR支持的配置和模型训练权重可以参考[算法介绍文档](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/algorithm_rec_svtr.md)
+
+**Step1:下载预训练模型**
+
+```
+# 下载 SVTR_Tiny 中文识别预训练模型和配置文件
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/rec_svtr_tiny_none_ctc_ch_train.tar
+# 解压模型参数
+tar -xf rec_svtr_tiny_none_ctc_ch_train.tar && rm -rf rec_svtr_tiny_none_ctc_ch_train.tar
+```
+**Step2:自定义字典文件**
+
+字典依然使用自定义的 digital_dict.txt
+
+**Step3:修改配置文件**
+
+配置文件中对应修改字典路径和数据路径
+
+**Step4:启动训练**
+
+```
+## 单卡训练
+python tools/train.py -c rec_svtr_tiny_none_ctc_ch_train/rec_svtr_tiny_6local_6global_stn_ch.yml \
+ -o Global.pretrained_model=./rec_svtr_tiny_none_ctc_ch_train/best_accuracy
+```
+
+### 3.4 验证效果
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+目前光功率计缺少将数据直接输出的功能,需要人工读数。这一项工作单调重复,如果可以使用机器替代人工,将节约大量成本。针对上述问题,希望通过摄像头拍照->智能读数的方式高效地完成此任务。
+
+为实现智能读数,通常会采取文本检测+文本识别的方案:
+
+第一步,使用文本检测模型定位出光功率计中的数字部分;
+
+第二步,使用文本识别模型获得准确的数字和单位信息。
+
+本项目主要介绍如何完成第二步文本识别部分,包括:真实评估集的建立、训练数据的合成、基于 PP-OCRv3 和 SVTR_Tiny 两个模型进行训练,以及评估和推理。
+
+本项目难点如下:
+
+- 光功率计数码管字符数据较少,难以获取。
+- 数码管中小数点占像素较少,容易漏识别。
+
+针对以上问题, 本例选用 PP-OCRv3 和 SVTR_Tiny 两个高精度模型训练,同时提供了真实数据挖掘案例和数据合成案例。基于 PP-OCRv3 模型,在构建的真实评估集上精度从 52% 提升至 72%,SVTR_Tiny 模型精度可达到 78.9%。
+
+aistudio项目链接: [光功率计数码管字符识别](https://aistudio.baidu.com/aistudio/projectdetail/4049044?contributionType=1)
+
+## 2. PaddleOCR 快速使用
+
+PaddleOCR 旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
+
+
+
+
+官方提供了适用于通用场景的高精轻量模型,首先使用官方提供的 PP-OCRv3 模型预测图片,验证下当前模型在光功率计场景上的效果。
+
+- 准备环境
+
+```
+python3 -m pip install -U pip
+python3 -m pip install paddleocr
+```
+
+
+- 测试效果
+
+测试图:
+
+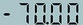
+
+
+```
+paddleocr --lang=ch --det=Fase --image_dir=data
+```
+
+得到如下测试结果:
+
+```
+('.7000', 0.6885431408882141)
+```
+
+发现数字识别较准,然而对负号和小数点识别不准确。 由于PP-OCRv3的训练数据大多为通用场景数据,在特定的场景上效果可能不够好。因此需要基于场景数据进行微调。
+
+下面就主要介绍如何在光功率计(数码管)场景上微调训练。
+
+
+## 3. 开始训练
+
+### 3.1 数据准备
+
+特定的工业场景往往很难获取开源的真实数据集,光功率计也是如此。在实际工业场景中,可以通过摄像头采集的方法收集大量真实数据,本例中重点介绍数据合成方法和真实数据挖掘方法,如何利用有限的数据优化模型精度。
+
+数据集分为两个部分:合成数据,真实数据, 其中合成数据由 text_renderer 工具批量生成得到, 真实数据通过爬虫等方式在百度图片中搜索并使用 PPOCRLabel 标注得到。
+
+
+- 合成数据
+
+本例中数据合成工具使用的是 [text_renderer](https://github.com/Sanster/text_renderer), 该工具可以合成用于文本识别训练的文本行数据:
+
+
+
+
+
+
+```
+export https_proxy=http://172.19.57.45:3128
+git clone https://github.com/oh-my-ocr/text_renderer
+```
+
+```
+import os
+python3 setup.py develop
+python3 -m pip install -r docker/requirements.txt
+python3 main.py \
+ --config example_data/example.py \
+ --dataset img \
+ --num_processes 2 \
+ --log_period 10
+```
+
+给定字体和语料,就可以合成较为丰富样式的文本行数据。 光功率计识别场景,目标是正确识别数码管文本,因此需要收集部分数码管字体,训练语料,用于合成文本识别数据。
+
+将收集好的语料存放在 example_data 路径下:
+
+```
+ln -s ./fonts/DS* text_renderer/example_data/font/
+ln -s ./corpus/digital.txt text_renderer/example_data/text/
+```
+
+修改 text_renderer/example_data/font_list/font_list.txt ,选择需要的字体开始合成:
+
+```
+python3 main.py \
+ --config example_data/digital_example.py \
+ --dataset img \
+ --num_processes 2 \
+ --log_period 10
+```
+
+合成图片会被存在目录 text_renderer/example_data/digital/chn_data 下
+
+查看合成的数据样例:
+
+
+
+
+- 真实数据挖掘
+
+模型训练需要使用真实数据作为评价指标,否则很容易过拟合到简单的合成数据中。没有开源数据的情况下,可以利用部分无标注数据+标注工具获得真实数据。
+
+
+1. 数据搜集
+
+使用[爬虫工具](https://github.com/Joeclinton1/google-images-download.git)获得无标注数据
+
+2. [PPOCRLabel](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.5/PPOCRLabel) 完成半自动标注
+
+PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注、表格标注、不规则文本标注、关键信息标注模式,导出格式可直接用于PaddleOCR检测和识别模型的训练。
+
+
+
+
+收集完数据后就可以进行分配了,验证集中一般都是真实数据,训练集中包含合成数据+真实数据。本例中标注了155张图片,其中训练集和验证集的数目为100和55。
+
+
+最终 `data` 文件夹应包含以下几部分:
+
+```
+|-data
+ |- synth_train.txt
+ |- real_train.txt
+ |- real_eval.txt
+ |- synthetic_data
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+ |- real_data
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+ ...
+```
+
+### 3.2 模型选择
+
+本案例提供了2种文本识别模型:PP-OCRv3 识别模型 和 SVTR_Tiny:
+
+[PP-OCRv3 识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md):PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。并进行了一系列结构改进加速模型预测。
+
+[SVTR_Tiny](https://arxiv.org/abs/2205.00159):SVTR提出了一种用于场景文本识别的单视觉模型,该模型在patch-wise image tokenization框架内,完全摒弃了序列建模,在精度具有竞争力的前提下,模型参数量更少,速度更快。
+
+以上两个策略在自建中文数据集上的精度和速度对比如下:
+
+| ID | 策略 | 模型大小 | 精度 | 预测耗时(CPU + MKLDNN)|
+|-----|-----|--------|----| --- |
+| 01 | PP-OCRv2 | 8M | 74.8% | 8.54ms |
+| 02 | SVTR_Tiny | 21M | 80.1% | 97ms |
+| 03 | SVTR_LCNet(h32) | 12M | 71.9% | 6.6ms |
+| 04 | SVTR_LCNet(h48) | 12M | 73.98% | 7.6ms |
+| 05 | + GTC | 12M | 75.8% | 7.6ms |
+| 06 | + TextConAug | 12M | 76.3% | 7.6ms |
+| 07 | + TextRotNet | 12M | 76.9% | 7.6ms |
+| 08 | + UDML | 12M | 78.4% | 7.6ms |
+| 09 | + UIM | 12M | 79.4% | 7.6ms |
+
+
+### 3.3 开始训练
+
+首先下载 PaddleOCR 代码库
+
+```
+git clone -b release/2.5 https://github.com/PaddlePaddle/PaddleOCR.git
+```
+
+PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以 PP-OCRv3 中文识别模型为例:
+
+**Step1:下载预训练模型**
+
+首先下载 pretrain model,您可以下载训练好的模型在自定义数据上进行finetune
+
+```
+cd PaddleOCR/
+# 下载PP-OCRv3 中文预训练模型
+wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
+# 解压模型参数
+cd pretrain_models
+tar -xf ch_PP-OCRv3_rec_train.tar && rm -rf ch_PP-OCRv3_rec_train.tar
+```
+
+**Step2:自定义字典文件**
+
+接下来需要提供一个字典({word_dict_name}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。
+
+因此字典需要包含所有希望被正确识别的字符,{word_dict_name}.txt需要写成如下格式,并以 `utf-8` 编码格式保存:
+
+```
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+-
+.
+```
+
+word_dict.txt 每行有一个单字,将字符与数字索引映射在一起,“3.14” 将被映射成 [3, 11, 1, 4]
+
+* 内置字典
+
+PaddleOCR内置了一部分字典,可以按需使用。
+
+`ppocr/utils/ppocr_keys_v1.txt` 是一个包含6623个字符的中文字典
+
+`ppocr/utils/ic15_dict.txt` 是一个包含36个字符的英文字典
+
+* 自定义字典
+
+内置字典面向通用场景,具体的工业场景中,可能需要识别特殊字符,或者只需识别某几个字符,此时自定义字典会更提升模型精度。例如在光功率计场景中,需要识别数字和单位。
+
+遍历真实数据标签中的字符,制作字典`digital_dict.txt`如下所示:
+
+```
+-
+.
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+B
+E
+F
+H
+L
+N
+T
+W
+d
+k
+m
+n
+o
+z
+```
+
+
+
+
+**Step3:修改配置文件**
+
+为了更好的使用预训练模型,训练推荐使用[ch_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml)配置文件,并参考下列说明修改配置文件:
+
+以 `ch_PP-OCRv3_rec_distillation.yml` 为例:
+```
+Global:
+ ...
+ # 添加自定义字典,如修改字典请将路径指向新字典
+ character_dict_path: ppocr/utils/dict/digital_dict.txt
+ ...
+ # 识别空格
+ use_space_char: True
+
+
+Optimizer:
+ ...
+ # 添加学习率衰减策略
+ lr:
+ name: Cosine
+ learning_rate: 0.001
+ ...
+
+...
+
+Train:
+ dataset:
+ # 数据集格式,支持LMDBDataSet以及SimpleDataSet
+ name: SimpleDataSet
+ # 数据集路径
+ data_dir: ./data/
+ # 训练集标签文件
+ label_file_list:
+ - ./train_data/digital_img/digital_train.txt #11w
+ - ./train_data/digital_img/real_train.txt #100
+ - ./train_data/digital_img/dbm_img/dbm.txt #3w
+ ratio_list:
+ - 0.3
+ - 1.0
+ - 1.0
+ transforms:
+ ...
+ - RecResizeImg:
+ # 修改 image_shape 以适应长文本
+ image_shape: [3, 48, 320]
+ ...
+ loader:
+ ...
+ # 单卡训练的batch_size
+ batch_size_per_card: 256
+ ...
+
+Eval:
+ dataset:
+ # 数据集格式,支持LMDBDataSet以及SimpleDataSet
+ name: SimpleDataSet
+ # 数据集路径
+ data_dir: ./data
+ # 验证集标签文件
+ label_file_list:
+ - ./train_data/digital_img/real_val.txt
+ transforms:
+ ...
+ - RecResizeImg:
+ # 修改 image_shape 以适应长文本
+ image_shape: [3, 48, 320]
+ ...
+ loader:
+ # 单卡验证的batch_size
+ batch_size_per_card: 256
+ ...
+```
+**注意,训练/预测/评估时的配置文件请务必与训练一致。**
+
+**Step4:启动训练**
+
+*如果您安装的是cpu版本,请将配置文件中的 `use_gpu` 字段修改为false*
+
+```
+# GPU训练 支持单卡,多卡训练
+# 训练数码管数据 训练日志会自动保存为 "{save_model_dir}" 下的train.log
+
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
+```
+
+
+PaddleOCR支持训练和评估交替进行, 可以在 `configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml` 中修改 `eval_batch_step` 设置评估频率,默认每500个iter评估一次。评估过程中默认将最佳acc模型,保存为 `output/ch_PP-OCRv3_rec_distill/best_accuracy` 。
+
+如果验证集很大,测试将会比较耗时,建议减少评估次数,或训练完再进行评估。
+
+### SVTR_Tiny 训练
+
+SVTR_Tiny 训练步骤与上面一致,SVTR支持的配置和模型训练权重可以参考[算法介绍文档](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/algorithm_rec_svtr.md)
+
+**Step1:下载预训练模型**
+
+```
+# 下载 SVTR_Tiny 中文识别预训练模型和配置文件
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/rec_svtr_tiny_none_ctc_ch_train.tar
+# 解压模型参数
+tar -xf rec_svtr_tiny_none_ctc_ch_train.tar && rm -rf rec_svtr_tiny_none_ctc_ch_train.tar
+```
+**Step2:自定义字典文件**
+
+字典依然使用自定义的 digital_dict.txt
+
+**Step3:修改配置文件**
+
+配置文件中对应修改字典路径和数据路径
+
+**Step4:启动训练**
+
+```
+## 单卡训练
+python tools/train.py -c rec_svtr_tiny_none_ctc_ch_train/rec_svtr_tiny_6local_6global_stn_ch.yml \
+ -o Global.pretrained_model=./rec_svtr_tiny_none_ctc_ch_train/best_accuracy
+```
+
+### 3.4 验证效果
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+
+
+
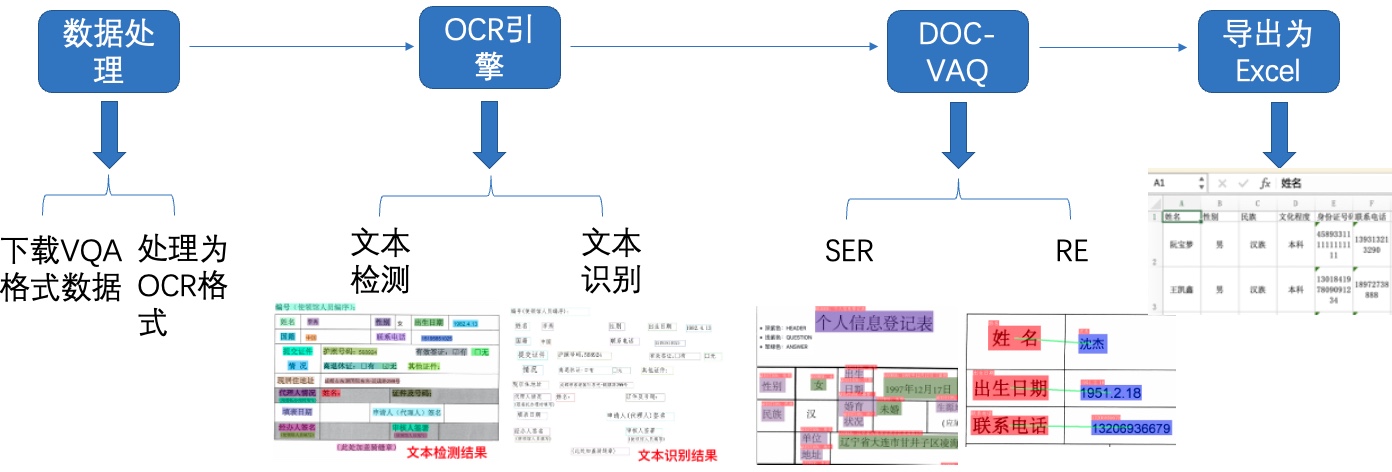 图1 多模态表单识别流程图
-注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375)(配备Tesla V100、A100等高级算力资源)
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375?contributionType=1)
-
-
-# 2 安装说明
+## 2 安装说明
下载PaddleOCR源码,上述AIStudio项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
```python
-! unzip -q PaddleOCR.zip
+unzip -q PaddleOCR.zip
```
```python
# 如仍需安装or安装更新,可以执行以下步骤
-# ! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
-# ! git clone https://gitee.com/PaddlePaddle/PaddleOCR
+# git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
+# git clone https://gitee.com/PaddlePaddle/PaddleOCR
```
```python
# 安装依赖包
-! pip install -U pip
-! pip install -r /home/aistudio/PaddleOCR/requirements.txt
-! pip install paddleocr
+pip install -U pip
+pip install -r /home/aistudio/PaddleOCR/requirements.txt
+pip install paddleocr
-! pip install yacs gnureadline paddlenlp==2.2.1
-! pip install xlsxwriter
+pip install yacs gnureadline paddlenlp==2.2.1
+pip install xlsxwriter
```
-# 3 数据准备
+## 3 数据准备
这里使用[XFUN数据集](https://github.com/doc-analysis/XFUND)做为实验数据集。 XFUN数据集是微软提出的一个用于KIE任务的多语言数据集,共包含七个数据集,每个数据集包含149张训练集和50张验证集
@@ -59,7 +86,7 @@
图1 多模态表单识别流程图
-注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375)(配备Tesla V100、A100等高级算力资源)
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3884375?contributionType=1)
-
-
-# 2 安装说明
+## 2 安装说明
下载PaddleOCR源码,上述AIStudio项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
```python
-! unzip -q PaddleOCR.zip
+unzip -q PaddleOCR.zip
```
```python
# 如仍需安装or安装更新,可以执行以下步骤
-# ! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
-# ! git clone https://gitee.com/PaddlePaddle/PaddleOCR
+# git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
+# git clone https://gitee.com/PaddlePaddle/PaddleOCR
```
```python
# 安装依赖包
-! pip install -U pip
-! pip install -r /home/aistudio/PaddleOCR/requirements.txt
-! pip install paddleocr
+pip install -U pip
+pip install -r /home/aistudio/PaddleOCR/requirements.txt
+pip install paddleocr
-! pip install yacs gnureadline paddlenlp==2.2.1
-! pip install xlsxwriter
+pip install yacs gnureadline paddlenlp==2.2.1
+pip install xlsxwriter
```
-# 3 数据准备
+## 3 数据准备
这里使用[XFUN数据集](https://github.com/doc-analysis/XFUND)做为实验数据集。 XFUN数据集是微软提出的一个用于KIE任务的多语言数据集,共包含七个数据集,每个数据集包含149张训练集和50张验证集
@@ -59,7 +86,7 @@
 图2 数据集样例,左中文,右法语
-## 3.1 下载处理好的数据集
+### 3.1 下载处理好的数据集
处理好的XFUND中文数据集下载地址:[https://paddleocr.bj.bcebos.com/dataset/XFUND.tar](https://paddleocr.bj.bcebos.com/dataset/XFUND.tar) ,可以运行如下指令完成中文数据集下载和解压。
@@ -69,13 +96,13 @@
```python
-! wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
-! tar -xf XFUND.tar
+wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
+tar -xf XFUND.tar
# XFUN其他数据集使用下面的代码进行转换
# 代码链接:https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.4/ppstructure/vqa/helper/trans_xfun_data.py
# %cd PaddleOCR
-# !python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
+# python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
# %cd ../
```
@@ -119,7 +146,7 @@
}
```
-## 3.2 转换为PaddleOCR检测和识别格式
+### 3.2 转换为PaddleOCR检测和识别格式
使用XFUND训练PaddleOCR检测和识别模型,需要将数据集格式改为训练需求的格式。
@@ -147,7 +174,7 @@ train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
```python
-! unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
+unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
```
已经提供转换脚本,执行如下代码即可转换成功:
@@ -155,21 +182,20 @@ train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
```python
%cd /home/aistudio/
-! python trans_xfund_data.py
+python trans_xfund_data.py
```
-# 4 OCR
+## 4 OCR
选用飞桨OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/README_ch.md)中的PP-OCRv2模型进行文本检测和识别。PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和[Enhanced CTC loss](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_ch/enhanced_ctc_loss.md)损失函数改进,进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCRv2[技术报告](https://arxiv.org/abs/2109.03144)。
-
-## 4.1 文本检测
+### 4.1 文本检测
我们使用2种方案进行训练、评估:
- **PP-OCRv2中英文超轻量检测预训练模型**
- **XFUND数据集+fine-tune**
-### **4.1.1 方案1:预训练模型**
+#### 4.1.1 方案1:预训练模型
**1)下载预训练模型**
@@ -195,8 +221,8 @@ PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示
```python
%cd /home/aistudio/PaddleOCR/pretrain/
-! wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
-! tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
+tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
% cd ..
```
@@ -226,7 +252,7 @@ Eval.dataset.label_file_list:指向验证集标注文件
```python
%cd /home/aistudio/PaddleOCR
-! python tools/eval.py \
+python tools/eval.py \
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_distill.yml \
-o Global.checkpoints="./pretrain_models/ch_PP-OCRv2_det_distill_train/best_accuracy"
```
@@ -237,9 +263,9 @@ Eval.dataset.label_file_list:指向验证集标注文件
| -------- | -------- |
| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% |
-使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型有一定的泛化能力。
+使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型具有泛化能力。
-### **4.1.2 方案2:XFUND数据集+fine-tune**
+#### 4.1.2 方案2:XFUND数据集+fine-tune
PaddleOCR提供的蒸馏预训练模型包含了多个模型的参数,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
@@ -281,7 +307,7 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
```python
-! CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+CUDA_VISIBLE_DEVICES=0 python tools/train.py \
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml
```
@@ -290,12 +316,18 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
图2 数据集样例,左中文,右法语
-## 3.1 下载处理好的数据集
+### 3.1 下载处理好的数据集
处理好的XFUND中文数据集下载地址:[https://paddleocr.bj.bcebos.com/dataset/XFUND.tar](https://paddleocr.bj.bcebos.com/dataset/XFUND.tar) ,可以运行如下指令完成中文数据集下载和解压。
@@ -69,13 +96,13 @@
```python
-! wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
-! tar -xf XFUND.tar
+wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
+tar -xf XFUND.tar
# XFUN其他数据集使用下面的代码进行转换
# 代码链接:https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.4/ppstructure/vqa/helper/trans_xfun_data.py
# %cd PaddleOCR
-# !python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
+# python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
# %cd ../
```
@@ -119,7 +146,7 @@
}
```
-## 3.2 转换为PaddleOCR检测和识别格式
+### 3.2 转换为PaddleOCR检测和识别格式
使用XFUND训练PaddleOCR检测和识别模型,需要将数据集格式改为训练需求的格式。
@@ -147,7 +174,7 @@ train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
```python
-! unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
+unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
```
已经提供转换脚本,执行如下代码即可转换成功:
@@ -155,21 +182,20 @@ train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
```python
%cd /home/aistudio/
-! python trans_xfund_data.py
+python trans_xfund_data.py
```
-# 4 OCR
+## 4 OCR
选用飞桨OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/README_ch.md)中的PP-OCRv2模型进行文本检测和识别。PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和[Enhanced CTC loss](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_ch/enhanced_ctc_loss.md)损失函数改进,进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCRv2[技术报告](https://arxiv.org/abs/2109.03144)。
-
-## 4.1 文本检测
+### 4.1 文本检测
我们使用2种方案进行训练、评估:
- **PP-OCRv2中英文超轻量检测预训练模型**
- **XFUND数据集+fine-tune**
-### **4.1.1 方案1:预训练模型**
+#### 4.1.1 方案1:预训练模型
**1)下载预训练模型**
@@ -195,8 +221,8 @@ PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示
```python
%cd /home/aistudio/PaddleOCR/pretrain/
-! wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
-! tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
+wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
+tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
% cd ..
