
@@ -200,7 +200,7 @@ UDML (Unified-Deep Mutual Learning) is a strategy proposed in PP-OCRv2 which is
**(6)UIM:Unlabeled Images Mining**
-UIM (Unlabeled Images Mining) is a very simple unlabeled data mining strategy. The main idea is to use a high-precision text recognition model to predict unlabeled images to obtain pseudo-labels, and select samples with high prediction confidence as training data for training lightweight models. Using this strategy, the accuracy of the recognition model is further improved to 79.4% (+1%).
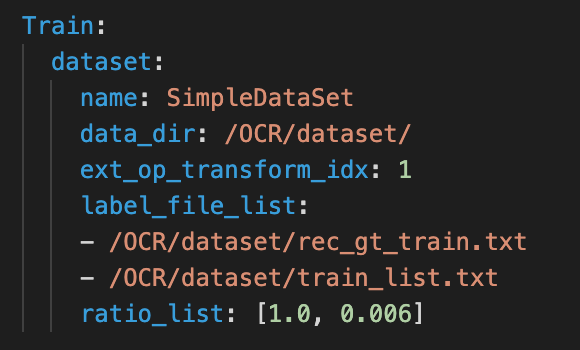
+UIM (Unlabeled Images Mining) is a very simple unlabeled data mining strategy. The main idea is to use a high-precision text recognition model to predict unlabeled images to obtain pseudo-labels, and select samples with high prediction confidence as training data for training lightweight models. Using this strategy, the accuracy of the recognition model is further improved to 79.4% (+1%). In practice, we use the full data set to train the high-precision SVTR_Tiny model (acc=82.5%) for data mining. [SVTR_Tiny model download and tutorial](../../applications/高精度中文识别模型.md).

diff --git a/doc/doc_en/detection_en.md b/doc/doc_en/detection_en.md
index 76e0f8509b92dfaae62dce7ba2b4b73d39da1600..8972581009fffabab815501521a2978f49b7692e 100644
--- a/doc/doc_en/detection_en.md
+++ b/doc/doc_en/detection_en.md
@@ -51,7 +51,7 @@ python3 tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
```
-In the above instruction, use `-c` to select the training to use the `configs/det/det_db_mv3.yml` configuration file.
+In the above instruction, use `-c` to select the training to use the `configs/det/det_mv3_db.yml` configuration file.
For a detailed explanation of the configuration file, please refer to [config](./config_en.md).
You can also use `-o` to change the training parameters without modifying the yml file. For example, adjust the training learning rate to 0.0001
diff --git a/doc/doc_en/inference_ppocr_en.md b/doc/doc_en/inference_ppocr_en.md
index 935f92f5144f582630a45edcc886b609ecdc82da..0f57b0ba6b226c19ecb1e0b60afdfa34302b8e78 100755
--- a/doc/doc_en/inference_ppocr_en.md
+++ b/doc/doc_en/inference_ppocr_en.md
@@ -8,7 +8,8 @@ This article introduces the use of the Python inference engine for the PP-OCR mo
- [Text Detection Model Inference](#text-detection-model-inference)
- [Text Recognition Model Inference](#text-recognition-model-inference)
- [1. Lightweight Chinese Recognition Model Inference](#1-lightweight-chinese-recognition-model-inference)
- - [2. Multilingual Model Inference](#2-multilingual-model-inference)
+ - [2. English Recognition Model Inference](#2-english-recognition-model-inference)
+ - [3. Multilingual Model Inference](#3-multilingual-model-inference)
- [Angle Classification Model Inference](#angle-classification-model-inference)
- [Text Detection Angle Classification and Recognition Inference Concatenation](#text-detection-angle-classification-and-recognition-inference-concatenation)
@@ -76,10 +77,31 @@ After executing the command, the prediction results (recognized text and score)
```bash
Predicts of ./doc/imgs_words_en/word_10.png:('PAIN', 0.988671)
```
+
+### 2. English Recognition Model Inference
-
+For English recognition model inference, you can execute the following commands,you need to specify the dictionary path used by `--rec_char_dict_path`:
-### 2. Multilingual Model Inference
+```
+# download en model:
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar
+tar xf en_PP-OCRv3_det_infer.tar
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./en_PP-OCRv3_det_infer/" --rec_char_dict_path="ppocr/utils/en_dict.txt"
+```
+
+
+
+
+After executing the command, the prediction result of the above figure is:
+
+```
+Predicts of ./doc/imgs_words/en/word_1.png: ('JOINT', 0.998160719871521)
+```
+
+
+
+
+### 3. Multilingual Model Inference
If you need to predict [other language models](./models_list_en.md#Multilingual), when using inference model prediction, you need to specify the dictionary path used by `--rec_char_dict_path`. At the same time, in order to get the correct visualization results,
You need to specify the visual font path through `--vis_font_path`. There are small language fonts provided by default under the `doc/fonts` path, such as Korean recognition:
diff --git a/doc/doc_en/ppocr_introduction_en.md b/doc/doc_en/ppocr_introduction_en.md
index b13d7f9bf1915de4bbbbec7b384d278e1d7ab8b4..5c0f6d2d7e5f82fce9a29b286a7e27b97306833a 100644
--- a/doc/doc_en/ppocr_introduction_en.md
+++ b/doc/doc_en/ppocr_introduction_en.md
@@ -29,10 +29,10 @@ PP-OCR pipeline is as follows:
PP-OCR system is in continuous optimization. At present, PP-OCR and PP-OCRv2 have been released:
-PP-OCR adopts 19 effective strategies from 8 aspects including backbone network selection and adjustment, prediction head design, data augmentation, learning rate transformation strategy, regularization parameter selection, pre-training model use, and automatic model tailoring and quantization to optimize and slim down the models of each module (as shown in the green box above). The final results are an ultra-lightweight Chinese and English OCR model with an overall size of 3.5M and a 2.8M English digital OCR model. For more details, please refer to the PP-OCR technical article (https://arxiv.org/abs/2009.09941).
+PP-OCR adopts 19 effective strategies from 8 aspects including backbone network selection and adjustment, prediction head design, data augmentation, learning rate transformation strategy, regularization parameter selection, pre-training model use, and automatic model tailoring and quantization to optimize and slim down the models of each module (as shown in the green box above). The final results are an ultra-lightweight Chinese and English OCR model with an overall size of 3.5M and a 2.8M English digital OCR model. For more details, please refer to the [PP-OCR technical report](https://arxiv.org/abs/2009.09941).
#### PP-OCRv2
-On the basis of PP-OCR, PP-OCRv2 is further optimized in five aspects. The detection model adopts CML(Collaborative Mutual Learning) knowledge distillation strategy and CopyPaste data expansion strategy. The recognition model adopts LCNet lightweight backbone network, U-DML knowledge distillation strategy and enhanced CTC loss function improvement (as shown in the red box above), which further improves the inference speed and prediction effect. For more details, please refer to the technical report of PP-OCRv2 (https://arxiv.org/abs/2109.03144).
+On the basis of PP-OCR, PP-OCRv2 is further optimized in five aspects. The detection model adopts CML(Collaborative Mutual Learning) knowledge distillation strategy and CopyPaste data expansion strategy. The recognition model adopts LCNet lightweight backbone network, U-DML knowledge distillation strategy and enhanced CTC loss function improvement (as shown in the red box above), which further improves the inference speed and prediction effect. For more details, please refer to the [PP-OCRv2 technical report](https://arxiv.org/abs/2109.03144).
#### PP-OCRv3
@@ -46,7 +46,7 @@ PP-OCRv3 pipeline is as follows:

-For more details, please refer to [PP-OCRv3 technical report](./PP-OCRv3_introduction_en.md).
+For more details, please refer to [PP-OCRv3 technical report](https://arxiv.org/abs/2206.03001v2).
## 2. Features
diff --git a/doc/doc_en/whl_en.md b/doc/doc_en/whl_en.md
index d81e5532cf1db0193abf61b972420bdc3bacfd0b..64757ad18bbe422b7e2f60c896f600458e3ce2fd 100644
--- a/doc/doc_en/whl_en.md
+++ b/doc/doc_en/whl_en.md
@@ -1,4 +1,4 @@
-# Paddleocr Package
+# PaddleOCR Package
## 1 Get started quickly
### 1.1 install package
diff --git a/paddleocr.py b/paddleocr.py
index 470dc60da3b15195bcd401aff5e50be5a2cfd13e..f6aca07ab5653b563337b000bc5eb2cce892ca6e 100644
--- a/paddleocr.py
+++ b/paddleocr.py
@@ -446,7 +446,7 @@ class PaddleOCR(predict_system.TextSystem):
"""
ocr with paddleocr
args:
- img: img for ocr, support ndarray, img_path and list or ndarray
+ img: img for ocr, support ndarray, img_path and list of ndarray
det: use text detection or not. If false, only rec will be exec. Default is True
rec: use text recognition or not. If false, only det will be exec. Default is True
cls: use angle classifier or not. Default is True. If true, the text with rotation of 180 degrees can be recognized. If no text is rotated by 180 degrees, use cls=False to get better performance. Text with rotation of 90 or 270 degrees can be recognized even if cls=False.
