Merge pull request #12965 from taosdata/docs/dingbo/webp-3.0
docs: use webp format images
Showing
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
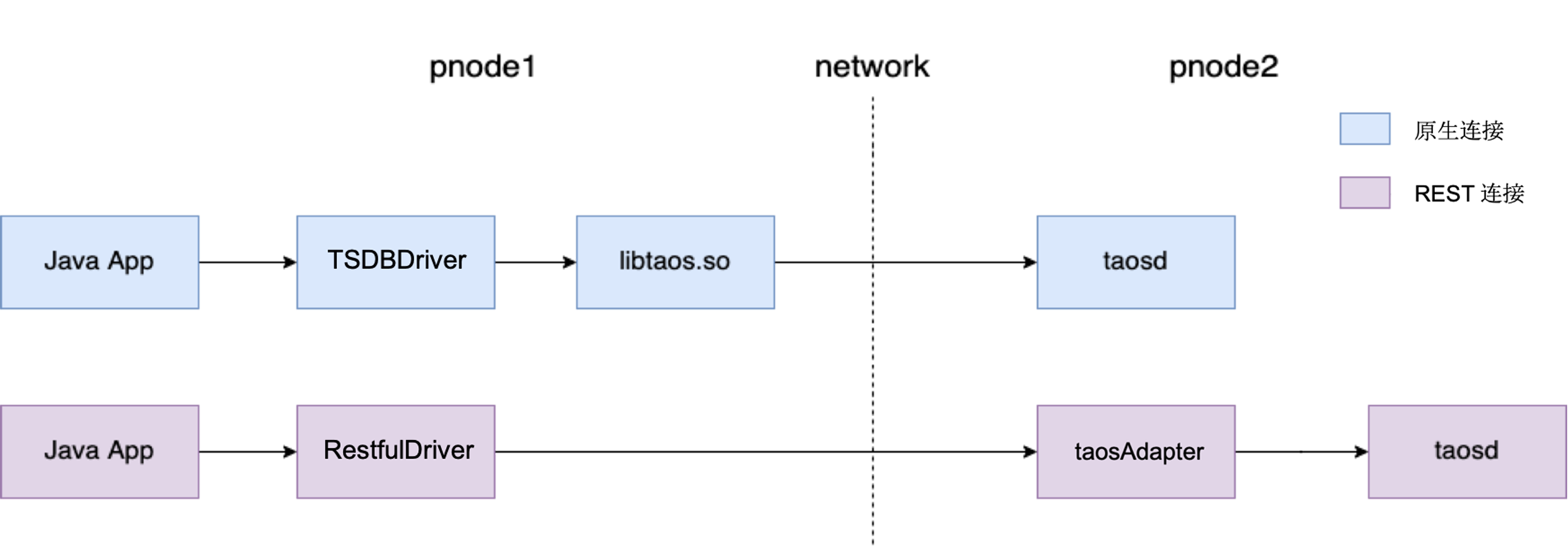
188.0 KB
{kind=link}
{kind=link}
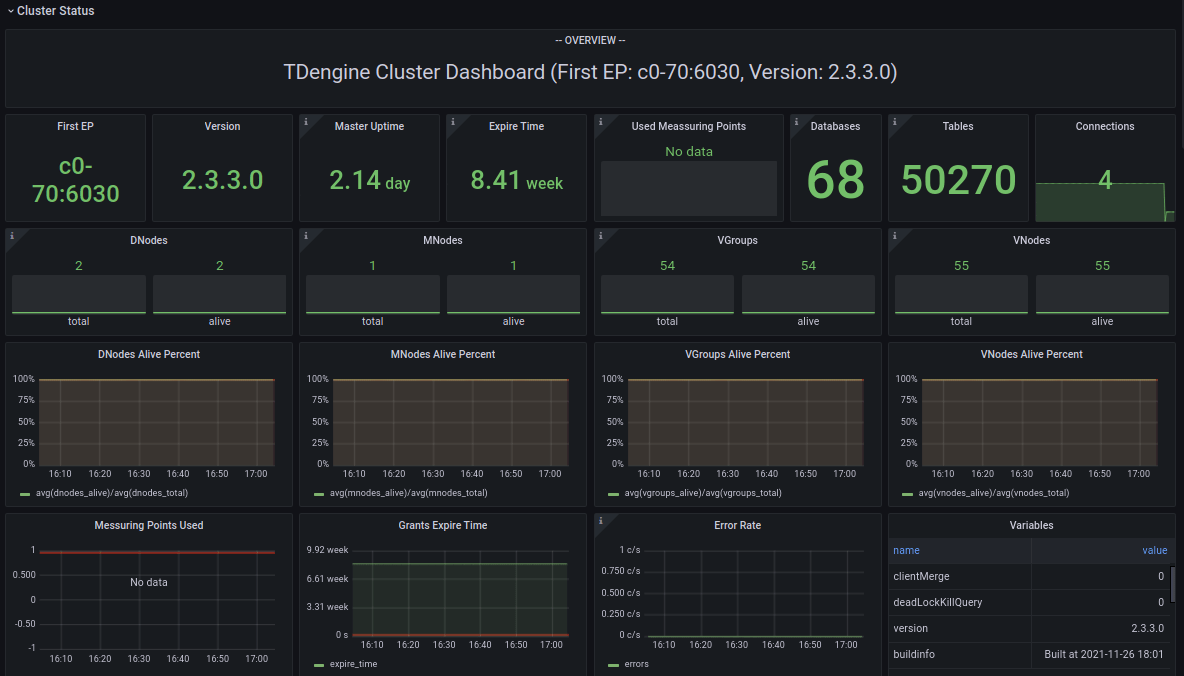
33.4 KB
{kind=link}
文件已添加
{kind=link}