```
@@ -226,7 +252,7 @@ Eval.dataset.label_file_list:指向验证集标注文件
```python
%cd /home/aistudio/PaddleOCR
-! python tools/eval.py \
+python tools/eval.py \
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_distill.yml \
-o Global.checkpoints="./pretrain_models/ch_PP-OCRv2_det_distill_train/best_accuracy"
```
@@ -237,9 +263,9 @@ Eval.dataset.label_file_list:指向验证集标注文件
| -------- | -------- |
| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% |
-使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型有一定的泛化能力。
+使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型具有泛化能力。
-### **4.1.2 方案2:XFUND数据集+fine-tune**
+#### 4.1.2 方案2:XFUND数据集+fine-tune
PaddleOCR提供的蒸馏预训练模型包含了多个模型的参数,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
@@ -281,7 +307,7 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
```python
-! CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+CUDA_VISIBLE_DEVICES=0 python tools/train.py \
-c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml
```
@@ -290,12 +316,18 @@ Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
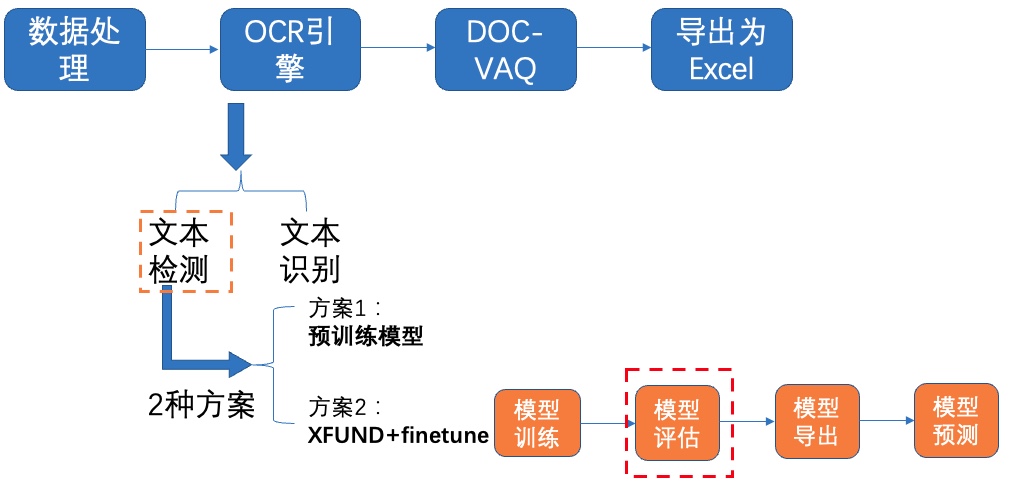 图8 文本检测方案2-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`,[模型下载地址](https://paddleocr.bj.bcebos.com/fanliku/sheet_recognition/ch_db_mv3-student1600-finetune.zip)
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
图8 文本检测方案2-模型评估
-使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`,[模型下载地址](https://paddleocr.bj.bcebos.com/fanliku/sheet_recognition/ch_db_mv3-student1600-finetune.zip)
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`。如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+
+
 图27 导出Excel
@@ -859,7 +879,7 @@ with open('output/re/infer_results.txt', 'r', encoding='utf-8') as fin:
workbook.close()
```
-# 更多资源
+## 更多资源
- 更多深度学习知识、产业案例、面试宝典等,请参考:[awesome-DeepLearning](https://github.com/paddlepaddle/awesome-DeepLearning)
@@ -869,7 +889,7 @@ workbook.close()
- 飞桨框架相关资料,请参考:[飞桨深度学习平台](https://www.paddlepaddle.org.cn/?fr=paddleEdu_aistudio)
-# 参考链接
+## 参考链接
- LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding, https://arxiv.org/pdf/2104.08836.pdf
diff --git "a/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md" "b/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md"
new file mode 100644
index 0000000000000000000000000000000000000000..ff2fb2cb4812f4f8366605b3c26af5b9aaaa290e
--- /dev/null
+++ "b/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md"
@@ -0,0 +1,616 @@
+# 基于PP-OCRv3的液晶屏读数识别
+
+- [1. 项目背景及意义](#1-项目背景及意义)
+- [2. 项目内容](#2-项目内容)
+- [3. 安装环境](#3-安装环境)
+- [4. 文字检测](#4-文字检测)
+ - [4.1 PP-OCRv3检测算法介绍](#41-PP-OCRv3检测算法介绍)
+ - [4.2 数据准备](#42-数据准备)
+ - [4.3 模型训练](#43-模型训练)
+ - [4.3.1 预训练模型直接评估](#431-预训练模型直接评估)
+ - [4.3.2 预训练模型直接finetune](#432-预训练模型直接finetune)
+ - [4.3.3 基于预训练模型Finetune_student模型](#433-基于预训练模型Finetune_student模型)
+ - [4.3.4 基于预训练模型Finetune_teacher模型](#434-基于预训练模型Finetune_teacher模型)
+ - [4.3.5 采用CML蒸馏进一步提升student模型精度](#435-采用CML蒸馏进一步提升student模型精度)
+ - [4.3.6 模型导出推理](#436-4.3.6-模型导出推理)
+- [5. 文字识别](#5-文字识别)
+ - [5.1 PP-OCRv3识别算法介绍](#51-PP-OCRv3识别算法介绍)
+ - [5.2 数据准备](#52-数据准备)
+ - [5.3 模型训练](#53-模型训练)
+ - [5.4 模型导出推理](#54-模型导出推理)
+- [6. 系统串联](#6-系统串联)
+ - [6.1 后处理](#61-后处理)
+- [7. PaddleServing部署](#7-PaddleServing部署)
+
+
+## 1. 项目背景及意义
+目前光学字符识别(OCR)技术在我们的生活当中被广泛使用,但是大多数模型在通用场景下的准确性还有待提高,针对于此我们借助飞桨提供的PaddleOCR套件较容易的实现了在垂类场景下的应用。
+
+该项目以国家质量基础(NQI)为准绳,充分利用大数据、云计算、物联网等高新技术,构建覆盖计量端、实验室端、数据端和硬件端的完整计量解决方案,解决传统计量校准中存在的难题,拓宽计量检测服务体系和服务领域;解决无数传接口或数传接口不统一、不公开的计量设备,以及计量设备所处的环境比较恶劣,不适合人工读取数据。通过OCR技术实现远程计量,引领计量行业向智慧计量转型和发展。
+
+## 2. 项目内容
+本项目基于PaddleOCR开源套件,以PP-OCRv3检测和识别模型为基础,针对液晶屏读数识别场景进行优化。
+
+Aistudio项目链接:[OCR液晶屏读数识别](https://aistudio.baidu.com/aistudio/projectdetail/4080130)
+
+## 3. 安装环境
+
+```python
+# 首先git官方的PaddleOCR项目,安装需要的依赖
+# 第一次运行打开该注释
+# git clone https://gitee.com/PaddlePaddle/PaddleOCR.git
+cd PaddleOCR
+pip install -r requirements.txt
+```
+
+## 4. 文字检测
+文本检测的任务是定位出输入图像中的文字区域。近年来学术界关于文本检测的研究非常丰富,一类方法将文本检测视为目标检测中的一个特定场景,基于通用目标检测算法进行改进适配,如TextBoxes[1]基于一阶段目标检测器SSD[2]算法,调整目标框使之适合极端长宽比的文本行,CTPN[3]则是基于Faster RCNN[4]架构改进而来。但是文本检测与目标检测在目标信息以及任务本身上仍存在一些区别,如文本一般长宽比较大,往往呈“条状”,文本行之间可能比较密集,弯曲文本等,因此又衍生了很多专用于文本检测的算法。本项目基于PP-OCRv3算法进行优化。
+
+### 4.1 PP-OCRv3检测算法介绍
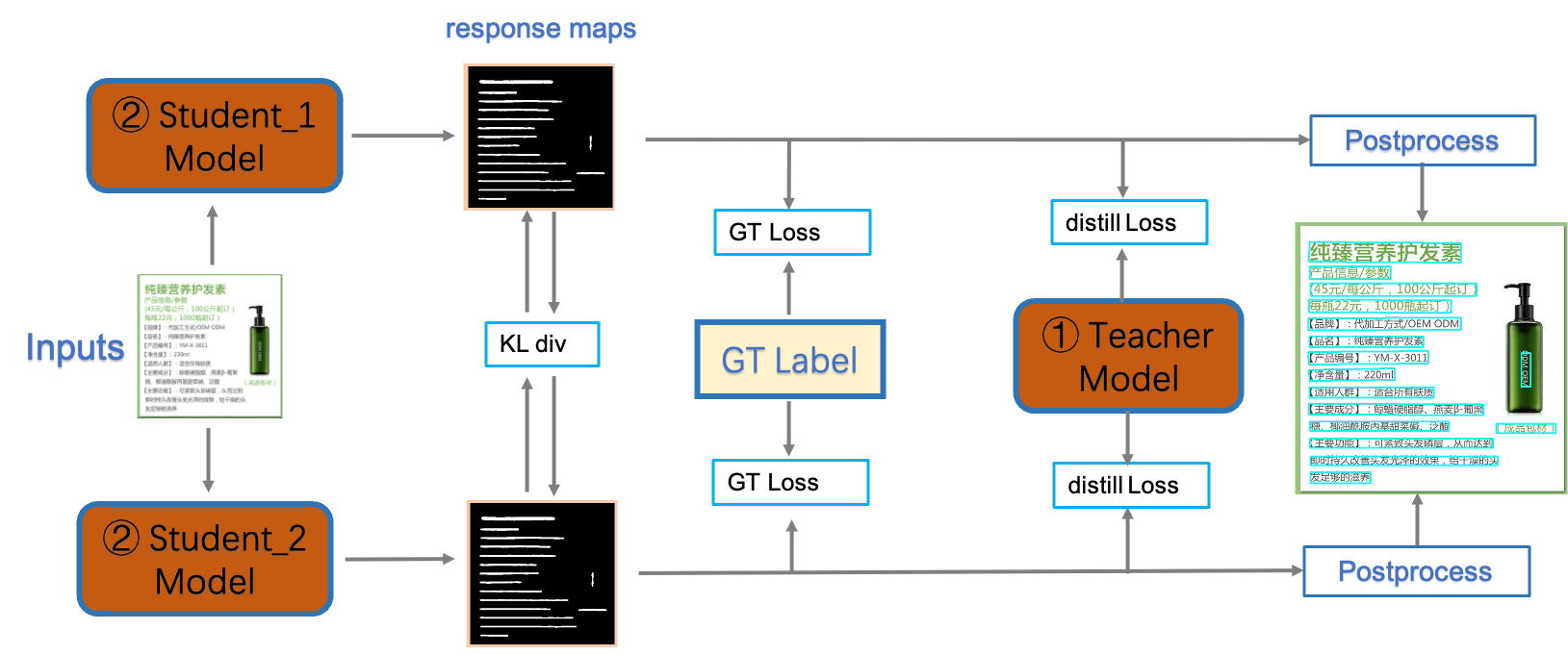
+PP-OCRv3检测模型是对PP-OCRv2中的CML(Collaborative Mutual Learning) 协同互学习文本检测蒸馏策略进行了升级。如下图所示,CML的核心思想结合了①传统的Teacher指导Student的标准蒸馏与 ②Students网络之间的DML互学习,可以让Students网络互学习的同时,Teacher网络予以指导。PP-OCRv3分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML(Deep Mutual Learning)蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
+
+
+详细优化策略描述请参考[PP-OCRv3优化策略](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md#2)
+
+### 4.2 数据准备
+[计量设备屏幕字符检测数据集](https://aistudio.baidu.com/aistudio/datasetdetail/127845)数据来源于实际项目中各种计量设备的数显屏,以及在网上搜集的一些其他数显屏,包含训练集755张,测试集355张。
+
+```python
+# 在PaddleOCR下创建新的文件夹train_data
+mkdir train_data
+# 下载数据集并解压到指定路径下
+unzip icdar2015.zip -d train_data
+```
+
+```python
+# 随机查看文字检测数据集图片
+from PIL import Image
+import matplotlib.pyplot as plt
+import numpy as np
+import os
+
+
+train = './train_data/icdar2015/text_localization/test'
+# 从指定目录中选取一张图片
+def get_one_image(train):
+ plt.figure()
+ files = os.listdir(train)
+ n = len(files)
+ ind = np.random.randint(0,n)
+ img_dir = os.path.join(train,files[ind])
+ image = Image.open(img_dir)
+ plt.imshow(image)
+ plt.show()
+ image = image.resize([208, 208])
+
+get_one_image(train)
+```
+
+
+### 4.3 模型训练
+
+#### 4.3.1 预训练模型直接评估
+下载我们需要的PP-OCRv3检测预训练模型,更多选择请自行选择其他的[文字检测模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/models_list.md#1-%E6%96%87%E6%9C%AC%E6%A3%80%E6%B5%8B%E6%A8%A1%E5%9E%8B)
+
+```python
+#使用该指令下载需要的预训练模型
+wget -P ./pretrained_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
+# 解压预训练模型文件
+tar -xf ./pretrained_models/ch_PP-OCRv3_det_distill_train.tar -C pretrained_models
+```
+
+在训练之前,我们可以直接使用下面命令来评估预训练模型的效果:
+
+```python
+# 评估预训练模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model="./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy"
+```
+
+结果如下:
+
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.5%|
+
+#### 4.3.2 预训练模型直接finetune
+##### 修改配置文件
+我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+```
+epoch:100
+save_epoch_step:10
+eval_batch_step:[0, 50]
+save_model_dir: ./output/ch_PP-OCR_v3_det/
+pretrained_model: ./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy
+learning_rate: 0.00025
+num_workers: 0 # 如果单卡训练,建议将Train和Eval的loader部分的num_workers设置为0,否则会出现`/dev/shm insufficient`的报错
+```
+
+##### 开始训练
+使用我们上面修改的配置文件configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml,训练命令如下:
+
+```python
+# 开始训练模型
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.5%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.2%|
+
+#### 4.3.3 基于预训练模型Finetune_student模型
+
+我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+```
+epoch:100
+save_epoch_step:10
+eval_batch_step:[0, 50]
+save_model_dir: ./output/ch_PP-OCR_v3_det_student/
+pretrained_model: ./pretrained_models/ch_PP-OCRv3_det_distill_train/student
+learning_rate: 0.00025
+num_workers: 0 # 如果单卡训练,建议将Train和Eval的loader部分的num_workers设置为0,否则会出现`/dev/shm insufficient`的报错
+```
+
+训练命令如下:
+
+```python
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/student
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det_student/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.5%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.2%|
+| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.0%|
+
+#### 4.3.4 基于预训练模型Finetune_teacher模型
+
+首先需要从提供的预训练模型best_accuracy.pdparams中提取teacher参数,组合成适合dml训练的初始化模型,提取代码如下:
+
+```python
+cd ./pretrained_models/
+# transform teacher params in best_accuracy.pdparams into teacher_dml.paramers
+import paddle
+
+# load pretrained model
+all_params = paddle.load("ch_PP-OCRv3_det_distill_train/best_accuracy.pdparams")
+# print(all_params.keys())
+
+# keep teacher params
+t_params = {key[len("Teacher."):]: all_params[key] for key in all_params if "Teacher." in key}
+
+# print(t_params.keys())
+
+s_params = {"Student." + key: t_params[key] for key in t_params}
+s2_params = {"Student2." + key: t_params[key] for key in t_params}
+s_params = {**s_params, **s2_params}
+# print(s_params.keys())
+
+paddle.save(s_params, "ch_PP-OCRv3_det_distill_train/teacher_dml.pdparams")
+
+```
+
+我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+```
+epoch:100
+save_epoch_step:10
+eval_batch_step:[0, 50]
+save_model_dir: ./output/ch_PP-OCR_v3_det_teacher/
+pretrained_model: ./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_dml
+learning_rate: 0.00025
+num_workers: 0 # 如果单卡训练,建议将Train和Eval的loader部分的num_workers设置为0,否则会出现`/dev/shm insufficient`的报错
+```
+
+训练命令如下:
+
+```python
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_dml
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det_teacher/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.5%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.2%|
+| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.0%|
+| 3 | PP-OCRv3中英文超轻量检测预训练模型fintune教师模型 |84.8%|
+
+#### 4.3.5 采用CML蒸馏进一步提升student模型精度
+
+需要从4.3.3和4.3.4训练得到的best_accuracy.pdparams中提取各自代表student和teacher的参数,组合成适合cml训练的初始化模型,提取代码如下:
+
+```python
+# transform teacher params and student parameters into cml model
+import paddle
+
+all_params = paddle.load("./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy.pdparams")
+# print(all_params.keys())
+
+t_params = paddle.load("./output/ch_PP-OCR_v3_det_teacher/best_accuracy.pdparams")
+# print(t_params.keys())
+
+s_params = paddle.load("./output/ch_PP-OCR_v3_det_student/best_accuracy.pdparams")
+# print(s_params.keys())
+
+for key in all_params:
+ # teacher is OK
+ if "Teacher." in key:
+ new_key = key.replace("Teacher", "Student")
+ #print("{} >> {}\n".format(key, new_key))
+ assert all_params[key].shape == t_params[new_key].shape
+ all_params[key] = t_params[new_key]
+
+ if "Student." in key:
+ new_key = key.replace("Student.", "")
+ #print("{} >> {}\n".format(key, new_key))
+ assert all_params[key].shape == s_params[new_key].shape
+ all_params[key] = s_params[new_key]
+
+ if "Student2." in key:
+ new_key = key.replace("Student2.", "")
+ print("{} >> {}\n".format(key, new_key))
+ assert all_params[key].shape == s_params[new_key].shape
+ all_params[key] = s_params[new_key]
+
+paddle.save(all_params, "./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_cml_student.pdparams")
+```
+
+训练命令如下:
+
+```python
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_cml_student Global.save_model_dir=./output/ch_PP-OCR_v3_det_finetune/
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det_finetune/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.5%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.2%|
+| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.0%|
+| 3 | PP-OCRv3中英文超轻量检测预训练模型fintune教师模型 |84.8%|
+| 4 | 基于2和3训练好的模型fintune |82.7%|
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
图27 导出Excel
@@ -859,7 +879,7 @@ with open('output/re/infer_results.txt', 'r', encoding='utf-8') as fin:
workbook.close()
```
-# 更多资源
+## 更多资源
- 更多深度学习知识、产业案例、面试宝典等,请参考:[awesome-DeepLearning](https://github.com/paddlepaddle/awesome-DeepLearning)
@@ -869,7 +889,7 @@ workbook.close()
- 飞桨框架相关资料,请参考:[飞桨深度学习平台](https://www.paddlepaddle.org.cn/?fr=paddleEdu_aistudio)
-# 参考链接
+## 参考链接
- LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding, https://arxiv.org/pdf/2104.08836.pdf
diff --git "a/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md" "b/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md"
new file mode 100644
index 0000000000000000000000000000000000000000..ff2fb2cb4812f4f8366605b3c26af5b9aaaa290e
--- /dev/null
+++ "b/applications/\346\266\262\346\231\266\345\261\217\350\257\273\346\225\260\350\257\206\345\210\253.md"
@@ -0,0 +1,616 @@
+# 基于PP-OCRv3的液晶屏读数识别
+
+- [1. 项目背景及意义](#1-项目背景及意义)
+- [2. 项目内容](#2-项目内容)
+- [3. 安装环境](#3-安装环境)
+- [4. 文字检测](#4-文字检测)
+ - [4.1 PP-OCRv3检测算法介绍](#41-PP-OCRv3检测算法介绍)
+ - [4.2 数据准备](#42-数据准备)
+ - [4.3 模型训练](#43-模型训练)
+ - [4.3.1 预训练模型直接评估](#431-预训练模型直接评估)
+ - [4.3.2 预训练模型直接finetune](#432-预训练模型直接finetune)
+ - [4.3.3 基于预训练模型Finetune_student模型](#433-基于预训练模型Finetune_student模型)
+ - [4.3.4 基于预训练模型Finetune_teacher模型](#434-基于预训练模型Finetune_teacher模型)
+ - [4.3.5 采用CML蒸馏进一步提升student模型精度](#435-采用CML蒸馏进一步提升student模型精度)
+ - [4.3.6 模型导出推理](#436-4.3.6-模型导出推理)
+- [5. 文字识别](#5-文字识别)
+ - [5.1 PP-OCRv3识别算法介绍](#51-PP-OCRv3识别算法介绍)
+ - [5.2 数据准备](#52-数据准备)
+ - [5.3 模型训练](#53-模型训练)
+ - [5.4 模型导出推理](#54-模型导出推理)
+- [6. 系统串联](#6-系统串联)
+ - [6.1 后处理](#61-后处理)
+- [7. PaddleServing部署](#7-PaddleServing部署)
+
+
+## 1. 项目背景及意义
+目前光学字符识别(OCR)技术在我们的生活当中被广泛使用,但是大多数模型在通用场景下的准确性还有待提高,针对于此我们借助飞桨提供的PaddleOCR套件较容易的实现了在垂类场景下的应用。
+
+该项目以国家质量基础(NQI)为准绳,充分利用大数据、云计算、物联网等高新技术,构建覆盖计量端、实验室端、数据端和硬件端的完整计量解决方案,解决传统计量校准中存在的难题,拓宽计量检测服务体系和服务领域;解决无数传接口或数传接口不统一、不公开的计量设备,以及计量设备所处的环境比较恶劣,不适合人工读取数据。通过OCR技术实现远程计量,引领计量行业向智慧计量转型和发展。
+
+## 2. 项目内容
+本项目基于PaddleOCR开源套件,以PP-OCRv3检测和识别模型为基础,针对液晶屏读数识别场景进行优化。
+
+Aistudio项目链接:[OCR液晶屏读数识别](https://aistudio.baidu.com/aistudio/projectdetail/4080130)
+
+## 3. 安装环境
+
+```python
+# 首先git官方的PaddleOCR项目,安装需要的依赖
+# 第一次运行打开该注释
+# git clone https://gitee.com/PaddlePaddle/PaddleOCR.git
+cd PaddleOCR
+pip install -r requirements.txt
+```
+
+## 4. 文字检测
+文本检测的任务是定位出输入图像中的文字区域。近年来学术界关于文本检测的研究非常丰富,一类方法将文本检测视为目标检测中的一个特定场景,基于通用目标检测算法进行改进适配,如TextBoxes[1]基于一阶段目标检测器SSD[2]算法,调整目标框使之适合极端长宽比的文本行,CTPN[3]则是基于Faster RCNN[4]架构改进而来。但是文本检测与目标检测在目标信息以及任务本身上仍存在一些区别,如文本一般长宽比较大,往往呈“条状”,文本行之间可能比较密集,弯曲文本等,因此又衍生了很多专用于文本检测的算法。本项目基于PP-OCRv3算法进行优化。
+
+### 4.1 PP-OCRv3检测算法介绍
+PP-OCRv3检测模型是对PP-OCRv2中的CML(Collaborative Mutual Learning) 协同互学习文本检测蒸馏策略进行了升级。如下图所示,CML的核心思想结合了①传统的Teacher指导Student的标准蒸馏与 ②Students网络之间的DML互学习,可以让Students网络互学习的同时,Teacher网络予以指导。PP-OCRv3分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML(Deep Mutual Learning)蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
+
+
+详细优化策略描述请参考[PP-OCRv3优化策略](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md#2)
+
+### 4.2 数据准备
+[计量设备屏幕字符检测数据集](https://aistudio.baidu.com/aistudio/datasetdetail/127845)数据来源于实际项目中各种计量设备的数显屏,以及在网上搜集的一些其他数显屏,包含训练集755张,测试集355张。
+
+```python
+# 在PaddleOCR下创建新的文件夹train_data
+mkdir train_data
+# 下载数据集并解压到指定路径下
+unzip icdar2015.zip -d train_data
+```
+
+```python
+# 随机查看文字检测数据集图片
+from PIL import Image
+import matplotlib.pyplot as plt
+import numpy as np
+import os
+
+
+train = './train_data/icdar2015/text_localization/test'
+# 从指定目录中选取一张图片
+def get_one_image(train):
+ plt.figure()
+ files = os.listdir(train)
+ n = len(files)
+ ind = np.random.randint(0,n)
+ img_dir = os.path.join(train,files[ind])
+ image = Image.open(img_dir)
+ plt.imshow(image)
+ plt.show()
+ image = image.resize([208, 208])
+
+get_one_image(train)
+```
+
+
+### 4.3 模型训练
+
+#### 4.3.1 预训练模型直接评估
+下载我们需要的PP-OCRv3检测预训练模型,更多选择请自行选择其他的[文字检测模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/models_list.md#1-%E6%96%87%E6%9C%AC%E6%A3%80%E6%B5%8B%E6%A8%A1%E5%9E%8B)
+
+```python
+#使用该指令下载需要的预训练模型
+wget -P ./pretrained_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
+# 解压预训练模型文件
+tar -xf ./pretrained_models/ch_PP-OCRv3_det_distill_train.tar -C pretrained_models
+```
+
+在训练之前,我们可以直接使用下面命令来评估预训练模型的效果:
+
+```python
+# 评估预训练模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model="./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy"
+```
+
+结果如下:
+
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.5%|
+
+#### 4.3.2 预训练模型直接finetune
+##### 修改配置文件
+我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+```
+epoch:100
+save_epoch_step:10
+eval_batch_step:[0, 50]
+save_model_dir: ./output/ch_PP-OCR_v3_det/
+pretrained_model: ./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy
+learning_rate: 0.00025
+num_workers: 0 # 如果单卡训练,建议将Train和Eval的loader部分的num_workers设置为0,否则会出现`/dev/shm insufficient`的报错
+```
+
+##### 开始训练
+使用我们上面修改的配置文件configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml,训练命令如下:
+
+```python
+# 开始训练模型
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.5%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.2%|
+
+#### 4.3.3 基于预训练模型Finetune_student模型
+
+我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+```
+epoch:100
+save_epoch_step:10
+eval_batch_step:[0, 50]
+save_model_dir: ./output/ch_PP-OCR_v3_det_student/
+pretrained_model: ./pretrained_models/ch_PP-OCRv3_det_distill_train/student
+learning_rate: 0.00025
+num_workers: 0 # 如果单卡训练,建议将Train和Eval的loader部分的num_workers设置为0,否则会出现`/dev/shm insufficient`的报错
+```
+
+训练命令如下:
+
+```python
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/student
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det_student/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.5%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.2%|
+| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.0%|
+
+#### 4.3.4 基于预训练模型Finetune_teacher模型
+
+首先需要从提供的预训练模型best_accuracy.pdparams中提取teacher参数,组合成适合dml训练的初始化模型,提取代码如下:
+
+```python
+cd ./pretrained_models/
+# transform teacher params in best_accuracy.pdparams into teacher_dml.paramers
+import paddle
+
+# load pretrained model
+all_params = paddle.load("ch_PP-OCRv3_det_distill_train/best_accuracy.pdparams")
+# print(all_params.keys())
+
+# keep teacher params
+t_params = {key[len("Teacher."):]: all_params[key] for key in all_params if "Teacher." in key}
+
+# print(t_params.keys())
+
+s_params = {"Student." + key: t_params[key] for key in t_params}
+s2_params = {"Student2." + key: t_params[key] for key in t_params}
+s_params = {**s_params, **s2_params}
+# print(s_params.keys())
+
+paddle.save(s_params, "ch_PP-OCRv3_det_distill_train/teacher_dml.pdparams")
+
+```
+
+我们使用configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml,主要修改训练轮数和学习率参相关参数,设置预训练模型路径,设置数据集路径。 另外,batch_size可根据自己机器显存大小进行调整。 具体修改如下几个地方:
+```
+epoch:100
+save_epoch_step:10
+eval_batch_step:[0, 50]
+save_model_dir: ./output/ch_PP-OCR_v3_det_teacher/
+pretrained_model: ./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_dml
+learning_rate: 0.00025
+num_workers: 0 # 如果单卡训练,建议将Train和Eval的loader部分的num_workers设置为0,否则会出现`/dev/shm insufficient`的报错
+```
+
+训练命令如下:
+
+```python
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_dml
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_dml.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det_teacher/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.5%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.2%|
+| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.0%|
+| 3 | PP-OCRv3中英文超轻量检测预训练模型fintune教师模型 |84.8%|
+
+#### 4.3.5 采用CML蒸馏进一步提升student模型精度
+
+需要从4.3.3和4.3.4训练得到的best_accuracy.pdparams中提取各自代表student和teacher的参数,组合成适合cml训练的初始化模型,提取代码如下:
+
+```python
+# transform teacher params and student parameters into cml model
+import paddle
+
+all_params = paddle.load("./pretrained_models/ch_PP-OCRv3_det_distill_train/best_accuracy.pdparams")
+# print(all_params.keys())
+
+t_params = paddle.load("./output/ch_PP-OCR_v3_det_teacher/best_accuracy.pdparams")
+# print(t_params.keys())
+
+s_params = paddle.load("./output/ch_PP-OCR_v3_det_student/best_accuracy.pdparams")
+# print(s_params.keys())
+
+for key in all_params:
+ # teacher is OK
+ if "Teacher." in key:
+ new_key = key.replace("Teacher", "Student")
+ #print("{} >> {}\n".format(key, new_key))
+ assert all_params[key].shape == t_params[new_key].shape
+ all_params[key] = t_params[new_key]
+
+ if "Student." in key:
+ new_key = key.replace("Student.", "")
+ #print("{} >> {}\n".format(key, new_key))
+ assert all_params[key].shape == s_params[new_key].shape
+ all_params[key] = s_params[new_key]
+
+ if "Student2." in key:
+ new_key = key.replace("Student2.", "")
+ print("{} >> {}\n".format(key, new_key))
+ assert all_params[key].shape == s_params[new_key].shape
+ all_params[key] = s_params[new_key]
+
+paddle.save(all_params, "./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_cml_student.pdparams")
+```
+
+训练命令如下:
+
+```python
+python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model=./pretrained_models/ch_PP-OCRv3_det_distill_train/teacher_cml_student Global.save_model_dir=./output/ch_PP-OCR_v3_det_finetune/
+```
+
+评估训练好的模型:
+
+```python
+# 评估训练好的模型
+python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml -o Global.pretrained_model="./output/ch_PP-OCR_v3_det_finetune/best_accuracy"
+```
+
+结果如下:
+| | 方案 |hmeans|
+|---|---------------------------|---|
+| 0 | PP-OCRv3中英文超轻量检测预训练模型直接预测 |47.5%|
+| 1 | PP-OCRv3中英文超轻量检测预训练模型fintune |65.2%|
+| 2 | PP-OCRv3中英文超轻量检测预训练模型fintune学生模型 |80.0%|
+| 3 | PP-OCRv3中英文超轻量检测预训练模型fintune教师模型 |84.8%|
+| 4 | 基于2和3训练好的模型fintune |82.7%|
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+
+
+
+
+
+
+
', ''] + dict_character
- return dict_character
-
-
class CTCLabelEncode(BaseRecLabelEncode):
""" Convert between text-label and text-index """
@@ -290,15 +259,26 @@ class E2ELabelEncodeTrain(object):
class KieLabelEncode(object):
- def __init__(self, character_dict_path, norm=10, directed=False, **kwargs):
+ def __init__(self,
+ character_dict_path,
+ class_path,
+ norm=10,
+ directed=False,
+ **kwargs):
super(KieLabelEncode, self).__init__()
self.dict = dict({'': 0})
+ self.label2classid_map = dict()
with open(character_dict_path, 'r', encoding='utf-8') as fr:
idx = 1
for line in fr:
char = line.strip()
self.dict[char] = idx
idx += 1
+ with open(class_path, "r") as fin:
+ lines = fin.readlines()
+ for idx, line in enumerate(lines):
+ line = line.strip("\n")
+ self.label2classid_map[line] = idx
self.norm = norm
self.directed = directed
@@ -439,7 +419,7 @@ class KieLabelEncode(object):
text_ind = [self.dict[c] for c in text if c in self.dict]
text_inds.append(text_ind)
if 'label' in ann.keys():
- labels.append(ann['label'])
+ labels.append(self.label2classid_map[ann['label']])
elif 'key_cls' in ann.keys():
labels.append(ann['key_cls'])
else:
@@ -907,15 +887,16 @@ class VQATokenLabelEncode(object):
for info in ocr_info:
if train_re:
# for re
- if len(info["text"]) == 0:
+ if len(info["transcription"]) == 0:
empty_entity.add(info["id"])
continue
id2label[info["id"]] = info["label"]
relations.extend([tuple(sorted(l)) for l in info["linking"]])
# smooth_box
+ info["bbox"] = self.trans_poly_to_bbox(info["points"])
bbox = self._smooth_box(info["bbox"], height, width)
- text = info["text"]
+ text = info["transcription"]
encode_res = self.tokenizer.encode(
text, pad_to_max_seq_len=False, return_attention_mask=True)
@@ -931,7 +912,7 @@ class VQATokenLabelEncode(object):
label = info['label']
gt_label = self._parse_label(label, encode_res)
- # construct entities for re
+# construct entities for re
if train_re:
if gt_label[0] != self.label2id_map["O"]:
entity_id_to_index_map[info["id"]] = len(entities)
@@ -975,29 +956,29 @@ class VQATokenLabelEncode(object):
data['entity_id_to_index_map'] = entity_id_to_index_map
return data
- def _load_ocr_info(self, data):
- def trans_poly_to_bbox(poly):
- x1 = np.min([p[0] for p in poly])
- x2 = np.max([p[0] for p in poly])
- y1 = np.min([p[1] for p in poly])
- y2 = np.max([p[1] for p in poly])
- return [x1, y1, x2, y2]
+ def trans_poly_to_bbox(self, poly):
+ x1 = np.min([p[0] for p in poly])
+ x2 = np.max([p[0] for p in poly])
+ y1 = np.min([p[1] for p in poly])
+ y2 = np.max([p[1] for p in poly])
+ return [x1, y1, x2, y2]
+ def _load_ocr_info(self, data):
if self.infer_mode:
ocr_result = self.ocr_engine.ocr(data['image'], cls=False)
ocr_info = []
for res in ocr_result:
ocr_info.append({
- "text": res[1][0],
- "bbox": trans_poly_to_bbox(res[0]),
- "poly": res[0],
+ "transcription": res[1][0],
+ "bbox": self.trans_poly_to_bbox(res[0]),
+ "points": res[0],
})
return ocr_info
else:
info = data['label']
# read text info
info_dict = json.loads(info)
- return info_dict["ocr_info"]
+ return info_dict
def _smooth_box(self, bbox, height, width):
bbox[0] = int(bbox[0] * 1000.0 / width)
@@ -1008,7 +989,7 @@ class VQATokenLabelEncode(object):
def _parse_label(self, label, encode_res):
gt_label = []
- if label.lower() == "other":
+ if label.lower() in ["other", "others", "ignore"]:
gt_label.extend([0] * len(encode_res["input_ids"]))
else:
gt_label.append(self.label2id_map[("b-" + label).upper()])
@@ -1046,3 +1027,99 @@ class MultiLabelEncode(BaseRecLabelEncode):
data_out['label_sar'] = sar['label']
data_out['length'] = ctc['length']
return data_out
+
+
+class NRTRLabelEncode(BaseRecLabelEncode):
+ """ Convert between text-label and text-index """
+
+ def __init__(self,
+ max_text_length,
+ character_dict_path=None,
+ use_space_char=False,
+ **kwargs):
+
+ super(NRTRLabelEncode, self).__init__(
+ max_text_length, character_dict_path, use_space_char)
+
+ def __call__(self, data):
+ text = data['label']
+ text = self.encode(text)
+ if text is None:
+ return None
+ if len(text) >= self.max_text_len - 1:
+ return None
+ data['length'] = np.array(len(text))
+ text.insert(0, 2)
+ text.append(3)
+ text = text + [0] * (self.max_text_len - len(text))
+ data['label'] = np.array(text)
+ return data
+
+ def add_special_char(self, dict_character):
+ dict_character = ['blank', '', '', ''] + dict_character
+ return dict_character
+
+
+class ViTSTRLabelEncode(BaseRecLabelEncode):
+ """ Convert between text-label and text-index """
+
+ def __init__(self,
+ max_text_length,
+ character_dict_path=None,
+ use_space_char=False,
+ ignore_index=0,
+ **kwargs):
+
+ super(ViTSTRLabelEncode, self).__init__(
+ max_text_length, character_dict_path, use_space_char)
+ self.ignore_index = ignore_index
+
+ def __call__(self, data):
+ text = data['label']
+ text = self.encode(text)
+ if text is None:
+ return None
+ if len(text) >= self.max_text_len:
+ return None
+ data['length'] = np.array(len(text))
+ text.insert(0, self.ignore_index)
+ text.append(1)
+ text = text + [self.ignore_index] * (self.max_text_len + 2 - len(text))
+ data['label'] = np.array(text)
+ return data
+
+ def add_special_char(self, dict_character):
+ dict_character = ['', ''] + dict_character
+ return dict_character
+
+
+class ABINetLabelEncode(BaseRecLabelEncode):
+ """ Convert between text-label and text-index """
+
+ def __init__(self,
+ max_text_length,
+ character_dict_path=None,
+ use_space_char=False,
+ ignore_index=100,
+ **kwargs):
+
+ super(ABINetLabelEncode, self).__init__(
+ max_text_length, character_dict_path, use_space_char)
+ self.ignore_index = ignore_index
+
+ def __call__(self, data):
+ text = data['label']
+ text = self.encode(text)
+ if text is None:
+ return None
+ if len(text) >= self.max_text_len:
+ return None
+ data['length'] = np.array(len(text))
+ text.append(0)
+ text = text + [self.ignore_index] * (self.max_text_len + 1 - len(text))
+ data['label'] = np.array(text)
+ return data
+
+ def add_special_char(self, dict_character):
+ dict_character = [''] + dict_character
+ return dict_character
diff --git a/ppocr/data/imaug/operators.py b/ppocr/data/imaug/operators.py
index 070fb7afa0b366c016edadb2b734ba5a6798743a..04cc2848fb4d25baaf553c6eda235ddb0e86511f 100644
--- a/ppocr/data/imaug/operators.py
+++ b/ppocr/data/imaug/operators.py
@@ -67,39 +67,6 @@ class DecodeImage(object):
return data
-class NRTRDecodeImage(object):
- """ decode image """
-
- def __init__(self, img_mode='RGB', channel_first=False, **kwargs):
- self.img_mode = img_mode
- self.channel_first = channel_first
-
- def __call__(self, data):
- img = data['image']
- if six.PY2:
- assert type(img) is str and len(
- img) > 0, "invalid input 'img' in DecodeImage"
- else:
- assert type(img) is bytes and len(
- img) > 0, "invalid input 'img' in DecodeImage"
- img = np.frombuffer(img, dtype='uint8')
-
- img = cv2.imdecode(img, 1)
-
- if img is None:
- return None
- if self.img_mode == 'GRAY':
- img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
- elif self.img_mode == 'RGB':
- assert img.shape[2] == 3, 'invalid shape of image[%s]' % (img.shape)
- img = img[:, :, ::-1]
- img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
- if self.channel_first:
- img = img.transpose((2, 0, 1))
- data['image'] = img
- return data
-
-
class NormalizeImage(object):
""" normalize image such as substract mean, divide std
"""
diff --git a/ppocr/data/imaug/rec_img_aug.py b/ppocr/data/imaug/rec_img_aug.py
index 32de2b3fc36757fee954de41686d09999ce4c640..26773d0a516dfb0877453c7a5c8c8a2b5da92045 100644
--- a/ppocr/data/imaug/rec_img_aug.py
+++ b/ppocr/data/imaug/rec_img_aug.py
@@ -19,6 +19,8 @@ import random
import copy
from PIL import Image
from .text_image_aug import tia_perspective, tia_stretch, tia_distort
+from .abinet_aug import CVGeometry, CVDeterioration, CVColorJitter
+from paddle.vision.transforms import Compose
class RecAug(object):
@@ -94,6 +96,36 @@ class BaseDataAugmentation(object):
return data
+class ABINetRecAug(object):
+ def __init__(self,
+ geometry_p=0.5,
+ deterioration_p=0.25,
+ colorjitter_p=0.25,
+ **kwargs):
+ self.transforms = Compose([
+ CVGeometry(
+ degrees=45,
+ translate=(0.0, 0.0),
+ scale=(0.5, 2.),
+ shear=(45, 15),
+ distortion=0.5,
+ p=geometry_p), CVDeterioration(
+ var=20, degrees=6, factor=4, p=deterioration_p),
+ CVColorJitter(
+ brightness=0.5,
+ contrast=0.5,
+ saturation=0.5,
+ hue=0.1,
+ p=colorjitter_p)
+ ])
+
+ def __call__(self, data):
+ img = data['image']
+ img = self.transforms(img)
+ data['image'] = img
+ return data
+
+
class RecConAug(object):
def __init__(self,
prob=0.5,
@@ -148,46 +180,6 @@ class ClsResizeImg(object):
return data
-class NRTRRecResizeImg(object):
- def __init__(self, image_shape, resize_type, padding=False, **kwargs):
- self.image_shape = image_shape
- self.resize_type = resize_type
- self.padding = padding
-
- def __call__(self, data):
- img = data['image']
- img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
- image_shape = self.image_shape
- if self.padding:
- imgC, imgH, imgW = image_shape
- # todo: change to 0 and modified image shape
- h = img.shape[0]
- w = img.shape[1]
- ratio = w / float(h)
- if math.ceil(imgH * ratio) > imgW:
- resized_w = imgW
- else:
- resized_w = int(math.ceil(imgH * ratio))
- resized_image = cv2.resize(img, (resized_w, imgH))
- norm_img = np.expand_dims(resized_image, -1)
- norm_img = norm_img.transpose((2, 0, 1))
- resized_image = norm_img.astype(np.float32) / 128. - 1.
- padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
- padding_im[:, :, 0:resized_w] = resized_image
- data['image'] = padding_im
- return data
- if self.resize_type == 'PIL':
- image_pil = Image.fromarray(np.uint8(img))
- img = image_pil.resize(self.image_shape, Image.ANTIALIAS)
- img = np.array(img)
- if self.resize_type == 'OpenCV':
- img = cv2.resize(img, self.image_shape)
- norm_img = np.expand_dims(img, -1)
- norm_img = norm_img.transpose((2, 0, 1))
- data['image'] = norm_img.astype(np.float32) / 128. - 1.
- return data
-
-
class RecResizeImg(object):
def __init__(self,
image_shape,
@@ -268,6 +260,84 @@ class PRENResizeImg(object):
return data
+class GrayRecResizeImg(object):
+ def __init__(self,
+ image_shape,
+ resize_type,
+ inter_type='Image.ANTIALIAS',
+ scale=True,
+ padding=False,
+ **kwargs):
+ self.image_shape = image_shape
+ self.resize_type = resize_type
+ self.padding = padding
+ self.inter_type = eval(inter_type)
+ self.scale = scale
+
+ def __call__(self, data):
+ img = data['image']
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
+ image_shape = self.image_shape
+ if self.padding:
+ imgC, imgH, imgW = image_shape
+ # todo: change to 0 and modified image shape
+ h = img.shape[0]
+ w = img.shape[1]
+ ratio = w / float(h)
+ if math.ceil(imgH * ratio) > imgW:
+ resized_w = imgW
+ else:
+ resized_w = int(math.ceil(imgH * ratio))
+ resized_image = cv2.resize(img, (resized_w, imgH))
+ norm_img = np.expand_dims(resized_image, -1)
+ norm_img = norm_img.transpose((2, 0, 1))
+ resized_image = norm_img.astype(np.float32) / 128. - 1.
+ padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
+ padding_im[:, :, 0:resized_w] = resized_image
+ data['image'] = padding_im
+ return data
+ if self.resize_type == 'PIL':
+ image_pil = Image.fromarray(np.uint8(img))
+ img = image_pil.resize(self.image_shape, self.inter_type)
+ img = np.array(img)
+ if self.resize_type == 'OpenCV':
+ img = cv2.resize(img, self.image_shape)
+ norm_img = np.expand_dims(img, -1)
+ norm_img = norm_img.transpose((2, 0, 1))
+ if self.scale:
+ data['image'] = norm_img.astype(np.float32) / 128. - 1.
+ else:
+ data['image'] = norm_img.astype(np.float32) / 255.
+ return data
+
+
+class ABINetRecResizeImg(object):
+ def __init__(self, image_shape, **kwargs):
+ self.image_shape = image_shape
+
+ def __call__(self, data):
+ img = data['image']
+ norm_img, valid_ratio = resize_norm_img_abinet(img, self.image_shape)
+ data['image'] = norm_img
+ data['valid_ratio'] = valid_ratio
+ return data
+
+
+class SVTRRecResizeImg(object):
+ def __init__(self, image_shape, padding=True, **kwargs):
+ self.image_shape = image_shape
+ self.padding = padding
+
+ def __call__(self, data):
+ img = data['image']
+
+ norm_img, valid_ratio = resize_norm_img(img, self.image_shape,
+ self.padding)
+ data['image'] = norm_img
+ data['valid_ratio'] = valid_ratio
+ return data
+
+
def resize_norm_img_sar(img, image_shape, width_downsample_ratio=0.25):
imgC, imgH, imgW_min, imgW_max = image_shape
h = img.shape[0]
@@ -386,6 +456,26 @@ def resize_norm_img_srn(img, image_shape):
return np.reshape(img_black, (c, row, col)).astype(np.float32)
+def resize_norm_img_abinet(img, image_shape):
+ imgC, imgH, imgW = image_shape
+
+ resized_image = cv2.resize(
+ img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_w = imgW
+ resized_image = resized_image.astype('float32')
+ resized_image = resized_image / 255.
+
+ mean = np.array([0.485, 0.456, 0.406])
+ std = np.array([0.229, 0.224, 0.225])
+ resized_image = (
+ resized_image - mean[None, None, ...]) / std[None, None, ...]
