
更新了部分文档
Showing
{kind=link}
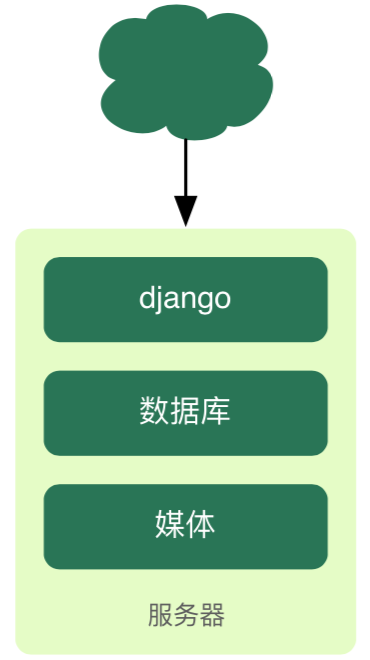
35.2 KB
{kind=link}
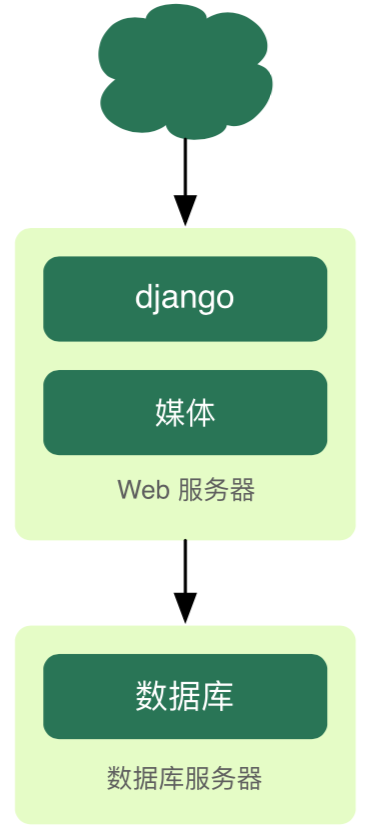
47.5 KB
{kind=link}
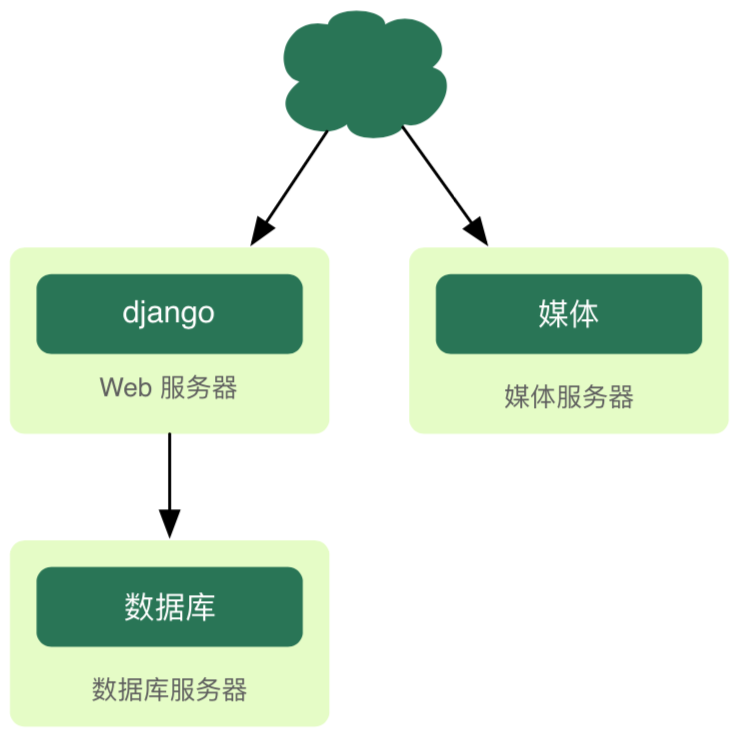
63.2 KB
{kind=link}
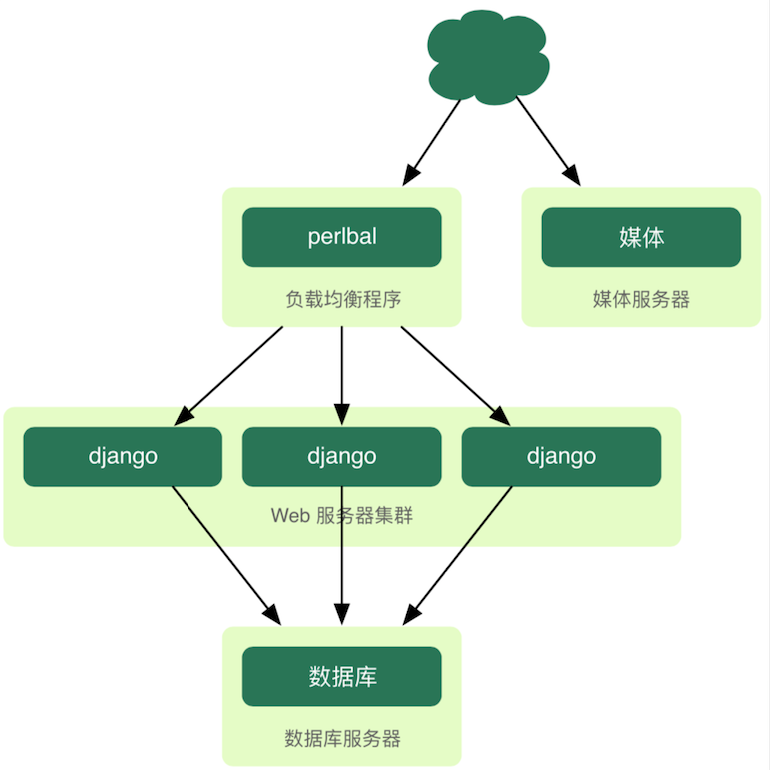
110.0 KB
{kind=link}
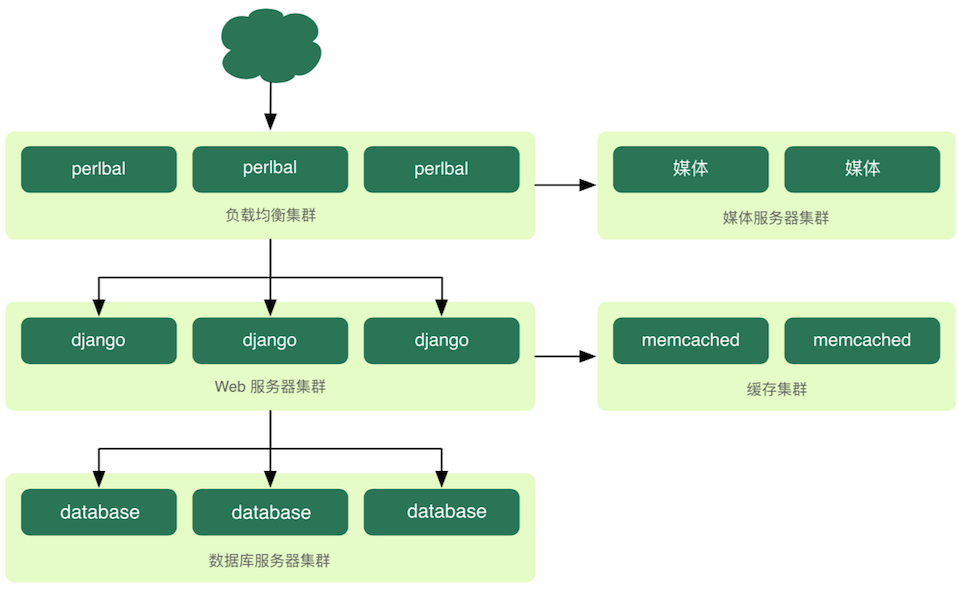
112.8 KB
Day91-100/res/Celery_RabitMQ.png
0 → 100644
{kind=link}
