# 端侧部署
本教程将介绍基于[Paddle Lite](https://github.com/PaddlePaddle/Paddle-Lite) 在移动端部署PaddleOCR超轻量中文检测、识别模型的详细步骤。
Paddle Lite是飞桨轻量化推理引擎,为手机、IOT端提供高效推理能力,并广泛整合跨平台硬件,为端侧部署及应用落地问题提供轻量化的部署方案。
## 1. 准备环境
### 运行准备
- 电脑(编译Paddle Lite)
- 安卓手机(armv7或armv8)
***注意: PaddleOCR 移动端部署当前不支持动态图模型,只支持静态图保存的模型。当前PaddleOCR静态图的分支是`develop`。***
### 1.1 准备交叉编译环境
交叉编译环境用于编译 Paddle Lite 和 PaddleOCR 的C++ demo。
支持多种开发环境,不同开发环境的编译流程请参考对应文档。
1. [Docker](https://paddle-lite.readthedocs.io/zh/latest/source_compile/compile_env.html#docker)
2. [Linux](https://paddle-lite.readthedocs.io/zh/latest/source_compile/compile_env.html#linux)
3. [MAC OS](https://paddle-lite.readthedocs.io/zh/latest/source_compile/compile_env.html#mac-os)
### 1.2 准备预测库
预测库有两种获取方式:
- 1. [推荐]编译Paddle-Lite得到预测库,Paddle-Lite的编译方式如下:
```
git clone https://github.com/PaddlePaddle/Paddle-Lite.git
cd Paddle-Lite
# 切换到Paddle-Lite release/v2.7 稳定分支
git checkout release/v2.7
./lite/tools/build_android.sh --arch=armv8 --with_cv=ON --with_extra=ON
```
注意:编译Paddle-Lite获得预测库时,需要打开`--with_cv=ON --with_extra=ON`两个选项,`--arch`表示`arm`版本,这里指定为armv8,
更多编译命令
介绍请参考[链接](https://paddle-lite.readthedocs.io/zh/latest/user_guides/Compile/Android.html#id2)。
- 2. 直接下载预测库,下载[链接](https://github.com/PaddlePaddle/Paddle-Lite/releases/tag/v2.7.1)。
直接下载预测库并解压后,可以得到`inference_lite_lib.android.armv8/`文件夹,通过编译Paddle-Lite得到的预测库位于
`Paddle-Lite/build.lite.android.armv8.gcc/inference_lite_lib.android.armv8/`文件夹下。
预测库的文件目录如下:
```
inference_lite_lib.android.armv8/
|-- cxx C++ 预测库和头文件
| |-- include C++ 头文件
| | |-- paddle_api.h
| | |-- paddle_image_preprocess.h
| | |-- paddle_lite_factory_helper.h
| | |-- paddle_place.h
| | |-- paddle_use_kernels.h
| | |-- paddle_use_ops.h
| | `-- paddle_use_passes.h
| `-- lib C++预测库
| |-- libpaddle_api_light_bundled.a C++静态库
