Merge remote-tracking branch 'origin/dygraph' into dygraph
Showing
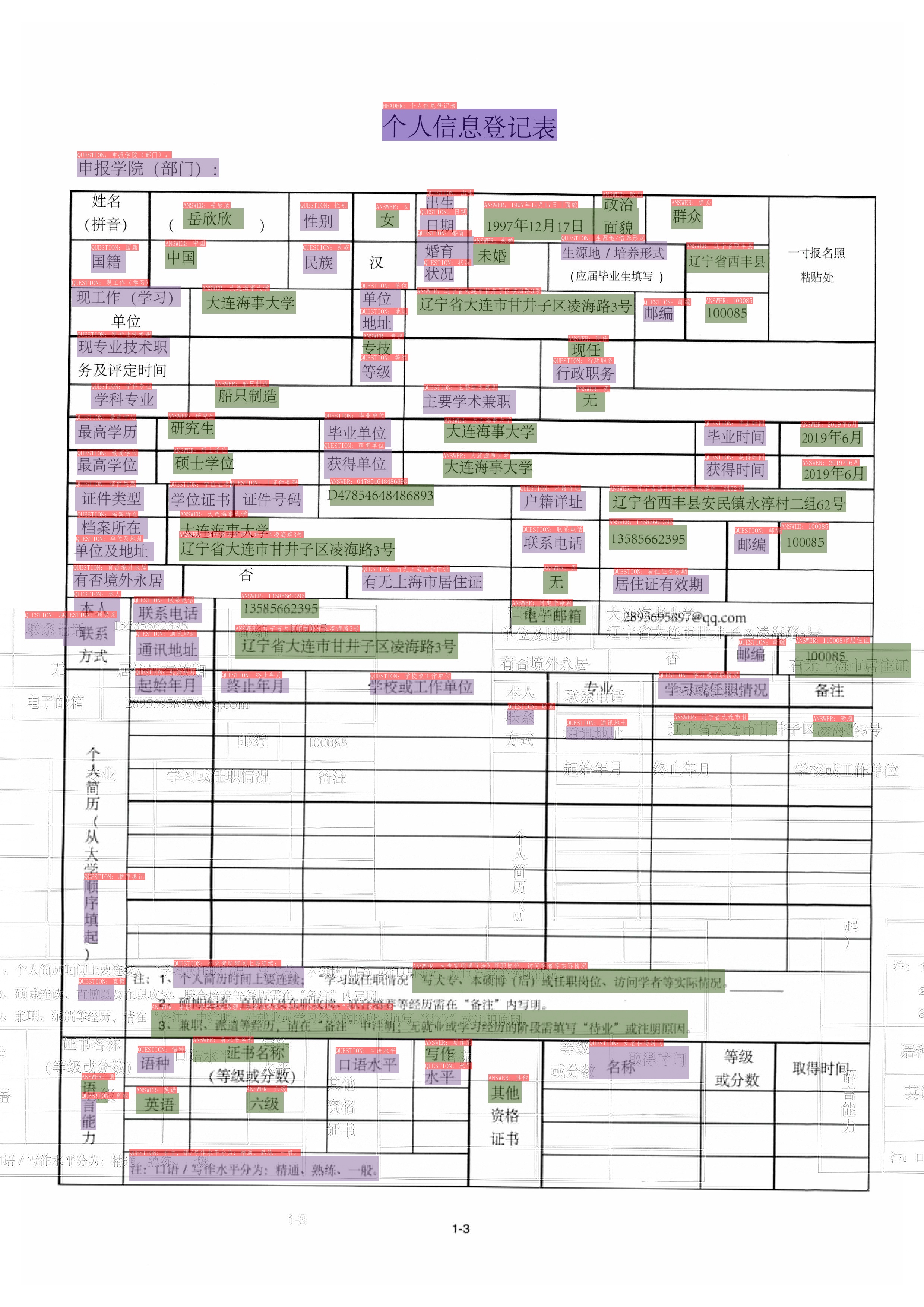
doc/datasets/ch_doc2.jpg
已删除
100644 → 0
{kind=link}

2.4 KB
ppstructure/vqa/data_collator.py
0 → 100644
{kind=link}

1.4 MB
{kind=link}

1.1 MB
{kind=link}

1.1 MB
{kind=link}

1004.8 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
{kind=link}

| W: | H:
| W: | H:
ppstructure/vqa/infer_re.py
0 → 100644
ppstructure/vqa/metric.py
0 → 100644
ppstructure/vqa/train_re.py
0 → 100644