Merge branch 'PaddlePaddle:dygraph' into dygraph
Showing
.github/ISSUE_TEMPLATE/custom.md
0 → 100644
doc/banner.png
0 → 100644
{kind=link}

138.3 KB
doc/doc_ch/models.md
0 → 100644
doc/doc_ch/thirdparty.md
0 → 100644
{kind=link}
{kind=link}

| W: | H:

| W: | H:
doc/pr.png
0 → 100644
{kind=link}
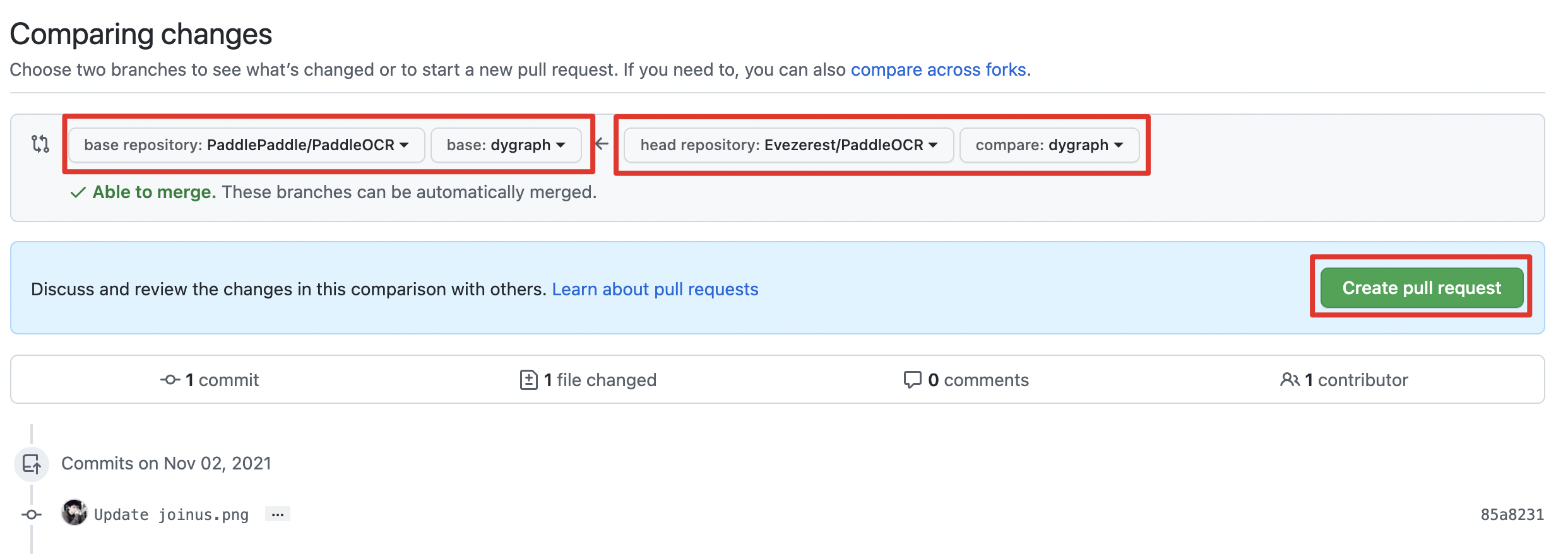
538.1 KB
tools/__init__.py
0 → 100644