Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
sven357
Paddle
提交
f1f8327c
P
Paddle
项目概览
sven357
/
Paddle
与 Fork 源项目一致
Fork自
PaddlePaddle / Paddle
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1
Issue
1
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
f1f8327c
编写于
6月 19, 2018
作者:
T
tensor-tang
浏览文件
操作
浏览文件
下载
差异文件
Merge remote-tracking branch 'ups/develop' into refine/mem
上级
a0c5fd83
49f23e63
变更
63
隐藏空白更改
内联
并排
Showing
63 changed file
with
2122 addition
and
1555 deletion
+2122
-1555
paddle/contrib/CMakeLists.txt
paddle/contrib/CMakeLists.txt
+0
-1
paddle/contrib/tape/CMakeLists.txt
paddle/contrib/tape/CMakeLists.txt
+0
-25
paddle/contrib/tape/README.md
paddle/contrib/tape/README.md
+0
-252
paddle/contrib/tape/computation_graph.png
paddle/contrib/tape/computation_graph.png
+0
-0
paddle/contrib/tape/function.h
paddle/contrib/tape/function.h
+0
-131
paddle/contrib/tape/tape.cc
paddle/contrib/tape/tape.cc
+0
-265
paddle/contrib/tape/variable.h
paddle/contrib/tape/variable.h
+0
-85
paddle/fluid/inference/analysis/CMakeLists.txt
paddle/fluid/inference/analysis/CMakeLists.txt
+24
-15
paddle/fluid/inference/analysis/argument.cc
paddle/fluid/inference/analysis/argument.cc
+1
-19
paddle/fluid/inference/analysis/argument.h
paddle/fluid/inference/analysis/argument.h
+55
-0
paddle/fluid/inference/analysis/data_flow_graph.cc
paddle/fluid/inference/analysis/data_flow_graph.cc
+2
-13
paddle/fluid/inference/analysis/data_flow_graph_to_fluid_pass.cc
...fluid/inference/analysis/data_flow_graph_to_fluid_pass.cc
+77
-0
paddle/fluid/inference/analysis/data_flow_graph_to_fluid_pass.h
.../fluid/inference/analysis/data_flow_graph_to_fluid_pass.h
+59
-0
paddle/fluid/inference/analysis/data_flow_graph_to_fluid_pass_tester.cc
...nference/analysis/data_flow_graph_to_fluid_pass_tester.cc
+2
-3
paddle/fluid/inference/analysis/dfg_graphviz_draw_pass.cc
paddle/fluid/inference/analysis/dfg_graphviz_draw_pass.cc
+54
-0
paddle/fluid/inference/analysis/dfg_graphviz_draw_pass.h
paddle/fluid/inference/analysis/dfg_graphviz_draw_pass.h
+23
-18
paddle/fluid/inference/analysis/dfg_graphviz_draw_pass_tester.cc
...fluid/inference/analysis/dfg_graphviz_draw_pass_tester.cc
+6
-4
paddle/fluid/inference/analysis/fluid_to_data_flow_graph_pass.cc
...fluid/inference/analysis/fluid_to_data_flow_graph_pass.cc
+13
-9
paddle/fluid/inference/analysis/fluid_to_data_flow_graph_pass.h
.../fluid/inference/analysis/fluid_to_data_flow_graph_pass.h
+8
-3
paddle/fluid/inference/analysis/fluid_to_data_flow_graph_pass_tester.cc
...nference/analysis/fluid_to_data_flow_graph_pass_tester.cc
+3
-3
paddle/fluid/inference/analysis/helper.h
paddle/fluid/inference/analysis/helper.h
+1
-0
paddle/fluid/inference/analysis/node.cc
paddle/fluid/inference/analysis/node.cc
+3
-0
paddle/fluid/inference/analysis/node.h
paddle/fluid/inference/analysis/node.h
+11
-12
paddle/fluid/inference/analysis/pass.h
paddle/fluid/inference/analysis/pass.h
+20
-7
paddle/fluid/inference/analysis/pass_manager.cc
paddle/fluid/inference/analysis/pass_manager.cc
+44
-0
paddle/fluid/inference/analysis/pass_manager.h
paddle/fluid/inference/analysis/pass_manager.h
+116
-0
paddle/fluid/inference/analysis/pass_manager_tester.cc
paddle/fluid/inference/analysis/pass_manager_tester.cc
+85
-0
paddle/fluid/inference/analysis/subgraph_splitter_tester.cc
paddle/fluid/inference/analysis/subgraph_splitter_tester.cc
+34
-11
paddle/fluid/inference/analysis/tensorrt_subgraph_pass.cc
paddle/fluid/inference/analysis/tensorrt_subgraph_pass.cc
+33
-0
paddle/fluid/inference/analysis/tensorrt_subgraph_pass.h
paddle/fluid/inference/analysis/tensorrt_subgraph_pass.h
+47
-0
paddle/fluid/inference/analysis/tensorrt_subgraph_pass_tester.cc
...fluid/inference/analysis/tensorrt_subgraph_pass_tester.cc
+71
-0
paddle/fluid/inference/analysis/ut_helper.h
paddle/fluid/inference/analysis/ut_helper.h
+25
-9
paddle/fluid/memory/detail/system_allocator.cc
paddle/fluid/memory/detail/system_allocator.cc
+5
-3
paddle/fluid/operators/activation_mkldnn_op.cc
paddle/fluid/operators/activation_mkldnn_op.cc
+196
-120
paddle/fluid/operators/activation_op.cc
paddle/fluid/operators/activation_op.cc
+18
-15
paddle/fluid/operators/chunk_eval_op.cc
paddle/fluid/operators/chunk_eval_op.cc
+33
-34
paddle/fluid/operators/clip_by_norm_op.cc
paddle/fluid/operators/clip_by_norm_op.cc
+10
-1
paddle/fluid/operators/conv_transpose_op.cc
paddle/fluid/operators/conv_transpose_op.cc
+1
-1
paddle/fluid/operators/cos_sim_op.cc
paddle/fluid/operators/cos_sim_op.cc
+2
-2
paddle/fluid/operators/crf_decoding_op.cc
paddle/fluid/operators/crf_decoding_op.cc
+8
-11
paddle/fluid/operators/detail/grpc_client.cc
paddle/fluid/operators/detail/grpc_client.cc
+1
-1
paddle/fluid/operators/detection/iou_similarity_op.cc
paddle/fluid/operators/detection/iou_similarity_op.cc
+6
-5
paddle/fluid/operators/detection/polygon_box_transform_op.cc
paddle/fluid/operators/detection/polygon_box_transform_op.cc
+3
-1
paddle/fluid/operators/linear_chain_crf_op.cc
paddle/fluid/operators/linear_chain_crf_op.cc
+2
-0
paddle/fluid/operators/lstm_op.cc
paddle/fluid/operators/lstm_op.cc
+20
-22
paddle/fluid/operators/pool_op.cc
paddle/fluid/operators/pool_op.cc
+13
-6
paddle/fluid/operators/roi_pool_op.cc
paddle/fluid/operators/roi_pool_op.cc
+14
-1
paddle/fluid/operators/scale_op.cc
paddle/fluid/operators/scale_op.cc
+4
-4
paddle/fluid/operators/shape_op.cc
paddle/fluid/operators/shape_op.cc
+6
-3
paddle/fluid/operators/sigmoid_cross_entropy_with_logits_op.cc
...e/fluid/operators/sigmoid_cross_entropy_with_logits_op.cc
+2
-2
paddle/fluid/operators/slice_op.cc
paddle/fluid/operators/slice_op.cc
+20
-17
paddle/fluid/operators/tensorrt_engine_op_test.cc
paddle/fluid/operators/tensorrt_engine_op_test.cc
+1
-1
paddle/fluid/operators/uniform_random_batch_size_like_op.cc
paddle/fluid/operators/uniform_random_batch_size_like_op.cc
+2
-2
python/paddle/fluid/framework.py
python/paddle/fluid/framework.py
+39
-2
python/paddle/fluid/layers/control_flow.py
python/paddle/fluid/layers/control_flow.py
+131
-50
python/paddle/fluid/layers/detection.py
python/paddle/fluid/layers/detection.py
+39
-34
python/paddle/fluid/layers/io.py
python/paddle/fluid/layers/io.py
+92
-6
python/paddle/fluid/layers/layer_function_generator.py
python/paddle/fluid/layers/layer_function_generator.py
+8
-13
python/paddle/fluid/layers/learning_rate_scheduler.py
python/paddle/fluid/layers/learning_rate_scheduler.py
+73
-34
python/paddle/fluid/layers/metric.py
python/paddle/fluid/layers/metric.py
+25
-1
python/paddle/fluid/layers/nn.py
python/paddle/fluid/layers/nn.py
+475
-257
python/paddle/fluid/layers/ops.py
python/paddle/fluid/layers/ops.py
+1
-2
python/paddle/fluid/layers/tensor.py
python/paddle/fluid/layers/tensor.py
+55
-19
未找到文件。
paddle/contrib/CMakeLists.txt
浏览文件 @
f1f8327c
...
...
@@ -14,4 +14,3 @@
#
add_subdirectory
(
inference
)
add_subdirectory
(
tape
)
paddle/contrib/tape/CMakeLists.txt
已删除
100644 → 0
浏览文件 @
a0c5fd83
# Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
if
(
APPLE
)
set
(
CMAKE_CXX_FLAGS
"
${
CMAKE_CXX_FLAGS
}
-Wno-error=pessimizing-move"
)
endif
(
APPLE
)
cc_library
(
tape_variable SRCS variable.cc DEPS
${
FLUID_CORE_MODULES
}
device_context framework_proto proto_desc operator
)
cc_library
(
tape SRCS tape.cc DEPS
${
FLUID_CORE_MODULES
}
${
GLOB_OP_LIB
}
tape_variable
)
cc_test
(
test_tape
SRCS test_tape.cc
DEPS tape tape_variable
)
paddle/contrib/tape/README.md
已删除
100644 → 0
浏览文件 @
a0c5fd83
# Dynamic Graph on Fluid
PaddlePaddle Fluid is targeting the autodiff without tape, which, however, is very
challenging and we are still way from there. DyNet and PyTorch provide a good design
idea, the
*tape*
, that significantly eases the challenge. Also, DyNet provides
a C++ API that is as convenient as Python but with higher efficiency and could
conveniently integrate with industrial/production systems. This package,
`tape`
,
combines the good of
1.
tape from PyTorch and DyNet
2.
C++ API and core from DyNet
3.
rich set of operators from PaddlePaddle
## Overview
We can implement Dynet-like Tape(See this
[
survey
](
https://github.com/PaddlePaddle/Paddle/blob/develop/doc/survey/dynamic_graph.md
)
)
by wrapping Paddle Fluid's
`Operator`
and
`Variable`
.
The user API is straight forward since
1.
it is imperative. And it uses host language's control flow logic.
1.
it avoids extra concepts such as
`Scope`
and
`Executor`
.
All of these benefits come at the cost of just adding one line
`reset_global_tape`
at every iteration.
## Code Structure
In short, the
`Tape`
contains a vector of
`OpHandle`
s. And an
`OpHandle`
contains its
`type`
, the pointers to the
`Variable`
s, and necessary attributes.
```
c++
class
Variable
{
public:
VriableHandle
Grad
();
// returns its gradient variable
private:
framework
::
VarDesc
desc_
;
// compile time infershape, necessary for lazy execution
framework
::
Variable
var_
;
// run time variable, holds data memory
};
using
VariableHandle
=
shared_ptr
<
Variable
>
;
struct
OpHandle
{
string
type_
;
map
<
string
,
vector
<
VariableHandle
>>
inputs_
;
map
<
string
,
vector
<
VariableHandle
>>
outputs_
;
AttributeMap
attrs_
;
};
class
Tape
{
public:
void
AddOp
(
OpHandle
);
// add op
void
Forward
();
// execute the tape_
void
Backward
();
// execute the backward of the tape_
private:
vector
<
OpHandle
>
tape_
;
};
```
We uses
`Function`
to indicate layers. It takes care of parameter
initialization and
`AddOp`
to the Tape when it is called.
```
c++
class
Linear
{
public:
Linear
(
int
in_dim
,
int
out_dim
,
const
std
::
string
&
act
)
:
w_
(
new
Variable
(
"LinearWeight"
)),
b_
(
new
Variable
(
"LinearBias"
)),
act_
(
act
)
{
Tape
init_tape
;
std
::
string
initializer
=
"fill_constant"
;
framework
::
AttributeMap
attrs
;
attrs
[
"dtype"
]
=
paddle
::
framework
::
proto
::
VarType
::
Type
::
VarType_Type_FP32
;
attrs
[
"shape"
]
=
std
::
vector
<
int
>
{
in_dim
,
out_dim
};
attrs
[
"value"
]
=
1.0
f
;
init_tape
.
AddOp
(
initializer
,
{},
{{
"Out"
,
{
w_
}}},
attrs
);
attrs
[
"dtype"
]
=
paddle
::
framework
::
proto
::
VarType
::
Type
::
VarType_Type_FP32
;
attrs
[
"shape"
]
=
std
::
vector
<
int
>
{
out_dim
};
attrs
[
"value"
]
=
1.0
f
;
init_tape
.
AddOp
(
initializer
,
{},
{{
"Out"
,
{
b_
}}},
attrs
);
init_tape
.
Forward
();
}
VariableHandle
operator
()(
VariableHandle
input
)
{
VariableHandle
pre_bias
(
new
Variable
(
"linear"
));
get_global_tape
().
AddOp
(
"mul"
,
{{
"X"
,
{
input
}},
{
"Y"
,
{
w_
}}},
{{
"Out"
,
{
pre_bias
}}},
{{
"x_num_col_dims"
,
1
},
{
"y_num_col_dims"
,
1
}});
VariableHandle
pre_act
(
new
Variable
(
"linear"
));
get_global_tape
().
AddOp
(
"elementwise_add"
,
{{
"X"
,
{
pre_bias
}},
{
"Y"
,
{
b_
}}},
{{
"Out"
,
{
pre_act
}}},
{{
"axis"
,
1
}});
VariableHandle
post_act
(
new
Variable
(
"linear"
));
get_global_tape
().
AddOp
(
act_
,
{{
"X"
,
{
pre_act
}}},
{{
"Out"
,
{
post_act
}}},
{});
return
post_act
;
}
std
::
vector
<
VariableHandle
>
Params
()
{
return
{
w_
,
b_
};
}
private:
VariableHandle
w_
;
VariableHandle
b_
;
std
::
string
act_
;
};
```
## User API
```
c++
// Model function
paddle
::
tape
::
Linear
linear1
(
3
,
3
,
"relu"
);
// init weight and bias
paddle
::
tape
::
Linear
linear2
(
3
,
3
,
"relu"
);
// init weight and bias
paddle
::
tape
::
Mean
mean
;
// Optimizer
paddle
::
tape
::
SGD
sgd
(
0.001
);
// Data Feeder
paddle
::
tape
::
Fill
data_feeder
(...);
VariableHandle
input
(
new
paddle
::
tape
::
Variable
(
"input"
));
VariableHandle
label
(
new
paddle
::
tape
::
Variable
(
"label"
));
for
(
int
i
=
0
;
i
<
2
;
++
i
)
{
reset_global_tape
();
data_feeder
(
input
,
label
);
auto
loss
=
softmax
(
linear2
(
linear1
(
input
)),
label
);
// compile time InferShape & InferVarType
LOG
(
INFO
)
<<
loss
.
value
();
// Run forward up to loss
// Run backward, store gradient of w at w->Grad()
get_global_tape
.
Backward
(
loss
);
// Update w
sgd
(
linear1
.
Params
());
sgd
(
linear2
.
Params
());
}
```
<details>
<summary></summary>
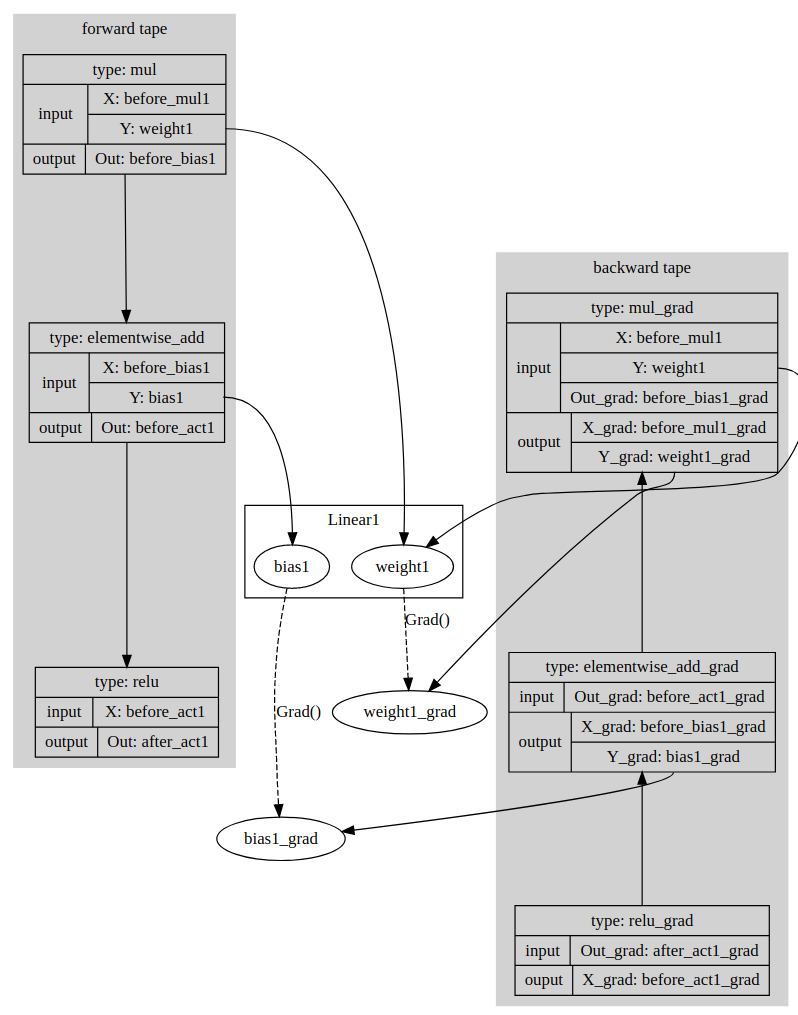
digraph G {
subgraph cluster_0 {
node [shape=record,style=filled];
style=filled;
color=lightgrey;
linear1 [label="{type: mul | {input | {<before_mul1>X: before_mul1 |<weight1> Y: weight1}} | {output |<before_bias1> Out: before_bias1}}"];
elementwise_add1 [label="{type: elementwise_add | {input | {<before_bias1>X: before_bias1 |<bias1> Y: bias1}} | {output |<before_act1> Out: before_act1}}"];
relu1 [label="{type: relu | {input | {<before_act1>X: before_act1 }} | {output |<after_act1> Out: after_act1}}"];
linear1 -> elementwise_add1->relu1;
label = "forward tape";
}
linear1:before_mul1->before_mul1
linear1:weight1->weight1
linear1:before_bias1->before_bias1
elementwise_add1:bias1->bias1
elementwise_add1:before_bias1->before_bias1
elementwise_add1:before_act1->before_act1
relu1:before_act1->before_act1
relu1:after_act1->after_act1
subgraph cluster_1 {
node [shape=record,style=filled];
style=filled;
color=lightgrey;
linear1_grad [label="{type: mul_grad | {input | {<before_mul1>X: before_mul1 |<weight1> Y: weight1|<before_bias1_grad> Out_grad: before_bias1_grad}} | {output |{<before_mul1_grad>X_grad: before_mul1_grad |<weight1_grad> Y_grad: weight1_grad}}}"];
elementwise_add1_grad [label="{type: elementwise_add_grad | {input | <before_act1_grad> Out_grad: before_act1_grad} | {output |{<before_bias1_grad>X_grad: before_bias1_grad |<bias1_grad> Y_grad: bias1_grad}}}"];
relu1_grad [label="{type: relu_grad | {input |<after_act1_grad> Out_grad: after_act1_grad} | {ouput | {<before_act1_grad>X_grad: before_act1_grad }}}"];
linear1_grad -> elementwise_add1_grad ->relu1_grad [dir=back];
label = "backward tape";
}
relu1_grad:after_act1_grad->after_act1_grad
relu1_grad:before_act1_grad->before_act1_grad
elementwise_add1_grad:before_act1_grad->before_act1_grad
elementwise_add1_grad:before_bias1_grad->before_bias1_grad
elementwise_add1_grad:bias1_grad->bias1_grad
linear1_grad:before_mul1->before_mul1
linear1_grad:weight1->weight1
linear1_grad:before_bias1_grad->before_bias1_grad
linear1_grad:before_mul1_grad->before_mul1_grad
linear1_grad:weight1_grad->weight1_grad
subgraph cluster_2 {
node [shape=record];
label = "Linear1";
weight1
bias1
}
weight1 -> weight1_grad [ label="Grad()", style="dashed" ];
bias1 -> bias1_grad [ label="Grad()", style="dashed"];
}
</details>

## Code Reuse
We want to stay close to Paddle Fluid as much as possible.
### Reuse All Operators
As all Ops are registered at
`OpInfoMap`
, the effort of adding a new
`Function`
is about 10 lines of code, similar to expose an operator to Python.
### Reuse Compile Time InferShape and InferVarType
Note that all the symbolic information is stored at
`tape::Varaible::desc_`
, instead
of
`ProgramDesc.block.vars`
, we create a temporary
`BlockDesc`
to do
`InferShape`
and
`InferVarType`
every time we
`AddOp`
to the tape.
### Reuse Operator::Run
We use smart pointer, instead of
`Scope`
, to manage memory. So we create a temporary
`Scope`
for every
`Operator::Run()`
.
## Possible Feature
### Release Memory on Backward
We can release memory aggressively. During backward, we can delete the OpHandle once
we have finished its backward. Since all the variable is managed by smart pointer, the
memory is automatically released when its
`ref_count`
goes to 0.
### Kernel Fusion
As a symbolic representation of the Tape is constructed first before the actual
execution, it would be possible to perform graph optimization. One use case is kernel
fusion.
paddle/contrib/tape/computation_graph.png
已删除
100644 → 0
浏览文件 @
a0c5fd83
94.4 KB
paddle/contrib/tape/function.h
已删除
100644 → 0
浏览文件 @
a0c5fd83
// Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#pragma once
#include <string>
#include "paddle/contrib/tape/tape.h"
#include "paddle/contrib/tape/variable.h"
#include "paddle/fluid/framework/type_defs.h"
namespace
paddle
{
namespace
tape
{
class
Function
{};
class
Fill
{
public:
Fill
(
const
std
::
string
&
initializer
,
const
framework
::
AttributeMap
&
attrs
)
:
initializer_
(
initializer
),
attrs_
(
attrs
)
{}
void
operator
()(
VariableHandle
var
)
{
get_global_tape
().
AddOp
(
initializer_
,
{},
{{
"Out"
,
{
var
}}},
attrs_
);
}
private:
const
std
::
string
initializer_
;
const
framework
::
AttributeMap
attrs_
;
};
class
Mean
{
public:
VariableHandle
operator
()(
VariableHandle
var
)
{
VariableHandle
out
(
new
Variable
(
"mean"
));
get_global_tape
().
AddOp
(
"mean"
,
{{
"X"
,
{
var
}}},
{{
"Out"
,
{
out
}}},
{});
return
out
;
}
};
class
Linear
{
public:
Linear
(
int
in_dim
,
int
out_dim
,
const
std
::
string
&
act
)
:
w_
(
new
Variable
(
"LinearWeight"
)),
b_
(
new
Variable
(
"LinearBias"
)),
act_
(
act
)
{
Tape
init_tape
;
std
::
string
initializer
=
"fill_constant"
;
framework
::
AttributeMap
attrs
;
attrs
[
"dtype"
]
=
paddle
::
framework
::
proto
::
VarType
::
Type
::
VarType_Type_FP32
;
attrs
[
"shape"
]
=
std
::
vector
<
int
>
{
in_dim
,
out_dim
};
attrs
[
"value"
]
=
1.0
f
;
init_tape
.
AddOp
(
initializer
,
{},
{{
"Out"
,
{
w_
}}},
attrs
);
attrs
[
"dtype"
]
=
paddle
::
framework
::
proto
::
VarType
::
Type
::
VarType_Type_FP32
;
attrs
[
"shape"
]
=
std
::
vector
<
int
>
{
out_dim
};
attrs
[
"value"
]
=
1.0
f
;
init_tape
.
AddOp
(
initializer
,
{},
{{
"Out"
,
{
b_
}}},
attrs
);
init_tape
.
Forward
();
}
VariableHandle
operator
()(
VariableHandle
input
)
{
VariableHandle
pre_bias
(
new
Variable
(
"linear"
));
get_global_tape
().
AddOp
(
"mul"
,
{{
"X"
,
{
input
}},
{
"Y"
,
{
w_
}}},
{{
"Out"
,
{
pre_bias
}}},
{{
"x_num_col_dims"
,
1
},
{
"y_num_col_dims"
,
1
}});
VariableHandle
pre_act
(
new
Variable
(
"linear"
));
get_global_tape
().
AddOp
(
"elementwise_add"
,
{{
"X"
,
{
pre_bias
}},
{
"Y"
,
{
b_
}}},
{{
"Out"
,
{
pre_act
}}},
{{
"axis"
,
1
}});
VariableHandle
post_act
(
new
Variable
(
"linear"
));
get_global_tape
().
AddOp
(
act_
,
{{
"X"
,
{
pre_act
}}},
{{
"Out"
,
{
post_act
}}},
{});
return
post_act
;
}
std
::
vector
<
VariableHandle
>
Params
()
{
return
{
w_
,
b_
};
}
private:
VariableHandle
w_
;
VariableHandle
b_
;
std
::
string
act_
;
};
class
SGD
{
public:
SGD
(
float
learning_rate
)
:
learning_rate_
(
new
Variable
(
"sgd"
))
{
Tape
init_tape
;
std
::
string
initializer
=
"fill_constant"
;
framework
::
AttributeMap
attrs
;
attrs
[
"dtype"
]
=
paddle
::
framework
::
proto
::
VarType
::
Type
::
VarType_Type_FP32
;
attrs
[
"shape"
]
=
std
::
vector
<
int
>
{
1
};
attrs
[
"value"
]
=
learning_rate
;
init_tape
.
AddOp
(
initializer
,
{},
{{
"Out"
,
{
learning_rate_
}}},
attrs
);
init_tape
.
Forward
();
}
void
operator
()(
VariableHandle
input
)
{
PADDLE_ENFORCE
(
get_global_tape
().
HasBeenBackwarded
(),
"optimization must happen after the backward"
);
Tape
temp_tape
;
temp_tape
.
AddOp
(
"sgd"
,
{{
"Param"
,
{
input
}},
{
"LearningRate"
,
{
learning_rate_
}},
{
"Grad"
,
{
input
->
Grad
()}}},
{{
"ParamOut"
,
{
input
}}},
{});
temp_tape
.
Forward
();
}
private:
VariableHandle
learning_rate_
;
};
}
}
paddle/contrib/tape/tape.cc
已删除
100644 → 0
浏览文件 @
a0c5fd83
// Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include "paddle/contrib/tape/tape.h"
#include <list>
#include <map>
#include <memory>
#include <string>
#include <vector>
#include "paddle/fluid/framework/data_type.h"
#include "paddle/fluid/framework/dim.h"
#include "paddle/fluid/framework/op_registry.h"
#include "paddle/fluid/framework/operator.h"
#include "paddle/fluid/framework/scope.h"
#include "paddle/fluid/platform/place.h"
#include "paddle/fluid/pybind/pybind.h"
namespace
paddle
{
namespace
tape
{
// borrowed from
// https://stackoverflow.com/questions/874134/find-if-string-ends-with-another-string-in-c
inline
bool
ends_with
(
std
::
string
const
&
value
,
std
::
string
const
&
ending
)
{
if
(
ending
.
size
()
>
value
.
size
())
return
false
;
return
std
::
equal
(
ending
.
rbegin
(),
ending
.
rend
(),
value
.
rbegin
());
}
std
::
ostream
&
operator
<<
(
std
::
ostream
&
os
,
const
framework
::
VarDesc
&
var_desc
)
{
os
<<
var_desc
.
