@@ -51,7 +51,7 @@ TDengine is a distributed and high performance time series database, there are a
...
@@ -51,7 +51,7 @@ TDengine is a distributed and high performance time series database, there are a
1. Set proper number of `vgroups` according to available CPU cores. Normally, we recommend 2 \* number_of_cores as a starting point. If the verification result shows this is not enough to utilize CPU resources, you can use a higher value.
1. Set proper number of `vgroups` according to available CPU cores. Normally, we recommend 2 \* number_of_cores as a starting point. If the verification result shows this is not enough to utilize CPU resources, you can use a higher value.
2. Set proper `minTablesPerVnode`, `tableIncStepPerVnode`, and `maxVgroupsPerDb` according to the number of tables so that tables are distributed even across vgroups. The purpose is to balance the workload among all vnodes so that system resources can be utilized better to get higher performance.
2. Set proper `minTablesPerVnode`, `tableIncStepPerVnode`, and `maxVgroupsPerDb` according to the number of tables so that tables are distributed even across vgroups. The purpose is to balance the workload among all vnodes so that system resources can be utilized better to get higher performance.
For more performance tuning tips, please refer to [Performance Optimization](../../operation/optimize) and [Configuration Parameters](../../reference/config).
For more performance tuning tips, please refer to [Performance Optimization](../../../operation/optimize) and [Configuration Parameters](../../../reference/config).
@@ -5,7 +5,7 @@ description: "The syntax supported by TDengine SQL "
...
@@ -5,7 +5,7 @@ description: "The syntax supported by TDengine SQL "
This section explains the syntax of SQL to perform operations on databases, tables and STables, insert data, select data and use functions. We also provide some tips that can be used in TDengine SQL. If you have previous experience with SQL this section will be fairly easy to understand. If you do not have previous experience with SQL, you'll come to appreciate the simplicity and power of SQL.
This section explains the syntax of SQL to perform operations on databases, tables and STables, insert data, select data and use functions. We also provide some tips that can be used in TDengine SQL. If you have previous experience with SQL this section will be fairly easy to understand. If you do not have previous experience with SQL, you'll come to appreciate the simplicity and power of SQL.
TDengine SQL is the major interface for users to write data into or query from TDengine. For ease of use, the syntax is similar to that of standard SQL. However, please note that TDengine SQL is not standard SQL. For instance, TDengine doesn't provide a delete function for time series data and so corresponding statements are not provided in TDengine SQL.
TDengine SQL is the major interface for users to write data into or query from TDengine. For ease of use, the syntax is similar to that of standard SQL. However, please note that TDengine SQL is not standard SQL. For instance, TDengine doesn't provide a delete function for time series data and so corresponding statements are not provided in TDengine SQL. However, TDengine Enterprise Edition provides the DELETE function since version 2.6.
-`t`, `T`, `true`, `True`, `TRUE`, `f`, `F`, `false`, and `False` will be handled directly as BOOL types.
-`t`, `T`, `true`, `True`, `TRUE`, `f`, `F`, `false`, and `False` will be handled directly as BOOL types.
...
@@ -67,13 +67,13 @@ Schemaless writes process row data according to the following principles.
...
@@ -67,13 +67,13 @@ Schemaless writes process row data according to the following principles.
Note that tag_key1, tag_key2 are not the original order of the tags entered by the user but the result of using the tag names in ascending order of the strings. Therefore, tag_key1 is not the first tag entered in the line protocol.
Note that tag_key1, tag_key2 are not the original order of the tags entered by the user but the result of using the tag names in ascending order of the strings. Therefore, tag_key1 is not the first tag entered in the line protocol.
The string's MD5 hash value "md5_val" is calculated after the ranking is completed. The calculation result is then combined with the string to generate the table name: "t_md5_val". "t*" is a fixed prefix that every table generated by this mapping relationship has.
