# 飞桨训推一体认证
## 1. 简介
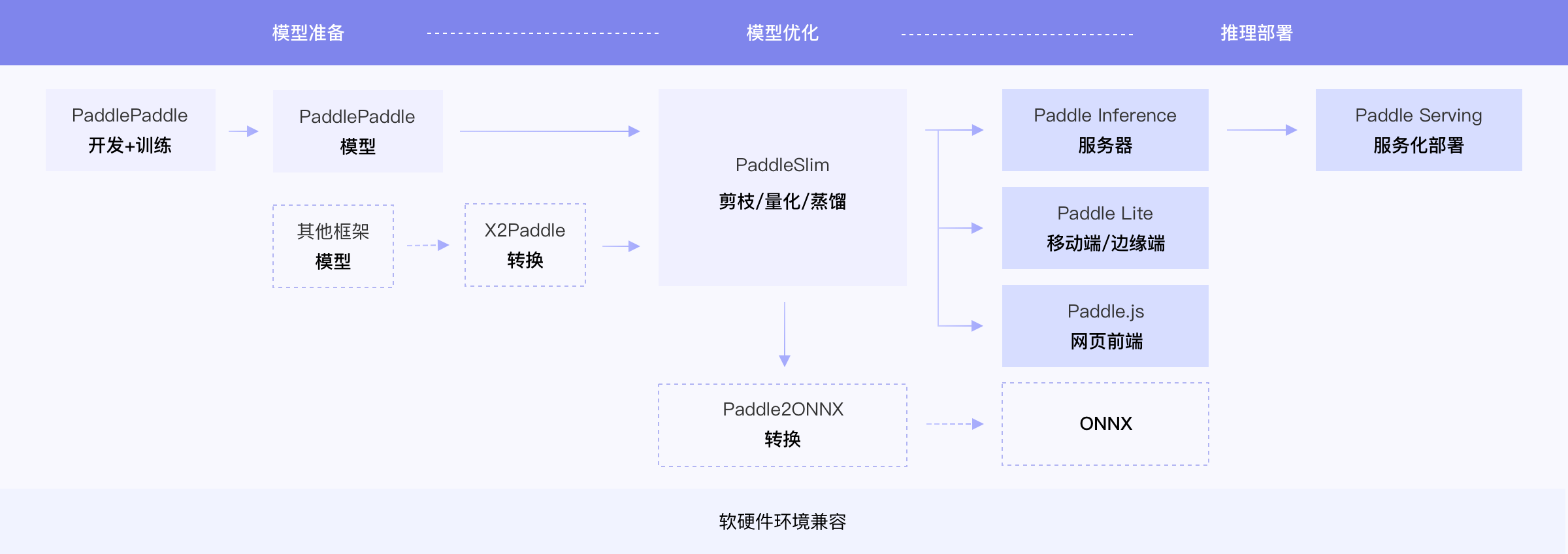
飞桨除了基本的模型训练和预测,还提供了支持多端多平台的高性能推理部署工具。
本文档提供了PaddleDetection中所有模型的飞桨训推一体认证 (Training and Inference Pipeline Certification(TIPC)) 信息和测试工具,
方便用户查阅每种模型的训练推理部署打通情况,并可以进行一键测试。
## 2. 汇总信息
已填写的部分表示可以使用本工具进行一键测试,未填写的表示正在支持中。
**字段说明:**
- 基础训练预测:包括模型训练、Paddle Inference Python预测。
- 更多训练方式:包括多机多卡、混合精度。
- 模型压缩:包括裁剪、离线/在线量化、蒸馏。
- 其他预测部署:包括Paddle Inference C++预测、Paddle Serving部署、Paddle-Lite部署等。
更详细的mkldnn、Tensorrt等预测加速相关功能的支持情况可以查看各测试工具的[更多教程](#more)。
| 算法论文 | 模型名称 | 模型类型 | 基础
训练预测 | 更多
训练方式 | 模型压缩 | 其他预测部署 |
| :--- | :--- | :----: | :--------: | :---- | :---- | :---- |
| [PPYOLO](https://arxiv.org/abs/2007.12099) | [ppyolo_mbv3_large_coco](../configs/ppyolo/ppyolo_mbv3_large_coco.yml) | 目标检测 | 支持 | 混合精度 | FPGM裁剪
PACT量化
离线量化 | Paddle Inference: C++ |
| [PPYOLOv2](https://arxiv.org/abs/2104.10419) | [ppyolov2_r50vd_dcn_365e_coco](../configs/ppyolo/ppyolov2_r50vd_dcn_365e_coco.yml) | 目标检测 | 支持 | 多机多卡
混合精度 | | Paddle Inference: C++ |
| [PP-PicoDet](https://arxiv.org/abs/2111.00902) | [picodet_s_320_coco](../configs/picodet/picodet_s_320_coco.yml) | 目标检测 | 支持 | 混合精度 | | Paddle Inference: C++ |
更详细的汇总信息可以查看[更多模型](docs/more_models.md)
## 3. 测试工具简介
### 目录介绍
```shell
test_tipc/
├── configs/ # 配置文件目录
│ ├── ppyolo # ppyolo参数目录
│ │ ├──ppyolo_mbv3_large_coco.txt
│ │ ├──ppyolo_r50vd_dcn_1x_coco.txt
│ │ ├──ppyolov2_r50vd_dcn_365e_coco.txt
│ ├── yolov3 # yolov3参数目录
│ │ ├──yolov3_darknet53_270e_coco.txt
│ ├── ...