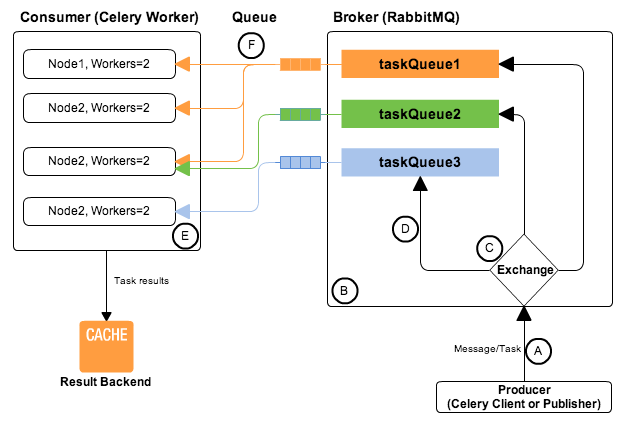
35.5 KB
{kind=link}
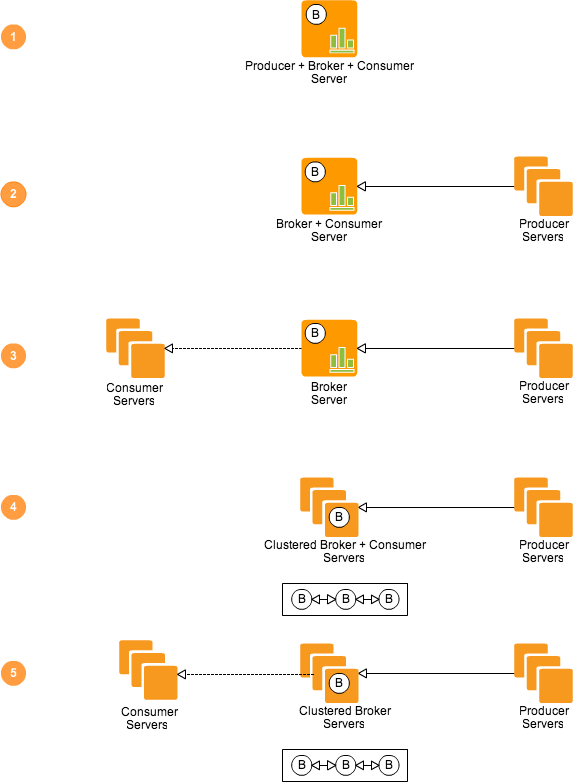
21.5 KB
{kind=link}
184.1 KB
{kind=link}
312.7 KB
Day91-100/res/aliyun-dnslist.png
0 → 100644
{kind=link}
194.9 KB
Day91-100/res/aliyun-domain.png
0 → 100644
{kind=link}

209.1 KB
{kind=link}

86.4 KB
{kind=link}
140.0 KB
Day91-100/res/app_folder_arch.png
0 → 100644
{kind=link}

58.1 KB
{kind=link}

