Merge remote-tracking branch 'origin/release/2.5' into release2.5
Showing
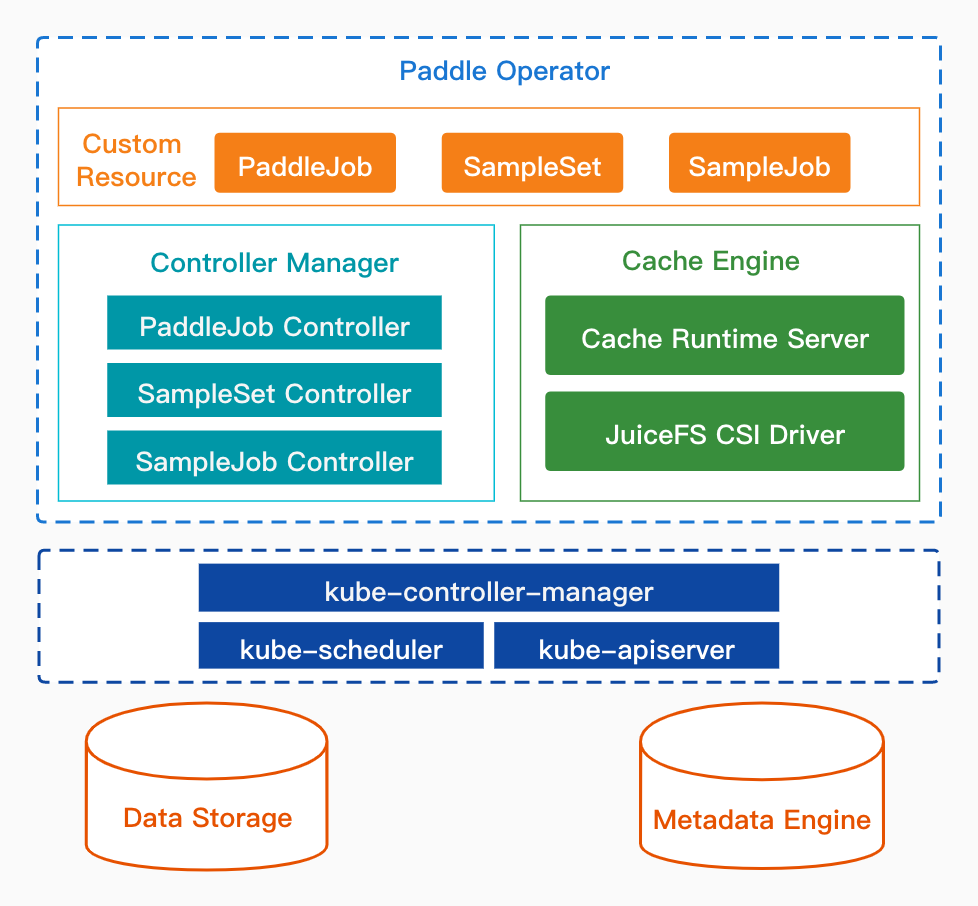
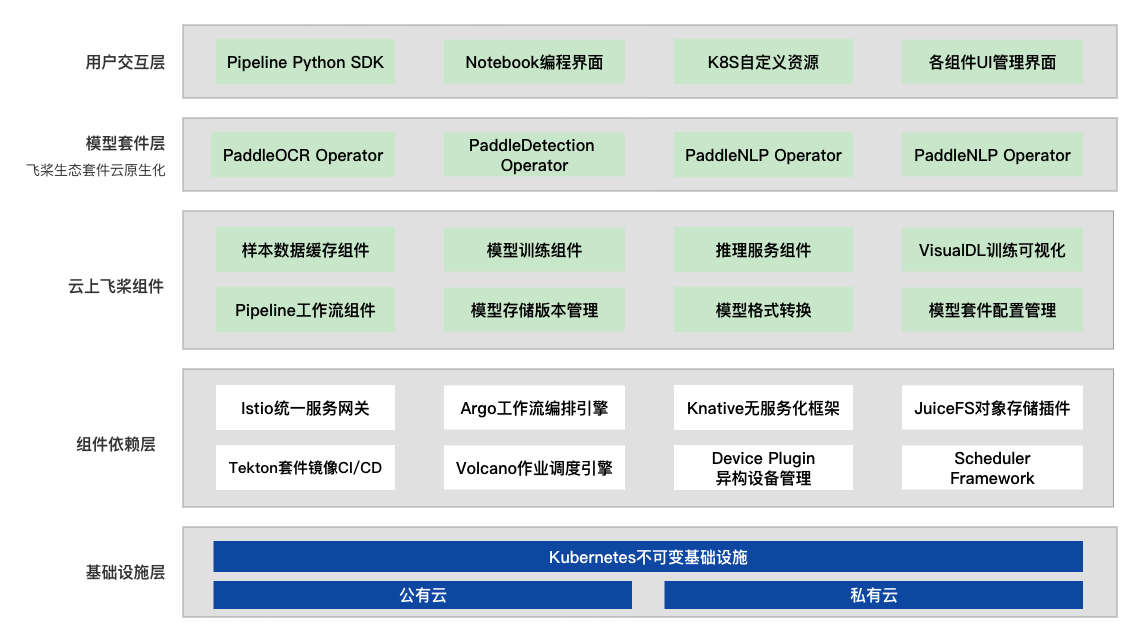
deploy/paddlecloud/README.md
