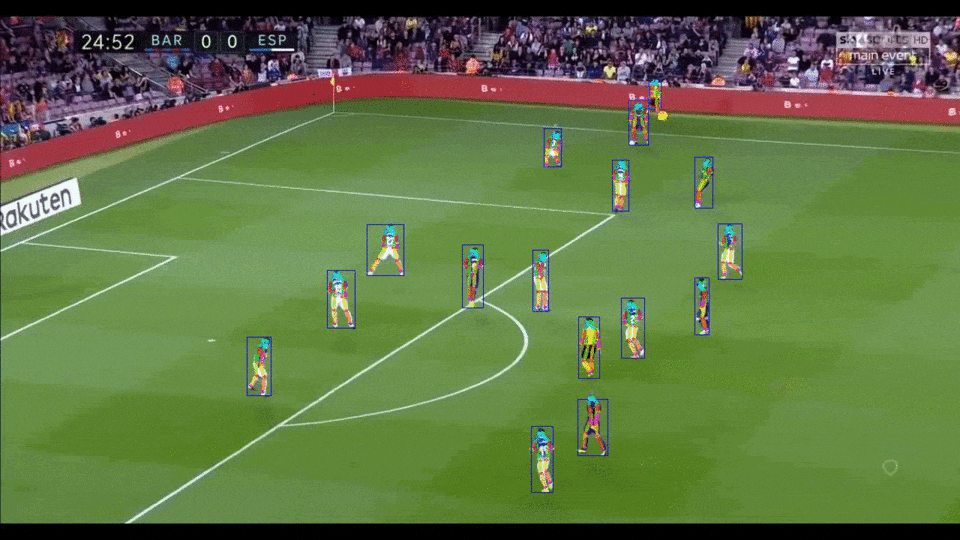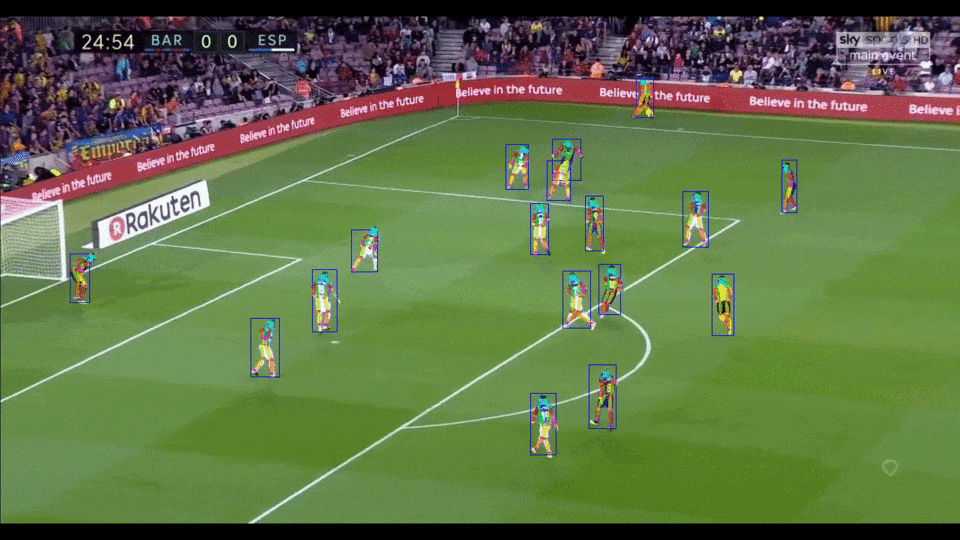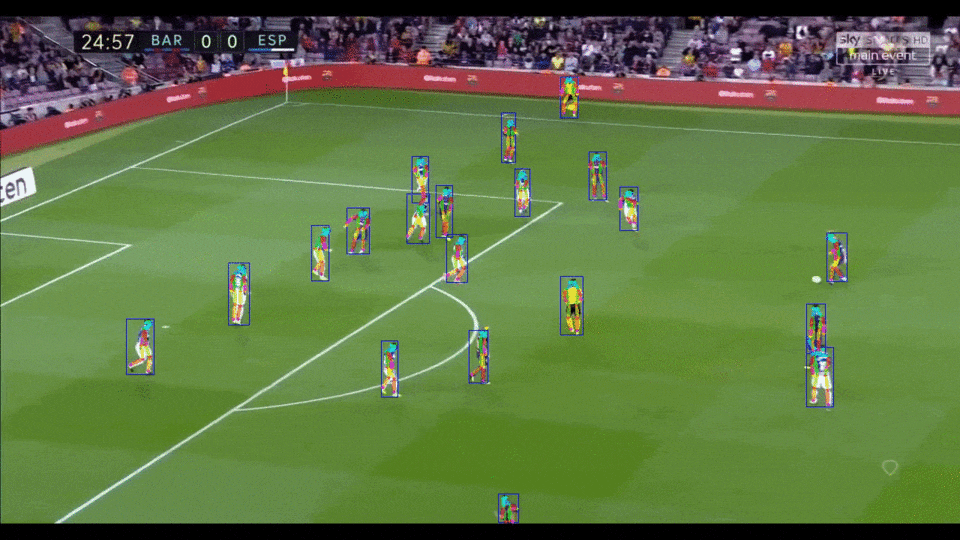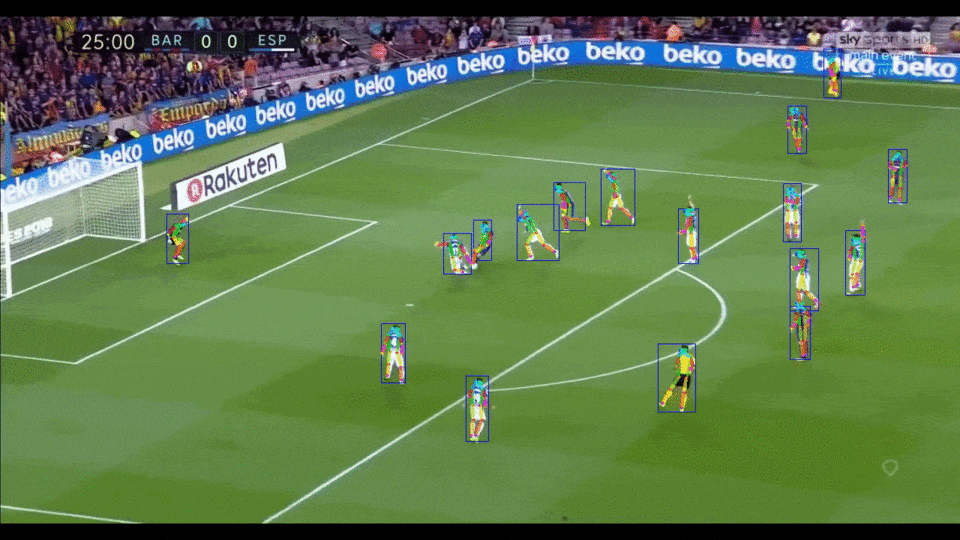
[简体中文](README.md) | English
# KeyPoint Detection Models
## Content
- [Introduction](#introduction)
- [Model Recommendation](#model-recommendation)
- [Model Zoo](#model-zoo)
- [Getting Start](#getting-start)
- [Environmental Installation](#1environmental-installation)
- [Dataset Preparation](#2dataset-preparation)
- [Training and Testing](#3training-and-testing)
- [Training on single GPU](#training-on-single-gpu)
- [Training on multiple GPU](#training-on-multiple-gpu)
- [Evaluation](#evaluation)
- [Inference](#inference)
- [Deploy Inference](#deploy-inference)
- [Deployment for Top-Down models](#deployment-for-top-down-models)
- [Deployment for Bottom-Up models](#deployment-for-bottom-up-models)
- [Joint Inference with Multi-Object Tracking Model FairMOT](#joint-inference-with-multi-object-tracking-model-fairmot)
- [Complete Deploy Instruction and Demo](#4Complete Deploy Instruction and Demo)
- [BenchMark](#benchmark)
## Introduction
The keypoint detection part in PaddleDetection follows the state-of-the-art algorithm closely, including Top-Down and Bottom-Up methods, which can satisfy the different needs of users.