Name
();
os
<<
"["
<<
var_desc
.
GetType
()
<<
"]"
;
os
<<
"["
<<
var_desc
.
GetDataType
()
<<
"]"
;
os
<<
"{"
;
for
(
auto
&
i
:
var_desc
.
GetShape
())
{
os
<<
i
<<
","
;
}
os
<<
"}"
;
return
os
;
}
std
::
string
to_string
(
const
std
::
string
&
type
,
const
VariableHandleMap
&
in_vars
,
const
VariableHandleMap
&
out_vars
,
const
framework
::
AttributeMap
&
attrs
)
{
std
::
stringstream
ss
;
ss
<<
type
<<
" "
;
for
(
auto
&
param_name
:
in_vars
)
{
for
(
auto
&
var
:
param_name
.
second
)
{
ss
<<
param_name
.
first
<<
":("
<<
var
->
Desc
()
<<
") "
;
}
}
for
(
auto
&
param_name
:
out_vars
)
{
for
(
auto
&
var
:
param_name
.
second
)
{
ss
<<
param_name
.
first
<<
":("
<<
var
->
Desc
()
<<
") "
;
}
}
return
ss
.
str
();
}
framework
::
OpDesc
CreateOpDesc
(
const
std
::
string
&
type
,
const
VariableHandleMap
&
in_vars
,
const
VariableHandleMap
&
out_vars
,
const
framework
::
AttributeMap
&
attrs
)
{
framework
::
VariableNameMap
inputs
;
for
(
auto
&
param_name
:
in_vars
)
{
for
(
auto
&
var
:
param_name
.
second
)
{
inputs
[
param_name
.
first
].
emplace_back
(
var
->
Name
());
}
}
framework
::
VariableNameMap
outputs
;
for
(
auto
&
param_name
:
out_vars
)
{
for
(
auto
&
var
:
param_name
.
second
)
{
outputs
[
param_name
.
first
].
emplace_back
(
var
->
Name
());
}
}
return
framework
::
OpDesc
(
type
,
inputs
,
outputs
,
attrs
);
}
void
InferShapeAndVarType
(
const
std
::
string
&
type
,
const
VariableHandleMap
&
in_vars
,
VariableHandleMap
*
out_vars
,
const
framework
::
AttributeMap
&
attrs
)
{
framework
::
OpDesc
op_desc
=
CreateOpDesc
(
type
,
in_vars
,
*
out_vars
,
attrs
);
// Create a temporary block for compile-time
framework
::
ProgramDesc
program_desc
;
framework
::
BlockDesc
*
block_desc
=
program_desc
.
MutableBlock
(
0
);
PADDLE_ENFORCE
(
block_desc
);
for
(
auto
&
param_name
:
in_vars
)
{
for
(
auto
&
var
:
param_name
.
second
)
{
*
block_desc
->
Var
(
var
->
Name
())
->
Proto
()
=
*
var
->
MutableDesc
()
->
Proto
();
}
}
for
(
auto
&
param_name
:
*
out_vars
)
{
for
(
auto
&
var
:
param_name
.
second
)
{
*
block_desc
->
Var
(
var
->
Name
())
->
Proto
()
=
*
var
->
MutableDesc
()
->
Proto
();
}
}
LOG
(
INFO
)
<<
"- "
<<
to_string
(
type
,
in_vars
,
*
out_vars
,
attrs
);
op_desc
.
InferShape
(
*
block_desc
);
op_desc
.
InferVarType
(
block_desc
);
for
(
auto
&
param_name
:
*
out_vars
)
{
for
(
auto
&
var
:
param_name
.
second
)
{
*
var
->
MutableDesc
()
->
Proto
()
=
*
block_desc
->
Var
(
var
->
Name
())
->
Proto
();
}
}
LOG
(
INFO
)
<<
"+ "
<<
to_string
(
type
,
in_vars
,
*
out_vars
,
attrs
);
}
void
Tape
::
AddOp
(
const
std
::
string
&
type
,
const
VariableHandleMap
&
in_vars
,
VariableHandleMap
out_vars
,
const
framework
::
AttributeMap
&
attrs
)
{
InferShapeAndVarType
(
type
,
in_vars
,
&
out_vars
,
attrs
);
tape_
.
emplace_back
(
type
,
in_vars
,
out_vars
,
attrs
);
}
// Temporary Scope for Operator::Run()
class
ScopeWrapper
:
public
framework
::
Scope
{
public:
ScopeWrapper
(
const
VariableHandleMap
&
in_vars
,
const
VariableHandleMap
&
out_vars
)
{
for
(
auto
&
v
:
in_vars
)
{
for
(
auto
&
vv
:
v
.
second
)
{
if
(
!
vars_
.
count
(
vv
->
Name
()))
{
vars_
[
vv
->
Name
()].
reset
(
vv
->
Var
());
}
}
}
for
(
auto
&
v
:
out_vars
)
{
for
(
auto
&
vv
:
v
.
second
)
{
if
(
!
vars_
.
count
(
vv
->
Name
()))
{
vars_
[
vv
->
Name
()].
reset
(
vv
->
Var
());
}
}
}
}
~
ScopeWrapper
()
{
for
(
auto
&
pair
:
vars_
)
{
pair
.
second
.
release
();
}
}
};
void
Tape
::
Forward
()
{
LOG
(
INFO
)
<<
"Starting forward -------------------------"
;
PADDLE_ENFORCE
(
!
has_been_backwarded_
);
while
(
current_position_
<
tape_
.
size
())
{
OpHandle
&
op
=
tape_
[
current_position_
];
// Create Output Tensor, this is only necessary for OpWithKernel
for
(
auto
&
param2var
:
op
.
outputs_
)
{
for
(
auto
&
var
:
param2var
.
second
)
{
var
->
InitializeVariable
();
}
}
framework
::
OpDesc
op_desc
=
CreateOpDesc
(
op
.
type_
,
op
.
inputs_
,
op
.
outputs_
,
op
.
attrs_
);
ScopeWrapper
scope
(
op
.
inputs_
,
op
.
outputs_
);
framework
::
OpRegistry
::
CreateOp
(
op_desc
)
->
Run
(
scope
,
platform
::
CPUPlace
());
current_position_
++
;
}
LOG
(
INFO
)
<<
"Finishing forward -------------------------"
;
}
void
Tape
::
Backward
(
VariableHandle
target
)
{
PADDLE_ENFORCE
(
!
has_been_backwarded_
);
Forward
();
// TODO(tonyyang-svail): check output of last op is target
backward_tape_
.
reset
(
new
Tape
());
framework
::
AttributeMap
attrs
;
// FIXME(tonyyang-svail): Need to infer_data_type
attrs
[
"dtype"
]
=
framework
::
proto
::
VarType
::
Type
::
VarType_Type_FP32
;
attrs
[
"shape"
]
=
std
::
vector
<
int
>
{
1
};
attrs
[
"value"
]
=
1.0
f
;
backward_tape_
->
AddOp
(
"fill_constant"
,
{},
{{
"Out"
,
{
target
->
Grad
()}}},
attrs
);
for
(
auto
it
=
tape_
.
rbegin
();
it
!=
tape_
.
rend
();
++
it
)
{
framework
::
OpDesc
op_desc
=
CreateOpDesc
(
it
->
type_
,
it
->
inputs_
,
it
->
outputs_
,
it
->
attrs_
);
std
::
unordered_map
<
std
::
string
,
std
::
string
>
grad_to_var
;
std
::
vector
<
std
::
unique_ptr
<
framework
::
OpDesc
>>
grad_op_descs
=
framework
::
OpInfoMap
::
Instance
()
.
Get
(
op_desc
.
Type
())
.
GradOpMaker
()(
op_desc
,
{},
&
grad_to_var
,
{});
for
(
auto
&
op_desc
:
grad_op_descs
)
{
std
::
unordered_map
<
std
::
string
,
VariableHandle
>
name2var
;
for
(
auto
&
param2vars
:
it
->
inputs_
)
{
for
(
auto
&
a
:
param2vars
.
second
)
{
name2var
[
a
->
Name
()]
=
a
;
}
}
for
(
auto
&
param2vars
:
it
->
outputs_
)
{
for
(
auto
&
a
:
param2vars
.
second
)
{
name2var
[
a
->
Name
()]
=
a
;
}
}
VariableHandleMap
in_vars
;
VariableHandleMap
out_vars
;
std
::
map
<
const
framework
::
VariableNameMap
*
,
VariableHandleMap
*>
loop_over
{{
&
op_desc
->
Inputs
(),
&
in_vars
},
{
&
op_desc
->
Outputs
(),
&
out_vars
}};
for
(
auto
&
each
:
loop_over
)
{
auto
&
vmp
=
*
each
.
first
;
auto
&
vhm
=
*
each
.
second
;
for
(
auto
&
p2a
:
vmp
)
{
for
(
auto
&
argu
:
p2a
.
second
)
{
if
(
name2var
.
count
(
argu
))
{
vhm
[
p2a
.
first
].
push_back
(
name2var
[
argu
]);
}
else
{
PADDLE_ENFORCE
(
ends_with
(
argu
,
framework
::
kGradVarSuffix
),
argu
.
c_str
());
std
::
string
name
=
argu
.
substr
(
0
,
argu
.
size
()
-
std
::
strlen
(
framework
::
kGradVarSuffix
));
PADDLE_ENFORCE
(
name2var
.
count
(
name
),
name
.
c_str
());
vhm
[
p2a
.
first
].
push_back
(
name2var
[
name
]
->
Grad
());
}
}
}
}
backward_tape_
->
AddOp
(
op_desc
->
Type
(),
in_vars
,
out_vars
,
op_desc
->
GetAttrMap
());
}
// TODO(tonyyang-svail): how to fill empty grad?
// TODO(tonyyang-svail): Sum var grad is necessary
}
backward_tape_
->
Forward
();
has_been_backwarded_
=
true
;
}
Tape
&
get_global_tape
()
{
static
Tape
T
;
return
T
;
}
void
reset_global_tape
()
{
get_global_tape
()
=
Tape
();
}
}
}
paddle/contrib/tape/variable.h
已删除
100644 → 0
浏览文件 @
a0c5fd83
// Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#pragma once
#include <memory>
#include "paddle/fluid/framework/operator.h" // framework::kGradVarSuffix
#include "paddle/fluid/framework/program_desc.h"
#include "paddle/fluid/framework/variable.h"
namespace
paddle
{
namespace
tape
{
class
Variable
;
using
VariableHandle
=
std
::
shared_ptr
<
Variable
>
;
/*
* Combination of
* framework::VarDesc desc_;
* framework::Variable var_;
*/
class
Variable
{
public:
Variable
(
const
std
::
string
pre_fix
)
:
desc_
(
pre_fix
+
std
::
to_string
(
count
()))
{}
Variable
(
const
std
::
string
pre_fix
,
bool
is_grad
)
:
desc_
(
pre_fix
+
(
is_grad
?
framework
::
kGradVarSuffix
:
std
::
to_string
(
count
())))
{}
~
Variable
()
{
LOG
(
INFO
)
<<
"Deleting "
<<
Name
();
}
// Instantiate LoDTensor/SelectedRow
void
InitializeVariable
();
VariableHandle
Grad
()
{
if
(
grad_
.
expired
())
{
VariableHandle
new_grad
(
new
Variable
(
desc_
.
Name
(),
true
));
grad_
=
new_grad
;
return
new_grad
;
}
else
{
return
VariableHandle
(
grad_
);
}
}
// Stochastic Gradient Descent with Momentum
// VariableHandle Momentum ();
// void init(const std::string& initializer,
// const framework::AttributeMap& attrs);
// void value() {};
const
framework
::
VarDesc
&
Desc
()
const
{
return
desc_
;
}
framework
::
VarDesc
*
MutableDesc
()
{
return
&
desc_
;
}
// TODO(tonyyang-svail): No need to expose name
std
::
string
Name
()
const
{
return
desc_
.
Name
();
}
framework
::
Variable
*
Var
()
{
return
&
var_
;
}
private:
int
count
()
{
static
int
counter
=
0
;
return
counter
++
;
}
framework
::
VarDesc
desc_
;
framework
::
Variable
var_
;
std
::
weak_ptr
<
Variable
>
grad_
;
};
}
}
paddle/fluid/inference/analysis/CMakeLists.txt
浏览文件 @
f1f8327c
set
(
FLUID_CORE_MODULES proto_desc memory lod_tensor executor init
)
cc_library
(
analysis SRCS dot.cc node.cc data_flow_graph.cc graph_traits.cc subgraph_splitter.cc fluid_to_data_flow_graph_pass.cc
DEPS paddle_fluid
)
cc_library
(
analysis SRCS pass_manager.cc dot.cc node.cc data_flow_graph.cc graph_traits.cc subgraph_splitter.cc
fluid_to_data_flow_graph_pass.cc
data_flow_graph_to_fluid_pass.cc
tensorrt_subgraph_pass.cc
dfg_graphviz_draw_pass.cc
DEPS framework_proto
)
cc_test
(
test_node SRCS node_tester.cc DEPS analysis
)
cc_test
(
test_dot SRCS dot_tester.cc DEPS analysis
)
set
(
PYTHON_TESTS_DIR
${
PADDLE_BINARY_DIR
}
/python/paddle/fluid/tests
)
cc_test
(
test_data_flow_graph SRCS data_flow_graph_tester.cc DEPS analysis
${
FLUID_CORE_MODULES
}
paddle_fluid
ARGS --inference_model_dir=
${
PYTHON_TESTS_DIR
}
/book/word2vec.inference.model
)
set_tests_properties
(
test_data_flow_graph PROPERTIES DEPENDS test_word2vec
)
function
(
inference_analysis_test TARGET
)
set
(
options
""
)
set
(
oneValueArgs
""
)
set
(
multiValueArgs SRCS
)
cmake_parse_arguments
(
analysis_test
"
${
options
}
"
"
${
oneValueArgs
}
"
"
${
multiValueArgs
}
"
${
ARGN
}
)
cc_test
(
test_subgraph_splitter
SRCS subgraph_splitter_tester.cc
DEPS analysis paddle_fluid tensor
ARGS --inference_model_dir=
${
PYTHON_TESTS_DIR
}
/book/word2vec.inference.model
)
set_tests_properties
(
test_subgraph_splitter PROPERTIES DEPENDS test_word2vec
)
cc_test
(
${
TARGET
}
SRCS
"
${
analysis_test_SRCS
}
"
DEPS analysis
ARGS --inference_model_dir=
${
PYTHON_TESTS_DIR
}
/book/word2vec.inference.model --fraction_of_gpu_memory_to_use=0.5
)
set_tests_properties
(
${
TARGET
}
PROPERTIES DEPENDS test_word2vec
)
endfunction
(
inference_analysis_test
)
cc_test
(
test_dfg_graphviz_draw_pass
SRCS dfg_graphviz_draw_pass_tester.cc
DEPS analysis
ARGS --inference_model_dir=
${
PYTHON_TESTS_DIR
}
/book/word2vec.inference.model
)
set_tests_properties
(
test_dfg_graphviz_draw_pass PROPERTIES DEPENDS test_word2vec
)
inference_analysis_test
(
test_data_flow_graph SRCS data_flow_graph_tester.cc
)
inference_analysis_test
(
test_data_flow_graph_to_fluid_pass SRCS data_flow_graph_to_fluid_pass_tester.cc
)
inference_analysis_test
(
test_fluid_to_data_flow_graph_pass SRCS fluid_to_data_flow_graph_pass_tester.cc
)
inference_analysis_test
(
test_subgraph_splitter SRCS subgraph_splitter_tester.cc
)
inference_analysis_test
(
test_dfg_graphviz_draw_pass SRCS dfg_graphviz_draw_pass_tester.cc
)
#inference_analysis_test(test_tensorrt_subgraph_pass SRCS tensorrt_subgraph_pass_tester.cc)
inference_analysis_test
(
test_pass_manager SRCS pass_manager_tester.cc
)
paddle/
contrib/tape/variable
.cc
→
paddle/
fluid/inference/analysis/argument
.cc
浏览文件 @
f1f8327c
...
...
@@ -12,22 +12,4 @@
// See the License for the specific language governing permissions and
// limitations under the License.
#include "paddle/contrib/tape/variable.h"
namespace
paddle
{
namespace
tape
{
void
Variable
::
InitializeVariable
()
{
LOG
(
INFO
)
<<
"Initialzing "
<<
desc_
.
Name
()
<<
" as "
<<
desc_
.
GetType
();
framework
::
proto
::
VarType
::
Type
var_type
=
desc_
.
GetType
();
if
(
var_type
==
framework
::
proto
::
VarType
::
LOD_TENSOR
)
{
var_
.
GetMutable
<
framework
::
LoDTensor
>
();
}
else
if
(
var_type
==
framework
::
proto
::
VarType
::
SELECTED_ROWS
)
{
var_
.
GetMutable
<
framework
::
SelectedRows
>
();
}
else
{
PADDLE_THROW
(
"Variable type %d is not in [LOD_TENSOR, SELECTED_ROWS]"
,
var_type
);
}
}
}
}
#include "paddle/fluid/inference/analysis/argument.h"
paddle/
contrib/tape/tape
.h
→
paddle/
fluid/inference/analysis/argument
.h
浏览文件 @
f1f8327c
...
...
@@ -11,54 +11,45 @@
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#pragma once
#include <map>
#include <memory>
#include <string>
#include <vector>
#include "paddle/contrib/tape/variable.h"
namespace
paddle
{
namespace
tape
{
using
VariableHandleMap
=
std
::
map
<
std
::
string
,
std
::
vector
<
VariableHandle
>>
;
struct
OpHandle
{
OpHandle
(
const
std
::
string
&
type
,
const
VariableHandleMap
&
in_vars
,
const
VariableHandleMap
&
out_vars
,
const
framework
::
AttributeMap
&
attrs
)
:
type_
(
type
),
inputs_
(
in_vars
),
outputs_
(
out_vars
),
attrs_
(
attrs
)
{}
/*
* This file defines the class Argument, which is the input and output of the
* analysis module. All the fields that needed either by Passes or PassManagers
* are contained in Argument.
*
* TODO(Superjomn) Find some way better to contain the fields when it grow too
* big.
*/
std
::
string
type_
;
VariableHandleMap
inputs_
;
VariableHandleMap
outputs_
;
framework
::
AttributeMap
attrs_
;
};
class
Tape
{
public:
void
AddOp
(
const
std
::
string
&
type
,
const
VariableHandleMap
&
in_vars
,
VariableHandleMap
out_vars
,
const
framework
::
AttributeMap
&
attrs
);
void
Forward
();
void
Backward
(
VariableHandle
target
);
bool
HasBeenBackwarded
()
{
return
has_been_backwarded_
;
}
#pragma once
private:
bool
has_been_backwarded_
=
false
;
size_t
current_position_
=
0
;
#include "paddle/fluid/framework/program_desc.h"
#include "paddle/fluid/inference/analysis/data_flow_graph.h"
std
::
vector
<
OpHandle
>
tape_
;
std
::
shared_ptr
<
Tape
>
backward_tape_
;
namespace
paddle
{
namespace
inference
{
namespace
analysis
{
/*
* The argument definition of both Pass and PassManagers.
*
* All the fields should be registered here for clearness.
*/
struct
Argument
{
// The graph that process by the Passes or PassManagers.
std
::
unique_ptr
<
DataFlowGraph
>
main_dfg
;
// The original program desc.
std
::
unique_ptr
<
framework
::
proto
::
ProgramDesc
>
origin_program_desc
;
};
Tape
&
get_global_tape
();
#define UNLIKELY(condition) __builtin_expect(static_cast<bool>(condition), 0)
#define ANALYSIS_ARGUMENT_CHECK_FIELD(field__) \
if (UNLIKELY(!(field__))) { \
LOG(ERROR) << "field " << #field__ << " should be set."; \
return false; \
}
void
reset_global_tape
();
}
}
}
// namespace analysis
}
// namespace inference
}
// namespace paddle
paddle/fluid/inference/analysis/data_flow_graph.cc
浏览文件 @
f1f8327c
...
...
@@ -14,6 +14,7 @@ limitations under the License. */
#include "paddle/fluid/inference/analysis/data_flow_graph.h"
#include "paddle/fluid/inference/analysis/dot.h"
#include "paddle/fluid/inference/analysis/node.h"
namespace
paddle
{
namespace
inference
{
...
...
@@ -57,19 +58,7 @@ std::string DataFlowGraph::DotString() const {
// Add nodes
for
(
size_t
i
=
0
;
i
<
nodes
.
size
();
i
++
)
{
const
Node
&
node
=
nodes
.
Get
(
i
);
switch
(
node
.
type
())
{
case
Node
::
Type
::
kValue
:
dot
.
AddNode
(
node
.
repr
(),
node
.
dot_attrs
());
break
;
case
Node
::
Type
::
kFunction
:
dot
.
AddNode
(
node
.
repr
(),
node
.
dot_attrs
());
break
;
case
Node
::
Type
::
kFunctionBlock
:
dot
.
AddNode
(
node
.
repr
(),
node
.
dot_attrs
());
break
;
default:
PADDLE_THROW
(
"unsupported Node type %d"
,
static_cast
<
int
>
(
node
.
type
()));
}
dot
.
AddNode
(
node
.
repr
(),
node
.
dot_attrs
());
}
// Add edges
...
...
paddle/fluid/inference/analysis/data_flow_graph_to_fluid_pass.cc
0 → 100644
浏览文件 @
f1f8327c
// Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#include "paddle/fluid/inference/analysis/data_flow_graph_to_fluid_pass.h"
#include "paddle/fluid/framework/proto_desc.h"
namespace
paddle
{
namespace
inference
{
namespace
analysis
{
bool
DataFlowGraphToFluidPass
::
Initialize
(
Argument
*
argument
)
{
ANALYSIS_ARGUMENT_CHECK_FIELD
(
argument
)
ANALYSIS_ARGUMENT_CHECK_FIELD
(
argument
->
origin_program_desc
)
desc_
=
argument
->
origin_program_desc
.
get
();
// Here some logic from program_desc.cc and will not add new interfaces into
// framework::ProgramDesc class, use some UT to assure the correctness.
auto
*
block
=
desc_
->
mutable_blocks
()
->
Add
();
block
->
set_idx
(
framework
::
kRootBlockIndex
);
block
->
set_parent_idx
(
framework
::
kNoneBlockIndex
);
return
true
;
}
bool
DataFlowGraphToFluidPass
::
Finalize
()
{
return
true
;
}
void
DataFlowGraphToFluidPass
::
Run
(
DataFlowGraph
*
graph
)
{
auto
traits
=
GraphTraits
<
DataFlowGraph
>
(
graph
);
for
(
auto
it
=
traits
.
nodes
().
begin
();
it
!=
traits
.
nodes
().
end
();
++
it
)
{
if
(
it
->
deleted
())
continue
;
switch
(
it
->
type
())
{
case
Node
::
Type
::
kFunction
:
LOG
(
INFO
)
<<
"add function "
<<
it
->
name
();
AddFluidOp
(
&
(
*
it
));
break
;
case
Node
::
Type
::
kFunctionBlock
:
AddEngineOp
(
&
(
*
it
));
break
;
default:
continue
;
}
}
}
void
DataFlowGraphToFluidPass
::
AddFluidOp
(
Node
*
node
)
{
LOG
(
INFO
)
<<
"processing func "
<<
node
->
name
();
auto
*
ori_op
=
static_cast
<
framework
::
proto
::
OpDesc
*>
(
node
->
pb_desc
());
// currently only the main block is analyzed.
auto
*
main_block
=
desc_
->
mutable_blocks
(
framework
::
kRootBlockIndex
);
auto
*
op
=
main_block
->
add_ops
();
LOG
(
INFO
)
<<
"to copy the op"
;
*
op
=
*
ori_op
;
// copy the attributes, by default, these will not be changed
// by analysis phrase.
// The inputs and outputs of the existing ops are not changed by tensorrt
// subgraph pass.
// NOTE It might be changed by other passes in the long run.
}
void
DataFlowGraphToFluidPass
::
AddEngineOp
(
Node
*
node
)
{
// auto* ori_op = static_cast<framework::proto::OpDesc*>(node->extra_info());
// auto* main_block = desc_->mutable_blocks(framework::kRootBlockIndex);
// auto* op = main_block->add_ops();
// TODO(Superjomn) Here need to expose some arguments for default setting.
}
}
// namespace analysis
}
// namespace inference
}
// namespace paddle
paddle/fluid/inference/analysis/data_flow_graph_to_fluid_pass.h
0 → 100644
浏览文件 @
f1f8327c
/* Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
/*
* This file implements the transformation from fluid ProgramDesc to data flow
* graph.
*/
#pragma once
#include "paddle/fluid/framework/program_desc.h"
#include "paddle/fluid/inference/analysis/data_flow_graph.h"
#include "paddle/fluid/inference/analysis/pass.h"
namespace
paddle
{
namespace
inference
{
namespace
analysis
{
class
DataFlowGraphToFluidPass
final
:
public
DataFlowGraphPass
{
public:
DataFlowGraphToFluidPass
()
=
default
;
bool
Initialize
(
Argument
*
argument
)
override
;
bool
Finalize
()
override
;
void
Run
(
DataFlowGraph
*
graph
)
override
;
std
::
string
repr
()
const
override
{
return
"DFG to fluid"
;
}
std
::
string
description
()
const
override
{
return
"Transform a DFG to a Fluid ProgramDesc"
;
}
Pass
*
CreatePrinterPass
(
std
::
ostream
&
os
,
const
std
::
string
&
banner
)
const
override
{
return
nullptr
;
}
protected:
// Add a Fluid Op into the ProgramDesc.
void
AddFluidOp
(
Node
*
node
);
// Add a EngineOp into the ProgramDesc.
void
AddEngineOp
(
Node
*
node
);
private:
framework
::
proto
::
ProgramDesc
*
desc_
;
};
}
// namespace analysis
}
// namespace inference
}
// namespace paddle
paddle/fluid/inference/analysis/data_flow_graph_to_fluid_pass_tester.cc
浏览文件 @
f1f8327c
...
...
@@ -27,13 +27,12 @@ namespace inference {
namespace
analysis
{
TEST_F
(
DFG_Tester
,
Test
)
{
framework
::
proto
::
ProgramDesc
new_desc
;
DataFlowGraph
graph
;
FluidToDataFlowGraphPass
pass0
;
DataFlowGraphToFluidPass
pass1
;
pass0
.
Initialize
(
desc
);
pass1
.
Initialize
(
&
new_desc
);
ASSERT_TRUE
(
pass0
.
Initialize
(
&
argument
)
);
ASSERT_TRUE
(
pass1
.
Initialize
(
&
argument
)
);
pass0
.
Run
(
&
graph
);
pass1
.
Run
(
&
graph
);
...
...
paddle/fluid/inference/analysis/dfg_graphviz_draw_pass.cc
0 → 100644
浏览文件 @
f1f8327c
/* Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "paddle/fluid/inference/analysis/dfg_graphviz_draw_pass.h"
namespace
paddle
{
namespace
inference
{
namespace
analysis
{
void
DFG_GraphvizDrawPass
::
Run
(
DataFlowGraph
*
graph
)
{
auto
content
=
Draw
(
graph
);
std
::
ofstream
file
(
GenDotPath
());
file
.
write
(
content
.
c_str
(),
content
.
size
());
file
.
close
();
LOG
(
INFO
)
<<
"draw dot to "
<<
GenDotPath
();
}
std
::
string
DFG_GraphvizDrawPass
::
Draw
(
DataFlowGraph
*
graph
)
{
Dot
dot
;
// Add nodes
for
(
size_t
i
=
0
;
i
<
graph
->
nodes
.
size
();
i
++
)
{
const
Node
&
node
=
graph
->
nodes
.
Get
(
i
);
if
(
config_
.
display_deleted_node
||
!
node
.
deleted
())
{
dot
.
AddNode
(
node
.
repr
(),
node
.
dot_attrs
());
}
}
// Add edges
for
(
size_t
i
=
0
;
i
<
graph
->
nodes
.
size
();
i
++
)
{
const
Node
&
node
=
graph
->
nodes
.
Get
(
i
);
if
(
!
config_
.
display_deleted_node
&&
node
.
deleted
())
continue
;
for
(
auto
&
in
:
node
.
inlinks
)
{
if
(
!
config_
.
display_deleted_node
&&
in
->
deleted
())
continue
;
for
(
auto
&
in
:
node
.
inlinks
)
{
dot
.