diff --git a/ppocr/data/imaug/__init__.py b/ppocr/data/imaug/__init__.py
index 548832fb0d116ba2de622bd97562b591d74501d8..65497e63f9da03d8fc1fd1aa6baba673461ab8bc 100644
--- a/ppocr/data/imaug/__init__.py
+++ b/ppocr/data/imaug/__init__.py
@@ -23,7 +23,8 @@ from .random_crop_data import EastRandomCropData, RandomCropImgMask
from .make_pse_gt import MakePseGt
from .rec_img_aug import RecAug, RecConAug, RecResizeImg, ClsResizeImg, \
- SRNRecResizeImg, NRTRRecResizeImg, SARRecResizeImg, PRENResizeImg
+ SRNRecResizeImg, NRTRRecResizeImg, SARRecResizeImg, PRENResizeImg, \
+ SVTRRecResizeImg
from .ssl_img_aug import SSLRotateResize
from .randaugment import RandAugment
from .copy_paste import CopyPaste
diff --git a/ppocr/data/imaug/copy_paste.py b/ppocr/data/imaug/copy_paste.py
index 0b3386c896792bd670cd2bfc757eb3b80f22bac4..79343da60fd40f8dc0ffe8927398b70cb751b532 100644
--- a/ppocr/data/imaug/copy_paste.py
+++ b/ppocr/data/imaug/copy_paste.py
@@ -35,10 +35,12 @@ class CopyPaste(object):
point_num = data['polys'].shape[1]
src_img = data['image']
src_polys = data['polys'].tolist()
+ src_texts = data['texts']
src_ignores = data['ignore_tags'].tolist()
ext_data = data['ext_data'][0]
ext_image = ext_data['image']
ext_polys = ext_data['polys']
+ ext_texts = ext_data['texts']
ext_ignores = ext_data['ignore_tags']
indexs = [i for i in range(len(ext_ignores)) if not ext_ignores[i]]
@@ -53,7 +55,7 @@ class CopyPaste(object):
src_img = cv2.cvtColor(src_img, cv2.COLOR_BGR2RGB)
ext_image = cv2.cvtColor(ext_image, cv2.COLOR_BGR2RGB)
src_img = Image.fromarray(src_img).convert('RGBA')
- for poly, tag in zip(select_polys, select_ignores):
+ for idx, poly, tag in zip(select_idxs, select_polys, select_ignores):
box_img = get_rotate_crop_image(ext_image, poly)
src_img, box = self.paste_img(src_img, box_img, src_polys)
@@ -62,6 +64,7 @@ class CopyPaste(object):
for _ in range(len(box), point_num):
box.append(box[-1])
src_polys.append(box)
+ src_texts.append(ext_texts[idx])
src_ignores.append(tag)
src_img = cv2.cvtColor(np.array(src_img), cv2.COLOR_RGB2BGR)
h, w = src_img.shape[:2]
@@ -70,6 +73,7 @@ class CopyPaste(object):
src_polys[:, :, 1] = np.clip(src_polys[:, :, 1], 0, h)
data['image'] = src_img
data['polys'] = src_polys
+ data['texts'] = src_texts
data['ignore_tags'] = np.array(src_ignores)
return data
diff --git a/ppocr/data/imaug/label_ops.py b/ppocr/data/imaug/label_ops.py
index 8b017b3219993328287d91a047e598eebaded198..c20eef2c8c4481d46fae3f9006946b7a1b5c6bda 100644
--- a/ppocr/data/imaug/label_ops.py
+++ b/ppocr/data/imaug/label_ops.py
@@ -23,7 +23,7 @@ import string
from shapely.geometry import LineString, Point, Polygon
import json
import copy
-
+from scipy.spatial import distance as dist
from ppocr.utils.logging import get_logger
@@ -74,9 +74,10 @@ class DetLabelEncode(object):
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
- diff = np.diff(pts, axis=1)
- rect[1] = pts[np.argmin(diff)]
- rect[3] = pts[np.argmax(diff)]
+ tmp = np.delete(pts, (np.argmin(s), np.argmax(s)), axis=0)
+ diff = np.diff(np.array(tmp), axis=1)
+ rect[1] = tmp[np.argmin(diff)]
+ rect[3] = tmp[np.argmax(diff)]
return rect
def expand_points_num(self, boxes):
@@ -443,7 +444,9 @@ class KieLabelEncode(object):
elif 'key_cls' in ann.keys():
labels.append(ann['key_cls'])
else:
- raise ValueError("Cannot found 'key_cls' in ann.keys(), please check your training annotation.")
+ raise ValueError(
+ "Cannot found 'key_cls' in ann.keys(), please check your training annotation."
+ )
edges.append(ann.get('edge', 0))
ann_infos = dict(
image=data['image'],
diff --git a/ppocr/data/imaug/rec_img_aug.py b/ppocr/data/imaug/rec_img_aug.py
index 7483dffe5b6d9a0a2204702757fcb49762a1cc7a..2c897dce07a7867b9dd2eed1e7b24fa046336f8c 100644
--- a/ppocr/data/imaug/rec_img_aug.py
+++ b/ppocr/data/imaug/rec_img_aug.py
@@ -207,6 +207,21 @@ class PRENResizeImg(object):
return data
+class SVTRRecResizeImg(object):
+ def __init__(self, image_shape, padding=True, **kwargs):
+ self.image_shape = image_shape
+ self.padding = padding
+
+ def __call__(self, data):
+ img = data['image']
+
+ norm_img, valid_ratio = resize_norm_img(img, self.image_shape,
+ self.padding)
+ data['image'] = norm_img
+ data['valid_ratio'] = valid_ratio
+ return data
+
+
def resize_norm_img_sar(img, image_shape, width_downsample_ratio=0.25):
imgC, imgH, imgW_min, imgW_max = image_shape
h = img.shape[0]
diff --git a/ppocr/losses/basic_loss.py b/ppocr/losses/basic_loss.py
index 2df96ea2642d10a50eb892d738f89318dc5e0f4c..a0ab10fbbaccaf6781598d5e788813d3febe07e4 100644
--- a/ppocr/losses/basic_loss.py
+++ b/ppocr/losses/basic_loss.py
@@ -57,17 +57,27 @@ class CELoss(nn.Layer):
class KLJSLoss(object):
def __init__(self, mode='kl'):
assert mode in ['kl', 'js', 'KL', 'JS'
- ], "mode can only be one of ['kl', 'js', 'KL', 'JS']"
+ ], "mode can only be one of ['kl', 'KL', 'js', 'JS']"
self.mode = mode
def __call__(self, p1, p2, reduction="mean"):
- loss = paddle.multiply(p2, paddle.log((p2 + 1e-5) / (p1 + 1e-5) + 1e-5))
-
- if self.mode.lower() == "js":
+ if self.mode.lower() == 'kl':
+ loss = paddle.multiply(p2,
+ paddle.log((p2 + 1e-5) / (p1 + 1e-5) + 1e-5))
loss += paddle.multiply(
p1, paddle.log((p1 + 1e-5) / (p2 + 1e-5) + 1e-5))
loss *= 0.5
+ elif self.mode.lower() == "js":
+ loss = paddle.multiply(
+ p2, paddle.log((2 * p2 + 1e-5) / (p1 + p2 + 1e-5) + 1e-5))
+ loss += paddle.multiply(
+ p1, paddle.log((2 * p1 + 1e-5) / (p1 + p2 + 1e-5) + 1e-5))
+ loss *= 0.5
+ else:
+ raise ValueError(
+ "The mode.lower() if KLJSLoss should be one of ['kl', 'js']")
+
if reduction == "mean":
loss = paddle.mean(loss, axis=[1, 2])
elif reduction == "none" or reduction is None:
@@ -95,7 +105,7 @@ class DMLLoss(nn.Layer):
self.act = None
self.use_log = use_log
- self.jskl_loss = KLJSLoss(mode="js")
+ self.jskl_loss = KLJSLoss(mode="kl")
def _kldiv(self, x, target):
eps = 1.0e-10
diff --git a/ppocr/losses/rec_aster_loss.py b/ppocr/losses/rec_aster_loss.py
index fbb99d29a638540b02649a8912051339c08b22dd..52605e46db35339cc22f7f1e6642456bfaf02f11 100644
--- a/ppocr/losses/rec_aster_loss.py
+++ b/ppocr/losses/rec_aster_loss.py
@@ -27,12 +27,12 @@ class CosineEmbeddingLoss(nn.Layer):
self.epsilon = 1e-12
def forward(self, x1, x2, target):
- similarity = paddle.fluid.layers.reduce_sum(
+ similarity = paddle.sum(
x1 * x2, dim=-1) / (paddle.norm(
x1, axis=-1) * paddle.norm(
x2, axis=-1) + self.epsilon)
one_list = paddle.full_like(target, fill_value=1)
- out = paddle.fluid.layers.reduce_mean(
+ out = paddle.mean(
paddle.where(
paddle.equal(target, one_list), 1. - similarity,
paddle.maximum(
diff --git a/ppocr/losses/table_att_loss.py b/ppocr/losses/table_att_loss.py
index d7fd99e6952aacc0182a482ca5ae5ddaf959a026..51377efa2b5e802fe9f9fc1973c74deb00fc4816 100644
--- a/ppocr/losses/table_att_loss.py
+++ b/ppocr/losses/table_att_loss.py
@@ -19,7 +19,6 @@ from __future__ import print_function
import paddle
from paddle import nn
from paddle.nn import functional as F
-from paddle import fluid
class TableAttentionLoss(nn.Layer):
def __init__(self, structure_weight, loc_weight, use_giou=False, giou_weight=1.0, **kwargs):
@@ -36,13 +35,13 @@ class TableAttentionLoss(nn.Layer):
:param bbox:[[x1,y1,x2,y2], [x1,y1,x2,y2],,,]
:return: loss
'''
- ix1 = fluid.layers.elementwise_max(preds[:, 0], bbox[:, 0])
- iy1 = fluid.layers.elementwise_max(preds[:, 1], bbox[:, 1])
- ix2 = fluid.layers.elementwise_min(preds[:, 2], bbox[:, 2])
- iy2 = fluid.layers.elementwise_min(preds[:, 3], bbox[:, 3])
+ ix1 = paddle.maximum(preds[:, 0], bbox[:, 0])
+ iy1 = paddle.maximum(preds[:, 1], bbox[:, 1])
+ ix2 = paddle.minimum(preds[:, 2], bbox[:, 2])
+ iy2 = paddle.minimum(preds[:, 3], bbox[:, 3])
- iw = fluid.layers.clip(ix2 - ix1 + 1e-3, 0., 1e10)
- ih = fluid.layers.clip(iy2 - iy1 + 1e-3, 0., 1e10)
+ iw = paddle.clip(ix2 - ix1 + 1e-3, 0., 1e10)
+ ih = paddle.clip(iy2 - iy1 + 1e-3, 0., 1e10)
# overlap
inters = iw * ih
@@ -55,12 +54,12 @@ class TableAttentionLoss(nn.Layer):
# ious
ious = inters / uni
- ex1 = fluid.layers.elementwise_min(preds[:, 0], bbox[:, 0])
- ey1 = fluid.layers.elementwise_min(preds[:, 1], bbox[:, 1])
- ex2 = fluid.layers.elementwise_max(preds[:, 2], bbox[:, 2])
- ey2 = fluid.layers.elementwise_max(preds[:, 3], bbox[:, 3])
- ew = fluid.layers.clip(ex2 - ex1 + 1e-3, 0., 1e10)
- eh = fluid.layers.clip(ey2 - ey1 + 1e-3, 0., 1e10)
+ ex1 = paddle.minimum(preds[:, 0], bbox[:, 0])
+ ey1 = paddle.minimum(preds[:, 1], bbox[:, 1])
+ ex2 = paddle.maximum(preds[:, 2], bbox[:, 2])
+ ey2 = paddle.maximum(preds[:, 3], bbox[:, 3])
