Update yolov3 tiny (#1033)
* add PPYOLO
Co-authored-by: Nlongxiang <longxiang@baidu.com>
Showing
configs/ppyolo/README.md
0 → 100644
configs/ppyolo/ppyolo.yml
0 → 100644
configs/ppyolo/ppyolo_lb.yml
0 → 100644
configs/ppyolo/ppyolo_reader.yml
0 → 100644
configs/ppyolo/ppyolo_tiny.yml
0 → 100755
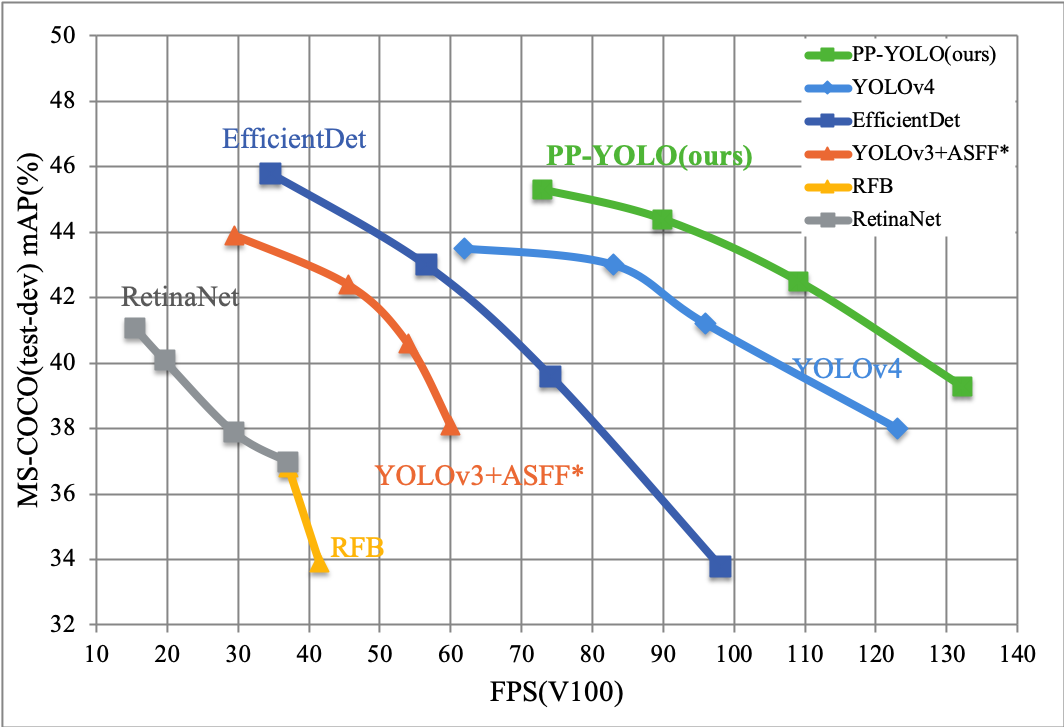
docs/images/ppyolo_map_fps.png
0 → 100644
{kind=link}
131.9 KB