diff --git "a/applications/\345\217\221\347\245\250\345\205\263\351\224\256\344\277\241\346\201\257\346\212\275\345\217\226.md" "b/applications/\345\217\221\347\245\250\345\205\263\351\224\256\344\277\241\346\201\257\346\212\275\345\217\226.md"
new file mode 100644
index 0000000000000000000000000000000000000000..cd7fa1a0b3c988b21b33fe8f123e7d7c3e851ca5
--- /dev/null
+++ "b/applications/\345\217\221\347\245\250\345\205\263\351\224\256\344\277\241\346\201\257\346\212\275\345\217\226.md"
@@ -0,0 +1,337 @@
+
+# 基于VI-LayoutXLM的发票关键信息抽取
+
+- [1. 项目背景及意义](#1-项目背景及意义)
+- [2. 项目内容](#2-项目内容)
+- [3. 安装环境](#3-安装环境)
+- [4. 关键信息抽取](#4-关键信息抽取)
+ - [4.1 文本检测](#41-文本检测)
+ - [4.2 文本识别](#42-文本识别)
+ - [4.3 语义实体识别](#43-语义实体识别)
+ - [4.4 关系抽取](#44-关系抽取)
+
+
+
+## 1. 项目背景及意义
+
+关键信息抽取在文档场景中被广泛使用,如身份证中的姓名、住址信息抽取,快递单中的姓名、联系方式等关键字段内容的抽取。传统基于模板匹配的方案需要针对不同的场景制定模板并进行适配,较为繁琐,不够鲁棒。基于该问题,我们借助飞桨提供的PaddleOCR套件中的关键信息抽取方案,实现对增值税发票场景的关键信息抽取。