The string's MD5 hash value "md5_val" is calculated after the ranking is completed. The calculation result is then combined with the string to generate the table name: "t_md5_val". "t*" is a fixed prefix that every table generated by this mapping relationship has.
2. If the super table obtained by parsing the line protocol does not exist, this super table is created.
2. If the super table obtained by parsing the line protocol does not exist, this super table is created(It is not recommended to create a super table manually, otherwise the inserted data may be abnormal).
If the subtable obtained by the parse line protocol does not exist, Schemaless creates the sub-table according to the subtable name determined in steps 1 or 2.
If the subtable obtained by the parse line protocol does not exist, Schemaless creates the sub-table according to the subtable name determined in steps 1 or 2.
4. If the specified tag or regular column in the data row does not exist, the corresponding tag or regular column is added to the super table (only incremental).
4. If the specified tag or regular column in the data row does not exist, the corresponding tag or regular column is added to the super table (only incremental).
5. If there are some tag columns or regular columns in the super table that are not specified to take values in a data row, then the values of these columns are set to NULL.
5. If there are some tag columns or regular columns in the super table that are not specified to take values in a data row, then the values of these columns are set to NULL.
6. For BINARY or NCHAR columns, if the length of the value provided in a data row exceeds the column type limit, the maximum length of characters allowed to be stored in the column is automatically increased (only incremented and not decremented) to ensure complete preservation of the data.