+ resized_image = resized_image.transpose((2, 0, 1))
+ resized_image = resized_image.astype('float32')
+
+ valid_ratio = min(1.0, float(resized_w / imgW))
+ return resized_image, valid_ratio
+
+
def srn_other_inputs(image_shape, num_heads, max_text_length):
imgC, imgH, imgW = image_shape
diff --git a/ppocr/data/imaug/vqa/__init__.py b/ppocr/data/imaug/vqa/__init__.py
index a5025e7985198e7ee40d6c92d8e1814eb1797032..bde175115536a3f644750260082204fe5f10dc05 100644
--- a/ppocr/data/imaug/vqa/__init__.py
+++ b/ppocr/data/imaug/vqa/__init__.py
@@ -13,7 +13,12 @@
# limitations under the License.
from .token import VQATokenPad, VQASerTokenChunk, VQAReTokenChunk, VQAReTokenRelation
+from .augment import DistortBBox
__all__ = [
- 'VQATokenPad', 'VQASerTokenChunk', 'VQAReTokenChunk', 'VQAReTokenRelation'
+ 'VQATokenPad',
+ 'VQASerTokenChunk',
+ 'VQAReTokenChunk',
+ 'VQAReTokenRelation',
+ 'DistortBBox',
]
diff --git a/ppocr/data/imaug/vqa/augment.py b/ppocr/data/imaug/vqa/augment.py
new file mode 100644
index 0000000000000000000000000000000000000000..fcdc9685e9855c3a2d8e9f6f5add270f95f15a6c
--- /dev/null
+++ b/ppocr/data/imaug/vqa/augment.py
@@ -0,0 +1,37 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import sys
+import numpy as np
+import random
+
+
+class DistortBBox:
+ def __init__(self, prob=0.5, max_scale=1, **kwargs):
+ """Random distort bbox
+ """
+ self.prob = prob
+ self.max_scale = max_scale
+
+ def __call__(self, data):
+ if random.random() > self.prob:
+ return data
+ bbox = np.array(data['bbox'])
+ rnd_scale = (np.random.rand(*bbox.shape) - 0.5) * 2 * self.max_scale
+ bbox = np.round(bbox + rnd_scale).astype(bbox.dtype)
+ data['bbox'] = np.clip(data['bbox'], 0, 1000)
+ data['bbox'] = bbox.tolist()
+ sys.stdout.flush()
+ return data
diff --git a/ppocr/losses/__init__.py b/ppocr/losses/__init__.py
index de8419b7c1cf6a30ab7195a1cbcbb10a5e52642d..7bea87f62f335a9a47c881d4bc789ce34aaa734a 100755
--- a/ppocr/losses/__init__.py
+++ b/ppocr/losses/__init__.py
@@ -30,7 +30,7 @@ from .det_fce_loss import FCELoss
from .rec_ctc_loss import CTCLoss
from .rec_att_loss import AttentionLoss
from .rec_srn_loss import SRNLoss
-from .rec_nrtr_loss import NRTRLoss
+from .rec_ce_loss import CELoss
from .rec_sar_loss import SARLoss
from .rec_aster_loss import AsterLoss
from .rec_pren_loss import PRENLoss
@@ -60,7 +60,7 @@ def build_loss(config):
support_dict = [
'DBLoss', 'PSELoss', 'EASTLoss', 'SASTLoss', 'FCELoss', 'CTCLoss',
'ClsLoss', 'AttentionLoss', 'SRNLoss', 'PGLoss', 'CombinedLoss',
- 'NRTRLoss', 'TableAttentionLoss', 'SARLoss', 'AsterLoss', 'SDMGRLoss',
+ 'CELoss', 'TableAttentionLoss', 'SARLoss', 'AsterLoss', 'SDMGRLoss',
'VQASerTokenLayoutLMLoss', 'LossFromOutput', 'PRENLoss', 'MultiLoss'
]
config = copy.deepcopy(config)
diff --git a/ppocr/losses/rec_ce_loss.py b/ppocr/losses/rec_ce_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..614384de863c15b106aef831f8e938b89dadc246
--- /dev/null
+++ b/ppocr/losses/rec_ce_loss.py
@@ -0,0 +1,66 @@
+import paddle
+from paddle import nn
+import paddle.nn.functional as F
+
+
+class CELoss(nn.Layer):
+ def __init__(self,
+ smoothing=False,
+ with_all=False,
+ ignore_index=-1,
+ **kwargs):
+ super(CELoss, self).__init__()
+ if ignore_index >= 0:
+ self.loss_func = nn.CrossEntropyLoss(
+ reduction='mean', ignore_index=ignore_index)
+ else:
+ self.loss_func = nn.CrossEntropyLoss(reduction='mean')
+ self.smoothing = smoothing
+ self.with_all = with_all
+
+ def forward(self, pred, batch):
+
+ if isinstance(pred, dict): # for ABINet
+ loss = {}
+ loss_sum = []
+ for name, logits in pred.items():
+ if isinstance(logits, list):
+ logit_num = len(logits)
+ all_tgt = paddle.concat([batch[1]] * logit_num, 0)
+ all_logits = paddle.concat(logits, 0)
+ flt_logtis = all_logits.reshape([-1, all_logits.shape[2]])
+ flt_tgt = all_tgt.reshape([-1])
+ else:
+ flt_logtis = logits.reshape([-1, logits.shape[2]])
+ flt_tgt = batch[1].reshape([-1])
+ loss[name + '_loss'] = self.loss_func(flt_logtis, flt_tgt)
+ loss_sum.append(loss[name + '_loss'])
+ loss['loss'] = sum(loss_sum)
+ return loss
+ else:
+ if self.with_all: # for ViTSTR
+ tgt = batch[1]
+ pred = pred.reshape([-1, pred.shape[2]])
+ tgt = tgt.reshape([-1])
+ loss = self.loss_func(pred, tgt)
+ return {'loss': loss}
+ else: # for NRTR
+ max_len = batch[2].max()
+ tgt = batch[1][:, 1:2 + max_len]
+ pred = pred.reshape([-1, pred.shape[2]])
+ tgt = tgt.reshape([-1])
+ if self.smoothing:
+ eps = 0.1
+ n_class = pred.shape[1]
+ one_hot = F.one_hot(tgt, pred.shape[1])
+ one_hot = one_hot * (1 - eps) + (1 - one_hot) * eps / (
+ n_class - 1)
+ log_prb = F.log_softmax(pred, axis=1)
+ non_pad_mask = paddle.not_equal(
+ tgt, paddle.zeros(
+ tgt.shape, dtype=tgt.dtype))
+ loss = -(one_hot * log_prb).sum(axis=1)
+ loss = loss.masked_select(non_pad_mask).mean()
+ else:
+ loss = self.loss_func(pred, tgt)
+ return {'loss': loss}
diff --git a/ppocr/losses/rec_nrtr_loss.py b/ppocr/losses/rec_nrtr_loss.py
deleted file mode 100644
index 200a6d0486dbf6f76dd674eb58f641b31a70f31c..0000000000000000000000000000000000000000
--- a/ppocr/losses/rec_nrtr_loss.py
+++ /dev/null
@@ -1,30 +0,0 @@
-import paddle
-from paddle import nn
-import paddle.nn.functional as F
-
-
-class NRTRLoss(nn.Layer):
- def __init__(self, smoothing=True, **kwargs):
- super(NRTRLoss, self).__init__()
- self.loss_func = nn.CrossEntropyLoss(reduction='mean', ignore_index=0)
- self.smoothing = smoothing
-
- def forward(self, pred, batch):
- pred = pred.reshape([-1, pred.shape[2]])
- max_len = batch[2].max()
- tgt = batch[1][:, 1:2 + max_len]
- tgt = tgt.reshape([-1])
- if self.smoothing:
- eps = 0.1
- n_class = pred.shape[1]
- one_hot = F.one_hot(tgt, pred.shape[1])
- one_hot = one_hot * (1 - eps) + (1 - one_hot) * eps / (n_class - 1)
- log_prb = F.log_softmax(pred, axis=1)
- non_pad_mask = paddle.not_equal(
- tgt, paddle.zeros(
- tgt.shape, dtype=tgt.dtype))
- loss = -(one_hot * log_prb).sum(axis=1)
- loss = loss.masked_select(non_pad_mask).mean()
- else:
- loss = self.loss_func(pred, tgt)
- return {'loss': loss}
diff --git a/ppocr/modeling/backbones/__init__.py b/ppocr/modeling/backbones/__init__.py
index 0d8e60e93aee57dc7f977e4dbeefcff89250200d..ab2939c24d92fcebcd9afe574cb02a6b113190fa 100755
--- a/ppocr/modeling/backbones/__init__.py
+++ b/ppocr/modeling/backbones/__init__.py
@@ -29,35 +29,37 @@ def build_backbone(config, model_type):
from .rec_mv1_enhance import MobileNetV1Enhance
from .rec_nrtr_mtb import MTB
from .rec_resnet_31 import ResNet31
+ from .rec_resnet_45 import ResNet45
from .rec_resnet_aster import ResNet_ASTER
from .rec_micronet import MicroNet
from .rec_efficientb3_pren import EfficientNetb3_PREN
from .rec_svtrnet import SVTRNet
+ from .rec_vitstr import ViTSTR
support_dict = [
'MobileNetV1Enhance', 'MobileNetV3', 'ResNet', 'ResNetFPN', 'MTB',
- "ResNet31", "ResNet_ASTER", 'MicroNet', 'EfficientNetb3_PREN',
- 'SVTRNet'
+ 'ResNet31', 'ResNet45', 'ResNet_ASTER', 'MicroNet',
+ 'EfficientNetb3_PREN', 'SVTRNet', 'ViTSTR'
]
- elif model_type == "e2e":
+ elif model_type == 'e2e':
from .e2e_resnet_vd_pg import ResNet
support_dict = ['ResNet']
elif model_type == 'kie':
from .kie_unet_sdmgr import Kie_backbone
support_dict = ['Kie_backbone']
- elif model_type == "table":
+ elif model_type == 'table':
from .table_resnet_vd import ResNet
from .table_mobilenet_v3 import MobileNetV3
- support_dict = ["ResNet", "MobileNetV3"]
+ support_dict = ['ResNet', 'MobileNetV3']
elif model_type == 'vqa':
from .vqa_layoutlm import LayoutLMForSer, LayoutLMv2ForSer, LayoutLMv2ForRe, LayoutXLMForSer, LayoutXLMForRe
support_dict = [
- "LayoutLMForSer", "LayoutLMv2ForSer", 'LayoutLMv2ForRe',
- "LayoutXLMForSer", 'LayoutXLMForRe'
+ 'LayoutLMForSer', 'LayoutLMv2ForSer', 'LayoutLMv2ForRe',
+ 'LayoutXLMForSer', 'LayoutXLMForRe'
]
else:
raise NotImplementedError
- module_name = config.pop("name")
+ module_name = config.pop('name')
assert module_name in support_dict, Exception(
"when model typs is {}, backbone only support {}".format(model_type,
support_dict))
diff --git a/ppocr/modeling/backbones/rec_resnet_45.py b/ppocr/modeling/backbones/rec_resnet_45.py
new file mode 100644
index 0000000000000000000000000000000000000000..9093d0bc99b78806d36662dec36b6cfbdd4ae493
--- /dev/null
+++ b/ppocr/modeling/backbones/rec_resnet_45.py
@@ -0,0 +1,147 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This code is refer from:
+https://github.com/FangShancheng/ABINet/tree/main/modules
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import paddle
+from paddle import ParamAttr
+from paddle.nn.initializer import KaimingNormal
+import paddle.nn as nn
+import paddle.nn.functional as F
+import numpy as np
+import math
+
+__all__ = ["ResNet45"]
+
+
+def conv1x1(in_planes, out_planes, stride=1):
+ return nn.Conv2D(
+ in_planes,
+ out_planes,
+ kernel_size=1,
+ stride=1,
+ weight_attr=ParamAttr(initializer=KaimingNormal()),
+ bias_attr=False)
+
+
+def conv3x3(in_channel, out_channel, stride=1):
+ return nn.Conv2D(
+ in_channel,
+ out_channel,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ weight_attr=ParamAttr(initializer=KaimingNormal()),
+ bias_attr=False)
+
+
+class BasicBlock(nn.Layer):
+ expansion = 1
+
+ def __init__(self, in_channels, channels, stride=1, downsample=None):
+ super().__init__()
+ self.conv1 = conv1x1(in_channels, channels)
+ self.bn1 = nn.BatchNorm2D(channels)
+ self.relu = nn.ReLU()
+ self.conv2 = conv3x3(channels, channels, stride)
+ self.bn2 = nn.BatchNorm2D(channels)
+ self.downsample = downsample
+ self.stride = stride
+
+ def forward(self, x):
+ residual = x
+
+ out = self.conv1(x)
+ out = self.bn1(out)
+ out = self.relu(out)
+
+ out = self.conv2(out)
+ out = self.bn2(out)
+
+ if self.downsample is not None:
+ residual = self.downsample(x)
+ out += residual
+ out = self.relu(out)
+
+ return out
+
+
+class ResNet45(nn.Layer):
+ def __init__(self, block=BasicBlock, layers=[3, 4, 6, 6, 3], in_channels=3):
+ self.inplanes = 32
+ super(ResNet45, self).__init__()
+ self.conv1 = nn.Conv2D(
+ 3,
+ 32,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ weight_attr=ParamAttr(initializer=KaimingNormal()),
+ bias_attr=False)
+ self.bn1 = nn.BatchNorm2D(32)
+ self.relu = nn.ReLU()
+
+ self.layer1 = self._make_layer(block, 32, layers[0], stride=2)
+ self.layer2 = self._make_layer(block, 64, layers[1], stride=1)
+ self.layer3 = self._make_layer(block, 128, layers[2], stride=2)
+ self.layer4 = self._make_layer(block, 256, layers[3], stride=1)
+ self.layer5 = self._make_layer(block, 512, layers[4], stride=1)
+ self.out_channels = 512
+
+ # for m in self.modules():
+ # if isinstance(m, nn.Conv2D):
+ # n = m._kernel_size[0] * m._kernel_size[1] * m._out_channels
+ # m.weight.data.normal_(0, math.sqrt(2. / n))
+
+ def _make_layer(self, block, planes, blocks, stride=1):
+ downsample = None
+ if stride != 1 or self.inplanes != planes * block.expansion:
+ # downsample = True
+ downsample = nn.Sequential(
+ nn.Conv2D(
+ self.inplanes,
+ planes * block.expansion,
+ kernel_size=1,
+ stride=stride,
+ weight_attr=ParamAttr(initializer=KaimingNormal()),
+ bias_attr=False),
+ nn.BatchNorm2D(planes * block.expansion), )
+
+ layers = []
+ layers.append(block(self.inplanes, planes, stride, downsample))
+ self.inplanes = planes * block.expansion
+ for i in range(1, blocks):
+ layers.append(block(self.inplanes, planes))
+
+ return nn.Sequential(*layers)
+
+ def forward(self, x):
+
+ x = self.conv1(x)
+ x = self.bn1(x)
+ x = self.relu(x)
+ # print(x)
+ x = self.layer1(x)
+ x = self.layer2(x)
+ x = self.layer3(x)
+ # print(x)
+ x = self.layer4(x)
+ x = self.layer5(x)
+ return x
diff --git a/ppocr/modeling/backbones/rec_svtrnet.py b/ppocr/modeling/backbones/rec_svtrnet.py
index c57bf46345d6e08f23b9258358f77f2285366314..c2c07f4476929d49237c8e9a10713f881f5f556b 100644
--- a/ppocr/modeling/backbones/rec_svtrnet.py
+++ b/ppocr/modeling/backbones/rec_svtrnet.py
@@ -147,7 +147,7 @@ class Attention(nn.Layer):
dim,
num_heads=8,
mixer='Global',
- HW=[8, 25],
+ HW=None,
local_k=[7, 11],
qkv_bias=False,
qk_scale=None,
@@ -210,7 +210,7 @@ class Block(nn.Layer):
num_heads,
mixer='Global',
local_mixer=[7, 11],
- HW=[8, 25],
+ HW=None,
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
@@ -274,7 +274,9 @@ class PatchEmbed(nn.Layer):
img_size=[32, 100],
in_channels=3,
embed_dim=768,
- sub_num=2):
+ sub_num=2,
+ patch_size=[4, 4],
+ mode='pope'):
super().__init__()
num_patches = (img_size[1] // (2 ** sub_num)) * \
(img_size[0] // (2 ** sub_num))
@@ -282,50 +284,56 @@ class PatchEmbed(nn.Layer):
self.num_patches = num_patches
self.embed_dim = embed_dim
self.norm = None
- if sub_num == 2:
- self.proj = nn.Sequential(
- ConvBNLayer(
- in_channels=in_channels,
- out_channels=embed_dim // 2,
- kernel_size=3,
- stride=2,
- padding=1,
- act=nn.GELU,
- bias_attr=None),
- ConvBNLayer(
- in_channels=embed_dim // 2,
- out_channels=embed_dim,
- kernel_size=3,
- stride=2,
- padding=1,
- act=nn.GELU,
- bias_attr=None))
- if sub_num == 3:
- self.proj = nn.Sequential(
- ConvBNLayer(
- in_channels=in_channels,
- out_channels=embed_dim // 4,
- kernel_size=3,
- stride=2,
- padding=1,
- act=nn.GELU,
- bias_attr=None),
- ConvBNLayer(
- in_channels=embed_dim // 4,
- out_channels=embed_dim // 2,
- kernel_size=3,
- stride=2,
- padding=1,
- act=nn.GELU,
- bias_attr=None),
- ConvBNLayer(
- in_channels=embed_dim // 2,
- out_channels=embed_dim,
- kernel_size=3,
- stride=2,
- padding=1,
- act=nn.GELU,
- bias_attr=None))
+ if mode == 'pope':
+ if sub_num == 2:
+ self.proj = nn.Sequential(
+ ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=embed_dim // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None),
+ ConvBNLayer(
+ in_channels=embed_dim // 2,
+ out_channels=embed_dim,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None))
+ if sub_num == 3:
+ self.proj = nn.Sequential(
+ ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=embed_dim // 4,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None),
+ ConvBNLayer(
+ in_channels=embed_dim // 4,
+ out_channels=embed_dim // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None),
+ ConvBNLayer(
+ in_channels=embed_dim // 2,
+ out_channels=embed_dim,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None))
+ elif mode == 'linear':
+ self.proj = nn.Conv2D(
+ 1, embed_dim, kernel_size=patch_size, stride=patch_size)
+ self.num_patches = img_size[0] // patch_size[0] * img_size[
+ 1] // patch_size[1]
def forward(self, x):
B, C, H, W = x.shape
diff --git a/ppocr/modeling/backbones/rec_vitstr.py b/ppocr/modeling/backbones/rec_vitstr.py
new file mode 100644
index 0000000000000000000000000000000000000000..d5d7d5148a1120e6f97a321b4135c6780c0c5db2
--- /dev/null
+++ b/ppocr/modeling/backbones/rec_vitstr.py
@@ -0,0 +1,120 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This code is refer from:
+https://github.com/roatienza/deep-text-recognition-benchmark/blob/master/modules/vitstr.py
+"""
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+from ppocr.modeling.backbones.rec_svtrnet import Block, PatchEmbed, zeros_, trunc_normal_, ones_
+
+scale_dim_heads = {'tiny': [192, 3], 'small': [384, 6], 'base': [768, 12]}
+
+
+class ViTSTR(nn.Layer):
+ def __init__(self,
+ img_size=[224, 224],
+ in_channels=1,
+ scale='tiny',
+ seqlen=27,
+ patch_size=[16, 16],
+ embed_dim=None,
+ depth=12,
+ num_heads=None,
+ mlp_ratio=4,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_path_rate=0.,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ norm_layer='nn.LayerNorm',
+ act_layer='nn.GELU',
+ epsilon=1e-6,
+ out_channels=None,
+ **kwargs):
+ super().__init__()
+ self.seqlen = seqlen
+ embed_dim = embed_dim if embed_dim is not None else scale_dim_heads[
+ scale][0]
+ num_heads = num_heads if num_heads is not None else scale_dim_heads[
+ scale][1]
+ out_channels = out_channels if out_channels is not None else embed_dim
+ self.patch_embed = PatchEmbed(
+ img_size=img_size,
+ in_channels=in_channels,
+ embed_dim=embed_dim,
+ patch_size=patch_size,
+ mode='linear')
+ num_patches = self.patch_embed.num_patches
+
+ self.pos_embed = self.create_parameter(
+ shape=[1, num_patches + 1, embed_dim], default_initializer=zeros_)
+ self.add_parameter("pos_embed", self.pos_embed)
+ self.cls_token = self.create_parameter(
+ shape=[1, 1, embed_dim], default_initializer=zeros_)
+ self.add_parameter("cls_token", self.cls_token)
+
+ self.pos_drop = nn.Dropout(p=drop_rate)
+
+ dpr = np.linspace(0, drop_path_rate, depth)
+ self.blocks = nn.LayerList([
+ Block(
+ dim=embed_dim,
+ num_heads=num_heads,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[i],
+ norm_layer=norm_layer,
+ act_layer=eval(act_layer),
+ epsilon=epsilon,
+ prenorm=False) for i in range(depth)
+ ])
+ self.norm = eval(norm_layer)(embed_dim, epsilon=epsilon)
+
+ self.out_channels = out_channels
+
+ trunc_normal_(self.pos_embed)
+ trunc_normal_(self.cls_token)
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ zeros_(m.bias)
+ elif isinstance(m, nn.LayerNorm):
+ zeros_(m.bias)
+ ones_(m.weight)
+
+ def forward_features(self, x):
+ B = x.shape[0]
+ x = self.patch_embed(x)
+ cls_tokens = paddle.tile(self.cls_token, repeat_times=[B, 1, 1])
+ x = paddle.concat((cls_tokens, x), axis=1)
+ x = x + self.pos_embed
+ x = self.pos_drop(x)
+ for blk in self.blocks:
+ x = blk(x)
+ x = self.norm(x)
+ return x
+
+ def forward(self, x):
+ x = self.forward_features(x)
+ x = x[:, :self.seqlen]
+ return x.transpose([0, 2, 1]).unsqueeze(2)
diff --git a/ppocr/modeling/heads/__init__.py b/ppocr/modeling/heads/__init__.py
index 1670ea38e66baa683e6faab0ec4b12bc517f3c41..14e6aab854d8942083f1e3466f554c0876bcf403 100755
--- a/ppocr/modeling/heads/__init__.py
+++ b/ppocr/modeling/heads/__init__.py
@@ -33,6 +33,7 @@ def build_head(config):
from .rec_aster_head import AsterHead
from .rec_pren_head import PRENHead
from .rec_multi_head import MultiHead
+ from .rec_abinet_head import ABINetHead
# cls head
from .cls_head import ClsHead
@@ -46,7 +47,7 @@ def build_head(config):
'DBHead', 'PSEHead', 'FCEHead', 'EASTHead', 'SASTHead', 'CTCHead',
'ClsHead', 'AttentionHead', 'SRNHead', 'PGHead', 'Transformer',
'TableAttentionHead', 'SARHead', 'AsterHead', 'SDMGRHead', 'PRENHead',
- 'MultiHead'
+ 'MultiHead', 'ABINetHead'
]
#table head
diff --git a/ppocr/modeling/heads/multiheadAttention.py b/ppocr/modeling/heads/multiheadAttention.py
deleted file mode 100755
index 900865ba1a8d80a108b3247ce1aff91c242860f2..0000000000000000000000000000000000000000
--- a/ppocr/modeling/heads/multiheadAttention.py
+++ /dev/null
@@ -1,163 +0,0 @@
-# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import paddle
-from paddle import nn
-import paddle.nn.functional as F
-from paddle.nn import Linear
-from paddle.nn.initializer import XavierUniform as xavier_uniform_
-from paddle.nn.initializer import Constant as constant_
-from paddle.nn.initializer import XavierNormal as xavier_normal_
-
-zeros_ = constant_(value=0.)
-ones_ = constant_(value=1.)
-
-
-class MultiheadAttention(nn.Layer):
- """Allows the model to jointly attend to information
- from different representation subspaces.
