Merge branch 'develop' into core_inference_prepare
Showing
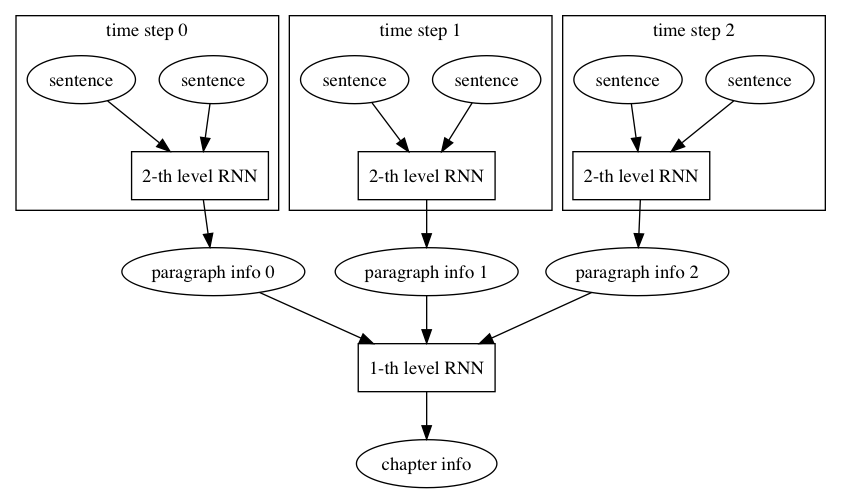
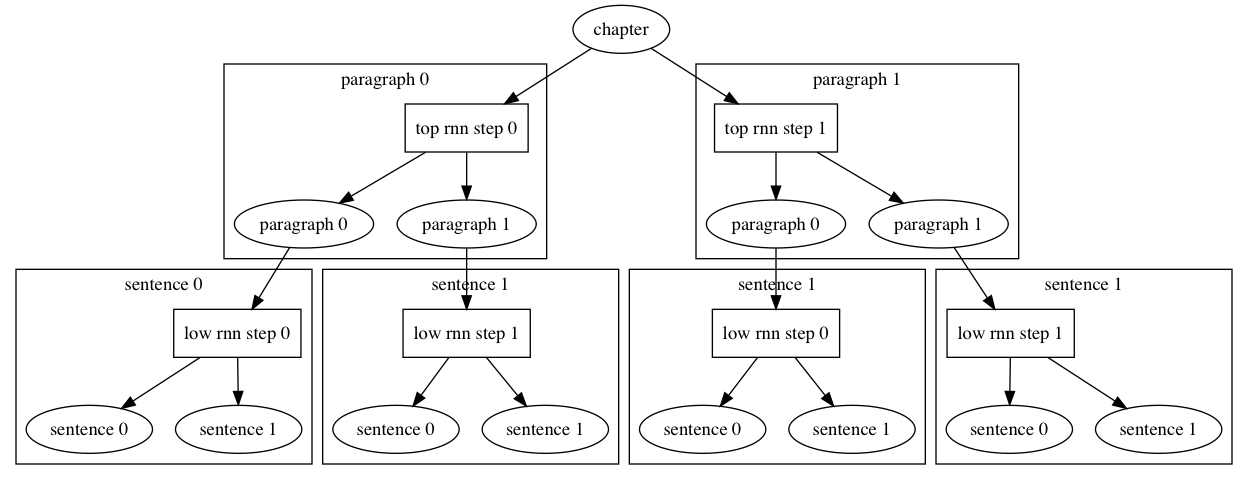
doc/fluid/images/2_level_rnn.dot
0 → 100644
doc/fluid/images/2_level_rnn.png
0 → 100644
{kind=link}
51.4 KB
{kind=link}
61.2 KB
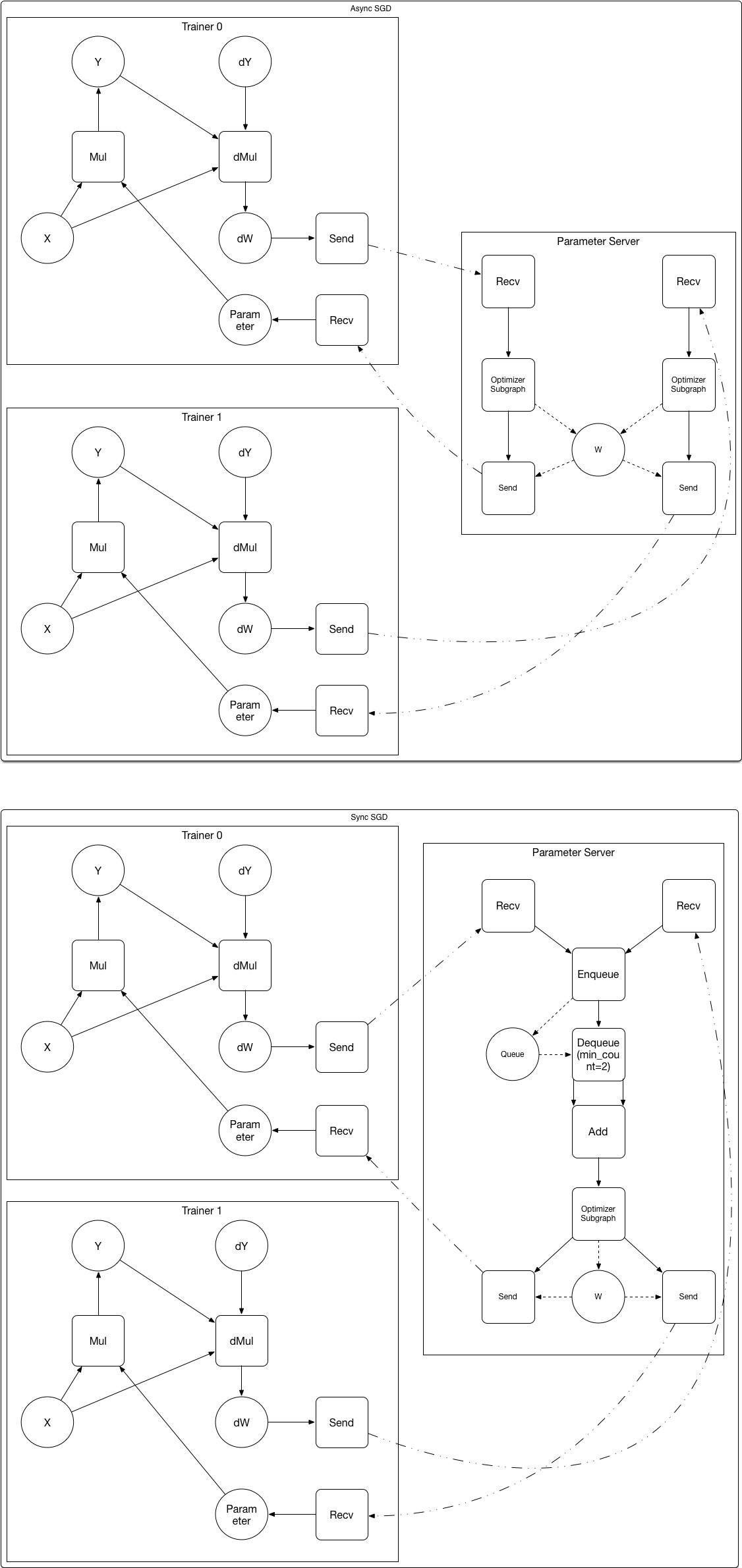
doc/fluid/images/asgd.gif
0 → 100644
{kind=link}
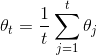
620 字节
{kind=link}
23.3 KB
{kind=link}
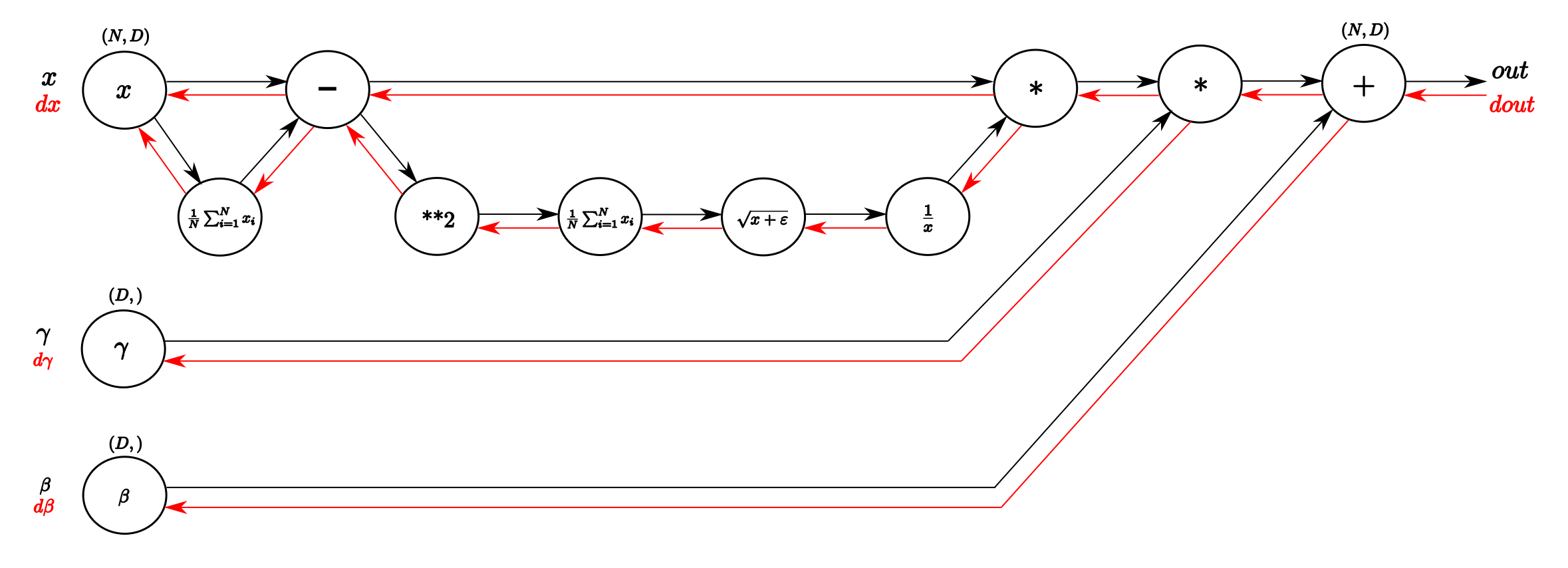