0 → 100644
{kind=link}
121.8 KB
{kind=link}
113.7 KB
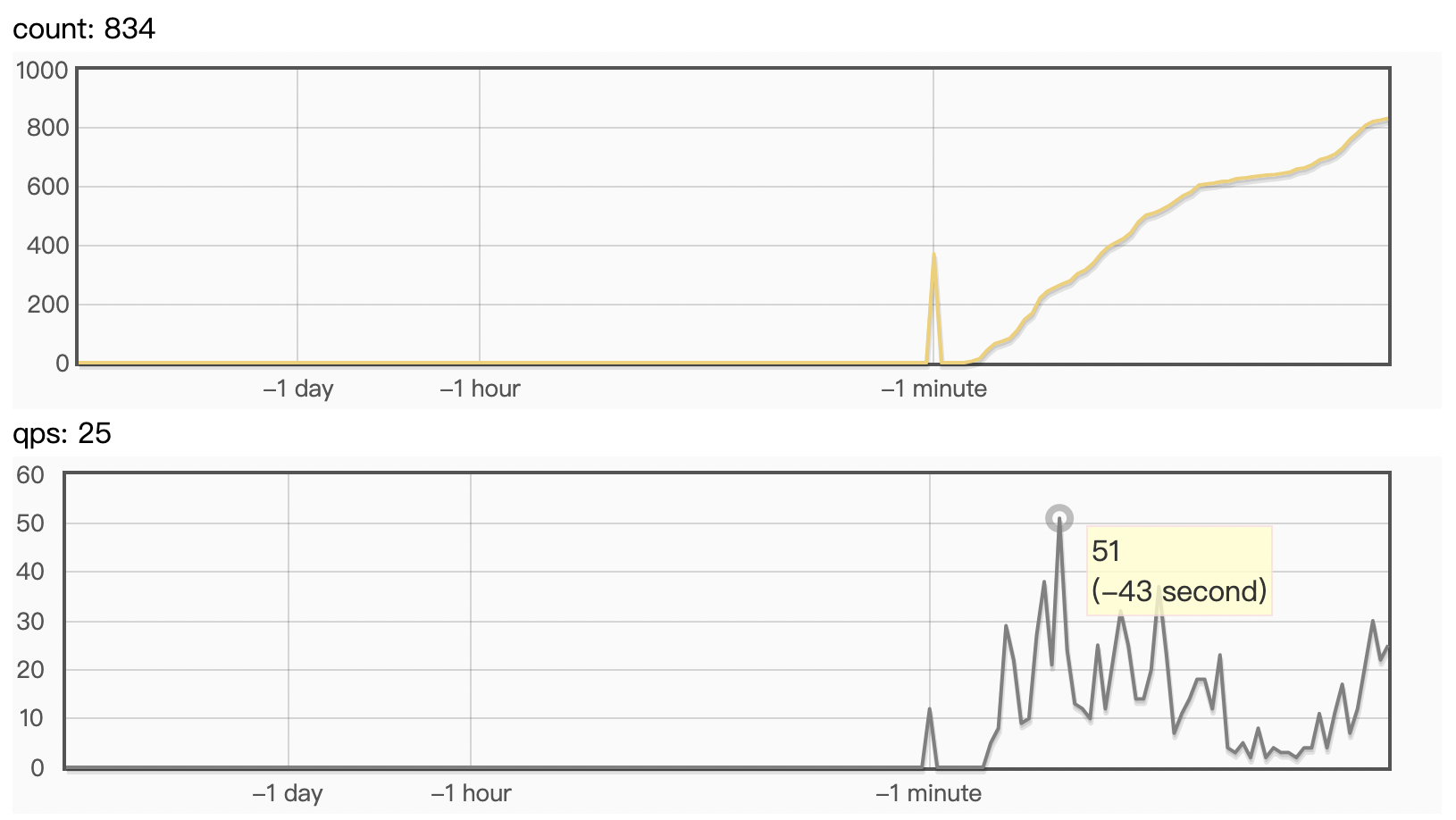
deploy/pdserving/imgs/c++_qps.png
0 → 100644
{kind=link}
317.9 KB
121.8 KB
113.7 KB
317.9 KB