+
+## 2. 项目内容
+
+本项目基于PaddleOCR开源套件,以VI-LayoutXLM多模态关键信息抽取模型为基础,针对增值税发票场景进行适配,提取该场景的关键信息。
+
+## 3. 安装环境
+
+```bash
+# 首先git官方的PaddleOCR项目,安装需要的依赖
+# 第一次运行打开该注释
+git clone https://gitee.com/PaddlePaddle/PaddleOCR.git
+cd PaddleOCR
+# 安装PaddleOCR的依赖
+pip install -r requirements.txt
+# 安装关键信息抽取任务的依赖
+pip install -r ./ppstructure/vqa/requirements.txt
+```
+
+## 4. 关键信息抽取
+
+基于文档图像的关键信息抽取包含3个部分:(1)文本检测(2)文本识别(3)关键信息抽取方法,包括语义实体识别或者关系抽取,下面分别进行介绍。
+
+### 4.1 文本检测
+
+
+本文重点关注发票的关键信息抽取模型训练与预测过程,因此在关键信息抽取过程中,直接使用标注的文本检测与识别标注信息进行测试,如果你希望自定义该场景的文本检测模型,完成端到端的关键信息抽取部分,请参考[文本检测模型训练教程](../doc/doc_ch/detection.md),按照训练数据格式准备数据,并完成该场景下垂类文本检测模型的微调过程。
+
+
+### 4.2 文本识别
+
+本文重点关注发票的关键信息抽取模型训练与预测过程,因此在关键信息抽取过程中,直接使用提供的文本检测与识别标注信息进行测试,如果你希望自定义该场景的文本检测模型,完成端到端的关键信息抽取部分,请参考[文本识别模型训练教程](../doc/doc_ch/recognition.md),按照训练数据格式准备数据,并完成该场景下垂类文本识别模型的微调过程。