AddEdge
(
in
->
repr
(),
node
.
repr
(),
{});
}
}
}
return
dot
.
Build
();
}
}
// namespace analysis
}
// namespace inference
}
// namespace paddle
paddle/fluid/inference/analysis/dfg_graphviz_draw_pass.h
浏览文件 @
f1f8327c
...
...
@@ -21,6 +21,7 @@ limitations under the License. */
#include <fstream>
#include <string>
#include "paddle/fluid/inference/analysis/dot.h"
#include "paddle/fluid/inference/analysis/pass.h"
namespace
paddle
{
...
...
@@ -32,35 +33,39 @@ namespace analysis {
*/
class
DFG_GraphvizDrawPass
:
public
DataFlowGraphPass
{
public:
DFG_GraphvizDrawPass
(
const
std
::
string
&
dir
,
const
std
::
string
&
id
)
:
dir_
(
dir
),
id_
(
id
)
{}
bool
Initialize
()
override
{
return
Pass
::
Initialize
();
}
void
Run
(
DataFlowGraph
*
graph
)
override
{
auto
content
=
Draw
(
graph
);
std
::
ofstream
file
(
GenDotPath
());
file
.
write
(
content
.
c_str
(),
content
.
size
());
file
.
close
();
LOG
(
INFO
)
<<
"draw dot to "
<<
GenDotPath
();
}
struct
Config
{
Config
(
const
std
::
string
&
dir
,
const
std
::
string
&
id
,
bool
display_deleted_node
=
false
)
:
dir
(
dir
),
id
(
id
),
display_deleted_node
(
display_deleted_node
)
{}
// The directory to store the .dot or .png files.
const
std
::
string
dir
;
// The identifier for this dot file.
const
std
::
string
id
;
// Whether to display deleted nodes, default false.
const
bool
display_deleted_node
;
};
DFG_GraphvizDrawPass
(
const
Config
&
config
)
:
config_
(
config
)
{}
bool
Initialize
(
Argument
*
argument
)
override
{
return
true
;
}
void
Run
(
DataFlowGraph
*
graph
)
override
;
bool
Finalize
()
override
{
return
Pass
::
Finalize
();
}
Pass
*
CreatePrinterPass
(
std
::
ostream
&
os
,
const
std
::
string
&
banner
)
const
override
{
return
nullptr
;
std
::
string
repr
()
const
override
{
return
"DFG graphviz drawer"
;
}
std
::
string
description
(
)
const
override
{
return
"Debug a DFG by draw with graphviz"
;
}
private:
// Path of the dot file to output.
std
::
string
GenDotPath
()
const
{
return
dir_
+
"/"
+
"graph_"
+
id_
+
".dot"
;
return
config_
.
dir
+
"/"
+
"graph_"
+
config_
.
id
+
".dot"
;
}
std
::
string
Draw
(
DataFlowGraph
*
graph
)
{
return
graph
->
DotString
();
}
std
::
string
Draw
(
DataFlowGraph
*
graph
);
std
::
string
dir_
;
std
::
string
id_
;
Config
config_
;
};
}
// namespace analysis
...
...
paddle/fluid/inference/analysis/dfg_graphviz_draw_pass_tester.cc
浏览文件 @
f1f8327c
...
...
@@ -24,9 +24,10 @@ namespace inference {
namespace
analysis
{
TEST_F
(
DFG_Tester
,
dfg_graphviz_draw_pass_tester
)
{
auto
dfg
=
ProgramDescToDFG
(
desc
);
DFG_GraphvizDrawPass
pass
(
"./"
,
"test"
);
pass
.
Initialize
();
auto
dfg
=
ProgramDescToDFG
(
*
argument
.
origin_program_desc
);
DFG_GraphvizDrawPass
::
Config
config
(
"./"
,
"test"
);
DFG_GraphvizDrawPass
pass
(
config
);
pass
.
Initialize
(
&
argument
);
pass
.
Run
(
&
dfg
);
// test content
...
...
@@ -38,7 +39,8 @@ TEST_F(DFG_Tester, dfg_graphviz_draw_pass_tester) {
while
(
std
::
getline
(
file
,
line
))
{
no
++
;
}
ASSERT_EQ
(
no
,
82
);
// DFG is sensitive to ProgramDesc, be careful to change the existing models.
ASSERT_EQ
(
no
,
112
);
}
}
// namespace analysis
...
...
paddle/fluid/inference/analysis/fluid_to_data_flow_graph_pass.cc
浏览文件 @
f1f8327c
...
...
@@ -21,19 +21,23 @@ namespace paddle {
namespace
inference
{
namespace
analysis
{
FluidToDataFlowGraphPass
::
FluidToDataFlowGraphPass
()
{}
bool
FluidToDataFlowGraphPass
::
Initialize
()
{
return
Pass
::
Initialize
();
}
bool
FluidToDataFlowGraphPass
::
Initialize
(
const
framework
::
proto
::
ProgramDesc
&
desc
)
{
desc_
=
&
desc
;
bool
FluidToDataFlowGraphPass
::
Initialize
(
Argument
*
argument
)
{
ANALYSIS_ARGUMENT_CHECK_FIELD
(
argument
);
ANALYSIS_ARGUMENT_CHECK_FIELD
(
argument
->
origin_program_desc
);
PADDLE_ENFORCE
(
argument
);
if
(
!
argument
->
main_dfg
)
{
LOG
(
INFO
)
<<
"Init DFG"
;
argument
->
main_dfg
.
reset
(
new
DataFlowGraph
);
}
desc_
=
argument
->
origin_program_desc
.
get
();
return
true
;
}
bool
FluidToDataFlowGraphPass
::
Finalize
()
{
return
Pass
::
Finalize
();
}
void
FluidToDataFlowGraphPass
::
Run
(
DataFlowGraph
*
graph
)
{
PADDLE_ENFORCE
(
graph
);
PADDLE_ENFORCE
(
desc_
);
// insert vars
std
::
unordered_map
<
std
::
string
,
size_t
>
var2id
;
auto
&
main_block
=
desc_
->
blocks
(
framework
::
kRootBlockIndex
);
...
...
@@ -41,7 +45,7 @@ void FluidToDataFlowGraphPass::Run(DataFlowGraph *graph) {
const
auto
&
var
=
main_block
.
vars
(
i
);
auto
*
v
=
graph
->
nodes
.
Create
(
Node
::
Type
::
kValue
);
v
->
SetName
(
var
.
name
());
v
->
Set
ExtraInfo
(
const_cast
<
void
*>
(
static_cast
<
const
void
*>
(
&
var
)));
v
->
Set
PbDesc
(
const_cast
<
void
*>
(
static_cast
<
const
void
*>
(
&
var
)));
var2id
[
var
.
name
()]
=
v
->
id
();
}
for
(
int
i
=
0
;
i
<
main_block
.
ops_size
();
i
++
)
{
...
...
@@ -51,7 +55,7 @@ void FluidToDataFlowGraphPass::Run(DataFlowGraph *graph) {
static_cast
<
Function
*>
(
o
)
->
SetFuncType
(
op
.
type
());
// Link to the original protobuf message's memory, make it easier to
// generate from a data flow graph to fluid ProgramDesc.
o
->
Set
ExtraInfo
(
const_cast
<
void
*>
(
static_cast
<
const
void
*>
(
&
op
)));
o
->
Set
PbDesc
(
const_cast
<
void
*>
(
static_cast
<
const
void
*>
(
&
op
)));
// set inputs and outputs
// TODO(Superjomn) make sure the InputNames is the real variable name.
for
(
int
j
=
0
;
j
<
op
.
inputs_size
();
j
++
)
{
...
...
paddle/fluid/inference/analysis/fluid_to_data_flow_graph_pass.h
浏览文件 @
f1f8327c
...
...
@@ -34,13 +34,18 @@ namespace analysis {
*/
class
FluidToDataFlowGraphPass
final
:
public
DataFlowGraphPass
{
public:
FluidToDataFlowGraphPass
();
bool
Initialize
()
override
;
bool
Initialize
(
const
framework
::
proto
::
ProgramDesc
&
desc
)
override
;
FluidToDataFlowGraphPass
()
=
default
;
bool
Initialize
(
Argument
*
argument
)
override
;
bool
Finalize
()
override
;
void
Run
(
DataFlowGraph
*
graph
)
override
;
std
::
string
repr
()
const
override
{
return
"fluid-to-data-flow-graph"
;
}
std
::
string
description
()
const
override
{
return
"transform a fluid ProgramDesc to a data flow graph."
;
}
Pass
*
CreatePrinterPass
(
std
::
ostream
&
os
,
const
std
::
string
&
banner
)
const
override
;
...
...
paddle/fluid/inference/analysis/fluid_to_data_flow_graph_pass_tester.cc
浏览文件 @
f1f8327c
...
...
@@ -23,11 +23,11 @@ namespace analysis {
TEST_F
(
DFG_Tester
,
Init
)
{
FluidToDataFlowGraphPass
pass
;
pass
.
Initialize
();
pass
.
Initialize
(
desc
);
pass
.
Initialize
(
&
argument
);
DataFlowGraph
graph
;
pass
.
Run
(
&
graph
);
ASSERT_GT
(
graph
.
nodes
.
size
(),
0
);
// Analysis is sensitive to ProgramDesc, careful to change the original model.
ASSERT_EQ
(
graph
.
nodes
.
size
(),
37
);
pass
.
Finalize
();
LOG
(
INFO
)
<<
'\n'
<<
graph
.
DotString
();
}
...
...
paddle/fluid/inference/analysis/helper.h
浏览文件 @
f1f8327c
...
...
@@ -62,6 +62,7 @@ struct DataTypeNamer {
SET_TYPE
(
int
);
SET_TYPE
(
bool
);
SET_TYPE
(
float
);
SET_TYPE
(
void
*
);
}
std
::
unordered_map
<
decltype
(
typeid
(
int
).
hash_code
()),
// NOLINT
...
...
paddle/fluid/inference/analysis/node.cc
浏览文件 @
f1f8327c
...
...
@@ -40,6 +40,9 @@ Node *NodeMap::Create(Node::Type type) {
case
Node
::
Type
::
kValue
:
nodes_
.
emplace_back
(
new
Value
);
break
;
case
Node
::
Type
::
kFunctionBlock
:
nodes_
.
emplace_back
(
new
FunctionBlock
);
break
;
default:
PADDLE_THROW
(
"Not supported node type."
);
}
...
...
paddle/fluid/inference/analysis/node.h
浏览文件 @
f1f8327c
...
...
@@ -71,12 +71,17 @@ class Node {
// Get an additional attribute and convert it to T data type. NOTE this will
// silently create a new attribute if not exists.
Attr
&
attr
(
const
std
::
string
&
name
)
{
return
attrs_
[
name
];
}
Attr
&
attr
(
const
std
::
string
&
name
)
const
{
return
attrs_
[
name
];
}
int
id
()
const
{
return
id_
;
}
bool
deleted
()
const
{
return
deleted_
;
}
// The Protobuf description is set/get with a void* to decouple Node interface
// from a specific kind of Protobuf message.
void
SetPbDesc
(
void
*
pb
)
{
attr
(
"pb_desc"
).
Pointer
()
=
pb
;
}
void
*
pb_desc
()
const
{
return
attr
(
"pb_desc"
).
Pointer
();
}
void
SetDeleted
()
{
deleted_
=
true
;
}
bool
deleted
()
const
{
return
deleted_
;
}
void
SetName
(
const
std
::
string
&
name
)
{
name_
=
name
;
}
const
std
::
string
&
name
()
const
{
return
name_
;
}
...
...
@@ -84,29 +89,25 @@ class Node {
void
SetType
(
Type
type
)
{
type_
=
type
;
}
Type
type
()
const
{
return
type_
;
}
void
*
extra_info
()
const
{
return
extra_info_
;
}
void
SetExtraInfo
(
void
*
extra_info
)
{
extra_info_
=
extra_info
;
}
// Input links.
std
::
vector
<
Node
*>
inlinks
;
// Output links.
std
::
vector
<
Node
*>
outlinks
;
// A helper class to maintain the status from Pass.
// TODO(superjomn) add a checker here to ensure the T is primary.
struct
Attr
{
// NOTE T should be a primary type or a struct combined by several primary
// types.
// NOTE the STL containers should not use here.
// Some usages
// Attr attr;
// T data;
// attr.data.assign((char*)data, sizeof(data));
// Attr attr;
// attr.Bool() = true;
bool
&
Bool
()
{
return
As
<
bool
>
();
}
float
&
Float
()
{
return
As
<
float
>
();
}
int32_t
&
Int32
()
{
return
As
<
int32_t
>
();
}
int64_t
&
Int64
()
{
return
As
<
int64_t
>
();
}
void
*&
Pointer
()
{
return
As
<
void
*>
();
}
private:
template
<
typename
T
>
...
...
@@ -130,6 +131,7 @@ class Node {
size_t
type_hash_
{
std
::
numeric_limits
<
size_t
>::
max
()};
};
// Type checks.
bool
IsFunction
()
const
{
return
type_
==
Node
::
Type
::
kFunction
;
}
bool
IsValue
()
const
{
return
type_
==
Node
::
Type
::
kValue
;
}
bool
IsFunctionBlock
()
const
{
return
type_
==
Node
::
Type
::
kFunctionBlock
;
}
...
...
@@ -148,9 +150,6 @@ class Node {
Type
type_
{
Type
::
kNone
};
// Mark this node is deleted by some pass.
bool
deleted_
{
false
};
void
*
extra_info_
;
mutable
std
::
unordered_map
<
std
::
string
,
Attr
>
attrs_
;
};
...
...
paddle/fluid/inference/analysis/pass.h
浏览文件 @
f1f8327c
...
...
@@ -19,6 +19,7 @@ limitations under the License. */
#include <string>
#include "paddle/fluid/framework/framework.pb.h"
#include "paddle/fluid/inference/analysis/argument.h"
#include "paddle/fluid/inference/analysis/data_flow_graph.h"
#include "paddle/fluid/inference/analysis/helper.h"
#include "paddle/fluid/inference/analysis/node.h"
...
...
@@ -30,19 +31,24 @@ namespace analysis {
class
Pass
{
public:
Pass
()
=
default
;
virtual
~
Pass
()
{}
virtual
~
Pass
()
=
default
;
// Virtual method overridden by subclasses to do only necessary initialization
// before any pass is run.
virtual
bool
Initialize
()
{
return
false
;
}
//
virtual bool Initialize() { return false; }
// There is some passes such as FlowToDataFlowGraphPass that needs a
// ProgramDesc. Here use the native ProgramDesc ProtoBuf message, so that it
// only couple with the proto file.
virtual
bool
Initialize
(
const
framework
::
proto
::
ProgramDesc
&
desc
)
{
return
false
;
}
// virtual bool Initialize(const framework::proto::ProgramDesc &desc) { return
// false; }
// There are some Passes such as DataFlowGraphToFluidPass that will output a
// ProgramDesc.
virtual
bool
Initialize
(
framework
::
proto
::
ProgramDesc
*
desc
)
{
return
false
;
}
// virtual bool Initialize(framework::proto::ProgramDesc *desc) { return
// false; }
// Mutable Pass.
virtual
bool
Initialize
(
Argument
*
argument
)
{
return
false
;
}
// Readonly Pass.
virtual
bool
Initialize
(
const
Argument
&
argument
)
{
return
false
;
}
// Virtual method overriden by subclasses to do any necessary clean up after
// all passes have run.
...
...
@@ -50,7 +56,9 @@ class Pass {
// Get a Pass appropriate to print the Node this pass operates on.
virtual
Pass
*
CreatePrinterPass
(
std
::
ostream
&
os
,
const
std
::
string
&
banner
)
const
=
0
;
const
std
::
string
&
banner
)
const
{
return
nullptr
;
}
// Run on a single Node.
virtual
void
Run
(
Node
*
x
)
{
LOG
(
FATAL
)
<<
"not valid"
;
}
...
...
@@ -60,6 +68,11 @@ class Pass {
virtual
void
Run
(
FunctionBlock
*
x
)
{
LOG
(
FATAL
)
<<
"not valid"
;
}
// Run on a single DataFlowGraph.
virtual
void
Run
(
DataFlowGraph
*
x
)
{
LOG
(
FATAL
)
<<
"not valid"
;
}
// Human-readable short representation.
virtual
std
::
string
repr
()
const
=
0
;
// Human-readable long description.
virtual
std
::
string
description
()
const
=
0
;
};
// NodePass process on any Node types.
...
...
paddle/fluid/inference/analysis/pass_manager.cc
0 → 100644
浏览文件 @
f1f8327c
/* Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "paddle/fluid/inference/analysis/pass_manager.h"
#include "paddle/fluid/inference/analysis/fluid_to_data_flow_graph_pass.h"
namespace
paddle
{
namespace
inference
{
namespace
analysis
{
void
DfgPassManager
::
RunAll
()
{
PADDLE_ENFORCE
(
argument_
);
for
(
auto
&
pass
:
data_
)
{
VLOG
(
4
)
<<
"Running pass ["
<<
pass
->
repr
()
<<
"]"
;
pass
->
Run
(
argument_
->
main_dfg
.
get
());
}
}
void
NodePassManager
::
RunAll
()
{
PADDLE_ENFORCE
(
argument_
);
PADDLE_ENFORCE
(
argument_
->
main_dfg
.
get
());
auto
trait
=
GraphTraits
<
DataFlowGraph
>
(
argument_
->
main_dfg
.
get
()).
nodes_in_DFS
();
for
(
auto
&
node
:
trait
)
{
for
(
auto
&
pass
:
data_
)
{
pass
->
Run
(
&
node
);
}
}
}
}
// namespace analysis
}
// namespace inference
}
// namespace paddle
paddle/fluid/inference/analysis/pass_manager.h
0 → 100644
浏览文件 @
f1f8327c
/* Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
/*
* This file defines the logic of pass management. The analysis for inference is
* a pipeline of Passes, a PassManager is a agency that helps to manage the
* executation of the Passes.
*
* There are two modes of Passes, the first one is called NodePass and takes
* an Node as input and output; the second one is called DFGPass and takes a
* DFG(Data Flow Graph) as input and output. It is hard to put all the passes in
* the same pipeline, there are two kinds of PassManagers, both takes a DFG as
* input and output a DFG, but the Passes inside are different:
*
* 1. NodePassManager: the passes inside are all NodePasses, it can have
* different graph trivial algorithm, for example, DFS_NodePassManager will
* trigger the passes in depth first order;
* 2. DfgPassManager: the passes inside are all DfgPasses.
*/
#pragma once
#include <string>
#include "paddle/fluid/framework/program_desc.h"
#include "paddle/fluid/inference/analysis/pass.h"
namespace
paddle
{
namespace
inference
{
namespace
analysis
{
/*
* PassManager is the base class for all pass managers, a pass manager has
* several Pass-es registered, and execute them in the linear order.
*/
class
PassManager
:
public
OrderedRegistry
<
Pass
>
{
public:
PassManager
()
=
default
;
// Call all the passes' Initialize methods. The desc and data_flow_graph are
// globally shared, so pass them as the arguemnts for all the pass managers.
virtual
bool
Initialize
(
const
Argument
&
argument
)
{
return
false
;
}
virtual
bool
Initialize
(
Argument
*
argument
)
{
argument_
=
argument
;
for
(
auto
&
pass
:
data_
)
{
LOG
(
INFO
)
<<
"Initializing pass "
<<
pass
->
repr
();
if
(
!
pass
->
Initialize
(
argument
))
{
LOG
(
ERROR
)
<<
"Failed to initialize pass ["
<<
pass
->
repr
()
<<
"]"
;
return
false
;
}
}
return
true
;
}
// Call all the passes' Finalize methods.
virtual
bool
Finalize
()
{
for
(
auto
&
pass
:
data_
)
{
if
(
!
pass
->
Finalize
())
{
LOG
(
ERROR
)
<<
"Failed to finalize pass ["
<<
pass
->
repr
()
<<
"]"
;
return
false
;
}
}
return
true
;
}
// Run all the passes.
virtual
void
RunAll
()
=
0
;
// Short identifier.
virtual
std
::
string
repr
()
const
=
0
;
// Long description.
virtual
std
::
string
description
()
const
=
0
;
virtual
~
PassManager
()
=
default
;
protected:
Argument
*
argument_
{
nullptr
};
};
/*
* A pass manager that process a DFG.
*/
class
DfgPassManager
:
public
PassManager
{
public:
DfgPassManager
()
=
default
;
void
RunAll
()
override
;
virtual
~
DfgPassManager
()
=
default
;
};
/*
* A pass manager that process a Node each time.
*/
class
NodePassManager
:
public
PassManager
{
public:
NodePassManager
()
=
default
;
void
RunAll
()
override
;
virtual
~
NodePassManager
()
=
default
;
};
}
// namespace analysis
}
// namespace inference
}
// namespace paddle
paddle/fluid/inference/analysis/pass_manager_tester.cc
0 → 100644
浏览文件 @
f1f8327c
/* Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "paddle/fluid/inference/analysis/pass_manager.h"
#include "paddle/fluid/inference/analysis/data_flow_graph_to_fluid_pass.h"
#include "paddle/fluid/inference/analysis/dfg_graphviz_draw_pass.h"
#include "paddle/fluid/inference/analysis/fluid_to_data_flow_graph_pass.h"
#include "paddle/fluid/inference/analysis/ut_helper.h"
#include <gtest/gtest.h>
namespace
paddle
{
namespace
inference
{
namespace
analysis
{
class
TestDfgPassManager
final
:
public
DfgPassManager
{
public:
TestDfgPassManager
()
=
default
;
virtual
~
TestDfgPassManager
()
=
default
;
// Short identifier.
std
::
string
repr
()
const
override
{
return
"test-pass-manager"
;
}
// Long description.
std
::
string
description
()
const
override
{
return
"test doc"
;
}
};
class
TestNodePassManager
final
:
public
NodePassManager
{
public:
virtual
~
TestNodePassManager
()
=
default
;
std
::
string
repr
()
const
override
{
return
"test-node-pass-manager"
;
}
std
::
string
description
()
const
override
{
return
"test doc"
;
}
};
class
TestNodePass
final
:
public
NodePass
{
public:
virtual
~
TestNodePass
()
=
default
;
bool
Initialize
(
Argument
*
argument
)
override
{
return
true
;
}
void
Run
(
Node
*
node
)
override
{
LOG
(
INFO
)
<<
"- Processing node "
<<
node
->
repr
();
}
std
::
string
repr
()
const
override
{
return
"test-node"
;
}
std
::
string
description
()
const
override
{
return
"some doc"
;
}
};
TEST_F
(
DFG_Tester
,
DFG_pass_manager
)
{
TestDfgPassManager
manager
;
DFG_GraphvizDrawPass
::
Config
config
(
"./"
,
"dfg.dot"
);
manager
.
Register
(
"fluid-to-flow-graph"
,
new
FluidToDataFlowGraphPass
);
manager
.
Register
(
"graphviz"
,
new
DFG_GraphvizDrawPass
(
config
));
manager
.
Register
(
"dfg-to-fluid"
,
new
DataFlowGraphToFluidPass
);
ASSERT_TRUE
(
manager
.
Initialize
(
&
argument
));
manager
.
RunAll
();
}
TEST_F
(
DFG_Tester
,
Node_pass_manager
)
{
// Pre-process: initialize the DFG with the ProgramDesc first.
FluidToDataFlowGraphPass
pass0
;
pass0
.
Initialize
(
&
argument
);
pass0
.
Run
(
argument
.
main_dfg
.
get
());
TestNodePassManager
manager
;
manager
.
Register
(
"test-node-pass"
,
new
TestNodePass
);
ASSERT_TRUE
(
manager
.
Initialize
(
&
argument
));
manager
.
RunAll
();
}
}
// namespace analysis
}
// namespace inference
}
// namespace paddle
paddle/fluid/inference/analysis/subgraph_splitter_tester.cc
浏览文件 @
f1f8327c
...
...
@@ -19,22 +19,23 @@ namespace paddle {
namespace
inference
{
namespace
analysis
{
SubGraphSplitter
::
NodeInsideSubgraphTeller
teller
=
[](
const
Node
*
node
)
{
if
(
node
->
type
()
!=
Node
::
Type
::
kFunction
)
return
false
;
const
auto
*
func
=
static_cast
<
const
Function
*>
(
node
);
if
(
func
->
func_type
()
==
"elementwise_add"
||
func
->
func_type
()
==
"relu"
||
func
->
func_type
()
==
"conv2d"
||
func
->
func_type
()
==
"mul"
||
func
->
func_type
()
==
"sigmoid"
||
func
->
func_type
()
==
"softmax"
)
{
LOG
(
INFO
)
<<
"sub-graph marked "
<<
node
->
repr
();
return
true
;
}
return
false
;
};
TEST_F
(
DFG_Tester
,
Split
)
{
auto
desc
=
LoadProgramDesc
();
auto
dfg
=
ProgramDescToDFG
(
desc
);
LOG
(
INFO
)
<<
"spliter
\n
"
<<
dfg
.
DotString
();
SubGraphSplitter
::
NodeInsideSubgraphTeller
teller
=
[](
const
Node
*
node
)
{
if
(
node
->
type
()
!=
Node
::
Type
::
kFunction
)
return
false
;
const
auto
*
func
=
static_cast
<
const
Function
*>
(
node
);
if
(
func
->
func_type
()
==
"elementwise_add"
||
func
->
func_type
()
==
"relu"
||
func
->
func_type
()
==
"conv2d"
||
func
->
func_type
()
==
"mul"
||
func
->
func_type
()
==
"sigmoid"
||
func
->
func_type
()
==
"softmax"
)
{
LOG
(
INFO
)
<<
"sub-graph marked "
<<
node
->
repr
();
return
true
;
}
return
false
;
};
ASSERT_GT
(
dfg
.
nodes
.
size
(),
5UL
);
auto
subgraphs
=
SubGraphSplitter
(
&
dfg
,
teller
)();
...
...
@@ -62,6 +63,28 @@ TEST_F(DFG_Tester, Split) {
ASSERT_EQ
(
subgraphs
.
back
().
size
(),
6UL
);
}
TEST_F
(
DFG_Tester
,
Fuse
)
{
auto
desc
=
LoadProgramDesc
();
auto
dfg
=
ProgramDescToDFG
(
desc
);
size_t
count0
=
dfg
.
nodes
.
size
();
SubGraphFuse
fuse
(
&
dfg
,
teller
);
fuse
();
int
count1
=
0
;
for
(
auto
&
node
:
dfg
.
nodes
.
nodes
())
{
if
(
node
->
deleted
())
{
LOG
(
INFO
)
<<
"deleted "
<<
node
->
repr
();
}
count1
+=
node
->
deleted
();
}
// At least one nodes should be deleted.
ASSERT_EQ
(
dfg
.
nodes
.
size
(),
count0
+
1
);
// added a new FunctionBlock
ASSERT_EQ
(
6UL
,
count1
);
}
}
// namespace analysis
}
// namespace inference
}
// namespace paddle
paddle/
contrib/tape/test_tape
.cc
→
paddle/
fluid/inference/analysis/tensorrt_subgraph_pass
.cc
浏览文件 @
f1f8327c
// Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
//
Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
...
...
@@ -12,50 +12,22 @@
// See the License for the specific language governing permissions and
// limitations under the License.
#include "
gtest/gtest
.h"
#include "paddle/
contrib/tape/function
.h"
#include "
paddle/fluid/inference/analysis/tensorrt_subgraph_pass
.h"
#include "paddle/
fluid/inference/analysis/subgraph_splitter
.h"
using
namespace
paddle
::
tape
;
namespace
paddle
{
namespace
inference
{
namespace
analysis
{
TEST
(
Tape
,
TestMLP
)
{
LOG
(
INFO
)
<<
"TestMLP"
;
Linear
linear1
(
3
,
3
,
"relu"
);
Linear
linear2
(
3
,
3
,
"relu"
);
Mean
mean
;
TensorRTSubGraphPass
::
TensorRTSubGraphPass
(
const
TensorRTSubGraphPass
::
NodeInsideSubgraphTeller
&
teller
)
:
node_inside_subgraph_teller_
(
teller
)
{}
SGD
sgd
(
0.001
);
std
::
string
initializer
=
"fill_constant"
;
paddle
::
framework
::
AttributeMap
attrs
;
attrs
[
"dtype"
]
=
paddle
::
framework
::
proto
::
VarType
::
Type
::
VarType_Type_FP32
;
attrs
[
"shape"
]
=
std
::
vector
<
int
>
{
3
,
3
};
attrs
[
"value"
]
=
1.0
f
;
Fill
filler
(
initializer
,
attrs
);
for
(
int
i
=
0
;
i
<
2
;
++
i
)
{
reset_global_tape
();
VariableHandle
input
(
new
Variable
(
"input"
));
filler
(
input
);
auto
loss
=
mean
(
linear2
(
linear1
(
input
)));
get_global_tape
().
