Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
s920243400
PaddleOCR
提交
ef38374e
P
PaddleOCR
项目概览
s920243400
/
PaddleOCR
与 Fork 源项目一致
Fork自
PaddlePaddle / PaddleOCR
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleOCR
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
ef38374e
编写于
4月 08, 2021
作者:
J
Jethong
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add pgnet.md
上级
32665fe5
变更
4
显示空白变更内容
内联
并排
Showing
4 changed file
with
176 addition
and
0 deletion
+176
-0
doc/doc_ch/pgnet.md
doc/doc_ch/pgnet.md
+176
-0
doc/imgs_results/e2e_res_img293_pgnet.png
doc/imgs_results/e2e_res_img293_pgnet.png
+0
-0
doc/imgs_results/e2e_res_img295_pgnet.png
doc/imgs_results/e2e_res_img295_pgnet.png
+0
-0
doc/pgnet_framework.png
doc/pgnet_framework.png
+0
-0
未找到文件。
doc/doc_ch/pgnet.md
0 → 100644
浏览文件 @
ef38374e
# 端对端OCR算法-PGNet
-
[
一、简介
](
#简介
)
-
[
二、环境配置
](
#环境配置
)
-
[
三、快速使用
](
#快速使用
)
-
[
四、快速训练
](
#开始训练
)
-
[
五、预测推理
](
#预测推理
)
<a
name=
"简介"
></a>
##简介
OCR算法可以分为两阶段算法和端对端的算法。二阶段OCR算法一般分为两个部分,文本检测和文本识别算法,文件检测算法从图像中得到文本行的检测框,然后识别算法去识别文本框中的内容。而端对端OCR算法可以在一个算法中完成文字检测和文字识别,其基本思想是设计一个同时具有检测单元和识别模块的模型,共享其中两者的CNN特征,并联合训练。由于一个算法即可完成文字识别,端对端模型更小,速度更快。
### PGNet算法介绍
近些年来,端对端OCR算法得到了良好的发展,包括MaskTextSpotter系列、TextSnake、TextDragon、PGNet系列等算法。在这些算法中,PGNet算法具备其他算法不具备的优势,包括:
-
设计PGNet loss指导训练,不需要字符级别的标注
-
不需要NMS和ROI相关操作,加速预测
-
提出预测文本行内的阅读顺序模块;
-
提出基于图的修正模块(GRM)来进一步提高模型识别性能
-
精度更高,预测速度更快
PGNet算法细节详见
[
论文
](
https://www.aaai.org/AAAI21Papers/AAAI-2885.WangP.pdf
)
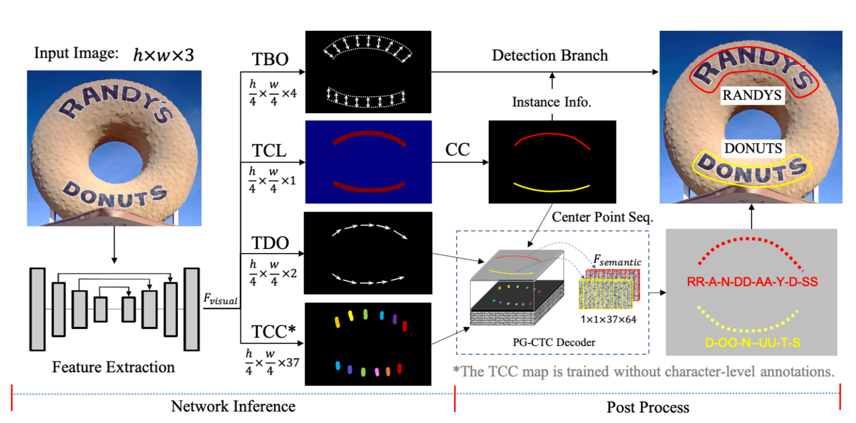
, 算法原理图如下所示:

输入图像经过特征提取送入四个分支,分别是:文本边缘偏移量预测TBO模块,文本中心线预测TCL模块,文本方向偏移量预测TDO模块,以及文本字符分类图预测TCC模块。
其中TBO以及TCL的输出经过后处理后可以得到文本的检测结果,TCL、TDO、TCC负责文本识别。
其检测识别效果图如下:


<a
name=
"环境配置"
></a>
##环境配置
请先参考
[
快速安装
](
./installation.md
)
配置PaddleOCR运行环境。
*注意:也可以通过 whl 包安装使用PaddleOCR,具体参考[Paddleocr Package使用说明](./whl.md)。*
<a
name=
"快速使用"
></a>
##快速使用
### inference模型下载
本节以训练好的端到端模型为例,快速使用模型预测,首先下载训练好的端到端inference模型
[
下载地址
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/pgnet/e2e_server_pgnetA_infer.tar
)
```
mkdir inference && cd inference
# 下载英文端到端模型并解压
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/pgnet/e2e_server_pgnetA_infer.tar && tar xf e2e_server_pgnetA_infer.tar
```
*
windows 环境下如果没有安装wget,下载模型时可将链接复制到浏览器中下载,并解压放置在相应目录下
解压完毕后应有如下文件结构:
```
├── e2e_server_pgnetA_infer
│ ├── inference.pdiparams
│ ├── inference.pdiparams.info
│ └── inference.pdmodel
```
### 单张图像或者图像集合预测
```
bash
# 预测image_dir指定的单张图像
python3 tools/infer/predict_e2e.py
--e2e_algorithm
=
"PGNet"
--image_dir
=
"./doc/imgs_en/img623.jpg"
--e2e_model_dir
=
"./inference/e2e/"
--e2e_pgnet_polygon
=
True
# 预测image_dir指定的图像集合
python3 tools/infer/predict_e2e.py
--e2e_algorithm
=
"PGNet"
--image_dir
=
"./doc/imgs_en/"
--e2e_model_dir
=
"./inference/e2e/"
--e2e_pgnet_polygon
=
True
# 如果想使用CPU进行预测,需设置use_gpu参数为False
python3 tools/infer/predict_e2e.py
--e2e_algorithm
=
"PGNet"
--image_dir
=
"./doc/imgs_en/img623.jpg"
--e2e_model_dir
=
"./inference/e2e/"
--e2e_pgnet_polygon
=
True
--use_gpu
=
False
```
<a
name=
"开始训练"
></a>
##开始训练
本节以totaltext数据集为例,介绍PaddleOCR中端到端模型的训练、评估与测试。
###数据形式为icdar, 十六点标注数据
解压数据集和下载标注文件后,PaddleOCR/train_data/total_text/train/ 有两个文件夹,分别是:
```
/PaddleOCR/train_data/total_text/train/
|- rgb/ total_text数据集的训练数据
|- gt_0.png
| ...
|- total_text.txt total_text数据集的训练标注
```
提供的标注文件格式如下,中间用"
\t
"分隔:
```
" 图像文件名 json.dumps编码的图像标注信息"
rgb/gt_0.png [{"transcription": "EST", "points": [[1004.0,689.0],[1019.0,698.0],[1034.0,708.0],[1049.0,718.0],[1064.0,728.0],[1079.0,738.0],[1095.0,748.0],[1094.0,774.0],[1079.0,765.0],[1065.0,756.0],[1050.0,747.0],[1036.0,738.0],[1021.0,729.0],[1007.0,721.0]]}, {...}]
```
json.dumps编码前的图像标注信息是包含多个字典的list,字典中的
`points`
表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。
`transcription`
表示当前文本框的文字,
**当其内容为“###”时,表示该文本框无效,在训练时会跳过。**
如果您想在其他数据集上训练,可以按照上述形式构建标注文件。
### 快速启动训练
模型训练一般分两步骤进行,第一步可以选择用合成数据训练,第二步加载第一步训练好的模型训练,这边我们提供了第一步训练好的模型,可以直接加载,从第二步开始训练
[
下载地址
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/pgnet/train_step1.tar
)
```
shell
cd
PaddleOCR/
下载ResNet50_vd的动态图预训练模型
wget
-P
./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/pgnet/train_step1.tar
可以得到以下的文件格式
./pretrain_models/train_step1/
└─ best_accuracy.pdopt
└─ best_accuracy.states
└─ best_accuracy.pdparams
```
*如果您安装的是cpu版本,请将配置文件中的 `use_gpu` 字段修改为false*
```
shell
# 单机单卡训练 e2e 模型
python3 tools/train.py
-c
configs/e2e/e2e_r50_vd_pg.yml
-o
Global.pretrained_model
=
./pretrain_models/train_step1/best_accuracy Global.load_static_weights
=
False
# 单机多卡训练,通过 --gpus 参数设置使用的GPU ID
python3
-m
paddle.distributed.launch
--gpus
'0,1,2,3'
tools/train.py
-c
configs/e2e/e2e_r50_vd_pg.yml
-o
Global.pretrained_model
=
./pretrain_models/train_step1/best_accuracy Global.load_static_weights