16.7 KB
{kind=link}
{kind=link}

10.3 KB
{kind=link}
{kind=link}
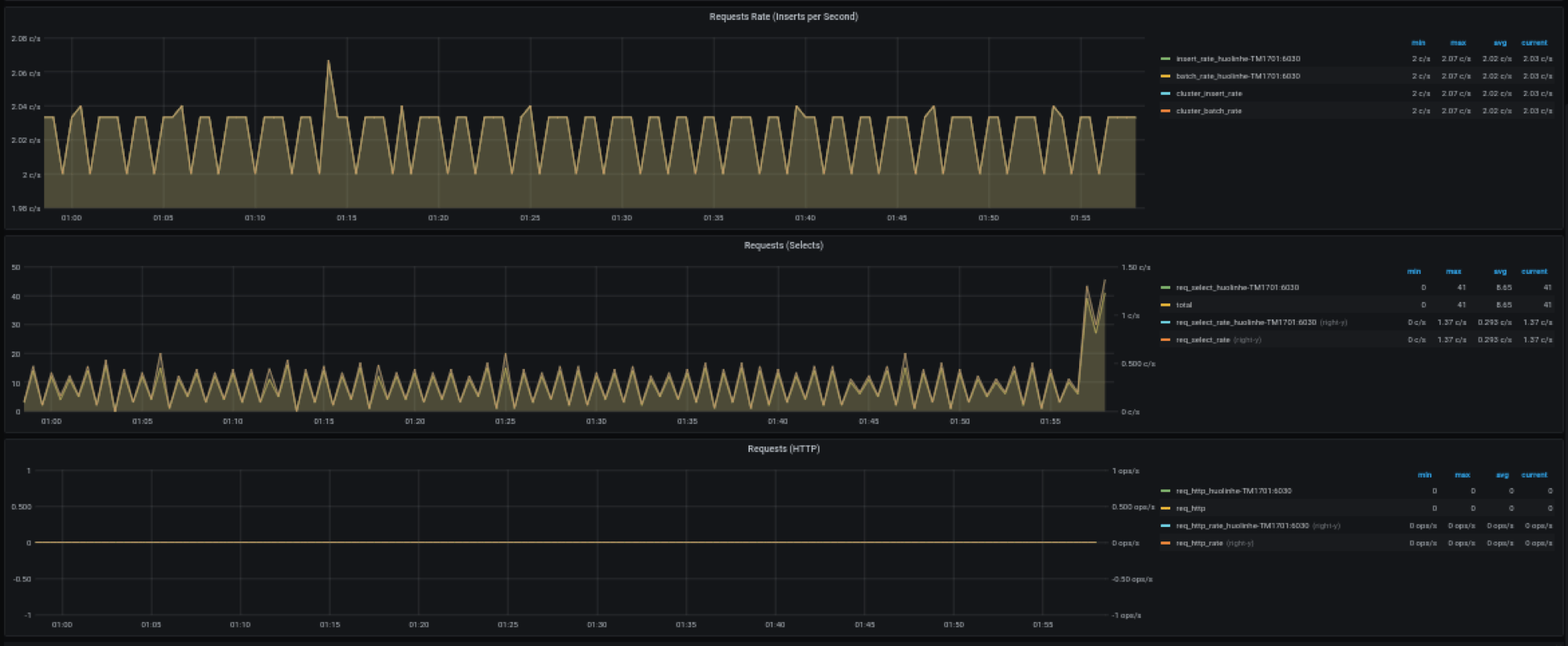
105.1 KB
{kind=link}
{kind=link}
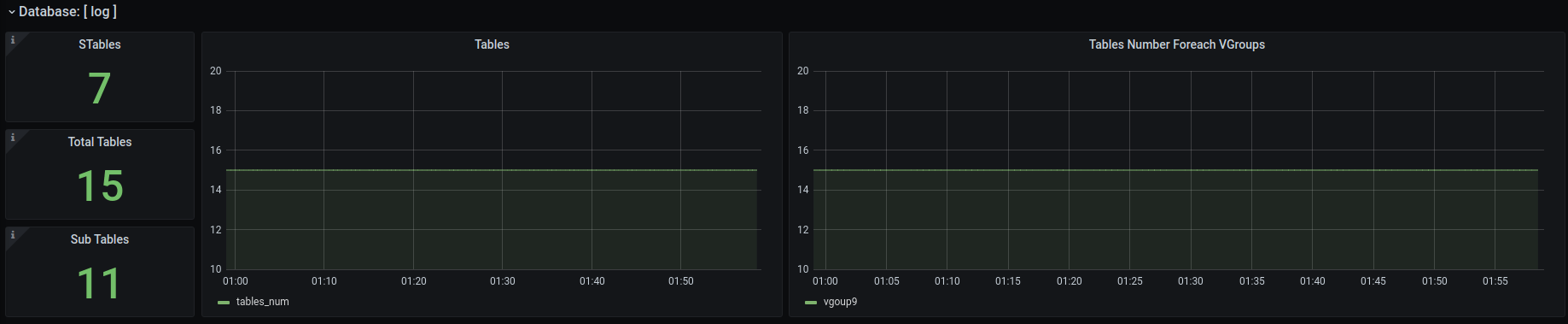
11.9 KB
{kind=link}
{kind=link}
121.6 KB
{kind=link}
文件已添加
{kind=link}
7.6 KB
{kind=link}
文件已添加
{kind=link}

24.9 KB
{kind=link}
文件已添加
{kind=link}
124.3 KB
{kind=link}
{kind=link}
12.6 KB
{kind=link}
{kind=link}
18.8 KB
{kind=link}
文件已添加
{kind=link}
23.8 KB
{kind=link}
{kind=link}
24.1 KB
{kind=link}
文件已添加
{kind=link}
24.6 KB
{kind=link}
{kind=link}
7.1 KB
{kind=link}
文件已添加
{kind=link}
7.3 KB
{kind=link}
文件已添加
{kind=link}