400.2 KB
Day91-100/res/celery.png
0 → 100644
{kind=link}
218.1 KB
Day91-100/res/click-jacking.png
0 → 100644
{kind=link}

290.3 KB
{kind=link}
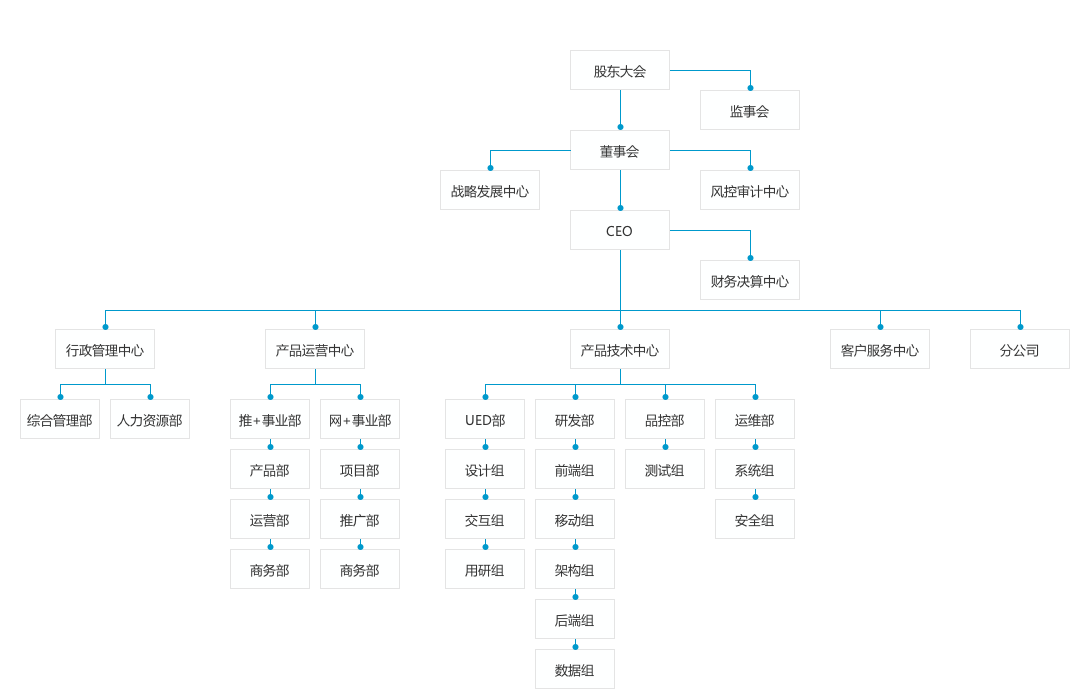
50.6 KB
{kind=link}

104.1 KB
{kind=link}
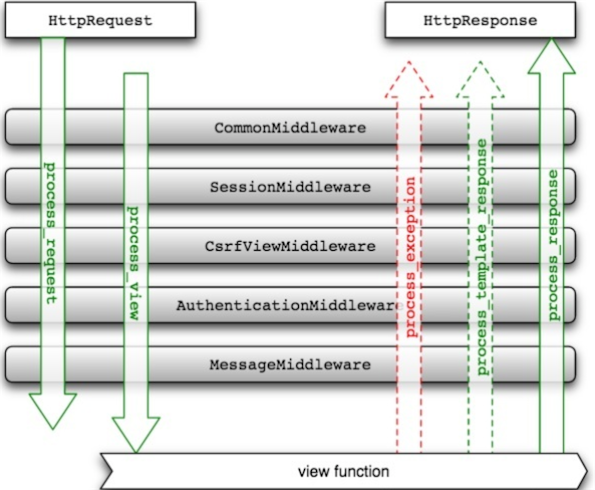
252.7 KB
Day91-100/res/django-mtv.png
0 → 100644
{kind=link}
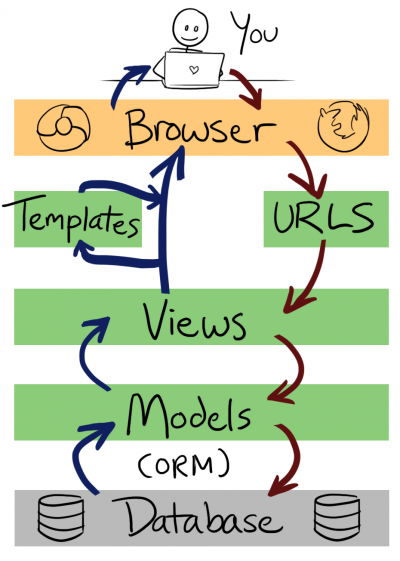
142.1 KB
{kind=link}