| `-- libpaddle_light_api_shared.so C++动态库
|-- java Java预测库
| |-- jar
| | `-- PaddlePredictor.jar
| |-- so
| | `-- libpaddle_lite_jni.so
| `-- src
|-- demo C++和Java示例代码
| |-- cxx C++ 预测库demo
| `-- java Java 预测库demo
```
## 2 开始运行
### 2.1 模型优化
Paddle-Lite 提供了多种策略来自动优化原始的模型,其中包括量化、子图融合、混合调度、Kernel优选等方法,使用Paddle-lite的opt工具可以自动
对inference模型进行优化,优化后的模型更轻量,模型运行速度更快。
如果已经准备好了 `.nb` 结尾的模型文件,可以跳过此步骤。
下述表格中也提供了一系列中文移动端模型:
|模型版本|模型简介|模型大小|检测模型|文本方向分类模型|识别模型|Paddle-Lite版本|
|-|-|-|-|-|-|-|
|V1.1|超轻量中文OCR 移动端模型|8.1M|[下载地址](https://paddleocr.bj.bcebos.com/20-09-22/mobile/lite/ch_ppocr_mobile_v1.1_det_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/20-09-22/mobile/lite/ch_ppocr_mobile_v1.1_cls_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/20-09-22/mobile/lite/ch_ppocr_mobile_v1.1_rec_opt.nb)|v2.7|
|【slim】V1.1|超轻量中文OCR 移动端模型|3.5M|[下载地址](https://paddleocr.bj.bcebos.com/20-09-22/mobile/lite/ch_ppocr_mobile_v1.1_det_prune_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/20-09-22/mobile/lite/ch_ppocr_mobile_v1.1_cls_quant_opt.nb)|[下载地址](https://paddleocr.bj.bcebos.com/20-09-22/mobile/lite/ch_ppocr_mobile_v1.1_rec_quant_opt.nb)|v2.7|
注意:V1.1 3.0M 轻量模型是使用PaddleSlim优化后的,需要配合Paddle-Lite最新预测库使用。
如果直接使用上述表格中的模型进行部署没有问题,可略过下述步骤,直接阅读 [2.2节](#2.2与手机联调)。
如果要部署的模型不在上述表格中,则需要按照如下步骤获得优化后的模型。
模型优化需要Paddle-Lite的opt可执行文件,可以通过编译Paddle-Lite源码获得,编译步骤如下:
```
# 如果准备环境时已经clone了Paddle-Lite,则不用重新clone Paddle-Lite
git clone https://github.com/PaddlePaddle/Paddle-Lite.git
cd Paddle-Lite
git checkout release/v2.7
# 启动编译
./lite/tools/build.sh build_optimize_tool
```
编译完成后,opt文件位于`build.opt/lite/api/`下,可通过如下方式查看opt的运行选项和使用方式;
```
cd build.opt/lite/api/
./opt
```
|选项|说明|
|-|-|
|--model_dir|待优化的PaddlePaddle模型(非combined形式)的路径|
|--model_file|待优化的PaddlePaddle模型(combined形式)的网络结构文件路径|