161.3 KB
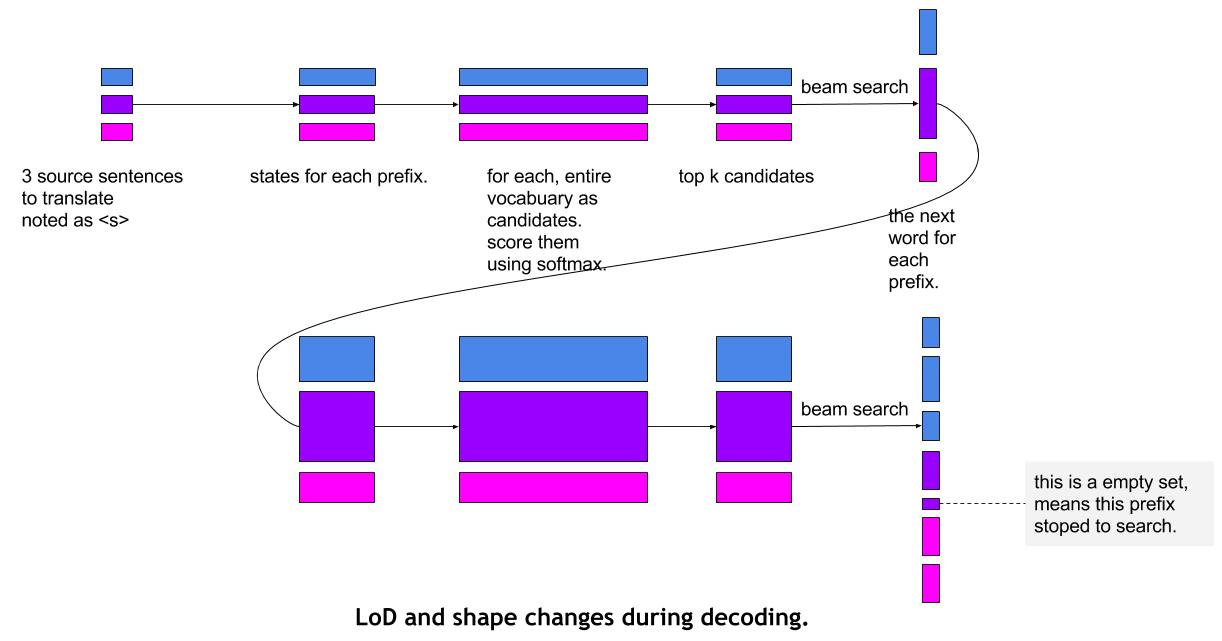
doc/fluid/images/beam_search.png
0 → 100644
{kind=link}

463.6 KB
doc/fluid/images/ci_build_whl.png
0 → 100644
{kind=link}
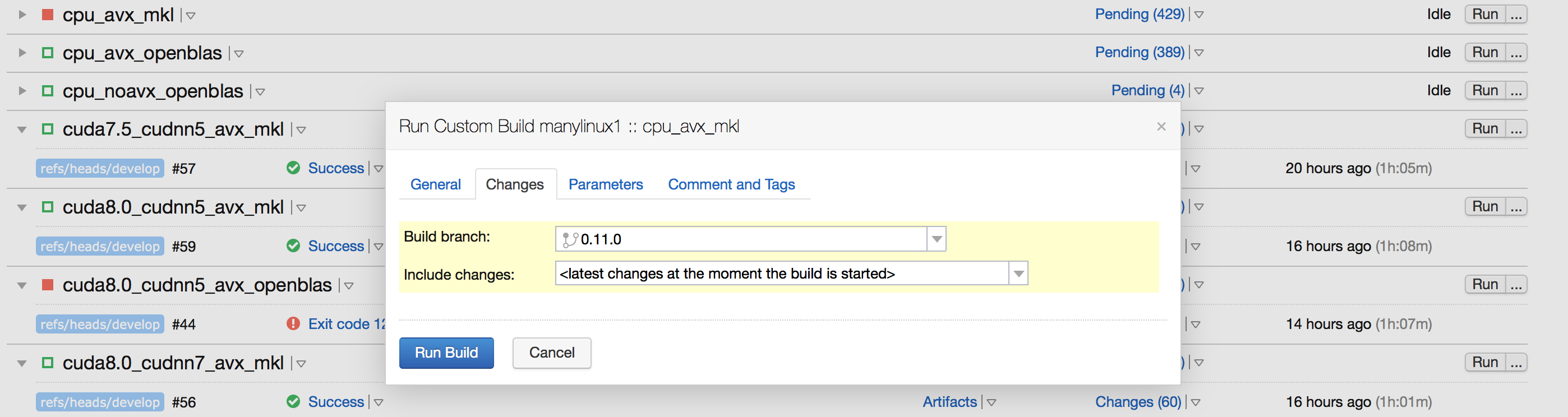
280.4 KB
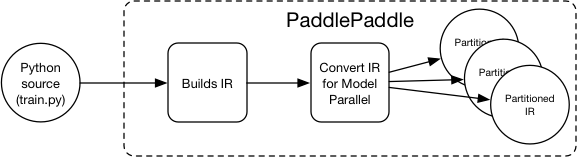
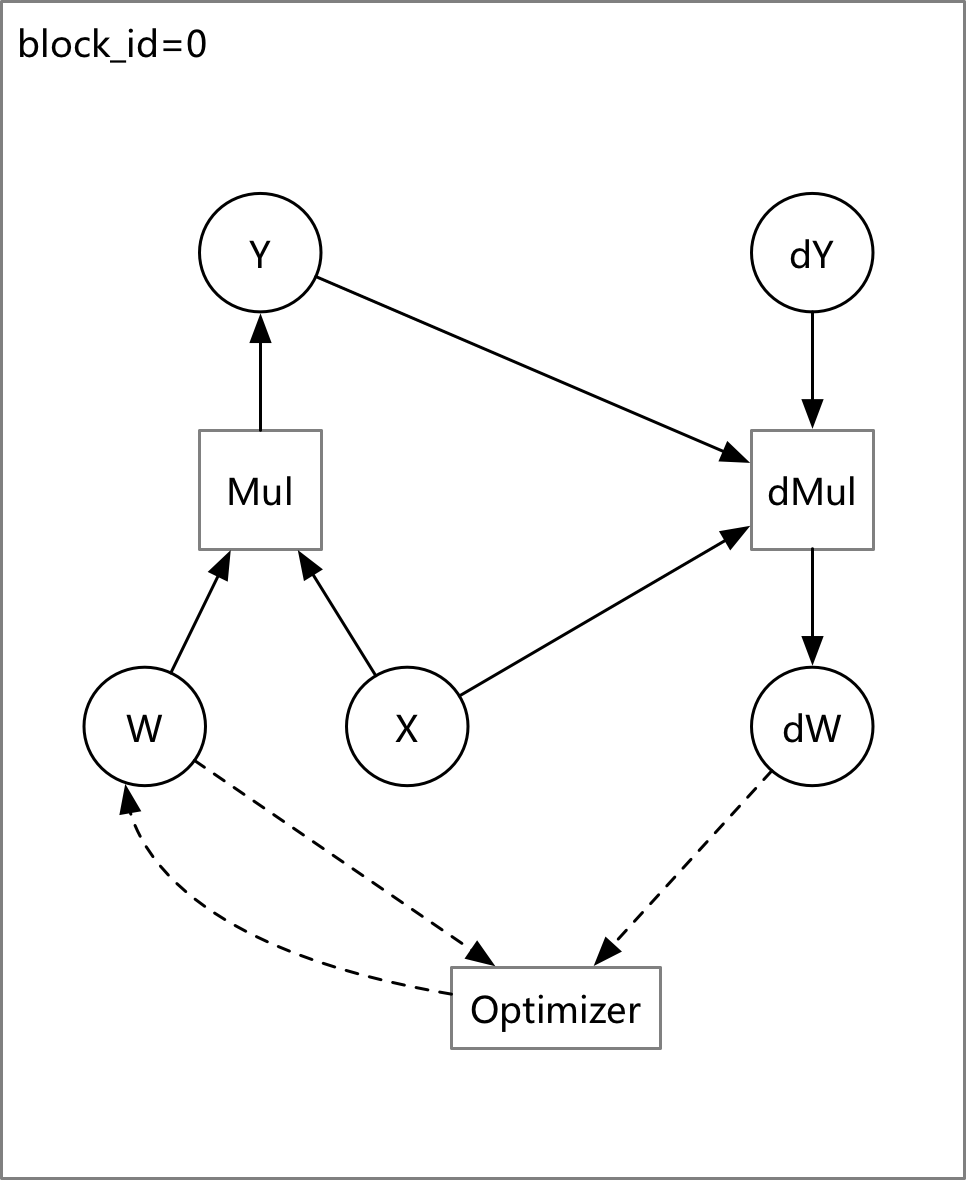
doc/fluid/images/compiler.graffle
0 → 100644
文件已添加
doc/fluid/images/compiler.png
0 → 100644
{kind=link}
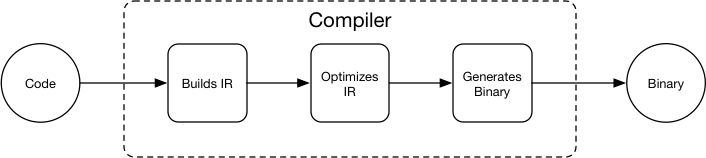
15.5 KB
{kind=link}