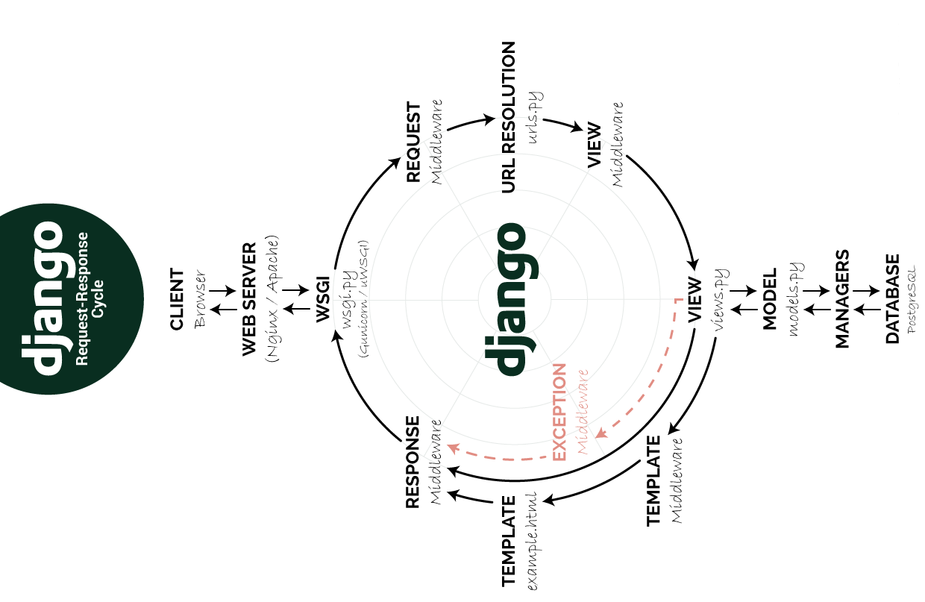
158.1 KB
Day91-100/res/docker_logo.png
0 → 100644
{kind=link}
12.7 KB
Day91-100/res/docker_vs_vm.png
0 → 100644
{kind=link}
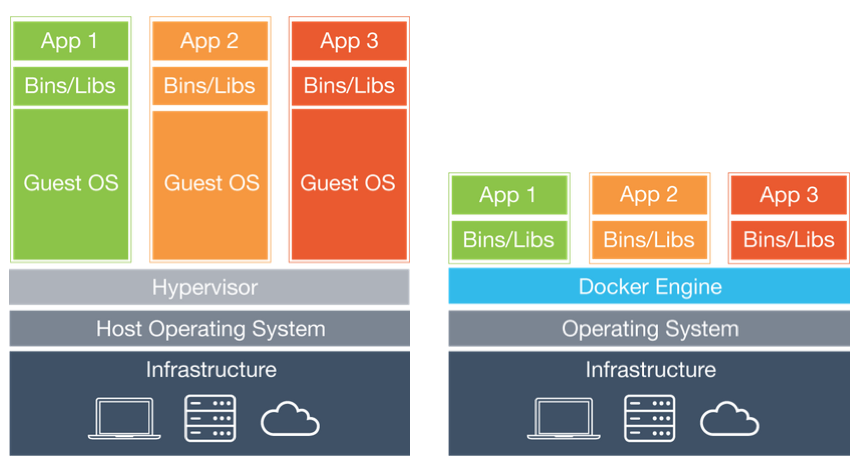
133.1 KB
Day91-100/res/er-graph.png
0 → 100644
{kind=link}
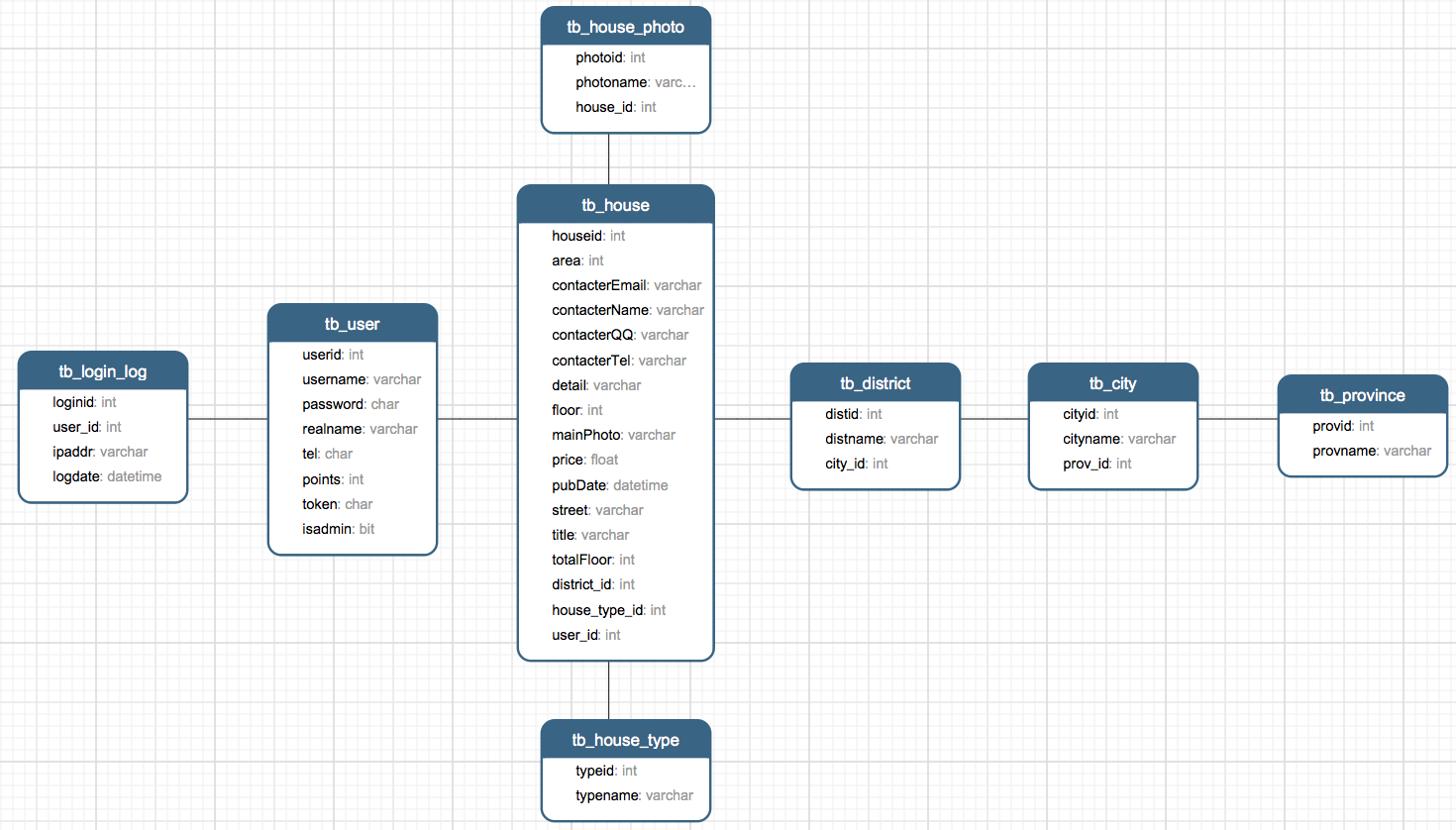
147.4 KB
Day91-100/res/git_logo.png
0 → 100644
{kind=link}
188.9 KB