- See reference: Attention Is All You Need
-
- .. math::
- \text{MultiHead}(Q, K, V) = \text{Concat}(head_1,\dots,head_h)W^O
- \text{where} head_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)
-
- Args:
- embed_dim: total dimension of the model
- num_heads: parallel attention layers, or heads
-
- """
-
- def __init__(self,
- embed_dim,
- num_heads,
- dropout=0.,
- bias=True,
- add_bias_kv=False,
- add_zero_attn=False):
- super(MultiheadAttention, self).__init__()
- self.embed_dim = embed_dim
- self.num_heads = num_heads
- self.dropout = dropout
- self.head_dim = embed_dim // num_heads
- assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
- self.scaling = self.head_dim**-0.5
- self.out_proj = Linear(embed_dim, embed_dim, bias_attr=bias)
- self._reset_parameters()
- self.conv1 = paddle.nn.Conv2D(
- in_channels=embed_dim, out_channels=embed_dim, kernel_size=(1, 1))
- self.conv2 = paddle.nn.Conv2D(
- in_channels=embed_dim, out_channels=embed_dim, kernel_size=(1, 1))
- self.conv3 = paddle.nn.Conv2D(
- in_channels=embed_dim, out_channels=embed_dim, kernel_size=(1, 1))
-
- def _reset_parameters(self):
- xavier_uniform_(self.out_proj.weight)
-
- def forward(self,
- query,
- key,
- value,
- key_padding_mask=None,
- incremental_state=None,
- attn_mask=None):
- """
- Inputs of forward function
- query: [target length, batch size, embed dim]
- key: [sequence length, batch size, embed dim]
- value: [sequence length, batch size, embed dim]
- key_padding_mask: if True, mask padding based on batch size
- incremental_state: if provided, previous time steps are cashed
- need_weights: output attn_output_weights
- static_kv: key and value are static
-
- Outputs of forward function
- attn_output: [target length, batch size, embed dim]
- attn_output_weights: [batch size, target length, sequence length]
- """
- q_shape = paddle.shape(query)
- src_shape = paddle.shape(key)
- q = self._in_proj_q(query)
- k = self._in_proj_k(key)
- v = self._in_proj_v(value)
- q *= self.scaling
- q = paddle.transpose(
- paddle.reshape(
- q, [q_shape[0], q_shape[1], self.num_heads, self.head_dim]),
- [1, 2, 0, 3])
- k = paddle.transpose(
- paddle.reshape(
- k, [src_shape[0], q_shape[1], self.num_heads, self.head_dim]),
- [1, 2, 0, 3])
- v = paddle.transpose(
- paddle.reshape(
- v, [src_shape[0], q_shape[1], self.num_heads, self.head_dim]),
- [1, 2, 0, 3])
- if key_padding_mask is not None:
- assert key_padding_mask.shape[0] == q_shape[1]
- assert key_padding_mask.shape[1] == src_shape[0]
- attn_output_weights = paddle.matmul(q,
- paddle.transpose(k, [0, 1, 3, 2]))
- if attn_mask is not None:
- attn_mask = paddle.unsqueeze(paddle.unsqueeze(attn_mask, 0), 0)
- attn_output_weights += attn_mask
- if key_padding_mask is not None:
- attn_output_weights = paddle.reshape(
- attn_output_weights,
- [q_shape[1], self.num_heads, q_shape[0], src_shape[0]])
- key = paddle.unsqueeze(paddle.unsqueeze(key_padding_mask, 1), 2)
- key = paddle.cast(key, 'float32')
- y = paddle.full(
- shape=paddle.shape(key), dtype='float32', fill_value='-inf')
- y = paddle.where(key == 0., key, y)
- attn_output_weights += y
- attn_output_weights = F.softmax(
- attn_output_weights.astype('float32'),
- axis=-1,
- dtype=paddle.float32 if attn_output_weights.dtype == paddle.float16
- else attn_output_weights.dtype)
- attn_output_weights = F.dropout(
- attn_output_weights, p=self.dropout, training=self.training)
-
- attn_output = paddle.matmul(attn_output_weights, v)
- attn_output = paddle.reshape(
- paddle.transpose(attn_output, [2, 0, 1, 3]),
- [q_shape[0], q_shape[1], self.embed_dim])
- attn_output = self.out_proj(attn_output)
-
- return attn_output
-
- def _in_proj_q(self, query):
- query = paddle.transpose(query, [1, 2, 0])
- query = paddle.unsqueeze(query, axis=2)
- res = self.conv1(query)
- res = paddle.squeeze(res, axis=2)
- res = paddle.transpose(res, [2, 0, 1])
- return res
-
- def _in_proj_k(self, key):
- key = paddle.transpose(key, [1, 2, 0])
- key = paddle.unsqueeze(key, axis=2)
- res = self.conv2(key)
- res = paddle.squeeze(res, axis=2)
- res = paddle.transpose(res, [2, 0, 1])
- return res
-
- def _in_proj_v(self, value):
- value = paddle.transpose(value, [1, 2, 0]) #(1, 2, 0)
- value = paddle.unsqueeze(value, axis=2)
- res = self.conv3(value)
- res = paddle.squeeze(res, axis=2)
- res = paddle.transpose(res, [2, 0, 1])
- return res
diff --git a/ppocr/modeling/heads/rec_abinet_head.py b/ppocr/modeling/heads/rec_abinet_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..a0f60f1be1727e85380eedb7d311ce9445f88b8e
--- /dev/null
+++ b/ppocr/modeling/heads/rec_abinet_head.py
@@ -0,0 +1,296 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+This code is refer from:
+https://github.com/FangShancheng/ABINet/tree/main/modules
+"""
+
+import math
+import paddle
+from paddle import nn
+import paddle.nn.functional as F
+from paddle.nn import LayerList
+from ppocr.modeling.heads.rec_nrtr_head import TransformerBlock, PositionalEncoding
+
+
+class BCNLanguage(nn.Layer):
+ def __init__(self,
+ d_model=512,
+ nhead=8,
+ num_layers=4,
+ dim_feedforward=2048,
+ dropout=0.,
+ max_length=25,
+ detach=True,
+ num_classes=37):
+ super().__init__()
+
+ self.d_model = d_model
+ self.detach = detach
+ self.max_length = max_length + 1 # additional stop token
+ self.proj = nn.Linear(num_classes, d_model, bias_attr=False)
+ self.token_encoder = PositionalEncoding(
+ dropout=0.1, dim=d_model, max_len=self.max_length)
+ self.pos_encoder = PositionalEncoding(
+ dropout=0, dim=d_model, max_len=self.max_length)
+
+ self.decoder = nn.LayerList([
+ TransformerBlock(
+ d_model=d_model,
+ nhead=nhead,
+ dim_feedforward=dim_feedforward,
+ attention_dropout_rate=dropout,
+ residual_dropout_rate=dropout,
+ with_self_attn=False,
+ with_cross_attn=True) for i in range(num_layers)
+ ])
+
+ self.cls = nn.Linear(d_model, num_classes)
+
+ def forward(self, tokens, lengths):
+ """
+ Args:
+ tokens: (B, N, C) where N is length, B is batch size and C is classes number
+ lengths: (B,)
+ """
+ if self.detach: tokens = tokens.detach()
+ embed = self.proj(tokens) # (B, N, C)
+ embed = self.token_encoder(embed) # (B, N, C)
+ padding_mask = _get_mask(lengths, self.max_length)
+ zeros = paddle.zeros_like(embed) # (B, N, C)
+ qeury = self.pos_encoder(zeros)
+ for decoder_layer in self.decoder:
+ qeury = decoder_layer(qeury, embed, cross_mask=padding_mask)
+ output = qeury # (B, N, C)
+
+ logits = self.cls(output) # (B, N, C)
+
+ return output, logits
+
+
+def encoder_layer(in_c, out_c, k=3, s=2, p=1):
+ return nn.Sequential(
+ nn.Conv2D(in_c, out_c, k, s, p), nn.BatchNorm2D(out_c), nn.ReLU())
+
+
+def decoder_layer(in_c,
+ out_c,
+ k=3,
+ s=1,
+ p=1,
+ mode='nearest',
+ scale_factor=None,
+ size=None):
+ align_corners = False if mode == 'nearest' else True
+ return nn.Sequential(
+ nn.Upsample(
+ size=size,
+ scale_factor=scale_factor,
+ mode=mode,
+ align_corners=align_corners),
+ nn.Conv2D(in_c, out_c, k, s, p),
+ nn.BatchNorm2D(out_c),
+ nn.ReLU())
+
+
+class PositionAttention(nn.Layer):
+ def __init__(self,
+ max_length,
+ in_channels=512,
+ num_channels=64,
+ h=8,
+ w=32,
+ mode='nearest',
+ **kwargs):
+ super().__init__()
+ self.max_length = max_length
+ self.k_encoder = nn.Sequential(
+ encoder_layer(
+ in_channels, num_channels, s=(1, 2)),
+ encoder_layer(
+ num_channels, num_channels, s=(2, 2)),
+ encoder_layer(
+ num_channels, num_channels, s=(2, 2)),
+ encoder_layer(
+ num_channels, num_channels, s=(2, 2)))
+ self.k_decoder = nn.Sequential(
+ decoder_layer(
+ num_channels, num_channels, scale_factor=2, mode=mode),
+ decoder_layer(
+ num_channels, num_channels, scale_factor=2, mode=mode),
+ decoder_layer(
+ num_channels, num_channels, scale_factor=2, mode=mode),
+ decoder_layer(
+ num_channels, in_channels, size=(h, w), mode=mode))
+
+ self.pos_encoder = PositionalEncoding(
+ dropout=0, dim=in_channels, max_len=max_length)
+ self.project = nn.Linear(in_channels, in_channels)
+
+ def forward(self, x):
+ B, C, H, W = x.shape
+ k, v = x, x
+
+ # calculate key vector
+ features = []
+ for i in range(0, len(self.k_encoder)):
+ k = self.k_encoder[i](k)
+ features.append(k)
+ for i in range(0, len(self.k_decoder) - 1):
+ k = self.k_decoder[i](k)
+ # print(k.shape, features[len(self.k_decoder) - 2 - i].shape)
+ k = k + features[len(self.k_decoder) - 2 - i]
+ k = self.k_decoder[-1](k)
+
+ # calculate query vector
+ # TODO q=f(q,k)
+ zeros = paddle.zeros(
+ (B, self.max_length, C), dtype=x.dtype) # (T, N, C)
+ q = self.pos_encoder(zeros) # (B, N, C)
+ q = self.project(q) # (B, N, C)
+
+ # calculate attention
+ attn_scores = q @k.flatten(2) # (B, N, (H*W))
+ attn_scores = attn_scores / (C**0.5)
+ attn_scores = F.softmax(attn_scores, axis=-1)
+
+ v = v.flatten(2).transpose([0, 2, 1]) # (B, (H*W), C)
+ attn_vecs = attn_scores @v # (B, N, C)
+
+ return attn_vecs, attn_scores.reshape([0, self.max_length, H, W])
+
+
+class ABINetHead(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ d_model=512,
+ nhead=8,
+ num_layers=3,
+ dim_feedforward=2048,
+ dropout=0.1,
+ max_length=25,
+ use_lang=False,
+ iter_size=1):
+ super().__init__()
+ self.max_length = max_length + 1
+ self.pos_encoder = PositionalEncoding(
+ dropout=0.1, dim=d_model, max_len=8 * 32)
+ self.encoder = nn.LayerList([
+ TransformerBlock(
+ d_model=d_model,
+ nhead=nhead,
+ dim_feedforward=dim_feedforward,
+ attention_dropout_rate=dropout,
+ residual_dropout_rate=dropout,
+ with_self_attn=True,
+ with_cross_attn=False) for i in range(num_layers)
+ ])
+ self.decoder = PositionAttention(
+ max_length=max_length + 1, # additional stop token
+ mode='nearest', )
+ self.out_channels = out_channels
+ self.cls = nn.Linear(d_model, self.out_channels)
+ self.use_lang = use_lang
+ if use_lang:
+ self.iter_size = iter_size
+ self.language = BCNLanguage(
+ d_model=d_model,
+ nhead=nhead,
+ num_layers=4,
+ dim_feedforward=dim_feedforward,
+ dropout=dropout,
+ max_length=max_length,
+ num_classes=self.out_channels)
+ # alignment
+ self.w_att_align = nn.Linear(2 * d_model, d_model)
+ self.cls_align = nn.Linear(d_model, self.out_channels)
+
+ def forward(self, x, targets=None):
+ x = x.transpose([0, 2, 3, 1])
+ _, H, W, C = x.shape
+ feature = x.flatten(1, 2)
+ feature = self.pos_encoder(feature)
+ for encoder_layer in self.encoder:
+ feature = encoder_layer(feature)
+ feature = feature.reshape([0, H, W, C]).transpose([0, 3, 1, 2])
+ v_feature, attn_scores = self.decoder(
+ feature) # (B, N, C), (B, C, H, W)
+ vis_logits = self.cls(v_feature) # (B, N, C)
+ logits = vis_logits
+ vis_lengths = _get_length(vis_logits)
+ if self.use_lang:
+ align_logits = vis_logits
+ align_lengths = vis_lengths
+ all_l_res, all_a_res = [], []
+ for i in range(self.iter_size):
+ tokens = F.softmax(align_logits, axis=-1)
+ lengths = align_lengths
+ lengths = paddle.clip(
+ lengths, 2, self.max_length) # TODO:move to langauge model
+ l_feature, l_logits = self.language(tokens, lengths)
+
+ # alignment
+ all_l_res.append(l_logits)
+ fuse = paddle.concat((l_feature, v_feature), -1)
+ f_att = F.sigmoid(self.w_att_align(fuse))
+ output = f_att * v_feature + (1 - f_att) * l_feature
+ align_logits = self.cls_align(output) # (B, N, C)
+
+ align_lengths = _get_length(align_logits)
+ all_a_res.append(align_logits)
+ if self.training:
+ return {
+ 'align': all_a_res,
+ 'lang': all_l_res,
+ 'vision': vis_logits
+ }
+ else:
+ logits = align_logits
+ if self.training:
+ return logits
+ else:
+ return F.softmax(logits, -1)
+
+
+def _get_length(logit):
+ """ Greed decoder to obtain length from logit"""
+ out = (logit.argmax(-1) == 0)
+ abn = out.any(-1)
+ out_int = out.cast('int32')
+ out = (out_int.cumsum(-1) == 1) & out
+ out = out.cast('int32')
+ out = out.argmax(-1)
+ out = out + 1
+ out = paddle.where(abn, out, paddle.to_tensor(logit.shape[1]))
+ return out
+
+
+def _get_mask(length, max_length):
+ """Generate a square mask for the sequence. The masked positions are filled with float('-inf').
+ Unmasked positions are filled with float(0.0).
+ """
+ length = length.unsqueeze(-1)
+ B = paddle.shape(length)[0]
+ grid = paddle.arange(0, max_length).unsqueeze(0).tile([B, 1])
+ zero_mask = paddle.zeros([B, max_length], dtype='float32')
+ inf_mask = paddle.full([B, max_length], '-inf', dtype='float32')
+ diag_mask = paddle.diag(
+ paddle.full(
+ [max_length], '-inf', dtype=paddle.float32),
+ offset=0,
+ name=None)
+ mask = paddle.where(grid >= length, inf_mask, zero_mask)
+ mask = mask.unsqueeze(1) + diag_mask
+ return mask.unsqueeze(1)
diff --git a/ppocr/modeling/heads/rec_nrtr_head.py b/ppocr/modeling/heads/rec_nrtr_head.py
index 38ba0c917840ea7d1e2a3c2bf0da32c2c35f2b40..bf9ef56145e6edfb15bd30235b4a62588396ba96 100644
--- a/ppocr/modeling/heads/rec_nrtr_head.py
+++ b/ppocr/modeling/heads/rec_nrtr_head.py
@@ -14,20 +14,15 @@
import math
import paddle
-import copy
from paddle import nn
import paddle.nn.functional as F
from paddle.nn import LayerList
-from paddle.nn.initializer import XavierNormal as xavier_uniform_
-from paddle.nn import Dropout, Linear, LayerNorm, Conv2D
+# from paddle.nn.initializer import XavierNormal as xavier_uniform_
+from paddle.nn import Dropout, Linear, LayerNorm
import numpy as np
-from ppocr.modeling.heads.multiheadAttention import MultiheadAttention
-from paddle.nn.initializer import Constant as constant_
+from ppocr.modeling.backbones.rec_svtrnet import Mlp, zeros_, ones_
from paddle.nn.initializer import XavierNormal as xavier_normal_
-zeros_ = constant_(value=0.)
-ones_ = constant_(value=1.)
-
class Transformer(nn.Layer):
"""A transformer model. User is able to modify the attributes as needed. The architechture
@@ -45,7 +40,6 @@ class Transformer(nn.Layer):
dropout: the dropout value (default=0.1).
custom_encoder: custom encoder (default=None).
custom_decoder: custom decoder (default=None).
-
"""
def __init__(self,
@@ -54,45 +48,49 @@ class Transformer(nn.Layer):
num_encoder_layers=6,
beam_size=0,
num_decoder_layers=6,
+ max_len=25,
dim_feedforward=1024,
attention_dropout_rate=0.0,
residual_dropout_rate=0.1,
- custom_encoder=None,
- custom_decoder=None,
in_channels=0,
out_channels=0,
scale_embedding=True):
super(Transformer, self).__init__()
self.out_channels = out_channels + 1
+ self.max_len = max_len
self.embedding = Embeddings(
d_model=d_model,
vocab=self.out_channels,
padding_idx=0,
scale_embedding=scale_embedding)
self.positional_encoding = PositionalEncoding(
- dropout=residual_dropout_rate,
- dim=d_model, )
- if custom_encoder is not None:
- self.encoder = custom_encoder
- else:
- if num_encoder_layers > 0:
- encoder_layer = TransformerEncoderLayer(
- d_model, nhead, dim_feedforward, attention_dropout_rate,
- residual_dropout_rate)
- self.encoder = TransformerEncoder(encoder_layer,
- num_encoder_layers)
- else:
- self.encoder = None
-
- if custom_decoder is not None:
- self.decoder = custom_decoder
+ dropout=residual_dropout_rate, dim=d_model)
+
+ if num_encoder_layers > 0:
+ self.encoder = nn.LayerList([
+ TransformerBlock(
+ d_model,
+ nhead,
+ dim_feedforward,
+ attention_dropout_rate,
+ residual_dropout_rate,
+ with_self_attn=True,
+ with_cross_attn=False) for i in range(num_encoder_layers)
+ ])
else:
- decoder_layer = TransformerDecoderLayer(
- d_model, nhead, dim_feedforward, attention_dropout_rate,
- residual_dropout_rate)
- self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers)
+ self.encoder = None
+
+ self.decoder = nn.LayerList([
+ TransformerBlock(
+ d_model,
+ nhead,
+ dim_feedforward,
+ attention_dropout_rate,
+ residual_dropout_rate,
+ with_self_attn=True,
+ with_cross_attn=True) for i in range(num_decoder_layers)
+ ])
- self._reset_parameters()
self.beam_size = beam_size
self.d_model = d_model
self.nhead = nhead
@@ -105,7 +103,7 @@ class Transformer(nn.Layer):
def _init_weights(self, m):
- if isinstance(m, nn.Conv2D):
+ if isinstance(m, nn.Linear):
xavier_normal_(m.weight)
if m.bias is not None:
zeros_(m.bias)
@@ -113,24 +111,20 @@ class Transformer(nn.Layer):
def forward_train(self, src, tgt):
tgt = tgt[:, :-1]
- tgt_key_padding_mask = self.generate_padding_mask(tgt)
- tgt = self.embedding(tgt).transpose([1, 0, 2])
+ tgt = self.embedding(tgt)
tgt = self.positional_encoding(tgt)
- tgt_mask = self.generate_square_subsequent_mask(tgt.shape[0])
+ tgt_mask = self.generate_square_subsequent_mask(tgt.shape[1])
if self.encoder is not None:
- src = self.positional_encoding(src.transpose([1, 0, 2]))
- memory = self.encoder(src)
+ src = self.positional_encoding(src)
+ for encoder_layer in self.encoder:
+ src = encoder_layer(src)
+ memory = src # B N C
else:
- memory = src.squeeze(2).transpose([2, 0, 1])
- output = self.decoder(
- tgt,
- memory,
- tgt_mask=tgt_mask,
- memory_mask=None,
- tgt_key_padding_mask=tgt_key_padding_mask,
- memory_key_padding_mask=None)
- output = output.transpose([1, 0, 2])
+ memory = src # B N C
+ for decoder_layer in self.decoder:
+ tgt = decoder_layer(tgt, memory, self_mask=tgt_mask)
+ output = tgt
logit = self.tgt_word_prj(output)
return logit
@@ -140,8 +134,8 @@ class Transformer(nn.Layer):
src: the sequence to the encoder (required).
tgt: the sequence to the decoder (required).
Shape:
- - src: :math:`(S, N, E)`.
- - tgt: :math:`(T, N, E)`.
+ - src: :math:`(B, sN, C)`.
+ - tgt: :math:`(B, tN, C)`.