|--param_file|待优化的PaddlePaddle模型(combined形式)的权重文件路径|
|--optimize_out_type|输出模型类型,目前支持两种类型:protobuf和naive_buffer,其中naive_buffer是一种更轻量级的序列化/反序列化实现。若您需要在mobile端执行模型预测,请将此选项设置为naive_buffer。默认为protobuf|
|--optimize_out|优化模型的输出路径|
|--valid_targets|指定模型可执行的backend,默认为arm。目前可支持x86、arm、opencl、npu、xpu,可以同时指定多个backend(以空格分隔),Model Optimize Tool将会自动选择最佳方式。如果需要支持华为NPU(Kirin 810/990 Soc搭载的达芬奇架构NPU),应当设置为npu, arm|
|--record_tailoring_info|当使用 根据模型裁剪库文件 功能时,则设置该选项为true,以记录优化后模型含有的kernel和OP信息,默认为false|
`--model_dir`适用于待优化的模型是非combined方式,PaddleOCR的inference模型是combined方式,即模型结构和模型参数使用单独一个文件存储。
下面以PaddleOCR的超轻量中文模型为例,介绍使用编译好的opt文件完成inference模型到Paddle-Lite优化模型的转换。
```
# 【推荐】 下载PaddleOCR V1.1版本的中英文 inference模型,V1.1比1.0效果更好,模型更小
wget https://paddleocr.bj.bcebos.com/20-09-22/mobile-slim/det/ch_ppocr_mobile_v1.1_det_prune_infer.tar && tar xf ch_ppocr_mobile_v1.1_det_prune_infer.tar
wget https://paddleocr.bj.bcebos.com/20-09-22/mobile-slim/rec/ch_ppocr_mobile_v1.1_rec_quant_infer.tar && tar xf ch_ppocr_mobile_v1.1_rec_quant_infer.tar
# 转换V1.1检测模型
./opt --model_file=./ch_ppocr_mobile_v1.1_det_prune_infer/model --param_file=./ch_ppocr_mobile_v1.1_det_prune_infer/params --optimize_out=./ch_ppocr_mobile_v1.1_det_prune_opt --valid_targets=arm
# 转换V1.1识别模型
./opt --model_file=./ch_ppocr_mobile_v1.1_rec_quant_infer/model --param_file=./ch_ppocr_mobile_v1.1_rec_quant_infer/params --optimize_out=./ch_ppocr_mobile_v1.1_rec_quant_opt --valid_targets=arm
# 或下载使用PaddleOCR的V1.0超轻量中英文 inference模型,解压并转换为移动端支持的模型
wget https://paddleocr.bj.bcebos.com/ch_models/ch_det_mv3_db_infer.tar && tar xf ch_det_mv3_db_infer.tar
wget https://paddleocr.bj.bcebos.com/ch_models/ch_rec_mv3_crnn_infer.tar && tar xf ch_rec_mv3_crnn_infer.tar