83.3 KB
{kind=link}
22.5 KB
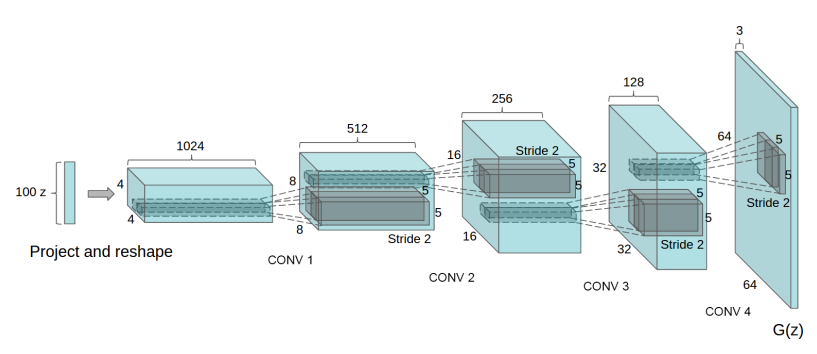
doc/fluid/images/dcgan.png
0 → 100644
{kind=link}
56.6 KB
{kind=link}
39.7 KB
文件已添加
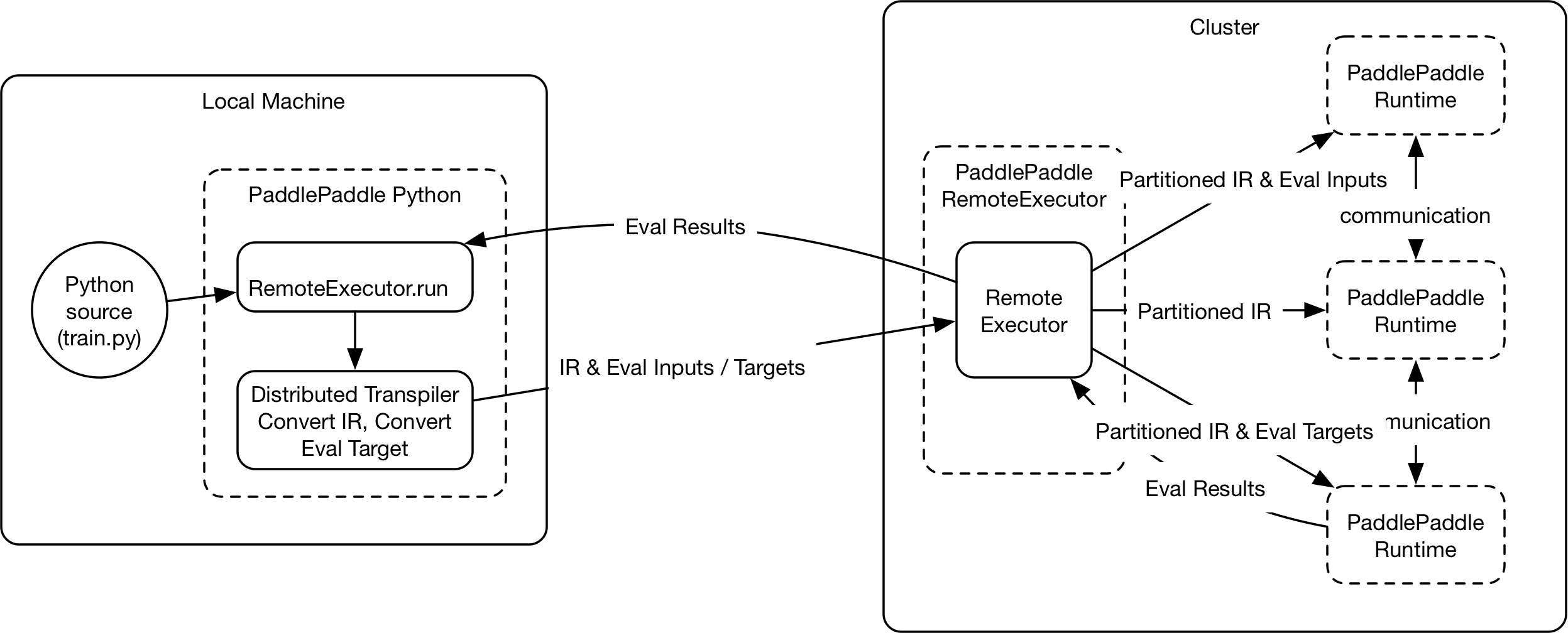
doc/fluid/images/dist-graph.png
0 → 100644
{kind=link}
222.2 KB
文件已添加
{kind=link}
189.2 KB
doc/fluid/images/ds2_network.png
0 → 100644
{kind=link}
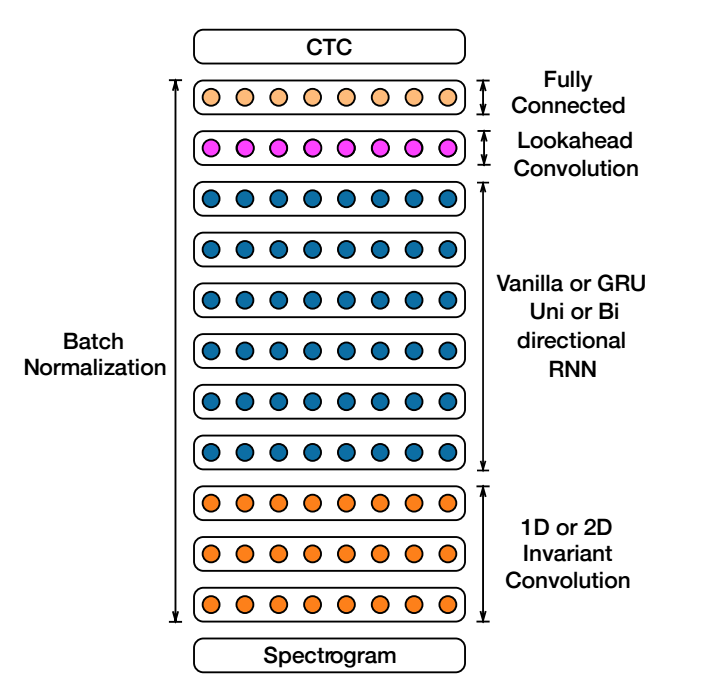
113.8 KB
doc/fluid/images/feed_forward.png
0 → 100644
{kind=link}
31.5 KB
{kind=link}