Backward
(
loss
);
for
(
auto
w
:
linear1
.
Params
())
{
sgd
(
w
);
}
for
(
auto
w
:
linear2
.
Params
())
{
sgd
(
w
);
}
}
void
TensorRTSubGraphPass
::
Run
(
DataFlowGraph
*
graph
)
{
SubGraphFuse
(
graph
,
node_inside_subgraph_teller_
);
}
int
main
(
int
argc
,
char
**
argv
)
{
std
::
vector
<
paddle
::
platform
::
Place
>
places
;
places
.
emplace_back
(
paddle
::
platform
::
CPUPlace
());
paddle
::
platform
::
DeviceContextPool
::
Init
(
places
);
}
// analysis
}
// inference
testing
::
InitGoogleTest
(
&
argc
,
argv
);
return
RUN_ALL_TESTS
();
}
}
// paddle
paddle/fluid/inference/analysis/tensorrt_subgraph_pass.h
0 → 100644
浏览文件 @
f1f8327c
/* Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#pragma once
#include "paddle/fluid/inference/analysis/node.h"
#include "paddle/fluid/inference/analysis/pass.h"
#include "paddle/fluid/inference/analysis/subgraph_splitter.h"
namespace
paddle
{
namespace
inference
{
namespace
analysis
{
/*
* Parse the graph and replace TensorRT supported nodes with SubGraphNode
*/
class
TensorRTSubGraphPass
:
public
DataFlowGraphPass
{
public:
// Tell whether to transform a sub-graph into TensorRT.
using
NodeInsideSubgraphTeller
=
SubGraphFuse
::
NodeInsideSubgraphTeller
;
TensorRTSubGraphPass
(
const
NodeInsideSubgraphTeller
&
teller
);
bool
Initialize
(
Argument
*
argument
)
override
{
return
true
;
}
// This class get a sub-graph as input and determine whether to transform this
// sub-graph into TensorRT.
void
Run
(
DataFlowGraph
*
graph
)
override
;
private:
NodeInsideSubgraphTeller
node_inside_subgraph_teller_
;
};
}
// namespace analysis
}
// namespace inference
}
// paddle
paddle/fluid/inference/analysis/tensorrt_subgraph_pass_tester.cc
0 → 100644
浏览文件 @
f1f8327c
/* Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
#include "paddle/fluid/inference/analysis/tensorrt_subgraph_pass.h"
#include <gflags/gflags.h>
#include <gtest/gtest.h>
#include "paddle/fluid/inference/analysis/dfg_graphviz_draw_pass.h"
#include "paddle/fluid/inference/analysis/ut_helper.h"
namespace
paddle
{
namespace
inference
{
namespace
analysis
{
DEFINE_string
(
model_dir
,
""
,
"inference test model dir"
);
TEST
(
TensorRTSubGraph
,
single_pass
)
{
auto
desc
=
LoadProgramDesc
();
auto
dfg
=
ProgramDescToDFG
(
desc
);
SubGraphSplitter
::
NodeInsideSubgraphTeller
teller
=
[](
const
Node
*
node
)
{
if
(
node
->
type
()
!=
Node
::
Type
::
kFunction
)
return
false
;
const
auto
*
func
=
static_cast
<
const
Function
*>
(
node
);
if
(
func
->
func_type
()
==
"elementwise_add"
||
func
->
func_type
()
==
"relu"
||
func
->
func_type
()
==
"conv2d"
||
func
->
func_type
()
==
"mul"
||
func
->
func_type
()
==
"sigmoid"
||
func
->
func_type
()
==
"softmax"
)
{
LOG
(
INFO
)
<<
"sub-graph marked "
<<
node
->
repr
();
return
true
;
}
return
false
;
};
DFG_GraphvizDrawPass
::
Config
config
{
"./"
,
"test"
};
DFG_GraphvizDrawPass
dfg_pass
(
config
);
dfg_pass
.
Initialize
();
DFG_GraphvizDrawPass
dfg_pass1
(
config
);
dfg_pass1
.
Initialize
();
dfg_pass
.
Run
(
&
dfg
);
TensorRTSubGraphPass
trt_pass
(
std
::
move
(
teller
));
trt_pass
.
Initialize
();
trt_pass
.
Run
(
&
dfg
);
dfg_pass1
.
Run
(
&
dfg
);
// Check the TRT op's block desc
for
(
auto
node
:
dfg
.
nodes
.
nodes
())
{
if
(
node
->
IsFunctionBlock
())
{
}
}
}
TEST
(
TensorRTSubGraph
,
pass_manager
)
{}
}
// namespace analysis
}
// namespace inference
}
// namespace paddle
paddle/fluid/inference/analysis/ut_helper.h
浏览文件 @
f1f8327c
...
...
@@ -15,33 +15,46 @@ limitations under the License. */
#pragma once
#include <gflags/gflags.h>
#include <gtest/gtest.h>
#include <fstream>
#include <string>
#include "paddle/fluid/framework/executor.h"
#include "paddle/fluid/inference/analysis/data_flow_graph.h"
#include "paddle/fluid/inference/analysis/fluid_to_data_flow_graph_pass.h"
#include "paddle/fluid/inference/analysis/ut_helper.h"
#include "paddle/fluid/inference/io.h"
namespace
paddle
{
namespace
inference
{
// Read ProgramDesc from a __model__ file, defined in io.cc
extern
void
ReadBinaryFile
(
const
std
::
string
&
filename
,
std
::
string
*
contents
);
namespace
analysis
{
DEFINE_string
(
inference_model_dir
,
""
,
"inference test model dir"
);
static
framework
::
proto
::
ProgramDesc
LoadProgramDesc
(
const
std
::
string
&
model_dir
=
FLAGS_inference_model_dir
)
{
paddle
::
platform
::
CPUPlace
place
;
paddle
::
framework
::
Executor
executor
(
place
);
paddle
::
framework
::
Scope
scope
;
auto
program
=
Load
(
&
executor
,
&
scope
,
model_dir
);
return
*
program
->
Proto
();
std
::
string
msg
;
std
::
string
net_file
=
FLAGS_inference_model_dir
+
"/__model__"
;
std
::
ifstream
fin
(
net_file
,
std
::
ios
::
in
|
std
::
ios
::
binary
);
PADDLE_ENFORCE
(
static_cast
<
bool
>
(
fin
),
"Cannot open file %s"
,
net_file
);
fin
.
seekg
(
0
,
std
::
ios
::
end
);
msg
.
resize
(
fin
.
tellg
());
fin
.
seekg
(
0
,
std
::
ios
::
beg
);
fin
.
read
(
&
(
msg
.
at
(
0
)),
msg
.
size
());
fin
.
close
();
framework
::
proto
::
ProgramDesc
program_desc
;
program_desc
.
ParseFromString
(
msg
);
return
program_desc
;
}
static
DataFlowGraph
ProgramDescToDFG
(
const
framework
::
proto
::
ProgramDesc
&
desc
)
{
DataFlowGraph
graph
;
FluidToDataFlowGraphPass
pass
;
pass
.
Initialize
(
desc
);
Argument
argument
;
argument
.
origin_program_desc
.
reset
(
new
framework
::
proto
::
ProgramDesc
(
desc
));
pass
.
Initialize
(
&
argument
);
pass
.
Run
(
&
graph
);
pass
.
Finalize
();
return
graph
;
...
...
@@ -49,9 +62,12 @@ static DataFlowGraph ProgramDescToDFG(
class
DFG_Tester
:
public
::
testing
::
Test
{
protected:
void
SetUp
()
override
{
desc
=
LoadProgramDesc
(
FLAGS_inference_model_dir
);
}
void
SetUp
()
override
{
auto
desc
=
LoadProgramDesc
(
FLAGS_inference_model_dir
);
argument
.
origin_program_desc
.
reset
(
new
framework
::
proto
::
ProgramDesc
(
desc
));
}
framework
::
proto
::
ProgramDesc
desc
;
Argument
argument
;
};
}
// namespace analysis
...
...
paddle/fluid/memory/detail/system_allocator.cc
浏览文件 @
f1f8327c
...
...
@@ -43,14 +43,16 @@ void* CPUAllocator::Alloc(size_t* index, size_t size) {
*
index
=
0
;
// unlock memory
void
*
p
;
void
*
p
=
nullptr
;
#ifdef PADDLE_WITH_MKLDNN
// refer to https://github.com/01org/mkl-dnn/blob/master/include/mkldnn.hpp
// memory alignment
PADDLE_ENFORCE_EQ
(
posix_memalign
(
&
p
,
4096ul
,
size
),
0
);
PADDLE_ENFORCE_EQ
(
posix_memalign
(
&
p
,
4096ul
,
size
),
0
,
"Alloc %ld error!"
,
size
);
#else
PADDLE_ENFORCE_EQ
(
posix_memalign
(
&
p
,
32ul
,
size
),
0
);
PADDLE_ENFORCE_EQ
(
posix_memalign
(
&
p
,
32ul
,
size
),
0
,
"Alloc %ld error!"
,
size
);
#endif
PADDLE_ENFORCE
(
p
,
"Fail to allocate CPU memory: size = %d ."
,
size
);
...
...
paddle/fluid/operators/activation_mkldnn_op.cc
浏览文件 @
f1f8327c
...
...
@@ -12,16 +12,20 @@
See the License for the specific language governing permissions and
limitations under the License. */
#include "mkldnn.hpp"
#include "paddle/fluid/operators/activation_op.h"
#include "paddle/fluid/operators/mkldnn_activation_op.h"
#include "paddle/fluid/platform/mkldnn_helper.h"
namespace
paddle
{
namespace
operators
{
using
paddle
::
framework
::
Tensor
;
using
paddle
::
platform
::
MKLDNNDeviceContext
;
using
framework
::
DataLayout
;
using
framework
::
Tensor
;
using
mkldnn
::
memory
;
using
mkldnn
::
primitive
;
using
mkldnn
::
stream
;
using
platform
::
GetMKLDNNFormat
;
using
platform
::
MKLDNNDeviceContext
;
using
platform
::
to_void_cast
;
namespace
{
std
::
string
gethash
(
const
mkldnn
::
memory
::
dims
&
operand_dims
,
...
...
@@ -35,188 +39,260 @@ std::string gethash(const mkldnn::memory::dims &operand_dims,
};
return
dim2str
(
operand_dims
)
+
std
::
to_string
(
algorithm
);
}
}
// namespace
template
<
typename
Functor
>
class
MKLDNNActivationKernel
:
public
framework
::
OpKernel
<
typename
Functor
::
ELEMENT_TYPE
>
{
public:
void
Compute
(
const
framework
::
ExecutionContext
&
ctx
)
const
override
{
const
auto
*
x
=
ctx
.
Input
<
Tensor
>
(
"X"
);
PADDLE_ENFORCE
(
x
->
layout
()
==
DataLayout
::
kMKLDNN
&&
x
->
format
()
!=
memory
::
format
::
format_undef
,
"Wrong layout/format set for Input x tensor"
);
Functor
functor
;
auto
attrs
=
functor
.
GetAttrs
();
for
(
auto
&
attr
:
attrs
)
{
*
attr
.
second
=
ctx
.
Attr
<
float
>
(
attr
.
first
);
}
functor
(
ctx
);
}
};
template
<
typename
T
,
typename
ExecContext
>
void
eltwise_forward
(
const
ExecContext
&
ctx
,
mkldnn
::
algorithm
algorithm
,
const
T
alpha
=
0
,
const
T
beta
=
0
)
{
template
<
typename
Functor
>
class
MKLDNNActivationGradKernel
:
public
framework
::
OpKernel
<
typename
Functor
::
ELEMENT_TYPE
>
{
public:
void
Compute
(
const
framework
::
ExecutionContext
&
ctx
)
const
override
{
const
auto
*
diff_y
=
ctx
.
Input
<
Tensor
>
(
framework
::
GradVarName
(
"Out"
));
PADDLE_ENFORCE
(
diff_y
->
layout
()
==
DataLayout
::
kMKLDNN
&&
diff_y
->
format
()
!=
memory
::
format
::
format_undef
,
"Wrong layout/format set for Input OutGrad tensor"
);
Functor
functor
;
auto
attrs
=
functor
.
GetAttrs
();
for
(
auto
&
attr
:
attrs
)
{
*
attr
.
second
=
ctx
.
Attr
<
float
>
(
attr
.
first
);
}
functor
(
ctx
);
}
};
template
<
typename
T
>
void
eltwise_forward
(
const
framework
::
ExecutionContext
&
ctx
,
mkldnn
::
algorithm
algorithm
,
const
T
alpha
=
0
,
const
T
beta
=
0
)
{
PADDLE_ENFORCE
(
paddle
::
platform
::
is_cpu_place
(
ctx
.
GetPlace
()),
"It must use CPUPlace."
);
auto
&
dev_ctx
=
ctx
.
template
device_context
<
MKLDNNDeviceContext
>();
const
auto
&
mkldnn_engine
=
dev_ctx
.
GetEngine
();
// get buffers
const
auto
*
src
=
ctx
.
template
Input
<
Tensor
>(
"X"
);
const
auto
*
src_data
=
src
->
template
data
<
T
>();
const
auto
*
x
=
ctx
.
Input
<
Tensor
>
(
"X"
);
auto
*
y
=
ctx
.
Output
<
Tensor
>
(
"Out"
);
auto
*
dst
=
ctx
.
template
Output
<
Tensor
>(
"Out"
);
T
*
dst_data
=
dst
->
template
mutable_data
<
T
>(
ctx
.
GetPlace
());
const
T
*
x_data
=
x
->
data
<
T
>
(
);
T
*
y_data
=
y
->
mutable_data
<
T
>
(
ctx
.
GetPlace
());
// get memory dim
PADDLE_ENFORCE
(
src
->
dims
().
size
()
==
2
||
src
->
dims
().
size
()
==
4
,
PADDLE_ENFORCE
(
x
->
dims
().
size
()
==
2
||
x
->
dims
().
size
()
==
4
,
"Input dim must be with 2 or 4"
);
std
::
vector
<
int
>
src_tz
=
framework
::
vectorize2int
(
src
->
dims
());
std
::
vector
<
int
>
src_tz
=
framework
::
vectorize2int
(
x
->
dims
());
auto
src_format
=
src_tz
.
size
()
==
2
?
mkldnn
::
memory
::
format
::
nc
:
x
->
format
();
const
std
::
string
key
=
gethash
(
src_tz
,
algorithm
);
const
std
::
string
key_src_data
=
key
+
ctx
.
op
().
Output
(
"Out"
)
+
"@eltwise_fwd_src_data"
;
const
std
::
string
key_src_mem
=
key
+
"@eltwise_fwd_src_mem"
;
const
std
::
string
key_dst_mem
=
key
+
"@eltwise_fwd_dst_mem"
;
const
std
::
string
key_fwd
=
key
+
"@eltwise_fwd"
;
const
std
::
string
key_src_layout
=
key
+
ctx
.
op
().
Output
(
"Out"
)
+
"@eltwise_fwd_src_layout"
;
const
std
::
string
key_with_layout
=
key
+
std
::
to_string
(
src_format
);
const
std
::
string
key_src_mem
=
key_with_layout
+
"@eltwise_fwd_src_mem"
;
const
std
::
string
key_dst_mem
=
key_with_layout
+
"@eltwise_fwd_dst_mem"
;
const
std
::
string
key_fwd
=
key_with_layout
+
"@eltwise_fwd"
;
const
std
::
string
key_fwd_pd
=
key_with_layout
+
"@eltwise_fwd_pd"
;
// save input data and layout to be referred in backward path
auto
p_src_data
=
std
::
make_shared
<
const
T
*>
(
x_data
);
dev_ctx
.
SetBlob
(
key_src_data
,
p_src_data
);
auto
p_src_layout
=
std
::
make_shared
<
memory
::
format
>
(
src_format
);
dev_ctx
.
SetBlob
(
key_src_layout
,
p_src_layout
);
auto
p_fwd
=
std
::
static_pointer_cast
<
mkldnn
::
eltwise_forward
>
(
dev_ctx
.
GetBlob
(
key_fwd
));
// save input data to be referred in backward path
auto
p_src_data
=
std
::
make_shared
<
const
T
*>
(
src_data
);
dev_ctx
.
SetBlob
(
key_src_data
,
p_src_data
);
std
::
shared_ptr
<
memory
>
dst_memory
;
if
(
p_fwd
==
nullptr
)
{
// create memory description
auto
data_md
=
src_tz
.
size
()
==
2
?
platform
::
MKLDNNMemDesc
(
src_tz
,
mkldnn
::
memory
::
f32
,
mkldnn
::
memory
::
format
::
nc
)
:
platform
::
MKLDNNMemDesc
(
src_tz
,
mkldnn
::
memory
::
f32
,
mkldnn
::
memory
::
format
::
nchw
);
// create memory primitives
auto
p_src_mem
=
std
::
make_shared
<
mkldnn
::
memory
>
(
mkldnn
::
memory
(
{
data_md
,
mkldnn_engine
},
platform
::
to_void_cast
(
src_data
)));
dev_ctx
.
SetBlob
(
key_src_mem
,
p_src_mem
);
auto
p_dst_mem
=
std
::
make_shared
<
mkldnn
::
memory
>
(
mkldnn
::
memory
(
{
data_md
,
mkldnn_engine
},
platform
::
to_void_cast
(
dst_data
)));
dev_ctx
.
SetBlob
(
key_dst_mem
,
p_dst_mem
);
auto
fwd_desc
=
mkldnn
::
eltwise_forward
::
desc
(
mkldnn
::
prop_kind
::
forward_training
,
algorithm
,
data_md
,
alpha
,
beta
);
auto
p_fwd_pd
=
std
::
make_shared
<
mkldnn
::
eltwise_forward
::
primitive_desc
>
(
fwd_desc
,
mkldnn_engine
);
const
std
::
string
key_fwd_pd
=
key
+
"eltwise_fwd_pd"
;
dev_ctx
.
SetBlob
(
key_fwd_pd
,
p_fwd_pd
);
p_fwd
=
std
::
make_shared
<
mkldnn
::
eltwise_forward
>
(
*
p_fwd_pd
,
*
(
p_src_mem
.
get
()),
*
(
p_dst_mem
.
get
()));
// create mkldnn memory for input X
auto
src_md
=
platform
::
MKLDNNMemDesc
(
src_tz
,
platform
::
MKLDNNGetDataType
<
T
>
(),
src_format
);
auto
src_memory
=
std
::
shared_ptr
<
memory
>
(
new
memory
({
src_md
,
mkldnn_engine
},
to_void_cast
(
x_data
)));
// save src_memory to be referred in backward path
dev_ctx
.
SetBlob
(
key_src_mem
,
src_memory
);
// create primitive descriptor for activation forward and save it
auto
forward_desc
=
mkldnn
::
eltwise_forward
::
desc
(
mkldnn
::
prop_kind
::
forward_training
,
algorithm
,
src_memory
->
get_primitive_desc
().
desc
(),
alpha
,
beta
);
auto
forward_pd
=
std
::
make_shared
<
mkldnn
::
eltwise_forward
::
primitive_desc
>
(
forward_desc
,
mkldnn_engine
);
// save prim desc into global device context to be referred in backward path
dev_ctx
.
SetBlob
(
key_fwd_pd
,
forward_pd
);
// create mkldnn memory for output y
dst_memory
=
std
::
make_shared
<
memory
>
(
forward_pd
->
dst_primitive_desc
(),
y_data
);
dev_ctx
.
SetBlob
(
key_dst_mem
,
dst_memory
);
// create activation primitive
p_fwd
=
std
::
make_shared
<
mkldnn
::
eltwise_forward
>
(
*
forward_pd
,
*
src_memory
,
*
dst_memory
);
dev_ctx
.
SetBlob
(
key_fwd
,
p_fwd
);
}
else
{
// primitives already exist
auto
p_src_mem
=
auto
src_memory
=
std
::
static_pointer_cast
<
mkldnn
::
memory
>
(
dev_ctx
.
GetBlob
(
key_src_mem
));
PADDLE_ENFORCE
(
p_src_mem
!=
nullptr
,
"Fail to find eltwise
p_src_mem
in device context."
);
auto
p_dst_mem
=
PADDLE_ENFORCE
(
src_memory
!=
nullptr
,
"Fail to find eltwise
src_memory
in device context."
);
dst_memory
=
std
::
static_pointer_cast
<
mkldnn
::
memory
>
(
dev_ctx
.
GetBlob
(
key_dst_mem
));
PADDLE_ENFORCE
(
p_dst_mem
!=
nullptr
,
"Fail to find eltwise
p_src_mem
in device context."
);
PADDLE_ENFORCE
(
dst_memory
!=
nullptr
,
"Fail to find eltwise
dst_memory
in device context."
);
p_src_mem
->
set_data_handle
(
platform
::
to_void_reinterpret_cast
(
src
_data
));
p_dst_mem
->
set_data_handle
(
dst
_data
);
src_memory
->
set_data_handle
(
platform
::
to_void_cast
(
x
_data
));
dst_memory
->
set_data_handle
(
y
_data
);
}
// push primitive to stream and wait until it's executed
std
::
vector
<
mkldnn
::
primitive
>
pipeline
=
{
*
(
p_fwd
.
get
())};
mkldnn
::
stream
(
mkldnn
::
stream
::
kind
::
eager
).
submit
(
pipeline
).
wait
();
std
::
vector
<
primitive
>
pipeline
;
pipeline
.
push_back
(
*
p_fwd
);
stream
(
stream
::
kind
::
eager
).
submit
(
pipeline
).
wait
();
y
->
set_layout
(
DataLayout
::
kMKLDNN
);
y
->
set_format
(
GetMKLDNNFormat
(
*
dst_memory
));
}
template
<
typename
T
,
typename
ExecContext
>
void
eltwise_grad
(
const
ExecContext
&
ctx
,
mkldnn
::
algorithm
algorithm
,
const
T
alpha
=
0
,
const
T
beta
=
0
)
{
template
<
typename
T
>
void
eltwise_grad
(
const
framework
::
ExecutionContext
&
ctx
,
mkldnn
::
algorithm
algorithm
,
const
T
alpha
=
0
,
const
T
beta
=
0
)
{
auto
&
dev_ctx
=
ctx
.
template
device_context
<
MKLDNNDeviceContext
>();
const
auto
&
mkldnn_engine
=
dev_ctx
.
GetEngine
();
// get buffers
const
auto
*
out
=
ctx
.
template
Input
<
Tensor
>(
"Out"
);
auto
*
dout
=
ctx
.
template
Input
<
Tensor
>(
framework
::
GradVarName
(
"Out"
));
const
auto
*
diff_dst
=
dout
->
template
data
<
T
>();
const
auto
*
diff_y
=
ctx
.
Input
<
Tensor
>
(
framework
::
GradVarName
(
"Out"
));
auto
*
diff_x
=
ctx
.
Output
<
Tensor
>
(
framework
::
GradVarName
(
"X"
));
auto
*
dx
=
ctx
.
template
Output
<
framework
::
Tensor
>(
framework
::
GradVarName
(
"X"
));
const
T
*
diff_src
=
dx
->
template
mutable_data
<
T
>(
ctx
.
GetPlace
());
const
T
*
diff_y_data
=
diff_y
->
data
<
T
>
();
T
*
diff_x_data
=
diff_x
->
mutable_data
<
T
>
(
ctx
.
GetPlace
());
// get memory dim
std
::
vector
<
int
>
src_tz
=
framework
::
vectorize2int
(
out
->
dims
());
std
::
vector
<
int
>
diff_dst_tz
=
framework
::
vectorize2int
(
diff_y
->
dims
());
const
std
::
string
key
=
gethash
(
src_tz
,
algorithm
);
const
std
::
string
key_diff_src_mem
=
key
+
"@eltwise_diff_src_mem"
;
const
std
::
string
key_diff_dst_mem
=
key
+
"@eltwise_diff_dst_mem"
;
const
std
::
string
key_grad
=
key
+
"@eltwise_grad"
;
auto
diff_y_format
=
diff_dst_tz
.
size
()
==
2
?
mkldnn
::
memory
::
format
::
nc
:
diff_y
->
format
();
const
std
::
string
key
=
gethash
(
diff_dst_tz
,
algorithm
);
const
std
::
string
key_src_data
=
key
+
ctx
.
op
().
Input
(
"Out"
)
+
"@eltwise_fwd_src_data"
;
const
std
::
string
key_src_layout
=
key
+
ctx
.
op
().
Input
(
"Out"
)
+
"@eltwise_fwd_src_layout"
;
const
auto
p_src_layout
=
std
::
static_pointer_cast
<
memory
::
format
>
(
dev_ctx
.
GetBlob
(
key_src_layout
));
const
std
::
string
key_src_mem
=
key
+
std
::
to_string
(
*
p_src_layout
)
+
"@eltwise_fwd_src_mem"
;
const
std
::
string
key_fwd_pd
=
key
+
std
::
to_string
(
*
p_src_layout
)
+
"@eltwise_fwd_pd"
;
const
std
::
string
key_with_layouts
=
key
+
std
::
to_string
(
*
p_src_layout
)
+
"-"
+
std
::
to_string
(
diff_y_format
);
const
std
::
string
key_diff_src_mem
=
key_with_layouts
+
"@eltwise_diff_src_mem"
;
const
std
::
string
key_diff_dst_mem
=
key_with_layouts
+
"@eltwise_diff_dst_mem"
;
const
std
::
string
key_grad
=
key_with_layouts
+
"@eltwise_grad"
;
const
auto
p_src_data
=
std
::
static_pointer_cast
<
T
*>
(
dev_ctx
.
GetBlob
(
key_src_data
));
const
std
::
string
key_src_mem
=
key
+
"@eltwise_fwd_src_mem"
;
auto
p_src_mem
=
auto
src_memory
=
std
::
static_pointer_cast
<
mkldnn
::
memory
>
(
dev_ctx
.
GetBlob
(
key_src_mem
));
p_src_mem
->
set_data_handle
(
*
p_src_data
.
get
());
PADDLE_ENFORCE
(
src_memory
!=
nullptr
,
"Fail to find src_memory in device context"
);
src_memory
->
set_data_handle
(
*
p_src_data
.
get
());
std
::
shared_ptr
<
memory
>
diff_src_memory
;
auto
p_grad
=
std
::
static_pointer_cast
<
mkldnn
::
eltwise_
forward
::
primitive
>
(
auto
p_grad
=
std
::
static_pointer_cast
<
mkldnn
::
eltwise_
backward
>
(
dev_ctx
.
GetBlob
(
key_grad
));
if
(
p_grad
==
nullptr
)
{
// create m
emory description
auto
d
ata_md
=
src_tz
.
size
()
==
2
?
platform
::
MKLDNNMemDesc
(
src_tz
,
mkldnn
::
memory
::
f32
,
mkldnn
::
memory
::
format
::
nc
)
:
platform
::
MKLDNNMemDesc
(
src_tz
,
mkldnn
::
memory
::
f32
,
mkldnn
::
memory
::
format
::
nchw
);
//
create memory primitives
std
::
shared_ptr
<
void
>
p_diff_src_mem
=
std
::
make_shared
<
mkldnn
::
memory
>
(
mkldnn
::
memory
(
{
data_md
,
mkldnn_engine
},
platform
::
to_void_cast
(
diff_src
)
));
dev_ctx
.
SetBlob
(
key_diff_src_mem
,
p_diff_src_mem
);
std
::
shared_ptr
<
void
>
p_diff_dst_mem
=
std
::
make_shared
<
mkldnn
::
memory
>
(
mkldnn
::
memory
(
{
data_md
,
mkldnn_engine
},
platform
::
to_void_cast
(
diff_dst
)));
dev_ctx
.