3.5 KB
{kind=link}
文件已添加
{kind=link}
13.4 KB
{kind=link}
{kind=link}
188.4 KB
{kind=link}
文件已添加
{kind=link}
11.4 KB
{kind=link}
文件已添加
{kind=link}
32.6 KB
{kind=link}
文件已添加
{kind=link}
6.3 KB
{kind=link}
文件已添加
{kind=link}
22.4 KB
{kind=link}
文件已添加
{kind=link}
10.8 KB
{kind=link}
文件已添加
{kind=link}
20.8 KB
{kind=link}
{kind=link}
58.9 KB
{kind=link}
{kind=link}
37.5 KB
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
60.3 KB
{kind=link}
文件已添加
{kind=link}
77.7 KB
{kind=link}
文件已添加
{kind=link}
49.6 KB
{kind=link}
文件已添加
{kind=link}
29.0 KB
{kind=link}
文件已添加
{kind=link}
78.8 KB
{kind=link}
文件已添加
{kind=link}
113.6 KB
{kind=link}
文件已添加
{kind=link}
70.4 KB
{kind=link}
文件已添加
{kind=link}
85.9 KB
{kind=link}
文件已添加
{kind=link}
77.9 KB
{kind=link}
文件已添加
{kind=link}
41.2 KB
{kind=link}
文件已添加
{kind=link}
82.5 KB
{kind=link}
文件已添加
{kind=link}
16.8 KB
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}

26.5 KB
{kind=link}
文件已添加
{kind=link}

279.8 KB
{kind=link}
文件已添加
{kind=link}
569.5 KB
{kind=link}
文件已添加
docs-cn/21-tdinternal/dnode.webp
0 → 100644
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
docs-cn/21-tdinternal/vnode.webp
0 → 100644
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
{kind=link}
{kind=link}
docs-cn/eco_system.png
已删除
100644 → 0
{kind=link}
45.0 KB
docs-cn/eco_system.webp
0 → 100644
{kind=link}
文件已添加
{kind=link}
45.0 KB
docs-en/02-intro/eco_system.webp
0 → 100644
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
164.1 KB
{kind=link}
{kind=link}
33.4 KB
{kind=link}
文件已添加
{kind=link}

16.7 KB
{kind=link}
{kind=link}

10.3 KB
{kind=link}
{kind=link}
105.1 KB
{kind=link}
{kind=link}
11.9 KB
{kind=link}
{kind=link}
121.6 KB
{kind=link}
文件已添加
{kind=link}
7.6 KB
{kind=link}
文件已添加
{kind=link}

24.9 KB
{kind=link}
文件已添加
{kind=link}
124.3 KB
{kind=link}
{kind=link}
12.6 KB
{kind=link}
{kind=link}
18.8 KB
{kind=link}
文件已添加
{kind=link}

23.8 KB
{kind=link}
{kind=link}
24.1 KB
{kind=link}
文件已添加
{kind=link}
24.6 KB
{kind=link}
{kind=link}
7.1 KB
{kind=link}
文件已添加
{kind=link}
7.3 KB
{kind=link}
文件已添加
{kind=link}

3.5 KB
{kind=link}
文件已添加
{kind=link}
13.4 KB
{kind=link}
{kind=link}
188.4 KB
{kind=link}
文件已添加
{kind=link}
11.4 KB
{kind=link}
文件已添加
{kind=link}
32.6 KB
{kind=link}
文件已添加
{kind=link}
6.3 KB
{kind=link}
文件已添加
{kind=link}
22.4 KB
{kind=link}
文件已添加
{kind=link}
10.8 KB
{kind=link}
文件已添加
{kind=link}
20.8 KB
{kind=link}
{kind=link}
58.9 KB
{kind=link}
{kind=link}
37.5 KB
{kind=link}
文件已添加
{kind=link}
60.3 KB
{kind=link}
文件已添加
{kind=link}
77.7 KB
{kind=link}
文件已添加
{kind=link}

49.6 KB
{kind=link}
文件已添加
{kind=link}
29.0 KB
{kind=link}
文件已添加
{kind=link}
78.8 KB
{kind=link}
文件已添加
{kind=link}
113.6 KB
{kind=link}
文件已添加
{kind=link}
70.4 KB
{kind=link}
文件已添加
{kind=link}

85.9 KB
{kind=link}
文件已添加
{kind=link}
77.9 KB
{kind=link}
文件已添加
{kind=link}

41.2 KB
{kind=link}
文件已添加
{kind=link}
82.5 KB
{kind=link}
文件已添加
{kind=link}
16.8 KB
{kind=link}
文件已添加
{kind=link}
53.4 KB
{kind=link}
文件已添加
{kind=link}
44.0 KB
{kind=link}
文件已添加
{kind=link}
55.0 KB
{kind=link}
文件已添加
{kind=link}
60.2 KB
{kind=link}
文件已添加
{kind=link}
90.8 KB
{kind=link}
文件已添加
{kind=link}
96.9 KB
{kind=link}
文件已添加
{kind=link}