+
+### 4.3 语义实体识别 (Semantic Entity Recognition)
+
+语义实体识别指的是给定一段文本行,确定其类别(如`姓名`、`住址`等类别)。PaddleOCR中提供了基于VI-LayoutXLM的多模态语义实体识别方法,融合文本、位置与版面信息,相比LayoutXLM多模态模型,去除了其中的视觉骨干网络特征提取部分,引入符合阅读顺序的文本行排序方法,同时使用UDML联合互蒸馏方法进行训练,最终在精度与速度方面均超越LayoutXLM。更多关于VI-LayoutXLM的算法介绍与精度指标,请参考:[VI-LayoutXLM算法介绍](../doc/doc_ch/algorithm_kie_vi_layoutxlm.md)。
+
+#### 4.3.1 准备数据
+
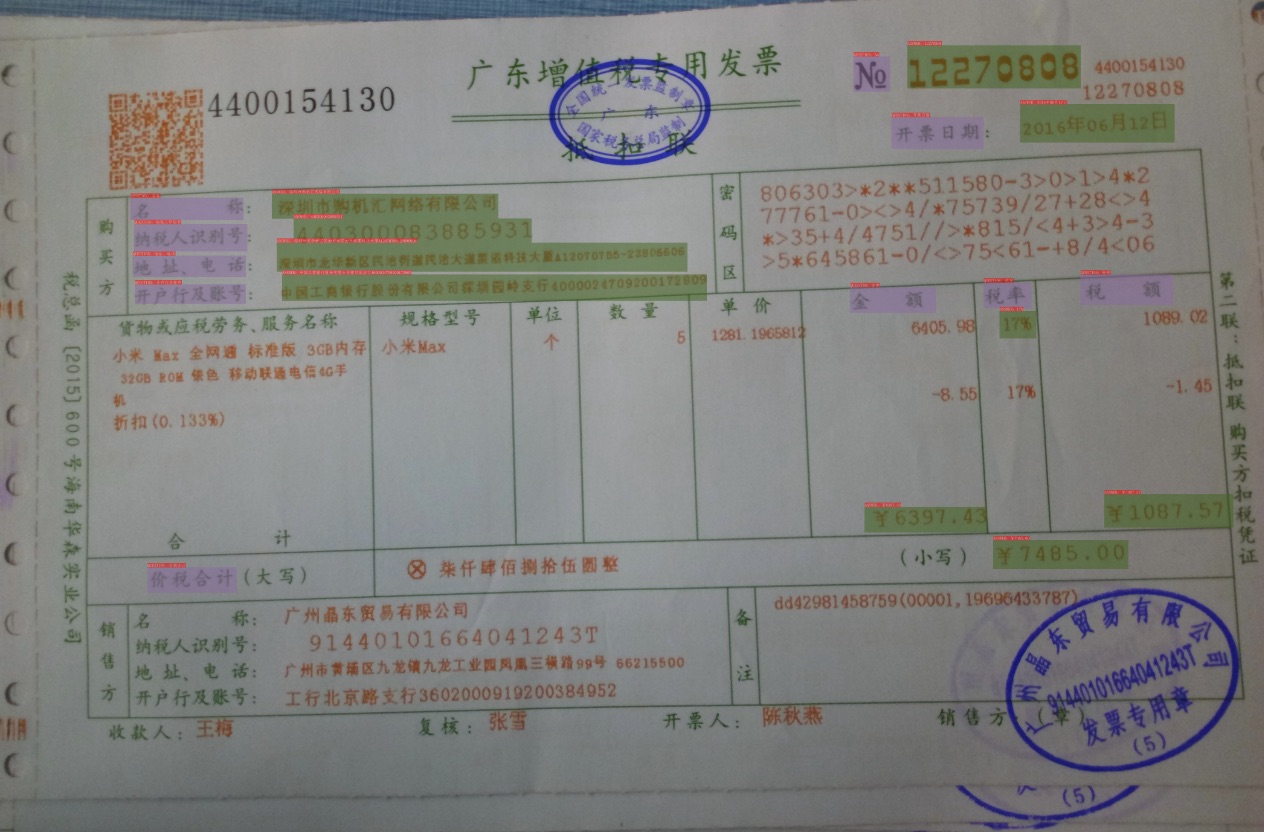
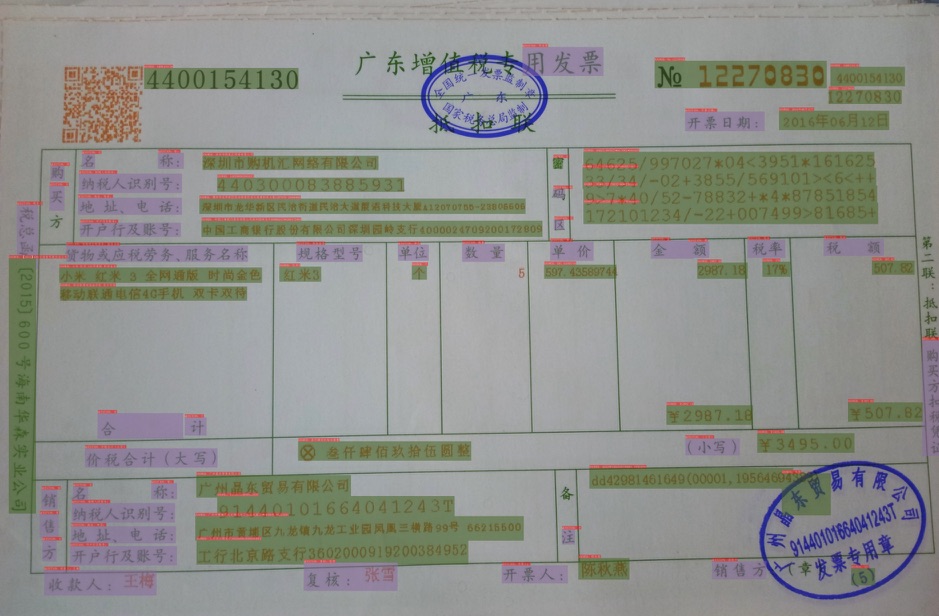
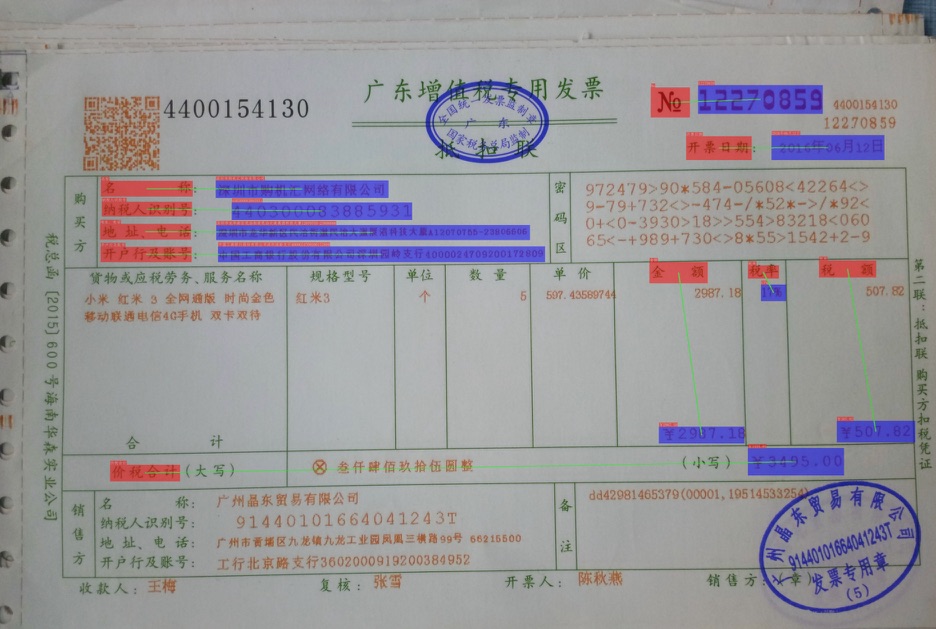
+发票场景为例,我们首先需要标注出其中的关键字段,我们将其标注为`问题-答案`的key-value pair,如下,编号No为12270830,则`No`字段标注为question,`12270830`字段标注为answer。如下图所示。
+
+
+
+
+

+
+
+
+
+
+

+
-

+

-
+
-
+
-

+

-

+

-

+

-
+
+
+
+

+
+
+
+

+

+
+
+
+
+
+
+
+
+
+
+
+

+
+
+
+

+
+

+
+
+
+

+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+

+
+

+
+

+