6. For BINARY or NCHAR columns, if the length of the value provided in a data row exceeds the column type limit, the maximum length of characters allowed to be stored in the column is automatically increased (only incremented and not decremented) to ensure complete preservation of the data.
7.If the specified data subtable already exists, and the specified tag column takes a value different from the saved value this time, the value in the latest data row overwrites the old tag column take value.
7.Errors encountered throughout the processing will interrupt the writing process and return an error code.
8.Errors encountered throughout the processing will interrupt the writing process and return an error code.
8.In order to improve the efficiency of writing, the order of fields in the same super table should be the same. If the order is different, you need to configure the parameter smlDataFormat to false, otherwise, the data in the library will be abnormal.
:::tip
:::tip
All processing logic of schemaless will still follow TDengine's underlying restrictions on data structures, such as the total length of each row of data cannot exceed 48k bytes. See [TAOS SQL Boundary Limits](/taos-sql/limit) for specific constraints in this area.
All processing logic of schemaless will still follow TDengine's underlying restrictions on data structures, such as the total length of each row of data cannot exceed 48k bytes. See [TAOS SQL Boundary Limits](/taos-sql/limit) for specific constraints in this area.
IDEA 全称 IntelliJ IDEA,是 Java 语言开发的集成环境,被公认为最友好且使用范围最广的 Java 开发工具之一。
IDEA Ultimate 版自带数据库管理工具,类似于一个小型 Navicat。这个工具让我们能在 IDEA 上对数据库做简单操作,不需要再切换到其他工具上。对于 TDengine 来说,用户可以通过 JDBC 驱动建立与 IDEA 的连接,不需要再到命令行去写 SQL 语句,直接在 IDEA 中执行即可。