+ ew = paddle.clip(ex2 - ex1 + 1e-3, 0., 1e10)
+ eh = paddle.clip(ey2 - ey1 + 1e-3, 0., 1e10)
# enclose erea
enclose = ew * eh + eps
diff --git a/ppocr/metrics/rec_metric.py b/ppocr/metrics/rec_metric.py
index 515b9372e38a7213cde29fdc9834ed6df45a0a80..6a13129eddc419c4bde70cd2c5a0c018035d63cd 100644
--- a/ppocr/metrics/rec_metric.py
+++ b/ppocr/metrics/rec_metric.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import Levenshtein
+from rapidfuzz.distance import Levenshtein
import string
@@ -45,8 +45,7 @@ class RecMetric(object):
if self.is_filter:
pred = self._normalize_text(pred)
target = self._normalize_text(target)
- norm_edit_dis += Levenshtein.distance(pred, target) / max(
- len(pred), len(target), 1)
+ norm_edit_dis += Levenshtein.normalized_distance(pred, target)
if pred == target:
correct_num += 1
all_num += 1
diff --git a/ppocr/modeling/backbones/kie_unet_sdmgr.py b/ppocr/modeling/backbones/kie_unet_sdmgr.py
index 545e4e7511e58c3d8220e9ec0be35474deba8806..4b1bd8030060b26acb9e60bd671a5b23d936347b 100644
--- a/ppocr/modeling/backbones/kie_unet_sdmgr.py
+++ b/ppocr/modeling/backbones/kie_unet_sdmgr.py
@@ -175,12 +175,7 @@ class Kie_backbone(nn.Layer):
img, relations, texts, gt_bboxes, tag, img_size)
x = self.img_feat(img)
boxes, rois_num = self.bbox2roi(gt_bboxes)
- feats = paddle.fluid.layers.roi_align(
- x,
- boxes,
- spatial_scale=1.0,
- pooled_height=7,
- pooled_width=7,
- rois_num=rois_num)
+ feats = paddle.vision.ops.roi_align(
+ x, boxes, spatial_scale=1.0, output_size=7, boxes_num=rois_num)
feats = self.maxpool(feats).squeeze(-1).squeeze(-1)
return [relations, texts, feats]
diff --git a/ppocr/modeling/backbones/rec_resnet_fpn.py b/ppocr/modeling/backbones/rec_resnet_fpn.py
index a7e876a2bd52a0ea70479c2009a291e4e2f8ce1f..79efd6e41e231ecad99aa4d01a8226a8550bd1ef 100644
--- a/ppocr/modeling/backbones/rec_resnet_fpn.py
+++ b/ppocr/modeling/backbones/rec_resnet_fpn.py
@@ -18,7 +18,6 @@ from __future__ import print_function
from paddle import nn, ParamAttr
from paddle.nn import functional as F
-import paddle.fluid as fluid
import paddle
import numpy as np
diff --git a/ppocr/modeling/heads/rec_srn_head.py b/ppocr/modeling/heads/rec_srn_head.py
index 8d59e4711a043afd9234f430a62c9876c0a8f6f4..1070d8cd648eb686c0a2e66df092b7dc6de29c42 100644
--- a/ppocr/modeling/heads/rec_srn_head.py
+++ b/ppocr/modeling/heads/rec_srn_head.py
@@ -20,13 +20,11 @@ import math
import paddle
from paddle import nn, ParamAttr
from paddle.nn import functional as F
-import paddle.fluid as fluid
import numpy as np
from .self_attention import WrapEncoderForFeature
from .self_attention import WrapEncoder
from paddle.static import Program
from ppocr.modeling.backbones.rec_resnet_fpn import ResNetFPN
-import paddle.fluid.framework as framework
from collections import OrderedDict
gradient_clip = 10
diff --git a/ppocr/modeling/heads/self_attention.py b/ppocr/modeling/heads/self_attention.py
index 6c27fdbe434166e9277cc8d695bce2743cbd8ec6..6e4c65e3931ae74a0fde2a16694a69fdfa69b5ed 100644
--- a/ppocr/modeling/heads/self_attention.py
+++ b/ppocr/modeling/heads/self_attention.py
@@ -22,7 +22,6 @@ import paddle
from paddle import ParamAttr, nn
from paddle import nn, ParamAttr
from paddle.nn import functional as F
-import paddle.fluid as fluid
import numpy as np
gradient_clip = 10
@@ -288,10 +287,10 @@ class PrePostProcessLayer(nn.Layer):
"layer_norm_%d" % len(self.sublayers()),
paddle.nn.LayerNorm(
normalized_shape=d_model,
- weight_attr=fluid.ParamAttr(
- initializer=fluid.initializer.Constant(1.)),
- bias_attr=fluid.ParamAttr(
- initializer=fluid.initializer.Constant(0.)))))
+ weight_attr=paddle.ParamAttr(
+ initializer=paddle.nn.initializer.Constant(1.)),
+ bias_attr=paddle.ParamAttr(
+ initializer=paddle.nn.initializer.Constant(0.)))))
elif cmd == "d": # add dropout
self.functors.append(lambda x: F.dropout(
x, p=dropout_rate, mode="downscale_in_infer")
@@ -324,7 +323,7 @@ class PrepareEncoder(nn.Layer):
def forward(self, src_word, src_pos):
src_word_emb = src_word
- src_word_emb = fluid.layers.cast(src_word_emb, 'float32')
+ src_word_emb = paddle.cast(src_word_emb, 'float32')
src_word_emb = paddle.scale(x=src_word_emb, scale=self.src_emb_dim**0.5)
src_pos = paddle.squeeze(src_pos, axis=-1)
src_pos_enc = self.emb(src_pos)
@@ -367,7 +366,7 @@ class PrepareDecoder(nn.Layer):
self.dropout_rate = dropout_rate
def forward(self, src_word, src_pos):
- src_word = fluid.layers.cast(src_word, 'int64')
+ src_word = paddle.cast(src_word, 'int64')
src_word = paddle.squeeze(src_word, axis=-1)
src_word_emb = self.emb0(src_word)
src_word_emb = paddle.scale(x=src_word_emb, scale=self.src_emb_dim**0.5)
diff --git a/ppocr/postprocess/db_postprocess.py b/ppocr/postprocess/db_postprocess.py
index 27b428ef2e73c9abf81d3881b23979343c8595b2..1c42cd55cd8f85dff3df90e2f5365ccde8a725f3 100755
--- a/ppocr/postprocess/db_postprocess.py
+++ b/ppocr/postprocess/db_postprocess.py
@@ -38,6 +38,7 @@ class DBPostProcess(object):
unclip_ratio=2.0,
use_dilation=False,
score_mode="fast",
+ visual_output=False,
**kwargs):
self.thresh = thresh
self.box_thresh = box_thresh
@@ -51,6 +52,7 @@ class DBPostProcess(object):
self.dilation_kernel = None if not use_dilation else np.array(
[[1, 1], [1, 1]])
+ self.visual = visual_output
def boxes_from_bitmap(self, pred, _bitmap, dest_width, dest_height):
'''
@@ -169,12 +171,19 @@ class DBPostProcess(object):
cv2.fillPoly(mask, contour.reshape(1, -1, 2).astype(np.int32), 1)
return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0]
+ def visual_output(self, pred):
+ im = np.array(pred[0] * 255).astype(np.uint8)
+ cv2.imwrite("db_probability_map.png", im)
+ print("The probalibity map is visualized in db_probability_map.png")
+
def __call__(self, outs_dict, shape_list):
pred = outs_dict['maps']
if isinstance(pred, paddle.Tensor):
pred = pred.numpy()
pred = pred[:, 0, :, :]
segmentation = pred > self.thresh
+ if self.visual:
+ self.visual_output(pred)
boxes_batch = []
for batch_index in range(pred.shape[0]):
diff --git a/ppocr/utils/save_load.py b/ppocr/utils/save_load.py
index b09f1db6e938e8eb99148d69efce016f1cbe8628..3647111fddaa848a75873ab689559c63dd6d4814 100644
--- a/ppocr/utils/save_load.py
+++ b/ppocr/utils/save_load.py
@@ -177,9 +177,9 @@ def save_model(model,
model.backbone.model.save_pretrained(model_prefix)
metric_prefix = os.path.join(model_prefix, 'metric')
# save metric and config
+ with open(metric_prefix + '.states', 'wb') as f:
+ pickle.dump(kwargs, f, protocol=2)
if is_best:
- with open(metric_prefix + '.states', 'wb') as f:
- pickle.dump(kwargs, f, protocol=2)
logger.info('save best model is to {}'.format(model_prefix))
else:
logger.info("save model in {}".format(model_prefix))
diff --git a/ppstructure/docs/kie.md b/ppstructure/docs/kie.md
index 35498b33478d1010fd2548dfcb8586b4710723a1..8fd5a7921e67922b69c9da1f72f7bb514c95323a 100644
--- a/ppstructure/docs/kie.md
+++ b/ppstructure/docs/kie.md
@@ -19,6 +19,24 @@ SDMGR是一个关键信息提取算法,将每个检测到的文本区域分类
wget https://paddleocr.bj.bcebos.com/dygraph_v2.1/kie/wildreceipt.tar && tar xf wildreceipt.tar
```
+数据集格式:
+```
+./wildreceipt
+├── class_list.txt # box内的文本类别,比如金额、时间、日期等。
+├── dict.txt # 识别的字典文件,数据集中包含的字符列表
+├── wildreceipt_train.txt # 训练数据标签文件
+└── wildreceipt_test.txt # 评估数据标签文件
+└── image_files/ # 图像数据文件夹
+```
+
+其中标签文件里的格式为:
+```
+" 图像文件名 json.dumps编码的图像标注信息"
+image_files/Image_16/11/d5de7f2a20751e50b84c747c17a24cd98bed3554.jpeg [{"label": 1, "transcription": "SAFEWAY", "points": [[550.0, 190.0], [937.0, 190.0], [937.0, 104.0], [550.0, 104.0]]}, {"label": 25, "transcription": "TM", "points": [[1048.0, 211.0], [1074.0, 211.0], [1074.0, 196.0], [1048.0, 196.0]]}, {"label": 25, "transcription": "ATOREMGRTOMMILAZZO", "points": [[535.0, 239.0], [833.0, 239.0], [833.0, 200.0], [535.0, 200.0]]}, {"label": 5, "transcription": "703-777-5833", "points": [[907.0, 256.0], [1081.0, 256.0], [1081.0, 223.0], [907.0, 223.0]]}......
+```
+
+**注:如果您希望在自己的数据集上训练,建议按照上述数据个数准备数据集。**
+
执行预测:
```
diff --git a/ppstructure/docs/kie_en.md b/ppstructure/docs/kie_en.md
index 1fe38b0b399e9290526dafa5409673dc87026db7..e895ee88d65911f4151096f56c17c9c13af3277c 100644
--- a/ppstructure/docs/kie_en.md
+++ b/ppstructure/docs/kie_en.md
@@ -18,6 +18,22 @@ This section provides a tutorial example on how to quickly use, train, and evalu
wget https://paddleocr.bj.bcebos.com/dygraph_v2.1/kie/wildreceipt.tar && tar xf wildreceipt.tar
```
+The dataset format are as follows:
+```
+./wildreceipt
+├── class_list.txt # The text category inside the box, such as amount, time, date, etc.