26.5 KB
{kind=link}
文件已添加
{kind=link}
279.8 KB
{kind=link}
文件已添加
{kind=link}

569.5 KB
{kind=link}
文件已添加
{kind=link}
96.9 KB
docs-en/21-tdinternal/dnode.webp
0 → 100644
{kind=link}
文件已添加
{kind=link}
43.2 KB
{kind=link}
文件已添加
{kind=link}
86.9 KB
{kind=link}
文件已添加
{kind=link}
65.7 KB
{kind=link}
文件已添加
{kind=link}
36.6 KB
{kind=link}
文件已添加
{kind=link}
114.5 KB
{kind=link}
文件已添加
{kind=link}
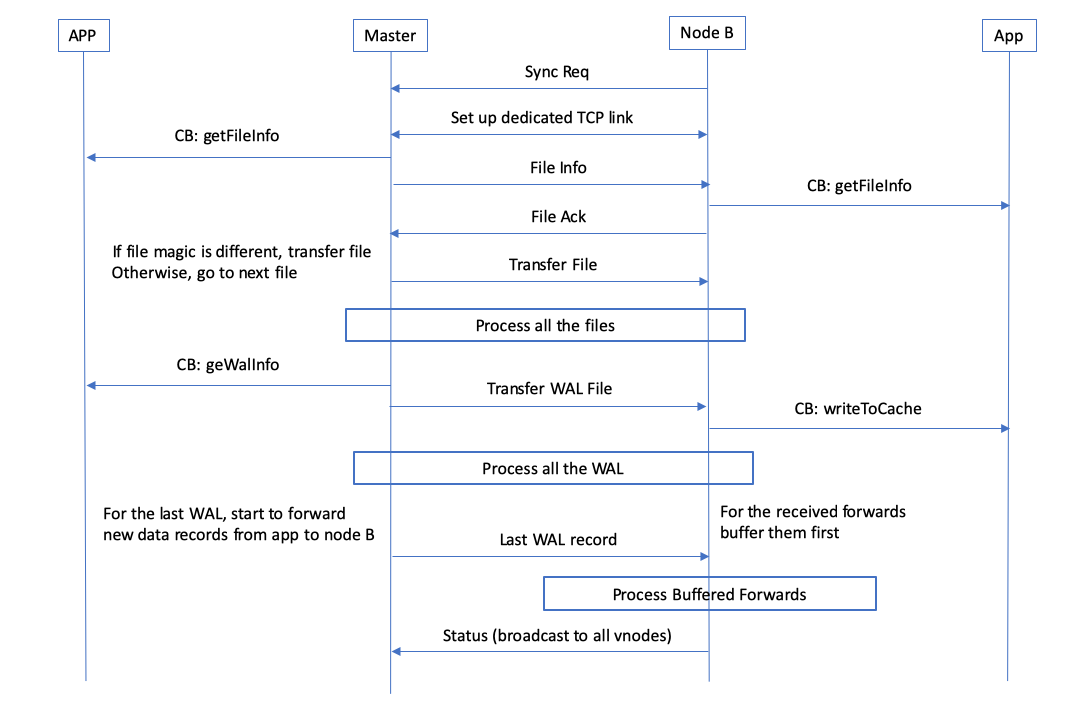
91.1 KB
{kind=link}
文件已添加
{kind=link}
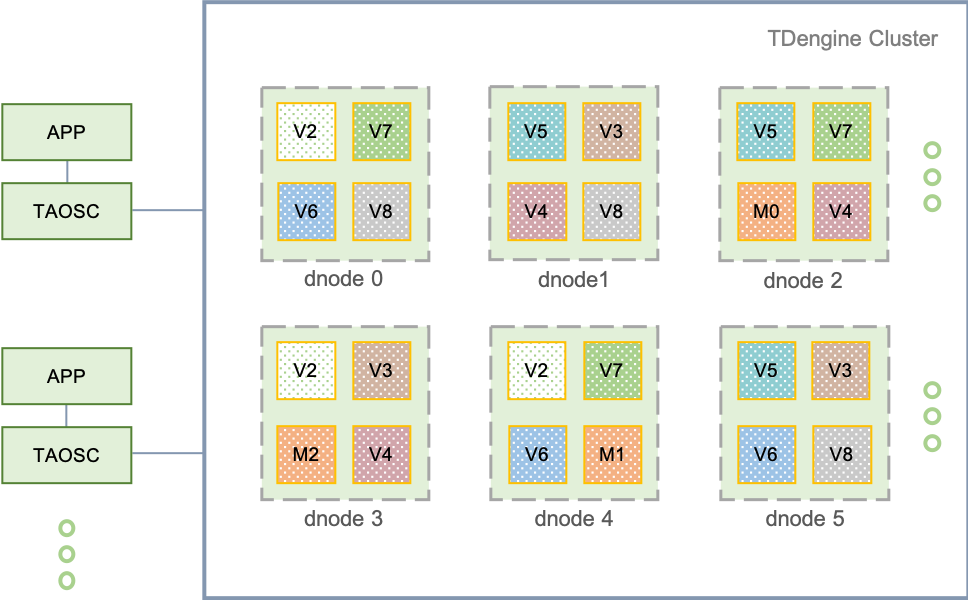
92.3 KB
{kind=link}
文件已添加
{kind=link}
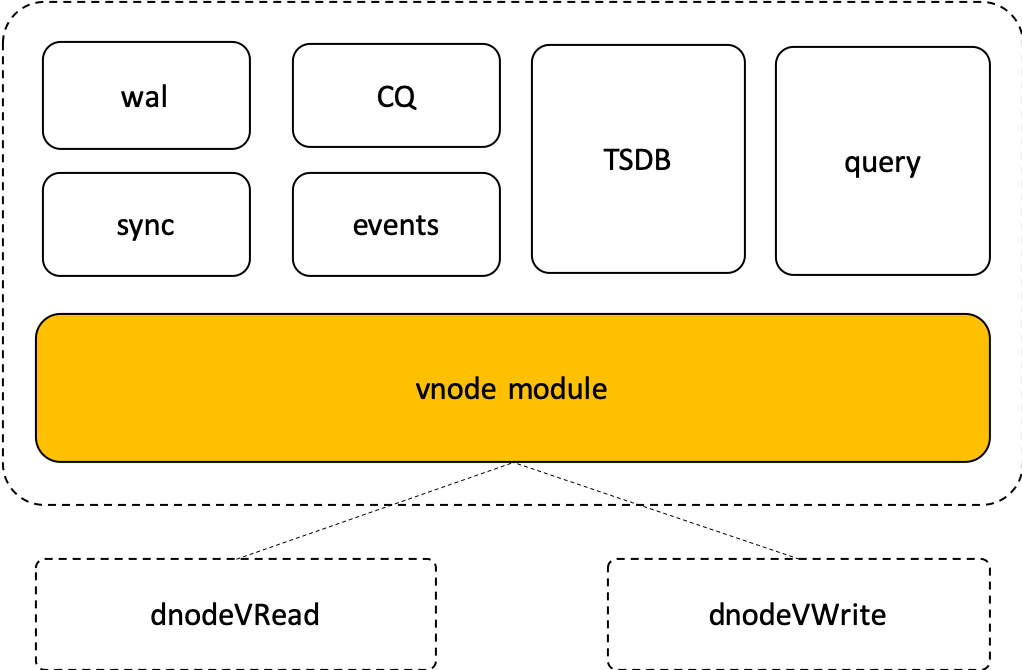
54.3 KB
docs-en/21-tdinternal/vnode.webp