45.0 KB
文件已添加
{kind=link}
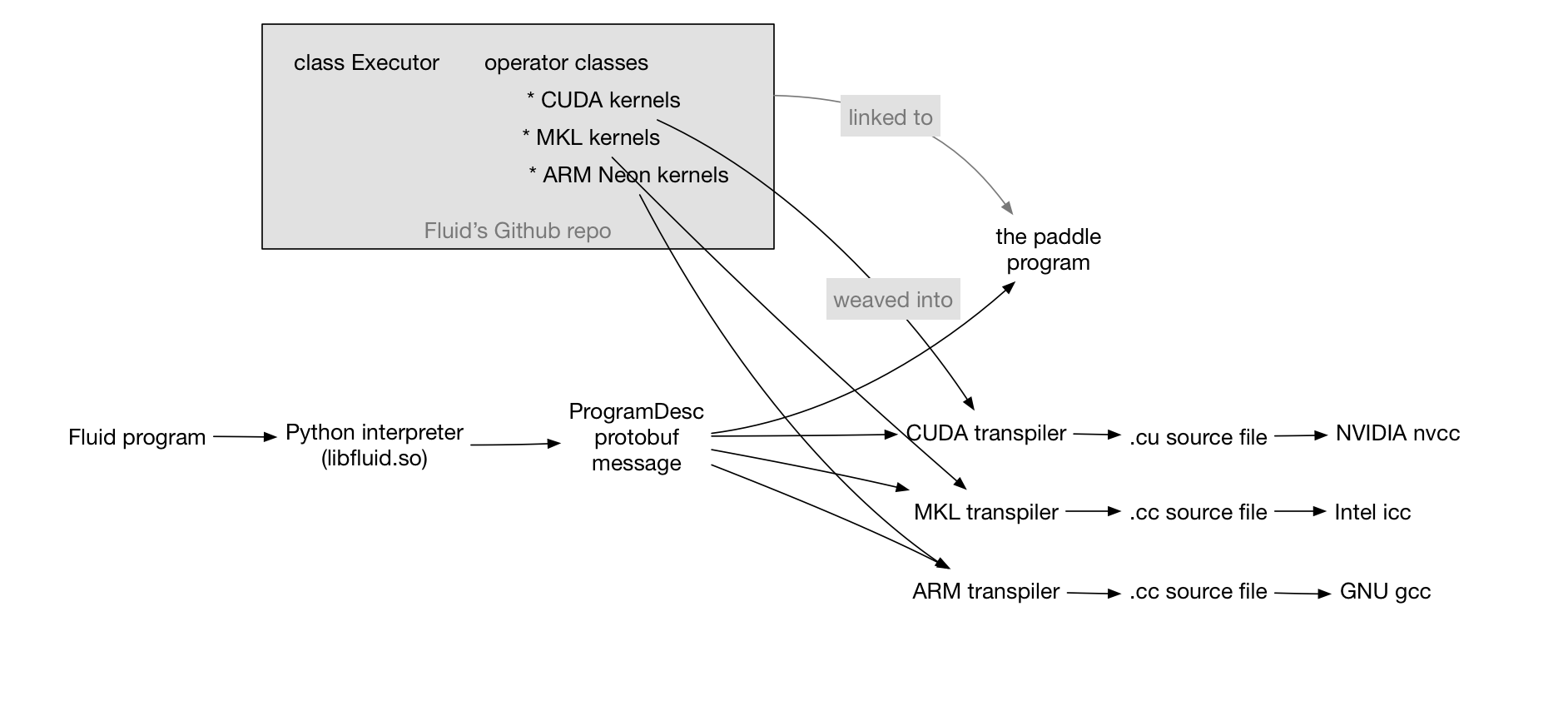
121.2 KB
{kind=link}
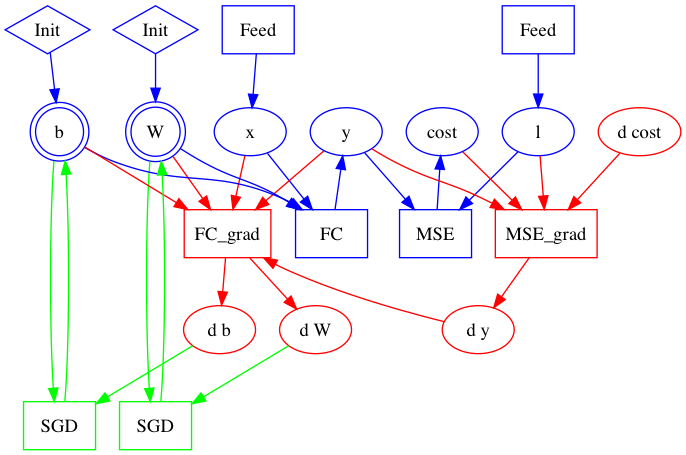
56.2 KB
{kind=link}
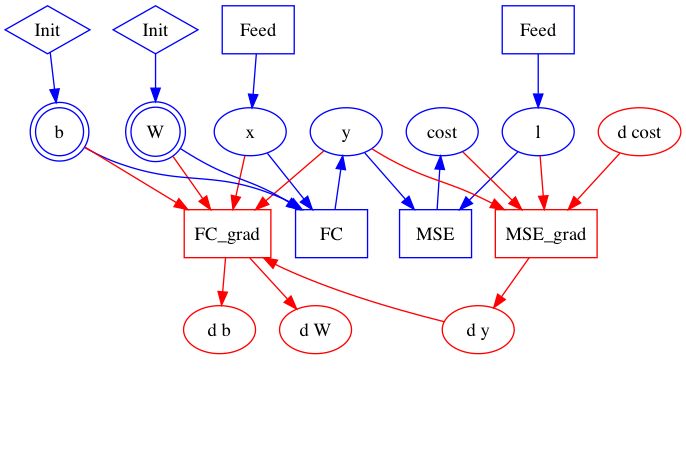
48.9 KB
{kind=link}
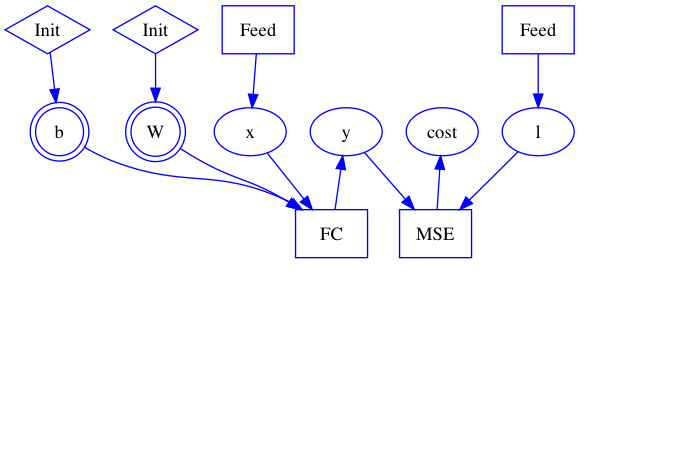
30.1 KB
{kind=link}
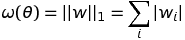
1.1 KB
{kind=link}
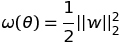
989 字节
文件已添加
doc/fluid/images/local-graph.png
0 → 100644
{kind=link}
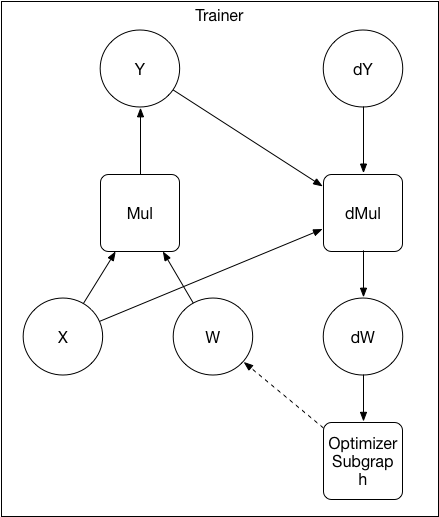