此处以 2.0.40 版本的 JDBC Connector 为例,给大家介绍如何使用源码编译、打包,以及如何使用 IDEA 数据库工具连接 TDengine。
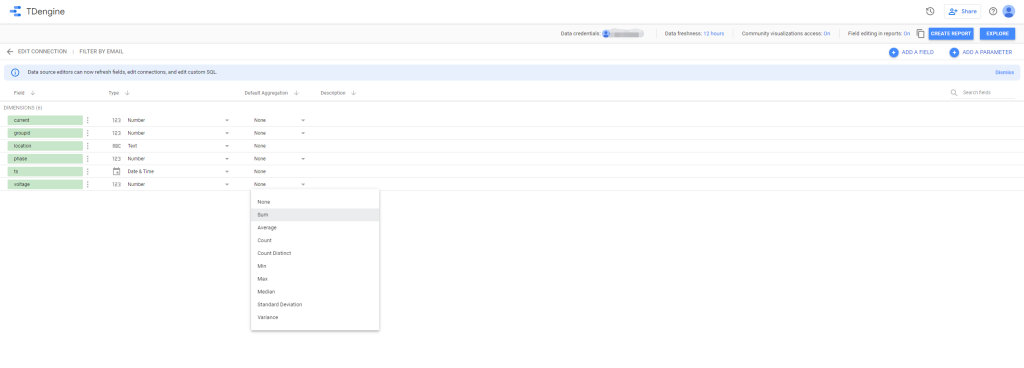
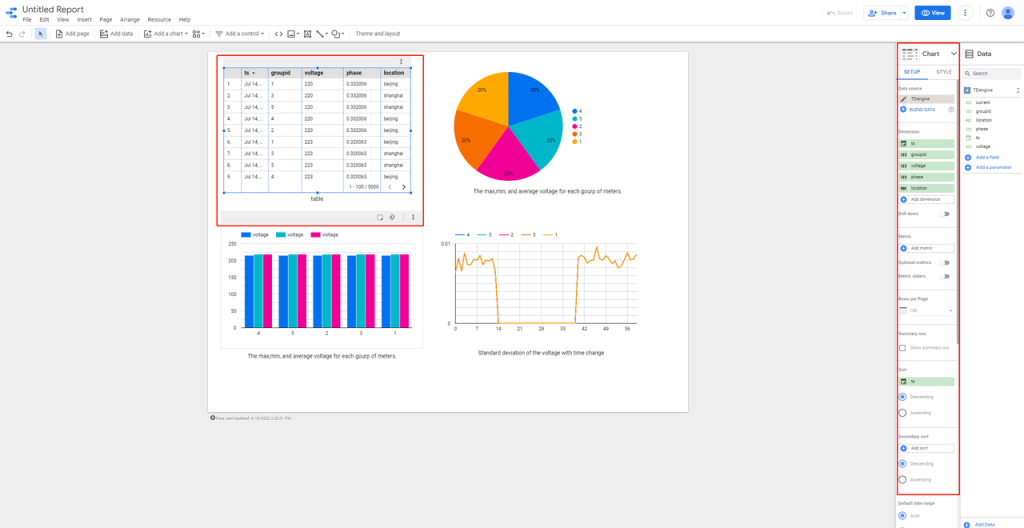
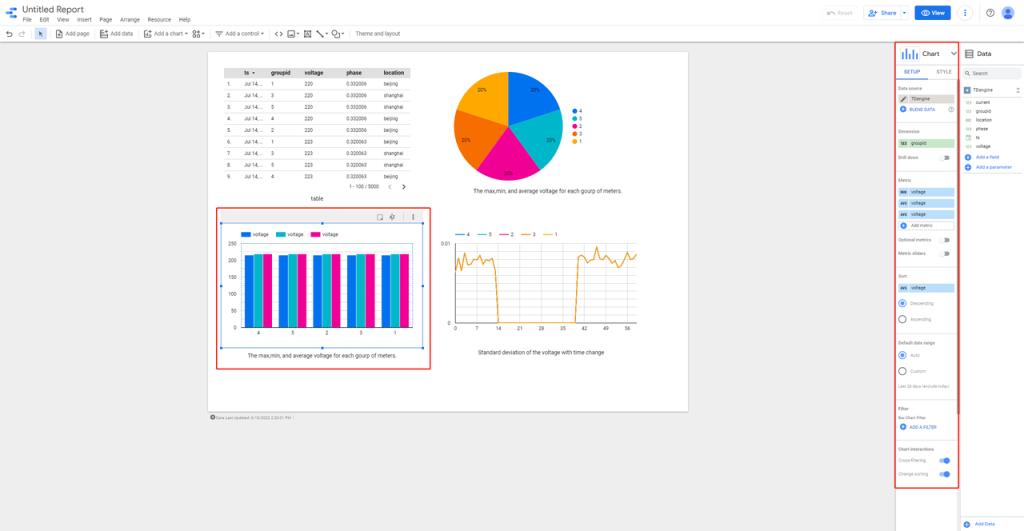
Google Data Studio 是一个强大的报表可视化工具,它提供了丰富的数据图表和数据连接,可以非常方便地按照既定模板生成报表。因其简便易用和生态丰富而在数据分析领域得到一众数据科学家的青睐。
Data Studio 可以支持多种数据来源,除了诸如 Google Analytics、Google AdWords、Search Console、BigQuery 等 Google 自己的服务之外,用户也可以直接将离线文件上传至 Google Cloud Storage,或是通过连接器来接入其它数据源。
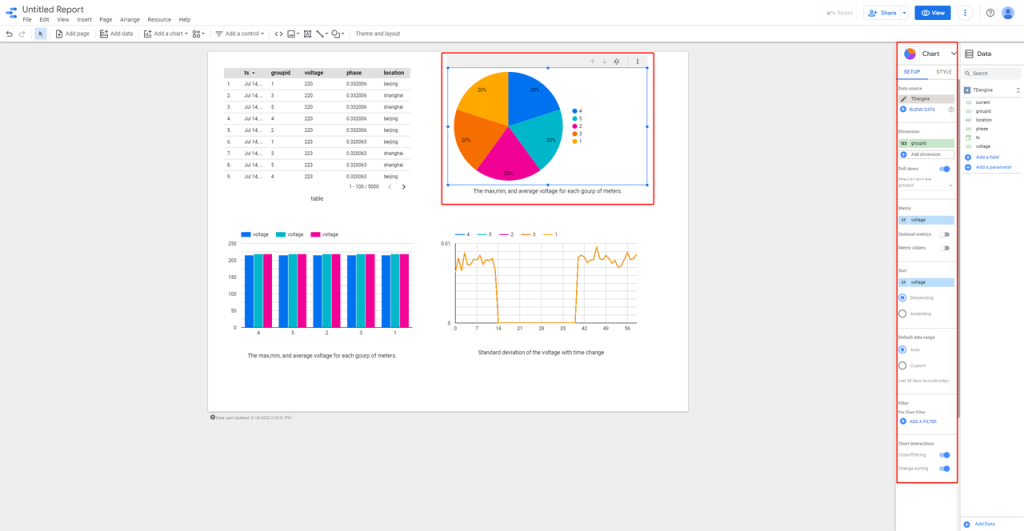
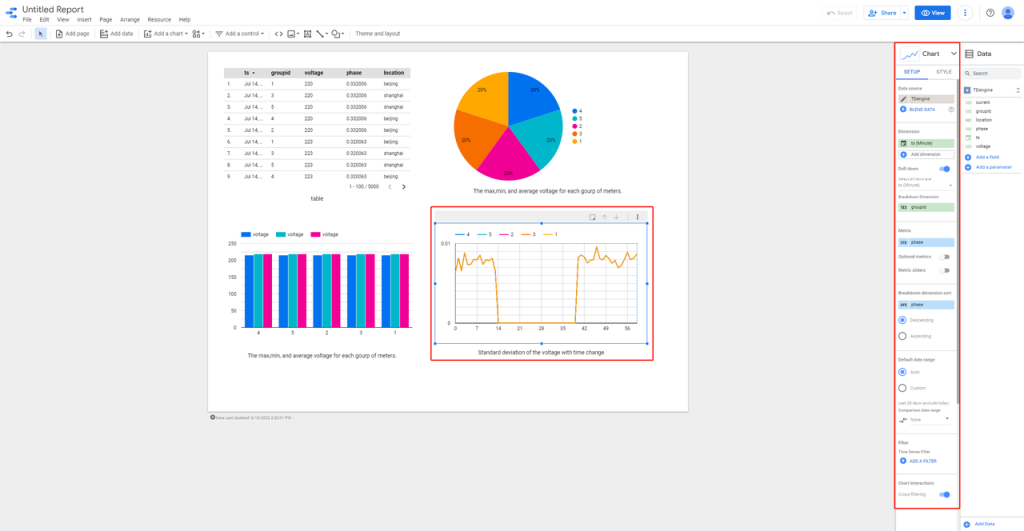
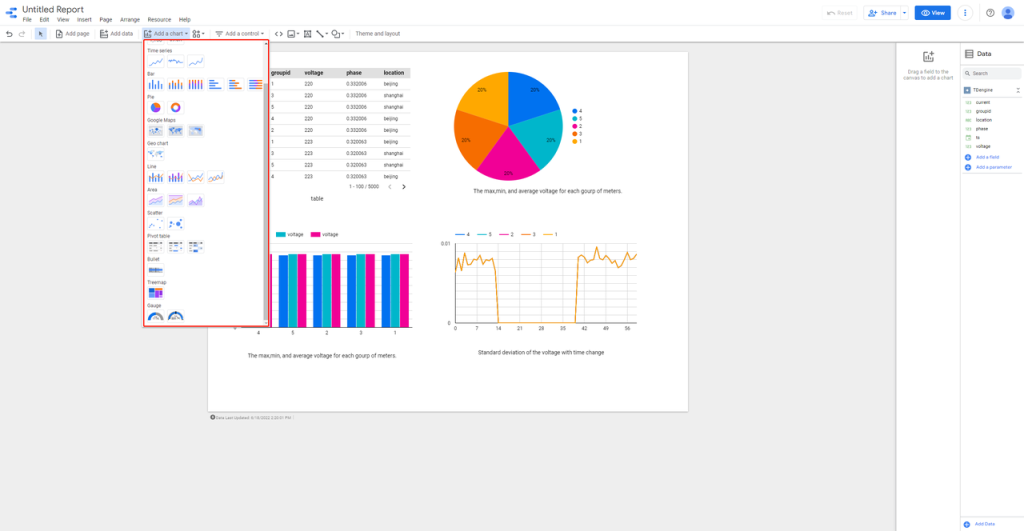
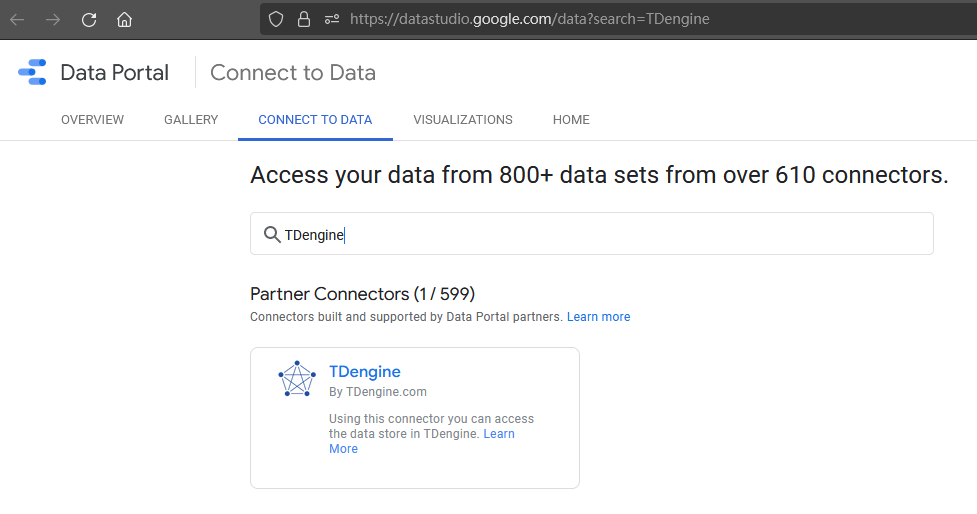
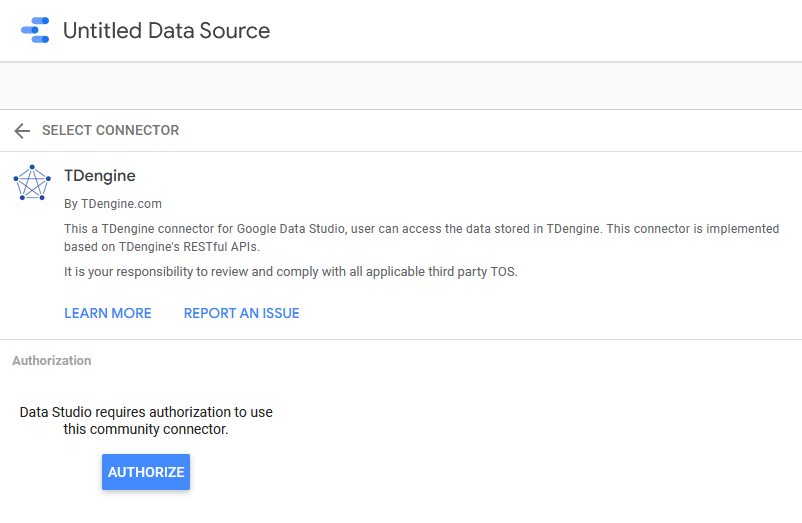
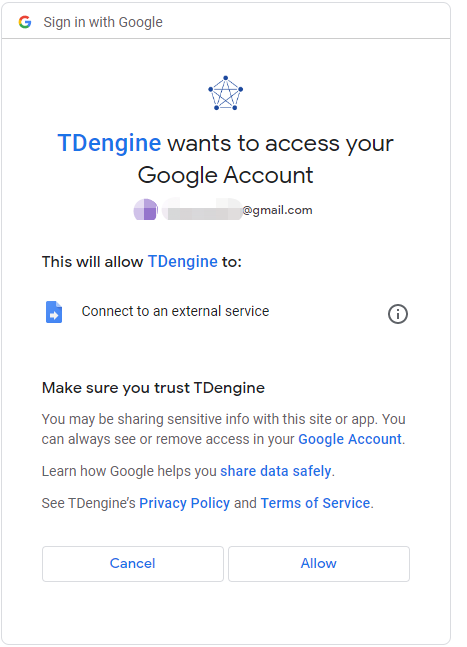
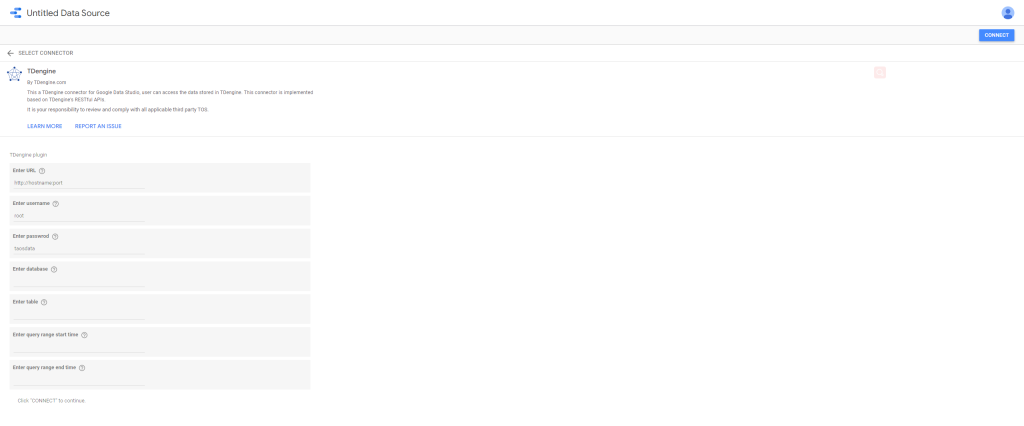
目前 TDengine 连接器已经发布到 Google Data Studio 应用商店,你可以在 “Connect to Data” 页面下直接搜索 TDengine,将其选作数据源。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}