# 转换V1.0检测模型
./opt --model_file=./ch_det_mv3_db/model --param_file=./ch_det_mv3_db/params --optimize_out_type=naive_buffer --optimize_out=./ch_det_mv3_db_opt --valid_targets=arm
# 转换V1.0识别模型
./opt --model_file=./ch_rec_mv3_crnn/model --param_file=./ch_rec_mv3_crnn/params --optimize_out_type=naive_buffer --optimize_out=./ch_rec_mv3_crnn_opt --valid_targets=arm
```
转换成功后,当前目录下会多出`.nb`结尾的文件,即是转换成功的模型文件。
注意:使用paddle-lite部署时,需要使用opt工具优化后的模型。 opt 工具的输入模型是paddle保存的inference模型
### 2.2 与手机联调
首先需要进行一些准备工作。
1. 准备一台arm8的安卓手机,如果编译的预测库和opt文件是armv7,则需要arm7的手机,并修改Makefile中`ARM_ABI = arm7`。
2. 打开手机的USB调试选项,选择文件传输模式,连接电脑。
3. 电脑上安装adb工具,用于调试。 adb安装方式如下:
3.1. MAC电脑安装ADB:
```
brew cask install android-platform-tools
```
3.2. Linux安装ADB
```
sudo apt update
sudo apt install -y wget adb
```
3.3. Window安装ADB
win上安装需要去谷歌的安卓平台下载adb软件包进行安装:[链接](https://developer.android.com/studio)
打开终端,手机连接电脑,在终端中输入
```
adb devices
```
如果有device输出,则表示安装成功。
```
List of devices attached
744be294 device
```
4. 准备优化后的模型、预测库文件、测试图像和使用的字典文件。
```
git clone https://github.com/PaddlePaddle/PaddleOCR.git
cd PaddleOCR/deploy/lite/
# 按照如下命令运行prepare.sh,将预测库文件、测试图像和使用的字典文件到预测库中的demo/cxx/ocr文件夹下
sh prepare.sh /{lite prediction library path}/inference_lite_lib.android.armv8
# 进入OCR demo的工作目录
cd /{lite prediction library path}/inference_lite_lib.android.armv8/
cd demo/cxx/ocr/
# 将C++预测动态库so文件复制到debug文件夹中
cp ../../../cxx/lib/libpaddle_light_api_shared.so ./debug/
```
准备测试图像,以`PaddleOCR/doc/imgs/11.jpg`为例,将测试的图像复制到`demo/cxx/ocr/debug/`文件夹下。
准备lite opt工具优化后的模型文件,比如使用`ch_ppocr_mobile_v1.1_det_prune_opt.nb,ch_ppocr_mobile_v1.1_rec_quant_opt.nb, ch_ppocr_mobile_cls_quant_opt.nb`,模型文件放置在`demo/cxx/ocr/debug/`文件夹下。
执行完成后,ocr文件夹下将有如下文件格式:
```
demo/cxx/ocr/
|-- debug/
| |--ch_ppocr_mobile_v1.1_det_prune_opt.nb 优化后的检测模型文件
| |--ch_ppocr_mobile_v1.1_rec_quant_opt.nb 优化后的识别模型文件