27.9 KB
文件已添加
{kind=link}
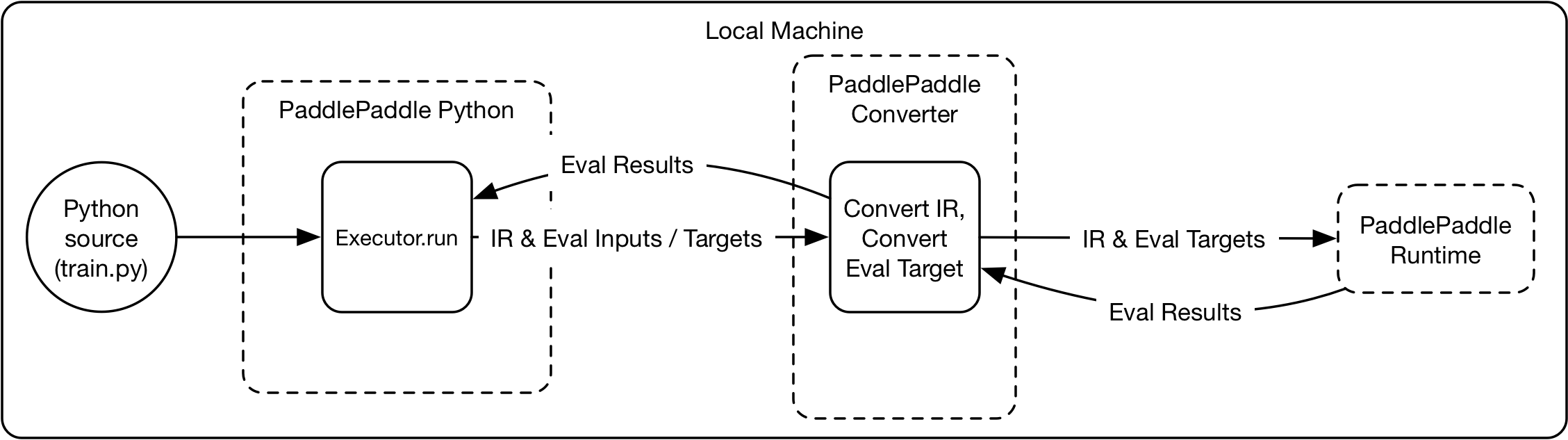
102.5 KB
doc/fluid/images/lookup_table.png
0 → 100644
{kind=link}
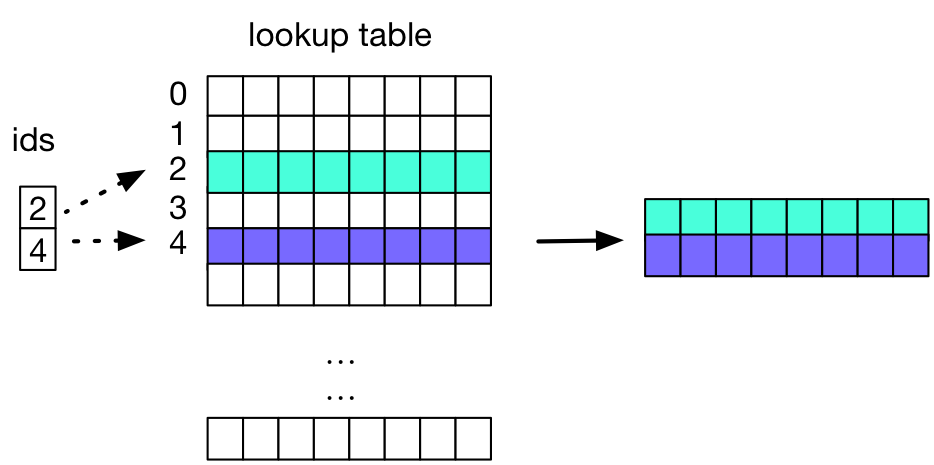
23.7 KB
{kind=link}
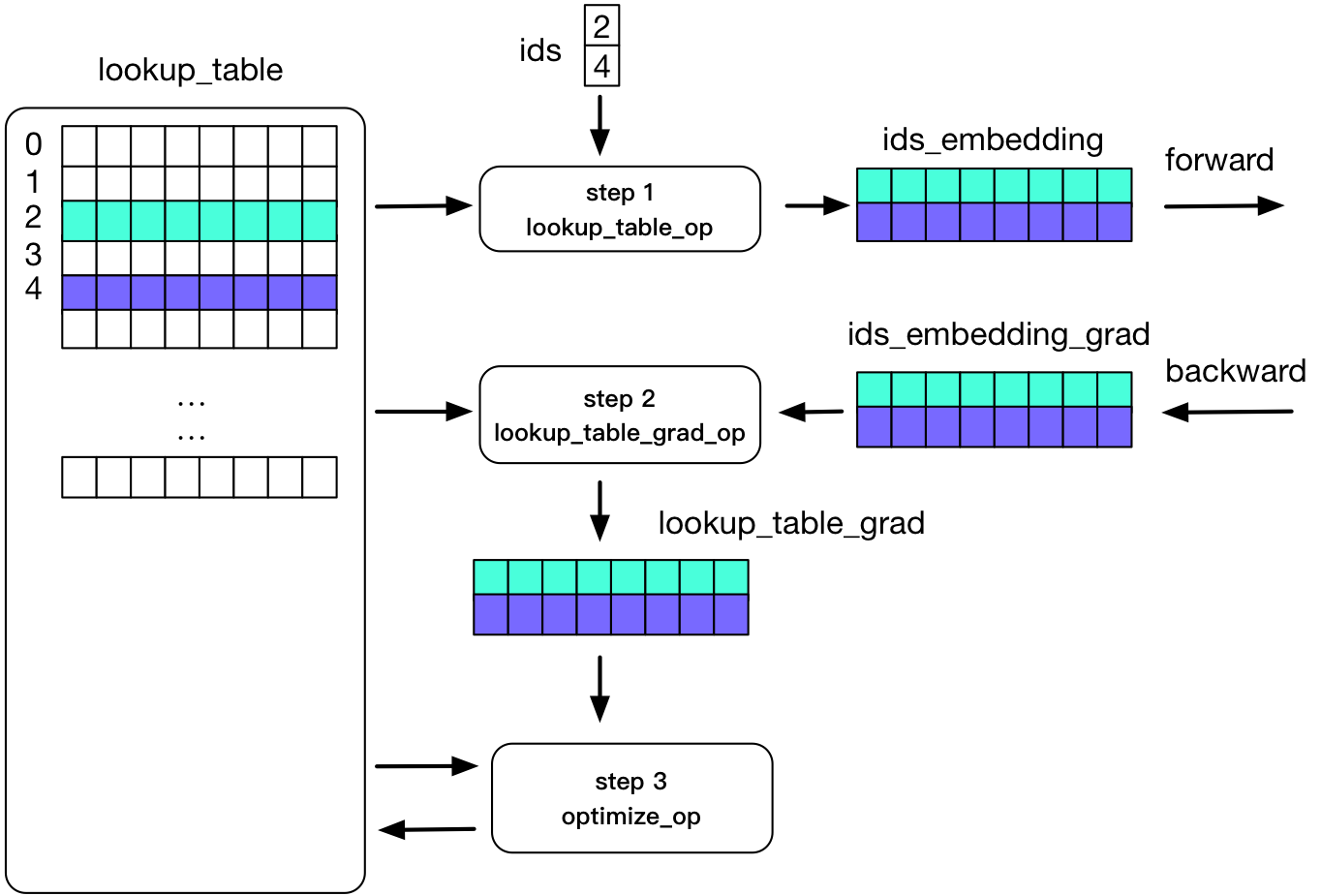
88.3 KB
{kind=link}
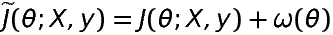
1.6 KB
文件已添加
{kind=link}
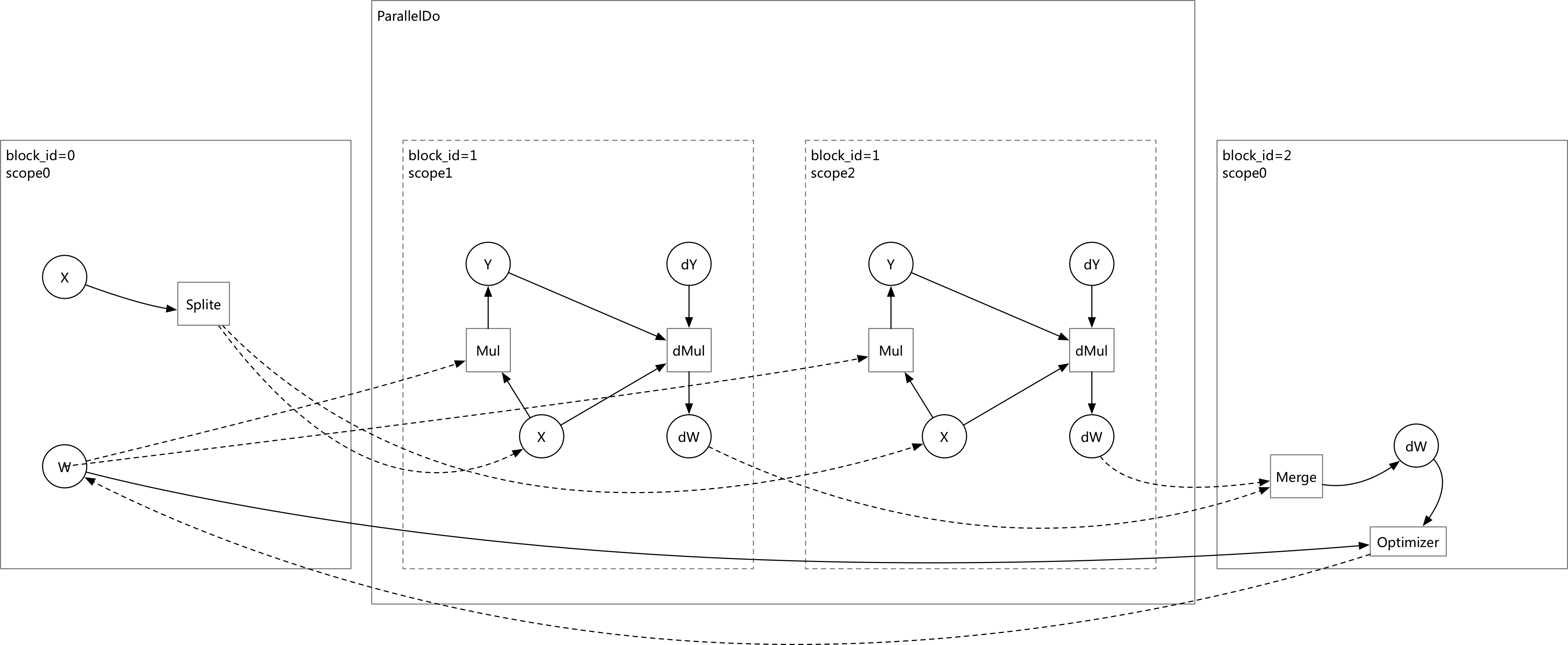
350.4 KB
文件已添加
{kind=link}
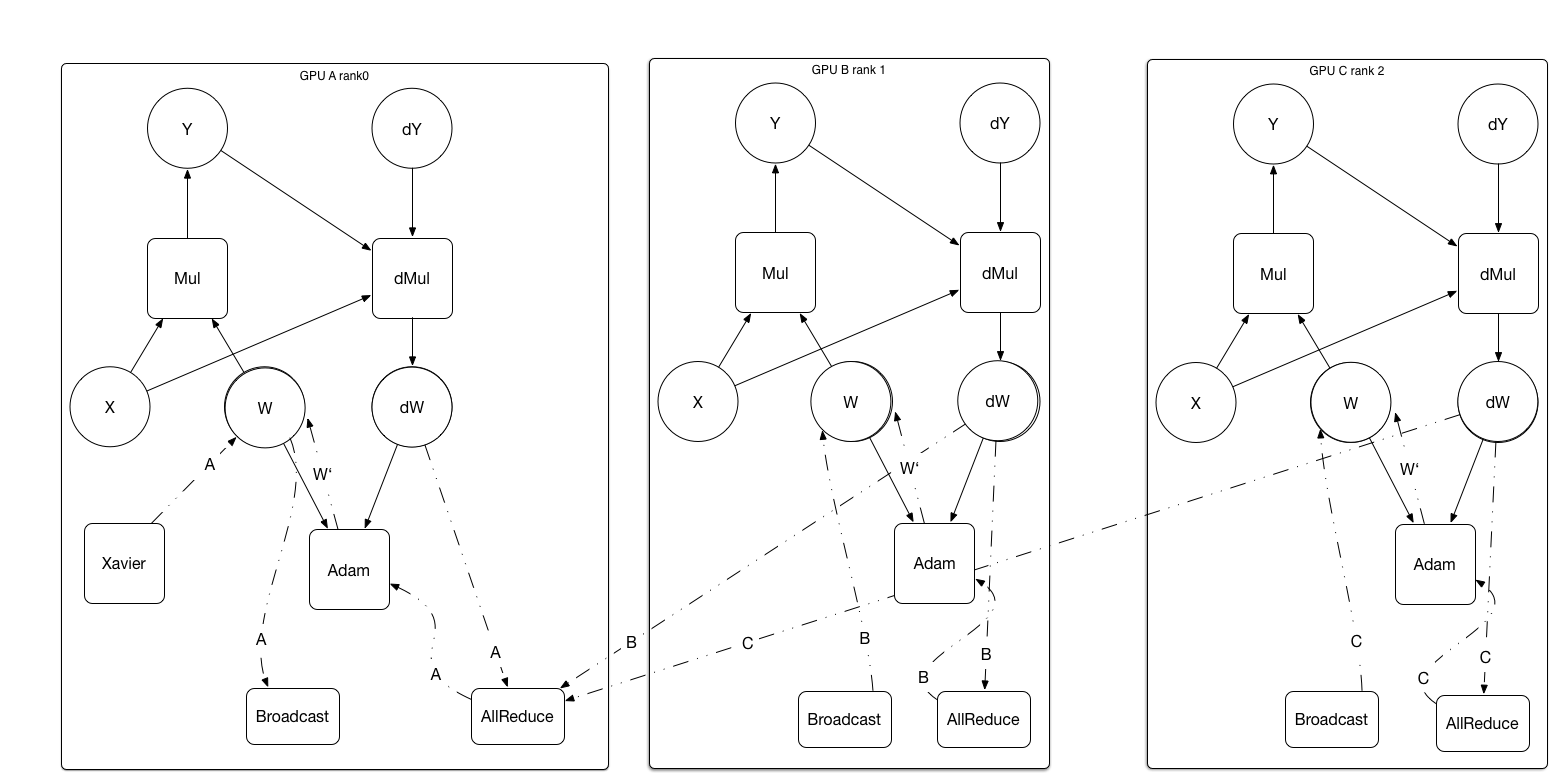
108.4 KB
文件已添加
{kind=link}