+├── dict.txt # A recognized dictionary file, a list of characters contained in the dataset
+├── wildreceipt_train.txt # training data label file
+└── wildreceipt_test.txt # testing data label file
+└── image_files/ # image dataset file
+```
+
+The format in the label file is:
+```
+" The image file path Image annotation information encoded by json.dumps"
+image_files/Image_16/11/d5de7f2a20751e50b84c747c17a24cd98bed3554.jpeg [{"label": 1, "transcription": "SAFEWAY", "points": [[550.0, 190.0], [937.0, 190.0], [937.0, 104.0], [550.0, 104.0]]}, {"label": 25, "transcription": "TM", "points": [[1048.0, 211.0], [1074.0, 211.0], [1074.0, 196.0], [1048.0, 196.0]]}, {"label": 25, "transcription": "ATOREMGRTOMMILAZZO", "points": [[535.0, 239.0], [833.0, 239.0], [833.0, 200.0], [535.0, 200.0]]}, {"label": 5, "transcription": "703-777-5833", "points": [[907.0, 256.0], [1081.0, 256.0], [1081.0, 223.0], [907.0, 223.0]]}......
+```
+
Download the pretrained model and predict the result:
```shell
diff --git a/ppstructure/table/table_metric/table_metric.py b/ppstructure/table/table_metric/table_metric.py
index 9aca98ad785d4614a803fa5a277a6e4a27b3b078..923a9c0071d083de72a2a896d6f62037373d4e73 100755
--- a/ppstructure/table/table_metric/table_metric.py
+++ b/ppstructure/table/table_metric/table_metric.py
@@ -9,7 +9,7 @@
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# Apache 2.0 License for more details.
-import distance
+from rapidfuzz.distance import Levenshtein
from apted import APTED, Config
from apted.helpers import Tree
from lxml import etree, html
@@ -39,17 +39,6 @@ class TableTree(Tree):
class CustomConfig(Config):
- @staticmethod
- def maximum(*sequences):
- """Get maximum possible value
- """
- return max(map(len, sequences))
-
- def normalized_distance(self, *sequences):
- """Get distance from 0 to 1
- """
- return float(distance.levenshtein(*sequences)) / self.maximum(*sequences)
-
def rename(self, node1, node2):
"""Compares attributes of trees"""
#print(node1.tag)
@@ -58,23 +47,12 @@ class CustomConfig(Config):
if node1.tag == 'td':
if node1.content or node2.content:
#print(node1.content, )
- return self.normalized_distance(node1.content, node2.content)
+ return Levenshtein.normalized_distance(node1.content, node2.content)
return 0.
class CustomConfig_del_short(Config):
- @staticmethod
- def maximum(*sequences):
- """Get maximum possible value
- """
- return max(map(len, sequences))
-
- def normalized_distance(self, *sequences):
- """Get distance from 0 to 1
- """
- return float(distance.levenshtein(*sequences)) / self.maximum(*sequences)
-
def rename(self, node1, node2):
"""Compares attributes of trees"""
if (node1.tag != node2.tag) or (node1.colspan != node2.colspan) or (node1.rowspan != node2.rowspan):
@@ -90,21 +68,10 @@ class CustomConfig_del_short(Config):
node1_content = ['####']
if len(node2_content) < 3:
node2_content = ['####']
- return self.normalized_distance(node1_content, node2_content)
+ return Levenshtein.normalized_distance(node1_content, node2_content)
return 0.
class CustomConfig_del_block(Config):
- @staticmethod
- def maximum(*sequences):
- """Get maximum possible value
- """
- return max(map(len, sequences))
-
- def normalized_distance(self, *sequences):
- """Get distance from 0 to 1
- """
- return float(distance.levenshtein(*sequences)) / self.maximum(*sequences)
-
def rename(self, node1, node2):
"""Compares attributes of trees"""
if (node1.tag != node2.tag) or (node1.colspan != node2.colspan) or (node1.rowspan != node2.rowspan):
@@ -120,7 +87,7 @@ class CustomConfig_del_block(Config):
while ' ' in node2_content:
print(node2_content.index(' '))
node2_content.pop(node2_content.index(' '))
- return self.normalized_distance(node1_content, node2_content)
+ return Levenshtein.normalized_distance(node1_content, node2_content)
return 0.
class TEDS(object):
diff --git a/ppstructure/vqa/README.md b/ppstructure/vqa/README.md
index e3a10671ddb6494eb15073e7ac007aa1e8e6a32a..3bfca3049731534aaa6799d79ec29af7f4219078 100644
--- a/ppstructure/vqa/README.md
+++ b/ppstructure/vqa/README.md
@@ -192,7 +192,7 @@ Finally, `precision`, `recall`, `hmean` and other indicators will be printed
Use the following command to complete the series prediction of `OCR engine + SER`, taking the pretrained SER model as an example:
```shell
-CUDA_VISIBLE_DEVICES=0 python3 tools/infer_vqa_token_ser.py -c configs/vqa/ser/layoutxlm.yml -o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/Global.infer_img=doc/vqa/input/zh_val_42.jpg
+CUDA_VISIBLE_DEVICES=0 python3 tools/infer_vqa_token_ser.py -c configs/vqa/ser/layoutxlm.yml -o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/ Global.infer_img=doc/vqa/input/zh_val_42.jpg
````
Finally, the prediction result visualization image and the prediction result text file will be saved in the directory configured by the `config.Global.save_res_path` field. The prediction result text file is named `infer_results.txt`.
@@ -203,7 +203,7 @@ First use the `tools/infer_vqa_token_ser.py` script to complete the prediction o
```shell
export CUDA_VISIBLE_DEVICES=0
-python3 tools/eval_with_label_end2end.py --gt_json_path XFUND/zh_val/xfun_normalize_val.json --pred_json_path output_res/infer_results.txt
+python3 ppstructure/vqa/tools/eval_with_label_end2end.py --gt_json_path XFUND/zh_val/xfun_normalize_val.json --pred_json_path output_res/infer_results.txt
````
@@ -247,7 +247,7 @@ Finally, `precision`, `recall`, `hmean` and other indicators will be printed
Use the following command to complete the series prediction of `OCR engine + SER + RE`, taking the pretrained SER and RE models as an example:
```shell
export CUDA_VISIBLE_DEVICES=0
-python3 tools/infer_vqa_token_ser_re.py -c configs/vqa/re/layoutxlm.yml -o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/Global.infer_img=doc/vqa/input/zh_val_21.jpg -c_ser configs/vqa/ser/layoutxlm. yml -o_ser Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/
+python3 tools/infer_vqa_token_ser_re.py -c configs/vqa/re/layoutxlm.yml -o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/ Global.infer_img=doc/vqa/input/zh_val_21.jpg -c_ser configs/vqa/ser/layoutxlm. yml -o_ser Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/
````
Finally, the prediction result visualization image and the prediction result text file will be saved in the directory configured by the `config.Global.save_res_path` field. The prediction result text file is named `infer_results.txt`.
diff --git a/ppstructure/vqa/README_ch.md b/ppstructure/vqa/README_ch.md
index b677dc07bce6c1a752d753b6a1c538b4d3f99271..abf8e4883c25d3092baa5d1fcc86d1571d04ac93 100644
--- a/ppstructure/vqa/README_ch.md
+++ b/ppstructure/vqa/README_ch.md
@@ -198,7 +198,7 @@ CUDA_VISIBLE_DEVICES=0 python3 tools/infer_vqa_token_ser.py -c configs/vqa/ser/l
```shell
export CUDA_VISIBLE_DEVICES=0
-python3 tools/eval_with_label_end2end.py --gt_json_path XFUND/zh_val/xfun_normalize_val.json --pred_json_path output_res/infer_results.txt
+python3 ppstructure/vqa/tools/eval_with_label_end2end.py --gt_json_path XFUND/zh_val/xfun_normalize_val.json --pred_json_path output_res/infer_results.txt
```
### 5.3 RE
diff --git a/ppstructure/vqa/tools/eval_with_label_end2end.py b/ppstructure/vqa/tools/eval_with_label_end2end.py
index b13ffb568fd9610fee5d5a246c501ed5b90de91a..b0fd84363f450dfb7e4ef18e53adc17ef088cf18 100644
--- a/ppstructure/vqa/tools/eval_with_label_end2end.py
+++ b/ppstructure/vqa/tools/eval_with_label_end2end.py
@@ -20,7 +20,7 @@ from shapely.geometry import Polygon
import numpy as np
from collections import defaultdict
import operator
-import Levenshtein
+from rapidfuzz.distance import Levenshtein
import argparse
import json
import copy
diff --git a/requirements.txt b/requirements.txt
index b15176db3eb42c381c1612f404fd15c6b020b3dc..976d29192abbbf89b8ee6064c0b4ec48d43ad268 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -6,7 +6,7 @@ lmdb
tqdm
numpy
visualdl
-python-Levenshtein
+rapidfuzz
opencv-contrib-python==4.4.0.46
cython
lxml
diff --git a/test_tipc/test_train_inference_python.sh b/test_tipc/test_train_inference_python.sh
index fe98cb00f6cc428995d7f91db55895e0f1cd9bfd..2c9a7e73e6843921b0aba176a725aed4629c5476 100644
--- a/test_tipc/test_train_inference_python.sh