=
False
```
上述指令中,通过-c 选择训练使用configs/e2e/e2e_r50_vd_pg.yml配置文件。
有关配置文件的详细解释,请参考
[
链接
](
./config.md
)
。
您也可以通过-o参数在不需要修改yml文件的情况下,改变训练的参数,比如,调整训练的学习率为0.0001
```
shell
python3 tools/train.py
-c
configs/e2e/e2e_r50_vd_pg.yml
-o
Optimizer.base_lr
=
0.0001
```
#### 断点训练
如果训练程序中断,如果希望加载训练中断的模型从而恢复训练,可以通过指定Global.checkpoints指定要加载的模型路径:
```
shell
python3 tools/train.py
-c
configs/e2e/e2e_r50_vd_pg.yml
-o
Global.checkpoints
=
./your/trained/model
```
**注意**
:
`Global.checkpoints`
的优先级高于
`Global.pretrain_weights`
的优先级,即同时指定两个参数时,优先加载
`Global.checkpoints`
指定的模型,如果
`Global.checkpoints`
指定的模型路径有误,会加载
`Global.pretrain_weights`
指定的模型。
<a
name=
"预测推理"
></a>
## 预测推理
PaddleOCR计算三个OCR端到端相关的指标,分别是:Precision、Recall、Hmean。
运行如下代码,根据配置文件
`e2e_r50_vd_pg.yml`
中
`save_res_path`
指定的测试集检测结果文件,计算评估指标。
评估时设置后处理参数
`max_side_len=768`
,使用不同数据集、不同模型训练,可调整参数进行优化
训练中模型参数默认保存在
`Global.save_model_dir`
目录下。在评估指标时,需要设置
`Global.checkpoints`
指向保存的参数文件。
```
shell
python3 tools/eval.py
-c
configs/e2e/e2e_r50_vd_pg.yml
-o
Global.checkpoints
=
"{path/to/weights}/best_accuracy"
```
### 测试端到端效果
测试单张图像的端到端识别效果
```
shell
python3 tools/infer_e2e.py
-c
configs/e2e/e2e_r50_vd_pg.yml
-o
Global.infer_img
=
"./doc/imgs_en/img_10.jpg"
Global.pretrained_model
=
"./output/det_db/best_accuracy"
Global.load_static_weights
=
false
```
测试文件夹下所有图像的端到端识别效果
```
shell
python3 tools/infer_e2e.py
-c
configs/e2e/e2e_r50_vd_pg.yml
-o
Global.infer_img
=
"./doc/imgs_en/"
Global.pretrained_model
=
"./output/det_db/best_accuracy"
Global.load_static_weights
=
false
```
###转为推理模型
### (1). 四边形文本检测模型(ICDAR2015)
首先将PGNet端到端训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,以英文数据集训练的模型为例
[
模型下载地址
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/pgnet/en_server_pgnetA.tar
)
,可以使用如下命令进行转换:
```
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/pgnet/en_server_pgnetA.tar && tar xf en_server_pgnetA.tar
python3 tools/export_model.py -c configs/e2e/e2e_r50_vd_pg.yml -o Global.pretrained_model=./en_server_pgnetA/iter_epoch_450 Global.load_static_weights=False Global.save_inference_dir=./inference/e2e
```
**PGNet端到端模型推理,需要设置参数`--e2e_algorithm="PGNet"`**
,可以执行如下命令:
```
python3 tools/infer/predict_e2e.py --e2e_algorithm="PGNet" --image_dir="./doc/imgs_en/img_10.jpg" --e2e_model_dir="./inference/e2e/" --e2e_pgnet_polygon=False
```
可视化文本检测结果默认保存到
`./inference_results`
文件夹里面,结果文件的名称前缀为'e2e_res'。结果示例如下:

### (2). 弯曲文本检测模型(Total-Text)
对于弯曲文本样例
**PGNet端到端模型推理,需要设置参数`--e2e_algorithm="PGNet"`,同时,还需要增加参数`--e2e_pgnet_polygon=True`,**
可以执行如下命令:
```
python3 tools/infer/predict_e2e.py --e2e_algorithm="PGNet" --image_dir="./doc/imgs_en/img623.jpg" --e2e_model_dir="./inference/e2e/" --e2e_pgnet_polygon=True
```
可视化文本端到端结果默认保存到
`./inference_results`
文件夹里面,结果文件的名称前缀为'e2e_res'。结果示例如下:

doc/imgs_results/e2e_res_img293_pgnet.png
0 → 100644
浏览文件 @
ef38374e
662.8 KB
doc/imgs_results/e2e_res_img295_pgnet.png
0 → 100644
浏览文件 @
ef38374e
466.8 KB
doc/pgnet_framework.png
0 → 100644
浏览文件 @
ef38374e
241.7 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}

{kind=link}

{kind=link}