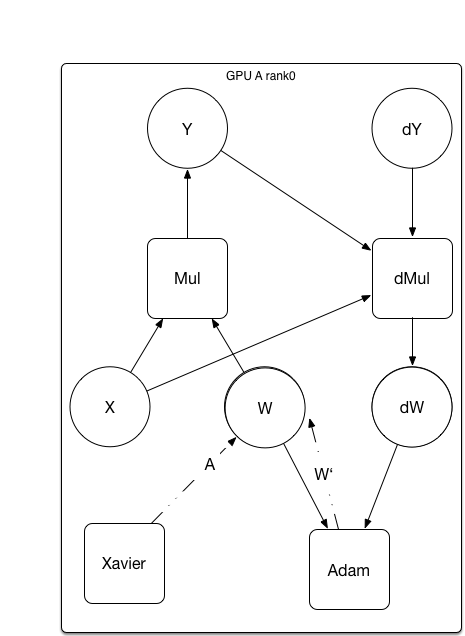
32.8 KB
{kind=link}
160.0 KB
文件已添加
{kind=link}
19.7 KB
doc/fluid/images/pprof_1.png
0 → 100644
{kind=link}
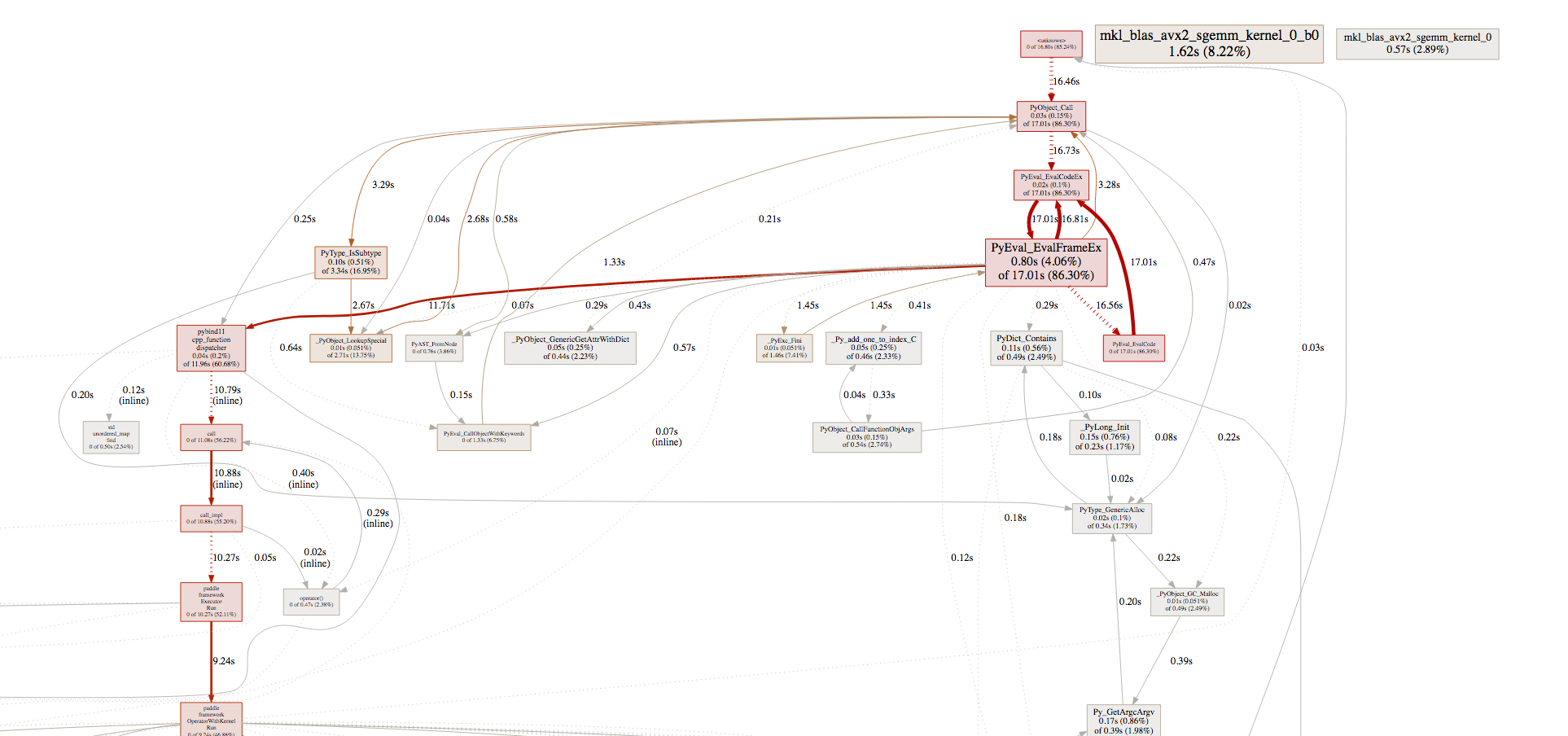
344.4 KB
doc/fluid/images/pprof_2.png
0 → 100644
{kind=link}

189.5 KB
doc/fluid/images/profiler.png
0 → 100644
{kind=link}
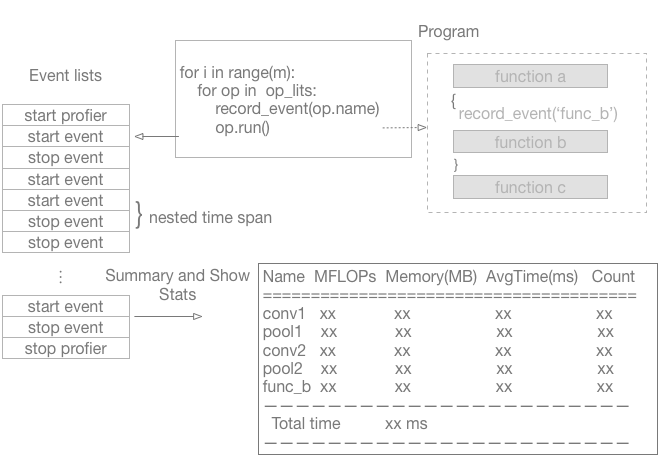
49.9 KB
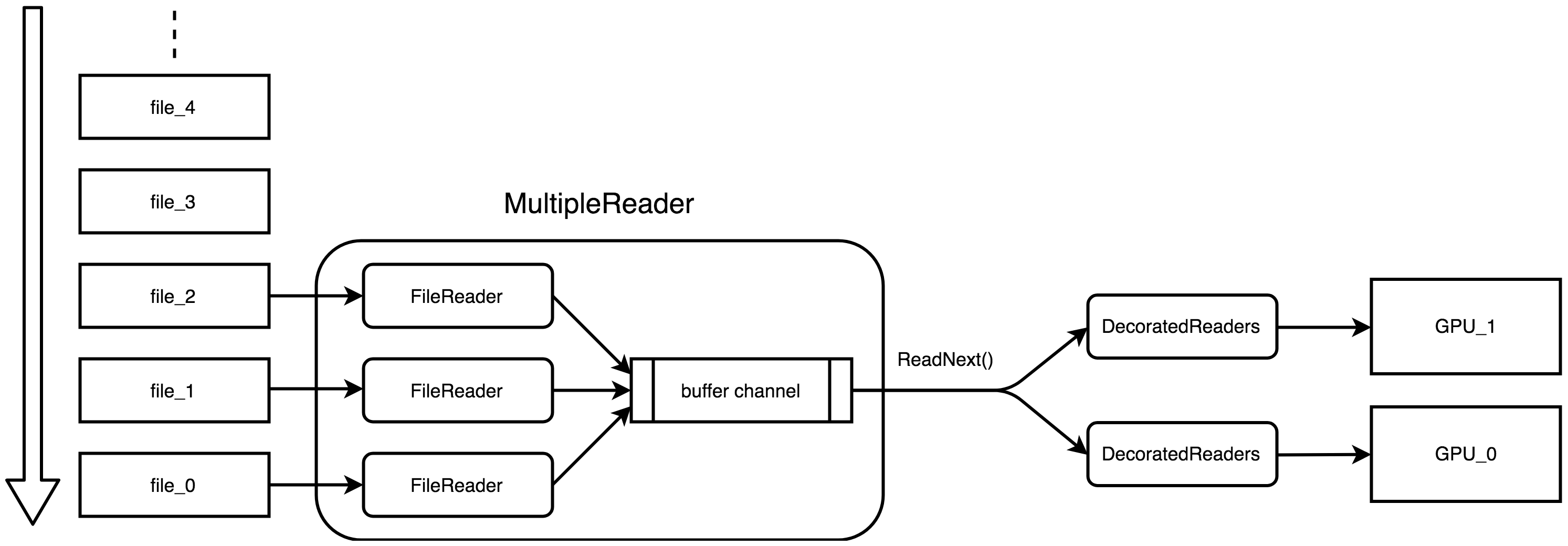
doc/fluid/images/readers.png
0 → 100644
{kind=link}
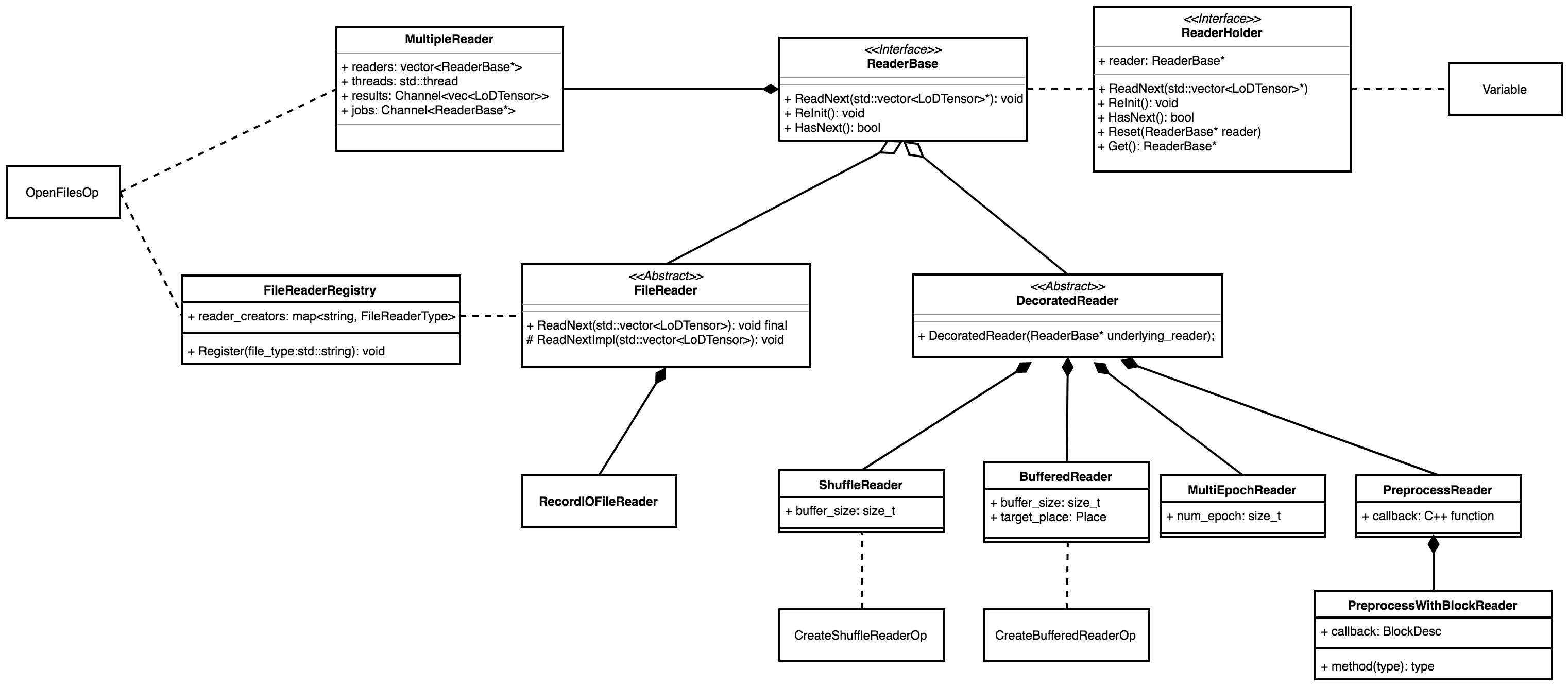