0 → 100644
{kind=link}
文件已添加
{kind=link}
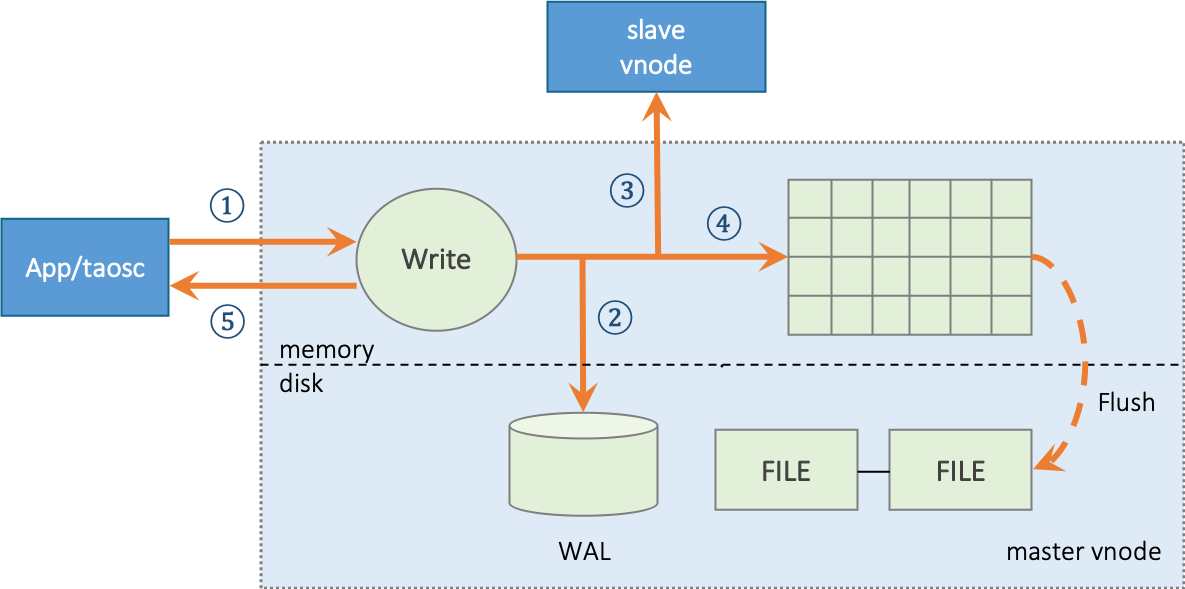
70.8 KB
{kind=link}
文件已添加
{kind=link}
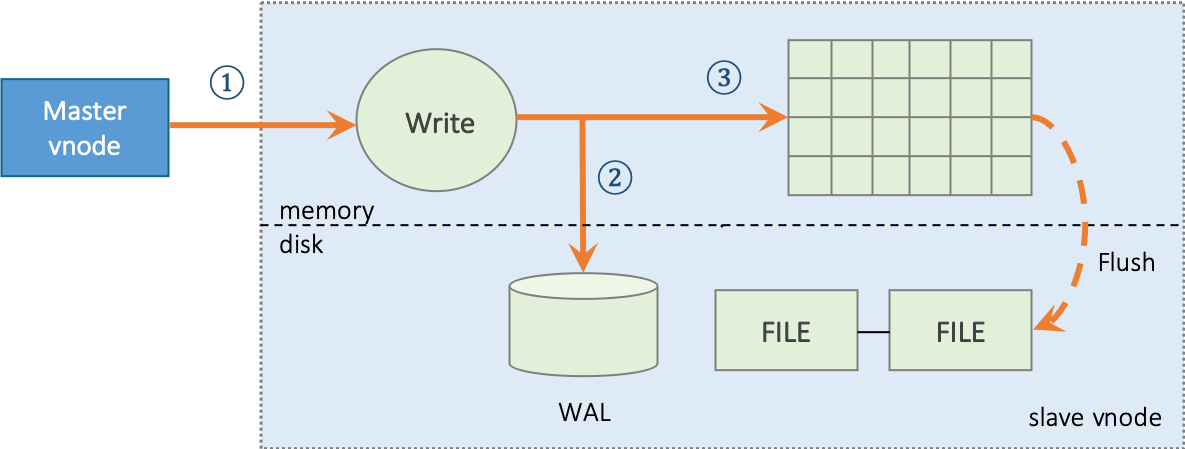
56.3 KB
{kind=link}
文件已添加
{kind=link}
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
文件已添加
{kind=link}
{kind=link}
{kind=link}