Day91-100/res/git_repository.png
0 → 100644
{kind=link}
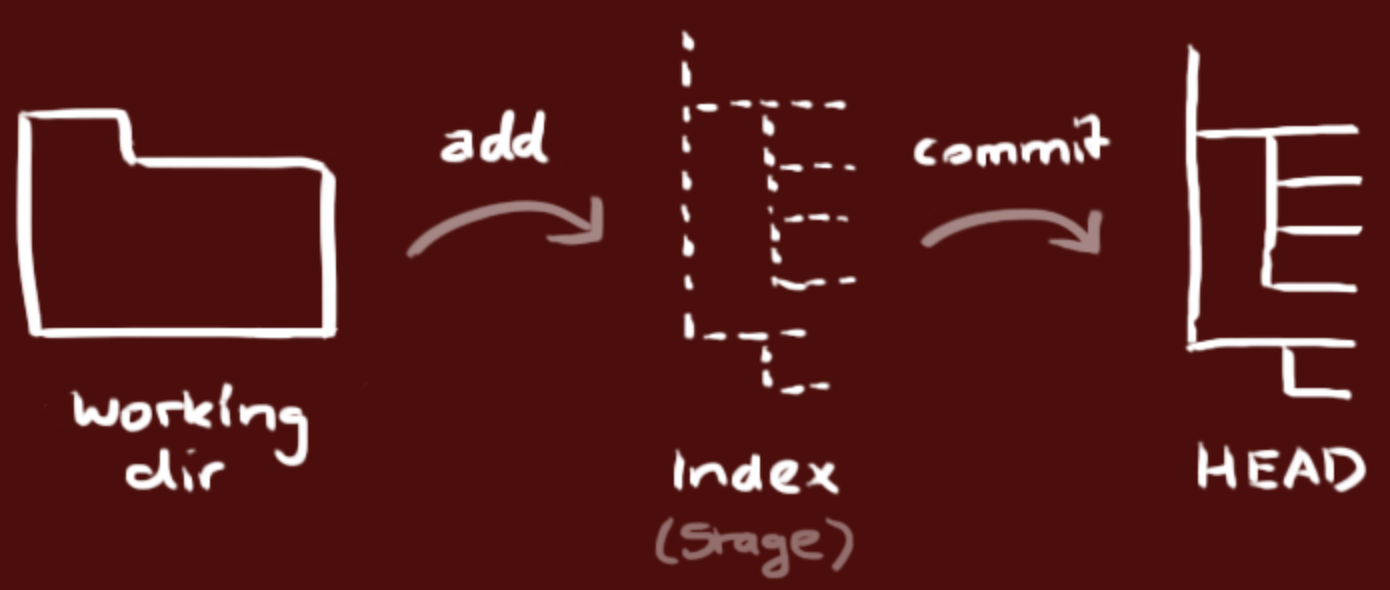
178.5 KB
Day91-100/res/gitignore_io.png
0 → 100644
{kind=link}
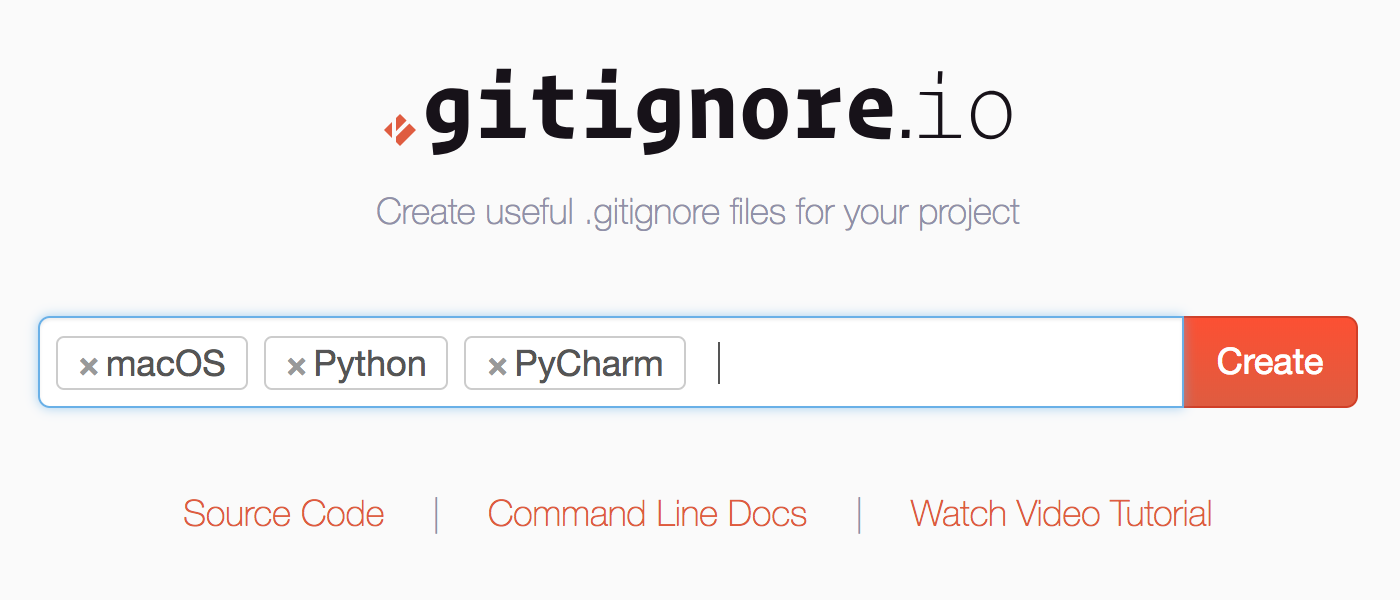
85.9 KB
Day91-100/res/greedy.png
0 → 100644
{kind=link}
27.1 KB
{kind=link}
1.0 MB
Day91-100/res/http-request.png
0 → 100644
{kind=link}
5.9 KB
Day91-100/res/http-response.png
0 → 100644
{kind=link}
6.4 KB