| |--ch_ppocr_mobile_cls_quant_opt.nb 优化后的文字方向分类器模型文件
| |--11.jpg 待测试图像
| |--ppocr_keys_v1.txt 中文字典文件
| |--libpaddle_light_api_shared.so C++预测库文件
| |--config.txt DB-CRNN超参数配置
|-- config.txt DB-CRNN超参数配置
|-- crnn_process.cc 识别模型CRNN的预处理和后处理文件
|-- crnn_process.h
|-- db_post_process.cc 检测模型DB的后处理文件
|-- db_post_process.h
|-- Makefile 编译文件
|-- ocr_db_crnn.cc C++预测源文件
```
#### 注意:
1. ppocr_keys_v1.txt是中文字典文件,如果使用的 nb 模型是英文数字或其他语言的模型,需要更换为对应语言的字典。
PaddleOCR 在ppocr/utils/下存放了多种字典,包括:
```
dict/french_dict.txt # 法语字典
dict/german_dict.txt # 德语字典
ic15_dict.txt # 英文字典
dict/japan_dict.txt # 日语字典
dict/korean_dict.txt # 韩语字典
ppocr_keys_v1.txt # 中文字典
```
2. `config.txt` 包含了检测器、分类器的超参数,如下:
```
max_side_len 960 # 输入图像长宽大于960时,等比例缩放图像,使得图像最长边为960
det_db_thresh 0.3 # 用于过滤DB预测的二值化图像,设置为0.-0.3对结果影响不明显
det_db_box_thresh 0.5 # DB后处理过滤box的阈值,如果检测存在漏框情况,可酌情减小
det_db_unclip_ratio 1.6 # 表示文本框的紧致程度,越小则文本框更靠近文本
use_direction_classify 0 # 是否使用方向分类器,0表示不使用,1表示使用
```
5. 启动调试
上述步骤完成后就可以使用adb将文件push到手机上运行,步骤如下:
```
# 执行编译,得到可执行文件ocr_db_crnn
# ocr_db_crnn可执行文件的使用方式为:
# ./ocr_db_crnn 检测模型文件 方向分类器模型文件 识别模型文件 测试图像路径 字典文件路径
make -j
# 将编译的可执行文件移动到debug文件夹中
mv ocr_db_crnn ./debug/
# 将debug文件夹push到手机上
adb push debug /data/local/tmp/
adb shell
cd /data/local/tmp/debug
export LD_LIBRARY_PATH=${PWD}:$LD_LIBRARY_PATH
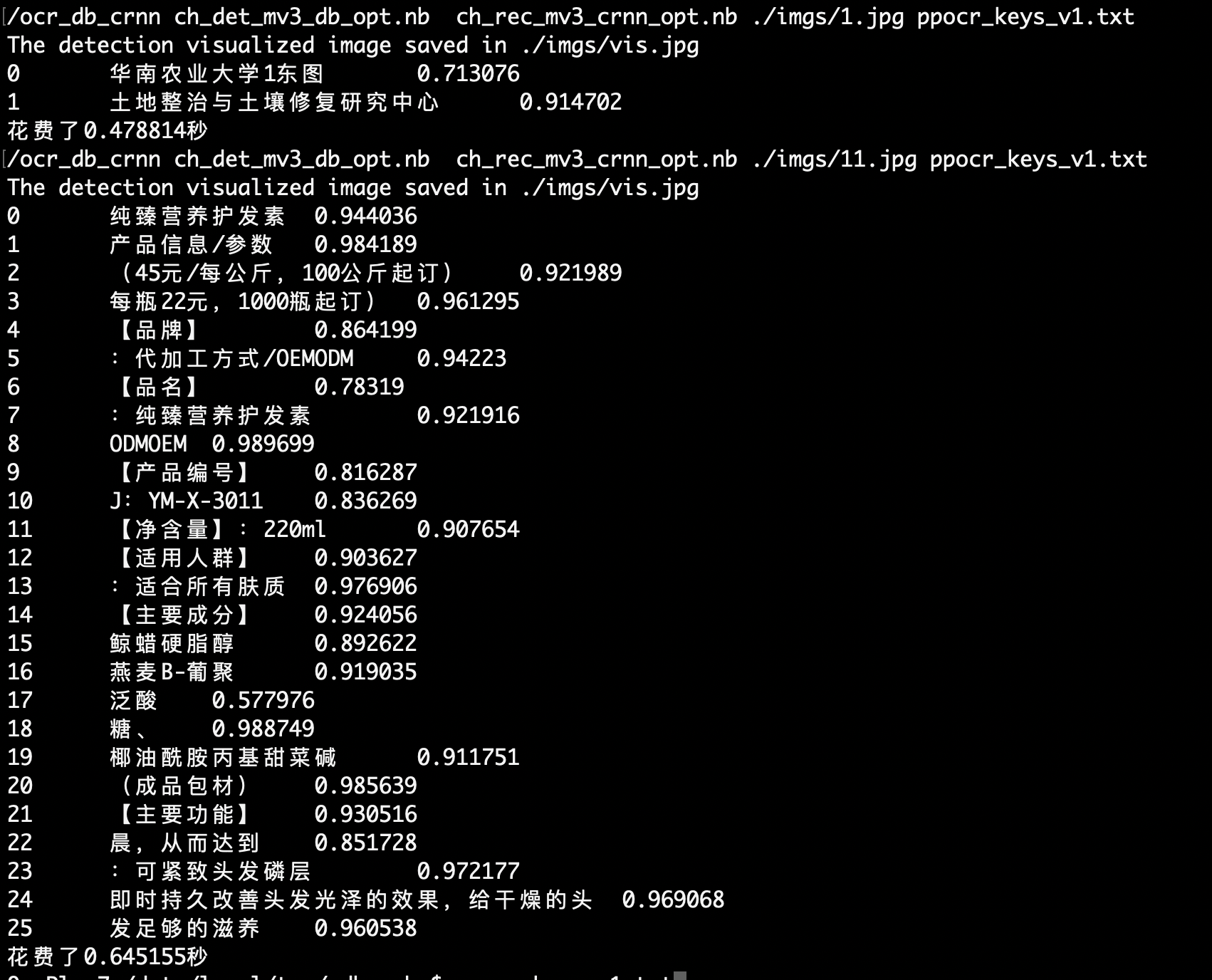
./ocr_db_crnn ch_ppocr_mobile_v1.1_det_prune_opt.nb ch_ppocr_mobile_v1.1_rec_quant_opt.nb ch_ppocr_mobile_cls_quant_opt.nb ./11.jpg ppocr_keys_v1.txt
```
如果对代码做了修改,则需要重新编译并push到手机上。
运行效果如下:
## FAQ
Q1:如果想更换模型怎么办,需要重新按照流程走一遍吗?
A1:如果已经走通了上述步骤,更换模型只需要替换 .nb 模型文件即可,同时要注意字典更新
Q2:换一个图测试怎么做?
A2:替换debug下的.jpg测试图像为你想要测试的图像,adb push 到手机上即可
Q3:如何封装到手机APP中?
A3:此demo旨在提供能在手机上运行OCR的核心算法部分,PaddleOCR/deploy/android_demo是将这个demo封装到手机app的示例,供参考