Top-Down detects the object first and then detect the specific keypoint. The accuracy of Top-Down models will be higher, but the time required will increase by the number of objects.
Differently, Bottom-Up detects the point first and then group or connect those points to form several instances of human pose. The speed of Bottom-Up is fixed and will not increase by the number of objects, but the accuracy will be lower.
At the same time, PaddleDetection provides [PP-TinyPose](./tiny_pose/README_en.md) specially for mobile devices.
## Model Recommendation
### Mobile Terminal
| Detection Model | Keypoint Model | Input Size | Accuracy of COCO | Average Inference Time (FP16) | Model Weight | Paddle-Lite Inference Model(FP16) |
|:--------------------------------------------------------------------------------------------------- |:------------------------------------- |:-------------------------------------:|:--------------------------------------:|:-----------------------------------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| [PicoDet-S-Pedestrian](../../picodet/application/pedestrian_detection/picodet_s_192_pedestrian.yml) | [PP-TinyPose](./tinypose_128x96.yml) | Detection:192x192
Keypoint:128x96 | Detection mAP:29.0
Keypoint AP:58.1 | Detection:2.37ms
Keypoint:3.27ms | [Detection](https://bj.bcebos.com/v1/paddledet/models/keypoint/picodet_s_192_pedestrian.pdparams)
[Keypoint](https://bj.bcebos.com/v1/paddledet/models/keypoint/tinypose_128x96.pdparams) | [Detection](https://bj.bcebos.com/v1/paddledet/models/keypoint/picodet_s_192_pedestrian_fp16.nb)
[Keypoint](https://bj.bcebos.com/v1/paddledet/models/keypoint/tinypose_128x96_fp16.nb) |
| [PicoDet-S-Pedestrian](../../picodet/application/pedestrian_detection/picodet_s_320_pedestrian.yml) | [PP-TinyPose](./tinypose_256x192.yml) | Detection:320x320
Keypoint:256x192 | Detection mAP:38.5
Keypoint AP:68.8 | Detection:6.30ms
Keypoint:8.33ms | [Detection](https://bj.bcebos.com/v1/paddledet/models/keypoint/picodet_s_320_pedestrian.pdparams)
[Keypoint](https://bj.bcebos.com/v1/paddledet/models/keypoint/tinypose_128x96.pdparams) | [Detection](https://bj.bcebos.com/v1/paddledet/models/keypoint/picodet_s_320_pedestrian_fp16.nb)
[Keypoint](https://bj.bcebos.com/v1/paddledet/models/keypoint/tinypose_256x192_fp16.nb) |
*Specific documents of PP-TinyPose, please refer to [Document]((./tiny_pose/README.md))。
### Terminal Server
| Detection Model | Keypoint Model | Input Size | Accuracy of COCO | Model Weight |
|:----------------------------------------------------------------------------------------------------------------------------- |:------------------------------------------ |:-------------------------------------:|:--------------------------------------:|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| [PP-YOLOv2](https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.3/configs/ppyolo/ppyolov2_r50vd_dcn_365e_coco.yml) | [HRNet-w32](./hrnet/hrnet_w32_384x288.yml) | Detection:640x640
Keypoint:384x288 | Detection mAP:49.5
Keypoint AP:77.8 | [Detection](https://paddledet.bj.bcebos.com/models/ppyolov2_r50vd_dcn_365e_coco.pdparams)
[Keypoint](https://paddledet.bj.bcebos.com/models/keypoint/hrnet_w32_256x192.pdparams) |
| [PP-YOLOv2](https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.3/configs/ppyolo/ppyolov2_r50vd_dcn_365e_coco.yml) | [HRNet-w32](./hrnet/hrnet_w32_256x192.yml) | Detection:640x640
Keypoint:256x192 | Detection mAP:49.5
Keypoint AP:76.9 | [Detection](https://paddledet.bj.bcebos.com/models/ppyolov2_r50vd_dcn_365e_coco.pdparams)
[Keypoint](https://paddledet.bj.bcebos.com/models/keypoint/hrnet_w32_384x288.pdparams) |
## Model Zoo
COCO Dataset
| Model | Input Size | AP(coco val) | Model Download | Config File |
| :---------------- | -------- | :----------: | :----------------------------------------------------------: | ----------------------------------------------------------- |
| HigherHRNet-w32 | 512 | 67.1 | [higherhrnet_hrnet_w32_512.pdparams](https://paddledet.bj.bcebos.com/models/keypoint/higherhrnet_hrnet_w32_512.pdparams) | [config](./higherhrnet/higherhrnet_hrnet_w32_512.yml) |
| HigherHRNet-w32 | 640 | 68.3 | [higherhrnet_hrnet_w32_640.pdparams](https://paddledet.bj.bcebos.com/models/keypoint/higherhrnet_hrnet_w32_640.pdparams) | [config](./higherhrnet/higherhrnet_hrnet_w32_640.yml) |
| HigherHRNet-w32+SWAHR | 512 | 68.9 | [higherhrnet_hrnet_w32_512_swahr.pdparams](https://paddledet.bj.bcebos.com/models/keypoint/higherhrnet_hrnet_w32_512_swahr.pdparams) | [config](./higherhrnet/higherhrnet_hrnet_w32_512_swahr.yml) |
| HRNet-w32 | 256x192 | 76.9 | [hrnet_w32_256x192.pdparams](https://paddledet.bj.bcebos.com/models/keypoint/hrnet_w32_256x192.pdparams) | [config](./hrnet/hrnet_w32_256x192.yml) |
| HRNet-w32 | 384x288 | 77.8 | [hrnet_w32_384x288.pdparams](https://paddledet.bj.bcebos.com/models/keypoint/hrnet_w32_384x288.pdparams) | [config](./hrnet/hrnet_w32_384x288.yml) |
| HRNet-w32+DarkPose | 256x192 | 78.0 | [dark_hrnet_w32_256x192.pdparams](https://paddledet.bj.bcebos.com/models/keypoint/dark_hrnet_w32_256x192.pdparams) | [config](./hrnet/dark_hrnet_w32_256x192.yml) |
| HRNet-w32+DarkPose | 384x288 | 78.3 | [dark_hrnet_w32_384x288.pdparams](https://paddledet.bj.bcebos.com/models/keypoint/dark_hrnet_w32_384x288.pdparams) | [config](./hrnet/dark_hrnet_w32_384x288.yml) |
| WiderNaiveHRNet-18 | 256x192 | 67.6(+DARK 68.4) | [wider_naive_hrnet_18_256x192_coco.pdparams](https://bj.bcebos.com/v1/paddledet/models/keypoint/wider_naive_hrnet_18_256x192_coco.pdparams) | [config](./lite_hrnet/wider_naive_hrnet_18_256x192_coco.yml) |
| LiteHRNet-18 | 256x192 | 66.5 | [lite_hrnet_18_256x192_coco.pdparams](https://bj.bcebos.com/v1/paddledet/models/keypoint/lite_hrnet_18_256x192_coco.pdparams) | [config](./lite_hrnet/lite_hrnet_18_256x192_coco.yml) |
| LiteHRNet-18 | 384x288 | 69.7 | [lite_hrnet_18_384x288_coco.pdparams](https://bj.bcebos.com/v1/paddledet/models/keypoint/lite_hrnet_18_384x288_coco.pdparams) | [config](./lite_hrnet/lite_hrnet_18_384x288_coco.yml) |
| LiteHRNet-30 | 256x192 | 69.4 | [lite_hrnet_30_256x192_coco.pdparams](https://bj.bcebos.com/v1/paddledet/models/keypoint/lite_hrnet_30_256x192_coco.pdparams) | [config](./lite_hrnet/lite_hrnet_30_256x192_coco.yml) |
| LiteHRNet-30 | 384x288 | 72.5 | [lite_hrnet_30_384x288_coco.pdparams](https://bj.bcebos.com/v1/paddledet/models/keypoint/lite_hrnet_30_384x288_coco.pdparams) | [config](./lite_hrnet/lite_hrnet_30_384x288_coco.yml) |
Note:The AP results of Top-Down models are based on bounding boxes in GroundTruth.
MPII Dataset
| Model | Input Size | PCKh(Mean) | PCKh(Mean@0.1) | Model Download | Config File |
| :---- | -------- | :--------: | :------------: | :----------------------------------------------------------: | -------------------------------------------- |
| HRNet-w32 | 256x256 | 90.6 | 38.5 | [hrnet_w32_256x256_mpii.pdparams](https://paddledet.bj.bcebos.com/models/keypoint/hrnet_w32_256x256_mpii.pdparams) | [config](./hrnet/hrnet_w32_256x256_mpii.yml) |
We also release [PP-TinyPose](./tiny_pose/README_en.md), a real-time keypoint detection model optimized for mobile devices. Welcome to experience.
## Getting Start
### 1.Environmental Installation
Please refer to [PaddleDetection Installation Guide](../../docs/tutorials/INSTALL.md) to install PaddlePaddle and PaddleDetection correctly.
### 2.Dataset Preparation
Currently, KeyPoint Detection Models support [COCO](https://cocodataset.org/#keypoints-2017) and [MPII](http://human-pose.mpi-inf.mpg.de/#overview). Please refer to [Keypoint Dataset Preparation](../../docs/tutorials/PrepareKeypointDataSet_en.md) to prepare dataset.
About the description for config files, please refer to [Keypoint Config Guild](../../docs/tutorials/KeyPointConfigGuide_en.md).
- Note that, when testing by detected bounding boxes in Top-Down method, We should get `bbox.json` by a detection model. You can download the detected results for COCO val2017 [(Detector having human AP of 56.4 on COCO val2017 dataset)](https://paddledet.bj.bcebos.com/data/bbox.json) directly, put it at the root path (`PaddleDetection/`), and set `use_gt_bbox: False` in config file.
### 3.Training and Testing
#### Training on single GPU
```shell
#COCO DataSet
CUDA_VISIBLE_DEVICES=0 python3 tools/train.py -c configs/keypoint/higherhrnet/higherhrnet_hrnet_w32_512.yml
#MPII DataSet
CUDA_VISIBLE_DEVICES=0 python3 tools/train.py -c configs/keypoint/hrnet/hrnet_w32_256x256_mpii.yml
```
#### Training on multiple GPU
```shell
#COCO DataSet
CUDA_VISIBLE_DEVICES=0,1,2,3 python3 -m paddle.distributed.launch tools/train.py -c configs/keypoint/higherhrnet/higherhrnet_hrnet_w32_512.yml
#MPII DataSet
CUDA_VISIBLE_DEVICES=0,1,2,3 python3 -m paddle.distributed.launch tools/train.py -c configs/keypoint/hrnet/hrnet_w32_256x256_mpii.yml
```
#### Evaluation
```shell
#COCO DataSet
CUDA_VISIBLE_DEVICES=0 python3 tools/eval.py -c configs/keypoint/higherhrnet/higherhrnet_hrnet_w32_512.yml
#MPII DataSet
CUDA_VISIBLE_DEVICES=0 python3 tools/eval.py -c configs/keypoint/hrnet/hrnet_w32_256x256_mpii.yml
#If you only need the prediction result, you can set --save_prediction_only. Then the result will be saved at output/keypoints_results.json by default.
CUDA_VISIBLE_DEVICES=0 python3 tools/eval.py -c configs/keypoint/higherhrnet/higherhrnet_hrnet_w32_512.yml --save_prediction_only
```
#### Inference
Note:Top-down models only support inference for a cropped image with single person. If you want to do inference on image with several people, please see "joint inference by detection and keypoint". Or you can choose a Bottom-up model.
```shell
CUDA_VISIBLE_DEVICES=0 python3 tools/infer.py -c configs/keypoint/higherhrnet/higherhrnet_hrnet_w32_512.yml -o weights=./output/higherhrnet_hrnet_w32_512/model_final.pdparams --infer_dir=../images/ --draw_threshold=0.5 --save_txt=True
```
#### Deploy Inference
##### Deployment for Top-Down models
```shell
#Export Detection Model
python tools/export_model.py -c configs/ppyolo/ppyolov2_r50vd_dcn_365e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyolov2_r50vd_dcn_365e_coco.pdparams
#Export Keypoint Model
python tools/export_model.py -c configs/keypoint/hrnet/hrnet_w32_256x192.yml -o weights=https://paddledet.bj.bcebos.com/models/keypoint/hrnet_w32_256x192.pdparams
#Deployment for detector and keypoint, which is only for Top-Down models
python deploy/python/det_keypoint_unite_infer.py --det_model_dir=output_inference/ppyolo_r50vd_dcn_2x_coco/ --keypoint_model_dir=output_inference/hrnet_w32_384x288/ --video_file=../video/xxx.mp4 --device=gpu
```
##### Deployment for Bottom-Up models
```shell
#Export model
python tools/export_model.py -c configs/keypoint/higherhrnet/higherhrnet_hrnet_w32_512.yml -o weights=output/higherhrnet_hrnet_w32_512/model_final.pdparams
#Keypoint independent deployment, which is only for bottom-up models
python deploy/python/keypoint_infer.py --model_dir=output_inference/higherhrnet_hrnet_w32_512/ --image_file=./demo/000000014439_640x640.jpg --device=gpu --threshold=0.5
```
##### Joint Inference with Multi-Object Tracking Model FairMOT
```shell
#export FairMOT model
python tools/export_model.py -c configs/mot/fairmot/fairmot_dla34_30e_1088x608.yml -o weights=https://paddledet.bj.bcebos.com/models/mot/fairmot_dla34_30e_1088x608.pdparams
#joint inference with Multi-Object Tracking model FairMOT
python deploy/python/mot_keypoint_unite_infer.py --mot_model_dir=output_inference/fairmot_dla34_30e_1088x608/ --keypoint_model_dir=output_inference/higherhrnet_hrnet_w32_512/ --video_file={your video name}.mp4 --device=GPU
```
**Note:**
To export MOT model, please refer to [Here](../../configs/mot/README_en.md).
### 4. Complete Deploy Instruction and Demo
We provide standalone deploy of PaddleInference(Server-GPU)、PaddleLite(mobile、ARM)、Third-Engine(MNN、OpenVino), which is independent of training codes。For detail, please click [Deploy-docs](https://github.com/PaddlePaddle/PaddleDetection/blob/develop/deploy/README_en.md)。
## BenchMark
We provide benchmarks in different runtime environments for your reference when choosing models. See [Keypoint Inference Benchmark](https://github.com/PaddlePaddle/PaddleDetection/blob/develop/configs/keypoint/KeypointBenchmark.md) for details.
## Reference
```
@inproceedings{cheng2020bottom,
title={HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation},
author={Bowen Cheng and Bin Xiao and Jingdong Wang and Honghui Shi and Thomas S. Huang and Lei Zhang},
booktitle={CVPR},
year={2020}
}
@inproceedings{SunXLW19,
title={Deep High-Resolution Representation Learning for Human Pose Estimation},
author={Ke Sun and Bin Xiao and Dong Liu and Jingdong Wang},
booktitle={CVPR},
year={2019}
}
@article{wang2019deep,
title={Deep High-Resolution Representation Learning for Visual Recognition},
author={Wang, Jingdong and Sun, Ke and Cheng, Tianheng and Jiang, Borui and Deng, Chaorui and Zhao, Yang and Liu, Dong and Mu, Yadong and Tan, Mingkui and Wang, Xinggang and Liu, Wenyu and Xiao, Bin},
journal={TPAMI},
year={2019}
}
@InProceedings{Zhang_2020_CVPR,
author = {Zhang, Feng and Zhu, Xiatian and Dai, Hanbin and Ye, Mao and Zhu, Ce},
title = {Distribution-Aware Coordinate Representation for Human Pose Estimation},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2020}
}
@inproceedings{Yulitehrnet21,
title={Lite-HRNet: A Lightweight High-Resolution Network},
author={Yu, Changqian and Xiao, Bin and Gao, Changxin and Yuan, Lu and Zhang, Lei and Sang, Nong and Wang, Jingdong},
booktitle={CVPR},
year={2021}
}
```