+++ b/test_tipc/test_train_inference_python.sh
@@ -329,6 +329,7 @@ else
set_save_model=$(func_set_params "${save_model_key}" "${save_log}")
if [ ${#gpu} -le 2 ];then # train with cpu or single gpu
+ eval ${env}
cmd="${python} ${run_train} ${set_use_gpu} ${set_save_model} ${set_epoch} ${set_pretrain} ${set_autocast} ${set_batchsize} ${set_train_params1} ${set_amp_config} "
elif [ ${#ips} -le 26 ];then # train with multi-gpu
cmd="${python} -m paddle.distributed.launch --gpus=${gpu} ${run_train} ${set_use_gpu} ${set_save_model} ${set_epoch} ${set_pretrain} ${set_autocast} ${set_batchsize} ${set_train_params1} ${set_amp_config}"
diff --git a/tools/export_model.py b/tools/export_model.py
index c0cbcd361cec31c51616a7154836c234f076a86e..8ccaea2908b6e6121e0d30f2769f6e93bef49392 100755
--- a/tools/export_model.py
+++ b/tools/export_model.py
@@ -31,7 +31,12 @@ from ppocr.utils.logging import get_logger
from tools.program import load_config, merge_config, ArgsParser
-def export_single_model(model, arch_config, save_path, logger, quanter=None):
+def export_single_model(model,
+ arch_config,
+ save_path,
+ logger,
+ input_shape=None,
+ quanter=None):
if arch_config["algorithm"] == "SRN":
max_text_length = arch_config["Head"]["max_text_length"]
other_shape = [
@@ -64,7 +69,7 @@ def export_single_model(model, arch_config, save_path, logger, quanter=None):
else:
other_shape = [
paddle.static.InputSpec(
- shape=[None, 3, 64, 256], dtype="float32"),
+ shape=[None] + input_shape, dtype="float32"),
]
model = to_static(model, input_spec=other_shape)
elif arch_config["algorithm"] == "PREN":
@@ -76,7 +81,7 @@ def export_single_model(model, arch_config, save_path, logger, quanter=None):
else:
infer_shape = [3, -1, -1]
if arch_config["model_type"] == "rec":
- infer_shape = [3, 32, -1] # for rec model, H must be 32
+ infer_shape = [3, 48, -1] # for rec model, H must be 32
if "Transform" in arch_config and arch_config[
"Transform"] is not None and arch_config["Transform"][
"name"] == "TPS":
@@ -157,6 +162,13 @@ def main():
arch_config = config["Architecture"]
+ if arch_config["algorithm"] == "SVTR" and arch_config["Head"][
+ "name"] != 'MultiHead':
+ input_shape = config["Eval"]["dataset"]["transforms"][-2][
+ 'SVTRRecResizeImg']['image_shape']
+ else:
+ input_shape = None
+
if arch_config["algorithm"] in ["Distillation", ]: # distillation model
archs = list(arch_config["Models"].values())
for idx, name in enumerate(model.model_name_list):
@@ -165,7 +177,8 @@ def main():
sub_model_save_path, logger)
else:
save_path = os.path.join(save_path, "inference")
- export_single_model(model, arch_config, save_path, logger)
+ export_single_model(
+ model, arch_config, save_path, logger, input_shape=input_shape)
if __name__ == "__main__":
diff --git a/tools/infer/predict_det.py b/tools/infer/predict_det.py
index 5f2675d667c2aab8186886a60d8d447f43419954..cf495c59c25cfe24ed0987b56cbe810579f1d542 100755
--- a/tools/infer/predict_det.py
+++ b/tools/infer/predict_det.py
@@ -24,6 +24,7 @@ import cv2
import numpy as np
import time
import sys
+from scipy.spatial import distance as dist
import tools.infer.utility as utility
from ppocr.utils.logging import get_logger
@@ -154,9 +155,10 @@ class TextDetector(object):
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
- diff = np.diff(pts, axis=1)
- rect[1] = pts[np.argmin(diff)]
- rect[3] = pts[np.argmax(diff)]
+ tmp = np.delete(pts, (np.argmin(s), np.argmax(s)), axis=0)
+ diff = np.diff(np.array(tmp), axis=1)
+ rect[1] = tmp[np.argmin(diff)]
+ rect[3] = tmp[np.argmax(diff)]
return rect
def clip_det_res(self, points, img_height, img_width):
diff --git a/tools/infer/predict_system.py b/tools/infer/predict_system.py
index 625d365f45c578d051974d7174e26246e9bc2442..1fac2918a15c8b1b858b83d032ecfd889679e6f9 100755
--- a/tools/infer/predict_system.py
+++ b/tools/infer/predict_system.py
@@ -114,11 +114,14 @@ def sorted_boxes(dt_boxes):
_boxes = list(sorted_boxes)
for i in range(num_boxes - 1):
- if abs(_boxes[i + 1][0][1] - _boxes[i][0][1]) < 10 and \
- (_boxes[i + 1][0][0] < _boxes[i][0][0]):
- tmp = _boxes[i]
- _boxes[i] = _boxes[i + 1]
- _boxes[i + 1] = tmp
+ for j in range(i, 0, -1):
+ if abs(_boxes[j + 1][0][1] - _boxes[j][0][1]) < 10 and \
+ (_boxes[j + 1][0][0] < _boxes[j][0][0]):
+ tmp = _boxes[j]
+ _boxes[j] = _boxes[j + 1]
+ _boxes[j + 1] = tmp
+ else:
+ break
return _boxes
@@ -135,7 +138,7 @@ def main(args):
logger.info("In PP-OCRv3, rec_image_shape parameter defaults to '3, 48, 320', "
"if you are using recognition model with PP-OCRv2 or an older version, please set --rec_image_shape='3,32,320")
-
+
# warm up 10 times
if args.warmup:
img = np.random.uniform(0, 255, [640, 640, 3]).astype(np.uint8)
@@ -198,7 +201,12 @@ def main(args):
text_sys.text_detector.autolog.report()
text_sys.text_recognizer.autolog.report()
- with open(os.path.join(draw_img_save_dir, "system_results.txt"), 'w', encoding='utf-8') as f:
+ if args.total_process_num > 1:
+ save_results_path = os.path.join(draw_img_save_dir, f"system_results_{args.process_id}.txt")
+ else:
+ save_results_path = os.path.join(draw_img_save_dir, "system_results.txt")
+
+ with open(save_results_path, 'w', encoding='utf-8') as f:
f.writelines(save_results)
diff --git a/tools/infer/utility.py b/tools/infer/utility.py
index d27aec63edd2fb5c0240ff0254ce1057b62162b0..6d9935a70e79bb20c5f6380783911ef141b0be17 100644
--- a/tools/infer/utility.py
+++ b/tools/infer/utility.py
@@ -55,6 +55,7 @@ def init_args():
parser.add_argument("--max_batch_size", type=int, default=10)
parser.add_argument("--use_dilation", type=str2bool, default=False)
parser.add_argument("--det_db_score_mode", type=str, default="fast")
+ parser.add_argument("--vis_seg_map", type=str2bool, default=False)
# EAST parmas
parser.add_argument("--det_east_score_thresh", type=float, default=0.8)
parser.add_argument("--det_east_cover_thresh", type=float, default=0.1)
@@ -276,6 +277,7 @@ def create_predictor(args, mode, logger):
min_input_shape = {"x": [1, 3, imgH, 10]}
max_input_shape = {"x": [args.rec_batch_num, 3, imgH, 2304]}
opt_input_shape = {"x": [args.rec_batch_num, 3, imgH, 320]}
+ config.exp_disable_tensorrt_ops(["transpose2"])
elif mode == "cls":
min_input_shape = {"x": [1, 3, 48, 10]}
max_input_shape = {"x": [args.rec_batch_num, 3, 48, 1024]}
@@ -587,7 +589,7 @@ def text_visual(texts,
def base64_to_cv2(b64str):
import base64
data = base64.b64decode(b64str.encode('utf8'))
- data = np.fromstring(data, np.uint8)
+ data = np.frombuffer(data, np.uint8)
data = cv2.imdecode(data, cv2.IMREAD_COLOR)
return data
diff --git a/tools/infer_kie.py b/tools/infer_kie.py
index 0cb0b8702cbd7ea74a7b7fcff69122731578a1bd..187b27adb20aec6418f7c32a09c15cefcbbcd29d 100755
--- a/tools/infer_kie.py
+++ b/tools/infer_kie.py
@@ -89,6 +89,29 @@ def draw_kie_result(batch, node, idx_to_cls, count):
cv2.imwrite(save_path, vis_img)
logger.info("The Kie Image saved in {}".format(save_path))
+def write_kie_result(fout, node, data):
+ """
+ Write infer result to output file, sorted by the predict label of each line.
+ The format keeps the same as the input with additional score attribute.
+ """
+ import json
+ label = data['label']
+ annotations = json.loads(label)
+ max_value, max_idx = paddle.max(node, -1), paddle.argmax(node, -1)
+ node_pred_label = max_idx.numpy().tolist()
+ node_pred_score = max_value.numpy().tolist()
+ res = []
+ for i, label in enumerate(node_pred_label):
+ pred_score = '{:.2f}'.format(node_pred_score[i])
+ pred_res = {
+ 'label': label,
+ 'transcription': annotations[i]['transcription'],
+ 'score': pred_score,
+ 'points': annotations[i]['points'],
+ }
+ res.append(pred_res)
+ res.sort(key=lambda x: x['label'])
+ fout.writelines([json.dumps(res, ensure_ascii=False) + '\n'])
def main():
global_config = config['Global']
@@ -116,7 +139,7 @@ def main():
warmup_times = 0
count_t = []
- with open(save_res_path, "wb") as fout:
+ with open(save_res_path, "w") as fout:
with open(config['Global']['infer_img'], "rb") as f:
lines = f.readlines()
for index, data_line in enumerate(lines):
@@ -141,6 +164,8 @@ def main():
node = F.softmax(node, -1)
count_t.append(time.time() - st)
draw_kie_result(batch, node, idx_to_cls, index)
+ write_kie_result(fout, node, data)
+ fout.close()
logger.info("success!")