Examples:
>>> output = transformer_model(src, tgt)
"""
@@ -157,36 +151,35 @@ class Transformer(nn.Layer):
return self.forward_test(src)
def forward_test(self, src):
+
bs = paddle.shape(src)[0]
if self.encoder is not None:
- src = self.positional_encoding(paddle.transpose(src, [1, 0, 2]))
- memory = self.encoder(src)
+ src = self.positional_encoding(src)
+ for encoder_layer in self.encoder:
+ src = encoder_layer(src)
+ memory = src # B N C
else:
- memory = paddle.transpose(paddle.squeeze(src, 2), [2, 0, 1])
+ memory = src
dec_seq = paddle.full((bs, 1), 2, dtype=paddle.int64)
dec_prob = paddle.full((bs, 1), 1., dtype=paddle.float32)
- for len_dec_seq in range(1, 25):
- dec_seq_embed = paddle.transpose(self.embedding(dec_seq), [1, 0, 2])
+ for len_dec_seq in range(1, self.max_len):
+ dec_seq_embed = self.embedding(dec_seq)
dec_seq_embed = self.positional_encoding(dec_seq_embed)
tgt_mask = self.generate_square_subsequent_mask(
- paddle.shape(dec_seq_embed)[0])
- output = self.decoder(
- dec_seq_embed,
- memory,
- tgt_mask=tgt_mask,
- memory_mask=None,
- tgt_key_padding_mask=None,
- memory_key_padding_mask=None)
- dec_output = paddle.transpose(output, [1, 0, 2])
+ paddle.shape(dec_seq_embed)[1])
+ tgt = dec_seq_embed
+ for decoder_layer in self.decoder:
+ tgt = decoder_layer(tgt, memory, self_mask=tgt_mask)
+ dec_output = tgt
dec_output = dec_output[:, -1, :]
- word_prob = F.softmax(self.tgt_word_prj(dec_output), axis=1)
- preds_idx = paddle.argmax(word_prob, axis=1)
+ word_prob = F.softmax(self.tgt_word_prj(dec_output), axis=-1)
+ preds_idx = paddle.argmax(word_prob, axis=-1)
if paddle.equal_all(
preds_idx,
paddle.full(
paddle.shape(preds_idx), 3, dtype='int64')):
break
- preds_prob = paddle.max(word_prob, axis=1)
+ preds_prob = paddle.max(word_prob, axis=-1)
dec_seq = paddle.concat(
[dec_seq, paddle.reshape(preds_idx, [-1, 1])], axis=1)
dec_prob = paddle.concat(
@@ -194,10 +187,10 @@ class Transformer(nn.Layer):
return [dec_seq, dec_prob]
def forward_beam(self, images):
- ''' Translation work in one batch '''
+ """ Translation work in one batch """
def get_inst_idx_to_tensor_position_map(inst_idx_list):
- ''' Indicate the position of an instance in a tensor. '''
+ """ Indicate the position of an instance in a tensor. """
return {
inst_idx: tensor_position
for tensor_position, inst_idx in enumerate(inst_idx_list)
@@ -205,7 +198,7 @@ class Transformer(nn.Layer):
def collect_active_part(beamed_tensor, curr_active_inst_idx,
n_prev_active_inst, n_bm):
- ''' Collect tensor parts associated to active instances. '''
+ """ Collect tensor parts associated to active instances. """
beamed_tensor_shape = paddle.shape(beamed_tensor)
n_curr_active_inst = len(curr_active_inst_idx)
@@ -237,9 +230,8 @@ class Transformer(nn.Layer):
return active_src_enc, active_inst_idx_to_position_map
def beam_decode_step(inst_dec_beams, len_dec_seq, enc_output,
- inst_idx_to_position_map, n_bm,
- memory_key_padding_mask):
- ''' Decode and update beam status, and then return active beam idx '''
+ inst_idx_to_position_map, n_bm):
+ """ Decode and update beam status, and then return active beam idx """
def prepare_beam_dec_seq(inst_dec_beams, len_dec_seq):
dec_partial_seq = [
@@ -249,19 +241,15 @@ class Transformer(nn.Layer):
dec_partial_seq = dec_partial_seq.reshape([-1, len_dec_seq])
return dec_partial_seq
- def predict_word(dec_seq, enc_output, n_active_inst, n_bm,
- memory_key_padding_mask):
- dec_seq = paddle.transpose(self.embedding(dec_seq), [1, 0, 2])
+ def predict_word(dec_seq, enc_output, n_active_inst, n_bm):
+ dec_seq = self.embedding(dec_seq)
dec_seq = self.positional_encoding(dec_seq)
tgt_mask = self.generate_square_subsequent_mask(
- paddle.shape(dec_seq)[0])
- dec_output = self.decoder(
- dec_seq,
- enc_output,
- tgt_mask=tgt_mask,
- tgt_key_padding_mask=None,
- memory_key_padding_mask=memory_key_padding_mask, )
- dec_output = paddle.transpose(dec_output, [1, 0, 2])
+ paddle.shape(dec_seq)[1])
+ tgt = dec_seq
+ for decoder_layer in self.decoder:
+ tgt = decoder_layer(tgt, enc_output, self_mask=tgt_mask)
+ dec_output = tgt
dec_output = dec_output[:,
-1, :] # Pick the last step: (bh * bm) * d_h
word_prob = F.softmax(self.tgt_word_prj(dec_output), axis=1)
@@ -281,8 +269,7 @@ class Transformer(nn.Layer):
n_active_inst = len(inst_idx_to_position_map)
dec_seq = prepare_beam_dec_seq(inst_dec_beams, len_dec_seq)
- word_prob = predict_word(dec_seq, enc_output, n_active_inst, n_bm,
- None)
+ word_prob = predict_word(dec_seq, enc_output, n_active_inst, n_bm)
# Update the beam with predicted word prob information and collect incomplete instances
active_inst_idx_list = collect_active_inst_idx_list(
inst_dec_beams, word_prob, inst_idx_to_position_map)
@@ -303,10 +290,10 @@ class Transformer(nn.Layer):
with paddle.no_grad():
#-- Encode
if self.encoder is not None:
- src = self.positional_encoding(images.transpose([1, 0, 2]))
+ src = self.positional_encoding(images)
src_enc = self.encoder(src)
else:
- src_enc = images.squeeze(2).transpose([0, 2, 1])
+ src_enc = images
n_bm = self.beam_size
src_shape = paddle.shape(src_enc)
@@ -317,11 +304,11 @@ class Transformer(nn.Layer):
inst_idx_to_position_map = get_inst_idx_to_tensor_position_map(
active_inst_idx_list)
# Decode
- for len_dec_seq in range(1, 25):
+ for len_dec_seq in range(1, self.max_len):
src_enc_copy = src_enc.clone()
active_inst_idx_list = beam_decode_step(
inst_dec_beams, len_dec_seq, src_enc_copy,
- inst_idx_to_position_map, n_bm, None)
+ inst_idx_to_position_map, n_bm)
if not active_inst_idx_list:
break # all instances have finished their path to
src_enc, inst_idx_to_position_map = collate_active_info(
@@ -354,261 +341,124 @@ class Transformer(nn.Layer):
shape=[sz, sz], dtype='float32', fill_value='-inf'),
diagonal=1)
mask = mask + mask_inf
- return mask
-
- def generate_padding_mask(self, x):
- padding_mask = paddle.equal(x, paddle.to_tensor(0, dtype=x.dtype))
- return padding_mask
+ return mask.unsqueeze([0, 1])
- def _reset_parameters(self):
- """Initiate parameters in the transformer model."""
- for p in self.parameters():
- if p.dim() > 1:
- xavier_uniform_(p)
+class MultiheadAttention(nn.Layer):
+ """Allows the model to jointly attend to information
+ from different representation subspaces.
+ See reference: Attention Is All You Need
+ .. math::
+ \text{MultiHead}(Q, K, V) = \text{Concat}(head_1,\dots,head_h)W^O
+ \text{where} head_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)
-class TransformerEncoder(nn.Layer):
- """TransformerEncoder is a stack of N encoder layers
Args:
- encoder_layer: an instance of the TransformerEncoderLayer() class (required).
- num_layers: the number of sub-encoder-layers in the encoder (required).
- norm: the layer normalization component (optional).
- """
+ embed_dim: total dimension of the model
+ num_heads: parallel attention layers, or heads
- def __init__(self, encoder_layer, num_layers):
- super(TransformerEncoder, self).__init__()
- self.layers = _get_clones(encoder_layer, num_layers)
- self.num_layers = num_layers
+ """
- def forward(self, src):
- """Pass the input through the endocder layers in turn.
- Args:
- src: the sequnce to the encoder (required).
- mask: the mask for the src sequence (optional).
- src_key_padding_mask: the mask for the src keys per batch (optional).
- """
- output = src
+ def __init__(self, embed_dim, num_heads, dropout=0., self_attn=False):
+ super(MultiheadAttention, self).__init__()
+ self.embed_dim = embed_dim
+ self.num_heads = num_heads
+ # self.dropout = dropout
+ self.head_dim = embed_dim // num_heads
+ assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
+ self.scale = self.head_dim**-0.5
+ self.self_attn = self_attn
+ if self_attn:
+ self.qkv = nn.Linear(embed_dim, embed_dim * 3)
+ else:
+ self.q = nn.Linear(embed_dim, embed_dim)
+ self.kv = nn.Linear(embed_dim, embed_dim * 2)
+ self.attn_drop = nn.Dropout(dropout)
+ self.out_proj = nn.Linear(embed_dim, embed_dim)
- for i in range(self.num_layers):
- output = self.layers[i](output,
- src_mask=None,
- src_key_padding_mask=None)
+ def forward(self, query, key=None, attn_mask=None):
- return output
+ qN = query.shape[1]
+ if self.self_attn:
+ qkv = self.qkv(query).reshape(
+ (0, qN, 3, self.num_heads, self.head_dim)).transpose(
+ (2, 0, 3, 1, 4))
+ q, k, v = qkv[0], qkv[1], qkv[2]
+ else:
+ kN = key.shape[1]
+ q = self.q(query).reshape(
+ [0, qN, self.num_heads, self.head_dim]).transpose([0, 2, 1, 3])
+ kv = self.kv(key).reshape(
+ (0, kN, 2, self.num_heads, self.head_dim)).transpose(
+ (2, 0, 3, 1, 4))
+ k, v = kv[0], kv[1]
-class TransformerDecoder(nn.Layer):
- """TransformerDecoder is a stack of N decoder layers
+ attn = (q.matmul(k.transpose((0, 1, 3, 2)))) * self.scale
- Args:
- decoder_layer: an instance of the TransformerDecoderLayer() class (required).
- num_layers: the number of sub-decoder-layers in the decoder (required).
- norm: the layer normalization component (optional).
+ if attn_mask is not None:
+ attn += attn_mask
- """
+ attn = F.softmax(attn, axis=-1)
+ attn = self.attn_drop(attn)
- def __init__(self, decoder_layer, num_layers):
- super(TransformerDecoder, self).__init__()
- self.layers = _get_clones(decoder_layer, num_layers)
- self.num_layers = num_layers
+ x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape(
+ (0, qN, self.embed_dim))
+ x = self.out_proj(x)
- def forward(self,
- tgt,
- memory,
- tgt_mask=None,
- memory_mask=None,
- tgt_key_padding_mask=None,
- memory_key_padding_mask=None):
- """Pass the inputs (and mask) through the decoder layer in turn.
+ return x
- Args:
- tgt: the sequence to the decoder (required).
- memory: the sequnce from the last layer of the encoder (required).
- tgt_mask: the mask for the tgt sequence (optional).
- memory_mask: the mask for the memory sequence (optional).
- tgt_key_padding_mask: the mask for the tgt keys per batch (optional).
- memory_key_padding_mask: the mask for the memory keys per batch (optional).
- """
- output = tgt
- for i in range(self.num_layers):
- output = self.layers[i](
- output,
- memory,
- tgt_mask=tgt_mask,
- memory_mask=memory_mask,
- tgt_key_padding_mask=tgt_key_padding_mask,
- memory_key_padding_mask=memory_key_padding_mask)
-
- return output
-
-
-class TransformerEncoderLayer(nn.Layer):
- """TransformerEncoderLayer is made up of self-attn and feedforward network.
- This standard encoder layer is based on the paper "Attention Is All You Need".
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez,
- Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in
- Neural Information Processing Systems, pages 6000-6010. Users may modify or implement
- in a different way during application.
-
- Args:
- d_model: the number of expected features in the input (required).
- nhead: the number of heads in the multiheadattention models (required).
- dim_feedforward: the dimension of the feedforward network model (default=2048).
- dropout: the dropout value (default=0.1).
-
- """
+class TransformerBlock(nn.Layer):
def __init__(self,
d_model,
nhead,
dim_feedforward=2048,
attention_dropout_rate=0.0,
- residual_dropout_rate=0.1):
- super(TransformerEncoderLayer, self).__init__()
- self.self_attn = MultiheadAttention(
- d_model, nhead, dropout=attention_dropout_rate)
-
- self.conv1 = Conv2D(
- in_channels=d_model,
- out_channels=dim_feedforward,
- kernel_size=(1, 1))
- self.conv2 = Conv2D(
- in_channels=dim_feedforward,
- out_channels=d_model,
- kernel_size=(1, 1))
-
- self.norm1 = LayerNorm(d_model)
- self.norm2 = LayerNorm(d_model)
- self.dropout1 = Dropout(residual_dropout_rate)
- self.dropout2 = Dropout(residual_dropout_rate)
-
- def forward(self, src, src_mask=None, src_key_padding_mask=None):
- """Pass the input through the endocder layer.
- Args:
- src: the sequnce to the encoder layer (required).
- src_mask: the mask for the src sequence (optional).
- src_key_padding_mask: the mask for the src keys per batch (optional).
- """
- src2 = self.self_attn(
- src,
- src,
- src,
- attn_mask=src_mask,
- key_padding_mask=src_key_padding_mask)
- src = src + self.dropout1(src2)
- src = self.norm1(src)
-
- src = paddle.transpose(src, [1, 2, 0])
- src = paddle.unsqueeze(src, 2)
- src2 = self.conv2(F.relu(self.conv1(src)))
- src2 = paddle.squeeze(src2, 2)
- src2 = paddle.transpose(src2, [2, 0, 1])
- src = paddle.squeeze(src, 2)
- src = paddle.transpose(src, [2, 0, 1])
-
- src = src + self.dropout2(src2)
- src = self.norm2(src)
- return src
-
-
-class TransformerDecoderLayer(nn.Layer):
- """TransformerDecoderLayer is made up of self-attn, multi-head-attn and feedforward network.
- This standard decoder layer is based on the paper "Attention Is All You Need".
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez,
- Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in
- Neural Information Processing Systems, pages 6000-6010. Users may modify or implement
- in a different way during application.
-
- Args:
- d_model: the number of expected features in the input (required).
- nhead: the number of heads in the multiheadattention models (required).
- dim_feedforward: the dimension of the feedforward network model (default=2048).
- dropout: the dropout value (default=0.1).
-
- """
+ residual_dropout_rate=0.1,
+ with_self_attn=True,
+ with_cross_attn=False,
+ epsilon=1e-5):
+ super(TransformerBlock, self).__init__()
+ self.with_self_attn = with_self_attn
+ if with_self_attn:
+ self.self_attn = MultiheadAttention(
+ d_model,
+ nhead,
+ dropout=attention_dropout_rate,
+ self_attn=with_self_attn)
+ self.norm1 = LayerNorm(d_model, epsilon=epsilon)
+ self.dropout1 = Dropout(residual_dropout_rate)
+ self.with_cross_attn = with_cross_attn
+ if with_cross_attn:
+ self.cross_attn = MultiheadAttention( #for self_attn of encoder or cross_attn of decoder
+ d_model,
+ nhead,
+ dropout=attention_dropout_rate)
+ self.norm2 = LayerNorm(d_model, epsilon=epsilon)
+ self.dropout2 = Dropout(residual_dropout_rate)
+
+ self.mlp = Mlp(in_features=d_model,
+ hidden_features=dim_feedforward,
+ act_layer=nn.ReLU,
+ drop=residual_dropout_rate)
+
+ self.norm3 = LayerNorm(d_model, epsilon=epsilon)
- def __init__(self,
- d_model,
- nhead,
- dim_feedforward=2048,
- attention_dropout_rate=0.0,
- residual_dropout_rate=0.1):
- super(TransformerDecoderLayer, self).__init__()
- self.self_attn = MultiheadAttention(
- d_model, nhead, dropout=attention_dropout_rate)
- self.multihead_attn = MultiheadAttention(
- d_model, nhead, dropout=attention_dropout_rate)
-
- self.conv1 = Conv2D(
- in_channels=d_model,
- out_channels=dim_feedforward,
- kernel_size=(1, 1))
- self.conv2 = Conv2D(
- in_channels=dim_feedforward,
- out_channels=d_model,
- kernel_size=(1, 1))
-
- self.norm1 = LayerNorm(d_model)
- self.norm2 = LayerNorm(d_model)
- self.norm3 = LayerNorm(d_model)
- self.dropout1 = Dropout(residual_dropout_rate)
- self.dropout2 = Dropout(residual_dropout_rate)
self.dropout3 = Dropout(residual_dropout_rate)
- def forward(self,
- tgt,
- memory,
- tgt_mask=None,
- memory_mask=None,
- tgt_key_padding_mask=None,
- memory_key_padding_mask=None):
- """Pass the inputs (and mask) through the decoder layer.
+ def forward(self, tgt, memory=None, self_mask=None, cross_mask=None):
+ if self.with_self_attn:
+ tgt1 = self.self_attn(tgt, attn_mask=self_mask)
+ tgt = self.norm1(tgt + self.dropout1(tgt1))
- Args:
- tgt: the sequence to the decoder layer (required).
- memory: the sequnce from the last layer of the encoder (required).
- tgt_mask: the mask for the tgt sequence (optional).
- memory_mask: the mask for the memory sequence (optional).
- tgt_key_padding_mask: the mask for the tgt keys per batch (optional).
- memory_key_padding_mask: the mask for the memory keys per batch (optional).
-
- """
- tgt2 = self.self_attn(
- tgt,
- tgt,
- tgt,
- attn_mask=tgt_mask,
- key_padding_mask=tgt_key_padding_mask)
- tgt = tgt + self.dropout1(tgt2)
- tgt = self.norm1(tgt)
- tgt2 = self.multihead_attn(
- tgt,
- memory,
- memory,
- attn_mask=memory_mask,
- key_padding_mask=memory_key_padding_mask)
- tgt = tgt + self.dropout2(tgt2)
- tgt = self.norm2(tgt)
-
- # default
- tgt = paddle.transpose(tgt, [1, 2, 0])
- tgt = paddle.unsqueeze(tgt, 2)
- tgt2 = self.conv2(F.relu(self.conv1(tgt)))
- tgt2 = paddle.squeeze(tgt2, 2)
- tgt2 = paddle.transpose(tgt2, [2, 0, 1])
- tgt = paddle.squeeze(tgt, 2)
- tgt = paddle.transpose(tgt, [2, 0, 1])
-
- tgt = tgt + self.dropout3(tgt2)
- tgt = self.norm3(tgt)
+ if self.with_cross_attn:
+ tgt2 = self.cross_attn(tgt, key=memory, attn_mask=cross_mask)
+ tgt = self.norm2(tgt + self.dropout2(tgt2))
+ tgt = self.norm3(tgt + self.dropout3(self.mlp(tgt)))
return tgt
-def _get_clones(module, N):
- return LayerList([copy.deepcopy(module) for i in range(N)])
-
-
class PositionalEncoding(nn.Layer):
"""Inject some information about the relative or absolute position of the tokens
in the sequence. The positional encodings have the same dimension as
@@ -651,8 +501,9 @@ class PositionalEncoding(nn.Layer):
Examples:
>>> output = pos_encoder(x)
"""
+ x = x.transpose([1, 0, 2])
x = x + self.pe[:paddle.shape(x)[0], :]
- return self.dropout(x)
+ return self.dropout(x).transpose([1, 0, 2])
class PositionalEncoding_2d(nn.Layer):
@@ -725,7 +576,7 @@ class PositionalEncoding_2d(nn.Layer):
class Embeddings(nn.Layer):
- def __init__(self, d_model, vocab, padding_idx, scale_embedding):
+ def __init__(self, d_model, vocab, padding_idx=None, scale_embedding=True):
super(Embeddings, self).__init__()
self.embedding = nn.Embedding(vocab, d_model, padding_idx=padding_idx)
w0 = np.random.normal(0.0, d_model**-0.5,
@@ -742,7 +593,7 @@ class Embeddings(nn.Layer):
class Beam():
- ''' Beam search '''
+ """ Beam search """
def __init__(self, size, device=False):
diff --git a/ppocr/postprocess/__init__.py b/ppocr/postprocess/__init__.py
index f50b5f1c5f8e617066bb47636c8f4d2b171b6ecb..2635117c84298bcf77a77cdcab553278f2df642b 100644
--- a/ppocr/postprocess/__init__.py
+++ b/ppocr/postprocess/__init__.py
@@ -27,7 +27,7 @@ from .sast_postprocess import SASTPostProcess
from .fce_postprocess import FCEPostProcess
from .rec_postprocess import CTCLabelDecode, AttnLabelDecode, SRNLabelDecode, \
DistillationCTCLabelDecode, TableLabelDecode, NRTRLabelDecode, SARLabelDecode, \
- SEEDLabelDecode, PRENLabelDecode
+ SEEDLabelDecode, PRENLabelDecode, ViTSTRLabelDecode, ABINetLabelDecode
from .cls_postprocess import ClsPostProcess
from .pg_postprocess import PGPostProcess
from .vqa_token_ser_layoutlm_postprocess import VQASerTokenLayoutLMPostProcess
@@ -42,7 +42,7 @@ def build_post_process(config, global_config=None):
'DistillationDBPostProcess', 'NRTRLabelDecode', 'SARLabelDecode',
'SEEDLabelDecode', 'VQASerTokenLayoutLMPostProcess',
'VQAReTokenLayoutLMPostProcess', 'PRENLabelDecode',
- 'DistillationSARLabelDecode'
+ 'DistillationSARLabelDecode', 'ViTSTRLabelDecode', 'ABINetLabelDecode'
]
if config['name'] == 'PSEPostProcess':
diff --git a/ppocr/postprocess/rec_postprocess.py b/ppocr/postprocess/rec_postprocess.py
index bf0fd890bf25949361665d212bf8e1a657054e5b..c77420ad19b76e203262568ba77f06ea248a1655 100644
--- a/ppocr/postprocess/rec_postprocess.py
+++ b/ppocr/postprocess/rec_postprocess.py
@@ -140,70 +140,6 @@ class DistillationCTCLabelDecode(CTCLabelDecode):
return output
-class NRTRLabelDecode(BaseRecLabelDecode):
- """ Convert between text-label and text-index """
-
- def __init__(self, character_dict_path=None, use_space_char=True, **kwargs):
- super(NRTRLabelDecode, self).__init__(character_dict_path,
- use_space_char)
-
- def __call__(self, preds, label=None, *args, **kwargs):
-
- if len(preds) == 2:
- preds_id = preds[0]
- preds_prob = preds[1]
- if isinstance(preds_id, paddle.Tensor):
- preds_id = preds_id.numpy()
- if isinstance(preds_prob, paddle.Tensor):
- preds_prob = preds_prob.numpy()
- if preds_id[0][0] == 2:
- preds_idx = preds_id[:, 1:]
- preds_prob = preds_prob[:, 1:]
- else:
- preds_idx = preds_id
- text = self.decode(preds_idx, preds_prob, is_remove_duplicate=False)
- if label is None:
- return text
- label = self.decode(label[:, 1:])
- else:
- if isinstance(preds, paddle.Tensor):
- preds = preds.numpy()
- preds_idx = preds.argmax(axis=2)
- preds_prob = preds.max(axis=2)
- text = self.decode(preds_idx, preds_prob, is_remove_duplicate=False)
- if label is None:
- return text
- label = self.decode(label[:, 1:])
- return text, label
-
- def add_special_char(self, dict_character):
- dict_character = ['blank', '', '', ''] + dict_character
- return dict_character
-
- def decode(self, text_index, text_prob=None, is_remove_duplicate=False):
- """ convert text-index into text-label. """
- result_list = []
- batch_size = len(text_index)
- for batch_idx in range(batch_size):
- char_list = []
- conf_list = []
- for idx in range(len(text_index[batch_idx])):
- if text_index[batch_idx][idx] == 3: # end
- break
- try:
- char_list.append(self.character[int(text_index[batch_idx][
- idx])])
- except:
- continue
- if text_prob is not None:
- conf_list.append(text_prob[batch_idx][idx])