SetBlob
(
key_diff_dst_mem
,
p_diff_dst_mem
);
auto
bwd_desc
=
mkldnn
::
eltwise_backward
::
desc
(
algorithm
,
data_md
,
data_md
,
alpha
,
beta
);
const
std
::
string
key_fwd_pd
=
key
+
"eltwise_fwd_pd"
;
auto
*
p_fwd_pd
=
static_cast
<
mkldnn
::
eltwise_forward
::
primitive_desc
*>
(
dev_ctx
.
GetBlob
(
key_fwd_pd
).
get
());
auto
eltwise_bwd_prim_desc
=
mkldnn
::
eltwise_backward
::
primitive_desc
(
bwd_desc
,
mkldnn_engine
,
*
p_fwd_pd
);
// create m
kldnn memory for input diff_y
auto
d
iff_dst_md
=
platform
::
MKLDNNMemDesc
(
diff_dst_tz
,
platform
::
MKLDNNGetDataType
<
T
>
(),
diff_y_format
);
auto
diff_dst_memory
=
std
::
shared_ptr
<
memory
>
(
new
memory
({
diff_dst_md
,
mkldnn_engine
},
to_void_cast
(
diff_y_data
)));
dev_ctx
.
SetBlob
(
key_diff_dst_mem
,
diff_dst_memory
);
//
retrieve eltwise primitive desc from device context
auto
forward_pd
=
std
::
static_pointer_cast
<
mkldnn
::
eltwise_forward
::
primitive_desc
>
(
dev_ctx
.
GetBlob
(
key_fwd_pd
));
PADDLE_ENFORCE
(
forward_pd
!=
nullptr
,
"Fail to find eltwise_fwd_pd in device context"
);
// ceate primitive descriptor for activation backward
auto
backward_desc
=
mkldnn
::
eltwise_backward
::
desc
(
algorithm
,
diff_dst_memory
->
get_primitive_desc
().
desc
(),
src_memory
->
get_primitive_desc
().
desc
(),
alpha
,
beta
);
auto
backward_pd
=
mkldnn
::
eltwise_backward
::
primitive_desc
(
backward_desc
,
mkldnn_engine
,
*
forward_pd
);
// create mkldnn memory for output diff_src
diff_src_memory
=
std
::
make_shared
<
memory
>
(
backward_pd
.
diff_src_primitive_desc
(),
diff_x_data
);
dev_ctx
.
SetBlob
(
key_diff_src_mem
,
diff_src_memory
);
// create activation backward primitive
p_grad
=
std
::
make_shared
<
mkldnn
::
eltwise_backward
>
(
eltwise_bwd_prim_desc
,
*
static_cast
<
mkldnn
::
memory
*>
(
p_src_mem
.
get
()),
*
(
static_cast
<
mkldnn
::
memory
*>
(
p_diff_dst_mem
.
get
())),
*
(
static_cast
<
mkldnn
::
memory
*>
(
p_diff_src_mem
.
get
())));
backward_pd
,
*
src_memory
,
*
diff_dst_memory
,
*
diff_src_memory
);
dev_ctx
.
SetBlob
(
key_grad
,
p_grad
);
}
else
{
// primitives already exist
auto
p_diff_src_mem
=
std
::
static_pointer_cast
<
mkldnn
::
memory
>
(
diff_src_memory
=
std
::
static_pointer_cast
<
mkldnn
::
memory
>
(
dev_ctx
.
GetBlob
(
key_diff_src_mem
));
auto
p_diff_dst_mem
=
std
::
static_pointer_cast
<
mkldnn
::
memory
>
(
auto
diff_dst_memory
=
std
::
static_pointer_cast
<
mkldnn
::
memory
>
(
dev_ctx
.
GetBlob
(
key_diff_dst_mem
));
p_diff_src_mem
->
set_data_handle
(
platform
::
to_void_reinterpret_cast
(
diff_
src
));
p_diff_dst_mem
->
set_data_handle
(
platform
::
to_void_reinterpret_cast
(
diff_
dst
));
diff_src_memory
->
set_data_handle
(
platform
::
to_void_reinterpret_cast
(
diff_
x_data
));
diff_dst_memory
->
set_data_handle
(
platform
::
to_void_reinterpret_cast
(
diff_
y_data
));
}
// push primitive to stream and wait until it's executed
std
::
vector
<
mkldnn
::
primitive
>
pipeline
=
{
*
(
p_grad
.
get
())};
mkldnn
::
stream
(
mkldnn
::
stream
::
kind
::
eager
).
submit
(
pipeline
).
wait
();
std
::
vector
<
primitive
>
pipeline
;
pipeline
.
push_back
(
*
p_grad
);
stream
(
stream
::
kind
::
eager
).
submit
(
pipeline
).
wait
();
diff_x
->
set_layout
(
DataLayout
::
kMKLDNN
);
diff_x
->
set_format
(
GetMKLDNNFormat
(
*
diff_src_memory
));
}
}
// anonymous namespace
template
<
typename
T
,
mkldnn
::
algorithm
algorithm
>
struct
MKLDNNActivationFunc
:
public
BaseActivationFunctor
<
T
>
{
template
<
typename
ExecContext
>
void
operator
()(
const
ExecContext
&
ctx
)
const
{
void
operator
()(
const
framework
::
ExecutionContext
&
ctx
)
const
{
eltwise_forward
<
T
>
(
ctx
,
algorithm
);
}
};
template
<
typename
T
,
mkldnn
::
algorithm
algorithm
>
struct
MKLDNNActivationGradFunc
:
public
BaseActivationFunctor
<
T
>
{
template
<
typename
ExecContext
>
void
operator
()(
const
ExecContext
&
ctx
)
const
{
void
operator
()(
const
framework
::
ExecutionContext
&
ctx
)
const
{
eltwise_grad
<
T
>
(
ctx
,
algorithm
);
}
};
...
...
paddle/fluid/operators/activation_op.cc
浏览文件 @
f1f8327c
...
...
@@ -19,18 +19,20 @@ limitations under the License. */
namespace
paddle
{
namespace
operators
{
#define REGISTER_ACTIVATION_OP_MAKER(OP_NAME, OP_COMMENT) \
class OP_NAME##OpMaker \
: public ::paddle::framework::OpProtoAndCheckerMaker { \
public: \
void Make() override { \
AddInput("X", "Input of " #OP_NAME " operator"); \
AddOutput("Out", "Output of " #OP_NAME " operator").Reuse("X"); \
AddAttr<bool>("use_mkldnn", \
"(default false) Only used in mkldnn kernel") \
.SetDefault(false); \
AddComment(OP_COMMENT); \
} \
using
paddle
::
framework
::
Tensor
;
#define REGISTER_ACTIVATION_OP_MAKER(OP_NAME, OP_COMMENT) \
class OP_NAME##OpMaker \
: public ::paddle::framework::OpProtoAndCheckerMaker { \
public: \
void Make() override { \
AddInput("X", "Input of " #OP_NAME " operator"); \
AddOutput("Out", "Output of " #OP_NAME " operator").Reuse("X"); \
AddAttr<bool>("use_mkldnn", \
"(bool, default false) Only used in mkldnn kernel") \
.SetDefault(false); \
AddComment(#OP_COMMENT); \
} \
}
#define REGISTER_ACTIVATION_OP_GRAD_MAKER(OP_NAME, KERNEL_TYPE) \
...
...
@@ -58,7 +60,6 @@ framework::OpKernelType GetKernelType(const framework::ExecutionContext& ctx,
const
framework
::
OperatorWithKernel
&
oper
,
const
std
::
string
&
name
)
{
framework
::
LibraryType
library
{
framework
::
LibraryType
::
kPlain
};
framework
::
DataLayout
layout
=
framework
::
DataLayout
::
kAnyLayout
;
#ifdef PADDLE_WITH_MKLDNN
auto
it
=
oper
.
Attrs
().
find
(
"use_mkldnn"
);
...
...
@@ -82,6 +83,7 @@ class ActivationOp : public framework::OperatorWithKernel {
ctx
->
ShareLoD
(
"X"
,
/*->*/
"Out"
);
}
protected:
framework
::
OpKernelType
GetExpectedKernelType
(
const
framework
::
ExecutionContext
&
ctx
)
const
override
{
return
GetKernelType
(
ctx
,
*
this
,
"X"
);
...
...
@@ -96,6 +98,7 @@ class ActivationOpGrad : public framework::OperatorWithKernel {
ctx
->
SetOutputDim
(
framework
::
GradVarName
(
"X"
),
ctx
->
GetInputDim
(
"Out"
));
}
protected:
framework
::
OpKernelType
GetExpectedKernelType
(
const
framework
::
ExecutionContext
&
ctx
)
const
override
{
return
GetKernelType
(
ctx
,
*
this
,
"Out"
);
...
...
@@ -133,7 +136,7 @@ $out = \max(x, 0)$
__attribute__
((
unused
))
constexpr
char
TanhDoc
[]
=
R"DOC(
Tanh Activation Operator.
$$out = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}$$
$$out = \
\
frac{e^{x} - e^{-x}}{e^{x} + e^{-x}}$$
)DOC"
;
...
...
@@ -443,7 +446,7 @@ class SwishOpMaker : public framework::OpProtoAndCheckerMaker {
AddComment
(
R"DOC(
Swish Activation Operator.
$$out = \frac{x}{1 + e^{- \beta x}}$$
$$out = \
\
frac{x}{1 + e^{- \beta x}}$$
)DOC"
);
}
...
...
paddle/fluid/operators/chunk_eval_op.cc
浏览文件 @
f1f8327c
...
...
@@ -91,32 +91,31 @@ class ChunkEvalOpMaker : public framework::OpProtoAndCheckerMaker {
"(int64_t). The number of chunks both in Inference and Label on the "
"given mini-batch."
);
AddAttr
<
int
>
(
"num_chunk_types"
,
"
(int). The number of chunk type. See below
for details."
);
AddAttr
<
std
::
string
>
(
"chunk_scheme"
,
"(string, default IOB). The labeling scheme indicating
"
"how to encode the chunks. Must be IOB, IOE, IOBES or plain. See below
"
"for details."
)
"
The number of chunk type. See the description
for details."
);
AddAttr
<
std
::
string
>
(
"chunk_scheme"
,
"The labeling scheme indicating "
"how to encode the chunks. Must be IOB, IOE, IOBES or
"
"plain. See the description
"
"for details."
)
.
SetDefault
(
"IOB"
);
AddAttr
<
std
::
vector
<
int
>>
(
"excluded_chunk_types"
,
"
(list<int>)
A list including chunk type ids "
"A list including chunk type ids "
"indicating chunk types that are not counted. "
"See
below
for details."
)
"See
the description
for details."
)
.
SetDefault
(
std
::
vector
<
int
>
{});
AddComment
(
R"DOC(
For some basics of chunking, please refer to
‘Chunking with Support Vector Machines <https://aclanthology.info/pdf/N/N01/N01-1025.pdf>’
.
'Chunking with Support Vector Machines <https://aclanthology.info/pdf/N/N01/N01-1025.pdf>'
.
CheckEvalOp computes the precision, recall, and F1-score of chunk detection,
ChunkEvalOp computes the precision, recall, and F1-score of chunk detection,
and supports IOB, IOE, IOBES and IO (also known as plain) tagging schemes.
Here is a NER example of labeling for these tagging schemes:
Li Ming works at Agricultural Bank of China in Beijing.
IO:
I-PER I-PER O O I-ORG I-ORG I-ORG I-ORG O I-LOC
IOB:
B-PER I-PER O O B-ORG I-ORG I-ORG I-ORG O B-LOC
IOE:
I-PER E-PER O O I-ORG I-ORG I-ORG E-ORG O E-LOC
IOBES:
B-PER E-PER O O I-ORG I-ORG I-ORG E-ORG O S-LOC
Li Ming works at Agricultural Bank of China in Beijing.
IO
I-PER I-PER O O I-ORG I-ORG I-ORG I-ORG O I-LOC
IOB
B-PER I-PER O O B-ORG I-ORG I-ORG I-ORG O B-LOC
IOE
I-PER E-PER O O I-ORG I-ORG I-ORG E-ORG O E-LOC
IOBES
B-PER E-PER O O I-ORG I-ORG I-ORG E-ORG O S-LOC
There are three chunk types(named entity types) including PER(person), ORG(organization)
and LOC(LOCATION), and we can see that the labels have the form <tag type>-<chunk type>.
...
...
@@ -124,31 +123,31 @@ and LOC(LOCATION), and we can see that the labels have the form <tag type>-<chun
Since the calculations actually use label ids rather than labels, extra attention
should be paid when mapping labels to ids to make CheckEvalOp work. The key point
is that the listed equations are satisfied by ids.
tag_type = label % num_tag_type
chunk_type = label / num_tag_type
tag_type = label % num_tag_type
chunk_type = label / num_tag_type
where `num_tag_type` is the num of tag types in the tagging scheme, `num_chunk_type`
is the num of chunk types, and `tag_type` get its value from the following table.
Scheme Begin Inside End Single
plain 0 - - -
IOB 0 1 - -
IOE - 0 1 -
IOBES 0 1 2 3
Scheme Begin Inside End Single
plain 0 - - -
IOB 0 1 - -
IOE - 0 1 -
IOBES 0 1 2 3
Still use NER as example, assuming the tagging scheme is IOB while chunk types are ORG,
PER and LOC. To satisfy the above equations, the label map can be like this:
B-ORG 0
I-ORG 1
B-PER 2
I-PER 3
B-LOC 4
I-LOC 5
O 6
B-ORG 0
I-ORG 1
B-PER 2
I-PER 3
B-LOC 4
I-LOC 5
O 6
It
’
s not hard to verify the equations noting that the num of chunk types
It
'
s not hard to verify the equations noting that the num of chunk types
is 3 and the num of tag types in IOB scheme is 2. For example, the label
id of I-LOC is 5, the tag type id of I-LOC is 1, and the chunk type id of
I-LOC is 2, which consistent with the results from the equations.
...
...
paddle/fluid/operators/clip_by_norm_op.cc
浏览文件 @
f1f8327c
...
...
@@ -54,10 +54,19 @@ be linearly scaled to make the L2 norm of $Out$ equal to $max\_norm$, as
shown in the following formula:
$$
Out = \
frac{max
\_norm * X}{norm(X)},
Out = \
\frac{max\
\_norm * X}{norm(X)},
$$
where $norm(X)$ represents the L2 norm of $X$.
Examples:
.. code-block:: python
data = fluid.layer.data(
name='data', shape=[2, 4, 6], dtype='float32')
reshaped = fluid.layers.clip_by_norm(
x=data, max_norm=0.5)
)DOC"
);
}
};
...
...
paddle/fluid/operators/conv_transpose_op.cc
浏览文件 @
f1f8327c
...
...
@@ -156,7 +156,7 @@ Parameters(strides, paddings) are two elements. These two elements represent hei
and width, respectively.
The input(X) size and output(Out) size may be different.
E
xample:
For an e
xample:
Input:
Input shape: $(N, C_{in}, H_{in}, W_{in})$
Filter shape: $(C_{in}, C_{out}, H_f, W_f)$
...
...
paddle/fluid/operators/cos_sim_op.cc
浏览文件 @
f1f8327c
...
...
@@ -76,9 +76,9 @@ class CosSimOpMaker : public framework::OpProtoAndCheckerMaker {
.
AsIntermediate
();
AddComment
(
R"DOC(
Cosine Similarity Operator.
**Cosine Similarity Operator**
$Out =
X^T * Y / (\sqrt{X^T * X} * \sqrt{Y^T * Y})
$
$Out =
\frac{X^T * Y}{(\sqrt{X^T * X} * \sqrt{Y^T * Y})}
$
The input X and Y must have the same shape, except that the 1st dimension
of input Y could be just 1 (different from input X), which will be
...
...
paddle/fluid/operators/crf_decoding_op.cc
浏览文件 @
f1f8327c
...
...
@@ -53,21 +53,18 @@ sequence of observed tags.
The output of this operator changes according to whether Input(Label) is given:
1. Input(Label) is given:
This happens in training. This operator is used to co-work with the chunk_eval
operator.
When Input(Label) is given, the crf_decoding operator returns a row vector
with shape [N x 1] whose values are fixed to be 0, indicating an incorrect
prediction, or 1 indicating a tag is correctly predicted. Such an output is the
input to chunk_eval operator.
This happens in training. This operator is used to co-work with the chunk_eval
operator.
When Input(Label) is given, the crf_decoding operator returns a row vector
with shape [N x 1] whose values are fixed to be 0, indicating an incorrect
prediction, or 1 indicating a tag is correctly predicted. Such an output is the
input to chunk_eval operator.
2. Input(Label) is not given:
This is the standard decoding process.
This is the standard decoding process.
The crf_decoding operator returns a row vector with shape [N x 1] whose values
range from 0 to maximum tag number - 1
.
Each element indicates an index of a
range from 0 to maximum tag number - 1
,
Each element indicates an index of a
predicted tag.
)DOC"
);
}
...
...
paddle/fluid/operators/detail/grpc_client.cc
浏览文件 @
f1f8327c
...
...
@@ -245,7 +245,7 @@ void GRPCClient::Proceed() {
if
(
c
->
status_
.
ok
())
{
c
->
Process
();
}
else
{
LOG
(
ERROR
)
<<
"var: "
<<
c
->
var_h_
.
String
()
LOG
(
FATAL
)
<<
"var: "
<<
c
->
var_h_
.
String
()
<<
" grpc error:"
<<
c
->
status_
.
error_message
();
}
delete
c
;
...
...
paddle/fluid/operators/detection/iou_similarity_op.cc
浏览文件 @
f1f8327c
...
...
@@ -68,15 +68,16 @@ class IOUSimilarityOpMaker : public framework::OpProtoAndCheckerMaker {
"representing pairwise iou scores."
);
AddComment
(
R"DOC(
IOU Similarity Operator.
**IOU Similarity Operator**
Computes intersection-over-union (IOU) between two box lists.
Box list 'X' should be a LoDTensor and 'Y' is a common Tensor,
boxes in 'Y' are shared by all instance of the batched inputs of X.
Given two boxes A and B, the calculation of IOU is as follows:
Box list 'X' should be a LoDTensor and 'Y' is a common Tensor,
boxes in 'Y' are shared by all instance of the batched inputs of X.
Given two boxes A and B, the calculation of IOU is as follows:
$$
IOU(A, B) =
\
frac{area(A\cap B)}{area(A)+area(B)-area(A
\cap B)}
\
\frac{area(A\\cap B)}{area(A)+area(B)-area(A\
\cap B)}
$$
)DOC"
);
...
...
paddle/fluid/operators/detection/polygon_box_transform_op.cc
浏览文件 @
f1f8327c
...
...
@@ -83,11 +83,13 @@ class PolygonBoxTransformOpMaker : public framework::OpProtoAndCheckerMaker {
AddComment
(
R"DOC(
PolygonBoxTransform Operator.
PolygonBoxTransform Operator is used to transform the coordinate shift to the real coordinate.
The input is the final geometry output in detection network.
We use 2*n numbers to denote the coordinate shift from n corner vertices of
the polygon_box to the pixel location. As each distance offset contains two numbers (xi, yi),
the geometry output contains 2*n channels.
PolygonBoxTransform Operator is used to transform the coordinate shift to the real coordinate.
)DOC"
);
}
};
...
...
paddle/fluid/operators/linear_chain_crf_op.cc
浏览文件 @
f1f8327c
...
...
@@ -84,6 +84,7 @@ CRF. Please refer to http://www.cs.columbia.edu/~mcollins/fb.pdf and
http://cseweb.ucsd.edu/~elkan/250Bwinter2012/loglinearCRFs.pdf for details.
Equation:
1. Denote Input(Emission) to this operator as $x$ here.
2. The first D values of Input(Transition) to this operator are for starting
weights, denoted as $a$ here.
...
...
@@ -106,6 +107,7 @@ Finally, the linear chain CRF operator outputs the logarithm of the conditional
likelihood of each training sample in a mini-batch.
NOTE:
1. The feature function for a CRF is made up of the emission features and the
transition features. The emission feature weights are NOT computed in
this operator. They MUST be computed first before this operator is called.
...
...
paddle/fluid/operators/lstm_op.cc
浏览文件 @
f1f8327c
...
...
@@ -184,34 +184,32 @@ Long-Short Term Memory (LSTM) Operator.
The defalut implementation is diagonal/peephole connection
(https://arxiv.org/pdf/1402.1128.pdf), the formula is as follows:
$$
i_t = \sigma(W_{ix}x_{t} + W_{ih}h_{t-1} + W_{ic}c_{t-1} + b_i) \\
$$ i_t = \\sigma(W_{ix}x_{t} + W_{ih}h_{t-1} + W_{ic}c_{t-1} + b_i) $$
f_t = \sigma(W_{fx}x_{t} + W_{fh}h_{t-1} + W_{fc}c_{t-1} + b_f) \\
$$ f_t = \\sigma(W_{fx}x_{t} + W_{fh}h_{t-1} + W_{fc}c_{t-1} + b_f) $$
\tilde{c_t} = act_g(W_{cx}x_t + W_{ch}h_{t-1} + b_c) \\
$$ \\tilde{c_t} = act_g(W_{cx}x_t + W_{ch}h_{t-1} + b_c) $$
o_t = \sigma(W_{ox}x_{t} + W_{oh}h_{t-1} + W_{oc}c_t + b_o) \\
$$ o_t = \\sigma(W_{ox}x_{t} + W_{oh}h_{t-1} + W_{oc}c_t + b_o) $$
c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c_t} \\
$$ c_t = f_t \\odot c_{t-1} + i_t \\odot \\tilde{c_t} $$
h_t = o_t \odot act_h(c_t)
$$
$$ h_t = o_t \\odot act_h(c_t) $$
where the
W terms denote weight matrices (e.g. $W_{xi}$ is the matrix
of weights from the input gate to the input), $W_{ic}, W_{fc}, W_{oc}$
are diagonal weight matrices for peephole connections. In our implementation,
we use vectors to reprenset these diagonal weight matrices. The b terms
denote bias vectors ($b_i$ is the input gate bias vector), $\sigma$
is the non-line activations, such as logistic sigmoid function, and
$i, f, o$ and $c$ are the input gate, forget gate, output gate,
and cell activation vectors, respectively, all of which have the same size as
the cell output activation vector $h$.
The $\odot$ is the element-wise product of the vectors. $act_g$ and $act_h$
are the cell input and cell output activation functions and `tanh` is usually
used for them.
$\tilde{c_t}$ is also called candidate hidden state,
which is computed based on the current input and the previous hidden state.
-
W terms denote weight matrices (e.g. $W_{xi}$ is the matrix
of weights from the input gate to the input), $W_{ic}, W_{fc}, W_{oc}$
are diagonal weight matrices for peephole connections. In our implementation,
we use vectors to reprenset these diagonal weight matrices.
- The b terms denote bias vectors ($b_i$ is the input gate bias vector).
- $\sigma$ is the non-line activations, such as logistic sigmoid function.
-
$i, f, o$ and $c$ are the input gate, forget gate, output gate,
and cell activation vectors, respectively, all of which have the same size as
the cell output activation vector $h$.
- The $\odot$ is the element-wise product of the vectors.
- $act_g$ and $act_h$ are the cell input and cell output activation functions
and `tanh` is usually used for them.
-
$\tilde{c_t}$ is also called candidate hidden state,
which is computed based on the current input and the previous hidden state.
Set `use_peepholes` False to disable peephole connection. The formula
is omitted here, please refer to the paper
...
...
paddle/fluid/operators/pool_op.cc
浏览文件 @
f1f8327c
...
...
@@ -204,8 +204,6 @@ void Pool2dOpMaker::Make() {
// TODO(dzhwinter): need to registered layout transform function
AddComment
(
R"DOC(
Pool2d Operator.
The pooling2d operation calculates the output based on
the input, pooling_type and ksize, strides, paddings parameters.
Input(X) and output(Out) are in NCHW format, where N is batch size, C is the
...
...
@@ -215,19 +213,28 @@ These two elements represent height and width, respectively.
The input(X) size and output(Out) size may be different.
Example:
Input:
X shape: $(N, C, H_{in}, W_{in})$
Output:
Out shape: $(N, C, H_{out}, W_{out})$
For ceil_mode = false:
$$
H_{out} = \frac{(H_{in} - ksize[0] + 2 * paddings[0])}{strides[0]} + 1 \\
W_{out} = \frac{(W_{in} - ksize[1] + 2 * paddings[1])}{strides[1]} + 1
H_{out} = \\frac{(H_{in} - ksize[0] + 2 * paddings[0])}{strides[0]} + 1
$$
$$
W_{out} = \\frac{(W_{in} - ksize[1] + 2 * paddings[1])}{strides[1]} + 1
$$
For ceil_mode = true:
$$
H_{out} = \frac{(H_{in} - ksize[0] + 2 * paddings[0] + strides[0] - 1)}{strides[0]} + 1 \\
W_{out} = \frac{(W_{in} - ksize[1] + 2 * paddings[1] + strides[1] - 1)}{strides[1]} + 1
H_{out} = \\frac{(H_{in} - ksize[0] + 2 * paddings[0] + strides[0] - 1)}{strides[0]} + 1
$$
$$
W_{out} = \\frac{(W_{in} - ksize[1] + 2 * paddings[1] + strides[1] - 1)}{strides[1]} + 1
$$
)DOC"
);
...
...
paddle/fluid/operators/roi_pool_op.cc
浏览文件 @
f1f8327c
...
...
@@ -139,7 +139,20 @@ class ROIPoolOpMaker : public framework::OpProtoAndCheckerMaker {
"The pooled output width."
)
.
SetDefault
(
1
);
AddComment
(
R"DOC(
ROIPool operator
**ROIPool Operator**
Region of interest pooling (also known as RoI pooling) is to perform
is to perform max pooling on inputs of nonuniform sizes to obtain
fixed-size feature maps (e.g. 7*7).
The operator has three steps:
1. Dividing each region proposal into equal-sized sections with
the pooled_width and pooled_height
2. Finding the largest value in each section
3. Copying these max values to the output buffer
ROI Pooling for Faster-RCNN. The link below is a further introduction:
https://stackoverflow.com/questions/43430056/what-is-roi-layer-in-fast-rcnn
...
...
paddle/fluid/operators/scale_op.cc
浏览文件 @
f1f8327c
...
...
@@ -41,13 +41,13 @@ class ScaleOpMaker : public framework::OpProtoAndCheckerMaker {
AddInput
(
"X"
,
"(Tensor) Input tensor of scale operator."
);
AddOutput
(
"Out"
,
"(Tensor) Output tensor of scale operator."
);
AddComment
(
R"DOC(
Scale operator
**Scale operator**
Multiply the input tensor with a float scalar to scale the input tensor.
$$Out = scale*X$$
)DOC"
);
AddAttr
<
float
>
(
"scale"
,
"(float, default 1.0)"
"The scaling factor of the scale operator."
)
AddAttr
<
float
>
(
"scale"
,
"The scaling factor of the scale operator."
)
.
SetDefault
(
1.0
);
}
};
...
...
paddle/fluid/operators/shape_op.cc
浏览文件 @
f1f8327c
...
...
@@ -36,10 +36,13 @@ class ShapeOpMaker : public framework::OpProtoAndCheckerMaker {
public:
void
Make
()
override
{
AddInput
(
"Input"
,
"(Tensor), The input tensor."
);
AddOutput
(
"Out"
,
"(Tensor), The shape of input tensor."
);
AddOutput
(
"Out"
,
"(Tensor), The shape of input tensor, the data type of the shape"
" is int64_t, will be on the same device with the input Tensor."
);
AddComment
(
R"DOC(
Shape Operator.
Get the shape of input tensor.
Shape Operator
Get the shape of input tensor. Only support CPU input Tensor now.
)DOC"
);
}
};
...
...
paddle/fluid/operators/sigmoid_cross_entropy_with_logits_op.cc
浏览文件 @
f1f8327c
...
...