├── docs/ # 相关说明文档目录
│ ├── ...
├── results/ # 预先保存的预测结果,用于和实际预测结果进行精读比对
│ ├── xxx.txt
│ ├── ...
├── compare_results.py # 用于对比log中的预测结果与results中的预存结果精度误差是否在限定范围内
├── prepare.sh # 完成test_*.sh运行所需要的数据和模型下载
├── README.md # 使用文档
├── test_inference_cpp.sh # 测试c++预测的主程序
├── test_lite.sh # 测试lite部署预测的主程序
├── test_serving.sh # 测试serving部署预测的主程序
├── test_train_inference_python.sh # 测试python训练预测的主程序
└── utils_func.sh # test_*.sh中需要用到的工具类函数
```
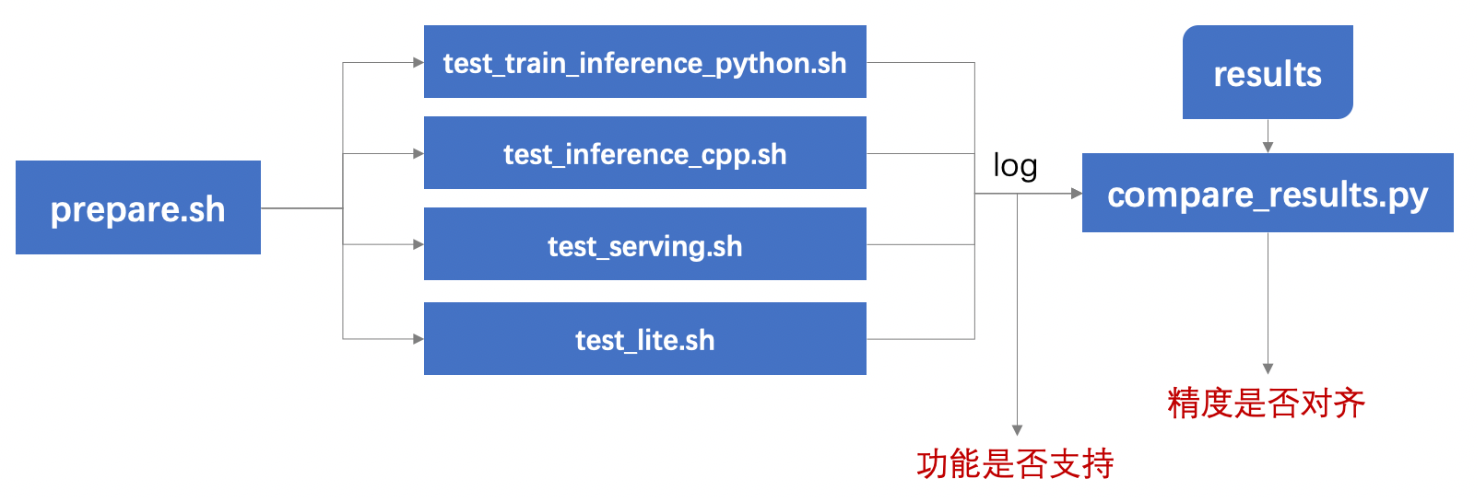
### 测试流程概述
使用本工具,可以测试不同功能的支持情况,以及预测结果是否对齐,测试流程概括如下:
1. 运行prepare.sh准备测试所需数据和模型;
2. 运行要测试的功能对应的测试脚本`test_*.sh`,产出log,由log可以看到不同配置是否运行成功;
3. 用`compare_results.py`对比log中的预测结果和预存在results目录下的结果,判断预测精度是否符合预期(在误差范围内)。
测试单项功能仅需两行命令,**如需测试不同模型/功能,替换配置文件即可**,命令格式如下:
```shell
# 功能:准备数据
# 格式:bash + 运行脚本 + 参数1: 配置文件选择 + 参数2: 模式选择
bash test_tipc/prepare.sh configs/[model_name]/[params_file_name] [Mode]
# 功能:运行测试
# 格式:bash + 运行脚本 + 参数1: 配置文件选择 + 参数2: 模式选择
bash test_tipc/test_train_inference_python.sh configs/[model_name]/[params_file_name] [Mode]
```
例如,测试基本训练预测功能的`lite_train_lite_infer`模式,运行:
```shell
# 准备数据
bash test_tipc/prepare.sh ./test_tipc/configs/yolov3/yolov3_darknet53_270e_coco_train_infer_python.txt 'lite_train_lite_infer'
# 运行测试
bash test_tipc/test_train_inference_python.sh ./test_tipc/configs/yolov3/yolov3_darknet53_270e_coco_train_infer_python.txt 'lite_train_lite_infer'
```
关于本示例命令的更多信息可查看[基础训练预测使用文档](docs/test_train_inference_python.md)。
### 配置文件命名规范
在`configs`目录下,**按模型名称划分为子目录**,子目录中存放所有该模型测试需要用到的配置文件,配置文件的命名遵循如下规范:
1. 基础训练预测配置简单命名为:`train_infer_python.txt`,表示**Linux环境下单机、不使用混合精度训练+python预测**,其完整命名对应`train_linux_gpu_normal_normal_infer_python_linux_gpu_cpu.txt`,由于本配置文件使用频率较高,这里进行了名称简化。
2. 其他带训练配置命名格式为:`train_训练硬件环境(linux_gpu/linux_dcu/…)_是否多机(fleet/normal)_是否混合精度(amp/normal)_预测模式(infer/lite/serving/js)_语言(cpp/python/java)_预测硬件环境(linux_gpu/mac/jetson/opencl_arm_gpu/...).txt`。如,linux gpu下多机多卡+混合精度链条测试对应配置 `train_linux_gpu_fleet_amp_infer_python_linux_gpu_cpu.txt`,linux dcu下基础训练预测对应配置 `train_linux_dcu_normal_normal_infer_python_linux_dcu.txt`。
3. 仅预测的配置(如serving、lite等)命名格式:`model_训练硬件环境(linux_gpu/linux_dcu/…)_是否多机(fleet/normal)_是否混合精度(amp/normal)_(infer/lite/serving/js)_语言(cpp/python/java)_预测硬件环境(linux_gpu/mac/jetson/opencl_arm_gpu/...).txt`,即,与2相比,仅第一个字段从train换为model,测试时模型直接下载获取,这里的“训练硬件环境”表示所测试的模型是在哪种环境下训练得到的。
**根据上述命名规范,可以直接从子目录名称和配置文件名找到需要测试的场景和功能对应的配置文件。**
## 4. 开始测试
各功能测试中涉及混合精度、裁剪、量化等训练相关,及mkldnn、Tensorrt等多种预测相关参数配置,请点击下方相应链接了解更多细节和使用教程:
- [test_train_inference_python 使用](docs/test_train_inference_python.md) :测试基于Python的模型训练、评估、推理等基本功能,包括裁剪、量化、蒸馏。
- [test_train_fleet_inference_python 使用](./docs/test_train_fleet_inference_python.md):测试基于Python的多机多卡训练与推理等基本功能。
- [test_inference_cpp 使用](docs/test_inference_cpp.md):测试基于C++的模型推理。
- [test_serving 使用](docs/test_serving.md):测试基于Paddle Serving的服务化部署功能。
- [test_lite_arm_cpu_cpp 使用](./):测试基于Paddle-Lite的ARM CPU端c++预测部署功能。
- [test_paddle2onnx 使用](docs/test_paddle2onnx.md):测试Paddle2ONNX的模型转化功能,并验证正确性。