- else:
- conf_list.append(1)
- text = ''.join(char_list)
- result_list.append((text.lower(), np.mean(conf_list).tolist()))
- return result_list
-
-
class AttnLabelDecode(BaseRecLabelDecode):
""" Convert between text-label and text-index """
@@ -752,3 +688,122 @@ class PRENLabelDecode(BaseRecLabelDecode):
return text
label = self.decode(label)
return text, label
+
+
+class NRTRLabelDecode(BaseRecLabelDecode):
+ """ Convert between text-label and text-index """
+
+ def __init__(self, character_dict_path=None, use_space_char=True, **kwargs):
+ super(NRTRLabelDecode, self).__init__(character_dict_path,
+ use_space_char)
+
+ def __call__(self, preds, label=None, *args, **kwargs):
+
+ if len(preds) == 2:
+ preds_id = preds[0]
+ preds_prob = preds[1]
+ if isinstance(preds_id, paddle.Tensor):
+ preds_id = preds_id.numpy()
+ if isinstance(preds_prob, paddle.Tensor):
+ preds_prob = preds_prob.numpy()
+ if preds_id[0][0] == 2:
+ preds_idx = preds_id[:, 1:]
+ preds_prob = preds_prob[:, 1:]
+ else:
+ preds_idx = preds_id
+ text = self.decode(preds_idx, preds_prob, is_remove_duplicate=False)
+ if label is None:
+ return text
+ label = self.decode(label[:, 1:])
+ else:
+ if isinstance(preds, paddle.Tensor):
+ preds = preds.numpy()
+ preds_idx = preds.argmax(axis=2)
+ preds_prob = preds.max(axis=2)
+ text = self.decode(preds_idx, preds_prob, is_remove_duplicate=False)
+ if label is None:
+ return text
+ label = self.decode(label[:, 1:])
+ return text, label
+
+ def add_special_char(self, dict_character):
+ dict_character = ['blank', '', '', ''] + dict_character
+ return dict_character
+
+ def decode(self, text_index, text_prob=None, is_remove_duplicate=False):
+ """ convert text-index into text-label. """
+ result_list = []
+ batch_size = len(text_index)
+ for batch_idx in range(batch_size):
+ char_list = []
+ conf_list = []
+ for idx in range(len(text_index[batch_idx])):
+ try:
+ char_idx = self.character[int(text_index[batch_idx][idx])]
+ except:
+ continue
+ if char_idx == '': # end
+ break
+ char_list.append(char_idx)
+ if text_prob is not None:
+ conf_list.append(text_prob[batch_idx][idx])
+ else:
+ conf_list.append(1)
+ text = ''.join(char_list)
+ result_list.append((text.lower(), np.mean(conf_list).tolist()))
+ return result_list
+
+
+class ViTSTRLabelDecode(NRTRLabelDecode):
+ """ Convert between text-label and text-index """
+
+ def __init__(self, character_dict_path=None, use_space_char=False,
+ **kwargs):
+ super(ViTSTRLabelDecode, self).__init__(character_dict_path,
+ use_space_char)
+
+ def __call__(self, preds, label=None, *args, **kwargs):
+ if isinstance(preds, paddle.Tensor):
+ preds = preds[:, 1:].numpy()
+ else:
+ preds = preds[:, 1:]
+ preds_idx = preds.argmax(axis=2)
+ preds_prob = preds.max(axis=2)
+ text = self.decode(preds_idx, preds_prob, is_remove_duplicate=False)
+ if label is None:
+ return text
+ label = self.decode(label[:, 1:])
+ return text, label
+
+ def add_special_char(self, dict_character):
+ dict_character = ['', ''] + dict_character
+ return dict_character
+
+
+class ABINetLabelDecode(NRTRLabelDecode):
+ """ Convert between text-label and text-index """
+
+ def __init__(self, character_dict_path=None, use_space_char=False,
+ **kwargs):
+ super(ABINetLabelDecode, self).__init__(character_dict_path,
+ use_space_char)
+
+ def __call__(self, preds, label=None, *args, **kwargs):
+ if isinstance(preds, dict):
+ preds = preds['align'][-1].numpy()
+ elif isinstance(preds, paddle.Tensor):
+ preds = preds.numpy()
+ else:
+ preds = preds
+
+ preds_idx = preds.argmax(axis=2)
+ preds_prob = preds.max(axis=2)
+ text = self.decode(preds_idx, preds_prob, is_remove_duplicate=False)
+ if label is None:
+ return text
+ label = self.decode(label)
+ return text, label
+
+ def add_special_char(self, dict_character):
+ dict_character = [''] + dict_character
+ return dict_character
diff --git a/ppocr/utils/utility.py b/ppocr/utils/utility.py
index 4a25ff8b2fa182faaf4f4ce8909c9ec2e9b55ccc..b881fcab20bc5ca076a0002bd72349768c7d881a 100755
--- a/ppocr/utils/utility.py
+++ b/ppocr/utils/utility.py
@@ -91,18 +91,19 @@ def check_and_read_gif(img_path):
def load_vqa_bio_label_maps(label_map_path):
with open(label_map_path, "r", encoding='utf-8') as fin:
lines = fin.readlines()
- lines = [line.strip() for line in lines]
- if "O" not in lines:
- lines.insert(0, "O")
- labels = []
- for line in lines:
- if line == "O":
- labels.append("O")
- else:
- labels.append("B-" + line)
- labels.append("I-" + line)
- label2id_map = {label: idx for idx, label in enumerate(labels)}
- id2label_map = {idx: label for idx, label in enumerate(labels)}
+ old_lines = [line.strip() for line in lines]
+ lines = ["O"]
+ for line in old_lines:
+ # "O" has already been in lines
+ if line.upper() in ["OTHER", "OTHERS", "IGNORE"]:
+ continue
+ lines.append(line)
+ labels = ["O"]
+ for line in lines[1:]:
+ labels.append("B-" + line)
+ labels.append("I-" + line)
+ label2id_map = {label.upper(): idx for idx, label in enumerate(labels)}
+ id2label_map = {idx: label.upper() for idx, label in enumerate(labels)}
return label2id_map, id2label_map
diff --git a/ppocr/utils/visual.py b/ppocr/utils/visual.py
index 7a8c1674a74f89299de59f7cd120b4577a7499d8..235eb572a3975b4446ae2f2c9ad9c8558d5c5ad8 100644
--- a/ppocr/utils/visual.py
+++ b/ppocr/utils/visual.py
@@ -19,7 +19,7 @@ from PIL import Image, ImageDraw, ImageFont
def draw_ser_results(image,
ocr_results,
font_path="doc/fonts/simfang.ttf",
- font_size=18):
+ font_size=14):
np.random.seed(2021)
color = (np.random.permutation(range(255)),
np.random.permutation(range(255)),
@@ -40,9 +40,15 @@ def draw_ser_results(image,
if ocr_info["pred_id"] not in color_map:
continue
color = color_map[ocr_info["pred_id"]]
- text = "{}: {}".format(ocr_info["pred"], ocr_info["text"])
+ text = "{}: {}".format(ocr_info["pred"], ocr_info["transcription"])
- draw_box_txt(ocr_info["bbox"], text, draw, font, font_size, color)
+ if "bbox" in ocr_info:
+ # draw with ocr engine
+ bbox = ocr_info["bbox"]
+ else:
+ # draw with ocr groundtruth
+ bbox = trans_poly_to_bbox(ocr_info["points"])
+ draw_box_txt(bbox, text, draw, font, font_size, color)
img_new = Image.blend(image, img_new, 0.5)
return np.array(img_new)
@@ -62,6 +68,14 @@ def draw_box_txt(bbox, text, draw, font, font_size, color):
draw.text((bbox[0][0] + 1, start_y), text, fill=(255, 255, 255), font=font)
+def trans_poly_to_bbox(poly):
+ x1 = np.min([p[0] for p in poly])
+ x2 = np.max([p[0] for p in poly])
+ y1 = np.min([p[1] for p in poly])
+ y2 = np.max([p[1] for p in poly])
+ return [x1, y1, x2, y2]
+
+
def draw_re_results(image,
result,
font_path="doc/fonts/simfang.ttf",
@@ -80,10 +94,10 @@ def draw_re_results(image,
color_line = (0, 255, 0)
for ocr_info_head, ocr_info_tail in result:
- draw_box_txt(ocr_info_head["bbox"], ocr_info_head["text"], draw, font,
- font_size, color_head)
- draw_box_txt(ocr_info_tail["bbox"], ocr_info_tail["text"], draw, font,
- font_size, color_tail)
+ draw_box_txt(ocr_info_head["bbox"], ocr_info_head["transcription"],
+ draw, font, font_size, color_head)
+ draw_box_txt(ocr_info_tail["bbox"], ocr_info_tail["transcription"],
+ draw, font, font_size, color_tail)
center_head = (
(ocr_info_head['bbox'][0] + ocr_info_head['bbox'][2]) // 2,
diff --git a/ppstructure/docs/kie.md b/ppstructure/docs/kie.md
index 35498b33478d1010fd2548dfcb8586b4710723a1..315dd9f7bafa6b6160489eab330e8d278b2d119d 100644
--- a/ppstructure/docs/kie.md
+++ b/ppstructure/docs/kie.md
@@ -16,7 +16,7 @@ SDMGR是一个关键信息提取算法,将每个检测到的文本区域分类
训练和测试的数据采用wildreceipt数据集,通过如下指令下载数据集:
```
-wget https://paddleocr.bj.bcebos.com/dygraph_v2.1/kie/wildreceipt.tar && tar xf wildreceipt.tar
+wget https://paddleocr.bj.bcebos.com/ppstructure/dataset/wildreceipt.tar && tar xf wildreceipt.tar
```
执行预测:
diff --git a/ppstructure/docs/kie_en.md b/ppstructure/docs/kie_en.md
index 1fe38b0b399e9290526dafa5409673dc87026db7..7b3752223dd765e780d56d146c90bd0f892aac7b 100644
--- a/ppstructure/docs/kie_en.md
+++ b/ppstructure/docs/kie_en.md
@@ -15,7 +15,7 @@ This section provides a tutorial example on how to quickly use, train, and evalu
[Wildreceipt dataset](https://paperswithcode.com/dataset/wildreceipt) is used for this tutorial. It contains 1765 photos, with 25 classes, and 50000 text boxes, which can be downloaded by wget:
```shell
-wget https://paddleocr.bj.bcebos.com/dygraph_v2.1/kie/wildreceipt.tar && tar xf wildreceipt.tar
+wget https://paddleocr.bj.bcebos.com/ppstructure/dataset/wildreceipt.tar && tar xf wildreceipt.tar
```
Download the pretrained model and predict the result:
diff --git a/ppstructure/vqa/README.md b/ppstructure/vqa/README.md
index e3a10671ddb6494eb15073e7ac007aa1e8e6a32a..711ffa313865cd5a210143819cd4604dc28ef4f4 100644
--- a/ppstructure/vqa/README.md
+++ b/ppstructure/vqa/README.md
@@ -125,13 +125,13 @@ If you want to experience the prediction process directly, you can download the
* Download the processed dataset
-The download address of the processed XFUND Chinese dataset: [https://paddleocr.bj.bcebos.com/dataset/XFUND.tar](https://paddleocr.bj.bcebos.com/dataset/XFUND.tar).
+The download address of the processed XFUND Chinese dataset: [link](https://paddleocr.bj.bcebos.com/ppstructure/dataset/XFUND.tar).
Download and unzip the dataset, and place the dataset in the current directory after unzipping.
```shell
-wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
+wget https://paddleocr.bj.bcebos.com/ppstructure/dataset/XFUND.tar
````
* Convert the dataset
diff --git a/ppstructure/vqa/README_ch.md b/ppstructure/vqa/README_ch.md
index b677dc07bce6c1a752d753b6a1c538b4d3f99271..297ba64f82e70eafd4a0b1fee0764899799219ad 100644
--- a/ppstructure/vqa/README_ch.md
+++ b/ppstructure/vqa/README_ch.md
@@ -122,13 +122,13 @@ python3 -m pip install -r ppstructure/vqa/requirements.txt
* 下载处理好的数据集
-处理好的XFUND中文数据集下载地址:[https://paddleocr.bj.bcebos.com/dataset/XFUND.tar](https://paddleocr.bj.bcebos.com/dataset/XFUND.tar)。
+处理好的XFUND中文数据集下载地址:[链接](https://paddleocr.bj.bcebos.com/ppstructure/dataset/XFUND.tar)。
下载并解压该数据集,解压后将数据集放置在当前目录下。
```shell
-wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
+wget https://paddleocr.bj.bcebos.com/ppstructure/dataset/XFUND.tar
```
* 转换数据集
diff --git a/ppstructure/vqa/labels/labels_ser.txt b/ppstructure/vqa/labels/labels_ser.txt
deleted file mode 100644
index 508e48112412f62538baf0c78bcf99ec8945196e..0000000000000000000000000000000000000000
--- a/ppstructure/vqa/labels/labels_ser.txt
+++ /dev/null
@@ -1,3 +0,0 @@
-QUESTION
-ANSWER
-HEADER
diff --git a/ppstructure/vqa/tools/trans_xfun_data.py b/ppstructure/vqa/tools/trans_xfun_data.py
index 93ec98163c6cec96ec93399c1d41524200ddc499..11d221bea40367f091b3e09dde42e87f2217a617 100644
--- a/ppstructure/vqa/tools/trans_xfun_data.py
+++ b/ppstructure/vqa/tools/trans_xfun_data.py
@@ -21,26 +21,22 @@ def transfer_xfun_data(json_path=None, output_file=None):
json_info = json.loads(lines[0])
documents = json_info["documents"]
- label_info = {}
with open(output_file, "w", encoding='utf-8') as fout:
for idx, document in enumerate(documents):
+ label_info = []
img_info = document["img"]
document = document["document"]
image_path = img_info["fname"]
- label_info["height"] = img_info["height"]
- label_info["width"] = img_info["width"]
-
- label_info["ocr_info"] = []
-
for doc in document:
- label_info["ocr_info"].append({
- "text": doc["text"],
+ x1, y1, x2, y2 = doc["box"]
+ points = [[x1, y1], [x2, y1], [x2, y2], [x1, y2]]
+ label_info.append({
+ "transcription": doc["text"],
"label": doc["label"],
- "bbox": doc["box"],
+ "points": points,
"id": doc["id"],
- "linking": doc["linking"],
- "words": doc["words"]
+ "linking": doc["linking"]
})
fout.write(image_path + "\t" + json.dumps(
diff --git a/test_tipc/configs/rec_mtb_nrtr/rec_mtb_nrtr.yml b/test_tipc/configs/rec_mtb_nrtr/rec_mtb_nrtr.yml
index 15119bb2a9de02c19684d21ad5a1859db94895ce..8118d587248b7e4797e3a75c897e7b0a3d71b364 100644
--- a/test_tipc/configs/rec_mtb_nrtr/rec_mtb_nrtr.yml
+++ b/test_tipc/configs/rec_mtb_nrtr/rec_mtb_nrtr.yml
@@ -49,7 +49,7 @@ Architecture:
Loss:
- name: NRTRLoss
+ name: CELoss
smoothing: True
PostProcess:
@@ -69,7 +69,7 @@ Train:
img_mode: BGR
channel_first: False
- NRTRLabelEncode: # Class handling label
- - NRTRRecResizeImg:
+ - GrayRecResizeImg:
image_shape: [100, 32]
resize_type: PIL # PIL or OpenCV
- KeepKeys:
@@ -90,7 +90,7 @@ Eval:
img_mode: BGR
channel_first: False
- NRTRLabelEncode: # Class handling label
- - NRTRRecResizeImg:
+ - GrayRecResizeImg:
image_shape: [100, 32]
resize_type: PIL # PIL or OpenCV
- KeepKeys:
@@ -99,5 +99,5 @@ Eval:
shuffle: False
drop_last: False
batch_size_per_card: 256
- num_workers: 1
+ num_workers: 4
use_shared_memory: False
diff --git a/test_tipc/configs/rec_r45_abinet/rec_r45_abinet.yml b/test_tipc/configs/rec_r45_abinet/rec_r45_abinet.yml
new file mode 100644
index 0000000000000000000000000000000000000000..5b5890e7728b9a1cb629744bd5d56488657c73f3
--- /dev/null
+++ b/test_tipc/configs/rec_r45_abinet/rec_r45_abinet.yml
@@ -0,0 +1,106 @@
+Global:
+ use_gpu: True
+ epoch_num: 10
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/rec/r45_abinet/
+ save_epoch_step: 1
+ # evaluation is run every 2000 iterations
+ eval_batch_step: [0, 2000]
+ cal_metric_during_train: True
+ pretrained_model:
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: False
+ infer_img: doc/imgs_words_en/word_10.png
+ # for data or label process
+ character_dict_path:
+ character_type: en
+ max_text_length: 25
+ infer_mode: False
+ use_space_char: False
+ save_res_path: ./output/rec/predicts_abinet.txt
+
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.99
+ clip_norm: 20.0
+ lr:
+ name: Piecewise
+ decay_epochs: [6]
+ values: [0.0001, 0.00001]
+ regularizer:
+ name: 'L2'
+ factor: 0.
+
+Architecture:
+ model_type: rec
+ algorithm: ABINet
+ in_channels: 3
+ Transform:
+ Backbone:
+ name: ResNet45
+
+ Head:
+ name: ABINetHead
+ use_lang: True
+ iter_size: 3
+
+
+Loss:
+ name: CELoss
+ ignore_index: &ignore_index 100 # Must be greater than the number of character classes
+
+PostProcess:
+ name: ABINetLabelDecode
+
+Metric:
+ name: RecMetric
+ main_indicator: acc
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/ic15_data/
+ label_file_list: ["./train_data/ic15_data/rec_gt_train.txt"]
+ transforms:
+ - DecodeImage: # load image
+ img_mode: RGB
+ channel_first: False
+ - ABINetRecAug:
+ - ABINetLabelEncode: # Class handling label
+ ignore_index: *ignore_index
+ - ABINetRecResizeImg:
+ image_shape: [3, 32, 128]
+ padding: False
+ - KeepKeys:
+ keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
+ loader:
+ shuffle: True
+ batch_size_per_card: 96
+ drop_last: True
+ num_workers: 4
+
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/ic15_data
+ label_file_list: ["./train_data/ic15_data/rec_gt_test.txt"]
+ transforms:
+ - DecodeImage: # load image
+ img_mode: RGB
+ channel_first: False
+ - ABINetLabelEncode: # Class handling label
+ ignore_index: *ignore_index
+ - ABINetRecResizeImg:
+ image_shape: [3, 32, 128]
+ padding: False
+ - KeepKeys:
+ keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
+ loader:
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 256
+ num_workers: 4
+ use_shared_memory: False
diff --git a/test_tipc/configs/rec_r45_abinet/train_infer_python.txt b/test_tipc/configs/rec_r45_abinet/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..ecab1bcbbde11fc6d14357b6715033704c2c3316
--- /dev/null
+++ b/test_tipc/configs/rec_r45_abinet/train_infer_python.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:rec_abinet
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:null
+Global.epoch_num:lite_train_lite_infer=2|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=64
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c test_tipc/configs/rec_r45_abinet/rec_r45_abinet.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:tools/eval.py -c test_tipc/configs/rec_r45_abinet/rec_r45_abinet.yml -o
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c test_tipc/configs/rec_r45_abinet/rec_r45_abinet.yml -o
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+##
+train_model:./inference/rec_r45_abinet_train/best_accuracy
+infer_export:tools/export_model.py -c test_tipc/configs/rec_r45_abinet/rec_r45_abinet.yml -o
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_char_dict_path=./ppocr/utils/ic15_dict.txt --rec_image_shape="3,32,128" --rec_algorithm="ABINet"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1|6
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+--save_log_path:./test/output/
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,128]}]
diff --git a/test_tipc/configs/rec_svtrnet/rec_svtrnet.yml b/test_tipc/configs/rec_svtrnet/rec_svtrnet.yml
new file mode 100644
index 0000000000000000000000000000000000000000..140b17e0e79f9895167e9c51d86ced173e44a541
--- /dev/null
+++ b/test_tipc/configs/rec_svtrnet/rec_svtrnet.yml
@@ -0,0 +1,117 @@
+Global:
+ use_gpu: True
+ epoch_num: 20
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/rec/svtr/
+ save_epoch_step: 1
+ # evaluation is run every 2000 iterations after the 0th iteration
+ eval_batch_step: [0, 2000]
+ cal_metric_during_train: True
+ pretrained_model:
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: False
+ infer_img: doc/imgs_words_en/word_10.png
+ # for data or label process
+ character_dict_path:
+ character_type: en
+ max_text_length: 25
+ infer_mode: False
+ use_space_char: False
+ save_res_path: ./output/rec/predicts_svtr_tiny.txt
+
+
+Optimizer:
+ name: AdamW
+ beta1: 0.9
+ beta2: 0.99
+ epsilon: 8.e-8
+ weight_decay: 0.05
+ no_weight_decay_name: norm pos_embed
+ one_dim_param_no_weight_decay: true
+ lr:
+ name: Cosine
+ learning_rate: 0.0005
+ warmup_epoch: 2
+
+Architecture:
+ model_type: rec
+ algorithm: SVTR
+ Transform:
+ name: STN_ON
+ tps_inputsize: [32, 64]
+ tps_outputsize: [32, 100]
+ num_control_points: 20
+ tps_margins: [0.05,0.05]
+ stn_activation: none
+ Backbone:
+ name: SVTRNet
+ img_size: [32, 100]
+ out_char_num: 25
+ out_channels: 192
+ patch_merging: 'Conv'
+ embed_dim: [64, 128, 256]
+ depth: [3, 6, 3]
+ num_heads: [2, 4, 8]
+ mixer: ['Local','Local','Local','Local','Local','Local','Global','Global','Global','Global','Global','Global']
+ local_mixer: [[7, 11], [7, 11], [7, 11]]
+ last_stage: True
+ prenorm: false
+ Neck:
+ name: SequenceEncoder
+ encoder_type: reshape
+ Head:
+ name: CTCHead
+
+Loss:
+ name: CTCLoss
+
+PostProcess:
+ name: CTCLabelDecode
+
+Metric:
+ name: RecMetric
+ main_indicator: acc
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/ic15_data/
+ label_file_list: ["./train_data/ic15_data/rec_gt_train.txt"]
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - CTCLabelEncode: # Class handling label
+ - SVTRRecResizeImg:
+ image_shape: [3, 64, 256]
+ padding: False
+ - KeepKeys:
+ keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
+ loader:
+ shuffle: True
+ batch_size_per_card: 512
+ drop_last: True
+ num_workers: 4
+
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/ic15_data
+ label_file_list: ["./train_data/ic15_data/rec_gt_test.txt"]
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - CTCLabelEncode: # Class handling label
+ - SVTRRecResizeImg:
+ image_shape: [3, 64, 256]
+ padding: False
+ - KeepKeys:
+ keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
+ loader:
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 256
+ num_workers: 2
diff --git a/test_tipc/configs/rec_svtrnet/train_infer_python.txt b/test_tipc/configs/rec_svtrnet/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a7e4a24063b2e248f2ab92d5efd257a2837c0a34
--- /dev/null
+++ b/test_tipc/configs/rec_svtrnet/train_infer_python.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:rec_svtrnet
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:null
+Global.epoch_num:lite_train_lite_infer=2|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=64
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c test_tipc/configs/rec_svtrnet/rec_svtrnet.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:tools/eval.py -c test_tipc/configs/rec_svtrnet/rec_svtrnet.yml -o
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c test_tipc/configs/rec_svtrnet/rec_svtrnet.yml -o
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+##
+train_model:./inference/rec_svtrnet_train/best_accuracy
+infer_export:tools/export_model.py -c test_tipc/configs/rec_svtrnet/rec_svtrnet.yml -o
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_char_dict_path=./ppocr/utils/ic15_dict.txt --rec_image_shape="3,64,256" --rec_algorithm="SVTR"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1|6
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+--save_log_path:./test/output/
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,64,256]}]
diff --git a/test_tipc/configs/rec_vitstr_none_ce/rec_vitstr_none_ce.yml b/test_tipc/configs/rec_vitstr_none_ce/rec_vitstr_none_ce.yml
new file mode 100644