{kind=link}
148.1 KB
Day91-100/res/mvc.png
0 → 100644
{kind=link}
296.0 KB
Day91-100/res/oauth2.png
0 → 100644
{kind=link}
81.6 KB
{kind=link}
726.5 KB
Day91-100/res/pylint.png
0 → 100644
{kind=link}
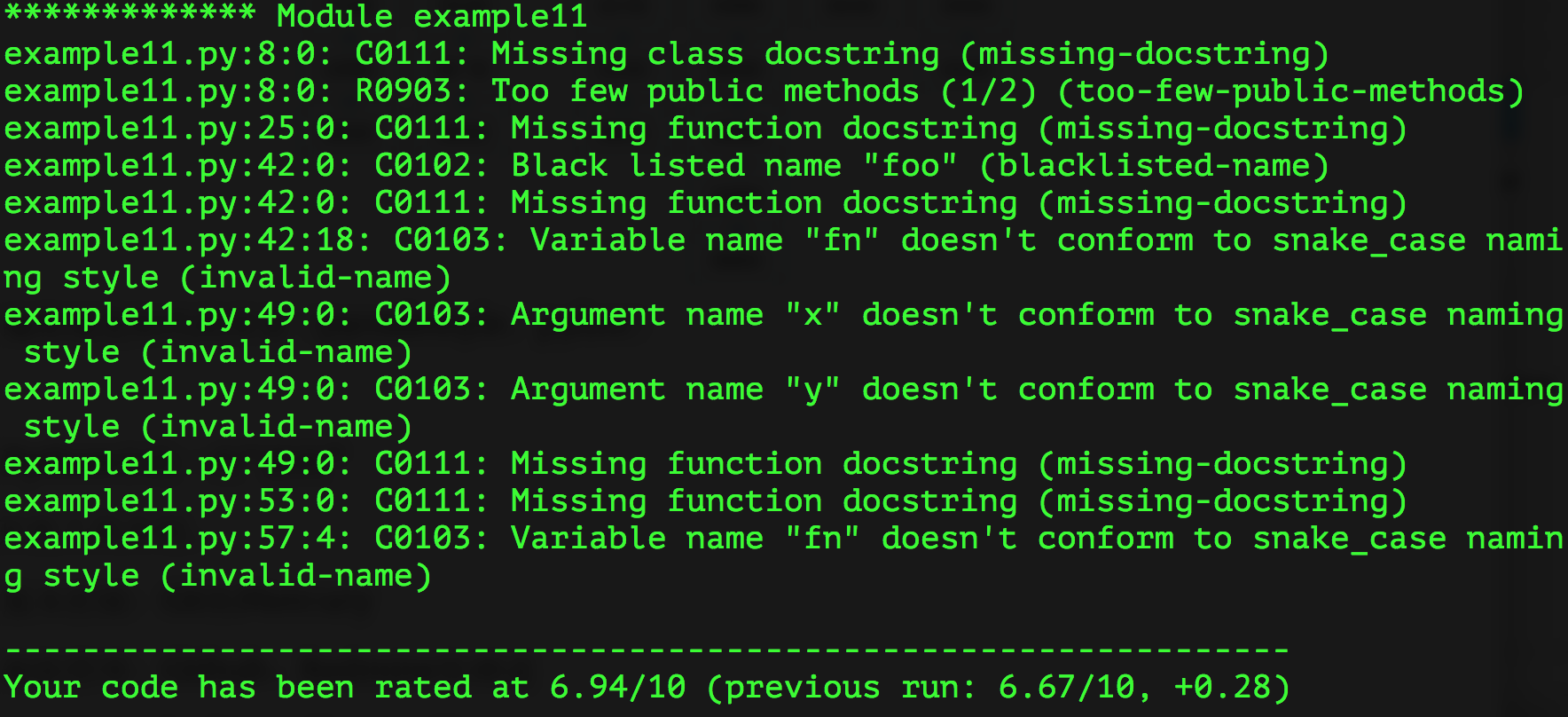
345.3 KB
Day91-100/res/python-str-join.png
0 → 100644
{kind=link}

43.8 KB
{kind=link}
298.0 KB
{kind=link}
212.5 KB
{kind=link}
237.9 KB
{kind=link}