347.4 KB
文件已添加
{kind=link}
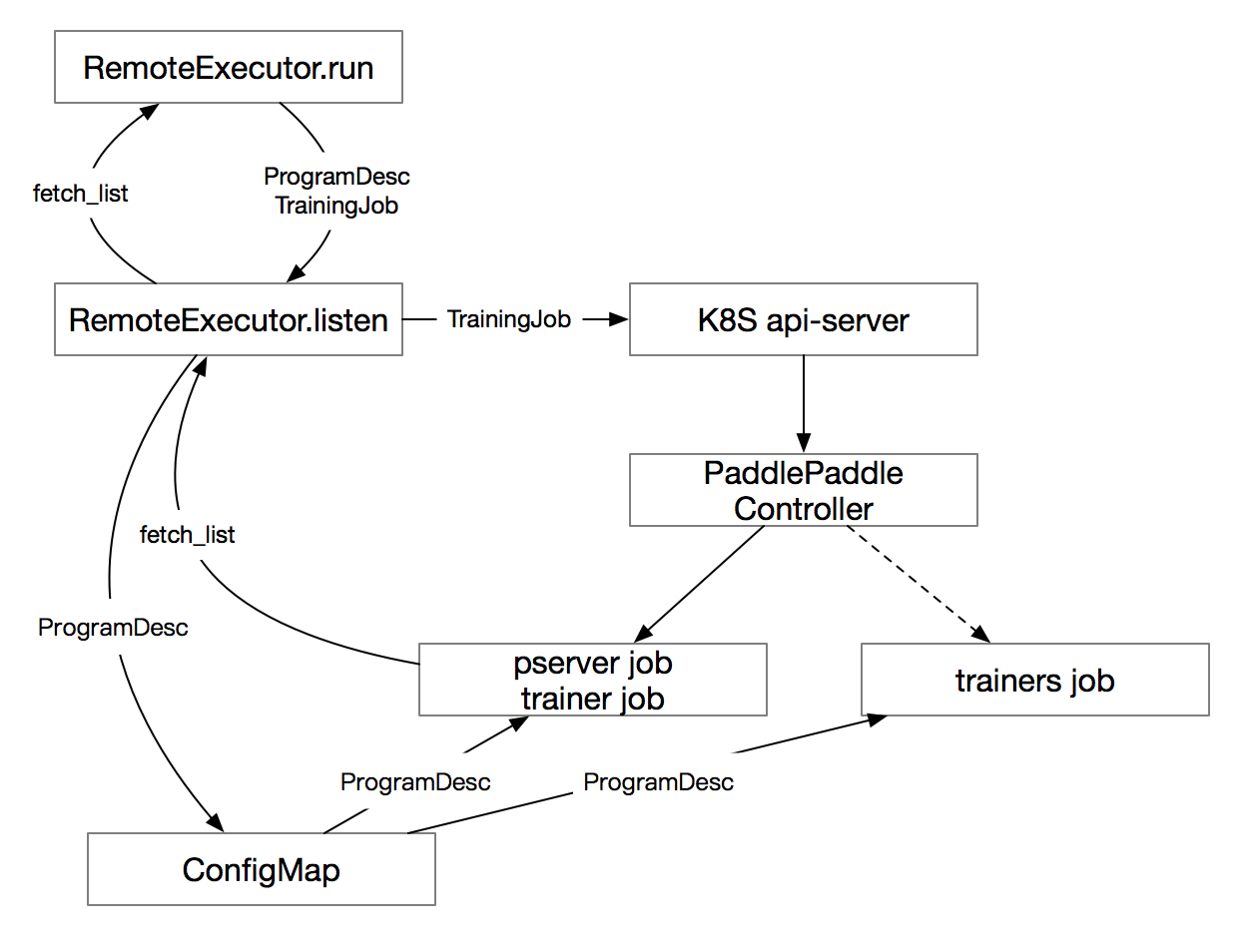
118.0 KB
doc/fluid/images/rnn.dot
0 → 100644
doc/fluid/images/rnn.jpg
0 → 100644
{kind=link}
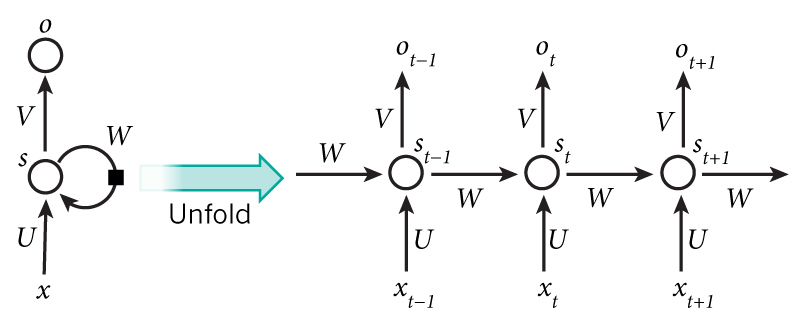
43.3 KB
doc/fluid/images/rnn.png
0 → 100644
{kind=link}
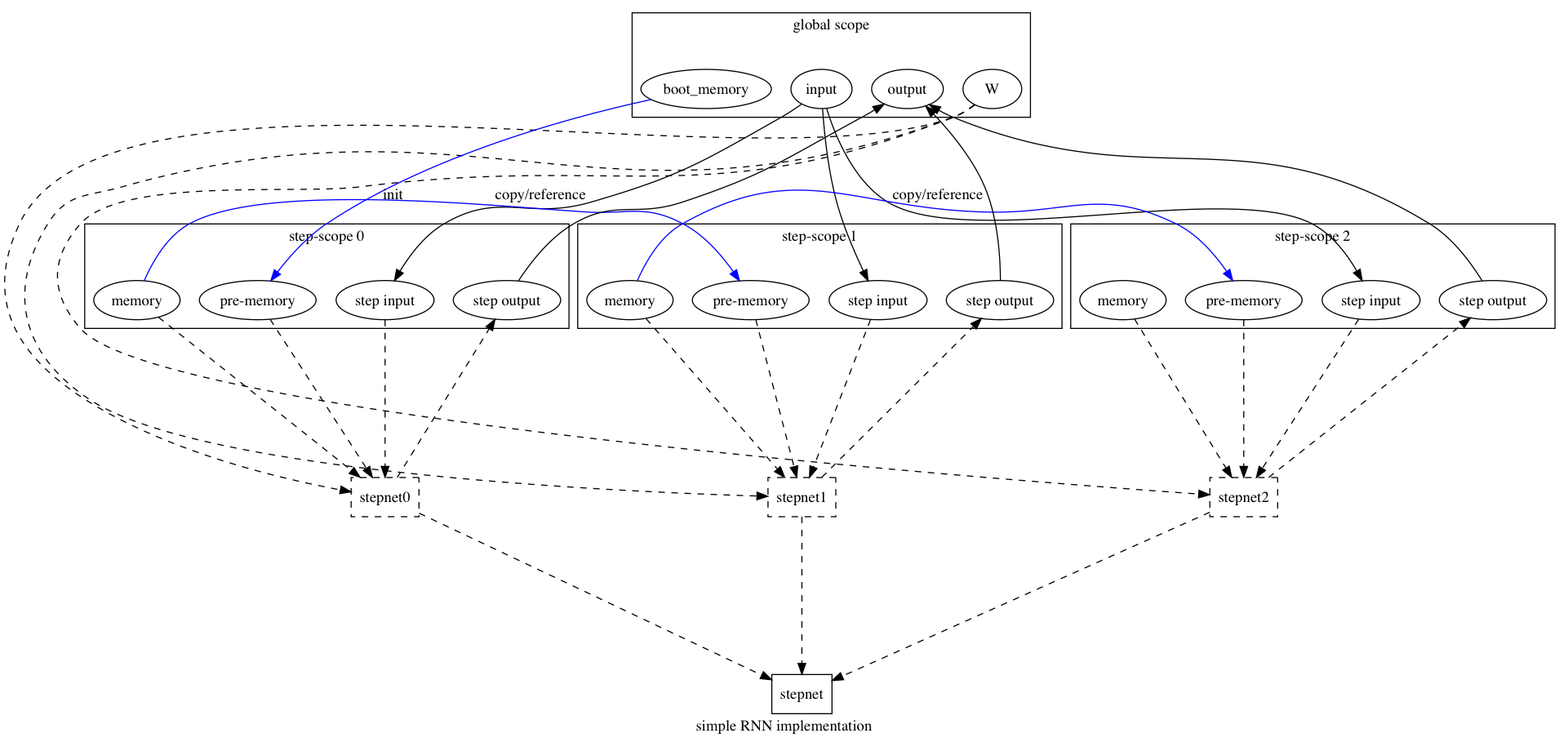
180.8 KB
{kind=link}
67.3 KB
{kind=link}
76.3 KB
文件已添加
{kind=link}
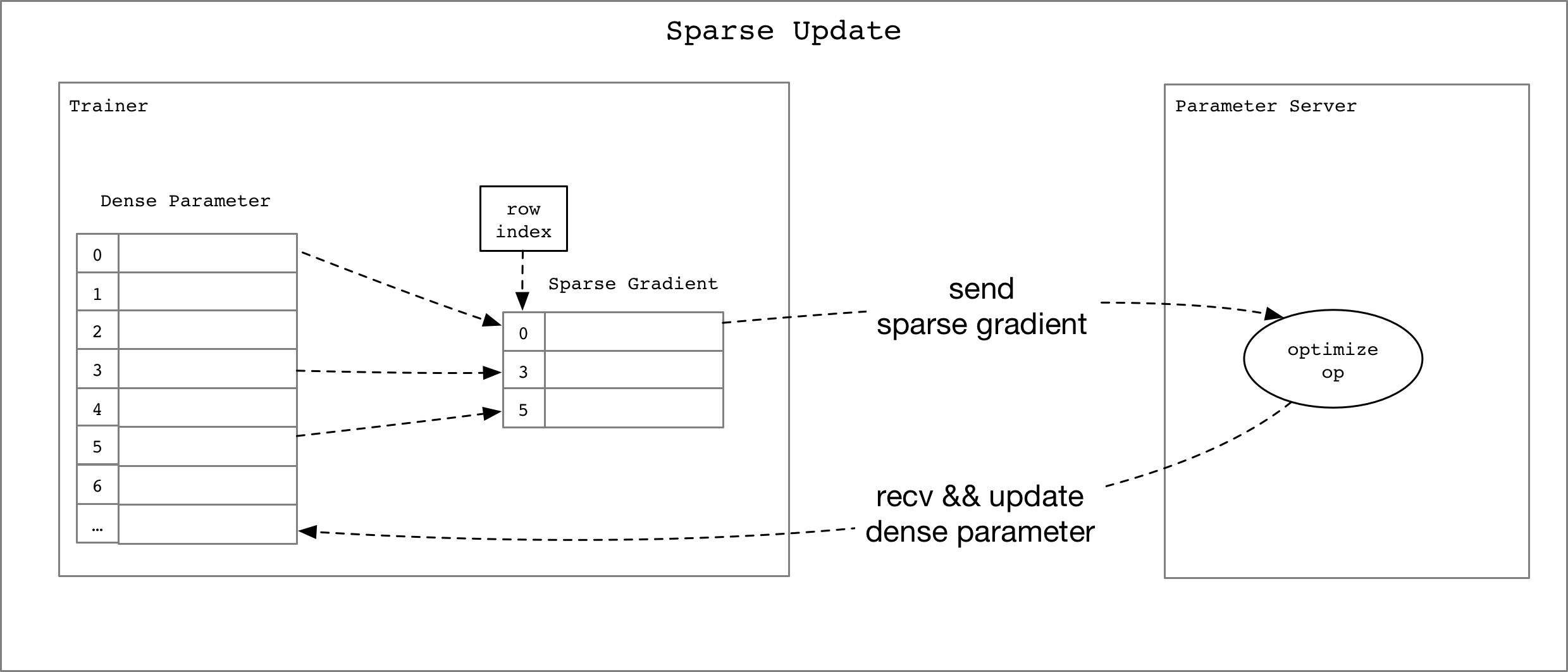
119.7 KB
doc/fluid/images/test.dot
0 → 100644
doc/fluid/images/test.dot.png
0 → 100644
{kind=link}
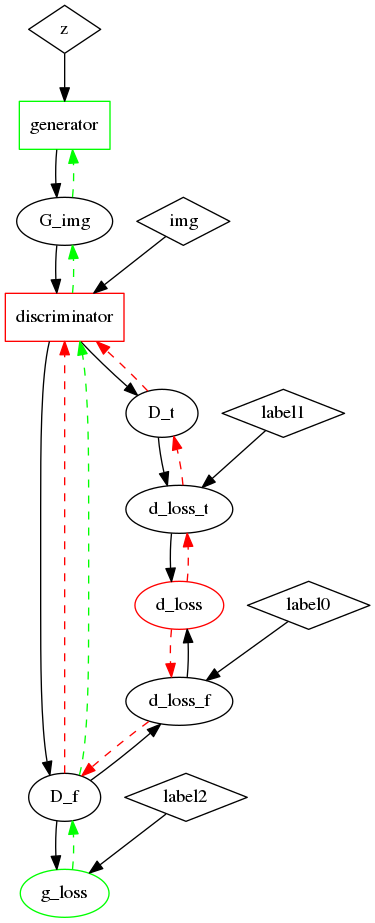
57.6 KB
doc/fluid/images/theta_star.gif
0 → 100644
{kind=link}
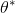
156 字节
doc/fluid/images/timeline.jpeg
0 → 100644
{kind=link}
此差异已折叠。
doc/fluid/images/tracing.jpeg
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/fluid/operators/fc_op.cc
0 → 100644
此差异已折叠。
paddle/fluid/operators/fc_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。