logger.info("It took {} s for predict {} images.".format(
np.sum(count_t), len(count_t)))
 +
+ |
|  |
| **irregular text annotation** | **key information annotation** |
-|
|
| **irregular text annotation** | **key information annotation** |
-|  |
|  |
+|
|
+|  -
-


 +
+


 |
+| 液晶屏读数识别 | 检测模型蒸馏、Serving部署 | [模型下载](#2) | [中文](./液晶屏读数识别.md)/English |
|
+| 液晶屏读数识别 | 检测模型蒸馏、Serving部署 | [模型下载](#2) | [中文](./液晶屏读数识别.md)/English | 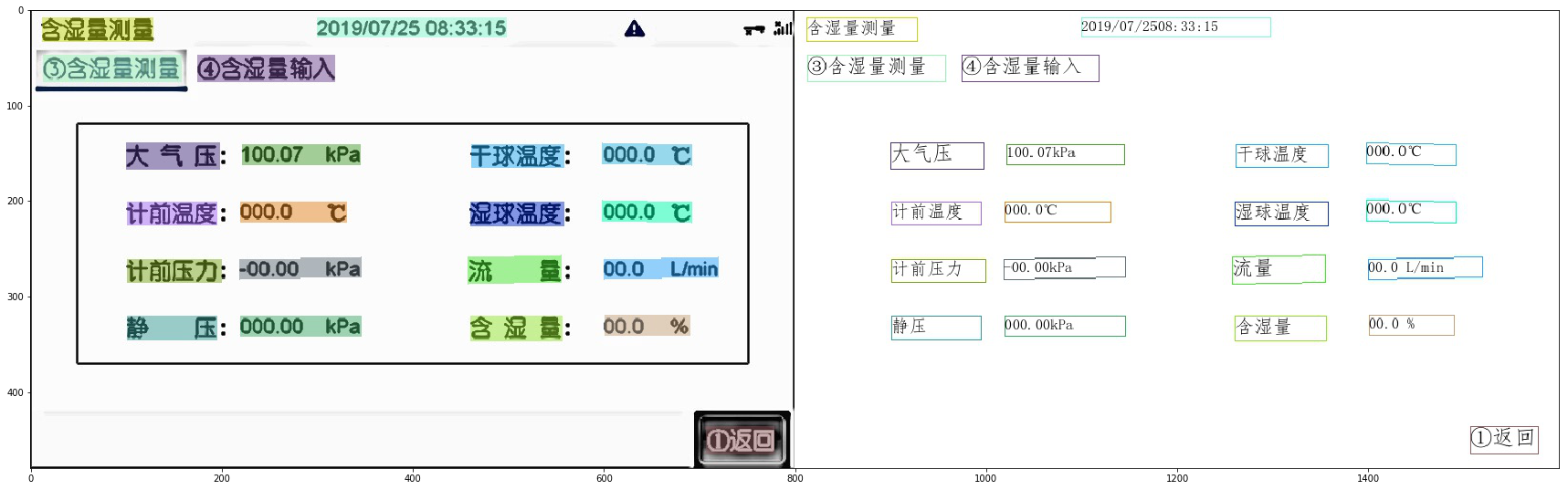 |
+| 包装生产日期 | 点阵字符合成、过曝过暗文字识别 | [模型下载](#2) | [中文](./包装生产日期识别.md)/English |
|
+| 包装生产日期 | 点阵字符合成、过曝过暗文字识别 | [模型下载](#2) | [中文](./包装生产日期识别.md)/English |  |
+| PCB文字识别 | 小尺寸文本检测与识别 | [模型下载](#2) | [中文](./PCB字符识别/PCB字符识别.md)/English |
|
+| PCB文字识别 | 小尺寸文本检测与识别 | [模型下载](#2) | [中文](./PCB字符识别/PCB字符识别.md)/English |  |
+| 增值税发票 | 尽请期待 | | | |
+| 印章检测与识别 | 端到端弯曲文本识别 | | | |
+| 通用卡证识别 | 通用结构化提取 | | | |
+| 身份证识别 | 结构化提取、图像阴影 | | | |
+| 合同比对 | 密集文本检测、NLP串联 | | | |
+
+
+
+### 交通
+
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| ----------------- | ------------------------------ | -------------- | ----------------------------------- | ------------------------------------------------------------ |
+| 车牌识别 | 多角度图像、轻量模型、端侧部署 | [模型下载](#2) | [中文](./轻量级车牌识别.md)/English |
|
+| 增值税发票 | 尽请期待 | | | |
+| 印章检测与识别 | 端到端弯曲文本识别 | | | |
+| 通用卡证识别 | 通用结构化提取 | | | |
+| 身份证识别 | 结构化提取、图像阴影 | | | |
+| 合同比对 | 密集文本检测、NLP串联 | | | |
+
+
+
+### 交通
+
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| ----------------- | ------------------------------ | -------------- | ----------------------------------- | ------------------------------------------------------------ |
+| 车牌识别 | 多角度图像、轻量模型、端侧部署 | [模型下载](#2) | [中文](./轻量级车牌识别.md)/English |  |
+| 驾驶证/行驶证识别 | 尽请期待 | | | |
+| 快递单识别 | 尽请期待 | | | |
+
+
+
+## 模型下载
+
+如需下载上述场景中已经训练好的垂类模型,可以扫描下方二维码,关注公众号填写问卷后,加入PaddleOCR官方交流群获取20G OCR学习大礼包(内含《动手学OCR》电子书、课程回放视频、前沿论文等重磅资料)
+
+
|
+| 驾驶证/行驶证识别 | 尽请期待 | | | |
+| 快递单识别 | 尽请期待 | | | |
+
+
+
+## 模型下载
+
+如需下载上述场景中已经训练好的垂类模型,可以扫描下方二维码,关注公众号填写问卷后,加入PaddleOCR官方交流群获取20G OCR学习大礼包(内含《动手学OCR》电子书、课程回放视频、前沿论文等重磅资料)
+
+ +
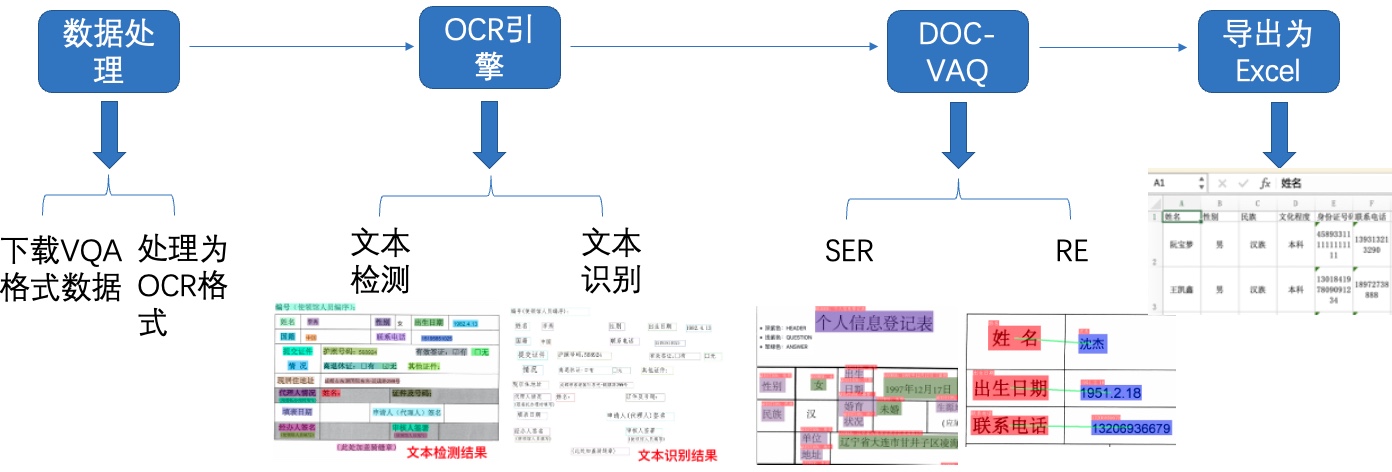
+目前光功率计缺少将数据直接输出的功能,需要人工读数。这一项工作单调重复,如果可以使用机器替代人工,将节约大量成本。针对上述问题,希望通过摄像头拍照->智能读数的方式高效地完成此任务。
+
+为实现智能读数,通常会采取文本检测+文本识别的方案:
+
+第一步,使用文本检测模型定位出光功率计中的数字部分;
+
+第二步,使用文本识别模型获得准确的数字和单位信息。
+
+本项目主要介绍如何完成第二步文本识别部分,包括:真实评估集的建立、训练数据的合成、基于 PP-OCRv3 和 SVTR_Tiny 两个模型进行训练,以及评估和推理。
+
+本项目难点如下:
+
+- 光功率计数码管字符数据较少,难以获取。
+- 数码管中小数点占像素较少,容易漏识别。
+
+针对以上问题, 本例选用 PP-OCRv3 和 SVTR_Tiny 两个高精度模型训练,同时提供了真实数据挖掘案例和数据合成案例。基于 PP-OCRv3 模型,在构建的真实评估集上精度从 52% 提升至 72%,SVTR_Tiny 模型精度可达到 78.9%。
+
+aistudio项目链接: [光功率计数码管字符识别](https://aistudio.baidu.com/aistudio/projectdetail/4049044?contributionType=1)
+
+## 2. PaddleOCR 快速使用
+
+PaddleOCR 旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
+
+
+
+
+官方提供了适用于通用场景的高精轻量模型,首先使用官方提供的 PP-OCRv3 模型预测图片,验证下当前模型在光功率计场景上的效果。
+
+- 准备环境
+
+```
+python3 -m pip install -U pip
+python3 -m pip install paddleocr
+```
+
+
+- 测试效果
+
+测试图:
+
+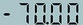
+
+
+```
+paddleocr --lang=ch --det=Fase --image_dir=data
+```
+
+得到如下测试结果:
+
+```
+('.7000', 0.6885431408882141)
+```
+
+发现数字识别较准,然而对负号和小数点识别不准确。 由于PP-OCRv3的训练数据大多为通用场景数据,在特定的场景上效果可能不够好。因此需要基于场景数据进行微调。
+
+下面就主要介绍如何在光功率计(数码管)场景上微调训练。
+
+
+## 3. 开始训练
+
+### 3.1 数据准备
+
+特定的工业场景往往很难获取开源的真实数据集,光功率计也是如此。在实际工业场景中,可以通过摄像头采集的方法收集大量真实数据,本例中重点介绍数据合成方法和真实数据挖掘方法,如何利用有限的数据优化模型精度。
+
+数据集分为两个部分:合成数据,真实数据, 其中合成数据由 text_renderer 工具批量生成得到, 真实数据通过爬虫等方式在百度图片中搜索并使用 PPOCRLabel 标注得到。
+
+
+- 合成数据
+
+本例中数据合成工具使用的是 [text_renderer](https://github.com/Sanster/text_renderer), 该工具可以合成用于文本识别训练的文本行数据:
+
+
+
+
+
+
+```
+export https_proxy=http://172.19.57.45:3128
+git clone https://github.com/oh-my-ocr/text_renderer
+```
+
+```
+import os
+python3 setup.py develop
+python3 -m pip install -r docker/requirements.txt
+python3 main.py \
+ --config example_data/example.py \
+ --dataset img \
+ --num_processes 2 \
+ --log_period 10
+```
+
+给定字体和语料,就可以合成较为丰富样式的文本行数据。 光功率计识别场景,目标是正确识别数码管文本,因此需要收集部分数码管字体,训练语料,用于合成文本识别数据。
+
+将收集好的语料存放在 example_data 路径下:
+
+```
+ln -s ./fonts/DS* text_renderer/example_data/font/
+ln -s ./corpus/digital.txt text_renderer/example_data/text/
+```
+
+修改 text_renderer/example_data/font_list/font_list.txt ,选择需要的字体开始合成:
+
+```
+python3 main.py \
+ --config example_data/digital_example.py \
+ --dataset img \
+ --num_processes 2 \
+ --log_period 10
+```
+
+合成图片会被存在目录 text_renderer/example_data/digital/chn_data 下
+
+查看合成的数据样例:
+
+
+
+
+- 真实数据挖掘
+
+模型训练需要使用真实数据作为评价指标,否则很容易过拟合到简单的合成数据中。没有开源数据的情况下,可以利用部分无标注数据+标注工具获得真实数据。
+
+
+1. 数据搜集
+
+使用[爬虫工具](https://github.com/Joeclinton1/google-images-download.git)获得无标注数据
+
+2. [PPOCRLabel](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.5/PPOCRLabel) 完成半自动标注
+
+PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注、表格标注、不规则文本标注、关键信息标注模式,导出格式可直接用于PaddleOCR检测和识别模型的训练。
+
+
+
+
+收集完数据后就可以进行分配了,验证集中一般都是真实数据,训练集中包含合成数据+真实数据。本例中标注了155张图片,其中训练集和验证集的数目为100和55。
+
+
+最终 `data` 文件夹应包含以下几部分:
+
+```
+|-data
+ |- synth_train.txt
+ |- real_train.txt
+ |- real_eval.txt
+ |- synthetic_data
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+ |- real_data
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+ ...