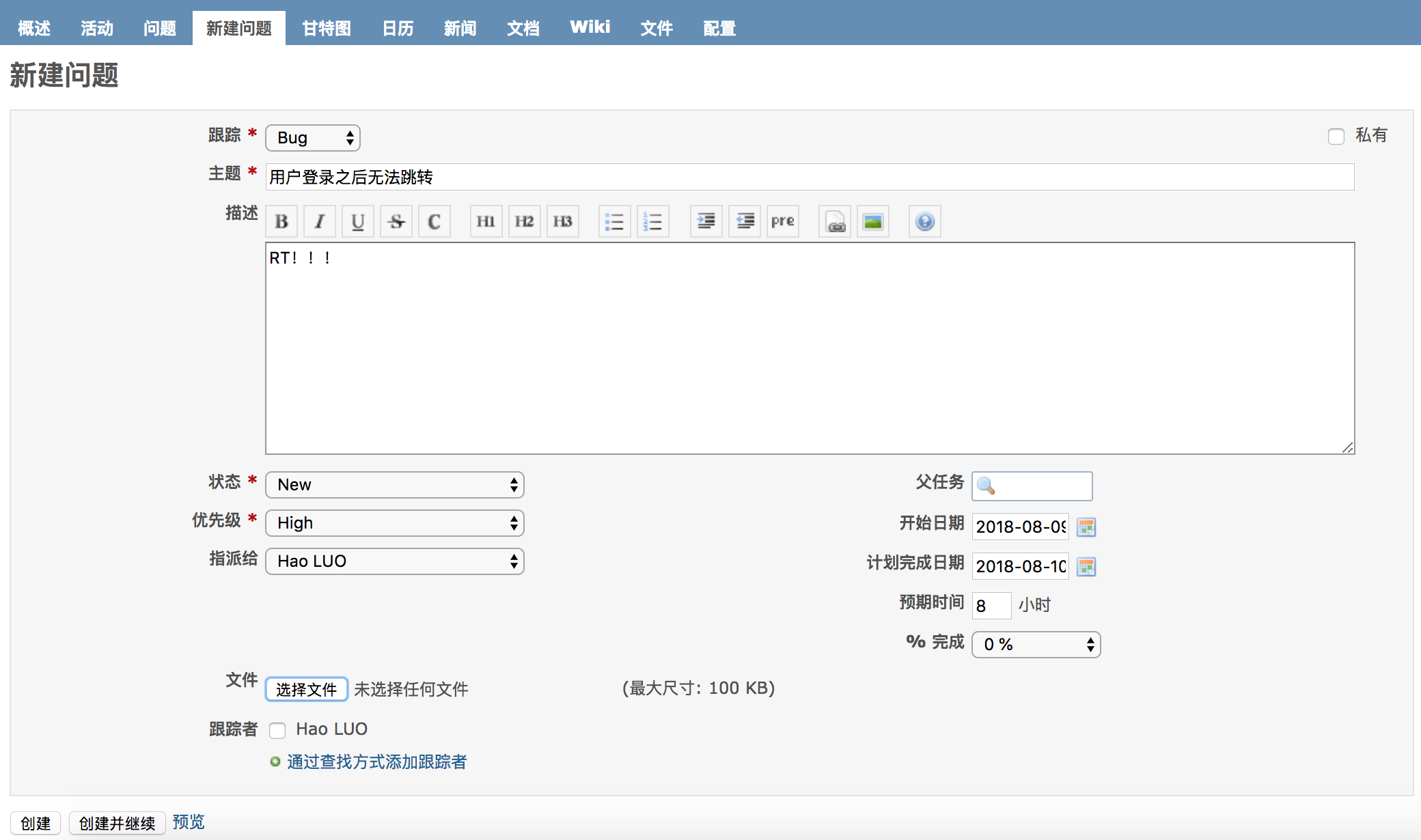
212.0 KB
{kind=link}
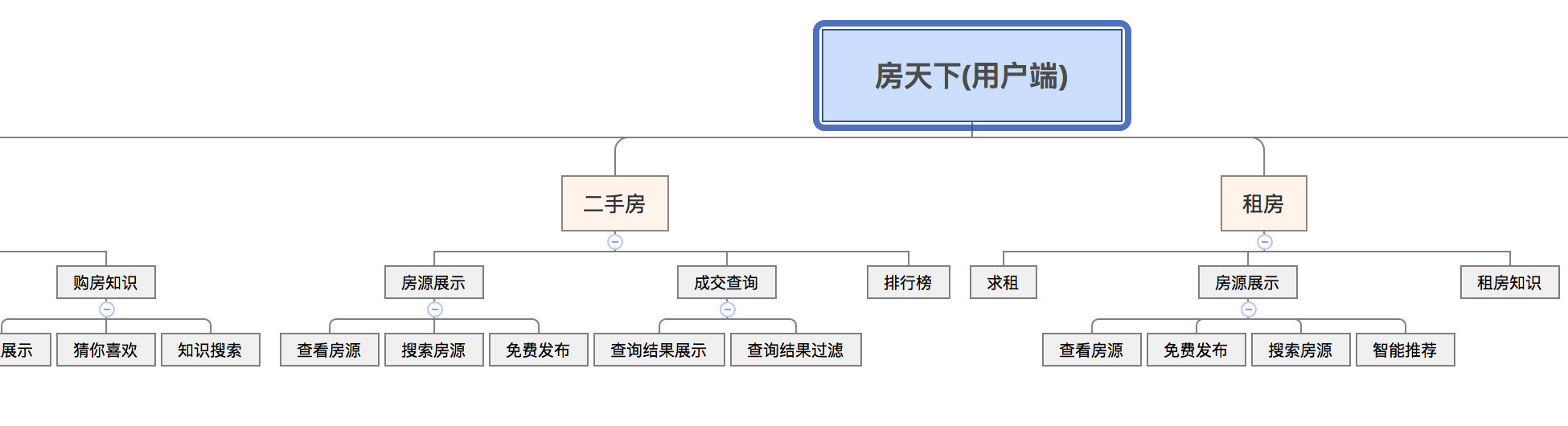
72.5 KB
Day91-100/res/selenium_ide.png
0 → 100644
{kind=link}
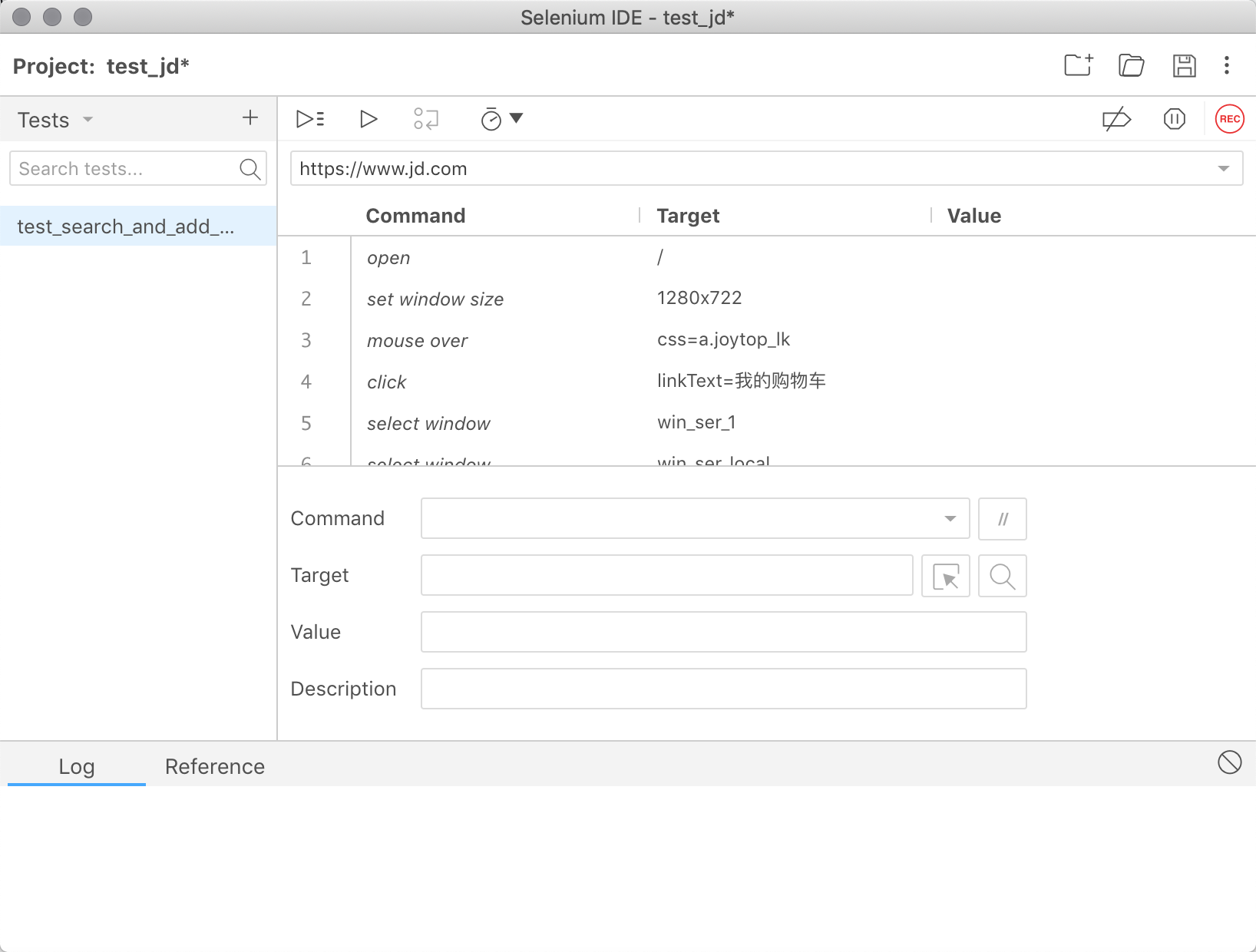
145.7 KB
Day91-100/res/shopping-pdm.png
0 → 100644
{kind=link}
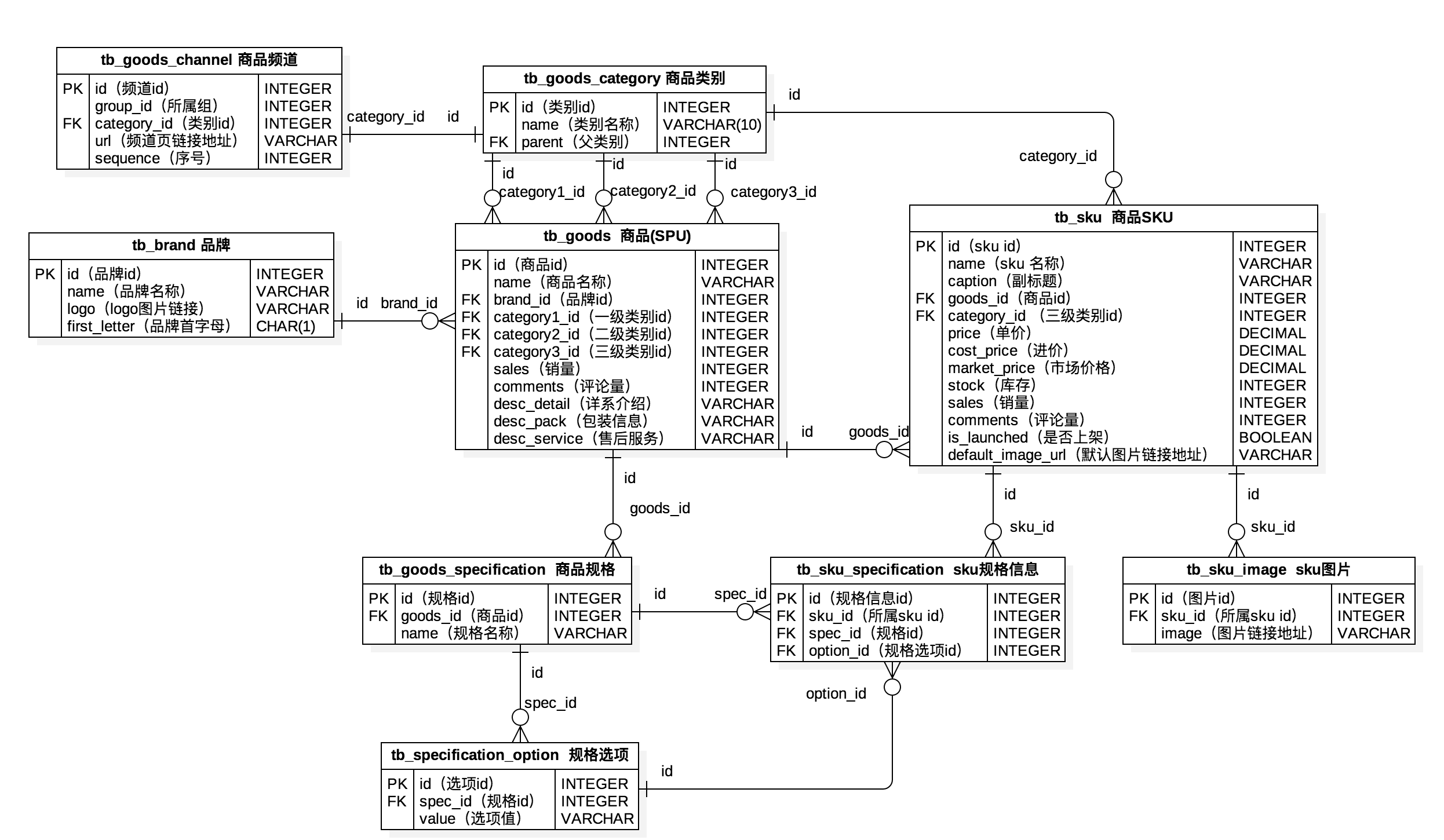
439.0 KB
Day91-100/res/uml-graph.png
0 → 100644
{kind=link}
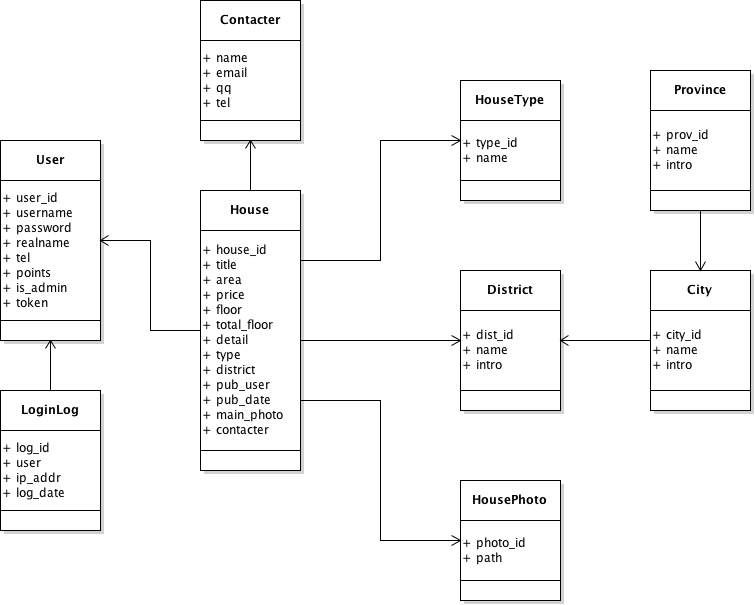
36.7 KB
Day91-100/res/uml.png
0 → 100644
{kind=link}
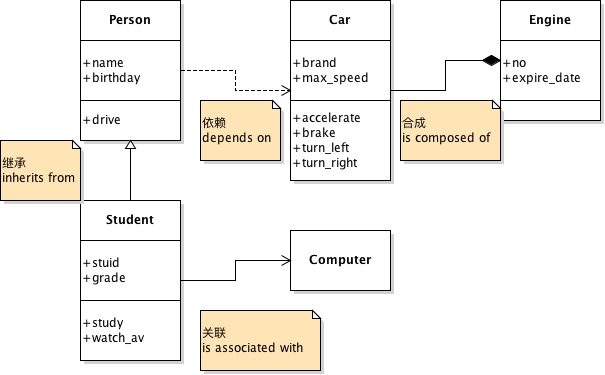
22.4 KB
Day91-100/res/web-application.png
0 → 100644
{kind=link}
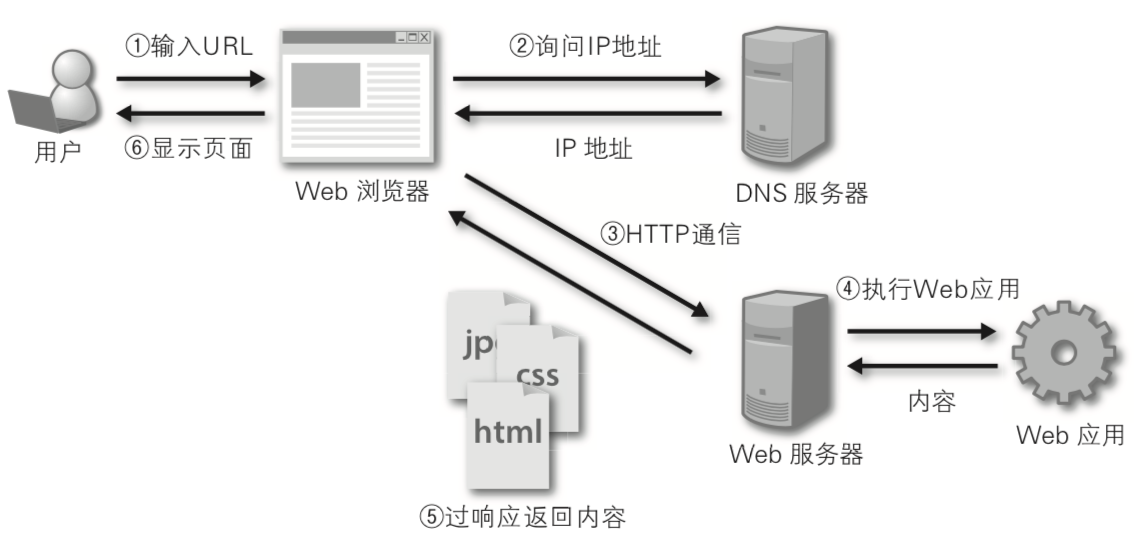
174.4 KB
{kind=link}
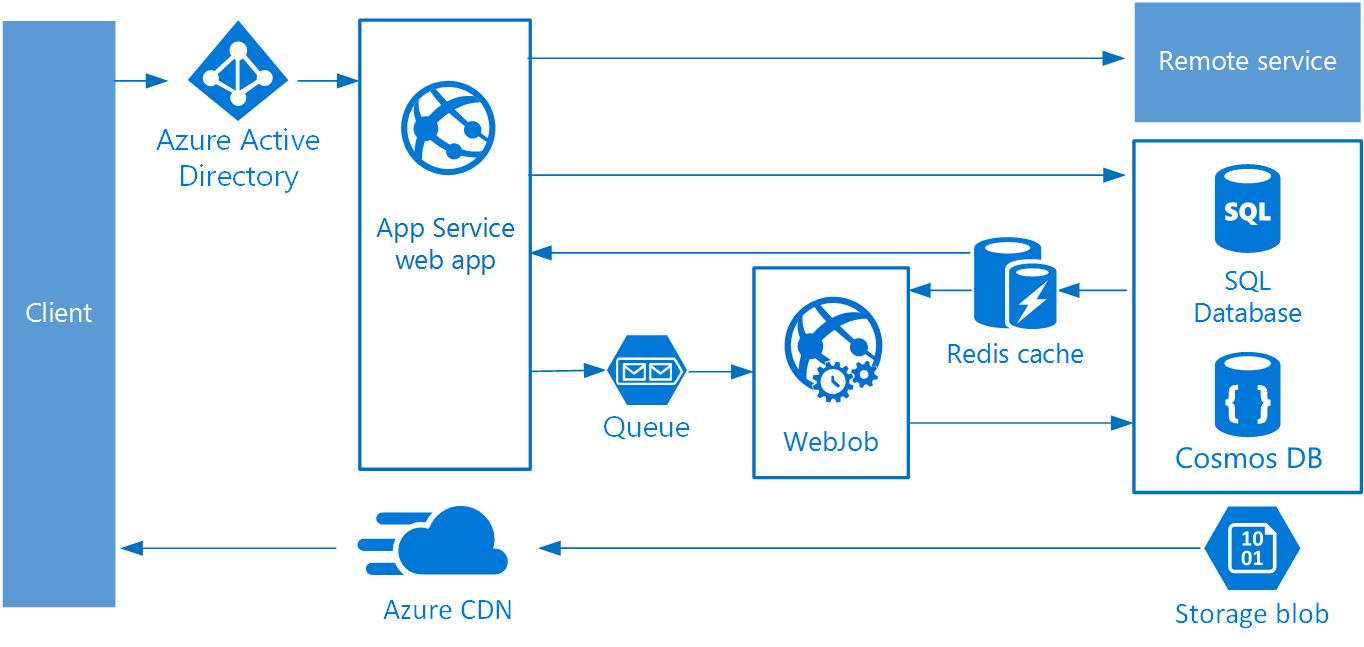
48.2 KB
Day91-100/电商网站技术要点剖析.md
0 → 100644
Day91-100/英语面试.md
0 → 100644
Day91-100/面试中的公共问题.md
0 → 100644