@@ -113,14 +113,14 @@ The logistic loss is given as follows:
$$loss = -Labels * \log(\sigma(X)) - (1 - Labels) * \log(1 - \sigma(X))$$
We know that $$\sigma(X) =
(1 / (1 + \exp(-X)))
$$. By substituting this we get:
We know that $$\sigma(X) =
\\frac{1}{1 + \exp(-X)}
$$. By substituting this we get:
$$loss = X - X * Labels + \log(1 + \exp(-X))$$
For stability and to prevent overflow of $$\exp(-X)$$ when X < 0,
we reformulate the loss as follows:
$$loss = \max(X, 0) - X * Labels + \log(1 + \exp(-
|X
|))$$
$$loss = \max(X, 0) - X * Labels + \log(1 + \exp(-
\|X\
|))$$
Both the input `X` and `Labels` can carry the LoD (Level of Details) information.
However the output only shares the LoD with input `X`.
...
...
paddle/fluid/operators/slice_op.cc
浏览文件 @
f1f8327c
...
...
@@ -95,23 +95,26 @@ of that dimension. If the value passed to start or end is larger than
the n (the number of elements in this dimension), it represents n.
For slicing to the end of a dimension with unknown size, it is recommended
to pass in INT_MAX. If axes are omitted, they are set to [0, ..., ndim-1].
Example 1:
Given:
data = [ [1, 2, 3, 4], [5, 6, 7, 8], ]
axes = [0, 1]
starts = [1, 0]
ends = [2, 3]
Then:
result = [ [5, 6, 7], ]
Example 2:
Given:
data = [ [1, 2, 3, 4], [5, 6, 7, 8], ]
starts = [0, 1]
ends = [-1, 1000]
Then:
result = [ [2, 3, 4], ]
Following examples will explain how slice works:
.. code-block:: text
Cast1:
Given:
data = [ [1, 2, 3, 4], [5, 6, 7, 8], ]
axes = [0, 1]
starts = [1, 0]
ends = [2, 3]
Then:
result = [ [5, 6, 7], ]
Cast2:
Given:
data = [ [1, 2, 3, 4], [5, 6, 7, 8], ]
starts = [0, 1]
ends = [-1, 1000]
Then:
result = [ [2, 3, 4], ]
)DOC"
);
}
};
...
...
paddle/fluid/operators/tensorrt_engine_op_test.cc
浏览文件 @
f1f8327c
...
...
@@ -240,7 +240,7 @@ void Execute(int batch_size, int input_dim, int output_dim, int nlayers = 1) {
}
// Test with a larger FC layer.
TEST
(
TensorRTEngineOp
,
fc
)
{
Execute
(
40
,
2
56
,
256
);
}
TEST
(
TensorRTEngineOp
,
fc
)
{
Execute
(
40
,
2
8
,
28
);
}
}
// namespace operators
}
// namespace paddle
...
...
paddle/fluid/operators/uniform_random_batch_size_like_op.cc
浏览文件 @
f1f8327c
...
...
@@ -35,10 +35,10 @@ class UniformRandomBatchSizeLikeOpMaker : public BatchSizeLikeOpMaker {
protected:
void
Apply
()
override
{
AddComment
(
R"DOC(
Uniform
random operator
Uniform
RandomBatchSizeLike operator.
This operator initializes a tensor with the same batch_size as the Input tensor
with random values sampled from a uniform distribution.
with random values sampled from a uniform distribution.
)DOC"
);
AddAttr
<
float
>
(
"min"
,
...
...
python/paddle/fluid/framework.py
浏览文件 @
f1f8327c
...
...
@@ -1034,6 +1034,37 @@ class Block(object):
class
Program
(
object
):
"""
Python Program. Beneath it is a ProgramDesc, which is used for
create c++ Program. A program is a self-contained programing
language like container. It has at least one Block, when the
control flow op like conditional_block, while_op is included,
it will contains nested block.
Please reference the framework.proto for details.
Notes: we have default_startup_program and default_main_program
by default, a pair of them will shared the parameters.
The default_startup_program only run once to initialize parameters,
default_main_program run in every minibatch and adjust the weights.
Args:
None
Returns:
Python Program
Examples:
.. code-block:: python
main_program = Program()
startup_program = Program()
with fluid.program_guard(main_program=main_program, startup_program=startup_program):
fluid.layers.data(name="x", shape=[-1, 784], dtype='float32')
fluid.layers.data(name="y", shape=[-1, 1], dtype='int32')
fluid.layers.fc(name="fc", shape=[10], dtype='float32', act="relu")
"""
def
__init__
(
self
):
self
.
desc
=
core
.
ProgramDesc
()
self
.
blocks
=
[
Block
(
self
,
0
)]
...
...
@@ -1099,6 +1130,8 @@ class Program(object):
def
clone
(
self
,
for_test
=
False
):
"""Clone the Program object
Args:
for_test(bool): indicate whether clone for test.
Set for_test to False when we want to clone the program for training.
Set for_test to True when we want to clone the program for testing.
...
...
@@ -1109,8 +1142,9 @@ class Program(object):
the is_test attributes in these operators will be set to True for
testing purposes, otherwise, they remain unchanged.
Returns(Program):
The cloned Program object.
Returns:
Program: The cloned Program object.
"""
if
for_test
:
p
=
self
.
inference_optimize
()
...
...
@@ -1228,6 +1262,7 @@ class Program(object):
def
copy_param_info_from
(
self
,
other
):
"""
Copy the information of parameters from other program.
Args:
other(Program): Other program
...
...
@@ -1246,6 +1281,7 @@ class Program(object):
def
copy_data_info_from
(
self
,
other
):
"""
Copy the information of data variables from other program.
Args:
other(Program): Other program
...
...
@@ -1299,6 +1335,7 @@ class Parameter(Variable):
def
to_string
(
self
,
throw_on_error
,
with_details
=
False
):
"""
To debug string.
Args:
throw_on_error(bool): raise exception when self is not initialized
when throw_on_error is True
...
...
python/paddle/fluid/layers/control_flow.py
浏览文件 @
f1f8327c
...
...
@@ -27,7 +27,6 @@ __all__ = [
'merge_lod_tensor'
,
'BlockGuard'
,
'BlockGuardWithCompletion'
,
'StaticRNNMemoryLink'
,
'WhileGuard'
,
'While'
,
'Switch'
,
...
...
@@ -56,34 +55,36 @@ __all__ = [
def
split_lod_tensor
(
input
,
mask
,
level
=
0
):
"""
**split_lod_tensor**
This function takes in an input that contains the complete lod information,
and takes in a mask which is used to mask certain parts of the input.
The output is the true branch and the false branch with the mask applied to
the input at a certain level in the tensor.
the input at a certain level in the tensor. Mainly used in IfElse to split
data into two parts.
Args:
input(tuple|list|None): The input tensor that contains complete
lod information needed to construct the output.
mask(list): A bool column vector which masks the input.
level(int): The specific lod level to
rank
.
level(int): The specific lod level to
split
.
Returns:
Variable: The true branch of tensor as per the mask applied to input.
Variable: The false branch of tensor as per the mask applied to input.
tuple(Variable, Variable):
The true branch of tensor as per the mask applied to input.
The false branch of tensor as per the mask applied to input.
Examples:
.. code-block:: python
x = layers.data(name='x', shape=[1])
x =
fluid.
layers.data(name='x', shape=[1])
x.persistable = True
y = layers.data(name='y', shape=[1])
y =
fluid.
layers.data(name='y', shape=[1])
y.persistable = True
out_true, out_false = layers.split_lod_tensor(
out_true, out_false =
fluid.
layers.split_lod_tensor(
input=x, mask=y, level=level)
"""
helper
=
LayerHelper
(
'split_lod_tensor'
,
**
locals
())
out_true
=
helper
.
create_tmp_variable
(
dtype
=
input
.
dtype
)
...
...
@@ -106,8 +107,9 @@ def merge_lod_tensor(in_true, in_false, x, mask, level=0):
This function takes in an input :math:`x`, the True branch, the False
branch and a binary :math:`mask`. Using this information, this function
merges the True and False branches of the tensor into a single Output
at a certain lod level indiacted by :math:`level`.
merges the True and False branches of the tensor into a single tensor as
output at a certain lod level indicated by :math:`level`. Used in IfElse
to merge the output if True block and False Block.
Args:
in_true(tuple|list|None): The True branch to be merged.
...
...
@@ -115,7 +117,7 @@ def merge_lod_tensor(in_true, in_false, x, mask, level=0):
x(tuple|list|None): The input tensor that contains complete
lod information needed to construct the output.
mask(list): A bool column vector which masks the input.
level(int): The specific lod level to
rank
.
level(int): The specific lod level to
merge
.
Returns:
Variable: The merged output tensor.
...
...
@@ -410,16 +412,17 @@ class StaticRNNMemoryLink(object):
"""
StaticRNNMemoryLink class.
Args:
init: the initial variable for Memory
init: Variable
pre_mem: the memory variable in previous time step
pre_mem: Variable
mem: the memory variable in current time step
mem: Variable
StaticRNNMemoryLink class is used to create a link between two
memory cells of a StaticRNN.
NOTE: This is a internal data structure of a very low-level API.
Please use StaticRNN instead.
Args:
init(Variable): the initial variable for Memory.
pre_mem(Variable): the memory variable in previous time step.
mem(Variable): the memory variable in current time step.
"""
def
__init__
(
self
,
init
,
pre_mem
,
mem
=
None
):
...
...
@@ -819,17 +822,25 @@ def max_sequence_len(rank_table):
def
lod_tensor_to_array
(
x
,
table
):
""" Convert a LOD_TENSOR to an LOD_TENSOR_ARRAY.
"""
Convert a LoDTensor to a LoDTensorArray.
This function split a LoDTesnor to a LoDTensorArray according to its LoD
information. LoDTensorArray is an alias of C++ std::vector<LoDTensor> in
PaddlePaddle. The generated LoDTensorArray of this function can be further read
or written by `read_from_array()` and `write_to_array()` operators. However,
this function is generally an internal component of PaddlePaddle `DynamicRNN`.
Users should not use it directly.
Args:
x (Variable|list): The L
OD tensor to be converted to a LOD tensor a
rray.
x (Variable|list): The L
oDTensor to be converted to a LoDTensorA
rray.
table (ParamAttr|list): The variable that stores the level of lod
which is ordered by sequence length in
descending order.
descending order. It is generally generated
by `layers.lod_rank_table()` API.
Returns:
Variable: The variable of type array that has been converted from a
tensor.
Variable: The LoDTensorArray that has been converted from the input tensor.
Examples:
.. code-block:: python
...
...
@@ -894,8 +905,7 @@ def increment(x, value=1.0, in_place=True):
in_place (bool): If the increment should be performed in-place.
Returns:
Variable: The tensor variable storing the transformation of
element-wise increment of each value in the input.
Variable: The elementwise-incremented object.
Examples:
.. code-block:: python
...
...
@@ -937,7 +947,7 @@ def array_write(x, i, array=None):
Variable: The output LOD_TENSOR_ARRAY where the input tensor is written.
Examples:
.. code-block::python
.. code-block::
python
tmp = fluid.layers.zeros(shape=[10], dtype='int32')
i = fluid.layers.fill_constant(shape=[1], dtype='int64', value=10)
...
...
@@ -958,14 +968,17 @@ def array_write(x, i, array=None):
def
create_array
(
dtype
):
"""This function creates an array of type :math:`LOD_TENSOR_ARRAY` using the
LayerHelper.
"""
**Create LoDTensorArray**
This function creates an array of LOD_TENSOR_ARRAY . It is mainly used to
implement RNN with array_write, array_read and While.
Args:
dtype (int|float): The data type of the elements in the array.
dtype (int|float): The data type of the elements in the
lod_tensor_
array.
Returns:
Variable: The
tensor
variable storing the elements of data type.
Variable: The
lod_tensor_array
variable storing the elements of data type.
Examples:
.. code-block:: python
...
...
@@ -1048,16 +1061,34 @@ def equal(x, y, cond=None, **ignored):
def
array_read
(
array
,
i
):
"""This function performs the operation to read the data in as an
"""
This function performs the operation to read the data in as an
LOD_TENSOR_ARRAY.
.. code-block:: text
Given:
array = [0.6, 0.1, 0.3, 0.1]
And:
i = 2
Then:
output = 0.3
Args:
array (Variable|list): The input tensor that
will be written to an array
.
i (Variable|list): The
subscript index in tensor array, that points the
place where data will be written to.
array (Variable|list): The input tensor that
store data to be read
.
i (Variable|list): The
index of the data to be read from input array.
Returns:
Variable: The tensor type variable that has the data written to it.
Examples:
.. code-block::python
.. code-block:: python
tmp = fluid.layers.zeros(shape=[10], dtype='int32')
i = fluid.layers.fill_constant(shape=[1], dtype='int64', value=10)
arr = layers.array_read(tmp, i=i)
...
...
@@ -1114,9 +1145,14 @@ def shrink_memory(x, i, table):
def
array_length
(
array
):
"""This function performs the operation to find the length of the input
"""
**Get the Length of Input LoDTensorArray**
This function performs the operation to find the length of the input
LOD_TENSOR_ARRAY.
Related API: array_read, array_write, While.
Args:
array (LOD_TENSOR_ARRAY): The input array that will be used
to compute the length.
...
...
@@ -1125,12 +1161,13 @@ def array_length(array):
Variable: The length of the input LoDTensorArray.
Examples:
.. code-block::python
.. code-block::
python
tmp = fluid.layers.zeros(shape=[10], dtype='int32')
i = fluid.layers.fill_constant(shape=[1], dtype='int64', value=10)
arr = fluid.layers.array_write(tmp, i=i)
arr_len = fluid.layers.array_length(arr)
"""
helper
=
LayerHelper
(
'array_length'
,
**
locals
())
tmp
=
helper
.
create_tmp_variable
(
dtype
=
'int64'
)
...
...
@@ -1141,6 +1178,13 @@ def array_length(array):
class
ConditionalBlockGuard
(
BlockGuard
):
"""
ConditionalBlockGuard is derived from BlockGuard. It is dedicated for
holding a ConditionalBlock, and helping users entering and exiting the
ConditionalBlock via Python's 'with' keyword. However, ConditionalBlockGuard
is generally an internal component of IfElse, users should not use it directly.
"""
def
__init__
(
self
,
block
):
if
not
isinstance
(
block
,
ConditionalBlock
):
raise
TypeError
(
"block should be conditional block"
)
...
...
@@ -1214,6 +1258,42 @@ class ConditionalBlock(object):
class
Switch
(
object
):
"""
Switch class works just like a `if-elif-else`. Can be used in learning rate scheduler
to modify learning rate
The Semantics:
1. A `switch` control-flow checks cases one-by-one.
2. The condition of each case is a boolean value, which is a scalar Variable.
3. It runs the first matched case, or the default case if there is one.
4. Once it matches a case, it runs the corresponding branch and only that branch.
Examples:
.. code-block:: python
lr = fluid.layers.tensor.create_global_var(
shape=[1],
value=0.0,
dtype='float32',
persistable=True,
name="learning_rate")
one_var = tensor.fill_constant(
shape=[1], dtype='float32', value=1.0)
two_var = tensor.fill_constant(
shape=[1], dtype='float32', value=2.0)
with fluid.layers.control_flow.Switch() as switch:
with switch.case(global_step == zero_var):
fluid.layers.tensor.assign(input=one_var, output=lr)
with switch.default():
fluid.layers.tensor.assign(input=two_var, output=lr)
"""
def
__init__
(
self
,
name
=
None
):
self
.
helper
=
LayerHelper
(
'switch'
,
name
=
name
)
self
.
inside_scope
=
False
...
...
@@ -1243,7 +1323,8 @@ class Switch(object):
return
ConditionalBlockGuard
(
cond_block
)
def
default
(
self
):
"""create a default case for this switch
"""
create a default case for this switch
"""
pre_cond_num
=
len
(
self
.
pre_not_conditions
)
if
pre_cond_num
==
0
:
...
...
@@ -1825,26 +1906,26 @@ def reorder_lod_tensor_by_rank(x, rank_table):
def
is_empty
(
x
,
cond
=
None
,
**
ignored
):
"""
**Is Empty**
This layer returns the truth value of whether the variable is empty.
Test whether a Variable is empty.
Args:
x
(Variable): Operand of *is_empty*
cond
(Variable|None): Optional output variable to store the result
of *is_empty*
x
(Variable): The Variable to be tested.
cond
(Variable|None): Output parameter. Returns the test result
of given 'x'. Default: None
Returns:
Variable:
The tensor variable storing the output of *is_empty*
.
Variable:
A bool scalar. True if 'x' is an empty Variable
.
Raises:
TypeError: If input cond is not a variable, or cond's dtype is
not bool
not bool
.
Examples:
.. code-block:: python
less = fluid.layers.is_empty(x=input)
res = fluid.layers.is_empty(x=input)
# or:
fluid.layers.is_empty(x=input, cond=res)
"""
helper
=
LayerHelper
(
"is_empty"
,
**
locals
())
if
cond
is
None
:
...
...
python/paddle/fluid/layers/detection.py
浏览文件 @
f1f8327c
...
...
@@ -620,7 +620,7 @@ def prior_box(input,
offset
=
0.5
,
name
=
None
):
"""
**Prior
box o
perator**
**Prior
Box O
perator**
Generate prior boxes for SSD(Single Shot MultiBox Detector) algorithm.
Each position of the input produce N prior boxes, N is determined by
...
...
@@ -649,26 +649,30 @@ def prior_box(input,
name(str): Name of the prior box op. Default: None.
Returns:
boxes(Variable): the output prior boxes of PriorBox.
The layout is [H, W, num_priors, 4].
H is the height of input, W is the width of input,
num_priors is the total
box count of each position of input.
Variances(Variable): the expanded variances of PriorBox.
The layout is [H, W, num_priors, 4].
H is the height of input, W is the width of input
num_priors is the total
box count of each position of input
tuple: A tuple with two Variable (boxes, variances)
boxes: the output prior boxes of PriorBox.
The layout is [H, W, num_priors, 4].
H is the height of input, W is the width of input,
num_priors is the total
box count of each position of input.
variances: the expanded variances of PriorBox.
The layout is [H, W, num_priors, 4].
H is the height of input, W is the width of input
num_priors is the total
box count of each position of input
Examples:
.. code-block:: python
box, var = prior_box(
input=conv1,
image=images,
min_sizes=[100.],
flip=True,
clip=True)
box, var = fluid.layers.prior_box(
input=conv1,
image=images,
min_sizes=[100.],
flip=True,
clip=True)
"""
helper
=
LayerHelper
(
"prior_box"
,
**
locals
())
dtype
=
helper
.
input_dtype
()
...
...
@@ -738,11 +742,9 @@ def multi_box_head(inputs,
stride
=
1
,
name
=
None
):
"""
**Prior_boxes**
Generate prior boxes for SSD(Single Shot MultiBox Detector)
algorithm. The details of this algorithm, please refer the
section 2.2 of SSD paper
(SSD: Single Shot MultiBox Detector)
section 2.2 of SSD paper
`SSD: Single Shot MultiBox Detector
<https://arxiv.org/abs/1512.02325>`_ .
Args:
...
...
@@ -783,24 +785,27 @@ def multi_box_head(inputs,
name(str): Name of the prior box layer. Default: None.
Returns:
mbox_loc(Variable): The predicted boxes' location of the inputs.
The layout is [N, H*W*Priors, 4]. where Priors
is the number of predicted boxes each position of each input.
mbox_conf(Variable): The predicted boxes' confidence of the inputs.
The layout is [N, H*W*Priors, C]. where Priors
is the number of predicted boxes each position of each input
and C is the number of Classes.
boxes(Variable): the output prior boxes of PriorBox.
The layout is [num_priors, 4]. num_priors is the total
box count of each position of inputs.
Variances(Variable): the expanded variances of PriorBox.
The layout is [num_priors, 4]. num_priors is the total
box count of each position of inputs
tuple: A tuple with four Variables. (mbox_loc, mbox_conf, boxes, variances)
mbox_loc: The predicted boxes' location of the inputs. The layout
is [N, H*W*Priors, 4]. where Priors is the number of predicted
boxes each position of each input.
mbox_conf: The predicted boxes' confidence of the inputs. The layout
is [N, H*W*Priors, C]. where Priors is the number of predicted boxes
each position of each input and C is the number of Classes.
boxes: the output prior boxes of PriorBox. The layout is [num_priors, 4].
num_priors is the total box count of each position of inputs.
variances: the expanded variances of PriorBox. The layout is
[num_priors, 4]. num_priors is the total box count of each position of inputs
Examples:
.. code-block:: python
mbox_locs, mbox_confs, box, var = layers.multi_box_head(
mbox_locs, mbox_confs, box, var = fluid.layers.multi_box_head(
inputs=[conv1, conv2, conv3, conv4, conv5, conv5],
image=images,
num_classes=21,
...
...
python/paddle/fluid/layers/io.py
浏览文件 @
f1f8327c
...
...
@@ -109,10 +109,35 @@ class BlockGuardServ(BlockGuard):
class
ListenAndServ
(
object
):
"""
ListenAndServ class.
**ListenAndServ Layer**
ListenAndServ is used to create a rpc server bind and listen
on specific TCP port, this server will run the sub-block when
received variables from clients.
Args:
endpoint(string): IP:port string which the server will listen on.
inputs(list): a list of variables that the server will get from clients.
fan_in(int): how many client are expected to report to this server, default: 1.
optimizer_mode(bool): whether to run the server as a parameter server, default: True.
ListenAndServ class is used to wrap listen_and_serv op to create a server
which can receive variables from clients and run a block.
Examples:
.. code-block:: python
with fluid.program_guard(main):
serv = layers.ListenAndServ(
"127.0.0.1:6170", ["X"], optimizer_mode=False)
with serv.do():
x = layers.data(
shape=[32, 32],
dtype='float32',
name="X",
append_batch_size=False)
fluid.initializer.Constant(value=1.0)(x, main.global_block())
layers.scale(x=x, scale=10.0, out=out_var)
exe = fluid.Executor(place)
exe.run(main)
"""
def
__init__
(
self
,
endpoint
,
inputs
,
fan_in
=
1
,
optimizer_mode
=
True
):
...
...
@@ -544,6 +569,41 @@ def shuffle(reader, buffer_size):
def
batch
(
reader
,
batch_size
):
"""
This layer is a reader decorator. It takes a reader and adds
'batching' decoration on it. When reading with the result
decorated reader, output data will be automatically organized
to the form of batches.
Args:
reader(Variable): The reader to be decorated with 'batching'.
batch_size(int): The batch size.
Returns:
Variable: The reader which has been decorated with 'batching'.
Examples:
.. code-block:: python
raw_reader = fluid.layers.io.open_files(filenames=['./data1.recordio',
'./data2.recordio'],
shapes=[(3,224,224), (1)],
lod_levels=[0, 0],
dtypes=['float32', 'int64'],
thread_num=2,
buffer_size=2)
batch_reader = fluid.layers.batch(reader=raw_reader, batch_size=5)
# If we read data with the raw_reader:
# data = fluid.layers.read_file(raw_reader)
# We can only get data instance by instance.
#
# However, if we read data with the batch_reader:
# data = fluid.layers.read_file(batch_reader)
# Each 5 adjacent instances will be automatically combined together
# to become a batch. So what we get('data') is a batch data instead
# of an instance.
"""
return
__create_unshared_decorated_reader__
(
'create_batch_reader'
,
reader
,
{
'batch_size'
:
int
(
batch_size
)})
...
...
@@ -589,15 +649,41 @@ def parallel(reader):
{})
def
read_file
(
file_obj
):
def
read_file
(
reader
):
"""
Execute the given reader and get data via it.
A reader is also a Variable. It can be a raw reader generated by
`fluid.layers.open_files()` or a decorated one generated by
`fluid.layers.double_buffer()` and so on.
Args:
reader(Variable): The reader to execute.
Returns:
Tuple[Variable]: Data read via the given reader.
Examples:
.. code-block:: python
data_file = fluid.layers.open_files(
filenames=['mnist.recordio'],
shapes=[(-1, 748), (-1, 1)],
lod_levels=[0, 0],
dtypes=["float32", "int64"])
data_file = fluid.layers.double_buffer(
fluid.layers.batch(data_file, batch_size=64))
input, label = fluid.layers.read_file(data_file)
"""
helper
=
LayerHelper
(
'read_file'
)
out
=
[
helper
.
create_tmp_variable
(
stop_gradient
=
True
,
dtype
=
'float32'
)
for
_
in
range
(
len
(
file_obj
.
desc
.
shapes
()))
for
_
in
range
(
len
(
reader
.
desc
.
shapes
()))
]
helper
.
append_op
(
type
=
'read'
,
inputs
=
{
'Reader'
:
[
file_obj
]},
outputs
=
{
'Out'
:
out
})
type
=
'read'
,
inputs
=
{
'Reader'
:
[
reader
]},
outputs
=
{
'Out'
:
out
})
if
len
(
out
)
==
1
:
return
out
[
0
]
else
:
...
...
python/paddle/fluid/layers/layer_function_generator.py
浏览文件 @
f1f8327c
...
...
@@ -49,6 +49,13 @@ _single_dollar_pattern_ = re.compile(r"\$([^\$]+)\$")
_two_bang_pattern_
=
re
.
compile
(
r
"!!([^!]+)!!"
)
def
escape_math
(
text
):
return
_two_bang_pattern_
.
sub
(
r
'$$\1$$'
,
_single_dollar_pattern_
.
sub
(
r
':math:`\1`'
,
_two_dollar_pattern_
.
sub
(
r
"!!\1!!"
,
text
)))
def
_generate_doc_string_
(
op_proto
):
"""
Generate docstring by OpProto
...
...
@@ -60,12 +67,6 @@ def _generate_doc_string_(op_proto):
str: the document string
"""
def
escape_math
(
text
):
return
_two_bang_pattern_
.
sub
(
r
'$$\1$$'
,
_single_dollar_pattern_
.
sub
(
r
':math:`\1`'
,
_two_dollar_pattern_
.
sub
(
r
"!!\1!!"
,
text
)))
if
not
isinstance
(
op_proto
,
framework_pb2
.
OpProto
):
raise
TypeError
(
"OpProto should be `framework_pb2.OpProto`"
)
...
...
@@ -233,9 +234,6 @@ def autodoc(comment=""):
return
__impl__
_inline_math_single_dollar
=
re
.
compile
(
r
"\$([^\$]+)\$"
)
def
templatedoc
(
op_type
=
None
):
"""
Decorator of layer function. It will use the docstring from the layer
...
...
@@ -253,9 +251,6 @@ def templatedoc(op_type=None):
def
trim_ending_dot
(
msg
):
return
msg
.
rstrip
(
'.'
)
def
escape_inline_math
(
msg
):
return
_inline_math_single_dollar
.
sub
(
repl
=
r
':math:`\1`'
,
string
=
msg
)
def
__impl__
(
func
):
if
op_type
is
None
:
op_type_name
=
func
.
__name__
...
...
@@ -269,7 +264,7 @@ def templatedoc(op_type=None):
for
line
in
comment_lines
:
line
=
line
.
strip
()
if
len
(
line
)
!=
0
:
comment
+=
escape_
inline_
math
(
line
)
comment
+=
escape_math
(
line
)
comment
+=
" "
elif
len
(
comment
)
!=
0
:
comment
+=
"
\n
\n
"
...
...
python/paddle/fluid/layers/learning_rate_scheduler.py
浏览文件 @
f1f8327c
...
...
@@ -71,21 +71,40 @@ def noam_decay(d_model, warmup_steps):
def
exponential_decay
(
learning_rate
,
decay_steps
,
decay_rate
,
staircase
=
False
):
"""Applies exponential decay to the learning rate.
"""
Applies exponential decay to the learning rate.
When training a model, it is often recommended to lower the learning rate as the
training progresses. By using this function, the learning rate will be decayed by
'decay_rate' every 'decay_steps' steps.
>>> if staircase == True:
>>> decayed_learning_rate = learning_rate * decay_rate ^ floor(global_step / decay_steps)
>>> else:
>>> decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)
```python
decayed_learning_rate = learning_rate *
decay_rate ^ (global_step / decay_steps)
```
Args:
learning_rate
: A scalar float32 value or a Variable. This
will be the initial learning rate during training
decay_
steps: A Python `int32` number
.
decay_rate: A Python `float` number
.
staircase: Boolean. If set true, decay the learning rate every decay_steps.
learning_rate
(Variable|float): The initial learning rate.
decay_steps(int): See the decay computation above.
decay_
rate(float): The decay rate. See the decay computation above
.
staircase(Boolean): If True, decay the learning rate at discrete intervals
.
Default: False
Returns:
The decayed learning rate
Variable: The decayed learning rate
Examples:
.. code-block:: python
base_lr = 0.1
sgd_optimizer = fluid.optimizer.SGD(
learning_rate=fluid.layers.exponential_decay(
learning_rate=base_lr,
decay_steps=10000,
decay_rate=0.5,
staircase=True))
sgd_optimizer.minimize(avg_cost)
"""
global_step
=
_decay_step_counter
()
...
...
@@ -129,22 +148,39 @@ def natural_exp_decay(learning_rate, decay_steps, decay_rate, staircase=False):
def
inverse_time_decay
(
learning_rate
,
decay_steps
,
decay_rate
,
staircase
=
False
):
"""Applies inverse time decay to the initial learning rate.
"""
Applies inverse time decay to the initial learning rate.
>>> if staircase:
When training a model, it is often recommended to lower the learning rate as the
training progresses. By using this function, an inverse decay function will be
applied to the initial learning rate.
>>> if staircase == True:
>>> decayed_learning_rate = learning_rate / (1 + decay_rate * floor(global_step / decay_step))
>>> else:
>>> decayed_learning_rate = learning_rate / (1 + decay_rate * global_step / decay_step)
Args:
learning_rate
: A scalar float32 value or a Variable. This
will be the initial learning rate during training
.
decay_
steps: A Python `int32` number
.
decay_rate: A Python `float` number
.
staircase: Boolean. If set true, decay the learning rate every decay_steps.
learning_rate
(Variable|float): The initial learning rate.
decay_steps(int): See the decay computation above
.
decay_
rate(float): The decay rate. See the decay computation above
.
staircase(Boolean): If True, decay the learning rate at discrete intervals
.
Default: False
Returns:
The decayed learning rate
Variable: The decayed learning rate
Examples:
.. code-block:: python
base_lr = 0.1
sgd_optimizer = fluid.optimizer.SGD(
learning_rate=fluid.layers.inverse_time_decay(
learning_rate=base_lr,
decay_steps=10000,
decay_rate=0.5,
staircase=True))
sgd_optimizer.minimize(avg_cost)
"""
global_step
=
_decay_step_counter
()
...
...
@@ -163,25 +199,28 @@ def polynomial_decay(learning_rate,
end_learning_rate
=
0.0001
,
power
=
1.0
,
cycle
=
False
):
"""Applies polynomial decay to the initial learning rate.
"""
Applies polynomial decay to the initial learning rate.
.. code-block:: python
if cycle:
decay_steps = decay_steps * ceil(global_step / decay_steps)
else:
global_step = min(global_step, decay_steps)
decayed_learning_rate = (learning_rate - end_learning_rate) *
(1 - global_step / decay_steps) ^ power + end_learning_rate
>>> if cycle:
>>> decay_steps = decay_steps * ceil(global_step / decay_steps)
>>> else:
>>> global_step = min(global_step, decay_steps)
>>> decayed_learning_rate = (learning_rate - end_learning_rate) *
>>> (1 - global_step / decay_steps) ^ power +
>>> end_learning_rate
Args:
learning_rate: A scalar float32 value or a Variable. This
will be the initial learning rate during training
decay_steps: A Python `int32` number.
end_learning_rate: A Python `float` number.
power
: A Python `float` number
cycle
: Boolean.
If set true, decay the learning rate every decay_steps.
learning_rate
(Variable|float32)
: A scalar float32 value or a Variable. This
will be the initial learning rate during training
.
decay_steps
(int32)
: A Python `int32` number.
end_learning_rate
(float)
: A Python `float` number.
power
(float): A Python `float` number.
cycle
(bool):
If set true, decay the learning rate every decay_steps.
Returns:
The decayed learning rate
Variable:
The decayed learning rate
"""
global_step
=
_decay_step_counter
()
...
...
python/paddle/fluid/layers/metric.py
浏览文件 @
f1f8327c
...
...
@@ -27,8 +27,32 @@ __all__ = ['accuracy', 'auc']
def
accuracy
(
input
,
label
,
k
=
1
,
correct
=
None
,
total
=
None
):
"""
accuracy layer.
Refer to the https://en.wikipedia.org/wiki/Precision_and_recall
This function computes the accuracy using the input and label.
The output is the top k inputs and their indices.
If the correct label occurs in top k predictions, then correct will increment by one.
Note: the dtype of accuracy is determined by input. the input and label dtype can be different.
Args:
input(Variable): The input of accuracy layer, which is the predictions of network.
Carry LoD information is supported.
label(Variable): The label of dataset.
k(int): The top k predictions for each class will be checked.
correct(Variable): The correct predictions count.
total(Variable): The total entries count.
Returns:
Variable: The correct rate.
Examples:
.. code-block:: python
data = fluid.layers.data(name="data", shape=[-1, 32, 32], dtype="float32")
label = fluid.layers.data(name="data", shape=[-1,1], dtype="int32")
predict = fluid.layers.fc(input=data, size=10)
acc = fluid.layers.accuracy(input=predict, label=label, k=5)
"""
helper
=
LayerHelper
(
"accuracy"
,
**
locals
())
topk_out
,
topk_indices
=
nn
.
topk
(
input
,
k
=
k
)
...
...
python/paddle/fluid/layers/nn.py
浏览文件 @
f1f8327c
...
...
@@ -91,6 +91,8 @@ __all__ = [
'gather'
,
'random_crop'
,
'mean_iou'
,
'relu'
,
'log'
,
]
...
...
@@ -106,14 +108,15 @@ def fc(input,
"""
**Fully Connected Layer**
The fully connected layer can take multiple tensors as its inputs. It
creates a variable called weights for each input tensor, which represents
a fully connected weight matrix from each input unit to each output unit.
The fully connected layer multiplies each input tensor with its coresponding
weight to produce an output Tensor. If multiple input tensors are given,
the results of multiple multiplications will be sumed up. If bias_attr is
not None, a bias variable will be created and added to the output. Finally,
if activation is not None, it will be applied to the output as well.
This function creates a fully connected layer in the network. It can take
multiple tensors as its inputs. It creates a variable called weights for
each input tensor, which represents a fully connected weight matrix from
each input unit to each output unit. The fully connected layer multiplies
each input tensor with its coresponding weight to produce an output Tensor.
If multiple input tensors are given, the results of multiple multiplications
will be sumed up. If bias_attr is not None, a bias variable will be created
and added to the output. Finally, if activation is not None, it will be applied
to the output as well.
This process can be formulated as follows:
...
...
@@ -154,7 +157,7 @@ def fc(input,
name (str, default None): The name of this layer.
Returns:
A tensor variable storing t
he transformation result.
Variable: T
he transformation result.
Raises:
ValueError: If rank of the input tensor is less than 2.
...
...
@@ -162,8 +165,7 @@ def fc(input,
Examples:
.. code-block:: python
data = fluid.layers.data(
name="data", shape=[32, 32], dtype="float32")
data = fluid.layers.data(name="data", shape=[32, 32], dtype="float32")
fc = fluid.layers.fc(input=data, size=1000, act="tanh")
"""
...
...
@@ -265,6 +267,7 @@ def embedding(input,
return
tmp
@
templatedoc
(
op_type
=
"lstm"
)
def
dynamic_lstm
(
input
,
size
,
h_0
=
None
,
...
...
@@ -279,56 +282,11 @@ def dynamic_lstm(input,
dtype
=
'float32'
,
name
=
None
):
"""
**Dynamic LSTM Layer**
The defalut implementation is diagonal/peephole connection
(https://arxiv.org/pdf/1402.1128.pdf), the formula is as follows:
.. math::
i_t & = \sigma(W_{ix}x_{t} + W_{ih}h_{t-1} + W_{ic}c_{t-1} + b_i)
f_t & = \sigma(W_{fx}x_{t} + W_{fh}h_{t-1} + W_{fc}c_{t-1} + b_f)
\\
tilde{c_t} & = act_g(W_{cx}x_t + W_{ch}h_{t-1} + b_c)
o_t & = \sigma(W_{ox}x_{t} + W_{oh}h_{t-1} + W_{oc}c_t + b_o)
c_t & = f_t \odot c_{t-1} + i_t \odot
\\
tilde{c_t}
h_t & = o_t \odot act_h(c_t)
where the :math:`W` terms denote weight matrices (e.g. :math:`W_{xi}` is
the matrix of weights from the input gate to the input), :math:`W_{ic},
\
W_{fc}, W_{oc}` are diagonal weight matrices for peephole connections. In
our implementation, we use vectors to reprenset these diagonal weight
matrices. The :math:`b` terms denote bias vectors (:math:`b_i` is the input
gate bias vector), :math:`\sigma` is the non-linear activations, such as
logistic sigmoid function, and :math:`i, f, o` and :math:`c` are the input
gate, forget gate, output gate, and cell activation vectors, respectively,
all of which have the same size as the cell output activation vector :math:`h`.
The :math:`\odot` is the element-wise product of the vectors. :math:`act_g`
and :math:`act_h` are the cell input and cell output activation functions
and `tanh` is usually used for them. :math:`
\\
tilde{c_t}` is also called
candidate hidden state, which is computed based on the current input and
the previous hidden state.
Set `use_peepholes` to `False` to disable peephole connection. The formula
is omitted here, please refer to the paper
http://www.bioinf.jku.at/publications/older/2604.pdf for details.
Note that these :math:`W_{xi}x_{t}, W_{xf}x_{t}, W_{xc}x_{t}, W_{xo}x_{t}`
operations on the input :math:`x_{t}` are NOT included in this operator.
Users can choose to use fully-connect layer before LSTM layer.
${comment}
Args:
input(Variable): The input of dynamic_lstm layer, which supports
variable-time length input sequence. The underlying
tensor in this Variable is a matrix with shape
(T X 4D), where T is the total time steps in this
mini-batch, D is the hidden size.
size(int): 4 * hidden size.
input (Variable): ${input_comment}
size (int): 4 * hidden size.
h_0(Variable): The initial hidden state is an optional input, default is zero.
This is a tensor with shape (N x D), where N is the
batch size and D is the hidden size.
...
...
@@ -343,32 +301,26 @@ def dynamic_lstm(input,
W_{fh}, W_{oh}`}
- The shape is (D x 4D), where D is the hidden
size.
bias_attr(ParamAttr|None): The bias attribute for the learnable bias
bias_attr
(ParamAttr|None): The bias attribute for the learnable bias
weights, which contains two parts, input-hidden
bias weights and peephole connections weights if
setting `use_peepholes` to `True`.
1. `use_peepholes = False`
- Biases = {:math:`b_c, b_i, b_f, b_o`}.
- The shape is (1 x 4D).
- Biases = {:math:`b_c, b_i, b_f, b_o`}.
- The shape is (1 x 4D).
2. `use_peepholes = True`
- Biases = { :math:`b_c, b_i, b_f, b_o, W_{ic},
\
- Biases = { :math:`b_c, b_i, b_f, b_o, W_{ic},
\
W_{fc}, W_{oc}`}.
- The shape is (1 x 7D).
use_peepholes(bool): Whether to enable diagonal/peephole connections,
default `True`.
is_reverse(bool): Whether to compute reversed LSTM, default `False`.
gate_activation(str): The activation for input gate, forget gate and
output gate. Choices = ["sigmoid", "tanh", "relu",
"identity"], default "sigmoid".
cell_activation(str): The activation for cell output. Choices = ["sigmoid",
"tanh", "relu", "identity"], default "tanh".
candidate_activation(str): The activation for candidate hidden state.
Choices = ["sigmoid", "tanh", "relu", "identity"],
default "tanh".
dtype(str): Data type. Choices = ["float32", "float64"], default "float32".
name(str|None): A name for this layer(optional). If set None, the layer
will be named automatically.
- The shape is (1 x 7D).
use_peepholes (bool): ${use_peepholes_comment}
is_reverse (bool): ${is_reverse_comment}
gate_activation (str): ${gate_activation_comment}
cell_activation (str): ${cell_activation_comment}
candidate_activation (str): ${candidate_activation_comment}
dtype (str): Data type. Choices = ["float32", "float64"], default "float32".
name (str|None): A name for this layer(optional). If set None, the layer
will be named automatically.
Returns:
tuple: The hidden state, and cell state of LSTM. The shape of both
\
...
...
@@ -845,11 +797,14 @@ def linear_chain_crf(input, label, param_attr=None):
Args:
input(${emission_type}): ${emission_comment}
input(${transition_type}): ${transition_comment}
label(${label_type}): ${label_comment}
param_attr(ParamAttr): The attribute of the learnable parameter.
Returns:
${log_likelihood_comment}
output(${emission_exps_type}): ${emission_exps_comment}
\n
output(${transition_exps_type}): ${transition_exps_comment}
\n
output(${log_likelihood_type}): ${log_likelihood_comment}
"""
helper
=
LayerHelper
(
'linear_chain_crf'
,
**
locals
())
...
...
@@ -884,11 +839,19 @@ def crf_decoding(input, param_attr, label=None):
Args:
input(${emission_type}): ${emission_comment}
param_attr(ParamAttr): The parameter attribute for training.
label(${label_type}): ${label_comment}
Returns:
${viterbi_path_comment}
Variable: ${viterbi_path_comment}
Examples:
.. code-block:: python
crf_decode = layers.crf_decoding(
input=hidden, param_attr=ParamAttr(name="crfw"))
"""
helper
=
LayerHelper
(
'crf_decoding'
,
**
locals
())
transition
=
helper
.
get_parameter
(
param_attr
.
name
)
...
...
@@ -903,15 +866,15 @@ def crf_decoding(input, param_attr, label=None):
return
viterbi_path
@
templatedoc
()
def
cos_sim
(
X
,
Y
):
"""
This function performs the cosine similarity between two tensors
X and Y and returns that as the output.
${comment}
Args:
X (Variable):
The input X
.
Y (Variable):
The input Y
.
X (Variable):
${x_comment}
.
Y (Variable):
${y_comment}
.
Returns:
Variable: the output of cosine(X, Y).
"""
...
...
@@ -1108,20 +1071,94 @@ def chunk_eval(input,
num_chunk_types
,
excluded_chunk_types
=
None
):
"""
**Chunk Evaluator**
This function computes and outputs the precision, recall and
F1-score of chunk detection.
For some basics of chunking, please refer to
'Chunking with Support Vector Machines <https://aclanthology.info/pdf/N/N01/N01-1025.pdf>'.
ChunkEvalOp computes the precision, recall, and F1-score of chunk detection,
and supports IOB, IOE, IOBES and IO (also known as plain) tagging schemes.
Here is a NER example of labeling for these tagging schemes:
.. code-block:: python
====== ====== ====== ===== == ============ ===== ===== ===== == =========
Li Ming works at Agricultural Bank of China in Beijing.
====== ====== ====== ===== == ============ ===== ===== ===== == =========
IO I-PER I-PER O O I-ORG I-ORG I-ORG I-ORG O I-LOC
IOB B-PER I-PER O O B-ORG I-ORG I-ORG I-ORG O B-LOC
IOE I-PER E-PER O O I-ORG I-ORG I-ORG E-ORG O E-LOC
IOBES B-PER E-PER O O I-ORG I-ORG I-ORG E-ORG O S-LOC
====== ====== ====== ===== == ============ ===== ===== ===== == =========
There are three chunk types(named entity types) including PER(person), ORG(organization)
and LOC(LOCATION), and we can see that the labels have the form <tag type>-<chunk type>.
Since the calculations actually use label ids rather than labels, extra attention
should be paid when mapping labels to ids to make CheckEvalOp work. The key point
is that the listed equations are satisfied by ids.
.. code-block:: python
tag_type = label % num_tag_type
chunk_type = label / num_tag_type
where `num_tag_type` is the num of tag types in the tagging scheme, `num_chunk_type`
is the num of chunk types, and `tag_type` get its value from the following table.
.. code-block:: python
Scheme Begin Inside End Single
plain 0 - - -
IOB 0 1 - -
IOE - 0 1 -
IOBES 0 1 2 3
Still use NER as example, assuming the tagging scheme is IOB while chunk types are ORG,
PER and LOC. To satisfy the above equations, the label map can be like this:
.. code-block:: python
B-ORG 0
I-ORG 1
B-PER 2
I-PER 3
B-LOC 4
I-LOC 5
O 6
It's not hard to verify the equations noting that the num of chunk types
is 3 and the num of tag types in IOB scheme is 2. For example, the label
id of I-LOC is 5, the tag type id of I-LOC is 1, and the chunk type id of
I-LOC is 2, which consistent with the results from the equations.
Args:
input (Variable): prediction output of the network.
label (Variable): label of the test data set.
chunk_scheme (str): ${chunk_scheme_comment}
num_chunk_types (int): ${num_chunk_types_comment}
excluded_chunk_types (list): ${excluded_chunk_types_comment}
Returns:
tuple: tuple containing: (precision, recall, f1_score,
num_infer_chunks, num_label_chunks,
num_correct_chunks)
tuple: tuple containing: precision, recall, f1_score,
num_infer_chunks, num_label_chunks,
num_correct_chunks
Examples:
.. code-block:: python
crf = fluid.layers.linear_chain_crf(
input=hidden, label=label, param_attr=ParamAttr(name="crfw"))
crf_decode = fluid.layers.crf_decoding(
input=hidden, param_attr=ParamAttr(name="crfw"))
fluid.layers.chunk_eval(
input=crf_decode,
label=label,
chunk_scheme="IOB",
num_chunk_types=(label_dict_len - 1) / 2)
"""
helper
=
LayerHelper
(
"chunk_eval"
,
**
locals
())
...
...
@@ -1177,15 +1214,11 @@ def sequence_conv(input,
bias_attr (ParamAttr|None): attributes for bias
param_attr (ParamAttr|None): attributes for parameter
act (str): the activation type
Returns:
Variable: output of sequence_conv
"""
# FIXME(dzh) : want to unify the argument of python layer
# function. So we ignore some unecessary attributes.
# such as, padding_trainable, context_start.
helper
=
LayerHelper
(
'sequence_conv'
,
**
locals
())
dtype
=
helper
.
input_dtype
()
filter_shape
=
[
filter_size
*
input
.
shape
[
1
],
num_filters
]
...
...
@@ -1257,6 +1290,45 @@ def sequence_softmax(input, param_attr=None, bias_attr=None, use_cudnn=True):
def
softmax
(
input
,
param_attr
=
None
,
bias_attr
=
None
,
use_cudnn
=
True
,
name
=
None
):
"""
The input of the softmax layer is a 2-D tensor with shape N x K (N is the
batch_size, K is the dimension of input feature). The output tensor has the
same shape as the input tensor.
For each row of the input tensor, the softmax operator squashes the
K-dimensional vector of arbitrary real values to a K-dimensional vector of real
values in the range [0, 1] that add up to 1.
It computes the exponential of the given dimension and the sum of exponential
values of all the other dimensions in the K-dimensional vector input.
Then the ratio of the exponential of the given dimension and the sum of
exponential values of all the other dimensions is the output of the softmax
operator.
For each row :math:`i` and each column :math:`j` in Input(X), we have:
.. math::
Out[i, j] =
\\
frac{\exp(X[i, j])}{\sum_j(exp(X[i, j])}
Args:
input (Variable): The input variable.
bias_attr (ParamAttr): attributes for bias
param_attr (ParamAttr): attributes for parameter
use_cudnn (bool): Use cudnn kernel or not, it is valid only when the cudnn
\
library is installed.
Returns:
Variable: output of softmax
Examples:
.. code-block:: python
fc = fluid.layers.fc(input=x, size=10)
softmax = fluid.layers.softmax(input=fc)
"""
helper
=
LayerHelper
(
'softmax'
,
**
locals
())
dtype
=
helper
.
input_dtype
()
softmax_out
=
helper
.
create_tmp_variable
(
dtype
)
...
...
@@ -1373,10 +1445,8 @@ def conv2d(input,
Examples:
.. code-block:: python
data = fluid.layers.data(
name='data', shape=[3, 32, 32], dtype='float32')
conv2d = fluid.layers.conv2d(
input=data, num_filters=2, filter_size=3, act="relu")
data = fluid.layers.data(name='data', shape=[3, 32, 32], dtype='float32')
conv2d = fluid.layers.conv2d(input=data, num_filters=2, filter_size=3, act="relu")
"""
num_channels
=
input
.
shape
[
1
]
...
...
@@ -1478,8 +1548,7 @@ def conv3d(input,
* :math:`
\\
ast`: Convolution operation.
* :math:`b`: Bias value, a 2-D tensor with shape [M, 1].
* :math:`
\\
sigma`: Activation function.
* :math:`Out`: Output value, the shape of :math:`Out` and :math:`X` may be
different.
* :math:`Out`: Output value, the shape of :math:`Out` and :math:`X` may be different.
Example:
...
...
@@ -1541,10 +1610,8 @@ def conv3d(input,
Examples:
.. code-block:: python
data = fluid.layers.data(
name='data', shape=[3, 12, 32, 32], dtype='float32')
conv2d = fluid.layers.conv3d(
input=data, num_filters=2, filter_size=3, act="relu")
data = fluid.layers.data(name='data', shape=[3, 12, 32, 32], dtype='float32')
conv3d = fluid.layers.conv3d(input=data, num_filters=2, filter_size=3, act="relu")
"""
l_type
=
'conv3d'
...
...
@@ -1745,6 +1812,7 @@ def sequence_last_step(input):
return
sequence_pool
(
input
=
input
,
pool_type
=
"last"
)
@
templatedoc
()
def
pool2d
(
input
,
pool_size
=-
1
,
pool_type
=
"max"
,
...
...
@@ -1756,24 +1824,45 @@ def pool2d(input,
use_mkldnn
=
False
,
name
=
None
):
"""
This function adds the operator for pooling in 2 dimensions, using the
pooling configurations mentioned in input parameters.
${comment}
Args:
input (Variable): ${input_comment}
pool_size (int): ${ksize_comment}
pool_type (str): ${pooling_type_comment}
input (Variable): The input tensor of pooling operator. The format of
input tensor is NCHW, where N is batch size, C is
the number of channels, H is the height of the
feature, and W is the width of the feature.
pool_size (int): The side length of pooling windows. All pooling
windows are squares with pool_size on a side.
pool_type: ${pooling_type_comment}
pool_stride (int): stride of the pooling layer.
pool_padding (int): padding size.
global_pooling
(bool)
: ${global_pooling_comment}
use_cudnn
(bool)
: ${use_cudnn_comment}
ceil_mode
(bool)
: ${ceil_mode_comment}
use_mkldnn
(bool)
: ${use_mkldnn_comment}
name (str
): A name for this layer(optional). If set None, the layer
will be named automatically.
global_pooling: ${global_pooling_comment}
use_cudnn: ${use_cudnn_comment}
ceil_mode: ${ceil_mode_comment}
use_mkldnn: ${use_mkldnn_comment}
name (str
|None): A name for this layer(optional). If set None, the
layer
will be named automatically.
Returns:
Variable: output of pool2d layer.
Variable: The pooling result.
Raises:
ValueError: If 'pool_type' is not "max" nor "avg"
ValueError: If 'global_pooling' is False and 'pool_size' is -1
ValueError: If 'use_cudnn' is not a bool value.
Examples:
.. code-block:: python
data = fluid.layers.data(
name='data', shape=[3, 32, 32], dtype='float32')
conv2d = fluid.layers.pool2d(
input=data,
pool_size=2,
pool_type='max',
pool_stride=1,
global_pooling=False)
"""
if
pool_type
not
in
[
"max"
,
"avg"
]:
raise
ValueError
(
...
...
@@ -1901,27 +1990,57 @@ def batch_norm(input,
moving_variance_name
=
None
,
do_model_average_for_mean_and_var
=
False
):
"""
This function helps create an operator to implement
the BatchNorm layer using the configurations from the input parameters.
**Batch Normalization Layer**
Can be used as a normalizer function for conv2d and fully_connected operations.
The required data format for this layer is one of the following:
1. NHWC `[batch, in_height, in_width, in_channels]`
2. NCHW `[batch, in_channels, in_height, in_width]`
Refer to `Batch Normalization: Accelerating Deep Network Training by Reducing
Internal Covariate Shift <https://arxiv.org/pdf/1502.03167.pdf>`_
for more details.
:math:`input` is the input features over a mini-batch.
.. math::
\\
mu_{
\\
beta} &
\\
gets
\\
frac{1}{m}
\\
sum_{i=1}^{m} x_i
\\
qquad &//
\\
\ mini-batch\ mean
\\\\
\\
sigma_{
\\
beta}^{2} &
\\
gets
\\
frac{1}{m}
\\
sum_{i=1}^{m}(x_i -
\\
\\
mu_{
\\
beta})^2
\\
qquad &//\ mini-batch\ variance
\\\\
\\
hat{x_i} &
\\
gets
\\
frac{x_i -
\\
mu_
\\
beta} {
\\
sqrt{
\\
\\
sigma_{
\\
beta}^{2} +
\\
epsilon}}
\\
qquad &//\ normalize
\\\\
y_i &
\\
gets
\\
gamma
\\
hat{x_i} +
\\
beta
\\
qquad &//\ scale\ and\ shift
Args:
input (Variable): the input variable.
act (str): activation type
is_test (bool): whether to run batch_norm as test mode.
momentum (float): momentum
epsilon (float): epsilon, default 1e-05
param_attr (ParamAttr|None): attributes for parameter
bias_attr (ParamAttr|None): attributes for bias
data_layout (str): data layout, default NCHW
in_place (bool): if True, do not create tmp variable
use_mkldnn (bool): ${use_mkldnn_comment}
name (str): The name of this layer. It is optional.
moving_mean_name (str): The name of moving mean variable name, optional.
moving_variance_name (str): The name of moving variance name, optional.
do_model_average_for_mean_and_var (bool):
input(variable): The input variable which is a LoDTensor.
act(string, Default None): Activation type, linear|relu|prelu|...
is_test(bool, Default False): Used for training or training.
momentum(float, Default 0.9):
epsilon(float, Default 1e-05):
param_attr(ParamAttr): The parameter attribute for Parameter `scale`.
bias_attr(ParamAttr): The parameter attribute for Parameter `bias`.
data_layout(string, default NCHW): NCHW|NHWC
in_place(bool, Default False): Make the input and output of batch norm reuse memory.
use_mkldnn(bool, Default false): ${use_mkldnn_comment}
name(string, Default None): A name for this layer(optional). If set None, the layer
will be named automatically.
moving_mean_name(string, Default None): The name of moving_mean which store the global Mean.
moving_variance_name(string, Default None): The name of the moving_variance which store the global Variance.
do_model_average_for_mean_and_var(bool, Default False): Do model average for mean and variance or not.
Returns:
Variable: output of batch_norm layer.
Variable: A tensor variable which is the result after applying batch normalization on the input.
Examples:
.. code-block:: python
hidden1 = fluid.layers.fc(input=x, size=200, param_attr='fc1.w')
hidden2 = fluid.layers.batch_norm(input=hidden1)
"""
helper
=
LayerHelper
(
'batch_norm'
,
**
locals
())
dtype
=
helper
.
input_dtype
()
...
...
@@ -2102,15 +2221,37 @@ def layer_norm(input,
def
beam_search_decode
(
ids
,
scores
,
name
=
None
):
"""
${beam_search_decode}
Beam Search Decode
This layers is to pack the output of beam search layer into sentences and
associated scores. It is usually called after the beam search layer.
Typically, the output of beam search layer is a tensor of selected ids, with
a tensor of the score of each id. Beam search layer's output ids, however,
are generated directly during the tree search, and they are stacked by each
level of the search tree. Thus we need to reorganize them into sentences,
based on the score of each id. This layer takes the output of beam search
layer as input and repack them into sentences.
Args:
ids (Variable): ${ids_comment}
scores (Variable): ${scores_comment}
ids (Variable): The selected ids, output of beam search layer.
scores (Variable): The associated scores of the ids, out put of beam
search layer.
name (str): The name of this layer. It is optional.
Returns:
tuple: a tuple of two output variable: sentence_ids, sentence_scores
tuple(Variable): a tuple of two output tensors: sentence_ids, sentence_scores.
sentence_ids is a tensor with shape [size, length], where size is the
beam size of beam search, and length is the length of each sentence.