+```
+
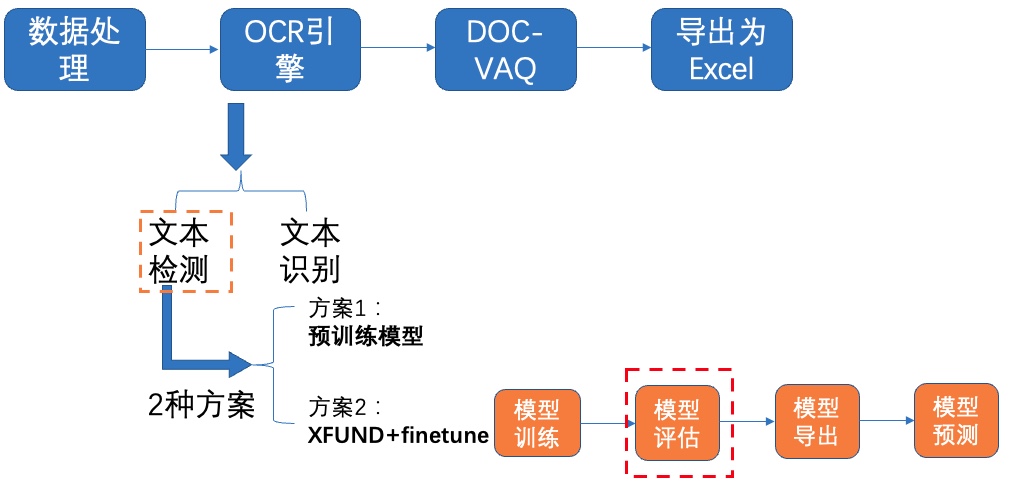
+### 3.2 模型选择
+
+本案例提供了2种文本识别模型:PP-OCRv3 识别模型 和 SVTR_Tiny:
+
+[PP-OCRv3 识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md):PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。并进行了一系列结构改进加速模型预测。
+
+[SVTR_Tiny](https://arxiv.org/abs/2205.00159):SVTR提出了一种用于场景文本识别的单视觉模型,该模型在patch-wise image tokenization框架内,完全摒弃了序列建模,在精度具有竞争力的前提下,模型参数量更少,速度更快。
+
+以上两个策略在自建中文数据集上的精度和速度对比如下:
+
+| ID | 策略 | 模型大小 | 精度 | 预测耗时(CPU + MKLDNN)|
+|-----|-----|--------|----| --- |
+| 01 | PP-OCRv2 | 8M | 74.8% | 8.54ms |
+| 02 | SVTR_Tiny | 21M | 80.1% | 97ms |
+| 03 | SVTR_LCNet(h32) | 12M | 71.9% | 6.6ms |
+| 04 | SVTR_LCNet(h48) | 12M | 73.98% | 7.6ms |
+| 05 | + GTC | 12M | 75.8% | 7.6ms |
+| 06 | + TextConAug | 12M | 76.3% | 7.6ms |
+| 07 | + TextRotNet | 12M | 76.9% | 7.6ms |
+| 08 | + UDML | 12M | 78.4% | 7.6ms |
+| 09 | + UIM | 12M | 79.4% | 7.6ms |
+
+
+### 3.3 开始训练
+
+首先下载 PaddleOCR 代码库
+
+```
+git clone -b release/2.5 https://github.com/PaddlePaddle/PaddleOCR.git
+```
+
+PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以 PP-OCRv3 中文识别模型为例:
+
+**Step1:下载预训练模型**
+
+首先下载 pretrain model,您可以下载训练好的模型在自定义数据上进行finetune
+
+```
+cd PaddleOCR/
+# 下载PP-OCRv3 中文预训练模型
+wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
+# 解压模型参数
+cd pretrain_models
+tar -xf ch_PP-OCRv3_rec_train.tar && rm -rf ch_PP-OCRv3_rec_train.tar
+```
+
+**Step2:自定义字典文件**
+
+接下来需要提供一个字典({word_dict_name}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。
+
+因此字典需要包含所有希望被正确识别的字符,{word_dict_name}.txt需要写成如下格式,并以 `utf-8` 编码格式保存:
+
+```
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+-
+.
+```
+
+word_dict.txt 每行有一个单字,将字符与数字索引映射在一起,“3.14” 将被映射成 [3, 11, 1, 4]
+
+* 内置字典
+
+PaddleOCR内置了一部分字典,可以按需使用。
+
+`ppocr/utils/ppocr_keys_v1.txt` 是一个包含6623个字符的中文字典
+
+`ppocr/utils/ic15_dict.txt` 是一个包含36个字符的英文字典
+
+* 自定义字典
+
+内置字典面向通用场景,具体的工业场景中,可能需要识别特殊字符,或者只需识别某几个字符,此时自定义字典会更提升模型精度。例如在光功率计场景中,需要识别数字和单位。
+
+遍历真实数据标签中的字符,制作字典`digital_dict.txt`如下所示:
+
+```
+-
+.
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+B
+E
+F
+H
+L
+N
+T
+W
+d
+k
+m
+n
+o
+z
+```
+
+
+
+
+**Step3:修改配置文件**
+
+为了更好的使用预训练模型,训练推荐使用[ch_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml)配置文件,并参考下列说明修改配置文件:
+
+以 `ch_PP-OCRv3_rec_distillation.yml` 为例:
+```
+Global:
+ ...
+ # 添加自定义字典,如修改字典请将路径指向新字典
+ character_dict_path: ppocr/utils/dict/digital_dict.txt
+ ...
+ # 识别空格
+ use_space_char: True
+
+
+Optimizer:
+ ...
+ # 添加学习率衰减策略
+ lr:
+ name: Cosine
+ learning_rate: 0.001
+ ...
+
+...
+
+Train:
+ dataset:
+ # 数据集格式,支持LMDBDataSet以及SimpleDataSet
+ name: SimpleDataSet
+ # 数据集路径
+ data_dir: ./data/
+ # 训练集标签文件
+ label_file_list:
+ - ./train_data/digital_img/digital_train.txt #11w
+ - ./train_data/digital_img/real_train.txt #100
+ - ./train_data/digital_img/dbm_img/dbm.txt #3w
+ ratio_list:
+ - 0.3
+ - 1.0
+ - 1.0
+ transforms:
+ ...
+ - RecResizeImg:
+ # 修改 image_shape 以适应长文本
+ image_shape: [3, 48, 320]
+ ...
+ loader:
+ ...
+ # 单卡训练的batch_size
+ batch_size_per_card: 256
+ ...
+
+Eval:
+ dataset:
+ # 数据集格式,支持LMDBDataSet以及SimpleDataSet
+ name: SimpleDataSet
+ # 数据集路径
+ data_dir: ./data
+ # 验证集标签文件
+ label_file_list:
+ - ./train_data/digital_img/real_val.txt
+ transforms:
+ ...
+ - RecResizeImg:
+ # 修改 image_shape 以适应长文本
+ image_shape: [3, 48, 320]
+ ...
+ loader:
+ # 单卡验证的batch_size
+ batch_size_per_card: 256
+ ...
+```
+**注意,训练/预测/评估时的配置文件请务必与训练一致。**
+
+**Step4:启动训练**
+
+*如果您安装的是cpu版本,请将配置文件中的 `use_gpu` 字段修改为false*
+
+```
+# GPU训练 支持单卡,多卡训练
+# 训练数码管数据 训练日志会自动保存为 "{save_model_dir}" 下的train.log
+
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
+```
+
+
+PaddleOCR支持训练和评估交替进行, 可以在 `configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml` 中修改 `eval_batch_step` 设置评估频率,默认每500个iter评估一次。评估过程中默认将最佳acc模型,保存为 `output/ch_PP-OCRv3_rec_distill/best_accuracy` 。
+
+如果验证集很大,测试将会比较耗时,建议减少评估次数,或训练完再进行评估。
+
+### SVTR_Tiny 训练
+
+SVTR_Tiny 训练步骤与上面一致,SVTR支持的配置和模型训练权重可以参考[算法介绍文档](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/algorithm_rec_svtr.md)
+
+**Step1:下载预训练模型**
+
+```
+# 下载 SVTR_Tiny 中文识别预训练模型和配置文件
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/rec_svtr_tiny_none_ctc_ch_train.tar
+# 解压模型参数
+tar -xf rec_svtr_tiny_none_ctc_ch_train.tar && rm -rf rec_svtr_tiny_none_ctc_ch_train.tar
+```
+**Step2:自定义字典文件**
+
+字典依然使用自定义的 digital_dict.txt
+
+**Step3:修改配置文件**
+
+配置文件中对应修改字典路径和数据路径
+
+**Step4:启动训练**
+
+```
+## 单卡训练
+python tools/train.py -c rec_svtr_tiny_none_ctc_ch_train/rec_svtr_tiny_6local_6global_stn_ch.yml \
+ -o Global.pretrained_model=./rec_svtr_tiny_none_ctc_ch_train/best_accuracy
+```
+
+### 3.4 验证效果
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+
+
+目前光功率计缺少将数据直接输出的功能,需要人工读数。这一项工作单调重复,如果可以使用机器替代人工,将节约大量成本。针对上述问题,希望通过摄像头拍照->智能读数的方式高效地完成此任务。
+
+为实现智能读数,通常会采取文本检测+文本识别的方案:
+
+第一步,使用文本检测模型定位出光功率计中的数字部分;
+
+第二步,使用文本识别模型获得准确的数字和单位信息。
+
+本项目主要介绍如何完成第二步文本识别部分,包括:真实评估集的建立、训练数据的合成、基于 PP-OCRv3 和 SVTR_Tiny 两个模型进行训练,以及评估和推理。
+
+本项目难点如下:
+
+- 光功率计数码管字符数据较少,难以获取。
+- 数码管中小数点占像素较少,容易漏识别。
+
+针对以上问题, 本例选用 PP-OCRv3 和 SVTR_Tiny 两个高精度模型训练,同时提供了真实数据挖掘案例和数据合成案例。基于 PP-OCRv3 模型,在构建的真实评估集上精度从 52% 提升至 72%,SVTR_Tiny 模型精度可达到 78.9%。
+
+aistudio项目链接: [光功率计数码管字符识别](https://aistudio.baidu.com/aistudio/projectdetail/4049044?contributionType=1)
+
+## 2. PaddleOCR 快速使用
+
+PaddleOCR 旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
+
+
+
+
+官方提供了适用于通用场景的高精轻量模型,首先使用官方提供的 PP-OCRv3 模型预测图片,验证下当前模型在光功率计场景上的效果。
+
+- 准备环境
+
+```
+python3 -m pip install -U pip
+python3 -m pip install paddleocr
+```
+
+
+- 测试效果
+
+测试图:
+
+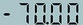
+
+
+```
+paddleocr --lang=ch --det=Fase --image_dir=data
+```
+
+得到如下测试结果:
+
+```
+('.7000', 0.6885431408882141)
+```
+
+发现数字识别较准,然而对负号和小数点识别不准确。 由于PP-OCRv3的训练数据大多为通用场景数据,在特定的场景上效果可能不够好。因此需要基于场景数据进行微调。
+
+下面就主要介绍如何在光功率计(数码管)场景上微调训练。
+
+
+## 3. 开始训练
+
+### 3.1 数据准备
+
+特定的工业场景往往很难获取开源的真实数据集,光功率计也是如此。在实际工业场景中,可以通过摄像头采集的方法收集大量真实数据,本例中重点介绍数据合成方法和真实数据挖掘方法,如何利用有限的数据优化模型精度。
+
+数据集分为两个部分:合成数据,真实数据, 其中合成数据由 text_renderer 工具批量生成得到, 真实数据通过爬虫等方式在百度图片中搜索并使用 PPOCRLabel 标注得到。
+
+
+- 合成数据
+
+本例中数据合成工具使用的是 [text_renderer](https://github.com/Sanster/text_renderer), 该工具可以合成用于文本识别训练的文本行数据:
+
+
+
+
+
+
+```
+export https_proxy=http://172.19.57.45:3128
+git clone https://github.com/oh-my-ocr/text_renderer
+```
+
+```
+import os
+python3 setup.py develop
+python3 -m pip install -r docker/requirements.txt
+python3 main.py \
+ --config example_data/example.py \
+ --dataset img \
+ --num_processes 2 \
+ --log_period 10
+```
+
+给定字体和语料,就可以合成较为丰富样式的文本行数据。 光功率计识别场景,目标是正确识别数码管文本,因此需要收集部分数码管字体,训练语料,用于合成文本识别数据。
+
+将收集好的语料存放在 example_data 路径下:
+
+```
+ln -s ./fonts/DS* text_renderer/example_data/font/
+ln -s ./corpus/digital.txt text_renderer/example_data/text/
+```
+
+修改 text_renderer/example_data/font_list/font_list.txt ,选择需要的字体开始合成:
+
+```
+python3 main.py \
+ --config example_data/digital_example.py \
+ --dataset img \
+ --num_processes 2 \
+ --log_period 10
+```
+
+合成图片会被存在目录 text_renderer/example_data/digital/chn_data 下
+
+查看合成的数据样例:
+
+
+
+
+- 真实数据挖掘
+
+模型训练需要使用真实数据作为评价指标,否则很容易过拟合到简单的合成数据中。没有开源数据的情况下,可以利用部分无标注数据+标注工具获得真实数据。
+
+
+1. 数据搜集
+
+使用[爬虫工具](https://github.com/Joeclinton1/google-images-download.git)获得无标注数据
+
+2. [PPOCRLabel](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.5/PPOCRLabel) 完成半自动标注
+
+PPOCRLabel是一款适用于OCR领域的半自动化图形标注工具,内置PP-OCR模型对数据自动标注和重新识别。使用Python3和PyQT5编写,支持矩形框标注、表格标注、不规则文本标注、关键信息标注模式,导出格式可直接用于PaddleOCR检测和识别模型的训练。
+
+
+
+
+收集完数据后就可以进行分配了,验证集中一般都是真实数据,训练集中包含合成数据+真实数据。本例中标注了155张图片,其中训练集和验证集的数目为100和55。
+
+
+最终 `data` 文件夹应包含以下几部分:
+
+```
+|-data
+ |- synth_train.txt
+ |- real_train.txt
+ |- real_eval.txt
+ |- synthetic_data
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+ |- real_data
+ |- word_001.png
+ |- word_002.jpg
+ |- word_003.jpg
+ | ...