index 0000000000000000000000000000000000000000..a0aed488755f7cb6fed18a5747e9b7f62f57da86
--- /dev/null
+++ b/test_tipc/configs/rec_vitstr_none_ce/rec_vitstr_none_ce.yml
@@ -0,0 +1,104 @@
+Global:
+ use_gpu: True
+ epoch_num: 20
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/rec/vitstr_none_ce/
+ save_epoch_step: 1
+ # evaluation is run every 2000 iterations after the 0th iteration#
+ eval_batch_step: [0, 2000]
+ cal_metric_during_train: True
+ pretrained_model:
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: False
+ infer_img: doc/imgs_words_en/word_10.png
+ # for data or label process
+ character_dict_path: ppocr/utils/EN_symbol_dict.txt
+ max_text_length: 25
+ infer_mode: False
+ use_space_char: False
+ save_res_path: ./output/rec/predicts_vitstr.txt
+
+
+Optimizer:
+ name: Adadelta
+ epsilon: 1.e-8
+ rho: 0.95
+ clip_norm: 5.0
+ lr:
+ learning_rate: 1.0
+
+Architecture:
+ model_type: rec
+ algorithm: ViTSTR
+ in_channels: 1
+ Transform:
+ Backbone:
+ name: ViTSTR
+ Neck:
+ name: SequenceEncoder
+ encoder_type: reshape
+ Head:
+ name: CTCHead
+
+Loss:
+ name: CELoss
+ smoothing: False
+ with_all: True
+ ignore_index: &ignore_index 0 # Must be zero or greater than the number of character classes
+
+PostProcess:
+ name: ViTSTRLabelDecode
+
+Metric:
+ name: RecMetric
+ main_indicator: acc
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/ic15_data/
+ label_file_list: ["./train_data/ic15_data/rec_gt_train.txt"]
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - ViTSTRLabelEncode: # Class handling label
+ ignore_index: *ignore_index
+ - GrayRecResizeImg:
+ image_shape: [224, 224] # W H
+ resize_type: PIL # PIL or OpenCV
+ inter_type: 'Image.BICUBIC'
+ scale: false
+ - KeepKeys:
+ keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
+ loader:
+ shuffle: True
+ batch_size_per_card: 48
+ drop_last: True
+ num_workers: 8
+
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/ic15_data
+ label_file_list: ["./train_data/ic15_data/rec_gt_test.txt"]
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - ViTSTRLabelEncode: # Class handling label
+ ignore_index: *ignore_index
+ - GrayRecResizeImg:
+ image_shape: [224, 224] # W H
+ resize_type: PIL # PIL or OpenCV
+ inter_type: 'Image.BICUBIC'
+ scale: false
+ - KeepKeys:
+ keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
+ loader:
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 256
+ num_workers: 2
diff --git a/test_tipc/configs/rec_vitstr_none_ce/train_infer_python.txt b/test_tipc/configs/rec_vitstr_none_ce/train_infer_python.txt
new file mode 100644
index 0000000000000000000000000000000000000000..04c5742ea2ddaf01e782d8b39c21bcbcfa0a7ce7
--- /dev/null
+++ b/test_tipc/configs/rec_vitstr_none_ce/train_infer_python.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:rec_vitstr
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:null
+Global.epoch_num:lite_train_lite_infer=2|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=64
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c test_tipc/configs/rec_vitstr_none_ce/rec_vitstr_none_ce.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:tools/eval.py -c test_tipc/configs/rec_vitstr_none_ce/rec_vitstr_none_ce.yml -o
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c test_tipc/configs/rec_vitstr_none_ce/rec_vitstr_none_ce.yml -o
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+##
+train_model:./inference/rec_vitstr_none_ce_train/best_accuracy
+infer_export:tools/export_model.py -c test_tipc/configs/rec_vitstr_none_ce/rec_vitstr_none_ce.yml -o
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_char_dict_path=./ppocr/utils/EN_symbol_dict.txt --rec_image_shape="1,224,224" --rec_algorithm="ViTSTR"
+--use_gpu:True|False
+--enable_mkldnn:False
+--cpu_threads:6
+--rec_batch_num:1|6
+--use_tensorrt:False
+--precision:fp32
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+--save_log_path:./test/output/
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[1,224,224]}]
diff --git a/test_tipc/test_serving_infer_cpp.sh b/test_tipc/test_serving_infer_cpp.sh
index 4088c66f576187215e5945793868d13fc74005af..0be6a45adf3105f088a96336dddfbe9ac612f19b 100644
--- a/test_tipc/test_serving_infer_cpp.sh
+++ b/test_tipc/test_serving_infer_cpp.sh
@@ -87,11 +87,12 @@ function func_serving(){
set_image_dir=$(func_set_params "${image_dir_key}" "${image_dir_value}")
python_list=(${python_list})
cd ${serving_dir_value}
+
# cpp serving
for gpu_id in ${gpu_value[*]}; do
if [ ${gpu_id} = "null" ]; then
server_log_path="${LOG_PATH}/cpp_server_cpu.log"
- web_service_cpp_cmd="${python_list[0]} ${web_service_py} --model ${det_server_value} ${rec_server_value} ${op_key} ${op_value} ${port_key} ${port_value} > ${server_log_path} 2>&1 "
+ web_service_cpp_cmd="nohup ${python_list[0]} ${web_service_py} --model ${det_server_value} ${rec_server_value} ${op_key} ${op_value} ${port_key} ${port_value} > ${server_log_path} 2>&1 &"
eval $web_service_cpp_cmd
last_status=${PIPESTATUS[0]}
status_check $last_status "${web_service_cpp_cmd}" "${status_log}" "${model_name}"
@@ -105,7 +106,7 @@ function func_serving(){
ps ux | grep -i ${port_value} | awk '{print $2}' | xargs kill -s 9
else
server_log_path="${LOG_PATH}/cpp_server_gpu.log"
- web_service_cpp_cmd="${python_list[0]} ${web_service_py} --model ${det_server_value} ${rec_server_value} ${op_key} ${op_value} ${port_key} ${port_value} ${gpu_key} ${gpu_id} > ${server_log_path} 2>&1 "
+ web_service_cpp_cmd="nohup ${python_list[0]} ${web_service_py} --model ${det_server_value} ${rec_server_value} ${op_key} ${op_value} ${port_key} ${port_value} ${gpu_key} ${gpu_id} > ${server_log_path} 2>&1 &"
eval $web_service_cpp_cmd
sleep 5s
_save_log_path="${LOG_PATH}/cpp_client_gpu.log"
diff --git a/test_tipc/test_serving_infer_python.sh b/test_tipc/test_serving_infer_python.sh
index 57dab6aeb5dab31605a56abd072cb1568368a66c..4ccccc06e23ce086e7dac1f3446aae9130605444 100644
--- a/test_tipc/test_serving_infer_python.sh
+++ b/test_tipc/test_serving_infer_python.sh
@@ -112,7 +112,7 @@ function func_serving(){
cd ${serving_dir_value}
python=${python_list[0]}
-
+
# python serving
for use_gpu in ${web_use_gpu_list[*]}; do
if [ ${use_gpu} = "null" ]; then
@@ -123,19 +123,19 @@ function func_serving(){
if [ ${model_name} = "ch_PP-OCRv2" ] || [ ${model_name} = "ch_PP-OCRv3" ] || [ ${model_name} = "ch_ppocr_mobile_v2.0" ] || [ ${model_name} = "ch_ppocr_server_v2.0" ]; then
set_det_model_config=$(func_set_params "${det_server_key}" "${det_server_value}")
set_rec_model_config=$(func_set_params "${rec_server_key}" "${rec_server_value}")
- web_service_cmd="${python} ${web_service_py} ${web_use_gpu_key}="" ${web_use_mkldnn_key}=${use_mkldnn} ${set_cpu_threads} ${set_det_model_config} ${set_rec_model_config} > ${server_log_path} 2>&1 "
+ web_service_cmd="nohup ${python} ${web_service_py} ${web_use_gpu_key}="" ${web_use_mkldnn_key}=${use_mkldnn} ${set_cpu_threads} ${set_det_model_config} ${set_rec_model_config} > ${server_log_path} 2>&1 &"
eval $web_service_cmd
last_status=${PIPESTATUS[0]}
status_check $last_status "${web_service_cmd}" "${status_log}" "${model_name}"
elif [[ ${model_name} =~ "det" ]]; then
set_det_model_config=$(func_set_params "${det_server_key}" "${det_server_value}")
- web_service_cmd="${python} ${web_service_py} ${web_use_gpu_key}="" ${web_use_mkldnn_key}=${use_mkldnn} ${set_cpu_threads} ${set_det_model_config} > ${server_log_path} 2>&1 "
+ web_service_cmd="nohup ${python} ${web_service_py} ${web_use_gpu_key}="" ${web_use_mkldnn_key}=${use_mkldnn} ${set_cpu_threads} ${set_det_model_config} > ${server_log_path} 2>&1 &"
eval $web_service_cmd
last_status=${PIPESTATUS[0]}
status_check $last_status "${web_service_cmd}" "${status_log}" "${model_name}"
elif [[ ${model_name} =~ "rec" ]]; then
set_rec_model_config=$(func_set_params "${rec_server_key}" "${rec_server_value}")
- web_service_cmd="${python} ${web_service_py} ${web_use_gpu_key}="" ${web_use_mkldnn_key}=${use_mkldnn} ${set_cpu_threads} ${set_rec_model_config} > ${server_log_path} 2>&1 "
+ web_service_cmd="nohup ${python} ${web_service_py} ${web_use_gpu_key}="" ${web_use_mkldnn_key}=${use_mkldnn} ${set_cpu_threads} ${set_rec_model_config} > ${server_log_path} 2>&1 &"
eval $web_service_cmd
last_status=${PIPESTATUS[0]}
status_check $last_status "${web_service_cmd}" "${status_log}" "${model_name}"
@@ -174,19 +174,19 @@ function func_serving(){
if [ ${model_name} = "ch_PP-OCRv2" ] || [ ${model_name} = "ch_PP-OCRv3" ] || [ ${model_name} = "ch_ppocr_mobile_v2.0" ] || [ ${model_name} = "ch_ppocr_server_v2.0" ]; then
set_det_model_config=$(func_set_params "${det_server_key}" "${det_server_value}")
set_rec_model_config=$(func_set_params "${rec_server_key}" "${rec_server_value}")
- web_service_cmd="${python} ${web_service_py} ${set_tensorrt} ${set_precision} ${set_det_model_config} ${set_rec_model_config} > ${server_log_path} 2>&1 "
+ web_service_cmd="nohup ${python} ${web_service_py} ${set_tensorrt} ${set_precision} ${set_det_model_config} ${set_rec_model_config} > ${server_log_path} 2>&1 &"
eval $web_service_cmd
last_status=${PIPESTATUS[0]}
status_check $last_status "${web_service_cmd}" "${status_log}" "${model_name}"
elif [[ ${model_name} =~ "det" ]]; then
set_det_model_config=$(func_set_params "${det_server_key}" "${det_server_value}")
- web_service_cmd="${python} ${web_service_py} ${set_tensorrt} ${set_precision} ${set_det_model_config} > ${server_log_path} 2>&1 "
+ web_service_cmd="nohup ${python} ${web_service_py} ${set_tensorrt} ${set_precision} ${set_det_model_config} > ${server_log_path} 2>&1 &"
eval $web_service_cmd
last_status=${PIPESTATUS[0]}
status_check $last_status "${web_service_cmd}" "${status_log}" "${model_name}"
elif [[ ${model_name} =~ "rec" ]]; then
set_rec_model_config=$(func_set_params "${rec_server_key}" "${rec_server_value}")
- web_service_cmd="${python} ${web_service_py} ${set_tensorrt} ${set_precision} ${set_rec_model_config} > ${server_log_path} 2>&1 "
+ web_service_cmd="nohup ${python} ${web_service_py} ${set_tensorrt} ${set_precision} ${set_rec_model_config} > ${server_log_path} 2>&1 &"
eval $web_service_cmd
last_status=${PIPESTATUS[0]}
status_check $last_status "${web_service_cmd}" "${status_log}" "${model_name}"
diff --git a/tools/export_model.py b/tools/export_model.py
index 3ea0228f857a2fadb36678ecd3b91bc865e56e46..b10d41d5b288258ad895cefa7d8cc243eff10546 100755
--- a/tools/export_model.py
+++ b/tools/export_model.py
@@ -31,7 +31,12 @@ from ppocr.utils.logging import get_logger
from tools.program import load_config, merge_config, ArgsParser
-def export_single_model(model, arch_config, save_path, logger, quanter=None):
+def export_single_model(model,
+ arch_config,
+ save_path,
+ logger,
+ input_shape=None,
+ quanter=None):
if arch_config["algorithm"] == "SRN":
max_text_length = arch_config["Head"]["max_text_length"]
other_shape = [
@@ -64,7 +69,7 @@ def export_single_model(model, arch_config, save_path, logger, quanter=None):
else:
other_shape = [
paddle.static.InputSpec(
- shape=[None, 3, 64, 256], dtype="float32"),
+ shape=[None] + input_shape, dtype="float32"),
]
model = to_static(model, input_spec=other_shape)
elif arch_config["algorithm"] == "PREN":
@@ -73,6 +78,25 @@ def export_single_model(model, arch_config, save_path, logger, quanter=None):
shape=[None, 3, 64, 512], dtype="float32"),
]
model = to_static(model, input_spec=other_shape)
+ elif arch_config["algorithm"] == "ViTSTR":
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None, 1, 224, 224], dtype="float32"),
+ ]
+ model = to_static(model, input_spec=other_shape)
+ elif arch_config["algorithm"] == "ABINet":
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None, 3, 32, 128], dtype="float32"),
+ ]
+ # print([None, 3, 32, 128])
+ model = to_static(model, input_spec=other_shape)
+ elif arch_config["algorithm"] == "NRTR":
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None, 1, 32, 100], dtype="float32"),
+ ]
+ model = to_static(model, input_spec=other_shape)
else:
infer_shape = [3, -1, -1]
if arch_config["model_type"] == "rec":
@@ -84,8 +108,6 @@ def export_single_model(model, arch_config, save_path, logger, quanter=None):
"When there is tps in the network, variable length input is not supported, and the input size needs to be the same as during training"
)
infer_shape[-1] = 100
- if arch_config["algorithm"] == "NRTR":
- infer_shape = [1, 32, 100]
elif arch_config["model_type"] == "table":
infer_shape = [3, 488, 488]
model = to_static(
@@ -157,6 +179,13 @@ def main():
arch_config = config["Architecture"]
+ if arch_config["algorithm"] == "SVTR" and arch_config["Head"][
+ "name"] != 'MultiHead':
+ input_shape = config["Eval"]["dataset"]["transforms"][-2][
+ 'SVTRRecResizeImg']['image_shape']
+ else:
+ input_shape = None
+
if arch_config["algorithm"] in ["Distillation", ]: # distillation model
archs = list(arch_config["Models"].values())
for idx, name in enumerate(model.model_name_list):
@@ -165,7 +194,8 @@ def main():
sub_model_save_path, logger)
else:
save_path = os.path.join(save_path, "inference")
- export_single_model(model, arch_config, save_path, logger)
+ export_single_model(
+ model, arch_config, save_path, logger, input_shape=input_shape)
if __name__ == "__main__":
diff --git a/tools/infer/predict_rec.py b/tools/infer/predict_rec.py
index 3664ef2caf4b888d6a3918202256c99cc54c5eb1..a95f55596647acc0eaca9616b5630917d7ebdf3a 100755
--- a/tools/infer/predict_rec.py
+++ b/tools/infer/predict_rec.py
@@ -69,6 +69,18 @@ class TextRecognizer(object):
"character_dict_path": args.rec_char_dict_path,
"use_space_char": args.use_space_char
}
+ elif self.rec_algorithm == 'ViTSTR':
+ postprocess_params = {
+ 'name': 'ViTSTRLabelDecode',
+ "character_dict_path": args.rec_char_dict_path,
+ "use_space_char": args.use_space_char
+ }
+ elif self.rec_algorithm == 'ABINet':
+ postprocess_params = {
+ 'name': 'ABINetLabelDecode',
+ "character_dict_path": args.rec_char_dict_path,
+ "use_space_char": args.use_space_char
+ }
self.postprocess_op = build_post_process(postprocess_params)
self.predictor, self.input_tensor, self.output_tensors, self.config = \
utility.create_predictor(args, 'rec', logger)
@@ -96,15 +108,22 @@ class TextRecognizer(object):
def resize_norm_img(self, img, max_wh_ratio):
imgC, imgH, imgW = self.rec_image_shape
- if self.rec_algorithm == 'NRTR':
+ if self.rec_algorithm == 'NRTR' or self.rec_algorithm == 'ViTSTR':
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# return padding_im
image_pil = Image.fromarray(np.uint8(img))
- img = image_pil.resize([100, 32], Image.ANTIALIAS)
+ if self.rec_algorithm == 'ViTSTR':
+ img = image_pil.resize([imgW, imgH], Image.BICUBIC)
+ else:
+ img = image_pil.resize([imgW, imgH], Image.ANTIALIAS)
img = np.array(img)
norm_img = np.expand_dims(img, -1)
norm_img = norm_img.transpose((2, 0, 1))
- return norm_img.astype(np.float32) / 128. - 1.
+ if self.rec_algorithm == 'ViTSTR':
+ norm_img = norm_img.astype(np.float32) / 255.
+ else:
+ norm_img = norm_img.astype(np.float32) / 128. - 1.
+ return norm_img
assert imgC == img.shape[2]
imgW = int((imgH * max_wh_ratio))
@@ -132,17 +151,6 @@ class TextRecognizer(object):
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
- def resize_norm_img_svtr(self, img, image_shape):
-
- imgC, imgH, imgW = image_shape
- resized_image = cv2.resize(
- img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
- resized_image = resized_image.astype('float32')
- resized_image = resized_image.transpose((2, 0, 1)) / 255
- resized_image -= 0.5
- resized_image /= 0.5
- return resized_image
-
def resize_norm_img_srn(self, img, image_shape):
imgC, imgH, imgW = image_shape
@@ -250,6 +258,35 @@ class TextRecognizer(object):
return padding_im, resize_shape, pad_shape, valid_ratio
+ def resize_norm_img_svtr(self, img, image_shape):
+
+ imgC, imgH, imgW = image_shape
+ resized_image = cv2.resize(
+ img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_image = resized_image.astype('float32')
+ resized_image = resized_image.transpose((2, 0, 1)) / 255
+ resized_image -= 0.5
+ resized_image /= 0.5
+ return resized_image
+
+ def resize_norm_img_abinet(self, img, image_shape):
+
+ imgC, imgH, imgW = image_shape
+
+ resized_image = cv2.resize(
+ img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_image = resized_image.astype('float32')
+ resized_image = resized_image / 255.
+
+ mean = np.array([0.485, 0.456, 0.406])
+ std = np.array([0.229, 0.224, 0.225])
+ resized_image = (
+ resized_image - mean[None, None, ...]) / std[None, None, ...]
+ resized_image = resized_image.transpose((2, 0, 1))
+ resized_image = resized_image.astype('float32')
+
+ return resized_image
+
def __call__(self, img_list):
img_num = len(img_list)
# Calculate the aspect ratio of all text bars
@@ -300,6 +337,11 @@ class TextRecognizer(object):
self.rec_image_shape)
norm_img = norm_img[np.newaxis, :]
norm_img_batch.append(norm_img)
+ elif self.rec_algorithm == "ABINet":
+ norm_img = self.resize_norm_img_abinet(
+ img_list[indices[ino]], self.rec_image_shape)
+ norm_img = norm_img[np.newaxis, :]
+ norm_img_batch.append(norm_img)
else:
norm_img = self.resize_norm_img(img_list[indices[ino]],
max_wh_ratio)
diff --git a/tools/infer_kie.py b/tools/infer_kie.py
index 0cb0b8702cbd7ea74a7b7fcff69122731578a1bd..346e2e0aeeee695ab49577b6b13dcc058150df1a 100755
--- a/tools/infer_kie.py
+++ b/tools/infer_kie.py
@@ -39,13 +39,12 @@ import time
def read_class_list(filepath):
- dict = {}
+ ret = {}
with open(filepath, "r") as f:
lines = f.readlines()
- for line in lines:
- key, value = line.split(" ")
- dict[key] = value.rstrip()
- return dict
+ for idx, line in enumerate(lines):
+ ret[idx] = line.strip("\n")
+ return ret
def draw_kie_result(batch, node, idx_to_cls, count):
@@ -71,7 +70,7 @@ def draw_kie_result(batch, node, idx_to_cls, count):
x_min = int(min([point[0] for point in new_box]))
y_min = int(min([point[1] for point in new_box]))
- pred_label = str(node_pred_label[i])
+ pred_label = node_pred_label[i]
if pred_label in idx_to_cls:
pred_label = idx_to_cls[pred_label]
pred_score = '{:.2f}'.format(node_pred_score[i])
@@ -109,8 +108,7 @@ def main():
save_res_path = config['Global']['save_res_path']
class_path = config['Global']['class_path']
idx_to_cls = read_class_list(class_path)
- if not os.path.exists(os.path.dirname(save_res_path)):
- os.makedirs(os.path.dirname(save_res_path))
+ os.makedirs(os.path.dirname(save_res_path), exist_ok=True)
model.eval()
diff --git a/tools/infer_vqa_token_ser.py b/tools/infer_vqa_token_ser.py
index 83ed72b392e627c161903c3945f57be0abfabc2b..39ada64a99847a910158b74672c89398ba08f032 100755
--- a/tools/infer_vqa_token_ser.py
+++ b/tools/infer_vqa_token_ser.py
@@ -86,15 +86,16 @@ class SerPredictor(object):
]
transforms.append(op)
- global_config['infer_mode'] = True
+ if config["Global"].get("infer_mode", None) is None:
+ global_config['infer_mode'] = True
self.ops = create_operators(config['Eval']['dataset']['transforms'],
global_config)
self.model.eval()
- def __call__(self, img_path):
- with open(img_path, 'rb') as f:
+ def __call__(self, data):
+ with open(data["img_path"], 'rb') as f:
img = f.read()
- data = {'image': img}
+ data["image"] = img
batch = transform(data, self.ops)
batch = to_tensor(batch)
preds = self.model(batch)
@@ -112,20 +113,35 @@ if __name__ == '__main__':
ser_engine = SerPredictor(config)
- infer_imgs = get_image_file_list(config['Global']['infer_img'])
+ if config["Global"].get("infer_mode", None) is False:
+ data_dir = config['Eval']['dataset']['data_dir']
+ with open(config['Global']['infer_img'], "rb") as f:
+ infer_imgs = f.readlines()
+ else:
+ infer_imgs = get_image_file_list(config['Global']['infer_img'])
+
with open(
os.path.join(config['Global']['save_res_path'],
"infer_results.txt"),
"w",
encoding='utf-8') as fout:
- for idx, img_path in enumerate(infer_imgs):
+ for idx, info in enumerate(infer_imgs):
+ if config["Global"].get("infer_mode", None) is False:
+ data_line = info.decode('utf-8')
+ substr = data_line.strip("\n").split("\t")
+ img_path = os.path.join(data_dir, substr[0])
+ data = {'img_path': img_path, 'label': substr[1]}
+ else:
+ img_path = info
+ data = {'img_path': img_path}
+
save_img_path = os.path.join(
config['Global']['save_res_path'],
os.path.splitext(os.path.basename(img_path))[0] + "_ser.jpg")
logger.info("process: [{}/{}], save result to {}".format(
idx, len(infer_imgs), save_img_path))
- result, _ = ser_engine(img_path)
+ result, _ = ser_engine(data)
result = result[0]
fout.write(img_path + "\t" + json.dumps(
{
diff --git a/tools/program.py b/tools/program.py
index e8e72fdd2dbf2a8da7826fdeb344397659038f7b..7bd54ba083b912bd489efb1a763a8169685f2d9a 100755
--- a/tools/program.py
+++ b/tools/program.py
@@ -255,6 +255,8 @@ def train(config,
with paddle.amp.auto_cast():
if model_type == 'table' or extra_input:
preds = model(images, data=batch[1:])
+ elif model_type in ["kie", 'vqa']:
+ preds = model(batch)
else:
preds = model(images)
else: