## Style Text Rec
### 目录
[TOC]
### 工具简介
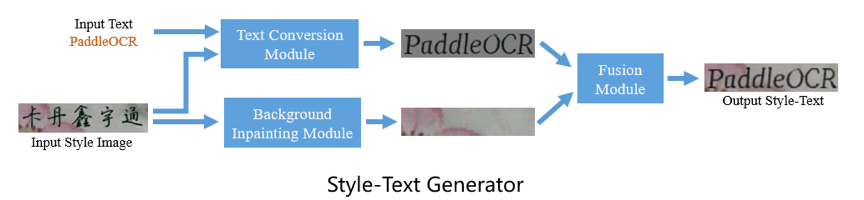
Style-Text是对百度自研文本编辑算法《Editing Text in the Wild》中提出的SRNet网络的改进,不同于常用的GAN的方法只选择一个分支,该工具将文本合成任务分解为三个子模块,文本风格迁移模块、背景抽取模块和前背景融合模块,来提升合成数据的效果。下图显示了一些示例结果。
此外,在实际铭牌文本识别场景和韩语文本识别场景,验证了该合成工具的有效性。
### 环境配置
1. 参考[快速安装](./installation.md),安装PaddleOCR。强烈建议您使用python3环境。
2. 进入`style_text_rec`目录,下载模型,并解压:
```bash
cd style_text_rec
wget /https://paddleocr.bj.bcebos.com/dygraph_v2.0/style_text/style_text_models.zip
unzip style_text_models.zip
```
如果您将模型保存再其他位置,请在`configs/config.yml`中修改模型文件的地址,修改时需要同时修改这三个配置:
```
bg_generator:
pretrain: style_text_models/bg_generator
...
text_generator:
pretrain: style_text_models/text_generator
...
fusion_generator:
pretrain: style_text_models/fusion_generator
```
### 快速上手
1. 运行tools/synth_image,生成示例图片:
```python
python3 -m tools.synth_image -c configs/config.yml
```
1. 运行后,会生成`fake_busion.jpg`,即为最终结果。
除此之外,程序还会生成并保存中间结果:
* `fake_bg.jpg`:为风格参考图去掉文字后的背景;
* `fake_text.jpg`:是用提供的字符串,仿照风格参考图中文字的风格,生成在灰色背景上的文字图片。
2. 如果您想尝试其他风格图像和文字的效果,可以在`tools/synth_image.py`中修改:
* `img = cv2.imread("examples/style_images/1.jpg")`:请在此处修改风格图像的目录;
* `corpus = "PaddleOCR"`:请在此处修改要使用的语料文本
* 注意:请修改语言选项(`language = "en"`)和语料相对应,目前我们支持英文、简体中文和韩语。
3. 在`tools/synth_image.py`中,我们还提供了一个`batch_synth_images`方法,可以两两组合语料和图片,批量生成一批数据。
### 高级使用
在开始合成数据集前,需要准备一些素材。
首先,需要风格图片作为合成图片的参考依据,这些数据可以是用作训练OCR识别模型的数据集。本例中使用带有标注文件的数据集作为风格图片.
1. 在`configs/dataset_config.yml`中配置输入数据路径。
* `StyleSamplerl`:
* `method`:使用的风格图片采样方法;
* `image_home`:风格图片目录;
* `label_file`:风格图片路径列表文件,如果所用数据集有label,则label_file为label文件路径;
* `with_label`:标志`label_file`是否为label文件。
* `CorpusGenerator`:
* `method`:语料生成方法,目前有`FileCorpus`和`EnNumCorpus`可选。如果使用`EnNumCorpus`,则不需要填写其他配置,否则需要修改`corpus_file`和`language`;
* `language`:语料的语种;
* `corpus_file`: 语料文件路径。
2. 运行`tools/synth_dataset`合成数据:
``` bash
python -m tools.synth_dataset -c configs/dataset_config.yml
```
3. 如果您想使用并行方式来快速合成数据,可以通过启动多个进程,在启动时需要指定不同的`tag`(`-t`),如下所示:
```bash
python3 -m tools.synth_dataset -t 0 -c configs/dataset_config.yml
python3 -m tools.synth_dataset -t 1 -c configs/dataset_config.yml
```
### 应用示例
在完成上述操作后,即可得到用于OCR识别的合成数据集,接下来请参考[OCR识别文档](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_ch/recognition.md#%E5%90%AF%E5%8A%A8%E8%AE%AD%E7%BB%83),完成训练。
### 项目结构
.
|-- arch
| |-- base_module.py
| |-- decoder.py
| |-- encoder.py
| |-- spectral_norm.py
| `-- style_text_rec.py
|-- configs
| |-- config.yml
| `-- dataset_config.yml
|-- engine
| |-- corpus_generators.py
| |-- predictors.py
| |-- style_samplers.py
| |-- synthesisers.py
| |-- text_drawers.py
| `-- writers.py
|-- examples
| |-- corpus
| | `-- example.txt
| |-- image_list.txt
| `-- style_images
| |-- 1.jpg
| `-- 2.jpg
|-- fonts
| |-- ch_standard.ttf
| |-- en_standard.ttf
| `-- ko_standard.ttf
|-- tools
| |-- __init__.py
| |-- synth_dataset.py
| `-- synth_image.py
`-- utils
|-- config.py
|-- load_params.py
|-- logging.py
|-- math_functions.py
`-- sys_funcs.py