+ ...
+```
+
+### 3.2 模型选择
+
+本案例提供了2种文本识别模型:PP-OCRv3 识别模型 和 SVTR_Tiny:
+
+[PP-OCRv3 识别模型](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md):PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。并进行了一系列结构改进加速模型预测。
+
+[SVTR_Tiny](https://arxiv.org/abs/2205.00159):SVTR提出了一种用于场景文本识别的单视觉模型,该模型在patch-wise image tokenization框架内,完全摒弃了序列建模,在精度具有竞争力的前提下,模型参数量更少,速度更快。
+
+以上两个策略在自建中文数据集上的精度和速度对比如下:
+
+| ID | 策略 | 模型大小 | 精度 | 预测耗时(CPU + MKLDNN)|
+|-----|-----|--------|----| --- |
+| 01 | PP-OCRv2 | 8M | 74.8% | 8.54ms |
+| 02 | SVTR_Tiny | 21M | 80.1% | 97ms |
+| 03 | SVTR_LCNet(h32) | 12M | 71.9% | 6.6ms |
+| 04 | SVTR_LCNet(h48) | 12M | 73.98% | 7.6ms |
+| 05 | + GTC | 12M | 75.8% | 7.6ms |
+| 06 | + TextConAug | 12M | 76.3% | 7.6ms |
+| 07 | + TextRotNet | 12M | 76.9% | 7.6ms |
+| 08 | + UDML | 12M | 78.4% | 7.6ms |
+| 09 | + UIM | 12M | 79.4% | 7.6ms |
+
+
+### 3.3 开始训练
+
+首先下载 PaddleOCR 代码库
+
+```
+git clone -b release/2.5 https://github.com/PaddlePaddle/PaddleOCR.git
+```
+
+PaddleOCR提供了训练脚本、评估脚本和预测脚本,本节将以 PP-OCRv3 中文识别模型为例:
+
+**Step1:下载预训练模型**
+
+首先下载 pretrain model,您可以下载训练好的模型在自定义数据上进行finetune
+
+```
+cd PaddleOCR/
+# 下载PP-OCRv3 中文预训练模型
+wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
+# 解压模型参数
+cd pretrain_models
+tar -xf ch_PP-OCRv3_rec_train.tar && rm -rf ch_PP-OCRv3_rec_train.tar
+```
+
+**Step2:自定义字典文件**
+
+接下来需要提供一个字典({word_dict_name}.txt),使模型在训练时,可以将所有出现的字符映射为字典的索引。
+
+因此字典需要包含所有希望被正确识别的字符,{word_dict_name}.txt需要写成如下格式,并以 `utf-8` 编码格式保存:
+
+```
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+-
+.
+```
+
+word_dict.txt 每行有一个单字,将字符与数字索引映射在一起,“3.14” 将被映射成 [3, 11, 1, 4]
+
+* 内置字典
+
+PaddleOCR内置了一部分字典,可以按需使用。
+
+`ppocr/utils/ppocr_keys_v1.txt` 是一个包含6623个字符的中文字典
+
+`ppocr/utils/ic15_dict.txt` 是一个包含36个字符的英文字典
+
+* 自定义字典
+
+内置字典面向通用场景,具体的工业场景中,可能需要识别特殊字符,或者只需识别某几个字符,此时自定义字典会更提升模型精度。例如在光功率计场景中,需要识别数字和单位。
+
+遍历真实数据标签中的字符,制作字典`digital_dict.txt`如下所示:
+
+```
+-
+.
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+B
+E
+F
+H
+L
+N
+T
+W
+d
+k
+m
+n
+o
+z
+```
+
+
+
+
+**Step3:修改配置文件**
+
+为了更好的使用预训练模型,训练推荐使用[ch_PP-OCRv3_rec_distillation.yml](../../configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml)配置文件,并参考下列说明修改配置文件:
+
+以 `ch_PP-OCRv3_rec_distillation.yml` 为例:
+```
+Global:
+ ...
+ # 添加自定义字典,如修改字典请将路径指向新字典
+ character_dict_path: ppocr/utils/dict/digital_dict.txt
+ ...
+ # 识别空格
+ use_space_char: True
+
+
+Optimizer:
+ ...
+ # 添加学习率衰减策略
+ lr:
+ name: Cosine
+ learning_rate: 0.001
+ ...
+
+...
+
+Train:
+ dataset:
+ # 数据集格式,支持LMDBDataSet以及SimpleDataSet
+ name: SimpleDataSet
+ # 数据集路径
+ data_dir: ./data/
+ # 训练集标签文件
+ label_file_list:
+ - ./train_data/digital_img/digital_train.txt #11w
+ - ./train_data/digital_img/real_train.txt #100
+ - ./train_data/digital_img/dbm_img/dbm.txt #3w
+ ratio_list:
+ - 0.3
+ - 1.0
+ - 1.0
+ transforms:
+ ...
+ - RecResizeImg:
+ # 修改 image_shape 以适应长文本
+ image_shape: [3, 48, 320]
+ ...
+ loader:
+ ...
+ # 单卡训练的batch_size
+ batch_size_per_card: 256
+ ...
+
+Eval:
+ dataset:
+ # 数据集格式,支持LMDBDataSet以及SimpleDataSet
+ name: SimpleDataSet
+ # 数据集路径
+ data_dir: ./data
+ # 验证集标签文件
+ label_file_list:
+ - ./train_data/digital_img/real_val.txt
+ transforms:
+ ...
+ - RecResizeImg:
+ # 修改 image_shape 以适应长文本
+ image_shape: [3, 48, 320]
+ ...
+ loader:
+ # 单卡验证的batch_size
+ batch_size_per_card: 256
+ ...
+```
+**注意,训练/预测/评估时的配置文件请务必与训练一致。**
+
+**Step4:启动训练**
+
+*如果您安装的是cpu版本,请将配置文件中的 `use_gpu` 字段修改为false*
+
+```
+# GPU训练 支持单卡,多卡训练
+# 训练数码管数据 训练日志会自动保存为 "{save_model_dir}" 下的train.log
+
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_rec_train/best_accuracy
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml -o Global.pretrained_model=./pretrain_models/en_PP-OCRv3_rec_train/best_accuracy
+```
+
+
+PaddleOCR支持训练和评估交替进行, 可以在 `configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml` 中修改 `eval_batch_step` 设置评估频率,默认每500个iter评估一次。评估过程中默认将最佳acc模型,保存为 `output/ch_PP-OCRv3_rec_distill/best_accuracy` 。
+
+如果验证集很大,测试将会比较耗时,建议减少评估次数,或训练完再进行评估。
+
+### SVTR_Tiny 训练
+
+SVTR_Tiny 训练步骤与上面一致,SVTR支持的配置和模型训练权重可以参考[算法介绍文档](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/algorithm_rec_svtr.md)
+
+**Step1:下载预训练模型**
+
+```
+# 下载 SVTR_Tiny 中文识别预训练模型和配置文件
+wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/rec_svtr_tiny_none_ctc_ch_train.tar
+# 解压模型参数
+tar -xf rec_svtr_tiny_none_ctc_ch_train.tar && rm -rf rec_svtr_tiny_none_ctc_ch_train.tar
+```
+**Step2:自定义字典文件**
+
+字典依然使用自定义的 digital_dict.txt
+
+**Step3:修改配置文件**
+
+配置文件中对应修改字典路径和数据路径
+
+**Step4:启动训练**
+
+```
+## 单卡训练
+python tools/train.py -c rec_svtr_tiny_none_ctc_ch_train/rec_svtr_tiny_6local_6global_stn_ch.yml \
+ -o Global.pretrained_model=./rec_svtr_tiny_none_ctc_ch_train/best_accuracy
+```
+
+### 3.4 验证效果
+
+如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
+


 -
-  +
+  +
+ 
 -
-  +
+  +
+ 
 -
-  +
+  +
+ 