Note that the length of sentences may vary.
sentence_scores is a tensor with the same shape as sentence_ids.
Examples:
.. code-block:: python
ids, scores = fluid.layers.beam_search(
pre_ids, ids, scores, beam_size, end_id)
sentence_ids, sentence_scores = fluid.layers.beam_search_decode(
ids, scores)
"""
helper
=
LayerHelper
(
'beam_search_decode'
,
**
locals
())
sentence_ids
=
helper
.
create_tmp_variable
(
dtype
=
ids
.
dtype
)
...
...
@@ -2152,32 +2293,36 @@ def conv2d_transpose(input,
represent height and width, respectively. The details of convolution transpose
layer, please refer to the following explanation and references
`therein <http://www.matthewzeiler.com/wp-content/uploads/2017/07/cvpr2010.pdf>`_.
If bias attribution and activation type are provided, bias is added to
the output of the convolution, and the corresponding activation function
is applied to the final result.
For each input :math:`X`, the equation is:
.. math::
Out =
W
\\
ast X
Out =
\sigma (W
\\
ast X + b)
In the above equation
:
Where
:
* :math:`X`: Input value, a tensor with NCHW format.
* :math:`W`: Filter value, a tensor with MCHW format.
* :math:`
\\
ast` : Convolution transpose operation.
* :math:`Out`: Output value, the shape of :math:`Out` and :math:`X` may be
different.
* :math:`
\\
ast`: Convolution operation.
* :math:`b`: Bias value, a 2-D tensor with shape [M, 1].
* :math:`
\\
sigma`: Activation function.
* :math:`Out`: Output value, the shape of :math:`Out` and :math:`X` may be different.
Example:
- Input:
Input shape:
$(N, C_{in}, H_{in}, W_{in})$
Input shape:
:math:`(N, C_{in}, H_{in}, W_{in})`
Filter shape:
$(C_{in}, C_{out}, H_f, W_f)$
Filter shape:
:math:`(C_{in}, C_{out}, H_f, W_f)`
- Output:
Output shape:
$(N, C_{out}, H_{out}, W_{out})$
Output shape:
:math:`(N, C_{out}, H_{out}, W_{out})`
Where
...
...
@@ -2231,10 +2376,8 @@ def conv2d_transpose(input,
Examples:
.. code-block:: python
data = fluid.layers.data(
name='data', shape=[3, 32, 32], dtype='float32')
conv2d_transpose = fluid.layers.conv2d_transpose(
input=data, num_filters=2, filter_size=3)
data = fluid.layers.data(name='data', shape=[3, 32, 32], dtype='float32')
conv2d_transpose = fluid.layers.conv2d_transpose(input=data, num_filters=2, filter_size=3)
"""
helper
=
LayerHelper
(
"conv2d_transpose"
,
**
locals
())
if
not
isinstance
(
input
,
Variable
):
...
...
@@ -2314,32 +2457,36 @@ def conv3d_transpose(input,
two elements. These two elements represent height and width, respectively.
The details of convolution transpose layer, please refer to the following
explanation and references `therein <http://www.matthewzeiler.com/wp-content/uploads/2017/07/cvpr2010.pdf>`_.
If bias attribution and activation type are provided, bias is added to
the output of the convolution, and the corresponding activation function
is applied to the final result.
For each input :math:`X`, the equation is:
.. math::
Out =
W
\\
ast X
Out =
\sigma (W
\\
ast X + b)
In the above equation:
* :math:`X`: Input value, a tensor with NCDHW format.
* :math:`W`: Filter value, a tensor with MCDHW format.
* :math:`
\\
ast` : Convolution transpose operation.
* :math:`Out`: Output value, the shape of :math:`Out` and :math:`X` may be
different.
* :math:`
\\
ast`: Convolution operation.
* :math:`b`: Bias value, a 2-D tensor with shape [M, 1].
* :math:`
\\
sigma`: Activation function.
* :math:`Out`: Output value, the shape of :math:`Out` and :math:`X` may be different.
Example:
- Input:
Input shape:
$(N, C_{in}, D_{in}, H_{in}, W_{in})$
Input shape:
:math:`(N, C_{in}, D_{in}, H_{in}, W_{in})`
Filter shape:
$(C_{in}, C_{out}, D_f, H_f, W_f)$
Filter shape:
:math:`(C_{in}, C_{out}, D_f, H_f, W_f)`
- Output:
Output shape:
$(N, C_{out}, D_{out}, H_{out}, W_{out})$
Output shape:
:math:`(N, C_{out}, D_{out}, H_{out}, W_{out})`
Where
...
...
@@ -2394,10 +2541,8 @@ def conv3d_transpose(input,
Examples:
.. code-block:: python
data = fluid.layers.data(
name='data', shape=[3, 12, 32, 32], dtype='float32')
conv2d_transpose = fluid.layers.conv3d_transpose(
input=data, num_filters=2, filter_size=3)
data = fluid.layers.data(name='data', shape=[3, 12, 32, 32], dtype='float32')
conv3d_transpose = fluid.layers.conv3d_transpose(input=data, num_filters=2, filter_size=3)
"""
l_type
=
"conv3d_transpose"
helper
=
LayerHelper
(
l_type
,
**
locals
())
...
...
@@ -2538,7 +2683,7 @@ def beam_search(pre_ids, ids, scores, beam_size, end_id, level=0):
beam_size (int): ${beam_size_comment}
end_id (int): ${end_id_comment}
level (int): ${level_comment}
Returns:
tuple: a tuple of beam_search output variables: selected_ids, selected_scores
'''
...
...
@@ -2987,7 +3132,7 @@ def split(input, num_or_sections, dim=-1, name=None):
will be named automatically.
Returns:
List
: The list of segmented tensor variables.
list(Variable)
: The list of segmented tensor variables.
Examples:
.. code-block:: python
...
...
@@ -3196,25 +3341,51 @@ def topk(input, k, name=None):
This operator is used to find values and indices of the k largest entries
for the last dimension.
If the input is a vector (
rank=1
), finds the k largest entries in the vector
If the input is a vector (
1-D Tensor
), finds the k largest entries in the vector
and outputs their values and indices as vectors. Thus values[j] is the j-th
largest entry in input, and its index is indices[j].
If the input is a Tensor with higher rank, this operator computes the top k
entries along the last dimension.
For example:
.. code-block:: text
If:
input = [[5, 4, 2, 3],
[9, 7, 10, 25],
[6, 2, 10, 1]]
k = 2
Then:
The first output:
values = [[5, 4],
[10, 25],
[6, 10]]
The second output:
indices = [[0, 1],
[2, 3],
[0, 2]]
Args:
input(Variable): The input variable which can be a vector or Tensor with
higher rank.
k(int): An integer value to specify the top k largest elements.
k(int): The number of top elements to look for along the last dimension
of input.
name(str|None): A name for this layer(optional). If set None, the layer
will be named automatically.
will be named automatically.
Default: None
Returns:
values(Variable): The k largest elements along each last dimensional
slice.
indices(Variable): The indices of values within the last dimension of
input.
Tuple[Variable]: A tuple with two elements. Each element is a Variable.
The first one is k largest elements along each last
dimensional slice. The second one is indices of values
within the last dimension of input.
Raises:
ValueError: If k < 1 or k is not less than the last dimension of input
Examples:
.. code-block:: python
...
...
@@ -3222,7 +3393,7 @@ def topk(input, k, name=None):
top5_values, top5_indices = layers.topk(input, k=5)
"""
shape
=
input
.
shape
if
k
<
1
and
k
>=
shape
[
-
1
]:
if
k
<
1
or
k
>=
shape
[
-
1
]:
raise
ValueError
(
"k must be greater than 0 and less than %d."
%
(
shape
[
-
1
]))
...
...
@@ -3240,8 +3411,7 @@ def topk(input, k, name=None):
return
values
,
indices
def
edit_distance
(
input
,
label
,
normalized
=
True
,
ignored_tokens
=
None
,
name
=
None
):
def
edit_distance
(
input
,
label
,
normalized
=
True
,
ignored_tokens
=
None
):
"""
EditDistance operator computes the edit distances between a batch of
hypothesis strings and their references. Edit distance, also called
...
...
@@ -3255,21 +3425,21 @@ def edit_distance(input, label, normalized=True, ignored_tokens=None,
"kitten" -> "sitten" -> "sittin" -> "sitting"
Input(Hyps)
is a LoDTensor consisting of all the hypothesis strings with
The input
is a LoDTensor consisting of all the hypothesis strings with
the total number denoted by `batch_size`, and the separation is specified
by the LoD information. And the `batch_size` reference strings are arranged
in order in the same way in the
LoDTensor Input(Refs)
.
in order in the same way in the
input LoDTensor
.
Output(Out)
contains the `batch_size` results and each stands for the edit
The output
contains the `batch_size` results and each stands for the edit
distance for a pair of strings respectively. If Attr(normalized) is true,
the edit distance will be divided by the length of reference string.
Args:
input(Variable): The indices for hypothesis strings.
label(Variable): The indices for reference strings.
normalized(bool): Indicated whether to normalize the edit distance by
normalized(bool
, default True
): Indicated whether to normalize the edit distance by
the length of reference string.
ignored_tokens(list
of int
): Tokens that should be removed before
ignored_tokens(list
<int>, default None
): Tokens that should be removed before
calculating edit distance.
name (str): The name of this layer. It is optional.
...
...
@@ -3281,7 +3451,6 @@ def edit_distance(input, label, normalized=True, ignored_tokens=None,
x = fluid.layers.data(name='x', shape=[8], dtype='float32')
y = fluid.layers.data(name='y', shape=[7], dtype='float32')
cost = fluid.layers.edit_distance(input=x,label=y)
"""
helper
=
LayerHelper
(
"edit_distance"
,
**
locals
())
...
...
@@ -3322,6 +3491,7 @@ def edit_distance(input, label, normalized=True, ignored_tokens=None,
def
ctc_greedy_decoder
(
input
,
blank
,
name
=
None
):
"""
This op is used to decode sequences by greedy policy by below steps:
1. Get the indexes of max value for each row in input. a.k.a.
numpy.argmax(input, axis=0).
2. For each sequence in result of step1, merge repeated tokens between two
...
...
@@ -3401,35 +3571,33 @@ def warpctc(input, label, blank=0, norm_by_times=False):
input tensor.
Args:
input(Variable): (LodTensor, default: LoDTensor<float>),
the unscaled probabilities of variable-length sequences,
which is a 2-D Tensor with LoD information.
It's shape is [Lp, num_classes + 1], where Lp is the sum of all input
sequences' length and num_classes is the true number of classes.
(not including the blank label).
label(Variable): (LodTensor, default: LoDTensor<int>), the ground truth
of variable-length sequence, which is a 2-D Tensor with LoD
information. It is of the shape [Lg, 1], where Lg is th sum of
all labels' length.
blank (int): default 0, the blank label index of Connectionist
Temporal Classification (CTC) loss, which is in the
half-opened interval [0, num_classes + 1).
norm_by_times (bool): default false, whether to normalize
the gradients by the number of time-step, which is also the
sequence's length. There is no need to normalize the gradients
if warpctc layer was follewed by a mean_op.
input (Variable): The unscaled probabilities of variable-length sequences,
which is a 2-D Tensor with LoD information.
It's shape is [Lp, num_classes + 1], where Lp is the sum of all input
sequences' length and num_classes is the true number of classes.
(not including the blank label).
label (Variable): The ground truth of variable-length sequence,
which is a 2-D Tensor with LoD information. It is of the shape [Lg, 1],
where Lg is th sum of all labels' length.
blank (int, default 0): The blank label index of Connectionist
Temporal Classification (CTC) loss, which is in the
half-opened interval [0, num_classes + 1).
norm_by_times(bool, default false): Whether to normalize the gradients
by the number of time-step, which is also the sequence's length.
There is no need to normalize the gradients if warpctc layer was
follewed by a mean_op.
Returns:
Variable: The Connectionist Temporal Classification (CTC) loss,
which is a 2-D Tensor of the shape [batch_size, 1].
Examples:
.. code-block:: python
y = layers.data(
name='y', shape=[11, 8], dtype='float32', lod_level=1)
y_predict = layers.data(
name='y_predict', shape=[11, 1], dtype='float32')
cost = layers.warpctc(input=y_predict, label=y)
label = fluid.layers.data(shape=[11, 8], dtype='float32', lod_level=1)
predict = fluid.layers.data(shape=[11, 1], dtype='float32')
cost = fluid.layers.warpctc(input=predict, label=label)
"""
helper
=
LayerHelper
(
'warpctc'
,
**
locals
())
...
...
@@ -3458,17 +3626,21 @@ def sequence_reshape(input, new_dim):
.. code-block:: text
x is a LoDTensor:
x.lod = [[2, 4]]
x.data = [[1, 2], [3, 4],
[5, 6], [7, 8], [9, 10], [11, 12]]
x.lod = [[0, 2, 6]]
x.data = [[1, 2], [3, 4],
[5, 6], [7, 8],
[9, 10], [11, 12]]
x.dims = [6, 2]
set new_dim = 4
then out is a LoDTensor:
out.lod = [[1, 2]]
out.data = [[1, 2, 3, 4],
[5, 6, 7, 8], [9, 10, 11, 12]]
out.lod = [[0, 1, 3]]
out.data = [[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]]
out.dims = [3, 4]
Currently, only 1-level LoDTensor is supported and please make sure
...
...
@@ -3476,19 +3648,19 @@ def sequence_reshape(input, new_dim):
no remainder for each sequence.
Args:
input (Variable): (LodTensor, default: LoDTensor<float>), a 2-D LoDTensor
with shape being [N, M] where M for dimension.
new_dim (int): New dimension which
the input LoDTensor is reshaped to.
input (Variable): A 2-D LoDTensor
with shape being [N, M] where M for dimension.
new_dim (int): New dimension that
the input LoDTensor is reshaped to.
Returns:
Variable: Reshaped LoDTensor according to new dimension.
Examples:
.. code-block:: python
x = fluid.layers.data(name='x', shape=[5, 20],
dtype='float32', lod_level=1)
x_reshaped = layers.sequence_reshape(input=x, new_dim=10)
x = fluid.layers.data(shape=[5, 20], dtype='float32', lod_level=1)
x_reshaped = fluid.layers.sequence_reshape(input=x, new_dim=10)
"""
helper
=
LayerHelper
(
'sequence_reshape'
,
**
locals
())
out
=
helper
.
create_tmp_variable
(
helper
.
input_dtype
())
...
...
@@ -3524,7 +3696,7 @@ def nce(input,
param_attr (ParamAttr|None): attributes for parameter
bias_attr (ParamAttr|None): attributes for bias
num_neg_samples (int): ${num_neg_samples_comment}
Returns:
Variable: The output nce loss.
...
...
@@ -3603,8 +3775,6 @@ def nce(input,
def
transpose
(
x
,
perm
,
name
=
None
):
"""
**transpose Layer**
Permute the dimensions of `input` according to `perm`.
The `i`-th dimension of the returned tensor will correspond to the
...
...
@@ -3694,8 +3864,6 @@ def im2sequence(input, filter_size=1, stride=1, padding=0, name=None):
Examples:
As an example:
.. code-block:: text
Given:
...
...
@@ -3739,7 +3907,7 @@ def im2sequence(input, filter_size=1, stride=1, padding=0, name=None):
output.lod = [[4, 4]]
The simple usage i
s:
Example
s:
.. code-block:: python
...
...
@@ -3991,8 +4159,9 @@ def one_hot(input, depth):
def
autoincreased_step_counter
(
counter_name
=
None
,
begin
=
1
,
step
=
1
):
"""
NOTE: The counter will be automatically increased by 1 every mini-batch
Return the run counter of the main program, which is started with 1.
Create an auto-increase variable
which will be automatically increased by 1 every mini-batch
Return the run counter of the main program, default is started from 1.
Args:
counter_name(str): The counter name, default is '@STEP_COUNTER@'.
...
...
@@ -4001,6 +4170,12 @@ def autoincreased_step_counter(counter_name=None, begin=1, step=1):
Returns:
Variable: The global run counter.
Examples:
.. code-block:: python
global_step = fluid.layers.autoincreased_step_counter(
counter_name='@LR_DECAY_COUNTER@', begin=begin, step=1)
"""
helper
=
LayerHelper
(
'global_step_counter'
)
if
counter_name
is
None
:
...
...
@@ -4224,9 +4399,7 @@ def lrn(input, n=5, k=1.0, alpha=1e-4, beta=0.75, name=None):
.. math::
Output(i, x, y) = Input(i, x, y) / \left(
k +
\a
lpha \sum\limits^{\min(C, c + n/2)}_{j = \max(0, c - n/2)}
(Input(j, x, y))^2
\r
ight)^{
\b
eta}
Output(i, x, y) = Input(i, x, y) /
\\
left(k +
\\
alpha
\\
sum
\\
limits^{
\\
min(C, c + n/2)}_{j =
\\
max(0, c - n/2)}(Input(j, x, y))^2
\\
right)^{
\\
beta}
In the above equation:
...
...
@@ -4410,34 +4583,20 @@ def label_smooth(label,
return
smooth_label
@
templatedoc
()
def
roi_pool
(
input
,
rois
,
pooled_height
=
1
,
pooled_width
=
1
,
spatial_scale
=
1.0
):
"""
Region of interest pooling (also known as RoI pooling) is to perform
is to perform max pooling on inputs of nonuniform sizes to obtain
fixed-size feature maps (e.g. 7*7).
The operator has three steps:
1. Dividing each region proposal into equal-sized sections with
the pooled_width and pooled_height
2. Finding the largest value in each section
3. Copying these max values to the output buffer
${comment}
Args:
input (Variable): The input for ROI pooling.
rois (Variable): ROIs (Regions of Interest) to pool over. It should
be a 2-D one level LoTensor of shape [num_rois, 4].
The layout is [x1, y1, x2, y2], where (x1, y1)
is the top left coordinates, and (x2, y2) is the
bottom right coordinates. The num_rois is the
total number of ROIs in this batch data.
pooled_height (integer): The pooled output height. Default: 1
pooled_width (integer): The pooled output width. Default: 1
spatial_scale (float): Multiplicative spatial scale factor. To
translate ROI coords from their input scale
to the scale used when pooling. Default: 1.0
input (Variable): ${x_comment}
rois (Variable): ROIs (Regions of Interest) to pool over.
pooled_height (integer): ${pooled_height_comment} Default: 1
pooled_width (integer): ${pooled_width_comment} Default: 1
spatial_scale (float): ${spatial_scale_comment} Default: 1.0
Returns:
pool_out (Variable): The output is a 4-D tensor of the shape
(num_rois, channels, pooled_h, pooled_w).
Variable: ${out_comment}.
Examples:
.. code-block:: python
...
...
@@ -4509,12 +4668,13 @@ def image_resize(input,
name
=
None
,
resample
=
'BILINEAR'
):
"""
Resize a batch of images.
**Resize a Batch of Images**
The input must be a tensor of the shape (num_batches, channels, in_h, in_w),
and the resizing only applies on the last two dimensions(hight and width).
Supporting resample methods:
'BILINEAR' : Bilinear interpolation
Args:
...
...
@@ -4534,8 +4694,8 @@ def image_resize(input,
Default: 'BILINEAR'
Returns:
out (Variable)
: The output is a 4-D tensor of the shape
(num_batches, channls, out_h, out_w).
Variable
: The output is a 4-D tensor of the shape
(num_batches, channls, out_h, out_w).
Examples:
.. code-block:: python
...
...
@@ -4619,8 +4779,8 @@ def image_resize_short(input, out_short_len, resample='BILINEAR'):
resample (str): resample method, default: BILINEAR.
Returns:
out (Variable)
: The output is a 4-D tensor of the shape
(num_batches, channls, out_h, out_w).
Variable
: The output is a 4-D tensor of the shape
(num_batches, channls, out_h, out_w).
"""
in_shape
=
input
.
shape
if
len
(
in_shape
)
!=
4
:
...
...
@@ -4639,6 +4799,8 @@ def image_resize_short(input, out_short_len, resample='BILINEAR'):
def
gather
(
input
,
index
):
"""
**Gather Layer**
Output is obtained by gathering entries of the outer-most dimension
of X indexed by `index` and concatenate them together.
...
...
@@ -4737,6 +4899,62 @@ def random_crop(x, shape, seed=None):
return
out
def
log
(
x
):
"""
Calculates the natural log of the given input tensor, element-wise.
.. math::
Out =
\\
ln(x)
Args:
x (Variable): Input tensor.
Returns:
Variable: The natural log of the input tensor computed element-wise.
Examples:
.. code-block:: python
output = fluid.layers.log(x)
"""
helper
=
LayerHelper
(
'log'
,
**
locals
())
dtype
=
helper
.
input_dtype
()
out
=
helper
.
create_tmp_variable
(
dtype
)
helper
.
append_op
(
type
=
"log"
,
inputs
=
{
"X"
:
input
},
outputs
=
{
"Out"
:
out
})
return
out
def
relu
(
x
):
"""
Relu takes one input data (Tensor) and produces one output data (Tensor)
where the rectified linear function, y = max(0, x), is applied to
the tensor elementwise.
.. math::
Out =
\\
max(0, x)
Args:
x (Variable): The input tensor.
Returns:
Variable: The output tensor with the same shape as input.
Examples:
.. code-block:: python
output = fluid.layers.relu(x)
"""
helper
=
LayerHelper
(
'relu'
,
**
locals
())
dtype
=
helper
.
input_dtype
()
out
=
helper
.
create_tmp_variable
(
dtype
)
helper
.
append_op
(
type
=
"relu"
,
inputs
=
{
"X"
:
input
},
outputs
=
{
"Out"
:
out
})
return
out
def
mean_iou
(
input
,
label
,
num_classes
):
"""
Mean Intersection-Over-Union is a common evaluation metric for
...
...
@@ -4745,8 +4963,8 @@ def mean_iou(input, label, num_classes):
IOU is defined as follows:
.. math::
IOU =
true_positive / (true_positive + false_positive + false_negative).
IOU =
\\
frac{true\_positiv}{(true\_positive + false\_positive + false\_negative)}.
The predictions are accumulated in a confusion matrix and mean-IOU
is then calculated from it.
...
...
@@ -4754,19 +4972,19 @@ def mean_iou(input, label, num_classes):
Args:
input (Variable): A Tensor of prediction results for semantic labels with type int32 or int64.
label (Variable):
A Tensor of ground truth labels with type int32 or int64.
label (Variable):
A Tensor of ground truth labels with type int32 or int64.
Its shape should be the same as input.
num_classes (int): The possible number of labels.
Returns:
mean_iou (Variable): A Tensor representing the mean intersection-over-union with shape [1].
out_wrong(Variable): A Tensor with shape [num_classes]. The wrong numbers of each class.
out_correct(Variable): A Tensor with shape [num_classes]. The correct numbers of each class.
Examples:
.. code-block:: python
iou, wrongs, corrects = fluid.layers.mean_iou(predict, label, num_classes)
"""
helper
=
LayerHelper
(
'mean_iou'
,
**
locals
())
...
...
python/paddle/fluid/layers/ops.py
浏览文件 @
f1f8327c
...
...
@@ -17,7 +17,6 @@ __activations__ = [
'sigmoid'
,
'logsigmoid'
,
'exp'
,
'relu'
,
'tanh'
,
'tanh_shrink'
,
'softshrink'
,
...
...
@@ -29,7 +28,6 @@ __activations__ = [
'sin'
,
'round'
,
'reciprocal'
,
'log'
,
'square'
,
'softplus'
,
'softsign'
,
...
...
@@ -70,6 +68,7 @@ __all__ = [
'slice'
,
'polygon_box_transform'
,
'shape'
,
'iou_similarity'
,
'maxout'
,
]
+
__activations__
...
...
python/paddle/fluid/layers/tensor.py
浏览文件 @
f1f8327c
...
...
@@ -35,10 +35,29 @@ __all__ = [
'argmax'
,
'ones'
,
'zeros'
,
'reverse'
,
]
def
create_tensor
(
dtype
,
name
=
None
,
persistable
=
False
):
"""
Create an variable, which will hold a LoDTensor with data type dtype.
Args:
dtype(string): 'float32'|'int32'|..., the data type of the
created tensor.
name(string): The name of the created tensor, if not set,
the name will be a random unique one.
persistable(bool): Set the persistable flag of the create tensor.
Returns:
Variable: The tensor variable storing the created tensor.
Examples:
.. code-block:: python
tensor = fluid.layers.create_tensor(dtype='float32')
"""
helper
=
LayerHelper
(
"create_tensor"
,
**
locals
())
return
helper
.
create_variable
(
name
=
helper
.
name
,
dtype
=
dtype
,
persistable
=
persistable
)
...
...
@@ -89,16 +108,29 @@ def create_global_var(shape,
force_cpu
=
False
,
name
=
None
):
"""
Create a global variable. such as global_step
Create a new variable in the global block(block 0).
Args:
shape(list[int]): shape of the variable
value(float): the value of the variable
dtype(string): element type of the parameter
persistable(bool): if this variable is persistable
force_cpu(bool): force this variable to be on CPU
value(float): the value of the variable. The new created
variable will be filled with it.
dtype(string): data type of the variable
persistable(bool): if this variable is persistable.
Default: False
force_cpu(bool): force this variable to be on CPU.
Default: False
name(str|None): The name of the variable. If set to None the variable
name will be generated automatically.
Default: None
Returns:
Variable: the created Variable
Examples:
.. code-block:: python
var = fluid.create_global_var(shape=[2,3], value=1.0, dtype='float32',
persistable=True, force_cpu=True, name='new_var')
"""
helper
=
LayerHelper
(
"global_var"
,
**
locals
())
var
=
helper
.
create_global_variable
(
...
...
@@ -156,7 +188,8 @@ def concat(input, axis=0, name=None):
Examples:
.. code-block:: python
out = fluid.layers.concat(input=[Efirst, Esecond, Ethird, Efourth])
out = fluid.layers.concat(input=[Efirst, Esecond, Ethird, Efourth])
"""
helper
=
LayerHelper
(
'concat'
,
**
locals
())
out
=
helper
.
create_tmp_variable
(
dtype
=
helper
.
input_dtype
())
...
...
@@ -169,19 +202,21 @@ def concat(input, axis=0, name=None):
def
sums
(
input
,
out
=
None
):
"""This function performs the sum operation on the input and returns the
"""
This function performs the sum operation on the input and returns the
result as the output.
Args:
input (Variable|list): The input tensor that has the elements
that need to be summed up.
out (Variable|None): Output parameter. The sum result.
Default: None
Returns:
Variable: The tensor type variable that has the sum of input
written to it.
Variable: the sum of input. The same as the argument 'out'
Examples:
.. code-block::python
.. code-block::
python
tmp = fluid.layers.zeros(shape=[10], dtype='int32')
i = fluid.layers.fill_constant(shape=[1], dtype='int64', value=10)
...
...
@@ -352,13 +387,13 @@ def argmin(x, axis=0):
x(Variable): The input to compute the indices of
the min elements.
axis(int): Axis to compute indices along.
Returns:
Variable: The tensor variable storing the output
Examples:
.. code-block:: python
out = fluid.layers.argmin(x=in, axis=0)
out = fluid.layers.argmin(x=in, axis=-1)
"""
...
...
@@ -383,13 +418,13 @@ def argmax(x, axis=0):
x(Variable): The input to compute the indices of
the max elements.
axis(int): Axis to compute indices along.
Returns:
Variable: The tensor variable storing the output
Examples:
.. code-block:: python
out = fluid.layers.argmax(x=in, axis=0)
out = fluid.layers.argmax(x=in, axis=-1)
"""
...
...
@@ -437,11 +472,12 @@ def zeros(shape, dtype, force_cpu=False):
It also sets *stop_gradient* to True.
Args:
shape(tuple|list|None): Shape of output tensor
dtype(np.dtype|core.VarDesc.VarType|str): Data type of output tensor
shape(tuple|list|None): Shape of output tensor.
dtype(np.dtype|core.VarDesc.VarType|str): Data type of output tensor.
force_cpu(bool, default False): Whether to make output stay on CPU.
Returns:
Variable: The tensor variable storing the output
Variable: The tensor variable storing the output
.
Examples:
.. code-block:: python
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}